|
�ֲ�ʽ Git
Ϊ�˱�����Ŀ�е����п����߷������룬����������һ̨���������Զ�� Git
�ֿ⡣����ǰ�漸�µ�ѧϰ�������Ѿ�ѧ����һЩ�����ı��ع��������������õ������������������Ҫѧϰ���������
Git ����֯����ɷֲ�ʽ�������̡�
�ر��ǣ�����Ϊ��Ŀ������ʱ�����Ǹ���ô�����ܷ���ά���߲��ɸ��£�������Ϊ��Ŀά����ʱ���ָ�������Ч�������������ߵ��ύ��
�ֲ�ʽ��������
ͬ��ͳ�ļ���ʽ�汾����ϵͳ��CVCS����ͬ��������֮���Э����ʽ���� Git
�ķֲ�ʽ���Զ���ø�Ϊ���������ڼ���ʽϵͳ�ϣ�ÿ�������߾����������ڼ������ϵĽڵ㣬�˴˵Ĺ�����ʽ����������
Git �����У�ÿ��������ͬʱ�����Žڵ�ͼ������Ľ�ɫ�������˵��ÿһ�������߶����Խ��Լ��Ĵ��빱������һ�������ߵIJֿ��У����߽����Լ��Ĺ����ֿ⣬���������������Լ��Ĺ�����ʼ��Ϊ�Լ��IJֿ�״��롣���ǣ�Git
�ķֲ�ʽЭ����������������ֲ�ͬ�Ĺ������̣��һ��ڽ��������½ڽ��ܼ��ֳ�����Ӧ�÷�ʽ�����ֱ����۸��Ե���ȱ�㡣�����ѡ�����е�һ�֣����߽��������Ӧ�õ����Լ�����Ŀ�С�
����ʽ������
ͨ��������ʽ��������ʹ�õĶ��ǵ���Э��ģ�͡�һ����Ŵ���ֿ�����ķ����������Խ������п������ύ�Ĵ��롣���еĿ����߶�����ͨ�Ľڵ㣬��Ϊ���ļ������������ߣ�ƽʱ�Ĺ������Ǻ����IJֿ�ͬ�����ݣ���ͼ
5-1����
ͼ 5-1. ����ʽ������
������������ߴ����IJֿ��¡����������ͬʱ����һЩ������ôֻ�е�һ�������߿���˳���ذ��������͵��������������ڶ������������ύ������֮ǰ�����������غϲ��������ϵ����ݣ������ͻ֮������������ݵ������������ϡ���
Git ����ô��Ҳ�������⣬��ͺñ������� Subversion�������� CVCS��һ�������Ժܺõع�����
�������ŶӲ��Ǻܴ��ߴ�Ҷ��Ѿ�ϰ����ʹ�ü���ʽ�������̣���ȫ���Բ������ּ�ģʽ��ֻ��Ҫ���ú�һ̨���ķ�����������ÿ�����������ݵ�Ȩ�ޣ��Ϳ��Կ�չ�����ˡ�������ύ����ʱ�г�ͻ��
Git �����Ͳ������û��������˴��룬��ֱ�Ӳ��صڶ����˵��ύ��������͵��ڸ����ύ�ߣ�������������ͨ�������fast-forward�����ϲ������������ȡ���������������ֹ������ͻ�ϲ����ܼ��������µ��ύ����������˶���Ϥ���˽�����ģʽ�Ĺ�����ʽ������ʹ��Ҳ�dz��㷺��
���ɹ���Ա������
���� Git ����ʹ�ö��Զ�ֿ̲⣬�����߱���Խ����Լ��Ĺ����ֿ⣬������д���ݲ����������ˣ���ͬʱ�ֿ��Դӱ��˵IJֿ�����ȡ���ǵĸ��¹�������������ͨ�������и������Źٷ���������Ŀ�ֿ⣨blessed
repository�������������ɴ˲ֿ��¡��һ���Լ��Ĺ����ֿ⣨developer public����Ȼ���Լ����ύ������ȥ������ٷ��ֿ��ά������ȡ���ºϲ�������Ŀ��ά�������Լ��ı���Ҳ�и���¡�ֿ⣨integration
manager���������Խ���Ĺ����ֿ���ΪԶ�ֿ̲����ӽ������������������ϲ������ɷ�֧��Ȼ�������͵��ٷ��ֿ⡣�������̿���������ͼ
5-2 ��ʾ��
��Ŀά���߿����������ݵ������ֿ� blessed repository��
2. �����߿�¡�˲ֿ⣬�����д�´��롣
�������������ݵ��Լ��Ĺ����ֿ� developer public�� 4. �����߸�ά���߷����ʼ���������ȡ�Լ�����������
ά�������Լ����ص� integration manger �ֿ��У��������ߵIJֿ��ΪԶ�ֿ̲⣬�ϲ����²������ԡ�
ά���߽��ϲ���ĸ������͵����ֿ� blessed repository��
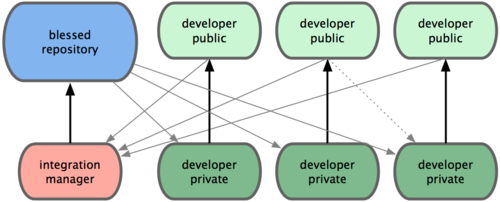
ͼ 5-2. ���ɹ���Ա������
�� GitHub ��վ��ʹ�õ����ľ������ֹ����������ǿ��Ը��ƣ�fork
�༴��¡��ij����Ŀ���Լ����б��У���Ϊ�Լ��Ĺ����ֿ⡣����Լ��ĸ����ύ������ֿ⣬�����˶����Կ������ÿ�θ��¡���ô������Ҫ���ŵ����ڣ���������Լ��Ľ�����������������صȴ�ά���ߴ������ύ�ĸ��£���ά����Ҳ�������Լ��Ľ��࣬�κ�ʱ���Թ�������������Ĺ��ס�
˾����븱�ٹ�����
����ʵ����һ�ֹ������ı��塣һ�㳬���͵���Ŀ�Ż��õ������Ĺ�����ʽ������ӵ������Э�������ߵ�
Linux �ں���Ŀ������ˡ��������ɹ���Ա�ֱ�����Ŀ�е��ض����֣����Գ�Ϊ���٣�lieutenant������������Щ���ɹ���Աͷ�ϻ���һλ����ͳ����ܼ��ɹ���Ա����Ϊ˾��٣�dictator����˾���ά���IJֿ������ṩ����Э������ȡ���¼��ɵ���Ŀ���롣�������̿�������ͼ
5-3 ��ʾ��
- һ��Ŀ��������Լ������Է�֧�Ϲ������������ڵظ������ɷ�֧��dictator �ϵ� master���ܺϡ�
- ���٣�lieutenant������ͨ�����ߵ����Է�֧�ϲ����Լ��� master ��֧�С�
- ˾��٣�dictator�������и��ٵ� master ��֧�����Լ��� master ��֧��
- ˾��٣�dictator�������ɺ�� master ��֧���͵������ֿ� blessed repository
�У��Ա����������������Դ�Ϊ���������ܺϡ�
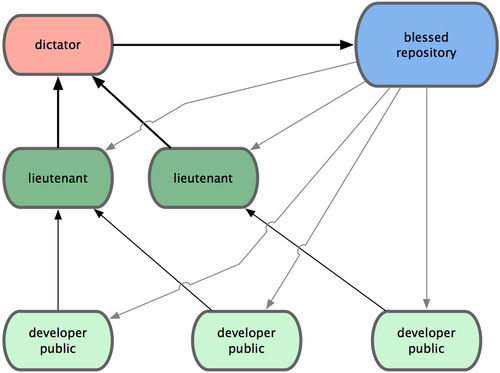
ͼ 5-3. ˾����븱�ٹ�����
���ֹ������̲������ã�ֻ�е���Ŀ��Ϊ���ӣ�������Ҫ�༶�����ʱ���Ż����ֳ����ơ��������ַ�ʽ����Ŀ�ܸ����ˣ���˾��٣����Ѵ�����ɢ�ļ��ɹ���ί�и���ͬ��С�鸺���˷ֱ����������ͳ����������˸��˵�ְ��������ȷ��Ҳ���׳�������ע�����˷ֶ���֮����
���Ͻ��ܵ��dz����ķֲ�ʽϵͳ����Ӧ�õĹ������̣���Ȼ��ֹ�� Git����ʵ�ʵĿ��������У�����ܻ���������Ϊ�������ض�����������仯�Ĺ�����ʽ������������Ӧ���Ѿ�������������Լ���Ҫ�����ַ�ʽ��չ�����ˡ��½��һ����پ�Щ���ӣ�������ʽ�������е�ÿ����ɫ����Ӧ����β�����
Ϊ��Ŀ������
��������������ѧϰһ����Ϊ��Ŀ�����ߣ�������Щ�����Ĺ���ģʽ��
����Ҫ˵�������Э��������ĺ��ѣ�Git ��������ǵ�Э����ʽ����Ը�ʽ������û�й̶�����ķ�ʽ��ѭ����ÿ����Ŀ�ľ�������ֶ��ٻ���Щ��ͬ������˵�����ߵĹ�ģ����ѡ��Ĺ������̣�ÿ���˵��ύȨ�ޣ��Լ�
Git ����ȵȣ�����Ӱ�쵽���������ϸ�ڡ�
�������Dz����߹�ģ����Ŀ���ж��ٿ������Ǿ����ύ����ģ��������Ƕ���أ�������������˵�С�Ŷӣ�һ���Լֻ�м����ύ���������ʲô������Ŀ�Ļ������ˡ���Ҫ���ڴ�˾����ߴ���Ŀ�У������߿��Զൽ��ǧ��ÿ�춼����ʮ�����ϰٸ������ύ���������ֲ��������Ӱ���������ģ�Խ�Ƕ���˲����������Խ�ѱ�֤ÿ�κϲ���ȷ���������ڹ����Ĵ��룬���ܻ���Ϊ�ϲ����������˵ĸ��¶���ù�ʱ�������ܴ������С����Ѿ��ύ��ȥ�ĸ��£�Ҳ�����ڵ�����˺ϲ��Ĺ����б�ù�ʱ����ô�����Ǹ�����������ȷ�����������µģ��ύ�IJ���Ҳ�ǿ��õ��أ�
������������Ŀ�����õĹ��������Ǽ���ʽ�ģ�ÿ�������߶����е�ͬ��дȨ�ޣ���Ŀ�Ƿ���ר�˸��������в������Dz������в���������ͬ�и��ģ�peer-review����ͨ����˵ģ����Ƿ������˹��̣����ʹ�ø���ϵͳ�������Dz�������ֻ����˸����ύ��
��������ύȨ�ޡ��л�û��������Ŀ�ύ���µ�Ȩ�ޣ������ȫ��ͬ��ֱ�Ӿ������ղ��������Ĺ��������������ֱ���ύ���£��Ǹ���ι����Լ��Ĵ����أ��Dz��Ǹ��и�ʲô���ԣ���ÿ�ι��״�����ж��������ύƵ���أ�
����������Щ���ⶼ�������Ӱ�쵽���ղ��õĹ����������������һ���һϵ���ɼ��뷱�ľ��������У���һ�������˺���ʵ��ʱ��Ӧ�ÿ��Խ����������ӣ�����������������ʵ����Ҫ�����Լ��Ĺ�������
�ύָ��
��ʼ�����ض�����֮ǰ�������˽������д�ύ˵����һ�ݺõ��ύָ�Ͽ�����Э���߸����ɸ���Ч����ϡ�Git
��Ŀ�������ṩ��һ���ĵ���Git ��ĿԴ����Ŀ¼�� Documentation/SubmittingPatches���������˴�����ʾ������α��ύ˵�����ύ��������һ���㡣
���ȣ��벻Ҫ�ڸ������ύ����İ��ַ���whitespace����Git ���ּ���������ķ��������ύ֮ǰ��������
git diff --check����ѿ��ܵĶ�����ַ������г����������ʾ�������Ѿ����ն�����ʾΪ��ɫ�İ��ַ���
X �滻����
$ git diff --check
lib/simplegit.rb:5: trailing whitespace.
+ @git_dir = File.expand_path(git_dir)XX
lib/simplegit.rb:7: trailing whitespace.
+ XXXXXXXXXXX
lib/simplegit.rb:26: trailing whitespace.
+ def command(git_cmd)XXXX
�������ύ֮ǰ��Ϳ��Կ����������⣬��ʱ��������������������ߡ�
���������뽫ÿ���ύ�������һ�������ܡ����ҿ��ܵĻ����ʵ��طֽ�Ϊ���С���£��Ա�ÿ��С���ύ�����������⡣�벻Ҫ����ĩ���ʹ�һ���Խ��������⣬������ϵ���һ���ύ������������Ҳ�뾡���������ݴ�����֮ǰ�ĸĶ��ֽ�Ϊÿ����һ�����⣬�ٷֱ��ύ�ͼ�ע˵������������������Ķ�����ͬһ���ļ����������Կ�
git add --patch �ķ�ʽ���������������ݴ��������ǻ��ڵ���������ϸ���ܣ������������С�ύ���ǻ�����һ��Ĵ��ύ�����շ�֧ĩ�˵���Ŀ����Ӧ�û���һ���ģ����ֽ��֮���������������߸��ġ���ô��Ҳ�����Լ�����ȡ��ij���ض�������������ǽ��ڵ����½���һЩ��д�ύ��ʷ��ͬ�ݴ������ļ��ɺ��ߣ��Ա����յõ�һ���ɾ������壬������������ύ��ʷ��
�����Ҫ���ǵ����ύ˵����д��д�úÿ����ô��Э�����������ɡ�һ����˵���ύ˵�����������һ�����ڣ�50
���ַ����£�������Ҫ�������������ݣ��տ�һ�к���չ����ϸע�⡣Git ��Ŀ������Ҫ������д�꾡ע�⣬���������������ɣ��Լ�ǰ��ͬʵ��֮��ıȽϣ�����Ҳ�ý���������������⣬�ύ˵��Ӧ������ʹ����ʽ��̬�����磬��Ҫ˵��
��I added tests for�� �� ��Adding tests for�� ��Ӧ���� ��Add tests
for�������������� tpope.net �� Tim Pope ԭ�����ύ˵����ʽģ�棬���ο���
���θ��µļ�Ҫ������50 ���ַ����ڣ�
�����Ҫ���˴�չ���꾡����������������� 72 ���ַ����ڡ�
ijЩ����£���һ�еļ�Ҫ�����������ʼ����⣬���ಿ����Ϊ�ʼ����ġ�
���Ŀ����DZ�Ҫ�ģ����������ߣ���Ȼû�������������ۣ���
�������һ��rebase �����Ĺ��߾Ϳ��ܻ��Ի�
������к��ٽ�һ����������˵����
- ����ʹ����������Ŀ�о�ʽ��
- һ���Ե����ո�����̻������Ǻ���Ϊÿ����Ŀ����ʼ����ÿ����Ŀ����һ���и�����
�������ﰴ�Լ���Ŀ��Լ�������������仯���������ύ˵�����������ĸ�ʽ����д���ö�����Ϳ��Ա��ʮ�ּ�Git
��Ŀ������������Ҫ��ģ���ǿ�ҽ����㵽 Git ��Ŀ�ֿ������� git log --no-merges
�����������ύ��ʷ��˵��������д�ġ�����ע��������ڻ�û�п�¡ git ��ĿԴ���룬��ʱ�� git clone
git://git.kernel.org/pub/scm/git/git.git �ˡ���
Ϊ��������ڽ����������ӣ�����������������ʾ���У��Ҷ����������ָ�ʽ����ʹ��
-m ѡ���ύ git commit�������뻹�ǰ�����֮ǰ����������ѧ������͵���ķ�ʽ��
˽�е�С���Ŷ�
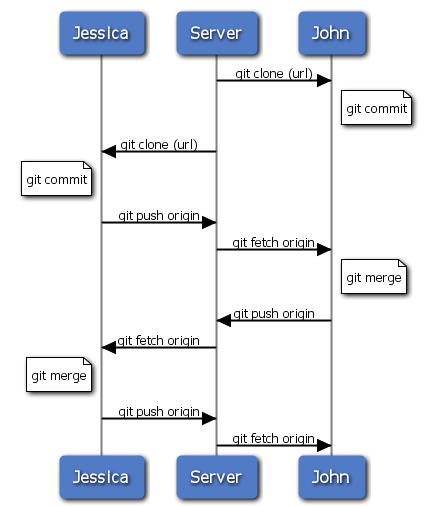
���Ǵ���������ʼ��һ��˽����Ŀ������һ��Э���Ļ�������һ����λ�����ߡ�����˵˽�У���ָԴ���벻��������������������Ŀ�ֿ⡣��������������������������ݵ��ֿ��Ȩ�ޡ�
��������£����ǿ����� Subversion ����������ʽ�汾����ϵͳ���ƵĹ�������Э��������Ȼ���Եõ�
Git �����������ô��������ύ�����ٷ�֧��ϲ��ȵȣ����������̻��Dz��ġ���Ҫ�������ڣ��ϲ����������ڿͻ��˶��Ƿ������ϡ�������������������������һ��ʹ��ͬһ�������ֿ⣬�ᷢ��Щʲô����һ���ˣ�John����¡�˲ֿ⣬����Щ���£��ڱ����ύ���������������ʡ���˳�����ʾ����
... �����Խ�Լ���档��
# John's Machine
$ git clone john@githost:simplegit.git
Initialized empty Git repository in /home/john/simplegit/.git/
...
$ cd simplegit/
$ vim lib/simplegit.rb
$ git commit -am 'removed invalid default value'
[master 738ee87] removed invalid default value
1 files changed, 1 insertions(+), 1 deletions(-)�ڶ��������ߣ�Jessica��һ����ô������¡�ֿ⣬�ύ���£�
# Jessica's Machine
$ git clone jessica@githost:simplegit.git
Initialized empty Git repository in /home/jessica/simplegit/.git/
...
$ cd simplegit/
$ vim TODO
$ git commit -am 'add reset task'
[master fbff5bc] add reset task
1 files changed, 1 insertions(+), 0 deletions(-)���ڣ�Jessica
�����Ĺ������͵��������ϣ�
# Jessica's Machine
$ git push origin master
...
To jessica@githost:simplegit.git
1edee6b..fbff5bc master -> masterJohn Ҳ���������Լ��Ĺ�����ȥ��
# John's Machine
$ git push origin master
To john@githost:simplegit.git
! [rejected] master -> master (non-fast forward)
error: failed to push some refs to 'john@githost:simplegit.
git'John �����Ͳ��������أ���Ϊ Jessica �Ѿ��������µ�������ȥ����ע�⣬�ر������ù���
Subversion �Ļ���������ʵ�ĵ��������ļ���������ͬһ���ļ���ͬһ���ط���Subversion
���ڷ��������Զ��ϲ��ύ�����ĸ��£��� Git ��������ڱ��غϲ���������͡����ǣ�John ���ò��Ȱ�
Jessica �ĸ�����������
$ git fetch origin
...
From john@githost:simplegit
+ 049d078...fbff5bc master -> origin/master�˿̣�John
�ı��زֿ���ͼ 5-4 ��ʾ��
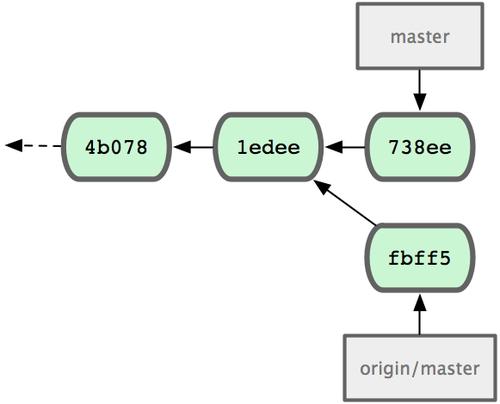
ͼ 5-4. John �IJֿ���ʷ
��Ȼ John ������ Jessica ���͵���������������£�fbff5������Ŀǰֻ��
origin/master ָ��ָ����������ǰ�ı��ط�֧ master ��Ȼָ���Լ��ĸ��£�738ee����������Ҫ�Ȱ������ύ�ϲ����������ܼ����������ݣ�
$ git merge origin/master
Merge made by recursive.
TODO | 1 +
1 files changed, 1 insertions(+), 0
deletions
(-)���ã��ϲ����̷dz�˳����û�г�ͻ������ John ���ύ��ʷ��ͼ
5-5 ��ʾ��
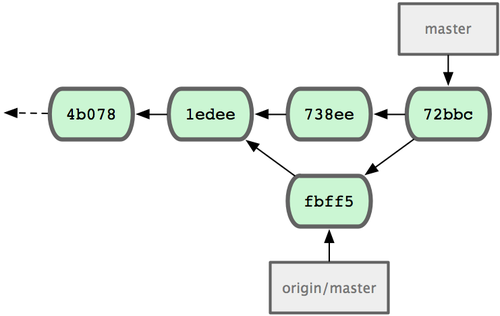
ͼ 5-5. �ϲ� origin/master �� John �IJֿ���ʷ
���ڣ�John Ӧ���ٲ���һ�´����Ƿ���Ȼ����������Ȼ�ϲ������72bbc�����͵��������ϣ�
$ git push origin master
...
To john@githost:simplegit.git
fbff5bc..72bbc59 master -> master���գ�John
���ύ��ʷ��Ϊͼ 5-6 ��ʾ��
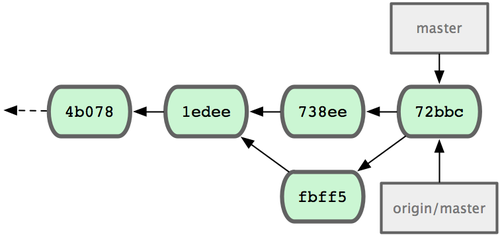
ͼ 5-6. ���ͺ� John �IJֿ���ʷ
�������ʱ�䣬Jessica �Ѿ���ʼ����һ�����Է�֧�����ˡ���������
issue54 ���ύ�����θ��¡�����û������ John �ύ�ĺϲ�����������ύ��ʷ��ͼ 5-7 ��ʾ��
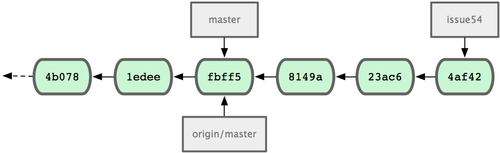
ͼ 5-7. Jessica ���ύ��ʷ
Jessica ��Ҫ�Ⱥͷ������ϵ�����ͬ�����������������ݣ�
# Jessica's Machine
$ git fetch origin
...
From jessica@githost:simplegit
fbff5bc..72bbc59 master -> origin/master����
Jessica �ı��زֿ���ʷ����� John �������ύ��738ee �� 72bbc������ͼ 5-8
��ʾ��
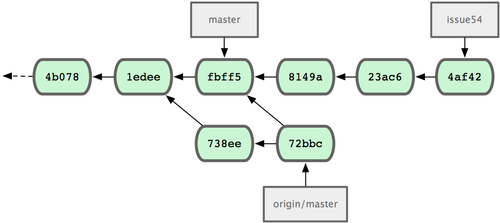
ͼ 5-8. ��ȡ John �ĸ���֮�� Jessica ���ύ��ʷ
��ʱ��Jessica �����Է�֧�ϵĹ����Ѿ���ɣ�����������������֮ǰ����ȷ����Ҫ�����������ݾ�����ʲô����������
git log �鿴��
$ git log --no-merges origin/master
^issue54
commit 738ee872852dfaa9d6634e0dea7a324040193016
Author: John Smith <jsmith@example.com>
Date: Fri May 29 16:01:27 2009 -0700
removed invalid default value���ڣ�Jessica
���Խ����Է�֧�ϵĹ������� master ��֧��Ȼ���ٲ��� John �Ĺ�����origin/master�����Լ���
master ��֧����������ͻط���������Ȼ�������л�����֧���ܼ����������ݣ�
$ git checkout master
Switched to branch "master"
Your branch is behind 'origin/master'
by 2 commits, and can be fast-forwarded.
Ҫ�ϲ� origin/master �� issue54 ��֧��˭��˭��û�й�ϵ����Ϊ���Ƕ������Σ�upstream������ע������ֲ�ĸ������ǻ����ɺӵ�Դͷ����������
upstream ��ָ���µ��ύ������������ν�Ⱥ�˳�����պϲ�������ݿ��ն���һ���ģ��������ύ��ʷ����������Щ�Ⱥ���Jessica
ѡ���Ⱥϲ� issue54��
$ git merge issue54
Updating fbff5bc..4af4298
Fast forward
README | 1 +
lib/simplegit.rb | 6 +++++-
2 files changed, 6 insertions(+), 1
deletions
(-)����������û�г�ͻ����������һ�μ�������� Jessica ��ʼ�ϲ�
John ������origin/master����
$ git merge origin/master
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1
deletions
(-)���еĺϲ����dz��ɾ������� Jessica ���ύ��ʷ��ͼ 5-9
��ʾ��
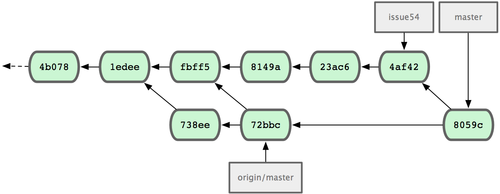
ͼ 5-9. �ϲ� John �ĸ��º� Jessica ���ύ��ʷ
���� Jessica �Ѿ��������Լ��� master ��֧�з��� origin/master
�����¸Ķ��ˣ�������Ӧ�ÿ��Գɹ��������ĺϲ�������������ϣ����� John ��ʱû��������������������
$ git push origin master
...
To jessica@githost:simplegit.git
72bbc59..8059c15 master -> master
���ˣ�ÿ�������߶��ύ�����ɴΣ��ҳɹ��ϲ��˶Է��Ĺ����ɹ������µ��ύ��ʷ��ͼ
5-10 ��ʾ��
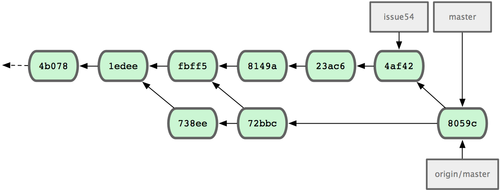
ͼ 5-10. Jessica �������ݺ���ύ��ʷ
���Ͼ������Э����ʽ֮һ�������Լ������Է�֧�й���һ��ʱ�䣬��ɺ�ϲ����Լ���
master ��֧��Ȼ�����غϲ� origin/master �ϵĸ��£�����еĻ��������ƻ�Զ�̷�������һ���Э��������ͼ
5-11 ��ʾ��
ͼ 5-11. ���û������ֿ�Э����ʽ��һ�㹤������ʱ��
˽���ŶӼ�Э��
����������������һ���ģ��˽���Ŷ�Э��������м���С���ͷ�����������ԵĿ����ͼ��ɣ�������֮���Э�������������ġ�
���� John �� Jessica һ����ij������ A����ͬʱ Jessica
�� Josie һ������һ��� B����˾ʹ�õ��͵ļ��ɹ���Աʽ��������ÿ���鶼��һ������Ա���ɱ�����룬��������Ŀ���ֿ��
master ��֧�����п������ڴ���С��ķ�֧�Ͻ��С�
�����Ǹ��� Jessica ���ӽǿ������Ĺ������̡������뿪���������ԣ�ͬʱ�Ͳ�ͬС��Ŀ�����һ��Э������¡���ɱ��زֿ�������������ֿ�������
A�����Ǵ������µ� featureA ��֧���̶���д���룺
# Jessica's Machine
$ git checkout -b featureA
Switched to a new branch "featureA"
$ vim lib/simplegit.rb
$ git commit -am 'add limit to log function'
[featureA 3300904] add limit to log
function
1 files changed, 1 insertions(+), 1
deletions(-)
�˿̣�����Ҫ����Ŀǰ�Ľ�չ�� John�����������Լ��� featureA
��֧�ύ�������������� Jessica û��Ȩ���������ݵ����ֿ�� master ��֧��ֻ�м��ɹ���Ա�д�Ȩ�ޣ�������ֻ�ܽ��˷�֧����ȥͬ
John ��������
$ git push origin featureA
...
To jessica@githost:simplegit.git
* [new branch] featureA -> featureAJessica
���ʼ��� John ������������ featureA ��֧�ϵĽ�չ���ڵȴ����ķ���֮ǰ��Jessica
���������������� Josie һ�� featureB �ϵ����� B����Ȼ���ȴ����˷�֧���ֲ���Է������ϵ�
master Ϊ��㣺
# Jessica's Machine
$ git fetch origin
$ git checkout -b featureB origin/master
Switched to a new branch "featureB"���Jessica
�� featureB ���ύ�����ɸ��£�
$ vim lib/simplegit.rb
$ git commit -am 'made the ls-tree function recursive'
[featureB e5b0fdc] made the ls-tree function recursive
1 files changed, 1 insertions(+), 1 deletions(-)
$ vim lib/simplegit.rb
$ git commit -am 'add ls-files'
[featureB 8512791] add ls-files
1 files changed, 5 insertions(+), 0 deletions(-)
���� Jessica �ĸ�����ʷ��ͼ 5-12 ��ʾ��
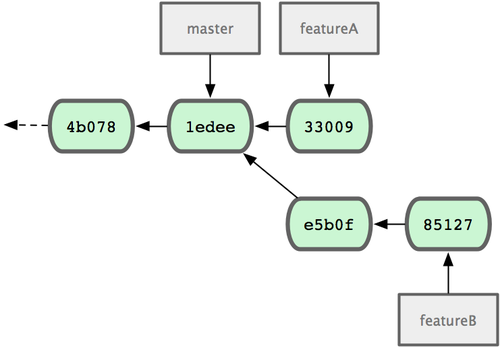
ͼ 5-12. Jessica �ĸ�����ʷ
Jessica ���������Լ��Ľ�չ��ȥ��ȴ�յ� Josie �����ţ�˵�����Ѿ����Լ��Ĺ����Ƶ��������ϵ�
featureBee ��֧�ˡ�������Jessica �ͱ����Ƚ� Josie �Ĵ���ϲ����Լ����ط�֧�У�������һ�����ͻط�����������
git fetch ���� Josie �����´��룺
$ git fetch origin
...
From jessica@githost:simplegit
* [new branch] featureBee -> origin/featureBee
Ȼ�� Jessica ʹ�� git merge ���˷�֧�ϲ����Լ���֧�У�
$ git merge origin/featureBee
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 4 ++++
1 files changed, 4 insertions(+), 0 deletions
(-)�ϲ���˳�����������и�С���⣺��Ҫ�����Լ��� featureB ��֧���������ϵ�
featureBee ��֧��ȥ����Ȼ��������ʹ��ð�ţ�:����ʽָ��Ŀ���֧��
$ git push origin featureB:featureBee
...
To jessica@githost:simplegit.git
fba9af8..cd685d1 featureB -> featureBee
���dzƴ�Ϊ_refspec_�������й��� Git refspec �����ۺ�ʹ�÷�ʽ���ڵھ�������ϸ������
��������John ���ʼ��� Jessica ��������������֮������Щ�ģ��Ѿ��ƻط�����
featureA ��֧��������Ŀ�¡����� Jessica ���� git fetch �����������ݣ�
$ git fetch origin
...
From jessica@githost:simplegit
3300904..aad881d featureA -> origin/featureA
������������� git log �鿴������Щʲô��
$ git log origin/featureA ^featureA
commit aad881d154acdaeb2b6b18ea0e827ed8a6d671e6
Author: John Smith <jsmith@example.com>
Date: Fri May 29 19:57:33 2009 -0700
changed log output to 30 from 25
������� John �Ĺ����ϲ����Լ��� featureA ��֧�У�
$ git checkout featureA
Switched to branch "featureA"
$ git merge origin/featureA
Updating 3300904..aad881d
Fast forward
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)Jessica
����һ��������ͬ������������
$ git commit -am 'small tweak'
[featureA ed774b3] small tweak
1 files changed, 1 insertions(+), 1 deletions(-)
$ git push origin featureA
...
To jessica@githost:simplegit.git
3300904..ed774b3 featureA -> featureA
���ڵ� Jessica �ύ��ʷ��ͼ 5-13 ��ʾ��
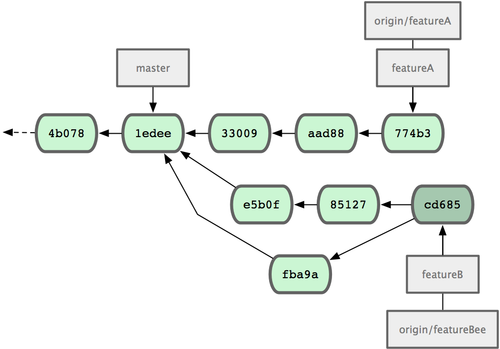
ͼ 5-13. �����Է�֧���ύ���º���ύ��ʷ
���ڣ�Jessica��Josie �� John ֪ͨ���ɹ���Ա�������ϵ�
featureA �� featureBee ��֧�Ѿ����ã����Բ��������ˡ��ڹ���Ա��ɼ��ɹ���������֧�ϱ���һ���µĺϲ��ύ��5399e������
fetch ������µ����غ��ύ��ʷ��ͼ 5-14 ��ʾ��
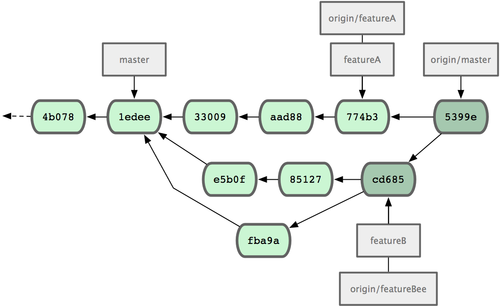
ͼ 5-14. �ϲ����Է�֧��� Jessica �ύ��ʷ
�����С����� Git ������Ϊ���������С��䲢�й����������Ժ�ǡ��ʱ�����кϲ���ͨ������Զ�̷�֧�ķ�ʽ���������������Ŀ�������Կ�չ���������ʹ��
Git ��С���ŶӼ�Э�����Ա�÷dz�������ɡ����Ϲ������̵�ʱ����ͼ 5-15 ��ʾ��
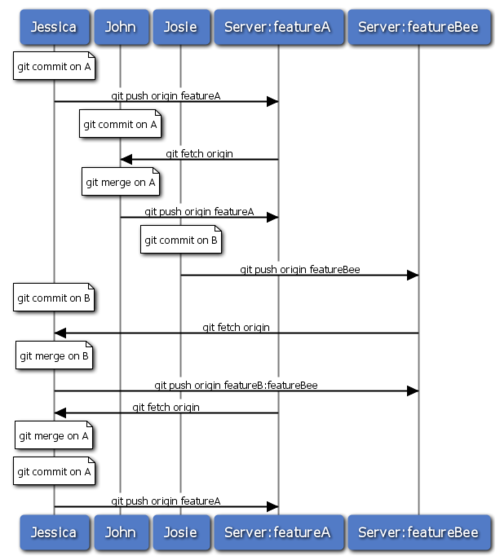
ͼ 5-15. �ŶӼ�Э���������̻���ʱ��
������С����Ŀ
����˵����˽����ĿЭ������Ҫ��������Ŀ�����ף��������Щ��ͬ�ˡ���Ϊ��û��ֱ�Ӹ������ֿ��֧��Ȩ�ޣ���Ѱ��������ʽ�ѹ����ɹ�������Ŀά���ˡ������������ַ�������һ��ʹ��
git �йܷ������ṩ�IJֿ⸴�ƹ��ܣ�һ����� fork������ repo.or.cz �� GitHub
��֧�������IJ���������������Ŀ����Ա��ϣ�����ʹ�������ķ�ʽ����һ�ַ�����ͨ�������ʼ������ļ�������
���������ַ�ʽ��������������Ҫ��¡ԭʼ�ֿ⣬�������Է�֧��չ���������������������£�
$ git clone (url)
$ cd project
$ git checkout -b featureA
$ (work)
$ git commit
$ (work)
$ git commit
������뵽�� rebase -i �����и����ȱ��������ύ���ֻ��������°����ύ֮��IJ��첹�����Է�����Ŀά��������
�C �йؽ���ʽ�ܺϲ�����ϸ�ڼ������¡�
����������Է�֧�������ύ����Ŀά����֮ǰ���ȵ�ԭʼ��Ŀ��ҳ���ϵ����Fork����ť������һ���Լ���д�Ĺ����ֿ⣨��ע���������
url ���֣����պ��������ӣ�Ӧ���� git://githost/simplegit.git����Ȼ�˲ֿ�����Ϊ���صĵڶ���Զ�˲ֿ⣬���ҳ�Ϊ
myfork��
$ git remote add myfork (url)����Ҫ�����ظ������͵�����ֿ⡣Ҫ�ǽ�Զ��
master �ϲ����������ƻ�ȥ����������������Է�֧����ȥ���øɴ�ֱ�ӡ����ң�������Ŀά����δ������Ĺ��Ļ���������ֱ�Ӻϲ�����
cherry pick���������û��ˣ�rewind���Լ��� master ��֧������ά���ߺϲ��� cherry-pick
����Ĺ���������ܻ����Դ����ǵĸ�����ͬ����Щ���롣�ðɣ������Ȱ� featureA ��֧��������ȥ��
$ git push myfork featureAȻ��֪ͨ��Ŀ����Ա��������ץȡ��Ĵ��롣ͨ�����ǰ�����½���
pull request������ֱ���� GitHub ����վ�ṩ�� ��pull request�� ��ť�Զ���������֪ͨ�����ֹ���
git request-pull �������������ʸ���Ŀ����Ա��
request-pull �������������������һ���DZ������Է�֧��ʼǰ��ԭʼ��֧���ڶ���������Է���ץȡ��
Git �ֿ� URL����ע�������� myfork ��ָ�ģ��Լ���д�Ĺ����ֿ⣩����������Jessica
��Ҫ�� John ��һ�� pull requst����֮ǰ���Լ������Է�֧���ύ�����θ��£����ѷ�֧�����Ƶ��˷������ϣ��������и�����ῴ����
$ git request-pull origin/master myfork
The following changes since commit 1edee6b1d61823a2de3b09c160d7080b8d1b3a40:
John Smith (1):
added a new function
are available in the git repository at:
git://githost/simplegit.git featureA
Jessica Smith (2):
add limit to log function
change log output to 30 from 25
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)
��������ݿ���ֱ�ӷ��ʼ��������ߣ����Ǿͻ��������Ǵ��Ĵ��ύ��ʼ��֧��ȥ�ģ��õ�����ȥץȡ�µĴ��룬�Լ��µĴ�����������Щ���ܵȵȡ�
��������ʱ�����Լ��� master ��֧�ٷ� origin/master
ͬ���������Լ��Ĺ������������Է�֧�ϵ��������ȷ����������ɺͶ���������١�����ԭʼ���ɷ����仯������Ҳ�������ܺ��ṩ�µIJ�������������Ҫ��ʼ�ڶ������ԵĿ�������Ҫ��ԭ�������͵����Է�֧�ϼ��������ǰ�ԭʼ
master ��ʼ��
$ git checkout -b featureB origin/master
$ (work)
$ git commit
$ git push myfork featureB
$ (email maintainer)
$ git fetch origin
���ڣ�A��B �������Է�֧�������ţ���ͬ��Ͳ������Ŷ��ӣ������е���������������ʱ�����Էֱ��ͷд���������ܺϣ������ģ������õ������Դ���Ľ�����ӡ���ͼ
5-16 ��ʾ��
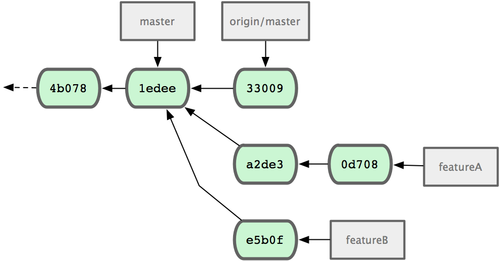
ͼ 5-16. featureB �Ժ���ύ��ʷ
������Ŀ����Ա��������������ύ�IJ�������Ҫ�������ύ�ĵ�һ����֧��ȴ������Ϊ�������һ�£��ϲ���������ȷ�ɾ�����ɡ������Ҫ���ٴ��ܺϵ����µ�
origin/master�������س�ͻ��Ȼ�������ύ����ģ�
$ git checkout featureA
$ git rebase origin/master
$ git push -f myfork featureA
��Ȼ�������д�ύ��ʷ����ͼ 5-17 ��ʾ��
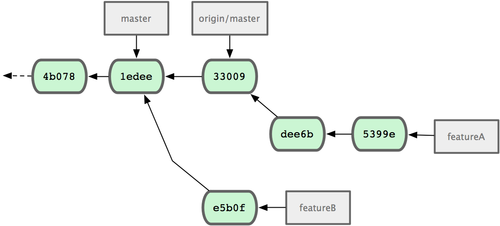
ͼ 5-17. featureA �����ܺϺ���ύ��ʷ
ע�⣬��ʱ���ͷ�֧����ʹ�� -f ѡ���ע����ʾ force���������ǿ����д���滻Զ�����е�
featureA ��֧����Ϊ�µ� commit ����ԭ���ĺ������¡���Ȼ��Ҳ����ֱ�����͵���һ���µķ�֧��ȥ���������
featureAv2��
�ٿ�����һ�����Σ�����Ա�����ڶ�����֧�����˼·��ӱ������������¾���ʵ�֡�����ֻ���Ե�ǰ
origin/master ��֧Ϊ������ʼһ���µ����Է�֧ featureBv2��Ȼ���ԭ���� featureB
�ĸ����ù����������ͻ����Ҫ������ʵ�ֲ��ִ��룬Ȼ�����Է�֧������ȥ��
$ git checkout -b featureBv2 origin/master
$ git merge --no-commit --squash featureB
$ (change implementation)
$ git commit
$ git push myfork featureBv2
����� --squash ѡ�Ŀ���֧�ϵ����и���ȫ����Ӧ�õ���ǰ��֧�ϣ���
--no-commit ѡ����� Git ��ʱ�����Զ����ɺͼ�¼���ϲ����ύ����������Ϳ�����ԭ����������ϣ�����������ֱ�����һ���ύ��
���ˣ����ڿ��������Աץȡ featureBv2 �ϵ����´����ˣ���ͼ
5-18 ��ʾ��
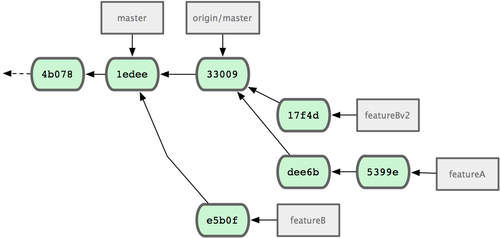
ͼ 5-18. featureBv2 ֮����ύ��ʷ
�����Ĵ�����Ŀ
���������Ŀ��������һ���Լ��Ľ��ܲ������̣���Ӧ��ע��������ϸ�ڡ���������Ŀ������ͨ���������ʼ��б����ܲ������������������������ӡ�
������������������������Σ�Ϊÿ�������������������Է�֧������֮ͬ����������ύ��Щ����������Ҫ�����Լ���д�Ĺ����ֿ⣬Ҳ���ý��Լ��ĸ������͵��Լ��ķ���������ֻ�轫ÿ���ύ�IJ��������Ե����ʼ��ķ�ʽ���η��͵��ʼ��б��м��ɡ�
$ git checkout -b topicA
$ (work)
$ git commit
$ (work)
$ git commit
���һ�������������ύҪ�����ʼ��б������ǿ����� git format-patch
���������� mbox ��ʽ���ļ�Ȼ����Ϊ�������͡�ÿ���ύ�����װΪһ�� .patch ���� mbox
�ļ���������ֻ����һ���ʼ����ʼ���������ύ��Ϣ����ע��������ǰ�������ӣ����ʼ����ݰ����������ĺ� Git
�汾�š����ַ�ʽ������ڽ��ܲ���ʱ�Կɱ���ԭ�����ύ��Ϣ���뿴�����������ӣ�
$ git format-patch -M origin/master
0001-add-limit-to-log-function.patch
0002-changed-log-output-to-30-from-25.patchformat-patch
�������δ��������ļ���������ļ���������� -M ѡ������ Git ����Ƿ��ж��ļ����������ύ�����������������ļ������ݣ�
$ cat 0001-add-limit-to-log-function.patch
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep
17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] add limit to log function
Limit log functionality to the first 20
---
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index 76f47bc..f9815f1 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -14,7 +14,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log #{treeish}")
+ command("git log -n 20 #{treeish}")
end
def ls_tree(treeish = 'master')
--
1.6.2.rc1.20.g8c5b.dirty
����ж�����Ϣ��Ҫ���䣬���ֲ�������ύ��Ϣ��˵�������Ա༭��Щ�����ļ����ڵ�һ��
--- ��֮ǰ����˵��������Ҫ������IJ������ģ����������е� Limit log functionality
to the first 20 ���֡��������������������Ķ������ڲ��ɲ���ʱ���Ὣ�˺ϲ�������
��������ʼ��ͻ�������������Щ�����ļ���Ҳ����ֱ���������з��͡���Щ��ν���ܵ��ʼ��ͻ����������������Ű��������ʽ������ճ���������ʼ�����ʱ���п��ܻᶪʧ���з������ɿո�Git
�ṩ��һ��ͨ�� IMAP ���Ͳ����ļ��Ĺ��ߡ��������һ���ʾ���ͨ�� Gmail �� IMAP ���������͡����⣬��
Git Դ�������и� Documentation/SubmittingPatches �ļ���������ϸ���������������ʼ��������ص�����
������ ~/.gitconfig �ļ������� imap �ÿ��ѡ�����
git config ����ֱ����ã���Ȼֱ�ӱ༭�ļ������������ݸ���ݣ�
[imap]
folder = "[Gmail]/Drafts"
host = imaps://imap.gmail.com
user = user@gmail.com
pass = p4ssw0rd
port = 993
sslverify = false
������ IMAP ������û������ SSL��������������������У�����
host Ӧ���� imap:// ��ͷ���������� s �� imaps://�����������ļ������� git
send-email ����Ѳ�����Ϊ�ʼ����η��͵�ָ���� IMAP �������ϵ��ļ����У���ע���������
Gmail �� [Gmail]/Drafts �ļ��С����������������ò���Ӣ�ģ��˴����ļ��� Drafts
�������Ϊ��Ӧ�����ԡ�����
$ git send-email *.patch
0001-added-limit-to-log-function.patch
0002-changed-log-output-to-30-from-25.patch
Who should the emails appear to be from? [Jessica Smith
<jessica@example.com>]
Emails will be sent from: Jessica Smith <jessica@example.com>
Who should the emails be sent to? jessica@example.com
Message-ID to be used as In-Reply-To for the first email?
y
��������Git �����ÿ������������������������־��
(mbox) Adding cc: Jessica Smith <jessica@example.com>
from
\line 'From: Jessica Smith <jessica@example.com>'
OK. Log says:
Sendmail: /usr/sbin/sendmail -i jessica@example.com
From: Jessica Smith <jessica@example.com>
To: jessica@example.com
Subject: [PATCH 1/2] added limit to log function
Date: Sat, 30 May 2009 13:29:15 -0700
Message-Id: <1243715356-61726-1-git-send-email-jessica@example.com>
X-Mailer: git-send-email 1.6.2.rc1.20.g8c5b.dirty
In-Reply-To: <y>
References: <y>
Result: OK��� Gmail �ϴ� Drafts �ļ��У��༭��Щ�ʼ������ռ��˵�ַΪ�ʼ��б���ַ�������Ҫ���͵���Ҳ�ӵ�
Cc �б��У�����͡�
��
������Ҫ�����˳��� Git ��ĿЭ���Ĺ������̣�����һЩ����������Щ������������ߡ�����������Ҫ�������ά��
Git ��Ŀ������Ϊһ���ϸ����Ŀ����Ա�����Ǽ��ɾ�����
��Ŀ�Ĺ���
��Ȼ���Э�����ڹ��״����ͬʱ��Ҳ�ⲻ��Ҫά�������Լ�����Ŀ��������ô����������
format-patch ���ɵIJ��������Ǽ���Զ�˲ֿ���ij����֧�ϵı仯�ȵȡ��������ǹ�������ֿ⣬���ǰ�æ����յ��IJ���������Ҫͬ������Լ��ij�ֳ��ڿɳ����Ĺ�����ʽ��
ʹ�����Է�֧���й���
�����Ҫ�����µĴ����������þ��������Է�֧��������ʱ�����Է�֧�����������Ⳣ�ԣ��������硣�������������������IJ����������ȸ����DZߣ�ֱ����ʱ����ϸ�˲���Ϊֹ�������ķ�֧��������ص�����ؼ�������������
ruby_client �����������Ƶ������Դ�������������䡣Git ��Ŀ������ʱ���ѷ�֧���Ʒ����ڲ�ͬ�����ռ��£�����
sc/ruby_client ��˵������ sc ����˹��ġ����ڴӵ�ǰ���ɷ�֧Ϊ�������½���ʱ��֧��
$ git branch sc/ruby_client master
���⣬�����ϣ������ת����֧��ȥ������������ checkout -b��
$ git checkout -b sc/ruby_client master
���ˣ������Ѿ��������������Ž����˹��Ĵ���ϲ������ˡ�֮������һ����û�����⣬����پ����Dz������Ҫ�������ɡ�
���������ʼ��IJ���
����յ�һ��ͨ�����ʷ����IJ�������Ӧ���Ȱ���Ӧ�õ����Է�֧�Ͻ���������������Ӧ�ò����ķ�����git
apply ���� git am��
ʹ�� apply ����Ӧ�ò���
����յ��IJ����ļ����� git diff �������� Unix �� diff
�������ɣ����� git apply ������Ӧ�ò��������貹���ļ����� /tmp/patch-ruby-client.patch�������������У�
$ git apply /tmp/patch-ruby-client.patch����ĵ�ǰ����Ŀ¼�µ��ļ���Ч������������
patch -p1 ��һ����������Ϊ�ϸ��Ҳ�����ֻ��ҡ������ git diff ��ʽ�����IJ��������������Ӧ�����ӣ�ɾ�����������ļ�����Ȼ����ͨ��
patch �����Dz�����ô���ġ�������ע�⣬git apply ��һ�������Բ��������Ҳ����˵��Ҫô���в���������ȥ��Ҫôȫ�����������Բ������
patch ����������һ�����ļ������˲�������һ����ȴû�У�����һ�ֲ��ϲ��µ���״̬�������ܵ���˵��git
apply Ҫ�� patch �Ͻ����ࡣ��Ϊ�����Ǹ��µ�ǰ���ļ������Դ�������Զ������ύ��������ֹ�������Ӧ�ļ��ĸ���״̬��ִ���ύ���
��ʵ�ʴ�֮ǰ���������� git apply --check �鿴�����Ƿ��ܹ��ɾ�˳����Ӧ�õ���ǰ��֧�У�
$ git apply --check 0001-seeing-if-this-helps-the-gem.patch
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
���û���κ��������ʾ���ǿ���˳�����ɸò�������������⣬���˱��������Ϣ֮�⣬������᷵��һ�������״̬��������
shell �ű�������ڼ��״̬��
ʹ�� am ����Ӧ�ò���
���������Ҳ�� Git������������ format-patch ����������ĺϲ���������dz����ɡ���Ϊ��Щ�����г����ļ����ݲ����⣬��������������Ϣ���ύ��Ϣ�������������������
format-patch ���ɲ��������ڴ�ͳ�� diff �������ɵIJ�������ֻ���� git apply
������
���� format-patch ��������ʽ������Ӧ��ʹ�� git am
����Ӽ�������˵��git am �ܹ���ȡ mbox ��ʽ���ļ��������ּĴ��ı��ļ��������������ʣ���ʽ����
From �ӿո��Լ����ʲô������Ϣ����ɵ�����Ϊ�ָ��У�������ÿ���ʼ�������������
From 330090432754092d704da8e76ca5c05c198e71a8
Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] add limit to log function
Limit log functionality to the first
20���� format-patch ��������Ŀ�ͷ���У�Ҳ��һ����Ч�� mbox �ļ���ʽ�����������
git send-email ���㷢��һ������������Խ����ʼ����ص����أ�Ȼ������ git am ������Ӧ������������������ʼ��ͻ����ܽ������ʵ���Ϊ
mbox ��ʽ���ļ����Ϳ����� git am һ����Ӧ�����е����IJ�����
��������߽� format-patch ���ɵIJ����ļ��ϴ������� Request
Ticket һ����������ϵͳ����ô���������ص����أ��̶�ʹ�� git am Ӧ�øò�����
$ git am 0001-limit-log-function.patch
Applying: add limit to log function
��ῴ�������ɾ���Ӧ�õ����ط�֧�����Զ��������µ��ύ����������Ϣȡ���ʼ�ͷ
From �� Date���ύ��Ϣ��ȡ�� Subject �Լ������в���֮ǰ�����ݡ���������ʵ��������֮ǰչʾ���Ǹ�
mbox ���ʲ��������µ��ύ����Ϊ��
$ git log --pretty=fuller -1
commit 6c5e70b984a60b3cecd395edd5b48a7575bf58e0
Author: Jessica Smith <jessica@example.com>
AuthorDate: Sun Apr 6 10:17:23 2008 -0700
Commit: Scott Chacon <schacon@gmail.com>
CommitDate: Thu Apr 9 09:19:06 2009 -0700
add limit to log function
Limit log functionality to the first 20Commit
������ʾ���Dz��ɲ������ˣ��Լ����ɵ�ʱ�䡣�� Author ��������ʾ����ԭ���ߣ��Լ�����������ʱ�䡣
��ʱ������Ҳ���������ϲ������������������Ϊ���ɷ�֧�Ͳ����Ļ�����֧���̫Զ����Ҳ��������ΪijЩ����������δӦ�á���������£�git
am �ᱨ����ѯ�ʸ���ô����
$ git am 0001-seeing-if-this-helps-the-gem.patch
Applying: seeing if this helps the gem
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
Patch failed at 0001.
When you have resolved this problem run "git am
--resolved".
If you would prefer to skip this patch, instead run
"git am --skip".
To restore the original branch and stop patching run
"git am --abort".
Git �����г�ͻ���ļ�������ͻ�����ǣ���ͬ�ϲ����ܺϲ���һ��������İ취Ҳһ�����ȱ༭�ļ�������ͻ��Ȼ���ݴ��ļ����������
git am --resolved �ύ���������
$ (fix the file)
$ git add ticgit.gemspec
$ git am --resolved
Applying: seeing if this helps the gem
������� Git �����ܵش�����ͻ�������� -3 ѡ����������ϲ��������ǰ��֧δ�����ò����Ļ�������������ȣ���ô�����ϲ��ͻ�ʧ�ܣ����Ը�ѡ��Ĭ��Ϊ�ر�״̬��һ����˵������ò����ǻ���ij���������ύ�������ɵĻ��������ǿ���ͨ��ͬ������ȡ�����ͬ���ȣ������������ϲ�ѡ����Խ���ܶ��鷳��
$ git am -3 0001-seeing-if-this-helps-the-gem.patch
Applying: seeing if this helps the gem
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
Using index info to reconstruct a base tree...
Falling back to patching base and 3-way merge...
No changes -- Patch already applied.
����������ӣ����ڴ���IJ��������ٴ�һ�飬��Ȼ�������ͻ������Ϊ������
-3 ѡ��������ܴ����ظ����ң�������£�ԭ�еIJ����Ѿ�Ӧ�á�
����һ��Ӧ�ö������ʱ���õ� mbox ��ʽ�ļ��������� am ����Ľ���ģʽѡ��
-i�������ͻ��ڴ�ÿ������ǰͣס��ѯ�ʸ���β�����
$ git am -3 -i mbox
Commit Body is:
--------------------------
seeing if this helps the gem
--------------------------
Apply? [y]es/[n]o/[e]dit/[v]iew patch/[a]ccept all
�ڶ������Ҫ�������£����Ǹ��dz��õİ취��һ�������Ԥ���²������ݣ�ͬʱҲ������ѡ���ԵĽ��ɻ�����ijЩ������
�������в���������������������Կ��������������ǾͿ����ĵؽ���ǰ���Է�֧�ϲ������ڷ�֧��ȥ�ˡ�
���Զ�̷�֧
������������Լ��� Git �ֿ⣬���������͵��˲ֿ��У���ô�����õ��ֿ�ķ��ʵ�ַ�Ͷ�Ӧ��֧�����ƺͿ��Լ�ΪԶ�̷�֧��Ȼ���ڱ��ؽ��кϲ���
���磬Jessica ����һ���ʼ���˵����������е� ruby-client
��֧���Ѿ�ʵ����ij���dz������¹��ܣ�ϣ�������ܰ�æ����һ�¡����ǿ����Ȱ����IJֿ��ΪԶ�ֿ̲⣬Ȼ��ץȡ���ݣ������ٽ�����˵�ķ�֧��������������ԣ�
$ git remote add jessica git://github.com/jessica/myproject.git
$ git fetch jessica
$ git checkout -b rubyclient jessica/ruby-client
���Dz������ַ����ʼ���˵���и��ܰ��Ĺ���ʵ������һ��֧�ϣ�������ֻ������ץȡ���������ݣ�Ȼ�����Ǹ���֧�����ؾͿ����ˣ������ظ�����Զ�ֿ̲⡣
������������ͬ���˱��ֳ��ڵĺ�����ϵ����ǰ����Ҫ���������Լ��ķ�������������Ҳ��ҪΪÿ���˽�һ��Զ�̷�֧����Щ�������ύ���벹�������Ǻ�Ƶ��������ͨ���ʼ����ղ���Ч�ʻ���ߡ�ͬʱ�����Լ�Ҳ����ϣ�����ϰ�������֧��ȴֻ��ÿ����֧ȡһ�����������������ýű���������������ֱ��ʹ�ô���ֿ��йܷ��Ϳ��Լ˹��̡���Ȼ��ѡ����ַ�ʽȡ����������ߵ�ϲ�á�
ʹ��Զ�̷�֧������һ���ô����ܹ��õ��ύ��ʷ�����ܴ���ϲ��Dz��ǻ������⣬��������֪���÷�֧����ʷ�ֲ�㣬����Ĭ�ϻ�ӹ�ͬ���ȿ�ʼ�Զ����������ϲ�������
-3 ѡ�Ҳ������������������ڹ�ͬ�Ļ��㡣
���ֻ����ʱ������ֻ���� git pull ����ץȡԶ�ֿ̲��ϵ����ݣ��ϲ���������ʱ��֧�Ϳ����ˡ�һ���Ե�ץȡ������Ȼ����Ѹòֿ��ַ��ΪԶ�ֿ̲⡣
$ git pull git://github.com/onetimeguy/project.git
From git://github.com/onetimeguy/project
* branch HEAD -> FETCH_HEAD
Merge made by recursive.���ϴ���ȡ��
�������Է�֧���Ѻϲ����˹����ߵĴ��룬��ʱ�����ȡ���ˡ����ڽ��ع�һЩ֮ǰѧ��������Կ��彫Ҫ�ϲ������ɵ�����Щ���룬�Ӷ��������ǵ�������Щʲô���Ƿ����Ҫ���롣
һ�����ǻ��ȿ��£����Է�֧�϶�����Щ�������ύ�������� contrib
���Է�֧�ϴ����������������鿴�������������ύ��Ϣ�������� --not ѡ��ָ��Ҫ���εķ�֧ master�������ͻ����ظ����ύ��ʷ��
$ git log contrib --not master
commit 5b6235bd297351589efc4d73316f0a68d484f118
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Oct 24 09:53:59 2008 -0700
seeing if this helps the gem
commit 7482e0d16d04bea79d0dba8988cc78df655f16a0
Author: Scott Chacon <schacon@gmail.com>
Date: Mon Oct 22 19:38:36 2008 -0700
updated the gemspec to hopefully work
better�����Բ鿴ÿ���ύ�ľ����ġ����μǣ��� git log ��� -p ѡ�չʾÿ���ύ�����ݲ��졣
����뿴��ǰ��֧ͬ������֧�ϲ�ʱ���������ݲ��죬�и�С���ţ�
$ git diff master��Ȼ�ܵõ��������ݣ������ס������п��ܺ����ǵ�Ԥ�ڲ�ͬ��һ������
master �����Է�֧����֮�������ģ���ôͨ�� diff �������Ƚϵģ������������ϵ��ύ���ա���Ȼ���ⲻ��������Ҫ�ġ��ȷ���
master ��֧��ij���ļ�������һ�У�Ȼ���������������ıȽ����¿������õ��Ľ���ֻ���ǣ����Է�֧��ɾ������һ�С�
����ܺ����⣺��� master �����Է�֧��ֱ�����ȣ���������κ����⣻������ǵ��ύ��ʷ�ڲ�ͬ�ķֲ��ϣ���ô���������ݲ��죬���������������������Է�֧�ϵ��´��룬ͬʱɾ����
master ��֧�ϵ��´��롣
ʵ��������������Ҫ���ģ����¼��뵽���Է�֧�Ĵ��룬Ҳ���Ǻϲ�ʱ�Ტ�����ɵĴ��롣���ԣ�ȷ�ؽ�������Ӧ�ñȽ����Է�֧����ͬ
master ��֧�Ĺ�ͬ����֮��IJ��졣
���ǿ����ֹ���λ���ǵĹ�ͬ���ȣ�Ȼ����֮�Ƚϣ�
$ git merge-base contrib master
36c7dba2c95e6bbb78dfa822519ecfec6e1ca649
$ git diff 36c7db ����ô�����鷳������ Git �ṩ�˱�ݵ�
... ������� diff ������� ... ����ԭʼ��֧��ӵ�й�ͬ���ȣ��͵�ǰ��֧֮�䣺
$ git diff master...contrib���ڿ����ģ�����ʵ�ʽ�Ҫ������´��롣����һ���dz����õ����Ӧ���μǡ�
���뼯��
һ�����Է�֧��ͣ���������������������μ��ɵ����������ߵķ�֧�С����Ҫ����ά����Ŀ�����岽����ʲô����Ȼ�кܶ�ѡ������������ֻ��������һ���֡�
�ϲ�����
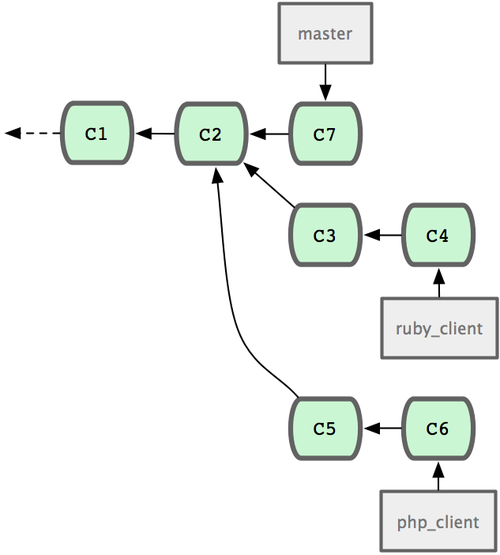
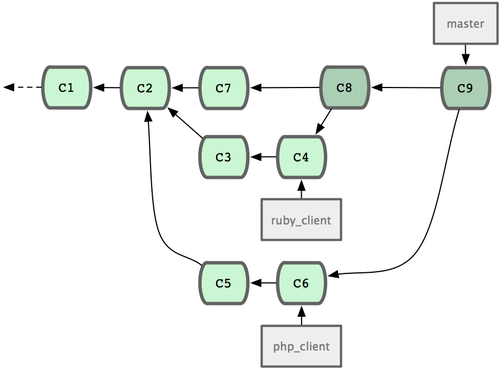
һ��������Σ����� master ��֧��ά���ȶ����룬Ȼ�������Է�֧�Ͽ����¹��ܣ�������˲��Ա��˹��Ĵ��룬���Ž����������ɣ����ɾ��������Է�֧����˷���������ʾ�������赱ǰ���������������֧���ֱ�Ϊ
ruby_client �� php_client����ͼ 5-19 ��ʾ��Ȼ���Ȱ� ruby_client
�ϲ������ɣ��ٺϲ� php_client�������ύ��ʷ��ͼ 5-20 ��ʾ��
ͼ 5-19. ������Է�֧
ͼ 5-20. �ϲ����Է�֧֮��
����������̣������ڴ�����һЩ����Ŀʱ���ܻ������⡣
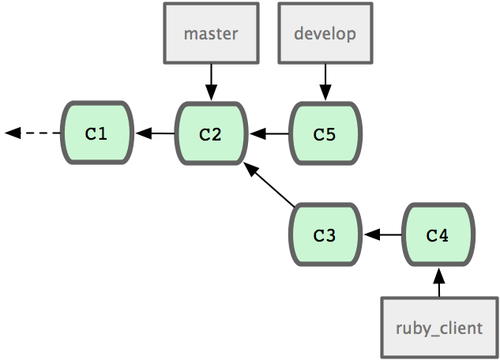
���ڴ�����Ŀ��������Ҫά���������ڷ�֧ master �� develop���´��루ͼ
5-21 �е� ruby_client�������Ȳ��� develop ��֧��ͼ 5-22 �е� C8��������һ���Σ�ȷ��
develop �еĴ������ȶ����ɷ���ʱ���ٽ� master ��֧������ȶ��㣨ͼ 5-23 �е� C8������ƽʱ��������֧���ᱻ���͵������Ĵ���⡣
ͼ 5-21. ���Է�֧�ϲ�ǰ
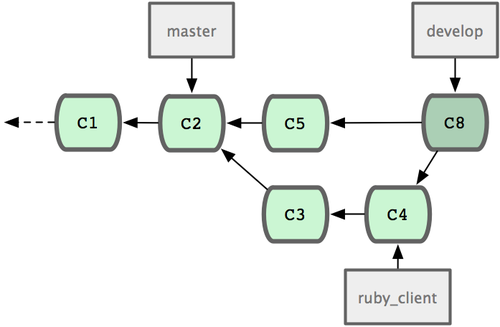
ͼ 5-22. ���Է�֧�ϲ���
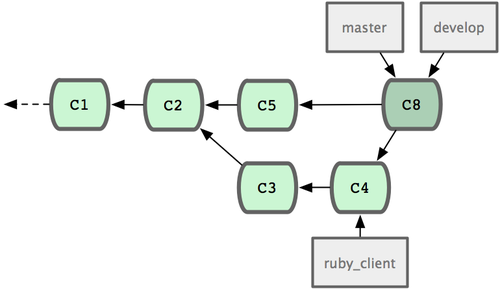
ͼ 5-23. ���Է�֧������
�����������ǿ�¡�ֿ�ʱ��������ѡ�ȿɼ�������ȶ��汾��ȷ������ʹ�ã�Ҳ�ܼ�������汾��������ǰ�ص������ԡ���Ҳ������չ�������Ƚ������´���ϲ�����ʱ���Է�֧���ȵ��÷�֧�ȶ�������ͨ�����Ժ��ٲ���
develop ��֧��Ȼ����ʱ�����һ�У������Щ����ȷʵ�������������൱��һ��ʱ�䣬�Ǿ��������������Ѿ��㹻�ȶ������Է��IJ������ɷ�֧������
����Ŀ�ĺϲ�����
Git ��Ŀ�������ĸ����ڷ�֧�����ڷ����� master ��֧�����ںϲ������ȶ����Ե�
next ��֧�����ںϲ�����Ľ����Ե� pu ��֧��pu �� proposed updates ����д�����Լ����ڳ���ά����
maint ��֧��maint ȡ�� maintenance����ά���߿�����֮ǰ���ܵķ������������ߵĴ�������Ϊ��ͬ�����Է�֧����ͼ
5-24 ��ʾ����Ȼ���������������Щ�������ȶ���������Щ����Ľ����ȶ������Կ��Բ��� next ��֧��Ȼ�������͵������ֿ⣬�Թ����������á�
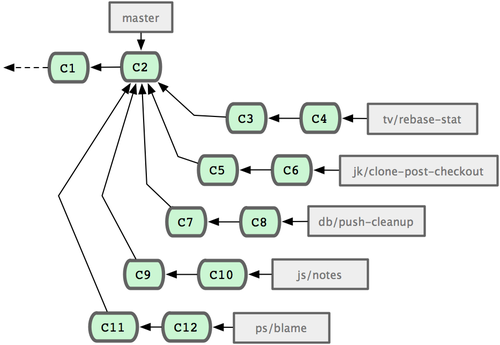
ͼ 5-24. �������ӵIJ��й���
����Ľ������Կ����Ȳ��� pu ��֧��ֱ��������ȫ�ȶ����ٲ��� master��ͬʱһ�������
next ��֧�����㹻�ȶ�������Ҳ���� master������һ����˵��master ʼ�����ڿ����next
ż�������ܺϣ��� pu ����Ƶ���ܺϣ���ͼ 5-25 ��ʾ��
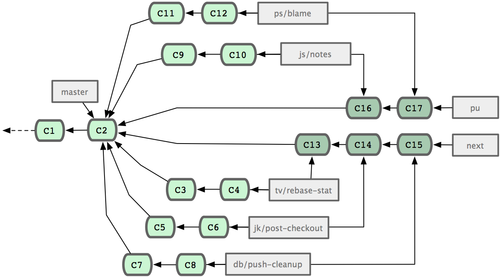
ͼ 5-25. �����Բ��볤�ڷ�֧
���� master ������Է�֧���Ѿ����豣����֧����������ɾ�����ˡ�Git
��Ŀ����һ�� maint ��֧�����������һ�η��а�Ϊ�����ֻ������ģ�����ά���������������Կ�¡ Git
��Ŀ�ֿ���õ����ĸ���֧��ͨ�������ͬ��֧�����˽���Խ�չ����������ǰ�����ԣ����ǹ��״��롣��ά������ͨ��������Щ��֧��������ز�����������ס�
�ܺ�������cherry-pick��������
һЩά���߸�ϲ���ܺϻ����������ߵĴ��룬�����Ǽĺϲ�����Ϊ�����ܹ��������Ե��ύ��ʷ������������һ�����ԵĿ������������������뵽���ɴ����У������ת���Ǹ����Է�֧Ȼ��ִ���ܺ��������������ɷ�֧�ϣ�Ҳ������develop��֧֮��ģ������ύ��Щ�ġ������Щ���빤���úܺã���Ϳ��Կ��master��֧���õ�һ�����Ե��ύ��ʷ��
��һ���������ķ����������������������ij���ض��ύ���ܺϡ���������ȡij���ύ�IJ�����Ȼ������Ӧ���ڵ�ǰ��֧�ϡ����ij�����Է�֧���ж��commits������ֻ����������֮һ�Ϳ���ʹ�����ַ�����Ҳ���ܽ�������Ϊ��ϲ�������������ܺϡ���������һ������ͼ
5-26 �Ĺ��̡�
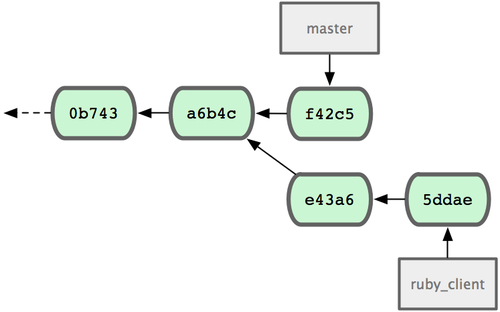
ͼ 5-26. ����cherry-pick��֮ǰ����ʷ
�����ϣ����ȡe43a6��������ɷ�֧������������
$ git cherry-pick e43a6fd3e94888d76779ad79fb568ed180e5fcdf
Finished one cherry-pick.
[master]: created a0a41a9: "More
friendly message when locking the index fails."
3 files changed, 17 insertions(+), 3
deletions(-)
�⽫������e43a6�Ĵ��룬���ǻ�õ���ͬ��SHA-1ֵ����ΪӦ�����ڲ�ͬ�����������ʷ��������ͼ
5-27.
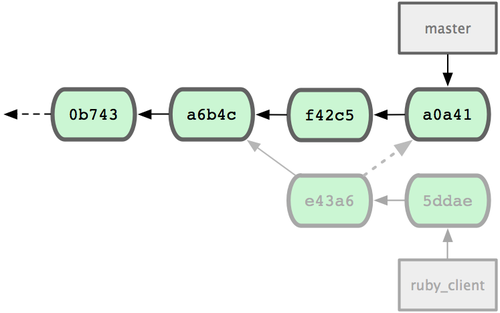
ͼ 5-27. ����cherry-pick��֮�����ʷ
���ڣ������ɾ��������Է�֧�������㲻���������Щcommit��
�����а�ǩ��
�����ɾ���ϴη����İ汾�����´��ǩ��Ҳ������ڶ�����˵����������һ���µı�ǩ������������ά���ߵ����ݸ����а�ǩ����Ӧ����������
$ git tag -s v1.5 -m 'my signed 1.5 tag'
You need a passphrase to unlock the secret key for
user: "Scott Chacon <schacon@gmail.com>"
1024-bit DSA key, ID F721C45A, created
2009-02-09���ǩ��֮����ηַ�PGP��Կ��public key���Ǹ����⡣������ע���ַ���Կ��Ϊ����֤��ǩ�������ã�Git��������뵽�˽���취������key���ȹ�Կ����Ϊblob����д��Git�⣬Ȼ�����������ֱ��д�ڱ�ǩ�gpg
--list-keys���������ʾ������ӵ�е�key��
$ gpg --list-keys
/Users/schacon/.gnupg/pubring.gpg
---------------------------------
pub 1024D/F721C45A 2009-02-09 [expires: 2010-02-09]
uid Scott Chacon <schacon@gmail.com>
sub 2048g/45D02282 2009-02-09 [expires: 2010-02-09]
Ȼ����key�����ݲ����ɹܵ������ݸ�git hash-object��֮��Կ����blob����д��Git�У�������blob����SHA-1ֵ��
$ gpg -a --export F721C45A | git hash-object
-w --stdin
659ef797d181633c87ec71ac3f9ba29fe5775b92�������Git�Ѿ����������key�������ˣ�����ͨ����ͬ��SHA-1ֵָ����ͬ��key��������ǩ��
$ git tag -a maintainer-pgp-pub 659ef797d181633c87ec71ac3f9ba29fe5775b92������git
push --tags����֮��maintainer-pgp-pub��ǩ�ͻṫ���������ˡ����������ҪУ���ǩ��������ʹ��������������key��
$ git show maintainer-pgp-pub | gpg
--import���ǿ��������keyУ����ǩ�������б�ǩ�����⣬��Ҳ�����ڱ�ǩ��Ϣ��д��һ���������û�ֻ��Ҫ����git
show <tag>�鿴��ǩ��Ϣ��Ȼ��������������У�顣
�����ڲ��汾��
��ΪGit����Ϊÿ���ύ�Զ��������ơ�v123���ĵ������У������������Ҫ�õ�һ������������ύ�ſ�������git
describe���Git���᷵��һ���ַ���������������ɣ����һ�α궨�İ汾�ţ��������Ǵα궨֮����ύ�������ټ���һ��SHA-1ֵof
the commit you��re describing��
$ git describe master
v1.6.2-rc1-20-g8c5b85c����ַ���������Ϊ���յ����֣������������⡣������Git�����Լ�����Դ��Ȼ����밲װ�ģ���ᷢ��git
--version��������������ַ�����ࡣ�����һ���ոմ����ǩ���ύ������describe���ֻ��õ���α궨�İ汾�ţ���û�к���������Ϣ��
git describe����ֻ�������б�ע�ı�ǩ��ͨ��-a����-sѡ����ı�ǩ�������Է��а�ı�ǩ��Ӧ���Ǵ��б�ע�ģ��Ա�֤git
describe�ܹ���ȷ��ִ�С���Ҳ��������ַ�����Ϊcheckout����show�����Ŀ�꣬��Ϊ�������ն�������һ����̵�SHA-1ֵ����Ȼ������SHA-1ֵʧЧ����Ҳ����ʧЧ�����Linux�ں�Ϊ�˱�֤SHA-1ֵ��Ψһ�ԣ���λ����8λ��չ��10λ����͵�����չ֮ǰ��git
describe�����ȫʧЧ�ˡ�
������
���ڿ��Է���һ���µİ汾�ˡ�����Ҫ�������ѹ�����鵵��������Щ�����Ļ�û��ʹ��Git�����ǡ�����ʹ��git
archive��
$ git archive master --prefix='project/'
| gzip > `git describe master`.tar.gz
$ ls *.tar.gz
v1.6.2-rc1-20-g8c5b85c.tar.gz���ѹ������ѹ��������һ���ļ��У�����������Ŀ�����´�����ա���Ҳ���������Ƶķ�������һ��zipѹ��������git
archive����--format=zipѡ�
$ git archive master --prefix='project/'
--format=zip > `git describe master`.zip����������һ��tar.gzѹ������һ��zipѹ���������������ϴ�������վ�ϻ�����e-mail�������ˡ�
������
��ʱ��֪ͨ�ʼ��б������������������ijɹ��ˡ�ʹ��git shortlog������Է����ݵ�����һ������־��changelog�������ߴ���ϴη���֮������������Щ���Ժ�������Щbug��ʵ������������ܹ�ͳ�Ƹ�����Χ�ڵ������ύ;��������һ�η����İ汾��v1.0.1���������������Դ��ϴη���֮��������ύ�ļ�飺
$ git shortlog --no-merges master --not v1.0.1
Chris Wanstrath (8):
Add support for annotated tags to Grit::Tag
Add packed-refs annotated tag support.
Add Grit::Commit#to_patch
Update version and History.txt
Remove stray `puts`
Make ls_tree ignore nils
Tom Preston-Werner (4):
fix dates in history
dynamic version method
Version bump to 1.0.2
Regenerated gemspec for version 1.0.2
������Դ�v1.0.1�汾�����������ύ�ļ�飬���ݰ������߷��飬�Ա����ܿ��ٵķ�e-mail�����ǡ�
��
��ѧ�������ʹ��GitΪ��Ŀ�����ף�Ҳѧ�������ʹ��Gitά�������Ŀ����ϲ�����Ѿ���Ϊһ����Ч�Ŀ����ߡ�����һ���㽫ѧ����ǿ��Ĺ������������Ӹ��ӵ����⣬֮�������һλGit��ʦ��
| 

