| 编辑推荐: |
| 本文来自于简书,本文教你用简单易学的工业级Python自然语言处理软件包Spacy,对自然语言文本做词性分析、命名实体识别、依赖关系刻画,以及词嵌入向量的计算和可视化。
|
|
盲维
我总爱重复一句芒格爱说的话:
To the one with a hammer, everything looks like a
nail. (手中有锤,看什么都像钉)
这句话是什么意思呢?
就是你不能只掌握数量很少的方法、工具。
否则你的认知会被自己能力框住。不只是存在盲点,而是存在“盲维”。
你会尝试用不合适的方法解决问题(还自诩“一招鲜,吃遍天”),却对原本合适的工具视而不见。
结果可想而知。
所以,你得在自己的工具箱里面,多放一些兵刃。
最近我又对自己的学生,念叨芒格这句话。
因为他们开始做实际研究任务的时候,一遇到自然语言处理(Natural Language Processing,
NLP),脑子里想到的就是词云、情感分析和LDA主题建模。
为什么?
因为我的专栏和公众号里,自然语言处理部分,只写过这些内容。
你如果认为,NLP只能做这些事,就大错特错了。
看看这段视频,你大概就能感受到目前自然语言处理的前沿,已经到了哪里。

当然,你手头拥有的工具和数据,尚不能做出Google展示的黑科技效果。
但是,现有的工具,也足可以让你对自然语言文本,做出更丰富的处理结果。
科技的发展,蓬勃迅速。
除了咱们之前文章中已介绍过的结巴分词、SnowNLP和TextBlob,基于Python的自然语言处理工具还有很多,例如
NLTK 和 gensim 等。
我无法帮你一一熟悉,你可能用到的所有自然语言处理工具。
但是咱们不妨开个头,介绍一款叫做 Spacy 的 Python 工具包。
剩下的,自己举一反三。
工具
Spacy 的 Slogan,是这样的:
Industrial-Strength Natural Language Processing. (工业级别的自然语言处理)

这句话听上去,是不是有些狂妄啊?
不过人家还是用数据说话的。
数据采自同行评议(Peer-reviewed)学术论文:
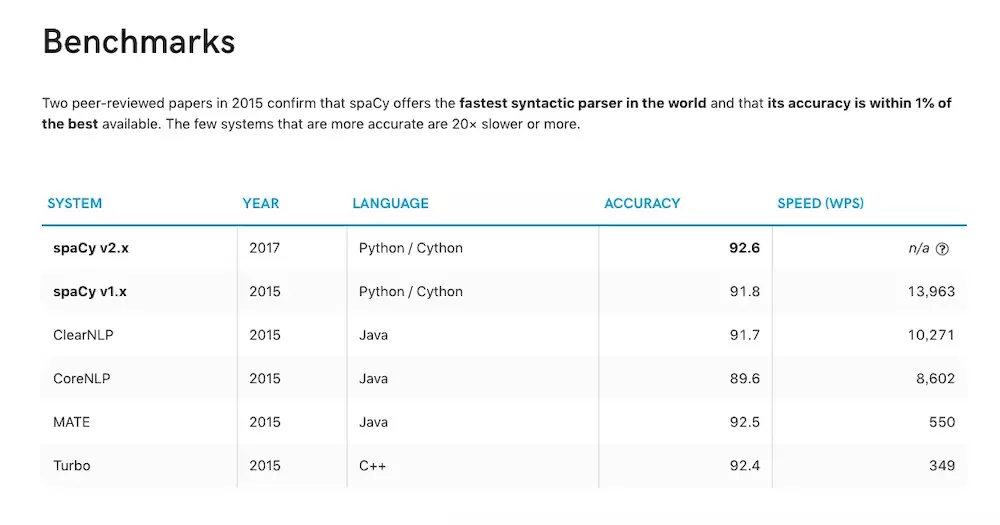
看完上述的数据分析,我们大致对于Spacy的性能有些了解。
但是我选用它,不仅仅是因为它“工业级别”的性能,更是因为它提供了便捷的用户调用接口,以及丰富、详细的文档。
仅举一例。
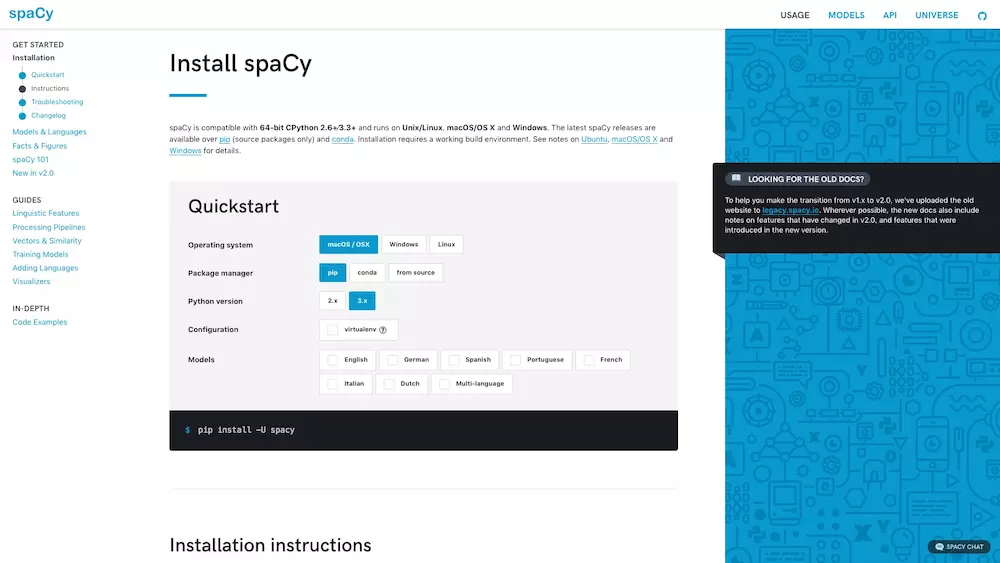
上图是Spacy上手教程的第一页。
可以看到,左侧有简明的树状导航条,中间是详细的文档,右侧是重点提示。
仅安装这一项,你就可以点击选择操作系统、Python包管理工具、Python版本、虚拟环境和语言支持等标签。网页会动态为你生成安装的语句。
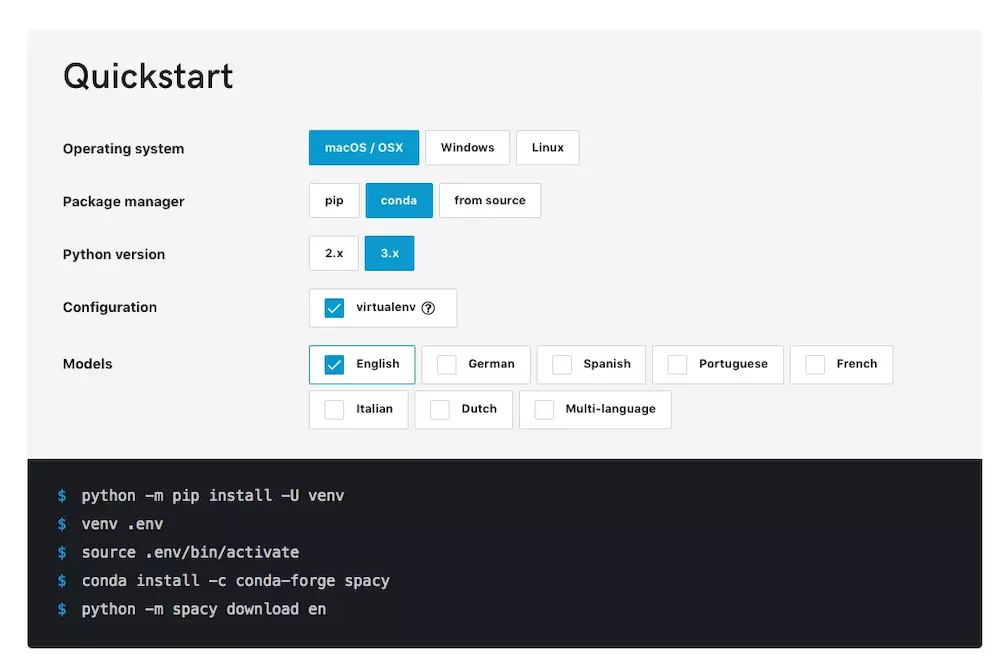
这种设计,对新手用户,很有帮助吧?
Spacy的功能有很多。
从最简单的词性分析,到高阶的神经网络模型,五花八门。
篇幅所限,本文只为你展示以下内容:
1.词性分析
2.命名实体识别
3.依赖关系刻画
4.词嵌入向量的近似度计算
5.词语降维和可视化
学完这篇教程,你可以按图索骥,利用Spacy提供的详细文档,自学其他自然语言处理功能。
我们开始吧。
环境
请点击这个链接(http://t.cn/R35fElv),直接进入咱们的实验环境。
对,你没看错。
你不需要在本地计算机安装任何软件包。只要有一个现代化浏览器(包括Google Chrome, Firefox,
Safari和Microsoft Edge等)就可以了。全部的依赖软件,我都已经为你准备好了。
打开链接之后,你会看见这个页面。
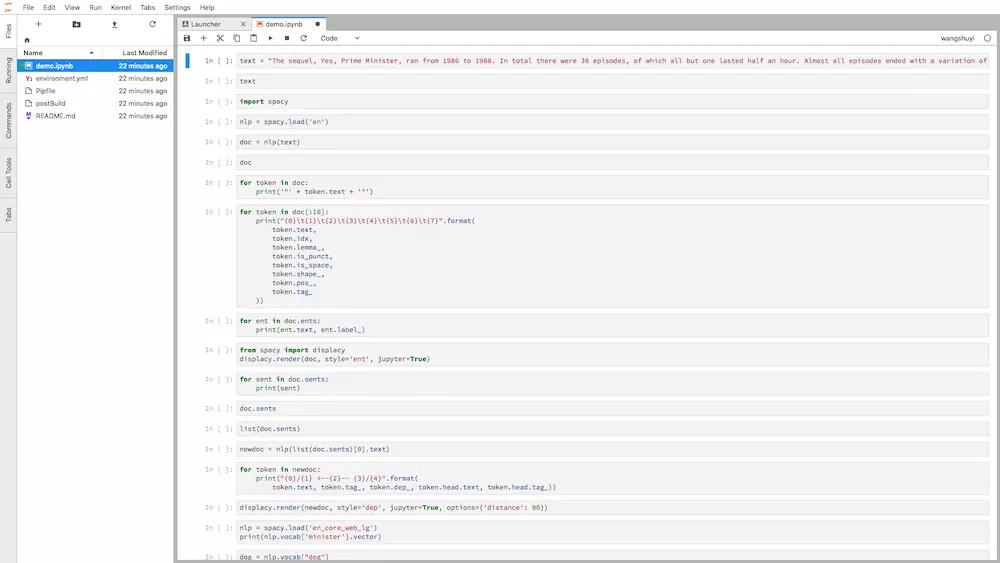
不同于之前的 Jupyter Notebook,这个界面来自 Jupyter Lab。
你可以将它理解为 Jupyter Notebook 的增强版,它具备以下特征:
代码单元直接鼠标拖动;
一个浏览器标签,可打开多个Notebook,而且分别使用不同的Kernel;
提供实时渲染的Markdown编辑器;
完整的文件浏览器;
CSV数据文件快速浏览
……
图中左侧分栏,是工作目录下的全部文件。
右侧打开的,是咱们要使用的ipynb文件。
根据咱们的讲解,请你逐条执行,观察结果。
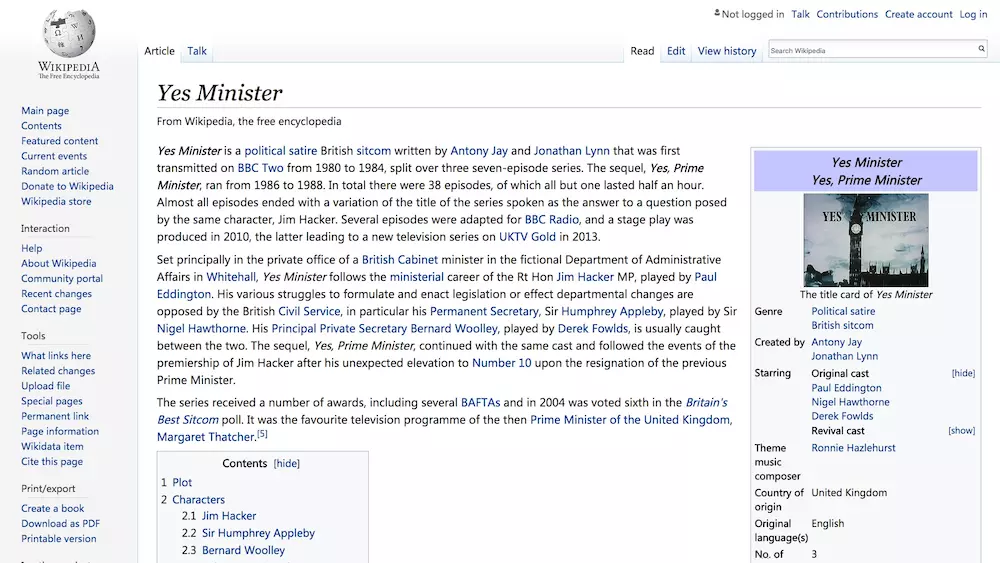
我们说一说样例文本数据的来源。
如果你之前读过我的其他自然语言处理方面的教程,应该记得这部电视剧。

对,就是"Yes, Minister"。
出于对这部80年代英国喜剧的喜爱,我还是用维基百科上"Yes, Minister"的介绍内容,作为文本分析样例。
下面,我们就正式开始,一步步执行程序代码了。
我建议你先完全按照教程跑一遍,运行出结果。
如果一切正常,再将其中的数据,替换为你自己感兴趣的内容。
之后,尝试打开一个空白 ipynb 文件,根据教程和文档,自己敲代码,并且尝试做调整。
这样会有助于你理解工作流程和工具使用方法。
实践
我们从维基百科页面的第一自然段中,摘取部分语句,放到text变量里面。
| text = "The
sequel, Yes, Prime Minister, ran from 1986 to
1988. In total there were 38 episodes, of which
all but one lasted half an hour. Almost all episodes
ended with a variation of the title of the series
spoken as the answer to a question posed by the
same character, Jim Hacker. Several episodes were
adapted for BBC Radio, and a stage play was produced
in 2010, the latter leading to a new television
series on UKTV Gold in 2013." |
显示一下,看是否正确存储。
| 'The sequel,
Yes, Prime Minister, ran from 1986 to 1988. In
total there were 38 episodes, of which all but
one lasted half an hour. Almost all episodes ended
with a variation of the title of the series spoken
as the answer to a question posed by the same
character, Jim Hacker. Several episodes were adapted
for BBC Radio, and a stage play was produced in
2010, the latter leading to a new television series
on UKTV Gold in 2013.' |
没问题了。
下面我们读入Spacy软件包。
我们让Spacy使用英语模型,将模型存储到变量nlp中。
下面,我们用nlp模型分析咱们的文本段落,将结果命名为doc。
我们看看doc的内容。
| The sequel, Yes,
Prime Minister, ran from 1986 to 1988. In total
there were 38 episodes, of which all but one lasted
half an hour. Almost all episodes ended with a
variation of the title of the series spoken as
the answer to a question posed by the same character,
Jim Hacker. Several episodes were adapted for
BBC Radio, and a stage play was produced in 2010,
the latter leading to a new television series
on UKTV Gold in 2013. |
好像跟刚才的text内容没有区别呀?不还是这段文本吗?
别着急,Spacy只是为了让我们看着舒服,所以只打印出来文本内容。
其实,它在后台,已经对这段话进行了许多层次的分析。
不信?
我们来试试,让Spacy帮我们分析这段话中出现的全部词例(token)。
for token in
doc:
print('"' + token.text + '"') |
你会看到,Spacy为我们输出了一长串列表。
"The"
"sequel"
","
"Yes"
","
"Prime"
"Minister"
","
"ran"
"from"
"1986"
"to"
"1988"
"."
"In"
"total"
"there"
"were"
"38"
"episodes"
","
"of"
"which"
"all"
"but"
"one"
"lasted"
"half"
"an"
"hour"
"."
"Almost"
"all"
"episodes"
"ended"
"with"
"a"
"variation"
"of"
"the"
"title"
"of"
"the"
"series"
"spoken"
"as"
"the"
"answer"
"to"
"a"
"question"
"posed"
"by"
"the"
"same"
"character"
","
"Jim"
"Hacker"
"."
"Several"
"episodes"
"were"
"adapted"
"for"
"BBC"
"Radio"
","
"and"
"a"
"stage"
"play"
"was"
"produced"
"in"
"2010"
","
"the"
"latter"
"leading"
"to"
"a"
"new"
"television"
"series"
"on"
"UKTV"
"Gold"
"in"
"2013"
"." |
你可能不以为然——这有什么了不起?
英语本来就是空格分割的嘛!我自己也能编个小程序,以空格分段,依次打印出这些内容来!
别忙,除了词例内容本身,Spacy还把每个词例的一些属性信息,进行了处理。
下面,我们只对前10个词例(token),输出以下内容:
文本
索引值(即在原文中的定位)
词元(lemma)
是否为标点符号
是否为空格
词性
标记
for token in
doc[:10]:
print("{0}\t{1}\t{2}\t{3}\t{4}\t{5}\t{6}\t{7}".format(
token.text,
token.idx,
token.lemma_,
token.is_punct,
token.is_space,
token.shape_,
token.pos_,
token.tag_
)) |
结果为:
The 0 the False
False Xxx DET DT
sequel 4 sequel False False xxxx NOUN NN
, 10 , True False , PUNCT ,
Yes 12 yes False False Xxx INTJ UH
, 15 , True False , PUNCT ,
Prime 17 prime False False Xxxxx PROPN NNP
Minister 23 minister False False Xxxxx PROPN NNP
, 31 , True False , PUNCT ,
ran 33 run False False xxx VERB VBD
from 37 from False False xxxx ADP IN |
看到Spacy在后台默默为我们做出的大量工作了吧?
下面我们不再考虑全部词性,只关注文本中出现的实体(entity)词汇。
for ent in doc.ents:
print(ent.text, ent.label_) |
1986 to 1988
DATE
38 CARDINAL
one CARDINAL
half an hour TIME
Jim Hacker PERSON
BBC Radio ORG
2010 DATE
UKTV Gold ORG
2013 DATE |
在这一段文字中,出现的实体包括日期、时间、基数(Cardinal)……Spacy不仅自动识别出了Jim
Hacker为人名,还正确判定BBC Radio和UKTV Gold为机构名称。
如果你平时的工作,需要从海量评论里筛选潜在竞争产品或者竞争者,那看到这里,有没有一点儿灵感呢?
执行下面这段代码,看看会发生什么:
from spacy import
displacy
displacy.render(doc, style='ent', jupyter=True)
|

如上图所示,Spacy帮我们把实体识别的结果,进行了直观的可视化。不同类别的实体,还采用了不同的颜色加以区分。
把一段文字拆解为语句,对Spacy而言,也是小菜一碟。
for sent in doc.sents:
print(sent) |
The sequel, Yes,
Prime Minister, ran from 1986 to 1988.
In total there were 38 episodes, of which all
but one lasted half an hour.
Almost all episodes ended with a variation of
the title of the series spoken as the answer to
a question posed by the same character, Jim Hacker.
Several episodes were adapted for BBC Radio, and
a stage play was produced in 2010, the latter
leading to a new television series on UKTV Gold
in 2013. |
注意这里,doc.sents并不是个列表类型。
| <generator
at 0x116e95e18> |
所以,假设我们需要从中筛选出某一句话,需要先将其转化为列表。
[The sequel,
Yes, Prime Minister, ran from 1986 to 1988.,
In total there were 38 episodes, of which all
but one lasted half an hour.,
Almost all episodes ended with a variation of
the title of the series spoken as the answer to
a question posed by the same character, Jim Hacker.,
Several episodes were adapted for BBC Radio, and
a stage play was produced in 2010, the latter
leading to a new television series on UKTV Gold
in 2013.] |
下面要展示的功能,分析范围局限在第一句话。
我们将其抽取出来,并且重新用nlp模型处理,存入到新的变量newdoc中。
| newdoc = nlp(list(doc.sents)[0].text)
|
对这一句话,我们想要搞清其中每一个词例(token)之间的依赖关系。
for token in
newdoc:
print("{0}/{1} <--{2}-- {3}/{4}".format(
token.text, token.tag_, token.dep_, token.head.text,
token.head.tag_)) |
The/DT <--det--
sequel/NN
sequel/NN <--nsubj-- ran/VBD
,/, <--punct-- sequel/NN
Yes/UH <--intj-- sequel/NN
,/, <--punct-- sequel/NN
Prime/NNP <--compound-- Minister/NNP
Minister/NNP <--appos-- sequel/NN
,/, <--punct-- sequel/NN
ran/VBD <--ROOT-- ran/VBD
from/IN <--prep-- ran/VBD
1986/CD <--pobj-- from/IN
to/IN <--prep-- from/IN
1988/CD <--pobj-- to/IN
./. <--punct-- ran/VBD |
很清晰,但是列表的方式,似乎不大直观。
那就让Spacy帮我们可视化吧。
| displacy.render(newdoc,
style='dep', jupyter=True, options={'distance':
90}) |
结果如下:

这些依赖关系链接上的词汇,都代表什么?
如果你对语言学比较了解,应该能看懂。
不懂?查查字典嘛。
跟语法书对比一下,看看Spacy分析得是否准确。
前面我们分析的,属于语法层级。
下面我们看语义。
我们利用的工具,叫做词嵌入(word embedding)模型。
之前的文章《如何用Python从海量文本抽取主题?》中,我们提到过如何把文字表达成电脑可以看懂的数据。
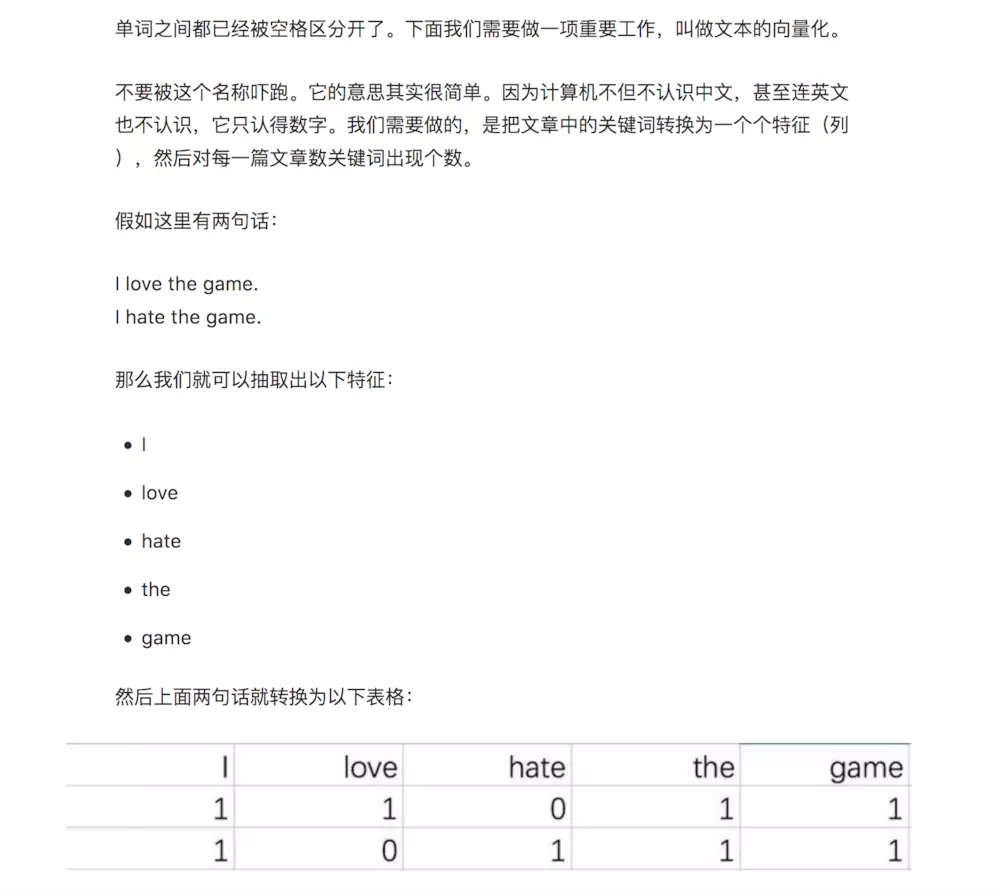
文中处理的每一个单词,都仅仅对应着词典里面的一个编号而已。你可以把它看成你去营业厅办理业务时领取的号码。
它只提供了先来后到的顺序信息,跟你的职业、学历、性别统统没有关系。
我们将这样过于简化的信息输入,计算机对于词义的了解,也必然少得可怜。
例如给你下面这个式子:
只要你学过英语,就不难猜到这里大概率应该填写“man”。
但是,如果你只是用了随机的序号来代表词汇,又如何能够猜到这里正确的填词结果呢?
幸好,在深度学习领域,我们可以使用更为顺手的单词向量化工具——词嵌入(word embeddings
)。
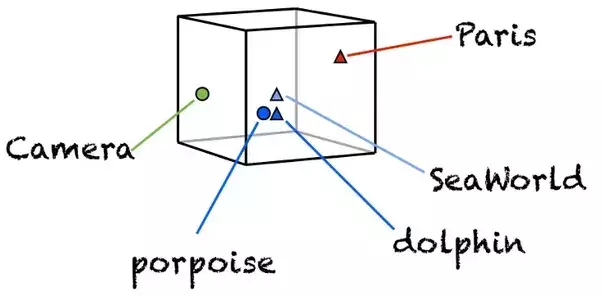
如上图这个简化示例,词嵌入把单词变成多维空间上面的向量。
这样,词语就不再是冷冰冰的字典编号,而是具有了意义。
使用词嵌入模型,我们需要Spacy读取一个新的文件。
| nlp = spacy.load('en_core_web_lg')
|
为测试读取结果,我们让Spacy打印“minister”这个单词对应的向量取值。
| print(nlp.vocab['minister'].vector)
|
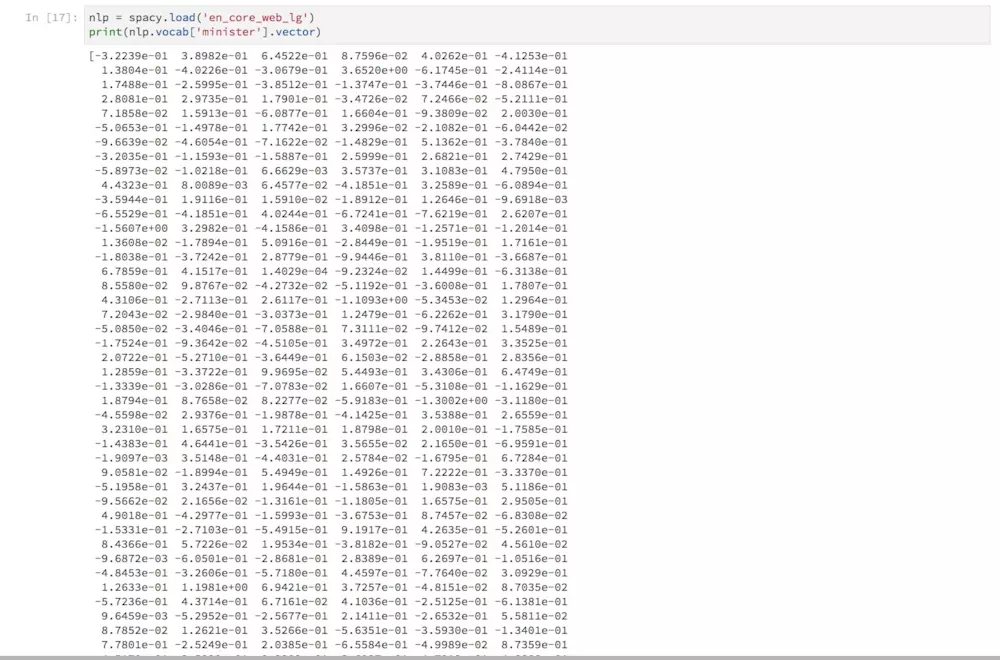
可以看到,每个单词,用总长度为300的浮点数组成向量来表示。
顺便说一句,Spacy读入的这个模型,是采用word2vec,在海量语料上训练的结果。
我们来看看,此时Spacy的语义近似度判别能力。
这里,我们将4个变量,赋值为对应单词的向量表达结果。
dog = nlp.vocab["dog"]
cat = nlp.vocab["cat"]
apple = nlp.vocab["apple"]
orange = nlp.vocab["orange"] |
我们看看“狗”和“猫”的近似度:
嗯,都是宠物,近似度高,可以接受。
下面看看“狗”和“苹果”。
一个动物,一个水果,近似度一下子就跌落下来了。
“狗”和“橘子”呢?
可见,相似度也不高。
那么“苹果”和“橘子”之间呢?
水果间近似度,远远超过水果与动物的相似程度。
测试通过。
看来Spacy利用词嵌入模型,对语义有了一定的理解。
下面为了好玩,我们来考考它。
这里,我们需要计算词典中可能不存在的向量,因此Spacy自带的similarity()函数,就显得不够用了。
我们从scipy中,找到相似度计算需要用到的余弦函数。
| from scipy.spatial.distance
import cosine |
对比一下,我们直接代入“狗”和“猫”的向量,进行计算。
| 1 - cosine(dog.vector,
cat.vector) |
除了保留数字外,计算结果与Spacy自带的similarity()运行结果没有差别。
我们把它做成一个小函数,专门处理向量输入。
def vector_similarity(x,
y):
return 1 - cosine(x, y) |
用我们自编的相似度函数,测试一下“狗”和“苹果”。
| vector_similarity(dog.vector,
apple.vector) |
与刚才的结果对比,也是一致的。
我们要表达的,是这个式子:
我们把问号,称为 guess_word
所以
| guess_word =
king - queen + woman |
我们把右侧三个单词,一般化记为 words。编写下面函数,计算guess_word取值。
def make_guess_word(words):
[first, second, third] = words
return nlp.vocab[first].vector - nlp.vocab[second].vector
+ nlp.vocab[third].vector |
下面的函数就比较暴力了,它其实是用我们计算的 guess_word 取值,和字典中全部词语一一核对近似性。把最为近似的10个候选单词打印出来。
| def get_similar_word(words,
scope=nlp.vocab):
guess_word = make_guess_word(words)
similarities = []
for word in scope:
if not word.has_vector:
continue
similarity = vector_similarity(guess_word,
word.vector)
similarities.append((word, similarity))
similarities = sorted(similarities, key=lambda
item: -item[1])
print([word[0].text for word in similarities[:10]])
|
好了,游戏时间开始。
我们先看看:
即:
| guess_word =
king - queen + woman |
输入右侧词序列:
| words = ["king",
"queen", "woman"] |
然后执行对比函数:
这个函数运行起来,需要一段时间。请保持耐心。
运行结束之后,你会看到如下结果:
| ['MAN', 'Man',
'mAn', 'MAn', 'MaN', 'man', 'mAN', 'WOMAN', 'womAn',
'WOman'] |
原来字典里面,“男人”(man)这个词汇有这么多的变形啊。
但是这个例子太经典了,我们尝试个新鲜一些的:
| ? - England =
Paris - London |
即:
| guess_word =
Paris - London + England |
对你来讲,绝对是简单的题目。左侧国别,右侧首都,对应来看,自然是巴黎所在的法国(France)。
问题是,Spacy能猜对吗?
我们把这几个单词输入。
| words = ["Paris",
"London", "England"] |
让Spacy来猜:
| ['france', 'FRANCE',
'France', 'Paris', 'paris', 'PARIS', 'EUROPE',
'EUrope', 'europe', 'Europe'] |
结果很令人振奋,前三个都是“法国”(France)。
下面我们做一个更有趣的事儿,把词向量的300维的高空间维度,压缩到一张纸(二维)上,看看词语之间的相对位置关系。
首先我们需要读入numpy软件包。
我们把词嵌入矩阵先设定为空。一会儿慢慢填入。
需要演示的单词列表,也先空着。
我们再次让Spacy遍历“Yes, Minister”维基页面中摘取的那段文字,加入到单词列表中。注意这次我们要进行判断:
如果是标点,丢弃;
如果词汇已经在词语列表中,丢弃。
for token in
doc:
if not(token.is_punct) and not(token.text in word_list):
word_list.append(token.text) |
看看生成的结果:
['The',
'sequel',
'Yes',
'Prime',
'Minister',
'ran',
'from',
'1986',
'to',
'1988',
'In',
'total',
'there',
'were',
'38',
'episodes',
'of',
'which',
'all',
'but',
'one',
'lasted',
'half',
'an',
'hour',
'Almost',
'ended',
'with',
'a',
'variation',
'the',
'title',
'series',
'spoken',
'as',
'answer',
'question',
'posed',
'by',
'same',
'character',
'Jim',
'Hacker',
'Several',
'adapted',
'for',
'BBC',
'Radio',
'and',
'stage',
'play',
'was',
'produced',
'in',
'2010',
'latter',
'leading',
'new',
'television',
'on',
'UKTV',
'Gold',
'2013'] |
检查了一下,一长串(63个)词语列表中,没有出现标点。一切正常。
下面,我们把每个词汇对应的空间向量,追加到词嵌入矩阵中。
for word in word_list:
embedding = np.append(embedding, nlp.vocab[word].vector)
|
看看此时词嵌入矩阵的维度。
可以看到,所有的向量内容,都被放在了一个长串上面。这显然不符合我们的要求,我们将不同的单词对应的词向量,拆解到不同行上面去。
| embedding = embedding.reshape(len(word_list),
-1) |
再看看变换后词嵌入矩阵的维度。
63个词汇,每个长度300,这就对了。
下面我们从scikit-learn软件包中,读入TSNE模块。
| from sklearn.manifold
import TSNE |
我们建立一个同名小写的tsne,作为调用对象。
tsne的作用,是把高维度的词向量(300维)压缩到二维平面上。我们执行这个转换过程:
| low_dim_embedding
= tsne.fit_transform(embedding) |
现在,我们手里拥有的 low_dim_embedding ,就是63个词汇降低到二维的向量表示了。
我们读入绘图工具包。
import matplotlib.pyplot
as plt
%pylab inline |
下面这个函数,用来把二维向量的集合,绘制出来。
如果你对该函数内容细节不理解,没关系。因为我还没有给你系统介绍过Python下的绘图功能。
好在这里我们只要会调用它,就可以了。
def plot_with_labels(low_dim_embs,
labels, filename='tsne.pdf'):
assert low_dim_embs.shape[0] >= len(labels),
"More labels than embeddings"
plt.figure(figsize=(18, 18)) # in inches
for i, label in enumerate(labels):
x, y = low_dim_embs[i, :]
plt.scatter(x, y)
plt.annotate(label,
xy=(x, y),
xytext=(5, 2),
textcoords='offset points',
ha='right',
va='bottom')
plt.savefig(filename) |
终于可以进行降维后的词向量可视化了。
请执行下面这条语句:
| plot_with_labels(low_dim_embedding,
word_list) |
你会看到这样一个图形。
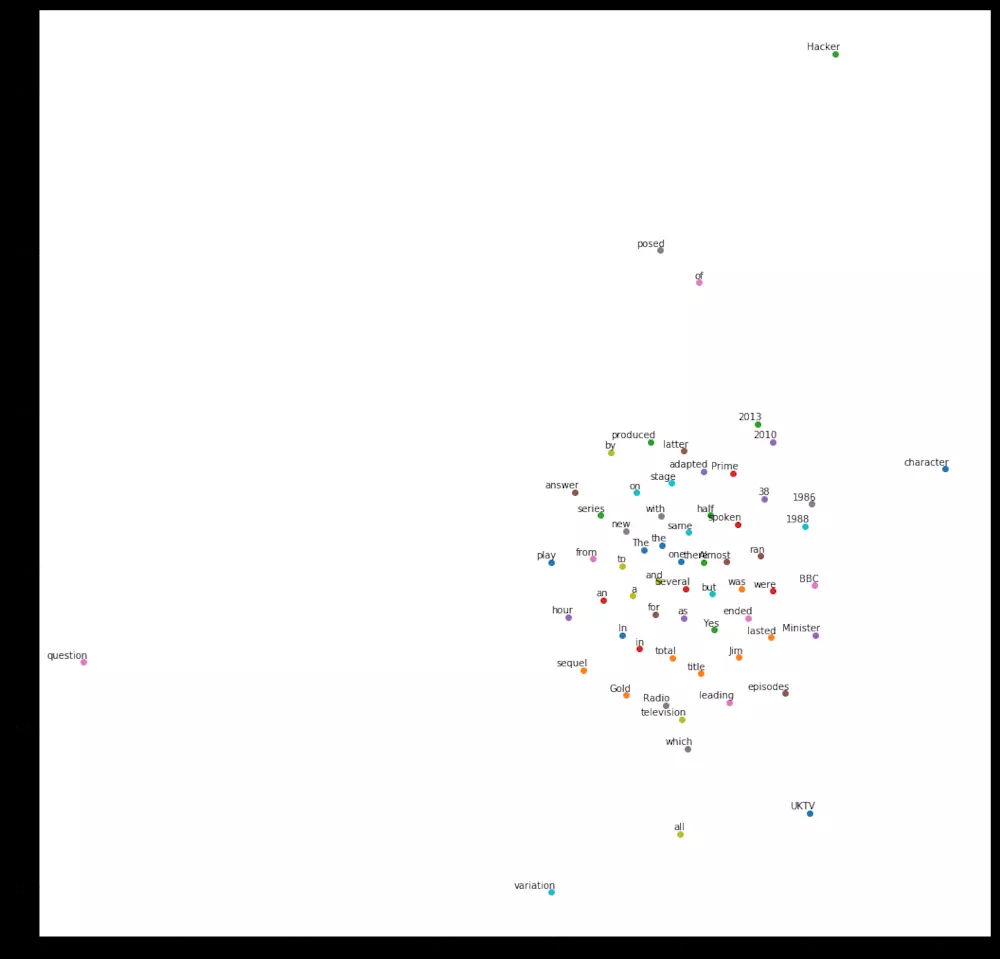
请注意观察图中的几个部分:
年份
同一单词的大小写形式
Radio 和 television
a 和 an
看看有什么规律没有?
我发现了一个有意思的现象——每次运行tsne,产生的二维可视化图都不一样!
不过这也正常,因为这段话之中出现的单词,并非都有预先训练好的向量。
这样的单词,被Spacy进行了随机化等处理。
因此,每一次生成高维向量,结果都不同。不同的高维向量,压缩到二维,结果自然也会有区别。
问题来了,如果我希望每次运行的结果都一致,该如何处理呢?
这个问题,作为课后思考题,留给你自行解答。
细心的你可能发现了,执行完最后一条语句后,页面左侧边栏文件列表中,出现了一个新的pdf文件。
这个pdf,就是你刚刚生成的可视化结果。你可以双击该文件名称,在新的标签页中查看。
看,就连pdf文件,Jupyter Lab也能正确显示。
下面,是练习时间。
请把ipynb出现的文本内容,替换为你感兴趣的段落和词汇,再尝试运行一次吧。
源码
执行了全部代码,并且尝试替换了自己需要分析的文本,成功运行后,你是不是很有成就感?
你可能想要更进一步挖掘Spacy的功能,并且希望在本地复现运行环境与结果。
没问题,请使用这个链接(http://t.cn/R35MIKh)下载本文用到的全部源代码和运行环境配置文件(Pipenv)压缩包。
如果你知道如何使用github,也欢迎用这个链接(http://t.cn/R35MEqk)访问对应的github
repo,进行clone或者fork等操作。
小结
本文利用Python自然语言处理工具包Spacy,非常简要地为你演示了以下NLP功能:
1.词性分析
2.命名实体识别
3.依赖关系刻画
4.词嵌入向量的近似度计算
5.词语降维和可视化
|








