| 编辑推荐: |
本文主要介绍了什么是数据清洗、为什么要数据清洗及清洗的步骤等相关内容。
本文来自于CSDN,由火龙果软件Linda编辑,推荐。 |
|
一、什么是数据清洗
数据清洗是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成。
二、为什么要数据清洗
现实生活中,数据并非完美的, 需要进行清洗才能进行后面的数据分析
数据清洗是整个数据分析项目最消耗时间的一步
数据的质量最终决定了数据分析的准确性
数据清洗是唯一可以提高数据质量的方法,使得数据分析的结果也变得更加可靠
三、清洗的步骤(处理工具以python为例)

预处理
一是将数据导入处理工具。通常来说,建议使用数据库,单机跑数搭建MySQL环境即可。如果数据量大(千万级以上),可以使用文本文件存储+Python操作的方式。
二是看数据。这里包含两个部分:一是看元数据,包括字段解释、数据来源、代码表等等一切描述数据的信息;二是抽取一部分数据,使用人工查看方式,对数据本身有一个直观的了解,并且初步发现一些问题,为之后的处理做准备。
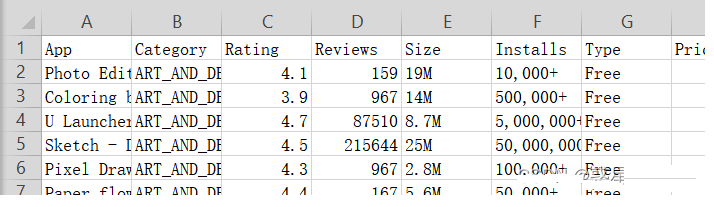
导入包和数据
import matplotlib.pyplot as plt df = pd.read_csv("./dataset/googleplaystore.csv",usecols = (0,1,2,3,4,5,6))
|
App Category Rating \
0 Photo Editor & Candy Camera & Grid & ScrapBook ART_AND_DESIGN 4.1
Reviews Size Installs Type
0 159 19M 10,000+ Free
|
(10841, 7)
App 10841
Category 10841
Rating 9367
Reviews 10841
Size 10841
Installs 10841
Type 10840
dtype: int64
|
min 1.000000
Rating
count 9367.000000
mean 4.193338
std 0.537431
min 1.000000
25% 4.000000
50% 4.300000
75% 4.500000
max 19.000000
|
阶段一:去除/补全有缺失的数据
1、确定缺失值范围:对每个字段都计算其缺失值比例,然后按照缺失比例和字段重要性,分别制定策略确定。
2、去除不需要的字段:这一步很简单,直接删掉即可。
3、填充缺失内容:某些缺失值可以进行填充,Pandas方法通常有以下几种:
填充具体数值,通常是0
填充某个统计值,比如均值、中位数、众数等
填充前后项的值
基于SimpleImputer类的填充
基于KNN算法的填充
阶段二:去除/修改格式和内容错误的数据
1、时间、日期、数值、全半角等显示格式不一致
date_obj = datetime.datetime.strptime(date_str, '%Y-%m-%d') formatted_date_str = date_obj.strftime('%m/%d/%Y') print("转换结果:" + formatted_date_str)
|
转换结果:09/11/2023字符
num_float = float(num_str) formatted_num_str = "{:.2f}".format(num_float) print("转换结果:"+formatted_num_str)
|
转换结果:123.46
2、内容与该字段应有内容不符
原始数据填写错误,并不能简单的以删除来处理,因为成因有可能是人工填写错误,也有可能是前端没有校验,还有可能是导入数据时部分或全部存在列没有对齐的问题,因此要详细识别问题类型。
阶段三:去除/修改逻辑错误的数据
1、去重
有的分析师喜欢把去重放在第一步,但我强烈建议把去重放在格式内容清洗之后,原因已经说过了(多个空格导致工具认为“陈丹奕”和“陈
丹奕”不是一个人,去重失败)。而且,并不是所有的重复都能这么简单的去掉……
我曾经做过电话销售相关的数据分析,发现销售们为了抢单简直无所不用其极……举例,一家公司叫做“ABC管家有限公司“,在销售A手里,然后销售B为了抢这个客户,在系统里录入一个”ABC官家有限公司“。你看,不仔细看你都看不出两者的区别,而且就算看出来了,你能保证没有”ABC官家有限公司“这种东西的存在么……这种时候,要么去抱RD大腿要求人家给你写模糊匹配算法,要么肉眼看吧。
当然,如果数据不是人工录入的,那么简单去重即可。
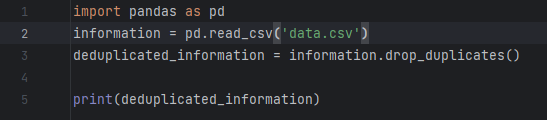
运行结果为:
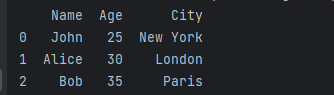
2、去除不合理值
一句话就能说清楚:有人填表时候瞎填,年龄200岁,年收入100000万(估计是没看见”万“字),这种的就要么删掉,要么按缺失值处理。这种值如何发现?提示:可用但不限于箱形图(Box-plot).
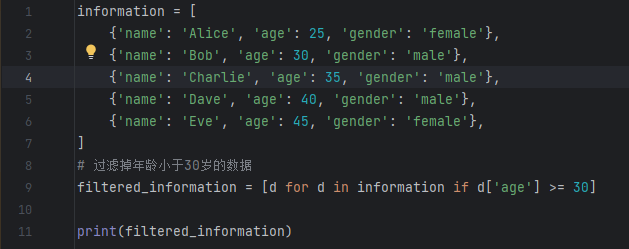
运行结果为:

3、修正矛盾内容
有些字段是可以互相验证的,举例:身份证号是1101031980XXXXXXXX,然后年龄填18岁,我们虽然理解人家永远18岁的想法,但得知真实年龄可以给用户提供更好的服务啊(又瞎扯……)。在这种时候,需要根据字段的数据来源,来判定哪个字段提供的信息更为可靠,去除或重构不可靠的字段。
逻辑错误除了以上列举的情况,还有很多未列举的情况,在实际操作中要酌情处理。另外,这一步骤在之后的数据分析建模过程中有可能重复,因为即使问题很简单,也并非所有问题都能够一次找出,我们能做的是使用工具和方法,尽量减少问题出现的可能性,使分析过程更为高效。
阶段四:去除不需要的数据
这一步说起来非常简单:把不要的字段删了。
但实际操作起来,有很多问题,例如:
把看上去不需要但实际上对业务很重要的字段删了;
某个字段觉得有用,但又没想好怎么用,不知道是否该删;
一时看走眼,删错字段了。
前两种情况我给的建议是:如果数据量没有大到不删字段就没办法处理的程度,那么能不删的字段尽量不删。第三种情况,请勤备份数据……

运行结果为:

阶段五:关联性验证
如果你的数据有多个来源,那么有必要进行关联性验证。
例如,你有汽车的线下购买信息,也有电话客服问卷信息,两者通过姓名和手机号关联,那么要看一下,同一个人线下登记的车辆信息和线上问卷问出来的车辆信息是不是同一辆,如果不是(别笑,业务流程设计不好是有可能出现这种问题的!),那么需要调整或去除数据。
运行结果为:

五、文本数据的基本处理
1.小写转换——将文本中的所有字母转换为小写形式。
lower()方法用于将字符串中的全部大写字母转换为小写字母。如果字符串中没有应该被转换的字符,则将原字符串返回;否则将返回一个新的字符串,将原字符串中每个该进行小写转换的字符都转换成等价的小写字符。字符长度与原字符长度相同。
lower()方法的语法格式如下:
str.lower()
其中,str为要进行转换的字符串。
例如,下面的代码将全部显示为小写字母。
str="TangRengui is a StuDeNt" print("lower转换为小写后:",str.lower())
|
运行结果为:
lower转换为小写后: tangrengui is a student
|
2.去除标点符号——从文本中删除所有标点符号,如句号、逗号、叹号等。
删除文本中的特殊字符、标点符号和非字母数字字符,如@、#、$等。
sentence = "+蚂=蚁!花!呗/期?免,息★.---《平凡的世界》:了*解一(#@)个“普通人”波涛汹涌的内心世界!" remove_chars = '[·’!"\#$%&\'()#!()*+,-./:;<=>?\@,:?¥★、….>【】[]《》?“”‘’\[\\]^_`{|}~]+' string = re.sub(remove_chars, "", sentence) sentenceClean.append(string)
|
运行结果为:
['蚂蚁花呗期免息平凡的世界了解一个普通人波涛汹涌的内心世界']
|
3.去除停用词——从文本中去除常见的无实际含义的词语,例如英语中的"a"、"an"、"the"等。
去停用词时,首先要用到停用词表,常见的有哈工大停用词表 及 百度停用词表,在网上随便下载一个即可。

在去停用词之前,首先要通过 load_stopword( ) 方法来加载停用词列表,接着按照上文所示,加载自定义词典,对句子进行分词,然后判断分词后的句子中的每一个词,是否在停用词表内,如果不在,就把它加入
outstr,用空格来区分 。
f_stop = open('stopword.txt', encoding='utf-8') sw = [line.strip() for line in f_stop] file_userDict = 'dict.txt' jieba.load_userdict(file_userDict) sentence_seged = jieba.cut(sentence.strip()) stopwords = load_stopword() for word in sentence_seged: if word not in stopwords: if __name__ == '__main__': sentence = "人们宁愿去关心一个蹩脚电影演员的吃喝拉撒和鸡毛蒜皮,而不愿了解一个普通人波涛汹涌的内心世界"
|
运行结果为:
人们 去 关心 蹩脚 电影演员 吃喝拉撒 鸡毛蒜皮 不愿 了解 普通人 波涛汹涌 内心世界
|
4.去除频现词——从文本中删除出现频率较高的词语,这些词语可能对文本分析任务的结果产生较少影响。
高频词是指文档中出现频率较高且非无用的词语,其一定程度上代表了文档的焦点所在。针对单篇文档可以作为一种关键词来看。对于如新闻这样的多篇文档,可以将其作为热词,发现舆论热点。
高频词提取的干扰项:
1)标点符号
2)停用词:类似“的”,“是”,“了”等无意义的词。
with open(path, 'r', encoding='gbk', errors='ignore') as f: def get_TF(words, topK=10): if w not in stop_words('stopword.txt'): tf_dic[w] = tf_dic.get(w, 0) + 1 return sorted(tf_dic.items(), key=lambda x: x[1], reverse=True)[:topK] with open(path, 'r', encoding='gbk', errors='ignore') as f: return [l.strip() for l in f] files = glob.glob('./news*.txt') corpus = [get_content(x) for x in files] split_words = list(jieba.cut(corpus[0])) print('样本之一:', corpus[0]) print('样本分词效果:', ','.join(split_words)) print('样本的top10热词:', str(get_TF(split_words)))
|
运行结果为:
样本之一:
先天性心脏病“几岁可根治,十几岁变难治,几十岁成不治”,
中国著名心血管学术领袖胡大一今天在此间表示救治心脏病应从儿
童抓起,他呼吁社会各界关心贫困地区的先天性心脏病儿童。据了解,
今年五月一日到五月三日,胡大一及其“爱心工程”专家组将联合北京
军区总医院在安徽太和县举办第三届先心病义诊活动。安徽太和县
是国家重点贫困县,同时又是先天性心脏病的高发区。由于受贫苦
地区医疗技术条件限制,当地很多孩子由于就医太晚而失去了治疗
时机,当地群众也因此陷入“生病—贫困—无力医治—病情加重—更
加贫困”的恶性循环中。胡大一表示,由于中国经济发展的不平衡与
医疗水平的严重差异化,目前中国有这种情况的绝不止一个太和县。
但按照现行医疗体制,目前医院、医生为社会提供的服务模式和力度
都远远不能适应社会需求。他希望,发达地区的医院、医生能积极走
出来,到患者需要的地方去。据悉,胡大一于二00二发起了面向全国
先天性心脏病儿童的“胡大一爱心工程”,旨在呼吁社会对于先心病儿童
的关注,同时通过组织大城市专家走进贫困地区开展义诊活动,对贫困地区贫
困家庭优先实施免费手术,并对其他先心病儿童给予适当资助。
(钟啸灵)
专家简介:胡大一、男、1946年7月生于河南开封,主任医师、教授、博士生导师,
国家突出贡献专家、享受政府专家津贴。现任同济大学医学院院长、首都
医科大学心脏病学系主任、北京大学人民医院心研所所长、心内科主任,
首都医科大学心血管疾病研究所所长,首都医科大学北京同仁医院心血管疾
病诊疗中心主任。任中华医学会心血管病分会副主任委员、中华医学会北京
心血管病分会主任委员、中国生物医学工程学会心脏起搏与电生理分会主
任委员、中国医师学会循证医学专业委员会主任委员、北京市健康协会理
事长、北京医师协会副会长及美国心脏病学院会员。(来源:北大人民医院网站)
样本分词效果: 先天性,心脏病,“,几岁,可,根治,,,十几岁,变,难治,,,几十岁,成不治,”,,,中国,
著名,心血管,学术,领袖,胡大一,今天,在,此间,表示,救治,心脏病,应从,儿童,抓起,,,
他,呼吁,社会各界,关心,贫困地区,的,先天性,心脏病,儿童,。,据,了解,,,今年,五月,一日,
到,五月,三日,,,胡大一,及其,“,爱心,工程,”,专家组,将,联合,
北京军区总医院,在,安徽,太和县,举办,第三届,先心病,义诊,活动,。,安徽,太和县,是,
国家,重点,贫困县,,,同时,又,是,先天性,心脏病,的,高发区,。,由于,受,贫苦,
地区,医疗,技术,条件,限制,,,当地,很多,孩子,由于,就医,太晚,而,失去,了,治疗,时机,,,当地,群众,
也,因此,陷入,“,生病,—,贫困,—,无力,医治,—,病情,加重,—,更加,贫困,”,的,恶性循环,
中,。,胡大一,表示,,,由于,中国,经济,发展,的,不,平衡,与,医疗,水平,的,严重,
差异化,,,目前,中国,有,这种,情况,的,绝,不止,一个,太和县,。,但,按照,现行,医疗,体制,,,
目前,医院,、,医生,为,社会,提供,的,服务,模式,和,力度,都,远远,不能,适应,社会,
需求,。,他,希望,,,发达,地区,的,医院,、,医生,能,积极,走,出来,,
,到,患者,需要,的,地方,去,。,据悉,,,胡大一,于,二,00,二,发起,了,面向全国,
先天性,心脏病,儿童,的,“,胡大一,爱心,工程,”,,,旨在,呼吁,社会,对于,先心病,
儿童,的,关注,,,同时,通过,组织,大城市,专家,走进,贫困地区,开展,义诊,活动,,,对,贫困地区,贫困家庭,
优先,实施,免费,手术,,,并,对,其他,先心病,儿童,给予,
适当,资助,。,
,(,钟啸灵,),专家,简介,:,胡大一,、,男,、,1946,年,7,月,生于,河南,开封,,,主任医师,
、,教授,、,博士生,导师,,,国家,突出贡献,专家,、,享受,政府,专家,津贴,。,现任,同济大学,
医学院,院长,、,首都医科大学,心脏病学,系主任,、,北京大学人民医院,心研,所,所长,、
,心内科,主任,,,首都医科大学,心血管,疾病,研究所,所长,,,首都医科大学,北京同仁医院,
心血管,疾病,诊疗,中心,主任,。,任,中华医学会,心血管病,分会,副,
主任委员,、,中华医学会,北京,心血管病,分会,主任委员,、,中国,
生物医学,工程,学会,心脏,起搏,与,电,生理,分会,主任委员,、,
中国,医师,学会,循证,医学专业,委员会,主任委员,、
,北京市,健康,协会,理事长,、,北京,医师,协会,副会长,及,
美国,心脏病,学院,会员,。,(,来源,:,北大人民医院,网站,)
样本的top10热词: [(',', 23), ('、', 15), ('的', 11),
('。', 11), ('心脏病', 6),
('胡大一', 6), ('中国', 5),
('儿童', 5), ('先天性', 4), ('“', 4)] |
5.去除稀疏词——从文本中删除出现频率较低的不常见词语,这些词语可能不具有足够的统计意义。
from nltk.tokenize import sent_tokenize from nltk.corpus import stopwords from nltk.stem import LancasterStemmer from nltk.probability import FreqDist def filter_punctuation(words): illegal_char = string.punctuation + '【·!…()—:“”?《》、;】' pattern=re.compile('[%s]' % re.escape(illegal_char)) new_word = pattern.sub(u'', word) new_words.append(new_word) def filter_stop_words(words): stops=set(stopwords.words('english')) words = [word for word in words if word.lower() not in stops] def Word_segmentation_and_extraction(text): words=nltk.word_tokenize(text) stemmerlan=LancasterStemmer() for i in range(len(words)): words[i] = stemmerlan.stem(words[i]) def filter_low_frequency_words(words): text_en = open(u'./data/text_en.txt',encoding='utf-8',errors='ignore').read() f1 = open("1.txt", "w",encoding='utf-8') words_seg=Word_segmentation_and_extraction(text_en) f2 = open("2.txt", "w",encoding='utf-8') words_no_stop=filter_stop_words(words_seg) for word in words_no_stop: f3 = open("3.txt", "w",encoding='utf-8') words_no_punc = filter_punctuation(words_no_stop) for word in words_no_punc: f4 = open("4.txt", "w",encoding='utf-8') fdist_no_low_fre = filter_low_frequency_words(words_no_punc) for key in fdist_no_low_fre: if(fdist_no_low_fre[key] > fre): f4.write(key + ' ' + str(fdist_no_low_fre[key])+'\n') f5 = open("5.txt", "w",encoding='utf-8') my_text = nltk.text.Text(nltk.word_tokenize(text_en)) name = ['Elizabeth', 'Darcy', 'Wickham', 'Bingley', 'Jane'] my_text.dispersion_plot(name[:]) fdist = FreqDist(words_no_punc)
|
部分运行结果为:
ssion to introduce his friend , Mr. Wickham , who had returned with him the day looked white , the other red . Mr. Wickham , after a few moments , touched his with his friend . Mr. Denny and Mr. Wickham walked with the young ladies to the p and down the street , and had Mr. Wickham appeared , Kitty and Lydia would ce sed to make her husband call on Mr. Wickham , and give him an invitation also , entered the drawing-room , that Mr. Wickham had accepted their uncle 's invitat ntlemen did approach , and when Mr. Wickham walked into the room , Elizabeth fe were of the present party ; but Mr. Wickham was as far beyond them all in perso o followed them into the room . Mr. Wickham was the happy man towards whom almo s for the notice of the fair as Mr. Wickham and the officers , Mr. Collins seem could not wait for his reason . Mr. Wickham did not play at whist , and with re he common demands of the game , Mr. Wickham was therefore at leisure to talk to r , was unexpectedly relieved . Mr. Wickham began the subject himself . He inqu rstand . '' `` Yes , '' replied Mr. Wickham ; `` his estate there is a noble on right to give my opinion , '' said Wickham , `` as to his being agreeable or o n not pretend to be sorry , '' said Wickham , after a short interruption , `` t ce , to be an ill-tempered man . '' Wickham only shook his head . `` I wonder , it prevented further inquiry . Mr. Wickham began to speak on more general topi myself on the subject , '' replied Wickham ; `` I can hardly be just to him . '' `` It is wonderful , '' replied Wickham , `` for almost all his actions may f regarding little matters . '' Mr. Wickham 's attention was caught ; and after both in a great degree , '' replied Wickham ; `` I have not seen her for many y st of the ladies their share of Mr. Wickham 's attentions . There could be no c e could think of nothing but of Mr. Wickham , and of what he had told her , all ext day what had passed between Mr. Wickham and herself . Jane listened with as Displaying 25 of 305 matches: ek . '' `` What is his name ? '' `` Bingley . '' `` Is he married or single ? ' re as handsome as any of them , Mr. Bingley may like you the best of the party ar , you must indeed go and see Mr. Bingley when he comes into the neighbourhoo crupulous , surely . I dare say Mr. Bingley will be very glad to see you ; and earliest of those who waited on Mr. Bingley . He had always intended to visit h addressed her with : '' I hope Mr. Bingley will like it , Lizzy . '' `` We are e are not in a way to know what Mr. Bingley likes , '' said her mother resentfu of your friend , and introduce Mr. Bingley to her . '' `` Impossible , Mr. Ben ontinued , `` let us return to Mr . Bingley . '' `` I am sick of Mr. Bingley , . Bingley . '' `` I am sick of Mr. Bingley , '' cried his wife . `` I am sorry u are the youngest , I dare say Mr. Bingley will dance with you at the next bal any satisfactory description of Mr. Bingley . They attacked him in various ways love ; and very lively hopes of Mr. Bingley 's heart were entertained . `` If I to wish for . '' In a few days Mr. Bingley returned Mr. Bennet 's visit , and arrived which deferred it all . Mr. Bingley was obliged to be in town the follo and a report soon followed that Mr. Bingley was to bring twelve ladies and seve sisted of only five altogether—Mr . Bingley , his two sisters , the husband of ldest , and another young man . Mr. Bingley was good-looking and gentlemanlike ared he was much handsomer than Mr. Bingley , and he was looked at with great a o be compared with his friend . Mr. Bingley had soon made himself acquainted wi with Mrs. Hurst and once with Miss Bingley , declined being introduced to any a conversation between him and Mr. Bingley , who came from the dance for a few astidious as you are , '' cried Mr. Bingley , `` for a kingdom ! Upon my honour wasting your time with me . '' Mr. Bingley followed his advice . Mr. Darcy wal ired by the Netherfield party . Mr. Bingley had danced with her twice , and she Displaying 25 of 288 matches: rg EBook of Pride and Prejudice , by Jane Austen Chapter 1 It is a truth unive sure she is not half so handsome as Jane , nor half so good-humoured as Lydia been distinguished by his sisters . Jane was as much gratified by this as her gh in a quieter way . Elizabeth felt Jane 's pleasure . Mary had heard herself t ball . I wish you had been there . Jane was so admired , nothing could be li ow ; and he seemed quite struck with Jane as she was going down the dance . So Maria Lucas , and the two fifth with Jane again , and the two sixth with Lizzy e detest the man . '' Chapter 4 When Jane and Elizabeth were alone , the forme second better . '' `` Oh ! you mean Jane , I suppose , because he danced with not there a little mistake ? '' said Jane . `` I certainly saw Mr. Darcy speak '' `` Miss Bingley told me , '' said Jane , `` that he never speaks much , unl xpressed towards the two eldest . By Jane , this attention was received with t like them ; though their kindness to Jane , such as it was , had a value as ar d to her it was equally evident that Jane was yielding to the preference which ered by the world in general , since Jane united , with great strength of feel mber , Eliza , that he does not know Jane 's disposition as you do . '' `` But gh of her . But , though Bingley and Jane meet tolerably often , it is never f be employed in conversing together . Jane should therefore make the most of ev should adopt it . But these are not Jane 's feelings ; she is not acting by d Well , '' said Charlotte , `` I wish Jane success with all my heart ; and if s while her daughter read , '' Well , Jane , who is it from ? What is it about it about ? What does he say ? Well , Jane , make haste and tell us ; make hast `` It is from Miss Bingley , '' said Jane , and then read it aloud . `` MY DEA `` Can I have the carriage ? '' said Jane . `` No , my dear , you had better g gment that the horses were engaged . Jane was therefore obliged to go on horse
|
6.拼写矫正——根据给定的文本,对其中可能存在的拼写错误进行自动纠正。这可以通过使用拼写纠正算法和词典来实现,以找到最可能的正确拼写。
拼写纠错步骤主要检查并改正两类文本错误,即单词的拼写错误(书写错误)和单词的语法使用错误。拼写错误纠正,首先检测词库外的单词识别为拼写错误单词,然后找出词库中与错误单词编辑距离最小的词作为改正项,替换它。而语法使用错误纠正,需借助语言模型实现。
vocab = set([line.rstrip() for line in open('vocab.txt')]) def generate_candidates(word): letters = 'abcdefghijklmnopqrstuvwxyz' splits = [(word[:i], word[i:]) for i in range(len(word)+1)] inserts = [L+c+R for L, R in splits for c in letters] deletes = [L+R[1:] for L,R in splits if R] replaces = [L+c+R[1:] for L,R in splits if R for c in letters] candidates = set(inserts+deletes+replaces) return [word for word in candidates if word in vocab] print(generate_candidates("apple")) from nltk.corpus import reuters categories = reuters.categories() corpus = reuters.sents(categories=categories) for i in range(0, len(doc)-1): bigram = ' '.join(bigram) if bigram in bigram_count: for line in open('spell-errors.txt'): correct = items[0].strip() mistakes = [item.strip() for item in items[1].strip().split(",")] channel_prob[correct] = {} channel_prob[correct][mis] = 1.0/len(mistakes) V = len(term_count.keys()) file = open("testdata.txt","r") items = line.rstrip().split('\t') candidates = generate_candidates(word) if candi in channel_prob and word in channel_prob[candi]: prob += np.log(channel_prob[candi][word]) pre_word = line[j-1]+" "+candi if pre_word in bigram_count and line[j-1] in term_count: prob += np.log((bigram_count[pre_word]+1.0)/(term_count[line[j-1]]+V)) pos_word = candi + " " + line[j+1] if pos_word in bigram_count and candi in term_count: prob += np.log((bigram_count[pos_word] + 1.0)/(term_count[candi]+V)) max_idx = probs.index(max(probs)) print(word,candidates[max_idx])
|
部分运行结果为:
protectionst protectionist
|
7.分词——将文本分割成具有一定意义的词语单元,这有助于后续的文本处理和分析任务。分词可以根据不同的语言和任务采用不同的分词算法或工具。
Jieba分词是结合了基于规则和基于统计两类方法的分词。它具有三种分词模式:
(1)精确模式:能够将句子精确的分开,适合做文本分析
(2)全模式:把句子中所有可能的词语都扫描出来,无法解决歧义问题
(3)搜索引擎模式:在精确模式的基础中,对长词再次进行切分,可以有效提高召回率。
三种模式的使用方法如下:
seg_list = jieba.cut(sentence,cut_all=True) print("全模式:","/".join(seg_list)) seg_list = jieba.cut(sentence,cut_all=False) print("精确模式:","/".join(seg_list)) seg_list = jieba.cut_for_search(sentence) print("搜索引擎模式:","/".join(seg_list)) seg_list = jieba.cut(sentence) print("默认模式:","/".join(seg_list))
|
运行结果为:
全模式: 你/需要/羽毛/羽毛球/羽毛球拍/球拍/吗/? 搜索引擎模式: 你/需要/羽毛/球拍/羽毛球/羽毛球拍/吗/?
|
8.题干提取——从一篇文章或一段文字中提取出主要的问题或主题。对于题目来说,题干提取是指从题目中提取出题目的关键内容或问题,以便更好地理解题目和回答问题。
import nltk.stem.porter as pt import nltk.stem.lancaster as lc import nltk.stem.snowball as sb words = ['table', 'probably', 'wolves', 'playing', 'is', 'the', 'beaches', 'grouded', 'dreamt', 'envision'] pt_stemmer = pt.PorterStemmer() lc_stemmer = lc.LancasterStemmer() sb_stemmer = sb.SnowballStemmer('english') pt_stem = pt_stemmer.stem(word) lc_stem = lc_stemmer.stem(word) sb_stem = sb_stemmer.stem(word) print('%8s %8s %8s %8s' % \ (word, pt_stem, lc_stem, sb_stem))
|
运行结果为:
probably probabl prob probabl beaches beach beach beach grouded groud groud groud dreamt dreamt dreamt dreamt envision envis envid envis Process finished with exit code 0
|
9.词形还原——将单词恢复为其原始的词干或基本形式。例如,对于英语中的单词"running",词形还原可以将其还原为"run"。词形还原有助于减少词形变化对文本处理和分析的干扰,以及提高文本处理的准确性。
“词形还原” 作用为英语分词后根据其词性将单词还原为字典中原型词汇。简单说来,词形还原就是去掉单词的词缀,提取单词的主干部分,通常提取后的单词会是字典中的单词,不同于词干提取(stemming),提取后的单词不一定会出现在单词中。比如,单词“cars”词形还原后的单词为“car”,单词“ate”词形还原后的单词为“eat”。
在Python的nltk模块中,使用WordNet为我们提供了稳健的词形还原的函数。如以下示例Python代码:
from nltk import word_tokenize, pos_tag from nltk.corpus import wordnet from nltk.stem import WordNetLemmatizer def get_wordnet_pos(tag): elif tag.startswith('V'): elif tag.startswith('N'): elif tag.startswith('R'): sentence = 'football is a family of team sports that
involve, to varying degrees, kicking a ball to score a goal.' tokens = word_tokenize(sentence) tagged_sent = pos_tag(tokens) wnl = WordNetLemmatizer() wordnet_pos = get_wordnet_pos(tag[1]) or wordnet.NOUN lemmas_sent.append(wnl.lemmatize(tag[0], pos=wordnet_pos))
|
运行结果为:
['football', 'be', 'a', 'family', 'of', 'team', 'sport', 'that',
'involve', ',', 'to', 'vary', 'degree', ',',
'kick', 'a', 'ball', 'to', 'score', 'a', 'goal', '.']
|
|






 订阅
订阅