| Git��Linus.TorvaldΪ�˹���Linux�ں˷�������һ����Դ�ֲ�ʽ�汾�ؼ�ϵͳ��DVCS������2002����Linux
�ں�һֱʹ��BitKeeper�����а汾������������2005��BitKeeper��Linux �ں˿�Դ�����ĺ�����ϵ������BitKeeper��Ҳ�������ʹ���ˣ�����ʹLinus��������һ����Դ�����ѵİ汾����ϵͳ��
��ͳ��SVN��CVS �Ȱ汾����ϵͳ��ֻ��һ���ֿ⣨repository)���û�����Ҫ��������ֿ���ܿ�ʼ�ύ����Git֮��ķֲ�ʽ�汾����ϵͳ����ȻҲ������
BitKeeper��Mercurial�ȵȣ�������ÿ������Ŀ¼������һ�������IJֿ⣬���ǿ���֧�����߹������Ȱѹ����ύ�����زֿ�����ύ��Զ�̵ķ������ϵIJֿ���ֲ�ʽ�Ĵ���Ҳ�ÿ�����Ϊ��ݣ�������Ա���Ժܷ�����ڱ��ش�����֧�������ճ�������ÿ���˵ı��زֿⶼ��ƽ���Ҷ�����������Ϊ��ı����ύ��ֱ��Ӱ����ˡ�
��ʵ˵��Git���ٶ������õİ汾����ϵͳ�����ģ�SVN Mercurial
Git����������˵���ٶȣ����������ύ(commit)������ǩ��(checkout)���ύ��Զ�ֿ̲�(git
push)�ʹ�Զ�ֿ̲��ȡ��git fetch ��git pull�������ı��ز����ٶȺͱ����ļ�ϵͳ��һ������Զ�ֿ̲�IJ����ٶȺ�SFTP�ļ�������һ�������Ȼ��Git���ڲ�ʵ�ֻ����йأ�����Ͳ���չ���ˣ�����Ȥ�����ѿ��Կ�һ�����Git
is the next Unix��
������ѧһ���µ�����ʱ�������Ǵ�һ����hello world�� ����ʼ�ģ���ôGit����Ҳ�ʹ�һ����hello
Git����ʼ�ɡ�
����������λͬѧ�ĵ��Զ�װ����Git�����û��װ�ã������ȿ�һ�������װGit������Ȼ��������½��һ�ר�Ž���װ���ܻ����������⡣
�������ȴ�Git�������У�windows���ǵ����Git Bash ��ݷ�ʽ����Linux����Unix
likeƽ̨�Ļ���ֱ�Ӵ������н���Ϳ����ˡ�
��ע��$���ź�����ַ��������������������룻��������������#��ʼ�ĺ����ַ�������ע�ͣ������IJ������������������
�������ý�һ���ֿ�ɣ�
$mkdir testGit #�����ֿ�Ŀ¼
$cd testGit #����ֿ�Ŀ¼
$git init #����ڵ�ǰ��Ŀ¼�½�һ���ֿ�
Initialized empty Git repository in e:/doc/Git/test/testGit/.git/ |
�õģ�ǰ�����������ͽ�����һ�����ص�Git�ֿ⡣����ֿ�������һ���յIJֿ⡣
��������������ִ�У�
$ git status #�鿴��ǰ�ֿ��״̬
# On branch master (��master��֧��)
#
# Initial commit
#
nothing to commit (create/copy files and use "git add" to track)
(����û���κ�̨���ύ���ļ������ƻ��µ��ļ������á�git add�� �������ӵ��ݴ�����)
$ git log #�鿴��ǰ�ֿ����ʷ��־
fatal: bad default revision 'HEAD'
(���ڲֿ���û�����ύ�����棬�������ᱨ�������BTW: ������ʾ�Dz����е㲻�Ѻ�ѽ��) ) |
���ھ�������������ֿ������ӵ����ݰɡ�
$ echo ��hello Git�� > readme.txt #����һ������ hello Git ���ı��ļ�
$ git add readme.txt #��readme.txt���ӵ��ݴ�����
$ git status #�鿴��ǰ�ֿ��״̬
# On branch master
#
# Initial commit
#
# Changes to be committed:(�ݴ����´ν����ύ����)
# (use "git rm --cached <file>..." to unstage)
#
# new file: readme.txt
# |
�õģ��ļ���Ȼ���ݴ浽�ݴ����У��������ھͿ������ύ���ֿ�����ȥ����
$ git commit -m "project init" #���ղŵ����ύ�����زֿ���
[master (root-commit) 8223db3] project init
1 files changed, 1 insertions(+), 0 deletions(-)
create mode 100644 readme.txt
$ git status
# On branch master
nothing to commit (working directory clean)
(�����������Ŀ¼��û��ʲôҪ�ύ�Ķ��������������) |
������ִ��һ��git log ����ͻῴ���ղŵ��ύ��¼
$ git log
commit 8223db3b064a9826375041c8fea020cb2e3b17d1
Author: liuhui998 <liuhui998@gmail.com>
Date: Sat Jan 1 18:12:38 2011 +0800
project init |
��8223db3b064a9826375041c8fea020cb2e3b17d1����һ���ַ�����������δ������ύ�����֡��������Dz��Ǻ��죬��������õ�¿�����Ѿͻᷢ�������Ǻ͵�¿�����ݱ�ʶ��һ��������SHA1����Gitͨ�����ύ���ݽ���
SHA1 Hash���㣬�õ����ǵ�SHA1��ֵ����Ϊÿ���ύ��Ψһ��ʶ������һ�������ѧԭ����˵����������ύ�����ݲ���ͬ����ô���ǵ����־Ͳ�����ͬ����֮��������ǵ�������ͬ������ζ�����ǵ�����Ҳ��ͬ��
���������һ�²ֿ����ļ������ݣ����ύ���ֿ���ȥ
$ echo "Git is Cool" >> readme.txt #���ļ����������һ��
$ git status #�鿴��ǰ�ֿ��״̬
# On branch master
# Changed but not updated: (���ˣ����ǻ�û���ݴ������)
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: readme.txt
#
no changes added to commit (use "git add" and/or "git commit -a")
(û���Ŀ��Ա��ύ��ʹ�� ��git add�� ���������ļ����ݴ���������ʹ�á�git commit -a�� ����ǿ���ύ��ǰĿ¼�µ������ļ�) |
OK����Ȼ�������˲ֿ��ﱻ�ύ���ļ�����ô���뿴һ������
��������Щ�ط����پ����Ƿ��ύ��
$ git diff #�鿴�ֿ���δ�ݴ����ݺͲֿ����ύ���ݵIJ���
diff --git a/readme.txt b/readme.txt
index 7b5bbd9..49ec0d6 100644
--- a/readme.txt
+++ b/readme.txt
@@ -1 +1,2 @@
hello Git
+Git is Cool |
�ܺã�����������Ը������ֻ����readme.txt�����һ��������һ�С�Git
is Cool����
�õģ����������ٰ� readme.txt�ŵ��ݴ����
$ git add readme.txt
�������ڿ�һ�²ֿ��״̬��
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: readme.txt
# |
�����ύ�ˣ�
$ git commit -m "Git is Cool"
[master 45ff891] Git is Cool
1 files changed, 1 insertions(+), 0 deletions(-)
(һ���ļ����ģ�һ�в��룬����ɾ��) |
�ٿ�һ���µ���־��
$ git log
commit 45ff89198f08365bff32364034aed98126009e44
Author: liuhui998 <liuhui998@gmail.com>
Date: Sat Jan 1 18:17:07 2011 +0800
Git is Cool
commit 8223db3b064a9826375041c8fea020cb2e3b17d1
Author: liuhui998 <liuhui998@gmail.com>
Date: Sat Jan 1 18:12:38 2011 +0800
project init |
��45ff89198f08365bff32364034aed98126009e44��
����������Ǹղ��ύ��ʱ�������ύ��
�����ôһ·���������Dz����е��Ϳ�ˡ�����û�й�ϵ�������ĵ���װ��Git����ô����������Щ����ȫ��ִ��һ�±�ͻ�����и��Ե���ʶ�ˡ�
����ĵ��½ڣ��һὲһ�������windows��Linux��װ����Git���Լ���Ҫע������⣺��
Git�İ�װ������
��λͬѧ���ϻ�Git���ռǣ�һ������һ�� ��hello Git�� ��С���¡��е�ͬѧ����������������ֲ�ʽ�汾����ϵͳ��DVCS��������֮��ʹ�����ͨ��Git����Ȼ�����ˣ�Ҳ�е�ͬѧ���ܻ����ҵ�������Gitһ������������������ͷ�ԡ�
����һƪ��ʼ���Ҿͽ��Ƚϡ����¡��ĺʹ��һ����㿪ʼ����Gitʹ�õ�ÿһ������Ȼ���Ҷ�����Ҳ��һ��������ʶGit�Ĺ��̡�
ʹ��Git�ĵ�һ���϶��ǰ�װGit����Ϊ�ڶ���ƽ̨��Git��û��Ԥװ�ġ���ƽʱ��Ҫ�Ĺ���������windows��Linux��ubuntu�������뿴��ƪ���µ�ͬѧ���Ҳ����������ƽ̨�¹����������ҽ�һ�������������ƽ̨�°�װ������Git��
BTW:�����ƻ��ƽ̨���û��İ�װ���Բο�һ������(1,2)�����ú������е�ʹ����windows��Linux��*nix��ƽ̨���
Linux (*nix) ƽ̨
Linus����Git�����Ŀ�ľ���Ϊ�˿���Linux�ں˷���ģ���Ȼ����Linux��ƽ̨֧��Ҳ������ġ���Linux�°�װGit��Լ�м��ַ�����
��Դ���뿪ʼ(���ַ���Ҳ�ʺ��ڶ���*nixƽ̨)
��Git����������ҳ�������������ȶ����Դ���룬�Ϳ��Դ�Դ���뿪ʼ���롢��װ��
$ wget http://kernel.org/pub/software/scm/git/git-1.7.3.5.tar.bz2
$ tar -xjvf git-1.7.3.5.tar.bz2
$ cd git-1.7.3.5
$ make prefix=/usr all ;# prefix�������Git��װĿ¼
$ sudo make prefix=/usr install ;# ��rootȨ������ |
Ϊ�˱���Git��Դ���룬���ǻ���ҪһЩ��: expat��curl�� zlib
�� openssl�� ����expat �⣬�����Ŀ��������Ļ����϶���װ�ˡ�
ʹ�ð�װ����������apt �� yum��
�� fedora ��ϵͳ����yum ��
$ yum install git-core
��debian, ubuntu��ϵͳ����apt ��
$ apt-get install git-core
��ʱ����ϵͳ��İ�װ�����������������⣬����Ҫ��װGit�Ļ�������������û�б������Ļ�������Դ������վ��ȥ����
��.deb�� �� ��.rpm���İ�װ����
Windowsƽ̨
windowsƽ̨������ģ��*nix like���л����Ĺ��ߣ�cygwin��msys��Git��cygwin��msys�¶�����Ӧ����ֲ�汾���Ҹ��˾���msysƽ̨�µ�msysGit����ã���������windows��Ҳ���õ�����汾��
�ܶ�ͬѧ����Ҫ�ʣ�����windows�����Ƕ�Git�û���ΪʲôGit��ֱ�ӳ�һ��windows
native�档�����귭����һ��Git��Դ���룬������ʹ���˴�����*nixƽ̨��native api������Щapi��windows����û�еģ����Ա���Ҫ��cygwin��msys������һ���м��������������ֲ��Ҫ��
�����ҡ����¡�һ�������windows�°�װmsysGit��
����
����������ҳ��ȥ����һ�����µ�������װ����������д����ʱ���ص��������
��װ
��װ�Ĺ���û��ʲô��˵�ģ�һ���ǿ�ʼ��װ��һ·�ĵ������һ����������windowsƽ̨�Ļ��з���CRLF����Linux(*nix)ƽ̨�Ļ��з���LF����ͬ����ô��windows�¿�������ƽ̨������������һ���ط�Ҫע�⣨����ͼ)��
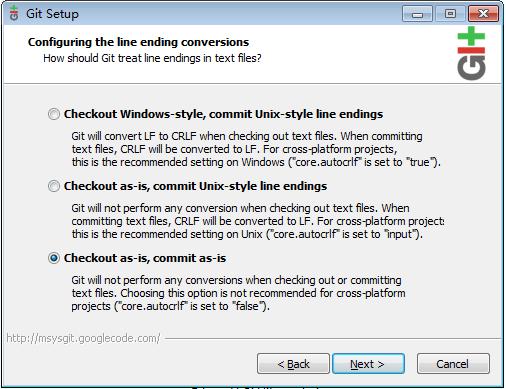
������һ���ѡ��Checkout as-is, commit as-is�����ѡ�������Git�Ͳ����������Ļ��з����
��ǰ�и�������Ϊѡ�������ѡ���������windowsƽ̨�µ�һǩ����checkout������ƽ̨�Ĵ��룬�ͻ���ʾ�����ġ���modified����������������msysGitҲ��ʶ����������ˣ��Ͱ�Ĭ��ѡ��ij������ѡ�
BTW: ��ʵǰ������Ҳ�����õģ������windows��Linux(*nix)ƽ̨��δ������з�����Ϥ�Ļ���Ҳ���Գ���һ��ǰ������ѡ���
����Git
��Linux�º�windows������Git�ķ�����ֻ࣬����Linux�£���������������ֱ��ʹ��git
config��������, ����windows����Ҫ�ȴ�Git Bash��������msysGit�����н��棬����git
config���������Ӧ�����ò�����
���ˣ�ǰ�氲װ����Git���������ǿ�ʼ���ã�
��һ����Ҫ���õľ����û����û�����email����Ϊ��Щ���ݻ���������ÿһ���ύ��commit������ģ�������������
$ git log #������git log�鿴��ǰ�ֿ���ύ��commit����־
commit 71948005382ff8e02dd8d5e8d2b4834428eece24
Author: author <author@corpmail.com>
Date: Thu Jan 20 12:58:05 2011 +0800
Project init |
�����������������������û�����email��
$ git config --global user.name author #���û�����Ϊauthor
$ git config --global user.email author@corpmail.com #���û�������Ϊauthor@corpmail.com |
Git��������Ϣ��Ϊȫ�ֺ���Ŀ���֣����������д��ˡ�--global"�����������ζ���ڽ���ȫ�����ã�����Ӱ�챾���ϵ�ÿ��һ��Git��Ŀ��
��ҿ��������������õ���@corpmail����˾���䣩��������ʱ�����ǿ���Ҳ������һЩ��Դ��Ŀ����ô����Ҫ�µ��û������Լ���˽�����䣬Git
����Ϊÿ����Ŀ�趨��ͬ��������Ϣ��
�������л���������Git��Ŀ����Ŀ¼��ִ����������
$ git config��user.name nickname#���û�����Ϊnickname
$ git config��user.email nickname@gmail.com #���û�������Ϊnickname@gmail.com |
Git�������ѧ��Linux��*nix��һ����������ʹ�á��ı�������Textuality���������澡�����ı�������ʽ�洢��Ϣ������������ϢҲ������ˣ��û�����Щ������Ϣȫ���Ǵ洢���ı��ļ��С�Git��ȫ�������ļ��Ǵ����"~/.gitconfig"���û�Ŀ¼�µ�.gitconfig���ļ��У�
������cat��head����鿴ȫ��������Ϣ�ļ������������������Ϣ�洢���ļ���ǰ3�У���ȻҲ�п��ܲ���ǰ3�У�����ֻ��Ϊ�˷����ʾ��
$ cat ~/.gitconfig | head -3
[user]
name = author
email = author@corpmail.com |
����Ŀ�����ļ��Ǵ����Git��Ŀ����Ŀ¼��".git/config"�ļ��У�����Ҳ������һ����cat��head����鿴һ�£�
$ cat .git/config | head -3
[user]
name = nickname |
�����Ҷ���Git��Ϥ����ֱ�ġ�~/.gitconfig��,��.git/config���������ļ��������á�
Git�ﻹ�кܶ�������õĵط�����ҿ��Բο�һ��git config ��
����git��
��һƪд�����е�ƽ�����棬������һ��Git�û������ĵ�һ���������һ�����һϵ�е����³����������Ҹ���ʹ�ù����еĸ���
���������ң���Ϊʲô�����½�������Git���ռǡ�����������Ϊ��ʹ��Git�������У���������N������⣻ͬʱҲ�������е�С���ӡ����ǵ���Щ��������ʱ���ò���̾����Ƶ�����֮����
�����Ҷ����ҵ�������ʲô����ͽ��飬��ӭ����д�ʼ���
֮ǰ�ҽ�����һ�� git�����û��� ����������ʹ��Git�Ĺ���������ʲô�鷳�£���ӭ��������û��������ʡ�
����һ���Լ��ı��زֿ�
v":* {behavior:url(#default#VML);}
o":* {behavior:url(#default#VML);} w":* {behavior:url(#default#VML);}
.shape {behavior:url(#default#VML);} st1":*{behavior:url(#ieooui)
}
�������Ҫ��һ����Ŀ���뵽Git�İ汾�����У���������Ŀ���ڵ�Ŀ¼��git
init�����һ���յı��زֿ⣬Ȼ������git add��������Ƕ����뵽Git���زֿ���ݴ�����stage
or index���У��������git commit�����ύ�����زֿ��
����һ���µ���ĿĿ¼��������һЩ���ļ����ݣ�
$ mkdir test_proj
$ cd test_proj
$ echo ��hello,world�� > readme.txt |
����ĿĿ¼�����µı��زֿ⣬������Ŀ��������ļ�ȫ�����ӡ��ύ�����زֿ���ȥ��
$ git init #�ڵ�ǰ��Ŀ¼�´���һ���µĿյı��زֿ�
Initialized empty Git repository in /home/user/test_proj/.git/
$ git add . #��ǰĿ¼�µ������ļ�ȫ�����ӵ��ݴ���
$ git commit -m 'project init' #�����ύ
[master (root-commit) b36a785] project init
1 files changed, 1 insertions(+), 0 deletions(-)
create mode 100644 readme.txt |
GitĿ¼�Ľṹ
git init��������Ŀ�Ķ���Ŀ¼�н���һ����Ϊ����.git����Ŀ¼�����ı�����
��GitĿ¼����Git directory������ʱ��GitĿ¼������Ȼ��һЩ�ļ�������û���κ��ύ��commit�������棬�������ǽ����ǿղֿ⣨empty
Git repository����
�� SVN��ͬ��һ��Git��Ŀһ��ֻ����Ŀ�ĸ�Ŀ¼�½�һ����.git��Ŀ¼����SVN�������Ŀ��ÿһ��Ŀ¼�½�һ����.svn��Ŀ¼����Ҳ��ϲ��Git��ԭ��֮һ����
Git�����е���ʷ�ύ��Ϣȫ���洢�ڡ�GitĿ¼���������һ��Git��Ŀ�IJֿ⣻��Ա��ص�Դ������б༭�ĺ����ύҲ�����ȱ����������棬Ȼ�������͵�Զ�˵ķ��������������Ұ���ĿĿ¼�͡�GitĿ¼��һ������������������������Ĺ��������е��ύ��Ϣȫ��������GitĿ¼
�����������ֻ�ѡ�GitĿ¼������Ҳ�У�����Ҫ��ǩ����checkout��һ�Ρ�
GitΪ�� ���Եķ��㣬������ָ����Ŀ��GitĿ¼��λ�á������ְ취��һ�����á�GIT_DIR���������������������������趨��--git-dir--git-dir������ָ������λ�ã���ҿ��Կ�һ������(git(1)
Manual Page)��
�Ҷ���ţ
ǰ�����Щ�������ڵ�һƪ��Ҳ��ŵĽ���һЩ�����ǽ��������벻��Ҫ���������С�Git�����ܳ������뿴����������Щʲô�������������ô���ɵġ�
OK��������������test_proj����Ŀ��ġ�GitĿ¼���Ľṹ��
$cd test_proj/.git
$ ls | more
branches/ # �°��Git�Ѿ�����ʹ�����Ŀ¼�����Դ�ҿ�����
#һ����ǿյ�
COMMIT_EDITMSG # ��������һ���ύʱ��ע����Ϣ
config # ��Ŀ��������Ϣ
description # ��Ŀ��������Ϣ
HEAD # ��Ŀ��ǰ���ĸ���֧����Ϣ
hooks/ # Ĭ�ϵġ�hooks�� �ű��ļ�
index # �����ļ���git add ���Ҫ���ӵ����ݴ浽����
info/ # ������һ��exclude�ļ���ָ������ĿҪ���Ե��ļ� #����һ������
logs/ # ����refs����ʷ��Ϣ
objects/ # ���Ŀ¼�dz���Ҫ������洢����Git�����ݶ���
# �������ύ(commits), ������(trees)�������ƶ��� #��blobs��,��ǩ����tags����
#������û�й�ϵ������ὲ�ġ�
refs/ # ��ʶ�����ÿ����ָ֧���ĸ��ύ��commit����
������git log��������һ�����Git��Ŀ������Щ�ύ��
$ git log
commit 58b53cfe12a9625865159b6fcf2738b2f6774844
Author: liuhui998 <liuhui998@nospam.com>
Date: Sat Feb 19 18:10:08 2011 +0800
project init |
��ҿ��Կ���Ŀǰֻ��һ���ύ��commit�������������־� �ǣ���58b53cfe12a9625865159b6fcf2738b2f6774844����������־��Ƕ������ݵ�һ��SHAǩ����ֵ��ֻҪ������������ݲ�ͬ����ô���ǾͿ�����Ϊ��������ֲ�����ͬ����֮Ҳ����������ʹ��ʱһ�㲻�ð����40���ַ���ȫ��ֻҪ��ǰ���5~8���ַ�����Ϳ��ԣ�ǰ����
�������Ķ���������ͻ����Ϊ�˷����ʾ���ڲ�Ӱ����������£��һ�ֻдSHA��ֵ��ǰ6���ַ���
���ǿ�����git cat-file����һ������ύ���������ʲô:
$ git cat-file -p 58b53c
tree 2bb9f0c9dc5caa1fb10f9e0ccbb3a7003c8a0e13
author liuhui998 <liuhui998@nospam.com> 1298110208 +0800
committer liuhui998 <liuhui998@nospam.com> 1298110208 +0800
project init |
��ҿ��Կ������ύ��58b53c�� ������һ����Ϊ��2bb9f0����������tree����һ��������tree����������һ�����������ƶ���blob��,
ÿ�������ƶ���Ӧһ���ļ��� ����һ��, ������Ҳ�������������������Ӷ�����һ��Ŀ¼��νṹ�������ٿ�һ�����������tree��������ʲô������
$ git cat-file -p 2bb9f0
100644 blob 2d832d9044c698081e59c322d5a2a459da546469
readme.txt
���ѿ�����2bb9f0�����������tree����������һ�������ƶ���blob������Ӧ��������ǰ�洴�����Ǹ���
��readme.txt�����ļ����������������������blob����������Dz��Ǻ�ǰ����ύ������һ�£�
$ git cat-file -p 2d832d
hello,world
��������Ϥ�ġ�hello,world���ֻ����ˡ�
�벻�뿴���ύ����������Ͷ����ƶ�������ô�ڡ�GitĿ¼���д洢�ģ�û�����⣬ִ����������������.git/objects��Ŀ¼������ݣ�
$ find .git/objects
.git/objects
.git/objects/2b
.git/objects/2b/b9f0c9dc5caa1fb10f9e0ccbb3a7003c8a0e13
.git/objects/2d
.git/objects/2d/832d9044c698081e59c322d5a2a459da546469
.git/objects/58
.git/objects/58/b53cfe12a9625865159b6fcf2738b2f6774844
.git/objects/info
.git/objects/pack |
��������ϸ����������ִ�н���еĴ����֣����еĶ���ʹ��SHAǩ����ֵ��Ϊ�����洢�ڡ�.git/objects��Ŀ¼֮�£�SHA����ǰ�����ַ���ΪĿ¼���������38���ַ���Ϊ�ļ�����
��Щ�ļ���������ʵ��ѹ�����������һ����ע���ͺͳ��ȵ�ͷ�����Ϳ������ύ����commit���������ƶ���blob����
������tree�����߱�ǩ����tag����
���cloneһ��Զ����Ŀ
�����ߵĺܶ���������ΪҪ�õ�ij����Դ��Ŀ�Ĵ��룬���Բſ�ʼѧϰʹ��Git������ȡһ����Ŀ�Ĵ����һ�������������git
clone�������ֱ�Ӹ��ơ�
���磬��Щ���ѿ����뿴һ�����µ�linux�ں�Դ���룬�����Ǵ�������վʱ���������������һ����ʾ��
URL
git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git
http://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git |
URL����������ַ�����ʾ������ַ�����ǿ���ͨ����������ַ�õ�ͬ����һ��Linux�ں�Դ���롣
Ҳ����˵�����������������յõ�����ͬһ��Դ���룺
git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git
git clone http://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git
git cone https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git |
����������һ��URL��git://��http://��https://��Щ�����Ǵ���git�ֿ��Э����ʽ������git.kernel.org���������Git�ֿ�洢�ķ��������֣�����������/pub/scm/linux/kernel/git/torvalds/linux-2.6.git��
�������Git�ֿ��ڷ�������λ�á�
Git �ֿ���˿���ͨ�������git��http��httpsЭ�鴫�������ͨ��ssh��ftp(s)��rsync��Э�������䡣git
clone�ı��ʾ��ǰѡ�GitĿ¼����������ݿ���������������뿴��һ��ġ�GitĿ¼�����г�ǧ����ĸ��ֶ����ύ�������������ƶ���......)�������һ���ƵĻ�����Ч�ʾͿ����֪��
���ͨ��git��sshЭ�鴫�䣬�������˻��ڴ���ǰ����Ҫ����ĸ��ֶ����ȴ�ð��ٽ��д��䣻��http��s��Э����ᷴ������Ҫ����IJ�ͬ��
������ֿ�������ύ����Ļ���ǰ�ߺͺ��ߵ�Ч�����ࣻ�������ֿ����кܶ��ύ�Ļ���git��sshЭ����д���������Ч�ʡ�
��������Git��http��s��Э�鴫��Git�ֿ�����һ�����Ż���http��s����������Ҳ�ܴﵽsshЭ���Ч�ʣ�����Ȥ�����ѿ��Կ�һ�����Smart
HTTP Transport����
�õģ���������ִ�����������������linux-2.6�����°�Դ����clone������
$cd ~/
$mkdir temp
$git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git
Initialized empty Git repository in /home/liuhui/temp/linux-2.6/.git/
remote: Counting objects: 1889189, done.
remote: Compressing objects: 100% (303141/303141), done.
Receiving objects: 100% (1889189/1889189), 385.03 MiB | 1.64 MiB/s, done.
remote: Total 1889189 (delta 1570491), reused 1887756 (delta 1569178)
Resolving deltas: 100% (1570491/1570491), done.
Checking out files: 100% (35867/35867), done. |
������ִ���ˡ�git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git������������ҿ��Կ������������
Initialized empty Git repository in
/home/user/temp/linux-2.6/.git/
�������ζ�������ڱ����Ƚ���һ����linux-2.6��Ŀ¼��Ȼ�������Ŀ¼����һ���յ�Git���زֿ⣨GitĿ¼�������潫��洢����������������ʷ�ύ��
������������������������ڵ��� git-pack-objects �����IJֿ���д����ѹ����
remote: Counting objects: 1888686, done
remote: Compressing objects: 100% (302932/302932),
done.
Ȼ��ͻ��˽��շ������˷������������ݣ�
Receiving objects: 100% (1889189/1889189),
385.03 MiB | 1.64 MiB/s, done.
������ִ���������clone linux-2.6����ĵIJ�����Git��ӡ�GitĿ¼��������µĴ��뵽ǩ����checkout������linux-2.6�����Ŀ¼���档����һ��ѱ��صġ�linux-2.6�����Ŀ¼����������Ŀ¼����work
directory���������汣������������ط�clone��or checkout�������Ĵ��롣��������Ŀ�IJ�ͬ��֧���л�ʱ��������Ŀ¼���е��ļ����ܻᱻ�滻����ɾ����������Ŀ¼��ֻ�DZ����ŵ�ǰ�Ĺ������������
�������ļ�������ֱ���´��ύΪֹ��
��һ��ǵ�ǰ��ġ��Ҷ���ţ�����Dz��Ǿ���ֻɱһͷ�С�hello,world����Сţ̫������ˡ�û�����⣬����ǰ����ǰ�С����������һ������������Ӳ������ͷ�С�linux-2.6����ţ����������һ���ܺ��档
�������ύ��Ļ�����
��һ��������
�������������Git���ռǡ���ǰ����ƪ���µ����ѿ����Ѿ�֪����ô��git
add��git commit�����������ˣ�֪������һ���ǰ��ļ��ݴ浽������Ϊ��һ���ύ������һ�������µ��ύ��commit������������̨ǰĻ���һЩ��Ȥ��ϸ�ڴ�Ҳ�һ��֪������������һһ������
Git ������һ������Ĺ���Ŀ¼��working tree������Ŀ�ֿ����ݴ�����(staging
area)��������, ������������ݵ���һ���ύ(commit)�� ����㴴����һ���ύ(commit)����ô�ύ��һ�����ݴ����������,
�����ǹ���Ŀ¼�е����ݡ�
һ��Git��Ŀ���ļ���״̬��ŷֳ�����������࣬���ڶ������ַ�Ϊ��С�ࣺ
- δ�����ٵ��ļ���untracked file��
- �ѱ����ٵ��ļ���tracked file��
- ���ĵ�δ���ݴ���ļ���changed but not updated��modified��
- ���ݴ���Ա��ύ���ļ���changes to be committed ��staged��
- ���ϴ��ύ������δ�ĵ��ļ�(clean �� unmodified)
�����������ô��Ĺ�������ͷ���˰ɡ��ϰ취�����ǽ�һ��Git������Ŀ������һ�£�
����������һ���յ���Ŀ��
$rm -rf stage_proj
$mkdir stage_proj
$cd stage_proj
$git init
Initialized empty Git repository in /home/test/work/test_stage_proj/.git/ |
���ǻ�����һ�������ǡ�hello, world�����ļ���
$echo "hello,world" > readme.txt
��������һ�µ�ǰ����Ŀ¼��״̬����ҿ��Կ�����readme.txt������δ�����ٵ�״̬��untracked
file����
$git status
# On branch master
#
# Initial commit
#
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# readme.txt
nothing added to commit but untracked files present (use "git add" to track) |
�ѡ�readme.txt"�ӵ��ݴ����� $git add readme.txt
�����ٿ�һ�µ�ǰ����Ŀ¼��״̬��
$git status
# On branch master
#
# Initial commit
#
# Changes to be committed:
# (use "git rm --cached <file>..." to unstage)
#
# new file: readme.txt
# |
���Կ�������"readme.txt"��״̬��������ݴ���Ա��ύ��changes
to be committed��������ζ��������һ������ֱ��ִ�С�git commit��������ļ��ύ�����صIJֿ���ȥ�ˡ�
�ݴ�����staging area��һ�����ڡ�gitĿ¼���µ�index�ļ���.git/index���У��������ǰ��ݴ�����ʱҲ����������index����������һ�������Ƹ�ʽ���ļ������������뵱ǰ�ݴ�������ص���Ϣ�������ݴ���ļ������ļ����ݵ�SHA1��ϣ��ֵ���ļ�����Ȩ�ޣ����������ļ����������ݴ���ļ�����������ġ�
�����Ҳ������ϾͰ��ļ��ύ�����뿴һ���ݴ�����staging area��������ݣ�����ִ��git
ls-files���һ�£�
$git ls-files --stage
100644 2d832d9044c698081e59c322d5a2a459da546469
0 readme.txt
��������п�����һƪ�������"�Ҷ���ţ", ��ᷢ�֡�gitĿ¼�������ˡ�.git/objects/2d/832d9044c698081e59c322d5a2a459da546469����ôһ���ļ�����ִ�С�git
cat-file -p 2d832d�� �Ļ����Ϳ��Կ���������������ǡ�hello,world"��Git�ڰ�һ���ļ������ݴ���ʱ�����������������ļ�(.git/index)����˺ţ����Ұ����������ȱ��浽�ˡ�gitĿ¼������ȥ�ˡ�
�������ִ�С�git add������ʱ��С�İѲ���Ҫ���ļ�Ҳ���뵽�ݴ����л�������ִ�С�git
rm --cached filename" ���������ӵ��ļ����ݴ������Ƴ���
������������"readme.txt"�ļ�����һЩ�ĺ�
$echo "hello,world2" >>
readme.txt
������һ���ݴ����ı仯:
$git status
# On branch master
#
# Initial commit
#
# Changes to be committed:
# (use "git rm --cached <file>..." to unstage)
#
# new file: readme.txt
#
# Changed but not updated:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: readme.txt
# |
��ҿ��Կ���������������һ�����ݣ���changed but not updated
...... modified: readme.txt������ҿ��ܻ���ú���֣���ǰ�治�ǰ�"readme.txt"����ļ������ӵ��ݴ�����ȥ����������ô����ʾ��δ���ӵ��ݴ�����changed
but not updated���أ��Dz���Git�����ѽ��
Git û�д���ÿ��ִ�С�git add�������ļ����ݴ���ʱ����������ļ����ݽ���SHA1��ϣ���㣬�������ļ����¼�һ��ٰ��ļ����ݴ�ŵ����صġ�gitĿ¼���������ϴ�ִ��
��git add��֮���ٶ��ļ������ݽ������ģ���ô��ִ�С�git status������ʱ��Git����ļ����ݽ���SHA1��ϣ����ͻᷢ���ļ��ֱ����ˣ���ʱ��readme.txt����ͬʱ����������״̬�����ĵ�δ���ݴ���ļ���changed
but not updated�������ݴ���Ա��ύ���ļ���changes to be committed�������������ʱ�ύ�Ļ�������ֻ���ύ��һ�Ρ�git
add"�����ݴ���ļ����ݡ�
�����ڶ��ڡ�hello,world2"������IJ��Ǻ����⣬��Ҫ��������ģ�����ִ��git
checkout������
$git checkout -- readme.txt
����������һ�²ֿ��﹤��Ŀ¼��״̬��
$git status
# On branch master
#
# Initial commit
#
# Changes to be committed:
# (use "git rm --cached <file>..." to unstage)
#
# new file: readme.txt
# |
�õģ�������Ŀ�ָ�������Ҫ��״̬�ˣ������Ҿ���git commit �����������ύ�˰ɣ�
$git commit -m "project init"
[master (root-commit) 6cdae57] project init 1 files changed, 1 insertions(+), 0 deletions(-) create mode
100644 readme.txt |
��������������һ�¹���Ŀ¼��״̬��
$git status
# On branch master
nothing to commit (working directory clean) |
��ҿ��Կ�����nothing to commit (working directory
clean)�������һ����������working tree�������е��Ķ����ύ���˵�ǰ��֧�current
head������ô��˵���Ǹɾ��ģ�clean������֮���������(dirty)��
SHA1ֵ����Ѱַ
����Git is the next Unix һ������˵��һ����Git��һ��ȫ�µ�ʹ�����ݵķ�ʽ��Git
is a totally new way to operate on data����Git���������������ж���blob��tree��commit��tag��������ȫ���������ǵ���������SHA1��ϣ��ֵ��Ϊ������������Ŀǰ����ѧ֪ʶ������������ݵ�SHA1��ϣ��ֵ��ȣ���ô���ǾͿ�����Ϊ��������������ͬ
�ġ�����������ļ����ô���
GitֻҪ�Ƚ϶��������Ϳ��Ժܿ���ж���������������Ƿ���ͬ��
��Ϊ��ÿ���ֿ⣨repository���ġ����������ļ��㷽������ȫһ�������ͬ�������ݴ���������ͬ�IJֿ��У��ͻ������ͬ�ġ�����������
Git������ͨ�����������ݵ�SHA1�Ĺ�ϣֵ�͡����������Ƿ�ƥ�䣬���ж϶��������Ƿ���ȷ��
����ͨ����������ӣ�����֤������˵���Ƿ���ʵ�����ڴ���һ���͡�readme.txt��������ȫ��ͬ���ļ���readme2.txt����Ȼ���ٰ����ύ�����زֿ��У�
$echo "hello,world" > readme2.txt
$git add readme2.txt
$git commit -m "add new file: readme2.txt"
[master 6200c2c] add new file: readme2.txt
1 files changed, 1 insertions(+), 0 deletions(-)
create mode 100644 readme2.txt |
����������ܸ��ӵ������Dz鿴��ǰ���ύ��HEAD����������blob����
$git cat-file -p HEAD | head -n 1 | cut -b6-15 | xargs git cat-file -p
100644 blob 2d832d9044c698081e59c322d5a2a459da546469 readme.txt
100644 blob 2d832d9044c698081e59c322d5a2a459da546469 readme2.txt |
��������������һ���ύ��HEAD^����������blob����
$git cat-file -p HEAD^ | head -n 1 | cut -b6-15 | xargs git cat-file -p
100644 blob 2d832d9044c698081e59c322d5a2a459da546469 readme.txt |
�����Դ�ҿ������ܵ�ǰ���ύ��ǰһ�ζ���һ���ļ�����������֮��ȴ���ڹ���ͬһ��blob����2d832d9����
No delta, just snapshot
Git �������Ϥ�İ汾����ϵͳ����Subversion��CVS��Perforce
֮��IJ���Ǻܴ�ġ���ͳϵͳʹ�õ��ǣ� �������ļ�ϵͳ�� ��Delta Storage systems�������Ǵ洢��ÿ���ύ֮��IJ��졣��Git������֮�෴�����DZ������ÿ���ύ���������ݣ�snapshot�����������ύǰ����Ҫ�ύ��������SHA1��ϣ��ֵ��Ϊ�����������ֿ����Ƿ�����ͬ�Ķ������û�оͽ��ڡ�.git/objects"Ŀ¼������Ӧ�Ķ�������оͻ��������еĶ����Խ�Լ�ռ䡣
��������������һ��Git�Ƿ�������ԡ�snapshot����ʽ�����ύ�����ݡ�
����һ��"readme.txt"��������ӵ����ݣ��ٰ����ݴ棬����ύ�����زֿ��У�
$echo "hello,world2" >> readme.txt
$git add readme.txt
$git commit -m "add new content for readme.txt"
[master c26c2e7] add new content for readme.txt 1 files changed, 1 insertions(+), 0 deletions(-) |
�������ڿ�����ǰ�汾��������blob��������Щ��
$git cat-file -p HEAD | head -n 1 | cut -b6-15 | xargs git cat-file -p
100644 blob 2e4e85a61968db0c9ac294f76de70575a62822e1 readme.txt
100644 blob 2d832d9044c698081e59c322d5a2a459da546469 readme2.txt |
�������������������ǿ��Կ���"readme.txt"�Ѿ���Ӧ��һ���µ�blob����2e4e85a������֮ǰ�汾��"readme.txt����Ӧ��blob�����ǣ���2d832d9������������������һ����������blob����������ݺ����ǵ�Ԥ���Ƿ���ͬ��
$git cat-file -p 2e4e85a
hello,world
hello,world2
$git cat-file -p 2d832d9
hello,world
|
��ҿ��Կ�����ÿһ���ύ���ļ����ݻ���ȫ������ģ�snapshot����
��
Git���ڻ��ƺ�������ͳ�İ汾����ϵͳ��VCS������ڱ��ʵIJ��죬����Git����"add"�����ĺ��������VCS���ڲ��Ҳ����Ϊ�棬��git
add�������ܰ�δ���ٵ��ļ���untracked file�����ӵ��汾����֮�£�Ҳ�������˵������ݴ浽�����С�
ͬʱ�����ڲ��á�SHA1��ϣ��ֵ����Ѱֵ���͡����մ洢��snapshot��������Git��Ϊһ���ٶȷdz��dz���İ汾����ϵͳ��VCS���� |


