| БрМЭЦМі: |
БОЮФжївЊНщЩмNumPy
Ъ§зщКЭ Python СаБэЁЂОиеѓЃКЖўЮЌЪ§зщЁЂШ§ЮЌМАИќИпЮЌЕШЯрЙиФкШнЁЃ
БОЮФРДздгкЮЂаХЛњЦїжЎаФЃЌгЩЛ№СњЙћШэМўAnnaБрМЃЌЭЦМіЁЃ |
|
жЇГжДѓСПЖрЮЌЪ§зщКЭОиеѓдЫЫуЕФ NumPy ШэМўПтЪЧаэЖрЛњЦїбЇЯАПЊЗЂепКЭбаОПепЕФБиБИЙЄОпЃЌБОЮФНЋЭЈЙ§жБЙлвзЖЎЕФЭМЪОНтЮіГЃгУЕФ
NumPy ЙІФмКЭКЏЪ§ЃЌАяжњФуРэНт NumPy ВйзїЪ§зщЕФФкдкЛњжЦЁЃ
NumPy ЪЧвЛИіЛљДЁШэМўПтЃЌКмЖрГЃгУЕФ Python Ъ§ОнДІРэШэМўПтЖМЪЙгУСЫЫќЛђЪмЕНСЫЫќЕФЦєЗЂЃЌАќРЈ
pandasЁЂPyTorchЁЂTensorFlowЁЂKeras ЕШЁЃРэНт NumPy ЕФЙЄзїЛњжЦФмЙЛАяжњФуЬсЩ§дкетаЉШэМўПтЗНУцЕФММФмЁЃЖјЧвдк
GPU ЩЯЪЙгУ NumPy ЪБЃЌЮоашаоИФЛђНіашЩйСПаоИФДњТыЁЃ
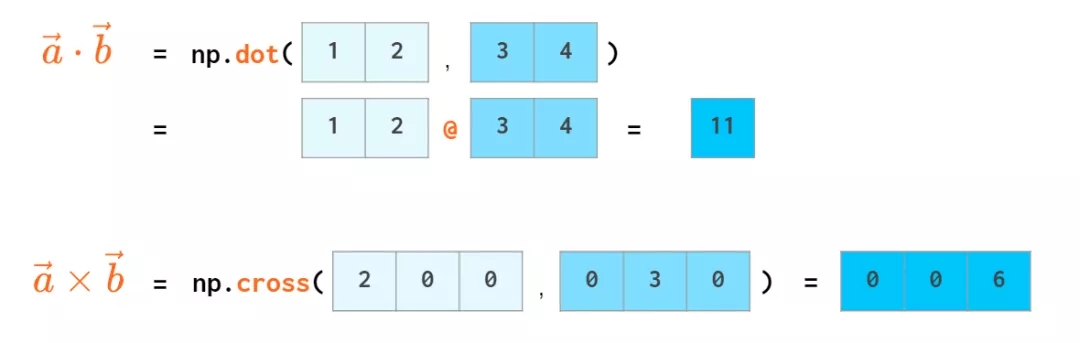
NumPy ЕФКЫаФИХФюЪЧ n ЮЌЪ§зщЁЃn ЮЌЪ§зщЕФУРРіжЎДІЪЧДѓЖрЪ§дЫЫуПДЦ№РДЖМвЛбљЃЌВЛЙмЪ§зщгаЖрЩйЮЌЁЃЕЋвЛЮЌКЭЖўЮЌгаЕуЬиЪтЁЃБОЮФЗжЮЊШ§ВПЗжЃК
1. ЯђСПЃКвЛЮЌЪ§зщ
2. ОиеѓЃКЖўЮЌЪ§зщ
3. Ш§ЮЌМАИќИпЮЌ
БОЮФВЮПМСЫ Jay Alammar ЕФЮФеТЁЖA Visual Intro
to NumPyЁЗВЂНЋЦфзїЮЊЦ№ЕуЃЌШЛКѓНјааСЫРЉГфЃЌВЂзіСЫвЛаЉЯИЮЂаоИФЁЃ
NumPy Ъ§зщКЭ Python СаБэ
еЇвЛПДЃЌNumPy Ъ§зщгы Python СаБэРрЫЦЁЃЫќУЧЖМПЩзїЮЊШнЦїЃЌФмЙЛПьЫйЛёШЁКЭЩшжУдЊЫиЃЌЕЋВхШыКЭвЦГ§дЊЫиЛсЩдТ§вЛаЉЁЃ
NumPy Ъ§зщЭъЪЄСаБэЕФзюМђЕЅР§згЪЧЫуЪѕдЫЫуЃК

Г§ДЫжЎЭтЃЌNumPy Ъ§зщЕФгХЪЦКЭЬиЕуЛЙАќРЈЃК
ИќНєДеЃЌгШЦфЪЧЕБЮЌЖШДѓгквЛЮЌЪБЃЛ
ЕБдЫЫуПЩвдЯђСПЛЏЪБЃЌЫйЖШБШСаБэИќПьЃЛ
ЕБдкКѓУцИНМгдЊЫиЪБЃЌЫйЖШБШСаБэТ§ЃЛ
ЭЈГЃЪЧЭЌжЪЕФЃКЕБдЊЫиЖМЪЧвЛжжРраЭЪБЫйЖШКмПьЁЃ
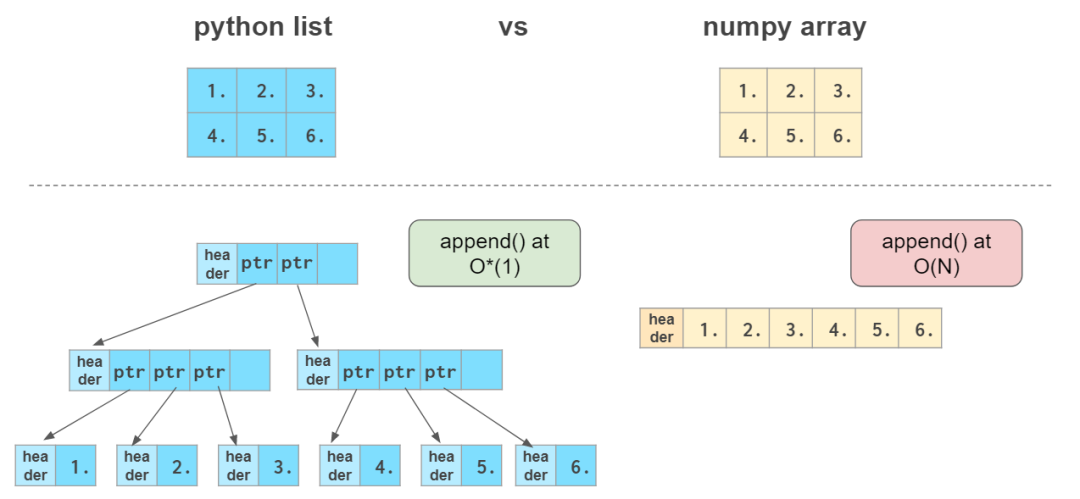
етРя O(N) ЕФвтЫМЪЧЭъГЩИУдЫЫуЫљашЕФЪБМфКЭЪ§зщЕФДѓаЁГЩе§БШЃЌЖј
O*(1)ЃЈМДЫљЮНЕФЁИОљЬЏ O(1)ЁЙЃЉЕФвтЫМЪЧЭъГЩдЫЫуЕФЪБМфЭЈГЃгыЪ§зщЕФДѓаЁЮоЙиЁЃ
ЯђСПЃКвЛЮЌЪ§зщ
ЯђСПГѕЪМЛЏ
ЮЊСЫДДНЈ NumPy Ъ§зщЃЌвЛжжЗНЗЈЪЧзЊЛЛ Python СаБэЁЃNumPy Ъ§зщРраЭПЩвджБНгДгСаБэдЊЫиРраЭЭЦЕМЕУЕНЁЃ

вЊШЗБЃЯђЦфЪфШыЕФСаБэЪЧЭЌвЛжжРраЭЃЌЗёдђФузюжеЛсЕУЕН dtype=ЁЏobjectЁЏЃЌетЛсгАЯьЫйЖШЃЌзюжежЛСєЯТ
NumPy жаКЌгаЕФгяЗЈЬЧЁЃ
NumPy Ъ§зщВЛФмЯё Python СаБэвЛбљдіГЄЁЃЪ§зщЕФФЉЖЫУЛгаСєЯТШЮКЮБугкПьЫйИНМгдЊЫиЕФПеМфЁЃвђДЫЃЌГЃМћЕФзіЗЈЪЧвЊУДЯШЪЙгУ
Python СаБэЃЌзМБИКУжЎКѓдйНЋЦфзЊЛЛЮЊ NumPy Ъ§зщЃЌвЊУДЪЧЪЙгУ np.zeros Лђ np.empty
дЄЯШСєЯТБивЊЕФПеМфЃК

ЭЈГЃЮвУЧгаБивЊДДНЈдкаЮзДКЭдЊЫиРраЭЩЯгывбгаЪ§зщЦЅХфЕФПеЪ§зщЁЃ

ЪТЪЕЩЯЃЌЫљгагУгкДДНЈЬюГфСЫГЃСПжЕЕФЪ§зщЕФКЏЪ§ЖМДјга _like ЕФаЮЪНЃК

NumPy жагаСНИіКЏЪ§ФмгУЕЅЕїађСажДааЪ§зщГѕЪМЛЏЃК
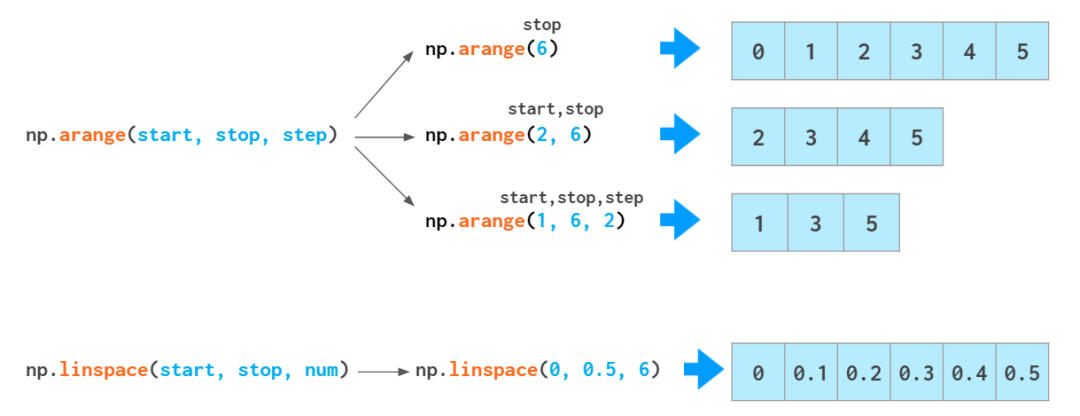
ШчЙћФуашвЊРрЫЦ [0., 1., 2.] етбљЕФИЁЕуЪ§Ъ§зщЃЌФуПЩвдаоИФ
arange ЪфГіЕФРраЭЃКarange(3).astype(float)ЃЌЕЋЛЙгавЛжжИќКУЕФЗНЗЈЁЃarange
КЏЪ§ЖдРраЭКмУєИаЃКШчЙћФувдећаЭЪ§зїЮЊВЮЪ§ЪфШыЃЌЫќЛсЩњГЩећаЭЪ§ЃЛШчЙћФуЪфШыИЁЕуЪ§ЃЈБШШч arange(3.)ЃЉЃЌЫќЛсЩњГЩИЁЕуЪ§ЁЃ
ЕЋ arange ВЂВЛЗЧГЃЩУГЄДІРэИЁЕуЪ§ЃК

дкЮвУЧблРяЃЌетИі 0.1 ПДЦ№РДЯёЪЧвЛИігаЯоЕФЪЎНјжЦЪ§ЃЌЕЋМЦЫуЛњВЛетУДПДЁЃдкЖўНјжЦБэЪОЯТЃЌ0.1
ЪЧвЛИіЮоЯоЗжЪ§ЃЌвђДЫБиаыНјаадМЗжЃЌвВгЩДЫБиШЛЛсВњЩњЮѓВюЁЃвВвђЮЊетИідвђЃЌШчЙћЯђ arange КЏЪ§ЪфШыДјЗжЪ§ВПЗжЕФ
stepЃЌЭЈГЃЕУВЛЕНЪВУДКУНсЙћЃКФуПЩФмЛсгіЕНВювЛДэЮѓ (off-by-one error)ЁЃФуПЩвдЪЙИУЧјМфЕФФЉЖЫТфдквЛИіЗЧећЪ§ЕФ
step Ъ§жаЃЈsolution1ЃЉЃЌЕЋетЛсНЕЕЭДњТыЕФПЩЖСадКЭПЩЮЌЛЄадЁЃетЪБКђЃЌlinspace ОЭПЩвдХЩЩЯгУГЁСЫЁЃЫќВЛЪмЩсШыЕФгАЯьЃЌзмФмЩњГЩФувЊЧѓЕФдЊЫиЪ§жЕЁЃВЛЙ§ЃЌЪЙгУ
linspace ЪБЛсгіЕНвЛИіГЃМћЕФЯнкхЃКЫќЭГМЦЕФЪЧЪ§ОнЕуЕФЪ§СПЃЌЖјВЛЪЧЧјМфЃЌвђДЫЦфзюКѓвЛИіВЮЪ§ num
ЭЈГЃБШФуЫљЯыЕФЪ§Дѓ 1ЁЃвђДЫЃЌЩЯУцзюКѓвЛИіР§згжаЕФЪ§ЪЧ 11ЃЌЖјВЛЪЧ 10ЁЃ
дкНјааВтЪдЪБЃЌЮвУЧЭЈГЃашвЊЩњГЩЫцЛњЪ§зщЃК

ЯђСПЫїв§
вЛЕЉФуЕФЪ§зщжагаСЫЪ§ОнЃЌNumPy ОЭФмвдЗЧГЃЧЩУюЕФЗНЪНЧсЫЩЕиЬсЙЉЫќУЧЃК
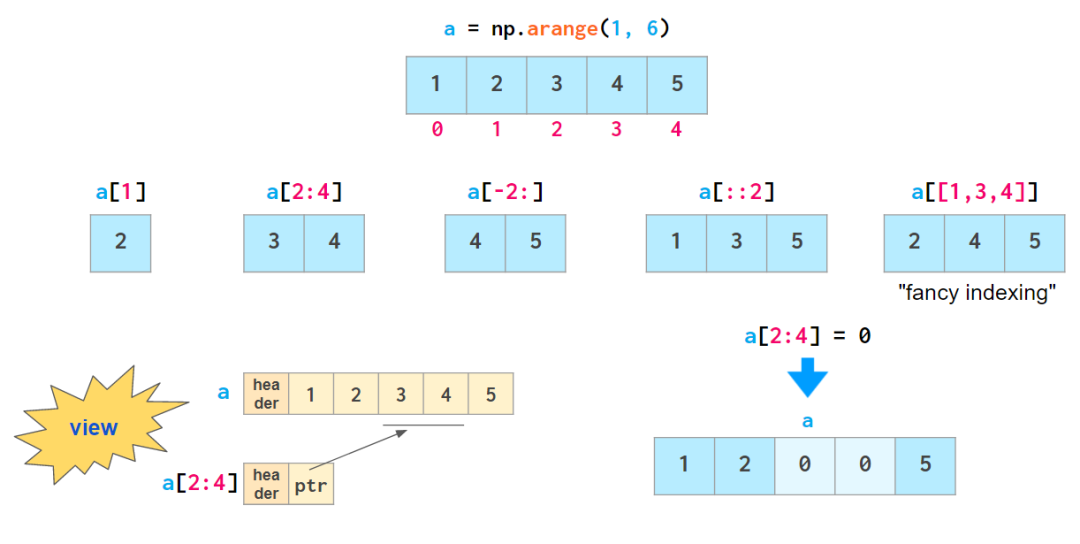
Г§СЫЁИЛЈЪНЫїв§ЃЈfancy indexingЃЉЁЙЭтЃЌЩЯУцИјГіЕФЫљгаЫїв§ЗНЗЈЖМБЛГЦЮЊЁИviewЁЙЃКЫќУЧВЂВЛДцДЂЪ§ОнЃЌвВВЛЛсдкЪ§ОнБЛЫїв§КѓЗЂЩњИФБфЪБЗДгГдЪ§зщЕФБфЛЏЧщПіЁЃ
ЫљгаАќКЌЛЈЪНЫїв§ЕФЗНЗЈЖМЪЧПЩБфЕФЃКЫќУЧдЪаэЭЈЙ§ЗжХфРДаоИФдЪМЪ§зщЕФФкШнЃЌШчЩЯЫљЪОЁЃетвЛЙІФмПЩЭЈЙ§НЋЪ§зщЧаЗжГЩВЛЭЌВПЗжРДБмУтзмЪЧИДжЦЪ§зщЕФЯАЙпЁЃ

Python СаБэгы NumPy Ъ§зщЕФЖдБШ
ЮЊСЫЛёШЁ NumPy Ъ§зщжаЕФЪ§ОнЃЌСэвЛжжГЌМЖгагУЕФЗНЗЈЪЧВМЖћЫїв§ЃЈboolean indexingЃЉЃЌЫќжЇГжЪЙгУИїРрТпМдЫЫуЗћЃК
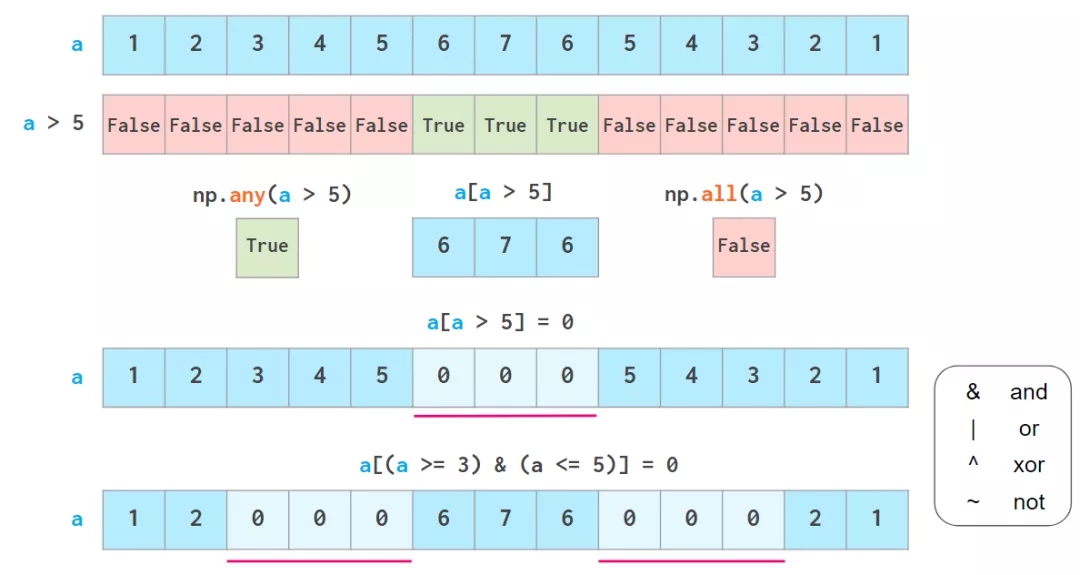
any КЭ all ЕФзїгУгыдк Python
жаРрЫЦЃЌЕЋВЛЛсЖЬТЗЁЃ
ВЛЙ§вЊзЂвтЃЌетРяВЛжЇГж Python ЕФЁИШ§дЊБШНЯЁЙЃЌБШШч 3<=a<=5ЁЃ
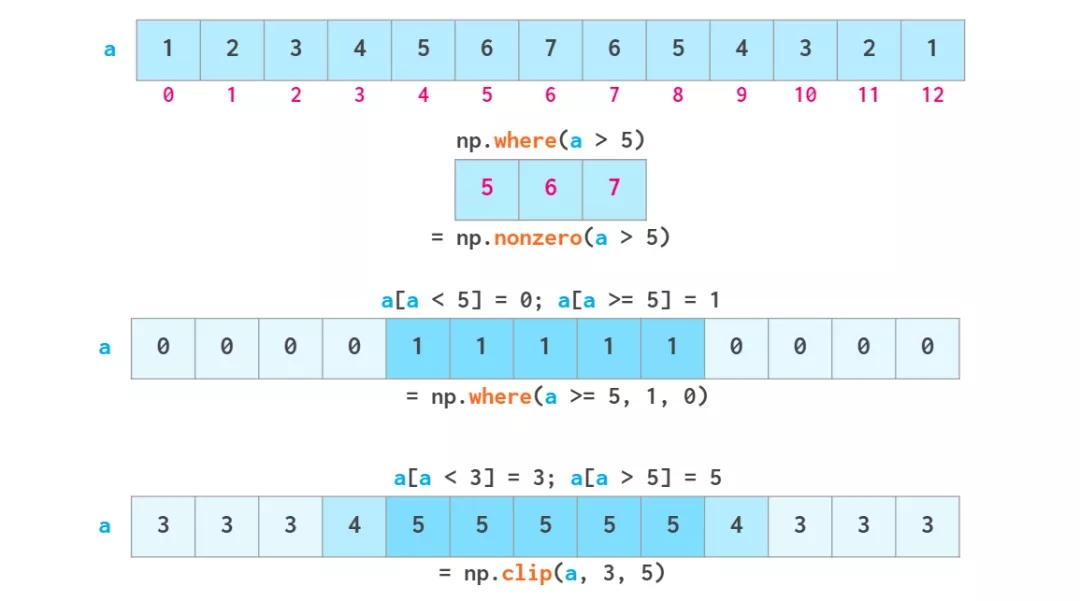
ШчЩЯЫљЪОЃЌВМЖћЫїв§вВЪЧПЩаДЕФЁЃЦфСНИіГЃгУЙІФмЖМгаИїздЕФзЈгУКЏЪ§ЃКЙ§ЖШжидиЕФ np.where КЏЪ§КЭ
np.clip КЏЪ§ЁЃЫќУЧЕФКЌвхШчЯТЃК
ЯђСПдЫЫу
NumPy дкЫйЖШЩЯКмГіВЪЕФвЛДѓгІгУСьгђЪЧЫуЪѕдЫЫуЁЃЯђСПдЫЫуЗћЛсБЛзЊЛЛЕН C++ ВуУцЩЯжДааЃЌДгЖјБмУтЛКТ§ЕФ
Python бЛЗЕФГЩБОЁЃNumPy жЇГжЯёВйзїЦеЭЈЕФЪ§ФЧбљВйзїећИіЪ§зщЁЃ
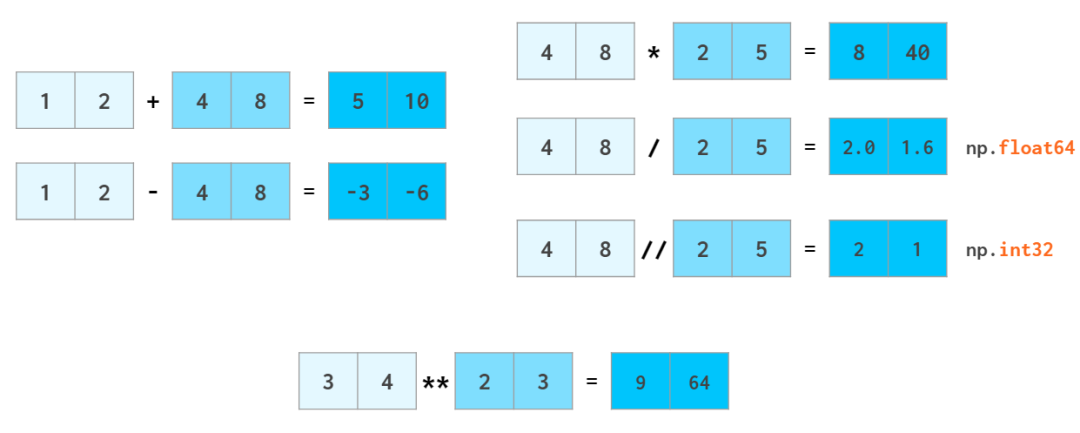
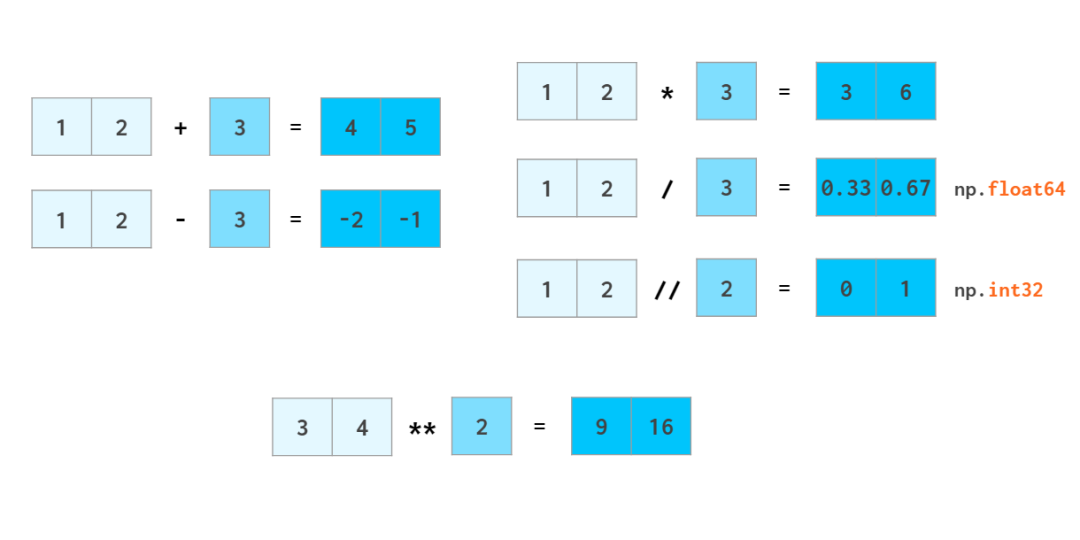
гы Python ОфЗЈвЛбљЃЌa//b
БэЪО a Г§ bЃЈГ§ЗЈЕФЩЬЃЉЃЌx**n БэЪО x?ЁЃ
е§ШчМгМѕИЁЕуЪ§ЪБећаЭЪ§ЛсБЛзЊЛЛГЩИЁЕуЪ§вЛбљЃЌБъСПвВЛсБЛзЊЛЛГЩЪ§зщЃЌетИіЙ§ГЬдк NumPy жаБЛГЦЮЊЙуВЅЃЈbroadcastЃЉЁЃ

ДѓЖрЪ§Ъ§бЇКЏЪ§ЖМгагУгкДІРэЯђСПЕФ NumPy ЖдгІКЏЪ§ЃК
БъСПЛ§газдМКЕФдЫЫуЗћЃК
жДааШ§НЧКЏЪ§ЪБвВЮоашбЛЗЃК

ЮвУЧПЩвддкећЬхЩЯЖдЪ§зщНјааЩсШыЃК

floor ЮЊЩсЁЂceil ЮЊШыЃЌaround
дђЪЧЩсШыЕНзюНќЕФећЪ§ЃЈЦфжа .5 ЛсБЛЩсЕєЃЉ
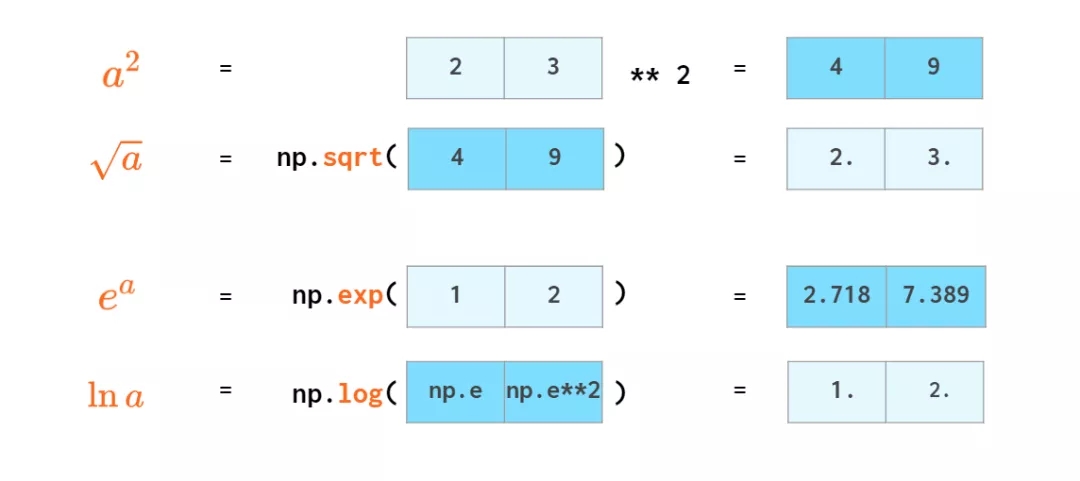
NumPy вВФмжДааЛљДЁЕФЭГМЦдЫЫуЃК

NumPy ЕФХХађКЏЪ§УЛга Python ЕФХХађКЏЪ§ФЧУДЧПДѓЃК

Python СаБэгы NumPy Ъ§зщЕФХХађКЏЪ§ЖдБШ
дквЛЮЌЧщПіЯТЃЌШчЙћШБЩй reversed ЙиМќзжЃЌФЧУДжЛашМђЕЅЕиЖдНсЙћдйжДааЗДЯђЃЌзюжеаЇЙћЛЙЪЧвЛбљЁЃЖўЮЌЕФЧщПідђЛсИќРЇФбвЛаЉЃЈШЫУЧе§дкЧыЧѓетвЛЙІФмЃЉЁЃ
ЫбЫїЯђСПжаЕФдЊЫи
гы Python СаБэЯрЗДЃЌNumPy Ъ§зщУЛгаЫїв§ЗНЗЈЁЃШЫУЧКмОУжЎЧАОЭдкЧыЧѓетИіЙІФмЃЌЕЋвЛжБЛЙУЛЪЕЯжЁЃ
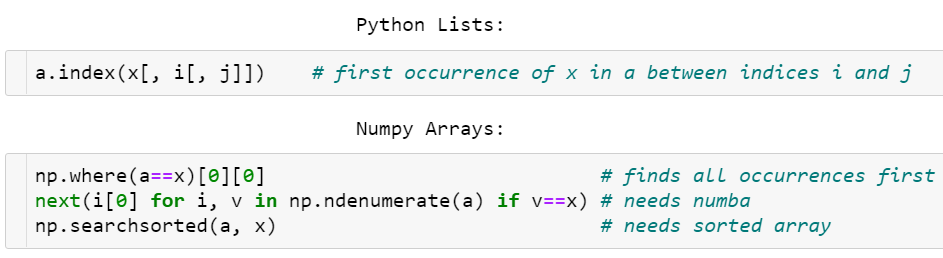
Python СаБэгы NumPy Ъ§зщЕФЖдБШЃЌindex()
жаЕФЗНРЈКХБэЪОПЩвдЪЁТд j ЛђЭЌЪБЪЁТд i КЭ jЁЃ
вЛжжВщевдЊЫиЕФЗНЗЈЪЧ np.where(a==x)[0][0]ЃЌЕЋетИіЗНЗЈМШВЛгХбХЃЌЫйЖШвВВЛПьЃЌвђЮЊЫќашвЊМьВщЪ§зщжаЕФЫљгадЊЫиЃЌМДБуЫљвЊевЕФФПБъОЭдкЪ§зщЦ№ЪМЮЛжУвВЪЧШчДЫЁЃ
СэвЛжжИќПьЕФЗНЪНЪЧЪЙгУ Numba РДМгЫй next((i[0] for
i, v in np.ndenumerate(a) if v==x), -1)ЁЃ
вЛЕЉЪ§зщЕФХХађЭъГЩЃЌЫбЫїОЭШнвзЖрСЫЃКv = np.searchsorted(a,
x); return v if a[v]==x else -1 ЕФЫйЖШКмПьЃЌЪБМфИДдгЖШЮЊ O(log
N)ЃЌЕЋЫќашвЊ O(N log N) ЪБМфЯШХХКУађЁЃ
ЪТЪЕЩЯЃЌгУ C РДЪЕЯжЫќНјЖјМгЫйЫбЫїВЂВЛЪЧЮЪЬтЁЃЮЪЬтЪЧИЁЕуБШНЯЁЃетЖдШЮКЮЪ§ОнРДЫЕЖМВЛЪЧвЛжжМђЕЅжБНгПЩгУЕФШЮЮёЁЃ
БШНЯИЁЕуЪ§
КЏЪ§ np.allclose(a, b) ФмдквЛЖЈЙЋВюЯТБШНЯИЁЕуЪ§Ъ§зщЁЃ
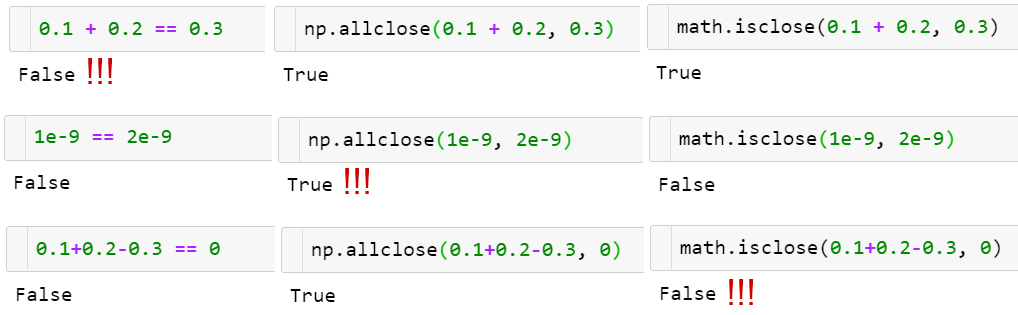
КЏЪ§ np.allclose(a, b)
ЕФЙЄзїЙ§ГЬЪОР§ЁЃВЂУЛгаЭђФмЗНЗЈЃЁ
np.allclose МйЩшЫљгаБЛБШНЯЕФЪ§ЖМдкЕфаЭЕФ 1 ЕФЗЖЮЇФкЁЃОйИіР§згЃЌШчЙћвЊдкФЩУыМЖЕФЫйЖШФкЭъГЩМЦЫуЃЌдђашвЊгУФЌШЯЕФ
atol ВЮЪ§жЕГ§вд 1e9ЃКnp.allclose(1e-9, 2e-9, atol=1e-17)
== False.
math.isclose дђВЛЛсЖдвЊБШНЯЕФЪ§НјааШЮКЮМйЩшЃЌЖјЪЧвРРЕгУЛЇИјГіКЯРэЕФ
abs_tol жЕЃЈЖдгкЕфаЭЕФ 1 ЕФЗЖЮЇФкЕФжЕЃЌШЁФЌШЯЕФ np.allclose atol жЕ 1e-8
ОЭзуЙЛКУСЫЃЉЃКmath.isclose(0.1+0.2ЈC0.3, abs_tol=1e-8)==True.
Г§ДЫжЎЭтЃЌnp.allclose дкОјЖджЕКЭЯрЖдЙЋВюЕФЙЋЪНЗНУцЛЙгавЛаЉаЁЮЪЬтЃЌОйИіР§згЃЌЖдгкИјЖЈЕФ
a КЭ bЃЌДцдк allclose(a, b) != allclose(b, a)ЁЃетаЉЮЪЬтвбдкЃЈБъСПЃЉКЏЪ§
math.isclose жаЕУЕНСЫНтОіЃЌЮвУЧНЋдкКѓУцНщЩмЫќЁЃЖдгкетЗНУцЕФИќЖрФкШнЃЌЧыВЮдФ GitHub
ЩЯЕФИЁЕуЪ§жИФЯКЭЖдгІЕФ NumPy ЮЪЬтЃЈhttps://floating-point-gui.de/errors/comparison/ЃЉЁЃ
ОиеѓЃКЖўЮЌЪ§зщ
NumPy дјгавЛИізЈУХЕФ matrix РрЃЌЕЋЯждквбОЦњгУСЫЃЌЫљвдБОЮФЛсНЛЬцЪЙгУЁИОиеѓЁЙКЭЁИЖўЮЌЪ§зщЁЙетСНИіЪѕгяЁЃ
ОиеѓЕФГѕЪМЛЏОфЗЈгыЯђСПРрЫЦЃК
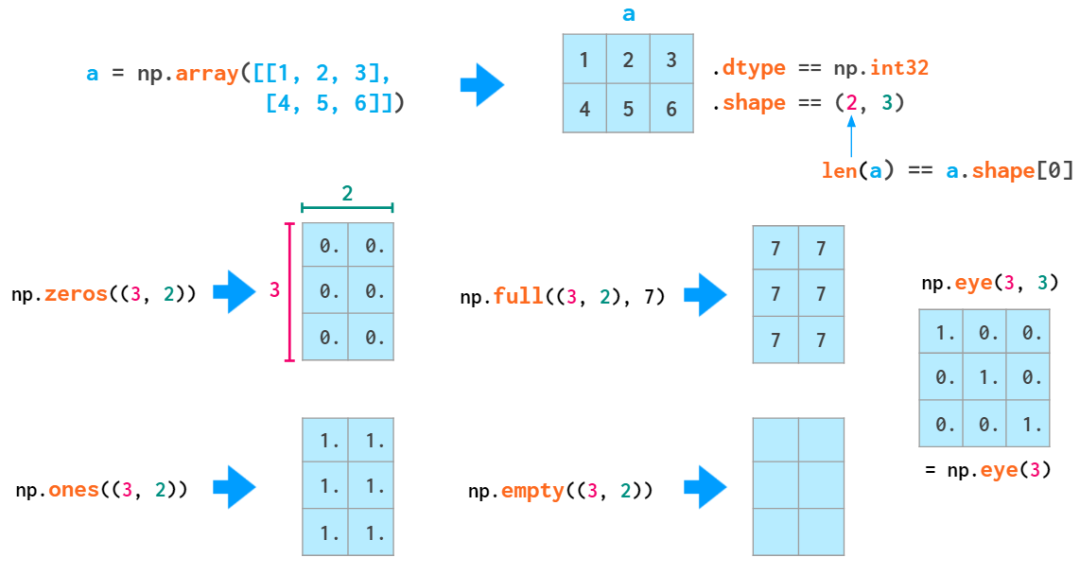
етРяБиаыЪЙгУЫЋРЈКХЃЌвђЮЊЕкЖўИіЮЛжУВЮЪ§ЪЧ dtypeЃЈПЩбЁЃЌвВНгЪмећЪ§ЃЉЁЃ
ЫцЛњОиеѓЩњГЩЕФОфЗЈвВгыЯђСПЕФРрЫЦЃК

ЖўЮЌЫїв§ЕФОфЗЈБШЧЖЬзСаБэИќЗНБуЃК

view ЗћКХЕФвтЫМЪЧЕБЧаЗжвЛИіЪ§зщЪБЪЕМЪЩЯУЛгажДааИДжЦЁЃЕБИУЪ§зщБЛаоИФЪБЃЌетаЉИФБфвВЛсЗДгГЕНЧаЗжЕУЕНЕФНсЙћЩЯЁЃ
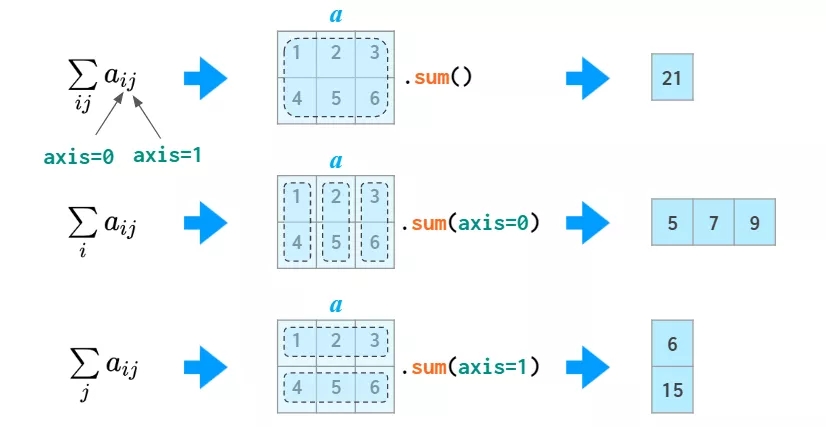
axis ВЮЪ§
дкКмЖрдЫЫужаЃЈБШШч sumЃЉЃЌФуашвЊИцЫп NumPy ЪЧдкСаЩЯЛЙЪЧааЩЯжДаадЫЫуЁЃЮЊСЫЛёШЁЪЪгУгкШЮвтЮЌЖШЕФЭЈгУЗћКХЃЌNumPy
в§ШыСЫ axis ЕФИХФюЃКЪТЪЕЩЯЃЌaxis ВЮЪ§ЕФжЕЪЧЯрЙиЮЪЬтжаЫїв§ЕФЪ§СПЃКЕквЛИіЫїв§ЮЊ axis=0ЃЌЕкЖўИіЫїв§ЮЊ
axis=1ЃЌвдДЫРрЭЦЁЃвђДЫдкЖўЮЌЧщПіЯТЃЌaxis=0 ЪЧАДСаМЦЫуЃЌaxis=1 ЪЧАДааМЦЫуЁЃ
ОиеѓЫуЪѕдЫЫу
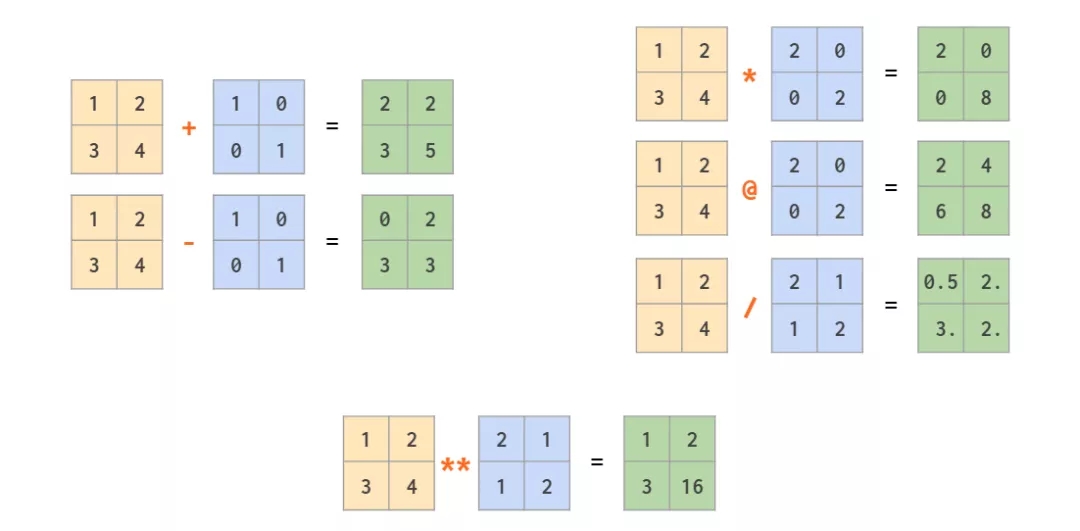
Г§СЫж№дЊЫижДааЕФГЃЙцдЫЫуЗћЃЈБШШч +ЁЂ-ЁЂЁЂ/ЁЂ//ЁЂ*ЃЉЃЌетРяЛЙгавЛИіМЦЫуОиеѓГЫЛ§ЕФ @ дЫЫуЗћЃК
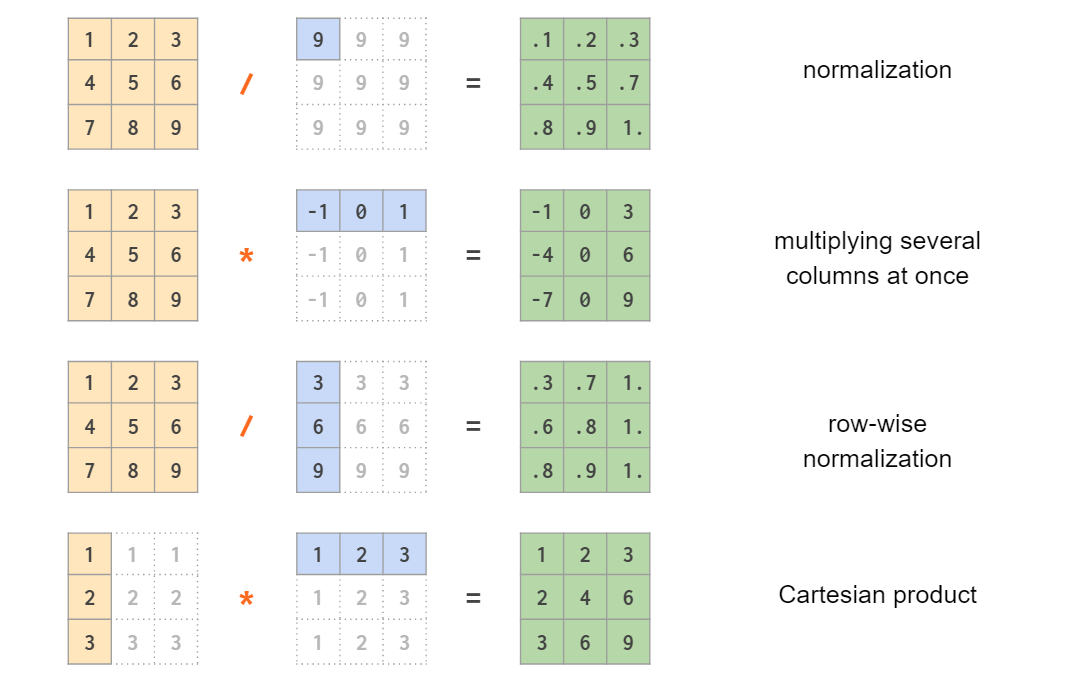
ЮвУЧвбдкЕквЛВПЗжНщЩмЙ§БъСПЕНЪ§зщЕФЙуВЅЃЌдкЦфЛљДЁЩЯНјааЗКЛЏКѓЃЌNumPy жЇГжЯђСПКЭОиеѓЕФЛьКЯдЫЫуЃЌЩѕжССНИіЯђСПжЎМфЕФдЫЫуЃК
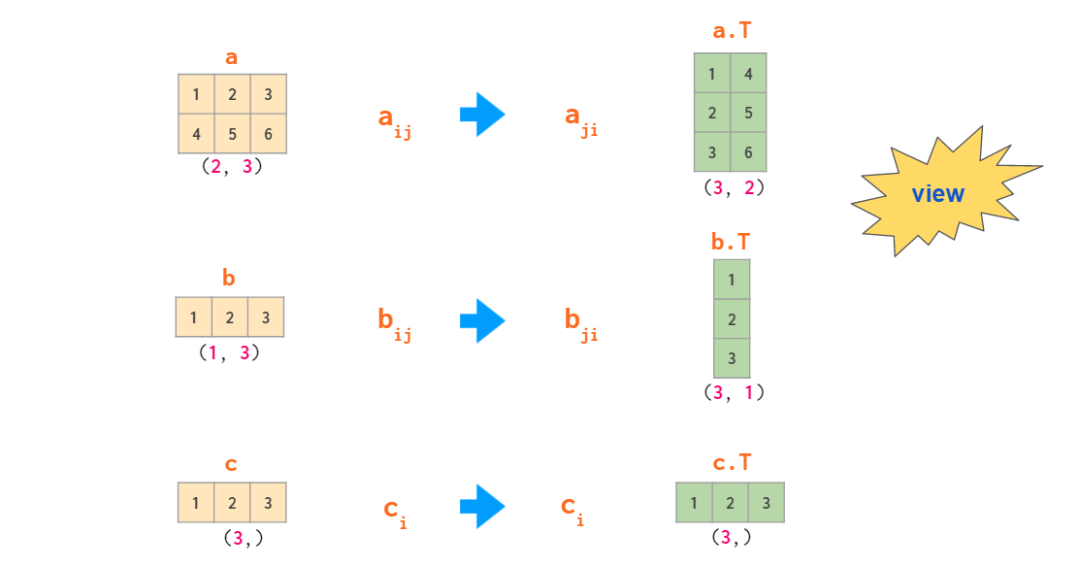
ЖўЮЌЪ§зщжаЕФЙуВЅ
ааЯђСПКЭСаЯђСП
е§ШчЩЯУцЕФР§згЫљЪОЃЌдкЖўЮЌЧщПіЯТЃЌааЯђСПКЭСаЯђСПЕФДІРэЗНЪНгаЫљВЛЭЌЁЃетгыОпБИФГРрвЛЮЌЪ§зщЕФ NumPy
ЪЕМљВЛЭЌЃЈБШШчЖўЮЌЪ§зщ aЁЊ ЕФЕк j Са a[:,j] ЪЧвЛИівЛЮЌЪ§зщЃЉЁЃФЌШЯЧщПіЯТЃЌвЛЮЌЪ§зщЛсБЛЪгЮЊЖўЮЌдЫЫужаЕФааЯђСПЃЌвђДЫЕБгУвЛИіОиеѓГЫвдвЛИіааЯђСПЪБЃЌФуПЩвдЪЙгУаЮзД
(n,) Лђ (1, n)ЁЊЁЊНсЙћЪЧвЛбљЕФЁЃШчЙћФуашвЊвЛИіСаЯђСПЃЌдђгаЖржжЗНЗЈПЩвдЛљгквЛЮЌЪ§зщЕУЕНЫќЃЌЕЋГіШЫвтСЯЕФЪЧЁИзЊжУЁЙВЛЪЧЦфжажЎвЛЁЃ
ЛљгквЛЮЌЪ§зщЕУЕНЖўЮЌЪ§зщЕФдЫЫугаСНжжЃКЪЙгУ reshape ЕїећаЮзДКЭЪЙгУ newaxis НјааЫїв§ЃК
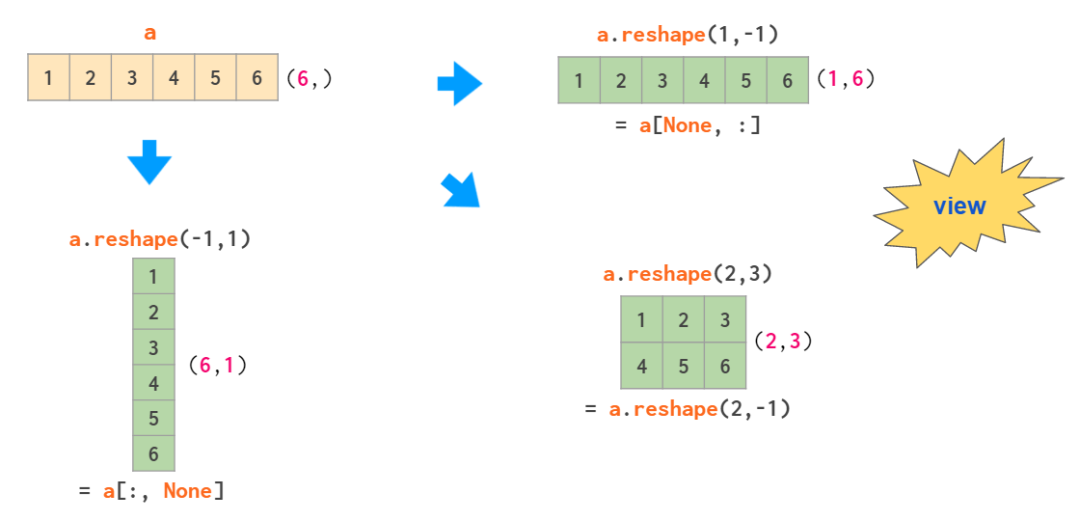
Цфжа -1 етИіВЮЪ§ЪЧИцЫп reshape здЖЏМЦЫуЦфжавЛИіЮЌЖШДѓаЁЃЌЗНРЈКХжаЕФ
None ЪЧгУзї np.newaxis ЕФПьНнЗНЪНЃЌетЛсдкжИЖЈЮЛжУЬэМгвЛИіПе axisЁЃ
вђДЫЃЌNumPy ЙВгаШ§РрЯђСПЃКвЛЮЌЯђСПЁЂЖўЮЌааЯђСПКЭЖўЮЌСаЯђСПЁЃЯТЭМеЙЪОСЫетШ§жжЯђСПжЎМфЕФзЊЛЛЗНЪНЃК
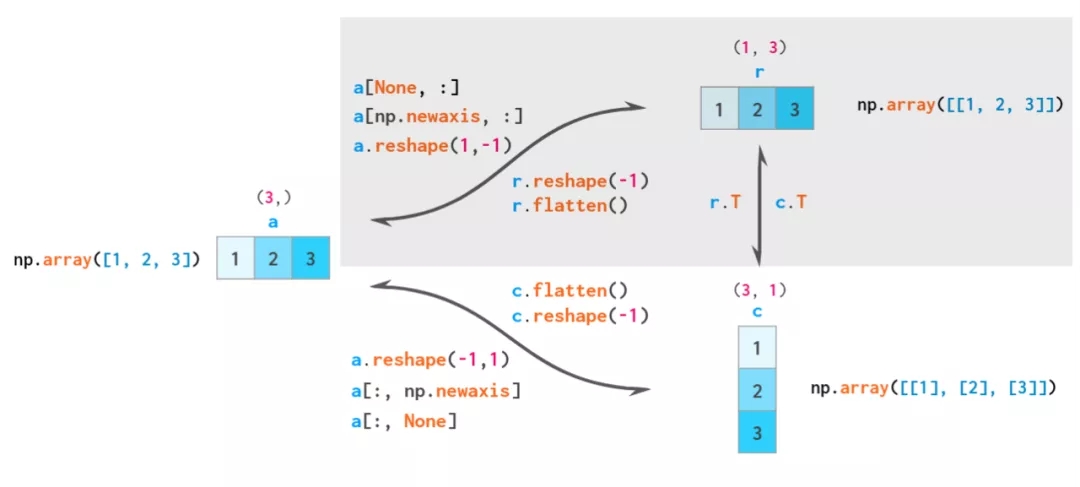
вЛЮЌЯђСПЁЂЖўЮЌааЯђСПКЭЖўЮЌСаЯђСПжЎМфЕФзЊЛЛЗНЪНЁЃИљОнЙуВЅЕФддђЃЌвЛЮЌЪ§зщПЩБЛвўКЌЕиЪгЮЊЖўЮЌааЯђСПЃЌвђДЫЭЈГЃУЛБивЊдкетСНепжЎМфжДаазЊЛЛЁЊЁЊвђДЫЯргІЕФЧјгђБЛвѕгАЛЏДІРэЁЃ
ОиеѓВйзї
КЯВЂЪ§зщЕФКЏЪ§жївЊгаСНИіЃК
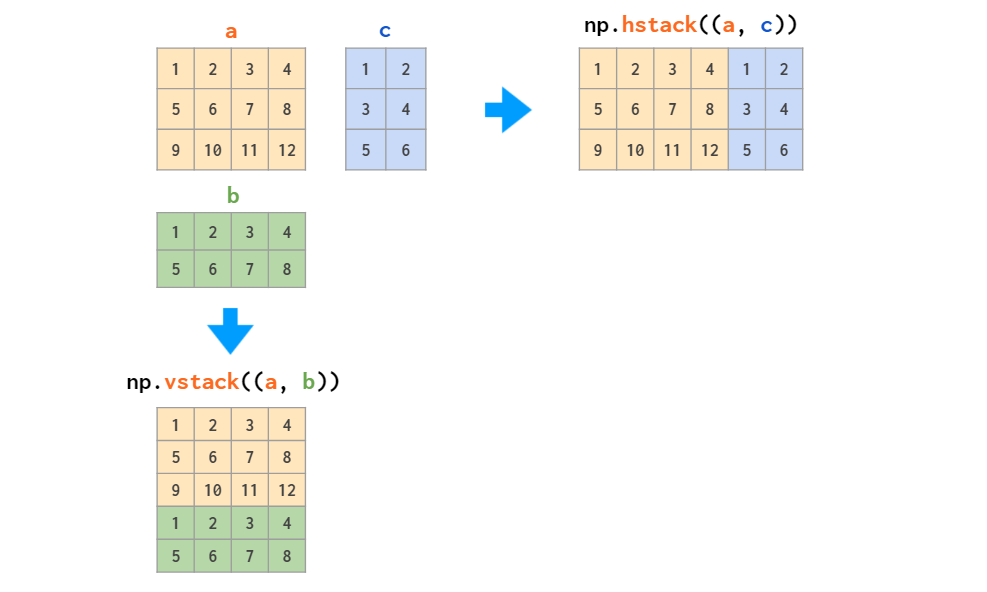
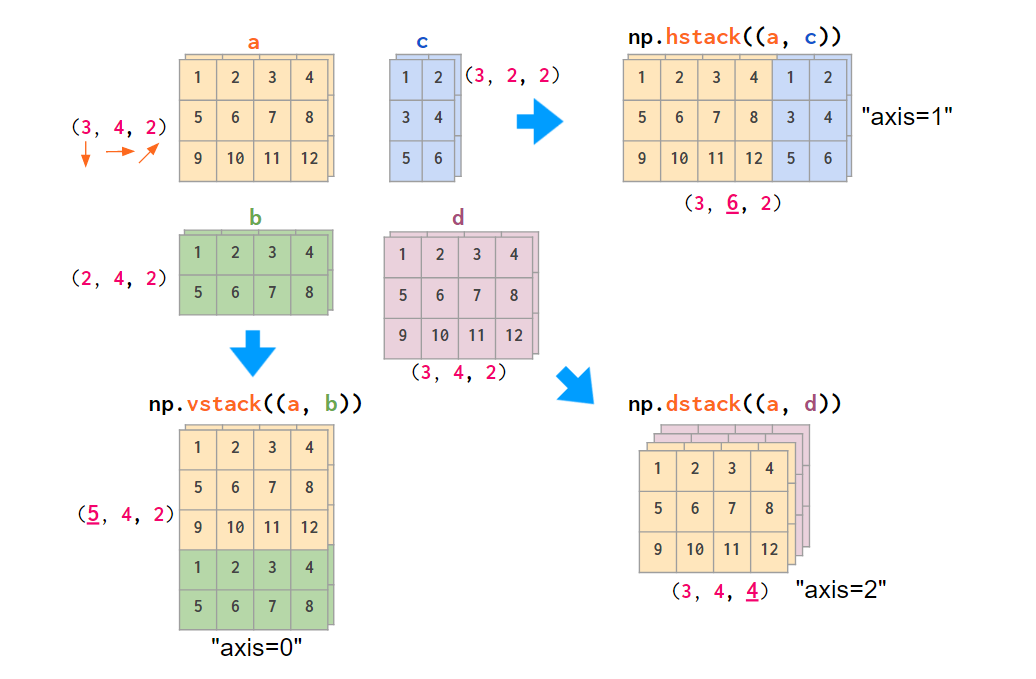
етСНИіКЏЪ§ЪЪгУгкжЛЖбЕўОиеѓЛђжЛЖбЕўЯђСПЃЌЕЋЕБашвЊЖбЕўвЛЮЌЪ§зщКЭОиеѓЪБЃЌжЛга vstack ПЩвдзраЇЃКhstack
ЛсГіЯжЮЌЖШВЛЦЅХфЕФДэЮѓЃЌдвђШчЧАЫљЪіЃЌвЛЮЌЪ§зщЛсБЛЪгЮЊааЯђСПЃЌЖјВЛЪЧСаЯђСПЁЃеыЖдетИіЮЪЬтЃЌНтОіЗНЗЈвЊУДЪЧНЋЦфзЊЛЛЮЊааЯђСПЃЌвЊУДЪЧЪЙгУФмздЖЏЭъГЩетвЛВйзїЕФ
column_stack КЏЪ§ЃК
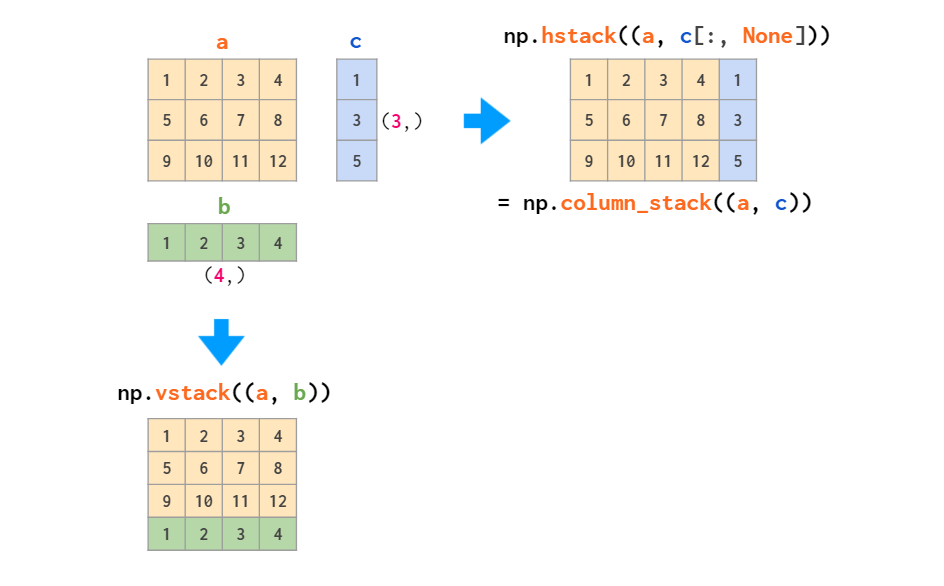
ЖбЕўЕФФцВйзїЪЧВ№ЗжЃК
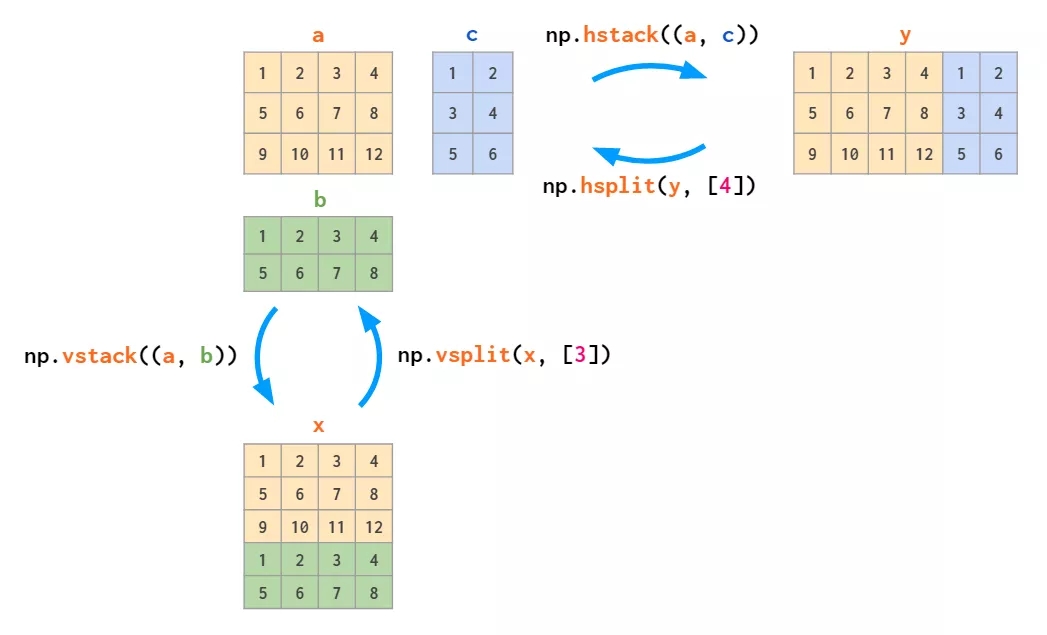
ИДжЦОиеѓЕФЗНЗЈгаСНжжЃКИДжЦ - еГЬљЪНЕФ tile КЭЗжвГДђгЁЪНЕФ repeatЃК
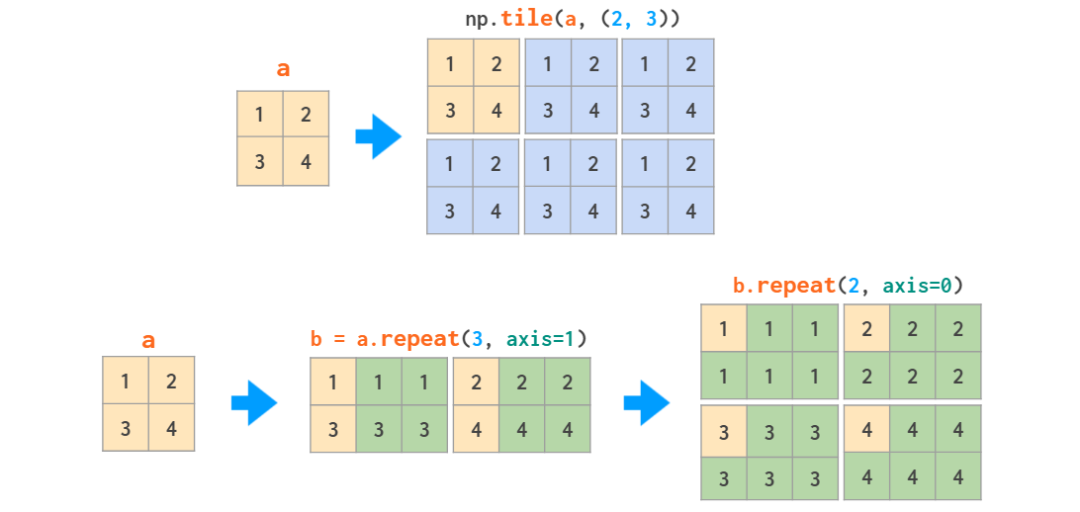
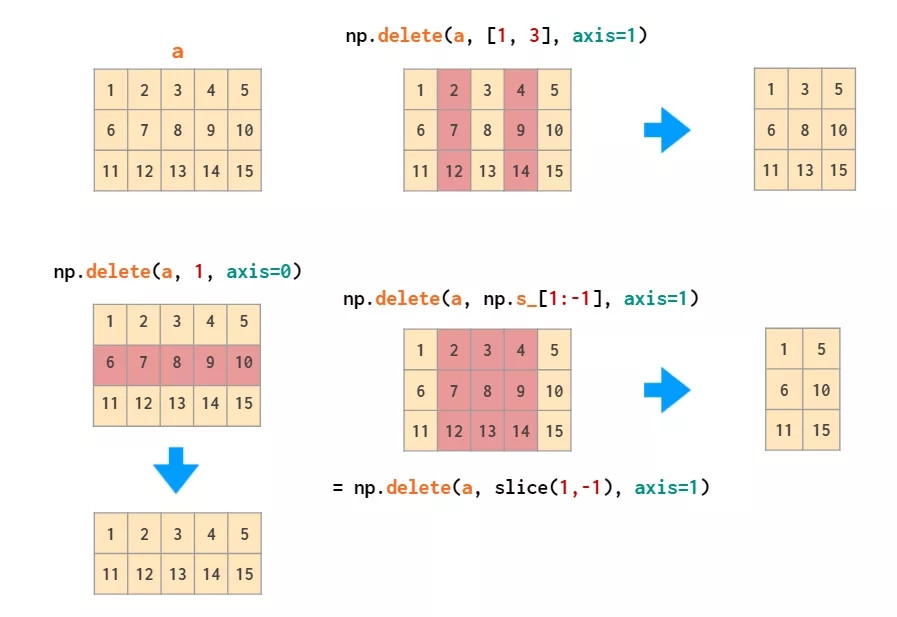
delete ПЩвдЩОГ§ЬиЖЈЕФааКЭСаЃК
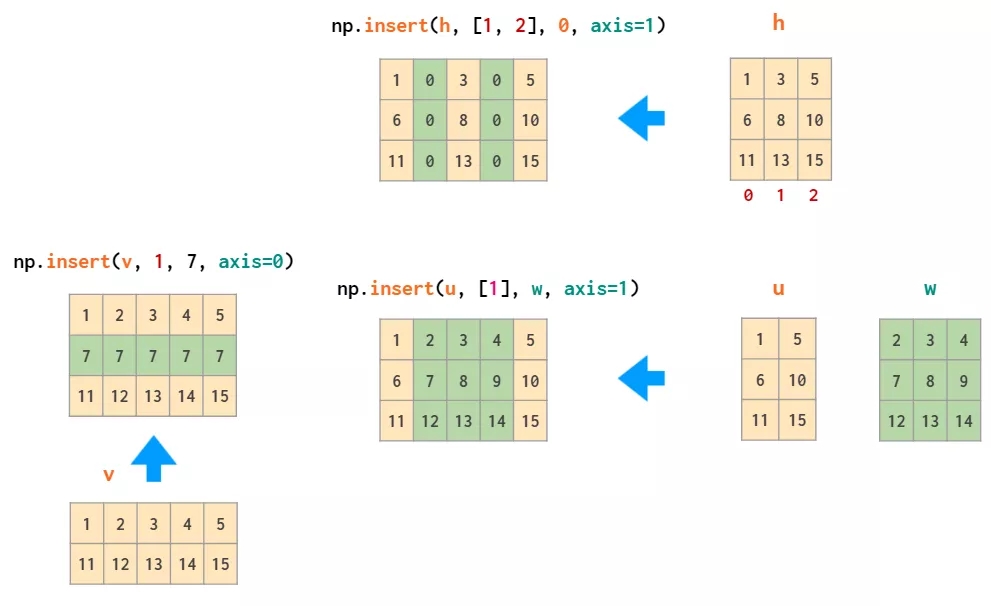
ЩОГ§ЕФФцВйзїЮЊВхШыЃЌМД insertЃК
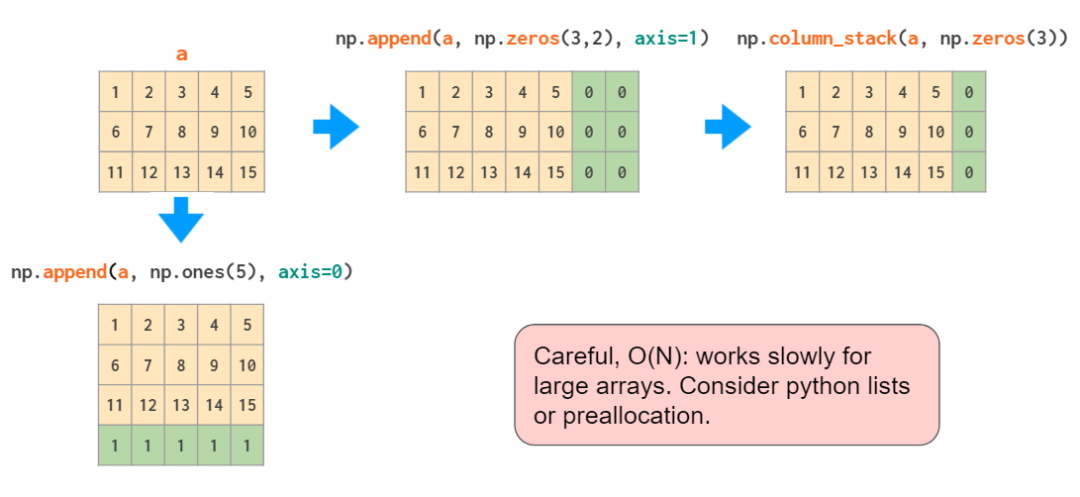
append КЏЪ§ОЭЯё hstack вЛбљЃЌВЛФмздЖЏЖдвЛЮЌЪ§зщжДаазЊжУЃЌвђДЫЭЌбљЕиЃЌвЊУДашвЊИФБфИУЯђСПЕФаЮзДЃЌвЊУДОЭашвЊдіМгвЛИіЮЌЖШЃЌЛђепЪЙгУ
column_stackЃК
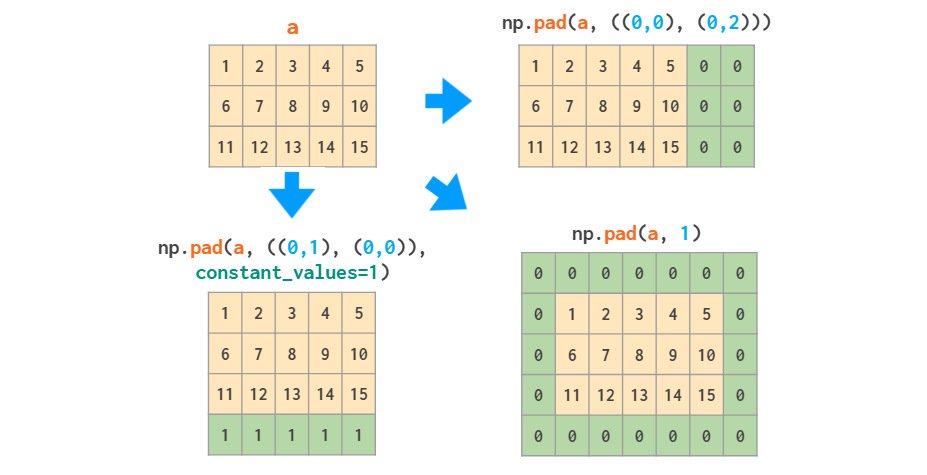
ЪТЪЕЩЯЃЌШчЙћФужЛашвЊЯђЪ§зщЕФБпдЕЬэМгГЃСПжЕЃЌФЧУДЃЈЩдЮЂИДдгЕФЃЉpad КЏЪ§гІИУОЭзуЙЛСЫЃК
ЭјИё
ЙуВЅЙцдђЪЙЕУЮвУЧФмИќМђЕЅЕиВйзїЭјИёЁЃМйЩшФугаШчЯТОиеѓЃЈЕЋЗЧГЃДѓЃЉЃК

ЪЙгУ C КЭЪЙгУ Python ДДНЈОиеѓЕФЖдБШ
етСНжжЗНЗЈНЯТ§ЃЌвђЮЊЫќУЧЛсЪЙгУ Python бЛЗЁЃЮЊСЫНтОіетбљЕФЮЪЬтЃЌMATLAB ЕФЗНЪНЪЧДДНЈвЛИіЭјИёЃК
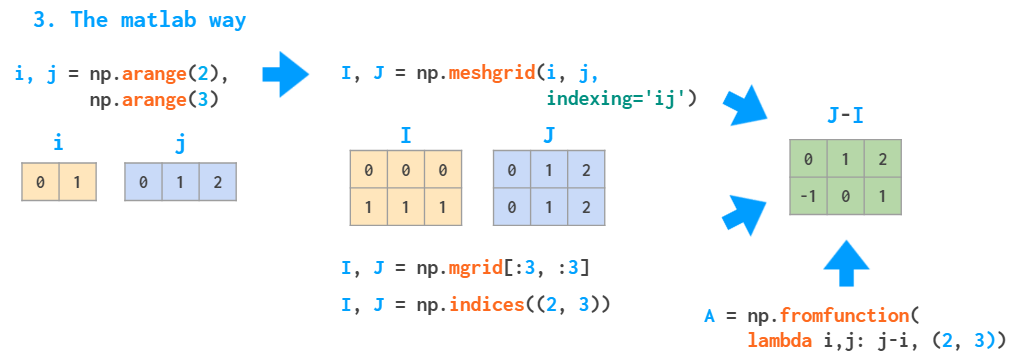
ЪЙгУ MATLAB ДДНЈЭјИёЕФЪОвтЭМ
ЪЙгУШчЩЯЬсЙЉЕФВЮЪ§ I КЭ JЃЌmeshgrid КЏЪ§НгЪмШЮвтЕФЫїв§МЏКЯзїЮЊЪфШыЃЌmgrid
жЛЪЧЧаЗжЃЌindices жЛФмЩњГЩЭъећЕФЫїв§ЗЖЮЇЃЌfromfunction жЛЛсЕїгУЫљЬсЙЉЕФКЏЪ§вЛДЮЁЃ
ЕЋЪЕМЪЩЯЃЌNumPy жаЛЙгавЛжжИќКУЕФЗНЗЈЁЃЮвУЧУЛБивЊНЋФкДцКФдкећИі I КЭ J ОиеѓЩЯЁЃДцДЂаЮзДКЯЪЪЕФЯђСПОЭзуЙЛСЫЃЌЙуВЅЙцдђПЩвдЭъГЩЦфгрЙЄзїЁЃ

ЪЙгУ NumPy ДДНЈЭјИёЕФЪОвтЭМ
УЛга indexing=ЁЏijЁЏ ВЮЪ§ЃЌmeshgrid ЛсИФБфетаЉВЮЪ§ЕФЫГађЃКJ,
I= np.meshgrid(j, i)ЁЊЁЊетЪЧвЛжж xy ФЃЪНЃЌЖдПЩЪгЛЏ 3D ЭМБэКмгагУЁЃ
Г§СЫдкЖўЮЌЛђШ§ЮЌЭјИёЩЯГѕЪМЛЏКЏЪ§ЃЌЭјИёвВПЩгУгкЫїв§Ъ§зщЃК

ЪЙгУ meshgrid Ыїв§Ъ§зщЃЌвВЪЪгУгкЯЁЪшЭјИёЁЃ
ЛёШЁОиеѓЭГМЦЪ§Он
КЭ sum вЛбљЃЌminЁЂmaxЁЂargminЁЂargmaxЁЂmeanЁЂstdЁЂvar ЕШЫљгаЦфЫќЭГМЦКЏЪ§ЖМжЇГж
axis ВЮЪ§ВЂФмОнДЫЭъГЩЭГМЦМЦЫуЃК
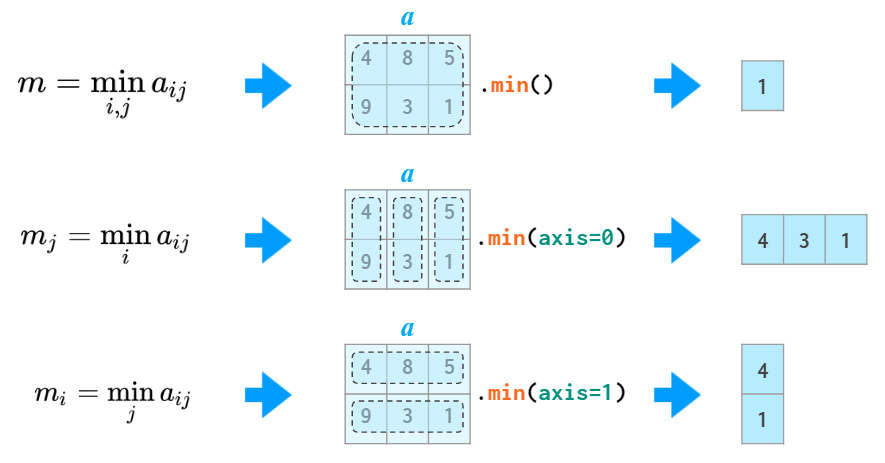
Ш§ИіЭГМЦКЏЪ§ЪОР§ЃЌЮЊСЫБмУтгы Python
ЕФ min ГхЭЛЃЌNumPy жаЖдгІЕФКЏЪ§УћЮЊ np.aminЁЃ
гУгкЖўЮЌМАИќИпЮЌЕФ argmin КЭ argmax КЏЪ§ЛсЗЕЛизюаЁКЭзюДѓжЕЕФЕквЛИіЪЕР§ЃЌдкЗЕЛиеЙПЊЕФЫїв§ЩЯгаЕуТщЗГЁЃЮЊСЫНЋЦфзЊЛЛГЩСНИізјБъЃЌашвЊЪЙгУ
unravel_index КЏЪ§ЃК
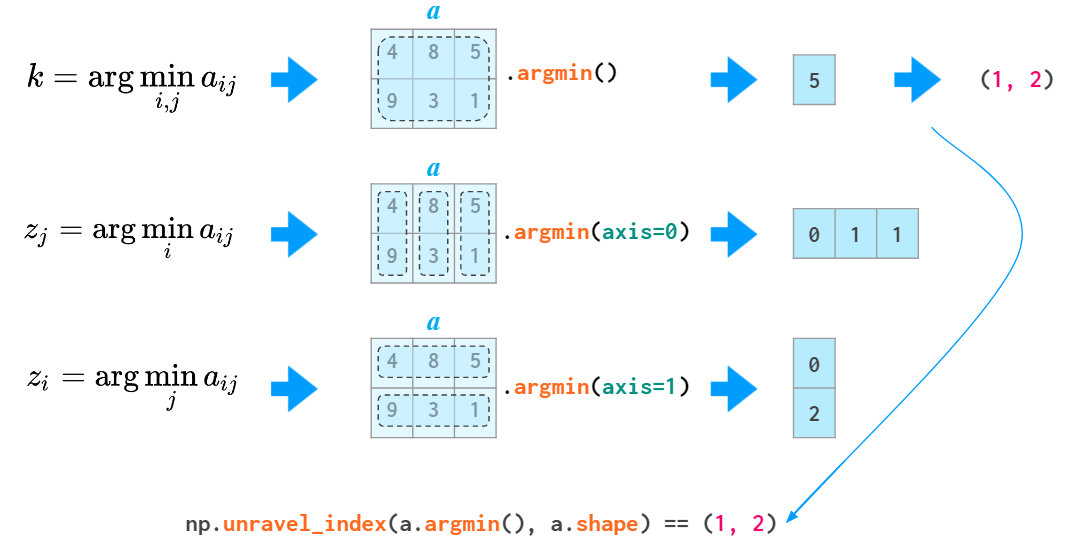
ЪЙгУ unravel_index КЏЪ§ЕФЪОР§
all КЭ any КЏЪ§вВжЇГж axis ВЮЪ§ЃК
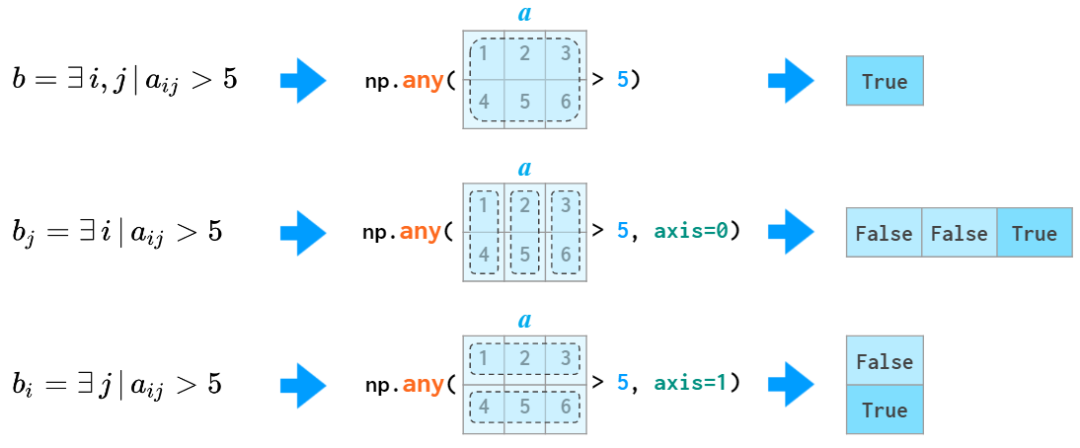
ЪЙгУ all КЭ any КЏЪ§ЕФЪОР§
ОиеѓХХађ
axis ВЮЪ§ЫфШЛЖдЩЯУцСаГіЕФКЏЪ§КмгагУЃЌЕЋЖдХХађКСЮогУДІЃК

ЪЙгУ Python СаБэКЭ NumPy
Ъ§зщжДааХХађЕФБШНЯ
етЭЈГЃВЛЪЧФудкХХађОиеѓЛђЕчзгБэИёЪБЯЃЭћПДЕНЕФНсЙћЃКaxis ИљБОВЛФмЬцДњ
key ВЮЪ§ЁЃЕЋавдЫЕФЪЧЃЌNumPy ЬсЙЉСЫвЛаЉжЇГжАДСаХХађЕФИЈжњКЏЪ§ЁЊЁЊЛђгаашвЊЕФЛАПЩАДЖрСаХХађЃК
1. a[a[:,0].argsort()] ПЩАДЕквЛСаЖдЪ§зщХХађЃК
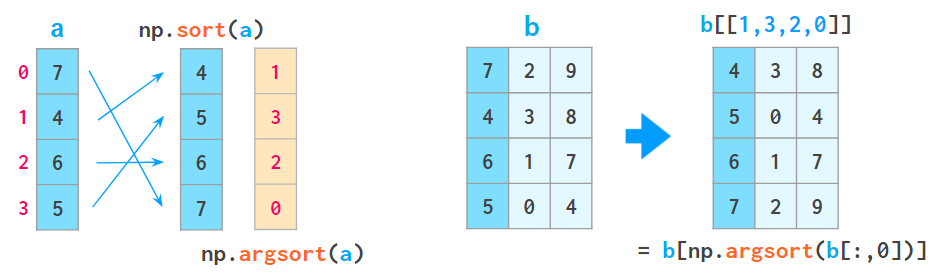
етРя argsort ЛсЗЕЛидЪ§зщХХађКѓЕФЫїв§ЕФЪ§зщЁЃ
етИіММЧЩПЩвджиИДЃЌЕЋБиаыНїЩїЃЌБ№ШУЯТвЛДЮХХађШХТвЩЯвЛДЮХХађЕФНсЙћЃК
a = a[a[:,2].argsort()]
a = a[a[:,1].argsort(kind='stable')]
a = a[a[:,0].argsort(kind='stable')]
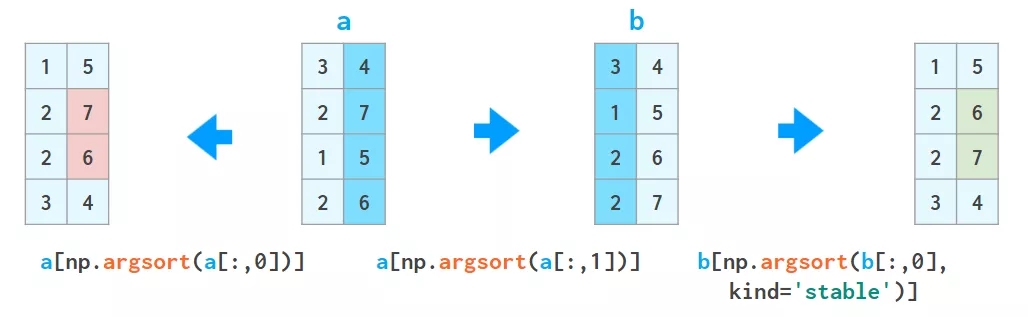
2. lexsort КЏЪ§ФмЪЙгУЩЯЪіЗНЪНИљОнЫљгаСаНјааХХађЃЌЕЋЫќзмЪЧАДаажДааЃЌЖјЧвЫљвЊХХађЕФааЕФЫГађЪЧЗДЯђЕФЃЈМДздЯТЖјЩЯЃЉЃЌвђДЫЪЙгУЫќЪБЛсгааЉВЛздШЛЃЌБШШч
- a[np.lexsort(np.flipud(a[2,5].T))] ЛсЪзЯШИљОнЕк 2 СаХХађЃЌШЛКѓЃЈЕБЕк
2 СаЕФжЕЯрЕШЪБЃЉдйИљОнЕк 5 СаХХађЁЃ
ЈC a[np.lexsort(np.flipud(a.T))] ЛсДгзѓЯђгвИљОнЫљгаСаХХађЁЃ
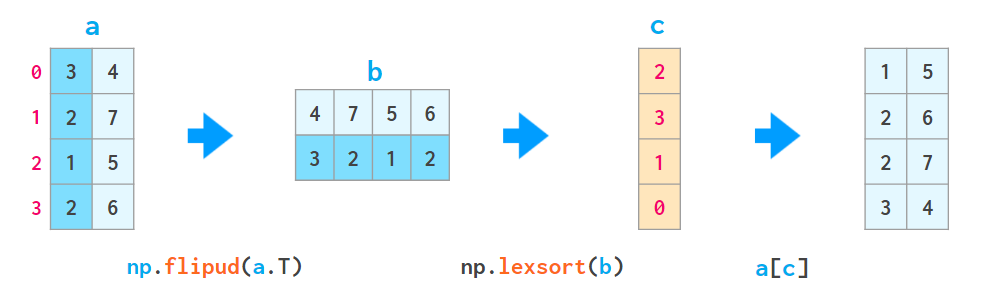
етРяЃЌflipud ЛсбиЩЯЯТЗНЯђЗзЊИУОиеѓЃЈзМШЗЕиЫЕЪЧ axis=0
ЗНЯђЃЌгы a[::-1,...] вЛбљЃЌЦфжаШ§ИіЕуБэЪОЁИЫљгаЦфЫќЮЌЖШЁЙЃЌвђДЫЗзЊетИівЛЮЌЪ§зщЕФЪЧЭЛШЛЕФ
flipudЃЌЖјВЛЪЧ fliplrЁЃ
3. sort ЛЙгавЛИі order ВЮЪ§ЃЌЕЋШчЙћвЛПЊЪМЪЧЦеЭЈЕФЃЈЗЧНсЙЙЛЏЃЉЪ§зщЃЌЫќжДааЦ№РДМШВЛПьЃЌвВВЛШнвзЪЙгУЁЃ
4. дк pandas жажДааЫќПЩФмЪЧИќКУЕФбЁдёЃЌвђЮЊдк pandas
жаЃЌИУЬиЖЈдЫЫуЕФПЩЖСадвЊИпЕУЖрЃЌвВВЛФЧУДШнвзГіДэЃК
ЈC pd.DataFrame(a).sort_values(by=[2,5]).to_numpy()
ЛсЯШИљОнЕк 2 СаХХађЃЌШЛКѓИљОнЕк 5 СаХХађЁЃ
ЈC pd.DataFrame(a).sort_values().to_numpy()
ЛсДгзѓЯђгвИљОнЫљгаСаХХађЁЃ
Ш§ЮЌМАИќИпЮЌ
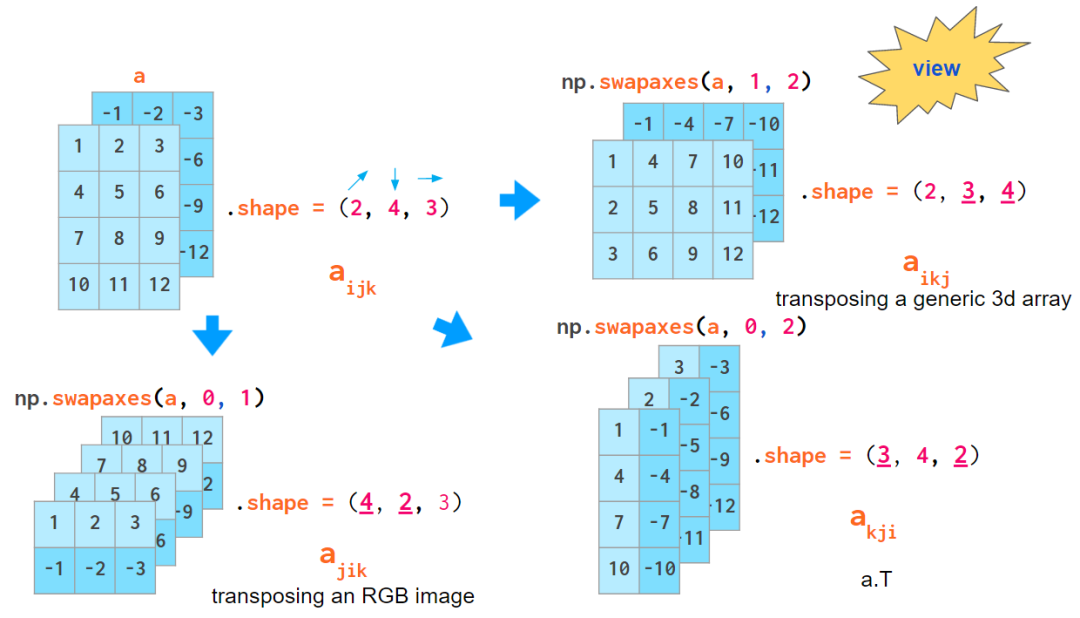
ЕБФуЭЈЙ§ЕїећвЛЮЌЯђСПЕФаЮзДЛђзЊЛЛЧЖЬзЕФ Python СаБэРДДДНЈ 3D Ъ§зщЪБЃЌЫїв§ЕФКЌвхЪЧ (z,y,x)ЁЃЕквЛИіЫїв§ЪЧЦНУцЕФЪ§СПЃЌШЛКѓЪЧдкИУЦНУцЩЯЕФзјБъЃК
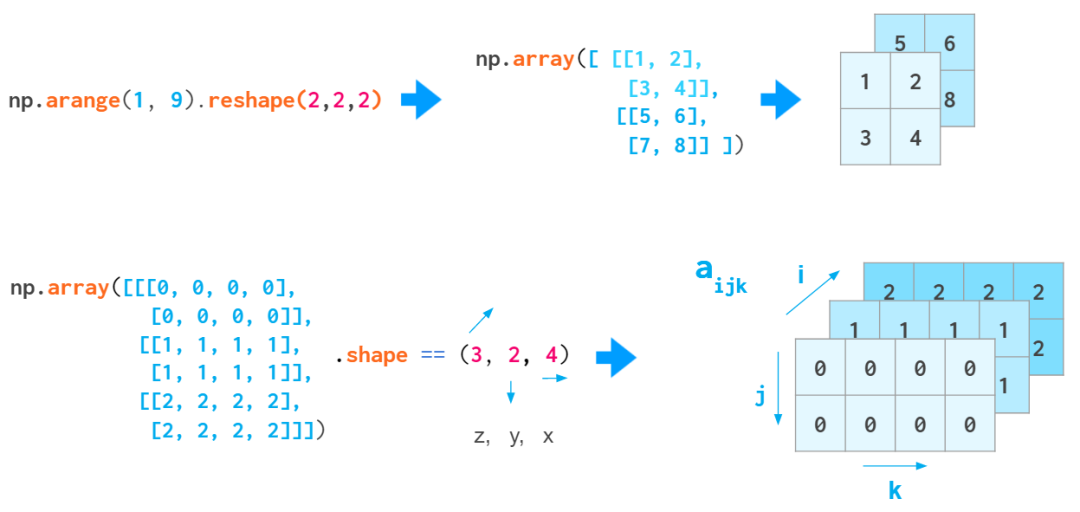
еЙЪО (z,y,x) ЫГађЕФЪОвтЭМ
етИіЫїв§ЫГађКмЗНБуЃЌОйИіР§згЃЌЫќПЩгУгкБЃДцвЛаЉЛвЖШЭМЯёЃКa[i] ЪЧЫїв§Ек
i еХЭМЯёЕФПьНнЗНЪНЁЃ
ЕЋетИіЫїв§ЫГађВЛЪЧЭЈгУЕФЁЃЕБВйзї RGB ЭМЯёЪБЃЌЭЈГЃЛсЪЙгУ (y,x,z) ЫГађЃКЪзЯШЪЧСНИіЯёЫизјБъЃЌзюКѓвЛИіЪЧбеЩЋзјБъЃЈMatplotlib
жаЪЧ RGBЃЌOpenCV жаЪЧ BGRЃЉЃК
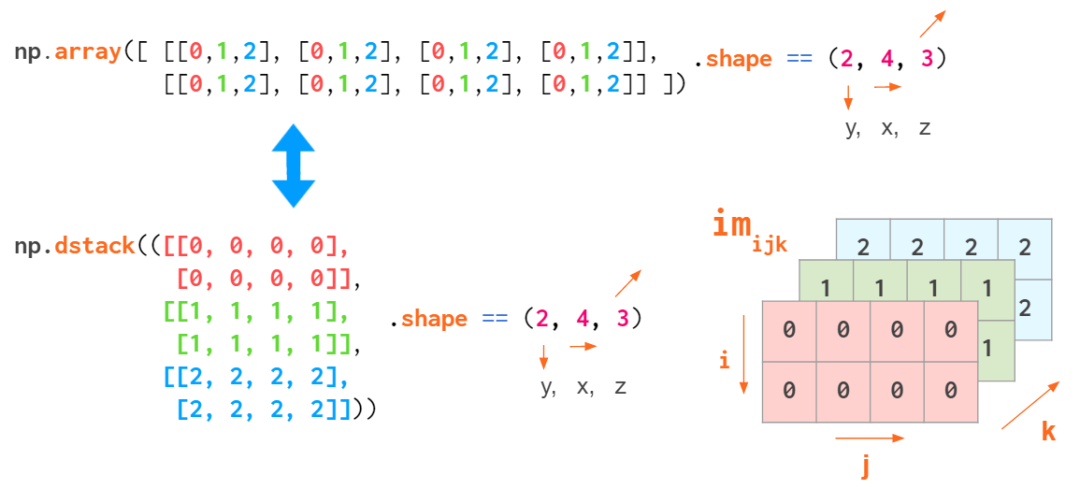
еЙЪО (y,x,z) ЫГађЕФЪОвтЭМ
етбљЃЌЮвУЧОЭФмКмЗНБуЕиЫїв§ЬиЖЈЕФЯёЫиЃКa[i,j] ФмЬсЙЉ (i,j)
ЮЛжУЕФ RGB дЊзщЁЃ
вђДЫЃЌДДНЈМИКЮаЮзДЕФЪЕМЪУќСюШЁОігкФуЫљдкСьгђЕФЙпР§ЃК
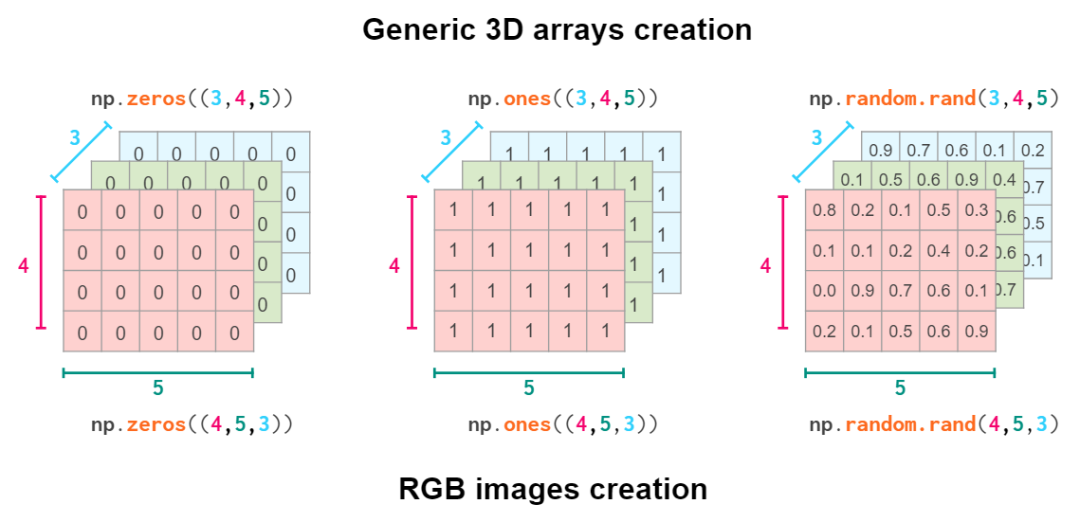
ДДНЈвЛАуЕФШ§ЮЌЪ§зщКЭ RGB ЭМЯё
КмЯдШЛЃЌhstackЁЂvstackЁЂdstack етаЉКЏЪ§ВЛжЇГжетаЉЙпР§ЁЃЫќУЧгВБрТыСЫ (y,x,z)
ЕФЫїв§ЫГађЃЌМД RGB ЭМЯёЕФЫГађЃК
NumPy ЪЙгУ (y,x,z) ЫГађЕФЪОвтЭМЃЌЖбЕў
RGB ЭМЯёЃЈетРяНігаСНжжбеЩЋЃЉ
ШчЙћФуЕФЪ§ОнВМОжВЛЭЌЃЌЪЙгУ concatenate УќСюРДЖбЕўЭМЯёЛсИќЗНБувЛаЉЃЌЯђвЛИі axis
ВЮЪ§ЪфШыУїШЗЕФЫїв§Ъ§жЕЃК
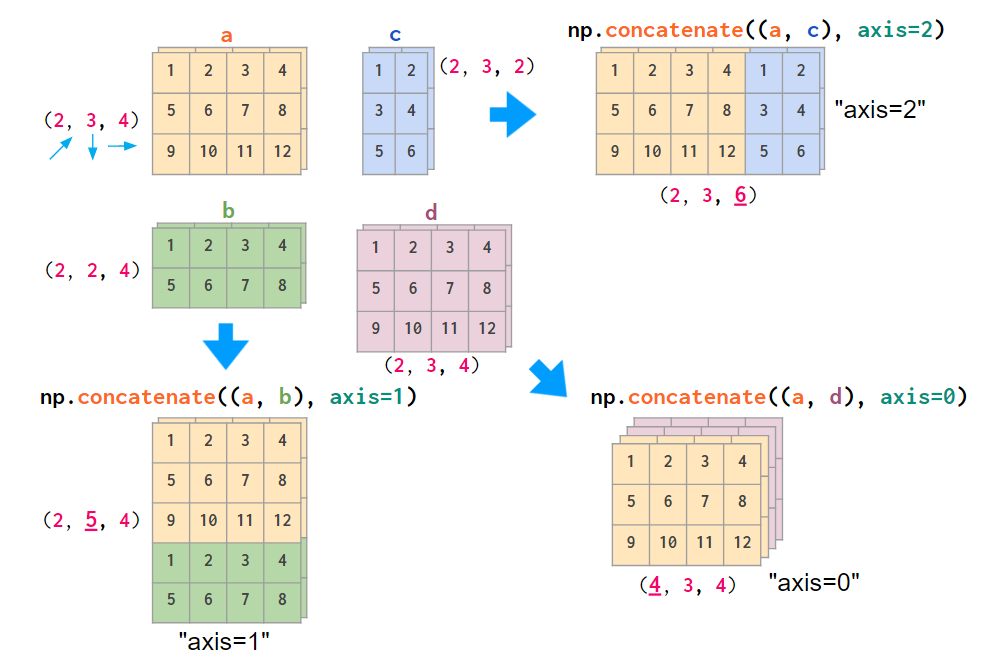
ЖбЕўвЛАуШ§ЮЌЪ§зщ
ШчЙћФуВЛЯАЙпЫМПМ axis Ъ§ЃЌФуПЩвдНЋИУЪ§зщзЊЛЛГЩ hstack ЕШКЏЪ§жагВБрТыЕФаЮЪНЃК

НЋЪ§зщзЊЛЛЮЊ hstack жагВБрТыЕФаЮЪНЕФЪОвтЭМ
етжжзЊЛЛЕФГЩБОКмЕЭЃКВЛЛсжДааЪЕМЪЕФИДжЦЃЌжЛЪЧжДааЙ§ГЬжаЛьКЯЫїв§ЕФЫГађЁЃ
СэвЛжжПЩвдЛьКЯЫїв§ЫГађЕФдЫЫуЪЧЪ§зщзЊжУЁЃСЫНтЫќПЩФмЛсШУФуИќМгЪьЯЄШ§ЮЌЪ§зщЁЃИљОнФуОіЖЈЪЙгУЕФ axis
ЫГађЕФВЛЭЌЃЌзЊжУЪ§зщЫљгаЦНУцЕФЪЕМЪУќСюЛсгаЫљВЛЭЌЃКЖдгквЛАуЪ§зщЃЌЫќЛсНЛЛЛЫїв§ 1 КЭ 2ЃЌЖд RGB
ЭМЯёЖјбдЪЧ 0 КЭ 1ЃК
зЊжУвЛИіШ§ЮЌЪ§ОнЕФЫљгаЦНУцЕФУќСю
ВЛЙ§гаШЄЕФЪЧЃЌtranspose ЕФФЌШЯ axes ВЮЪ§ЃЈвдМАНігаЕФ
a.T дЫЫуФЃЪНЃЉЛсЕїзЊЫїв§ЫГађЕФЗНЯђЃЌетгыЩЯЪіСНИіЫїв§ЫГађЙпР§ЖМВЛЯрЗћЁЃ
зюКѓЃЌЛЙгавЛИіКЏЪ§ФмБмУтФудкДІРэЖрЮЌЪ§зщЪБЪЙгУЬЋЖрбЕСЗЃЌЛЙФмШУФуЕФДњТыИќМђНрЁЊЁЊeinsumЃЈАЎвђЫЙЬЙЧѓКЭЃЉЃК
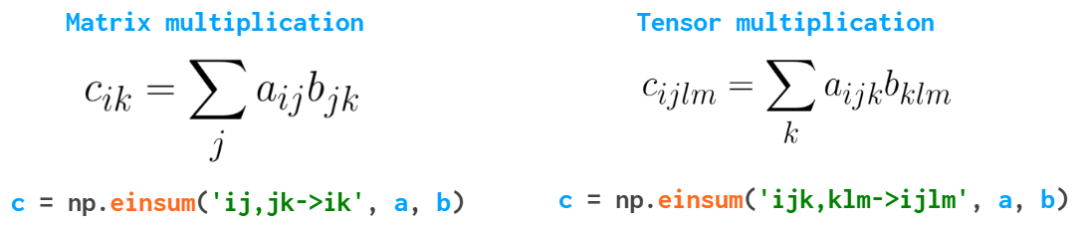
ЫќЛсбижиИДЕФЫїв§ЖдЪ§зщЧѓКЭЁЃдкетИіЬиЖЈЕФР§згжаЃЌnp.tensordot(a, b, axis=1)
зувдгІЖдетСНжжЧщПіЃЌЕЋдкИќИДдгЕФЧщПіжаЃЌeinsum ЕФЫйЖШПЩФмИќПьЃЌЖјЧвЭЈГЃвВИќШнвзЖСаДЁЊЁЊжЛвЊФуРэНтЦфБГКѓЕФТпМЁЃ
ШчЙћФуЯЃЭћВтЪдФуЕФ NumPy ММФмЃЌGitHub га 100 ЕРЯрЕБРЇФбЕФСЗЯАЬтЁЃ
|





