| БрМЭЦМі: |
| БОЮФРДздгкoutofmemory,ЮФеТжївЊНВНтШчКЮРћгУ
Cython КЭ spaCy ШУ Python дкздШЛгябдДІРэШЮЮёжаЕФЫйЖШЬсИпАйБЖЁЃ |
|
ПЊЪМЧАЃЌЮвЃЈзїепЃЉЕУГаШЯЮФеТТдЮЂгааЉБъЬтЕГЃЌвђЮЊЫфШЛЮвУЧЛсЬжТлPythonЃЌЕЋвВЛсАќКЌвЛаЉCythonММЧЩЁЃВЛЙ§ЃЌФужЊЕРТ№ЃПCythonОЭЪЧPythonЕФГЌМЏАЁЃЌЫљвдВЛвЊБЛЫќЯХХмЃЁ
ФуЕБЧАЫљаДЕФPythonЯюФПвбОЫуЪЧвЛжжCythonЯюФПСЫ ЁЃ
ЯТУцЪЧвЛаЉФуПЩФмашвЊБОЮФЫљЫЕPythonМгЫйВпТдЕФЧщПіЃК
ФудкгУPythonПЊЗЂвЛПюгУгкNLPШЮЮёЕФВњЦЗФЃПщЁЃ
ФудкгУPythonМЦЫувЛИіДѓаЭNLPЪ§ОнМЏЕФЗжЮіЪ§ОнЁЃ
ФудкЮЊPyTorch/TensorFlowетбљЕФЩюЖШбЇЯАПђМмдЄДІРэДѓаЭбЕСЗЪ§ОнМЏЃЌЛђФуЕФЩюЖШбЇЯАФЃаЭЕФХњДЮМгдиЦїЃЈbatch
loaderЃЉВЩгУСЫЗЧГЃИДдгЕФДІРэТпМЃЌбЯжиМѕЛКСЫФуЕФбЕСЗЪБМфЁЃ
ЪЕЯжАйБЖМгЫйЕквЛВНЃКЗжЮіДњТы
ЕквЛМўФуашвЊжЊЕРЕФЪТЧщОЭЪЧЃЌФуЕФДѓВПЗжДњТыдкДПPythonЛЗОГЖМФмдЫааСМКУЃЌЕЋЦфжаЕФвЛаЉадФмЦПОБЮЪЬтЃЌжЛвЊФуТдБэЁАЙиЧаЁБЃЌОЭФмШУГЬађЕФЫйЖШМгЫйМИИіСПМЖЁЃ
вђДЫЃЌФугІИУзХЪжЗжЮіФуЕФPythonДњТыЃЌевЕНФЧаЉдЫааКмТ§ЕФВПЗжЁЃНтОіетИіЮЪЬтЕФвЛжжЗНЗЈОЭЪЧЪЙгУcProfileЃК
import cProfile
import pstats
import my_slow_module
cProfile.run('my_slow_module.run()', 'restats')
p = pstats.Stats('restats')
p.sort_stats('cumulative').print_stats(30) |
ФуЛсЗЂЯждЫааЛКТ§ЕФВПЗжЛљБООЭЪЧвЛаЉбЛЗЃЌЛђепФугУЕФЩёОЭјТчРягаЬЋЖрЕФNumpyЪ§зщВйзїЃЈетРяОЭВЛдйЯъЯИЬжТлNumpyЕФЮЪЬтСЫЃЌвђЮЊвбОгаКмЖретЗНУцЕФЗжЮізЪСЯЃЉЁЃ
ФЧУДЃЌЮвУЧИУдѕУДМгЫйетаЉбЛЗЃП
НшжњвЛЕуCythonММЧЩЃЌЮЊPythonжаЕФбЛЗЬсЫй
ЮвУЧвдвЛИіМђЕЅЕФР§згНВНтвЛЯТЁЃБШЗНЫЕЮвУЧгаКмЖрОиаЮЃЌНЋЫќУЧБЃДцЮЊвЛСаPythonЖдЯѓЃЌБШШчRectangleРрЕФЪЕР§ЁЃЮвУЧФЃПщЕФжївЊЙЄзїОЭЪЧЕќДњИУСаБэЃЌМЦЫугаЖрЩйОиаЮЕФУцЛ§ДѓгкЫљЩшукжЕЁЃ
ЮвУЧЕФPythonФЃПщЛсЗЧГЃМђЕЅЃЌОЭЯёетбљЃК
from random
import random
class Rectangle:
def __init__(self, w, h):
self.w = w
self.h = h
def area(self):
return self.w * self.h
def check_rectangles(rectangles, threshold):
n_out = 0
for rectangle in rectangles:
if rectangle.area() > threshold:
n_out += 1
return n_out
def main():
n_rectangles = 10000000
rectangles = list(Rectangle(random(), random())
for i in range(n_rectangles))
n_out = check_rectangles(rectangles, threshold=0.25)
print(n_out) |
етРяЕФCheck_rectanglesКЏЪ§ОЭЪЧЮвУЧвЊНтОіЕФЦПОБЃЁЫќбЛЗСЫДѓСПЕФPythonЖдЯѓЃЌетЛсБфЕУЗЧГЃТ§ЃЌвђЮЊPythonЕќДњЦїУПДЮЕќДњЪБЖМвЊдкБГКѓзіДѓСПЙЄзїЃЈВщбЏРржаЕФareaЗНЗЈЃЌДђАќКЭНтАќВЮЪ§ЃЌЕїШЁPython
APIЁЄЁЄЁЄЃЉЁЃ
етРяЮвУЧПЩвдНшжњCythonАяЮвУЧМгПьбЛЗЫйЖШЁЃ
CythonгябдЪЧPythonЕФГЌМЏЃЌPythonАќКЌСНжжЖдЯѓЃК
PythonЖдЯѓОЭЪЧЮвУЧдкГЃЙцPythonжаВйзїЕФЖдЯѓЃЌБШШчЪ§зжЁЂзжЗћДЎЁЂСаБэЁЂРрЪЕР§ЁЄЁЄЁЄ
Cython CЖдЯѓЪЧCЛђC++ЖдЯѓЃЌБШШчЫЋОЋЖШЁЂећаЭЁЂИЁЕуЪ§ЁЂНсЙЙКЭЯђСПЃЌCythonФмвддЫааГЌПьЕФЕЭМЖДњТыБрвыЫќУЧЁЃ
етРяЕФбЛЗЮвУЧЪЙгУCythonбЛЗОЭФмЛёЕУИќПьЕФдЫааЫйЖШЃЌЖјЮвУЧжЛашЛёШЁCython CЖдЯѓЁЃ
ЩшМЦетжжбЛЗЕФвЛИіжБНгЗНЗЈОЭЪЧЖЈвхCНсЙЙЃЌЫќЛсАќКЌЮвУЧМЦЫужаЫљашЕФШЋВПЖЋЮїЃКдкЮвУЧетРяЫљОйЕФР§згжаЃЌОЭЪЧОиаЮЕФГЄКЭПэЁЃ
ШЛКѓЮвУЧНЋОиаЮСаБэБЃДцдкЫљЖЈвхЕФCНсЙЙЕФЪ§зщжаЃЌЮвУЧЛсНЋЪ§зщДЋШыcheck_rectangleКЏЪ§жаЁЃИУКЏЪ§ЯждкБиашНгЪмCЪ§зщзїЮЊЪфШыЃЌетбљОЭЛсБЛЖЈвхЮЊCythonКЏЪ§ЃЌЪЙгУcdefЙиМќзжЖјЗЧdefЃЈcdefвВгУгкЖЈвхCython
CЖдЯѓЃЉЁЃ
етРяЪЧЮвУЧЕФPythonФЃПщЕФИпЫйCythonАцЕФбљзгЃК
from cymem.cymem
cimport Pool
from random import random
cdef struct Rectangle:
float w
float h
cdef int check_rectangles(Rectangle* rectangles,
int n_rectangles, float threshold):
cdef int n_out = 0
# C arrays contain no size information =>
we need to give it explicitly
for rectangle in rectangles[:n_rectangles]:
if rectangle[i].w * rectangle[i].h > threshold:
n_out += 1
return n_out
def main():
cdef:
int n_rectangles = 10000000
float threshold = 0.25
Pool mem = Pool()
Rectangle* rectangles = <Rectangle*>mem.alloc(n_rectangles,
sizeof(Rectangle))
for i in range(n_rectangles):
rectangles[i].w = random()
rectangles[i].h = random()
n_out = check_rectangles(rectangles, n_rectangles,
threshold)
print(n_out) |
етРяЮвУЧЪЙгУCжИеыЕФдЩњЪ§зщЃЌЕЋЪЧФувВПЩвдбЁдёЦфЫћбЁЯюЃЌгШЦфЪЧC++НсЙЙЃЌБШШчЯђСПЁЂЖўдЊзщЁЂЖгСажЎРрЁЃдкетРяЕФНХБОжаЃЌЮвЛЙЪЙгУСЫcymemЕФКмЗНУцЕФPool()ФкДцЙмРэЖдЯѓЃЌБмУтСЫБиаыЪжЖЏЪЭЗХЫљЩъЧыЕФCЪ§зщФкДцПеМфЁЃЕБPythonВЛдйашвЊPoolЪБЃЌЫќЛсздЖЏЪЭЗХЮвУЧгУЫќЩъЧыЪБЫљеМЕФФкДцЁЃ
ЮвУЧЪдЪдДњТыЃЁ ЮвУЧгаКмЖржжЗНЗЈПЩвдВтЪдЁЂБрМКЭЗжЗЂCythonДњТыЃЁCythonЩѕжСЛЙФмЯёPythonвЛбљжБНгдкJupyter
NotebookжаЪЙгУЁЃ
ЪзЯШгУpip install cythonАВзАCythonЁЃ
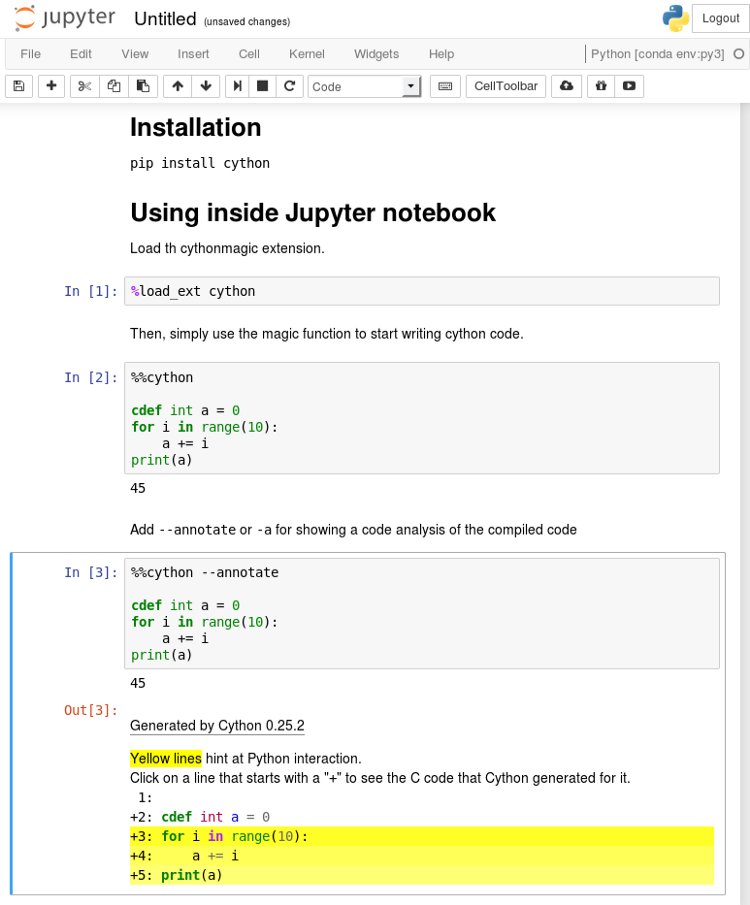
ЪзЯШдкJupyterжаВтЪд
дкJupyter notebookжагУ%load_ext CythonМгдиCythonРЉеЙЯюЁЃ
ЯждкЮвУЧОЭПЩвдгУЩёЦцЕФУќСю%%cythonЯёаДPythonДњТывЛбљБраДCythonДњТыЁЃ
ШчЙћФудкжДааCythonДњТыПщЪБГіЯжСЫБрвыДэЮѓЃЌвЛЖЈвЊМьВщвЛЯТJupyterжеЖЫЪфГіЃЌПДПДаХЯЂЪЧЗёЭъећЁЃ
ДѓЖрЪ§ЪБКђФуПЩФмЛсБрвыГЩC++ЪБЃЌдк %%cythonКѓУцТЉЕєСЫ a-+ БъЧЉЃЈР§ШчдкФуЪЙгУspaCy
Cython APIЪБЃЉЃЌЛђепШчЙћБрвыЦїГіЯжЙигкNumpyЕФБЈДэЃЌФуПЩФмЪЧвХТЉСЫimport NumpyЁЃ
БраДЁЂЪЙгУКЭЗжЗЂCythonДњТы
CythonДњТыБраДЮЊ.pyxЮФМўЁЃетаЉЮФМўБЛCythonБрвыЦїБрвыЮЊCЛђC++ЮФМўЃЌШЛКѓНјвЛВНгЩЯЕЭГЕФCБрвыЦїБрвыЮЊзжНкТыЮФМўЁЃНгзХЃЌзжНкТыЮФМўОЭФмБЛPythonНтЪЭЦїЪЙгУСЫЁЃ
ФуПЩвддкPythonРяжБНггУpyximportМгди.pyxЮФМўЃК
>>>
import pyximport; pyximport.install()
>>> import my_cython_module |
ФувВПЩвдНЋздМКЕФCythonДњТыДДНЈЮЊPythonАќЃЌНЋЦфзїЮЊе§ГЃPythonАќЕМШыЛђЗжЗЂЁЃетВПЗжЙЄзїЛђЛЈЗбвЛЕуЪБМфЁЃШчЙћФуашвЊвЛИіЙЄзїЪОР§ЃЌspaCyЕФАВзАНХБОЪЧБШНЯЯъЯИЕФР§згЁЃ
дкЮвУЧНВNLPжЎЧАЃЌЯШПьЫйЫЕЫЕdef,cdefКЭcpdefЙиМќзжЃЌвђЮЊЫќУЧЪЧФузХЪжЪЙгУCythonашвЊРэНтЕФжївЊжЊЪЖЕуЁЃ
ФуПЩвддкCythonжаЪЙгУ3жжРраЭЕФКЏЪ§ЃК
PythonКЏЪ§ЪЧгУГЃМћЙиМќзжdefЖЈвхЕФЁЃЫќЕФЪфШыКЭЪфГіОљЮЊPythonЖдЯѓЁЃдкКЏЪ§ФкВПМШПЩвдЪЙгУPythonЖдЯѓЃЌвВФмЪЙгУC/C++ЖдЯѓЃЌЭЌбљФмЕїгУPythonКЭCythonКЏЪ§ЁЃ
CythonКЏЪ§ЪЧвдЙиМќзжcdefЖЈвхЕФЁЃПЩвдНЋPythonКЭC/C++ЖдЯѓзїЮЊЪфШыКЭЪфГіЃЌвВФмдкФкВПВйзїЫќУЧЁЃCythonКЏЪ§ВЛФмДгPythonЛЗОГжажБНгЗУЮЪЃЈPythonНтЪЭЦїКЭЦфЫќДПPythonФЃПщЛсЕМШыФуЕФCythonФЃПщЃЉЃЌЕЋФмБЛЦфЫќCythonФЃПщЕМШыЁЃ
Cython КЏЪ§гУcpdefЙиМќзжЖЈвхЪБКЭcdefЖЈвхЕФКЏЪ§вЛбљЃЌЕЋЫќУЧДјгаPythonАќзАЦїЃЌвђДЫДгPythonЛЗОГЃЈPythonЖдЯѓЮЊЪфШыКЭЪфГіЃЉКЭЦфЫќCythonФЃПщЃЈC/C
++ЛђPythonЖдЯѓЮЊЪфШыЃЉжаЖМФмЕїгУЫќУЧЁЃ
CdefЙиМќзжЛЙгаСэвЛИігУЭОЃЌМДдкДњТыжаЪфШыCython C/C ++ЁЃШчЙћФуУЛгагУИУЙиМќзжЪфШыФуЕФЖдЯѓЃЌЫќУЧЛсБЛЕБГЩPythonЖдЯѓЃЈетбљОЭЛсбгЛКЗУЮЪЫйЖШЃЉЁЃ
ЪЙгУCythonКЭspaCyМгПьНтОіNLPЮЪЬтЕФЫйЖШ
ЯждквЛЧаНјааЕФКмКУвВКмПьЃЌЕЋЪЧЁЄЁЄЁЄЮвУЧЛЙУЛЩцМАздШЛгябдДІРэШЮЮёФиЃЁУЛгазжЗћДЎВйзїЃЌУЛгаUnicodeБрТыЃЌвВУЛгаЮвУЧдкздШЛгябдДІРэжаФмЙЛЪЙгУЕФУюМЦЁЃ
змЕФРДЫЕЃЌГ§ЗЧФуКмЧхГўздМКЫљзіЕФШЮЮёЃЌВЛШЛОЭВЛвЊЪЙгУCРраЭзжЗћДЎЃЌЖјЪЧЪЙгУPythonзжЗћДЎЖдЯѓЁЃ
ЫљвдЃЌЮвУЧВйзїзжЗћДЎЪБЃЌИУдѕбљЩшМЦCythonжаЕФПьЫйбЛЗФиЃП
spaCyЪЧЮвУЧЕФЁАЛЄЩэЗћЁБЁЃspaCyНтОіетИіЮЪЬтЕФЗНЪНЗЧГЃжЧФмЁЃ
НЋЫљгазжЗћДЎзЊЛЛЮЊ64ЮЛЙўЯЃТы
дкspaCyжаЃЌЫљгаЕФUnicodeзжЗћДЎЃЈtokenЕФЮФБОЃЌЫќЕФаЁаДаЮЪНЮФБОЃЌPOS БъМЧБъЧЉЁЂНтЮіЪївРРЕБъЧЉЁЂУќУћЪЕЬхБъЧЉЕШЕШЃЉЖМБЛДцДЂдквЛИіНаStringStoreЕФЕЅЪ§ОнНсЙЙжаЃЌПЩвдБЛ64ЮЛЙўЯЃТыЫїв§ЃЌвВОЭЪЧCРраЭunit64_t
ЁЃ
StringStoreЖдЯѓЪЕЯжСЫPython unicode зжЗћДЎгы 64 ЮЛЙўЯЃТыжЎМфЕФВщевгГЩфЁЃ
ЫќПЩвдДг spaCy ЕФШЮКЮЕиЗНКЭШЮвтЖдЯѓНјааЗУЮЪЃЈШчЯТЭМЫљЪОЃЉЃЌБШШч npl.vocab.stringsЁЂdoc.vocab.strings
Лђеп span.doc.vocab.stringЁЃ
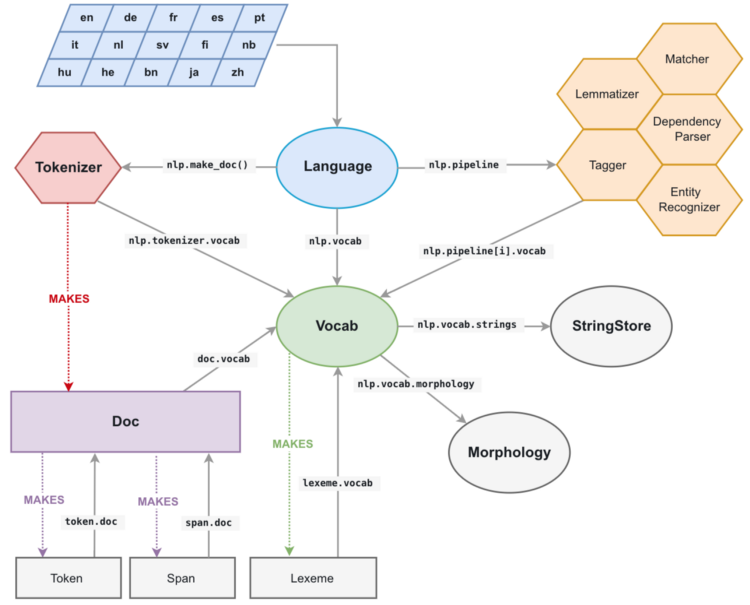
ЕБФГИіФЃПщашвЊдкФГаЉtokensЩЯЛёЕУИќПьЕФДІРэЫйЖШЪБЃЌОЭПЩвдЪЙгУ C гябдРраЭЕФ 64 ЮЛЙўЯЃТыДњЬцзжЗћДЎРДЪЕЯжЁЃЕїгУ
StringStore ВщевБэНЋЗЕЛигыИУЙўЯЃТыЯрЙиСЊЕФ Python unicode зжЗћДЎЁЃ
ЕЋЪЧspaCyЕФзїгУВЛжЙШчДЫЃЌЫќЛЙФмШУЮвУЧЛёШЁЮФЕЕКЭДЪЛуБэЕФЭъШЋЬюГфЕФCгябдРраЭНсЙЙЃЌЮвУЧПЩвддкCythonбЛЗжагУЕНетвЛЕуЃЌЖјВЛБиДДНЈЮвУЧздМКЕФНсЙЙЁЃ
spaCyЕФФкВПЪ§ОнНсЙЙ КЭspaCyЯрЙиЕФжївЊЪ§ОнНсЙЙЪЧDocЖдЯѓЃЌЫќгаБЛДІРэЕФзжЗћДЎЕФtokenађСаЃЌЫќдкCгябдРраЭЖдЯѓжаЕФЫљгазЂЪЭЖМБЛГЦЮЊdoc.cЃЌЪЧЮЊTokenCНсЙЙЕФЪ§зщЁЃ
TokenCНсЙЙАќКЌСЫЮвУЧЙигкУПИіtokenЫљашЕФШЋВПаХЯЂЁЃИУаХЯЂвд64ЮЛЙўЯЃТыЕФаЮЪНБЃДцЃЌФмЙЛгыЮвУЧИеИеПДЕНЕФUnicodeзжЗћДЎжиаТЙиСЊЁЃ
ШчЙћЯыПДПДетаЉCРраЭНсЙЙжаЕНЕзгаЪВУДЃЌжЛашВщПДаТНЈЕФspaCyЕФCython API docМДПЩЁЃ
ЮвУЧНгЯТРДПДвЛИіМђЕЅЕФздШЛгябдДІРэЕФР§згЁЃ
ЪЙгУspaCyКЭCythonПьЫйжДааздШЛгябдДІРэШЮЮё МйЩшЮвУЧгавЛИіЮФБОЮФЕЕЪ§ОнМЏашвЊЗжЮіЁЃ
ЯТУцЪЧЮваДЕФвЛЖЮНХБОЃЌДДНЈвЛИіСаБэЃЌАќКЌ10ИігЩspaCyНтЮіЕФЮФЕЕЃЌУПИіЮФЕЕАќКЌДѓдМ17ЭђИіДЪЛуЁЃЮвУЧвВПЩвдНтЮі17ЭђЗнЮФЕЕЃЌУПЗнЮФЕЕАќКЌ10ИіДЪЛуЃЈОЭЯёЖдЛАПђЪ§ОнМЏЃЉЃЌЕЋетжжДДНЈЗНЪНвЊТ§ЕФЖрЃЌЫљвдЮвУЧЛЙЪЧВЩШЁ10ЗнЮФЕЕЕФаЮЪНЁЃ
import urllib.request
import spacy
with urllib.request.urlopen('https:// raw.githubusercontent.com
/pytorch/examples/master/word_language_model /data/wikitext-2/valid.txt')
as response:
text = response.read()
nlp = spacy.load('en')
doc_list = list(nlp(text[:800000].decode('utf8'))
for i in range(10)) |
ЮвУЧЯыгУетИіЪ§ОнМЏжДаавЛаЉздШЛгябдДІРэШЮЮёЁЃР§ШчЃЌЮвУЧЯыМЦЫуДЪЛуЁАrunЁБдкЪ§ОнМЏжагУзїУћДЪЕФДЮЪ§ЃЈБШШчЃЌБЛ
spaCy БъМЧЮЊЁИNNЁЙДЪадБъЧЉЃЉЁЃ
ЪЙгУPython бЛЗЪЕЯжЩЯЪіЗжЮіЕФЙ§ГЬЗЧГЃМђЕЅжБНгЃК
def slow_loop(doc_list,
word, tag):
n_out = 0
for doc in doc_list:
for tok in doc:
if tok.lower_ == word and tok.tag_ == tag:
n_out += 1
return n_out
def main_nlp_slow(doc_list):
n_out = slow_loop(doc_list, 'run', 'NN')
print(n_out) |
ЕЋЪЧЫќдЫааЕФЗЧГЃТ§ЃЁдкЮвЕФБЪМЧБОЩЯЃЌетЕуДњТыЛЈСЫ1.4УыВХЕУЕННсЙћЁЃШчЙћЮвУЧгаЪ§АйЭђЗнЮФЕЕЃЌОЭашвЊЛЈЗбвЛЬьЖрЕФЪБМфВХФмЕУЕНД№АИЁЃ
ЮвУЧПЩвдЪЙгУЖрЯпГЬДІРэЃЌЕЋдкPythonжаетЭЈГЃвВВЛЪЧИіКмКУЕФНтОіЗНЗЈЃЌвђЮЊФуБиаыДІРэGILЮЪЬтЃЈGILМДglobal
interpreter lockЃЌШЋОжНтЪЭЦїЫјЃЉЁЃЖјЧвЃЌCythonвВФмЪЙгУЖрЯпГЬЃЁЪЕМЪЩЯЃЌетПЩФмЪЧCythonжазюАєЕФВПЗжЃЌвђЮЊCythonЛљБОЩЯФмдкКѓЬЈжБНгЕїгУOpenMPЁЃетРяВЛдйЯъЯИЬжТлВЂааадЕФЮЪЬтЃЌПЩвдЕуЛї
етРя ВщПДИќЖраХЯЂЁЃ
НгЯТРДЃЌЮвУЧгУspaCyКЭCythonМгПьЮвУЧЕФPythonДњТыЕФдЫааЫйЖШЁЃ
ЪзЯШЃЌЮвУЧБиаыПМТЧКУЪ§ОнНсЙЙЁЃЮвУЧашвЊЮЊЪ§ОнМЏЛёШЁвЛИіCРраЭЪ§зщЃЌВЂгажИеыжИЯђУПИіЮФЕЕЕФTokenCЪ§зщЁЃЮвУЧЛЙашвЊНЋЫљгУЕФВтЪдзжЗћДЎЃЈЁАrunЁБКЭЁАNNЁБЃЉзЊЛЛЮЊ64ЮЛЙўЯЃТыЁЃ
ШчЙћЮвУЧДІРэЙ§ГЬжаЫљашЕФШЋВПЪ§ОнЖМЪЧCРраЭЖдЯѓЃЌШЛКѓЮвУЧПЩвдвдДПCгябдЕФЫйЖШЕќДњећИіЪ§ОнМЏЁЃ
ЯТУцЪЧПЩвдгУCythonКЭspaCyЪЕЯжЕФЪОР§ЃК
import numpy
# Sometime we have a fail to import numpy compilation
error if we don't import numpy
from cymem.cymem cimport Pool
from spacy.tokens.doc cimport Doc
from spacy.typedefs cimport hash_t
from spacy.structs cimport TokenC
cdef struct DocElement:
TokenC* c
int length
cdef int fast_loop(DocElement* docs, int n_docs,
hash_t word, hash_t tag):
cdef int n_out = 0
for doc in docs[:n_docs]:
for c in doc.c[:doc.length]:
if c.lex.lower == word and c.tag == tag:
n_out += 1
return n_out
def main_nlp_fast(doc_list):
cdef int i, n_out, n_docs = len(doc_list)
cdef Pool mem = Pool()
cdef DocElement* docs = <DocElement*>mem.alloc(n_docs,
sizeof(DocElement))
cdef Doc doc
for i, doc in enumerate(doc_list): # Populate
our database structure
docs[i].c = doc.c
docs[i].length = (<Doc>doc).length
word_hash = doc.vocab.strings.add('run')
tag_hash = doc.vocab.strings.add('NN')
n_out = fast_loop(docs, n_docs, word_hash, tag_hash)
print(n_out) |
ДњТыгаЕуГЄЃЌвђЮЊЮвУЧБиаыдкЕїгУCythonКЏЪ§[*]жЎЧАдкmain_nlp_fastжЎжаЩљУїКЭЬюГфCНсЙЙЁЃ
ЕЋЪЧДњТыЕФдЫааЫйЖШПьСЫКмЖрЃЁдкЮвЕФJupyter notebookжаЃЌетЖЮCythonДњТыдЫааЫйЖШДѓИХжЛга20ЮЂУыЃЌЯрБШЮвУЧДЫЧАЕФЭъШЋгЩPythonБраДЕФбЛЗЃЌдЫааЫйЖШПьСЫ80БЖЁЃ
ЪЙгУJupyter NotebookБраДФЃПщЕФЫйЖШЭЌбљСюШЫжѕФПЃЌЫќПЩвдКЭЦфЫќPythonФЃПщКЭКЏЪ§здШЛЕиСЌНгЃК20ЮЂУыФкПЩДІРэЖрДя170ЭђИіДЪЛуЃЌвВОЭЪЧЫЕЮвУЧУПУыДІРэЕФДЪЛуЪ§СПИпДя8000ЭђЃЁ
вдЩЯОЭЪЧЮвУЧЭХЖгШчКЮгУCythonДІРэNLPШЮЮёЕФПьЫйНщЩмЃЌЯЃЭћФуФмЯВЛЖЁЃ
Нсгя
ЙигкCythonЃЌЛЙгаКмЖрашвЊбЇЯАЕФжЊЪЖЃЌПЩвдВщПД CythonЙйЗННЬГЬ ЛёЕУДѓжТЕФСЫНтЃЌвдМАspaCyЩЯ
гУгкДІРэNLPШЮЮёЕФCythonФкШн ЁЃ
ШчЙћФудкФуЕФДњТыжаЪ§ДЮЪЙгУЕЭМЖНсЙЙЃЌЯрБШУПДЮЬюГфCРраЭНсЙЙЃЌИќКУЕФбЁдёЪЧЮЇШЦЕЭМЖНсЙЙЩшМЦЮвУЧЕФPythonДњТыЃЌЪЙгУCythonРЉеЙРраЭАќзАCРраЭНсЙЙЁЃетвВЪЧДѓВПЗжspaCyЕФЙЙНЈЗНЪНЃЌВЛНідЫааЫйЖШПьЃЌФкДцЯћКФаЁЃЌЖјЧвЛЙФмШУЮвУЧКмШнвзЕФСЌНгЭтВПPythonПтКЭКЏЪ§ЁЃ
ИНБОЮФШЋВПДњТы
|








