针对 Subversion 1.1
(本书编译对应1876修订版本)
版权 © 2002, 2003, 2004, 2005 Ben Collins-Sussman, Brian W. Fitzpatrick, C. Michael Pilato
(TBA)
- 译者序
- 前言
- 序言
- 1. 介绍
- 2. 基本概念
- 3. 指导教程
- 4. 分支与合并
- 5. 版本库管理
- 6. 配置服务器
- 7. 高级主题
- 8. 开发者信息
- 9. Subversion完全参考
- A. Subversion对于CVS用户
- B. 故障解决
-
- 共同问题
-
- 使用Subversion的问题
-
- 每当我尝试访问版本库,我的Subversion客户端挂起。
- 每当我尝试运行svn,它告诉我工作拷贝已经锁定。
- 我在查找和打开版本库时得到错误,而我知道我的版本库URL是正确的。
-
我怎样在
file://的URL中指定一个Windows驱动器盘符? - 通过网络对Subversion版本库进行写操作发生问题。
- 在Windows XP下,Subversion服务器有时候看起来发送损坏的数据。
- 跟踪Subversion客户端和Apache服务器通话最好的方法是什么?
- 我刚刚编译了二进制分发版本,当我尝试检出Subversion,我得到一个“Unrecognized URL scheme”错误。
- 为什么svn revert命令要有一个明确的目标?为什么缺省不是递归的?它的行为方式与大多数其它子命令不同。
- 当我启动Apache,mod_dav_svn抱怨说发现一个“bad database version”,它发现了db-3.X而不是db-4.X。
- 我在RedHat 9得到“Function not implemented”错误,无法工作,我如何修正这个问题?
- 为什么日志说通过Apache(ra_dav)提交或导入的文件“(no author)”?
- 我偶然在Windows得到“Access Denied”错误,它们看起来随即出现。
- 在FreeBSD,某些操作(特别是svnadmin create)有时会挂起。
-
我可以在web浏览器看到我的版本库,但是svn
checkout给我一个
301 Moved Permanently错误。 - 我尝试察看我的文件的一个老版本,但是svn告诉我“path not found”。
- C. WebDAV和自动版本化
- D. 第三方工具
- E. 版权
- 术语表
- 1.1. Subversion的架构
- 2.1. 一个典型的客户/服务器系统
- 2.2. 需要避免的问题
- 2.3. 锁定-修改-解锁 方案
- 2.4. 拷贝-修改-合并 方案
- 2.5. 拷贝-修改-合并 方案(续)
- 2.6. 版本库的文件系统
- 2.7. 版本库
- 4.1. 分支开发
- 4.2. 开始规划版本库
- 4.3. 拷贝后的版本库
- 4.4. 一个文件的分支历史
- 8.1. 二维的文件目录
- 8.2. 版本时间—第三维!
- 2.1. 版本库访问URL
- 5.1. 版本库数据存储对照表
- 6.1. 网络服务器比较
- 8.1. Subversion库的摘要目录
- 5.1. 使用svnshell浏览版本库
- 5.2. txn-info.sh(异常事务报告)
- 6.1. 匿名访问的配置实例。
- 6.2. 一个认证访问的配置实例。
- 6.3. 一个混合认证/匿名访问的配置实例。
- 6.4. 关闭所有的路经检查
- 7.1. 注册表条目(.reg)样本文件。
- 8.1. 使用版本库层
- 8.2. 使用Python处理版本库层
- 8.3. 一段检出工作拷贝的简单脚本
- 8.4.
典型的
.svn/entries文件内容 - 8.5. 有效地池使用
最早接触这本书是在2004上半年,当时Subversion 1.0刚刚发布,而我很快把它引入到我们的项目当中,相对于CVS的简陋,Subversion显得非常的完备,是一个经过了深思熟虑的产品,是新一代开源项目的代表。
当我看到这本免费共享的图书,注意到了它已经在O'Reilly出版,而网站上有最新的版本可以下载,对于这种开源文化赞叹不已,萌生了自己翻译这本书的想法,但是苦于当时对DocBook非常不熟悉,于是使用文本格式,利用闲暇时间翻译了前四章,但后来杂事渐多,竟然慢慢忘了此事。
一转眼到了2005年,Subversion 1.2发布了,我的注意力又转到了这个领域,正好我有了做一个网站的念头,所以就有了Subversion中文站(http://www.subversion.org.cn),而同时我也开始申请成为这本书的中文官方翻译。
这本书的官方翻译要求我必须使用DocBook,要求我必须有一个团队,于是我在这两方面进行了努力,于是有人开始与我并肩工作了。在这段翻译的时间里陆续有人加入进来,按照时间顺序是rocksun、jerry、nashwang、gxio、MichaelDuan、viv、lifengliu2000、genedna、luyongshou、leasun和nannan。但是必须要说明这不是对翻译贡献大小的排序,大家都在自己的能力范围内为这个翻译做出了自己的贡献,感谢我们成员的努力,也感谢许多对我们提出建议的朋友。
开始的时候并没有觉得做好这件事有多难,但当看到翻译的东西自己都读不懂的时候,我感到了一种压力。如果这翻译还不如英文,我们还有没有必要继续。好在在大家的支持下,我越来越喜欢这本书了,渐渐的发现自己可以把这本书当作自己的参考材料了。
但是,我也有过许多疑惑,在中国人们似乎只是把版本控制工具当做一个代码分享的工具,而没有把它融入到整个软件开发的生命周期当中,这也难怪,大多数中国软件的寿命似乎并不长,不需要那么多复杂的配置管理。所以我们的这些翻译能够给大家带来多大的帮助要由中国软件的发展决定,希望我们的工作能够伴随着中国软件的腾飞不断成长。
让我们一起努力吧!
— ,青岛,2005年11月29日
一个不太好的常见问题列表(FAQ),常常并不是由人们实际上的问题组成,而经常是由作者期待的问题组成。或许你曾经见过这种类型的问题:
Q:怎样使用Glorbosoft XYZ提高生产率?
A:许多客户希望知道怎样通过革新我们特许的办公室群件来提高生产率,回答非常简单:首先点击“
文件” 菜单,鼠标移到“提高生产率”,然后…
这样的FAQ并不是其字面意义上的FAQ,没有人会这样询问支持者,“怎样提高生产率?”相反,人们经常询问一些更具体的问题,像“怎样修改日程系统提前两天而不是提前一天去提醒被提醒人?”等等。但是通过想象比去发现一个这样的问题列表更容易,编辑一个真实的问题列表需要持续的,有组织的工作,覆盖软件的整个生命周期,提出的问题必须被追踪,要监控反馈,所有问题要收集为一个一致的,可查询的整体,并且能够反映所有用户的经验。这需要耐心,像实地博物学家一样严谨的态度,不应该有浮华的假设,虚幻的断言—而需要开放的视野和精确的记录。
之所以会喜欢这本书,是因为这本书非凡的成长过程,这体现在每一页里,这是作者与用户直接交流的结果。这一切的基础是Ben Collins-Sussman's关于Subversion常见问题邮件列表的研究:使用subversion通常的流程是怎样的?分支与标签同其它版本控制系统的工作方式是一样的吗?我怎样知道某一处修改是谁做的?
由于每天看到相同问题的失落,Ben在2002年夏天努力工作了一个月,撰写了一本Subversion手册,一本六十页,涵盖了所有基础使用知识的手册。这本手册没有说明什么时候要结束,伴随着Subversion的版本,帮助用户开始最初的学习。当O'Reilly决定出版一本完备的Subversion图书的时候,最快捷的方式很明显,就是扩充这本书。
三个联合作者因而面临了一个不寻常的机会。从职责上讲,他们的任务是以一些原始内容为基础,从头到尾写一个草稿。但实际上他们正在使用着一些丰富的自下而上的原材料,像一条稳定的河流,也可能是一口不可预料的间歇泉。Subversion被数以千计的用户采用,这些用户提供了大量的反馈,不仅仅针对Subversion,还包括业已存在的文档。
在写这本书的过程里,Ben,Mike 和 Brian想鬼魂一样一直游荡在Subversion邮件列表和聊天室中,仔细的研究用户实际遇到的问题。监视这些反馈是他们在CollabNet工作的一部分,这给他们开始写这本书时提供了巨大的便利。这本书建立在丰富经验的根基之上,并不是在流沙一样的想象之上;它结合了用户手册和FAQ最好的一面,在第一次阅读时,这种二元性并不明显,按照顺序,从前到后,这本书只是简单的从头到尾的关于软件细节的描述。有一个总的看法,有一个教程,有一章关于管理配置,还有一些高级主题,当然也有一个命令参考和故障指南。只有当你过一段时间之后,返回来找一些特定问题的解决方案时,这种二元性才得以显现:这些生动的细节一定来自不可预料的实际用例的提炼,大多是源于用户的需要和视点。
当然,没人可以承诺这本书可以回答所有问题。尽管有时候一些前人提问的惊人一致性让你感觉是心灵感应;你仍有可能在社区的知识库里摔跤,空手而归。如果有这种情况,最好的办法是写明问题发送email到<users@subversion.tigris.org>,作者还在那里关注着社区,不仅仅封面提到的三位,还包括许多曾经作出修正与提供原始材料的人。从社区的视角,帮你解决问题只是逐步的调整这本书,进一步调整Subversion本身以更合理的适合用户使用这样一个大工程的一个有趣的额外效用。他们渴望你的信息,不仅仅可以帮助你,也因为可以帮助他们。与Subversion这样活跃的自由软件项目一起,你并不孤单。
让这本书将成为你的第一个伙伴。
— ,芝加哥,2004年3月15日
“如果C给你足够的绳子吊死你自己,试着用Subversion作为一种存放绳子的工具。” —Brian W. Fitzpatrick
在开源软件领域,并行版本系统(CVS)一直是版本控制的选择。恰如其分的是,CVS本身是一个自由软件,它的非限制性的技法和对网络操作的支持—允许大量的不同地域分散的程序员可以共享他们工作的特性—非常符合开源软件领域合作的精神,CVS和它半混乱状态的开发模型成为了开源文化的基石。
但是像许多其他工具一样,CVS开始显露出衰老的迹象。Subversion是一个被设计成为CVS继任者的新版本控制系统。设计者通过两个办法来争取现有的CVS用户: 使用它构建一个开源软件系统的版本控制过程,从感觉和体验上与CVS类似,同时Subversion努力弥补CVS许多明显的缺陷,结果就是不需要版本控制系统一个大的革新。Subversion是非常强大、有用及灵活的工具。
这本书是为Subversion 1.1 系列撰写的,我们试图涵盖Subversion的所有内容,但是Subversion有一个兴盛和充满活力的开发社区,已经有许多特性和改进计划在新的版本中实现,可能会与目前这本书中的命令与细节不一致。
这本书的目标读者非常的广泛—从从未使用过版本控制的新手到经验丰富的系统管理员。根据你的基础,特定的章节可能对你更有用,下面的内容可以看作是为各类用户提供的“推荐阅读清单”:
- 资深管理员
-
假设你以前已经使用过CVS,希望得到一个Subversion服务器并且尽快运行起来,第5、6章将会告诉你怎样建立第一个版本库,并且使之在网络上可用,此后,根据你的CVS使用经验,第3章和附录A告诉你怎样使用Subversion客户端。
- 新用户
-
你的管理员已经为你准备好了Subversion服务,你将学习如何使用客户端。如果你没有使用过版本控制系统(像CVS),那么第2、3章是重要的介绍,如果你是CVS的老手,最好从第3章和附录A开始。
- 高级用户
-
无论你只是个使用者还是管理员,最终你的项目会长大,你想通过Subversion作许多高级的事情,像如何使用分支和执行合并(第4章),怎样使用Subversion的属性支持,怎样配制运行参数(第7章)等等。第4、7章一开始并不重要,但你适应了基本操作之后一定要读一下。
- 开发者
-
大概你已经很熟悉Subversion了,你想扩展它并在它的API基础之上开发新软件,第8章将是为你准备的。
这本书以一个参考材料作为结束—第9章包括了所有命令的参考,这个附录包括了许多有用的主题,当你完成了本书的阅读,你会经常去看这个章节。
这一部分包括书中各种约定。
以下是章节和其中的内容介绍:
- 第1章,介绍
-
记述了Subversion的历史与特性、架构、组件和安装方法,还包括一个快速入门指南。
- 第2章,基本概念
-
解释了版本控制的基础知识,介绍了不同的版本模型,随同讲述了Subversion的版本库,工作拷贝和修订版本的概念。
- 第3章,指导教程
-
带领你作为一个Subversion用户开始工作,示范了怎样使用Subversion获得、修改和提交数据。
- 第4章,分支和合并
-
讨论分支、合并与标签,包括一个最佳实践,通常的用例,怎样取消修改,以及怎样从一个分支转到另一个分支。
- 第5章,版本库管理
-
讲述Subversion版本库的基本概念,怎样建立、配置和维护版本库,以及你可以使用的工具。
- 第6章,配置服务器
-
解释了怎样配置Subversion服务器,以及三种访问版本库的方式,
HTTP、svn协议和本地访问。这里也介绍了认证的细节,以及授权与匿名访问方式。 - 第7章,高级主题
-
研究Subversion客户配置文件,文件和目录属性,怎样
忽略工作拷贝中的文件,怎样引入外部版本树到工作拷贝,最后介绍了如何掌握卖主分支。 - 第8章,开发者信息
-
介绍了Subversion的核心,Subversion文件系统,以及从程序员的角度如何看待工作拷贝的管理区域,介绍了如何使用公共APIs写程序使用Subversion,最重要的是,怎样投身到Subversion的开发当中去。
- 第9章,Subversion完全手册
-
深入研究研究所有的命令,包括 svn、svnadmin、和svnlook以及大量的相关实例
- 附录A,Subversion对于CVS用户
-
比较Subversion与CVS的异同点,消除多年使用CVS养出的坏习惯的建议,包括subversion版本号、标记版本的目录、离线操作、update与status、分支、标签、元数据、冲突和认证。
- 附录B,故障解决
-
叙述常见的问题,以及使用和编译Subversion的难点。
- 附录C,WebDAV与自动版本化
-
描述了WebDAV与DeltaV的细节,和怎样将你的Subversion版本库作为可读/写的DAV共享装载。
- 附录D,第三方工具
-
讨论一些支持和使用Subversion的工具,包括可选的客户端工具,版本库浏览工具等等。
本版图书覆盖了Subversion 1.1的新特性,下面是一个1.1主要变化的列表。
- 非数据库的版本库
-
现在可以创建不使用Berkeley DB数据库的版本库,作为替代,这个新的版本库使用普通的文件系统,使用自定义的文件格式,这个版本库不是一个脆弱的“楔入”,它和Berkeley DB版本库一样经过很好的测试,见“版本库数据存储”一节。
- 对象链接纳入版本控制
-
Unix用户可以创建一个对象链接,使用svn add放置到版本控制,见svn add和“
svn:special”一节。 - 客户可以追踪拷贝和改名
-
文件和目录的分支(拷贝)维护着他们与历史的联系,但是在Subversion 1.0中svn log追踪历史的方式与svn diff、svn merge、svn list或svn cat都不同,在Subversion 1.1,所有的客户端子命令可以透明的回溯到拷贝和改名之前的历史文件和目录。
- 客户端自动转化URI和IRI
-
在1.0的命令行客户端,用户需要手工的回避URL,客户端只能接收“合法正确的”URL,例如
http://host/path%20with%20space/project/espa%F1a。1.1命令行客户端现在知道了web浏览器长久以来所做的事情:它会自动回避用户在shell放置的空格和重音字符之类的字符:"http://host/path with space/project/españa" - 本地化的用户信息
-
Subversion 1.1现在使用
gettext()来为用户显示翻译的错误信息和帮助消息。现在有的翻译包括德国、西班牙、波兰、瑞典、繁体中文、日本、巴西、葡萄牙和挪威Bokmal,为了本地化你的Subversion客户端,只需要设置你的shell的LANG环境变量为支持的某个值(例如de_DE)。 - 可分享的工作拷贝
-
允许多个用户分享一个工作拷贝有一些历史问题,现在相信已经修正了。
store-passwords运行变量-
这是一个新的运行变量用来关闭密码缓存,所以服务器证书可以缓存,见“config”一节。
- 优化和bug修正
-
svn checkout、svn update、svn status和 svn blame会更快,超过50个小bug被修正,都在项目的CHANGES文件(在
http://svn.collab.net/repos/svn/trunk/CHANGES)里描述。 - 新的命令选项
-
-
svn blame --verbose:见 svn blame.
-
svn export --native-eol EOL:见 svn export.
-
svn add --force:见 svn add.
-
svnadmin dump --deltas:见 “版本库的移植”一节.
-
svnadmin create --fs-type TYPE:见 svnadmin create.
-
svnadmin recover --wait:见 svnadmin recover.
-
svnserve --tunnel-user=NAME:见 “svnserve选项”一节.
-
这本书是作为Subversion项目的文档,由开发者开始撰写的,后来成为一个独立工作并进行了重写,因此,它一直有一个免费许可证(见附录 E, 版权。)实际上,这本书是在公众关注中写出来的,作为Subversion的一部分,它有两种含义:
-
你一直可以在Subversion的版本库里找到本书的最新版本。
-
对于这本书,你可以任意分发或者修改—它是免费许可证,当然,相对于发布你的私有版本,你最好向Subversion开发社区提供反馈。为了能够参与到社区,见“为Subversion做贡献”一节来学习如何加入到社区。
你可以向O'Reilly发布评论和问题:###insert boilerplate.
一个相对新的在线版本可以在http://svnbook.red-bean.com找到。
没有Subversion就没有可能(或者有用)有这本书,所以作者很乐意去感谢Brian Behlendorf和CollabNet,有眼光开始这样一个冒险和野心勃勃的开源项目;Jim Blandy给了Subversion这个名字和最初的设计—我们爱你。还有Karl Fogel,伟大社区领导和好朋友。 [1]
感谢O'Reilly和我们的编辑Linda Mui和Tatiana对我们的耐心的支持。
最后,我们要感谢数不清的曾经为社区作出贡献的人们,他们提供了非正式的审计、建议和修正:这一定不是一个最终的完整列表,离开了这些人的帮助,这本书不会这样完整和正确:Jani Averbach, Ryan Barrett, Francois Beausoleil, Jennifer Bevan, Matt Blais, Zack Brown, Martin Buchholz, Brane Cibej, John R. Daily, Peter Davis, Olivier Davy, Robert P. J. Day, Mo DeJong, Brian Denny, Joe Drew, Nick Duffek, Ben Elliston, Justin Erenkrantz, Shlomi Fish, Julian Foad, Chris Foote, Martin Furter, Dave Gilbert, Eric Gillespie, Matthew Gregan, Art Haas, Greg Hudson, Alexis Huxley, Jens B. Jorgensen, Tez Kamihira, David Kimdon, Mark Benedetto King, Andreas J. Koenig, Nuutti Kotivuori, Matt Kraai, Scott Lamb, Vincent Lefevre, Morten Ludvigsen, Paul Lussier, Bruce A. Mah, Philip Martin, Feliciano Matias, Patrick Mayweg, Gareth McCaughan, Jon Middleton, Tim Moloney, Mats Nilsson, Joe Orton, Amy Lyn Pilato, Kevin Pilch-Bisson, Dmitriy Popkov, Michael Price, Mark Proctor, Steffen Prohaska, Daniel Rall, Tobias Ringstrom, Garrett Rooney, Joel Rosdahl, Christian Sauer, Larry Shatzer, Russell Steicke, Sander Striker, Erik Sjoelund, Johan Sundstroem, John Szakmeister, Mason Thomas, Eric Wadsworth, Colin Watson, Alex Waugh, Chad Whitacre, Josef Wolf, Blair Zajac, 以及整个Subversion社区。
非常非常感谢我的妻子Marie的理解,支持和最重要的耐心。感谢引导我学会UNIX编程的兄弟Eric,感谢我的母亲和外祖母的支持,对我在圣诞夜里埋头工作的理解。
Mike和Ben:与你们一起工作非常快乐,Heck,我们在一起工作很愉快!
感谢所有在Subversion和Apache软件基金会的人们给我机会与你们在一起,没有一天我不从你们那里学到知识。
最后,感谢我的祖父,他一直跟我说“自由等于责任”,我深信不疑。
特别感谢我的妻子Amy,由于她的耐心照顾,由于她对我熬夜的容忍,由于她用难以想象的优雅方式修订我的每一个章节—你总能先行一步。Gavin,你已经大到可以阅读了,我希望你能为我这样一个爸爸感到骄傲,像我为你骄傲一样。爸爸妈妈(家庭的其余部分),感谢你们恒久不变的支持和鼓励。
向你们致敬,Shep Kendall,为我打开了计算机世界的大门;Ben Collins Sussman,我在开源世界的导师;Karl Fogel—你是我的.emacs;Greg Stain,让我在困境中知道怎样编程;Brain Fitzpatrick—同我分享他的写作经验。所有我曾经从你们那里获得知识的人—尽管又不断忘记。
最后,对所有为我展现完美卓越创造力的人们—感谢。
版本控制是管理信息变化的艺术,它很早就成为了程序员重要的工具,程序员经常会花时间做一点小修改然后第二天又把它改回来。但是版本控制的作用不仅在软件开发领域,任何需要管理频繁信息改变的地方都需要它,这就是Subversion发挥的舞台。
这一章是一个对Subversion高层次的介绍—它是什么;它能做什么;它是怎样做到的。
早在2000年,CollabNet, Inc. (http://www.collab.net) 开始寻找CVS替代产品的开发人员,CollabNet提供了一个协作软件套件SourceCast,它的一个组件是版本控制系统。尽管SourceCast在初始时使用CVS作为其版本控制系统,但是CVS的局限性在一开始就很明显,CollabNet知道迟早要找到一个更好的替代品。遗憾的是,CVS成为了开源世界事实上的标准,因为没有更好的产品,至少是没有可以自由使用的。所以CollabNet决定写一个新的版本控制系统,建立在CVS思想之上的,但是修正其错误和不合理的特性。
2000年2月,他们联系Open Source Development with CVS(Coriolis, 1999)的作者Karl Fogel,并且询问他是否希望为这个新项目工作,巧合的是,当时Karl正在与朋友Jim Blandy讨论设计一个新的版本控制系统。在1995年,他们两个曾经开办一个提供CVS支持的公司Cyclic Software,尽管他们最终卖掉了公司,但还是天天使用CVS进行日常工作,在使用CVS时的挫折最终促使他们认真地去考虑如何管理标记版本的数据,而且他们当时不仅仅提出了“Subversion”这个名字,并且做出了Subversion版本库的基础设计。所以当CollabNet提出邀请的时候,Karl马上同意为这个项目工作,同时Jim也得到了他的雇主,RedHat软件赞助他到这个项目并提供了一个宽松的时间。CollabNet雇佣了Karl和Ben Collins Sussman,详细的设计从三月开始,在Behlendorf 、CollabNet、Jason Robbins 和 Greg Stein(当时是一个独立开发者,活跃在WebDAV/DeltaV系统规范阶段)的恰当激励的帮助下,Subversion很快吸引了许多活跃的开发者,结果是许多有CVS经验的人们很乐于有机会为这个项目做些事情。
最初的设计小组固定在简单的目标上,他们不想在版本控制方法学中开垦处女地,他们只是希望修正CVS,他们决定Subversion匹配CVS的特性,保留相同的开发模型,但不复制CVS明显的缺陷。尽管它不需要成为CVS的继任者,它也应该与CVS保持足够的相似性,使得CVS用户可以轻松的做出转换。
经过14个月的编码,2001年8月31日,Subversion自己能够“成为服务”了,开发者停止使用CVS保存Subversion的代码,而使用Subversion本身。
当CollabNet开始这个项目的时候,曾经资助了大量的工作(它为全职的Subversion开发者提供薪水),Subversion像许多开源项目一样,被一些激励知识界精英的宽松透明的规则支配着。CollabNet的版权许可证完全符合Debian的自由软件方针,也就是说,任何人可以自由的下载,修改和重新发布,不需要经过CollabNet或其他人的允许。
当讨论Subversion为版本控制领域带来的特性的时候,通过学习它在CVS基础上所作的改进会是比较有效的方法。如果你不熟悉CVS,你会不太明白所有的特性,如果你根本就不熟悉版本控制,你会瞪着眼无所适从,你最好首先阅读一下第 2 章 基本概念,它提供了一个版本控制的简单介绍。
Subversion提供:
- 版本化的目录
-
CVS只记录单个文件的历史,但是Subversion实现了一个可以跟踪目录树更改的“虚拟”版本化文件系统,文件和目录都是有版本的。
- 真实的版本历史
-
因为CVS只记录单个文件的版本,对于拷贝和改名—这些文件经常发生的操作,会改变一个目录的内容—在CVS中并不支持。在CVS里你也不可以用一个完全不同的文件覆盖原来的同名文件而又不继承原来文件的历史。通过Subversion,你可以对文件或是目录进行增加、拷贝和改名操作,也可以新增一个具有干净历史的文件。
- 原子提交
-
一系列的改动,要么全部提交到版本库,要么一个也不提交,这样可以让用户构建一个所要提交修改的逻辑块,防止部分修改提交到版本库。
- 版本化的元数据
-
每一个文件或目录都有一套属性—键和它们的值,你可以建立并存储任何键/值对,属性也是随时间的流逝而纳入版本控制的,很像文件的内容。
- 可选的网络层
-
Subversion在版本库访问方面有一个抽象概念,利于人们去实现新的网络机制,Subversion可以作为一个扩展模块与Apache结合,这给了Subversion在稳定性和交互性方面很大的好处,可以直接使用服务器的特性—认证、授权和传输压缩等等。也有一个轻型的,单独运行的Subversion服务,这个服务使用自己的协议可以轻松的用SSH封装。
- 一致的数据操作
-
Subversion表示文件是建立在二进制文件区别算法基础上的,对于文本(可读)和二进制(不可读)文件具备一致的操作方式,两种类型的文件都压缩存放在版本库中,区别信息是在网络上双向传递的。
- 有效率的分支和标签
-
分支与标签的代价不与工程的大小成比例,Subversion建立分支与标签时只是拷贝整个工程,使用了一种类似于硬链接的机制,因而这类操作通常只会花费很少并且相对固定的时间。
- 可修改性
-
Subversion没有历史负担,它由一系列良好的共享C库实现,具有定义良好的API,这使得Subversion非常容易维护,可以轻易的用其他语言操作。
图 1.1 “Subversion的架构”从高处“俯视”Subersion的设计。
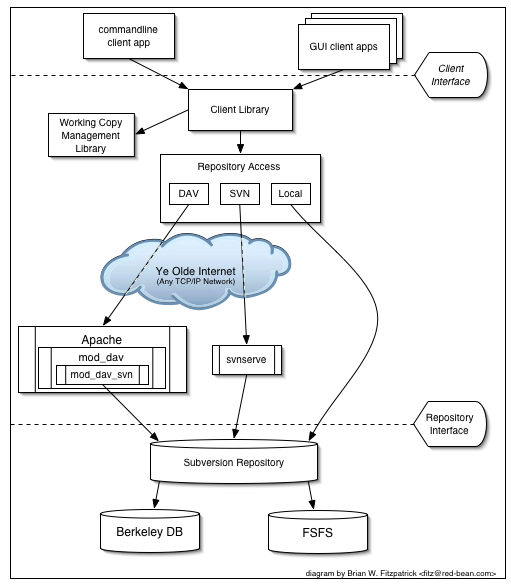
一端是保存你所有纳入版本控制的数据的Subversion版本库,在另一端是你的Subvesion客户端程序,管理着所有纳入版本控制数据的本地影射(叫做“工作拷贝”),在这两极之间是各种各样的版本库访问(RA)层,一些使用电脑网络通过网络服务器访问版本库,一些则绕过网络服务器直接访问版本库。
Subversion建立在一个可移植层上,叫做APR(Apache Portable Runtime library),这意味着Subversion可以在所有可运行Apache服务器的平台上工作:Windows、Linux、各种BSD、Mac OS X、Netware以及其他。
最简单的安装办法就是下载相应操作系统的二进制包,Subversion的网站(http://subversion.tigris.org)上通常会有志愿者提供的包可以下载,对于微软操作系统,网站上通常会有图形化的安装包,对于类Unix系统,你可以使用它们本身的打包系统(PRMs、DEBs、ports tree等等)得到Subversion。
你也可以选择从源代码直接编译Subversion,从网站下载最新的源代码,解压缩,根据INSTALL文件的指导进行编译。注意,通过这些源代码可以完全编译访问服务器的命令行客户端工具(通常是apr,apr-util和neno库)。但是可选部分有许多依赖,如Berkeley DB和Apache httpd。如果你希望做一个完全的编译,确定你有所有INSTALL文件中记述的包。如果你计划通过Subversiong本身工作,你可以使用客户端程序取得最新的,带血的源代码,这部分内容见“取得源代码”一节。
许多人为“从头到尾”的方式读一本介绍有趣新技术的书感到发愁,这一小节是一个很短的介绍,给许多“实用”的用户一个实战的机会,如果你是一个喜欢通过实验进行学习的用户,以下将告诉你怎么做,相对应,我们给出这本书相关的链接。
如果版本控制或者Subversion和CVS都用到的“拷贝-修改-合并”模型对于你来说是完全的新概念,在进一步阅读之前,你首先要读第 2 章 基本概念。
注意
以下的例子假定你有了svn这个客户端程序,也有svnadmin这个管理程序,你的svn也应该在Berkeley DB的基础上进行编译。为了验证这些,运行svn --version,确定ra_local模块存在,如果没有,这个程序不能访问file://的URL。
Subversion存储所有版本控制的数据到一个中心版本库,作为开始,新建一个版本库:
$ svnadmin create /path/to/repos $ ls /path/to/repos conf/ dav/ db/ format hooks/ locks/ README.txt
这个命令建立了一个新的目录 /path/to/repos,包含了一个Subversion版本库。确定这个目录在本地磁盘上,而不是一个网络共享,这个新的目录保存着一些Berkeley DB的数据库文件,你打开后看不到你的已经版本化的文件。更多的版本库创建和维护信息,见第5章第 5 章 版本库管理。
第二步,建立一些将要导入到版本库的文件与目录,为了以后使用更清楚(见第 4 章 分支与合并),你的文件应该包括三个顶级子目录,分别是branches、tags和trunk:
/tmp/project/branches/
/tmp/project/tags/
/tmp/project/trunk/
foo.c
bar.c
Makefile
…
一旦你有了树形结构和数据你就可以继续了,使用svn import导入数据到版本库(见“svn import”一节部分):
$ svn import /tmp/project file:///path/to/repos -m "initial import" Adding /tmp/project/branches Adding /tmp/project/tags Adding /tmp/project/trunk Adding /tmp/project/trunk/foo.c Adding /tmp/project/trunk/bar.c Adding /tmp/project/trunk/Makefile … Committed revision 1. $
现在版本库已经包含你的目录和数据了,注意原先的/tmp/project目录没有任何变化;Subversion不管这个,(事实上,你甚至可以任意删除这个目录)。为了处理 版本库的数据,你需要创建一个新的包含数据的“工作拷贝”,一个私人的工作空间。告诉Subversion来“取出”版本库的trunk目录:
$ svn checkout file:///path/to/repos/trunk project A project/foo.c A project/bar.c A project/Makefile … Checked out revision 1.
你现在在project目录里有了一个版本库的个人拷贝,你可以编辑你的工作备份中的文件,并且提交到版本库。
-
进入到你的工作备份,编辑一个文件的内容。
-
运行svn diff来查看你的修改的标准区别输出。
-
运行svn commit来提交你的改变到版本库。
-
运行svn update将你的工作拷贝与版本库“同步”。
对于你对工作拷贝可做操作的完全教程可以察看第 3 章 指导教程。
目前,你可以选择使你的版本库在网络上可见,可以参考第 6 章 配置服务器,学习使用不同的服务器以及配置。
这一章是对Subversion一个简短和随意的介绍,如果你对版本控制很陌生,这一章节完全为你准备的,我们从讨论基本概念开始,深入理解Subversion的思想,然后展示许多简单的实例。
尽管我们的例子展示了人们如何分享程序源代码,仍然要记住Subversion可以控制所有类型的文件—它并没有限制在只为程序员工作。
Subversion是一种集中的分享信息的系统,它的核心是版本库,它储存所有的数据,版本库按照文件树形式储存数据—包括文件和目录。任意数量的客户端可以连接到版本库,读写这些文件。通过写,别人可以看到这些信息,通过读数据,可以看到别人的修改。图 2.1 “一个典型的客户/服务器系统”描述了这种关系:
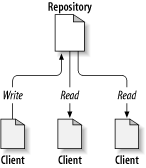
所以为什么这很有趣呢?讲了这么多,让人感觉这是一种普通的文件服务器,但实际上,版本库是另一种文件服务器,而不是你常见的那一种。最特别的是Subversion会记录每一次的更改,不仅针对文件也包括目录本身,包括增加、删除和重新组织文件和目录。
当一个客户端从版本库读取数据时,通常只会看到最新的版本,但是客户端也可以去看以前的任何一个版本。举个例子,一个客户端可以发出这样的历史问题“上个星期三的目录是怎样的?”或是“谁最后一个更改了这个文件,更改了什么?”,这些是每一种版本控制系统的核心问题:系统是设计来记录和跟踪每一次改动的。
版本控制系统的核心任务是提供协作编辑和数据共享,但是不同的系统使用不同的策略来达到目的。
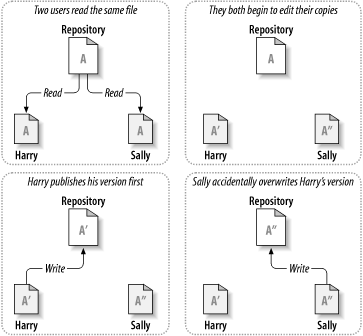
所有的版本控制系统都需要解决这样一个基础问题:怎样让系统允许用户共享信息,而不会让他们因意外而互相干扰?版本库里意外覆盖别人的更改非常的容易。
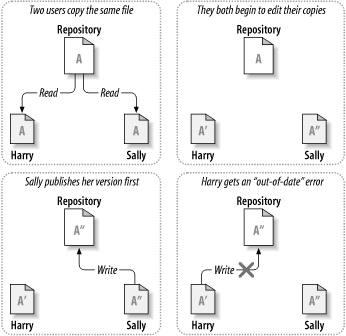
考虑图 2.2 “需要避免的问题”的情景,我们有两个共同工作者,Harry和Sally,他们想同时编辑版本库里的同一个文件,如果首先Harry保存它的修改,过了一会,Sally可能凑巧用自己的版本覆盖了这些文件,Harry的更改不会永远消失(因为系统记录了每次修改),Harry所有的修改不会出现在Sally的文件中,所以Harry的工作还是丢失了—至少是从最新的版本中丢失了—而且是意外的,这就是我们要明确避免的情况!
许多版本控制系统使用锁定-修改-解锁这种机制解决这种问题,在这样的系统里,在一个时间段里版本库的一个文件只允许被一个人修改。首先在修改之前,Harry要“锁定”住这个文件,锁定很像是从图书馆借一本书,如果Harry锁住这个文件,Sally不能做任何修改,如果Sally想请求得到一个锁,版本库会拒绝这个请求。在Harry结束编辑并且放开这个锁之前,她只可以阅读文件。Harry解锁后,就要换班了,Sally得到自己的轮换位置,锁定并且开始编辑这个文件。图 2.3 “锁定-修改-解锁 方案”描述了这样的解决方案。
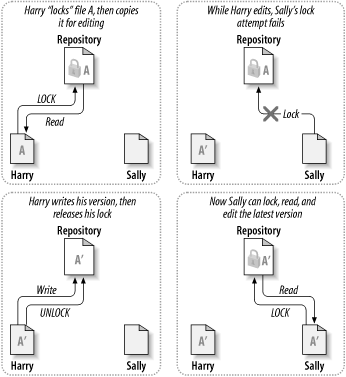
锁定-修改-解锁模型有一点问题就是限制太多,经常会成为用户的障碍:
-
锁定可能导致管理问题。有时候Harry会锁住文件然后忘了此事,这就是说Sally一直等待解锁来编辑这些文件,她在这里僵住了。然后Harry去旅行了,现在Sally只好去找管理员放开锁,这种情况会导致不必要的耽搁和时间浪费。
-
锁定可能导致不必要的线性化开发。如果Harry编辑一个文件的开始,Sally想编辑同一个文件的结尾,这种修改不会冲突,设想修改可以正确的合并到一起,他们可以轻松的并行工作而没有太多的坏处,没有必要让他们轮流工作。
-
锁定可能导致错误的安全状态。假设Harry锁定和编辑一个文件A,同时Sally锁定并编辑文件B,如果A和B互相依赖,这种变化是必须同时作的,这样A和B不能正确的工作了,锁定机制对防止此类问题将无能为力—从而产生了一种处于安全状态的假相。很容易想象Harry和Sally都以为自己锁住了文件,而且从一个安全,孤立的情况开始工作,因而没有尽早发现他们不匹配的修改。
Subversion,CVS和一些版本控制系统使用拷贝-修改-合并模型,在这种模型里,每一个客户联系项目版本库建立一个个人工作拷贝—版本库中文件和目录的本地映射。用户并行工作,修改各自的工作拷贝,最终,各个私有的拷贝合并在一起,成为最终的版本,这种系统通常可以辅助合并操作,但是最终要靠人工去确定正误。
这是一个例子,Harry和Sally为同一个项目各自建立了一个工作拷贝,工作是并行的,修改了同一个文件A,Sally首先保存修改到版本库,当Harry想去提交修改的时候,版本库提示文件A已经过期,换句话说,A在他上次更新之后已经更改了,所以当他通过客户端请求合并版本库和他的工作拷贝之后,碰巧Sally的修改和他的不冲突,所以一旦他把所有的修改集成到一起,他可以将工作拷贝保存到版本库,图 2.4 “拷贝-修改-合并 方案”和图 2.5 “拷贝-修改-合并 方案(续)”展示了这一过程。
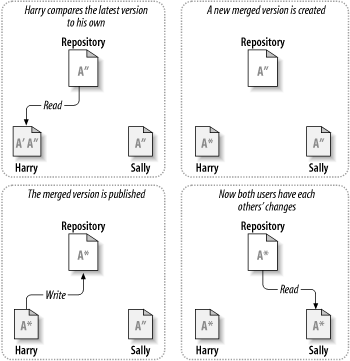
但是如果Sally和Harry的修改交迭了该怎么办?这种情况叫做冲突,这通常不是个大问题,当Harry告诉他的客户端去合并版本库的最新修改到自己的工作拷贝时,他的文件A就会处于冲突状态:他可以看到一对冲突的修改集,并手工的选择保留一组修改。需要注意的是软件不能自动的解决冲突,只有人可以理解并作出智能的选择,一旦Harry手工的解决了冲突—也许需要与Sally讨论—它可以安全的把合并的文件保存到版本库。
拷贝-修改-合并模型感觉是有一点混乱,但在实践中,通常运行的很平稳,用户可以并行的工作,不必等待别人,当工作在同一个文件上时,也很少会有交迭发生,冲突并不频繁,处理冲突的时间远比等待解锁花费的时间少。
最后,一切都要归结到一条重要的因素:用户交流。当用户交流贫乏,语法和语义的冲突就会增加,没有系统可以强制用户完美的交流,没有系统可以检测语义上的冲突,所以没有任何证据能够承诺锁定系统可以防止冲突,实践中,锁定除了约束了生产力,并没有做什么事。
是时候从抽象转到具体了,在本小节,我们会展示一个Subversion真实使用的例子。
你已经阅读过了关于工作拷贝的内容,现在我们要讲一讲客户端怎样建立和使用它。
一个Subversion工作拷贝是你本地机器一个普通的目录,保存着一些文件,你可以任意的编辑文件,而且如果是源代码文件,你可以像平常一样编译,你的工作拷贝是你的私有工作区,在你明确的做了特定操作之前,Subversion不会把你的修改与其他人的合并,也不会把你的修改展示给别人。
当你在工作拷贝作了一些修改并且确认它们工作正常之后,Subversion提供了一个命令可以“发布”你的修改给项目中的其他人(通过写到版本库),如果别人发布了各自的修改,Subversion提供了手段可以把这些修改与你的工作目录进行合并(通过读取版本库)。
一个工作拷贝也包括一些由Subversion创建并维护的额外文件,用来协助执行这些命令。通常情况下,你的工作拷贝每一个文件夹有一个以.svn为名的文件夹,也被叫做工作拷贝管理目录,这个目录里的文件能够帮助Subversion识别哪一个文件做过修改,哪一个文件相对于别人的工作已经过期了。
一个典型的Subversion的版本库经常包含许多项目的文件(或者说源代码),通常每一个项目都是版本库的子目录,在这种安排下,一个用户的工作拷贝往往对应版本库的的一个子目录。
举一个例子,你的版本库包含两个软件项目,paint和calc。每个项目在它们各自的顶级子目录下,见图 2.6 “版本库的文件系统”。
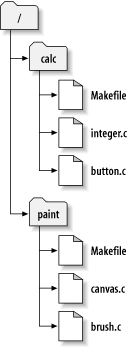
为了得到一个工作拷贝,你必须检出(check out)版本库的一个子树,(术语“check out”听起来像是锁定或者保存资源,实际上不是,只是简单的得到一个项目的私有拷贝),举个例子,你检出 /calc,你可以得到这样的工作拷贝:
$ svn checkout http://svn.example.com/repos/calc A calc A calc/Makefile A calc/integer.c A calc/button.c $ ls -A calc Makefile integer.c button.c .svn/
列表中的A表示Subversion增加了一些条目到工作拷贝,你现在有了一个/calc的个人拷贝,有一个附加的目录—.svn—保存着前面提及的Subversion需要的额外信息。
假定你修改了button.c,因为.svn目录记录着文件的修改日期和原始内容,Subversion可以告诉你已经修改了文件,然而,在你明确告诉它之前,Subversion不会将你的改变公开。将改变公开的操作被叫做提交(committing,或者是checking in)修改到版本库。
发布你的修改给别人,你可以使用Subversion的提交(commit)命令:
$ svn commit button.c Sending button.c Transmitting file data . Committed revision 57.
这时你对button.c的修改已经提交到了版本库,如果其他人取出了/calc的一个工作拷贝,他们会看到这个文件最新的版本。
假设你有个合作者,Sally,她和你同时取出了/calc的一个工作拷贝,你提交了你对button.c的修改,Sally的工作拷贝并没有改变,Subversion只在用户要求的时候才改变工作拷贝。
要使项目最新,Sally可以要求Subversion更新她的工作备份,通过使用更新(update)命令,将结合你和所有其他人在她上次更新之后的改变到她的工作拷贝。
$ pwd /home/sally/calc $ ls -A .svn/ Makefile integer.c button.c $ svn update U button.c
svn update命令的输出表明Subversion更新了button.c的内容,注意,Sally不必指定要更新的文件,subversion利用.svn以及版本库的进一步信息决定哪些文件需要更新。
一个svn commit操作可以作为一个原子事务操作发布任意数量文件和目录的修改,在你的工作拷贝里,你可以改变文件内容、删除、改名和拷贝文件和目录,然后作为一个整体提交。
在版本库中,每一次提交被当作一次原子事务操作:要么所有的改变发生,要么都不发生,Subversion努力保持原子性以应对程序错误、系统错误、网络问题和其他用户行为。
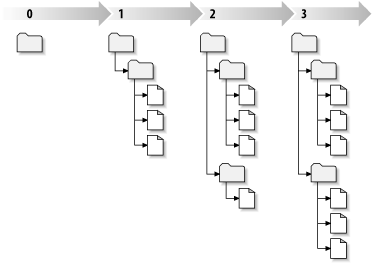
每当版本库接受了一个提交,文件系统进入了一个新的状态,叫做一次修订(revision),每一个修订版本被赋予一个独一无二的自然数,一个比一个大,初始修订号是0,只创建了一个空目录,没有任何内容。
图 2.7 “版本库”可以更形象的描述版本库,想象有一组修订号,从0开始,从左到右,每一个修订号有一个目录树挂在它下面,每一个树好像是一次提交后的版本库“快照”。
需要特别注意的是,工作拷贝并不一定对应版本库中的单个修订版本,他们可能包含多个修订版本的文件。举个例子,你从版本库检出一个工作拷贝,最近的修订号是4:
calc/Makefile:4
integer.c:4
button.c:4
此刻,工作目录与版本库的修订版本4完全对应,然而,你修改了button.c并且提交之后,假设没有别的提交出现,你的提交会在版本库建立修订版本5,你的工作拷贝会是这个样子的:
calc/Makefile:4
integer.c:4
button.c:5
假设此刻,Sally提交了对integer.c的修改,建立修订版本6,如果你使用svn update来更新你的工作拷贝,你会看到:
calc/Makefile:6
integer.c:6
button.c:6
Sally对integer.c的改变会出现在你的工作拷贝,你对button.c的改变还在,在这个例子里,Makefile在4、5、6修订版本都是一样的,但是Subversion会把他的Makefile的修订号设为6来表明它是最新的,所以你在工作拷贝顶级目录作一次干净的更新,会使得所有内容对应版本库的同一修订版本。
对于工作拷贝的每一个文件,Subversion在管理区域.svn/记录两项关键的信息:
-
工作文件所作为基准的修订版本(叫做文件的工作修订版本)和
-
一个本地拷贝最后更新的时间戳。
给定这些信息,通过与版本库通讯,Subversion可以告诉我们工作文件是处与如下四种状态的那一种:
- 未修改且是当前的
-
文件在工作目录里没有修改,在工作修订版本之后没有修改提交到版本库。svn commit操作不做任何事情,svn update不做任何事情。
- 本地已修改且是当前的
-
在工作目录已经修改,从基本修订版本之后没有修改提交到版本库。本地修改没有提交,因此svn commit会成功的提交,svn update不做任何事情。
- 未修改且不是当前的了
-
这个文件在工作目录没有修改,但在版本库中已经修改了。这个文件最终将更新到最新版本,成为当时的公共修订版本。svn commit不做任何事情,svn update将会取得最新的版本到工作拷贝。
- 本地已修改且不是最新的
-
这个文件在工作目录和版本库都得到修改。一个svn commit将会失败,这个文件必须首先更新,svn update命令会合并公共和本地修改,如果Subversion不可以自动完成,将会让用户解决冲突。
这看起来需要记录很多事情,但是svn status命令可以告诉你工作拷贝中文件的状态,关于此命令更多的信息,请看“svn status”一节。
我们在这一章里学习了许多Subversion的基本概念:
-
我们介绍了中央版本库的概念、客户工作拷贝和版本修订树。
-
我们介绍了两个协作者如何使用Subversion发布和获得对方的修改,使用“拷贝-修改-合并”模型。
-
我们讨论了一些Subversion跟踪和管理工作拷贝信息的方式。
现在,你一定对Subversion在多数情形下的工作方式有了很好的认识,有了这些知识的武装,你一定已经准备好跳到下一章去了,一个关于Subversion命令与特性的详细教程。
现在,我们将要深入到Subversion到使用细节当中,完成本章,你将学会所有日常使用的Subversion命令,你将从一个初始化检出开始,做出修改并检查,你也将会学到如何将别人的修改取到工作拷贝,检查他们,并解决所有可能发生的冲突。
这一章并不是Subversion命令的完全列表—而是你将会遇到的最常用任务的介绍,这一章假定你已经读过并且理解了第 2 章 基本概念,而且熟悉Subversion的模型,如果想查看所有命令的参考,见第 9 章 Subversion完全参考。
使用svn import来导入一个新项目到Subversion的版本库,这恐怕是使用Subversion必定要做的第一步操作,但不是经常发生的事情,详细介绍可以看本章后面的“svn import”一节。
在继续之前你一定要知道如何识别版本库的一个修订版本,像你在“修订版本”一节看到的,一个修订版本就是版本库的一个“快照”,当你的版本库持续扩大,你必须有手段来识别这些快照。
你可以使用--revision(-r)参数来选择特定修订版本(svn --revision REV),你也可以指定在两个修订版本之间的一个范围 (svn --revision REV1:REV2)。你可以在Subversion中通过修订版本号、关键字或日期指定特定修订版本。
Subversion客户端可以理解一些修订版本关键字,这些关键字可以用来代替--revision的数字参数,这会被Subversion解释到特定版本:
注意
工作拷贝中的每一个目录都有一个叫作.svn的管理目录,工作目录中的每一个文件,Subversion在管理区域为它保留了一个备份,这是上一个版本(叫做“BASE”版本)没有修改的(没有关键字变化,没有行结束符号转化,没有任何改动)拷贝,我们把这个文件当作原始拷贝或基准文件使用,它与版本库中的文件完全一样。
- HEAD
-
版本库中最新的版本。
- BASE
-
工作拷贝中的“原始”修订版本。
- COMMITTED
-
在
BASE版本之前(或在Base)一个项目最后修改的版本。 - PREV
-
一个项目最后修改版本之前的那个版本(技术上为COMMITTED -1)。
注意
PREV、BASE、和COMMITTED指的都是本地路径而不是URL。
下面是一些关键字使用的例子,不要担心现在没有意义,我们将在本章的后面解释这些命令:
$ svn diff --revision PREV:COMMITTED foo.c
# shows the last change committed to foo.c
$ svn log --revision HEAD
# shows log message for the latest repository commit
$ svn diff --revision HEAD
# compares your working file (with local mods) to the latest version
# in the repository.
$ svn diff --revision BASE:HEAD foo.c
# compares your “pristine” foo.c (no local mods) with the
# latest version in the repository
$ svn log --revision BASE:HEAD
# shows all commit logs since you last updated
$ svn update --revision PREV foo.c
# rewinds the last change on foo.c.
# (foo.c's working revision is decreased.)
这些关键字允许你执行许多常用(而且有用)的操作,而不必去查询特定的修订版本号,或者记住本地拷贝的修订版本号。
在任何你使用特定版本号和版本关键字的地方,你也可以在“{}”中使用日期,你也可通过日期或者版本号配合使用来访问一段时间的修改!
如下是一些Subversion能够接受的日期格式,注意在日期中有空格时需要使用引号。
$ svn checkout --revision {2002-02-17}
$ svn checkout --revision {15:30}
$ svn checkout --revision {15:30:00.200000}
$ svn checkout --revision {"2002-02-17 15:30"}
$ svn checkout --revision {"2002-02-17 15:30 +0230"}
$ svn checkout --revision {2002-02-17T15:30}
$ svn checkout --revision {2002-02-17T15:30Z}
$ svn checkout --revision {2002-02-17T15:30-04:00}
$ svn checkout --revision {20020217T1530}
$ svn checkout --revision {20020217T1530Z}
$ svn checkout --revision {20020217T1530-0500}
…
当你指定一个日期,Subversion会在版本库找到接近这个日期的最新版本:
$ svn log --revision {2002-11-28}
------------------------------------------------------------------------
r12 | ira | 2002-11-27 12:31:51 -0600 (Wed, 27 Nov 2002) | 6 lines
…
你可以使用时间段,Subversion会找到这段时间的所有版本:
$ svn log --revision {2002-11-20}:{2002-11-29}
…
我们也曾经指出,你可以混合日期和修订版本号:
$ svn log --revision {2002-11-20}:4040
用户一定要认识到这种精巧会成为处理日期的绊脚石,因为一个版本的时间戳是作为一个属性存储的—不是版本化的,而是可以编辑的属性—版本号的时间戳可以被修改,从而建立一个虚假的年代表,也可以被完全删除。这将大大破坏Subversion的这种时间—版本转化功能的表现。
大多数时候,你会使用checkout从版本库取出一个新拷贝开始使用Subversion,这样会在本机创建一个项目的本地拷贝,这个拷贝包括版本库中的HEAD(最新的)版本:
$ svn checkout http://svn.collab.net/repos/svn/trunk A trunk/subversion.dsw A trunk/svn_check.dsp A trunk/COMMITTERS A trunk/configure.in A trunk/IDEAS … Checked out revision 2499.
尽管上面的例子取出了trunk目录,你也完全可以通过输入特定URL取出任意深度的子目录:
$ svn checkout http://svn.collab.net/repos/svn/trunk/doc/book/tools A tools/readme-dblite.html A tools/fo-stylesheet.xsl A tools/svnbook.el A tools/dtd A tools/dtd/dblite.dtd … Checked out revision 2499.
因为Subversion使用“拷贝-修改-合并”模型而不是“锁定-修改-解锁”模型(见第 2 章 基本概念),你可以开始修改工作拷贝中的目录和文件,你的工作拷贝和你的系统中的其它文件和目录完全一样,你可以编辑并改变它,移动它,也可以完全的删掉它,把它忘了。
注意
因为你的工作拷贝“同你的系统上的文件和目录没有什么区别”,如果你希望重新规划工作拷贝,你必须要让Subversion知道,当你希望拷贝或者移动工作拷贝的一个项目时,你应该使用svn copy或者 svn move而不要使用操作系统的命令,我们会在以后的章节详细介绍。
除非你准备好了提交一个新文件或目录,或改变了已存在的,否则没有必要通知Subversion你做了什么。
因为你可以使用版本库的URL作为唯一参数取出一个工作拷贝,你也可以在版本库URL之后指定一个目录,这样会将你的工作目录放到你的新目录,举个例子:
$ svn checkout http://svn.collab.net/repos/svn/trunk subv A subv/subversion.dsw A subv/svn_check.dsp A subv/COMMITTERS A subv/configure.in A subv/IDEAS … Checked out revision 2499.
这样将把你的工作拷贝放到subv而不是和前面那样放到trunk。
Subversion有许多特性、选项和华而不实的高级功能,但日常的工作中你只使用其中的一小部分,有一些只在特殊情况才会使用,在这一节里,我们会介绍许多你在日常工作中常见的命令。
典型的工作周期是这样的:
-
更新你的工作拷贝
-
svn update
-
-
做出修改
-
svn add
-
svn delete
-
svn copy
-
svn move
-
-
检验修改
-
svn status
-
svn diff
-
svn revert
-
-
合并别人的修改到工作拷贝
-
svn update
-
svn resolved
-
-
提交你的修改
-
svn commit
-
当你在一个团队的项目里工作时,你希望更新你的工作拷贝得到所有其他人这段时间作出的修改,使用svn update让你的工作拷贝与最新的版本同步。
$ svn update U foo.c U bar.c Updated to revision 2.
这种情况下,其他人在你上次更新之后提交了对foo.c和bar.c的修改,因此Subversion更新你的工作拷贝来引入这些更改。
让我们认真检查svn update的输出,当服务器发送修改到你的工作拷贝,一个字母显示在每一个项目之前,来让你知道Subversion对你的工作拷贝做了什么操作:
U foo-
文件
foo更新了(从服务器收到修改)。 A foo-
文件或目录
foo被添加到工作拷贝。 D foo-
文件或目录
foo在工作拷贝被删除了。 R foo-
文件或目录
foo在工作拷贝已经被替换了,这是说,foo被删除,而一个新的同样名字的项目添加进来,它们具有同样的名字,但是版本库会把它们看作具备不同历史的不同对象。 G foo-
文件
foo接收到版本库的更改,你的本地版本也已经修改,但改变没有互相影响,Subversion成功的将版本库和本地文件合并,没有发生任何问题。 C foo-
文件
foo的修改与服务器冲突,服务器的修改与你的修改交迭在一起,不要恐慌,这种冲突需要人(你)来解决,我们在后面的章节讨论这种情况。
现在你可以开始工作并且修改你的工作拷贝了,你很容易决定作出一个修改(或者是一组),像写一个新的特性,修正一个错误等等。这时可以使用的Subversion命令包括svn add、 svn delete、svn copy和svn move。如果你只是修改版本库中已经存在的文件,在你提交之前,不必使用上面的任何一个命令。你可以对工作备份作的修改包括:
- 文件修改
-
这是最简单的一种修改,你不必告诉Subversion你想修改哪一个文件,只需要去修改,然后Subversion会自动地探测到哪些文件已经更改了。
- 目录树修改
-
你可以“标记”目录或者文件为预定要删除、增加、复制或者移动,也许这些改动在你的工作拷贝马上发生,而版本库只在你提交的时候才发生改变。
修改文件,可以使用文本编辑器、字处理软件、图形程序或任何你常用的工具,Subverion处理二进制文件像同文本文件一样—效率也一样。
这些是常用的可以修改目录树结构的子命令(我们会在后面包括svn import和svn mkdir)。
警告
你可以使用任何你喜欢的工具编辑文件,但你不可以在修改目录结构时不通知Subversion,需要使用svn copy、svn delete和svn move命令修改工作拷贝的结构,使用svn add增加版本控制的新文件或目录。
- svn add foo
-
预定将文件、目录或者符号链
foo添加到版本库,当你下次提交后,foo会成为其父目录的一个子对象。注意,如果foo是目录,所有foo中的内容也会预定添加进去,如果你只想添加foo本身,使用--non-recursive(-N)参数。 - svn delete foo
-
预定将文件、目录或者符号链
foo从版本库中删除掉,如果foo是文件,它马上从工作拷贝中删除,如果是目录,不会被删除,但是Subversion准备好删除了,当你提交你的修改,foo就会在你的工作拷贝和版本库中被删除。[2] - svn copy foo bar
-
建立一个新的项目
bar作为foo的复制品,当在下次提交时会将bar添加到版本库,这种拷贝历史会记录下来(按照来自foo的方式记录),svn copy并不建立中介目录。 - svn move foo bar
-
这个命令与与运行svn copy foo bar; svn delete foo完全相同,
bar作为foo的拷贝准备添加,foo已经预定要被删除,svn move不建立中介的目录。
当你完成修改,你需要提交他们到版本库,但是在此之前,检查一下做过什么修改是个好主意,通过提交前的检查,你可以整理一份精确的日志信息,你也可以发现你不小心修改的文件,给了你一次恢复修改的机会。此外,这是一个审查和仔细察看修改的好机会,你可通过命令svn status、svn diff和svn revert精确地察看所做的修改。你可以使用前两个命令察看工作拷贝中的修改,使用第三个来撤销部分(或全部)的修改。
Subversion已经被优化来帮助你完成这个任务,可以在不与版本库通讯的情况下做许多事情,详细来说,对于每一个文件,你的的工作拷贝在.svn包含了一个“原始的”拷贝,所以Subversion可以快速的告诉你那些文件修改了,甚至允许你在不与版本库通讯的情况下恢复修改。
相对于其他命令,你会更多地使用这个svn status命令。
如果你在工作拷贝的顶级目录运行不带参数的svn status命令,它会检测你做的所有的文件或目录的修改,以下的例子是来展示svn status可能返回的状态码(注意,#之后的不是svn status打印的)。
L abc.c # svn已经在.svn目录锁定了abc.c
M bar.c # bar.c的内容已经在本地修改过了
M baz.c # baz.c属性有修改,但没有内容修改
X 3rd_party # 这个目录是外部定义的一部分
? foo.o # svn并没有管理foo.o
! some_dir # svn管理这个,但它可能丢失或者不完整
~ qux # 作为file/dir/link进行了版本控制,但类型已经改变
I .screenrc # svn不管理这个,配置确定要忽略它
A + moved_dir # 包含历史的添加,历史记录了它的来历
M + moved_dir/README # 包含历史的添加,并有了本地修改
D stuff/fish.c # 这个文件预定要删除
A stuff/loot/bloo.h # 这个文件预定要添加
C stuff/loot/lump.c # 这个文件在更新时发生冲突
R xyz.c # 这个文件预定要被替换
S stuff/squawk # 这个文件已经跳转到了分支
在这种格式下,svn status打印五列字符,紧跟一些空格,接着是文件或者目录名。第一列告诉一个文件的状态或它的内容,返回代码解释如下:
A item-
文件、目录或是符号链
item预定加入到版本库。 C item-
文件
item发生冲突,在从服务器更新时与本地版本发生交迭,在你提交到版本库前,必须手工的解决冲突。 D item-
文件、目录或是符号链
item预定从版本库中删除。 M item-
文件
item的内容被修改了。 R item-
文件、目录或是符号链
item预定将要替换版本库中的item,这意味着这个对象首先要被删除,另外一个同名的对象将要被添加,所有的操作发生在一个修订版本。 X item? item-
文件、目录或是符号链
item不在版本控制之下,你可以通过使用svn status的--quiet(-q)参数或父目录的svn:ignore属性忽略这个问题,关于忽略文件的使用,见“svn:ignore”一节。 ! item-
文件、目录或是符号链
item在版本控制之下,但是已经丢失或者不完整,这可能因为使用非Subversion命令删除造成的,如果是一个目录,有可能是检出或是更新时的中断造成的,使用svn update可以重新从版本库获得文件或者目录,也可以使用svn revert file恢复原来的文件。 ~ item-
文件、目录或是符号链
item在版本库已经存在,但你的工作拷贝中的是另一个。举一个例子,你删除了一个版本库的文件,新建了一个在原来的位置,而且整个过程中没有使用svn delete或是svn add。 I item-
文件、目录或是符号链
item不在版本控制下,Subversion已经配置好了会在svn add、svn import和svn status命令忽略这个文件,关于忽略文件,见“svn:ignore”一节。注意,这个符号只会在使用svn status的参数--no-ignore时才会出现—否则这个文件会被忽略且不会显示!
第二列说明文件或目录的属性的状态(更多细节可以看“属性”一节),如果一个M出现在第二列,说明属性被修改了,否则显示空白。
第三列只显示空白或者L,L表示Subversion已经在.svn工作区域锁定了这个项目,当你的svn commit正在运行的时候—也许正在输入log信息,运行svn status你可以看到L标记,如果这时候Subversion并没有运行,可以推测Subversion发生中断并且已经锁定,你必须运行svn cleanup来清除锁定(本节后面将有更多论述)。
第四列只会显示空白或+,+的意思是一个有附加历史信息的文件或目录预定添加或者修改到版本库,通常出现在svn move或是svn copy时,如果是看到A +就是说要包含历史的增加,它可以是一个文件或是拷贝的根目录。+表示它是即将包含历史增加到版本库的目录的一部分,也就是说他的父目录要拷贝,它只是跟着一起的。 M +表示将要包含历史的增加,并且已经更改了。当你提交时,首先会随父目录进行包含历史的增加,然后本地的修改提交到更改后的版本。
第五列只显示空白或是S,表示这个目录或文件已经转到了一个分支下了(使用svn switch)。
如果你传递一个路径给svn status,它只给你这个项目的信息:
$ svn status stuff/fish.c D stuff/fish.c
svn status也有一个--verbose(-v)选项,它可以显示工作拷贝中的所有项目,即使没有改变过:
$ svn status --verbose
M 44 23 sally README
44 30 sally INSTALL
M 44 20 harry bar.c
44 18 ira stuff
44 35 harry stuff/trout.c
D 44 19 ira stuff/fish.c
44 21 sally stuff/things
A 0 ? ? stuff/things/bloo.h
44 36 harry stuff/things/gloo.c
这是svn status的“加长形式”,第一列保持相同,第二列显示一个工作版本号,第三和第四列显示最后一次修改的版本号和修改人。
上面所有的svn status调用并没有联系版本库,只是与.svn中的元数据进行比较的结果,最后,是--show-updates(-u)参数,它将会联系版本库为已经过时的数据添加新信息:
$ svn status --show-updates --verbose
M * 44 23 sally README
M 44 20 harry bar.c
* 44 35 harry stuff/trout.c
D 44 19 ira stuff/fish.c
A 0 ? ? stuff/things/bloo.h
Status against revision: 46
注意这两个星号:如果你现在执行svn update,你的README和trout.c会被更新,这告诉你许多有用的信息—你可以在提交之前,需要使用更新操作得到文件README的更新,或者说文件已经过时,版本库会拒绝了你的提交。(后面还有更多关于此主题)。
另一种检查修改的方式是svn diff命令,你可以通过不带参数的svn diff精确的找出你所做的修改,这会输出统一区别格式:[3]
$ svn diff
Index: bar.c
===================================================================
--- bar.c (revision 3)
+++ bar.c (working copy)
@@ -1,7 +1,12 @@
+#include <sys/types.h>
+#include <sys/stat.h>
+#include <unistd.h>
+
+#include <stdio.h>
int main(void) {
- printf("Sixty-four slices of American Cheese...\n");
+ printf("Sixty-five slices of American Cheese...\n");
return 0;
}
Index: README
===================================================================
--- README (revision 3)
+++ README (working copy)
@@ -193,3 +193,4 @@
+Note to self: pick up laundry.
Index: stuff/fish.c
===================================================================
--- stuff/fish.c (revision 1)
+++ stuff/fish.c (working copy)
-Welcome to the file known as 'fish'.
-Information on fish will be here soon.
Index: stuff/things/bloo.h
===================================================================
--- stuff/things/bloo.h (revision 8)
+++ stuff/things/bloo.h (working copy)
+Here is a new file to describe
+things about bloo.
svn diff命令通过比较你的文件和.svn的“原始”文件来输出信息,预定要增加的文件会显示所有增加的文本,要删除的文件会显示所有要删除的文本。
输出的格式为统一区别格式(unified diff format),删除的行前面加一个-,添加的行前面有一个+,svn diff命令也打印文件名和打补丁需要的信息,所以你可以通过重定向一个区别文件来生成“补丁”:
$ svn diff > patchfile
举个例子,你可以把补丁文件发送邮件到其他开发者,在提交之前审核和测试。
我们可以使用svn status -u来预测冲突,当你运行svn update一些有趣的事情发生了:
$ svn update U INSTALL G README C bar.c Updated to revision 46.
U和G没必要关心,文件干净的接受了版本库的变化,文件标示为U表明本地没有修改,文件已经根据版本库更新。G标示合并,标示本地已经修改过,与版本库没有重迭的地方,已经合并。
但是C表示冲突,说明服务器上的改动同你的改动冲突了,你需要自己手工去解决。
当冲突发生了,有三件事可以帮助你注意到这种情况和解决问题:
-
Subversion打印
C标记,并且标记这个文件已冲突。 -
如果Subversion认为这个文件是可合并的,它会置入冲突标记—特殊的横线分开冲突的“两面”—在文件里可视化的描述重叠的部分(Subversion使用
svn:mime-type属性来决定一个文件是否可以使用上下文的,以行为基础合并,更多信息可以看“svn:mime-type”一节)。 -
对于每一个冲突的文件,Subversion放置三个额外的未版本化文件到你的工作拷贝:
filename.mine-
你更新前的文件,没有冲突标志,只是你最新更改的内容。(如果Subversion认为这个文件不可以合并,
.mine文件不会创建,因为它和工作文件相同。) filename.rOLDREV-
这是你的做更新操作以前的
BASE版本文件,就是你在上次更新之后未作更改的版本。 filename.rNEWREV-
这是你的Subversion客户端从服务器刚刚收到的版本,这个文件对应版本库的
HEAD版本。
这里
OLDREV是你的.svn目录中的修订版本号,NEWREV是版本库中HEAD的版本号。
举一个例子,Sally修改了sandwich.txt,Harry刚刚改变了他的本地拷贝中的这个文件并且提交到服务器,Sally在提交之前更新它的工作拷贝得到了冲突:
$ svn update C sandwich.txt Updated to revision 2. $ ls -1 sandwich.txt sandwich.txt.mine sandwich.txt.r1 sandwich.txt.r2
在这种情况下,Subversion不会允许你提交sandwich.txt,直到你的三个临时文件被删掉。
$ svn commit --message "Add a few more things" svn: Commit failed (details follow): svn: Aborting commit: '/home/sally/svn-work/sandwich.txt' remains in conflict
如果你遇到冲突,三件事你可以选择:
-
“手动”合并冲突文本(检查和修改文件中的冲突标志)。
-
用某一个临时文件覆盖你的工作文件。
-
运行svn revert <filename>来放弃所有的修改。
一旦你解决了冲突,你需要通过命令svn resolved让Subversion知道,这样就会删除三个临时文件,Subversion就不会认为这个文件是在冲突状态了。[4]
$ svn resolved sandwich.txt Resolved conflicted state of 'sandwich.txt'
第一次尝试解决冲突让人感觉很害怕,但经过一点训练,它简单的像是骑着车子下坡。
这里一个简单的例子,由于不良的交流,你和同事Sally,同时编辑了sandwich.txt。Sally提交了修改,当你准备更新你的版本,冲突发生了,我们不得不去修改sandwich.txt来解决这个问题。首先,看一下这个文件:
$ cat sandwich.txt Top piece of bread Mayonnaise Lettuce Tomato Provolone <<<<<<< .mine Salami Mortadella Prosciutto ======= Sauerkraut Grilled Chicken >>>>>>> .r2 Creole Mustard Bottom piece of bread
小于号、等于号和大于号串是冲突标记,并不是冲突的数据,你一定要确定这些内容在下次提交之前得到删除,前两组标志中间的内容是你在冲突区所做的修改:
<<<<<<< .mine Salami Mortadella Prosciutto =======
后两组之间的是Sally提交的修改冲突:
======= Sauerkraut Grilled Chicken >>>>>>> .r2
通常你并不希望只是删除冲突标志和Sally的修改—当她收到三明治时,会非常的吃惊。所以你应该走到她的办公室或是拿起电话告诉Sally,你没办法从从意大利熟食店得到想要的泡菜。[5]一旦你们确认了提交内容后,修改文件并且删除冲突标志。
Top piece of bread Mayonnaise Lettuce Tomato Provolone Salami Mortadella Prosciutto Creole Mustard Bottom piece of bread
现在运行svn resolved,你已经准备好提交了:
$ svn resolved sandwich.txt $ svn commit -m "Go ahead and use my sandwich, discarding Sally's edits."
记住,如果你修改冲突时感到混乱,你可以参考subversion生成的三个文件—包括你未作更新的文件。你也可以使用第三方的合并工具检验这三个文件。
如果你得到冲突,经过检查你决定取消自己的修改并且重新编辑,你可以恢复你的修改:
$ svn revert sandwich.txt Reverted 'sandwich.txt' $ ls sandwich.* sandwich.txt
注意,当你恢复一个冲突的文件时,不需要再运行svn resolved。
现在我们准备好提交修改了,注意svn resolved不像我们本章学过的其他命令一样需要参数,在任何你认为解决了冲突的时候,只需要小心运行svn resolved,—一旦删除了临时文件,Subversion会让你提交这文件,即使文件中还存在冲突标记。
最后!你的修改结束了,你合并了服务器上所有的修改,你准备好提交修改到版本库。
svn commit命令发送所有的修改到版本库,当你提交修改时,你需要提供一些描述修改的日志信息,你的信息会附到这个修订版本上,如果信息很简短,你可以在命令行中使用--message(-m)选项:
$ svn commit --message "Corrected number of cheese slices." Sending sandwich.txt Transmitting file data . Committed revision 3.
然而,如果你把写日志信息当作工作的一部分,你也许会希望通过告诉Subversion一个文件名得到日志信息,使用--file选项:
$ svn commit --file logmsg Sending sandwich.txt Transmitting file data . Committed revision 4.
如果你没有指定--message或者--file选项,Subversion会自动地启动你最喜欢的编辑器(见“config”一节的editor-cmd部分)来编辑日志信息。
提示
如果你使用编辑器撰写日志信息时希望取消提交,你可以直接关掉编辑器,不要保存,如果你已经做过保存,只要简单的删掉所有的文本并再次保存。
$ svn commit Waiting for Emacs...Done Log message unchanged or not specified a)bort, c)ontinue, e)dit a $
版本库不知道也不关心你的修改作为一个整体是否有意义,它只检查是否有其他人修改了同一个文件,如果别人已经这样做了,你的整个提交会失败,并且提示你一个或多个文件已经过时了:
$ svn commit --message "Add another rule" Sending rules.txt svn: Commit failed (details follow): svn: Out of date: 'rules.txt' in transaction 'g'
此刻,你需要运行svn update来处理所有的合并和冲突,然后再尝试提交。
我们已经覆盖了Subversion基本的工作周期,还有许多其它特性可以管理你得版本库和工作拷贝,但是只使用前面介绍的命令你就可以很轻松的工作了。
我们曾经说过,版本库就像是一台时间机器,它记录了所有提交的修改,允许你检查文件或目录以及相关元数据的历史。通过一个Subversion命令你可以根据时间或修订号取出一个过去的版本(或者恢复现在的工作拷贝),然而,有时候我们只是想看看历史而不想回到历史。
有许多命令可以为你提供版本库历史:
- svn log
-
展示给你主要信息:附加在版本上的日志信息和所有版本的路径修改。
- svn diff
-
展示一个文件改变的详细情况。
- svn cat
-
取得在特定版本的某一个文件显示在当前屏幕。
- svn list
-
显示一个目录在某一版本存在的文件。
找出一个文件或目录的历史信息,使用svn log命令,svn log将会提供你一条记录,包括:谁对文件或目录作了修改、哪个修订版本作了修改、修订版本的日期和时间、还有如果你当时提供了日志信息,也会显示。
$ svn log ------------------------------------------------------------------------ r3 | sally | Mon, 15 Jul 2002 18:03:46 -0500 | 1 line Added include lines and corrected # of cheese slices. ------------------------------------------------------------------------ r2 | harry | Mon, 15 Jul 2002 17:47:57 -0500 | 1 line Added main() methods. ------------------------------------------------------------------------ r1 | sally | Mon, 15 Jul 2002 17:40:08 -0500 | 1 line Initial import ------------------------------------------------------------------------
注意日志信息缺省根据时间逆序排列,如果希望察看特定顺序的一段修订版本或者单一版本,使用--revision (-r)选项:
$ svn log --revision 5:19 # shows logs 5 through 19 in chronological order $ svn log -r 19:5 # shows logs 5 through 19 in reverse order $ svn log -r 8 # shows log for revision 8
你也可以检查单个文件或目录的日志历史,举个例子:
$ svn log foo.c … $ svn log http://foo.com/svn/trunk/code/foo.c …
这样只会显示这个工作文件(或者URL)做过修订的版本的日志信息。
如果你希望得到目录和文件更多的信息,你可以对svn log命令使用--verbose (-v)开关,因为Subversion允许移动和复制文件和目录,所以跟踪路径修改非常重要,在详细模式下,svn log 输出中会包括一个路径修改的历史:
$ svn log -r 8 -v ------------------------------------------------------------------------ r8 | sally | 2002-07-14 08:15:29 -0500 | 1 line Changed paths: M /trunk/code/foo.c M /trunk/code/bar.h A /trunk/code/doc/README Frozzled the sub-space winch. ------------------------------------------------------------------------
我们已经看过svn diff—使用标准区别文件格式显示区别,它在提交前用来显示本地工作拷贝与版本库的区别。
事实上,svn diff有三种不同的用法:
-
检查本地修改
-
比较工作拷贝与版本库
-
比较版本库和版本库
像我们看到的,不使用任何参数调用时,svn diff将会比较你的工作文件与缓存在.svn的“原始”拷贝:
$ svn diff Index: rules.txt =================================================================== --- rules.txt (revision 3) +++ rules.txt (working copy) @@ -1,4 +1,5 @@ Be kind to others Freedom = Responsibility Everything in moderation -Chew with your mouth open +Chew with your mouth closed +Listen when others are speaking $
如果传递一个--revision(-r)参数,你的工作拷贝会与指定的版本比较。
$ svn diff --revision 3 rules.txt Index: rules.txt =================================================================== --- rules.txt (revision 3) +++ rules.txt (working copy) @@ -1,4 +1,5 @@ Be kind to others Freedom = Responsibility Everything in moderation -Chew with your mouth open +Chew with your mouth closed +Listen when others are speaking $
如果通过--revision (-r)传递两个版本号,通过冒号分开,这两个版本会进行比较。
$ svn diff --revision 2:3 rules.txt Index: rules.txt =================================================================== --- rules.txt (revision 2) +++ rules.txt (revision 3) @@ -1,4 +1,4 @@ Be kind to others -Freedom = Chocolate Ice Cream +Freedom = Responsibility Everything in moderation Chew with your mouth open $
你不仅可以用svn diff比较你工作拷贝中的文件,你甚至可以通过提供一个URL参数来比较版本库中两个文件的的区别,通常在本地机器没有工作拷贝时非常有用:
$ svn diff --revision 4:5 http://svn.red-bean.com/repos/example/trunk/text/rules.txt … $
如果你只是希望检查一个过去的版本而不希望察看它们的区别,使用svn cat:
$ svn cat --revision 2 rules.txt Be kind to others Freedom = Chocolate Ice Cream Everything in moderation Chew with your mouth open $
你可以重定向输出到一个文件:
$ svn cat --revision 2 rules.txt > rules.txt.v2 $
你一定疑惑为什么不只是使用svn update --revision ,将文件更新到旧的文件,我们有使用svn cat的原因。
首先,你或许希望使用外置的比较工具(或许是一个图形化的工具,或者你的格式无法用标准区别格式察看)察看这两个版本的区别,这种情况下,你需要得到一个旧的版本的拷贝,所以重定向到一个文件,并且在你的比较工具中指定这两个版本来察看区别。
有时候察看整个文件比只看区别要容易。
svn list可以在不下载文件到本地目录的情况下来察看目录中的文件:
$ svn list http://svn.collab.net/repos/svn README branches/ clients/ tags/ trunk/
如果你希望察看详细信息,你可以使用--verbose (-v)参数:
$ svn list --verbose http://svn.collab.net/repos/svn 2755 harry 1331 Jul 28 02:07 README 2773 sally Jul 29 15:07 branches/ 2769 sally Jul 29 12:07 clients/ 2698 harry Jul 24 18:07 tags/ 2785 sally Jul 29 19:07 trunk/
这些列告诉你文件和目录最后修改的修订版本、做出修改的用户、如果是文件还会有文件的大小,最后是修改日期和项目的名字。
除了以上的命令,你可以使用带参数--revision的svn update和svn checkout来使整个工作拷贝“回到过去”[6]:
$ svn checkout --revision 1729 # Checks out a new working copy at r1729 … $ svn update --revision 1729 # Updates an existing working copy to r1729 …
不象这章前面讨论的那些经常用到的命令,这些命令只是偶尔被用到。
当Subversion改变你的工作拷贝(或是.svn中的任何信息),它会尽可能的小心,在修改任何事情之前,它把意图写到日志文件中去,然后执行log文件中的命令,然后删掉日志文件,这与分类帐的文件系统架构类似。如果Subversion的操作中断了(举个例子:进程被杀死了,机器死掉了),日志文件会保存在硬盘上,通过重新执行日志文件,Subversion可以完成上一次开始的操作,你的工作拷贝可以回到一致的状态。
这就是svn cleanup所作的:它查找工作拷贝中的所有遗留的日志文件,删除进程中的锁。如果Subversion告诉你工作拷贝中的一部分已经“锁定”了,你就需要运行这个命令了。同样,svn status将会使用L 显示锁定的项目:
$ svn status L somedir M somedir/foo.c $ svn cleanup $ svn status M somedir/foo.c
svn import命令是拷贝用户的一个未被版本化的目录树到版本库最快的方法,如果需要,它也要建立一些中介文件。
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/some/project Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/quux.h Committed revision 1.
在上一个例子里,将会拷贝目录mytree到版本库的some/project下:
$ svn list file:///usr/local/svn/newrepos/some/project bar.c foo.c subdir/
注意,在导入之后,原来的目录树并没有转化成工作拷贝,为了开始工作,你还是需要运行svn checkout导出一个工作拷贝。
我们已经覆盖了大多数Subversion的客户端命令,引人注目的例外是处理分支与合并(见第 4 章 分支与合并)以及属性(见“属性”一节)的命令,然而你也许会希望跳到第 9 章 Subversion完全参考来察看所有不同的命令—怎样利用它们使你的工作更容易。
HEAD里消失了,你可以通过检出(或者更新你的工作拷贝)你做出删除操作的前一个修订版本来找回所有的东西。--diff-cmd指定外置的区别程序,并且通过--extensions传递其他参数,举个例子,察看本地文件foo.c的区别,同时忽略空格修改,你可以运行svn diff --diff-cmd /usr/bin/diff --extensions '-bc' foo.c。分支、标签和合并是所有版本控制系统的共同概念,如果你并不熟悉这些概念,我们会在这一章里很好的介绍,如果你很熟悉,非常希望你有兴趣知道Subversion是怎样实现这些概念的。
分支是版本控制的基础组成部分,如果你允许Subversion来管理你的数据,这个特性将是你所必须依赖的 ,这一章假定你已经熟悉了Subversion的基本概念(第 2 章 基本概念)。
假设你的工作是维护本公司一个部门的手册文档,一天,另一个部门问你要相同的手册,但一些地方会有“区别”,因为他们有不同的需要。
这种情况下你会怎样做?显而易见的方法是:作一个版本的拷贝,然后分别维护两个版本,只要任何一个部门告诉要做一些小修改,你必须选择在对应的版本进行更改。
你也许希望在两个版本同时作修改,举个例子,你在第一个版本发现了一个拼写错误,很显然这个错误也会出现在第二个版本里。两份文档几乎相同,毕竟,只有许多特定的微小区别。
这是分支的基本概念—正如它的名字,开发的一条线独立于另一条线,如果回顾历史,可以发现两条线分享共同的历史,一个分支总是从一个备份开始的,从那里开始,发展自己独有的历史(见 图 4.1 “分支开发”)。
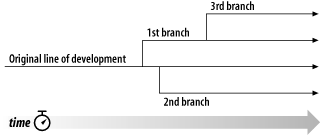
Subversion允许你并行的维护文件和目录的分支,它允许你通过拷贝数据建立分支,记住,分支互相联系,它也帮助你从一个分支复制修改到另一个分支。最终,它可以让你的工作拷贝反映到不同的分支上,所以你在日常工作可以“混合和比较”不同的开发线。
在这一点上,你必须理解每一次提交是怎样建立整个新的文件系统树(叫做“修订版本”)的,如果没有,可以回头去读“修订版本”一节。
对于本章节,我们会回到第2章的同一个例子,还记得你和你的合作者Sally分享一个包含两个项目的版本库,paint和calc。注意图 4.2 “开始规划版本库”,然而,现在每个项目的都有一个trunk和branches子目录,它们存在的理由很快就会清晰起来。
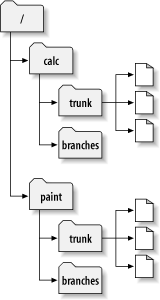
像以前一样,假定Sally和你都有“calc”项目的一份拷贝,更准确地说,你有一份/calc/trunk的工作拷贝,这个项目的所有的文件在这个子目录里,而不是在/calc下,因为你的小组决定使用/calc/trunk作为开发使用的“主线”。
假定你有一个任务,将要对项目做基本的重新组织,这需要花费大量时间来完成,会影响项目的所有文件,问题是你不会希望打扰Sally,她正在处理这样或那样的程序小Bug,一直使用整个项目(/calc/trunk)的最新版本,如果你一点一点的提交你的修改,你一定会干扰Sally的工作。
一种策略是自己闭门造车:你和Sally可以停止一个到两个星期的共享,也就是说,开始作出本质上的修改和重新组织工作拷贝的文件,但是在完成这个任务之前不做提交和更新。这样会有很多问题,首先,这样并不安全,许多人习惯频繁的保存修改到版本库,工作拷贝一定有许多意外的修改。第二,这样并不灵活,如果你的工作在不同的计算机(或许你在不同的机器有两份/calc/trunk的工作拷贝),你需要手工的来回拷贝修改,或者只在一个计算机上工作,这时很难做到共享你即时的修改,一项软件开发的“最佳实践”就是允许审核你做过的工作,如果没有人看到你的提交,你失去了潜在的反馈。最后,当你完成了公司主干代码的修改工作,你会发现合并你的工作拷贝和公司的主干代码会是一件非常困难的事情,Sally(或者其他人)也许已经对版本库做了许多修改,已经很难和你的工作拷贝结合—当你单独工作几周后运行svn update时就会发现这一点。
最佳方案是创建你自己的分支,或者是版本库的开发线。这允许你保存破坏了一半的工作而不打扰别人,尽管你仍可以选择性的同你的合作者分享信息,你将会看到这是怎样工作的。
建立分支非常的简单—使用svn copy命令给你的工程做个拷贝,Subversion不仅可以拷贝单个文件,也可以拷贝整个目录,在目前情况下,你希望作/calc/trunk的拷贝,新的拷贝应该在哪里?在你希望的任何地方—它只是在于项目的政策,我们假设你们项目的政策是在/calc/branches建立分支,并且你希望把你的分支叫做my-calc-branch,你希望建立一个新的目录/calc/branches/my-calc-branch,作为/calc/trunk的拷贝开始它的生命周期。
有两个方法作拷贝,我们首先介绍一个混乱的方法,只是让概念更清楚,作为开始,取出一个工程的根目录,/calc:
$ svn checkout http://svn.example.com/repos/calc bigwc A bigwc/trunk/ A bigwc/trunk/Makefile A bigwc/trunk/integer.c A bigwc/trunk/button.c A bigwc/branches/ Checked out revision 340.
建立一个备份只是传递两个目录参数到svn copy命令:
$ cd bigwc $ svn copy trunk branches/my-calc-branch $ svn status A + branches/my-calc-branch
在这个情况下,svn copy命令迭代的将trunk工作目录拷贝到一个新的目录branhes/my-calc-branch,像你从svn status看到的,新的目录是准备添加到版本库的,但是也要注意A后面的“+”号,这表明这个准备添加的东西是一份备份,而不是新的东西。当你提交修改,Subversion会通过拷贝/calc/trunk建立/calc/branches/my-calc-branch目录,而不是通过网络传递所有数据:
$ svn commit -m "Creating a private branch of /calc/trunk." Adding branches/my-calc-branch Committed revision 341.
现在,我们必须告诉你建立分支最简单的方法:svn copy可以直接对两个URL操作。
$ svn copy http://svn.example.com/repos/calc/trunk \
http://svn.example.com/repos/calc/branches/my-calc-branch \
-m "Creating a private branch of /calc/trunk."
Committed revision 341.
其实这两种方法没有什么区别,两个过程都在版本341建立了一个新目录作为/calc/trunk的一个备份,这些可以在图 4.3 “拷贝后的版本库”看到,注意第二种方法,只是执行了一个立即提交。 [7]这是一个简单的过程,因为你不需要取出版本库一个庞大的镜像,事实上,这个技术不需要你有工作拷贝。
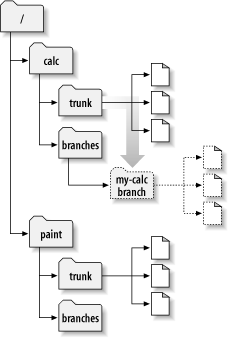
现在你已经在项目里建立分支了,你可以取出一个新的工作拷贝来开始使用:
$ svn checkout http://svn.example.com/repos/calc/branches/my-calc-branch A my-calc-branch/Makefile A my-calc-branch/integer.c A my-calc-branch/button.c Checked out revision 341.
这一份工作拷贝没有什么特别的,它只是版本库另一个目录的一个镜像罢了,当你提交修改时,Sally在更新时不会看到改变,她是/calc/trunk的工作拷贝。(确定要读本章后面的“转换工作拷贝”一节,svn switch命令是建立分支工作拷贝的另一个选择。)
我们假定本周就要过去了,如下的提交发生:
-
你修改了
/calc/branches/my-calc-branch/button.c,生成版本号342。 -
你修改了
/calc/branches/my-calc-branch/integer.c,生成版本号343。 -
Sally修改了
/calc/trunk/integer.c,生成了版本号344。
现在有两个独立开发线,图 4.4 “一个文件的分支历史”显示了integer.c的历史。
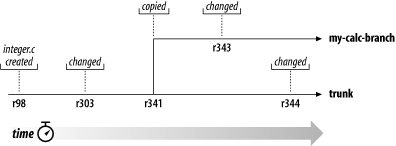
当你看到integer.c的改变时,你会发现很有趣:
$ pwd /home/user/my-calc-branch $ svn log --verbose integer.c ------------------------------------------------------------------------ r343 | user | 2002-11-07 15:27:56 -0600 (Thu, 07 Nov 2002) | 2 lines Changed paths: M /calc/branches/my-calc-branch/integer.c * integer.c: frozzled the wazjub. ------------------------------------------------------------------------ r341 | user | 2002-11-03 15:27:56 -0600 (Thu, 07 Nov 2002) | 2 lines Changed paths: A /calc/branches/my-calc-branch (from /calc/trunk:340) Creating a private branch of /calc/trunk. ------------------------------------------------------------------------ r303 | sally | 2002-10-29 21:14:35 -0600 (Tue, 29 Oct 2002) | 2 lines Changed paths: M /calc/trunk/integer.c * integer.c: changed a docstring. ------------------------------------------------------------------------ r98 | sally | 2002-02-22 15:35:29 -0600 (Fri, 22 Feb 2002) | 2 lines Changed paths: M /calc/trunk/integer.c * integer.c: adding this file to the project. ------------------------------------------------------------------------
注意,Subversion追踪分支上的integer.c的历史,包括所有的操作,甚至追踪到拷贝之前。这表示了建立分支也是历史中的一次事件,因为在拷贝整个/calc/trunk/时已经拷贝了一份integer.c。现在看Sally在她的工作拷贝运行同样的命令:
$ pwd /home/sally/calc $ svn log --verbose integer.c ------------------------------------------------------------------------ r344 | sally | 2002-11-07 15:27:56 -0600 (Thu, 07 Nov 2002) | 2 lines Changed paths: M /calc/trunk/integer.c * integer.c: fix a bunch of spelling errors. ------------------------------------------------------------------------ r303 | sally | 2002-10-29 21:14:35 -0600 (Tue, 29 Oct 2002) | 2 lines Changed paths: M /calc/trunk/integer.c * integer.c: changed a docstring. ------------------------------------------------------------------------ r98 | sally | 2002-02-22 15:35:29 -0600 (Fri, 22 Feb 2002) | 2 lines Changed paths: M /calc/trunk/integer.c * integer.c: adding this file to the project. ------------------------------------------------------------------------
sally看到她自己的344修订,你做的343修改她看不到,从Subversion看来,两次提交只是影响版本库中不同位置上的两个文件。然而,Subversion显示了两个文件有共同的历史,在分支拷贝之前,他们使用同一个文件,所以你和Sally都看到版本号303到98的修改。
在这个章节你需要记住两个重要的经验。
-
不像其他版本控制系统,Subversion的分支存在于真实的正常文件系统中,并不是存在于另外的维度,这些目录只是恰巧保留了额外的历史信息。
-
Subversion并没有内在的分支概念—只有拷贝,当你拷贝一个目录,这个结果目录就是一个“分支”,只是因为你给了它这样一个含义而已。你可以换一种角度考虑,或者特别处理,但是对于Subversion它只是一个普通的拷贝的结果。
现在你与Sally在同一个项目的并行分支上工作:你在私有分支上,而Sally在主干(trunk)或者叫做开发主线上。
由于有众多的人参与项目,大多数人拥有主干拷贝是很正常的,任何人如果进行一个长周期的修改会使得主干陷入混乱,所以通常的做法是建立一个私有分支,提交修改到自己的分支,直到这阶段工作结束。
所以,好消息就是你和Sally不会互相打扰,坏消息是有时候分离会太远。记住“闭门造车”策略的问题,当你完成你的分支后,可能因为太多冲突,已经无法轻易合并你的分支和主干的修改。
相反,在你工作的时候你和Sally仍然可以继续分享修改,这依赖于你决定什么值得分享,Subversion给你在分支间选择性“拷贝”修改的能力,当你完成了分支上的所有工作,所有的分支修改可以被拷贝回到主干。
在上一章节,我们提到你和Sally对integer.c在不同的分支上做过修改,如果你看了Sally的344版本的日志信息,你会知道她修正了一些拼写错误,毋庸置疑,你的拷贝的文件也一定存在这些拼写错误,所以你以后的对这个文件修改也会保留这些拼写错误,所以你会在将来合并时得到许多冲突。最好是现在接收Sally的修改,而不是作了许多工作之后才来做。
是时间使用svn merge命令,这个命令的结果非常类似svn diff命令(在第3章的内容),两个命令都可以比较版本库中的任何两个对象并且描述其区别,举个例子,你可以使用svn diff来查看Sally在版本344作的修改:
$ svn diff -r 343:344 http://svn.example.com/repos/calc/trunk
Index: integer.c
===================================================================
--- integer.c (revision 343)
+++ integer.c (revision 344)
@@ -147,7 +147,7 @@
case 6: sprintf(info->operating_system, "HPFS (OS/2 or NT)"); break;
case 7: sprintf(info->operating_system, "Macintosh"); break;
case 8: sprintf(info->operating_system, "Z-System"); break;
- case 9: sprintf(info->operating_system, "CPM"); break;
+ case 9: sprintf(info->operating_system, "CP/M"); break;
case 10: sprintf(info->operating_system, "TOPS-20"); break;
case 11: sprintf(info->operating_system, "NTFS (Windows NT)"); break;
case 12: sprintf(info->operating_system, "QDOS"); break;
@@ -164,7 +164,7 @@
low = (unsigned short) read_byte(gzfile); /* read LSB */
high = (unsigned short) read_byte(gzfile); /* read MSB */
high = high << 8; /* interpret MSB correctly */
- total = low + high; /* add them togethe for correct total */
+ total = low + high; /* add them together for correct total */
info->extra_header = (unsigned char *) my_malloc(total);
fread(info->extra_header, total, 1, gzfile);
@@ -241,7 +241,7 @@
Store the offset with ftell() ! */
if ((info->data_offset = ftell(gzfile))== -1) {
- printf("error: ftell() retturned -1.\n");
+ printf("error: ftell() returned -1.\n");
exit(1);
}
@@ -249,7 +249,7 @@
printf("I believe start of compressed data is %u\n", info->data_offset);
#endif
- /* Set postion eight bytes from the end of the file. */
+ /* Set position eight bytes from the end of the file. */
if (fseek(gzfile, -8, SEEK_END)) {
printf("error: fseek() returned non-zero\n");
svn merge命令几乎完全相同,但不是打印区别到你的终端,它会直接作为本地修改作用到你的本地拷贝:
$ svn merge -r 343:344 http://svn.example.com/repos/calc/trunk U integer.c $ svn status M integer.c
svn merge的输出告诉你的integer.c文件已经作了补丁(patched),现在已经保留了Sally修改—修改从主干“拷贝”到你的私有分支的工作拷贝,现在作为一个本地修改,在这种情况下,要靠你审查本地的修改来确定它们工作正常。
在另一种情境下,事情并不会运行得这样正常,也许integer.c也许会进入冲突状态,你必须使用标准过程(见第三章)来解决这种状态,或者你认为合并是一个错误的决定,你只需要运行svn revert放弃。
但是当你审查过你的合并结果后,你可以使用svn commit提交修改,在那一刻,修改已经合并到你的分支上了,在版本控制术语中,这种在分支之间拷贝修改的行为叫做搬运修改。
当你提交你的修改时,确定你的日志信息中说明你是从某一版本搬运了修改,举个例子:
$ svn commit -m "integer.c: ported r344 (spelling fixes) from trunk." Sending integer.c Transmitting file data . Committed revision 360.
你将会在下一节看到,这是一条非常重要的“最佳实践”。
一个警告:为什么svn diff和svn merge在概念上是很接近,但语法上有许多不同,一定阅读第9章来查看其细节或者使用svn help查看帮助。举个例子,svn merge需要一个工作拷贝作为目标,就是一个地方来施展目录树修改,如果一个目标都没有指定,它会假定你要做以下某个普通的操作:
-
你希望合并目录修改到工作拷贝的当前目录。
-
你希望合并修改到你的当前工作目录的相同文件名的文件。
如果你合并一个目录而没有指定特定的目标,svn merge假定第一种情况,在你的当前目录应用修改。如果你合并一个文件,而这个文件(或是一个有相同的名字文件)在你的当前工作目录存在,svn merge假定第二种情况,你想对这个同名文件使用合并。
如果你希望修改应用到别的目录,你需要说出来。举个例子,你在工作拷贝的父目录,你需要指定目标目录:
$ svn merge -r 343:344 http://svn.example.com/repos/calc/trunk my-calc-branch U my-calc-branch/integer.c
合并修改听起来很简单,但是实践起来会是很头痛的事,如果你重复合并两个分支,你也许会合并两次同样的修改。当这种事情发生时,有时候事情会依然正常,当对文件打补丁时,Subversion如果注意到这个文件已经有了相应的修改,而不会作任何操作,但是如果已经应用的修改又被修改了,你会得到冲突。
理想情况下,你的版本控制系统应该会阻止对一个分支做两次改变操作,必须自动的记住那一个分支的修改已经接收了,并且可以显示出来,用来尽可能帮助自动化的合并。
不幸的是,Subversion不是这样一个系统,类似于CVS,Subversion并不记录任何合并操作,当你提交本地修改,版本库并不能判断出你是通过svn merge还是手工修改得到这些文件。
这对你这样的用户意味着什么?这意味着除非Subversion以后发展这个特性,你必须手工的记录这些信息。最佳的方式是使用提交日志信息,像前面的例子提到的,推荐你在日志信息中说明合并的特定版本号(或是版本号的范围),之后,你可以运行svn log来查看你的分支包含哪些修改。这可以帮助你小心的依序运行svn merge命令而不会进行多余的合并。
在下一小节,我们要展示一些这种技巧的例子。
因为合并只是导致本地修改,它不是一个高风险的操作,如果你在第一次操作错误,你可以运行svn revert来再试一次。
有时候你的工作拷贝很可能已经改变了,合并会针对存在的那一个文件,这时运行svn revert不会恢复你在本地作的修改,两部分的修改无法识别出来。
在这个情况下,人们很乐意能够在合并之前预测一下,一个简单的方法是使用运行svn merge同样的参数运行svn diff,另一种方式是传递--dry-run选项给merge命令:
$ svn merge --dry-run -r 343:344 http://svn.example.com/repos/calc/trunk U integer.c $ svn status # nothing printed, working copy is still unchanged.
--dry-run选项实际上并不修改本地拷贝,它只是显示实际合并时的状态信息,对于得到“整体”的印象,这个命令很有用,因为svn diff包括太多细节。
就像svn update命令,svn merge会把修改应用到工作拷贝,因此它也会造成冲突,因为svn merge造成的冲突有时候会有些不同,本小节会解释这些区别。
作为开始,我们假定本地没有修改,当你svn update到一个特定修订版本时,修改会“干净的”应用到工作拷贝,服务器产生比较两树的增量数据:一个工作拷贝和你关注的版本树的虚拟快照,因为比较的左边同你拥有的完全相同,增量数据确保你把工作拷贝转化到右边的树。
但是svn merge没有这样的保证,会导致很多的混乱:用户可以询问服务器比较任何两个树,即使一个与工作拷贝毫不相关的!这意味着有潜在的人为错误,用户有时候会比较两个错误的树,创建的增量数据不会干净的应用,svn merge会尽力应用更多的增量数据,但是有一些部分也许会难以完成,就像Unix下patch命令有时候会报告“failed hunks”错误,svn merge会报告“skipped targets”:
$ svn merge -r 1288:1351 http://svn.example.com/repos/branch U foo.c U bar.c Skipped missing target: 'baz.c' U glub.c C glorb.h $
在前一个例子中,baz.c也许会存在于比较的两个分支快照里,但工作拷贝里不存在,比较的增量数据要应用到这个文件,这种情况下会发生什么?“skipped”信息意味着用户可能是在比较错误的两棵树,这是经典的驱动器错误,当发生这种情况,可以使用迭代恢复(svn revert --recursive)合并所作的修改,删除恢复后留下的所有未版本化的文件和目录,并且使用另外的参数运行svn merge。
也应当注意前一个例子显示glorb.h发生了冲突,我们已经规定本地拷贝没有修改:冲突怎么会发生呢?因为用户可以使用svn merge将过去的任何变化应用到当前工作拷贝,变化包含的文本修改也许并不能干净的应用到工作拷贝文件,即使这些文件没有本地修改。
另一个svn update和svn merge的小区别是冲突产生的文件的名字不同,在“解决冲突(合并别人的修改)”一节,我们看到过更新产生的文件名字为filename.mine、filename.rOLDREV和filename.rNEWREV,当svn merge产生冲突时,它产生的三个文件分别为 filename.working、filename.left和filename.right。在这种情况下,术语“left”和“right”表示了两棵树比较时的两边,在两种情况下,不同的名字会帮助你区分冲突是因为更新造成的还是合并造成的。
当与Subversion开发者交谈时你一定会听到提及术语祖先,这个词是用来描述两个对象的关系:如果他们互相关联,一个对象就是另一个的祖先,或者相反。
举个例子,假设你提交版本100,包括对foo.c的修改,则foo.c@99是foo.c@100的一个“祖先”,另一方面,假设你在版本101删除这个文件,而在102版本提交一个同名的文件,在这个情况下,foo.c@99与foo.c@102看起来是关联的(有同样的路径),但是事实上他们是完全不同的对象,它们并不共享同一个历史或者说“祖先”。
指出svn diff和svn merge区别的重要性在于,前一个命令忽略祖先,如果你询问svn diff来比较文件foo.c的版本99和102,你会看到行为基础的区别,区别命令只是盲目的比较两条路径,但是如果你使用svn merge是比较同样的两个对象,它会注意到他们是不关联的,而且首先尝试删除旧文件,然后添加新文件,你会看到A foo.c后面紧跟D foo.c。
大多数合并包括比较包括祖先关联的两条树,因此svn merge这样运作,然而,你也许会希望合并命令能够比较两个不相关的目录树,举个例子,你有两个目录树分别代表了卖主软件项目的不同版本(见“卖主分支”一节),如果你使用svn merge进行比较,你会看到第一个目录树被删除,而第二个树添加上!
在这个情况下,你只是希望svn merge能够做一个以路径为基础的比较,忽略所有文件和目录的关系,增加--ignore-ancestry选项会导致命令象svn diff一样。(相应的,--notice-ancestry选项会使svn diff象合并命令一样行事。)
分支和svn merge有很多不同的用法,这个小节描述了最常见的用法。
为了完成这个例子,我们将时间往前推进,假定已经过了几天,在主干和你的分支上都有许多更改,假定你完成了分支上的工作,已经完成了特性或bug修正,你想合并所有分支的修改到主干上,让别人也可以使用。
这种情况下如何使用svn merge?记住这个命令比较两个目录树,然后应用比较结果到工作拷贝,所以要接受这种变化,你需要主干的工作拷贝,我们假设你有一个最初的主干工作拷贝(完全更新),或者是你最近取出了/calc/trunk的一个干净的工作拷贝。
但是要哪两个树进行比较呢?乍一看,回答很明确,只要比较最新的主干与分支。但是你要意识到—这个想法是错误的,伤害了许多新用户!因为svn merge的操作很像svn diff,比较最新的主干和分支树不仅仅会描述你在分支上所作的修改,这样的比较会展示太多的不同,不仅包括分支上的增加,也包括了主干上的删除操作,而这些删除根本就没有在分支上发生过。
为了表示你的分支上的修改,你只需要比较分支的初始状态与最终状态,在你的分支上使用svn log命令,你可以看到你的分支在341版本建立,你的分支最终的状态用HEAD版本表示,这意味着你希望能够比较版本341和HEAD的分支目录,然后应用这些分支的修改到主干目录的工作拷贝。
提示
查找分支产生的版本(分支的“基准”)的最好方法是在svn log中使用--stop-on-copy选项,log子命令通常会显示所有关于分支的变化,包括 创建分支的过程,就好像你在主干上一样,--stop-on-copy会在svn log检测到目标拷贝或者改名时中止日志输出。
所以,在我们的例子里,
$ svn log --verbose --stop-on-copy \
http://svn.example.com/repos/calc/branches/my-calc-branch
…
------------------------------------------------------------------------
r341 | user | 2002-11-03 15:27:56 -0600 (Thu, 07 Nov 2002) | 2 lines
Changed paths:
A /calc/branches/my-calc-branch (from /calc/trunk:340)
$
正如所料,最后的打印出的版本正是my-calc-branch生成的版本。
如下是最终的合并过程,然后:
$ cd calc/trunk $ svn update At revision 405. $ svn merge -r 341:405 http://svn.example.com/repos/calc/branches/my-calc-branch U integer.c U button.c U Makefile $ svn status M integer.c M button.c M Makefile # ...examine the diffs, compile, test, etc... $ svn commit -m "Merged my-calc-branch changes r341:405 into the trunk." Sending integer.c Sending button.c Sending Makefile Transmitting file data ... Committed revision 406.
再次说明,日志信息中详细描述了合并到主干的的修改范围,记住一定要这么做,这是你以后需要的重要信息。
举个例子,你希望在分支上继续工作一周,来进一步加强你的修正,这时版本库的HEAD版本是480,你准备好了另一次合并,但是我们在“合并的最佳实践”一节提到过,你不想合并已经合并的内容,你只想合并新的东西,技巧就是指出什么是“新”的。
第一步是在主干上运行svn log察看最后一次与分支合并的日志信息:
$ cd calc/trunk $ svn log … ------------------------------------------------------------------------ r406 | user | 2004-02-08 11:17:26 -0600 (Sun, 08 Feb 2004) | 1 line Merged my-calc-branch changes r341:405 into the trunk. ------------------------------------------------------------------------ …
阿哈!因为分支上341到405之间的所有修改已经在版本406合并了,现在你只需要合并分支在此之后的修改—通过比较406和HEAD。
$ cd calc/trunk $ svn update At revision 480. # We notice that HEAD is currently 480, so we use it to do the merge: $ svn merge -r 406:480 http://svn.example.com/repos/calc/branches/my-calc-branch U integer.c U button.c U Makefile $ svn commit -m "Merged my-calc-branch changes r406:480 into the trunk." Sending integer.c Sending button.c Sending Makefile Transmitting file data ... Committed revision 481.
现在主干有了分支上第二波修改的完全结果,此刻,你可以删除你的分支(我们会在以后讨论),或是继续在你分支上工作,重复这个步骤。
svn merge另一个常用的做法是取消已经做得提交,假设你愉快的在/calc/trunk工作,你发现303版本对integer.c的修改完全错了,它不应该被提交,你可以使用svn merge来“取消”这个工作拷贝上所作的操作,然后提交本地修改到版本库,你要做得只是指定一个相反的区别:
$ svn merge -r 303:302 http://svn.example.com/repos/calc/trunk U integer.c $ svn status M integer.c $ svn diff … # verify that the change is removed … $ svn commit -m "Undoing change committed in r303." Sending integer.c Transmitting file data . Committed revision 350.
我们可以把版本库修订版本想象成一组修改(一些版本控制系统叫做修改集),通过-r选项,你可以告诉svn merge来应用修改集或是一个修改集范围到你的工作拷贝,在我们的情况例子里,我们使用svn merge合并修改集#303到工作拷贝。
记住回滚修改和任何一个svn merge命令都一样,所以你应该使用svn status或是svn diff来确定你的工作处于期望的状态中,然后使用svn commit来提交,提交之后,这个特定修改集不会反映到HEAD版本了。
继续,你也许会想:好吧,这不是真的取消提交吧!是吧?版本303还依然存在着修改,如果任何人取出calc的303-349版本,他还会得到错误的修改,对吧?
是的,这是对的。当我们说“删除”一个修改时,我们只是说从HEAD删除,原始的修改还保存在版本库历史中,在多数情况下,这是足够好的。大多数人只是对追踪HEAD版本感兴趣,在一些特定情况下,你也许希望毁掉所有提交的证据(或许某个人提交了一个秘密文件),这不是很容易的,因为Subversion设计用来不丢失任何信息,每个修订版本都是不可变的目录树 ,从历史删除一个版本会导致多米诺效应,会在后面的版本导致混乱甚至会影响所有的工作拷贝。 [9]
版本控制系统非常重要的一个特性就是它的信息从不丢失,即使当你删除了文件或目录,它也许从HEAD版本消失了 ,但这个对象依然存在于历史的早期版本 ,一个新手经常问到的问题是“怎样找回我的文件和目录?”
第一步首先要知道需要拯救的项目是什么,这里有个很有用的比喻:你可以认为任何存在于版本库的对象生活在一个二维的坐标系统里,第一维是一个特定的版本树,第二维是在树中的路径,所以你的文件或目录的任何版本可以有这样一对坐标定义。
Subversion没有向CVS一样的古典目录, [10] 所以你需要svn log来察看你需要找回的坐标对,一个好的策略是使用svn log --verbose来察看你删除的项目,--verbose选项显示所有改变的项目的每一个版本 ,你只需要找出你删除文件或目录的那一个版本。你可以通过目测找出这个版本,也可以使用另一种工具来检查日志的输出 (通过grep或是在编辑器里增量查找)。
$ cd parent-dir $ svn log --verbose … ------------------------------------------------------------------------ r808 | joe | 2003-12-26 14:29:40 -0600 (Fri, 26 Dec 2003) | 3 lines Changed paths: D /calc/trunk/real.c M /calc/trunk/integer.c Added fast fourier transform functions to integer.c. Removed real.c because code now in double.c. …
在这个例子里,你可以假定你正在找已经删除了的文件real.c,通过查找父目录的历史 ,你知道这个文件在808版本被删除,所以存在这个对象的版本在此之前 。结论:你想从版本807找回/calc/trunk/real.c。
以上是最重要的部分—重新找到你需要恢复的对象。现在你已经知道该恢复的文件,而你有两种选择。
一种是对版本反向使用svn merge到808(我们已经学会了如何取消修改,见“取消修改”一节),这样会重新添加real.c,这个文件会列入增加的计划,经过一次提交,这个文件重新回到HEAD。
在这个例子里,这不是一个好的策略,这样做不仅把real.c加入添加到计划,也取消了对integer.c的修改,而这不是你期望的。确实,你可以恢复到版本808,然后对integer.c执行取消svn revert操作,但这样的操作无法扩大使用,因为如果从版本808修改了90个文件怎么办?
所以第二个方法不是使用svn merge,而是使用svn copy命令,精确的拷贝版本和路径“坐标对”到你的工作拷贝:
$ svn copy --revision 807 \
http://svn.example.com/repos/calc/trunk/real.c ./real.c
$ svn status
A + real.c
$ svn commit -m "Resurrected real.c from revision 807, /calc/trunk/real.c."
Adding real.c
Transmitting file data .
Committed revision 1390.
加号标志表明这个项目不仅仅是计划增加中,而且还包含了历史,Subversion记住了它是从哪个拷贝过来的。在将来,对这个文件运行svn log会看到这个文件在版本807之前的历史,换句话说,real.c不是新的,而是原先删除的那一个的后代。
尽管我们的例子告诉我们如何找回文件,对于恢复删除的目录也是一样的。
版本控制在软件开发中广泛使用,这里是团队里程序员最常用的两种分支/合并模式的介绍,如果你不是使用Subversion软件开发,可随意跳过本小节,如果你是第一次使用版本控制的软件开发者,请更加注意,以下模式被许多老兵当作最佳实践,这个过程并不只是针对Subversion,在任何版本控制系统中都一样,但是在这里使用Subversion术语会感觉更方便一点。
大多数软件存在这样一个生命周期:编码、测试、发布,然后重复。这样有两个问题,第一,开发者需要在质量保证小组测试假定稳定版本时继续开发新特性,新工作在软件测试时不可以中断,第二,小组必须一直支持老的发布版本和软件;如果一个bug在最新的代码中发现,它一定也存在已发布的版本中,客户希望立刻得到错误修正而不必等到新版本发布。
这是版本控制可以做的帮助,典型的过程如下:
-
开发者提交所有的新特性到主干。 每日的修改提交到
/trunk:新特性,bug修正和其他。 -
这个主干被拷贝到“发布”分支。 当小组认为软件已经做好发布的准备(如,版本1.0)然后
/trunk会被拷贝到/branches/1.0。 -
项目组继续并行工作,一个小组开始对分支进行严酷的测试,同时另一个小组在
/trunk继续新的工作(如,准备2.0),如果一个bug在任何一个位置被发现,错误修正需要来回运送。然而这个过程有时候也会结束,例如分支已经为发布前的最终测试“停滞”了。 -
分支已经作了标签并且发布,当测试结束,
/branches/1.0作为引用快照已经拷贝到/tags/1.0.0,这个标签被打包发布给客户。 -
分支多次维护。当继续在
/trunk上为版本2.0工作,bug修正继续从/trunk运送到/branches/1.0,如果积累了足够的bug修正,管理部门决定发布1.0.1版本:拷贝/branches/1.0到/tags/1.0.1,标签被打包发布。
整个过程随着软件的成熟不断重复:当2.0完成,一个新的2.0分支被创建,测试、打标签和最终发布,经过许多年,版本库结束了许多版本发布,进入了“维护”模式,许多标签代表了最终的发布版本。
一个特性分支是本章中那个重要例子中的分支,你正在那个分支上工作,而Sally还在/trunk继续工作,这是一个临时分支,用来作复杂的修改而不会干扰/trunk的稳定性,不象发布分支(也许要永远支持),特性分支出生,使用了一段时间,合并到主干,然后最终被删除掉,它们在有限的时间里有用。
还有,关于是否创建特性分支的项目政策也变化广泛,一些项目永远不使用特性分支:大家都可以提交到/trunk,好处是系统的简单—没有人需要知道分支和合并,坏处是主干会经常不稳定或者不可用,另外一些项目使用分支达到极限:没有修改曾经直接提交到主干,即使最细小的修改都要创建短暂的分支,然后小心的审核合并到主干,然后删除分支,这样系统保持主干一直稳定和可用,但是造成了巨大的负担。
许多项目采用折中的方式,坚持每次编译/trunk并进行回归测试,只有需要多次不稳定提交时才需要一个特性分支,这个规则可以用这样一个问题检验:如果开发者在好几天里独立工作,一次提交大量修改(这样/trunk就不会不稳定。),是否会有太多的修改要来回顾?如果答案是“是”,这些修改应该在特性分支上进行,因为开发者增量的提交修改,你可以容易的回头检查。
最终,有一个问题就是怎样保持一个特性分支“同步”于工作中的主干,在前面提到过,在一个分支上工作数周或几个月是很有风险的,主干的修改也许会持续涌入,因为这一点,两条线的开发会区别巨大,合并分支回到主干会成为一个噩梦。
这种情况最好通过有规律的将主干合并到分支来避免,制定这样一个政策:每周将上周的修改合并到分支,注意这样做时需要小心,需要手工记录合并的过程,以避免重复的合并(在“手工追踪合并”一节描述过),你需要小心的撰写合并的日志信息,精确的描述合并包括的范围(在“合并一条分支到另一支”一节中描述过),这看起来像是胁迫,可是实际上是容易做到的。
在一些时候,你已经准备好了将“同步的”特性分支合并回到主干,为此,开始做一次将主干最新修改和分支的最终合并,这样以后,除了你的分支修改的部分,最新的分支和主干将会绝对一致,所以在这个特别的例子里,你会通过直接比较分支和主干来进行合并:
$ cd trunk-working-copy
$ svn update
At revision 1910.
$ svn merge http://svn.example.com/repos/calc/trunk@1910 \
http://svn.example.com/repos/calc/branches/mybranch@1910
U real.c
U integer.c
A newdirectory
A newdirectory/newfile
…
通过比较HEAD修订版本的主干和HEAD修订版本的分支,你确定了只在分支上的增量信息,两条开发线都有了分枝的修改。
可以用另一种考虑这种模式,你每周按时同步分支到主干,类似于在工作拷贝执行svn update的命令,最终的合并操作类似于在工作拷贝运行svn commit,毕竟,工作拷贝不就是一个非常浅的分支吗?只是它一次只可以保存一个修改。
svn switch命令改变存在的工作拷贝到另一个分支,然而这个命令在分支上工作时不是严格必要的,它只是提供了一个快捷方式。在前面的例子里,完成了私有分支的建立,你取出了新目录的工作拷贝,相反,你可以简单的告诉Subversion改变你的/calc/trunk的工作拷贝到分支的路径:
$ cd calc $ svn info | grep URL URL: http://svn.example.com/repos/calc/trunk $ svn switch http://svn.example.com/repos/calc/branches/my-calc-branch U integer.c U button.c U Makefile Updated to revision 341. $ svn info | grep URL URL: http://svn.example.com/repos/calc/branches/my-calc-branch
完成了到分支的“跳转”,你的目录与直接取出一个干净的版本没有什么不同。这样会更有效率,因为分支只有很小的区别,服务器只是发送修改的部分来使你的工作拷贝反映分支。
svn switch命令也可以带--revision(-r)参数,所以你不需要一直移动你的工作拷贝到最新版本。
当然,许多项目比我们的calc要复杂的多,有更多的子目录,Subversion用户通常用如下的法则使用分支:
-
拷贝整个项目的“trunk”目录到一个新的分支目录。
-
只是转换工作拷贝的部分目录到分支。
换句话说,如果一个用户知道分支工作只发生在部分子目录,我们使用svn switch来跳转部分目录(有时候只是单个文件),这样的话,他们依然可以继续得到普通的“trunk”主干的更新,但是已经跳转的部分则被免去了更新(除非分支上有更新)。这个特性给“混合工作拷贝”概念添加了新的维度—不仅工作拷贝的版本可以混合,在版本库中的位置也可以混合。
如果你的工作拷贝包含许多来自不同版本库目录跳转的子树,它会工作如常。当你更新时,你会得到每一个目录适当的补丁,当你提交时,你的本地修改会一直作为一个单独的原子修改提交到版本库。
注意,因为你的工作拷贝可以在混合位置的情况下工作正常,但是所有的位置必须在同一个版本库,Subversion的版本库不能互相通信,这个特性还不在Subversion 1.0的计划里。[11]
因为svn switch是svn update的一个变种,具有相同的行为,当新的数据到达时,任何工作拷贝的已经完成的本地修改会被保存,这里允许你作各种聪明的把戏。
举个例子,你的工作拷贝目录是/calc/trunk,你已经做了很多修改,然后你突然发现应该在分支上修改更好,没问题!你可以使用svn switch,而你本地修改还会保留,你可以测试并提交它们到分支。
另一个常见的版本控制系统概念是标签(tag),一个标签只是一个项目某一时间的“快照”,在Subversion里这个概念无处不在—每一次提交的修订版本都是一个精确的快照。
然而人们希望更人性化的标签名称,像release-1.0。他们也希望可以对一个子目录快照,毕竟,记住release-1.0是修订版本4822的某一小部分不是件很容易的事。
svn copy再次登场,你希望建立一个/calc/trunk的一个快照,就像HEAD修订版本,建立这样一个拷贝:
$ svn copy http://svn.example.com/repos/calc/trunk \
http://svn.example.com/repos/calc/tags/release-1.0 \
-m "Tagging the 1.0 release of the 'calc' project."
Committed revision 351.
这个例子假定/calc/tags目录已经存在(如果不是,见svn mkdir),拷贝完成之后,一个表示当时HEAD版本的/calc/trunk目录的镜像已经永久的拷贝到release-1.0目录。当然,你会希望更精确一点,以防其他人在你不注意的时候提交修改,所以,如果你知道/calc/trunk的版本350是你想要的快照,你可以使用svn copy加参数 -r 350。
但是等一下:标签的产生过程与建立分支是一样的?是的,实际上在Subversion中标签与分支没有区别,都是普通的目录,通过copy命令得到,与分支一样,一个目录之所以是标签只是人们决定这样使用它,只要没有人提交这个目录,它永远是一个快照,但如果人们开始提交,它就变成了分支。
如果你管理一个版本库,你有两种方式管理标签,第一种方法是禁止命令:作为项目的政策,我们要决定标签所在的位置,确定所有用户知道如何处理拷贝的目录(也就是确保他们不会提交他们),第二种方法看来很过分:使用访问控制脚本来阻止任何想对标签目录做的非拷贝的操作(见第 6 章 配置服务器)这种方法通常是不必要的,如果一个人不小心提交了到标签目录一个修改,你可以简单的取消,毕竟这是版本控制啊。
你一定注意到了Subversion极度的灵活性,因为它用相同的底层机制(目录拷贝)实现了分支和标签,因为分支和标签是作为普通的文件系统出现,会让人们感到害怕,因为它太灵活了,在这个小节里,我们会提供安排和管理数据的一些建议。
有一些标准的,推荐的组织版本库的方式,许多人创建一个trunk目录来保存开发的“主线”,一个branches目录存放分支拷贝,一个目录保存标签拷贝,如果一个版本库只是存放一个项目,人们会在顶级目录创建这些目录:
/trunk /branches /tags
如果一个版本库保存了多个项目,管理员会通过项目来布局(见“选择一种版本库布局”一节关于“项目根目录”):
/paint/trunk /paint/branches /paint/tags /calc/trunk /calc/branches /calc/tags
当然,你可以自由的忽略这些通常的布局方式,你可以创建任意的变化,只要是对你和你的项目有益,记住无论你选择什么,这不会是一种永久的承诺,你可以随时重新组织你的版本库。因为分支和标签都是普通的目录,svn move命令可以任意的改名和移动它们,从一种布局到另一种大概只是一系列服务器端的移动,如果你不喜欢版本库的组织方式,你可以任意修改目录结构。
记住,尽管移动目录非常容易,你必须体谅你的用户,你的修改会让你的用户感到迷惑,如果一个用户的拥有一个版本库目录的工作拷贝,你的svn move命令也许会删除最新的版本的这个路径,当用户运行svn update,会被告知这个工作拷贝引用的路径已经不再存在,用户需要强制使用svn switch转到新的位置。
我们已经在本章覆盖了许多基础知识,我们讨论了标签和分支的概念,然后描述了Subversion怎样用svn copy命令拷贝目录实现了这些概念,我们也已经展示了怎样使用svn merge命令来在分支之间拷贝修改,或是撤销错误的修改。我们仔细研究了使用svn switch来创建混合位置的工作拷贝,然后我们也讨论了怎样管理和组织版本库中分支的生命周期。
记住Subversion的曼特罗(mantra):分支和标签是廉价的,自由的使用它们吧!
古典区域用来保存增量数据。--relocate的svn switch命令转换URL,见第 9 章 Subversion完全参考的svn switch查看更多信息和例子。Subversion版本库是保存任意数量项目版本化数据的中央仓库,因此,版本库成为管理员关注的对象。版本库的维护一般并不需要太多的关注,但为了避免一些潜在的问题和解决一些实际问题,理解怎样适当的配置和维护还是非常重要的。
在这一章里,我们将讨论如何建立和配置一个Subversion版本库,还会讨论版本库的维护,包括svnlook和svnadmin工具的使用(它们都包含在Subversion中)。我们将说明一些常见的问题和错误,并提供一些安排版本库数据的建议。
如果您只是以普通用户的身份访问版本库对数据进行版本控制(就是说通过Subversion客户端),您完全可以跳过本章。但是如果您已经是或打算成为Subversion版本库的管理员,[12]您一定要关注一下本章的内容。
在进入版本库管理这块宽广的主题之前,让我们进一步确定一下版本库的定义,它是怎样工作的?让人有什么感觉?它希望茶是热的还是冰的,加糖或柠檬吗?作为一名管理员,你应该既从逻辑视角-数据在版本库中如何展示,又能从物理具体细节的视角-版本库如何响应一个非Subversion的工具,来理解版本库的组成。下面的小节从一个比较高的层面覆盖了这些基本概念。
从概念上来说,Subversion的版本库就是一串目录树。每一个目录树,就是版本库的文件和目录在某一时刻的快照。这些快照是客户端使用者操作的结果,叫做修订版本。
每一个修订版本都是以事务树开始其生命周期。做提交操作时,客户端建立了一个映射本地修改的Subversion事务(加上客户端提交操作后任何对版本库的更改),然后指导版本库将该树存储为下一个快照。要是提交成功,这个事务就会成为新的修订版本树,并被赋予新的修订版本号。如果因为某些原因提交失败,事务会被销毁,客户端将被通知这个事务失败。
更新的动作也类似这样。客户端建立一个临时的事务树,映射工作文件的状态。然后版本库比较事务树和被请求的修订版本树(通常是最新的,也就是最“年轻”的修订版本树),然后发回消息通知客户端哪些变更需要将拷贝发送到修订版本树。更新完成后,临时事务将被删除。
事务树的使用是对版本库中版本控制文件系统产生永久变更的唯一方法。一个事务的生命周期非常灵活,了解这一点很重要。在更新的情况下,事务只是马上会被销毁的临时树。在提交的情况下,事务会变成固定的修订版本(如果失败的情况下,则会被删除)。在出现错误或bug的情况下,事务可能会被留在版本库中(不会影响任何东西,但是会占据空间)。
理论上,有一天整个流程能够发展到对事务进行更加细密的流程控制。可以想象一个系统,在客户端完成操作,将要保存到版本库中时,每个加到它的事务都变成一个修订版本。这将会使每一个新的提交都可以被别人查看到,也许是主管,也许是质量保证小组,他们可以决定是要接收这个事务成为修订版本,还是放弃它。
事务和修订版本在Subversion版本库中可以附加属性。这些属性就是普通的属性名和属性值的映射,被用来存储与对应目录树有关的信息。这些属性名和属性值跟你的其他数据一样,被存储在版本库文件系统中。
修订版本和事务的属性对于存储一个跟目录树相关,但与树中的某个具体目录或文件不相关的性质很有用-即并不被客户端工作拷贝所管理的属性。举例来说,当一个新的提交事务在版本库中被创建时,Subversion给这个事务添加一个叫做svn:date的属性—一个表示事务何时被创建的时间戳。当提交进程结束,该事务成为一个固定的修订版本,这个目录树被赋予一个用来存储这个版本作者名称的属性(svn:author)和一个用来存储与这个修订版本关联日志信息的属性(svn:log)。
修订版本和事务的属性都是未受版本控制的-因为当它们被修改时,先前的值就被完全舍弃了。修订版本树自身是不能变更的,与之关联的属性可以修改。你可在日后添加、删除、修改修订版本的属性。如果你提交一个新的修订版本之后意识到遗漏了一些信息或在日志中的拼写错误,你可以直接以正确的信息覆盖svn:log它的值。
在Subversion1.1中,版本库中存储数据有两种方式。一种是在Berkeley DB数据库中存储数据;另一种是使用普通的文件,使用自定义格式。因为Subversion的开发者称版本库为[版本化的]文件系统,他们接受了称后一种存储方式为FSFS的习惯,也就是说,使用本地操作系统文件系统来存储数据的版本化文件系统。
建立一个版本库时,管理员必须决定使用Berkeley DB还是FSFS。它们各有优缺点,我们将详细描述。这两个中并没有一个是更正式的,访问版本库的程序与采用哪一种实现方式无关。访问程序并不知道版本库如何存储数据,它们只是从版本库的API读取到修订版本和事务树。
下面的表从总体上比较了Berkeley DB和FSFS版本库,下一部分将会详细讲述细节。
表 5.1. 版本库数据存储对照表
| 特性 | Berkeley DB | FSFS |
|---|---|---|
| 对操作中断的敏感 | 很敏感;系统崩溃或者权限问题会导致数据库“塞住”,需要定期进行恢复。 | 不敏感。 |
| 可只读加载 | 不能 | 可以 |
| 存储平台无关 | 不能 | 可以 |
| 可从网络文件系统访问 | 不能 | 可以 |
| 版本库大小 | 稍大 | 稍小 |
| 可扩展性:修订版本树的数量 | 数据库,没有限制 | 许多古老的本地文件系统在处理单一目录包含上千个条目时出现问题。 |
| 可扩展性:文件较多的目录 | 较慢 | 较快 |
| 速度:检出最新的代码 | 较快 | 较慢 |
| 速度: 大的提交 | 较慢,但是时间被分配在整个提交操作中 | 较快,但是最后较长的延时可能会导致客户端操作超时 |
| 组访问权处理 | 对于用户的umask设置十分敏感,最好只由一个用户访问。 | 对umask设置不敏感 |
| 功能成熟时间 | 2001年开始使用 | 2004年开始使用 |
在Subversion的初始设计阶段,开发者因为多种原因而决定采用Berkeley DB,比如它的开源协议、事务支持、可靠性、性能、简单的API、线程安全、支持游标等。
Berkeley DB提供了真正的事务支持-这或许是它最强大的特性,访问你的Subversion版本库的多个进程不必担心偶尔会破坏其他进程的数据。事务系统提供的隔离对于任何给定的操作,Subversion版本库代码看到的只是数据库的静态视图-而不是一个在其他进程影响不断变化的数据库-并能够根据该视图作出决定。如果该决定正好同其他进程所做操作冲突,整个操作会回滚,就像什么都没有发生一样,并且Subversion会优雅的再次对更新的静态视图进行操作。
Berkeley DB另一个强大的特性是热备份-不必“脱机”就可以备份数据库环境的能力。我们将会在“版本库备份”一节讨论如何备份你的版本库,能够不停止系统对版本库做全面备份的好处是显而易见的。
Berkeley DB同时是一个可信赖的数据库系统。Subversion利用了Berkeley DB可以记日志的便利,这意味着数据库先在磁盘上写一个日志文件,描述它将要做的修改,然后再做这些修改。这是为了确保如果如果任何地方出了差错,数据库系统能恢复到先前的检查点—一个日志文件认为没有错误的位置,重新开始事务直到数据恢复为一个可用的状态。关于Berkeley DB日志文件的更多信息请查看“管理磁盘空间”一节。
但是每朵玫瑰都有刺,我们也必须记录一些Berkeley DB已知的缺陷。首先,Berkeley DB环境不是跨平台的。你不能简单的拷贝一个在Unix上创建的Subversion版本库到一个Windows系统并期望它能够正常工作。尽管Berkeley DB数据库的大部分格式是不受架构约束的,但环境还是有一些方面没有独立出来。其次,使用Berkeley DB的Subversion不能在95/98系统上运行—如果你需要将版本库建在一个Windows机器上,请装到Windows2000或WindowsXP上。另外,Berkeley DB版本库不能放在网络共享文件夹中,尽管Berkeley DB承诺如果按照一套特定规范的话,可以在网络共享上正常运行,但实际上已知的共享类型几乎都不满足这套规范。
最后,因为Berkeley DB的库直接链接到了Subversion中,它对于中断比典型的关系型数据库系统更为敏感。大多数SQL系统,举例来说,有一个主服务进程来协调对数据库表的访问。如果一个访问数据库的程序因为某种原因出现问题,数据库守护进程察觉到连接中断会做一些清理。因为数据库守护进程是唯一访问数据库表的进程,应用程序不需要担心访问许可的冲突。但是,这些情况与Berkeley DB不同。Subversion(和使用Subversion库的程序)直接访问数据库的表,这意味着如果有一个程序崩溃,就会使数据库处于一个暂时的不一致、不可访问的状态。当这种情况发生时,管理员需要让Berkeley DB恢复到一个检查点,这的确有点讨厌。除了崩溃的进程,还有一些情况能让版本库出现异常,比如程序在数据库文件的所有权或访问权限上发生冲突。因为Berkeley DB版本库非常快,并且可以扩展,非常适合使用一个单独的服务进程,通过一个用户来访问—比如Apache的httpd或svnserve(参见第 6 章 配置服务器)—而不是多用户通过file:///或svn+ssh://URL的方式多用户访问。如果将Berkeley DB版本库直接用作多用户访问,请先阅读“支持多种版本库访问方法”一节。
创建一个 Subversion 版本库出乎寻常的简单。 Subversion 提供的svnadmin 工具,有一个执行这个功能的子命令。要建立一个新的版本库,只需要运行:
$ svnadmin create /path/to/repos
这个命令在目录/path/to/repos创建了一个新的版本库。这个新的版本库会以修订版本版本0开始其生命周期,里面除了最上层的根目录(/),什么都没有。刚开始,修订版本0有一个修订版本属性svn:date,设置为版本库创建的时间。
在 Subversion 1.1中,版本库默认使用Berkeley DB后端存储方式来创建。在以后的发行版中这个行为会被改变。不管怎样,存储类型可以使用--fs-type参数明确说明。:
$ svnadmin create --fs-type fsfs /path/to/repos $ svnadmin create --fs-type bdb /path/to/other/repos
警告
不要在网络共享上创建Berkeley DB版本库—它不能存在于诸如NFS, AFS或Windows SMB的远程文件系统中,Berkeley 数据要求底层文件系统实现严格的POSIX锁定语义,几乎没有任何网络文件系统提供这些特性,假如你在网络共享上使用Berkeley DB,结果是不可预知的——许多错误可能会立刻发现,也有可能在几个月之后才能发现
假如你需要多台计算机来访问,你需要在网络共享上创建FSFS版本库,而不是Berkeley DB的版本库。或者更好的办法,你建立一个真正的服务进程(例如Apache或svnserve),把版本库放在服务器能访问到的本地文件系统中,以便能通过网络访问。详情请参看第 6 章 配置服务器
你可能已经注意到了,svnadmin命令的路径参数只是一个普通的文件系统路径,而不是一个svn客户端程序访问版本库时使用的URL。svnadmin和svnlook都被认为是服务器端工具—它们在版本库所在的机器上使用,用来检查或修改版本库,不能通过网络来执行任务。一个Subversion的新手通常会犯的错误,就是试图将URL(甚至“本地”file:路径)传给这两个程序。
所以,当你运行svnadmin create命令后,就会在运行目录创建一个崭新的Subversion版本库,让我们看一下在这个目录创建中创建了什么。
$ ls repos conf/ dav/ db/ format hooks/ locks/ README.txt
除了README.txt和format文件,版本库目录就是一些子目录了。就像Subversion其它部分的设计一样,模块化是一个很重要的原则,而且层次化的组织要比杂乱无章好。下面是对新的版本库目录中各个项目的简要介绍:
- conf
-
一个存储版本库配置文件的目录。
- dav
-
提供给Apache和mod_dav_svn的目录,让它们存储自己的数据。
- db
-
你所有的受版本控制数据的所在之处。这个目录或者是个Berkeley DB环境(满是数据表和其他东西),或者是一个包含修订版本文件的FSFS环境。
- format
-
包含了用来表示版本库布局版本号的整数。
- hooks
-
一个存储钩子脚本模版的目录(还有钩子脚本本身, 如果你安装了的话)。
- locks
-
一个存储Subversion版本库锁定数据的目录,被用来追踪对版本库的访问。
- README.txt
-
这个文件只是用来告诉它的阅读者,他现在看的是 Subversion 的版本库。
一般来说,你不需要手动干预版本库。svnadmin工具应该足以用来处理对版本库的任何修改,或者你也可以使用第三方工具(比如Berkeley DB的工具包)来调整部分版本库。不过还是会有些例外情况,我们会在这里提到。
所谓钩子就是与一些版本库事件触发的程序,例如新修订版本的创建,或是未版本化属性的修改。每个钩子都会被告知足够多的信息,包括那是什么事件,所操作的对象,和触发事件的用户名。通过钩子的输出或返回状态,钩子程序能让工作继续、停止或是以某种方式挂起。
默认情况下,钩子的子目录中包含各种版本库钩子模板。
$ ls repos/hooks/ post-commit.tmpl pre-revprop-change.tmpl post-revprop-change.tmpl start-commit.tmpl pre-commit.tmpl
对每种Subversion版本库支持的钩子的都有一个模板,通过查看这些脚本的内容,你能看到是什么事件触发了脚本及如何给传脚本传递数据。同时,这些模版也是如何使用这些脚本,结合Subversion支持的工具来完成有用任务的例子。要实际安装一个可用的钩子,你需要在repos/hooks目录下安装一些与钩子同名(如 start-commit或者post-commit)的可执行程序或脚本。
在Unix平台上,这意味着要提供一个与钩子同名的脚本或程序(可能是shell 脚本,Python 程序,编译过的c语言二进制文件或其他东西)。当然,脚本模板文件不仅仅是展示了一些信息—在Unix下安装钩子最简单的办法就是拷贝这些模板,并且去掉.tmpl扩展名,然后自定义钩子的内容,确定脚本是可运行的。Windows用文件的扩展名来决定一个程序是否可运行,所以你要使程序的基本名与钩子同名,同时,它的扩展名是Windows系统所能辨认的,例如exe、com和批处理的bat。
提示
由于安全原因,Subversion版本库在一个空环境中执行钩子脚本—就是没有任何环境变量,甚至没有$PATH或%PATH%。由于这个原因,许多管理员会感到很困惑,它们的钩子脚本手工运行时正常,可在Subversion中却不能运行。要注意,必须在你的钩子中设置好环境变量或为你的程序指定好绝对路径。
目前Subversion有已实现了五种钩子:
start-commit-
它在提交事务产生前已运行,通常用来判定一个用户是否有权提交。版本库传给该程序两个参数:到版本库的路径,和要进行提交的用户名。如果程序返回一个非零值,会在事务产生前停止该提交操作。如果钩子程序要在stderr中写入数据,它将排队送至客户端。
pre-commit-
在事务完成提交之前运行,通常这个钩子是用来保护因为内容或位置(例如,你要求所有到一个特定分支的提交必须包括一个bug追踪的ticket号,或者是要求日志信息不为空)而不允许的提交。版本库传递两个参数到程序:版本库的路径和正在提交的事务名称,如果程序返回非零值,提交会失败,事务也会删除。如果钩子程序在stderr中写入了数据,也会传递到客户端。
Subversion的分发版本包括了一些访问控制脚本(在Subversion源文件目录树的
tools/hook-scripts目录),可以用来被pre-commit调用来实现精密的写访问控制。另一个选择是使用Apache的httpd模块mod_authz_svn,可以对单个目录进行读写访问控制(见“每目录访问控制”一节)。在未来的Subversion版本中,我们计划直接在文件系统中实现访问控制列表(ACLs)。 post-commit-
它在事务完成后运行,创建一个新的修订版本。大多数人用这个钩子来发送关于提交的描述性电子邮件,或者作为版本库的备份。版本库传给程序两个参数:到版本库的路径和被创建的新的修订版本号。退出程序会被忽略。
Subversion分发版本中包括mailer.py和commit-email.pl脚本(存于Subversion源代码树中的
tools/hook-scripts/目录中)可以用来发送描述给定提交的email(并且或只是追加到一个日志文件),这个mail包含变化的路径清单,提交的日志信息、日期和作者以及修改文件的GNU区别样式输出。Subversion提供的另一个有用的工具是hot-backup.py脚本(在Subversion源代码树中的tools/backup/目录中)。这个脚本可以为Subversion版本库进行热备份(Berkeley DB数据库后端支持的一种特性),可以制作版本库每次提交的快照作为归档和紧急情况的备份。
pre-revprop-change-
因为Subversion的修订版本属性不是版本化的,对这类属性的修改(例如提交日志属性
svn:log)将会永久覆盖以前的属性值。因为数据在此可能丢失,所以Subversion提供了这种钩子(及与之对应的post-revprop-change),因此版本库管理员可用一些外部方法记录变化。作为对丢失未版本化属性数据的防范,Subversion客户端不能远程修改修订版本属性,除非为你的版本库实现这个钩子。这个钩子在对版本库进行这种修改时才会运行,版本库给钩子传递四个参数:到版本库的路径,要修改属性的修订版本,经过认证的用户名和属性自身的名字。
post-revprop-change-
我们在前面提到过,这个钩子与
pre-revprop-change对应。事实上,因为多疑的原因,只有存在pre-revprop-change时这个脚本才会执行。当这两个钩子都存在时,post-revprop-change在修订版本属性被改变之后运行,通常用来发送包含新属性的email。版本库传递四个参数给该钩子:到版本库的路径,属性存在的修订版本,经过校验的产生变化的用户名,和属性自身的名字。Subversion分发版本中包含propchange-email.pl脚本(在Subversion源代码树中的
tools/hook-scripts/目录中),可以用来发送修订版本属性修改细节的email(并且或只是追加到一个日志文件)。这个email包含修订版本和发生变化的属性名,作出修改的用户和新属性值。
警告
不要尝试用钩子脚本修改事务。一个常见的例子就是在提交时自动设置svn:eol-style或svn:mime-type这类属性。这看起来是个好主意,但它会引起问题。主要的问题是客户并不知道由钩子脚本进行的修改,同时没有办法通告客户它的数据是过时的,这种矛盾会导致出人意料和不能预测的行为。
作为尝试修改事务的替代,我们通过检查pre-commit钩子的事务,在不满足要求时拒绝提交。
Subversion会试图以当前访问版本库的用户身份执行钩子。通常,对版本库的访问总是通过Apache HTTP服务器和mod_dav_svn进行,因此,执行钩子的用户就是运行Apache的用户。钩子本身需要具有操作系统级的访问许可,用户可以运行它。另外,其它被钩子直接或间接使用的文件或程序(包括Subversion版本库本身)也要被同一个用户访问。换句话说,要注意潜在的访问控制问题,它可能会让你的钩子无法按照你的目的顺利执行。
维护一个Subversion版本库是一项令人沮丧的工作,主要因为有数据库后端与生俱来的复杂性。做好这项工作需要知道一些工具——它们是什么,什么时候用以及如何使用。这一节将会向你介绍Subversion自带的版本库管理工具,以及如何使用它们来完成诸如版本库移植、升级、备份和整理之类的任务。
Subversion提供了一些用来创建、查看、修改和修复版本库的工具。让我们首先详细了解一下每个工具,然后,我们再看一下仅在Berkeley DB后端分发版本中提供的版本数据库工具。
svnlook是Subversion提供的用来查看版本库中不同的修订版本和事务。这个程序不会修改版本库内容-这是个“只读”的工具。svnlook通常用在版本库钩子程序中,用来记录版本库即将提交(用在pre-commit钩子时)或者已经提交的(用在post-commit钩子时)修改。版本库管理员可以将这个工具用于诊断。
svnlook 的语法很直接:
$ svnlook help
general usage: svnlook SUBCOMMAND REPOS_PATH [ARGS & OPTIONS ...]
Note: any subcommand which takes the '--revision' and '--transaction'
options will, if invoked without one of those options, act on
the repository's youngest revision.
Type "svnlook help <subcommand>" for help on a specific subcommand.
…
几乎svnlook的每一个子命令都能操作修订版本或事务树,显示树本身的信息,或是它与版本库中上一个修订版本的不同。你可以用--revision 和 --transaction选项指定要查看的修订版本或事务。注意,虽然修订版本号看起来像自然数,但是事务名称是包含英文字母与数字的字符串。请记住文件系统只允许浏览未提交的事务(还没有形成一个新的修订版本的事务)。多数版本库没有这种事务,因为事务通常或者被提交了(这样便不能被查看),或者被中止并删除了。
如果没有--revision和--transaction选项,svnlook会查看版本库中最年轻的修订版本(或“HEAD”)。当版本库中的/path/to/repos的最年轻的修订版本是19时,下边的两个命令执行结果完全相同:
$ svnlook info /path/to/repos $ svnlook info /path/to/repos --revision 19
这些子命令的唯一例外,是svnlook youngest命令,它不需要选项,只会显示出HEAD的修订版本号。
$ svnlook youngest /path/to/repos 19
svnlook的输出被设计为人和机器都易理解,拿info子命令举例来说:
$ svnlook info /path/to/repos sally 2002-11-04 09:29:13 -0600 (Mon, 04 Nov 2002) 27 Added the usual Greek tree.
info子命令的输出定义如下:
-
作者,后接换行。
-
日期,后接换行。
-
日志消息的字数,后接换行。
-
日志信息本身, 后接换行。
这种输出是人可阅读的,像是时间戳这种有意义的条目,使用文本表示,而不是其他比较晦涩的方式(例如许多无聊的人推荐的十亿分之一秒的数量)。这种输出也是机器可读的—因为日志信息可以有多行,没有长度的限制,svnlook在日志消息之前提供了消息的长度,这使得脚本或者其他对这个命令进行的封装提供了更强的功能,比如日志消息使用了多少内存,或在这个输出成为最后一个字节之前应该略过多少字节。
另一个svnlook常见的用法是查看修订版本树或事务树的内容。svnlook tree 命令显示在请求的树中的目录和文件。如果你提供了--show-ids选项,它还会显示每个路径的文件系统节点修订版本ID(这一点对开发者往往更有用)。
$ svnlook tree /path/to/repos --show-ids
/ <0.0.1>
A/ <2.0.1>
B/ <4.0.1>
lambda <5.0.1>
E/ <6.0.1>
alpha <7.0.1>
beta <8.0.1>
F/ <9.0.1>
mu <3.0.1>
C/ <a.0.1>
D/ <b.0.1>
gamma <c.0.1>
G/ <d.0.1>
pi <e.0.1>
rho <f.0.1>
tau <g.0.1>
H/ <h.0.1>
chi <i.0.1>
omega <k.0.1>
psi <j.0.1>
iota <1.0.1>
如果你看过树中目录和文件的布局,你可以使用svnlook cat,svnlook propget, 和svnlook proplist命令来查看这些目录和文件的细节。
svnlook还可以做很多别的查询,显示我们先前提到的信息的一些子集,报告指定的修订版本或事务中哪些路径曾经被修改过,显示对文件和目录做过的文本和属性的修改,等等。下面是svnlook命令能接受的子命令的介绍,以及这些子命令的输出:
author-
显示该树的作者。
cat-
显示树中某文件的内容。
changed-
显示树中修改过的所有文件和目录。
date-
显示该树的时间戳。
diff-
使用统一区别格式显示被修改的文件。
dirs-changed-
显示树中本身被修改或者其中文件被修改的目录。
history-
显示受到版本控制的路径(更改和复制发生过的地方)中重要的历史点。
info-
显示树的作者、时间戳、日志大小和日志信息。
log-
显示树的日志信息。
propget-
显示树中路径的属性值。
proplist-
显示树中属性集合的名字与值。
tree-
显示树列表,可选的显示与路径有关的文件系统节点的修订版本号。
uuid-
显示版本库的UUID—全局唯一标示。
youngest-
显示最年轻的修订版本号。
svnadmin程序是版本库管理员最好的朋友。除了提供创建Subversion版本库的功能,这个程序使你可以维护这些版本库。svnadmin的语法跟 svnlook类似:
$ svnadmin help general usage: svnadmin SUBCOMMAND REPOS_PATH [ARGS & OPTIONS ...] Type "svnadmin help <subcommand>" for help on a specific subcommand. Available subcommands: create deltify dump help (?, h) …
我们已经提过svnadmin的create子命令(参照“版本库的创建和配置”一节)。本章中我们会详细讲解大多数其他的命令。现在,我们来简单的看一下每个可用的子命令提供了什么功能。
create-
创建一个新的Subversion版本库。
deltify-
在指定的修订版本范围内,对其中修改过的路径做增量化操作。如果没有指定修订版本,这条命令会修改
HEAD修订版本。 dump-
导出版本库修订一定版本范围内的内容,使用可移植转储格式。
hotcopy-
对版本库做热拷贝,用这个方法你能任何时候安全的备份版本库而无需考虑是否正在使用。
list-dblogs-
(Berkeley DB版本库专有)列出Berkeley DB中与版本库有关的日志文件清单。这个清单包括所有的日志文件—仍然被版本库使用的和不再使用的。
list-unused-dblogs-
(Berkeley DB版本库专有)列出Berkeley DB版本库有关的不在使用日志文件路径清单。你能安全的从版本库中删除那些日志文件,也可以将它们存档以用来在灾难事件后版本库的恢复。
load-
导入由
dump子命令导出的可移植转储格式的一组修订版本。 lstxns-
列出刚刚在版本库的没有提交的Subversion事务清单。
recover-
恢复版本库,通常在版本库发生了致命错误的时候,例如阻碍进程干净的关闭同版本库的连接的错误。
rmtxns-
从版本库中清除Subversion事务(通过加工
lstxns子命令的输出即可)。 setlog-
替换给定修订版本的
svn:log(提交日志信息)属性值。 verify-
验证版本库的内容,包括校验比较本地版本化数据和版本库。
因为Subversion使用底层的数据库储存各类数据,手工调整是不明智的,即使这样做并不困难。何况,一旦你的数据存进了版本库,通常很难再将它们从版本库中删除。[13]但是不可避免的,总会有些时候你需要处理版本库的历史数据。你也许想把一个不应该出现的文件从版本库中彻底清除。或者,你曾经用一个版本库管理多个工程,现在又想把它们分开。要完成这样的工作,管理员们需要更易于管理和扩展的方法表示版本库中的数据,Subversion版本库转储文件格式就是一个很好的选择。
Subversion版本库转储文件记录了所有版本数据的变更信息,而且以易于阅读的格式保存。可以使用svnadmin dump命令生成转储文件,然后用svnadmin load命令生成一个新的版本库。(参见 “版本库的移植”一节)。转储文件易于阅读意味着你可以小心翼翼的查看和修改它。当然,问题是如果你有一个运行了两年的版本库,那么生成的转储文件会很庞大,阅读和手工修改起来都会花费很多时间。
虽然在管理员的日常工作中并不会经常使用,不过svndumpfilter可以对特定的路径进行过滤。这是一个独特而很有意义的用法,可以帮助你快速方便的修改转储的数据。使用时,只需提供一个你想要保留的(或者不想保留的)路径列表,然后把你的版本库转储文件送进这个过滤器。最后你就可以得到一个仅包含你想保留的路径的转储数据流。
svndumpfilter的语法如下:
$ svndumpfilter help general usage: svndumpfilter SUBCOMMAND [ARGS & OPTIONS ...] Type "svndumpfilter help <subcommand>" for help on a specific subcommand. Available subcommands: exclude include help (?, h)
有意义的子命令只有两个。你可以使用这两个子命令说明你希望保留和不希望保留的路径:
exclude-
将指定路径的数据从转储数据流中排除。
include-
将指定路径的数据添加到转储数据流中。
现在我来演示如何使用这个命令。我们会在其它章节(参见 “选择一种版本库布局”一节)讨论关于如何选择设定版本库布局的问题,比如应该使用一个版本库管理多个项目还是使用一个版本库管理一个项目,或者如何在版本库中安排数据等等。不过,有些时候,即使在项目已经展开以后,你还是希望对版本库的布局做一些调整。最常见的情况是,把原来存放在同一个版本库中的几个项目分开,各自成家。
假设有一个包含三个项目的版本库: calc,calendar,和 spreadsheet。它们在版本库中的布局如下:
/
calc/
trunk/
branches/
tags/
calendar/
trunk/
branches/
tags/
spreadsheet/
trunk/
branches/
tags/
现在要把这三个项目转移到三个独立的版本库中。首先,转储整个版本库:
$ svnadmin dump /path/to/repos > repos-dumpfile * Dumped revision 0. * Dumped revision 1. * Dumped revision 2. * Dumped revision 3. … $
然后,将转储文件三次送入过滤器,每次仅保留一个顶级目录,就可以得到三个转储文件:
$ cat repos-dumpfile | svndumpfilter include calc > calc-dumpfile … $ cat repos-dumpfile | svndumpfilter include calendar > cal-dumpfile … $ cat repos-dumpfile | svndumpfilter include spreadsheet > ss-dumpfile … $
现在你必须要作出一个决定了。这三个转储文件中,每个都可以用来创建一个可用的版本库,不过它们保留了原版本库的精确路径结构。也就是说,虽然项目calc现在独占了一个版本库,但版本库中还保留着名为calc的顶级目录。如果希望trunk、tags和branches这三个目录直接位于版本库的根路径下,你可能需要编辑转储文件,调整Node-path和Copyfrom-path头参数,将路径calc/删除。同时,你还要删除转储数据中创建calc目录的部分。一般来说,就是如下的一些内容:
Node-path: calc Node-action: add Node-kind: dir Content-length: 0
警告
如果你打算通过手工编辑转储文件来移除一个顶级目录,注意不要让你的编辑器将换行符转换为本地格式(比如将\r\n转换为\n)。否则文件的内容就与所需的格式不相符,这个转储文件也就失效了。
剩下的工作就是创建三个新的版本库,然后将三个转储文件分别导入:
$ svnadmin create calc; svnadmin load calc < calc-dumpfile
<<< Started new transaction, based on original revision 1
* adding path : Makefile ... done.
* adding path : button.c ... done.
…
$ svnadmin create calendar; svnadmin load calendar < cal-dumpfile
<<< Started new transaction, based on original revision 1
* adding path : Makefile ... done.
* adding path : cal.c ... done.
…
$ svnadmin create spreadsheet; svnadmin load spreadsheet < ss-dumpfile
<<< Started new transaction, based on original revision 1
* adding path : Makefile ... done.
* adding path : ss.c ... done.
…
$
svndumpfilter的两个子命令都可以通过选项设定如何处理“空”修订版本。如果某个指定的修订版本仅包含路径的更改,过滤器就会将它删除,因为当前为空的修订版本通常是无用的甚至是让人讨厌的。为了让用户有选择的处理这些修订版本,svndumpfilter提供了以下命令行选项:
--drop-empty-revs-
不生成任何空修订版本,忽略它们。
--renumber-revs-
如果空修订版本被剔除(通过使用
--drop-empty-revs选项),依次修改其它修订版本的编号,确保编号序列是连续的。 --preserve-revprops-
如果空修订版本被保留,保持这些空修订版本的属性(日志信息,作者,日期,自定义属性,等等)。如果不设定这个选项,空修订版本将仅保留初始时间戳,以及一个自动生成的日志信息,表明此修订版本由svndumpfilter处理过。
尽管svndumpfilter十分有用,能节省大量的时间,但它却是把不折不扣的双刃剑。首先,这个工具对路径语义极为敏感。仔细检查转储文件中的路径是不是以斜线开头。也许Node-path和Copyfrom-path这两个头参数对你有些帮助。
… Node-path: spreadsheet/Makefile …
如果这些路径以斜线开头,那么你传递给svndumpfilter include和svndumpfilter exclude的路径也必须以斜线开头(反之亦然)。如果因为某些原因转储文件中的路径没有统一使用或不使用斜线开头,[14]也许需要修正这些路径,统一使用斜线开头或不使用斜线开头。
此外,复制操作生成的路径也会带来麻烦。Subversion支持在版本库中进行复制操作,也就是复制一个存在的路径,生成一个新的路径。问题是,svndumpfilter保留的某个文件或目录可能是由某个svndumpfilter排除的文件或目录复制而来的。也就是说,为了确保转储数据的完整性,svndumpfilter需要切断这些复制自被排除路径的文件与源文件的关系,还要将这些文件的内容以新建的方式添加到转储数据中。但是由于Subversion版本库转储文件格式中仅包含了修订版本的更改信息,因此源文件的内容基本上无法获得。如果你不能确定版本库中是否存在类似的情况,最好重新考虑一下到底保留/排除哪些路径。
Subversion源代码树中有一个类似于shell的版本库访问界面。Python脚本svnshell.py(位于源代码树的tools/examples/下)通过Subversion语言绑定接口(所以运行这个脚本须要正确的编译和安装这些程序包)连接到版本库和文件系统库。
运行这个脚本,你可以浏览版本库中的目录,就像在shell下浏览文件系统一样。一开始,你“位于”修订版本HEAD的根目录中, 在命令提示符中可以看到相应的提示。 任何时候都可以使用help命令显示当前可用的命令帮助。
$ svnshell.py /path/to/repos <rev: 2 />$ help Available commands: cat FILE : dump the contents of FILE cd DIR : change the current working directory to DIR exit : exit the shell ls [PATH] : list the contents of the current directory lstxns : list the transactions available for browsing setrev REV : set the current revision to browse settxn TXN : set the current transaction to browse youngest : list the youngest browsable revision number <rev: 2 />$
浏览版本库的目录结构就像在Unix或Windows shell中一样——使用cd命令。任何时候,命令提示符中都会显示当前所在的修订版本(前缀为rev:)或事务(前缀为txn:,以及你所在的路径。你可以用setrev和settxn切换到其它修订版本或事务中去。你可以像在Unix shell中那样,使用ls命令列出目录的内容,使用cat命令列出文件的内容。
例 5.1. 使用svnshell浏览版本库
<rev: 2 />$ ls
REV AUTHOR NODE-REV-ID SIZE DATE NAME
----------------------------------------------------------------------------
1 sally < 2.0.1> Nov 15 11:50 A/
2 harry < 1.0.2> 56 Nov 19 08:19 iota
<rev: 2 />$ cd A
<rev: 2 /A>$ ls
REV AUTHOR NODE-REV-ID SIZE DATE NAME
----------------------------------------------------------------------------
1 sally < 4.0.1> Nov 15 11:50 B/
1 sally < a.0.1> Nov 15 11:50 C/
1 sally < b.0.1> Nov 15 11:50 D/
1 sally < 3.0.1> 23 Nov 15 11:50 mu
<rev: 2 /A>$ cd D/G
<rev: 2 /A/D/G>$ ls
REV AUTHOR NODE-REV-ID SIZE DATE NAME
----------------------------------------------------------------------------
1 sally < e.0.1> 23 Nov 15 11:50 pi
1 sally < f.0.1> 24 Nov 15 11:50 rho
1 sally < g.0.1> 24 Nov 15 11:50 tau
<rev: 2 /A>$ cd ../..
<rev: 2 />$ cat iota
This is the file 'iota'.
Added this text in revision 2.
<rev: 2 />$ setrev 1; cat iota
This is the file 'iota'.
<rev: 1 />$ exit
$
在上例中可以看到,可以将几条命令现在同一行中,并以分号隔开。此外,这个shell也能正确处理相对路径和绝对路径,以及特殊的路径.和..。
youngest命令将列出最年轻的修订版本。这可以用来确定setrev命令参数的范围—你可以浏览所有0到最年轻修订版本中的任何一个(它们都以整数为标识)。确定可以浏览的事务就不这么简单了。你需要使用lstxns命令列出哪些事务可以浏览。lstxns命令的输出与svnadmin lstxns的输出相同,设置了--transaction选项的svnlook命令也可以得到相同的结果。
使用exit命令可以退出这个shell。也可以使用文件结束符—Control-D(在某些Win32的Python版本中用Control-Z代替)。
如果你使用Berkeley DB版本库,那么所有纳入版本控制的文件系统结构和数据都储存在一系列数据库的表中,而这个位于版本库的db子目录下。这个子目录是一个标准的Berkeley DB环境目录,可以应用任何Berkeley数据库工具进行操作(参考SleepyCat网站http://www.sleepycat.com/上关于这些工具的介绍)。
对于Subversion的日常使用来说,这些工具并没有什么用处。大多数Subversion版本库必须的数据库操作都集成到svnadmin工具中。比如,svnadmin list-unused-dblogs和svnadmin list-dblogs实现了Berkeley db_archive命令功能的一个子集,而svnadmin recover则起到了 db_recover工具的作用。
当然,还有一些Berkeley DB工具有时是有用的。db_dump将Berkeley DB数据库中的键值对以特定的格式写入文件中,而db_load则可以将这些键值对注入到数据库中。Berkeley数据库本身不支持跨平台转移,这两个工具在这样的情况下就可以实现在平台间转移数据库的功能,而无需关心操作系统或机器架构。此外,db_stat工具能够提供关于Berkeley DB环境的许多有用信息,包括详细的锁定和存储子系统的统计信息。
Subversion版本库一旦按照需要配置完成,一般情况下不需要特别的关照。不过有些时候还是需要管理员手工干预一下。svnadmin工具就能够帮你完成以下这类工作:
-
修改提交日志信息,
-
移除中止的事务,
-
恢复“塞住”的版本库,以及
-
将一个版本库中的内容搬移到另一个版本库中。
svnadmin的子命令中最经常用到的恐怕就是setlog。用户在提交时输入的日志信息随着相关事务提交到版本库并升级成为修订版本后,便作为新修订版本的非版本化(即没有进行版本管理)属性保存下来。换句话说,版本库只记得最新的属性值,而忽略以前的。
有时用户输入的日志信息有错误(比如拼写错误或者内容错误)。如果配置版本库时设置了(使用pre-revprop-change和 post-revprop-change钩子;参见“钩子脚本”一节)允许用户在提交后修改日志信息的选项,那么用户可以使用svn程序的propset命令(参见第 9 章 Subversion完全参考)“修正”日志信息中的错误。不过为了避免永远丢失信息,Subversion版本库通常设置为仅能由管理员修改非版本化属性(这也是默认的选项)。
如果管理员想要修改日志信息,那么可以使用svnadmin setlog命令。这个命令从指定的文件中读取信息,取代版本库中某个修订版本的日志信息(svn:log属性)。
$ echo "Here is the new, correct log message" > newlog.txt $ svnadmin setlog myrepos newlog.txt -r 388
即使是svnadmin setlog命令也受到限制。pre-和 post-revprop-change钩子同样会被触发,因此必须进行相应的设置才能允许修改非版本化属性。不过管理员可以使用svnadmin setlog命令的--bypass-hooks选项跳过钩子。
警告
不过需要注意的是,一旦跳过钩子也就跳过了钩子所提供的所有功能,比如邮件通知(通知属性有改动)、系统备份(可以用来跟踪非版本化的属性变更)等等。换句话说,要留心你所作出的修改,以及你作出修改的方式。
svnadmin的另一个常见用途是查询异常的—可能是已经死亡的—Subversion事务。通常提交操作失败时,与之相关的事务就会被清除。也就是说,事务本身及所有与该事务相关(且仅与该事务相关)的数据会从版本库中删除。不过偶尔也会出现操作失败而事务没有被清除的情况。出现这种情况可能有以下原因:客户端的用户粗暴的结束了操作,操作过程中出现网络故障,等等。不管是什么原因,死亡的事务总是有可能会出现。这类事务不会产生什么负面影响,仅仅是消耗了一点点磁盘空间。不过,严厉的管理员总是希望能够将它们清除出去。
可以使用svnadmin的lstxns 命令列出当前的异常事务名。
$ svnadmin lstxns myrepos 19 3a1 a45 $
将输出的结果条目作为svnlook(设置--transaction选项)的参数,就可以获得事务的详细信息,如事务的创建者、创建时间,事务已作出的更改类型,由这些信息可以判断出是否可以将这个事务安全的删除。如果可以安全删除,那么只需将事务名作为参数输入到svnadmin rmtxns,就可以将事务清除掉了。其实rmtxns子命令可以直接以lstxns的输出作为输入进行清理。
$ svnadmin rmtxns myrepos `svnadmin lstxns myrepos` $
在按照上面例子中的方法清理版本库之前,你或许应该暂时关闭版本库和客户端的连接。这样在你开始清理之前,不会有正常的事务进入版本库。下面例子中的shell脚本可以用来迅速获得版本库中异常事务的信息:
可以用下面的命令使用上例中脚本: /path/to/txn-info.sh /path/to/repos。该命令的输出主要由多个svnlook info参见“svnlook”一节)的输出组成,类似于下面的例子:
$ txn-info.sh myrepos ---[ Transaction 19 ]------------------------------------------- sally 2001-09-04 11:57:19 -0500 (Tue, 04 Sep 2001) 0 ---[ Transaction 3a1 ]------------------------------------------- harry 2001-09-10 16:50:30 -0500 (Mon, 10 Sep 2001) 39 Trying to commit over a faulty network. ---[ Transaction a45 ]------------------------------------------- sally 2001-09-12 11:09:28 -0500 (Wed, 12 Sep 2001) 0 $
一个废弃了很长时间的事务通常是提交错误或异常中断的结果。事务的时间戳可以提供给我们一些有趣的信息,比如一个进行了9个月的操作居然还是活动的等等。
简言之,作出事务清理的决定前应该仔细考虑一下。许多信息源—比如Apache的错误和访问日志,已成功完成的Subversion提交日志等等—都可以作为决策的参考。管理员还可以直接和那些似乎已经死亡事务的提交者直接交流(比如通过邮件),来确认该事务确实已经死亡了。
虽然存储器的价格在过去的几年里以让人难以致信的速度滑落,但是对于那些需要对大量数据进行版本管理的管理员们来说,磁盘空间的消耗依然是一个重要的因素。版本库每增加一个字节都意味着需要多一个字节的磁盘空间进行备份,对于多重备份来说,就需要消耗更多的磁盘空间。Berkeley DB版本库的主要存储机制是基于一个复杂的数据库系统建立的,因此了解一些数据性质是有意义的,比如哪些数据必须保留。哪些数据需要备份、哪些数据可以安全的删除等等。本节的内容专注于Berkeley DB类型的版本库。FSFS类型的版本库不需要进行数据清理和回收。
目前为止,Subversion版本库中耗费磁盘空间的最大凶手是日志文件,每次Berkeley DB在修改真正的数据文件之前都会进行预写入(pre-writes)操作。这些文件记录了数据库从一个状态变化到另一个状态的所有动作——数据库文件反应了特定时刻数据库的状态,而日志文件则记录了所有状态变化的信息。因此,日志文件会以很快的速度膨胀起来。
幸运的是,从版本4.2开始,Berkeley DB的数据库环境无需额外的操作即可删除无用的日志文件。如果编译svnadmin时使用了高于4.2版本的Berkeley DB,那么由此svnadmin程序创建的版本库就具备了自动清除日志文件的功能。如果想屏蔽这个功能,只需设置svnadmin create命令的--bdb-log-keep选项即可。如果创建版本库以后想要修改关于此功能的设置,只需编辑版本库中db目录下的DB_CONFIG文件,注释掉包含set_flags DB_LOG_AUTOREMOVE内容的这一行,然后运行svnadmin recover强制设置生效就行了。查阅“Berkeley DB配置”一节获得更多关于数据库配置的帮助信息。
如果不自动删除日志文件,那么日志文件会随着版本库的使用逐渐增加。这多少应该算是数据库系统的特性,通过这些日志文件可以在数据库严重损坏时恢复整个数据库的内容。但是一般情况下,最好是能够将无用的日志文件收集起来并删除,这样就可以节省磁盘空间。使用svnadmin list-unused-dblogs命令可以列出无用的日志文件:
$ svnadmin list-unused-dblogs /path/to/repos /path/to/repos/log.0000000031 /path/to/repos/log.0000000032 /path/to/repos/log.0000000033 $ svnadmin list-unused-dblogs /path/to/repos | xargs rm ## disk space reclaimed!
为了尽可能减小版本库的体积,Subversion在版本库中采用了增量化技术(或称为“增量存储技术”)。增量化技术可以将一组数据表示为相对于另一组数据的不同。如果这两组数据十分相似,增量化技术就可以仅保存其中一组数据以及两组数据的差别,而不需要同时保存两组数据,从而节省了磁盘空间。每次一个文件的新版本提交到版本库,版本库就会将之前的版本(之前的多个版本)相对于新版本做增量化处理。采用了这项技术,版本库的数据量大小基本上是可以估算出来的—主要是版本化的文件的大小—并且远小于“全文”保存所需的数据量。
注意
由于Subversion版本库的增量化数据保存在单一Berkeley DB数据库文件中,减少数据的体积并不一定能够减小数据库文件的大小。但是,Berkeley DB会在内部记录未使用的数据库文件区域,并且在增加数据库文件大小之前会首先使用这些未使用的区域。因此,即使增量化技术不能立杆见影的节省磁盘空间,也可以极大的减慢数据库的膨胀速度。
“Berkeley DB”一节中曾提到,Berkeley DB版本库如果没有正常关闭可能会进入冻结状态。这时,就需要管理员将数据库恢复到正常状态。
Berkeley DB使用一种锁机制保护版本库中的数据。锁机制确保数据库不会同时被多个访问进程修改,也就保证了从数据库中读取到的数据始终是稳定而且正确的。当一个进程需要修改数据库中的数据时,首先必须检查目标数据是否已经上锁。如果目标数据没有上锁,进程就将它锁上,然后作出修改,最后再将锁解除。而其它进程则必须等待锁解除后才能继续访问数据库中的相关内容。
在操作Subversion版本库的过程中,致命错误(如内存或硬盘空间不足)或异常中断可能会导致某个进程没能及时将锁解除。结果就是后端的数据库系统被“塞住”了。一旦发生这种情况,任何访问版本库的进程都会挂起(每个访问进程都在等待锁被解除,但是锁已经无法解除了)。
首先,如果你的版本库出现这种情况,没什么好惊慌的。Berkeley DB的文件系统采用了数据库事务、检查点以及预写入日志等技术来取保只有灾难性的事件[15]才能永久性的破坏数据库环境。所以虽然一个过于稳重的版本库管理员通常都会按照某种方案进行大量的版本库离线备份,不过不要急着通知你的管理员进行恢复。
然后,使用下面的方法试着“恢复”你的版本库:
-
确保没有其它进程访问(或者试图访问)版本库。对于网络版本库,关闭Apache HTTP服务器是个好办法。
-
成为版本库的拥有者和管理员。这一点很重要,如果以其它用户的身份恢复版本库,可能会改变版本库文件的访问权限,导致在版本库“恢复”后依旧无法访问。
-
运行命令svnadmin recover /path/to/repos。 输出如下:
Repository lock acquired。 Please wait; recovering the repository may take some time... Recovery completed. The latest repos revision is 19.
此命令可能需要数分钟才能完成。
-
重新启动Subversion服务器。
这个方法能修复几乎所有版本库锁住的问题。记住,要以数据库的拥有者和管理员的身份运行这个命令,而不一定是root用户。恢复过程中可能会使用其它数据存储区(例如共享内存区)重建一些数据库文件。如果以root用户身份恢复版本库,这些重建的文件拥有者将变成root用户,也就是说,即使恢复了到版本库的连接,一般的用户也无权访问这些文件。
如果因为某些原因,上面的方法没能成功的恢复版本库,那么你可以做两件事。首先,将破损的版本库保存到其它地方,然后从最新的备份中恢复版本库。然后,发送一封邮件到Subversion用户列表(地址是:<users@subversion.tigris.org>),写清你所遇到的问题。对于Subversion的开发者来说,数据安全是最重要的问题。
Subversion文件系统将数据保存在许多数据库表中,而这些表的结构只有Subversion开发者们才了解(也只有他们才感兴趣)不过,有些时候我们会想到把所有的数据(或者一部分数据)保存在一个独立的、可移植的、普通格式的文件中。Subversion通过svnadmin的两个子命令dump和load提供了类似的功能。
对版本库的转储和装载的需求主要还是由于Subversion自身处于变化之中。在Subversion的成长期,后端数据库的设计多次发生变化,这些变化导致之前的版本库出现兼容性问题。当然,将Berkeley DB版本库移植到不同的操作系统或者CPU架构上,或者在Berkeley DB和FSFS后端之间进行转化也需要转储和装载功能。按照下面的介绍,只需简单几步就可以完成数据库的移植:
-
使用当前版本的svnadmin将版本库转储到文件中。
-
升级Subversion。
-
移除以前的版本库,并使用新版本的svnadmin在原来版本库的位置建立空的版本库。
-
还是使用新版本的svnadmin从转储文件中将数据装载到新建的空版本库中。
-
记住从以前的版本库中复制所有的定制文件到新版本库中,包括
DB_CONFIG文件和钩子脚本。最好阅读一下新版本的release notes,看看此次升级是否会影响钩子和配置选项。 -
如果移植的同时改变的版本库的访问地址(比如移植到另一台计算机或者改变了访问策略),那么可以通知用户运行svn switch --relocate来切换他们的工作副本。参见svn switch。
svnadmin dump命令会将版本库中的修订版本数据按照特定的格式输出到转储流中。转储数据会输出到标准输出流,而提示信息会输出到标准错误流。这就是说,可以将转储数据存储到文件中,而同时在终端窗口中监视运行状态。例如:
$ svnlook youngest myrepos 26 $ svnadmin dump myrepos > dumpfile * Dumped revision 0. * Dumped revision 1. * Dumped revision 2. … * Dumped revision 25. * Dumped revision 26.
最后,版本库中的指定的修订版本数据被转储到一个独立的文件中(在上面的例子中是dumpfile)。注意,svnadmin dump从版本库中读取修订版本树与其它“读者”(比如svn checkout)的过程相同,所以可以在任何时候安全的运行这个命令。
另一个命令,svnadmin load,从标准输入流中读取Subversion转储数据,并且高效的将数据转载到目标版本库中。这个命令的提示信息输出到标准输出流中:
$ svnadmin load newrepos < dumpfile
<<< Started new txn, based on original revision 1
* adding path : A ... done.
* adding path : A/B ... done.
…
------- Committed new rev 1 (loaded from original rev 1) >>>
<<< Started new txn, based on original revision 2
* editing path : A/mu ... done.
* editing path : A/D/G/rho ... done.
------- Committed new rev 2 (loaded from original rev 2) >>>
…
<<< Started new txn, based on original revision 25
* editing path : A/D/gamma ... done.
------- Committed new rev 25 (loaded from original rev 25) >>>
<<< Started new txn, based on original revision 26
* adding path : A/Z/zeta ... done.
* editing path : A/mu ... done.
------- Committed new rev 26 (loaded from original rev 26) >>>
既然svnadmin使用标准输入流和标准输出流作为转储和装载的输入和输出,那么更漂亮的用法是(管道两端可以是不同版本的svnadmin:
$ svnadmin create newrepos $ svnadmin dump myrepos | svnadmin load newrepos
默认情况下,转储文件的体积可能会相当庞大——比版本库自身大很多。这是因为在转储文件中,每个文件的每个版本都以完整的文本形式保存下来。这种方法速度很快,而且很简单,尤其是直接将转储数据通过管道输入到其它进程中时(比如一个压缩程序,过滤程序,或者一个装载进程)。不过如果要长期保存转储文件,那么可以使用--deltas选项来节省磁盘空间。设置这个选项,同一个文件的数个连续修订版本会以增量式的方式保存—就像储存在版本库中一样。这个方法较慢,但是转储文件的体积则基本上与版本库的体积相当。
之前我们提到svnadmin dump输出指定的修订版本。使用--revision选项可以指定一个单独的修订版本,或者一个修订版本的范围。如果忽略这个选项,所有版本库中的修订版本都会被转储。
$ svnadmin dump myrepos --revision 23 > rev-23.dumpfile $ svnadmin dump myrepos --revision 100:200 > revs-100-200.dumpfile
Subversion在转储修订版本时,仅会输出与前一个修订版本之间的差异,通过这些差异足以从前一个修订版本中重建当前的修订版本。换句话说,在转储文件中的每一个修订版本仅包含这个修订版本作出的修改。这个规则的唯一一个例外是当前svnadmin dump转储的第一个修订版本。
默认情况下,Subversion不会把转储的第一个修订版本看作对前一个修订版本的更改。 首先,转储文件中没有比第一个修订版本更靠前的修订版本了!其次,Subversion不知道装载转储数据时(如果真的需要装载的话)的版本库是什么样的情况。为了保证每次运行svnadmin dump都能得到一个独立的结果,第一个转储的修订版本默认情况下会完整的保存目录、文件以及属性等数据。
不过,这些都是可以改变的。如果转储时设置了--incremental选项,svnadmin会比较第一个转储的修订版本和版本库中前一个修订版本,就像对待其它转储的修订版本一样。转储时也是一样,转储文件中将仅包含第一个转储的修订版本的增量信息。这样的好处是,可以创建几个连续的小体积的转储文件代替一个大文件,比如:
$ svnadmin dump myrepos --revision 0:1000 > dumpfile1 $ svnadmin dump myrepos --revision 1001:2000 --incremental > dumpfile2 $ svnadmin dump myrepos --revision 2001:3000 --incremental > dumpfile3
这些转储文件可以使用下列命令装载到一个新的版本库中:
$ svnadmin load newrepos < dumpfile1 $ svnadmin load newrepos < dumpfile2 $ svnadmin load newrepos < dumpfile3
另一个有关的技巧是,可以使用--incremental选项在一个转储文件中增加新的转储修订版本。举个例子,可以使用post-commit钩子在每次新的修订版本提交后将其转储到文件中。或者,可以编写一个脚本,在每天夜里将所有新增的修订版本转储到文件中。这样,svnadmin的dump和load命令就变成了很好的版本库备份工具,万一出现系统崩溃或其它灾难性事件,它的价值就体现出来了。
转储还可以用来将几个独立的版本库合并为一个版本库。使用svnadmin load的--parent-dir选项,可以在装载的时候指定根目录。也就是说,如果有三个不同版本库的转储文件,比如calc-dumpfile,cal-dumpfile,和ss-dumpfile,可以在一个新的版本库中保存所有三个转储文件中的数据:
$ svnadmin create /path/to/projects $
然后在版本库中创建三个目录分别保存来自三个不同版本库的数据:
$ svn mkdir -m "Initial project roots" \
file:///path/to/projects/calc \
file:///path/to/projects/calendar \
file:///path/to/projects/spreadsheet
Committed revision 1.
$
最后,将转储文件分别装载到各自的目录中:
$ svnadmin load /path/to/projects --parent-dir calc < calc-dumpfile … $ svnadmin load /path/to/projects --parent-dir calendar < cal-dumpfile … $ svnadmin load /path/to/projects --parent-dir spreadsheet < ss-dumpfile … $
我们再介绍一下Subversion版本库转储数据的最后一种用途——在不同的存储机制或版本控制系统之间转换。因为转储数据的格式的大部分是可以阅读的,[16]所以使用这种格式描述变更集(每个变更集对应一个新的修订版本)会相对容易一些。事实上,cvs2svn.py工具(参见 “转化CVS版本库到Subversion”一节)正是将CVS版本库的内容转换为转储数据格式,如此才能将CVS版本库的数据导入Subversion版本库之中。
尽管现代计算机的诞生带来了许多便利,但有一件事听起来是完全正确的—有时候,事情变的糟糕,很糟糕,动力损耗、网络中断、坏掉的内存和损坏的硬盘都是对魔鬼的一种体验,即使对于最尽职的管理员,命运也早已注定。所以我们来到了这个最重要的主题—怎样备份你的版本库数据。
Subversion版本库管理员通常有两种备份方式—增量的和完全的。我们在早先的章节曾经讨论过如何使用svnadmin dump --incremental命令执行增量备份(见“版本库的移植”一节),从本质上讲,这个方法只是备份了从你上次备份版本库到现在的变化。
一个完全的版本库备份照字面上讲就是对整个版本库目录的复制(包括伯克利数据库或者文件FSFS环境),现在,除非你临时关闭了其他对版本库的访问,否则仅仅做一次迭代的拷贝会有产生错误备份的风险,因为有人可能会在并行的写数据库。
如果是伯克利数据库,恼人的文档描述了保证安全拷贝的步骤,对于FSFS的数据,也有类似的顺序。我们有更好的选择,我们不需要自己去实现这个算法,因为Subversion开发小组已经为你实现了这些算法。Subversion源文件分发版本的tools/backup/目录有一个hot-backup.py文件。只要给定了版本库路径和备份路径,hot-backup.py—一个包裹了svnadmin hotcopy但更加智能的命令—将会执行必要的步骤来备份你的活动的版本库—不需要你首先禁止公共的版本库访问—而且之后会从你的版本库清理死掉的伯克利日志文件。
甚至当你用了一个增量备份时,你也会希望有计划的运行这个程序。举个例子,你考虑在你的调度程序(如Unix下的cron)里加入hot-backup.py,或者你喜欢更加细致的备份解决方案,你可以让你的post-commit的钩子脚本执行hot-backup.py(见see “钩子脚本”一节),这样会导致你的版本库的每次提交执行一次备份,只要在你的hooks/post-commit脚本里添加如下代码:
(cd /path/to/hook/scripts; ./hot-backup.py ${REPOS} /path/to/backups &)
作为结果的备份是一个完全功能的版本库,当发生严重错误时可以作为你的活动版本库的替换。
两种备份方式都有各自的优点,最简单的方式是完全备份,将会每次建立版本库的完美复制品,这意味着如果当你的活动版本库发生了什么事情,你可以用备份恢复。但不幸的是,如果你维护多个备份,每个完全的备份会吞噬掉和你的活动版本库同样的空间。
增量备份会使用的版本库转储格式,在Subversion的数据库模式改变时非常完美,因此当我们升级Subversion数据库模式的时候,一个完整的版本库导出和导入是必须的,做一半工作非常的容易(导出部分),不幸的是,增量备份的创建和恢复会占用很长时间,因为每一次提交都会被重放。
在每一种备份情境下,版本库管理员需要意识到对未版本化的修订版本属性的修改对备份的影响,因为这些修改本身不会产生新的修订版本,所以不会触发post-commit的钩子程序,也不会触发pre-revprop-change和post-revprop-change的钩子。 [17] 而且因为你可以改变修订版本的属性,而不需要遵照时间顺序—你可在任何时刻修改任何修订版本的属性—因此最新版本的增量备份不会捕捉到以前特定修订版本的属性修改。
通常说来,在每次提交时,只有妄想狂才会备份整个版本库,然而,假设一个给定的版本库拥有一些恰当粒度的冗余机制(如每次提交的邮件)。版本库管理员也许会希望将版本库的热备份引入到系统级的每夜备份,对大多数版本库,归档的提交邮件为保存资源提供了足够的冗余措施,至少对于最近的提交。但是它是你的数据—你喜欢怎样保护都可以。
通常情况下,最好的版本库备份方式是混合的,你可以平衡完全和增量备份,另外配合提交邮件的归档,Subversion开发者,举个例子,在每个新的修订版本建立时备份Subversion的源代码版本库,并且保留所有的提交和属性修改通知文件。你的解决方案类似,必须迎合你的需要,平衡便利和你的偏执。然而这些不会改变你的硬件来自钢铁的命运。[18] 这一定会帮助你减少尝试的时间。
一旦你的版本库已经建立并且配置好了,剩下的就是使用了。如果你已经准备好了需要版本控制的数据,那么可以使用客户端软件svn的import子命令来实现你的期望。不过在这样做之前,你最好对版本库仔细的作一个长远的规划。本节,我们会给你一些好的建议,这些建议可以帮助你设计版本库的文件布局,以及如何在特定的布局中安排你的数据。
在Subversion版本库中,移动版本化的文件和目录不会损失任何信息,但是这样一来那些经常访问版本库并且以为文件总是在同一个路径的用户可能会受到干扰。为将来着想,最好预先对你的版本库布局进行规划。以一种高效的“布局”开始项目,可以减少将来很多不必要的麻烦。
在建立Subversion版本库之前,有很多事情需要考虑。假如你是一个版本库管理员,需要向多个项目提供版本控制支持。那么,你首先要决定的是,用一个版本库支持多个项目,还是为每个项目建立一个版本库,还是为其中的某些项目提供独立的版本库支持,而将另外一些项目分布在几个版本库中。
使用一个版本库支持多个项目有很多好处,最明显的无过于不需要维护好几个版本库。单一版本库就意味着只有一个钩子集,只需要备份一个数据库,当Subversion进行不兼容升级时,只需要一次转储和装载操作,等等。还有,你可以轻易的在项目之间移动数据,还不会损失任何历史版本信息。
单一版本库的缺点是,不同的项目通常都有不同的提交邮件列表或者不同的权限认证和权限要求。还有,别忘了Subversion的修订版本号是针对整个版本库的。即使最近没有对某个项目作出修改,版本库的修订版本号还是会因为其它项目的修改而不停的提升,许多人并不喜欢这样的事实。
可以采用折中的办法。比如,可以把许多项目按照彼此之间的关联程度划分为几个组合,然后为每一个项目组合建立一个版本库。这样,在相关项目之间共享数据依旧很简单,而如果修订版本号有了变化,至少开发人员知道,改变的东西多少和他们有些关系。
在决定了如何用版本库组织项目以后,就该决定如何设置版本库的目录层次了。由于Subversion按普通的目录复制方式完成分支和标签操作(参见第 4 章 分支与合并),Subversion社区建议为每一个项目建立一个项目根目录—项目的“顶级”目录—然后在根目录下建立三个子目录:trunk,保存项目的开发主线;branches,保存项目的各种开发分支;tags,保存项目的标签,也就是创建后永远不会修改的分支(可能会删除)。
举个例子,一个版本库可能会有如下的布局:
/
calc/
trunk/
tags/
branches/
calendar/
trunk/
tags/
branches/
spreadsheet/
trunk/
tags/
branches/
…
项目在版本库中的根目录地址并不重要。如果每个版本库中只有一个项目,那么就可以认为项目的根目录就是版本库的根目录。如果版本库中包含多个项目,那么可以将这些项目划分成不同的组合(按照项目的目标或者是否需要共享代码甚至是字母顺序)保存在不同子目录中,下面的例子给出了一个类似的布局:
/
utils/
calc/
trunk/
tags/
branches/
calendar/
trunk/
tags/
branches/
…
office/
spreadsheet/
trunk/
tags/
branches/
…
按照你因为合适方式安排版本库的布局。Subversion自身并不强制或者偏好某一种布局形式,对于Subversion来说,目录就是目录。最后,在设计版本库布局的时候,不要忘了考虑一下项目参与者们的意见。
设计好版本库的布局后,就该在版本库中实现布局和导入初始数据了。在Subversion中,有很多种方法完成这项工作。可以使用svn mkdir命令(参见第 9 章 Subversion完全参考)在版本库中逐个创建需要的目录。更快捷的方法是使用svn import命令(参见“svn import”一节)。首先,在硬盘上创建一个临时目录,并按照设计好的布局在其中创建子目录,然后通过导入命令一次性的提交整个布局到版本库中:
$ mkdir tmpdir $ cd tmpdir $ mkdir projectA $ mkdir projectA/trunk $ mkdir projectA/branches $ mkdir projectA/tags $ mkdir projectB $ mkdir projectB/trunk $ mkdir projectB/branches $ mkdir projectB/tags … $ svn import . file:///path/to/repos --message 'Initial repository layout' Adding projectA Adding projectA/trunk Adding projectA/branches Adding projectA/tags Adding projectB Adding projectB/trunk Adding projectB/branches Adding projectB/tags … Committed revision 1. $ cd .. $ rm -rf tmpdir $
然后可以使用svn list命令确认导入的结果是否正确::
$ svn list --verbose file:///path/to/repos
1 harry May 08 21:48 projectA/
1 harry May 08 21:48 projectB/
…
$
创建了版本库布局以后,如果有项目的初始数据,那么可以将这些数据导入到版本库中。同样有很多种方法完成这项工作。首先,可以使用svn import命令。也可以先从版本库中取出工作副本,将已有的项目数据复制到工作副本中,再使用svn add和svn commit命令提交修改。不过这些工作就不属于版本库管理方面的内容了。如果对svn 客户端程序还不熟悉,请阅读第 3 章 指导教程。
一个Subversion的版本库可以和客户端同时运行在同一个机器上,使用file:///访问,但是一个典型的Subversion设置应该包括一个单独的服务器,可以被办公室的所有客户端访问—或者有可能是整个世界。
本小节描述了怎样将一个Subversion的版本库暴露给远程客户端,我们会覆盖Subversion已存在的服务器机制,讨论各种方式的配置和使用。经过阅读本小节,你可以决定你需要哪种网络设置,并且明白怎样在你的主机上进行配置。
Subversion的设计包括一个抽象的网络层,这意味着版本库可以通过各种服务器进程访问,而且客户端“版本库访问”的API允许程序员写出相关协议的插件,理论上讲,Subversion可以使用无限数量的网络协议实现,目前实践中存在着两种服务器。
Apache是最流行的web服务器,通过使用mod_dav_svn模块,Apache可以访问版本库,并且可以使客户端使用HTTP的扩展协议WebDAV/DeltaV进行访问,另一个是svnserve:一个小的,独立服务器,使用自己定义的协议和客户端,表格6-1比较了这两种服务器。
需要注意到Subversion作为一个开源的项目,并没有官方的指定何种服务器是“主要的”或者是“官方的”,并没有那种网络实现被视作二等公民,每种服务器都有自己的优点和缺点,事实上,不同的服务器可以并行工作,分别通过自己的方式访问版本库,它们之间不会互相阻碍(见“支持多种版本库访问方法”一节)。以下是对两种存在的Subversion服务器的比较—作为一个管理员,你更加胜任给你和你的用户挑选服务器的任务。
表 6.1. 网络服务器比较
| 特性 | Apache + mod_dav_svn | svnserve |
|---|---|---|
| 认证选项 | HTTP(S) basic auth、X.509 certificates、LDAP、NTLM或任何Apache httpd已经具备的方式 | CRAM-MD5或SSH |
| 用户帐号选项 | 私有的'users'文件 | 私有的'users'文件,或存在的系统(SSH)帐户 |
| 授权选项 | 整体的读/写访问,或者是每目录的读/写访问 | 整体的读/写访问,或者是使用pre-commit钩子的每目录写访问(但不是读) |
| 加密 | 通过选择SSL | 通过选择SSH通道 |
| 交互性 | 可以部分的被其他WebDAV客户端使用 | 不能被其他客户端使用 |
| Web浏览能力 | 有限的内置支持,或者通过第三方工具,如ViewCVS | 通过第三方工具,如ViewCVS |
| 速度 | 有些慢 | 快一点 |
| 初始化配置 | 有些复杂 | 相当简单 |
这部分是讨论了Subversion客户端和服务器怎样互相交流,不考虑具体使用的网络实现,通过阅读,你会很好的理解服务器的行为方式和多种客户端与之响应的配置方式。
Subversion客户端花费大量的时间来管理工作拷贝,当它需要版本库信息,它会做一个网络请求,然后服务器给一个恰当的回答,具体的网络协议细节对用户不可见,客户端尝试去访问一个URL,根据URL模式的不同,会使用特定的协议与服务器联系(见版本库的URL),用户可以运行svn --version来查看客户端可以使用的URL模式和协议。
当服务器处理一个客户端请求,它通常会要求客户端确定它自己的身份,它会发出一个认证请求给客户端,而客户端通过提供凭证给服务器作为响应,一旦认证结束,服务器会响应客户端最初请求的信息。注意这个系统与CVS之类的系统不一样,它们会在请求之前,预先提供凭证(“logs in”)给服务器,在Subversion里,服务器通过请求客户端适时地“拖入”凭证,而不是客户端“推”出。这使得这种操作更加的优雅,例如,如果一个服务器配置为世界上的任何人都可以读取版本库,在客户使用svn checkout时,服务器永远不会发起一个认证请求。
如果客户端请求往版本库写入新的数据(例如svn commit),这会建立新的修订版本树,如果客户端的请求是经过认证的,认证过的用户的用户名就会作为svn:author属性的值保存到新的修订本里(见“未受版本控制的属性”一节)。如果客户端没有经过认证(换句话说,服务器没有发起过认证请求),这时修订本的svn:author的值是空的。[19]
许多服务器配置为在每次请求时要求认证,这对一次次输入用户名和密码的用户来说是非常恼人的事情。
令人高兴的是,Subversion客户端对此有一个修补:存在一个在磁盘上保存认证凭证缓存的系统,缺省情况下,当一个命令行客户端成功的在服务器上得到认证,它会保存一个认证文件到用户的私有运行配置区—类Unix系统下会在~/.subversion/auth/,Windows下在%APPDATA%/Subversion/auth/(运行区在“运行配置区”一节会有更多细节描述)。成功的凭证会缓存在磁盘,以主机名、端口和认证域的组合作为唯一性区别。
当客户端接收到一个认证请求,它会首先查找磁盘中的认证凭证缓存,如果没有发现,或者是缓存的凭证认证失败,客户端会提示用户需要这些信息。
十分关心安全的人们一定会想“把密码缓存在磁盘?太可怕了,永远不要这样做!”但是请保持冷静,首先,auth/是访问保护的,只有用户(拥有者)可以读取这些数据,不是整个世界,如果这对你还不够安全,你可以关闭凭证缓存,只需要一个简单的命令,使用参数--no-auth-cache:
$ svn commit -F log_msg.txt --no-auth-cache Authentication realm: <svn://host.example.com:3690> example realm Username: joe Password for 'joe': Adding newfile Transmitting file data . Committed revision 2324. # password was not cached, so a second commit still prompts us $ svn delete newfile $ svn commit -F new_msg.txt Authentication realm: <svn://host.example.com:3690> example realm Username: joe [...]
或许,你希望永远关闭凭证缓存,你可以编辑你的运行配置文件(坐落在auth/目录),只需要把store-auth-creds设置为no,这样就不会有凭证缓存在磁盘。
[auth] store-auth-creds = no
有时候,用户希望从磁盘缓存删除特定的凭证,为此你可以浏览到auth/区域,删除特定的缓存文件,凭证都是作为一个单独的文件缓存,如果你打开每一个文件,你会看到键和值,svn:realmstring描述了这个文件关联的特定服务器的域:
$ ls ~/.subversion/auth/svn.simple/ 5671adf2865e267db74f09ba6f872c28 3893ed123b39500bca8a0b382839198e 5c3c22968347b390f349ff340196ed39 $ cat ~/.subversion/auth/svn.simple/5671adf2865e267db74f09ba6f872c28 K 8 username V 3 joe K 8 password V 4 blah K 15 svn:realmstring V 45 <https://svn.domain.com:443> Joe's repository END
一旦你定位了正确的缓存文件,只需要删除它。
客户端认证的行为的最后一点:对使用--username和--password选项的一点说明,许多客户端和子命令接受这个选项,但是要明白使用这个选项不会主动地发送凭证信息到服务器,就像前面讨论过的,服务器会在需要的时候才会从客户端“拖”入凭证,客户端不会随意“推”出。如果一个用户名和/或者密码作为选项传入,它们只会在服务器需要时展现给服务器。[20]通常,只有在如下情况下才会使用这些选项:
-
用户希望使用与登陆系统不同的名字认证,或者
-
一段不希望使用缓存凭证但需要认证的脚本
这里是Subversion客户端在收到认证请求的时候的行为方式:
-
检查用户是否通过
--username和/或--password命令选项指定了任何凭证信息,如果没有,或者这些选项没有认证成功,然后 -
查找运行中的
auth/区域保存的服务器域信息,来确定用户是否已经有了恰当的认证缓存,如果没有,或者缓存凭证认证失败,然后 -
提示用户输入。
如果客户端通过以上的任何一种方式成功认证,它会尝试在磁盘缓存凭证(除非用户已经关闭了这种行为方式,在前面提到过。)
svnserve是一个轻型的服务器,可以同客户端通过在TCP/IP基础上的自定义有状态协议通讯,客户端通过使用开头为svn://或者svn+ssh://svnserve的URL来访问一个svnserve服务器。这一小节将会解释运行svnserve的不同方式,客户端怎样实现服务器的认证,怎样配置版本库恰当的访问控制。
有许多调用svnserve的方式,如果调用时没有参数,你只会看到一些帮助信息,然而,如果你计划使用inetd启动进程,你可以传递-i(--inetd)选项:
$ svnserve -i ( success ( 1 2 ( ANONYMOUS ) ( edit-pipeline ) ) )
当用参数--inetd调用时,svnserve会尝试使用自定义协议通过stdin和stdout来与Subversion客户端通话,这是使用inetd工作的标准方式,IANA为Subversion协议保留3690端口,所以在类Unix系统你可以在/etc/services添加如下的几行(如果他们还不存在):
svn 3690/tcp # Subversion svn 3690/udp # Subversion
如果系统是使用经典的类Unix的inetd守护进程,你可以在/etc/inetd.conf添加这几行:
svn stream tcp nowait svnowner /usr/bin/svnserve svnserve -i
确定“svnowner”用户拥有访问版本库的适当权限,现在如果一个客户连接来到你的服务器的端口3690,inetd会产生一个svnserve进程来做服务。
在一个Windows系统,有第三方工具可以将svnserve作为服务运行,请看Subversion的网站的工具列表。
svnserve的第二个选项是作为独立“守护”进程,为此要使用-d选项:
$ svnserve -d $ # svnserve is now running, listening on port 3690
当以守护模式运行svnserve时,你可以使用--listen-port=和--listen-host=选项来自定义“绑定”的端口和主机名。
也一直有第三种方式,使用-t选项的“管道模式”,这个模式假定一个分布式服务程序如RSH或SSH已经验证了一个用户,并且以这个用户调用了一个私有svnserve进程,svnserve运作如常(通过stdin和stdout通讯),并且可以设想通讯是自动转向到一种通道传递回客户端,当svnserve被这样的通道代理调用,确定认证用户对版本数据库有完全的读写权限,(见服务器和访问许可:一个警告。)这与本地用户通过file:///URl访问版本库同样重要。
一旦svnserve已经运行,它会将你系统中所有版本库发布到网络,一个客户端需要指定版本库在URL中的绝对路径,举个例子,如果一个版本库是位于/usr/local/repositories/project1,则一个客户端可以使用svn://host.example.com/usr/local/repositories/project1 来进行访问,为了提高安全性,你可以使用svnserve的-r选项,这样会限制只输出指定路径下的版本库:
$ svnserve -d -r /usr/local/repositories …
使用-r可以有效地改变文件系统的根位置,客户端可以使用去掉前半部分的路径,留下的要短一些的(更加有提示性)URL:
$ svn checkout svn://host.example.com/project1 …
如果一个客户端连接到svnserve进程,如下事情会发生:
-
客户端选择特定的版本库。
-
服务器处理版本库的
conf/svnserve.conf文件,并且执行里面定义的所有认证和授权政策。 -
依赖于位置和授权政策,
-
如果没有收到认证请求,客户端可能被允许匿名访问,或者
-
客户端收到认证请求,或者
-
如果操作在“通道模式”,客户端会宣布自己已经在外部得到认证。
-
在撰写本文时,服务器还只知道怎样发送CRAM-MD5[21]认证请求,本质上讲,就是服务器发送一些数据到客户端,客户端使用MD5哈希算法创建这些数据组合密码的指纹,然后返回指纹,服务器执行同样的计算并且来计算结果的一致性,真正的密码并没有在互联网上传递。
当然也有可能,如果客户端在外部通过通道代理认证,如SSH,在那种情况下,服务器简单的检验作为那个用户的运行,然后使用它作为认证用户名,更多信息请看“SSH认证和授权”一节。
像你已经猜测到的,版本库的svnserve.conf文件是控制认证和授权政策的中央机构,这文件与其它配置文件格式相同(见“运行配置区”一节):小节名称使用方括号标记([和]),注释以井号(#)开始,每一小节都有一些参数可以设置(variable = value),让我们浏览这个文件并且学习怎样使用它们。
此时,svnserve.conf文件的[general]部分包括所有你需要的变量,开始先定义一个保存用户名和密码的文件和一个认证域:
[general] password-db = userfile realm = example realm
realm是你定义的名称,这告诉客户端连接的“认证命名空间”,Subversion会在认证提示里显示,并且作为凭证缓存(见“客户端凭证缓存”一节。)的关键字(还有服务器的主机名和端口),password-db参数指出了保存用户和密码列表文件,这个文件使用同样熟悉的格式,举个例子:
[users] harry = foopassword sally = barpassword
password-db的值可以是用户文件的绝对或相对路径,对许多管理员来说,把文件保存在版本库conf/下的svnserve.conf旁边是一个简单的方法。另一方面,可能你的多个版本库使用同一个用户文件,此时,这个文件应该在更公开的地方,版本库分享用户文件时必须配置为相同的域,因为用户列表本质上定义了一个认证域,无论这个文件在哪里,必须设置好文件的读写权限,如果你知道运行svnserve的用户,限定这个用户对这个文件有读权限是必须的。
svnserve.conf有两个或多个参数需要设置:它们确定未认证(匿名)和认证用户可以做的事情,参数anon-access和auth-access可以设置为none、read或者write,设置为none会限制所有方式的访问,read允许只读访问,而write允许对版本库完全的读/写权限:
[general] password-db = userfile realm = example realm # anonymous users can only read the repository anon-access = read # authenticated users can both read and write auth-access = write
实例中的设置实际上是参数的缺省值,你一定不要忘了设置它们,如果你希望更保守一点,你可以完全封锁匿名访问:
[general] password-db = userfile realm = example realm # anonymous users aren't allowed anon-access = none # authenticated users can both read and write auth-access = write
注意svnserve只能识别“整体”的访问控制,一个用户可以有全体的读/写权限,或者只读权限,或没有访问权限,没有对版本库具体路径访问的细节控制,很多项目和站点,这种 访问控制已经完全足够了,然而,如果你希望单个目录访问控制,你会需要使用包括mod_authz_svn(见“钩子脚本”一节)的Apache,或者是使用pre-commit钩子脚本来控制写访问(见“钩子脚本”一节),Subversion的分发版本包含一个commit-access-control.pl和一个更加复杂的svnperms.py脚本可以作为pre-commit脚本使用。
svnserve的内置认证会非常容易得到,因为它避免了创建真实的系统帐号,另一方面,一些管理员已经创建好了SSH认证框架,在这种情况下,所有的项目用户已经拥有了系统帐号和有能力“SSH到”服务器。
SSH与svnserve结合很简单,客户端只需要使用svn+ssh://的URL模式来连接:
$ whoami harry $ svn list svn+ssh://host.example.com/repos/project harry@host.example.com's password: ***** foo bar baz …
在这个例子里,Subversion客户端会调用一个ssh进程,连接到host.example.com,使用用户harry认证,然后会有一个svnserve私有进程以用户harry运行。svnserve是以管道模式调用的(-t),它的网络协议是通过ssh“封装的”,被管道代理的svnserve会知道程序是以用户harry运行的,如果客户执行一个提交,认证的用户名会作为版本的参数保存到新的修订本。
这里要理解的最重要的事情是Subversion客户端不是连接到运行中的svnserve守护进程,这种访问方法不需要一个运行的守护进程,也不需要在必要时唤醒一个,它依赖于ssh来发起一个svnserve进程,然后网络断开后终止进程。
当使用svn+ssh://的URL访问版本库时,记住是ssh提示请求认证,而不是svn客户端程序。这意味着密码不会有自动缓存(见“客户端凭证缓存”一节),Subversion客户端通常会建立多个版本库的连接,但用户通常会因为密码缓存特性而没有注意到这一点,当使用svn+ssh://的URL时,用户会为ssh在每次建立连接时重复的询问密码感到讨厌,解决方案是用一个独立的SSH密码缓存工具,像类Unix系统的ssh-agent或者是Windows下的pageant。
当在一个管道上运行时,认证通常是基于操作系统对版本库数据库文件的访问控制,这同Harry直接通过file:///的URL直接访问版本库非常类似,如果有多个系统用户要直接访问版本库,你会希望将他们放到一个常见的组里,你应该小心的使用umasks。(确定要阅读“支持多种版本库访问方法”一节)但是即使是在管道模式时,文件svnserve.conf还是可以阻止用户访问,如auth-access = read或者auth-access = none。
你会认为SSH管道的故事该结束了,但还不是,Subversion允许你在运行配置文件config(见“运行配置区”一节)创建一个自定义的管道行为方式,举个例子,假定你希望使用RSH而不是SSH,在config文件的[tunnels]部分作如下定义:
[tunnels] rsh = rsh
现在你可以通过指定与定义匹配的URL模式来使用新的管道定义:svn+rsh://host/path。当使用新的URL模式时,Subversion客户端实际上会在后台运行rsh host svnserve -t这个命令,如果你在URL中包括一个用户名(例如,svn+rsh://username@host/path),客户端也会在自己的命令中包含这部分(rsh username@host svnserve -t),但是你可以定义比这个更加智能的新的管道模式:
[tunnels] joessh = $JOESSH /opt/alternate/ssh -p 29934
这个例子里论证了一些事情,首先,它展现了如何让Subversion客户端启动一个特定的管道程序(这个在/opt/alternate/ssh),在这个例子里,使用svn+joessh://的URL会以-p 29934参数调用特定的SSH程序—对连接到非标准端口的程序非常有用。
第二点,它展示了怎样定义一个自定义的环境变量来覆盖管道程序中的名字,设置SVN_SSH环境变量是覆盖缺省的SSH管道的一种简便方法,但是如果你需要为多个服务器做出多个不同的覆盖,或许每一个都联系不同的端口或传递不同的SSH选项,你可以使用本例论述的机制。现在如果我们设置JOESSH环境变量,它的值会覆盖管道中的变量值—会执行$JOESSH而不是/opt/alternate/ssh -p 29934。
不仅仅是可以控制客户端调用ssh方式,也可以控制服务器中的sshd的行为方式,在本小节,我们会展示怎样控制sshd执行svnserve,包括如何让多个用户分享同一个系统帐户。
作为开始,定位到你启动svnserve的帐号的主目录,确定这个账户已经安装了一套SSH公开/私有密钥对,用户可以通过公开密钥认证,因为所有如下的技巧围绕着使用SSHauthorized_keys文件,密码认证在这里不会工作。
如果这个文件还不存在,创建一个authorized_keys文件(在UNIX下通常是~/.ssh/authorized_keys),这个文件的每一行描述了一个允许连接的公钥,这些行通常是下面的形式:
ssh-dsa AAAABtce9euch.... user@example.com
第一个字段描述了密钥的类型,第二个字段是未加密的密钥本身,第三个字段是注释。然而,这是一个很少人知道的事实,可以使用一个command来处理整行:
command="program" ssh-dsa AAAABtce9euch.... user@example.com
当command字段设置后,SSH守护进程运行命名的程序而不是通常Subversion客户端询问的svnserve -t。这为实施许多服务器端技巧开启了大门,在下面的例子里,我们简写了文件的这些行:
command="program" TYPE KEY COMMENT
因为我们可以指定服务器端执行的命令,我们很容易来选择运行一个特定的svnserve程序来并且传递给它额外的参数:
command="/path/to/svnserve -t -r /virtual/root" TYPE KEY COMMENT
在这个例子里,/path/to/svnserve也许会是一个svnserve程序的包裹脚本,会来设置umask(见“支持多种版本库访问方法”一节)。它也展示了怎样在虚拟根目录定位一个svnserve,就像我们经常在使用守护进程模式下运行svnserve一样。这样做不仅可以把访问限制在系统的一部分,也可以使用户不需要在svn+ssh://URL里输入绝对路径。
多个用户也可以共享同一个帐号,作为为每个用户创建系统帐户的替代,我们创建一个公开/私有密钥对,然后在authorized_users文件里放置各自的公钥,一个用户一行,使用--tunnel-user选项:
command="svnserve -t --tunnel-user=harry" TYPE1 KEY1 harry@example.com command="svnserve -t --tunnel-user=sally" TYPE2 KEY2 sally@example.com
这个例子允许Harry和Sally通过公钥认证连接同一个的账户,每个人自定义的命令将会执行。--tunnel-user选项告诉svnserve -t命令采用命名的参数作为经过认证的用户,如果没有--tunnel-user,所有的提交会作为共享的系统帐户提交。
最后要小心:设定通过公钥共享账户进行用户访问时还会允许其它形式的SSH访问,即使你设置了authorized_keys的command值,举个例子,用户仍然可以通过SSH得到shell访问,或者是通过服务器执行X11或者是端口转发。为了给用户尽可能少的访问权限,你或许希望在command命令之后指定一些限制选项:
command="svnserve -t --tunnel-user=harry",no-port-forwarding,\
no-agent-forwarding,no-X11-forwarding,no-pty \
TYPE1 KEY1 harry@example.com
Apache的HTTP服务器是一个Subversion可以利用的“重型”网络服务器,通过一个自定义模块,httpd可以让Subversion版本库通过WebDAV/DeltaV协议在客户端前可见,WebDAV/DeltaV协议是HTTP 1.1的扩展(见http://www.webdav.org/来查看详细信息)。这个协议利用了无处不在的HTTP协议是广域网的核心这一点,添加了写能力—更明确一点,版本化的写—能力。结果就是这样一个标准化的健壮的系统,作为Apache 2.0软件的一部分打包,被许多操作系统和第三方产品支持,网络管理员也不需要打开另一个自定义端口。 [22]这样一个Apache-Subversion服务器具备了许多svnserve没有的特性,但是也有一点难于配置,灵活通常会带来复杂性。
下面的讨论包括了对Apache配置指示的引用,给了一些使用这些指示的例子,详细地描述不在本章的范围之内,Apache小组维护了完美的文档,公开存放在他们的站点http://httpd.apache.org。例如,一个一般的配置参考位于http://httpd.apache.org/docs-2.0/mod/directives.html。
同样,当你修改你的Apache设置,很有可能会出现一些错误,如果你还不熟悉Apache的日志子系统,你一定需要认识到这一点。在你的文件httpd.conf里会指定Apache生成的访问和错误日志(CustomLog和ErrorLog指示)的磁盘位置。Subversion的mod_dav_svn使用Apache的错误日志接口,你可以浏览这个文件的内容查看信息来查找难于发现的问题根源。
一旦你安装了必须的组件,剩下的工作就是在httpd.conf里配置Apache,使用LoadModule来加载mod_dav_svn模块,这个指示必须先与其它Subversion相关的其它配置出现,如果你的Apache使用缺省布局安装,你的mod_dav_svn模块一定在Apache安装目录(通常是在/usr/local/apache2)的modules子目录,LoadModule指示的语法很简单,影射一个名字到它的共享库的物理位置:
LoadModule dav_svn_module modules/mod_dav_svn.so
注意,如果mod_dav是作为共享对象编译(而不是静态链接到httpd程序),你需要为它使用使用LoadModule语句,一定确定它在mod_dav_svn之前:
LoadModule dav_module modules/mod_dav.so LoadModule dav_svn_module modules/mod_dav_svn.so
在你的配置文件后面的位置,你需要告诉Apache你在什么地方保存Subversion版本库(也许是多个),位置指示有一个很像XML的符号,开始于一个开始标签,以一个结束标签结束,配合中间许多的其它配置。Location指示的目的是告诉Apache在特定的URL以及子URL下需要特殊的处理,如果是为Subversion准备的,你希望可以通过告诉Apache特定URL是指向版本化的资源,从而把支持转交给DAV层,你可以告诉Apache将所有路径部分(URL中服务器名称和端口之后的部分)以/repos/开头的URL交由DAV服务提供者处理。一个DAV服务提供者的版本库位于/absolute/path/to/repository,可以使用如下的httpd.conf语法:
<Location /repos> DAV svn SVNPath /absolute/path/to/repository </Location>
如果你计划支持多个具备相同父目录的Subversion版本库,你有另外的选择,SVNParentPath指示,来表示共同的父目录。举个例子,如果你知道你会在/usr/local/svn下创建多个Subversion版本库,并且通过类似http://my.server.com/svn/repos1,http://my.server.com/svn/repos2的URL访问,你可以用后面例子中的httpd.conf配置语法:
<Location /svn> DAV svn # any "/svn/foo" URL will map to a repository /usr/local/svn/foo SVNParentPath /usr/local/svn </Location>
使用上面的语法,Apache会代理所有URL路径部分为/svn/的请求到Subversion的DAV提供者,Subversion会认为SVNParentPath指定的目录下的所有项目是真实的Subversion版本库,这通常是一个便利的语法,不像是用SVNPath指示,我们在此不必为创建新的版本库而重启Apache。
请确定当你定义新的位置,不会与其它输出的位置重叠,例如你的主要DocumentRoot是/www,不要把Subversion版本库输出到<Location /www/repos>,如果一个请求的URI是/www/repos/foo.c,Apache不知道是直接到repos/foo.c访问这个文件还是让mod_dav_svn代理从Subversion版本库返回foo.c。
在本阶段,你一定要考虑访问权限问题,如果你已经作为普通的web服务器运行过Apache,你一定有了一些内容—网页、脚本和其他。这些项目已经配置了许多在Apache下可以工作的访问许可,或者更准确一点,允许Apache与这些文件一起工作。Apache当作为Subversion服务器运行时,同样需要正确的访问许可来读写你的Subversion版本库。(见服务器和访问许可:一个警告。)
你会需要检验权限系统的设置满足Subversion的需求,同时不会把以前的页面和脚本搞乱。这或许意味着修改Subversion的访问许可来配合Apache服务器已经使用的工具,或者可能意味着需要使用httpd.conf的User和Group指示来指定Apache作为运行的用户和Subversion版本库的组。并不是只有一条正确的方式来设置许可,每个管理员都有不同的原因来以特定的方式操作,只需要意识到许可关联的问题经常在为Apache配置Subversion版本库的过程中被疏忽。
此时,如果你配置的httpd.conf保存如下的内容
<Location /svn> DAV svn SVNParentPath /usr/local/svn </Location>
这样你的版本库对全世界是可以“匿名”访问的,直到你配置了一些认证授权政策,你通过Location指示来使Subversion版本库可以被任何人访问,换句话说,
-
任何人可以使用Subversion客户端来从版本库URL取出一个工作拷贝(或者是它的子目录),
-
任何人可以在浏览器输入版本库URL交互浏览的方式来查看版本库的最新修订版本,并且
-
任何人可以提交到版本库。
最简单的客户端认证方式是通过HTTP基本认证机制,简单的使用用户名和密码来验证一个用户所自称的身份,Apache提供了一个htpasswd工具来管理可接受的用户名和密码,这些就是你希望赋予Subversion特别权限的用户,让我们给Sally和Harry赋予提交权限,首先,我们需要添加他们到密码文件。
$ ### First time: use -c to create the file $ ### Use -m to use MD5 encryption of the password, which is more secure $ htpasswd -cm /etc/svn-auth-file harry New password: ***** Re-type new password: ***** Adding password for user harry $ htpasswd -m /etc/svn-auth-file sally New password: ******* Re-type new password: ******* Adding password for user sally $
下一步,你需要在httpd.conf的Location区里添加一些指示来告诉Apache如何来使用这些密码文件,AuthType指示指定系统使用的认证类型,这种情况下,我们需要指定Basic认证系统,AuthName是你提供给认证域一个任意名称,大多数浏览器会在向用户询问名称和密码的弹出窗口里显示这个名称,最终,使用AuthUserFile指示来指定使用htpasswd创建的密码文件的位置。
添加完这三个指示,你的<Location>区块一定像这个样子:
<Location /svn> DAV svn SVNParentPath /usr/local/svn AuthType Basic AuthName "Subversion repository" AuthUserFile /etc/svn-auth-file </Location>
这个<Location>区块还没有结束,还不能做任何有用的事情,它只是告诉Apache当需要授权时,要去向Subversion客户端索要用户名和密码。我们这里遗漏的,是一些告诉Apache什么样客户端需要授权的指示。哪里需要授权,Apache就会在哪里要求认证,最简单的方式是保护所有的请求,添加Require valid-user来告诉Apache任何请求需要认证的用户:
<Location /svn> DAV svn SVNParentPath /usr/local/svn AuthType Basic AuthName "Subversion repository" AuthUserFile /etc/svn-auth-file Require valid-user </Location>
一定要阅读后面的部分(“授权选项”一节)来得到Require的细节,和授权政策的其他设置方法。
需要警惕:HTTP基本认证的密码是用明文传输,因此非常不可靠的,如果你担心密码偷窥,最好是使用某种SSL加密,所以客户端认证使用https://而不是http://,为了方便,你可以配置Apache为自签名认证。 [23] 参考Apache的文档(和OpenSSL文档)来查看怎样做。
商业应用需要越过公司防火墙的版本库访问,防火墙需要小心的考虑非认证用户“吸取”他们的网络流量的情况,SSL让那种形式的关注更不容易导致敏感数据泄露。
如果Subversion使用OpenSSL编译,它就会具备与Subversion服务器使用https://的URL通讯的能力,Subversion客户端使用的Neon库不仅仅可以用来验证服务器证书,也可以必要时提供客户端证书,如果客户端和服务器交换了SSL证书并且成功地互相认证,所有剩下的交流都会通过一个会话关键字加密。
怎样产生客户端和服务器端证书以及怎样使用它们已经超出了本书的范围,许多书籍,包括Apache自己的文档,描述这个任务,现在我们可以覆盖的是普通的客户端怎样来管理服务器与客户端证书。
当通过https://与Apache通讯时,一个Subversion客户端可以接收两种类型的信息:
-
一个服务器证书
-
一个客户端证书的要求
如果客户端接收了一个服务器证书,它需要去验证它是可以相信的:这个服务器是它自称的那一个吗?OpenSSL库会去检验服务器证书的签名人或者是核证机构(CA)。如果OpenSSL不可以自动信任这个CA,或者是一些其他的问题(如证书过期或者是主机名不匹配),Subversion命令行客户端会询问你是否愿意仍然信任这个证书:
$ svn list https://host.example.com/repos/project Error validating server certificate for 'https://host.example.com:443': - The certificate is not issued by a trusted authority. Use the fingerprint to validate the certificate manually! Certificate information: - Hostname: host.example.com - Valid: from Jan 30 19:23:56 2004 GMT until Jan 30 19:23:56 2006 GMT - Issuer: CA, example.com, Sometown, California, US - Fingerprint: 7d:e1:a9:34:33:39:ba:6a:e9:a5:c4:22:98:7b:76:5c:92:a0:9c:7b (R)eject, accept (t)emporarily or accept (p)ermanently?
这个对话看起来很熟悉,这是你会在web浏览器(另一种HTTP客户端,就像Subversion)经常看到的问题,如果你选择(p)ermanent选项,服务器证书会存放在你存放那个用户名和密码缓存(见“客户端凭证缓存”一节。)的私有运行区auth/中,缓存后,Subversion会自动记住在以后的交流中信任这个证书。
你的运行中servers文件也会给你能力可以让Subversion客户端自动信任特定的CA,包括全局的或是每主机为基础的,只需要设置ssl-authority-files为一组逗号隔开的PEM加密的CA证书列表:
[global] ssl-authority-files = /path/to/CAcert1.pem;/path/to/CAcert2.pem
许多OpenSSL安装包括一些预先定义好的可以普遍信任的“缺省的”CA,为了让Subversion客户端自动信任这些标准权威,设置ssl-trust-default-ca为true。
当与Apache通话时,Subversion客户端也会收到一个证书的要求,Apache是询问客户端来证明自己的身份:这个客户端是否是他所说的那一个?如果一切正常,Subversion客户端会发送回一个通过Apache信任的CA签名的私有证书,一个客户端证书通常会以加密方式存放在磁盘,使用本地密码保护,当Subversion收到这个要求,它会询问你证书的路径和保护用的密码:
$ svn list https://host.example.com/repos/project Authentication realm: https://host.example.com:443 Client certificate filename: /path/to/my/cert.p12 Passphrase for '/path/to/my/cert.p12': ******** …
注意这个客户端证书是一个“p12”文件,为了让Subversion使用客户端证书,它必须是运输标准的PKCS#12格式,大多数浏览器可以导入和导出这种格式的证书,另一个选择是用OpenSSL命令行工具来转化存在的证书为PKCS#12格式。
再次,运行中servers文件允许你为每个主机自动响应这种要求,单个或两条信息可以用运行参数来描述:
[groups] examplehost = host.example.com [examplehost] ssl-client-cert-file = /path/to/my/cert.p12 ssl-client-cert-password = somepassword
一旦你设置了ssl-client-cert-file和 ssl-client-cert-password参数,Subversion客户端可以自动响应客户端证书请求而不会打扰你。 [24]
此刻,你已经配置了认证,但是没有配置授权,Apache可以要求用户认证并且确定身份,但是并没有说明这个身份的怎样允许和限制,这个部分描述了两种控制访问版本库的策略。
最简单的访问控制形式是授权特定用户为只读版本库访问或者是读/写访问版本库。
你可以通过在<Location>区块添加Require valid-user指示来限制所有的版本库操作,使用我们前面的例子,这意味着只有客户端只可以是harry或者sally,而且他们必须提供正确的用户名及对应密码,这样允许对Subversion版本库做任何事:
<Location /svn> DAV svn SVNParentPath /usr/local/svn # how to authenticate a user AuthType Basic AuthName "Subversion repository" AuthUserFile /path/to/users/file # only authenticated users may access the repository Require valid-user </Location>
有时候,你不需要这样严密,举个例子,Subversion自己在http://svn.collab.net/repos/svn的源代码允许全世界的人执行版本库的只读操作(例如检出我们的工作拷贝和使用浏览器浏览版本库),但是限定只有认证用户可以执行写操作。为了执行特定的限制,你可以使用Limit和LimitExcept配置指示,就像Location指示,这个区块有开始和结束标签,你需要在<Location>中添加这个指示。
在Limit和LimitExcept中使用的参数是可以被这个区块影响的HTTP请求类型,举个例子,如果你希望禁止所有的版本库访问,只是保留当前支持的只读操作,你可以使用LimitExcept指示,并且使用GET,PROPFIND,OPTIONS和REPORT请求类型参数,然后前面提到过的Require valid-user指示将会在<LimitExcept>区块中而不是在<Location>区块。
<Location /svn>
DAV svn
SVNParentPath /usr/local/svn
# how to authenticate a user
AuthType Basic
AuthName "Subversion repository"
AuthUserFile /path/to/users/file
# For any operations other than these, require an authenticated user.
<LimitExcept GET PROPFIND OPTIONS REPORT>
Require valid-user
</LimitExcept>
</Location>
这里只是一些简单的例子,想看关于Apache访问控制Require指示的更深入信息,可以查看Apache文档中的教程集http://httpd.apache.org/docs-2.0/misc/tutorials.html中的Security部分。
也可以使用Apache的httpd模块mod_authz_svn更加细致的设置访问权限,这个模块收集客户端传递过来的不同的晦涩的URL信息,询问mod_dav_svn来解码,然后根据在配置文件定义的访问政策来裁决请求。
如果你从源代码创建Subversion,mod_authz_svn会自动附加到mod_dav_svn,许多二进制分发版本也会自动安装,为了验证它是安装正确,确定它是在httpd.conf的LoadModule指示中的mod_dav_svn后面:
LoadModule dav_module modules/mod_dav.so LoadModule dav_svn_module modules/mod_dav_svn.so LoadModule authz_svn_module modules/mod_authz_svn.so
为了激活这个模块,你需要配置你的Location区块的AuthzSVNAccessFile指示,指定保存路径中的版本库访问政策的文件。(一会儿我们将会讨论这个文件的格式。)
Apache非常的灵活,你可以从三种模式里选择一种来配置你的区块,作为开始,你选择一种基本的配置模式。(下面的例子非常简单;见Apache自己的文档中的认证和授权选项来查看更多的细节。)
最简单的区块是允许任何人可以访问,在这个场景里,Apache决不会发送认证请求,所有的用户作为“匿名”对待。
例 6.1. 匿名访问的配置实例。
<Location /repos>
DAV svn
SVNParentPath /usr/local/svn
# our access control policy
AuthzSVNAccessFile /path/to/access/file
</Location>
在另一个极端,你可以配置为拒绝所有人的认证,所有客户端必须提供证明自己身份的证书,你通过Require valid-user指示来阻止无条件的认证,并且定义一种认证的手段。
例 6.2. 一个认证访问的配置实例。
<Location /repos>
DAV svn
SVNParentPath /usr/local/svn
# our access control policy
AuthzSVNAccessFile /path/to/access/file
# only authenticated users may access the repository
Require valid-user
# how to authenticate a user
AuthType Basic
AuthName "Subversion repository"
AuthUserFile /path/to/users/file
</Location>
第三种流行的模式是允许认证和匿名用户的组合,举个例子,许多管理员希望允许匿名用户读取特定的版本库路径,但希望只有认证用户可以读(或者写)更多敏感的区域,在这个设置里,所有的用户开始时用匿名用户访问版本库,如果你的访问控制策略在任何时候要求一个真实的用户名,Apache将会要求认证客户端,为此,你可以同时使用Satisfy Any和Require valid-user指示。
例 6.3. 一个混合认证/匿名访问的配置实例。
<Location /repos>
DAV svn
SVNParentPath /usr/local/svn
# our access control policy
AuthzSVNAccessFile /path/to/access/file
# try anonymous access first, resort to real
# authentication if necessary.
Satisfy Any
Require valid-user
# how to authenticate a user
AuthType Basic
AuthName "Subversion repository"
AuthUserFile /path/to/users/file
</Location>
一旦你的基本Location区块已经配置了,你可以创建一个定义一些授权规则的访问文件。
访问文件的语法与svnserve.conf和运行中配置文件非常相似,以(#)开头的行会被忽略,在它的简单形式里,每一小节命名一个版本库和一个里面的路径,认证用户名是在每个小节中的选项名,每个选项的值描述了用户访问版本库的级别:r(只读)或者rw(读写),如果用户没有提到,访问是不允许的。
具体一点:这个小节的名称是[repos-name:path]或者[path]的形式,如果你使用SVNParentPath指示,指定版本库的名字是很重要的,如果你漏掉了他们,[/some/dir]部分就会与/some/dir的所有版本库匹配,如果你使用SVNPath指示,因此在你的小节中只是定义路径也很好—毕竟只有一个版本库。
[calc:/branches/calc/bug-142] harry = rw sally = r
在第一个例子里,用户harry对calc版本库中/branches/calc/bug-142具备完全的读写权利,但是用户sally只有读权利,任何其他用户禁止访问这个目录。
当然,访问控制是父目录传递给子目录的,这意味着我们可以为Sally指定一个子目录的不同访问策略:
[calc:/branches/calc/bug-142] harry = rw sally = r # give sally write access only to the 'testing' subdir [calc:/branches/calc/bug-142/testing] sally = rw
现在Sally可以读取分支的testing子目录,但对其他部分还是只可以读,同时,Harry对整个分支还继续有完全的读写权限。
也可以通过继承规则明确的的拒绝某人的访问,只需要设置用户名参数为空:
[calc:/branches/calc/bug-142] harry = rw sally = r [calc:/branches/calc/bug-142/secret] harry =
在这个例子里,Harry对bug-142目录树有完全的读写权限,但是对secret子目录没有任何访问权利。
有一件事需要记住的是需要找到最匹配的目录,mod_authz_svn模块首先找到匹配自己的目录,然后父目录,然后父目录的父目录,就这样继续下去,更具体的路径控制会覆盖所有继承下来的访问控制。
缺省情况下,没有人对版本库有任何访问,这意味着如果你已经从一个空文件开始,你会希望给所有用户对版本库根目录具备读权限,你可以使用*实现,用来代表“所有用户”:
[/] * = r
这是一个普通的设置;注意在小节名中没有提到版本库名称,这让所有版本库对所有的用户可读,不管你是使用SVNPath或是SVNParentPath。当所有用户对版本库有了读权利,你可以赋予特定用户对特定子目录的rw权限。
星号(*)参数需要在这里详细强调:这是匹配匿名用户的唯一模式,如果你已经配置了你的Location区块允许匿名和认证用户的混合访问,所有用户作为Apache匿名用户开始访问,mod_authz_svn会在要访问路径的定义中查找*值;如果找不到,Apache就会要求真实的客户端认证。
访问文件也允许你定义一组的用户,很像Unix的/etc/group文件:
[groups] calc-developers = harry, sally, joe paint-developers = frank, sally, jane everyone = harry, sally, joe, frank, sally, jane
组可以被赋予通用户一样的访问权限,使用“at”(@)前缀来加以区别:
[calc:/projects/calc] @calc-developers = rw [paint:/projects/paint] @paint-developers = rw jane = r
...并且非常接近。
mod_dav_svn模块做了许多工作来确定你标记为“不可读”的数据不会因意外而泄露,这意味着需要紧密监控通过svn checkout或是svn update返回的路径和文件内容,如果这些命令遇到一些根据认证策略不是可读的路径,这个路径通常会被一起忽略,在历史或者重命名操作时—例如运行一个类似svn cat -r OLD foo.c的命令来操作一个很久以前改过名字的文件 — 如果一个对象的以前的名字检测到是只读的,重命令追踪就会终止。
所有的路径检查在有时会非常昂贵,特别是svn log的情况。当检索一列修订版本时,服务器会查看所有修订版本修改的路径,并且检查可读性,如果发现了一个不可读路径,它会从修订版本的修改路径中忽略(可以查看--verbose选项),并且整个的日志信息会被禁止,不必多说,这种影响大量文件修订版本的操作会非常耗时。这是安全的代价:即使你并没有配置mod_authz_svn模块,mod_dav_svn还是会询问httpd来对所有路径运行认证检查,mod_dav_svn模块没有办法知道那个认证模块被安装,所以只有询问Apache来调用所提供的模块。
在另一方面,也有一个安全舱门允许你用安全特性来交换速度,如果你不是坚持要求有每目录授权(如不使用 mod_authz_svn和类似的模块),你就可以关闭所有的路径检查,在你的httpd.conf文件,使用SVNPathAuthz指示:
例 6.4. 关闭所有的路经检查
<Location /repos>
DAV svn
SVNParentPath /usr/local/svn
SVNPathAuthz off
</Location>
SVNPathAuthz指示缺省是打开的,当设置为“off”时,所有的路径为基础的授权都会关闭;mod_dav_svn停止对每个目录调用授权检查。
我们已经覆盖了关于认证和授权的Apache和mod_dav_svn的大多数选项,但是Apache还提供了许多很好的特性。
一个非常有用的好处是使用Apache/WebDAV配置Subversion版本库时可以用普通的浏览器察看最新的版本库文件,因为Subversion使用URL来鉴别版本库版本化的资源,版本库使用的HTTP为基础的URL也可以直接输入到Web浏览器中,你的浏览器会发送一个GET请求到URL,根据访问的URL是指向一个版本化的目录还是文件,mod_dav_svn会负责列出目录列表或者是文件内容。
因为URL不能确定你所希望看到的资源的版本,mod_dav_svn会一直返回最新的版本,这样会有一些美妙的副作用,你可以直接把Subversion的URL传递给文档作为引用,这些URL会一直指向文档最新的材料,当然,你也可以在别的网站作为超链使用这些URL。
你通常会在版本化的文件的URL之外得到更多地用处—毕竟那里是有趣的内容存在的地方,但是你会偶尔浏览一个Subversion的目录列表,你会很快发现展示列表生成的HTML非常基本,并且一定没有在外观上(或者是有趣上)下功夫,为了自定义这些目录显示,Subversion提供了一个XML目录特性,一个单独的SVNIndexXSLT指示在你的httpd.conf文件版本库的Location块里,它将会指导mod_dav_svn在显示目录列表的时候生成XML输出,并且引用你选择的XSLT样式表文件:
<Location /svn> DAV svn SVNParentPath /usr/local/svn SVNIndexXSLT "/svnindex.xsl" … </Location>
使用SVNIndexXSLT指示和创建一个XSLT样式表,你可以让你的目录列表的颜色模式与你的网站的其它部分匹配,否则,如果你愿意,你可以使用Subversion源分发版本中的tools/xslt/目录下的样例样式表。记住提供给SVNIndexXSLT 指示的路径是一个URL路径—浏览器需要阅读你的样式表来利用它们!
Apache作为一个健壮的Web服务器的许多特性也可以用来增加Subversion的功能性和安全性,Subversion使用Neon与Apache通讯,这是一种一般的HTTP/WebDAV库,可以支持SSL和Deflate压缩(是gzip和PKZIP程序用来“压缩”文件为数据块的一样的算法)之类的机制。你只需要编译你希望Subversion和Apache需要的特性,并且正确的配置程序来使用这些特性。
Deflate压缩给服务器和客户端带来了更多地负担,压缩和解压缩减少了网络传输的实际文件的大小,如果网络带宽比较紧缺,这种方法会大大提高服务器和客户端之间发送数据的速度,在极端情况下,这种最小化的传输会造成超时和成功的区别。
不怎么有趣,但同样重要,是Apache和Subversion关系的一些特性,像可以指定自定义的端口(而不是缺省的HTTP的80)或者是一个Subversion可以被访问的虚拟主机名,或者是通过代理服务器访问的能力,这些特性都是Neon所支持的,所以Subversion轻易得到这些支持。
最后,因为mod_dav_svn是使用一个半完成的WebDAV/DeltaV方言,所以通过第三方的DAV客户端访问也是可能的,几乎所有的现代操作系统(Win32、OS X和Linux)都有把DAV服务器影射为普通的网络“共享”的内置能力,这是一个复杂的主题;察看附录 C, WebDAV和自动版本化来得到更多细节。
如果你是从头到尾按章节阅读本书,你一定已经具备了使用Subversion客户端执行大多数不同的版本控制操作足够的知识,你理解了怎样从Subversion版本库取出一个工作拷贝,你已经熟悉了通过svn commit和svn update来提交和接收修改,你甚至也经常下意识的使用svn status,无论目的是什么,你已经可以正常使用Subversion了。
但是Subversion的特性集可不只是“一般的版本控制操作”。
本章重点介绍一些Subversion不常用的特性,在这里,我们会讨论Subversion的属性(或者说“元数据”)支持,和如何通过更改运行配置区来改变Subversion的缺省行为方式,我们会描述怎样使用外部定义来指导Subversion从多个版本库得到数据,我们会覆盖一些Subversion分发版本附加的客户端和服务器端的工具的细节。
在阅读本章之前,你一定要熟悉Subversion对文件和目录的基本版本操作能力,如果你还没有阅读这些内容,或者是需要一个复习,我们建议你重读第 2 章 基本概念和第 3 章 指导教程,一旦你已经掌握了基础知识和本章的内容,你会变成Subversion的超级用户!
Subversion提供了许多用户可以控制的可选行为方式,许多是用户希望添加到所有的Subversion操作中的选项,为了避免强制用户记住命令行参数并且在每个命令中使用,Subversion使用配置文件,并且将配置文件保存在独立的Subversion配置区。
Subversion配置区是一个双层结构,保存了可选项的名称和值。通常,Subversion配置区是一个保存配置文件的特殊目录(第一层结构),目录中保存了一些标准INI格式的文本文件(文件中的“section”形成第二层结构)。这些文件可以简单用你喜欢的文本编辑器编辑(如Emacs或vi),而且保存了客户端可以读取的指示,用来指导用户的一些行为选项。
svn命令行客户端第一次执行时,会创建一个用户配置区,在类Unix系统中,配置区位于用户主目录中,名为.subversion。在Win32系统,Subversion创建一个名为Subversion的目录,这个目录通常位于用户配置目录(顺便说一句,通常是一个隐藏目录)的Application Data子目录下。然而,在Win32平台上,此目录的具体位置在不同的系统上是不一样的,由Windows注册表决定。 [25] 我们以Unix下的名字.subversion来表示用户配置区。
除了用户配置区,Subversion也提供了系统配置区,通过系统配置区,系统管理员可以为某个机器的所有用户建立缺省配置值。注意系统配置区不会规定强制性的策略—每个用户配置区都可以覆盖系统配置区中的配置项,而svn的命令行参数决定了最后的行为。在类Unix的平台上,系统配置区位于/etc/subversion目录下,在Windows平台上,系统配置区位于Application Data(再说一次,是由Windows注册表决定的)的Subversion目录中。与用户配置区不同,svn不会试图创建系统配置区。
目前,Subversion的配置区包含三个文件—两个配置文件(config和servers),和一个INI文件格式的README.txt描述文件。配置文件创建的时候,Subversion的选项都设置为默认值。配置文件中的选项都按功能划分成组,大多数选项还有详细的文字描述注释,说明这些选项的值对Subversion的主要影响。要修改选项,只需用文本编辑器打开并编辑配置文件。如果想要恢复缺省的配置,可以直接删除(或者重命名)配置目录,并且运行一些如svn --version之类的无关紧要的svn命令,一个包含缺省值的新配置目录就会创建起来。
用户配置区也缓存了认证信息,auth目录下的子目录中缓存了一些Subversion支持的各种认证方法的信息,这个目录需要相应的用户权限才可以访问。
除了基于INI文件的配置区,运行在Windows平台的Subversion客户端也可以使用Windows注册表来保存配置数据。注册表中保存的选项名称和值的含义与INI文件中相同,“file/section”在注册表中表现为注册表键树的层级,使得双层结构得以保留下来。
Subversion的系统配置值保存在键HKEY_LOCAL_MACHINE\Software\Tigris.org\Subversion下。举个例子,global-ignores选项位于config文件的miscellany小节,在Windows注册表中,则位于HKEY_LOCAL_MACHINE\Software\Tigris.org\Subversion\Config\Miscellany\global-ignores。用户配置值存放在HKEY_CURRENT_USER\Software\Tigris.org\Subversion下。
基于注册表的配置项在基于文件的配置项之前解析,所以其配置项的值会被配置文件中相同配置项的值覆盖,换句话说,在Windows系统下配置项的优先级是:
-
命令行选项
-
用户INI配置文件
-
用户注册表值
-
系统INI配置文件
-
系统注册表值
此外,虽然Windows注册表不支持“注释掉”这种概念,但是Subversion会忽略所有以井号(#)开始的字符,这允许你快速的取消一个选项而不需要删除整个注册表键,明显简化了恢复选项的过程。
svn命令行客户端不会尝试写Windows注册表,也不会在注册表中创建默认配置区。不过可以使用REGEDIT创建所需的键。此外,还可以创建一个.reg文件,并在文件浏览器中双击这个文件,文件中的数据就会合并到注册表中。
例 7.1. 注册表条目(.reg)样本文件。
REGEDIT4 [HKEY_LOCAL_MACHINE\Software\Tigris.org\Subversion\Servers\groups] [HKEY_LOCAL_MACHINE\Software\Tigris.org\Subversion\Servers\global] "#http-proxy-host"="" "#http-proxy-port"="" "#http-proxy-username"="" "#http-proxy-password"="" "#http-proxy-exceptions"="" "#http-timeout"="0" "#http-compression"="yes" "#neon-debug-mask"="" "#ssl-authority-files"="" "#ssl-trust-default-ca"="" "#ssl-client-cert-file"="" "#ssl-client-cert-password"="" [HKEY_CURRENT_USER\Software\Tigris.org\Subversion\Config\auth] "#store-auth-creds"="no" [HKEY_CURRENT_USER\Software\Tigris.org\Subversion\Config\helpers] "#editor-cmd"="notepad" "#diff-cmd"="" "#diff3-cmd"="" "#diff3-has-program-arg"="" [HKEY_CURRENT_USER\Software\Tigris.org\Subversion\Config\miscellany] "#global-ignores"="*.o *.lo *.la #*# .*.rej *.rej .*~ *~ .#* .DS_Store" "#log-encoding"="" "#use-commit-times"="" "#template-root"="" "#enable-auto-props"="" [HKEY_CURRENT_USER\Software\Tigris.org\Subversion\Config\tunnels] [HKEY_CURRENT_USER\Software\Tigris.org\Subversion\Config\auto-props]
上面例子里显示的.reg文件中,包含了一些最常用的配置选项和它们的缺省值。注意,上面的例子中不仅包含了系统设置(关于网络代理相关的选项),也包含了用户设置(指定的编辑器程序,是否保存密码,以及其它选项)。同时要注意的是,所有选项都注释掉了,要启用其中的选项,只需删除该选项名称前面的井号(#),然后设置相应的值就可以了。
本节我们会详细讨论Subversion目前支持的运行配置选项。
servers文件保存了Subversion关于网络层的配置选项,这个文件有两个特别的小节:groups 和global。groups小节是一个交叉引用表,其中的关键字是servers文件中其它小节的名字,值则是一个可以包含通配符的字符序列,对应于接收Subversion请求的主机名,称为glob。
[groups] beanie-babies = *.red-bean.com collabnet = svn.collab.net [beanie-babies] … [collabnet] …
当通过网络访问Subversion服务器时,客户端会设法匹配正在尝试连接的服务器名字和groups小节中的glob名称,如果发现匹配,Subversion会在servers文件中查找对应于这个glob名称的小节,并从该小节中去读取真实的网络配置设置。
如果没有能够匹配到groups中的glob名称,global小节中的选项就会发生作用。global小节中的选项与其他小节一样(当然是除了groups小节),这些选项是:
http-proxy-host-
代理服务器的详细主机名,是HTTP为基础的Subversion请求必须通过的,缺省值为空,意味着Subversion不会尝试通过代理服务器进行HTTP请求,而会尝试直接连接目标机器。
http-proxy-port-
代理服务器的详细端口,缺省值为空。
http-proxy-username-
代理服务器的用户名,缺省值为空。
http-proxy-password-
代理服务器的密码,缺省为空。
http-timeout-
等待服务器响应的时间,以秒为单位,如果你的网络速度较慢,导致Subversion的操作超时,你可以加大这个数值,缺省值是
0,意思是让HTTP库Neon使用自己的缺省值。 http-compression-
这说明是否在与设置好DAV的服务器通讯时使用网络压缩请求,缺省值是
yes(尽管只有在这个功能编译到网络层时压缩才会有效),设置no来关闭压缩,如调试网络传输时。 neon-debug-mask-
只是一个整形的掩码,底层的HTTP库Neon用来选择产生调试的输出,缺省值是
0,意思是关闭所有的调试输出,关于Subversion使用Neon的详细信息,见第 8 章 开发者信息。 ssl-authority-files-
这是一个分号分割的路径和文件列表,这些文件包含了Subversion客户端在用HTTPS访问时可以接受的认证授权(或者CA)证书。
ssl-trust-default-ca-
如果你希望Subversion可以自动相信OpenSSL携带的缺省的CA,可以设置为
yes。 ssl-client-cert-file-
如果一个主机(或是一些主机)需要一个SSL客户端证书,你会收到一个提示说需要证书的路径。通过设置这个路径你的Subversion客户端可以自动找到你的证书而不会打扰你。没有标准的存放位置;Subversion会从任何你指定的路径得到这个文件。
ssl-client-cert-password-
如果你的SSL客户端证书文件是用密码加密的,Subversion会在每次使用证书时请你输入密码,如果你发现这很讨厌(并且不介意把密码存放在
servers文件中),你可以设置这个参数为证书的密码,这样就不会再收到密码输入提示了。
其它的Subversion运行选项保存在config文件中,这些运行选项与网络连接无关,只是一些正在使用的选项,但是为了应对未来的扩展,也按小节划分成组。
auth小节保存了Subversion相关的认证和授权的设置,它包括:
store-passwords-
这告诉Subversion是否缓存服务器认证要求时用户提供的密码,缺省值是
yes。设置为no可以关闭在存盘的密码缓存,你可以通过svn的--no-auth-cache命令行参数(那些支持这个参数的子命令)来覆盖这个设置,详细信息请见“客户端凭证缓存”一节。 store-auth-creds-
这个设置与
store-passwords相似,不过设置了这个选项将会保存所有认证信息,如用户名、密码、服务器证书,以及其他任何类型的可以缓存的凭证。
helpers小节控制完成Subversion任务的外部程序,正确的选项包括:
editor-cmd-
Subversion在提交操作时用来询问用户日志信息的程序,例如使用svn commit而没有指定
--message(-m)或者--file(-F)选项。这个程序也会与svn propedit一起使用—一个临时文件跳出来包含已经存在的用户希望编辑的属性,然后用户可以对这个属性进行编辑(见“属性”一节),这个选项的缺省值为空,如果这个选项没有设置,Subversion会依次检查环境变量SVN_EDITOR、VISUAL和EDITOR(这个顺序)来找到一个编辑器命令。 diff-cmd-
这个命令是比较程序的绝对路径,当Subversion生成了“diff”输出时(例如当使用svn diff命令)就会使用,缺省Subversion会使用一个内置的比较库—设置这个参数会强制它使用外部程序执行这个任务。
diff3-cmd-
这指定了一个三向的比较程序,Subversion使用这个程序来合并用户和从版本库接受的修改,缺省Subversion会使用一个内置的比较库—设置这个参数会导致它会使用外部程序执行这个任务。
diff3-has-program-arg-
如果
diff3-cmd选项设置的程序接受一个--diff-program命令行参数,这个标记必须设置为true。
tunnels小节允许你定义一个svnserve和svn://客户端连接使用的管道模式,更多细节见“SSH认证和授权”一节。
miscellany小节是一些没法归到别处的选项。 [26] 在本小节,你会找到:
global-ignores-
当运行svn status命令时,Subversion会和版本化的文件一样列出未版本化的文件和目录,并使用
?字符(见see “svn status”一节)标记,有时候察看无关的未版本化文件会很讨厌—比如程序编译产生的对象文件—的显示出来。global-ignores选项是一个空格分隔的列表,用来描述Subversion在它们版本化之前不想显示的文件和目录,缺省值是*.o *.lo *.la #*# .*.rej *.rej .*~ *~ .#* .DS_Store。就像svn status,svn add和svn import命令也会忽略匹配这个列表的文件,你可以用单个的
--no-ignore命令行参数来覆盖这个选项,关于更加细致的控制忽略的项目,见“svn:ignore”一节。 enable-auto-props-
这里指示Subversion自动对新加的或者导入的文件设置属性,缺省值是
no,可以设置为yes来开启自动添加属性,这个文件的auto-props小节会说明哪些属性会被设置到哪些文件。 log-encoding-
这个变量设置提交日志缺省的字符集,是
--encoding选项(见“svn选项”一节)的永久形式,Subversion版本库保存了一些UTF8的日志信息,并且假定你的日志信息是用操作系统的本地编码,如果你提交的信息使用别的编码方式,你一定要指定不同的编码。 use-commit-times-
通常你的工作拷贝文件会有最后一次被进程访问的时间戳,不管是你自己的编辑器还是用svn子命令。这通常对人们开发软件提供了便利,因为编译系统通常会通过查看时间戳来决定那些文件需要重新编译。
在其他情形,有时候如果工作拷贝的文件时间戳反映了上一次在版本库中更改的时间会非常好,svn export命令会一直放置这些“上次提交的时间戳”放到它创建的目录树。通过设置这个config参数为
yes,svn checkout、svn update、 svn switch和svn revert命令也会为它们操作的文件设置上次提交的时间戳。
auto-props小节控制Subversion客户端自动设置提交和导入的文件的属性的能力,它可以包含任意数量的键-值对,格式是PATTERN = PROPNAME=PROPVALUE,其中PATTERN是一个文件模式,匹配一系列文件名,此行其它两项为属性和值。如果一个文件匹配多次,会导致有多个属性集;然而,没有手段保障自动属性不会按照配置文件中的顺序应用,所以你可以一个规则“覆盖”另一个。你可以在config文件找到许多自动属性的用法实例。最后,如果你希望开启自动属性,不要忘了设置miscellany小节的enable-auto-props为yes。
我们已经详细讲述了Subversion存储和检索版本库中不同版本的文件和目录的细节,并且用了好几个章节来论述这个工具的基本功能。到此为止,Subversion还仅仅表现出一个普通的版本控制理念。但是Subversion并没有就此止步。
作为目录和文件版本化的补充,Subversion提供了对每一个版本化的目录和文件添加、修改和删除版本化的元数据的接口,我们用属性来表示这些元数据。我们可以认为它们是一个两列的表,附加到你的工作拷贝的每个条目上,映射属性名到任意的值。一般来说,属性的名称和值可以是你希望的任何值,限制就是名称必须是可读的文本,并且最好的一点是这些属性也是版本化的,就像你的文本内容文件,你可以像提交文本修改一样修改、提交和恢复属性修改,当你更新时也会接收到别人的属性修改。
在本小节,我们将会检验这个工具—不仅是对Subversion的用户,也对Subversion本身—对于属性的支持。你会学到与属性相关的svn子命令,和属性怎样影响你的普通Subversion工作流,希望你会感到Subversion的属性可以提高你的版本控制体验。
属性可能会是工作拷贝的有益补充,实际上,Subversion本身使用属性来存放特殊的信息,作为支持特别操作的一种方法,同样,你也可以使用属性来实现自己的目的,当然,你对属性作的任何事情也可以针对普通的版本化文件,但是先考虑下面Subversion使用属性的例子。
假定你希望设计一个网站存放许多数码图片,并且显示他们的标题和时间戳,现在你的图片集经常修改,所以你希望你的网站能够尽量的自动化,这些图片可能非常大,所以根据这个网站的特性,你希望在网站给用户提供图标图像。你可以用传统的文件做这件事,你可以有一个image123.jpg和一个image123-thumbnail.jpg对应在同一个目录,有时候你希望保持文件名相同,你可以使用不同的目录,如thumbnails/image123.jpg。你可以用一种相似的样式来保存你的标题和时间戳同原始图像文件分开。很快你的目录树会是一团糟,每个新图片的添加都会成倍的增加混乱。
现在考虑使用Subversion文件的属性来做相同的设置,想象我们有一个单独的图像文件image123.jpg,然后这个文件的属性集包括caption、datestamp甚至thumbnail。现在你的工作拷贝目录看起来更容易管理—实际上,它看起来只有图像文件,但是你的自动化脚本知道得更多,它们知道可以用svn(更好的选择是使用Subversion的语言绑定—见“使用C和C++以外的语言”一节)来挖掘更多的站点显示需要的额外信息,而不必去阅读一个索引文件或者是玩一个路径处理的游戏。
你怎样(而且如果)使用Subversion完全在你,像我们提到的,Subversion拥有它自己的属性集,我们会在后面的章节讨论,但首先,让我们讨论怎样使用svn的属性处理选项。
svn命令提供一些方法来添加和修改文件或目录的属性,对于短的,可读的属性,最简单的添加方法是在propset子命令里指定正确的名称和值。
$ svn propset copyright '(c) 2003 Red-Bean Software' calc/button.c property 'copyright' set on 'calc/button.c' $
但是我们已经“吹嘘”过Subversion为属性值提供的灵活性,如果你计划有一个多行的可读文本,甚至是二进制文件的属性值,你通常不希望在命令行里指定,所以propset子命令使用--file(-F)选项来指定一个保存新属性值的文件的名字。
$ svn propset license -F /path/to/LICENSE calc/button.c property 'license' set on 'calc/button.c' $
作为propset命令的补充,svn提供了一个propedit命令,这个命令使用定制的编辑器程序(见“config”一节)来添加和修改属性。当你运行这个命令,svn调用你的编辑器程序打开一个临时文件,文件中保存当前的属性值(或者是空文件,如果你正在添加新的属性)。然后你只需要修改为你想要的值,保存临时文件,然后离开编辑器程序。如果Subversion发现你已经修改了属性值,就会接受新值,如果你未作任何修改而离开,不会产生属性修改操作。
$ svn propedit copyright calc/button.c ### exit the editor without changes No changes to property 'copyright' on 'calc/button.c' $
我们也应该注意导,像其它svn子命令一样,这些关联的属性可以一次添加到多个路径上,这样就可以通过一个命令修改一组文件的属性。举个例子,我们可以:
$ svn propset copyright '(c) 2002 Red-Bean Software' calc/* property 'copyright' set on 'calc/Makefile' property 'copyright' set on 'calc/button.c' property 'copyright' set on 'calc/integer.c' … $
如果不能方便的得到存储的属性值,那么属性的添加和编辑操作也不会很容易,所以svn提供了两个子命令来显示文件和目录存储的属性名和值。svn proplist命令会列出路径上存在的所有属性名称,一旦你知道了某个节点的属性名称,你可以用svn propget获取它的值,这个命令获取给定的路径(或者是一组路径)和属性名称,打印这个属性的值到标准输出。
$ svn proplist calc/button.c Properties on 'calc/button.c': copyright license $ svn propget copyright calc/button.c (c) 2003 Red-Bean Software
还有一个proplist变种命令会列出所有属性的名称和值,只需要设置--verbose(-v)选项。
$ svn proplist --verbose calc/button.c Properties on 'calc/button.c': copyright : (c) 2003 Red-Bean Software license : ================================================================ Copyright (c) 2003 Red-Bean Software. All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: 1. Redistributions of source code must retain the above copyright notice, this list of conditions, and the recipe for Fitz's famous red-beans-and-rice. …
最后一个与属性相关的子命令是propdel,因为Subversion允许属性值为空,所有不能用propedit或者propset命令删除一个属性。举个例子,这个命令不会产生预期的效果:
$ svn propset license '' calc/button.c property 'license' set on 'calc/button.c' $ svn proplist --verbose calc/button.c Properties on 'calc/button.c': copyright : (c) 2003 Red-Bean Software license : $
你需要用propdel来删除属性,语法与其它与属性相关命令相似:
$ svn propdel license calc/button.c property 'license' deleted from ''. $ svn proplist --verbose calc/button.c Properties on 'calc/button.c': copyright : (c) 2003 Red-Bean Software $
现在你已经熟悉了所有与属性相关的svn子命令,让我们看看属性修改如何影响Subversion的工作流。我们前面提到过,文件和目录的属性是版本化的,这一点类似于版本化的文件内容。后果之一,就是Subversion具有了同样的机制来合并—用干净或者冲突的方式—其他人的修改应用到你的修改。
就像文件内容,你的属性修改是本地修改,只有使用svn commit命令提交后才会保存到版本库中,属性修改也可以很容易的取消—svn revert命令会恢复你的文件和目录为编辑前状态,包括内容、属性和其它的信息。另外,你可以使用svn status和svn diff接受感兴趣的文件和目录属性的状态信息。
$ svn status calc/button.c M calc/button.c $ svn diff calc/button.c Property changes on: calc/button.c ___________________________________________________________________ Name: copyright + (c) 2003 Red-Bean Software $
注意status子命令显示的M在第二列而不是在第一列,这是因为我们修改了calc/button.c的属性,而不是它的文本内容,如果我们都修改了,我们也会看到M出现在第一列(见“svn status”一节)。
你也许已经注意到了Subversion在显示属性时的非标准方式。你还可以运行svn diff并且重定向输出来产生一个有用的补丁文件,patch程序会忽略属性补丁—作为规则,它会忽略任何不理解的噪音。很遗憾,这意味着完全应用svn diff产生的补丁时,任何属性修改必须手工实施。
就象你看到的,属性修改的出现并没有对典型的Subversion工作流有显著的影响,更新工作拷贝、检查文件和目录的状态、报告所作的修改和提交修改到版本库等等的工作方式完全与属性的存在与否无关。svn程序有一些额外的子命令用来进行属性修改,但那是唯一显而易见不对称的命令。
Subversion没有关于属性的特殊政策—你可以通过它们实现自己的目的。Subversion只是要求你不要使用svn:开头的命名空间作为属性名,这是Subversion自己使用的命名空间。实际上,Subversion定义了某些特殊的属性,这些属性对它们所附加的文件和目录有特殊的影响。在本小节,我们会解开这个谜团,并且描述这些属性怎样让你的生活更加容易。
svn:executable属性用来控制一个版本化的文件自动执行文件权限设定,这个属性没有特定的值—它只是说明一个Subversion可以保留的文件权限的期望值,删除这个属性会恢复操作系统对这些权限的完全控制。
在多数操作系统,执行一个文件或命令的能力是由执行位管理的,这些位通常是关闭的,必须由用户显式的指定,这意味着你必须改变文件的执行位,然后更新你的工作拷贝,燃火如果你的文件成为更新的一部分,它的执行位会被关闭,所以Subversion提供了svn:executable这个属性来保持打开执行位。
这个属性对于没有可执行权限位的文件系统无效,如FAT32和NTFS。 [28] 也就是说,尽管它没有定义的值,在设置这个属性时,Subversion会强制它的值为*,最后,这个属性只对文件有效,目录无效。
这个svn:ignore属性保存了一个Subversion特定操作忽略的文件模式列表,或许这个是最常用的属性,它可以与global-ignores运行配置选项配合使用(见“config”一节)来过滤svn status、svn add和svn import命令中操作的未版本化文件。
svn:ignore背后的基本原理很容易解释,Subversion不会假定工作拷贝中的所有文件或子目录是版本控制的一部分,资源必须被显式的使用svn add或者svn import放到Subversion的管理控制之下,作为结果,经常有许多工作拷贝的资源并没有版本化。
现在,svn status命令会的显示会包括所有未纳入版本控制且没有用global-ignores(或是内置的缺省值)过滤掉的文件和子目录,这样可以帮助用户查看是否忘记了把某些自愿加入到版本控制。
但是Subversion不可能猜测到每个需要忽略的资源的名字,但是也有一些资源是所有特定版本库的工作拷贝都有忽略的,强制版本库的每个用户来添加这些模式到他们的运行配置区域不仅仅是一个负担,也会与用户取出的其他工作拷贝配置需要存在潜在的冲突。
解决方案是保存的忽略模式必须对出现在给定目录和这个目录本身的资源是独立的,一个常见的例子就是一个未版本化资源对一个目录来说是唯一的,会出现在那个位置,包括程序编译的输出,或者是—用一个本书的例子—DocBook的文件生成的HTML、PDF或者是PostScript文件。
为了这个目的,svn:ignore属性是解决方案,它的值是一个多行的文件模式集,一行一个模式,这个属性已经设置到这个你希望应用模式的目录。 [29] 举个例子,你的svn status有如下的输出:
$ svn status calc M calc/button.c ? calc/calculator ? calc/data.c ? calc/debug_log ? calc/debug_log.1 ? calc/debug_log.2.gz ? calc/debug_log.3.gz
在这个例子里,你对button.c文件作了一些属性修改,但是你的工作拷贝也有一些未版本化的文件:你从源代码编译的最新的计算器程序是data.c,一系列调试输出日志文件,现在你知道你的编译系统会编译生成计算器程序。 [30] 就像你知道的,你的测试组件总是会留下这些调试日志,这对所有的工作拷贝都是一样的,不仅仅使你的。你也知道你不会有兴趣在svn status命令中显示这些信息,所以使用svn propedit svn:ignore calc来为calc目录增加一些忽略模式,举个例子,你或许会添加如下的值作为svn:ignore属性:
calculator debug_log*
当你添加完这些属性,你会在calc目录有一个本地修改,但是注意你的svn status输出有什么其他的不同:
$ svn status M calc M calc/button.c ? calc/data.c
现在,所有多余的输出不见了!当然,这些文件还在工作拷贝中,Subversion仅仅是不再提醒你它们的存在和未版本化。现在所有讨厌的噪音都已经删除了,你留下了更加感兴趣的项目—如你忘记添加到版本控制的源代码文件。
如果想查看被忽略的文件,可以设置Subversion的--no-ignore选项:
$ svn status --no-ignore M calc/button.c I calc/calculator ? calc/data.c I calc/debug_log I calc/debug_log.1 I calc/debug_log.2.gz I calc/debug_log.3.gz
svn add和svn import也会使用这个忽略模式列表,这两个操作都包括了询问Subversion来开始管理一组文件和目录。比强制用户挑拣目录树中那个文件要纳入版本控制的方式更好,Subversion使用忽略模式来检测那个文件不应该在大的迭代添加和导入操作中进入版本控制系统。
Subversion具备有添加关键字的能力—一些有用的,关于版本化的文件动态信息的片断—不必直接添加到文件本身。关键字通常会用来描述文件最后一次修改的一些信息,因为这些信息每次都有改变,更重要的一点,这是在文件修改之后,除了版本控制系统,对于任何处理完全保持最新的数据都是一场争论,作为人类作者,信息变得陈旧是不可避免的。
举个例子,你有一个文档希望显示最后修改的日期,你需要麻烦每个作者提交之前做这件事情,同时会改变描述这部分细细的部分,但是迟早会有人忘记做这件事,不选择简单的告诉Subversion来执行替换LastChangedDate关键字的操作,在你的文档需要放置这个关键字的地方放置一个keyword anchor,这个anchor只是一个格式为$KeywordName$字符串。
所有作为anchor出现在文件里的关键字是大小写敏感的:为了关键字的扩展,你必须使用正确的按顺序大写。你必须考虑svn:keywords的属性值也是大小写敏感—特定的关键字名会忽略大小写,但是这个特性已经被废弃了。
Subversion定义了用来替换的关键字列表,这个列表保存了如下五个关键字,有一些也包括了可用的别名:
Date-
这个关键字保存了文件最后一次在版本库修改的日期,看起来类似于
$Date: 2002-07-22 21:42:37 -0700 (Mon, 22 Jul 2002) $,它也可以用LastChangedDate来指定。 Revision-
这个关键字描述了这个文件最后一次修改的修订版本,看起来像
$Revision: 144 $,也可以通过LastChangedRevision或者Rev引用。 Author-
这个关键字描述了最后一个修改这个文件的用户,看起来类似
$Author: harry $,也可以用LastChangedBy来指定。 HeadURL-
这个关键字描述了这个文件在版本库最新的版本的完全URL,看起来类似
$HeadURL: http://svn.collab.net/repos/trunk/README $,可以缩写为URL。 Id-
这个关键字是其他关键字一个压缩组合,它看起来就像
$Id: calc.c 148 2002-07-28 21:30:43Z sally $,可以解释为文件calc.c上一次修改的修订版本号是148,时间是2002年7月28日,作者是sally。
只在你的文件增加关键字anchor不会做什么特别的事情,Subversion不会尝试对你的文件内容执行文本替换,除非明确的被告知这样做,毕竟,你可以撰写一个文档 [31] 关于如何使用关键字,你希望Subversion不会替代你漂亮的关于不需要替换的关键字anchor实例!
为了告诉Subversion是否替代某个文件的关键字,我们要再次求助于属性相关的子命令,当svn:keywords属性设置到一个版本化的文件,这些属性控制了那些关键字将会替换到那个文件。这个值是空格分隔的前面列表的名称或是别名列表。
举个例子,假定你有一个版本化的文件weather.txt,内容如下:
Here is the latest report from the front lines. $LastChangedDate$ $Rev$ Cumulus clouds are appearing more frequently as summer approaches.
当没有svn:keywords属性设置到这个文件,Subversion不会有任何特别操作,现在让我们允许LastChangedDate关键字的替换。
$ svn propset svn:keywords "Date Author" weather.txt property 'svn:keywords' set on 'weather.txt' $
现在你已经对weather.txt的属性作了修改,你会看到文件的内容没有改变(除非你之前做了一些属性设置),注意这个文件包含了Rev的关键字anchor,但我们没有在属性值中包括这个关键字,Subversion会高兴的忽略替换这个文件中的关键字,也不会替换svn:keywords属性中没有出现的关键字。
在你提交了属性修改后,Subversion会立刻更新你的工作文件为新的替代文本,你将无法找到$LastChangedDate$的关键字anchor,你会看到替换的结果,这个结果也保存了关键字的名字,与美元符号($)绑定在一起,而且我们预测的,Rev关键字不会被替换,因为我们没有要求这样做。
注意我们设置svn:keywords属性为"Date Author",关键字anchor使用别名$LastChangedDate$并且正确的扩展。
Here is the latest report from the front lines. $LastChangedDate: 2002-07-22 21:42:37 -0700 (Mon, 22 Jul 2002) $ $Rev$ Cumulus clouds are appearing more frequently as summer approaches.
如果有其他人提交了weather.txt的修改,你的此文件的拷贝还会显示同样的替换关键字值—直到你更新你的工作拷贝,此时你的weather.txt重的关键字将会被替换来反映最新的提交信息。
属性是Subversion一个强大的特性,成为本章和其它章讨论的许多Subversion特性的关键组成部分—文本区别和合并支持、关键字替换、新行的自动转换等等。但是为了从属性得到完全的利益,他们必须设置到正确的文件和目录。不幸的是,在日常工作中很容易忘记这一步工作,特别是当没有设置属性不会引起明显的错误时(至少相对与未能添加一个文件到版本控制这种操作),为了帮助你在需要添加属性的文件上添加属性,Subversion提供了一些简单但是有用的特性。
当你使用svn add或是svn import准备加入一个版本控制的文件时,Subversion会运行一个基本探测来检查文件是包括了可读还是不可读的内容,如果Subversion猜测错误,或者是你希望使用svn:mime-type属性更精确的设置—或许是image/png或者application/x-shockwave-flash—你可以一直删除或编辑那个属性。
Subversion也提供了自动属性特性,允许你创建文件名到属性名称与值影射,这个影射在你的运行配置区域设置,它们会影响添加和导入操作,而且不仅仅会覆盖Subversion所有缺省的MIME类型判断操作,也会设置额外的Subversion或者自定义的属性。举个例子,你会创建一个影射文件说在任何时候你添加了一个JPEG文件—一些符合*.jpg的文件—Subversion一定会自动设置它们的svn:mime-type属性为image/jpeg。或者是任何匹配*.cpp的文件,必须把svn:eol-style设置为native,并且svn:keywords设置为Id。自动属性支持是Subversion工具箱中属性相关最垂手可得的工具,见“config”一节来查看更多的配置支持。
文件和目录的拷贝、移动和改名能力可以让我们可以删除一个对象,然后在同样的路径添加一个新的—这是我们在电脑上对文件和目录经常作的操作,我们认为这些操作都是理所当然的。Subversion很乐意你认为这些操作已经赋予给你,Subversion的文件管理操作是这样的解放,提供了几乎和普通文件一样的操作版本化文件的灵活性,但是灵活意味着在整个版本库的生命周期中,一个给定的版本化的资源可能会出现在许多不同的路径,一个给定的路径会展示给我们许多完全不同的版本化资源。
Subversion可以非常聪明的注意到一个对象的版本历史变化包括一个“地址改变”,举个例子,如果你询问一个曾经上周改过名的文件的所有的日志信息,Subversion会很高兴提供所有的日志—重命名发生的修订版本,外加相关版本之前和之后的修订版本日志,所以大多数时间里,你不需要考虑这些事情,但是偶尔,Subversion会需要你的帮助来清除混淆。
这个最简单的例子发生在当一个目录或者文件从版本控制中删除时,然后一个新的同样名字目录或者文件添加到版本控制,清除了你删除的东西,然后你添加的不是同样的东西,它们仅仅是有同样的路径,我们会把它叫做/trunk/object。什么,这意味着询问Subversion来查看/trunk/object的历史?你是询问当前这个位置的东西还是你在这个位置删除的那个对象?你是希望询问对这个对象的所有操作还是这个路径的所有对象?很明显,Subversion需要线索知道你真实的想法。
由于移动,版本化资源历史会变得非常扭曲。举个例子,你会有一个目录叫做concept,保存了一些你用来试验的初生的软件项目,最终,这个项目变得足够成熟,说明这个注意确实需要一些翅膀了,所以你决定给这个项目一个名字。 [32] 假定你叫你的软件为Frabnaggilywort,此刻,有必要把你的目录命名为反映项目名称的名字,所以concept改名为frabnaggilywort。生活还在继续,Frabnaggilywort发布了1.0版本,并且被许多希望改进他们生活的分散用户天天使用。
这是一个美好的故事,但是没有在这里结束,作为主办人,你一定想到了另一件事,所以你创建了一个目录叫做concept,周期重新开始。实际上,这个循环在几年里开始了多次,每一个想法从使用旧的concept目录开始,然后有时在想法成熟之后重新命名,有时你放弃了这个注意而删除了这个目录。或者更加变态一点,或许你把concept改成其他名字之后又因为一些原因重新改回concept。
当这样的情景发生时,指导Subversion工作在重新使用的路径上的尝试就像指导一个芝加哥西郊的乘客驾车到东面的罗斯福路并且左转到主大道。仅仅20分钟,你可以穿过惠顿、格伦埃林何朗伯德的“主大道”,但是它们不是一样的街道,我们的乘客—和我们的Subversion—需要更多的细节来做正确的事情。
在1.1版本,Subversion提供了一种方法来说明你所指是哪一个街道,叫做peg修订版本,这是一个提供给Subversion的一个区别一个独立历史线路的单独目的修订版本,因为一个版本化的文件会在任何时间占用某个路径—路径和peg修订版本的合并是可以指定一个历史的特定线路。Peg修订版本可以在Subversion命令行客户端中用at语法指定,之所以使用这个名称是因为会在关联的修订版本的路径后面追加一个“at符号”(@)。
但是我们在本书多次提到的--revision (-r)到底是什么?修订版本(或者是修订版本集)叫做实施的修订版本(或者叫做实施的修订版本范围),一旦一个特定历史线路通过一个路径和peg修订版本指定,Subversion会使用实施的修订版本执行要求的操作。类似的,为了指出这个到我们芝加哥的道路,如果我们被告知到惠顿主大道606号, [33] 我们可以把“主大道”看作路径,把“惠顿”当作我们的peg修订版本。这两段信息确认了我们可以旅行(主大道的北方或南方)的唯一路径,也会保持我们不会在前前后后寻找目标时走到错误的主大道。现在我们把“606 N.”作为我们实施的修订版本,我们精确的知道到哪里。
当使用peg和实施修订版本来查找我们需要工作文件时,Subversion会执行一个很直接的算法。首先,找到与peg修订版本相关的路径坐落于版本库的那个修订版本,Subversion开始从那里开始向后查询这个对象的历史前辈。每个前辈表示这个对象的以前的一个版本,每一个版本的对象都保存了自己被创建的修订版本和路径,所以通过前辈集,Subversion可以注意到哪个版本是这个实施修订版本最年轻的版本,如果是,可以将实施修订版本影射到前辈创建的路径/创建修订版本对。算法在所有的实施修订版本影射到真实的对象位置后,或者是没有更多的前辈时完成,就是任何未影射的实施修订版本已经标记为不符合操作的对象。
也就是说很久以前我们创建了我们的版本库,在修订版本1添加我们第一个concept目录,并且在这个目录增加一个IDEA文件与concept相关,在几个修订版本之后,真实的代码被添加和修改,我们在修订版本20,修改这个目录为frabnaggilywort。通过修订版本27,我们有了一个新的概念,所以一个新的concept目录用来保存这些东西,一个新的IDEA文件来描述这个概念,然后经过5年20000个修订版本,就像他们都有一个非常浪漫的历史。
现在,一年之后,我们想知道IDEA在修订版本1时是什么样子,但是Subversion需要知道我们是想询问当前文件在修订版本1时的样子,还是希望知道concepts/IDEA在修订版本1时的那个文件?确定这些问题有不同的答案,并且因为peg修订版本,你可以用两种方式询问。为了知道当前的IDEA文件在旧版本1的样子,我们可以运行:
$ svn cat -r 1 concept/IDEA subversion/libsvn_client/ra.c:775: (apr_err=20014) svn: Unable to find repository location for 'concept/IDEA' in revision 1
当然,在这个例子里,当前的IDEA文件在修订版本1中并不存在,所以Subversion给出一个错误,这个上面的命令是长的peg修订版本命令一个缩写,扩展的写法是:
$ svn cat -r 1 concept/IDEA@BASE subversion/libsvn_client/ra.c:775: (apr_err=20014) svn: Unable to find repository location for 'concept/IDEA' in revision 1
当执行时会有预料中的结果,当应用到工作拷贝路径时,Peg修订版本通常缺省值是BASE(在当前工作拷贝现在的修订版本),当应用到URL时,缺省值是HEAD。
然后让我们询问另一个问题—在修订版本1 ,占据concepts/IDEA路径的文件的内容到底是什么?我们会使用一个明确的peg修订版本来帮助我们完成。
$ svn cat concept/IDEA@1 The idea behind this project is to come up with a piece of software that can frab a naggily wort. Frabbing naggily worts is tricky business, and doing it incorrectly can have serious ramifications, so we need to employ over-the-top input validation and data verification mechanisms.
这看起来是正确的输出,这些文本甚至提到“frabbing naggily worts”,所以这就是现在叫做Frabnaggilywort项目的那个文件,实际上,我们可以使用显示的peg修订版本和实施修订版本的组合核实这一点。我们知道在HEAD,Frabnaggilywort项目坐落在frabnaggilywort目录,所以我们指定我们希望看到HEAD的frabnaggilywort/IDEA路经在历史上的修订版本1的内容。
$ svn cat -r 1 frabnaggilywort/IDEA@HEAD The idea behind this project is to come up with a piece of software that can frab a naggily wort. Frabbing naggily worts is tricky business, and doing it incorrectly can have serious ramifications, so we need to employ over-the-top input validation and data verification mechanisms.
而且peg修订版本和实施修订版本也不需要这样琐碎,举个例子,我们的frabnaggilywort已经在HEAD删除,但我们知道在修订版本20它是存在的,我们希望知道IDEA从修订版本4到10的区别,我们可以使用peg修订版本20和IDEA文件的修订版本20的URL的组合,然后使用4到10作为我们的实施修订版本范围。
$ svn diff -r 4:10 http://svn.red-bean.com/projects/frabnaggilywort/IDEA@20 Index: frabnaggilywort/IDEA =================================================================== --- frabnaggilywort/IDEA (revision 4) +++ frabnaggilywort/IDEA (revision 10) @@ -1,5 +1,5 @@ -The idea behind this project is to come up with a piece of software -that can frab a naggily wort. Frabbing naggily worts is tricky -business, and doing it incorrectly can have serious ramifications, so -we need to employ over-the-top input validation and data verification -mechanisms. +The idea behind this project is to come up with a piece of +client-server software that can remotely frab a naggily wort. +Frabbing naggily worts is tricky business, and doing it incorrectly +can have serious ramifications, so we need to employ over-the-top +input validation and data verification mechanisms.
幸运的是,几乎所有的人们不会面临如此复杂的情形,但是如果是,记住peg修订版本是帮助Subversion清除混淆的额外提示。
有时候创建一个由多个不同检出得到的工作拷贝是非常有用的,举个例子,你或许希望不同的子目录来自不同的版本库位置,或者是不同的版本库。你可以手工设置这样一个工作拷贝—使用svn checkout来创建这种你需要的嵌套的工作拷贝结构。但是如果这个结构对所有的用户是很重要的,每个用户需要执行同样的检出操作。
很幸运,Subversion提供了外部定义的支持,一个外部定义是一个本地路经到URL的影射—也有可能一个特定的修订版本—一些版本化的资源。在Subversion你可以使用svn:externals属性来定义外部定义,你可以用svn propset或svn propedit(见“为什么需要属性?”一节)创建和修改这个属性。它可以设置到任何版本化的路经,它的值是一个多行的子目录和完全有效的Subversion版本库URL的列表(相对于设置属性的版本化目录)。
$ svn propget svn:externals calc third-party/sounds http://sounds.red-bean.com/repos third-party/skins http://skins.red-bean.com/repositories/skinproj third-party/skins/toolkit -r21 http://svn.red-bean.com/repos/skin-maker
svn:externals的方便之处是这个属性设置到版本化的路径后,任何人可以从那个目录取出一个工作拷贝,同样得到外部定义的好处。换句话说,一旦一个人努力来定义这些嵌套的工作拷贝检出,其他任何人不需要再麻烦了—Subversion会在原先的工作拷贝检出之后,也会检出外部工作拷贝。
注意前一个外部定义实例,当有人取出了一个calc目录的工作拷贝,Subversion会继续来取出外部定义的项目。
$ svn checkout http://svn.example.com/repos/calc A calc A calc/Makefile A calc/integer.c A calc/button.c Checked out revision 148. Fetching external item into calc/third-party/sounds A calc/third-party/sounds/ding.ogg A calc/third-party/sounds/dong.ogg A calc/third-party/sounds/clang.ogg … A calc/third-party/sounds/bang.ogg A calc/third-party/sounds/twang.ogg Checked out revision 14. Fetching external item into calc/third-party/skins …
如果你希望修改外部定义,你可以使用普通的属性修改子命令,当你提交一个svn:externals属性修改后,当你运行svn update时,Subversion会根据修改的外部定义同步检出的项目,同样的事情也会发生在别人更新他们的工作拷贝接受你的外部定义修改时。
svn status命令也认识外部定义,会为外部定义的子目录显示X状态码,然后迭代这些子目录来显示外部项目的子目录状态信息。
Subversion目前对外部定义的支持可能会引起误导,首先,一个外部定义只可以指向目录,而不是文件。第二,外部定义不可以指向相对路径(如../../skins/myskin)。第三,同过外部定义创建的工作拷贝与主工作拷贝没有连接,所以举个例子,如果你希望提交一个或多个外部定义的拷贝,你必须在这些工作拷贝显示的运行svn commit—对主工作拷贝的提交不会迭代到外部定义的部分。
另外,因为定义本身使用绝对路径,移动和拷贝路径他们附着的路径不会影响他们作为外部的检出(尽管相对的本地目标子目录会这样,当然,根据重命名的目录)。这看起来有些迷惑—甚至让人沮丧—在特定情形。举个例子,如果你在/trunk开发线对一个目录使用外部定义,指向同一条线上的其他区域,然后使用svn copy把分支开发线拷贝到/branches/my-branch这个新位置,这个项目新分支的外部定义仍然指向/trunk版本化资源。另外,需要意识到如果你需要一个重新规划你的工作拷贝的父目录(使用svn switch --relocate),外部定义不会重新选择父目录。
当开发软件时有这样一个情况,你版本控制的数据可能关联于或者是依赖于其他人的数据,通常来讲,你的项目的需要会要求你自己的项目对外部实体提供的数据保持尽可能最新的版本,同时不会牺牲稳定性,这种情况总是会出现—只要某个小组的信息对另一个小组的信息有直接的影响。
举个例子,软件开发者会工作在一个使用第三方库的应用,Subversion恰好是和Apache的Portable Runtime library(见“Apache可移植运行库”一节)有这样一个关系。Subversion源代码依赖于APR库来实现可移植需求。在Subversion的早期开发阶段,项目紧密地追踪APR的API修改,经常在库代码的“流血的边缘”粘住,现在APR和Subversion都已经成熟了,Subversion只尝试同步APR的经过良好测试的,稳定的API库。
现在,如果你的项目依赖于其他人的信息,有许多方法可以用来尝试同步你的信息,最痛苦的,你可以为项目所有的贡献者发布口头或书写的指导,告诉他们确信他们拥有你们的项目需要的特定版本的第三方信息。如果第三方信息是用Subversion版本库维护,你可以使用Subversion的外部定义来有效的“强制”特定的版本的信息在你的工作拷贝的的位置(见“外部定义”一节)。
但是有时候,你希望在你自己的版本控制系统维护一个针对第三方数据的自定义修改,回到软件开发的例子,程序员为了他们自己的目的会需要修改第三方库,这些修改会包括新的功能和bug修正,在成为第三方工具官方发布之前,只是内部维护。或者这些修改永远不会传给库的维护者,只是作为满足软件开发需要的单独的自定义修改存在。
现在你会面对一个有趣的情形,你的项目可以用某种脱节的样式保持它关于第三方数据自己的修改,如使用补丁文件或者是完全的可选版本的文件和目录。但是这很快会成为维护的头痛的事情,需要一种机制来应用你对第三方数据的自定义修改,并且迫使在第三方数据的后续版本重建这些修改。
这个问题的解决方案是使用卖主分支,一个卖主分支是一个目录树保存了第三方实体或卖主的信息,每一个卖主数据的版本吸收到你的项目叫做卖主drop。
卖主分支提供了两个关键的益处,第一,通过在我们的版本控制系统保存现在支持的卖主drop,你项目的成员不需要指导他们是否有了正确版本的卖主数据,他们只需要作为不同工作拷贝更新的一部份,简单的接受正确的版本就可以了。第二,因为数据存在于你自己的Subversion版本库,你可以在恰当的位置保存你的自定义修改—你不需要一个自动的(或者是更坏,手工的)方法来交换你的自定义行为。
管理卖主分支通常会像这个样子,你创建一个顶级的目录(如/vendor)来保存卖主分支,然后你导入第三方的代码到你的子目录。然后你将拷贝这个子目录到主要的开发分支(例如/trunk)的适当位置。你一直在你的主要开发分支上做本地修改,当你的追踪的代码有了新版本,你会把带到卖主分支并且把它合并到你的/trunk,解决任何你的本地修改和他们的修改的冲突。
也许一个例子有助于我们阐述这个算法,我们会使用这样一个场景,我们的开发团队正在开发一个计算器程序,与一个第三方的复杂数字运算库libcomplex关联。我们从卖主分支的初始创建开始,并且导入卖主drop,我们会把每株分支目录叫做libcomplex,我们的代码drop会进入到卖主分支的子目录current,并且因为svn import创建所有的需要的中间父目录,我们可以使用一个命令完成这一步。
$ svn import /path/to/libcomplex-1.0 \
http://svn.example.com/repos/vendor/libcomplex/current \
-m 'importing initial 1.0 vendor drop'
…
我们现在在/vendor/libcomplex/current有了libcomplex当前版本的代码,现在我们为那个版本作标签(见“标签”一节),然后拷贝它到主要开发分支,我们的拷贝会在calc项目目录创建一个新的目录libcomplex,它是这个我们将要进行自定义的卖主数据的拷贝版本。
$ svn copy http://svn.example.com/repos/vendor/libcomplex/current \
http://svn.example.com/repos/vendor/libcomplex/1.0 \
-m 'tagging libcomplex-1.0'
…
$ svn copy http://svn.example.com/repos/vendor/libcomplex/1.0 \
http://svn.example.com/repos/calc/libcomplex \
-m 'bringing libcomplex-1.0 into the main branch'
…
我们取出我们项目的主分支—现在包括了第一个卖主drop的拷贝—我们开始自定义libcomplex的代码,我们知道,我们的libcomplex修改版本是已经与我们的计算器程序完全集成。 [34]
几周之后,libcomplex得开发者发布了一个新的版本—版本1.1—包括了我们很需要的一些特性和功能。我们很希望升级到这个版本,但不希望失去在当前版本所作的修改。我们本质上会希望把我们当前基线版本是的libcomplex1.0的拷贝替换为libcomplex 1.1,然后把前面自定义的修改应用到新的版本。但是实际上我们通过一个相反的方向解决这个问题,应用libcomplex从版本1.0到1.1的修改到我们修改的拷贝。
为了执行这个升级,我们取出一个我们卖主分支的拷贝,替换current目录为新的libcomplex 1.1的代码,我们只是拷贝新文件到存在的文件上,或者是解压缩libcomplex 1.1的打包文件到我们存在的文件和目录。此时的目标是让我们的current目录只保留libcomplex 1.1的代码,并且保证所有的代码在版本控制之下,哦,我们希望在最小的版本控制历史扰动下完成这件事。
完成了这个从1.0到1.1的代码替换,svn status会显示文件的本地修改,或许也包括了一些未版本化或者丢失的文件,如果我们做了我们应该做的事情,未版本化的文件应该都是libcomplex在1.1新引入的文件—我们运行svn add来将它们加入到版本控制。丢失的文件是存在于1.1但是不是在1.1,在这些路径我们运行svn delete。最终一旦我们的current工作拷贝只是包括了libcomplex1.1的代码,我们可以提交这些改变目录和文件的修改。
我们的current分支现在保存了新的卖主drop,我们为这个新的版本创建一个新的标签(就像我们为1.0版本drop所作的),然后合并这从个标签前一个版本的区别到主要开发分支。
$ cd working-copies/calc
$ svn merge http://svn.example.com/repos/vendor/libcomplex/1.0 \
http://svn.example.com/repos/vendor/libcomplex/current \
libcomplex
… # resolve all the conflicts between their changes and our changes
$ svn commit -m 'merging libcomplex-1.1 into the main branch'
…
在这个琐碎的用例里,第三方工具的新版本会从一个文件和目录的角度来看,就像前一个版本。没有任何libcomplex源文件会被删除、被改名或是移动到别的位置—新的版本只会保存针对上一个版本的文本修改。在完美世界,我们对呢修改会干净得应用到库的新版本,不会产生任何并发和冲突。
但是事情总不是这样简单,实际上源文件在不同的版本间的移动是很常见的,这种过程复杂性可以确保我们的修改会一直对新的版本代码有效,可以很快使形势退化到我们需要在新版本手工的重新创建我们的自定义修改。一旦Subversion知道了给定文件的历史—包括了所有以前的位置—合并到新版本的进程就会很简单,但是我们需要负责告诉Subversion卖主drop之间源文件布局的改变。
本地化是让程序按照地区特定方式运行的行为,如果一个程序的格式、数字或者是日期是你的本地方式,或者是打印的信息(或者是接受的输入)是你本地的语言,这个程序被叫做已经本地化了,这部分描述了针对本地化的Subversion的步骤。
许多现代操作系统都有一个“当前地区”的概念—也就是本地化习惯服务的国家和地区。这些习惯—通常是被一些运行配置机制选择—影响程序展现数据的方式,也有接受用户输入的方式。
在类Unix的系统,你可以运行locale命令来检查本地关联的运行配置的选项值:
$ locale LANG= LC_COLLATE="C" LC_CTYPE="C" LC_MESSAGES="C" LC_MONETARY="C" LC_NUMERIC="C" LC_TIME="C" LC_ALL="C"
输出是一个本地相关的环境变量和它们的值,在这个例子里,所有的变量设置为缺省的C地区,但是用户可以设置这些变量为特定的国家/语言代码组合。举个例子,如果有人设置LC_TIME变量为fr_CA,然后程序会知道使用讲法语的加拿大期望的格式来显示时间和日期信息。如果一个人会设置LC_MESSAGES变量为zh_TW,程序会知道使用繁体中文显示可读信息。如果设置LC_ALL的效果同分别设置所有的位置变量为同一个值有相同的效果。LANG用来作为没有设置地区变量的缺省值,为了查看Unix系统所有的地区列表,运行locale -a命令。
在Windows,地区配置是通过“地区和语言选项”控制面板管理的,可以从已存在的地区查看选择,甚至可以自定义(会是个很讨厌的复杂事情)许多显示格式习惯。
Subversion客户端,svn通过两种方式支持当前的地区配置。首先,它会注意LC_MESSAGES的值,然后尝试使用特定的语言打印所有的信息,例如:
$ export LC_MESSAGES=de_DE $ svn help cat cat: Ausgabe des Inhaltes der angegebenen Dateien oder URLs Aufruf: cat ZIEL... …
这个行为在Unix和Windows上同样工作,注意,尽管有时你的操作系统支持某个地区,Subversion客户端可能不能讲特定的语言。为了制作本地化信息,志愿者可以提供各种语言的翻译。翻译使用GNU gettext包编写,相关的翻译模块使用.mo作为后缀名。举个例子,德国翻译文件为de.mo。翻译文件安装到你的系统的某个位置,在Unix它们会在/usr/share/locale/,而在Windows它们通常会在Subversion安装的\share\locale\目录。一旦安装,一个命名在程序后面的模块会为此提供翻译。举个例子,de.mo会最终安装到/usr/share/locale/de/LC_MESSAGES/subversion.mo,通过查看安装的.mo文件,我们可以看到Subversion支持的语言。
第二种支持地区设置的方式包括svn怎样解释你的输入,版本库使用UTF-8保存了所有的路径,文件名和日志信息。在这种情况下,版本库是国际化的—也就是版本库准备接受任何人类的语言。这意味着,无论如何Subversion客户端要负责发送UTF-8的文件名和日志信息到版本库,为此,必须将数据从本地位置转化为UTF-8。
举个例子,你创建了一个文件叫做caffè.txt,然后提交了这个文件,你写的日志信息是“Adesso il caffè è più forte”,文件名和日志信息都包含非ASCII字符,但是因为你的位置设置为it_IT,Subversion知道把它们作为意大利语解释,在发送到版本库之前,它用一个意大利字符集转化数据为UTF-8。
注意当版本库要求UTF-8文件名和日志信息时,它不会注意到文件的内容,Subversion会把文件内容看作字节串,没有任何客户端和服务器会尝试理解或是编码这些内容。