| БрМЭЦМі: |
| БОЮФРДздгкcnblogsЃЌжївЊМђЕЅНщЩмСЫPandasЕФЪ§ОнРраЭЃЌЪ§ОнЙ§ТЫЃЌВйзївЛИіЪ§ОнМЏНсЙЙЕШЯрЙижЊЪЖЁЃ |
|
дкЮвПДРДЃЌЖдгкNumpyвдМАMatplotlibЃЌPandasПЩвдАяжњДДНЈвЛИіЗЧГЃРЮЙЬЕФгУгкЪ§ОнЭкОђгыЗжЮіЕФЛљДЁЁЃЖјScipyЃЈЛсдкНгЯТРДЕФЬћзгжаЬсМАЃЉЕБШЛЪЧСэвЛИіжївЊЕФвВЪЎЗжГіЩЋЕФПЦбЇМЦЫуПтЃЌЕЋЪЧЮвШЯЮЊЧАШ§епВХЪЧеце§ЕФPythonПЦбЇМЦЫуЕФжЇжљЁЃ
ЕМШыPandas
ЮвУЧЪзЯШвЊЕМШыЮвУЧЕФбнГіУїаЧЁЊЁЊPandasЁЃ

етЪЧЕМШыPandasЕФБъзМЗНЪНЁЃЯдШЛЃЌЮвУЧВЛЯЃЭћУПЪБУППЬЖМдкГЬађжааДЁЏpandasЁЏЃЌЕЋЪЧБЃГжДњТыМђНрЁЂБмУтУќУћГхЭЛЛЙЪЧЯрЕБживЊЕФЁЃвђЖјЮвУЧелждвЛЯТЃЌгУЁЎpdЁЏДњЬцЁАpandasЁЏЁЃШчЙћФузаЯИВщПДЦфЫћШЫЪЙгУPandasЕФДњТыЃЌФуЛсЗЂЯжетЬѕЕМШыгяОфЁЃ
PandasЕФЪ§ОнРраЭ
PandasЛљгкСНжжЪ§ОнРраЭЃКseriesгыdataframeЁЃ
вЛИіseriesЪЧвЛИівЛЮЌЕФЪ§ОнРраЭЃЌЦфжаУПвЛИідЊЫиЖМгавЛИіБъЧЉЁЃШчЙћФудФЖСЙ§етИіЯЕСаЕФЙигкNumpyЕФЮФеТЃЌФуОЭПЩвдЗЂЯжseriesРрЫЦгкNumpyжадЊЫиДјБъЧЉЕФЪ§зщЁЃЦфжаЃЌБъЧЉПЩвдЪЧЪ§зжЛђепзжЗћДЎЁЃ
вЛИіdataframeЪЧвЛИіЖўЮЌЕФБэНсЙЙЁЃPandasЕФdataframeПЩвдДцДЂаэЖржжВЛЭЌЕФЪ§ОнРраЭЃЌВЂЧвУПвЛИізјБъжсЖМгаздМКЕФБъЧЉЁЃФуПЩвдАбЫќЯыЯѓГЩвЛИіseriesЕФзжЕфЯюЁЃ
НЋЪ§ОнЕМШыPandas
дкЮвУЧПЊЪМЭкОђгыЗжЮіжЎЧАЃЌЮвУЧЪзЯШашвЊЕМШыФмЙЛДІРэЕФЪ§ОнЁЃавКУЃЌPandasдкетвЛЕувЊБШNumpyИќЗНБуЁЃ
дкетРяЮвЭЦМіФуЪЙгУздМКЫљИааЫШЄЕФЪ§ОнМЏРДЪЙгУЁЃФуЕФЛђЦфЫћЙњМвЕФеўИЎЭјеОЩЯЛсгавЛаЉКУЕФЪ§ОндДЁЃР§ШчЃЌФуПЩвдЫбЫїгЂЙњеўИЎЪ§ОнЛђУРЙњеўИЎЪ§ОнРДЛёШЁЪ§ОндДЁЃЕБШЛЃЌKaggleЪЧСэвЛИіКУгУЕФЪ§ОндДЁЃ
дкДЫЃЌЮвНЋВЩгУгЂЙњеўИЎЪ§ОнжаЙигкНЕгъСПЪ§ОнЃЌвђЮЊЫћУЧЪЎЗжвзгкЯТдиЁЃДЫЭтЃЌЮвЛЙЯТдиСЫвЛаЉШеБОНЕгъСПЕФЪ§ОнРДЪЙгУЁЃ

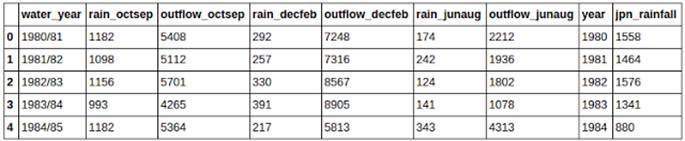
етРяЮвУЧДгcsvЮФМўжаЖСШЁЕНСЫЪ§ОнЃЌВЂНЋЫћУЧДцШыСЫdataframeжаЁЃЮвУЧжЛашвЊЕїгУread_csvКЏЪ§ВЂНЋcsvЮФМўЕФТЗОЖзїЮЊКЏЪ§ВЮЪ§МДПЩЁЃheaderЙиМќзжИцЫпPandasетаЉЪ§ОнЪЧЗёгаСаУћЃЌдкФФРяЁЃШчЙћУЛгаСаУћЃЌФуПЩвдНЋЦфжУЮЊNoneЁЃPandasЗЧГЃжЧФмЃЌЫљвдФуПЩвдЪЁТдетвЛЙиМќзжЁЃ
НЋФуЕФЪ§ОнзМБИКУвдНјааЭкОђКЭЗжЮі
ЯждкЮвУЧвбОНЋЪ§ОнЕМШыСЫPandasЁЃдкЮвУЧПЊЪМЩюШыЬНОПетаЉЪ§ОнжЎЧАЃЌЮвУЧвЛЖЈЦШЧаЕиЯыДѓжТфЏРРвЛЯТЫќУЧЃЌВЂДгжаЛёЕУвЛаЉгагУаХЯЂЃЌАяжњЮвУЧШЗСЂЬНОПЕФЗНЯђЁЃ
ЯывЊПьЫйВщПДЧАxааЪ§ОнЃК

ЮвУЧНіНіашвЊЪЙгУhead()КЏЪ§ВЂДЋШыЮвУЧЦкЭћЛёЕУЕФааЪ§ЁЃ
ФуНЋЛёЕУвЛИіРрЫЦЯТЭМвЛбљЕФБэЃК

СэвЛЗНУцЃЌФуПЩФмЯывЊЛёЕУзюКѓxааЕФЪ§ОнЃК

РрЫЦгкheadЃЌЮвУЧжЛашвЊЕїгУtailКЏЪ§ВЂДЋШыЮвУЧЯыЛёШЁЕФааЪ§ЁЃашвЊзЂвтЕФЪЧЃЌPandasВЛЪЧДгdataframeЕФНсЮВДІПЊЪМЕЙзХЪфГіЪ§ОнЃЌЖјЪЧАДееЫќУЧдкdataframeжаЙЬгаЕФЫГађЪфГіИјФуЁЃ
ФуНЋЛёЕУРрЫЦЯТЭМЕФБэ

ЕБФудкPandasжаВщевСаЪБЃЌФуЭЈГЃашвЊЪЙгУСаУћЁЃетбљЫфШЛЗЧГЃБугкЪЙгУЃЌЕЋгаЪБКђЃЌЪ§ОнПЩФмЛсгаЬиБ№ГЄЕФСаУћЃЌР§ШчЃЌгааЉСаУћПЩФмЪЧЮЪОэБэжаЕФФГећИіЮЪЬтЁЃАбетаЉСаУћБфЖЬЛсШУФуЕФЙЄзїИќМгЧсЫЩЃК

гавЛЕуашвЊзЂвтЕФЪЧЃЌдкетРяЮвЙЪвтШУЫљгаСаЕФБъЧЉЖМУЛгаПеИёКЭКсЯпЁЃКѓУцФуНЋЛсПДЕНЃЌШчЙћЮвУЧетбљУќУћБфСПЃЌPandasЛсНЋЫќУЧДцГЩЪВУДРраЭЁЃ
ФуНЋЛёЕУЭЌжЎЧАвЛбљЕФЪ§ОнЃЌЕЋЪЧСаУћвбОБфСЫЃК
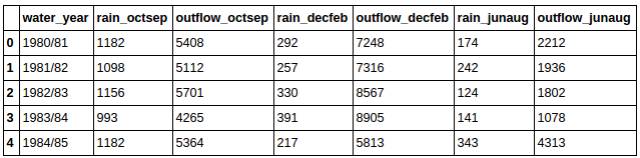
СэвЛМўФуКмЯыжЊЕРЕФЙигкФуЕФЪ§ОнЕФживЊЕФЪТЧщЪЧЪ§ОнвЛЙВгаЖрЩйЬѕФПЁЃдкPandasжаЃЌвЛИіЬѕФПЕШЭЌгквЛааЃЌЫљвдЮвУЧПЩвдЭЈЙ§lenЗНЗЈЛёШЁЪ§ОнЕФааЪ§ЃЌМДЬѕФПЪ§ЁЃ

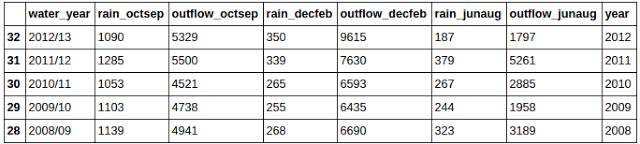
етНЋИјФувЛИіећЪ§ИцЫпФуЪ§ОнЕФааЪ§ЁЃдкЮвЕФЪ§ОнМЏжаЃЌЮвга33ааЁЃ
ДЫЭтЃЌФуПЩФмашвЊжЊЕРФуЪ§ОнЕФвЛаЉЛљБОЕФЭГМЦаХЯЂЁЃPandasШУетМўЪТБфЕУЗЧГЃМђЕЅЁЃ

етНЋЗЕЛивЛИіАќКЌЖржжЭГМЦаХЯЂЕФБэИёЃЌР§ШчЃЌМЦЪ§ЃЌОљжЕЃЌБъзМЗНВюЕШЁЃЫќПДЦ№РДЯёетбљЃК
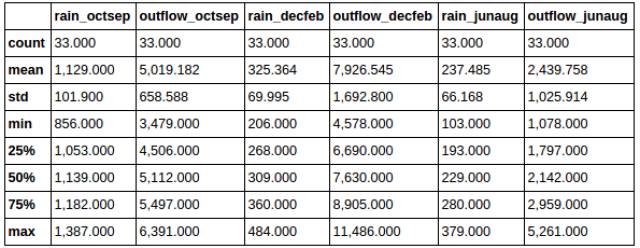

Й§ТЫ
ЕБФуВщПДФуЕФЪ§ОнМЏЪБЃЌФуПЩФмЯЃЭћЛёЕУвЛИіЬиЪтЕФбљБОЪ§ОнЁЃР§ШчЃЌШчЙћФугавЛИіЙигкЙЄзїТњвтЖШЕФЮЪОэЕїВщЪ§ОнЃЌФуПЩФмЯывЊЛёЕУЫљгадкЭЌвЛаавЕЛђЭЌвЛФъСфЖЮЕФШЫЕФЪ§ОнЁЃ
PandasЮЊЮвУЧЬсЙЉСЫЖржжЗНЗЈРДЙ§ТЫЮвУЧЕФЪ§ОнВЂЬсШЁГіЮвУЧЯывЊЕФаХЯЂЁЃгаЪБКђФуЯывЊЬсШЁвЛећСаЁЃПЩвджБНгЪЙгУСаБъЧЉЃЌЗЧГЃШнвзЁЃ

зЂвтЕНЕБЮвУЧЬсШЁСЫвЛСаЃЌPandasНЋЗЕЛивЛИіseriesЃЌЖјВЛЪЧвЛИіdataframeЁЃЪЧЗёЛЙМЧЕУЃЌФуПЩвдНЋdataframeЪгзїseriesЕФзжЕфЁЃЫљвдЃЌШчЙћЮвУЧШЁГіСЫФГвЛСаЃЌЮвУЧЛёЕУЕФздШЛЪЧвЛИіseriesЁЃ
ЛЙМЧЕУЮвЫљЫЕЕФУќУћСаБъЧЉЕФзЂвтЪТЯюТ№ЃПВЛЪЙгУПеИёКЭКсЯпЕШПЩвдШУЮвУЧвдЗУЮЪРрЪєадЯрЭЌЕФЗНЗЈРДЗУЮЪСаЃЌМДЪЙгУЕудЫЫуЗћЁЃ

етРяЗЕЛиЕФНсЙћКЭжЎЧАЕФвЛФЃвЛбљЃЌМДвЛИіАќКЌЮвУЧЫљбЁСаЕФЪ§ОнЕФseriesЁЃ
ШчЙћФуЖСЙ§етвЛЯЕСажаNumpyФЧвЛЦЊЬћзгЃЌФуПЩФмЛсМЧЕУвЛЯюММЪѕНазіЁЎboolean maskingЁЏ,МДЮвУЧПЩвддкЪ§зщЩЯдЫаавЛИіЬѕМўгяОфРДЛёЕУЖдгІЕФВМЖћжЕЪ§зщЁЃКУЃЌЮвУЧвВПЩвддкPandasжазіЭЌбљЕФЪТЁЃ

ЩЯЪіДњТыНЋЗЖЮЇвЛИіВМЖћжЕЕФdataframeЃЌЦфжаЃЌШчЙћ9ЁЂ10дТЕФНЕгъСПЕЭгк1000КСУзЃЌдђЖдгІЕФВМЖћжЕЮЊЁЎTrueЁЏ,ЗДжЎЃЌдђЮЊЁЏFalseЁЏЁЃ
ЮвУЧвВПЩвдЪЙгУетаЉЬѕМўБэДяЪНРДЙ§ТЫвЛИівбжЊЕФdataframeЁЃ

етНЋЗЕЛивЛИіНіНіАќКЌ9ЁЂ10дТНЕгъСПЕЭгк1000mmЕФЬѕФПЕФdataframeЁЃ

ФувВПЩвдЪЙгУЖрЬѕЬѕМўБэДяЪНРДНјааЙ§ТЫЃК

етНЋЗЕЛиrain_octsepаЁгк1000ВЂЧвoutflow_octsepаЁгк4000ЕФФЧаЉЬѕФПЁЃ
жЕЕУзЂвтЕФЪЧЃЌгЩгкВйзїЗћгХЯШМЖЕФЮЪЬтЃЌдкетРяФуВЛПЩвдЪЙгУЙиМќзжЁЎandЁЏЃЌЖјжЛФмЪЙгУЁЏ&ЁЏгыРЈКХ
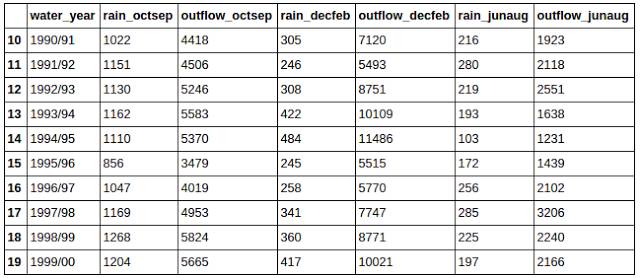
КУЯћЯЂЪЧЃЌШчЙћдкФуЕФЪ§ОнжагазжЗћДЎЃЌФувВПЩвдЪЙгУзжЗћДЎЗНЗЈРДЙ§ТЫЪ§ОнЁЃ

зЂвтЕНФуБиаыЪЙгУ.str.[string method]ЃЌФуВЛФмжБНгдкзжЗћДЎЩЯжБНгЕїгУзжЗћДЎЗНЗЈЁЃетвЛгяОфЗЕЛи1990ФъДњЕФЫљгаЬѕФПЁЃ
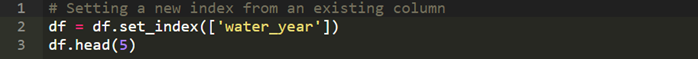
Ыїв§
ЧАМИВПЗжЮЊЮвУЧеЙЪОСЫШчКЮЭЈЙ§СаВйзїРДЛёЕУЪ§ОнЁЃЪЕМЪЩЯЃЌPandasЭЌбљгаБъЧЉЛЏЕФааВйзїЁЃетаЉааБъЧЉПЩвдЪЧЪ§зжЛђЪЧЦфЫћБъЧЉЁЃЛёШЁааЪ§ОнЕФЗНЗЈвВШЁОігкетаЉБъЧЉЕФРраЭЁЃ
ШчЙћФуЕФаагаЪ§зжЫїв§ЃЌФуПЩвдЪЙгУilocв§гУЫћУЧЃК

ilocНіНізїгУгкЪ§зжЫїв§ЁЃЫќНЋЛсЗЕЛиИУааЕФвЛИіseriesЁЃдкЗЕЛиЕФseriesжаЃЌетвЛааЕФУПвЛСаЖМЪЧвЛИіЖРСЂЕФдЊЫиЁЃ
ПЩФмдкФуЕФЪ§ОнМЏРягаФъЗнЕФСаЃЌЛђепФъДњЕФСаЃЌВЂЧвФуЯЃЭћПЩвдгУетаЉФъЗнЛђФъДњРДЫїв§ФГаЉааЁЃетбљЃЌЮвУЧПЩвдЩшжУвЛИіЃЈЛђЖрИіЃЉаТЕФЫїв§ЁЃ

етНЋЛсИјЁЏwater_yearЁЏвЛИіаТЕФЫїв§жЕЁЃзЂвтЕНСаУћЫфШЛжЛгавЛИідЊЫиЃЌШДЪЕМЪЩЯашвЊАќКЌгквЛИіСаБэжаЁЃШчЙћФуЯывЊЖрИіЫїв§ЃЌФуПЩвдМђЕЅЕидкСаБэжадіМгСэвЛИіСаУћЁЃ

дкЩЯУцетИіР§згжаЃЌЮвУЧАбЮвУЧЕФЫїв§жЕШЋВПЩшжУЮЊСЫзжЗћДЎЁЃетвтЮЖзХЮвУЧВЛПЩвдЪЙгУilocЫїв§етаЉСаСЫЁЃетжжЧщПіИУШчКЮЃПЮвУЧЪЙгУlocЁЃ

етРяЃЌlocКЭilocвЛбљЛсЗЕЛиФуЫљЫїв§ЕФааЪ§ОнЕФвЛИіseriesЁЃЮЈвЛЕФВЛЭЌЪЧДЫЪБФуЪЙгУЕФЪЧзжЗћДЎБъЧЉНјаав§гУЃЌЖјВЛЪЧЪ§зжБъЧЉЁЃ
ixЪЧСэвЛИіГЃгУЕФв§гУвЛааЕФЗНЗЈЁЃФЧУДЃЌШчЙћlocЪЧзжЗћДЎБъЧЉЕФЫїв§ЗНЗЈЃЌilocЪЧЪ§зжБъЧЉЕФЫїв§ЗНЗЈЃЌФЧЪВУДЪЧixФиЃПЪТЪЕЩЯЃЌixЪЧвЛИізжЗћДЎБъЧЉЕФЫїв§ЗНЗЈЃЌЕЋЪЧЫќЭЌбљжЇГжЪ§зжБъЧЉЫїв§зїЮЊЫќЕФБИбЁЁЃ
е§ШчlocКЭilocЃЌЩЯЪіДњТыНЋЗЕЛивЛИіseriesАќКЌФуЫљЫїв§ЕФааЕФЪ§ОнЁЃ
МШШЛixПЩвдЭъГЩlocКЭilocЖўепЕФЙЄзїЃЌЮЊЪВУДЛЙашвЊЫќУЧФи?зюжївЊЕФдвђЪЧixгавЛаЉЧсЮЂЕФВЛПЩдЄВтадЁЃЛЙМЧЕУЮвЫЕЪ§зжБъЧЉЫїв§ЪЧixЕФБИбЁТ№ЃПЪ§зжБъЧЉПЩФмЛсШУixзіГівЛаЉЦцЙжЕФЪТЧщЃЌР§ШчНЋвЛИіЪ§зжНтЪЭГЩвЛИіЮЛжУЁЃЖјlocКЭilocдђЮЊФуДјРДСЫАВШЋЕФЁЂПЩдЄВтЕФЁЂФкаФЕФФўОВЁЃШЛЖјБиаыжИГіЕФЪЧЃЌixвЊБШlocКЭilocИќПьЁЃ
ЭЈГЃЮвУЧЖМЯЃЭћЫїв§ЪЧећЦыгаађЕиЁЃЮвУЧПЩвддкPandasжаЭЈЙ§ЕїгУsort_indexРДЖдdataframeЪЕЯжХХађЁЃ

гЩгкЮвЕФЫљвдвбОЪЧгаађЕФСЫЃЌЫљвдЮЊСЫбнЪОЃЌЮвЩшжУСЫЙиМќзжВЮЪ§ЁЏascendingЁЏЮЊFalseЁЃетбљЃЌЮвЕФЪ§ОнЛсвдНЕађХХСаЁЃ

ЕБФуЮЊвЛСаЪ§ОнЩшжУСЫвЛИіЫїв§ЪБЃЌЫќУЧНЋВЛдйЪЧЪ§ОнБОЩэСЫЁЃШчЙћФуЯыАбЫїв§ЩшжУЮЊдЪМЪ§ОнЕФаЮЪНЃЌФуПЩвдЪЙгУКЭset_indexЯрЗДЕФВйзїЁЊЁЊreset_indexЁЃ
етНЋЗЕЛиЪ§ОндЪМЕФЫїв§аЮЪНЁЃ

ЖдЪ§ОнМЏгІгУКЏЪ§
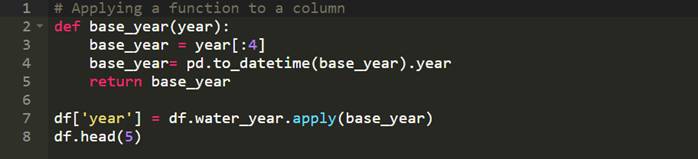
гаЪБКђФуЛсЯывдФГаЉЗНЪНИФБфЛђЪЧВйзїФуЪ§ОнМЏжаЕФЪ§ОнЁЃР§ШчЃЌШчЙћФугавЛСаФъЗнЕФЪ§ОнЖјФуЯЃЭћДДНЈвЛИіаТЕФСаЯдЪОетаЉФъЗнЫљЖдгІЕФФъДњЁЃPandasЖдДЫИјГіСЫСНИіЗЧГЃгагУЕФКЏЪ§ЃЌapplyКЭapplymapЁЃ
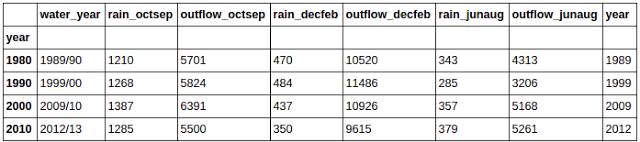
етЛсДДНЈвЛИіУћЮЊЁЎyearЁЎЕФаТСаЁЃетвЛСаЪЧгЩЁЏwater_yearЁЏСаЫљЕМГіЕФЁЃЫќЛёШЁЕФЪЧжїФъЗнЁЃетБуЪЧЪЙгУapplyЕФЗНЗЈЃЌМДШчКЮЖдвЛСагІгУвЛИіКЏЪ§ЁЃШчЙћФуЯыЖдећИіЪ§ОнМЏгІгУФГИіКЏЪ§ЃЌФуПЩвдЪЙгУdataset.applymap()ЁЃ
ВйзївЛИіЪ§ОнМЏНсЙЙ
СэвЛМўОГЃЛсЖдdataframeЫљзіЕФВйзїЪЧЮЊСЫШУЫќУЧГЪЯжГівЛжжИќБугкЪЙгУЕФаЮЪНЖјЖдЫќУЧНјааЕФжиЙЙЁЃ
ЪзЯШЃЌgroupbyЃК

groubyЫљзіЕФЪЧНЋФуЫљбЁдёЕФСазщГЩвЛзщЁЃЩЯЪіДњТыЪзЯШНЋФъДњзщГЩвЛзщЁЃЫфШЛетбљзіУЛгаИјЮвУЧДјРДШЮКЮБуРћЃЌЕЋЮвУЧПЩвдНєНгзХдкетИіЛљДЁЩЯЕїгУЦфЫќЗНЗЈЃЌР§Шчmax,
min, meanЕШЁЃР§згжаЃЌЮвУЧПЩвдЕУЕН90ФъДњЕФОљжЕЁЃ
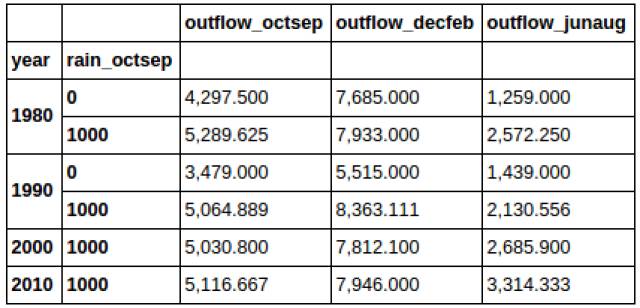
ФувВПЩвдЖдЖрааНјааЗжзщВйзї:

НгЯТРДЕФunstackВйзїПЩФмЦ№ГѕгавЛаЉРЇЛѓЁЃЫќЕФЙІФмЪЧНЋФГвЛСаЧАжУГЩЮЊСаБъЧЉЁЃЮвУЧзюКУШчЯТПДПДЫќЕФЪЕМЪаЇЙћЁЃ

етИіВйзїЛсНЋЮвУЧдкЩЯУцаЁНкДДНЈЕФdataframeзЊБфГЩШчЯТаЮЪНЁЃЫќНЋБъЪЖЁЎyearЁЏЫїв§ЕФЕк0СаЭЦЦ№РДЃЌБфЮЊСЫСаБъЧЉЁЃ

ЮвУЧдйИНМгвЛИіunstackВйзїЁЃетДЮЮвУЧЖдЁЏrain_octsepЁЏЫїв§ЕФЕк1СаВйзїЃК
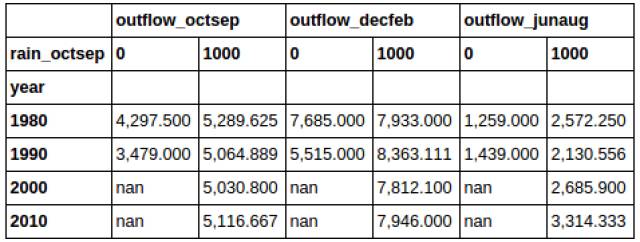
ЯждкЃЌдкЮвУЧЯТвЛИіВйзїЧАЃЌЮвУЧЪзЯШДДдьвЛИіаТЕФdataframeЁЃ

ЩЯЪіДњТыЮЊЮвУЧДДНЈСЫШчЯТЕФdataframeЃЌЮвУЧНЋЖдЫќНјааpivotВйзїЁЃ

pivotЪЕМЪЩЯЪЧдкБОЮФжаЮвУЧвбОМћЙ§ЕФВйзїЕФзщКЯЁЃЪзЯШЃЌЫќЩшжУСЫвЛИіаТЕФЫїв§(set_index())ЃЌШЛКѓЫќЖдетИіЫїв§ХХађ(sort_index())ЃЌзюКѓЫќЛсНјааunstackВйзїЁЃзщКЯЦ№РДОЭЪЧвЛИіpivotВйзїЁЃПДПДФуФмВЛФмЯыЯыЛсЗЂЩњЪВУДЃК

зЂвтЕНзюКѓгавЛИі.fillna(ЁЎЁЏ)ЁЃетИіpivotДДдьСЫаэЖрПеЕФЛђжЕЮЊNaNЕФЬѕФПЁЃЮвИіШЫОѕЕУЮвЕФdataframeБЛТвЦпАЫдуЕФNaNЗжЩЂСЫзЂвтСІЃЌЫљвдЪЙгУСЫfillna(ЁЎЁЏ)НЋЫћУЧБфГЩСЫПезжЗћДЎЁЃФувВПЩвдЪфШыШЮКЮФуЯВЛЖЕФЖЋЮїЃЌР§ШчвЛИі0ЁЃЮвУЧвВПЩвдЪЙгУКЏЪ§dropna(how=ЁЏanyЁЏ)РДЩОГ§ЫљгаЕФДјгаNaNЕФааЁЃШЛЖјдкетИіР§згРяЃЌЫќПЩФмЛсАбЫљгаЖЋЮїЖМЩОСЫЃЌЫљвдЮвУЧУЛгаетбљзіЁЃ
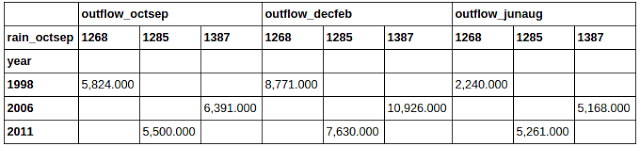
ЩЯЪіdataframeЮЊЮвУЧеЙЯжСЫЫљгаНЕгъСПДѓгк1250ЕФФъЗнжаЕФзмгъСПЁЃВЛПЩЗёШЯЕФЪЧЃЌетИіВЂВЛЪЧвЛИіpivotЕФзюКУЕФЪОЗЖЃЌЕЋЪЧЯЃЭћФуФмgetЕНЫќЕФКЫаФЁЃПДПДФуФмдкФуздМКЕФЪ§ОнМЏжаЯыГіЪВУДЕузгЁЃ
КЯВЂЪ§ОнМЏ
гаЪБКђФугаСНИіЕЅЖРЕФЪ§ОнМЏЃЌЫќУЧжБНгЛЅЯрЙиСЊЃЌЖјФуЯывЊБШНЯЫќУЧЕФВювьЛђепКЯВЂЫќУЧЁЃУЛЮЪЬтЃЌPandasПЩвдКмШнвзЪЕЯжЃК

ПЊЪМЪБФуашвЊЭЈЙ§ЁЏonЁЏЙиМќзжВЮЪ§жИЖЈФуЯывЊКЯВЂЕФСаЁЃФувВПЩвдКіТдетИіВЮЪ§ЃЌетбљPandasЛсздЖЏШЗЖЈКЯВЂФФСаЁЃ
ШчЯТФуПЩвдПДЕНЃЌСНИіЪ§ОнМЏдкФъЗнетвЛРрЩЯвбОКЯВЂСЫЁЃrain_jpnЪ§ОнМЏНіНіАќКЌФъЗнвдМАНЕгъСПЁЃЕБЮвУЧвдФъЗнетвЛСаНјааКЯВЂЪБЃЌНіНіЁЏjpn_rainfallЁЏетвЛСаКЭЮвУЧUKгъСПЪ§ОнМЏЕФЖдгІСаНјааСЫКЯВЂЁЃ
ВЩгУPandasПьЫйЛцжЦЭМБэ
MatplotlibКмКУгУЃЌЕЋЪЧЯывЊЛГівЛИіжаЭОЯТНЕЕФЭМБэЛЙЪЧашвЊЗбвЛЗЌЙІЗђЕФЁЃЖјгаЕФЪБКђФуНіНіЯывЊПьЫйЛГівЛИіЪ§ОнЕФДѓжТзпЪЦРДАяжњФуЗЂОђИуЧхетаЉЪ§ОнЕФвтвхЁЃPandasЬсЙЉСЫplotКЏЪ§ТњзуФуЕФашЧѓЃК

етРяЗЧГЃЧсЫЩПьЫйЕиРћгУplotЛГіСЫвЛИіФуЕФЪ§ОнЕФЭМБэЁЃРћгУетИіЭМБэЃЌФуПЩвдНєНгзХжБЙлЕиЗЂЯжЩюШыЭкОђЕФЗНЯђЁЃР§ШчЃЌШчЙћФуПДЮвЛГіЕФЮвЪ§ОнЕФЭМБэЃЌФуПЩвдПДЕН1995ФъгЂЙњПЩФмЗЂЩњСЫИЩКЕЁЃ
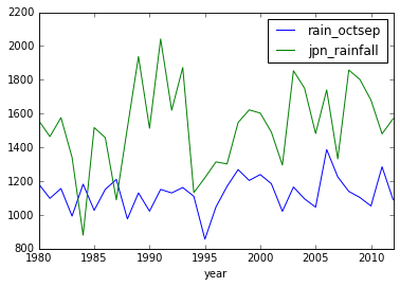
ФувВФмЗЂЯжгЂЙњЕФНЕгъСПУїЯдЕЭгкШеБОЃЌШЛЖјШЫУЧШДЫЕгЂЙњгъЯТЕУКмЖрЃЁ
ДцДЂФуЕФЪ§ОнМЏ
дкЧхРэЁЂжиЙЙвдМАЭкОђЭъФуЕФЪ§ОнКѓЃЌФуЭЈГЃЛсЪЃЯТвЛаЉЗЧГЃживЊгагУЕФЖЋЮїЁЃФуВЛНігІЕББЃСєЯТФуЕФдЪМЪ§ОнЃЌвВЭЌбљашвЊБЃДцЯТФузюаТДІРэЙ§ЕФЪ§ОнМЏЁЃ

ЩЯЪіДњТыЛсНЋФуЕФЪ§ОнДцШывЛИіcsvЮФМўвдБИЯТДЮЪЙгУЁЃ
ЕНДЫЮЊжЙЃЌЮвУЧМђЕЅНщЩмСЫPandasЁЃе§ШчЮвжЎЧАЫЕЕФЃЌPandasЪЧЗЧГЃКУгУЕФПтЃЌЖјЮвУЧНіНіЪЧНгДЅСЫвЛЕуЦЄУЋЁЃЕЋЪЧЮвЯЃЭћЭЈЙ§ЮвЕФНщЩмЃЌФуПЩвдПЊЪМНјааеце§ЕФЪ§ОнЧхРэгыЭкОђЙЄзїСЫЁЃ
ЯёЭљГЃвЛбљЃЌЮвЗЧГЃЯЃЭћФуФмОЁПьПЊЪМГЂЪдPandasЁЃеввЛСНИіФуЯВЛЖЕФЪ§ОнМЏЃЌПЊвЛЦПЦЁОЦЃЌзјЯТРДЃЌШЛКѓПЊЪМЬНЫїФуЕФЪ§ОнАЩЁЃетШЗЪЕЪЧЮЈвЛЕФЪьЯЄPandasвдМАЦфЫћетвЛЯЕСаЮФеТжаЬсЕНЕФПтЕФЗНЪНЁЃдйМгЩЯФугРдЖВЛжЊЕРЕФЃЌФуЛсевЕНвЛаЉФуИааЫШЄЕФЖЋЮїЕФЁЃ |





