| БрМЭЦМі: |
БОЮФжївЊвдТлЮФАцБОПижЦЯЕЭГР§згЕФЗжЮіЮЊв§ЃЌНщЩмСЫGit
ЕФЩшМЦРэФювдМАЗжжЇЙмРэЕФЯъЯИЪЕМљЙ§ГЬЃЌЯЃЭћЖдФњФмгаЫљАяжњЁЃ
БОЮФРДздгкgiteeЃЌгЩЛ№СњЙћШэМўLucaБрМЁЂЭЦМіЁЃ |
|
Linux & Git БЛГЦЮЊ Linus Travis
ЕФСНДѓЩёзї, ЪЕжСУћЙщ!
дкЬИ Git жЎЧА, ЯШЬИвЛЯТ LinuxЁЃ
Linux КЭ Windows зїЮЊСНИіЙуЗКЪЙгУЕФВйзїЯЕЭГ, газХМЋДѓЕФВювь, дкИїжжЙуЗКЕФЦРМлКЭељжДжа,
ЮвЖдЯТУцЕФЦРМлЪЎЗждоЭЌ :
Linux гы Windows зюБОжЪЕФЧјБ№дкФФРяЁЃгаШЫЛсЫЕЧАепУтЗбЃЌКѓепашвЊТђ (ЛђЭЕ)ЁЃетжЛЪЧЖд
ЁАfree softwareЁБ ЕФЧњНтЁЃдкЮвПДРДЃЌЖўепзюживЊЕФЧјБ№ФЫЪЧЫќУЧЖдздМКЕФгУЛЇЫљзіЕФМйЩшЁЃ
Ждгк LinuxЃЌетИіМйЩшЪЧЃКгУЛЇжЊЕРздМКЯывЊЪВУДЃЌвВУїАзздМКдкзіЪВУДЃЌВЂЧвЛсЮЊздМКЕФааЮЊИКд№ЁЃ
Жј Windows дђЧЁКУЯрЗДЃКгУЛЇВЛжЊЕРздМКЯывЊЪВУДЃЌвВВЛУїАзздМКдкзіЪВУДЃЌИќВЛДђЫуЮЊздМКЕФааЮЊИКд№ЁЃ
ЮвВЛЯўЕУЩЯЪіЙлЕузюГѕдДздФФРя, ЛђаэЪЧетРя: Zaikun's BlogЁЃ
ЮвВЛЪЧвЛИіМЋЖЫжївхеп, етСНжжРэФюУЛгаЫЪЧЫЗЧ, ЪыгХЪыСг. КЃФЩАйДЈ, гаШнФЫДѓ, ЮвЛсГЂЪдЗЂЯжУПвЛжжРэФюЕФгХЪЦКЭЪЪгУГЁОА,
ЖјВЛЪЧвЛЮЖЕиШЅЗёЖЈЪВУДЁЃ
дкЙЄзїГЁОАЩЯ, ЮвИќЯВЛЖ Linux ЕФРэФю :
Ювдјrm -rfЮѓЩОЙ§/etcФПТМ, ЕМжТЯЕЭГЯнШыЬБЛО; вВдјвђАќЙмРэвРРЕЮЪЬтЖјЕМжТШэМўЫ№ЛЕ ...
дкЮвПДРД, етаЉЖМВЛПЩХТ, Linux ЛсзМШЗЕФЯђЮвеЙЪОЙЪеЯдвђ, ЖјВЛЪЧЁИЧыЩдКѓ...ЁЙ, ЁИЮвУЧе§дкзівЛаЉзМБИЙЄзїЁЙ
етРяЙЪеЯдвђЪЧжИвЛИіЛљгкЙуЗКШЯжЊЛљДЁЩЯЕФНтЪЭ. БШШч: ШчЙћвђЮЊДњТыБраДЕФЪЇЮѓ, ЕМжТвЛЖЮГЬађУЛгаАДееЩшМЦвтЭМжДаа,
ЮвжЛашСЫНтДњТыВуУцЕФТпМДэЮѓМДПЩ, ЖјВЛЪЧЩюОПДэЮѓЕФДњТыдкЕчТЗВуУцЕМжТСЫЪВУДбљЕФЮЪЬтЗЂЩњ
ШеИДвЛШеЕФЪЙгУ, ЮвЗИДэЮѓЕФИХТЪдНРДдНЕЭ, Жд Linux БОЩэЕФРэНтдНРДдНЩюШы, Жд Linux
дНРДдНаХШЮ, ВЂЧвж№НЅгаСЫвЛжжЖд Linux ЕФеЦПиИаЁЃ
ШЛЖјдкгЮЯЗгщРжГЁОАЩЯ, ЮвИќаРЩЭ Windows ЕФРэФю:
ЕБЮвЯыЭцгЮЯЗЗХЫЩвЛЯТЪБ, ЮвЯЃЭћ Windows ЮЊЮвАќАьвЛЧа, ЮввЊзіЕФОЭЪЧЫЋЛїдЫаа, ШЛКѓПЊЪМгЮЯЗЁЃ
Git гы Linux ЭЌдДЭЌзк, врЪЧгазХЯрЫЦЕФРэФю, ЦфБОЩэгазХМЋЮЊСщЛюЕФЩшМЦ, Git ШЯЮЊ
:
гУЛЇжЊЕРздМКдкзіЪВУД, ВЂЧвЛсЮЊздМКЕФааЮЊИКд№ЁЃ
дкПЊдДСьгђЕФЙуЗКЪЙгУжааЮГЩСЫШ§жжБЛЙуЗКНгЪмЕФзюМбЪЕМљ : Git flow,
Github flow, Gitlab flow.
ДгЪжУІНХТвПЊЪМ
ЕБЮвГѕбЇ Git ЪБ, ЮвЙизЂ Git ЕФЙЄГЬЪЕМљЪЄЙ§ЦфФкдкЕФЩшМЦРэФю, вджСгкЦШЧаЕФШЅбАеввЛаЉЫљЮНЕФзюМбЪЕМљ,
ШЛКѓНЉгВЕиФЃЗТЩѕжСЩњАсгВЬз, НсЙћЯдЖјвзМћ, ЮвЪМжеЮоЗЈзіЕН
flowЃЌдвтЪЧЫЎСїЃЌБШгїЯюФПЯёЫЎСїФЧбљЃЌЫГГЉЁЂздШЛЕиЯђЧАСїЖЏЃЌВЛЛсЗЂЩњГхЛїЁЂЖдзВЁЂЩѕжСфіЮа.

РэЯыЪЧаадЦСїЫЎ, ЯжЪЕШДЭљЭљВвВЛШЬЖУ
ОВЯТаФРДЯывЛЯы
ЪеЦ№МБЙІНќРћЕФаФЬЌ, ЮвПЊЪМЫМПМ, Git ЕФЩшМЦРэФюЕНЕзЪЧЪВУДЁЃ
Git ЪЧвЛжжАцБОПижЦЯЕЭГ, ЯШВЛЬИ Git ЪЧШчКЮЩшМЦЕФ, ШчЙћШУЮвРДЩшМЦвЛИіАцБОЙмРэЯЕЭГ, ИУШчКЮЯТЪж?
ЩшМЦвЛИізюМђЕЅЕФАцБОПижЦЯЕЭГ

етОЭЪЧвЛИіМђЕЅДжБЉЕФАцБОПижЦЯЕЭГ, МђЕЅЕФЮФМўПНБДМгжиУќУћвбОФмТњзуЖдгкБЯвЕТлЮФЕФАцБОПижЦ, ЕНзюКѓ,
ФмФУГівЛИіЦЏССЕФБЯвЕТлЮФжеАхМДЭђЪТДѓМЊЁЃ
ЩЯУцЕФУПвЛИіАцБОЖМЪЧЛљгкЩЯвЛИіАцБОаоИФЖјРДЕФ, ВЂЧвЕБаТЕФАцБОГіРДжЎКѓ, РЯОЩАцБОЕФМлжЕОЭМИКѕВЛДцдкСЫ,
дкЪЙгУ SVN Лђеп Git вЛИіШЫПЊЗЂаЁЯюФПЛђМЧБЪМЧЕФЪБКђ, ГЁОАгыДЫРрЫЦЁЃ
ШчЙћГЁОАИДдгвЛЕуЖљФи?
ШчЙћЕМЪІАяЮввЛПщИФ, ЖМЛљгкЁИБЯвЕТлЮФзюжеАц1.docЁЙаоИФ, ЕМЪІИФГіСЫЁИC.docЁЙ, ЮвИФГіСЫЁИD.docЁЙ,
етЪБШєЯыБЃСєСНШЫЫљгаЕФаоИФ, ВЂКЯВЂГівЛИіаТЕФАцБОЁИE.docЁЙ, ЫЦКѕОЭвЊЛЈаЉЙІЗђСЫЁЃ
ЪзЯШвЊевГіРДЕМЪІИФСЫФФаЉ, ЮвИФСЫФФаЉ;
ШЛКѓЛљгкЁИБЯвЕТлЮФзюжеАц1.docЁЙ, АбЕМЪІЕФаоИФКЭЮвЕФаоИФгІгУЙ§РД;
ШчЙћЕМЪІЕФаоИФКЭЮвЕФаоИФЪЧдкВЛЭЌЕиЗНаоИФЕФ, ФЧУДЛЅВЛгАЯь, ЗжБ№гІгУ;
ШчЙћЕМЪІЕФаоИФКЭЮвЕФаоИФдкЭЌвЛДІ, вЊбЁдёвдЕМЪІЕФЮЊзМ, ЛЙЪЧвдЮвЕФЮЊзМ;
МДЪЙЕМЪІЕФаоИФКЭЮвЕФаоИФВЛдкЭЌвЛДІ, ЕЋЪЧЗёЛсдьГЩећЬхТпМЕФУЌЖм, вЊДгећЬхЩЯаое§ТпМ.
Йў! етВЛОЭЪЧ git merge Тя!

ВЛКУвтЫМ, ЭМЗХДэСЫ

ЙизЂЕуЕНЕздкФФРя?
ЕМЪІЕФМгШыЪЙЕУЮвУЧМђвзЕФБЯвЕТлЮФАцБОПижЦЯЕЭГБфЕУгаЕуЖљСІВЛДгаФ, ЮвУЧБиаыаЁаФДІРэЕМЪІЕФаоИФгыЮвЕФаоИФЖдТлЮФБОЩэдьГЩЕФгАЯь,
ШчЙћгжРДвЛИіШШаФбЇГЄЭЌЪБЖдЮвЕФТлЮФМгвджИЕМ(аоИФ), ЮЪЬтЫЦКѕБфЕУИќМгИДдгСЫЁЃ
ВЛжЊВЛОѕжа, ЮвУЧЕФЙизЂЕувбОДгТлЮФБОЩэзЊЯђСЫаоИФ, ЖрШЫЭЌЪБНјаааоИФЪЙЕУЮвБиаыаЁаФДІРэУПИіШЫЕФаоИФ,
ВЛФмвХТЉ, ВЛФмГхЭЛ, вВВЛФмТпМУЌЖм, етМђжБЬЋЛьТвСЫЁЃ
Git ЕФЩшМЦРэФю
РэНт Commit
ЭЈЙ§ЖдЩЯУцР§згЕФЗжЮі, ЯраХФувбОЬхЛс, ТлЮФАцБОПижЦЯЕЭГЕФКЫаФЙизЂЕугІИУЪЧаоИФ, ЖјВЛЪЧТлЮФБОЩэЁЃ
ШУЫМТЗЛиЕН Git ЩЯРД, Git ЗжжЇЭМжаЕФУПИіЕугЩgit commitУќСюВњЩњ, ВЂЧвЛсВњЩњвЛИіЮЈвЛЕФsha1жЕ,
вђДЫПЩвдЭЈЙ§sha1жЕРДЮЈвЛШЗЖЈвЛИіЬсНЛЕуЁЃ
дкЩЯЭМжа, BЕугІгаСНжжКЌвх :
БэЪОвЛИіПьее, МДЯюФПЙЄГЬЫљгаЮФМўдкетвЛПЬЕФзДЬЌ;
БэЪОвЛИіВювь, МДBзДЬЌгыAзДЬЌЮФМўЕФВювь, врГЦзїВЙЖЁ(patch)ЁЃ
РрБШгкБЯвЕТлЮФ, ПьеевВОЭЪЧБЯвЕТлЮФзюжеАц1.docТлЮФБОЩэ, ВювьвВОЭЪЧаоИФ.
ШчКЮЬхЯжBЕуЕФетСНИіЪєад? (ЮвУЧгУ[B]РДБэЪОBЕуЕФsha1жЕ)
ЛиЕНBЕуЕФПьее: git checkout [B]
ВщПДBЕугыЩЯвЛИіЬсНЛЕуЕФВювь: git show [B]
ЪЙгУgit checkoutУќСюЮвУЧПЩвддкећИі Git ЬсНЛРњЪЗЩЯЕФЫљгаПьееАцБОДЉЫѓ,
ФуПЩФмЬ§Й§ЫЕHEADжИеы, git checkoutе§ЪЧЭЈЙ§ХВЖЏHEADжИеыРДДяЕНПьееЧаЛЛЕФФПЕФ,
ШчЙћЖрДЮДЉЫѓКѓ, ФуУдЪЇСЫздМК, евВЛЕНЕБЧАдкФФвЛИіПьее, ЧыВщПД Git ЗжжЇЭМ, евЕНHEADжИеы,
етОЭЪЧФуЫљДІЕФПьееАцБОЁЃ
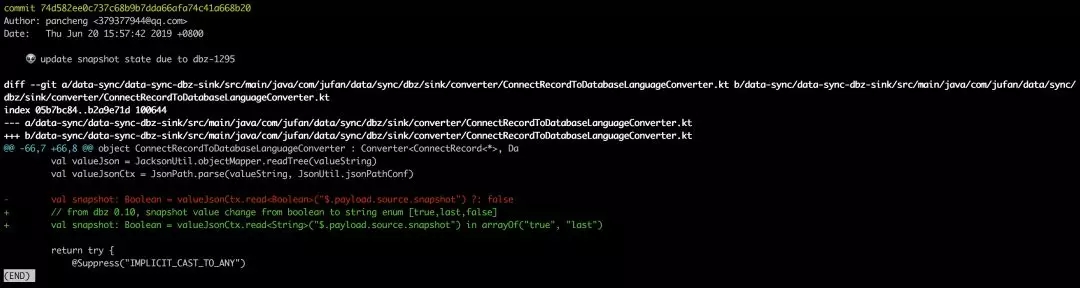
ПЩвдПДЕН, git showУќСюЭъећЕФеЙЪОСЫBЕугыЦфЩЯгаНкЕуAЕуЕФВювь,
Git зїЮЊвЛИіУцЯђдДТыЕФАцБОПижЦЙЄОп, НЋВювьвдааЮЊЛљБОЕЅЮЛБэЪОЪЧБШНЯКЯРэЕФвЛИібЁдё. етвВвтЮЖзХНЋ
Git гУгкЗЧЮФБОзЪдДЕФАцБОПижЦЙЄОпЛђаэВЛЪЧзюМббЁдёЁЃ
ЖдвЛИіЬсНЛЕуКЌвхЕФЫЋжиНтЪЭПДЩЯШЅКмВЛДэ, ВЛЙ§, дкетИіЗжжЇЭМЩЯ, EЕугаЕуЖљЬиЪт, жЛгаEЕугаСНИіЩЯгЮНкЕуCКЭD,
ГЂЪджДааgit show [E], ЗЂЯжВЂУЛгаЯёЦфЫћНкЕувЛбљ, ЯдЪОГіdiffаХЯЂ, етЫЕЕУЙ§ШЅ,
ВЛШЛЕНЕзИУЯдЪОEКЭCЕФВювь, ЛЙЪЧEКЭDЕФВювьФи?
етЪБОЭжЛФмНшжњ Git ЕФСэвЛИіУќСюgit diff [X] [Y]РДЯдЪНЩљУївЊБШНЯШЮвтСНИіНкЕуXКЭYЕФВювьЁЃ
зЉЭЗгаСЫ, ГЧБЄдкФФФи?
ШеГЃвЛЬь
дквЛаЉЯюФПзщРя, ФуПЩФмЛсБЛИцНыЕР: "МЧЕУУПЬьЯТАрЧАЬсНЛЯТФуЕФДњТы." вВаэЫћУЧвбОЗЂЯж:
"дѕУДДњТыгжГхЭЛСЫ", "ЮваДЕФДњТыдѕУДБЛИВИЧСЫ", ЛсЖдФуЖрЬсвЛОфИцНы:
"МЧЕУЬсНЛЧАЯШРвЛЯТДњТы, Б№АбЭЌЪТаДЕФИВИЧСЫ". гкЪЧ, Git ОЭНіНіГЩЮЊСЫвЛИідЖГЬДњТыВжПтЁЃ
ВњЦЗ: "ЩЯДЮЬсЕФ3ИіашЧѓ, НёЬьОЭЩЯ1Иі, СэЭт2ИіВЛгУСЫ"
ПЊЗЂ: "ЮвДњТызђЬьЖМаДЭъЬсНЛСЫ, ФЧжЛФмАб2ИіашЧѓДњТыЩОЕєСЫ. ЮвПЩЪЧгаДњТыНрёБЕФ,
ВЛФмШУЮвЕФЯюФПРяетУДЖрЮогУДњТыСєзХ"
[СНаЁЪБКѓ]
ВњЦЗ: "ЮвЯыСЫвЛЯТ, BЙІФмЛЙЪЧвЊЩЯЕФ, вЛЙВЩЯ2ИіЙІФм"
ПЊЗЂ: "ааАЩ, ЮвдйАбДњТыПНБДЛиРД"
[СйЩЯЯп]
ВњЦЗ: "ВЛаа, ЯТЕєBЙІФм, ЩЯCЙІФм! Пь!!!"
ПЊЗЂ: "W-- ЮвЗ№ДШБЏ!"
[ЩЯЯпКѓ]
РЯДѓ: "CЙІФмгаbug, СЂПЬЛиЙі"
ПЊЗЂ: "КУ, ЮвЭЫЛиЕНЩЯДЮЗЂАцЕФПьее"
етЪЧШеГЃЕФвЛЬь, вВЪЧдуИтЕФвЛЬь, ДѓАбЕФЪБМфРЫЗбдкДњТыЕФЩОГ§КЭПНБДЩЯ, ЖјВЛЪЧдкДДдьЩЯЁЃ
ЮЪЬтГідкФФСЫ?
ЩЯНкЮвУЧЬсЕН, Git УПИі Commit ЖМгаСНжжЪєад, ПьееКЭВЙЖЁ. дкЩЯУцЕФЪЙгУГЁОАжа, Git
жЛЗЂЛгГіСЫВЛЕНвЛВуЙІСІ, ДѓМвЙизЂЕФНіНіЪЧзюаТЬсНЛЕуЕФПьее, ЕБШЛ, етИіПьееЪЧМЋЮЊживЊЕФ, живЊЕНЮвУЧЕФHEADжИеыМИКѕзмЪЧдкжИЯђЫћ,
живЊЕНЮвУЧЛсАбЫћГЦЮЊзюаТЕФmasterЗжжЇЁЃ
ЮвУЧАбЙизЂЕузЊвЦЕН Git ЕФВЙЖЁЪєадЩЯРД, ФуУПЬьЬсНЛЕФ commit ДњБэзХФуетвЛЬьЕФЙЄзїГЩЙћ,
ФЧУДУшЪідѕУДаД?
"еХШ§20190622ЙЄзї"? ЛЙЪЧ "діМгСЫAЙІФм, BЙІФм, CЙІФмаДСЫвЛАы"
ЛђаэКѓепЩдЮЂКУвЛЕуЖљ, жСЩйдкМИЬьЪБКђВщПД Git ЬсНЛМЧТМЪБФмвЛФПСЫШЛЕФжЊЕРетДЮЬсНЛАќКЌЪВУДаоИФЁЃ
ЛЙМЧЕУgit diffЕФЪфГіТ№? ЪЧааМЖЕФВювьЁЃ ЮЊЪВУДВЛЪЧЮФМўМЖБ№, ЛђепзжЗћМЖБ№? УПДЮДњТыЬсНЛвдЬьЮЊЕЅЮЛецЕФКЯЪЪТ№?
ЕБШЛВЛКЯЪЪ, УПИі commit ЕФзюМбСЃЖШгІИУЪЧЯрЖдЖРСЂЕФЬиад(feature), БШШчЩЯЮФЬсЕНЕФA,
B, CШ§ИіЙІФмЁЃ
РэЯыЧщПіЯТ, A, B, CЪЧШ§ИіЖРСЂЕФЙІФм, ЗжБ№зїЮЊШ§ДЮ commitЁЃ

ИќКУЕФзіЗЈЪЧЪВУД?
ЛЙМЧЕУТ№? A, B, CЖМЪЧЖРСЂЕФВЙЖЁ(patch), ФЧУДA, B, CЕФДЮађЪЧУЛгаЙиЯЕЕФ,
вВОЭЪЧЫЕC1, B2, A3ЕФДњТыПьеегІИУЪЧвЛбљЕФ. ВЛаХЪдвЛЯТ, ПЩвдгУgit diffбщжЄНсЙћЁЃ
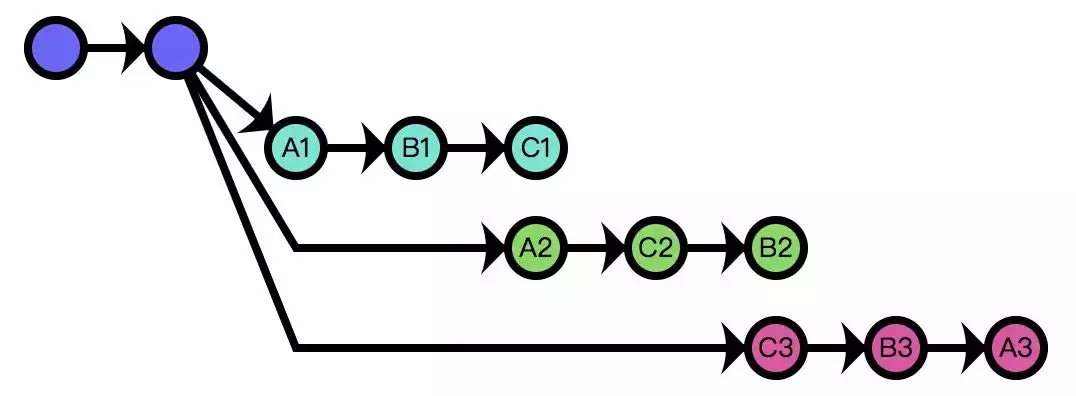
ЕБвЊЧѓГЗЕє B ЙІФмЪБ, ШчЙћПЩвджБНгЩОЕє B етДЮЬсНЛ, ФЧУДЫВМфОЭДяЕНФПЕФСЫ. ЕЋЪЧ, гаСНЕуЪЧашвЊПМТЧЕФ
:
вЛАуРДЫЕ, ДѓМвЭЌЪБЪЙгУЕФЗжжЇжЛЧАНј, ВЛКѓЭЫ, МДВЛФмДлИФРњЪЗ;
ШєецЕФДлИФСЫРњЪЗ, ФЧУД B ЙІФмЕФДњТыОЭДгЬсНЛМЧТМЩЯЯћЪЇСЫ, ЭђвЛашвЊдйДЮЬэМг B ЙІФм, етНЋЪЧБЏОчЁЃ
ЮвУЧПЩвдЛЛвЛжжЫМТЗРДДяЕНЯрЭЌЕФФПЕФ: ЙЙдьвЛИіВЙЖЁ, ИУВЙЖЁBЭъШЋЯрЗД, МДАбBдіМгЕФааЩОГ§, аТдіBЩОГ§ЕФааЁЃЕБШЛ,
етвЛЧаЖМЪЧздЖЏЕФ, жЛвЊЪЙгУgit revert [B]УќСю, МДПЩДДНЈвЛИіBЕФЗДЯђЬсНЛЁЃЯдШЛ, -B1КЭC2ЕФПьеезДЬЌЪЧвЛжТЕФ,
ПЩвдгУgit diffУќСюбщжЄЁЃ

ЕБвЊЧѓАб B ЙІФмМгЛиРДЪБ, ЪЧИУМРГіЩёЦїСЫТ№?

ЕБШЛВЛЪЧ, ЮвУЧПЩвддйжЦзївЛИі-BЕФЗДЯђВЙЖЁ--B, ИКИКЕУе§ТяЁЃВЛЙ§етПДЦ№РДЙжЙжЕФ,
ШчЙћФмИДжЦвЛЗнBВЙЖЁжиаТДђЩЯОЭКУСЫ, git cherry-pick [B]е§ЪЧЮвУЧвЊевЕФД№АИЁЃЯдШЛ,
--B1, B2, C3ЕФПьеезДЬЌБиШЛЪЧвЛжТЕФЁЃ
зЂвт : ЭЈЙ§git cherry-pickИДжЦЕФBКЭдгаЕФBгаВЛвЛбљЕФsha1,
МДБуетСНИі commit ЕФФкШнЯрЭЌЁЃ
МШШЛетШ§жжзДЬЌЪЧЕШМлЕФ, ФЧУДзїЮЊЧуЯђгкЭъУРжївхЕФЮвУЧ, ИќЯЃЭћдк Git ЬсНЛРњЪЗЩЯСєЯТЕФЪЧзюКѓвЛжжИЩОЛЕФзДЬЌ.ЁЃЕЋЮввбОдкB2зДЬЌСЫ,
дѕУДВХФмЪЕЯжC3? ЯраХФувбОЯыЕНСЫАьЗЈ, ЛиЕНзюГѕЕФМьГіЕу, ЭЈЙ§cherry-pickЪАШЁA,
B, C3ИіВЙЖЁ, МДПЩДДНЈвЛИіИЩОЛЕФЬсНЛРњЪЗЁЃЛђаэФуЛЙЬ§ЫЕЙ§git rebase, етЪЧвЛИіЗЧГЃЧПДѓЕФУќСю,
ЮвУЧЛсдкКѓЮФЬжТлЁЃ
жиаТШЯЪЖЗжжЇ
ЕБЬсГіA, B, CШ§ИіашЧѓЕФЪБКђ, ШчЙћЗжХЩИјШ§ИіШЫ, УПИіШЫИКд№вЛИіЙІФм, ЭЌЪБЛљгкзюаТЕФДњТыПЊЗЂ,
ФЧУДНЋЛсНјШыетжжзДЬЌЃК
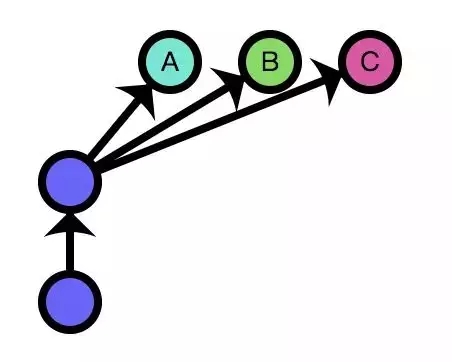
ЕЋЪЧ, ШчЙћЮвУЧзёбmaster, developЗжжЇФЃаЭПЊЗЂ, ФЧУДгРдЖВЛЛсдк Git ЗжжЇЭМЩЯПДЕНетжжзДЬЌЁЃ
ЮвУЧжегкЬжТлЕНЗжжЇСЫ, ЛђаэФувбОЗЂЯж, ДѓМвдкЬИТл Git ЕФЪБКђ, ЗжжЇЫЦКѕЪЧзюживЊЕФЪТЧщ,
МИКѕШ§ОфВЛРыЗжжЇ; ЖјЮвУЧЫЕСЫетУДЖр, ЛЙУЛгаЬсМАЗжжЇетМўЪТ; ЩЯУцЫљгаЕФВхЭМжа, ОЁЙмЮвАбЫћГЦзїЗжжЇЭМ,
ШДУЛгаЗжжЇБъМЧ, етВЂВЛгАЯьЮвУЧЖд Git ЕФРэНтЁЃ
дйДЮжиЩъвЛЯТ, ЮвУЧЕФЙизЂЕуЪЧcommit, гУЮЈвЛЕФsha1БъЪЖ, ЫћгаСНжжКЌвхПьееКЭВЙЖЁЁЃ
ЕЋЪЧ, sha1ВЛЪЧвЛИіКУМЧЕФБъЪЖ, ЮвУЧашвЊИјвЛаЉживЊЕФcommitБ№УћЁЃ ЧАУцЮвУЧвбОЬсЕНСЫHEADжИеы,
ЫћжИЯђЕБЧАЕФcommit, етОЭЪЧвЛИіБъЪЖ. Г§ДЫжЎЭт, Git ЛЙгаСНжжживЊЕФБъЪЖ, ЗжжЇ(branch)КЭБъЧЉ(tag)ЁЃ
ЗжжЇКЭБъЧЉЪЧФГИіcommitЕФБ№Ућ, вђДЫ, дк Git УќСюжаПЩвдЪЙгУЗжжЇКЭБъЧЉРДДњЬцcommitЕФsha1жЕЁЃБШШчЧаЛЛЕНФГИіЗжжЇ,
git checkout [branch-name], ЦфЪЕОЭЪЧЧаЛЛЕНСЫетИіcommitЕуЕФПьееЁЃ
ЪЙгУЗжжЇЧаЛЛКЭЪЙгУsha1ЧаЛЛЛсгавЛаЉВювь, Git ЛсЮЌГжвЛИі Context, МЧТМСЫЕБЧАМЄЛюЕФЗжжЇ,
ШчЙћФуЕФУќСюЬсЪОЗћЩЯга Git ЗжжЇЕФБъЪЖ(macOSжеЖЫФЌШЯгаИУБъЪЖ), НЋЛсПДЕНетжжВювьЁЃ
ЗжжЇКЭБъЧЉЖМПЩвдзїЮЊШЮКЮвЛИіcommitЕФБъЪЖ, ЫћУЧЧјБ№дкгк:
ЗжжЇ(branch)ОпгаЧАНјЙІФм, ПЩвдЧАНјЕНЯТгЮcommitНкЕуЩЯ;
БъЧЉ(tag)НіНіАѓЖЈдквЛИіcommit, жївЊгІгУГЁОАЪЧзїЮЊАцБОЗЂВМЕФБъЪЖЁЃ
ЮвУЧжївЊЬжТлЗжжЇ(branch). ЗжжЇдѕбљЧАНјФи?
ЕБжДааgit commitКѓ, ЗжжЇОЭЧАНјСЫ;


жДааgit mergeКѓ, ЗжжЇЛсЧАНјЁЃ
ЕБ Git ЙиСЊЕНдЖГЬВжПтЪБ, УПИіЗжжЇПЩвдЩшжУвЛИідЖГЬзЗзйЗжжЇgit branch --set-upstream-to=[origin]/[branch],
ЕБжДааgit fetch, git pull, git pushЪБ, ФЌШЯЖМЪЧдкВйзїЙиСЊЕФдЖГЬЗжжЇЁЃ
вЛИіБОЕи Git ВжПтПЩвдЙиСЊЖрИідЖГЬВжПт, ЯАЙпЩЯФЌШЯВжПтЛђепжїВжПтНазіoriginЁЃ

ЕББОЕиmasterЗжжЇТфКѓдЖГЬorigin/masterЗжжЇЪБ, вЛАуЛсжДааgit pullУќСюИњНј,
ЕЋетКѓУцЕНЕзЗЂЩњСЫЪВУД?
git pullУќСюЦфЪЕЪЧИіgit fetchКЭgit mergeЕФзщКЯУќСю, git fetchЪЧНіНіРШЁдЖГЬЗжжЇЕФНјЖШ,
ЩЯЭМетжжзДЬЌ, дЖГЬorigin/masterГЌЧАСЫБОЕиmaster, БиШЛЪЧжДааСЫgit fetchКѓВХФмПДЕН,
вЛАужЇГж Git ЕФЭМаЮЙЄОпЛђеп IDE ЛсдкКѓЬЈЖЈЦкзіетЯюЙЄзї, дкдЖГЬЗжжЇИќаТКѓМАЪБЭЈжЊЁЃ
ЕБHEADжИеыдкmasterЪБ, жДааgit merge origin/master, masterМДЛсЧАНјЕНorigin/masterЁЃ
Merge ВЛЪЧКЯВЂЗжжЇТ№? дѕУДБфГЩСЫЗжжЇЧАНј?
ЮЃЯеЕФ Merge
ЮвАбgit mergeЖЈвхЮЊИпЮЃВйзї! вЛАуПЊЗЂШЫдБ(ЗЧЯюФПleader)гІОЁПЩФмБмУтЪЙгУжБНгЛђМфНгЪЙгУИУУќСюЁЃ
ЬсЕН Merge, ЛђаэЯТУцЕФетжжГЁОАЪЧЮвУЧЕквЛЪБМфЯыЕНЕФ :

ЕБЮвДІдкmasterЪБ, вВОЭЪЧHEADжИеыжИЯђmaster, жДааgit
merge iss53 : ШєЮоГхЭЛ, МДЛсЕУЕНЯТЭМНсЙћ; ШєгаГхЭЛ, дђЛсЬсЪОЪжЖЏНтОі, ШЛКѓзїЮЊвЛДЮаТЕФ
commit, ЭЌбљвВЛсЕУЕНЯТЭМНсЙћЁЃ

вВаэФуЗЂЯжСЫ, етРяЗжжЇЭМЗчИёБфЛЏСЫ, ВЛНіНіЪЧЛЗчЕФзЊБф, зюживЊЕФЪЧМ§ЭЗЗНЯђ.
етСНеХЭМЪЧЮвДг Git ЙйЗНЮФЕЕИДжЦЙ§РДЕФ, ЫљвдЧыВЛвЊжЪвЩЫћЕФШЈЭўЁЃФЧУДЪЧЮвжЎЧАЕФМ§ЭЗЗНЯђЛДэСЫТ№?
гаОфЛАдѕУДЫЕРДзХ? ШЈЭўОЭЪЧгУРДжЪвЩЕФ! ВЛЙ§жЪвЩжЎЧА, ЮвУЧЯШГЂЪдРэНтЁЃ
ЕБМ§ЭЗгЩЩЯгЮНкЕужИЯђЯТгЮНкЕу, ОЭЯёЮвзюГѕЕФВхЭМФЧбљ. ДгећИіЗжжЇЭМЩЯ, ЮвУЧФмПДЕНвђЮЊЭХЖгЕФХЌСІ,
ЗжжЇе§дкЧАНј, ЯюФПе§дкНјеЙ. вВОЭЪЧЫЕ, ИќЗћКЯКъЙлЩЯЕФЧїЪЦ;
ЕБМ§ЭЗгЩЯТгЮНкЕужИЯђЩЯгЮНкЕу, ОЭЯёЙйЗНЮФЕЕЕФВхЭМФЧбљ. ЛЙМЧЕУУПИіcommitЕФКЌвхТ№? ПьееКЭВювь,
ЪЧИУНкЕугыЦфЩЯгЮНкЕуЕФВювь, Ыљвддк Git ФкВПДцДЂЪБ, УПИіcommitвЛЖЈЛсБЃСєвЛИіжИеы, жИЯђЦфЩЯгЮНкЕу.
вВОЭЪЧЫЕ, етбљЕФЩшМЦИќФмЬхЯж Git ЕФФкВПЩшМЦ.
КУСЫ, ЮвУЧИУЙизЂ Merge ЕНЕззіСЫЪВУД:
ЙЙдьвЛИіНкЕуC6, етИіНкЕуНЋЛсгаСНИіЩЯгЮНкЕу: C4, C5;
НЋЗжжЇmasterгЩC4вЦЖЏЕНC6ЁЃ
етПДЦ№РДУЛгаЪВУДФбЕФ, Git ЕФdiffЙІФмЛсздЖЏАяЮвУЧМЦЫуВювь, ЪЃЯТЕФЙЄзївВЪЧ Git ФЌФЌАяЮвУЧЭъГЩЕФЁЃЕЋЪЧ,
ФуЛЙМЧЕУЮвУЧЕФТлЮФАцБОПижЦЯЕЭГТ№?
ШчЙћC4КЭC5ЖдЭЌвЛИіаазіСЫаоИФ, ИУШЁФФИіФи? ШЁСЫC4ЕФ, ФЧУДC5ЦфЫћДњТыЛЙФмЙЄзїТ№? ЛђепЗДжЎ.
гжЛђепСНепЖМВЛФмШЁ, ЖјгІИУжиаДетааДњТы, вдМцШнСНепЕФаоИФЁЃ
МДБуЫћУЧаоИФЕФЕиЗНЛЅВЛНЛВц, ФЧУДЛсВЛЛсееГЩећЬхЩЯЕФТпМДэЮѓФи? БШШчC4аое§СЫвЛИіГЩдББфСПЕФЦДаДДэЮѓ,
C5дкдіЕФДњТыжаЛЙдкв§гУдгаЕФБфСПУћ, етЪБЙЙдьC6ЪБВЂВЛЛсгаШЮКЮГхЭЛЬсаб, ЕЋЙЙдьГіЕФДњТыШДЪЧЮоЗЈЭЈЙ§БрвыЕФЁЃ
ЛђаэФувбОЯАЙп, УПЕБЮвУЧгіЕНЮЪЬтЪБ, Git МИКѕЖМФмИјЮвУЧЬсЙЉздЖЏЛЏЕФНтОіЗНАИЁЃ БШШч : ЕБашвЊЖдБШВювьЪБ,
ПЩвдЪЙгУgit diff; ЕБашвЊжЦзїЗДЯђВЙЖЁЪБ, ПЩвдЪЙгУgit revert; ЕБашвЊИДжЦВЙЖЁЪБ,
ПЩвдЪЙгУgit cherry-pickЁЃФЧУД, ЯждкетжжГЁОА, Git гаЪВУДУќСюФмАяжњЮвУЧФи? КмвХКЖ,
УЛга, Git ФмИјЮвУЧЕФНіНіЪЧЕБГіЯжааМЖГхЭЛЪБ, ИјЮвУЧвЛИі conflict ЬсЪО, Г§ДЫжЎЭт,
жЛФмППЮвУЧРДЗЂЯжКЭНтОіСЫЁЃ
ЮвУЧЯраХ, дкФуЛђФуЕФЭЌЪТЬсНЛC4, C5ЪБ, ЫћУЧЖМЪЧвЛИіПЩвдЙЄзїЕФАцБО, жСЩйгІИУФмЙЛе§ГЃБрвыКЭЭЈЙ§ВтЪдгУР§ЁЃЕЋЪЧШчЙћДцдкЮвУЧУшЪіЕФЕкЖўжжГЁОА,
КЯВЂC6ЪБУЛгаГхЭЛ, ЕЋШДЮоЗЈЭЈЙ§БрвыЁЃ
вдЩЯе§ЪЧЮвАб merge ВйзїЖЈвхЮЊИпЮЃВйзїЕФдвђЁЃ
МШШЛ Git ВЛФмИјгшЮвУЧАяжњ, ФЧБиаывЊбАевЛКНт merge ДјРДЕФЧБдкЮЃЯеЕФДыЪЉСЫЁЃ
вЛИіЗНЗЈЪЧАбЮЃЯеХзИјИќгаОбщЕФШЫЕФЁЃ ОЭЯёБОНкПЊЪМЬсЕНЕФФЧбљ, вЛАуПЊЗЂШЫдБ(ЗЧЯюФПleader)гІОЁПЩФмБмУтЪЙгУжБНгЛђМфНгЪЙгУИУУќСюЁЃЫћУЧВШЙ§ИќЖрЕФПг,
дкКЯВЂЗжжЇЪБЛсПМТЧЕФИќЖрИќШЋУц, ВЂЧвЫћУЧНЋЖдБОДЮКЯВЂЕФГЩЙћ(МДаТЕФ commit, ОЭЯёЩЯЭМжаЕФC6)ИКд№ЁЃ
МЦЫуЛњЙЄГЬжазюВЛПЩППЕФВПЗжЪЧШЫМўЁЃ дйЯИжТЕФШЫвВгаЗИДэЕФЪБКђ, ВЂЧвЯрБШгкМЦЫуЛњРДЫЕ, етИіИХТЪвЊдЖдЖИпЕФЖр,
вђДЫЛЙгІИУв§ШыздЖЏЛЏВтЪдЛњжЦЁЃБШШчГжајМЏГЩ(CI), УПЕБвЛДЮКЯВЂНсЪјКѓ, здЖЏДЅЗЂБрвыКЭВтЪд, ВЂЗЂЫЭВтЪдБЈИцЁЃ
змЪЧАбетаЉЗчЯеЭЦИјгаОбщЕФШЫ, етЪЧВЛЙЋЦНЕФЁЃ ПіЧв, зїЮЊОбщЧЗШБЕФЮвУЧ, УЛгаЛњЛсДІРэЗчЯе,
ЮвУЧдѕУДЛ§РлОбщФи? зюживЊЕФЪЧ, ЮвУЧФмзіЕФНіНіЪЧЪТКѓВЙОШТ№? ФмВЛФмДгИљдДЩЯБмУтетжжЗчЯе?
ЮвУЧРДПДвЛЯТСэвЛжж merge ГЁОА:

ВхЭМЗчИёгжЛЛСЫ, етДЮЕФВхЭМРДзд КязгЖМФмЖЎЕФ Git ШыУХ
bugfixЗжжЇДгmasterМьГі, КмавдЫ, masterЗжжЇЛЙУЛгаИќаТ. етЪБ, НЋbugfixКЯШыmasterЁЃ
ЮвУЧЪзЯШШУHEADжИеыжИЯђmaster, ШЛКѓжДааgit merge bugfix --no-ff,
ЗжжЇЭМНЋЛсБфГЩетИібљзгЁЃ

УЛгавтЭт, етИљЮвУЧЩЯУцЖд merge ааЮЊЕФУшЪіЪЧвЛбљЕФ : ЙЙдьвЛИіаТЕФ commit НкЕуC,
ЦфЩЯгЮНкЕуЗжБ№ЮЊBКЭY, ШЛКѓНЋmasterЗжжЇБъЧЉжИЯђCЁЃЯрНЯгкЩЯУцЕФГЁОА, етжжЧщПіЯТЙЙдьCЪЧвЛЖЈВЛЛсВњЩњГхЭЛЕФ.ЁЃЮЊЪВУД?
ЮвУЧДг commit ЕФВЙЖЁЪєадШыЪж, АбB->CПДГЩвЛИіВЙЖЁ, ФЧУДЮвУЧЖд merge ЖЏзїЕФЦкЭћНсЙћгІИУЪЧB->XКЭX->YСНИіВЙЖЁРлМЦзїгУЁЃвВОЭЪЧЫЕ:
B->C = B->X + X->Y (1)
ЕЋЪЧДгЭМжа, ДгBЕНCгаСНЬѕТЗОЖ, вЛЬѕЪЧжБДя, СэвЛЬѕЪЧЗжВН:
B->C = B->X + X->Y + Y->C (2)
ФЧУДY->CФи? ШєЯыШУЮвУЧЕФЦкЭћ(1)КЭЪТЪЕ(2)ЖМГЩСЂ, Y->CБиаыЪЧЪЧвЛИіПеВЙЖЁ,
вВОЭЪЧЫЕ, CКЭYЕФПьеезДЬЌЪЧЭъШЋвЛжТЕФ, ПЩвдгУgit diff [C] [Y]бщжЄвЛЯТЮвУЧЕФЭЦТлЁЃ
ЮЊЪВУДвЊгаетИіПеВЙЖЁ, жБНгНЋЪЙгУYНкЕуВЛааТ№? ЕБШЛПЩвд!
ЙлВьвЛЯТЮвУЧЕФ merge УќСю, гавЛИіИНМгВЮЪ§--no-ff, етИіВЮЪ§ЧПжЦЙиЕєСЫ fast-forward
Ьиад. ШчЙћЮвУЧВЛЬэМгетИіВЮЪ§, жБНгжЛгУgit merge bugfix, ФЧУДЕУЕНЕФНсЙћНЋЪЧетбљЕФ:

masterжБНгБЛжИЯђСЫYНкЕуЁЃ ЛЙМЧЕУТ№, ШУЗжжЇЧАНјЕФЕкЖўжжЗНЗЈЪЧЪВУДРДзХ? git merge,
етВЛЪЧОЭР§згТя!
жДааgit merge [X]ЖЏзїЪБ, ШєЮоашЙЙдьаТЕФ commit НкЕу, жБНгНЋЕБЧАЗжжЇБъЧЉЧАНјЕНвЊXНкЕу,
етОЭЪЧЫљЮНЕФ fast-forward ЬиадЁЃ
етжжЧщПіЯТЕФ merge ЖЏзїШУЗчЯеДѓДѓНЕЕЭЁЃ ЪзЯШ commit X, YЕФЬсНЛепвЊЖдСНДЮаоИФИКд№,
ЫћУЧгад№ШЮБЃжЄУПДЮЬсНЛКѓЕФДњТыЪЧПЩвдЭЈЙ§БрвыКЭВтЪдЕФ; ЦфДЮ, ЯюФПИКд№ШЫдкНЋbugfixЗжжЇКЯШыmasterжЎЧА,
жЛашШЗБЃYЕФПьееАцБОЪЧе§ШЗЕФ, вђЮЊ merge ЖЏзїНЋВЛЛсДјРДШЮКЮдйДЮЕФБфИќ, жЛЪЧНЋЗжжЇЧАНјЕНYЕФПьее,
етДѓДѓНЕЕЭСЫ merge ЕФЗчЯеЁЃ
дйДЮЬсаб, ЩїгУgit pull, етЬѕУќСювўКЌСЫgit fetch, git mergeСНЬѕУќСюЁЃвЛИіИќКУЕФзіЗЈЪЧЯШgit
fetchЛёШЁдЖГЬЗжжЇзДЬЌ, ЕБФуШЗШЯБОЕиЙиСЊЕФЗжжЇФмгыдЖГЬЗжжЇвдfast-forwardКЯВЂЕФЪБКђ,
дйжДааgit mergeЛђепgit pullЁЃ
НЈжўРэЯыЕФГЧБЄ
РэЯыЕФЗжжЇЭМ
ЮвУЧвбОевЕНСЫвЛжжРДОЁСПБмУт merge ЗчЯеЕФГЁОА, дкетжжГЁОАЯТ, ЮвУЧЛсЙЙдьГідѕбљЕФЗжжЇЭМ?
ШчЙћЪЙгУ fast-forward Ьиад, НсЙћНЋЪЧетбљ:

ШчЙћЮвУЧЪЙгУgit merge --no-ffВЮЪ§, НсЙћНЋЪЧетбљЕФ:

ПДЕНЧјБ№СЫТ№? fast-forward НсЙћНЋЛсЪЧвЛЬѕвЛЯп, етЪЧзюИЩОЛећНрЕФЗжжЇЭМ, ЕЋЪЧЯргІЕФ,
ЮвУЧвбОЮоЗЈвЛФПСЫШЛЕФЧјЗжГіФФМИИі commit ЙЙГЩвЛИіЙІФм, БиаыЭЈЙ§ЙцЗЖЕФзЂЪЭ(БШШчЩЯЭМжаШЋВПвд
JIRA БрКХПЊЭЗ)РДзіЗжЧј; Жј--no-ffВЮЪ§ЫфШЛШУЗжжЇЭМБфЕУПДЩЯШЅИДдгСЫвЛЕуЖљ, ЕЋШДЗЧГЃжБЙлЕиБЃСєСЫ
commit МЏКЯКЭЙІФмЕФЖдгІЙиЯЕЁЃ
СНжжЗНЪНФФИіИќКУ? ЯёЮФеТзюГѕЫЕЕФФЧбљ, ЮвВЛЪЧвЛИіМЋЖЫжївхеп, СНжжИїгагХСг, вЊЗжГЁОАЖдД§ЁЃ
ЖдгкГЌДѓЙцФЃЕФПЊдДЯюФПРДНВ, УПвЛИі commit ЖМВЛЪЧЫцвтЕФ, БиаывЊга JIRA, гЪМўСаБэ,
Github Issue СаБэЕШжюШчДЫРрЕФЬжТл, УїШЗ commit ЕФЙІФмКЭгАЯь, ШЗБЃУПИі Commit
жЛзівЛМўЪТ, БфЖЏзюаЁЛЏ, ШЛКѓЭЈЙ§ Pull Request ЗНЪНЧыЧѓКЯВЂжСжїВжПтЕФжїЯпЗжжЇЁЃдкетжжЧщПіЯТ,
ЪЙгУ--no-ffЕФЛА, МИКѕУПИі commit ЖМЛсВњЩњвЛИіПеЕФ merge НкЕу, ЗжжЇЭМОЭБфГЩСЫОтГнзД,
ДјРДЕФЪевцЮЂКѕЦфЮЂ; ЖјЙцЗЖ commit зЂЪЭ, ВЂЧвЪЙгУ fast-forward ЛђаэЪЧвЛИіИќКУЕФбЁдёЁЃ
ЖдгкашвЊПьЫйЯьгІБфЛЏЕФЛЅСЊЭјЙЋЫОРДЫЕ, УПвЛДЮИФЖЏжЎЧАЖМЯШНЈСЂ JIRA Лђеп Issue, етМИКѕВЛЬЋЯжЪЕ,
ЭЈЙ§--no-ffЕФНкЕуМгЩЯЯрЖдМђНрУїСЫЕФзЂЪЭПЩФмЪЧвЛИіИќУїжЧЕФбЁдёЁЃ
ЯжЪЕгыРэЯыЕФВюОр
ЕЋЖрЪ§ЧщПіЯТ, ЯжЪЕГЁОАВЂВЛТњзуетбљЕФзДЬЌ, вђЮЊЯюФПВЛЪЧвЛИіШЫдкПЊЗЂ, дкЮвУЧЬсНЛЕФЭЌЪБ, Б№ШЫвВдкЬсНЛ,
ЕБЮвУЧЕФЗжжЇзМБИКЯШыmasterЪБ, masterвбОЧАНјСЫ, гжЛиЕНСЫзюГѕФЧжждуИтЕФзДЬЌ. ЪЧШЅУцЖддуИтЕФзДЬЌ,
ЛЙЪЧБмУтдуИтЕФзДЬЌ, ЯыАьЗЈаое§Ыќ?

ЯђРэЯыППТЃ
ШчЙћЮвУЧдкЯђжїЗжжЇКЯШыжЎЧА, АбетСНИіcommitЭЈЙ§git cherry-pickУќСюМоНгЕНзюаТЕФ
master ЗжжЇЩЯ, ПДЦ№РДвЛЧаЖМБфКУСЫЁЃЕБШЛ, X'КЭY'ЛсБЛЪгзїШЋаТЕФcommit, ЫћУЧЖМЛсгааТЕФsha1ЁЃ

ВЛЙ§етРягаИіЮЪЬт, ЧАЮФЬсЙ§, ЗжжЇ(branch)ЪЧвЛИіПЩвдЯђЧАЛЌЖЏЕФБъЧЉ, ДгYЕНY'ЫЦКѕВЛФмжБНгЧАНј,
ЮвУЧЕФЗжжЇБъМЧдѕУДВХФмзЊвЦЕНY'ЩЯФи?
вЛИіДжБЉЕФЗНЗЈЪЧ, ЮвУЧПЩвдЯШЩОЕєbugfixЗжжЇ, ШЛКѓДгY'ДДНЈЫќЁЃВЛЙ§, Git вВЬсЙЉСЫНЋЗжжЇБъЧЉжИЯђШЮвтcommitНкЕуЕФУќСю,
МДgit resetЁЃ
ЕБHEADжИеыжИЯђbugfix(Y)ЗжжЇЪБ, жДааgit reset --hard [Y'], ЛсНЋHEADжИеыжИЯђbugfixЗжжЇЭЌЪБжИЯђY'ЁЃ(ВЮЪ§--hardЛсЧхПеЙЄзїЧјКЭднДцЧј,
ДЫЭтЛЙга--mixed, --softбЁЯю, ЛсЖдЙЄзїЧјКЭднДцЧјгаВЛЭЌЕФгАЯь, ШчЙћФуВЛСЫНт, вВаэФуашвЊбАевЦфЫћЕФНЬГЬ,
БОЮФВЛЬжТлетаЉ)
ЮЊСЫДяЕНетжжРэЯыЕФЗжжЇзДЬЌ, ЮвУЧвЊОГЃетУДИЩ, етвЛЧаЙЄзїЫЦКѕБфЕУгаЕуЖљЗБЫі, вЊжДааетУДЖрВНжшВХФмДяЕНЗжжЇМоНгЕФФПЕФЁЃ
ЖдЕФ, Git ЮЊЮвУЧЬсЙЉСЫздЖЏЛЏЗНАИ, ФЧОЭЪЧЧПДѓЕФ rebaseЁЃ
Rebase вызїБфЛљ, ДгзжУцЩЯРэНт, rebase УќСюПЩвдИФБфЕБЧАЗжжЇЕФЛљЕу, ЮвУЧЯждкНіЙизЂ
rebase ЙІФмЦфжаЕФвЛИіЬиад, РДДяЕНЮвУЧЗжжЇМоНгЕФФПЕФОЭзуЙЛСЫЁЃ ЛиЕНзюГѕЕФГЁОА, bugfix
ЗжжЇЛЙжИЯђY, етЪЧЮвУЧжЛвЊжДааgit rebase master, МДПЩДяЕНФПЕФЁЃ
ЮвУЧБОЕиЕФbugfixвбОБфЛљЭъГЩ, ШєЫќвбОЙиСЊЙ§дЖГЬЗжжЇ, ФЧУДorigin/bugfixЛЙДІдкY,
ЮвУЧвЊАбБОЕиЕФзДЬЌБфИќЭЦЫЭЕНдЖГЬ, ШчЙћНгзХжДааgit push, НЋЛсБЈДэ :

ПЩвдПДЕН, Git ЗўЮёЦїОмОјСЫЮвУЧЕФЭЦЫЭЧыЧѓ, ВЂЗЕЛиСЫвЛаЉЬсЪОаХЯЂ,
ЛђаэПДЕНетГЁУц, ФувЛЯТОЭЛХСЫ, ЮваСПраДЕФЕФДњТыВЛЛсЖЊЕєАЩ! ЬсЪОРяУцгаgit pullУќСю, ЮвЪЧВЛЪЧгІИУжДаа,
ЭьОШвЛЯТ!
ЕБеце§жДааСЫgit pullУќСюКѓ, етВХЪЧдуИтЕФГЁУц!
Б№ЭќСЫ, git pullАЕКЌgit mergeгявх, етЛсЕМжТвЛДЮКЯВЂ, ЙЙдьЕФвЛИіаТЕФ commit
Z, ЩЯгЮЗжБ№ЪЧ bugfix Y'КЭ origin/bugfix Y, bugfix жИЯђСЫZ.
ШчЙћетЪБдйжДааСЫgit pushУќСю, ФЧУДетдуИтЕФЗжжЇЭМОЭЭЦЕНСЫЗўЮёЦїЩЯ, ећИіЭХЖгНЋЛсПДЕНФуАбЗжжЇЭМИуТвСЫ,
етЛУцМђжБВЛПЩУшЪі! (ШчЙћФуФдВЙВЛГіРДетЪБЗжжЇЭМЕФбљзг, ЯТИіЪЕВйАИР§жаЛсбнЪО)
МЧзЁ, ВЛвЊЛХ, ФувбОСЫНтСЫ Git ЕФдРэ, ФугаФмСІеЦПи Git, ЖјВЛЪЧБЛвЛСНИіФЊУћЕФДэЮѓЯХЭЫСЫЁЃЛЙМЧЕУИеИеЪЙгУЕФgit
resetУќСюТ№? ЫћПЩвдАбЗжжЇЧПжЦжИЯђШЮвЛcommit, ЮвУЧЪЙгУgit reset --hard
[Y'] ВЛОЭЛиЕНИеВХЕФзДЬЌСЫТ№?
КУСЫ, МйзАИеВХЪВУДЖМУЛЗЂЩњ, ЮвУЧзаЯИПДПДЗўЮёЦїЗЕЛиЕФДэЮѓ, ВЂЧвЫМПМвЛЯТЮЪЬтЕНЕзГідкФФРя?
ЪзЯШ, git pushЕНЕздкзіЪВУД? pull КЭ push ЪЧвЛЖдЗДвхДЪ, git pullЪЧАбдЖГЬЗжжЇНјЖШЭЌВНЕНБОЕи,
ШЛКѓГЂЪдНЋдЖГЬЗжжЇКЯВЂЕНЙиСЊЕФБОЕиЗжжЇ; git pushдкзіРрЫЦЕФЪТЧщ, ВЛЙ§ЪЧЯрЗДЕФ, ЫћЛсЯШАбБОЕиЗжжЇЭЌВНЕНдЖГЬ,
ШЛКѓГЂЪдНЋБОЕиЗжжЇКЯВЂЕНЙиСЊЕФдЖГЬЗжжЇЁЃЕЋЪЧ, ЕБЮоЗЈТњзу fast-forward ЬѕМўЪБ, git
pushЛсжБНгБЈДэ, ЖјВЛЪЧГЂЪдЙЙдьвЛИіаТЕФcommitЃЌ етОЭЪЧЮвУЧИеИегіЕНЕФДэЮѓГЁОАЁЃ
ЕЋКмЯдШЛ, ЮвУЧдкБОЕиЕїећСЫЗжжЇ, ВЂЧвЦкЭћАбЕїећКѓЕФзДЬЌЭЦЫЭЕНдЖГЬ, ИВИЧдЖГЬЗжжЇдгаЕФзДЬЌ.
етЪБашвЊЬэМгвЛИіВЮЪ§git push --force, ЧПжЦИВИЧдЖГЬЙиСЊЗжжЇЁЃЯждкдЖГЬЕФ bugfix
ЗжжЇКЭБОЕи bugfix БЃГжЭЌВНСЫ, ЖМжИЯђСЫY'ЁЃteam leader ПЩвд review ДњТы,
ШЛКѓКЯШы master СЫЁЃ

ЖджїЗжжЇБЃГжОДЮЗ
ЩЯУцЕФgit rebase, git push --forceПДЦ№РДКмгааЇЙћЁЃЕЋЪЧ, етдказїжаЫЦКѕЛсееГЩвЛИіЮЪЬт
: ШчЙћДѓМвЖМдк force push, ФЧЦёВЛОЭТвЬзСЫ?
Ыљвд, гІИУжЦЖЈвЛИідМЖЈ : ЙЋЙВЗжжЇВЛдЪаэ force pushЁЃвВОЭЪЧЫЕ, ЙЋЙВЗжжЇжЛФмЧАНјЁЃ
дкГЃгУЕФ Git ЗўЮёЦїЩЯ, БШШчТыдЦ, GitLab, GithubЖМжЇГжЗжжЇБЃЛЄЙІФм, ЮвУЧжСЩйвЊЩшЖЈвЛИіБЃЛЄЗжжЇ(вд
master ЮЊР§), зїЮЊЙІФмЗжжЇЁЃ ИУЗжжЇгІИУгавдЯТЬиад:
жЛФмЧАНј, вВОЭЪЧВЛдЪаэ force push;
ВЛдЪаэжБНг commit, жЛФмЭЈЙ§ merge ЖЏзїЪЙЗжжЇЧАНј;
ЪеНє merge ШЈЯо, жЛдЪаэВПЗжИпМЖЙЄГЬЪІжДаа merge;
жЛдЪаэ merge Тњзу fast-forward ЬѕМўЕФ commit;
УПДЮ merge ЧА, БиаыНјаа code review КЭГжајМЏГЩ(CI);
Commit ЬсНЛеп, code review еп, merge епЖМвЊЖдДњТыБфИќИКд№.
дкетжжФЃЪНЯТ, ЫљгаЭХЖгГЩдБвд master ЗжжЇЮЊКЫаФНјааПЊЗЂЁЃ УПИіШЫНгЕНПЊЗЂашЧѓКѓ:
ДгзюаТЕФдЖГЬ master ЗжжЇМьГіздМКЕФПЊЗЂЗжжЇ;
ПЊЗЂ;
ПЊЗЂНсЪјКѓ, вдзюаТЕФдЖГЬ master ЮЊЛљЕу, жДаа rebase Вйзї, НтОіЕєГхЭЛ;
Яђга merge ШЈЯоЕФШЫЬсНЛКЯВЂЧыЧѓ(ТыдЦКЭ Github ГЦзї Pull Request, Gitlab
ГЦзї Merge Request)ЃЛ
Code review КЭ CIЃЛ
ШєЕк5ВНЭЈЙ§, ЬсНЛБЛКЯВЂ, master ЧАНј; ЗёдђЛиЕНЕк2ВНЃЛ
вбБЛКЯШыЕФПЊЗЂЗжжЇЩњУќжмЦкНсЪј, БЛЩОГ§ЁЃ
ЙигкЕк7ВН, ФуУЛПДДэ, вЛИіЗжжЇЕФЩњУќжмЦкОЭЪЧетУДЖЬдн! етШЁОігквЛИіЬиадЕФДѓаЁ, ПЩФмжЛгаМИЗжжг,
ЛђаэгаМИЬь, ЖјВЛЪЧЯё master ЗжжЇвЛбљгРдЖДцдкЁЃ
УПИіШЫдкПЊЗЂЙ§ГЬжаЖМгІИУгаздМКЕФЗжжЇ, (ЮвЭЦМівдФуЕФУћзжНсЮВ, етбљБугкБъЪЖ), етЬѕЗжжЇЪЧФуЕФЫНгаЗжжЇ.
ФугІИУЖд master ЗжжЇБЃГжОДЮЗ, ЕЋЖдгкФуЕФЫНгаЗжжЇ, ФуПЩвдШЮвтЕФ force push,
rebase, ЩѕжСФуВЛАбЫћЗХЕНЯюФПЕФЙЋгаВжПт, ЗХЕНздМК fork ЕФЫНгаВжПтРя, етОЭЪЧвЛеХВнИхжН!
ШУЮвУЧДлИФРњЪЗАЩ!
дкЮвУЧздМКЕФЗжжЇ(ВнИхжН)ЩЯ, ЮвУЧПЩвдЯрЖдЫцвтЕиаоИФ, ЕЋЪЧЕБЬсНЛ PR ЪБ, БиаыећРэГівЛЗнИЩОЛећНрЕФЬсНЛМЧТМ,
етБиШЛЩцМАЕН commit РњЪЗЕФаоИФЁЃ ЛЙМЧЕУЩЯЮФЬсЕНЕФвЛИіЧПДѓУќСюТ№? ЖдЕФ, ОЭЪЧgit rebase!
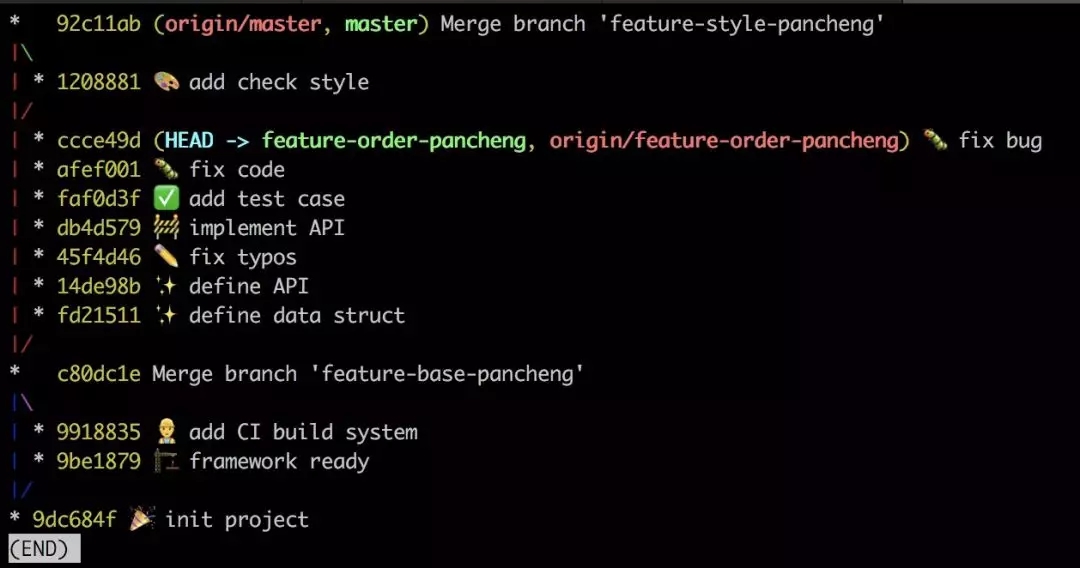
дкmacOSжеЖЫЩЯЭЈЙ§git log --oneline --graph --allПЩвдДђгЁГіЩЯУцЕФЗжжЇЭМ,
етЪЧЮвзюГЃгУЕФвЛИіУќСю, дкlinuxЩЯЕФБэЯжааЮЊПЩФмЛсгаЕуЖљЧјБ№, ЛђаэФуПЩвдГЂЪдgit log
--oneline --graph --all --decorate=short | less -r,
ЛђепВЮПМgit log --helpНјааЕїећ, РДДяЕНФуЯывЊЕФДђгЁаЇЙћЁЃЕБШЛ, ЪЙгУЭМаЮШэМўВщПДЗжжЇЭМвВЪЧвЛИіКмКУЕФбЁдёЁЃ
ПД, ЮвдкПЊЗЂвЛИіЖЉЕЅЙІФм, ЕБЮвПЊЪМПЊЗЂЕФЪБКђ, master дкc80dc1eетИіЬсНЛЕу, ЮвЭЈЙ§git
checkout -b feature-order-panchengМьГівЛИіздМКЕФПЊЗЂЗжжЇЁЃ
ЮвдкПЊЗЂЙ§ГЬжа, зіСЫ7ДЮ commit, ЕЋЪТЪЕЩЯжЛга4ИіЪЧгавтвхЕФ, ЦфЫћЕФМИИіНіНіЪЧЮвдкЬсНЛКѓСЂПЬОЭЗЂЯжСЫКмУїЯдЕФДэЮѓ,
ШЛКѓаое§Й§РДСЫ, етПДЦ№РДОЭЪЧИіВнИх, ШчЙћЭЌЪТ review ЮвЕФДњТы, ПДЕНШчДЫЕЭМЖЕФДэЮѓ, ЫЦКѕВЛЬЋКУЁЃ
етРязюКУЕФзіЗЈОЭЪЧДлИФ Git ЬсНЛРњЪЗ, Аб fix РраЭЕФ commit гыЩЯвЛИі commit
КЯВЂЁЃ
ЮвУЧЯждкжДааgit rebase -i c80dc1e, -iДњБэНЛЛЅФЃЪН
:
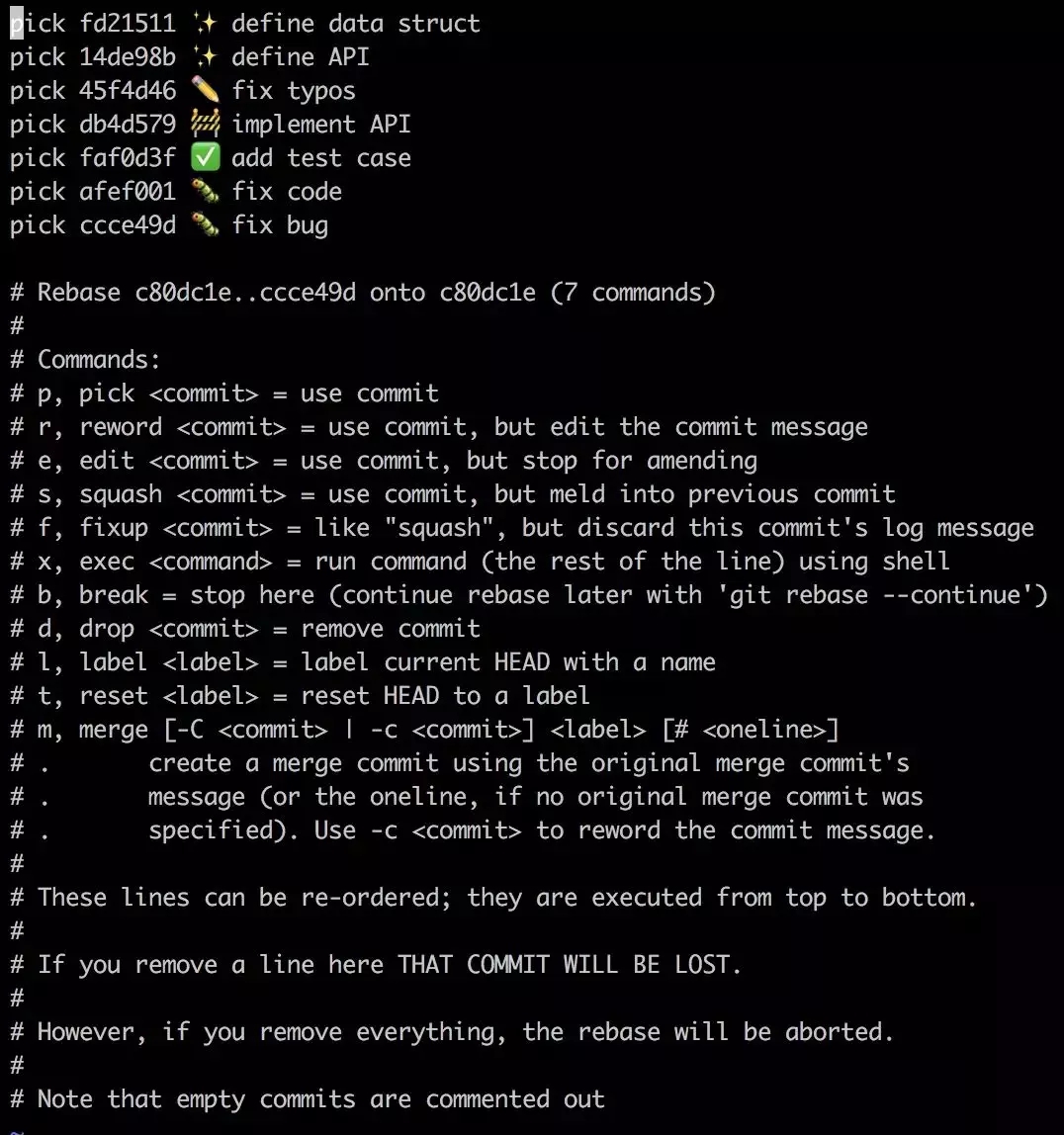
НјШыСЫвЛИі vim НчУц(вВПЩФмЪЧ nano, ШЁОігкФуХфжУЕФФЌШЯБрМЦї),
ЩЯУцСаГіСЫЮвУЧЕФУПДЮЬсНЛЁЃзЂвт, етРяЪЧДгЩЯЭљЯТХХСаЕФ, ЩЯвЛИіЗжжЇЭМжаЪБДгЯТЭљЩЯХХСаЕФ, дкВЛЭЌЕФУќСюЛђШэМўжа,
ЗНЯђПЩФмВЛвЛбљЁЃ
УПИі commit зюЧАУцЖМЪЧ pick УќСю, етОЭгыЮвУЧЧАУцЪЙгУЕФ cherry-pick УќСюзїгУЯрЫЦ,
ЯТУцгаЖдЫљгаУќСюЕФНтЪЭ, ФуПЩвдздааГЂЪдЁЃ
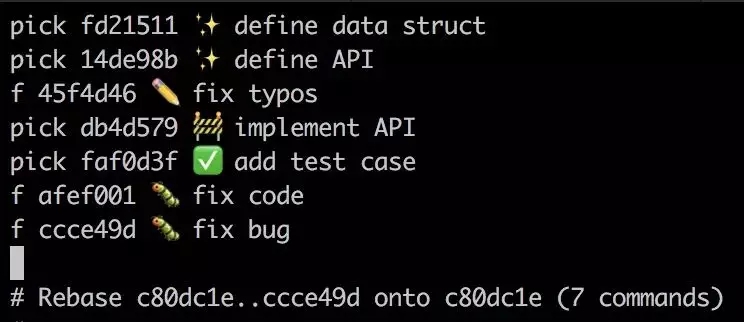
ЮвУЧПДЕН, гавЛИі fixup УќСюЫЦКѕе§ЪЧЮвУЧЯывЊевЕФ:
БЃДцЭЫГі, дйДЮВщПДЗжжЇЭМ :
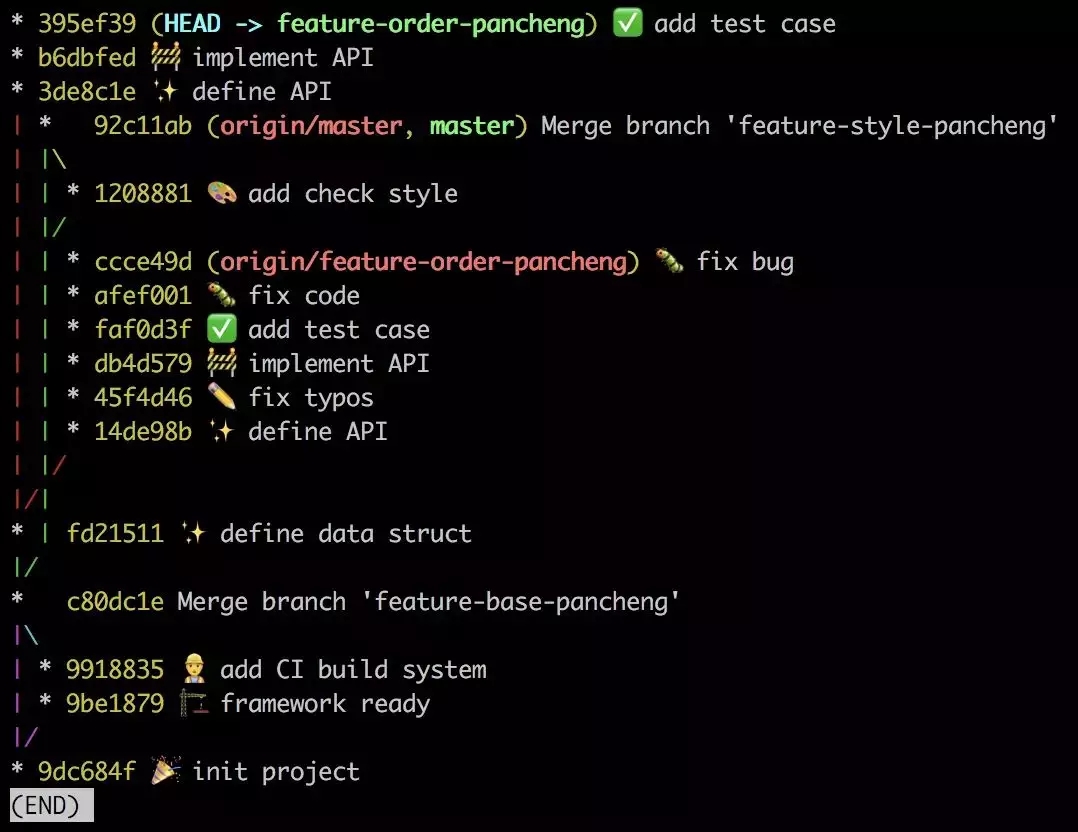
Йў! ЮвУЧЕФКкРњЪЗдкБОЕиЕФ feature-order-pancheng
ЗжжЇБЛФЈЕєСЫ! ШЛКѓАбЫќЭЦЫЭЕНдЖГЬЁЃ
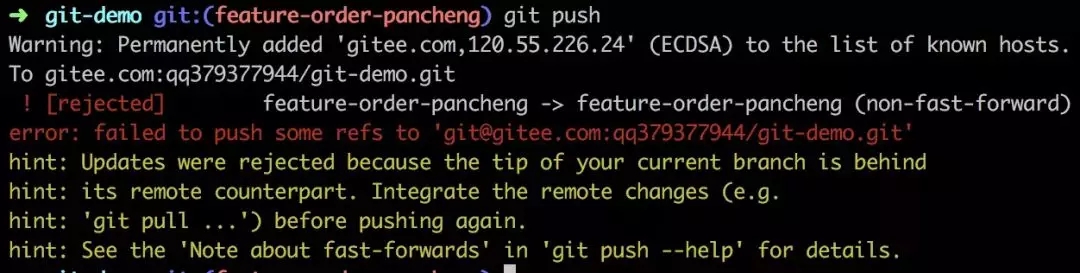
ВЛГівтЭт, Git ЗўЮёЦїОмОјСЫЮвУЧЕФЭЦЫЭЧыЧѓ, вђЮЊВЛТњзу fast-forward
ЬѕМўЁЃ ЯждкФугІИУВЛЛсЛХСЫАЩ! ЮвУЧМйзАЛХвЛАб, "ИљОнЬсЪО"жДааgit pull:
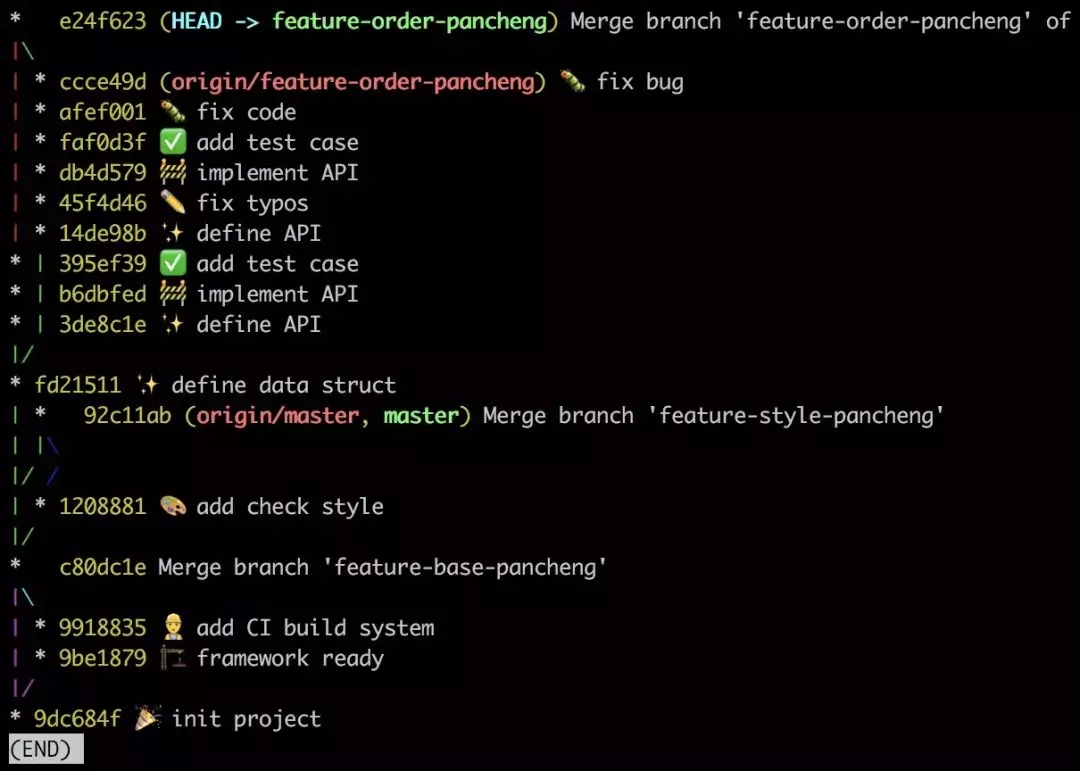
Йў! ЫЋЗнЬсНЛ! БЛРЯДѓПДМћЫЕВЛЖЈвЊАЄХњЕФ! ЛЙМЧЕУетЪБКђгІИУзіЪВУДТ№?
ЯШЛиЕН merge ЧАЕФзДЬЌ, жДааgit reset --hard 395ef39:

ШЛКѓжДааgit push -f :
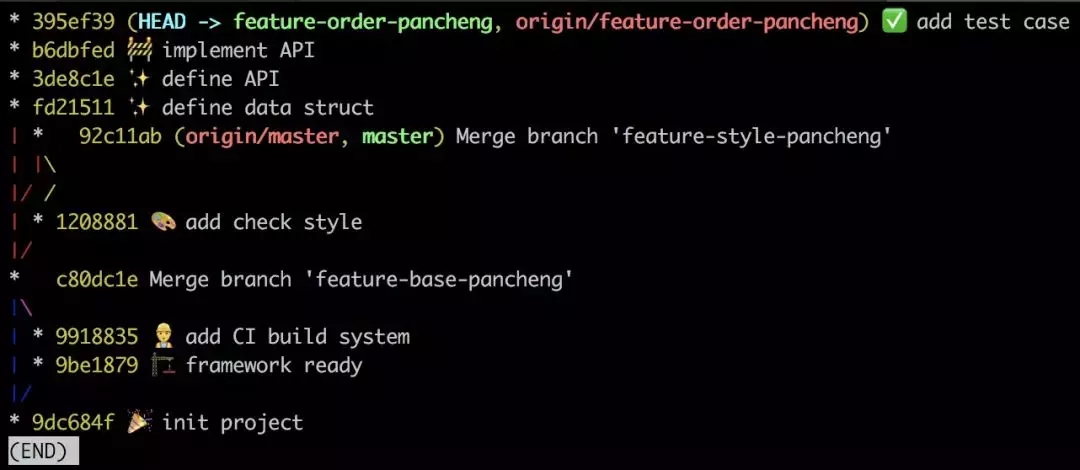
жЎЧАЕФ origin/feature-order-pancheng ЗжжЇЫљДІЕФЕуДгЭМЩЯЯћЪЇСЫ, ЮвУЧЛЙгаПЩФмевЛиЫћТ№?
ХЖЖдСЫ, ЗжжЇУћжЛЪЧИіБъЧЉЖјвб, ЮвЛЙМЧЕУФЧИіЕужЎЧАЕФsha1ЪЧccce49d, жДааgit checkout
ccce49d, ЗжжЇгжЛиРДСЫ, дРДжЛЪЧвўВиСЫ! ЮвУЧАбетжжУЛгаШЮКЮБъЧЉЕФЗжжЇГЦЮНгЮРыЗжжЇ, ЫћФЌШЯВЛЛсдкЗжжЇЭМжаЯдЪО,
ВЂЧвЛсдквЛЖЮЪБМфКѓгЩ Git НјааРЌЛјЛиЪе, ВХЛсеце§ЕФЯћЪЇ, дкДЫжЎЧА, ЮвУЧПЩвдЭЈЙ§git reglogевЕНЫћУЧЕФsha1,
ЛиЕНФЧИіПьееЁЃ
ЖЉЕЅЙІФмПЊЗЂКУСЫ, ПЩвдЯђжїЗжжЇЬсКЯВЂЧыЧѓСЫ, ХЖ, ЖдСЫ, master вбОЧАНјСЫ, ЮвУЧЬс
PR жЎЧАБиаыЯШИњНјЁЃжДааgit rebase master, git push -f, ШЛКѓдйВщПДЗжжЇЭМ
:
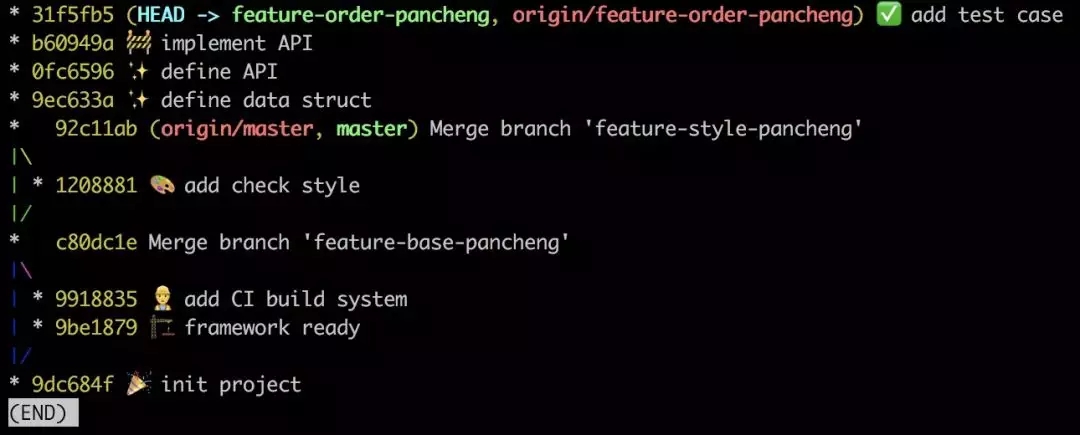
етЪБОЭПЩвдШЅЬсНЛ Pull Request СЫЁЃ
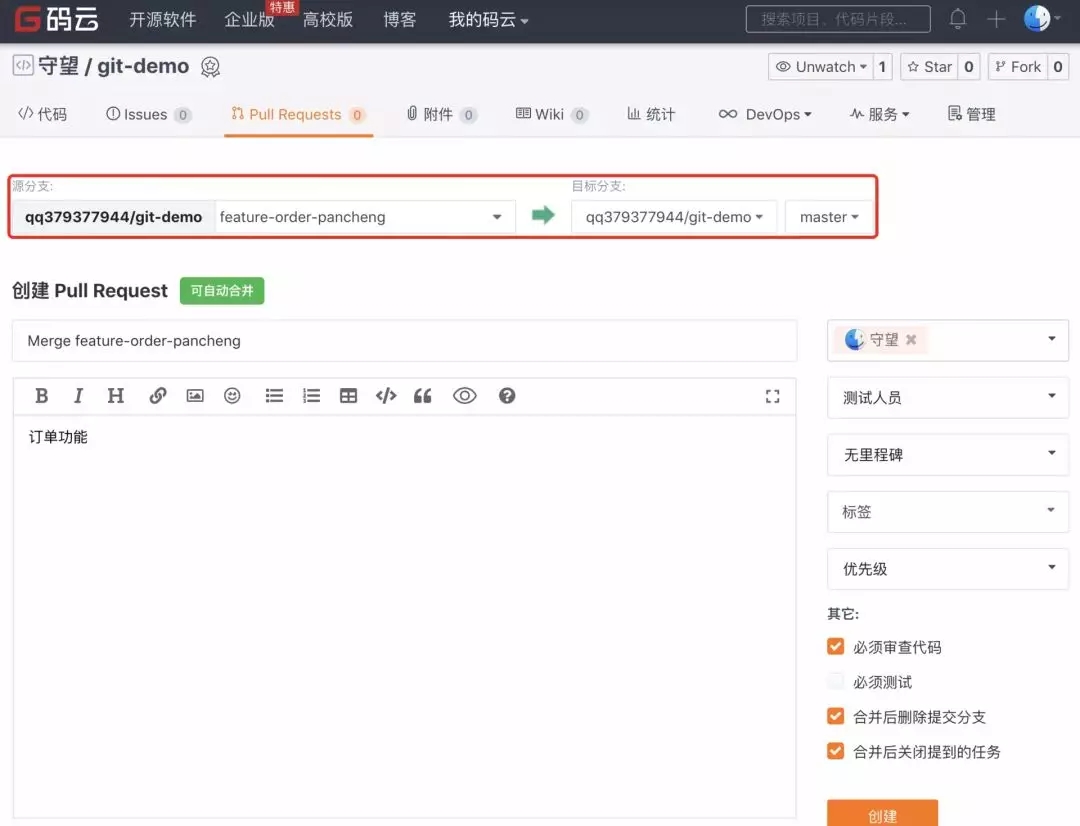
ЕБ PR ЭЈЙ§Кѓ, ФуЕФЗжжЇНЋБЛКЯШы master ЗжжЇ, жДааgit
fetchРШЁдЖГЬЗжжЇаХЯЂ, ШЛКѓВщПДЗжжЇЭМ :
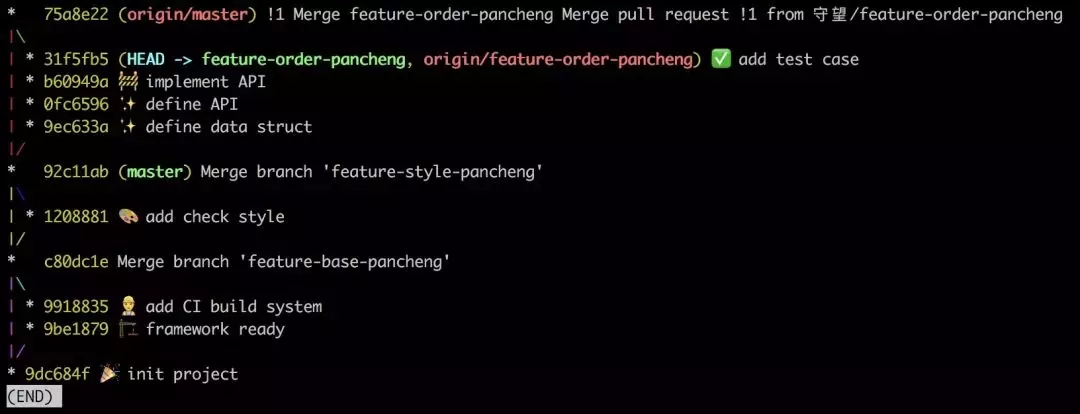
рХ, вЛДЮгфПьЕФПЊЗЂНсЪјСЫЁЃ
ШчЙћДѓМвЖМзёЪиетИідМЖЈ, ФЧУДЮвУЧЕФЗжжЇЭМНЋЛсЪЧетбљ :
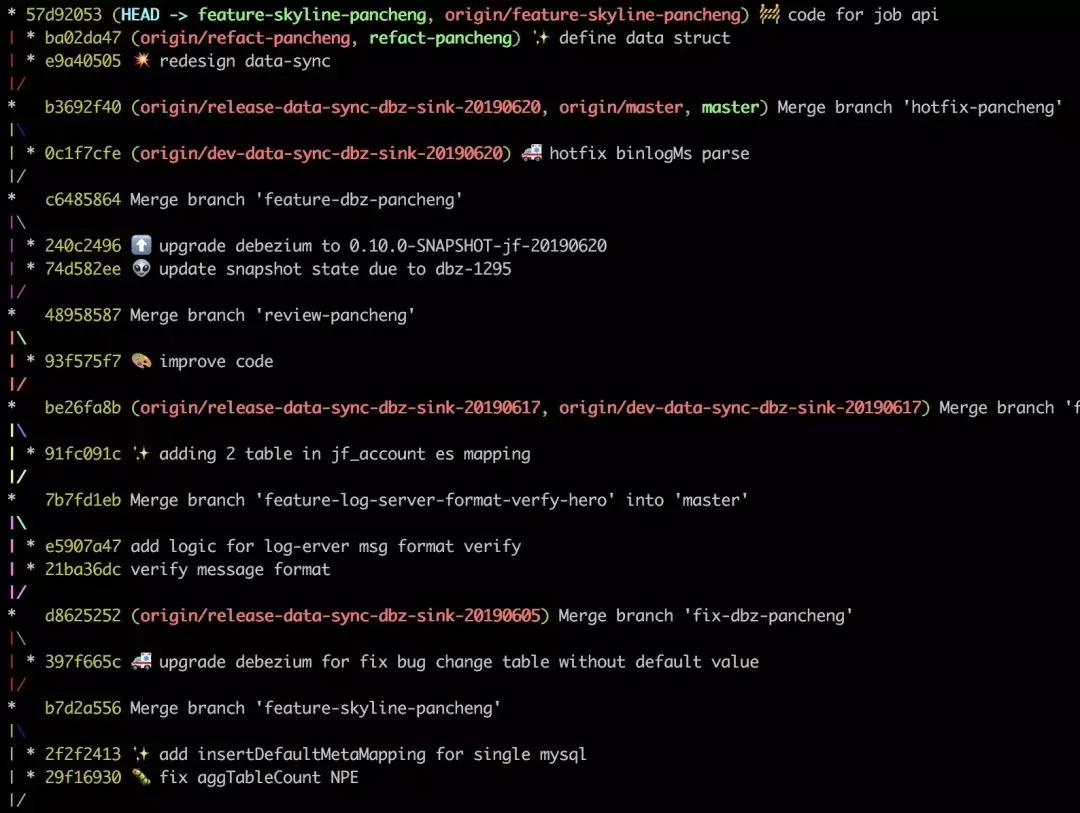
ЫфШЛЮвУЧдк master ЗжжЇКЯВЂЩЯЪЙгУСЫ--no-ffЗНЪН, ЕЋЪЧЫќЕШМлгкЪЧвЛЬѕжБЯп, етЖд code
review КЭазїПЊЗЂНЋЪЎЗжгбКУЁЃ
ФЧУДЗЂАцФи?
ЯрБШгкЭљ master ЩЯ merge ЬсНЛ, ЯюФПЗЂАцЪЧвЛИіИќНїЩїЕФЛАЬтЁЃ
ЮвУЧЩЯУцвбОЬсЕНГжајМЏГЩ(CI), етЪЧвЛжжздЖЏЛЏЕФДђАќКЭВтЪдЛњжЦ, ЭљЭљЛсгыГжајНЛИЖ(CD)вЛЦ№азїЁЃЮвУЧПЩвдНЋ
Git ЕФФГаЉааЮЊзїЮЊ CI/CD ЕФДЅЗЂЬѕМў, РДДяЕНздЖЏЛЏДђАќ, ВтЪд, ВПЪ№ЕФФмСІЁЃ
ЮвУЧЖдЗжжЇзівдЯТЙцЗЖ:
master жїЙІФмЗжжЇ;
feature-xxx-[developer name] ЬиадПЊЗЂЗжжЇ;
fix-xxx-[developer name] ЗЧНєМБbugаоИДЗжжЇ;
hotfix-xxx-[developer name] ЯпЩЯНєМБbugаоИДЗжжЇ;
dev-[date] ПЊЗЂЛЗОГЗЂВМЗжжЇ(Лђtag);
test-[date] ВтЪдЛЗОГЗЂВМЗжжЇ(Лђtag);
uat-[date] зМЩњВњЛЗОГЗЂВМЗжжЇ(Лђtag);
release-[date] ЯпЩЯЗЂВМЗжжЇ(Лђtag)ЁЃ
дк Git ЗўЮёЦїжа, МИКѕЖМЛсЬсЙЉ CI/CD ЙІФм, CI/CD ДЅЗЂЬѕМўИљОне§дђБэДяЪНЦЅХфbranchЛђtag,
здЖЏДЅЗЂЯюФПЕФБрвы, ДђАќ, ВтЪд, ВПЪ№ЕШааЮЊЁЃ
дкЗжжЇЙмРэжа, dev-[date]ЗжжЇПЩвдгЩШЮвтПЊЗЂШЫдБЫцЪБМьГіЗЂВМЕНПЊЗЂЛЗОГСЊЕї; test-[date],
uat-[date], release-[date]ддђЩЯБиаыДгmasterЩЯж№МЖМьГі, ЗжБ№ВтЪд,
ШєЗЂЯжЮЪЬт, Нјаа bugfixЁЃ
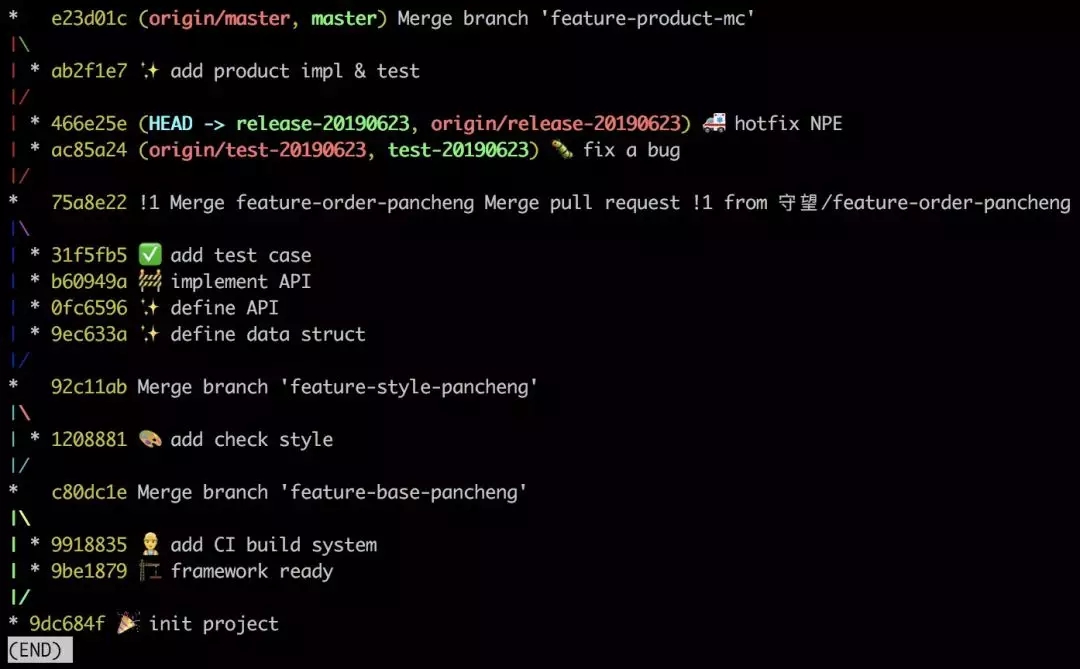
ПД, ЮвУЧДг75a8e22МьГіtest-20190623ЗжжЇ, ЕБЭЦЫЭЕНЗўЮёЦїЩЯЪБ, CI/CD
ЛсздЖЏДЅЗЂ, зюжеЯюФПБЛВПЪ№ЕНВтЪдЗўЮёЦїЩЯ. ЮвУЧдкВтЪдЩЯЗЂЯжвЛИі bug, дкеце§ЩЯЯпЧАЗЂЯжЕФ bug
змБШЩЯЯпКѓКУЁЃbugfix Кѓ, ЮвУЧШЯЮЊУЛгаЮЪЬтСЫ, МьГіrelease-20190623ЗжжЇ,
ДЅЗЂ CI/CD, ВПЪ№ЕНЩњВњЛЗОГ. АыЬьКѓ, ЮвУЧЗЂЯжвЛИіНєМБЕФЯпЩЯ bug, ЮвУЧНєМБДДНЈСЫ hotfix
ЗжжЇ, дк CI ЭЈЙ§Кѓ, НЋЦфКЯШыЕНrelease-20190623ЗжжЇ, ШЛКѓЩОГ§ hotfix
ЗжжЇЁЃ
ПДЩЯШЅетДЮЗЂАцГЩЙІСЫ, ФЧУДетСНИі bugfix commit дѕУДКЯШыЕН master Фи?
ЛЙМЧЕУЮвУЧЫЕ master ЗжжЇЕФ merge ддђТ№? жЛдЪаэ merge Тњзу fast-forward
ЬѕМўЕФ commit. дкЮвУЧПЊЪМВтЪдКѓ, master вбОЧАНј, bugfix commit(МДдкtest-[date],
uat-[date], release-[date]ЩЯЕФ hotfix) ОЭВЛФмжБНгКЯВЂЕН master,
ВЂЧвЗЂВМЕу rebase ЪЧгаЗчЯеЕФ, етЪБОЭжЛФмЭЈЙ§ cherry-pick РДАбВЙЖЁЪжЖЏДђЛиЕН
master ЗжжЇЩЯСЫ!
ЮвУЧДгзюаТ master ЧаГівЛИі fix ЗжжЇ, ВЂАбСНИіВЙЖЁЭЈЙ§
cherry-pick вЦжВЙ§РД:
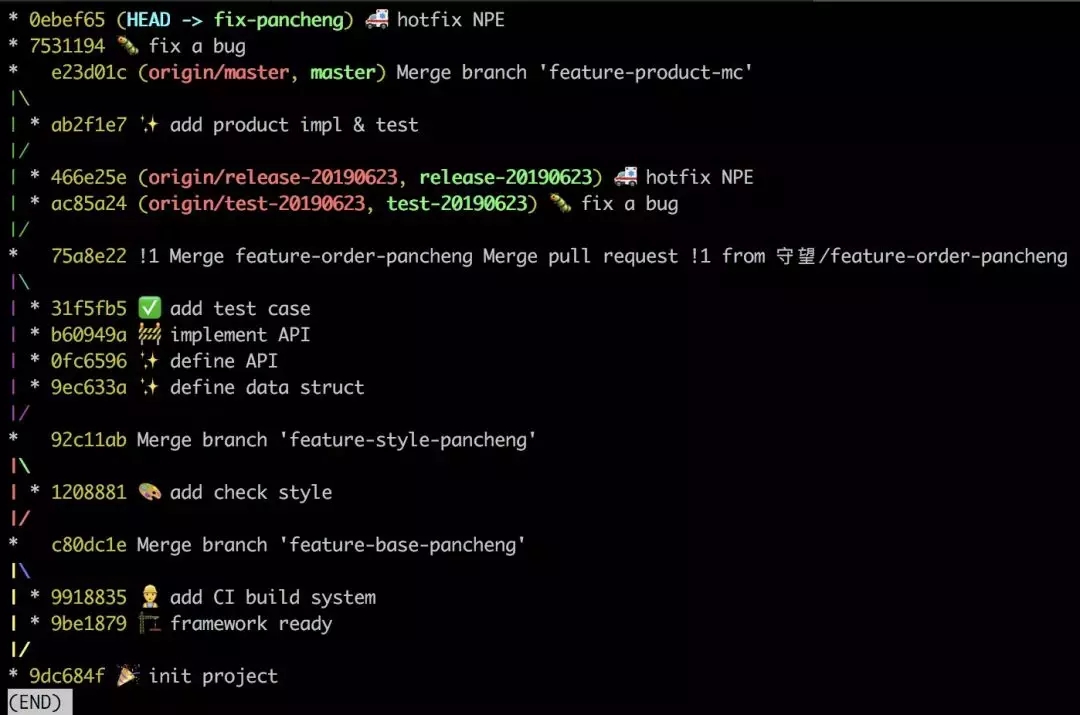
НгЯТРДОЭЪЧ PR СїГЬ, ЕБКЯШы master Кѓ, ЩОГ§ИУ fix
ЗжжЇ:
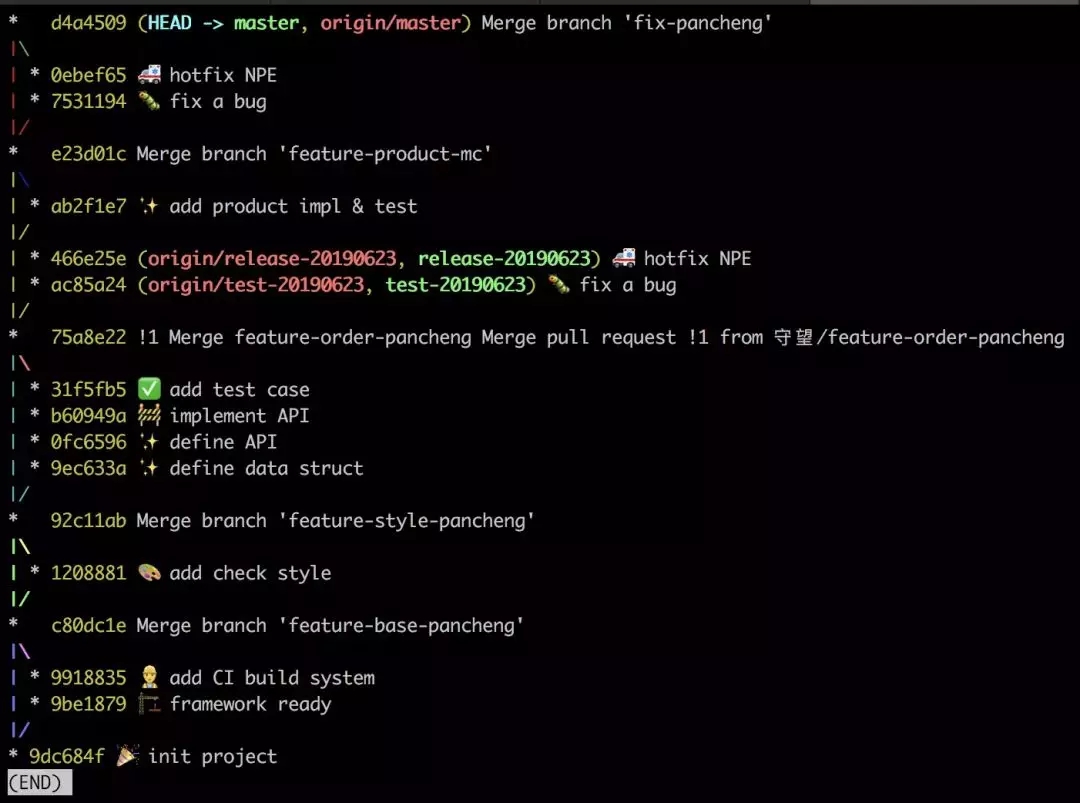
рХ, етЦЊЮФеТЧАКѓДѓдМаДСЫвЛИіРёАн, ЪЧЪБКђЬс PR СЫ, ЮввЊШЅ
rebase СЫЁЃ
|








