����
1.Git���ĸ���ɲ���
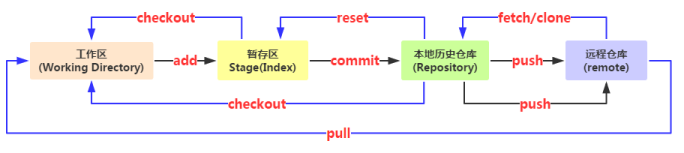
2.�ļ��ļ���״̬
������֣���Ϊ����״̬��Tracked(�Ѹ���)��Untracked(δ����)��
�����ǣ����ļ��Ƿ��Ѽ���汾���ƣ�
���̼�����
����ij����Ŀ�Ѽ���汾����ϵͳ
1.�½�һ���ļ������ļ����� Untracked ״̬��
2.ͨ��git add�������ӵ�����������ʱ�ļ�����Tracked״̬�ֻ���˵
��ʱ����ļ��Ѿ����汾����ϵͳ�����٣�����������Staged(�ݴ�)״̬��
3.ͨ��git commit������ݴ������ļ��ύ�ύ�����زֿ⣬��ʱ�ļ�
����Unmodified(δ��)״̬��
4.��ʱ���ȥ�༭����ļ����ļ��ֻ���Modified(��)״̬��
3.Git��SVN�汾�汾���ƴ洢����
Git���ĵ��ǣ��ļ������Ƿ����仯����SVN���ĵ��ǣ��ļ����ݵľ�����죡
SVNÿ���ύ��¼���ǣ���Щ�ļ��������ģ��Լ�������Щ�е���Щ����
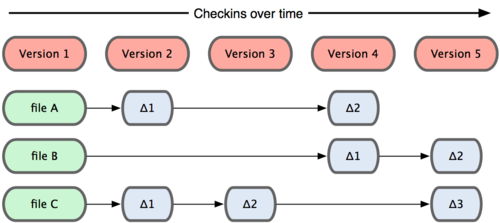
��ͼ���汾2�м�¼�����ļ�A��C�ı仯�����汾3�м�¼�ļ�C�ı仯���Դ����ƣ�
��Git�У�����������Щǰ��仯�IJ������ݣ����DZ�֤�����������е������ļ���
�ֽп��գ��б仯���ļ����棬û�仯���ļ������棬���Ƕ���һ�εı���Ŀ���
��һ�����ӣ���Ϊ���ֲ�ͬ�ı��淽ʽ��Git�л���֧���ٶȱ�SVN��ܶ࣡
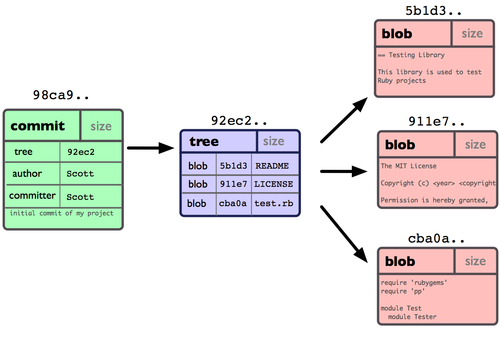
4.ÿ��Commitʱ�ֿ��е����ݽṹ
��Ϊ�ĸ�����
blob������ļ����ݣ�
tree����Ŀ¼������Ϊblob�����ָ�������tree�����ָ��
commit�����գ�����ָ��ǰһ���ύ�����ָ�룬commit��ص���
ͨ�������ҵ��ļ����ա�
tag����һ�������commit����һ���ij����Ҫ��commit��TAG����ʾ��Ҫ(������)
���ز�������
1.������á�git config��
����global �� local��ǰ�ߴ��� ȫ�����ã�����������������ϵͳ�У�
���еĴ�Git�汾��������Ŀ�������������ã����ߴ��� �������� ����ij����Ŀ
�ж��������ã��������ȼ�����ǰ�ߡ�����ȫ�����õ��û����ǡ�Coder-pig��������
���õ��ǡ�Jay����commit��ʱ��author����Jay������Coder-pig��
����ͨ���������ģ�������ֱ���Ķ�Ӧ�ļ���
ȫ�������ļ���etc/gitconfig
���������ļ�����ǰ�ֿ�/.git/config
# ��װ��Git���һ��Ҫ�����£�
�����û���Ϣ(global�ɻ���local�ڵ�����Ŀ��Ч)��
git config --global user.name "�û���" # �����û���
git config --global user.email "�û�����" #��������
git config --global user.name # �鿴�û����Ƿ����óɹ�
git config --global user.email # �鿴�����Ƿ�����
# �����鿴�������
git config --global --list # �鿴ȫ��������ز����б�
git config --local --list # �鿴����������ز����б�
git config --system --list # �鿴ϵͳ���ò����б�
git config --list # �鿴����Git������(ȫ��+����+ϵͳ) |
2.��ȡ������git help��
git help ���� # �磺git help init |
3.�������زֿ⡾git init��
git init �ֿ��� # ����һ���µĴ�Git�ֿ����Ŀ
git init # Ϊ�Ѵ��ڵ���Ŀ����һ��Git�ֿ� |
4.�����ļ����ݴ���/�ļ����ٱ�ǡ�git add��
git add �ļ��� # ����������ij���ļ����ӵ��ݴ���
git add -u #
�������б�tracked�ļ��б��Ļ�ɾ�����ļ���Ϣ���ݴ�����
������untracked���ļ�
git add -A
# �������б�tracked�ļ��б��Ļ�ɾ�����ļ���Ϣ���ݴ�����
����untracked���ļ�
git add . # ����ǰ�������������ļ��������ݴ���
git add -i # ���뽻������ģʽ�����������ļ��������� |
������������ģʽʾ��
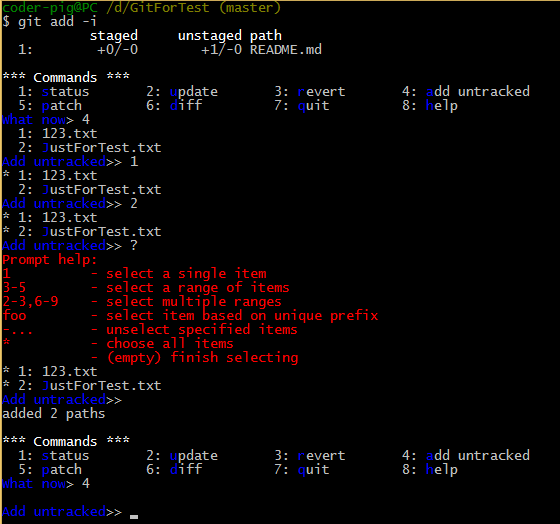
��ͼ���̣�
1.����GitForTest���ļ����ﴴ���������ļ�
2.����git add -i���������4��ѡ������untracked���ļ�
3.���������г���untracked���ļ���Ȼ�����Ǹ�������������ļ�
4.����?�ᵯ�������ʾ��Ȼ��ֱ�ӻس�������ѡ��
5.Ȼ���ٴ�����git add -i������4�����Կ����Ѳ�����untacked���ļ��ˣ� |
5.��Git��Tracked�ض��ļ���.gitignore�ļ����á�
��δtracked���ļ����ӵ���������Git�ͻῪʼ��������ļ��ˣ�
����һЩ���磺�Զ����ɵ��ļ�����־����ʱ�����ļ��ȣ���
û��Ҫ���и����ˣ����ʱ����Ա�д.gitignore�ļ���������
�Ѳ���Ҫ���ٵ��ļ����ļ��ж�д�ϣ�git�Ͳ������Щ�ļ����и��٣�
����.gitignore�ļ���.git�ļ�����ͬ��Ŀ¼�£�
��������Լ�д������ֱ�ӵ���https://github.com/github/gitignore ����ճ����
Ҳ�������б�д��֧�ּ��˵��������ʽ(�淶��ʾ��ģ��ժ�ԣ�Git���߳���֮·)
* �� ƥ��������������ַ�
[abc]��ֻƥ���������е�����һ���ַ�
[0-9]��- ������Χ��ƥ��0-9֮����κ��ַ�
?��ƥ������һ���ַ�
*��ƥ��������м�Ŀ¼������a/*/z����ƥ��:a/z,a/b/z,a/b/c/z�� |
ʾ��ģ�壺
# ���������� .c��β���ļ�
*.c
# ���� stream.c �ᱻgit��
!stream.c
# ֻ���Ե�ǰ�ļ����µ�TODO�ļ�, �����������ļ����µ�TODO����: subdir/TODO
/TODO
# ����������build�ļ����µ��ļ�
build/
# ���� doc/notes.txt, �������������.txt����: doc/server/arch.txt
doc/*.txt
# ����������docĿ¼�µ�.pdf�ļ�
doc/**/*.pdf |
6.���ݴ��������ύ�����زֿ⡾git commit��
git commit -m "�ύ˵��" # ���ݴ��������ύ�����زֿ�
git commit -a -m "
�ύ˵��" # ����������������ֱ�Ӱѹ����������ύ�����زֿ� |
�������-m ���ύ˵������git����������Ĭ�ϱ༭��(��vi)����д�ύ˵����
vi����(�����Ҳ�����)��Ҫô��©��-m ���ύ˵������Ҫô�Լ����ñ�������
git config --global core.edit ϲ���ı༭�� |
����֮�⣬��ʱ������Ҫ���ϴ��ύ�����ݣ��������ύ˵�����������ļ��ȣ�
# �ϲ��ݴ����������һ��commit�������µ�commit���滻���ϵ�
# ���������û���ݣ�����amend�������ϴ�commit���ύ˵��
# ע����Ϊamend�����ɵ�commit��һ��ȫ�µ�commit���ɵĻᱻ
# ɾ�������Ա��ڹ�����commit��ʹ��amend���мǣ�����
git commit --amend
git commit --amend --no-edit # �����ϴ�commit���ύ˵�� |
7.�鿴�������뻺������״̬��git status��
git status # �鿴���������ݴ����ĵ�ǰ���
git status -s # �ý���Ը���̵���ʽ��� |
8.����Ա�(���ݱ仯)��git diff��
git diff # �������뻺�����IJ���
git diff ��֧�� #��������ij��֧�IJ��죬
Զ�̷�֧����д��remotes/origin/��֧��
git diff HEAD # ��������HEADָ��ָ������ݲ���
git diff �ύid �ļ�·��
# ������ij�ļ���ǰ�汾����ʷ�汾�IJ���
git diff --stage #
�������ļ����ϴ��ύ�IJ���(1.6 �汾ǰ�� --cached)
git diff �汾TAG # �鿴��ij���汾�Ķ�����
git diff ��֧A ��֧B # �Ƚϴӷ�֧A�ͷ�֧B�IJ���(Ҳ֧�ֱȽ�����TAG)
git diff ��֧A...��֧B # �Ƚ�����֧�ڷֿ�����ԵĸĶ�
# ���⣺���ֻ��ͳ����Щ�ļ����Ķ���
�����б��Ķ����������� --stat ���� |
9.�鿴��ʷ�ύ��¼��git log��
git log # �鿴����commit��¼(SHA-AУ��ͣ�
�������ƣ����䣬�ύʱ�䣬�ύ˵��)
git log -p -���� # �鿴������ٴε��ύ��¼
git log --stat # ������ʾÿ���ύ�����ݸ���
git log --name-only # ����ʾ���ĵ��ļ��嵥
git log --name-status # ��ʾ�������ģ�ɾ�����ļ��嵥
git log --oneline # ���ύ��¼�Ծ����һ�����
git log �Cgraph �Call --online # ͼ��չʾ��֧�ĺϲ���ʷ
git log --author=���� # ��ѯ���ߵ��ύ��¼
(��grepͬʱʹ��Ҫ��һ��--all--match����)
git log --grep=������Ϣ # �г��ύ��Ϣ�а���������Ϣ���ύ��¼
git log -S��ѯ���� # ��--grep���ƣ�S�Ͳ�ѯ���ݼ�û�пո�
git log fileName # �鿴ij�ļ����ļ�¼���ұ���ר�� |
����֮�⣬������ͨ�� �Cpretty ���ύ��Ϣ���ж��ƣ����磺

��������붨������(ժ�ԣ�Git���߳���֮·)����μ���Viewing the Commit History��
format��Ӧ�ij���ռλ����(ע��������ָ���һ�����ļ����ˣ��ύ�����ύ���ļ�����)
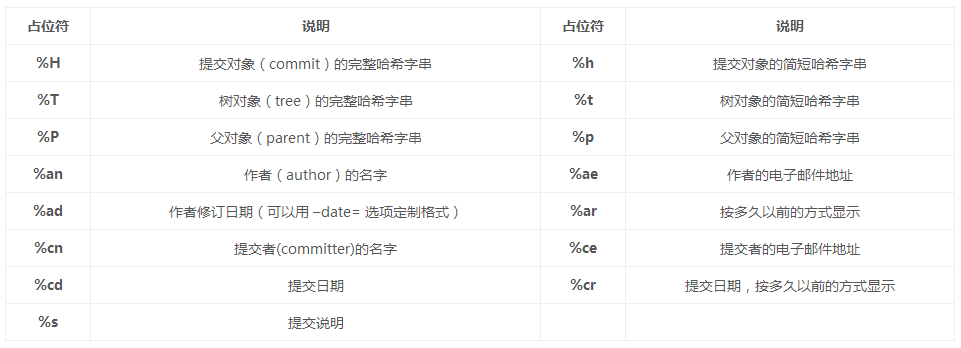
һЩ����������

����һЩ����log�����ѡ��

ѡ�� ˵��
-(n) ����ʾ����� n ���ύ
�Csince, �Cafter ����ʾָ��ʱ��֮����ύ��
�Cuntil, �Cbefore ����ʾָ��ʱ��֮ǰ���ύ��
�Cauthor ����ʾָ��������ص��ύ��
�Ccommitter ����ʾָ���ύ����ص��ύ��
�Cgrep ����ʾ��ָ���ؼ��ֵ��ύ
-S ����ʾ���ӻ��Ƴ���ij���ؼ��ֵ��ύ
10.�鿴ij�д�����˭д�ġ�git blame��
git blame �ļ��� # �鿴ij�ļ���ÿһ�д�������ߣ�����commit���ύʱ�� |

11.����Git���������git config �Cglobal alias��
����Ϊ��������������ı������Ͳ���ÿ�ζ��������������������ã�
statusΪst��checkoutΪco ; commitΪci ; branchΪbr��
git config --global alias.st status |
12.Ϊ��Ҫ��commit���ǩ��git tag��
����ijЩ�ύ�����ǿ���Ϊ������Tag����ʾ����ύ����Ҫ��
����ΪһЩ��ʽ������汾��commit������TAG����ij���汾
�������ˣ�ͨ��TAG���Կ����ҵ��˴��ύ���õ�SHA1ֵ����
ȥ�������⣬����һ����commit����ʡ�ºܶ࣡
Git��ǩ�����֣�������ǩ �� ���ӱ�ǩ
ǰ��ֻ�����ύ�ϼӸ�Tag��ָ���ύ��Hashֵ��
�������ᱣ����ǩ�ߵ���Ϣ��ʱ�������Ϣ��
git tag ������� # ������ǩ
git tag -a ������� -m "������Ϣ" # ���ӱ�ǩ |
�����Ϊ֮ǰ��ij��commit��TAG�Ļ����������ҳ�SHA1ֵ�����õ��������
git tag -a ������� �汾id # ���磺git tag -a v1.1 bcfed96 |
Ĭ�������git push����ѱ�ǩ����TAG��Զ�ֿ̲⣬��������͵������������ԣ�
git push origin ������� # ����ij��ǩ��
# ɾ�����б��زֿ��в����ڵ�TAG��
git push origin --tags |
���⣬�������½���֧��ʱ��Ҳ����TAG
git checkout -b ��֧�� ������� |
���������show����鿴��ǩ��Ӧ����Ϣ
13.Git�����Զ���ȫ���������ʱ������tab����
�ļ��ظ�/�汾����
1.�ļ��ָ�(δcommit)��git checkout��
����ڹ�����ֱ��ɾ����Git Tracked���ļ����ݴ����л�����ڸ��ļ���
��ʱ���룺git status������������
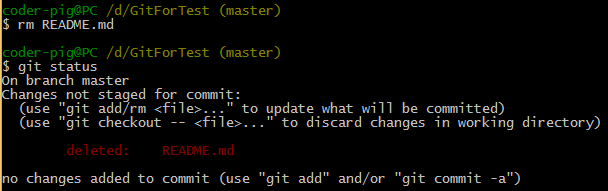
Git�����㹤�������ļ���ɾ���ˣ������ ɾ���ݴ�������ļ��� �ָ���ɾ�ļ�
# ɾ���ݴ����е��ļ���
git rm �ļ���
git commit -m "�ύ˵��"
# ��ɾ�ָ��ļ�
git checkout -- �ļ���
# ����ע�⣺git checkout��������ǰ�������ĸ���!!!���ɻָ����������С�ģ����� |
2.�ļ��ָ�(��addδcommit)��git reset HEAD��
������ĺ�add�����ݴ�������ָ�ԭ״������ָ��������ļ��ָ�ԭ״��
git reset HEAD �ļ���
git checkout �ļ��� |
3.�汾����(��commit)��git reset �Chard��
�ļ��Ѿ�commit�ˣ���ָ����ϴ�commit�İ汾�������ϴΣ����ԣ�
git reset HEAD^ # �ָ����ϴ��ύ�İ汾
git reset HEAD^^ # �ָ������ϴ��ύ�İ汾�����Ƕ��^���Դ����ƻ���~����
git reset --hard
�汾�� # git log�鿴����SHA1ֵ��ȡǰ��λ���ɣ����ݰ汾�Ż��� |
reset������ʵ���ǣ�����HEADָ�룬����ָ����һ��commit
������������ܻ�Թ������뻺�������Ӱ�죬�ٸ�����
�����ķ�֧�ߣ�- A - B - C (HEAD, master)
git reset B��- A - B (HEAD, master)
���ͣ�������C�ˣ����������Ǵ��ڵģ�
����ͨ��git reset C�汾���һأ�ǰ����
Cû�б�Git��������������(һ����30��)�� |
reset������ѡ����������
�Csoft��ֻ�Ǹı�HEADָ��ָ���������������䣻
�Cmixed����HEADָ��ָ���ݴ������ݶ�ʧ�����������䣻
�Chard����HEADָ��ָ���ݴ������ݶ�ʧ���������ָ���ǰ״̬�� |
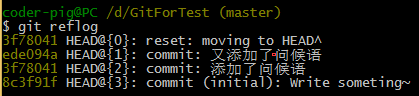
4.�鿴����ָ���¼��git reflog��
Git���ס�������ÿ��Gitָ����������git reset �л���һ���ɵ�
commit��Ȼ��git log�������ύ�ļ�¼û�ˣ����л����µ��Ǵ�commit��
�����ȵ�git reflog ��ȡ��commit��SHA1�룬Ȼ��git reset ��ȥ��
ע�⣺���ָ���¼�������ñ��棡Git�ᶨʱ�����ò����Ķ�����
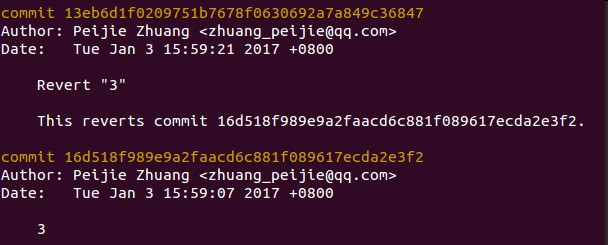
5.����ij���ύ��git revert��
��ʱ���������볷��ij���ύ�����ĸ��ģ�����ʹ��revert����
git revert HEAD # ���������һ���ύ
git revert �汾�� # ����ij��commit |
������İ��ύ�������ˣ���������һ���µ��ύ�����Ǿɵ��ύ�����������ύ
���µ��ύ��¼���ᱣ�棡�����������ٵ�һ��revert HEAD �ᷢ�ֱ������ĸ���
�ֱ�����ˣ����⣬ÿ��revert����Ҫ�����µ�commit��
��˵��������ֻ���ļ��仯���ύ��¼�����Ǵ��ڵģ�
6.�鿴ij���ύ�����ݡ�git show��
git show �ύid # �鿴ij��commit�������� |
7.�鿴ij����֧�İ汾�š�git rev-parse��
git rev-parse ��֧�� # �鿴��֧commit�İ汾�ţ�����дHEAD |
8.�һض�ʧ��������һ��ϣ����git fsck��
��Ϊ���ij�����������commit��ʧ�����git reflog���Ҳ�������
���Կ���ʹ��git fsck���ҵ���ʧ�Ķ���İ汾id��Ȼ��ָ����ɡ�

���ط�֧
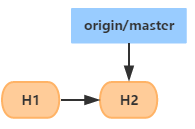
1.��֧����
�ύ��¼���ɵ�ʱ���ߣ�Ĭ�ϳ�ʼ�����ķ�֧(ʱ����) ���� master��֧��
������л���������֧�ϣ�ÿ��commit���ɵĿ��ն��ᴮ��������֧�ϣ�
����и� ���� HEADָ�룬��ָ��ָ�����ڹ����ı��ط�֧��ǰ��İ�
��������ʵ�ĵľ������HEADָ���ָ��
���磺��master��֧��ִ���Ĵ�commit����֧��״̬ͼ����
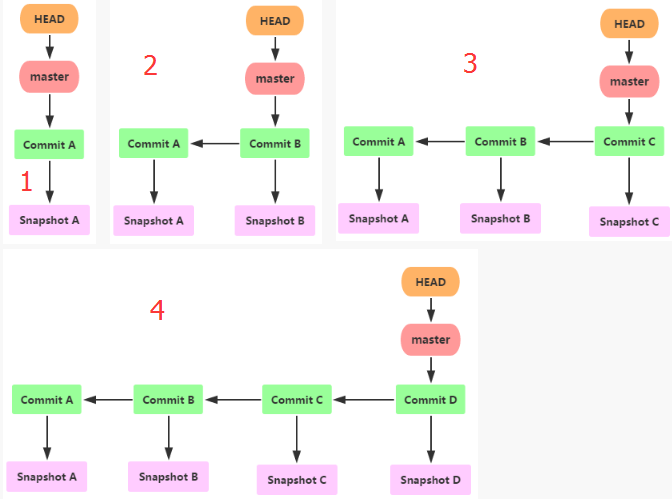
���ѷ��������Ĺ��ɣ�
ÿ��commit��master������ǰ�ƶ�һ����ָ�����µ��ύ
HEAD��ָ�����ڹ����ı��ط�֧����git reset�ĵľ���HEADָ���ָ��
2.����������֧��ԭ��
ͨ��������������ᴴ��������֧�ı�Ҫ��
����һ��
��Ŀһ�㶼��һ�������������ģ��д�汾��С�汾�ĸ��£���汾һ���Ǹ�
ͷ����ĸ��£�����UI��ģ��ܹ���ģ��汾�ǣ�v2.0.0������С�汾�ĸ���
һ����UIС�ģ�Bug���Ż��ȣ��汾�ǣ�v2.0.11������
ֻ��һ��master��֧����ζ�ţ���ķ�֧��dz��dz��ij�,�������Ѿ�����
���˵ڶ�����汾��Ȼ���û�������һ���汾�к����ص�BUG����ʱ�����л�
��һ���汾��BUG��Ȼ�����BUG�лصڶ�����汾�����빻Ǻ��
��������
ֻ��һ��master��֧�Ļ�������ij���ύ��ͻ�ˣ��������ͻ���ѽ������
������ˣ� ��ô���Ǹ����������Ϳ�ס�������ˣ��������������ˣ�
3.һ�����ʵ�õķ�֧��������
Ϊ�˽��ֻ��һ��master��֧��������⣬���������֧���������һ�ֲ������£�
��master��֧�Ͽ���һ���µ�develop��֧��Ȼ�����Ǹ��ݹ��ܻ���ҵ������develop
��֧�������������֧����ɷ�֧�ϵ�������ٽ������֧�ϲ���develop��֧�ϣ�
master��develop��֧����Ϊ���ڷ�֧�������������ķ�֧��Ϊ��ʱ�Է�֧��
����������֧�Ļ��֣�
master��֧����ֱ�����ڲ�Ʒ�����Ĵ��룬������ʽ��Ĵ���
develop��֧���ճ������õķ�֧���Ŷ��е��˶��������֧�Ͻ��п���
��ʱ�Է�֧�������ض�Ŀ�Ŀ��ٵķ�֧����������(feature)��֧������Ԥ����(release)��֧��
�ֻ�������bug ��fixbug����֧�������Ŀ�ĺѸ÷�֧�ϲ���develop��֧��
Ȼ��ɾ�� �÷�֧��ʹ�òֿ��еij��÷�֧ʼ��ֻ�У�master��develop�������ڷ�֧��
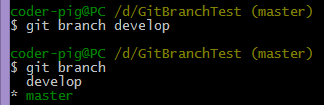
4.��֧�������л���git branch��
git branch ��֧�� # ������֧
git branch # �鿴���ط�֧ |
������master��֧�ϴ���develop��֧����ʱ�ķ�֧״�����£�
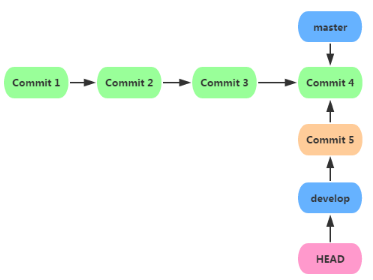
git checkout ��֧�� # �л���֧
git checkout -b ��֧�� # ������֧ͬʱ�л��������֧ |
�л���develop��֧�ĵ㶫������commit����ʱ�ķ�֧״�����£�
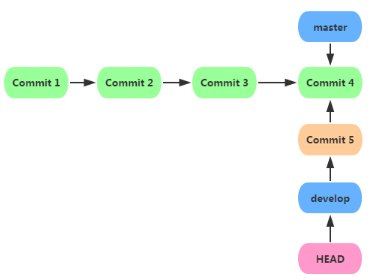
git checkout master �л�master��֧����֮ǰ�ĵ��ļ�����������
��û�з������ģ���Ϊ�ոյĸ�������develop���ύ�ģ���master��û��
�仯����ʱ�ķ�֧״�����£�
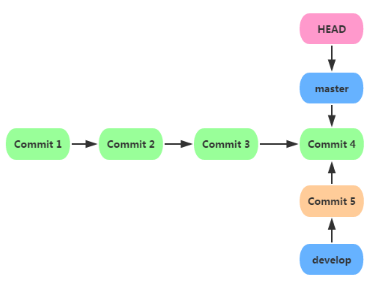
5.��֧�ĺϲ���git merge�� VS ��git rebase��
Git�У�����ʹ�� git merge �� git rebase �������������з�֧�ĺϲ�
git merge�ϲ���֧
�ϲ��ķ�ʽ��Ϊ���֣����ٺϲ� �� ��ͨ�ϲ������ߵ��������ڣ�
ǰ�ߺϲ��������������ϲ�������ϲ������ʷ���з�֧��¼����ͼ��
���ٺϲ��� 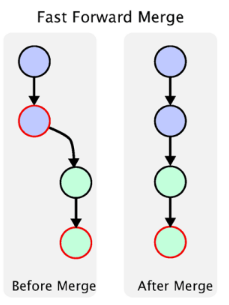
��ͨ�ϲ� �� 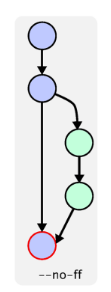
ʾ����
���ٺϲ�����develop��֧�ϲ���master��֧�ϣ�����master��֧������������
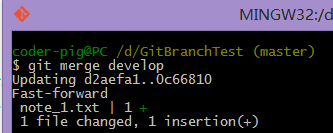
���ļ���

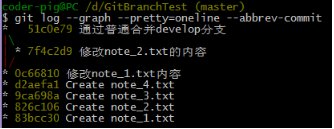
��ͨ�ϲ����е�develop��֧�£���note_2.txt�����ݣ���ͨ������ָ��ϲ���֧��
ע���Cno-ff������ʾ���ÿ��ٺϲ���
git merge --no-ff -m "�ϲ�����Ϣ(TAG)" develop |
 > >
��֧�������
git reabse�ϲ���֧
rebase(�ܺ�)�����ֺܶ���ν�Ľ̳̰��������д��̫����ˣ���ʵ��û��
��ô���ӣ�ֻ�����ֺϲ���ʹ�������࣬���ڸ��٣��ٸ����������Ա���
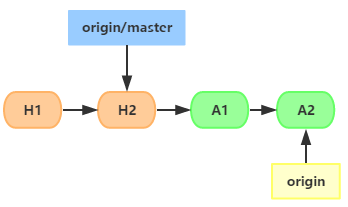
��һ����Ŀ��������ͬʱ������ ��ǰԶ�ֿ̲���ύ��¼�������ģ�
Ȼ��A��B���Կ���һ������֧�������Ӧ���ܣ������������Լ���
��֧�϶����˶�ε�commit����ʱ���˵ķֱ��֧���������ģ�
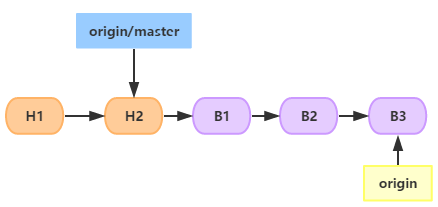
A�Ⱥϲ����ٵ�B�ϲ����������Ǽ���������������ȫ��������ģ�飬�ϲ�û�г�ͻ
merge�ϲ�
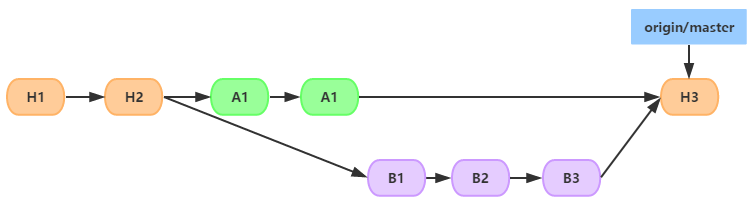
rebase�ϲ�
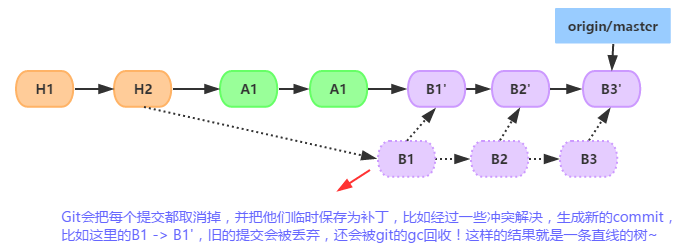
�÷���
git rebase ��ϲ����ĸ���֧�ķ�֧�� |
6.����ϲ���ͻ
�����Ǻϲ���֧��ʱ����ʱ�������ϲ���ͻ��Ȼ��ϲ�ʧ�ܵ����⣬
��ʱ��Ҫ�����Ƚ����ͻ����ܽ��кϲ������˿��������ٻ�����������
������ʱ�������ϲ���ͻ���Ǽҳ��㷹��
һ��������ӣ�A��B��develop��֧�Ͽ��ٳ�������֧�������ص�
���ܣ�A�����ˣ����Լ��ķ�֧�ϲ���develop��֧����ʱdevelop��֧��ǰ
�ƶ��˼���commit������BҲ��������Ĺ��ܣ�����Լ���֧�ϲ���develop
��֧������Ķ����ļ��ͺ�A�Ķ����ļ���ͬ�Ļ�����ʱ�ͻ�ϲ�ʧ�ܣ�
Ȼ����Ҫ�������ͻ�����ܹ������ϲ�����ģ����������ӣ�������merge��
merge��֧������ͻ

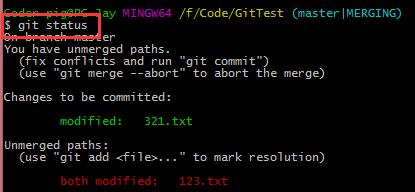
��ͻ�ļ���Ȼ������ͻ���֣�����ʲô�������Լ���������������
<<< �� >>> ��Щȥ����
������
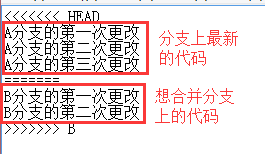
Ȼ��add��Ȼ��commit���ɣ��ϲ�������
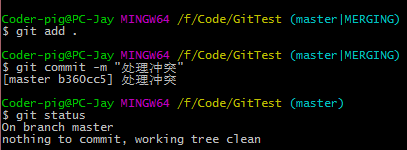
��ʱ�ķ�֧�ߣ�
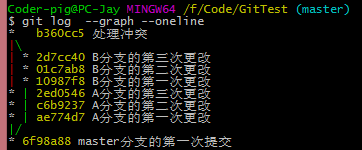
��������
rebase��֧������ͻ
������һ�飬Ȼ���Aֱ��merge��master�����е�B��rebase master����ʱ����
�ϲ���ͻ��������������ѡ�IJ�����
git rebase --continue # �������ͻ����������һ������
git rebase --abort # �������еij�ͻ�������ָ�rebaseǰ�����
git rebase --skip # ������ǰ�IJ�����
������һ��������������ʹ�ã��������ֵ�commit�ᶪʧ�� |
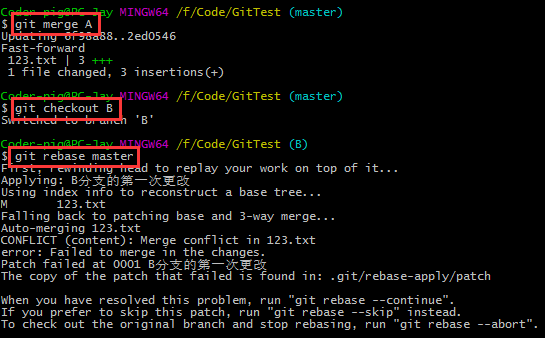
�õģ������β���Ҫ������һ��������
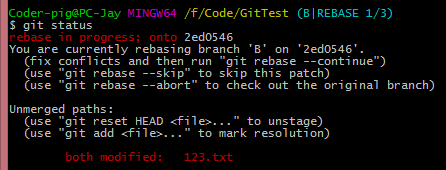

������

����git add �����ĺ���ļ���git rebase �Ccontinue��������������
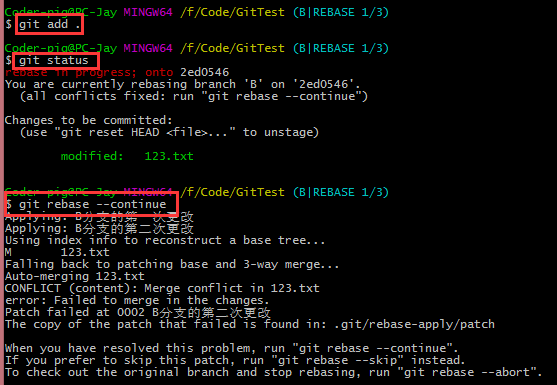
�����ظ�֮ǰ�Ĺ��̣�
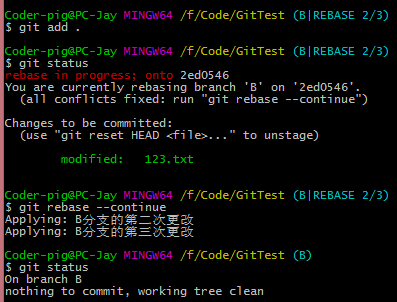

������

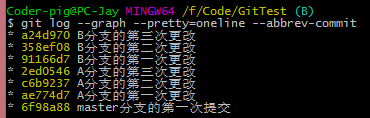
��������������A��֧�����ĸĶ�������û�г�ͻ������Ҳ��ֱ�Ӻϲ��ˣ�
����ϲ���;����ʲô�������git rebase �Cabort �ָ�rebaseǰ��״����
����·�֧�ᷢ����һ��ֱ�ߣ���Ҳ����rebase�ϲ���֧���ŵ㣺
�������ӣ������Լ����ԣ�GitTest.7z
7.ɾ����֧
���ںϲ���ķ�֧��������ûʲô�����ˣ�����ʹ����������ɾ����
git branch -d ��֧�� # ɾ����֧����֧����δ�ύ�����Dz���ɾ����
git branch -D ��֧�� # ǿ��ɾ����֧�����������֧����δ�ύ�ĸ��� |
8.�ָ���ɾ��֧
�������ҳ���ɾ����֧������commit�İ汾�ţ�Ȼ��ָ���֧
git log --branches="��ɾ���ķ�֧��" # �ҵ���ɾ��֧���µ�commitb�汾��
git branch ��֧�� �汾��(ǰ��λ����) # �ָ���ɾ��֧ |
9.�л���֧ʱ����δcommit�ĸ��ġ�git stash��
��ʱ���ǿ�����ij����֧������д�Ŵ��룬Ȼ����һЩͻ�����������Ҫ
������ʱ�л���������֧�ϣ�����Ҫ������bug�������л���֧��ͬ��
review���룬��ʱ���ֱ���л���֧�ǻ���ʾ�л�ʧ�ܵģ���Ϊ�����֧
�����ĸ��Ļ�û���ύ�������ֱ��add��commit��Ȼ�����л�����������
ϰ��д��ij���������ύ�������룺
���ݴ������֧�ϵĸĶ�����ȥ������֧�ϸ����£�Ȼ���������
������֮ǰ�ĸĶ���д���롣
��ô����ʹ�ã�
Ȼ����ĵ��л���֧��Ȼ�����л�����������ʹ�ã�
git stash apply #���ָ�����Ķ� |
������һ��һ��Ҫע�⣡��������stash����Ķ�����������л�
����һ����֧��stash�ˣ�Ȼ���л�����stash apply�ǻָ�����һ��
��֧��stash������
���������stash�˶�εĻ����ҽ������ȼ��룺
git stash list # �鿴stash�б� |
�ҵ��Լ���ָ����Ǹ�

����������ָ���Ӧ����netword�ϵ�stash������һ��stash��devlop�ϵ�
ֱ��git stash apply�ָ��ľ��������Ȼ���ָ���Ӧ����network���Ǹ�stash��
git stash apply stash@{1} |
�������������Լ���Ҫ�ָ����ɣ�
10.��֧������
git branch -m �Ϸ�֧�� �·�֧�� # ��֧������ |
Զ�ֿ̲���Զ�̷�֧
1.Զ�ֿ̲����
���ڴ����йܣ������Լ��Զ�ֿ̲⣬����ѡ��רҵ�Ĵ����й�ƽ̨��
�Լ���ĺô��У��ɿأ�������ȫ��������һЩ���ƣ����缯�ɱ��룬IM�ȣ�
��Ȼ���϶�����ҪһЩѧϰ�ɱ��ģ�(PS���ҳ������Լ����Gitlab)
�����Ĵ����й�ƽ̨(�Լ��ѹؼ���ȥ~)��
Github��Git@OSC��GitCafe��GitLab��coding.NET��gitc��BitBucket��Geakit��Douban
CODE
2.���ͱ��زֿԶ�ֿ̲⡾git push��
���Ƚ������뱾�زֿ�ͬ����Զ�ֿ̲⣬Ȼ������Զ�ֿ̲�ĵ�ַ�����磺

���������������������Զ�ֿ̲�
git remote add origin Զ�ֿ̲��ַ |
���Լ�����������ɲ鿴Զ�ֿ̲�״��
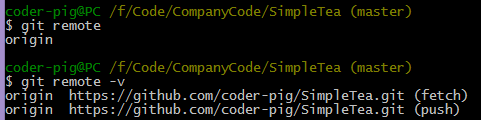
���Űѱ��زֿ����͵�Զ�ֿ̲⣬����� -u���� ��Ϊ��һ���ύʹ�ã�
�����ǰѱ���master��֧��Զ��master��֧��������(����Ĭ��Զ������)��
�����ύ����Ҫ���������
git push -u origin master |
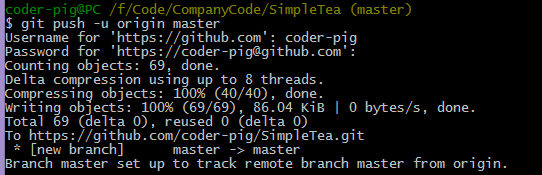
���⣬�������Զ�ֿ̲��ַ���ɼ��룺
| git
remote set-url origin Զ�ֿ̲��ַ
# Ҳ������ɾ��origin��������
git remote rm origin # ɾ���ֿ����
git remote add origin Զ�ֿ̲��ַ
# ���Ӳֿ����
|
��ֱ����.git�ļ����е�config�ļ���ֱ���滻Ȧסλ��
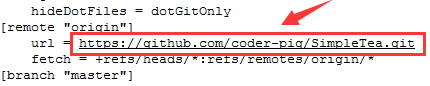
��Ҫ˵��һ�㣬origin �����ǹ̶��Ķ�����ֻ�Ǻ���ֿ��ַ��һ�� ��������
����д�������Ķ�����Ȼ����Ҳ�������ö���ֿ�������ò�ͬ�ı�����־�����磺
| git
remote add github https://github.com/coder-pig/SimpleTea.git
git remote add osc git@git.oschina.net:coder-pig/SimpleTea.git
|
3.��¡Զ�ֿ̲⡾git clone��
����Ŀ���͵�Զ�ֿ̲�����������߾Ϳ�����Ŀclone������
| git
clone �ֿ��ַ # ��¡��Ŀ����ǰ�ļ�����
git clone �ֿ��ַ Ŀ¼�� # ��¡��Ŀ���ض�Ŀ¼�� |
4.ͬ��Զ�ֿ̲���¡�git fetch��VS ��git pull��
���ڻ�ȡԶ�̷��������µķ�ʽ�����֣����Ƿֱ���fetch��pull��
���ܶ����Ի�ȡԶ�̷��������£���������ȴ���Dz�һ���ġ�
git fetch��
����ֻ�Ǵ�Զ����������ȡ�����°汾�����أ������㲻ȥ�ϲ�(merge)
�Ļ������ع����ռ��Dz��ᷢ���仯�ģ����磺
������Github�ϴ���һ��README.md�ļ���Ȼ��� git fetch ȥ��ȡԶ��
�ֿ�ĸ��¡�
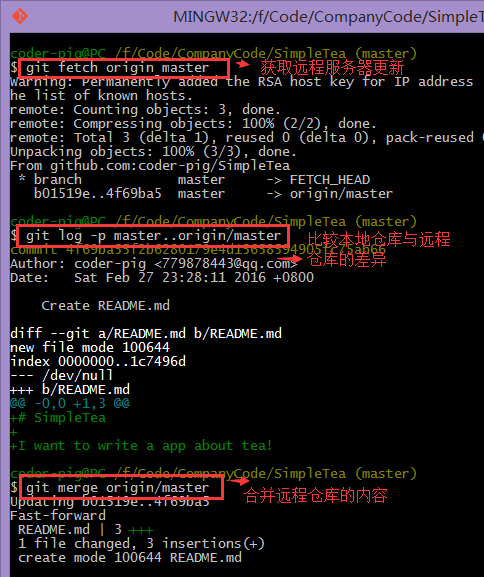
git pull��
һ����λ������˵��pull = fetch + merge�����磺ͬ����Github�ϵ�
README.md �ļ���Ȼ��git pull ͬ��Զ�ֿ̲�ĸ���
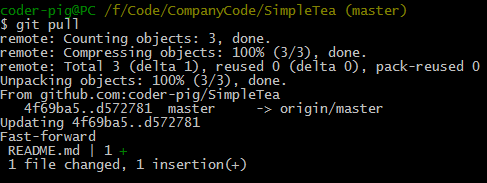
�����Զ�����ʵ�ʿ����У�ʹ��git fetch�����ȫһЩ���Ͼ�merge��ʱ��
���ǿ��Բ鿴���µ�������پ����Ƿ���кϲ�����Ȼ��ʵ����Ҫ�ɣ�
5.���ͱ��ط�֧��Զ�ֿ̲�
����ǰ���������ڱ��ؿ��ٷ�֧�����ijЩ�����������ύ�˶�κ�
����ѷ�֧���͵�Զ�ֿ̲⣬��ʱԶ�ֿ̲Ⲣû�������֧������ԣ�
| git
push origin ��֧�� # ���ͱ��ط�֧�����ݵ�Զ�̷�֧
|
6.�鿴Զ�̷�֧
7.��ȡԶ�̷�֧�����زֿ�
| git
checkout -b ���ط�֧ Զ�̷�֧ # ���ڱ����½���֧�����Զ��л����÷�֧
git fetch origin Զ�̷�֧:���ط�֧ #
���ڱ����½���֧���������Զ��л�������checkout
git branch --set-upstream ���ط�֧
Զ�̷�֧ # �������ط�֧��Զ�̷�֧������ |
8.ɾ��Զ�̷�֧
git push origin :��֧�� # ����ǰ��ı��ط�֧���ij�һ���ʺŶ��� |
9.������Զ�̷�֧
��ɾ��Զ�̷�֧��Ȼ�����������ط�֧��������Push��Զ�ֿ̲�
10.Ϊ��Ŀ����SSH Key��ȥ�ύ�����˺�������鷳
��֪��ϸ�ĵ�����û�з��֣��ֿ��ַ����Https�⣬����һ��SSH��
�������Ǽ��������ߵ����𣬵�һ�㣺ʹ��Https url���������¡
Github�ϵ���Ŀ��������SSH url��¡�Ļ������������Ŀ��ӵ����
����Ա�����һ�Ҫ����SSH Key�����������¡������һ���ǣ�
Httpsÿ��push����Ҫ�����û��������룬��ʹ��SSH����Ҫ����
�û����������SSH Keyʱ���������룬����Ҫ�������룬����ֱ��
git push�Ϳ����ˣ�
���⣬SSH��Secure shell(��ȫ���Э��)��רΪԶ�̵�½�Ự
��������������ṩ��ȫ�Ե�Э�飬��SSH����������ǿ��Ծ���ѹ���ģ�
���Լӿ촫����ٶȣ����ڰ�ȫ�����ٶȣ��������ȿ���ʹ��SSHЭ�飬
��SSH�İ�ȫ��֤�����ַ�Ϊ��������ͻ�����Կ���֣�
���������õ��ǻ��ڵڶ��ֵģ����ڱ��ش���һ����Կ��
��Կ(id_rsa.pub)��˽Կ(id_rsa),Ȼ��ѹ�Կ����������
Github�˺ŵ�ssh keys�У������ͽ����˱��غ�Զ�̵���֤��ϵ��
��������push��Զ�ֿ̲⣬�Ὣ�㱾�صĹ�����Կ��������Ľ���ƥ�䣬
���һ����֤ͨ��ֱ�������£�
��������������ssh key�������������Եĸ�Ŀ¼�£�����ٶ�����û
������SSH key��
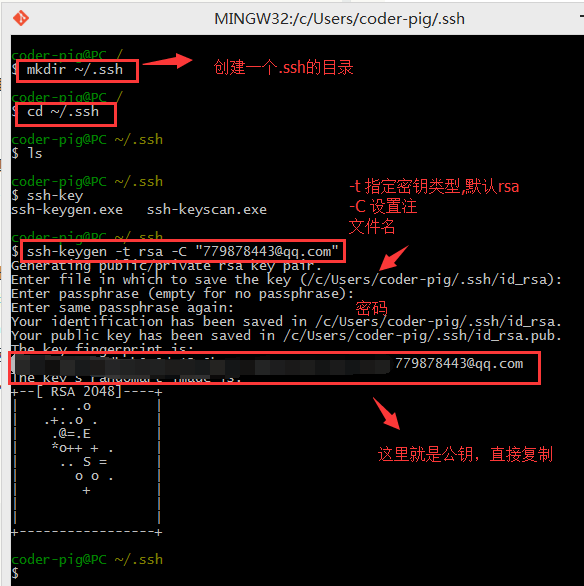
ִ����ssh-keygen�Ǹ�ָ���������Ҫ�������ļ�����
ֱ�ӻس�����������Ĭ�ϵ���Կ�ļ���������ʾ�������룬
ֱ�ӻس���������������������˵Ļ�����ôpush��ʱ��
�㻹����Ҫ�������룬���������һ�����룬ͬ���س���
Ȼ�������������������˵��ssh key�Ѿ������ɹ��ˣ�
���ǽ��ſ����ñ༭����id_rsa.pub�ļ�������:
�����ļ����ݣ�Ȼ���Github��������ͷ��ѡ��Settings��
Ȼ�������SSH Keys,Ȼ��New SSH Key
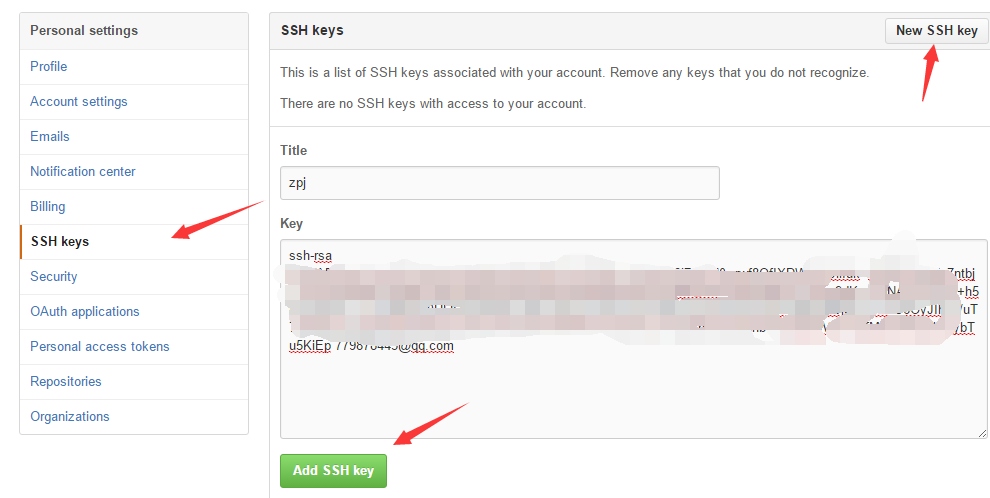
Ȼ��Github����㷢��һ����ʾ������һ����ssh key���ʼ���
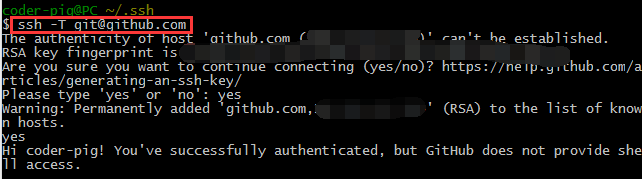
���Ӿͺã����������ǿ��Լ��룺ssh -T git@github.com��
Ȼ��������������ù���������Ҫ�������룬
����ֱ������yesȻ��һֱ���س��ͺã���������Hi xxx�Ǿ仰
��˵��ssh key���óɹ��ˣ�
PS������Զ�ֿ̲����÷��������ͬ��
���ݲο��ԣ�https://help.github.com/articles/generating-an-ssh-key/
��1��Github�ͻ���
��ʵ����װ��Git��һ��һ��GitGui�Ķ����ˣ��Ϳ���ֱ��
�����û������Git�����汾�����Ĺ����ˣ���Github�ͻ�������
Github�������ṩ��һ��ר����������Github��Ŀ��һ�����߶��ѡ�
���磬������װ��Github�ͻ��ˣ���Clone��Ŀ��ʱ����ֻ������

����ֱ�Ӱ���Ŀclone����������һЩGit������ͼ�λ����ˣ������������������
����Github�ͻ��ˣ�https://desktop.github.com/
�ļ���С�������������ļ�������Ҫ�������ذ�װ��100��m��
Ȼ��ɵ��ʽ��װ����װ��ɺ��Զ���Github�ͻ��ˣ�Ȼ��
ʹ�����Github�˺ŵ�½����������Ĭ��Ϊ�㴴��SSH Key��Ϣ��
���ŵ����Լ������ˣ�
�������ⲹ��һ�㣬����win 8.1װGithub�ͻ��˵����⣬
������װ��ʱ��һֱ���������
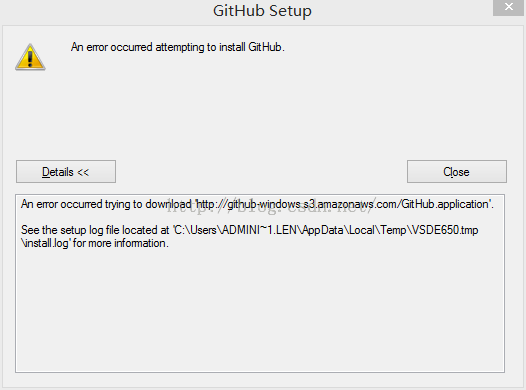
ֱ�ӣ�win + x��ѡ����������ʾ��(����Ա)����ִ��������������ָ�
%SYSTEMROOT%\SYSTEM32\REGSVR32.EXE
%SYSTEMROOT%\SYSTEM32\WUAUENG.DLL |
Ȼ���ٵ��Github�İ�װ���ȴ���װ��ɼ��ɣ����ز��������ӡ�
��2��ɾ��Git�ֿ�
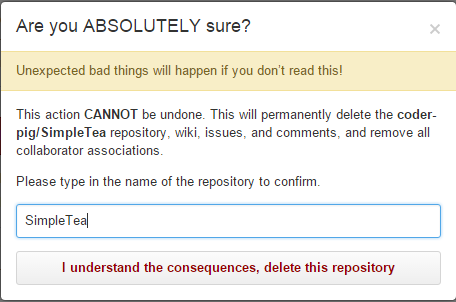
���������IJֿ⣬���Setting���������

���Delete this repository

�����ĶԻ���������Ҫɾ���IJֿ����ƣ����ŵ��ɾ��
��3��Ϊ��Դ��Ŀ���״���
�����Clone���˵Ŀ�Դ��Ŀ���ڿ����˴����ʱ�������������
ijЩ�ط�д�ò��ã�д�����������и��õ��뷨�����ڱ����ĺ�
�����push���͵���Դ��Ŀ�ϣ��뷨�ܺã������㲻����Ŀ��ӵ
���źͲ����ߣ����������ĵģ�����������Ϊ��
�����ܺ��ӣ��Ͼ��ܺ��������ڣ����뿪Դ��Ŀ�ķ��������֣�
��һ�ַ�����
�������߰����Ϊд���ߣ�����Э�������̣�����ֿ��Settings
�C>CollaboratorsȻ�����������ӵ��˵��û����������䣬���
���Ӽ��ɡ�
�ڶ��ַ�����
���Fork��ť���������Ŀfork���Լ����˺��£�Ȼ��Clone
�����أ�Ȼ�������������ģ�commit�ύ��Ȼ��push���Լ���
����IJֿ⣬Ȼ���Դ��Ŀ�������Ȼ���½�һ��
pull request�����������Լ��IJֿ�ΪԴ�ֿ⣬����Դ��֧��
Ŀ��ֿ���Ŀ���֧��Ȼ����pull request�ı����������Ϣ��
��д��Ϻ�ȷ�������ʱ��Դ��Ŀ�����߾ͻ��յ�һ��pull
request������������������ˣ����������������û����
�Ļ��������Ե��һ��merge��ť���ɽ����pull request�ϲ�
���Լ�����Ŀ�У��������߷�����������л���Щbug��������
ͨ��Pull Request����˵����Ҫ����xxBUG�������ϲ�����ô
��������BUG���ύ�����ĺ���ύ�����Pull Request��
Ȼ�����������������
PS:�������߲��رջ���merge������Pull Request�������һֱ
commitɧ������Ŀ��( �s���t )
Git������
����Git������������һƪͼ�IJ�ï�ܺõ����£��Ͳ��ظ��������ˣ�
�˴�ֻ�����¶�Ӧ�������ļ������������Git Workflows and Tutorials
1.����ʽ������
������SVN������ֻ��һ��master��֧��Ȼ��һȺ�˾���������֧���ˣ�������СA��СB��
(��ͻ��������������·)
1.��Ŀ�����߳�ʼ���ֿ⣬Ȼ���Ƶ�Զ�ֿ̲�
2.�����˿�¡Զ�ֿ̲���Ŀ������
3.СA��СB��ɸ��ԵĹ���
4.СA������ˣ�git push origin master �Ѵ������͵�Զ�ֿ̲�
5.СB������ˣ���ʱ���ʹ��뵽Զ�ֿ̲⣬�����ļ��ij�ͻ
6.СB��Ҫ�Ƚ����ͻ��git pull �Crebase origin master��Ȼ��rebase������
7.СB�ѳ�ͻ�����git push origin master �Ѵ������͵�Զ�ֿ̲�
2.���ܷ�֧������
�ͼ���ʽ�ֲ������ֻ�Ƿ�֧�ٲ���ֻ��master�����Ǹ��ݹ��ܿ����µķ�֧���ѣ�ʾ����
ע������IJֿ��������ӵ�вֿ����Ȩ����
1.СAҪ�����¹��ܣ�git branch -b new-feature �����·�֧
2.СA��new-feature���¹�����صı�д�������������֧�Ƶ�Զ�ֿ̲�
3.������ɺ�������pull request(�ϲ�����)����new-feature�ϲ���master��֧
4.�ֿ����Ա���Կ���СA�ĸ��ģ����Խ���һЩ��ע����СA��ijЩ���ģ�
Ȼ���ٷ���pull request�����߰�pull request�������������ġ�
5.�ֿ����Ա���ÿ����ˣ��ϲ���֧��master�ϣ�Ȼ���new-feature��֧ɾ��
3.Gitflow������
��ʵ���ǹ��ܷ�֧����������һЩ�淶���ѣ�������̲μ�����Git��֧��ģ�
һ�����ʵ�õķ�֧�������ԡ�
4.Forking������
�ֲ�ʽ��������ÿ�������߶�ӵ���Լ������IJֿ⣬������ĸ�3��Ϊ��Դ��Ŀ���״���
��·���ƣ�����Ŀfork���Լ���Զ�ֿ̲⣬�����Ӧ���ģ�Ȼ��pull request��Դ�ֿ⣬
Դ�ֿ�����߿��Ծ����Ƿ�ϲ���
5.Pull Request������
��Forking���������ƣ�Pull Requests��Bitbucket�Ϸ��㿪����֮��Э���Ĺ���
|






