| 编辑推荐: |
本文主要介绍了Git最佳实践相关内容。希望对你的学习有帮助。
本文来自于微信公众号腾讯云开发者,由火龙果软件Linda编辑、推荐。 |
|
很多 Git 的操作,都有多种方法达到目的,但其中往往只有一种方法是最佳路径。
Git 是个超级强大也非常流行的版本控制系统(VCS)。它的设计理念和其他VCS非常不同。纵观整个业界,很多人在用旧的思维方式来解决
Git 的使用问题,有 svn 方式的、p4 方式的、奇怪方式的、错误方式的,等等,而不是更新成 Git
的思维方式。虽然 Git 非常灵活,确实可以用这些方式来使用,但其实操作起来反而更难,而且效率更低,吃力不讨好。这里我打算把二十多年的各种版本控制系统的使用经验和十多年
Git 的使用经验,总结出一些 Git 的最佳实践。其实很多时候,正确的做法比错误的更简单,更不容易出错。
01 什么是 Git
不开玩笑。最常见的 git 错误使用,正是来自于没意识到 Git 是什么。大部分 Git 的属性,可以从定义用逻辑推导出来。逻辑是最重要的,只要逻辑错了,就一定是错了。哪怕所有人都这么做,也是错的。

Git 是一个分布式版本控制系统,跟踪目录里的修改。它的工作流是非线性的(不同电脑上的平行分支形成了一个
graph)。和主从式的系统不一样的是,每台电脑上的每个 Git 目录都是一个完整的 repo,包含全部历史和完整的版本跟踪能力。(LFS
是个例外,后面会提到。)
因为 Git 的本质是一个基于目录的分布式 VCS,这里面并没有中心服务器的角色。去中心化是未来。同个项目的所有
repo 都是平等的端点。一个 repo 可以在服务器、本地目录、其他人的电脑上。只是为了团队协作的目的,会认为指定一个或多个端点作为“服务器”。是的,可以同时有多个上游服务器。很多时候这么做很有必要。比如对内开发的
repo 和对外开源的 repo,就是两个不同的端点。可以有不同的分支和推送频率。本地只要一个 repo
就都管理了。
非线性的工作流表示提交和分支操控是一个常规的操作。建立分支、rebase、修订
commit、强制推送、cherry-pick、分支复位,在 Git 都是很正常的使用方式。
02 什么不是 Git
很多东西经常和 Git 一起出现,但是并不是 Git 的一部分。
2.1 GitHub/GitLab
这些都不是 git,而是提供 git 服务和社区的网站。Git 是个基于目录的 VCS,并不需要网站服务或者网络访问才能工作。早期经常有人没法区分
GitHub 和 git。当要说 git 的时候,会说 GitHub,制造的混乱不是一星半点。
2.2 Fork
Fork 仍然也是 Git 服务网站的功能,用来简化协作流程。在没有 fork 的时候,如果你想往开源项目里修
bug 或者加 feature,会需要这样的流程:
克隆 repo;
修改代码;
生成补丁;
发到论坛或者支持的邮件列表;
找作者来 review,合并补丁。
很多项目到现在还是这么做的。如果有了 fork,可以简化成:
Fork 并克隆 repo;
修改代码;
发出 merge request 或者 pull request。
虽然 fork 很有用,但这仍然不是 git 的一部分。它用到的是 git 的分布式能力。本质上,在
fork 的时候,它会克隆一份 repo,把原来的 repo 设置成上游。所以其实如果你的目标不是为了继续把
repo 放在网络服务上,那就克隆到本地就是了。太多的人把 fork 当作 like 来用,根本就是错的。如果没打算改代码,fork
是没意义的。机器学习界这个问题尤其严重。经常放一个 README 就假开源了,还有几百个 fork,都不知道能
fork 到什么。
2.3 Merge request/Pull request
GitHub 上叫 Pull Request,GitLab 上叫 merge request,其实是一个东西的不同视角。这些都是
code review 和合并的流程,不是 git 的一部分。
需要注意的是,它们的重点在“request”,而不是 merge 或者 pull。如果你要把一个分支
merge 到你自己的,没必要开一个 MR 然后自己给自己通过。在本地 merge 就是了,更简单更快。
2.4 Import
很多 git 服务支持“Import”,用来从别的 git、svn、cvs、p4 等 VCS 导入一个库。如果原本的
repo 已经是 git,那直接 push 到新的地方就是了,比 import 更简单。而且这样绝对不会丢失历史记录或者搞错文件。如果是其他
VCS 的 repo,那也可以用插件或脚本来先转成一个本地的 git repo,然后再 push 到新的地方。
03 选对工具
Git 本身是个命令行工具。但是,非线性工作流的本质就让它没可能在字符界面显示出分支的 graph。选个好的
GUI 非常关键。不但可以大幅度增加工作效率,更重要的是,减少出错的机会。第二个常见的 git 使用错误来源,正是因为用错了工具造成了。
Windows 上最好的 git GUI 是 TortoiseGit,没有之一。它只是个 GUI,git
命令行需要事先安装。和其他 Tortoise 打头的工具(TortoiseCVS、TortoiseSVN)一样,它的风格是没有主
UI,而集成到 Windows 的文件管理器里面。Repo 里的文件(也就是目录里的)图标上会覆盖上状态。右键点击这个目录,菜单里可以看到
TortoiseGit 的子菜单,包含 git 的一些操作。大部分 VCS 的 GUI 工具,比如
P4V、SourceTree,UGit,都有个主 UI 显示映射了的工作空间,而不是目录本身。对于
git 来说,这其实是个错误,因为 git 是基于目录的,不存在工作空间这个概念。而且,这种情况下非常常见的错误就是忘记提交新增的文件。在
TortoiseGit 里,除了盖在图标上的状态之外,提交窗口也可以显示出哪些文件还没添加,不会出现遗漏的情况。
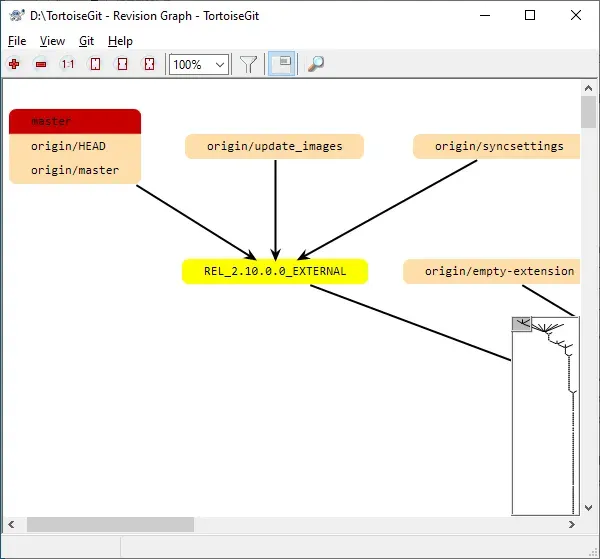
另外,TortoiseGit 有一个独特的版本 graph 查看器,里面可以显示出 repo 的整个分支结构。通过这个查看器,可以很方便地看出来
repo 是怎么成长的,有那些不必要的分支,如何从一个分支跳到另一个,等等。这是 TortoiseGit
比其他 git UI 好的一个重要原因。不管是 Visual Studio 里的、SourceTree、还是
UGit,在 UI 设计上都像用传统的 VCS 思路来套用到 git 上,而不是 git 的思路。主它们的共同问题就是,基本只关注于当前分支。而有能力同时看所有分支,对
git 来说非常重要,因为 git 的工作流是非线性的。
其他高级功能,比如打补丁、处理 submodule(非常重要),都可以在 TortoiseGit
的 GUI 里完成。但它没法覆盖所有的功能。有些很少用的,还是得通过命令行。
04 尽量在本地
所有的 git 操作都可以在本地 repo 上完成,因为服务端的并没有更高优先级。虽然大部分提供
git 服务的网站都在网页界面里有 cherry-pick、新建分支、合并这些操作,但是在本地执行更容易,而且比在服务端执行了再拉下来要更快。
05 分支策略
Git 的工作流是基于分支的。不但每个 repo 是平等的,每个分支也是。Master/main、develop
这些只是为了简化管理而人工指定的有特殊含义的分支。这里的分支策略是为了更好地协作而产生的习惯规范,不是
git 的工作流本身必须定义的。分支可以分为几个层次。
5.1 Main 分支
这是整个项目的稳定分支,里面的内容可能相对较老,但是这个分支里的内容都是经过测试和验证的。原先都叫
master,因为政治正确的要求,最近越来越多新项目开始用 main。有些快速开发的项目甚至不采用
main 分支。
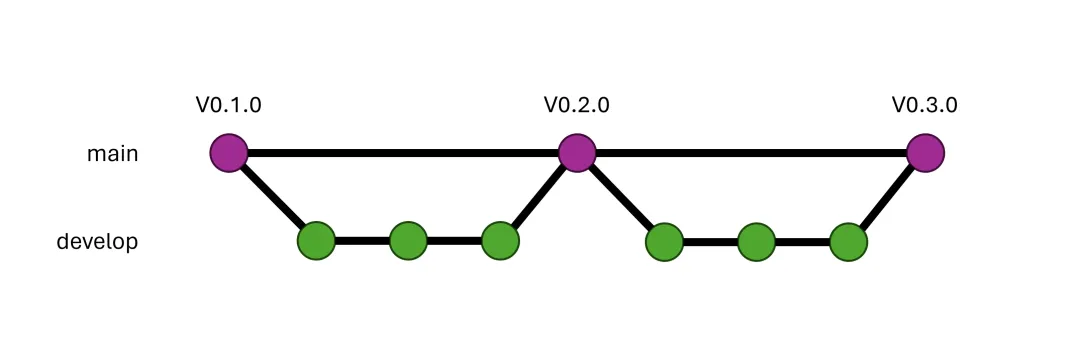
5.2 Develop 分支
开发主要发生在 develop 分支。新特性先放到这个分支,再去优化和增强稳定性。
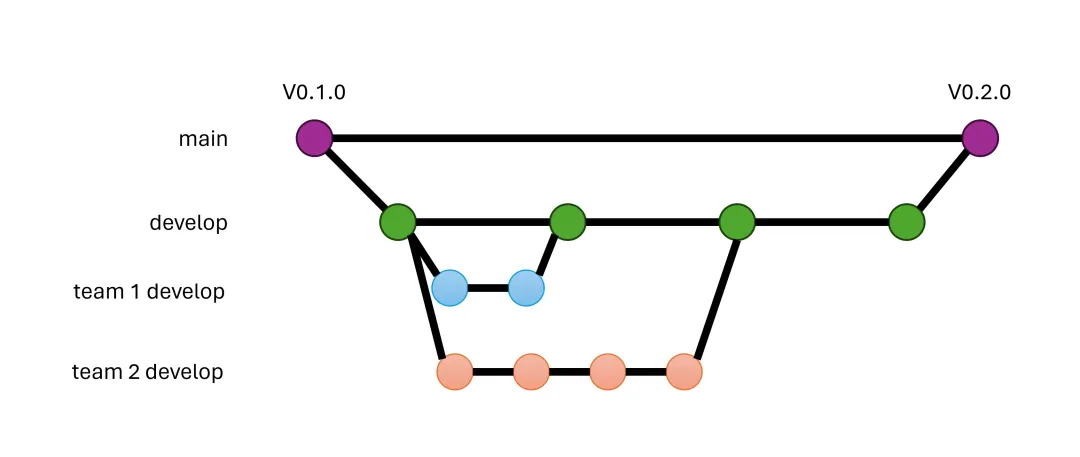
5.3 大项目可选的团队 Develop 分支
对于跨团队的大项目,每个团队都有自己的兴趣点和发布周期。很常见的做法是,每个团队有自己的 develop
分支。每过一段时间合并到总的 develop 分支。 一般来说,中等大小的团队,专注于 repo 的某一部分,可以采取这样的分支形式。小团队或者个人没有必要有自己的
develop 分支。那样反而会浪费时间和增加合并过程中的风险。
5.4 Feature 分支
Feature 分支是生命期很短的分支,专注于单个特性的开发。和其他 VCS 不一样的是,在 git
里开分支开销非常低,所以可以高频地开分支和合并分支。在做一个特性的时候,常规的流程是这样的:
从 develop 分支上新建一个 feature 分支;
提交一些关于这个 feature 的代码;
合并回去;
删除这个 feature 分支。
对于本地 repo 里的 feature 分支,你可以做任何事。常见的用法是在开发过程中非常频繁地提交,走一小步就提交一次。在发出
MR 之前,先合并成一个 commit,把这个分支变整洁,方便后续操作。
当 feature 分支合并之后,绝对不存在任何理由让这个分支仍然存在于服务器上。WOA 现在有自动删除的选项,可以设置成默认开启。但有时候仍然会出些问题,这个选项会消失,需要手工删除分支(其实就是在
MR 页面上点一下的事)。记住:服务器上只是一个端点,删掉那边的一个分支不会影响你的本地 repo。如果你有后续工作需要在那个分支上做,就继续在你本地的分支上完成就是了。这和服务端有没有这个分支一点关系都没有。
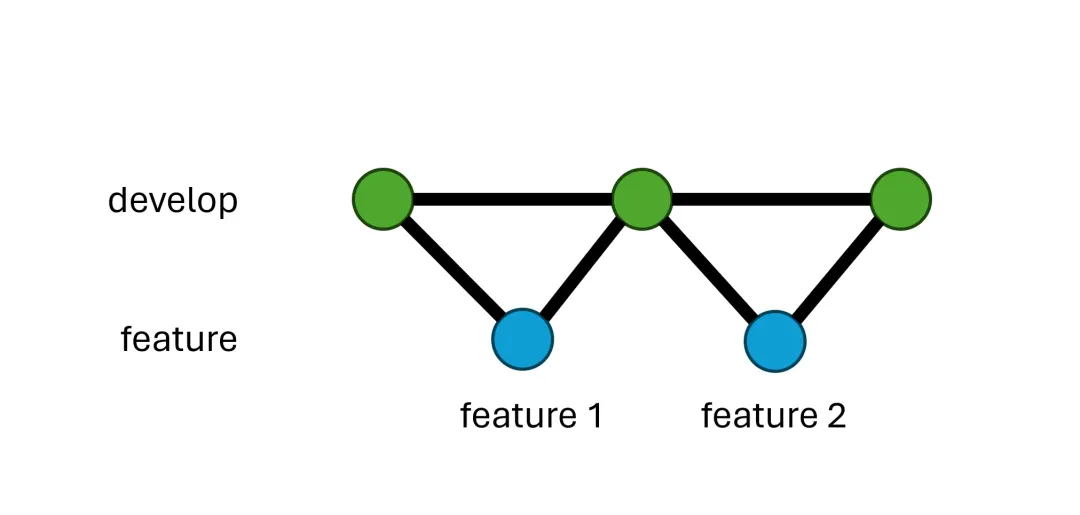
因为每个分支都是平等的,可以推出在任何一个分支上都可以新建分支。比如,如果特性 B 依赖于特性 A,你不用等特性
A 合并了才开始做特性 B。只要在特性 A 的分支上建立一个特性 B 的分支就可以了,即便特性 A
不是你的分支也可以。等到特性 A 合并了,把特性 B 的分支 rebase 一下就是了。少了等待环节,效率提高很多,也不必催人做
code review。
能建立大量 feature 分支,对于提高工作效率非常关键。每个特性建立一个 feature 分支,在上面完成特性,发出
MR。在 code review 通过之前,已经可以新建另一个特性专用的 feature 分支,切换过去,开始做另一个特性。在
code review 过程中还能来回切换,同时做多个特性。其他 VCS 是做不到这一点的,效率也自然低很多。
5.5 Release 分支群
Release 不只是一个分支,而是一群以“release/”打头的分支。就好像一个目录,包含了不同版本给不同产品线的
release 分支。一般来说他们从 main 或者 develop 分支出来。当发现一个 bug
的时候,在 main 或者 develop 分支修好,然后 cherry-pick 到 release
分支里。这种单向的处理可以方便管理,并且不用担心某个 commit 是不是只有 release 分支有。Release
分支经常在每个 sprint 的开头创建,包含这个 sprint 要发布的东西;或者在每个 sprint
的结尾创建,包含下一个 sprint 要发布的东西。
06 Merge 还是 rebase
虽然在提及把 commit 从 feature 分支放到 develop 分支的时候,我们一直说“合并”,但其实这里存在两个维度。是的,不是有两个操作,是有两个维度。
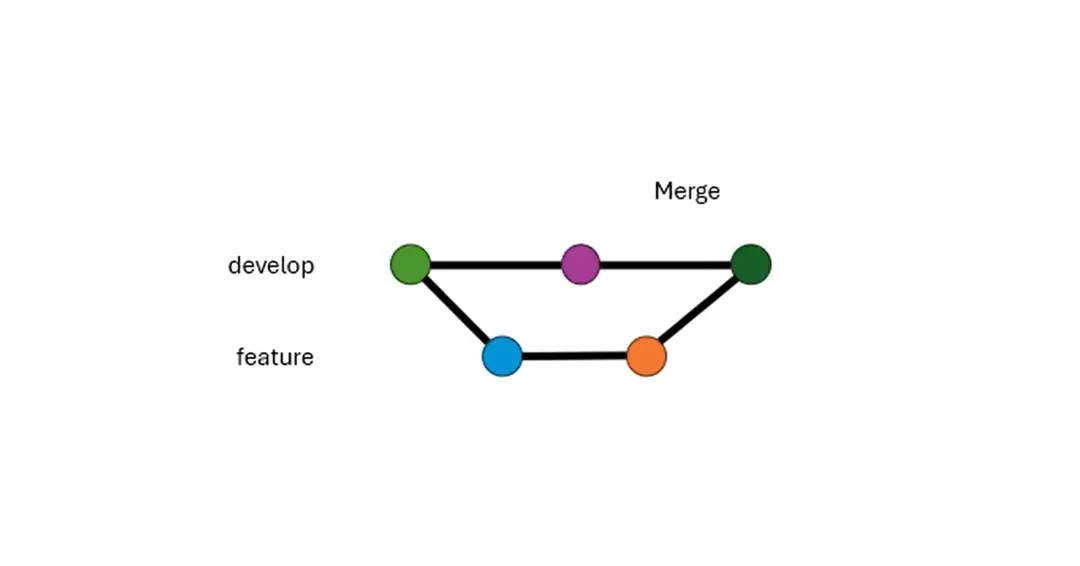
第一个维度,是 merge 还是 rebase。这是两种“合并”的方式。第一种是普通的合并,和传统的
VCS 一样。它会把一个分支合并到目标分支,在顶上建立一个 commit 用来合并,两个分支里已有的
commit 不会有变化。
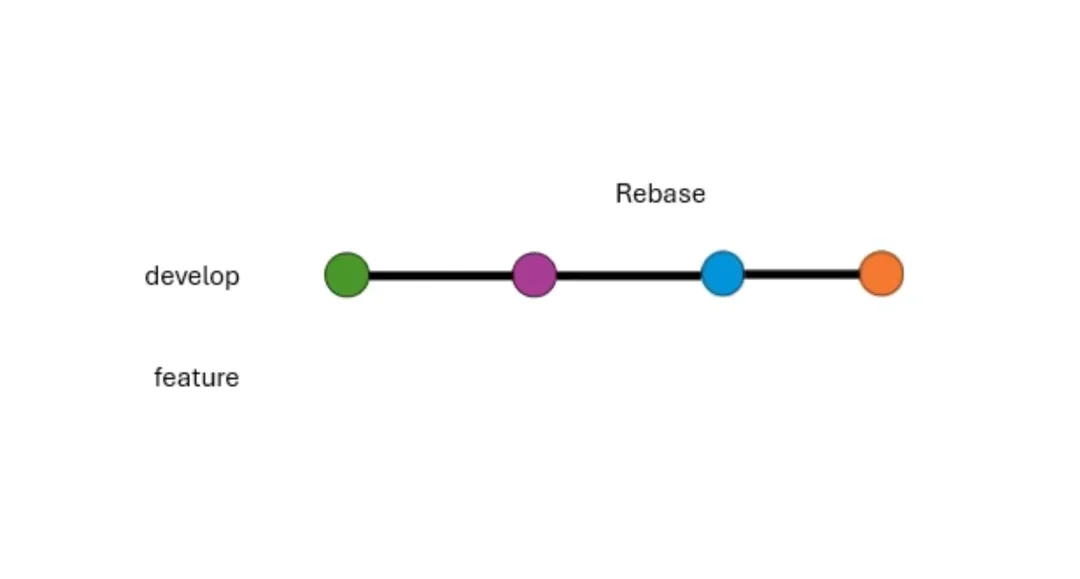
另一个就是 rebase。它会从分支分出来的地方切开,嫁接到目标分支的顶端上。(我一直认为 rebase
应该翻译成嫁接,而不是“变基”。)
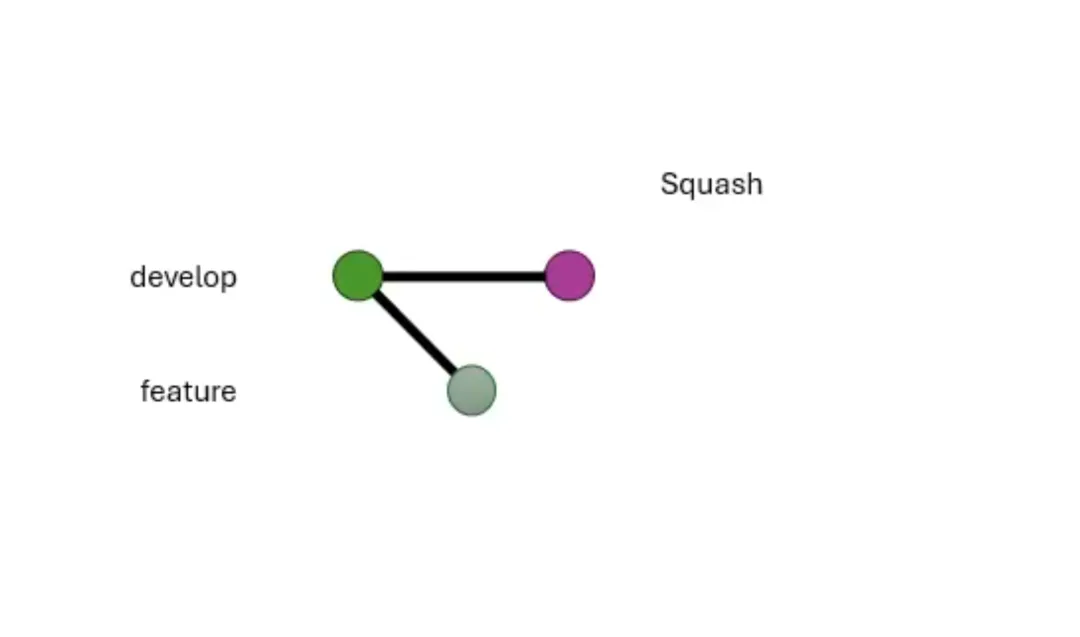
第二个维度是是否 squash,也就是选择一个分支里的一些 commit,压扁成一个 commit。这个任何时间都能做,即便不是为了合并也行。在
TortoiseGit 里,这叫“combine into one commit”。
两个维度组合之后,我们就得到了4个操作。但是“squash 再 merge”没有任何意义,所以就剩下“不
squash 就 merge”, “不 squash 就 rebase”,以及“squash 再 rebase”。(微软的
DevOps 文档曾经有个严重的错误。里面描述成 merge 表示不 squash 就 merge、rebase
表示 squash 在 rebase,而没有把它们当作两个维度来看。是我在2018年左右提出了这个问题,并且要求他们修改,还提供了多个图片解释它们到底有什么区别。过了大概半年之后才改成对的。但很多人就是从那里学的
git,都被带坏了。)
其实还可以有第三个维度,修订与否。但这个更多的是发生在 merge 之前的过程。修订,amend,表示当提交的时候,是不是要覆盖掉上一个
commit。打开的话,提交之后还会只有一个 commit,而不是两个。
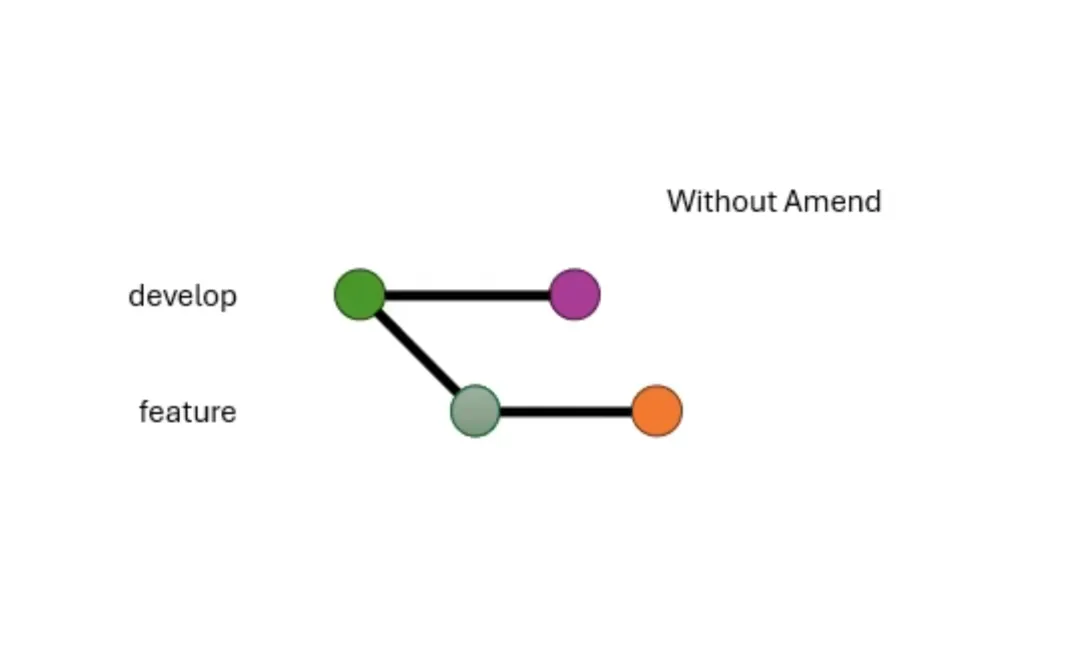
关闭 amend
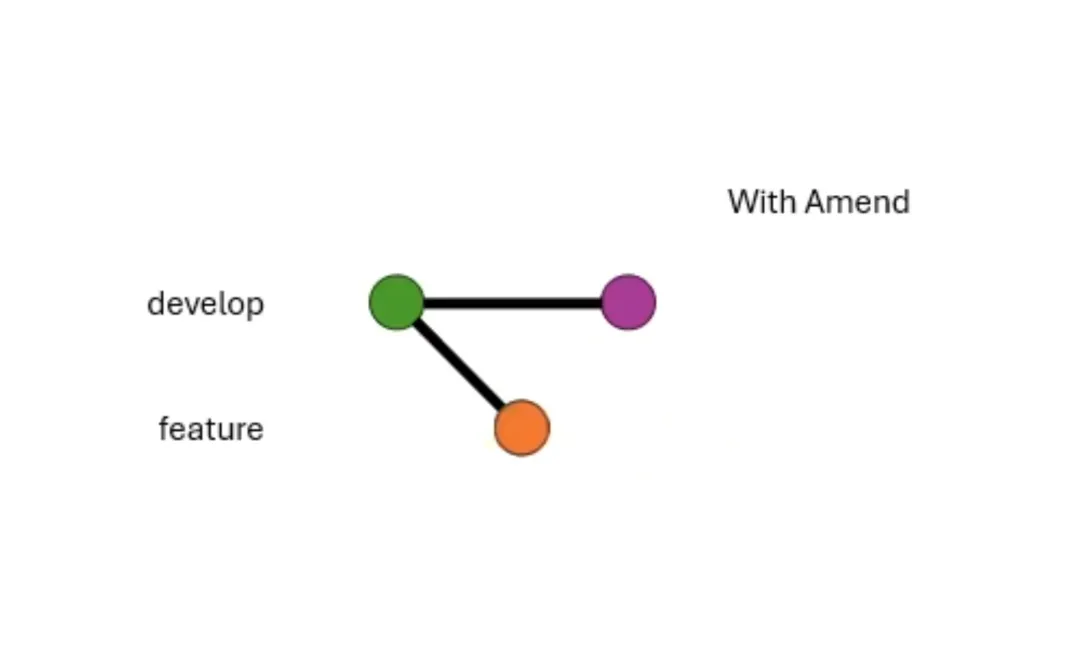
打开 amend
现在的问题就是,什么时候用什么。要是要处理的是长生命周期的分支,比如团队的 develop 分支、develop
分支、main 分支,合乎逻辑的选择是 merge。因为它们的结构需要保留,而且合并后分支也不打算消失。
对于 feature 分支,不同团队可以有不同选择。这里我只说最高效,开销最低的。一个 feature
分支里可以有多个 commits,但它们只有合在一起的时候才会成为一个 feature。中间的 commit
以后就再也用不到了。留着只会浪费空间和时间。所以逻辑上,这些 commit 就需要被 squash。这时候如果
merge 一个只包含一个 commit 的分支,就会出现这样的 graph:

这里有个什么都不做的 commit,只是把两个分支抓在一起,以及一个永远挂在外面的 commit。即便
git 里开分支和合并的开销很低,但这会一直积累的。这里用 merge,就完全是在浪费时间和空间。对于
feature 到 develop 的合并来说,rebase 是最佳选择。
现在,如果早晚需要把多个 commit 合成一个,那就该用 amend。是的,大部分时候,一路 amend
过去,比最后才来 squash 更好。首先,rebase 一个 commit,会比 rebase 一串来得容易得多,特别是有代码冲突的时候。其次,如果
MR 的最后才 squash & merge,那 commit 的消息就是没有经过 review
的,增加了犯错的风险。(是的,非常经常发生)
所有这些操作都可以在本地完成。这比在 Web UI 上操作远程的 repo 要容易而且高效。总结起来,这里的最佳实践是:
在开发过程中可以用 commit 或者 amend commit;
在发出 MR 的时候 squash 成一个 commit;
在 MR 的迭代内持续用 amend commit;
在 MR 通过后用 rebase 进行合并。
(其实,p4 里面的每一次 submit,都是 amend + rebase。之前只是因为没有人告诉你这个事实。而且
p4 里只有一种 submit 的方式,没有思考和选择的空间,做就是了。但这绝不代表不需要思考“有没有更好的做法”这个问题,这非常重要。)
更复杂的情况是在跨公司的 repo 上工作,比如 UE。这时候规则需要做一些改变。一般来说,这种情况下你的
feature 分支是从 release 分支上建出来的,而不是 develop 分支。而且这种 feature
分支其实是作为 develop 分支来用,有长的生命周期。这时候,如果你要把一个特性从比如 UE 5.1移植到5.2,rebase
就不是最佳选择了。因为那样的话会把5.1 release 分支里的所有 commit 和你的所有 feature
commit 一起 rebase。而你真正想要的是只把你的 commit 给 cherry-pick
过去。这其实还是因为工具。如果用的是 TortoiseGit,就不会有这个疑惑。因为里面 rebase
默认是交互式的。你可以精确选择哪些 commit 需要操作。这就让 rebase 和 cherry-pick
变成一样的东西。唯一的区别,是 rebase 是让 git 选一个 commit 的列表,让你从中选哪个要哪个不要。而
cherry-pick 是让你直接选 commit 的列表。
07 处理合并冲突
当出现合并冲突的时候,最好的方式是先把你的 feature 分支 rebase 到目标分支的顶端,这时候解决冲突,然后
force push。如果用 WOA 的冲突解决(可能有些别的基于 web 的 git 服务也有),它会每次都做
merge。结果经常把简单的单个 commit rebase,变成了复杂的三分支合并。
7.1 常见错误:解决合并冲突后建了个新的 MR
因为冲突解决的错误行为,有可能在解决之后,修改被提交到了一个新的分支。这时候应该把你的分支 reset
到新的去,force push,再删掉新的;而不是关掉原先的 MR,在新分支上开个新 MR。
7.2 常见错误:把分支搞乱
如果真的遇到了多分支复杂交错的情况,有两个方法可以尝试清理出来。
强制 rebase。Fetch 一下整个 repo;把你的分支 rebase 到目标分支上的时候勾选
force;这时候在列表里选要拿去 rebase 的 commit。大部分时候这都能行。但有时候 git
因为分支太错综复杂而搞不清楚 commit,在列表里会有遗漏。
Cherry-pick。在目标分支上新建一个临时分支;把有用的 commit 都 cherry-pick
过去;把你的分支 reset 到那个临时分支上;最后删掉那个临时分支。
两个方法最后都需要 force push。
08 不要 pull,要 fetch
很多教程都说 push 和 pull 是在本地和远程 repo 之间同步的指令。但是其实 push
是基础指令,pull 不是。它是 fetch 当前分支->和本地分支合并->reset
到合并后的顶端。这里就产生了不必要的合并。你可以打开 rebase pull,这就简化成 fetch
当前分支->rebase 本地分支。
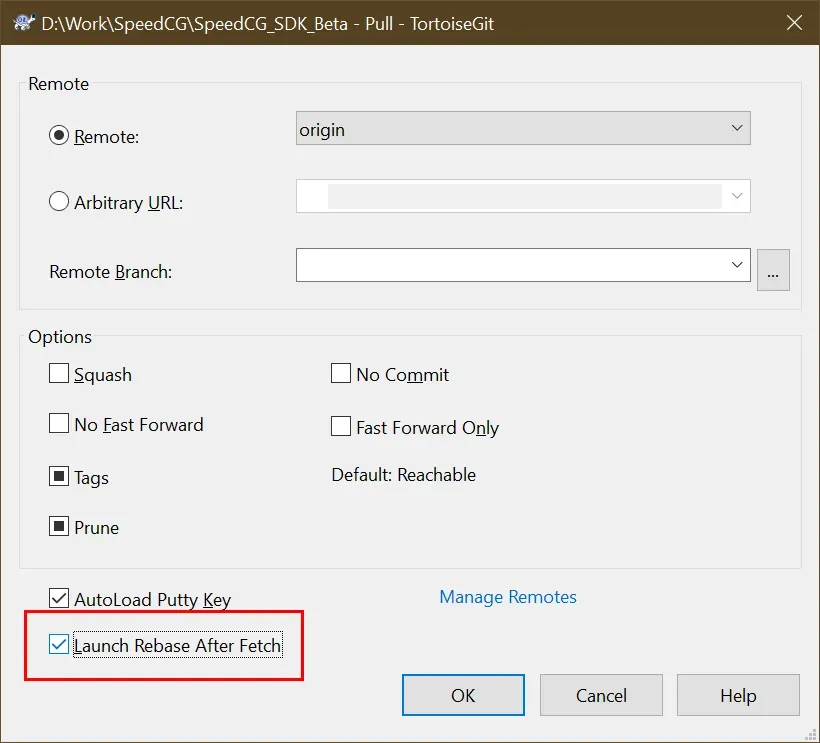
好一些,但是每次 pull 的时候都会开启 rebase 的窗口,即便没什么好 rebase 的。其实如果改用手动运行
fetch 和 rebase,同样的工作量可以获得更多。因为默认的 fetch 可以拿到所有分支,而不是只有当前分支。然后你可以决定哪个分支
rebase 到哪里。整个过程中都可以保证没有错误的 merge 发生。
09 小而完整的 commit
每个 commit 都该小而完整,有些人把这个叫做“原子性”。不要把多个特性压到一个 commit
里,同时不要有一堆必须合起来才能用的 commit。
9.1 常见错误:一个 commit 里做多件事情
这是一个非常常见的错误。一个大的 commit 包含多个任务的代码。这样的 commit 必须要拆成多个才行。在
git 里,这样的拆分比较容易。如果一个分支“Feature”包含了特性 A 和特性 B 的代码,那么,
在“Feature”的顶端建立“Feature A”和“Feature B”两个分支;
切换到“Feature A”分支,删掉其中特性 B 的代码,开 amend 提交;
把“Feature B”分支 rebase 到新的“Feature A”分支。
这就行了。现在两个分支都分别只包含一个特性。如果特性 B 不依赖于特性 A,它还可以继续 rebase
到 develop 分支去。
9.2 常见错误:多个不完整的 commit
另一个非常常见的错误是不完整的 commit,比如不能编译、不能运行、只包含琐碎的修改、或者仅仅为了未来的使用而做的修改。这样的
commit 只是中间结果,没法单独存在,需要和其他 commit 合起来才变成一个完整的 commit。那它们就需要合并之后才发
MR。
9.3 拆分大的 commit
是的,有时候是需要把一个大的 commit 拆分成多个,让 MR 更容易看。但是这里的拆分并不能让
commit 变得不完整。如果一个大 commit 中的一部分,本身就能对现在的代码库有帮助,拿着就能提出来变成一个独立的
commit。常见的是独立的 bug 修复、代码整理、或者重构。
10 LFS 技巧
LFS 是 git 里蛮特殊的一部分。为了让 git 更好地支持大(二进制)文件,LFS 其实让
git 的设计做了一些妥协。LFS 比 git 晚了9年发布,而且花了好多年才让主流 git 服务都提供支持。
10.1 LFS 是怎么回事
保存完整历史的大文件,特别是大的二进制文件超级占空间和处理时间。在 LFS 里,默认子保存一个版本的大文件,历史则放在另一个端点,一般是服务器。本地其实也可以这样拉取完整的历史:
当从一个 git 转移到另一个的时候,会要求做这件事情。其他时候一个版本就够了。
另外,LFS 有加锁解锁的功能。但是和主从式的 VCS 不同的是,加锁解锁不会自动扩散到所有端点。这还是因为并不存在中心服务器的概念。
10.2 常见错误:没开 LFS
非常重要的一件事情是,LFS 不负责鉴别哪些文件是大文件。在添加大文件之前,它们路径需要加到 .gitattributes
里,可以用通配符。一旦路径在 .gitattributes 里了,文件操作就会自动通过 LFS 过滤,不需要额外的手工操作。
但是,如果一个文件在没有改 .gitattributes 之前就添加了,那它会被当作普通文件。要纠正这个,需要把文件路径放到
.gitattributes,然后执行:
才能把当前目录下的 LFS 状态修正过来。但历史里面的没法改,一旦提交了,大文件就会永远在那边。除非用我的另一篇文章提到的方法来精简。通过那样的方法过滤
git 库,删除不小心提交的大文件非常痛苦。过程中会有很多手工操作和确认,但至少这件事情是可做的。在实际项目中,我曾经把一个野蛮生长到
1.6GB 的 git 库,通过去掉没开 LFS 的情况下提交的第三方依赖和数据,精简到了 10MB,而且所有历史记录都在。其他
VCS 甚至不会有机会这么做,只能无限增长下去,或者砍掉一段历史记录。
10.3 滥用 LFS
另一个极端就是滥用 LFS。把所有的文件都当做大文件来添加,这样 git repo 就表现成了个
svn。当然,git 相对 svn 的大部分优点也没了,开发效率下降5-10倍。要进一步把效率下降10倍,可以锁上所有的文件。这样所有人都需要
checkout 文件才能编辑。这样的 git repo 就退化成了一个 p4 库。(要再次把效率下降10倍,就在同个项目上混合使用
git 和 p4。可以肯定,到不了10次 commit,就会有人搞错,把文件同时放到两边,造成两边都混乱。)
10.4 封装 LFS 锁
刚提到,LFS 锁所有的东西可以很容易把开发效率下降2个数量级。但是,对于非编程的工作流,比如美术工作,反正是没有
diff 的操作。这就会变成加锁->check out->修改->提交->解锁,和主从式
VCS 的工作流一样。一个常见的解决方法是写一个脚本来加锁、扩散锁的状态,另一个脚本来做提交、解锁、扩散锁的状态。把
LFS 锁封装之后,工作流既可以符合美术类,也同时保持编程类工作流的效率。从另一个角度想这个问题:git
有机会封装成同时符合编程类和非编程类工作流,保证两边的效率;但是 svn/p4 却没可能封装成提高编程类工作流效率的。
11 Git 的缺点
当然,git 不是完美的,有些地方仍然比其他 VCS 有些缺点。解决这些问题的办法,有,但支持并不广泛。
11.1 缺乏分支权限管理
Git 没有内建权限管理(来自于 Linus Torvalds 的设计理念)。当一个人获得访问 repo
的权限,所有的分支都能访问到。有些服务通过控制“.git/refs/heads”下的文件访问,提供了基于分支的权限管理。这就能有基本的权限管理,又不需要修改
git。
11.2 巨型库(单一库)
当 Linus Torvalds 设计 git 的时候,首要目标是支持 Linux 内核的开发,需求限于这样的中等规模。对于一个巨大的项目,git
的性能并不好。想想在“git status”的时候,git 需要穷举目录下的所有文件,比较当前的和
repo 里的区别。这肯定会花不少时间。
这几年,git 也在这上面做了一些改进。Git 2.25里引入的部分 clone 和稀疏 checkout
可以让你不需要把整个 repo 都 clone 或者 checkout,只要你需要的一部分子目录就行。但这些还比较新,不是所有服务提供方都支持。
要解决存放 Android 源代码的需求,Google 有个工具叫“repo”。它可以管理多个 git
repo,就好像一个巨大的 repo 一样。这个工具支持 Linux 和 macOS,但是 Windows
上基本没法用。同时,因为本质上其实还是一堆git库的集合,把文件从一个 git 挪到另一个,就会丢失历史。Google
的另一个工作是 Git protocol v2。它可以加速 repo 之间传输的速度。
微软的 Windows 长期以来一直用的 fork 的 p4,叫做 source depot(SD),作为版本控制。在2015年的某个时候,p4
已经无法满足现代的敏捷开发和协作的需求,于是考虑切换到 git。即便代价非常大(切换了一个用了20年以上的系统,大量修改
bug 跟踪、自动编译、测试、部署系统,培训部门里的每个人,配发大容量 SSD。),也要坚持去做,因为都知道这才是未来。直接转的话,单个
git 库的大小是270GB,clone 一次得花12小时,checkout 花3小时,甚至连“git
status”都要10分钟,简直没法用。于是有人开始考虑通过引入一些主从的特性来改进 git。但因为他们对开源社区的无知,甚至连搜索一下都不,就给这个东西起名叫
gvfs(git virtual files ystem),全然不顾已经有叫这个名字的知名项目 GNOME
virtual file system。被诟病了几年才改名叫 VFSForGit。
它不是 git 的直接替代。首先是引入了一个新的协议,用于虚拟化 repo 里的文件。在克隆的时候,不用
git clone,而用 gvfs clone。在 .git 和工作目录下的所有文件都只是个符号链接,指向服务器上的真实文件(有了中心服务器的概念),在本地硬盘上不占空间。然后有个后台驻留程序在监视这个虚拟化。读文件的时候,它就把文件内容从服务器取到本地的
cache,修改文件的时候,它就把符号链接替换成硬盘上的普通文件(相当于自动 checkout)。同时这个驻留程序还监控文件读写的操作。如果文件没有被写过,就认为内容不变。这样就只需要比较被写过的文件,而不是目录下所有文件(相当于不按内容判断是否相同)。然而,这其实破坏了
git 的很多设计原则,以及放弃了按文件内容决定是否发生改变的规则。显而易见没可能被官方的 git
采纳。这些对规则的破坏,这也使得 VFSForGit 无法和很多 git GUI 很好地配合使用,包括
TortoiseGit。
因此,微软换了个方向,新做了一个叫做 Scalar 的系统。这个就不用虚拟化了,也不会改变 git
的工作流。它是以扩展的形式,优化原有 git 的部分 clone 和稀疏 checkout,不再修改
git 的基础。但它的适用性仍然是个问题。目前只有微软 fork 的 git 和 Azure devops
支持这个。实际上 meta 和 google 也一直在等待着 git 能更好地支持单一巨型库,并时不时尝试从自己开发的系统里切换过去。
但是随着时间的发展,总会有更多改进被合并到官方的 git 去。这个问题会慢慢改善。对绝大部分项目来说,这些问题并不会遇到,也不会是问题。
12 总结
像 git 这样灵活的系统,达到同个目的往往存在多条路径。这里提到的这些
git 最佳实践,希望能帮助朋友们找到路径中最优的一条。你越是了解 git,越能明白逻辑正确的版本控制应该是什么样的,越会支持
git 的使用。而正好相反的是 p4。你越是不了解 p4,越会支持 p4 的使用,因为它并没有给人思考的余地,所以用再久也没法了解什么是版本控制,也无法发现
p4 是多么难用。 |









