| БрМЭЦМі: |
БОЮФЭЈЙ§АИР§жаМИИіЮЪЬтЃЌРДНщЩмGitЪЧЪВУДЃПЪВУДЪЧАцБОПижЦЃПАцБОПижЦЯЕЭГЃЌЮФМўДцДЂЗНЪНЃЌДцДЂаЮЪНЃЌGitЙЄзїдРэЕШЯрЙиФкШнЁЃ
БОЮФРДздгкЮЂаХТэИчLinuxдЫЮЌЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
GitЪЧЪВУДЃП
GitЪЧвЛИіПЊдДЗжВМЪНАцБОПижЦЯЕЭГЃЌПЩвдИпЫйВЂЧвгааЇЕФДІРэКмаЁЕНЗЧГЃДѓЕФЯюФПАцБОЙмРэЁЃGitЪЧLinus
TorvaldsЮЊСЫАяжњЙмРэLinuxФкКЫПЊЗЂЖјПЊЗЂЕФвЛИіПЊдДАцБОПижЦШэМў
ЪВУДЪЧАцБОПижЦЃП
АцБОПижЦвЛАуЪЧжИГЬађПЊЗЂЙ§ГЬжаЕФДњТыАцБОЃЌХфжУЮФМўМАЫЕУїЮФЕЕЕШЮФМўаоИФБфИќЕФЙмРэЃЌАцБОПижЦзюжївЊЕФЙІФмОЭЪЧзЗзйЮФМўЕФаоИФБфИќЕШВйзїЃЌГЦжЎЮЊАцБОПижЦЃЁ
Р§зг-ДњТы
ЙЋЫОбаЗЂВПУХНгЕНРЯАхвЊЧѓПЊЗЂвЛЬзЮЊЙЋЫОФкВПдЫгЊШЫдБЫљЪЙгУЕФФкВПЙмРэЯЕЭГЃЌЙЋЫОбаЗЂгажїЙмЁЂаЁеХЁЂаЁЭѕЁЂаЁаьЕШЫФШЫЃЌЯюФПашЧѓГѕВНЖЈЮЊДЫЬзЯЕЭГашвЊ20ИіЙІФмЃЌЫћУЧЫФШЫИїИКд№ПЊЗЂ5ИіЙІФмЃЌвЛИідТКѓЫћУЧИїздаДКУСЫздМКЫљПЊЗЂЕФЙІФмЃЛжїЙмЫЕЃКЁААбФуУЧЕФДњТыЖМИјЮвАЩЃЌЮвАбдлУЧЕФЫљгаДњТыећКЯЕНвЛЦ№ЁБЃЌЫцКѓЃЌ20ИіЙІФмБЛжїЙмећКЯЕНСЫвЛЦ№ЃЌвђДЫЃЌДЫЯюФПЕФЁАГѕАцЁБвбГЩаЭЃЌШЛКѓАбДњТыЗХЕНВтЪдЛЗОГНјааВтЪдЃЌЗЂЯжаЁеХЕФФГИіЙІФмгаЮЪЬтЃЌШУаЁеХевГіBUGВЂаоИДЃЌаЁеХаоИДКѓЃЌећИіЯюФПЕФДњТыЕШгкдкЁАГѕАцЁБжЎЩЯЕїећвЛДЮЃЌГЩЮЊСЫЁАЖўАцЁБЃЌдйДЮЩЯВтЪдЛЗОГНјааВтЪджЎКѓЃЌЭъећЭЈЙ§ЃЌРЯАхПЊЪМбщЪеЫћздМКЯывЊЕФет20ИіЙІФмЃЌРЯАхПДЕНЙІФмКѓЗЂЯжЦфжага8ИіЙІФмБъзМВЛЗћКЯЫћдЄЦкЃЌвЊЧѓжизіЃЌВЂЧвдйДЮдіМг5ИіЙІФмЃЌбаЗЂВПУХПЊЪМЗжЙЄжизіМАПЊЗЂаТЙІФмЃЌбаЗЂРлЫРРлЛюШ§ЬьЃЌУПШЫЖМАОСЫСНИіУдШЫКкблШІКѓЃЌаоИФМАаТПЊЙІФмЭъГЩЃЌВтЪдЛЗОГЭЈЙ§ЃЌетДЮЃЌЪЧЕкШ§ДЮаоИФДњТыЃЌЮвУЧетРяГЦжЎЮЊЁАШ§АцЁБЃЌШЛКѓдйДЮЯђРЯАхЬсЙІФмбщЪеЃЌРЯАхбщЪеГЩЙІЃЌбаЗЂЬєСЫИіЛЦГНМЊШеЃЌШЛКѓЬсГіаТЯЕЭГЩЯЯпЩъЧыЃЌЩъЧыЭЈЙ§КѓЃЌЭЈжЊдЫЮЌДѓИчУЧЃЌвЊЧѓЛЦГНМЊШеФЧЬьвЛЦ№ажњаТЯЕЭГЩЯЯпЃЌаТЯЕЭГБЯОЙЪзДЮЩЯЯпЃЌЯпЩЯАцБОЖЈЮЊ0.1VАцБОЃЁ
Р§згНВНт
жїЙмЁЂаЁеХЁЂаЁЭѕЁЂаЁаьЫћУЧЫФШЫГѕЦкИїПЊЗЂ5ИіЙІФмЃЌЙУЧвВЛЫЕЫћУЧИїздЖдздМКЫљПЊЗЂЕФЙІФмЪЧдѕбљЙмРэЕФЃЌЫћУЧ20ИіЙІФмећКЯЕНвЛЦ№КѓЃЌЕквЛИіЁАГѕАцЭъГЩЁБЃЌВтЪдЕНаЁеХЕФФГИіЙІФмгаЮЪЬтЃЌаЁеХаоИДКѓЃЌЁАЖўАцЭъГЩЁБЃЌетИіЪБКђОЭПЩвдЪЙгУАцБОЙмРэЯЕЭГЃЌУПДЮДњТыЕФБфИќЖМЪєгкАцБОПижЦЕФЙмРэЗЖЮЇжЎФкЃЛР§ШчБфЮЊСЫЖўАцЃЌаЮГЩСЫаТЕФФПБъАцБОЃЌЖјЖдгкВЛЪмБфИќгАЯьЕФХфжУЯюдђВЛгІЗЂВњЩњБфЖЏЁЃЭЌЪБЃЌгІФмЙЛНЋБфИќЫљВњЩњЕФЖдАцБОЕФгАЯьНјааМЧТМКЭИњзйЁЃБивЊЪБЛЙПЩвдЛиЭЫЕНвдЧАЕФАцБОЁЃР§ШчЕБПЊЗЂашЧѓЛђашЧѓБфИќБЛШЁЯћЪБЃЌОЭашвЊгаФмСІНЋАцБОЛиЭЫЕНПЊЗЂЛљЯпАцБОЁЃдкдјОГіЯжЙ§ЕФМОЖШЩ§МЖАќВ№АќКЭжиаТзщАќЕФЙ§ГЬжаЃЌЦфЪЕОЭЪЧНЋВПЗжХфжУЯюЕФАцБОЛиЭЫЕНПЊЗЂЛљЯпЃЌНЋЖдгІВЛЭЌашЧѓЕФВЛЭЌЗжжЇжиаТзщКЯЙщВЂЃЌаЮГЩаТЕФЩ§МЖАќАцБОЁЃ
Р§зг-МђРњ
МйШчЮвУЧЯыаоИФМђРњЕФЯюФПОбщетвЛПщФкШнЃЌЕЋЪЧгжХТаоИФКѓЛЙВЛШчВЛИФжЎЧАИќСюШЫаХЗўЃЌЮвУЧГЃЙцЕФАьЗЈОЭЪЧЃЌИДжЦвЛЗнЁАИББОЁБЃЌдкИББОжЎЩЯзіаоИФЃЌЗДЗДИДИДМИДЮЃЌОЭБфГЩСЫКмЖрИББОЛђепАцБОетбљЃЌР§ШчЙ§СЫСНИідТЃЌФугжЯыЬјВлСЫЃЌФуЯыевЕНМђРњФкФуЯывЊЕФФкШнЃЌжЛФмвРДЮДђПЊШЅевЃЌецЭЗДѓЃЁетИіЪБКђЮвУЧОЭПЩвдЪЙгУЕНАцБОЙмРэЯЕЭГЃЌАцБОЙмРэЯЕЭГЙІФмЭЌЩЯНВЕФДњТыР§згвЛжТ
АцБОПижЦЯЕЭГ
БОЕиАцБОПижЦ
ЦфжавЛжжНазі RCSЃЌКмЩйМћЕФЯЕЭГЃЌвбОБЛЬдЬЕєСЫЃЌЫЕЪЕЛАЮвУЛЬ§Й§ЃЌ ЫќЕФЙЄзїдРэЪЧдкгВХЬЩЯБЃДцВЙЖЁМЏЃЈВЙЖЁЪЧжИЮФМўаоЖЉЧАКѓЕФБфЛЏЃЉЃЛЭЈЙ§гІгУЫљгаЕФВЙЖЁЃЌПЩвджиаТМЦЫуГіИїИіАцБОЕФЮФМўФкШнЁЃФуУЧЭќСЫАЩRCSАЩЃЌМЧзЁЫћЕФЙЄзїдРэОЭааЁЃ
БЃДцВЙЖЁМЏ

ЮвУЧОГЃгУЕФОЭЪЧИДжЦећИіЯюФПФПТМЕФЗНЪНРДБЃДцВЛЭЌЕФАцБОЃЌЛђепНјааАцБОЕќДњМАЪБМфЕќДњЃЌетУДзіЕФЮЈвЛКУДІОЭЪЧМђЕЅЃЌЕЋЪЧЬиБ№ШнвзЗИДэЃЌгаЪБКђЛсЛьЯ§ЫљдкЕФЙЄзїФПТМЃЌвЛВЛаЁаФЛсаДДэЮФМўЛђепИВИЧЕєживЊЮФМўЁЃЮЊСЫНтОіетИіЮЪЬтЃЌКмОУвдЧАОЭПЊЗЂСЫаэЖржжБОЕиАцБОПижЦЯЕЭГЃЌдкБОЕиДюНЈАцБОПижЦЯЕЭГЃЌДѓЖрЖМЪЧВЩгУФГжжМђЕЅЕФЪ§ОнПтРДМЧТМЮФМўЕФРњДЮИќаТВювьЁЃБугкАцБОЛиЭЫЕШВйзїЁЃ
ЮЪЬтЃКЮвУЧЯюФПзщФкга8ИіШЫЃЌ8ИіШЫШчЙћдкВЛЭЌЕФЯЕЭГЩЯаЭЌЙЄзїФиЃПетИіОЭЪЧЯТУцЮвУЧвЊНВЕФМЏжаЛЏАцБОПижЦЯЕЭГСЫ
МЏжаЛЏАцБОПижЦ
МЏжаЛЏЕФАцБОПижЦЯЕЭГЃЈCentralized Version Control SystemsЃЌМђГЦ
CVCSЃЉгІдЫЖјЩњЁЃетРрЯЕЭГЃЌжюШч CVSЁЂSubversion вдМА Perforce ЕШЃЌЖМгавЛИіЕЅвЛЕФМЏжаЙмРэЕФЗўЮёЦїЃЌБЃДцЫљгаЮФМўЕФаоЖЉАцБОЃЌЖјаЭЌЙЄзїЕФШЫУЧЖМЭЈЙ§ПЭЛЇЖЫСЌЕНетЬЈЗўЮёЦїЃЌШЁГізюаТЕФЮФМўЛђепЬсНЛИќаТЁЃИіШЫРэНтЃЌЯёвЛИіFTPЗўЮёЦїЃЌЮФМўЩЯДЋЯТдивдМАаоИФЖМвЊдкБОЕиЪЙгУПЩftpПЭЛЇЖЫРДЯТдиЛђепЩЯДЋЮФМўЃЌЖрФъвдРДЃЌетвбГЩЮЊАцБОПижЦЯЕЭГЕФБъзМзіЗЈЁЃ

етжжзіЗЈДјРДСЫаэЖрКУДІЃЌЬиБ№ЪЧЯрНЯгкРЯЪНЕФБОЕи VCS РДЫЕЁЃЯждкЃЌУПИіШЫЖМПЩвддквЛЖЈГЬЖШЩЯПДЕНЯюФПжаЕФЦфЫћШЫе§дкзіаЉЪВУДЁЃЖјЙмРэдБвВПЩвдЧсЫЩеЦПиУПИіПЊЗЂепЕФШЈЯоЃЌВЂЧвЙмРэвЛИі
CVCS вЊдЖБШдкИїИіПЭЛЇЖЫЩЯЮЌЛЄБОЕиЪ§ОнПтРДЕУЧсЫЩШнвзЁЃНгЯТРДЮвУЧНВНВЛЕДІЃК
1.етжжМЏжаЛЏАцБОПижЦЕФЧщПіБиаывЊСЊЭјАЩЃПЮоТлЪЧЙЋЭјЛЙЪЧЙЋЫОФкЭјЖМашвЊНгШыinternetЃЌМйШчЮвдкЮоЭјЛЗОГЯТашвЊетаЉЮФМўФиЃПР§ШчдкЗЩЛњЩЯашвЊНєМБЙЄзїЃЌИќИФДњТыЃЌШДЗЂЯжСЌНгВЛСЫАцБОПижЦЗўЮёЦїЃЁЃЁЃЁ
2.гЩгкЪЧМЏжаЛЏЕФАцБОПижЦЃЌашвЊвЛЬЈЕЅЖРЕФЙмРэЗўЮёЦїРДзіАцБОПижЦЯЕЭГАЩЃЌШчЙћМЏжаЙмРэЗўЮёЦїЕФЕЅЕуЙЪеЯЁЃШчЙћхДЛњвЛаЁЪБЃЌФЧУДдкетвЛаЁЪБФкЃЌЫЖМЮоЗЈЬсНЛИќаТЃЌвВОЭЮоЗЈаЭЌЙЄзїЁЃШчЙћАцБОЙмРэЪ§ОнПтЫљдкЕФДХХЬЗЂЩњЫ№ЛЕЃЌгжУЛгазіЧЁЕББИЗнЃЌКСЮовЩЮЪФуНЋЖЊЪЇЫљгаЪ§ОнЃЌАќРЈЯюФПЕФећИіБфИќРњЪЗЃЌжЛЪЃЯТШЫУЧдкИїздЛњЦїЩЯБЃСєЕФЕЅЖРПьееЁЃБОЕиАцБОПижЦЯЕЭГвВДцдкРрЫЦЮЪЬтЃЌжЛвЊећИіЯюФПЕФРњЪЗМЧТМБЛБЃДцдкЕЅвЛЮЛжУЃЌОЭгаЖЊЪЇЫљгаРњЪЗИќаТМЧТМЕФЗчЯеЁЃSubversionВЩгУЕФОЭЪЧМЏжаЛЏАцБОПижЦЯЕЭГЁЃ
ЮЪЬтЃКФЧУДдѕУДШУДѓМвЭЌЪБаЭЌЙЄзїЕФЪБКђВЛашвЊСЊЭјгжВЛХТАцБОПижЦЗўЮёЦїЕЅЕуЙЪеЯМАДХХЬЫ№ЛЕФиЃПЪзЯШЃЌШчЙћЙЋЫОmoneyГфзуЃЌПЩвдИјАцБОЙмРэЗўЮёЦїзіИіШШБИЗўЮёЦїЃЌДХХЬПЩвдзіRAID5ЛђепRAID10
ЕЋЪЧЃЌЮвУЧЮоЗЈНтОіДѓМвдкЮоЭјТчЕФЧщПіЯТе§ГЃЙЄзїЃЌЮвУЧЯТУцвЊНВЕФЗжВМЪНАцБОПижЦЯЕЭГПЩвдКмКУЕФНтОіетИіЮЪЬт
ЗжВМЪНАцБОПижЦ
ЮЊСЫНтОіДѓМвЭЌЪБаЭЌЙЄзїЕФЪБКђВЛашвЊСЊЭјгжВЛХТАцБОПижЦЗўЮёЦїЕЅЕуЙЪеЯМАДХХЬЫ№ЛЕЃЌгкЪЧЗжВМЪНАцБОПижЦЯЕЭГЃЈDistributed
Version Control SystemЃЌМђГЦ DVCSЃЉУцЪРСЫЁЃдкетРрЯЕЭГжаЃЌЯё GitЁЂMercurialЁЂBazaar
вдМА Darcs ЕШЃЌПЭЛЇЖЫВЂВЛжЛЬсШЁзюаТАцБОЕФЮФМўПьееЃЌЖјЪЧАбДњТыВжПтЭъећЕиОЕЯёЯТРДЁЃећИіВжПтЕФОЕЯёИДжЦЕНБОЕивдКѓЛЙашвЊСЊЭјТ№ЃПВЛашвЊСЫАЩЃЌГ§ЗЧДѓМвашвЊЭЌВНЪ§ОнЃЌЮвУЧУПШЫЕФПЭЛЇЖЫЖМПЩвдГЩЮЊАцБОПижЦЯЕЭГЦНЬЈЃЌ
етУДвЛРДЃЌШЮКЮвЛДІаЭЌЙЄзїгУЕФЗўЮёЦїЗЂЩњЙЪеЯЃЌЪТКѓЖМПЩвдгУШЮКЮвЛИіОЕЯёГіРДЕФБОЕиВжПтЛжИДЁЃвђЮЊУПвЛДЮЕФПЫТЁВйзїЃЌЪЕМЪЩЯЖМЪЧвЛДЮЖдДњТыВжПтЕФЭъећБИЗнЁЃ

ОйИіР§згЃЌвЊфЏРРЯюФПЕФРњЪЗЃЌGit ВЛашЭтСЌЕНЗўЮёЦїШЅЛёШЁРњЪЗЃЌШЛКѓдйЯдЪОГіРДЁЊЁЊЫќжЛашжБНгДгБОЕиЪ§ОнПтжаЖСШЁЁЃФуФмСЂМДПДЕНЯюФПРњЪЗЁЃШчЙћФуЯыВщПДЕБЧААцБОгывЛИідТЧАЕФАцБОжЎМфв§ШыЕФаоИФЃЌGit
ЛсВщевЕНвЛИідТЧАЕФЮФМўзівЛДЮБОЕиЕФВювьМЦЫуЃЌЖјВЛЪЧгЩдЖГЬЗўЮёЦїДІРэЛђДгдЖГЬЗўЮёЦїРЛиОЩАцБОЮФМўдйРДБОЕиДІРэЁЃаэЖретРрЯЕЭГЖМПЩвджИЖЈКЭШєИЩВЛЭЌЕФдЖЖЫДњТыВжПтНјааНЛЛЅЁЃМЎДЫЃЌФуОЭПЩвддкЭЌвЛИіЯюФПжаЃЌЗжБ№КЭВЛЭЌЙЄзїаЁзщЕФШЫЯрЛЅазїЁЃФуПЩвдИљОнашвЊЩшЖЈВЛЭЌЕФазїСїГЬЃЌБШШчВуДЮФЃаЭЪНЕФЙЄзїСїЃЌЖјетдквдЧАЕФМЏжаЪНЯЕЭГжаЪЧЮоЗЈЪЕЯжЕФЁЃ
GitЬиад ЫйЖШ ? МђЕЅЕФЩшМЦ ? ЖдЗЧЯпадПЊЗЂФЃЪНЕФЧПСІжЇГжЃЈдЪаэГЩЧЇЩЯЭђИіВЂааПЊЗЂЕФЗжжЇЃЉ ? ЭъШЋЗжВМЪН
? гаФмСІИпаЇЙмРэРрЫЦ Linux ФкКЫвЛбљЕФГЌДѓЙцФЃЯюФПЃЈЫйЖШКЭЪ§ОнСПЃЉ
ЮФМўДцДЂЗНЪН
Delta Storage
cvsКЭsvnЕФЮФМўДцДЂЗНЪНВЩгУDelta StorageЕФЗНЪНЃЌЮвУЧЛСЫвЛеХЭМРДбнЪОDelta StorageЕФДцДЂдРэЃКЮвУЧгаЫФИіЮФМўЃЛ

дкЕквЛНзЖЮЖМЮЊЭЌвЛзДЬЌ ЕкЖўИіНзЖЮКѓfileBКЭfileDЗЂЩњСЫаоИФЃЌетИіЪБКђDelta StorageНЋЛсЖдаоИФЙ§ЕФfileBКЭfileDНјаавЛДЮПьееЃЌПьееБИЗнФкШнЮЊfileBКЭfileDаоИФКѓКЭаоИФЧАНјааВювьБШНЯЃЌБИЗнВювьФкШнЃЌВЂМЧТМПьееЃЌЖјfileAКЭfileCУЛгаЗЂЩњаоИФдђВЛМЧТМ ЕкШ§НзЖЮКѓfile1КЭfileCЗЂЩњСЫаоИФDelta StorageвВНЋЛсЖдfileAКЭfileCНјаавЛДЮПьееЃЌБОНзЖЮfileBКЭfileDЮДЗЂЩњаоИФдђВЛМЧТМ ЕкЫФНзЖЮКЭЕкЮхНзЖЮвВЪЧвЛбљ
змНсЃКDelta StorageжЛЖдЗЂЩњаоИФЙ§ЕФЮФМўНјааПьееБИЗнЃЌПьееБИЗнБЃДцЕФЪЧБОДЮаоИФКЭЩЯДЮЮФМўЕФВювьЃЌЮДЗЂЩњаоИФЕФЮФМўВЛМЧТМЁЃ
DAG Storage
GitЫљВЩгУЕФЮФМўДцДЂЗНЪНЮЊDAG StorageЃЌвВЪЧЛСЫвЛеХЭМРДбнЪОDAG StorageЕФДцДЂдРэЃКЭЌбљгаЫФИіЮФМў
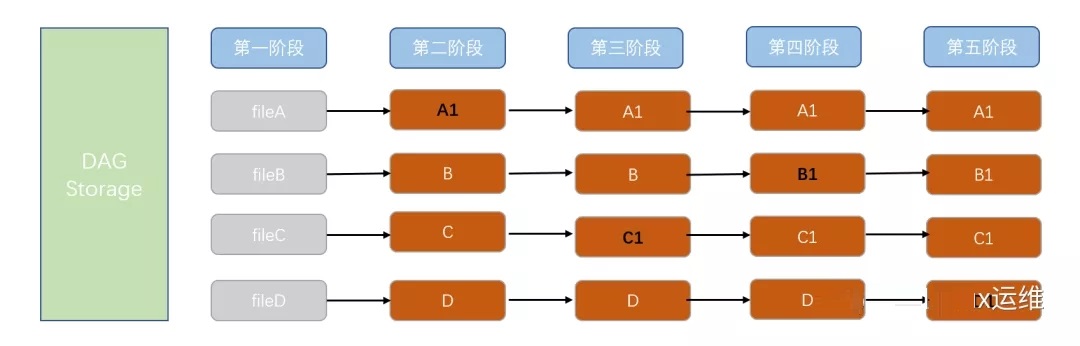
дкЕквЛНзЖЮЖМЮЊГѕЪМзДЬЌ ЕкЖўНзЖЮЃЌfileAЗЂЩњСЫЕквЛДЮБфЛЏЃЌDAG StorageОЭЛсЖдfileAНјаавЛИіПьееВЂБЃДцетИіПьееЕФЫїв§ЃЌЦфЫќЮФМўЮДЗЂЩњБфЛЏЃЌDAG
StorageЮЊСЫИпаЇЃЌЛсдкДЫНзЖЮЛсБЃСєвЛИіСДНгжИЯђжЎЧАДцДЂВЂЮДаоИФЕФЮФМў ЕкШ§НзЖЮЃЌfileCЗЂЩњСЫЕквЛДЮБфЛЏЃЌDAG StorageЫќНјааПьееБИЗнЮЊC1зДЬЌЃЌDAG StorageвВЛсЖдfileCНјаавЛИіПьееВЂБЃДцетИіПьееЕФЫїв§ЃЌЦфЫќЮДЗЂЩњИФБфЕФЮФМўЃЌМЬајБЃСєвЛИіСДНгжИЯђЮДаоИФЕФЮФМў ЕкЫФКЭЕкЮхНзЖЮвВЪЧШчДЫ
змНсЃКDAG StorageВЂВЛЯёDelta StorageвЛбљЕФДцДЂЪ§ОнЃЌDAG StorageЪЧАбЪ§ОнПДзіаЁаЭЮФМўЯЕЭГЕФвЛзщПьееЃЌМйШчдкGitжаЃЌФуУПДЮЬсНЛИќаТЃЌDAG
StorageЖдФуЕФЕФШЋВПЮФМўжЦзївЛИіПьееВЂБЃДцетИіПьееЕФЫїв§ЁЃЮЊСЫИпаЇЃЌШчЙћЮФМўУЛгааоИФЃЌGit
ВЛдйжиаТДцДЂИУЮФМўЃЌЖјЪЧжЛБЃСєвЛИіСДНгжИЯђжЎЧАДцДЂЕФЮФМўЁЃGit ЖдД§Ъ§ОнИќЯёЪЧвЛИі ПьееСїЁЃ
ДцДЂаЮЪН
УПИіДцДЂЗНЪНЖМгаШ§жжаЮЪНРДЗНЪНРДДцДЂЪ§ОнЃЌОЭЪЧЮвУЧЩЯУцНВЕНЕФШ§жжАцБОПижЦЯЕЭГ
Local == БОЕиАцБОПижЦДцДЂЗНЪН Centralized == МЏжаЛЏАцБОПижЦДцДЂЗНЪН Distributed == ЗжВМЪНАцБОПижЦДцДЂЗНЪН
Delta Storage 
LocalБОЕиАцБОПижЦДцДЂЗНЪНЕФАцБОПижЦЯЕЭГгаЮвУЧЩЯУцНВЕФЮвЖМУЛЬ§Й§ЕФrcsЯЕЭГ CentralizedМЏжаЛЏАцБОПижЦДцДЂЗНЪНЕФАцБОПижЦЯЕЭГгаcvsЁЂSubversionЁЂperforceЃЌетМИИіЯЕЭГЮвУЧгІИУТдгаЖњЮХЃЌЬиБ№ЪЧSubversion
SVNЃЌSVNЪЧDelta StorageДцДЂЗНЪНЕФДњБэзїЃЌПЩвдЫЕSVNЪЧЛљгкдкCVSжЎЩЯЫљЙЙНЈЕФвЛЬзЯЕЭГЃЌгаМЬГаCVSЕФзкжМЃЌвВгаДДаТ
DistributedЗжВМЪНАцБОПижЦДцДЂЗНЪНЕФАцБОПижЦЯЕЭГгаdarcsЁЂmercurialЃЌdarcsЪЧЛљгкrcsжЎЩЯЕФАцБОПижЦЯЕЭГЃЌmercurialЪЧзпЩЬвЕЛЏЕФАцБОПижЦЯЕЭГ
DAG Storage 
LocalБОЕиАцБОПижЦДцДЂЗНЪНАцБОПижЦЯЕЭГгаЮвУЧДЋЭГЪЙгУЕФcp -rКЭtime machineЯЕЭГ
CentralizedМЏжаЛЏАцБОПижЦДцДЂЗНЪНЕФАцБОПижЦЯЕЭГгаbitkeeperЃЌЕЋbitkeeperгжгаDistributedЗжВМЪНДцДЂЯЕЭГЕФЬиад
DistributedЗжВМЪНАцБОПижЦДцДЂЗНЪНЕФАцБОПижЦЯЕЭГгаgitЁЂbazaarЃЌЦфжаgitЪЧDAG
StorageЕФДњБэзї
GitЙЄзїдРэ
Ш§жжзДЬЌ
GitгаШ§жжзДЬЌЗжБ№ЪЧЃКвбЬсНЛЃЈcommittedЃЉЁЂвбаоИФЃЈmodifiedЃЉЁЂвбднДцЃЈstagedЃЉ
вбЬсНЛЃЈcommittedЃЉЃКвбЬсНЛБъЪЖЪ§ОнвбОАВШЋБЃДцдкБОЕиЪ§ОнПтжаЁЃ
вбаоИФЃЈmodifiedЃЉЃКвбаоИФБэЪОаоИФСЫЮФМўЃЌЕЋЛЙУЛДцЕНЪ§ОнПтжаЁЃ
вбднДцЃЈstagedЃЉЃКвбднДцБэЪОЖдвЛИівбаоИФЕФЕБЧААцБОзіСЫБъМЧЃЌШУДЫАќКЌдкЯТДЮЬсНЛЕФПьеежаЁЃ
Ш§ИіЙЄзїЧјгђ
GitШ§ИіЙЄзїЧјгђЕФИХФюЗжБ№ЪЧЃКGitВжПтЁЂЙЄзїФПТМЁЂднДцЧјгђ

GitВжПтЃКФПТМЪЧGitгУРДБЃДцЯюФПЕФдЊЪ§ОнКЭЖдЯѓЪ§ОнПтЕФЕижЗЃЌетИіGitжазюживЊЕФВПЗжЃЌДгЦфЫќМЦЫуЛњПЫТЁВжПтЪБЃЌЛЛОфЛАЫЕЃЌОЭЪЧДгGitПЭЛЇЖЫРДЛёШЁЪ§ОнЪБЃЌПНБДЕФОЭЪЧетРяЕФЪ§ОнЃЌGitВжПтЃЁЮвУЧАВзАКУGitжЎКѓЃЌдкЮвУЧГѕЪМЛЏЕФЙЄзїФПТМЯТгавЛИівўВиЕФ.gitФПТМЃЌ.gitФПТМФкгаИіobject
databaseФПТМЃЌДЫФПТММДЮЊGitВжПтЁЃ
ЙЄзїФПТМЃКЙЄзїФПТМЪЧЖдЯюФПЕФФГИіАцБОЖРСЂЬсШЁГіРДЕФФкШнЁЃетаЉДгGitВжПтЕФбЙЫѕЪ§ОнПтжаЬсШЁГіРДЕФЮФМўЃЌЗХдкДХХЬЩЯЙЉФуЪЙгУЛђепаоИФЕФвЛИіФПТМЁЃвЊЯыgitФмЙЛЙЄзїЃЌОЭБиаывЊЩшжУЦфЙЄзїФПТМЃЌДДНЈвЛИіФПТМЃЌШЛКѓЪЙгУgit
init ФПТМУћГЦРДАбДЫФПТМЖЈвхЮЊЙЄзїФПТМЁЃ
днДцЧјгђЃКднДцЧјгђЪЧвЛИіЮФМўЃЌБЃДцСЫЯТДЮНЋЬсНЛЕФЮФМўСаБэаХЯЂЃЌвЛАудкGitВжПтФПТМжаЁЃгаЪБКђвВБЛГЦзїЁАЫїв§ЁБЃЌВЛЙ§вЛАуЫЕЗЈЛЙЪЧНаднДцЧјгђЁЃдкЮвУЧАВзАКУGitвдКѓЃЌдкЮвУЧГѕЪМЛЏЕФФПТМЯТгавЛИівўВиЕФ.gitФПТМЃЌ.gitФПТМФкгаИіindexФПТМЃЌМДГЩЮЊЁАднДцЧјЁБгжНазіЁАЫїв§ФПТМЁБЁЃ
GitЙЄзїСїГЬ
1.дкЙЄзїФПТМжааоИФЮФМўЁЃ2.днДцЮФМўЃЌНЋЮФМўЕФПьееЗХШыднДцЧјгђЁЃ3.ЬсНЛИќаТЃЌевЕНднДцЧјгђЕФЮФМўЃЌНЋПьеегРОУадДцДЂЕН
Git ВжПтФПТМЁЃ
змНсЃКШчЙћGitФПТМжаБЃДцзХЬиЖЈАцБОЕФЮФМўЃЌОЭЪєгквбЬсНЛзДЬЌЁЃШчЙћзіСЫаоИФВЂЗХШыднДцЧјгђЃЌОЭЪєгквбднДцзДЬЌЁЃШчЙћздЩЯДЮШЁГіКѓЃЌзіСЫаоИФЕЋЛЙУЛгаЗХЕНднДцЧјгђЃЌОЭЪЧвбаоИФзДЬЌ.
GitЪЧдѕУДДцДЂЪ§ОнЕФ
GitХфжУЮФМўМђНщ
GitАВзАЭъГЩКѓЃЌЛсдкГѕЪМЛЏЕФЙЄзїФПТМЯТЩњГЩвЛИівўВиЕФ.gitЮФМўЃЌеЙПЊ.gitЮФМўгавдЯТЮФМў

object databaseЪЧдѕбљДцДЂЖдЯѓЕФ

ВЮЪ§НтЪЭЃК
contentЃКМйШчЮЊвЛИіЮФМўЕФГѕЪМАцБО
new_contentЃКЮЊвЛИіcontentаоИФКѓЕФcontentЃЌБЛГЦЮЊаТЕФЮФМўЃЌдкГѕЪМАцБОЩЯНјааСЫФФаЉВйзїВХЛсЩњГЩвЛИіаТЕФnew_contentФиЃП
typeЃКЮФМўРраЭЃЌдкетРяБэЪОcontentЕФЮФМўРраЭ
content.sizeЃКcontentЮФМўФкШнЕФДѓаЁ
\0ЃКcontentЕФдЊЪ§Он
hashЃКвдМЦЫуаЃбщКЭЕФЛњжЦНазі SHA-1 ЩЂСаЃЈhashЃЌЙўЯЃЃЉЃЌгЩ40 ИіЪЎСљНјжЦзжЗћЃЈ0-9
КЭ a-fЃЉзщГЩзжЗћДЎЃЌЛљгк Git жаЮФМўЕФФкШнЛђФПТМНсЙЙМЦЫуГіРД
аТЮФМўЩњГЩНтЪЭЃК
вЛИіаТЕФnew_contentЩњГЩ = contentЕФЮФМўРраЭ + contentЮФМўФкШнДѓаЁ
+ \0ЮФМўЕФдЊЪ§Он + МгcontentБОЩэРДзіhashНјааМЦЫуГЩhashТы
зюКѓЮФМўУћГЦБЛМЦЫуГЩСЫhashТыБЃДцдкobject databaseжаЃЌМШШЛБЃДцЕФЪЧhashТыЃЌФЧУДУПИіЮФМўЕФhashЪЧОјЖдВЛЛсжиИДЕФЁЃЕБЮвУЧЖСШЁФГИіЮФМўЪБЃЌgitОЭЛсИљОнЫќЕФhashТыРДЫїв§ЕНЮФМўЮЛжУВЂДђПЊГЪЯжИјФуЃЌФЧУДgitжЛДцДЂСЫЮФМўМЦЫуЕФhashТыЃПNOЁЂNOЁЂNO
ЮФМўФкШнФЌШЯЭЈЙ§zlibНјаабЙЫѕЙщЕЕДцДЂСЫЃЌФЧУДЙщЕЕЕНФФРяСЫФиЃПФЌШЯgitЪЧНиШЁЮФМўЕФhashТыЕФЪзСНЮЛзїЮЊзгФПТМРДЗжВуДцЗХетИіЮФМўЃЌШчЩЯЭМЫљЪОЃЌЧАСНЮЛЪЧhashТызїЮЊзгФПТМЃЌКѓУц38ЮЛhashТыЮЊбЙЫѕКѓЕФЮФМўУћГЦ
GitЕФЫФжжРраЭЖдЯѓ
ЙЄзїФПТМЯТгазгФПТМЃЌЕБЮвУЧЙЄзїЕБжаАбЙЄзїФПТМФкЕФЮФМўЩОГ§СЫЃЌЕЋЪЧ.gitФПТМЮДБЛЩОГ§ЃЌЯждкашвЊЪЙгУobject
databaseРДЛжИДЃЌЛжИДЛиРДЪЧжИЖЈУЛгаЮЪЬтЕФЃЌЕЋЪЧЮвУЧВЛЕЋвЊЛжИДЮФМўЃЌЛЙвЊЛжИДЛиРДЮФМўЫљЪєЕФЮФМўФПТМВуМЖНсЙЙЃЌДгетЕуПЩвдПДГіЃЌЮвУЧЕФobject
databaseВЛЙтЪЧвЊДцДЂФуЕФЮФМўФкШнБОЩэЃЌЛЙвЊДцДЂФуЕФЮФМўФПТМВуМЖНсЙЙЃЌФЧУДетаЉФПТМВуМЖНсЙЙППЪВУДРДДцДЂФиЃП
ШчЧыПДЯТЭМЃЌGitвЛЙВгаЫФжжРраЭЕФЖдЯѓ

blobЃКДцДЂЮФМўЖдЯѓЃЌДцДЂЖўНјжЦФкШнЃЌЮЊДцДЂЮФМўФкШн
treeЃКБэУцвтЫМЮЊЪїЃЌЮвУЧlinuxжавВгаtreeУќСюЃЌЪЧгУРДеЙПЊЫљдкТЗОЖЯТЕФЫљгаФПТМЃЌетРяЕФtreeзїгУОЭЪЧДцДЂЙЄзїФПТМЕБжаФПТМЕФВуМЖНсЙЙ
commitЃКБэУцвтЫМЮЊЬсНЛЃЌдкЮвУЧgitжаЃЌУПДЮЬсНЛЖМЛсаДШыЕНobject databaseЖдЯѓДцДЂЯЕЭГжаЃЌвВПЩвдЫЕЮЊgitВжПтжаЃЌвЛЕЉДцДЂОЭЛсЩњГЩПьее
tagЃКБэУцвтЫМЮЊБъЧЉЃЌЮвУЧУПДЮЬсНЛЖМжЊЕРgitДцДЂЕФЪЧвЛИіhashТыЃЌЕЋЪЧhashТыЬЋГЄСЫФиЃЌЮвВЛКУМЧЃЌдѕУДАьФиЃПОЭПЩвдгУЕНtagБъЧЉРДДђБъЃЌПЩвдРэНтЮЊlinuxЛузмЕФaliasБ№УћУќСю
змНсЃКGitвЛЙВгаЫФжжЖдЯѓЃЌblobЁЂtreeЮЊКЫаФЖдЯѓЃЌcommitФуЕФУПвЛДЮЬсНЛЖМгавЛИіcommitЖдЯѓЃЌвЛАуtagВЂВЛЪЧБиаыЪЙгУЕФЖдЯѓ
|








