| 编辑推荐: |
本文主要介绍了 git 底层原理,存储结构组织形式, 以及几个实用的 git 指令 ,在了解原理的基础上对底层实现进行推演 ,希望对你的学习有帮助。
本文来自于小徐先生的编程世界,由火龙果软件Linda编辑、推荐。 |
|
0 前言
本期和大家探讨编程开发领域中非常重要的一项软技能——git.
本期会探讨到的内容包括:
• git 底层原理,存储结构组织形式
• 介绍几个实用的 git 指令 ,在了解原理的基础上对底层实现进行推演
可能有同学会疑惑,git 操作指令本身并不复杂,翻来覆去就是几个常用指令,我们反复使用做到孰能生巧就可以了,为啥还要去深究其底层实现原理呢.
这里我想多提些个人观点——我喜欢工科而非文科的重要原因就是, 工科很多东西都有一套底层逻辑的,得出结论更多靠的是“推导”而非“记忆” .(很怕背书- -).
放到 git 的学习使用上来说,如果我们不了解 git 底层存储原理,只是死记硬背操作指令的话,其实只能形成一些表层的肌肉记忆并不能做到融会贯通,容易出现了【反复学了又忘】,【拓展新知识成本高】的问题. 但是倘若掌握了原理就完全不同了, 哪怕一个知识点对应结论忘了 也完全不慌,大不了我们 基于原理机制,从起点出发重新推导一轮 即可.
那么言归正传,本期我们就从零到一出发,和大家一起梳理一下 git 版本控制背后的存储模型和原理机制 ;并且在掌握了存储模型的基础上,和大家一一梳理和推演每个 git 指令背后涉及到的模型变动和实现原理.
1 核心概念串讲 1.1 git
git 是当下最流行的 开源版本控制工具 ,能极致地 提高研发团队的开发协作效率 . 作为一名研发,应该不太可能会有人会对 git 感到陌生,有关 git 的概念,我也无需多作赘述.

这里附上 git 相关传送门:
git 官网:https://git-scm.com/
在 git 基础上衍生的开源项目托管平台 github:https://github.com/

1.2 中央仓库
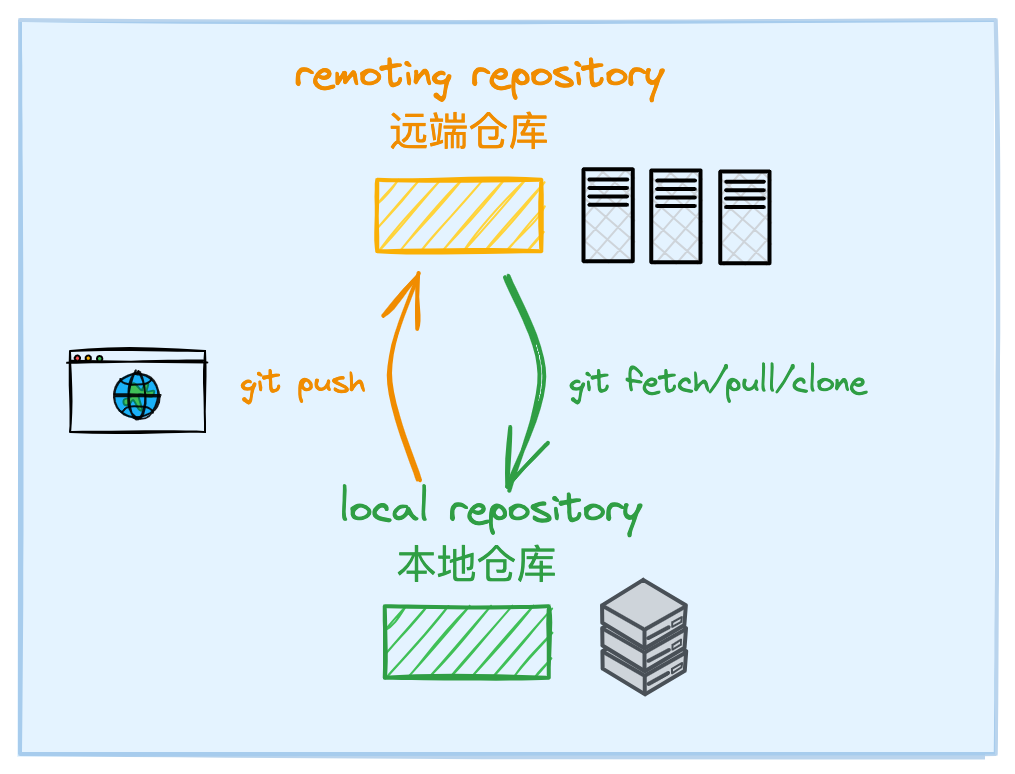
首先梳理一下 git 的宏观架构. 使用 git 时,接触到存储介质包括托管在 远端集群的中央仓库 (如 github)以及拉取到 单机的本地仓库 .
中央仓库(remoting repository) 下存储的项目内容可以理解为达成全局共识的最终结果,而本地仓库存储的项目内容可以理解为一份临时缓存,内容可能在中央仓库的标准版本的基础上进行一些本地修改,最终需要在遵循规则的前提下才能汇总合并到中央仓库中.
• 中央仓库->本地仓库 :在本地可以通过 git clone、pull、fetch 等指令,从中央仓库克隆、更新到标准版本的项目内容
• 本地仓库->中央仓库 :在本地可以通过 git push 指令将修改后的项目内容推送到中央仓库,当然这个过程中需要达成一定的共识机制,这一点后文详述
1.3 本地仓库
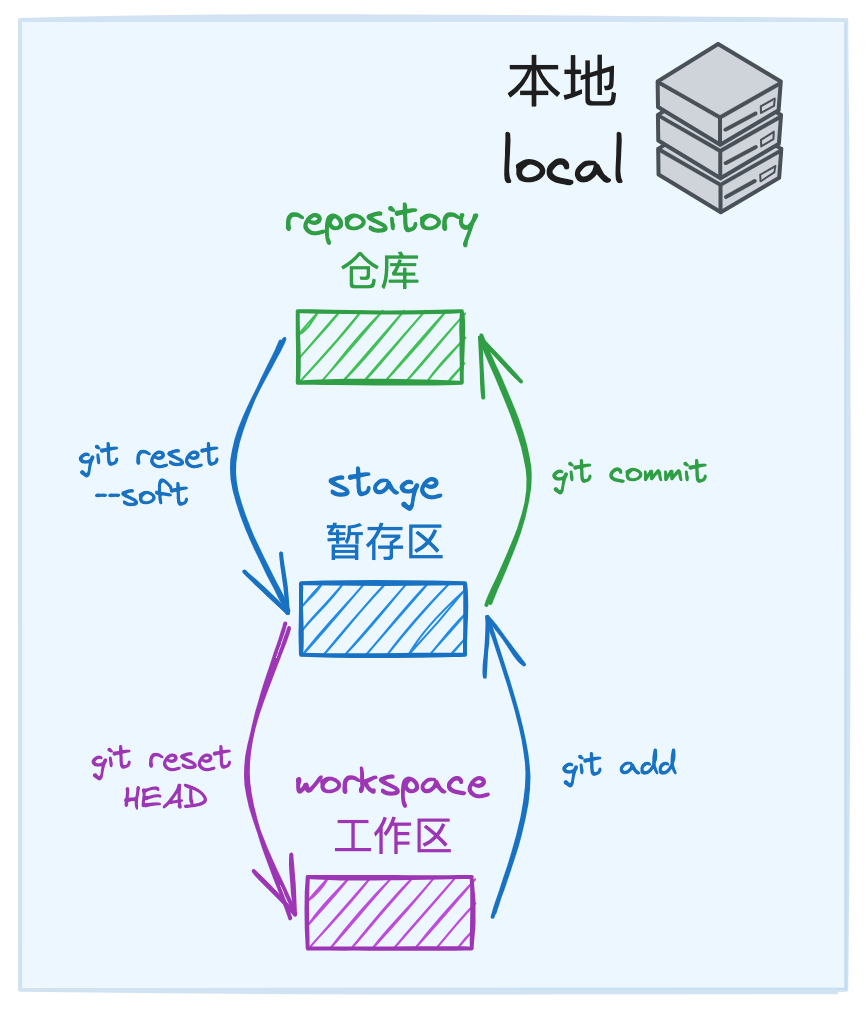
本地仓库(local repository) 在逻辑意义上可以分为: 工作区(workspace)、暂存区(stage)、仓库(repository) 三个部分,各自含义展示如下:
• 工作区(workspace):对应为磁盘中实际存在的项目文件内容
• 暂存区(stage):存储修改后还未提交到仓库的一些临时变更
• 仓库(repository):存储执行提交操作后进入 git 本地版本链中的内容
下面通过几个 git 指令展示一下三个模块间的数据流动规律:
• 工作区 -> 暂存区:git add {file}
• 暂存区 -> 仓库:git commit
• 仓库 -> 暂存区:git reset --soft {commit id}
• 暂存区 -> 工作区:git reset HEAD -- {file}
1.4 提交&分支
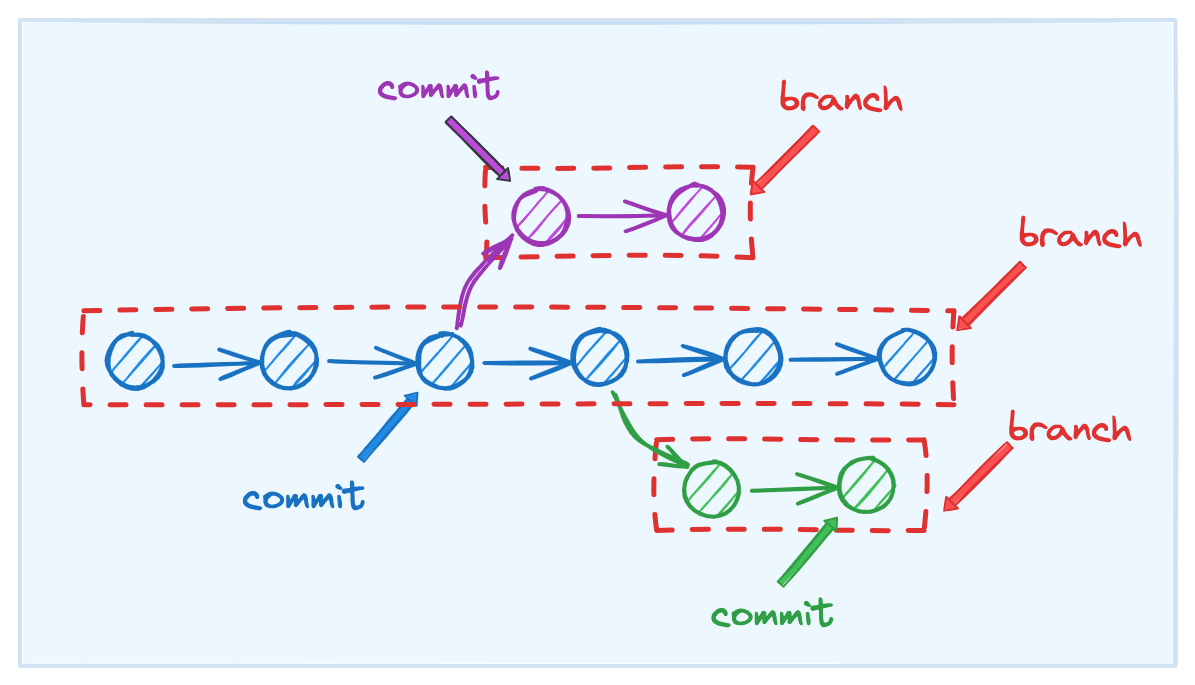
git 号称最好的版本控制工具,离不开两个 核心特性 的支持: 提交(commit) 和 分支(branch) .
所谓 版本 ,对应的就是 一笔 commit 记录 ; 版本控制 指的是在由一系列 有明确先后顺序的 commit 组成的版本链 的基础上进行的一系列操作,比如 向后延伸、向前回溯、平行分叉 等.
所谓 分支 ,指的是在 版本链 上的一条 独立开发线. 不同的研发哪怕复用相同仓库,也可以通过 拉分支 的方式对版本链进行 平行分叉 ,最后再执行 合并操作 ,实现不同 feature 的并行开发.
1.5 几个问题
在进入探测实战以及原理剖析之前,我们先抛出几个核心问题,让大家能带着问题进入到后续章节的学习,期望大家在完成阅读时,都能找到属于自己的圆满答案.
• 问题一:每笔提交需要有一个全局的 commit id 进行 唯一性标识 ,在中央仓库的分布式模型下,如何保证每笔 commit id 的全局唯一性?
• 问题二: commit 模型 如何实现?如何实现版本链的延伸、回溯、分叉操作?
• 问题三: branch 模型 如何实现?拉取分支、合并分支的操作如何实现?
2 底层存储形式探测
在本章中,我们会通过一系列的 git 实战操作,带大家一起深入到 git 存储模型底层,探测其中的实现细节. 这部分内容主要是为第 3 章的原理串讲打下基础,如果把整个学习过程类比为 【拼图游戏】 ,那么 本章 扮演的作用就是 【集齐拼图碎片】 ,而 第三章 则是 【完成整张拼图】 .
由于本章中获得到的一些线索可能是碎片化的,因此大家第一遍看的时候可能会感到云里雾里,因此我建议大家不妨 按照 【第 2 章 -> 第 3 章 -> 复读第 2 章】的顺序来完成学习 ,相信在第二轮阅读本章时能获得到截然不同的学习体验.
此外,这里需要声明一下,本章内容中的操作指令、观测内容在很大程度上都是借鉴了 b 站 Zhengyaying 大佬的视频后得到的,这期视频很有干货,很建议大家可以抽时间观看一下. 附上视频传送门:https://www.bilibili.com/video/BV11z4y1X79p 2.1 操作总览
在本章实战环节中,我们会遵循下述流程依次执行各项操作:
• step1:初始化一个 git 项目
• step2:创建监听任务,持续观察 .git 文件夹的变化
• step3:master 分支提交
• step4:test 分支提交
• step5:master 分支二次提交
• step6:master merge test 2.2 step1:项目初始化
首先初始化一个名为 git-example 的项目:
此时我们创建了一个空的项目文件夹. 但可以看到,在文件夹下存在一个名为 .git 的隐藏文件夹 ,这部分是我们后续的探讨重点:
ls -al
total 0
drwxr-xr-x 9 didi staff 288 12 6 10:16 .git
# ... |
2.3 step2:创建监听任务
接下来,我们拆分一个终端,创建一个监听任务,按照 0.5 秒的轮询频率 持续观测 .git 文件夹 中的内容是否发生变化,一旦发生变化后则会 以树状图的形式输出文件夹下的内容 :
watch -n .5 tree .git
.git
├── HEAD
├── config
├── description
├── info
│ └── exclude
├── objects
│ ├── info
│ └── pack
└── refs
├── heads
└── tags
7 directories, 4 files |
2.4 step3:在 master 分支提交
此时我们使用的默认分支为 master.
I 首先,我们在工作区中创建一个文件:1.txt
执行 git status 可以查看到新增的文件
git status
On branch master
Untracked files:
1.txt |
II 接下来,我们执行 git add 指令后,将新增文件添加到缓存区中:
执行 git status 后可以查看到,1.txt 已经被添加到暂存区中:
git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: 1.txt |
在此刻,我们的监听任务也随之报备了 .git 文件夹发生的变化. 可以看到,在 .git/objects 目录下新增了一个名为 d00491xxxx 的文件,后续我们 将该目录下的内容都称为 object :
.git
├── HEAD
├── config
├── description
├── index
├── info
│ └── exclude
├── objects
# 新增部分
│ ├── d0
│ │ └── 0491fd7e5bb6fa28c517a0bb32b8b506539d4d
│ ├── info
│ └── pack
└── refs
├── heads
└── tags
8 directories, 6 files |
不难联想到,这个新增文件和刚通过 git add 指令添加的 1.txt 文件有所关联,接下来我们通过 git cat-file 指令查看该文件的类型和内容:
• 查看类型:发现 object 类型为 blob
git cat-file -t d00491
blob |
• 查看内容:发现 object 内容正是 1.txt 中的内容
值得一提的是,这个新增 object 的文件名正是基于文件内容通过 SHA-1 哈希算法生成的哈希字符串: 1 (input)-> d00491xxxx(hashed)
需要注意,后续所有在 .git/objects 目录下新生成的 object 都是基于这种哈希摘要的规则生成的名称,我们把其名称称为 object 的 key
III 下面,我们通过 commit 操作将暂存区中的文件添加到仓库中:
git commit -m "first commit" |
与此同时,.git 目录下的内容也在发生着变化:
.git
├── COMMIT_EDITMSG
├── HEAD
├── config
├── description
├── index
├── info
│ └── exclude
├── logs
│ ├── HEAD
│ └── refs
│ └── heads
│ └── master
├── objects
# 新增部分
│ ├── 38
│ │ └── fd29697b220f7e4ca15b044c3222eefe5afdc1
│ ├── 3a
│ │ └── 3ad2837c7ce33c88c85744b3cddb96a4b0e4dd
# ....
│ ├── info
│ └── pack
└── refs
├── heads
│ └── master
└── tags |
可以看到,在 .git/objects 中新增了 38fd29xxx 和 3a3ad2xxxx 两个 object ,我们分别对其类型和内容进行观察:
• 观察 38fd29xxx
发现 类型是 tree
git cat-file -t 38fd29
tree |
发现 object 内容是记录了其下 blob object 的 key 以及类型,而这个 blob 对应的正是本次提交后仓库文件夹中存在的 1.txt 文件.
不难看出,这个 tree object 类似于一个文件夹 的作用.
git cat-file -p 38fd29
100644 blob d00491fd7e5bb6fa28c517a0bb32b8b506539d4d1.txt |
• 观察 3a3ad2xxxx
查看 object 类型,发现 类型是 commit
git cat-file -t 3a3ad2
commit |
查看 object 内容,发现其中包含了本次提交行为所涉及的内容:
• tree:正好对应了本次提交后仓库文件夹对应的 tree 文件的名称
• author、commiter:分支作者、提交人以及提交时间
• first commit:本次提交的摘要信息
git cat-file -p 3a3ad2
tree 38fd29697b220f7e4ca15b044c3222eefe5afdc1
author weixuxu <weixuxu@didiglobal.com> 1701832729 +0800
committer weixuxu <weixuxu@didiglobal.com> 1701832729 +0800
first commit |
IV:最后查看 master 分支的 head 指向,可以看到指向了最新提交对应 commit object 的 key
cat .git/refs/heads/master
3a3ad2837c7ce33c88c85744b3cddb96a4b0e4dd |
2.5 step4:在 test 分支提交
I 首先,我们在 master 分支上创建并切换到一个新的 test 分支
git checkout -b test
Switched to a new branch 'test' |
在 test 分支下,可以看到 test 分支此时也指向了相同的 commit object,其下自然也包含了相同的 tree 和 blob 内容.
cat .git/refs/heads/test
3a3ad2837c7ce33c88c85744b3cddb96a4b0e4dd |
这一点并不难理解,因为我们正式在 master 分支的完成 3a3ad2xxxx 这笔 commit 的基础上,创建出的 test 分支,因此内容被继承了下来.
II 在 test 分支分别执行 git add、git commit 操作,完成一个 2.txt 文件的提交行为
echo 2 > 2.txt
git add 2.txt
git commit -m "second commit" |
至此,.git 目录下的文件树又发生了变化:
.git
├── COMMIT_EDITMSG
├── HEAD
├── config
├── description
├── index
├── info
│ └── exclude
├── logs
│ ├── HEAD
│ └── refs
│ └── heads
│ ├── master
│ └── test
├── objects
# objects 新增部分
│ ├── 0c
│ │ └── fbf08886fca9a91cb753ec8734c84fcbe52c9f
│ ├── 43
│ │ └── 4943a8265129a744745e5d12fa2625a784b283
│ ├── a2
│ │ └── 4e6d8b3409d1095425282e1d2d9bca5b322c85
# ...
│ ├── info
│ └── pack
└── refs
├── heads
│ ├── master
│ └── test
└── tags |
可以看到其分别新增了 0cfbf0xxxx、434943xxxx、a24e6dxxxx 三个 object,我们一一观察一下:
• 观察 0cfbf0xxxx
该 object 类型为 blob , 内容对应为 2.txt 文件 的内容:
• 观察 434943xxxx
其 类型为 tree , 内容为两个 blob object :(d00491xxxx 对应存量的 1.txt;0cfbf0 对应新增的 2.txt)
git cat-file -p 434943
100644 blob d00491fd7e5bb6fa28c517a0bb32b8b506539d4d1.txt
100644 blob 0cfbf08886fca9a91cb753ec8734c84fcbe52c9f2.txt |
• 观察 a24e6dxxxx
其 类型为 commit ,内容包含了本次提交行为的一些信息:
• tree:对应版本下的项目文件夹
• author、commiter、note:分支作者、提交人、摘要信息、提交时间
此外还有一项 额外关注的重点 :
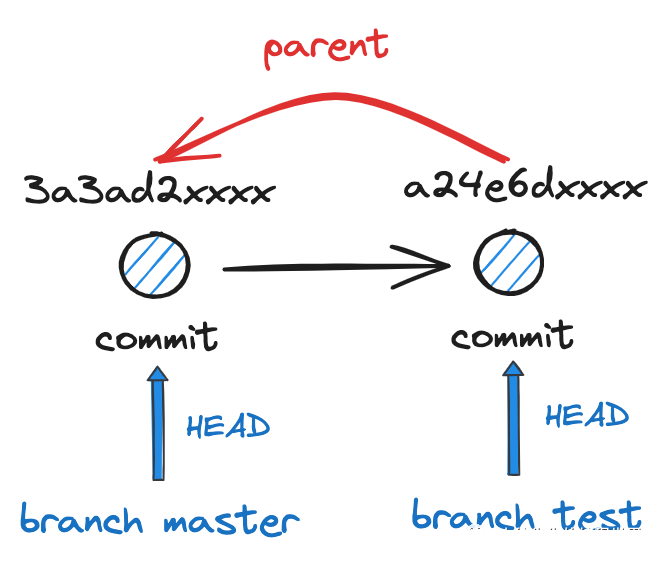
• parent:指向了前一个版本的 commit
git cat-file -p a24e6dxxxx
nt 3a3ad2837c7ce33c88c85744b3cddb96a4b0e4dd
author weixuxu <weixuxu@didiglobal.com> 1701844934 +0800
committer weixuxu <weixuxu@didiglobal.com> 1701844934 +0800
second commit |
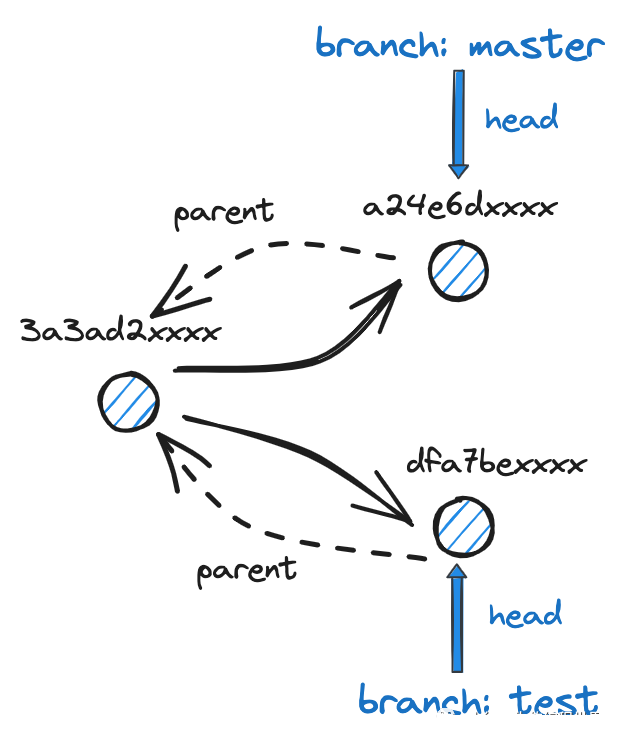
至此,所谓版本链的结构已经形成,正是通过每个 commit 的 parent 指针串联起来形成的链表:
III 最后观察一下两个分支的 HEAD 指针
可以看到,test 分支的已经指向了当前最新的一个 commit
cat .git/refs/heads/test
a24e6d8b3409d1095425282e1d2d9bca5b322c85 |
而 master 分支则仍然指向前一个版本的 commit:
cat .git/refs/heads/master
3a3ad2837c7ce33c88c85744b3cddb96a4b0e4dd |
2.6 step5:在 master 分支二次提交
下面,我们从 test 分支切换回到 master 分支,再执行一轮 git add、git commit 指令,把同样的一份 2.txt 文件添加到本地仓库:
I 切换分支回 master
git checkout master
Switched to branch 'master' |
II 提交文件到仓库
echo 2 > 2.txt
git add 2.txt
git commit -m "second commit" |
此时观察 .git 目录的变化情况,发现仅仅在 .git/objects 下新增了一个 object:dfa7bexxxx
.git
├── COMMIT_EDITMSG
├── HEAD
├── config
├── description
├── index
├── info
│ └── exclude
├── logs
│ ├── HEAD
│ └── refs
│ └── heads
│ ├── master
│ └── test
├── objects
# objects 新增部分
│ ├── df
│ │ └── a7be245fd6f1bc15c07432fccbefb5716c81e8
# ...
│ ├── info
│ └── pack
└── refs
├── heads
│ ├── master
│ └── test
└── tags |
III 观察新增 commit
查看新增的 dfa7bexxxx object后,发现了几个现象:
• parent:指向了 master 分支的前一个 commit object:3a3ad2xxxx,这一点很好理解
• author、commiter、note:记录了提交的作者、时间、摘要
下面这个现象是重点:
• tree:和 test 分支下的 commit object:a24e6d 指向了 相同的 tree object ,可见自此以下的内容, 包括文件夹 tree 和文件 blob 都得到了复用
git cat-file -p dfa7be
tree 434943a8265129a744745e5d12fa2625a784b283
parent 3a3ad2837c7ce33c88c85744b3cddb96a4b0e4dd
author weixuxu <weixuxu@didiglobal.com> 1701849620 +0800
committer weixuxu <weixuxu@didiglobal.com> 1701849620 +0800
second commit |
关于上述内容我们加以解释:
• 相同的 tree object :由于 master 分支 commit dfa7bexxxx 下的项目文件夹和 test 分支 a24e6d 下完全一致(两个内容完全相同的 blob 文件:1.txt,2.txt),因此无论是 blob 还是 tree 通过哈希生成的文件名都是一致的,最终这部分内容得到了复用
• 不同的 commit object :commit 内容中,尽管 tree、parent、author、comitter、note 等信息都相同,但是提交时间的时间戳不同,因此因为内容差异而生成了两个独立的 commit object 2.7 step6:分支 merge
一通操作至此,分支 master 和 test 以及发生了分叉,当前对应的结构如下:
下面,我们的目标是执行 merge 合并操作,将 test 分支的变更同步到 master 分支中.
I 执行 merge 指令
II 观察 .git 内容变化
可以发现,.git/objects 中又有新增的 commit 项:8e4b52xxxx
.git
├── COMMIT_EDITMSG
├── HEAD
├── config
├── description
├── index
├── info
│ └── exclude
├── logs
│ ├── HEAD
│ └── refs
│ └── heads
│ ├── master
│ └── test
├── objects
# objects 新增部分
│ ├── 8e
│ │ └── 4b529b01914679de0b7d94d84a3604a6991c90
# ...
│ ├── info
│ └── pack
└── refs
├── heads
│ ├── master
│ └── test
└── tags |
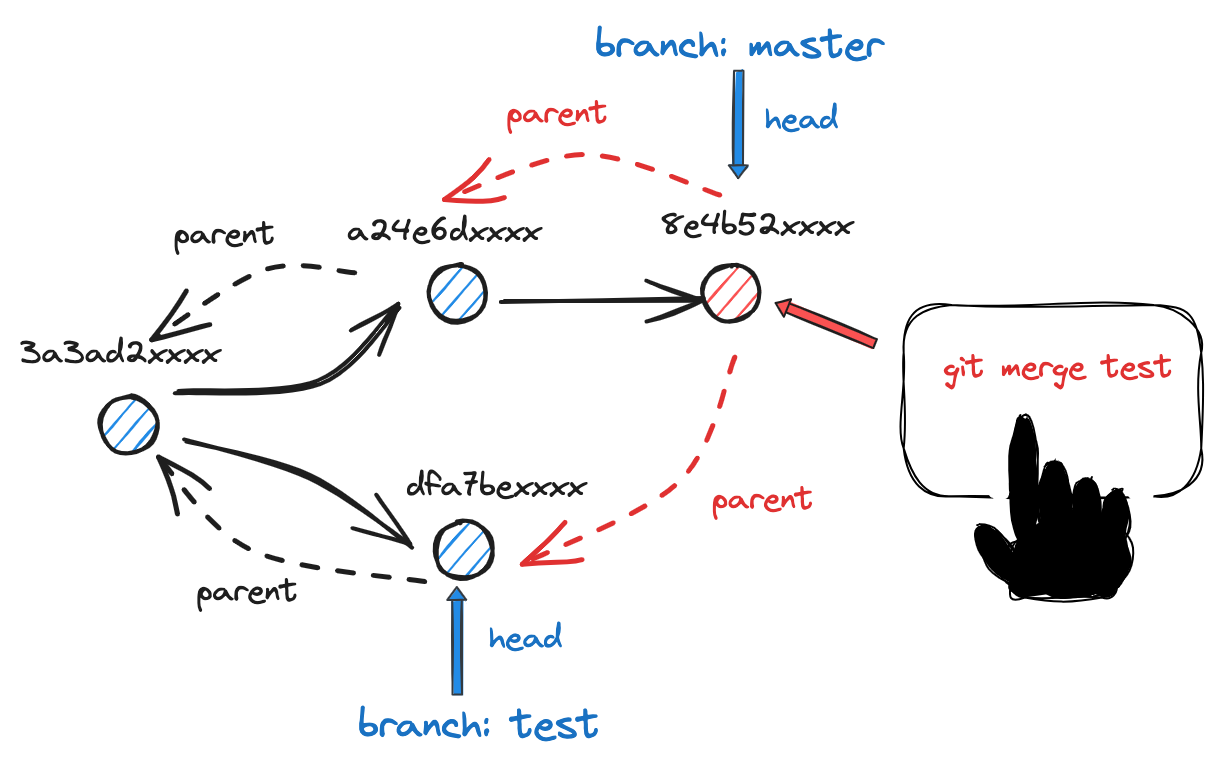
III 观察 8e4b52xxxx
查看该 object 后得到的结果,可以看到,执行 merge 操作之后,会将原本版本链基础上衍生出一个新的 commit,并且该 commit 拥有两个 parent 父指针:
git cat-file -p 8e4b52
tree 434943a8265129a744745e5d12fa2625a784b283
parent dfa7be245fd6f1bc15c07432fccbefb5716c81e8
parent a24e6d8b3409d1095425282e1d2d9bca5b322c85
author weixuxu <weixuxu@didiglobal.com> 1701862112 +0800
committer weixuxu <weixuxu@didiglobal.com> 1701862112 +0800
Merge branch 'test' |
至此,版本链的形式更新如下:
IV 校验分支 HEAD 指针
我们进一步检查各分支的 HEAD 指针对上述结论进行验证,得到的结果果然是符合预期的:
cat .git/refs/heads/test
a24e6d8b3409d1095425282e1d2d9bca5b322c85 |
2.8 小结
通过上面的实测环节,我们零星获得了一些线索,下面我们进行一轮小结:
• git 底层存储放在 .git/objects 文件夹 下,分为 commit、tree、blob 三类 object
• 每个 object 以 key-value 形式 存在: key(文件名) 是基于 value 生成的哈希字符串
• commit object: 对应于每一次的提交行为,内容包含指向前一个 commit object 的 key,当前 commit 下 tree 的 key;此外还记录了提交人、时间、摘要等信息
• tree object: 对应于每个文件夹,记录了文件夹下子 object 的信息. tree 之间可以进行嵌套
• blob object: 对应为每个文件. value 是文件内容,key 是以文件内容生成的 hash 字符串
• branch head: 对应为每个分支的头指针,指向该分支下一个 commit object 的 key
3 实现原理总结串讲
完成第 2 章的学习后,下面我们进一步对所有获得的线索进行串联总结,还原出 git 版本控制底层存储形式以及实现原理的原始样貌.
这里我们先简要概括出两个重要结论:
• git 存储模型本质上是一个 依赖于哈希算法的 kv 数据库
• git 版本控制框架在纵向上是 以 commit object 组成的链表 ,在横向上是 以 commit object、tree object、blob object 组成的多叉树
下面我们逐个展开每个核心概念: 3.1 哈希散列
哈希散列函数(hash)想比大家都是耳熟能详,这是一种能把原始输入压缩输出成指定规格的无意义字符串的摘要算法.
hash 的核心点包括了:
• 可重入:相同输入必然产生相同输出
• 散列性:两个不同输入会被均匀映射到输出域上
• 存在冲突: 由于输入域远大于输出域,所以可能存在不同输入映射到相同输出
尽管 hash 存在冲突问题,但是在 git 中,使用到的是安全性较高的 SHA-1 哈希算法 ,输出结果为 160 位 (20字节),具有非常优秀的散列性,因此可以 近似认为,只要原始输入内容不同,则输出的结果也一定不同.
3.2 kv 数据库
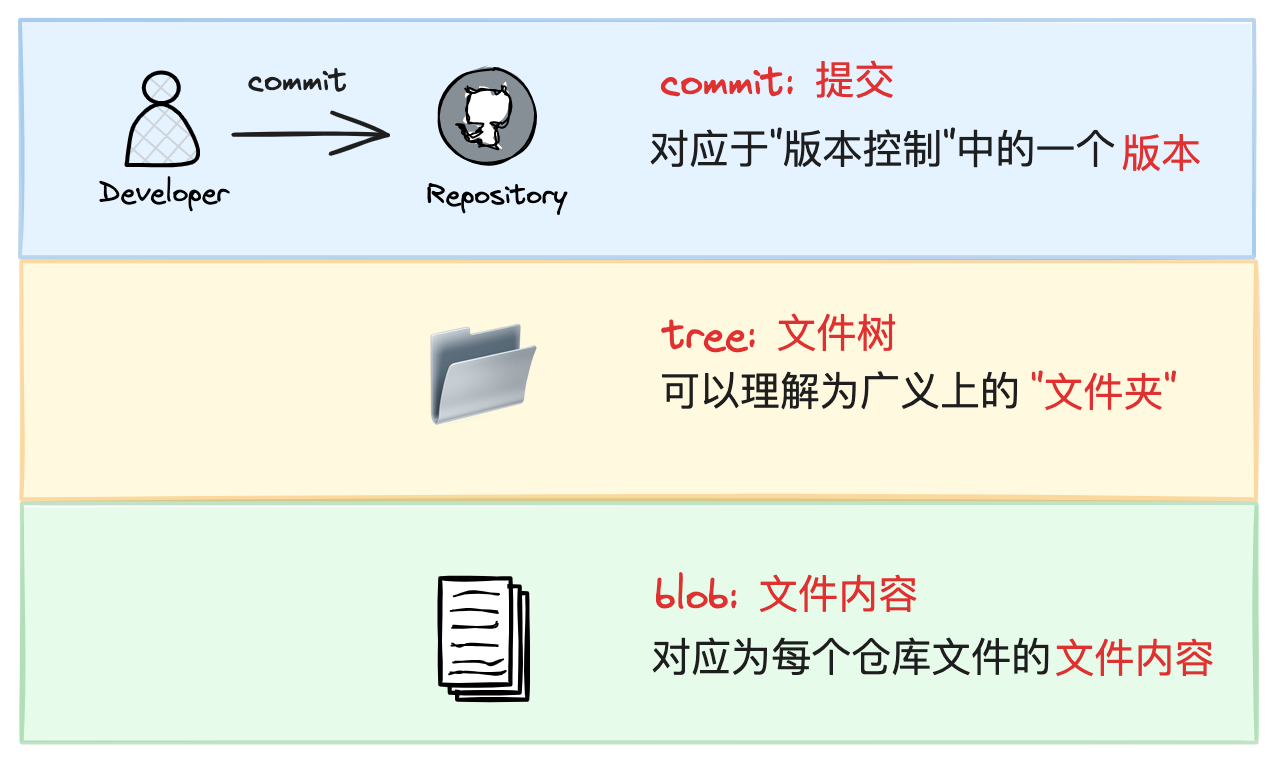
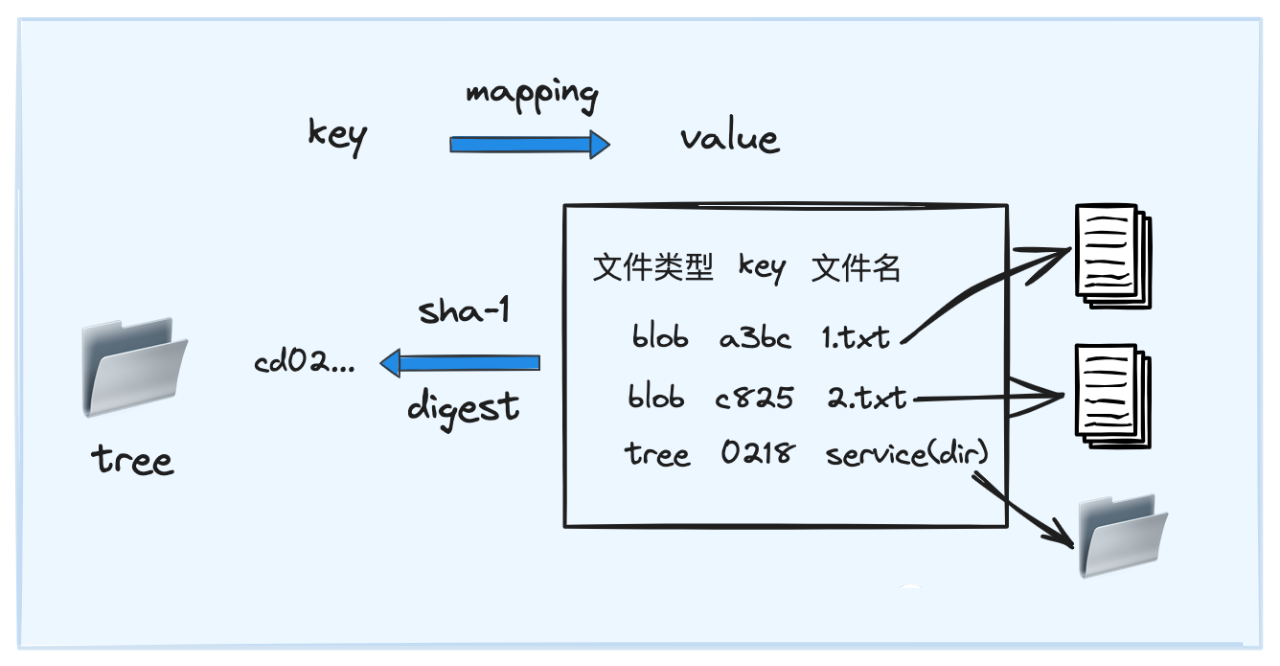
git 存储模型本质上是一个 依赖哈希算法的 kv 数据库 ,其中的 每一个 kv 对叫作一个 object ,自上而下分为 commit、tree、blob 三类 object .
对于每个 kv 对,value 对应的该 object 的具体内容,key 是在 value 基础上通过 SHA-1 算法生成的摘要信息. 由于 SHA-1 的高度散列性,于是可以认为,在这个 kv 数据库中, 只要 object 的 value 值不同,那么其 key 值一定也不同 ,因此在 kv 数据库中就会是 两个独立的 object .
下面我们分别展开介绍一下 blob、tree 和 commit 三类 object: 3.3 blob
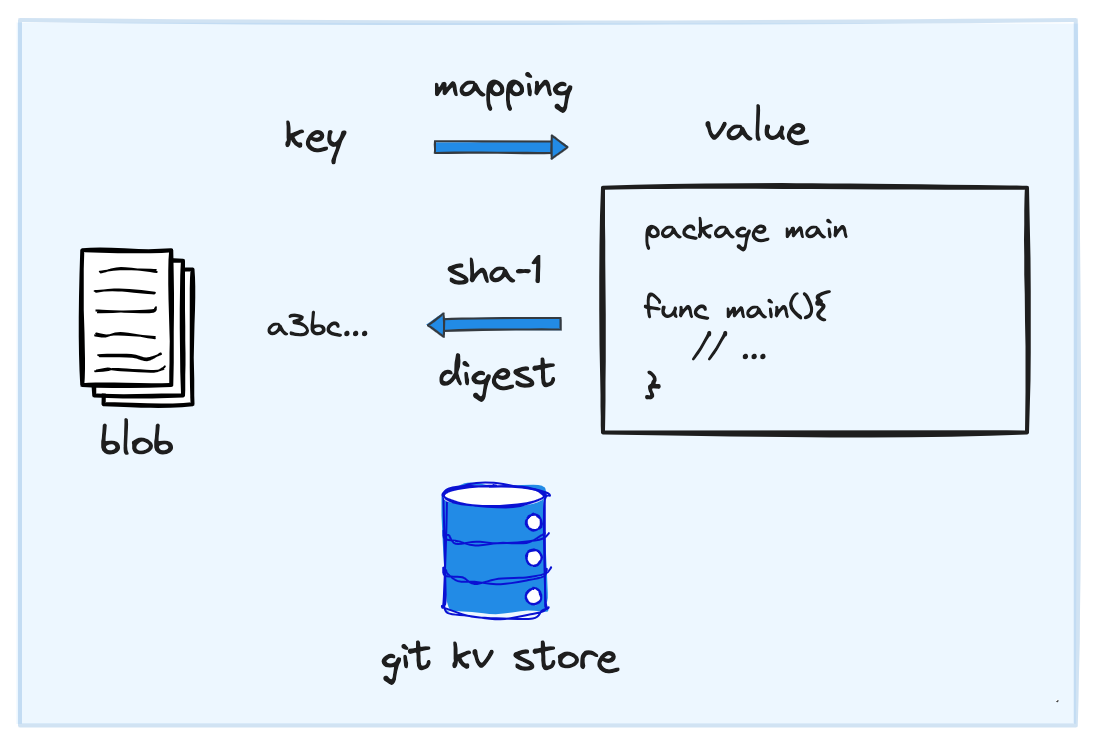
针对 blob object:
• blob object 与文件一一对应
• value:为文件的内容
• key:基于 value 通过 SHA-1 生成的摘要

3.4 tree
针对 tree object:
• tree object 与文件夹一一对应
• value :为该文件夹下 所有子 object 的概要信息 ,包括 object 的类型、key、名称信息(子 object 可以是 blob 类型,也可以是 tree 类型,因为文件夹可以嵌套)
• key:基于 value 通过 SHA-1 生成的摘要
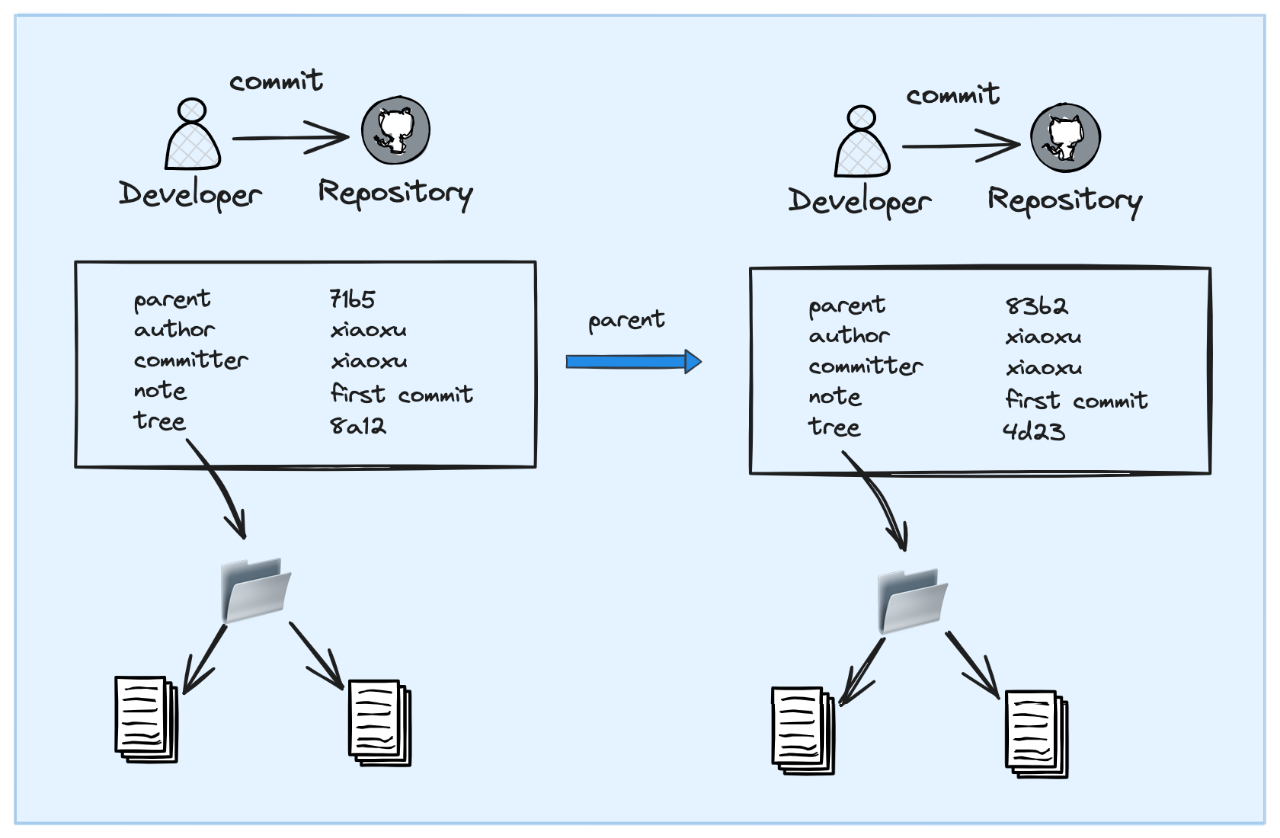
3.5 commit
针对 commit object:
• commit object 与提交记录一一对应
• value :包含下述内容:
• parent:父 commit object 的 key (可能存在多个 parent)
• author、committer:作者,提交人
• note:提交时携带的摘要信息
• tree:仓库文件夹对应 tree object 的 key
• key:基于 value 通过 SHA-1 生成的摘要
3.6 commit 链
我个人觉得 git 中 commit 版本链 是一种 类似于【区块链】 的设计:
• 每个 commit object 的 key 基于 value 通过 SHA-1 算法生成
• 每个 commit object 的 value 包含 parent 字段,是指向 parent commit object 的 key
I commit 内容安全性
基于以上两点,所有合入版本链达到一定深度的 commit object 内容是无法被篡改的 ,因为其一旦发生变化,自身对应的 object key 也会变化,其后续节点也会因为 parent 值的变更而需要调整对应的 key 值,最终发生多米诺骨牌效应.
II commit id 全局唯一性
commit object 的 key 又称为 commit id. 由于其是 基于提交人、提交时间戳、提交摘要、parent commit id、tree object key 的五维信息取 SHA-1 生成 ,因此但凡上述任何一项内容有差异,生成的 commit id 都是不同的.
因此即便是在分布式场景下,也能保证每次提交行为对应的 commit id 是全局唯一的.
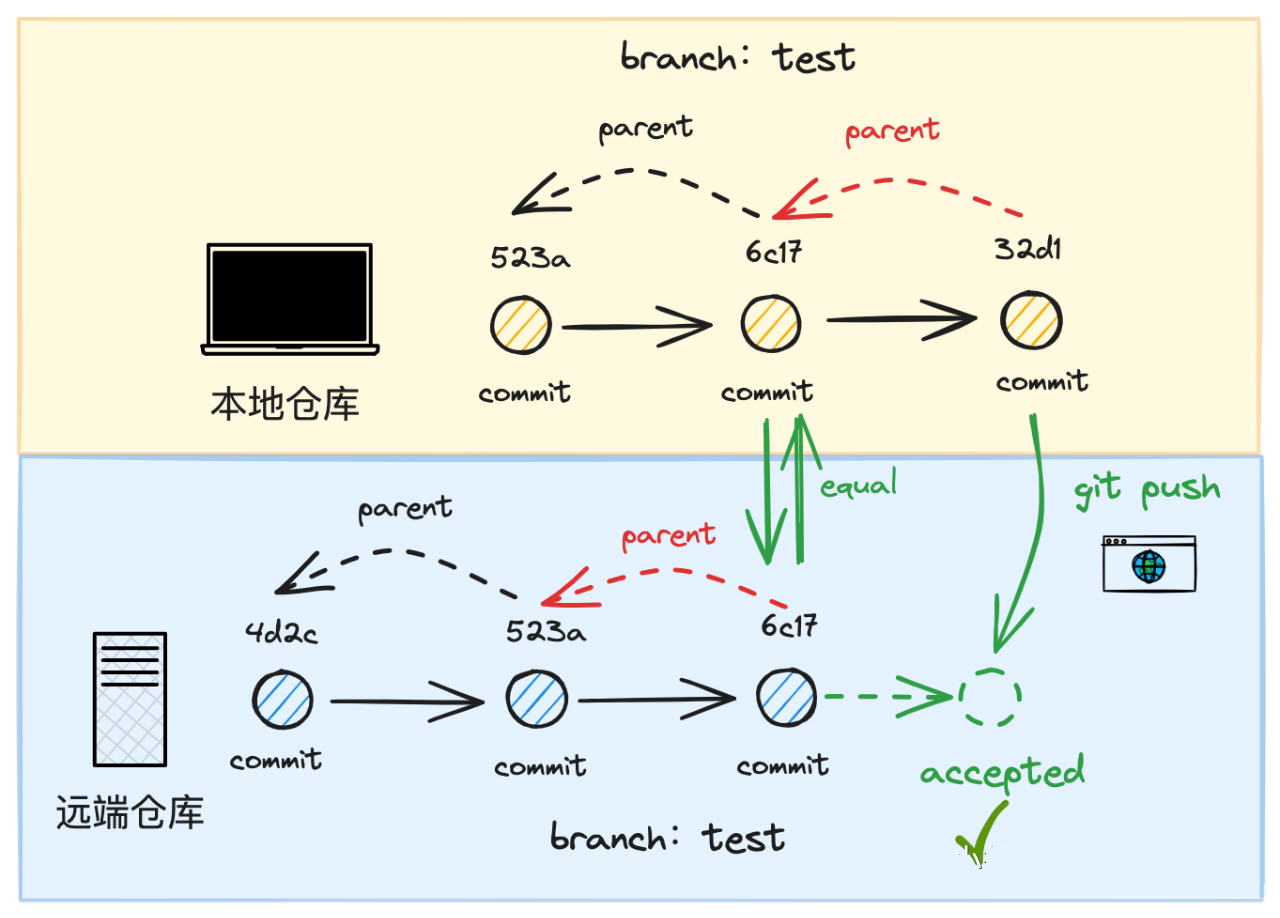
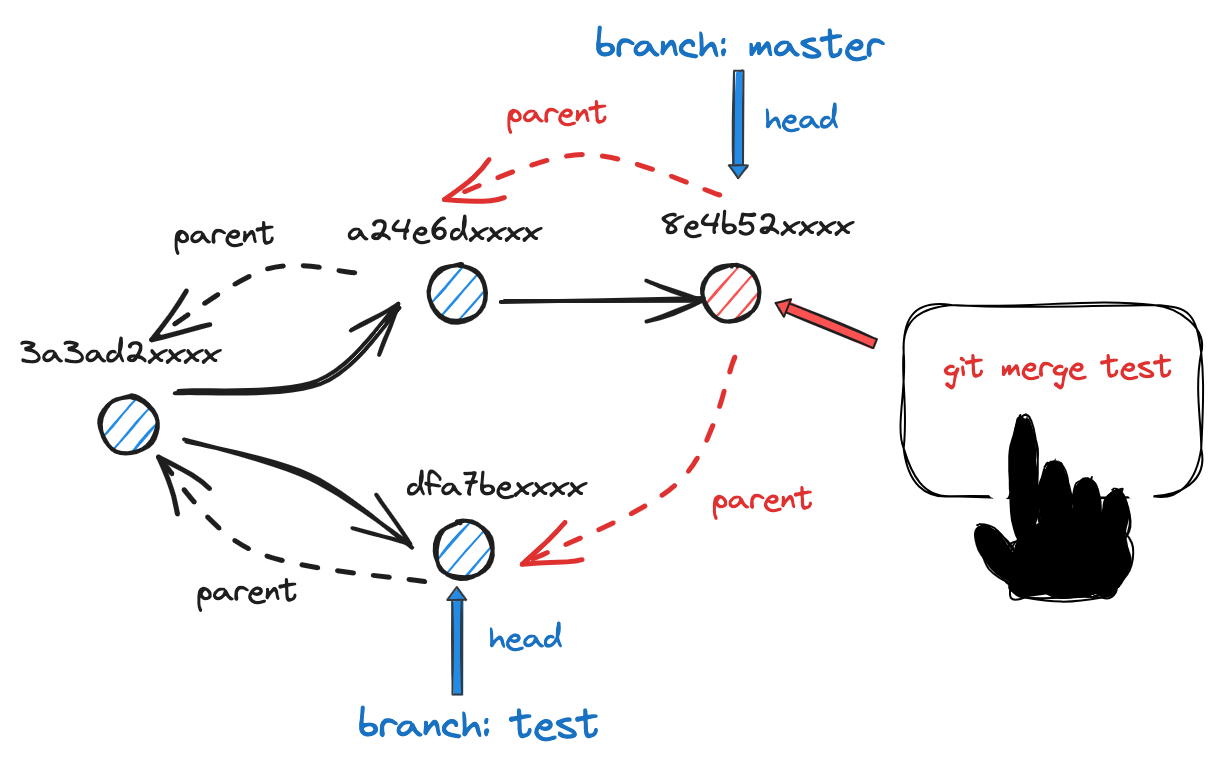
对于处在远端的中央仓库,我们每次尝试通过 push 向远端推送一个 commit 时, 远端仓库都会对提交版本的正确性进行校验 ,校验方式是沿 拟提交 commit object 的 parent 指针向前遍历,倘若能找到某个 parent commit object 和远端分支上最后一个 commit object 的 key 值 相同,才可能允许这次 push 行为,以此保证版本链的连贯性.
上述流程示意图如下:
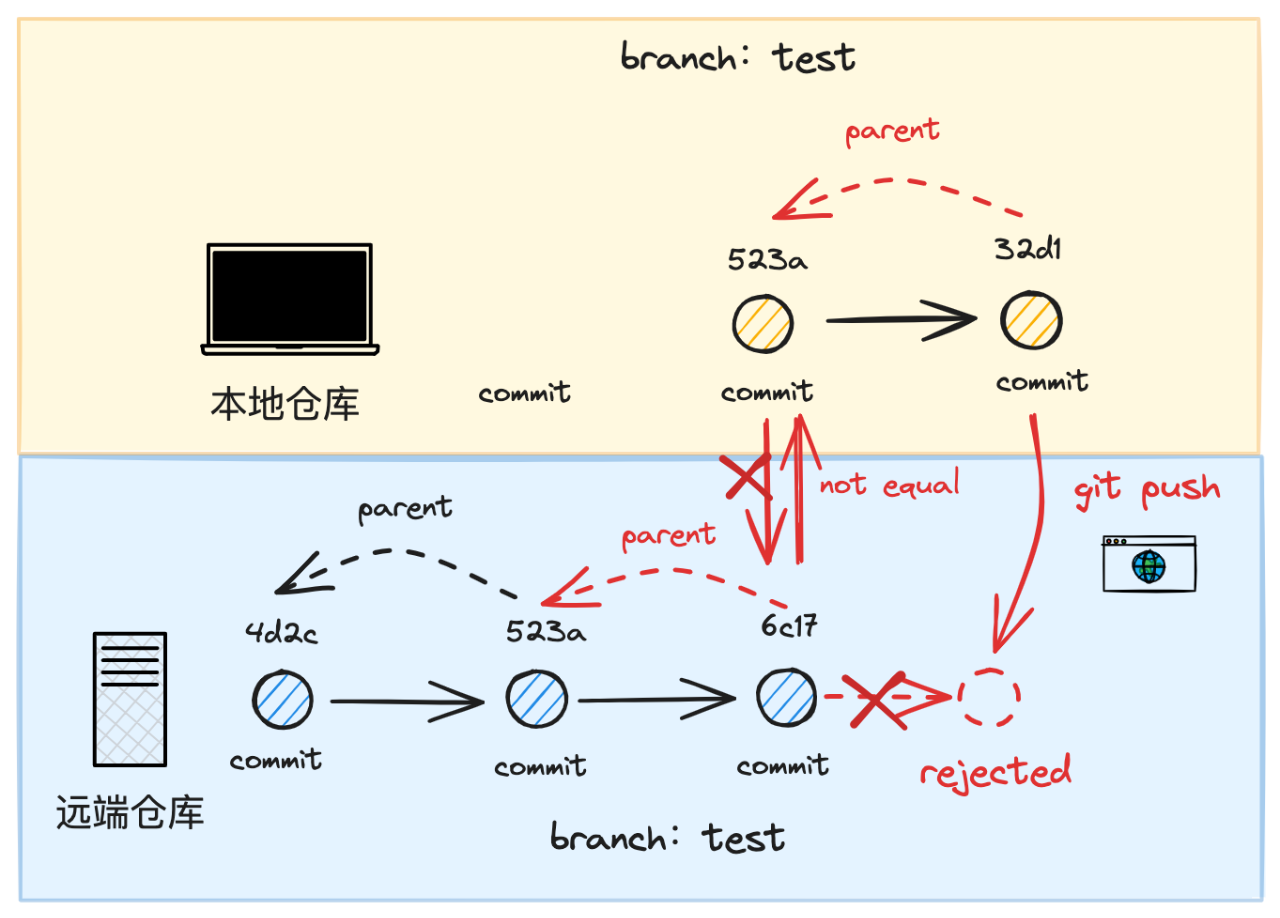
如果发现拟提交 commit object 的 parent 链上不存在和远端分支最后一笔 commit object key 值相同的 object,则这次 push 行为会被拒绝. 本地分支需要先执行 merge 或者 rebase 操作,保证本地分支先同步到远端分支的变更后,再尝试进行 push 操作.
3.7 三层结构
我们总结 commit、tree、blob 三类 object 特征后可以发现,所谓 git 版本控制的底层模型 ,本质上就是 由一系列链表 + 多叉树组成 的:
• 链表: 由 commit object 组成,通过 parent 指针串联
• 多叉树: 由 comit、tree、blob 组成. 根节点为 commit object(对应提交记录),枝干节点为 tree object(对应文件夹),叶子节点为 blob object(对应文件)
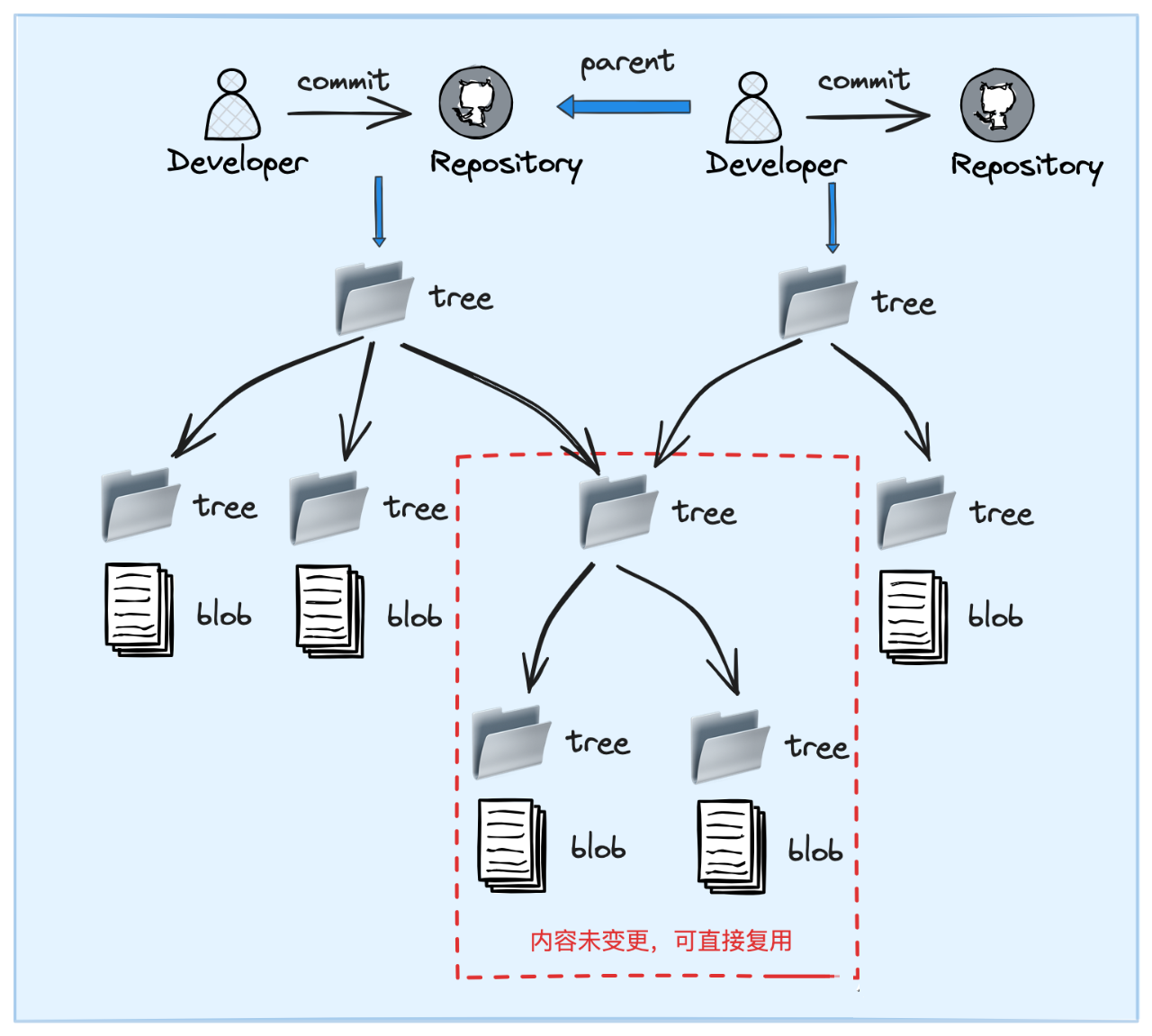
于是我们可以得出重要结论,git 版本控制中 所谓的【版本】指的就是对应了一次提交行为的一个 commit object.
所谓版本控制,自然要在多版本延伸、回溯、切换的过程中实现性能优化,压缩空间了. 那么在这个过程中,有 哪些内容是可以复用的呢 ?
要找到这个问题的答案,只需要搞明白一个原则: 只要一个 object value 不变,那么 object key 就不变,这个 object 就能得到复用.
打个比方, 只要文件内容相同 ,不管其文件名是否相同,是否从属于不同的 commit 不同的 branch, 其对应的 blob object 都是同一个,都能得到复用 ;同理, 只要一个文件夹下所有子 object 的名称、类型和内容均相同 ,则其 对应的 tree object 就能得到复用 .
反之,一个文件只要内容发生了变化,但凡只是加了一行注释,或者作了一个字符的修改,最终也会冗余生成一个全新独立的 blob object. 3.8 branch
梳理清楚版本链的概念后,再理解分支的概念就很轻松了.
我们可以把分支 branch 理解为一条独立的 commit 版本链( 每次拉分支就是在 commit 链上进行分叉 ) , branch HEAD 体现为在 commit 版本链上移动的指针 ,其指向了分支链上某个特定 commit object 的 key.
我们在参与团队协作时,应该要充分利用分支的特性,因为我们在切换分支或者重置分支 commit id 时,本质上只是在作指针的创建和移动,因此成本是很低的. 分支的特性也正是 git 中最亮眼的设计.
4 git 实用指令分享
本章会向大家介绍几个我个人觉得比较实用的 git 指令,整体算是偏进阶的一些操作指令. 4.1 git log --graph
首先来一道开胃小菜,相信大家都不会对 git log 指令感到陌生,它能帮助我们罗列出当前分支下 commit 链的概要.
然而如前文所介绍, 分支与分支之间是可能存在分叉和合并的拓扑关系的,比如在执行 checkout -b {new branch} 或者 merge {new branch} 操作 时, 版本链可能演化成分叉并交汇的模型 . 此时我们可以在 git log 基础上 添加上 ——graph 和 ——oneline 的子参数 ,以树状单行的形式更清晰直观地展示 commit 链的拓扑结构.
git log --graph --oneline |
以 2.7 小节中执行过 merge 操作的 master 分支为例,对应输出对应的版本链拓扑结构内容为:
git log --graph --oneline
* 8e4b529 (HEAD -> master) Merge branch 'test'
|\
| * a24e6d8 (test) second commit
* | dfa7be2 second commit
|/
* 3a3ad28 first commit |
对照下图,可以看到其很好地还原了 master 分支与 test 分支之间分叉和聚合的拓扑结构:
4.2 git merge 与 git rebase
接下来介绍的是我们在分支管理中,用来合并不同分支版本链是最常用的两个指令:git merge 和 git rebase.
• git merge
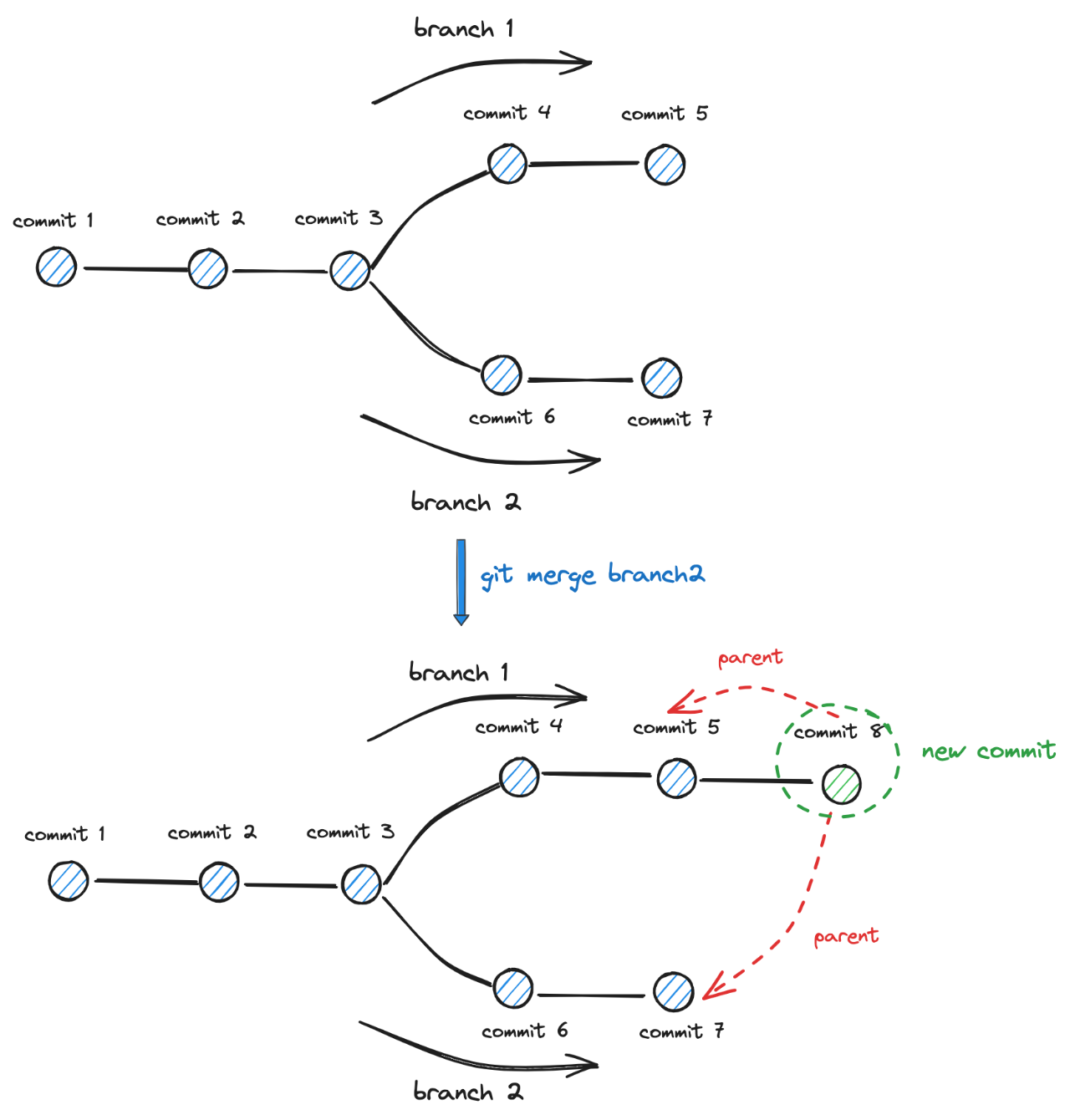
git merge 对应为 分支的合并操作 ,以下述流程示例加以说明:
• 背景是:我们有 branch1 和 branch2 两个分支;两个分支 公共 commit 祖先为 commit1、commit2、commit3 ; branch1 独有的 commit 为 commit4、commit5 ; branch2 独有的 commit 为 commit6、commit7 .
• 接下来切换到 branch1, branch HEAD 指向 commit5 ,然后执行 git merge branch2 指令
• 最后得到的结果是在 branch1 commit5 的基础上 新生成了一个 commit8 ,其汇总了本次合并操作所涉及到的 branch2 的变更内容,并且有 两个 parent 指针 同时 指向 branch1 commit5 和 branch2 commit7
git checkout branch 1
git merge branch2 |
执行完 merge 操作后,在 branch1 下执行 git log 指令后得到的信息如下所示,可以看到与上面的示意图是一一对应的:
git log --oneline --graph
* b79e36c (HEAD -> master) commit 8
|\
| * 9a75b57 (branch2) commit 7
| * fad3156 commit 6
* | c440186 commit 5
* | 3d1198d commit 4
|/
* 5845278 commit 3
* 10f4b01 commit 2
* 0d3a41d commit 1 |
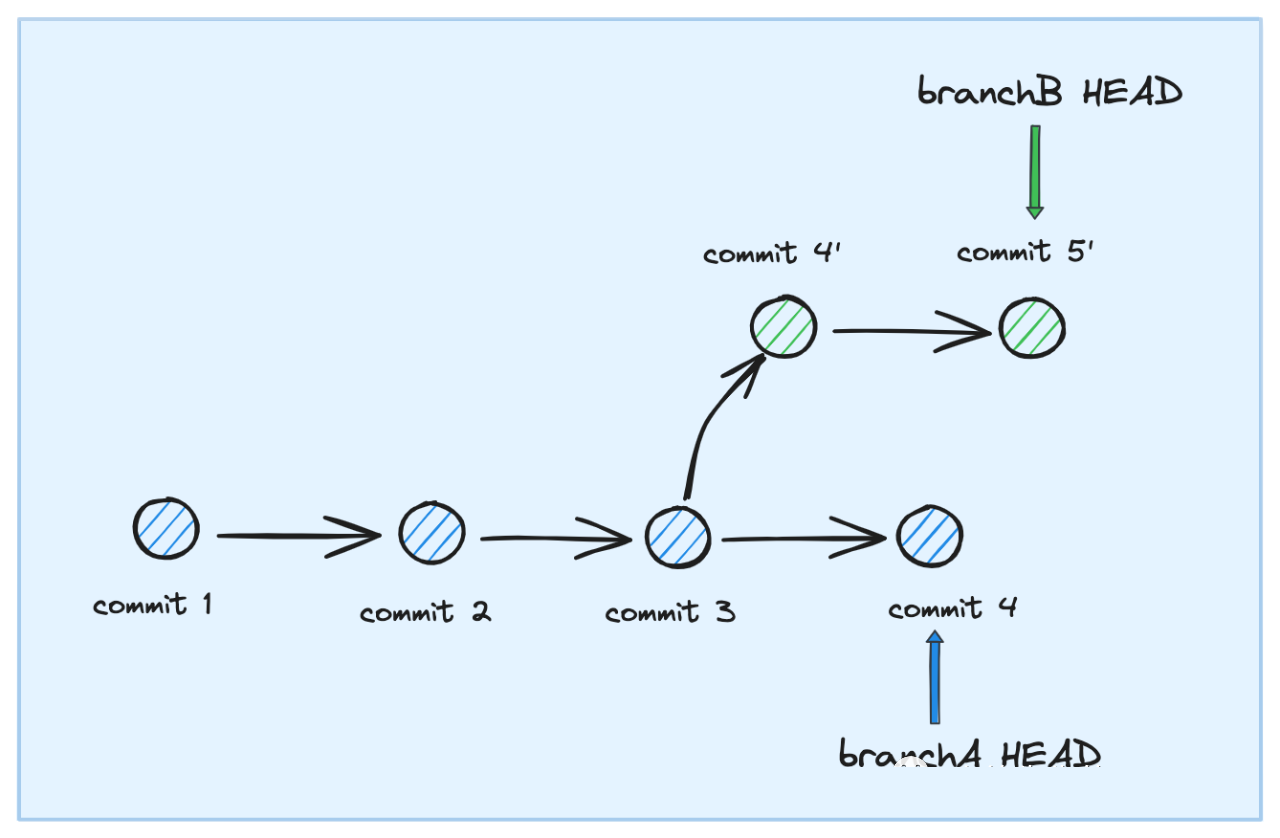
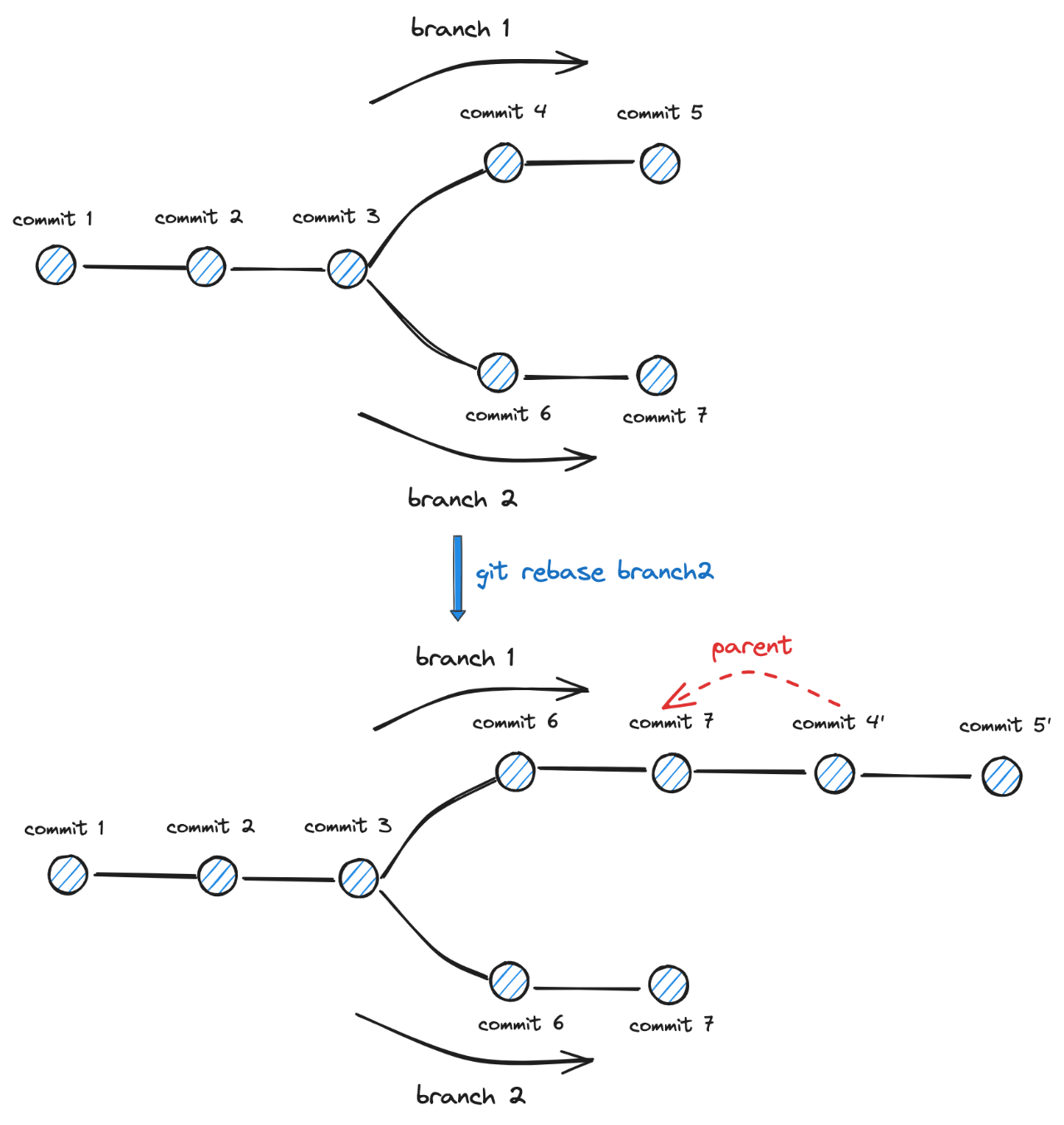
git rebase 对应为分支的 变基操作 ,以下面的流程图加以示意:
• 背景是:我们有 branch1 和 branch2 两个分支;两个分支 公共 commit 祖先为 commit1、commit2、commit3 ; branch1 独有的 commit 为 commit4、commit5 ; branch2 独有的 commit 为 commit6、commit7 .
• 接下来切换到 branch1, branch HEAD 指向 commit5 ,然后执行 git rebase branch2 指令
• 最后得到的结果是在 branch1 会复用 branch2 的 commit6 和 commit7 作为基点, 然后将对应于 commit4 和 commit5 的两次提交挂载在 commit7 之后 . 需要强调的是,执行完 rebase 操作后,新追加的两个 commit 应该称为 commit4' 和 commit5' 更为合适一些,虽然其提交的内容和 commit4、commit5 相同,但此时需要和 commit6、commit7 进行合并并解决可能存在的冲突,且其指向的 parent 也由 commit3 变为了 commit7 ,因此本质上是两批独立的 commit.
执行完 rebase 操作后,下面在 branch1 下执行 git log 指令,展示结果和上图一致:
git log --oneline --graph
* 19b585d (HEAD -> master) commit 5'
* 64c93c4 commit 4'
* 9a75b57 (branch2) commit 7
* fad3156 6th commit 6
* 5845278 3rd commmit 3
* 10f4b01 2nd commit 2
* 0d3a41d 1st commit 1 |
在 rebase 过程中,倘若变基操作发生冲突,可以在手动修复冲突后 执行 git add/rm 操作 后,进一步执行 rebase continue 指令 推进 rebase 流程:
倘若 rebase 过程中发生错误,需要 回滚本次操作 ,可以 执行 abort 操作 进行回滚:
至此我们做一轮小结:
git merge 和 git rebase 都能实现分支之间合并交互的效果,但是团队协作时大家往往比较 推崇使用 rebase 指令胜过 merge 指令 ,主要原因在于:
• 相比于 merge 操作后形成环状交汇的版本链, rebase 操作 后的 版本链仍保持为单向链表 ,更加清爽直观
• rebase 还支持 git rebase -i 的交互式变基操作 ,可以提供更加灵活的变基功能,这部分我们在 4.3 小节中展开 4.3 交互式 git rebase
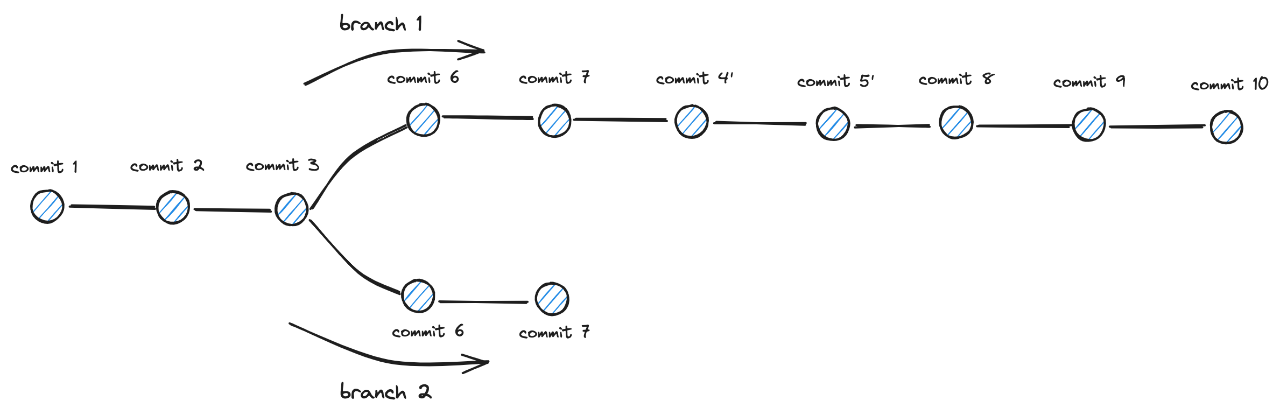
下面我们演示一下交互式 rebase 操作的效果.
首先,我们以 4.2 小节执行完 rebase 操作操作后的 branch1 作为起点,依次追加三笔提交如下所示:
echo 8 > 8.txt
git add 8.txt
git commit -m "commit 8"
echo 9 > 9.txt
git add 9.txt
git commit -m "commit 9"
echo 10 > 10.txt
git add 10.txt
git commit -m "commit 10" |
此时 branch1 和 branch2 的版本链拓扑关系如下图所示:
在此基础上,我们对 branch1 执行交互式 rebase 操作指令:
交互变基的过程 会自动打开 vim 模式 ,让用户能够手动编辑变基过程中所涉及到的一系列 commit:
• pick commit:正常使用一个 commit
• squash commit:压缩一个 commit
• drop commit:弃用一个 commit
此过程中我们 vim 修改各 commit 之前的关键字,执行指令如下所示:
pick 64c93c4 commit 4 #
squash 19b585d commit 5 # squash,将 commit 5 和 commit 4 合并成一个 commit,以 commit 4 作为代表
drop dabda0e commit 8 # drop,丢弃 commit 8
pick 32d3ec6 commit 9
pick 7a58d7c commit 10
# Rebase 9a75b57..7a58d7c onto 9a75b57 (5 commands)
#
# Commands:
# p, pick <commit> = 使用某个 commit
# s, squash <commit> = 自该 commit 向前进行压缩操作
# d, drop <commit> = 移除某个 commit |
完成上述交互变基操作后,branch1 对应的版本链结构对应如下图所示:
进一步执行 git log 指令加以佐证,发现变基效果是符合预期的:(commit4、commit5 实现了压缩;commit8 被丢弃了)
git log --oneline --graph
* 0c3d861 (HEAD -> master) 10th
* 2c4d722 9th
* 5685f7e 4th
* 9a75b57 (branch2) 7th
* fad3156 6th
* 5845278 3rd
* 10f4b01 2nd
* 0d3a41d 1st |
4.4 git cherry-pick
cherry-pick 直译为 【摘樱桃】 ,指的是在像摘取樱桃一样轻松地获取到一个个 commit 对象并将其延伸到当前分支的尾部:
下面我们演示一下 cherry-pick 具体效果.
在 4.3 小节的基础上,我们首先切换到 branch2 分支:
接下来执行 cherry-pick 指令,一次性 摘取 branch1 当中的 commit4'‘、commit9、commit10 三个 commit, 延伸追加到 branch2 的尾部 :
git cherry-pick 5685f7e .. 0c3d861 |
执行上述 cherry-pick 操作前后,branch2 分支拓扑结构的变化示意如下图所示:
需要注意的是,摘取后延伸到 branch2 尾部的 commit4‘'‘、commit9'、comit10‘ 相较于 branch1 中的 commit4'‘、commit9、commit10 也分别是独立的 commit 对象 ,原理同 4.2 小节.
git log --oneline --graph
* 4bf9f47 (HEAD -> branch2) 10th
* 445e4ab 9th
* 4164373 4th
* 9a75b57 7th
* fad3156 6th
* 5845278 3rd
* 10f4b01 2nd
* 0d3a41d 1st |
在 git cherry-pick 的过程很可能会发生 内容冲突 ,此时需要 手动修复冲突,通过 git add/rm 指令 将修复后的内容进行添加或者移除,并在此之后 执行 continue 指令 继续推进 cherry-pick 进程:
git cherry-pick --continue |
倘若本次 cherry-pick 操作需要 回滚,执行 abort 指令 即可:
5 总结
至此艺术已成!最后我们回过头,对本期所探讨的内容做一轮总结:
• git 底层存储介质是一个 kv 数据库,key 是基于 value 通过 SHA-1 算法生成的摘要字符串
• git kv 数据库中包含 3 类 object,commit、tree、blob:
• blob object:与仓库下的一个文件一一对应. value 是文件内容,key 是哈希摘要
• tree object:与仓库的一个文件夹一一对应. value 是文件夹下的子 object 信息,key 是哈希摘要
• commit object:与一次提交行为一一对应. value 包含了前一次提交的 key(parent);整个仓库文件夹的 key(tree);以及提交行为信息(committer、note 等)
• 所谓【git版本控制】,概念拆解后得到:
• 其中的【版本】,对应为一次提交行为及其生成的 commit object
• 其中的【版本控制】,是在基于 commit 版本链的基础上进行延伸、修改和移动操作
• 【版本控制】过程中的复用策略是,能复用所有 value 值未发生变化的 object
• 最后,向大家重点介绍了 git rebase 和 git cherry-pick 两个实用的操作指令,希望能对大家有所帮助
|






 订阅
订阅