| 编辑推荐: |
本文主要是介绍了Git 的工作原理,Git 是如何工作的,希望本文对您的学习有所帮助。
本文来自于微信公众号AI技术前线,由火龙果软件Linda编辑、推荐。 |
|
01
前言
Git 是一个常用的去中心化源代码仓库。它由 Linux 之父 Linus Torvalds 创建,用于管理
Linux 内核源代码。GitHub 的整个服务都基于Git。因此,如果您使用Git管理在 Linux
环境中的工程,或者将 IBM 的 DevOps 服务与 Git 结合使用,会帮助你更好地理解 Git。
在我刚开始使用 Git 的时候,我对并发版本系统 (CVS) 和 Apache Subversion
(SVN) 已经有一些经验,因此我尝试从那些传统的源代码仓库系统的逻辑来理解它,这种思维方式限制了我对
Git 功能的了解。
发现这个问题之后,我通过进一步的使用和学习,对 Git 有了更加深入的理解,所以这篇文章是一篇“个人笔记”,用来记录
Git 是如何工作的,也可以作为初学者的学习资料。本文假设您对其他传统的源代码仓库已经有了一定的了解,例如
CVS 或 SVN。
02
基础
首先,让我们从传统源代码仓库中的一个基本示例开始,如图 1 所示。在传统源代码仓库中,包含文件和子文件夹的文件夹作为内容处理(CVS
和 Git 实际上并不处理文件夹,而只是处理位于特定路径的文件)。仓库包含工程内容的所有版本,而工作目录是您修改代码的地方。您将代码从仓库检出(checkout)到工作目录,并将您在此工作目录中所做的更改作为一个新版本提交回仓库中。
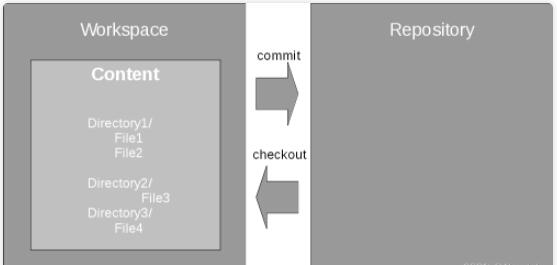
图1. 传统源代码仓库工作空间处理逻辑
Git 的每次提交都会创建一个新的子版本内容,该版本来源于修改过的上一个父版本,如图 2 所示。内容存储为一系列版本,也称为快照(snapshots),由提交操作创建的父子关系进行链接。通过提交在父版本和子版本之间发生更改的信息称为更改集。
这一系列版本称为流(stream)或分支(branch)。在SVN中,主分支称为trunk;在 CVS
中,通常称为HEAD;在 Git 中,它通常称为master。在实际的工程项目中,分支用来分离一个特定功能的开发,或着用来保留旧版本。
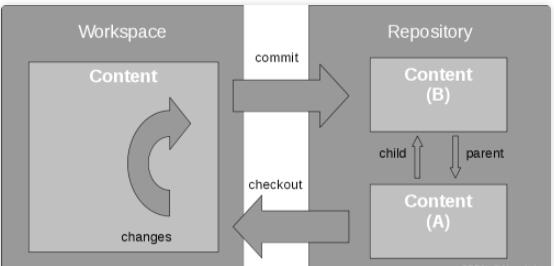
图2. 在传统仓库中创建一个新版本
03
Git 的工作原理
一旦你理解了Git 的主要工作原理,就会非常简单。
Git 可以管理版本中的内容,每个提交对应一个版本,并且知道如何在两个版本之间应用或回滚更改集。这是概念很重要,理解应用和回滚变更集的概念会让
Git 更容易理解和使用。
这是最基本的原则,其他一切都由此而来,因此,接下来让我们更深入地探索 Git。
Git 的使用
首先,列出 Git 中的常用命令:
git init —— 初始化仓库
git checkout <branch> —— 将存储库中的分支检出到工作目录中
git add <file> —— 将文件中的更改添加到更改集中
git commit —— 将工作目录中的更改集提交到仓库中
在使用Git之前,只需要运行 git init 命令,它会将当前目录转换为 一个Git 工作目录,并在
.git 目录下(隐藏目录)创建一个仓库。然后,就可以开始使用 Git 了。checkout 和 commit
命令与其他源代码仓库类似,但在 Git 中还有一个 add 命令,因为 Git 对更改集也很关注,这一点与
SVN 类似,该命令将工作目录中的更改添加到暂存区域为下一次提交做准备。这个暂存区通常称为索引。图
3 说明了创建从版本 A 到版本 B 的变更集的过程。
git status 命令用来跟踪当前所在的分支上已添加以及未添加的更改。

图3. 在 Git 中创建变更集
git log 命令用于显示工作目录中更改(提交)的历史记录,使用 git log <path>
命令可查看特定路径下的更改。
git status 命令可用于列出工作区中修改的文件以及索引中的文件,同时也可以使用 git diff
命令查看文件之间的差异。使用 git diff(不带参数)仅显示工作目录中尚未添加到索引中的更改,使用
git diff --cached 可用来查看已经添加到索引中的更改(staged change)。git
diff <name> 命令用于显示当前工作目录和特定 commit 之间的差异,git
diff <name> --<path> 命令相比于上一条命令,增加了特定路径的限制。<name>
可以是 commit ID、分支名称或其他名称。借此,下面将谈论命名的相关知识。
命名(Naming)
注意:由于 commit ID 的长度过长,本文在图中将使用“(A)”、“(B)”等缩写。
让我们来看一下Git中的命名机制。版本是 Git 中的主要元素,它们以 commit ID 命名,该
ID 是一个哈希 ID,例“c69e0cc32f3c1c8f2730cade36a8f75dc8e3d480”,它来源于版本的内容,包括实际内容和一些元数据,如提交时间、作者信息等。commit
ID 没有像 CVS 中的版本ID有点号,也没有像SVN中的事务编号(transaction number)。
所以 Git 无法像在其他仓库中那样从版本名称中确定任何类型的顺序。为方便起见,Git 可以通过从
commit ID 开头取最少字符数将这些长哈希缩写为短名称,这样短名称在存储库中仍然是唯一的。例如,上面示例的短名称是“c69e0cc”。
通常一般不会使用 commit ID ,而是各种分支。在其他源代码仓库中,更改的命名流称为分支。而在
Git 中,更改流是更改集的有序列表,因为它们被一个接一个地被应用,并对应着从一个版本转到下一个版本。Git
中的分支只是一个指向特定版本的命名指针,它指出了使用此分支时对应新变更的位置。当要使用一个分支时,分支标签也会移动到新的提交。
工作空间中变更存放的位置就是 HEAD 指向的地方。HEAD 是上次检出代码到工作空间的地方,也是提交更改的地方。HEAD
通常指向上次检出的分支。注意,这不同于 CVS 将 HEAD 一词解释为默认分支开发的顶部。
tag 命令用来命名一次 commit,并且可以让你使用一个可读性强的名称去处理特定的某次提交,也就是说
tag 是 commit ID 的别名。此外也可以使用一些快捷方式来处理提交,HEAD 作为工作目录中的开发的顶部。HEAD^1
是 HEAD 的第一个父项, HEAD^2 是第二个,依此类推。
更多详细信息,可以参阅 gitrevisions 的主页。因为标签或分支等名称是对 commits
的引用,所以它们被称为 refnames。一个 reflog 显示了在名称的生命周期(从它被创建到当前状态)内发生了什么变化。
分支(Branching)
分支这个概念暗指每个版本可以有多个孩子。将第二个新的更改集应用到同一个版本会创建一个新的、单独的开发分支。如果它被命名,它被称为分支。
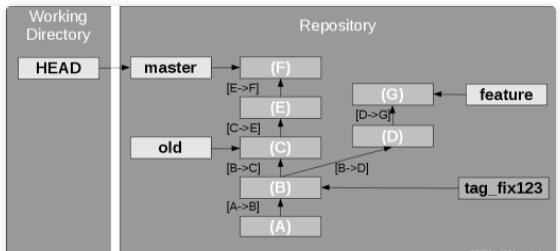
图4. Git 中的分支结构示例
如图4所示,当前正在开发某些功能的 master 分支指向版本 F。另一个 old 分支标记了一个旧版本,可能是一个潜在的修复开发点。feature
分支是针对特定功能的一些其他更改。变更集被标注为从一个版本到另一个版本,例如“[B->D]”。在这个例子中,版本
B 处有两个分支,一个对应 feature 分支,另一个对应 old 和 master 分支。commit
ID B 对应一个别名 tag_fix123。
以下是 Git 中一些其他重要的命令:
git branch <branchname> —— 从当前 HEAD(工作目录)创建一个新分支
git checkout -b <branchname> —— 从当前 HEAD 创建一个新分支,并将工作目录切换到新分支
git diff <branchname> --<path> —— 显示当前工作目录和分支
branchname 之间在路径 path 下的差异
git checkout <branchname> --<path> ——
将分支 branchname 中路径 path 下的文件检出到当前工作目录中
git merge <branchname> —— 将分支 branchname 合并到当前分支
git merge --abort —— 取消存在冲突的合并
git branch <branch name> 命令基于当前 HEAD创建分支,git
branch <branch name> <commit id> 命令基于指定的任何有效版本创建分支,这两个命令会在仓库中创建一个新的分支指针。需要注意的是,这两种创建方式并不会自动切换到新的分支上,需要手动切换到新的分支上,不然工作空间还是留在旧的分支上面。不过
git checkout -b <branch name> 命令可以一次性实现上述功能,即在创建新分支的同时,也将工作空间自动切换到新分支。
合并(Merging)
当开发一个新功能时,需要切换到一个仓库,例如切换到上文提到的 feature 分支上。当新功能开发完成后,需要将其合并回
master 分支,可以通过切换到 master 分支,然后使用 git merge <branch
name> 命令将新功能合并到 master 分支。为了实现上述的合并功能,Git 将 feature
分支中的所有变更集应用到 master 分支的顶部。
根据两个分支中更改的类型以及可能发生的冲突,在合并时会存在以下三种可能:
(1) Fast forward merge(快速向前合并)
从新建 feature 分支后,master 分支上没有产生任何的更改。master 分支一直指向
feature 分支创建前的最后一次 commit 的位置。在这种情况下,Git 将 master
分支的指针直接向前移动,如图 5 所示。由于除了向前移动指针之外没有进行其他的操作,故该情形称为 Fast
forward merge。
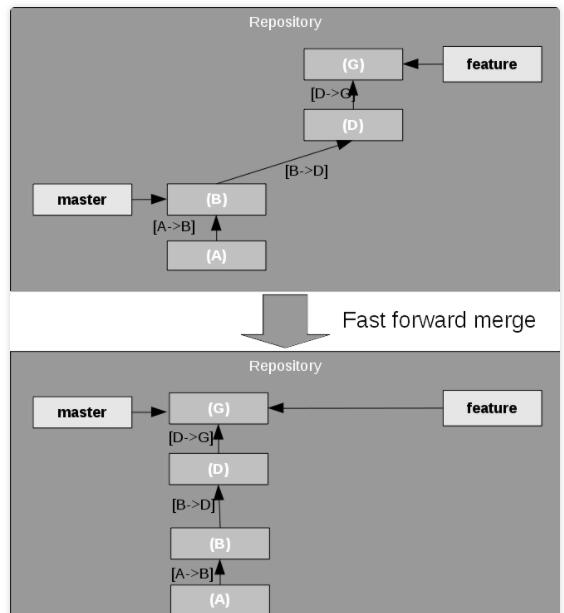
图5. Fast forward merge
(2) No-conflict merge(无冲突合并)
master 和 feature 两个分支都有产生变更,但两者之间的变更并不冲突。例如,两个分支中的变更修改的是不同的文件。Git
可以自动将来自 feature 分支的所有变更合并到到 master 分支,并创建包含这些变更的新
commit,然后 master 分支向前移动到该 commit 的位置,如图 6 所示。
注意,新合并的 commit 有两个父项,图6中没有标出相应的更改集。原则上,从 (E) 到 (H)
的变更集应该是从 (B) 到 (G) 路径上的所有变更集的集合,这条路径涉及到的变更集过多,故没有在图上明确画出来。
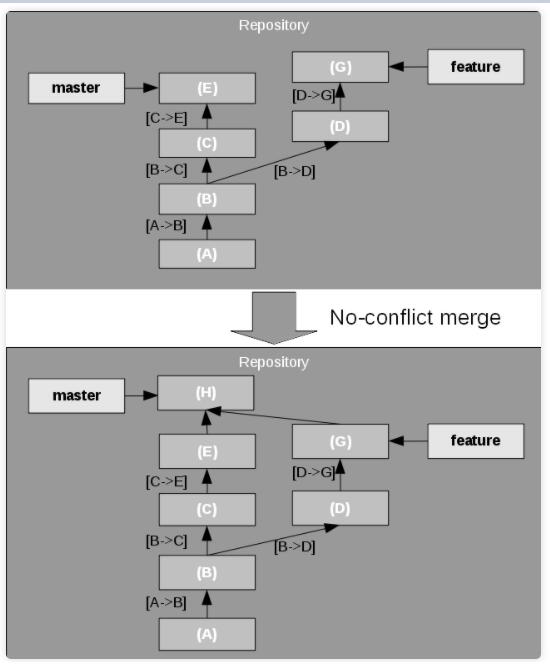
图6. No-conflict merge(无冲突合并)
(3) Conflicting merge(冲突合并)
master 和 feature 两个分支都有变更,且两者的变更存在冲突。在这种情况下,冲突的详情将保留在工作目录中,用户可以根据冲突详情进行修复和提交,或者使用
git merge –abort 取消合并。
值得一提的事,如果两个分支中都进行了某些相同的变更,这种情况通常会导致冲突,但由于 Git 足够智能,实际上合并时可以检测到两者的变更是相同的,此时相当于进行了一次
Fast forward merge。
回滚(rolling back)和重放变更集(replaying change sets)的概念中包含了
Git 中一些更高级的特性,例如变基(rebasing)和择优挑选(cherry picking)。
有时在 feature 分支上开发了一个新的功能时,master 分支上的开发也在同时进行,这时你还不想合并新功能到
master,随着时间的推移,两个分支之间的差异越来越大。为了避免两个分支差异过大给后续合并带来的一些不必要的麻烦,Git
提供了 rebase 和 cherry-picking 操作,可以将变更集从一个分支应用到另一个分支。
变基(Rebasing)
rebasing 相关的 Git 命令:
git rebase —— 将当前分支重新定位到给定其他分支的尖端。
git rebase -i —— 交互式变基。
假设你正在 feature 分支上开发一个新的功能,并且需要将 master 分支上最新的变更合并到
feature 分支,以跟上最新的开发进度。上述操作称为变基(rebasing)feature 分支,即重新复位
feature 分支的基底;具体而言,该操作将两个分支之间的起始分岔点在其中一个分支上向上移动,即将其中一个分支(feature
分支)上的变更集放在另一个分支(master 分支)的顶端,如图7的所示,并且为每个分支中原始 commit
创建新的 commit。
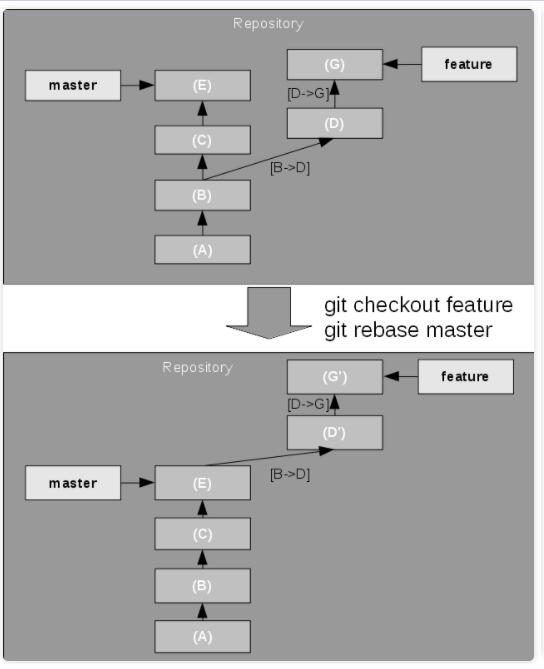
图7. Rebasing a branch(变基分支)
如果上述操作导致了冲突,rebase 会在第一个发生冲突的位置停止,并将冲突状态留在工作目录中供用户修复,然后用户可以继续或中止
rebase。
如果想要将分拆点在 master 分支上向上移动到指定的版本, 可以使用 --onto 选项指定版本ID。
择优挑选(Cherry picking)
Cherry picking 相关的 Git 命令:
git cherry-pick —— 中止导致冲突的 cherry-pick。
假设你现在正在 feature 分支上开发一个功能,并且已经做一些应该立即放到 master 分支中的更改。这些更改可能是一个错误的修复,或者是一个很酷的新功能,但你现在还不想将整个
feature 分支合并到 master 分支,或这对 feature 分支进行变基。此时,Git
允许你使用则有挑选(Cherry picking)功能将更改集从一个分支复制到另一个分支。
如图 8 所示,Git 只是将 feature 分枝上特定版本的更改集应用到 master 分支的
HEAD 上。git cherry-pick G 中的G通常是commit ID。
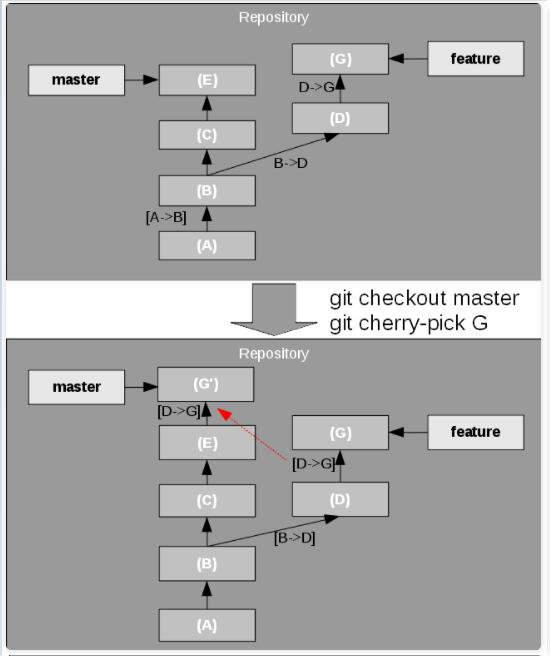
图8. 择优选择一个提交(Cherry picking a commit)
恢复(Revert)
Revert 相关的 Git 命令:
git cherry-pick —— 中止导致冲突的 cherry-pick。
revert 命令回滚工作目录上的一个或多个补丁集,然后在当前分支的顶端创建一个新的提交(commit)。revert
几乎可以认为是 cherry pick 的一个反向操作。如图 9中的例子所示。
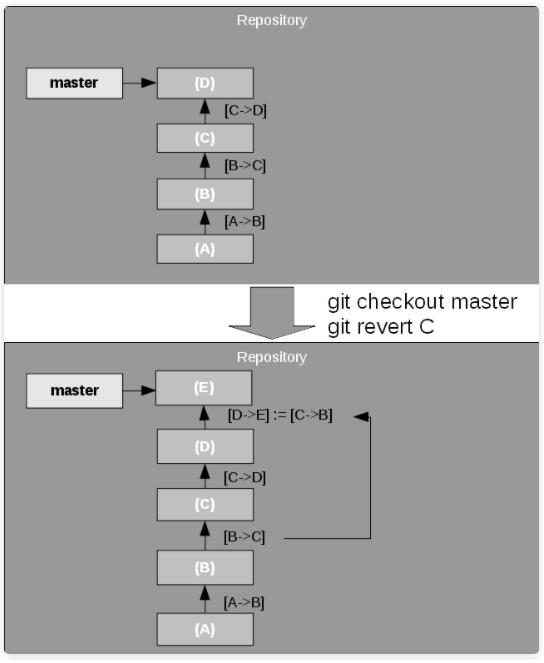
图9. 恢复一个提交(Reverting a commit)
revert 命令将恢复操作记录为一个新的提交。如果你不希望将其记录下来,你可以将指针重置为较早的提交,但这超出了本文的范围,感兴趣的小伙棒可以查阅相关资料。
第3节 Git 的工作原理的相关讨论暂告一段落,如此详细地讨论这一节的原因,是因为本节的知识对下一节多人协作(Collaboration)特性的讨论至关重要。事实上,这一节你一旦理解了,那么下一节将会变得很简单。大多数多人协作的功能都是基于上述讨论的基本功能。
04
多人写作(Collaboration)
Collaboration 涉及到的相关 Git 命令:
git clone —— 将远程仓库“克隆”到本地。
git remote add —— 添加一个名为给定连接 URL的远程仓库 。
git fetch —— 从远程仓库获取远程跟踪分支的变更到本地。
git pull —— 获取远程仓库的变更,并合并到本地仓库。
git push —— 将本地分支的更改通过远程跟踪分支推送到远程仓库。
在传统的源代码仓库中,总是有一个明确的概念,即分支是什么?它存在于中央仓库中。
但是在 Git 中,没有 master 分支这样的东西。等等,我不是在上文写了仓库中通常有一个主分支吗?是的,上文是这样说的。然而实际情况是,这个
master 分支只存在于你的本地。一个仓库中的 master 分支与另一个仓库中的 master
分支之间没有关系,除非你明确创建。
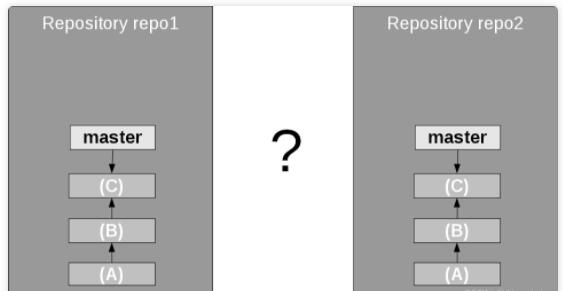
图10. 两个仓库
如果你已经有了一个仓库,可以使用 git remote add 命令添加远程仓库。然后,可以使用
fetch 命令在自己的存储库中获取远程分支的镜像。这称为远程跟踪分支(remote tracking
branch),因为它跟踪的是远程系统上的开发。
当你切换到一个远程跟踪分支(而不是本地分支)时,Git 会自动从远程跟踪分支创建相对应的本地分支,并将其检出。
一旦你有了本地分支,你就可以将远程分支的内容合并到你自己的分支中。图 11 显示了检出到本地 master
分支的情况,除此之外,你也可以像使用正常的合并命令那样,将其合并到具有共同历史记录的任何其他分支中。
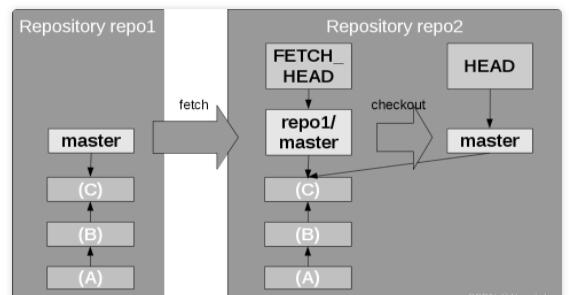
图11. 获取并检出远程分支(Fetching and checking out a remote
branch)
另一种方法是使用 git clone 命令获取远程仓库,例如从主机服务(hosting service)获取。这会自动获取所有远程分支(但本地还没有引用)并自动切换到主分支。
正如你所见,此时出现了一种模式。因为远程仓库中的分支“只是一个分支”,所以上面讨论的所有关于分支、合并等的事情几乎都可以无缝地应用在当前这个场景,尤其当从远程仓库获取变更时。
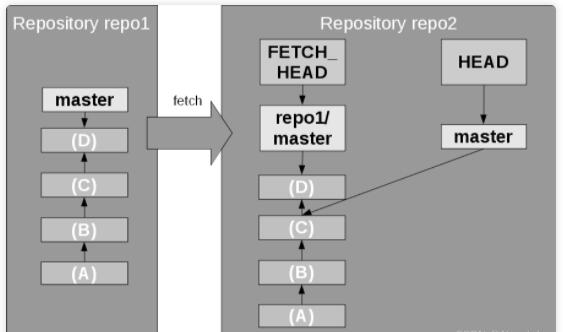
图12. 获取远程变更(Fetching remote changes)
在图12中,展示了使用 git fetch 命令的例子。它将远程跟踪分支的内容更新到本地分支。然后你只需在远程跟踪分支和本地分支之间进行正常的合并操作,例如在图12的例子中使用命令
git checkout master 和命令 git merge repo1/master。fetch操作之后,你可以在
merge 操作中使用 FETCH_HEAD 这个名字代替 repo1/master 合并 fetch
到的远程跟踪分支的内容,即 git merge FETCH_HEAD 命令。同样的,与3.4节中讨论的类似,此合并可能会导致快进向前合并、无冲突合并或需要手动解决的冲突合并。
获取远程变更更方便的一个命令是 git pull 命令,该命令是 fetch 与 merge 两个命令的组合。
当变更已经 commit 到本地分支时,必须将这些变更传输到远程分支,可以通过 git push
命令将本地变更推送到远程分支。它的反向操作是 fetch ,而不是 pull 。但是,push 操作不仅仅是
fetch 的反向操作,因为它不仅更新远程分支的本地副本,而且还更新了其他仓库中的远程分支,如图 13
所示。push 操作还允许你在远程仓库中创建新的分支。
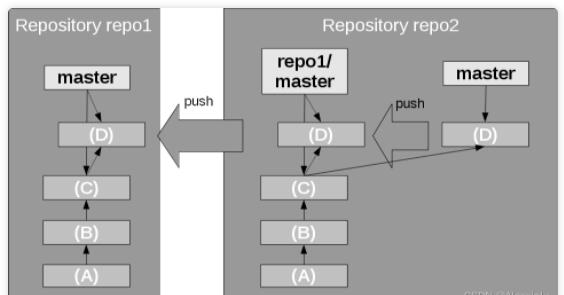
图13. 向远程仓库更新变更(Pushing a change)
push 操作有一个保护措施,即只有当 push 操作在远程仓库的分支中触发的合并方式是 fast-forward
merge,该操作才会成功,否则会中止。如果不是 fast-forward merge,那么说明远程分支上已经有来自其他仓库或提交者提交的一些更改。Git
中止 push 操作并保持原样。然后您必须先 fetch 远程仓库上的更改,将它们合并到你的本地分支中,最后再次重新尝试
push。
请注意,在这种情况下,您可以进行正常的合并,但也可以选择进行变基合并,将本地分支中的变更变基到本地
fetch 远程内容后的本地分支的顶端。
除了 fetch 和 push 命令之外,还有另一种分发补丁的方式,即通过邮件。首先,使用 git
format-patch <start-name> 命令,从给定 commit ID 到当前分支状态的每一个
commit 创建一个补丁文件。然后,使用 git am <mail files> 将这些补丁文件应用到当前分支。
注意事项
如果你尝试直接 push 变更到有其他人也在跟踪的仓库上时,这可能会对分支管理造成混乱,因此 Git
会警告并告诉你,应该首先使用 pull 操作将远程分支的状态同步到本地.
此外,你不应该对远程跟踪分支进行变基操作,这样会导致本地分支与远程分支不再匹配,所以当你进行 push
操作的时候无法触发 fast-forward merge,因为仓库的结构已经被破坏了。
05
高级 Git(Advanced Git) 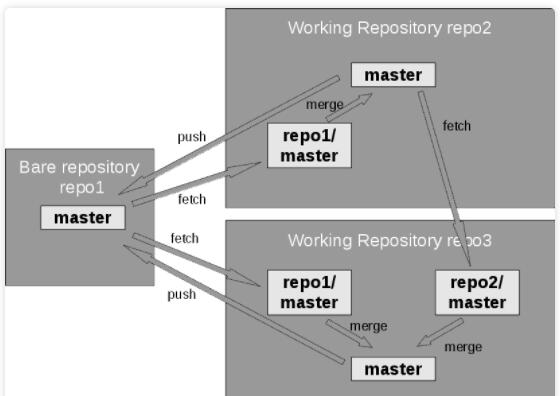
图14. 多存储库结构示例
通常情况下,即使是使用 Git,也会存在一个星型结构,再这个结构中存在一个中央仓库作为主仓库,以及每个用户有自己的本地仓库。但事实并非如此。你可以像在
Web 中一样添加远程仓库的连接,例如使用交叉连接,如图 14 所示。
上文已经将变基描述为在原始分支的不同分支点之上重放(replay)更改集。Git 通常按照提交的顺序进行重放。作为一项高级功能
git rebase -i 可以实际选择应按什么顺序进行哪些提交,甚至可以删除提交或可以合并两个提交(“压缩”)。只要确保你不要对已经推送的提交执行此操作,否则,那些基于这些提交的相关工作可能会发生很多冲突。
我还写了如何检出特定分支,实际上你也可以检出任何的 commit。这会让 HEAD 指针指向提交,而不是分支。这被称为分离
HEAD模式(detached HEAD mode)。当你在这种情况下提交更改时,您就开始了新的开发流。基本上你分支出来,但没有给这个新分支一个分支名称,只有使用提交
ID 才能访问开发的顶端,任何引用名都无法访问它。你可以使用 git branch <branchname>
命令从此 HEAD 创建一个分支。
任何引用都无法访问的 commits 会发生什么?如果你不做任何特殊的操作,它们将直接保存在仓库中。但是,你和主机服务都可以运行
git gc ,该 Git 垃圾收集器可以用来删除没用的文件。任何引用名都无法访问的提交被认为是无用的,因此会被删除掉。因此,始终在真正的分支上工作是一个好习惯,尤其是当在
Git 中能够快速和容易地创建新分支时。
06
总结
一方面,Git 基于简单的原则,但它提供的灵活性有时会让人难以抗拒。第一个要点,Git 是用来管理版本,以及版本之间的更改集。命令在不同分支之间应用和回滚这些更改集。第二个要点,Git
是处理远程分支与处理本地分支基本相同,因为甚至还有远程分支的本地镜像。
本文提到的命令基本上涵盖了我使用 Git 所做的所有事情。所有命令的更多详细信息可以在相应的手册页中找到,并且借助此处提供的知识,希望你能够更好地理解和使用它们。此外,git
status 通常会为下一步做什么提供有价值的提示。
另一个能帮助你理解 Git 的好工具是图形化的 gitk 工具,它显示了本地仓库的结构。用于gitk
--all 显示所有分支和标签等。它还提供了一个简单的界面来执行 Git 相关的操作。
Linux 系统上通常已经安装了 Git。您可能还需要从你的包管理器中安装一些开发工具。对于 Windows
系统用户,可以在 Git 主页上进行下载。
我希望现你对 Git 的工作原理已经有了更好的理解,并且不害怕使用它的灵活性。
感谢关于这个主题的一些有趣的讨论,感谢我的同事 Witold Szczeponik,他比我更了解
Git。
|






 订阅
订阅