| БрМЭЦМі: |
| БОЮФРДдДcsdnЃЌвЛПЊЪМзлКЯНВЪіСЫвЛЯТЃЌНгзХНВНтСЫЖЅВуЩшМЦЃЌШежОЪеМЏЕШЁЃ |
|
1ЁЂИХЪі
дкЮвПЊЪМЙЙЫМетМИЦЊЙигкЁАздМКЖЏЪжЩшМЦESBжаМфМўЁБЕФЮФеТЪБЃЌдјгаКУМИДЮЖЏЙ§ЗХЦњЕФФюЭЗЁЃдвђЕЙВЛЪЧвђЮЊЖдШпГЄЕФЮФеТВњЩњСЫЖшадЃЌЖјЪЧESBжаЫљЩцМАЕНЕФММЪѕжЊЪЖКЭашвЊЭЛЦЦЕФЩшМЦФбЕуЪЕдкЪЧБШНЯЖрЃЌдйШпГЄЕФМИЦЊВЉЮФЩѕжСЮоЗЈЖдЫќУЧШЋВПНјааИХЪіЃЌСэЭтШчЙћдкЫМТЗЩЯЩдЮЂгавЛЕуВюГиОЭЛсЮѓЕМЖСепЁЃвЛИіПЩвдЮШЖЈЪЙгУЕФESBжаМфМўФ§ОлСЫвЛИіЭХЖгКмЖрВЮгыепЕФаФбЊЃЌвЛИіШЫПЯЖЈЪЧЮоЗЈЭъГЩетаЉЙЄзїЕФЁЃЕЋЪЧБЪепЫМЫїдйШ§ЃЌЛЙЪЧЯТОіаФНЋететМДБуЮФеТЭъГЩЃЌвђЮЊетЪЧЖдБОзЈЬтДгЕк19ЦЊЮФеТЕНЕк39ЦЊЮФеТжаЫљНщЩмЕФжЊЪЖЕуЕФзюКУЕФзмНсЁЃЮвУЧздМКЖЏЪжЩшМЦESBжаМфМўЃЌВЛЪЧЮЊСЫШУЫќЩЬгУЃЌвВВЛЪЧЮЊСЫШУЫќПЩвдБШФтЪаУцЩЯФГПюESBжаМфМўЃЌЩѕжСВЛЪЧЮЊСЫАбESBжаЕФММЪѕФбЕуЕФНтОіШЋВПЗНАИЛЏЁЃЮвУЧЕФФПЕФЪЧМьбщећИізЈЬтжаЫљНщЩмЕФжЊЪЖЕуЪЧЗёФмдкЖСепздМКЯћЛЏКѓНјаазлКЯгІгУЃЌЪЧЗёФмзіЕНММЪѕжЊЪЖЕФЛюбЇЛюгУЁЂАДашбЁаЭЁЃ
2ЁЂESBЕФЖЅВуЩшМЦ

ЃЈЖЅВуЩшМЦЭМЃЉ
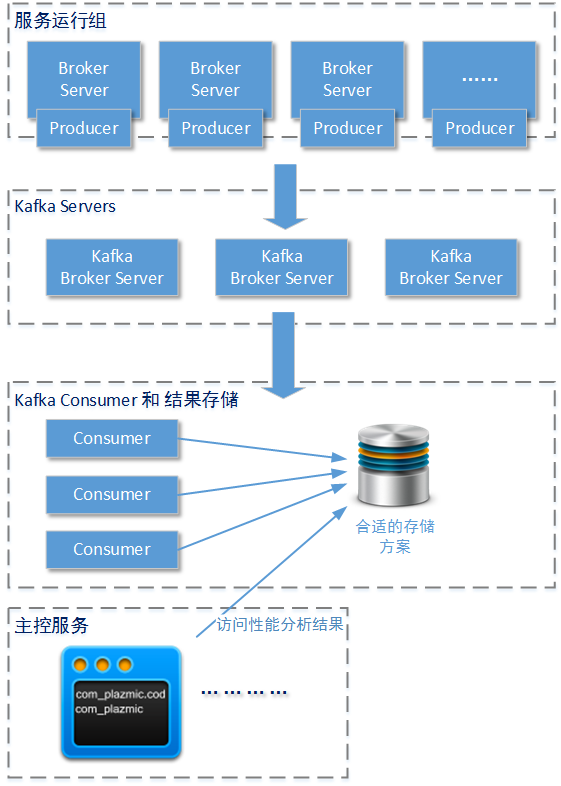
ЩЯЭМЪЧЮвУЧвЊНјааЪЕЯжЕФESBжаМфМўЕФЖЅВуЩшМЦЁЃДгЩЯЭМжаПЩвдПДЕНЃЌећИіESBжаМфМўЗжЮЊвдЯТМИИіФЃПщЃКClientПЭЛЇЖЫЁЂСїГЬБрХХ/зЂВсЙЄОпЁЂжїПиЗўЮёФЃПщЁЂЗўЮёзДЬЌаЕїзщЃЈФЃПщЃЉЁЂЗўЮёдЫаазщЃЈФЃПщЃЉЁЃЪзЯШЮвУЧДѓжТУшЪівЛЯТетаЉФЃПщЕФЙЄзїФкШнЃК
ClientПЭЛЇЖЫЪЧашвЊНгШыESBжаМфМўЕФИїИівЕЮёЗўЮёЯЕЭГЁЃР§ШчЮяСїЯЕЭГЁЂСЊеЫЯЕЭГЁЂCRMЯЕЭГЕШЕШЁЃдкетаЉПЭЛЇЖЫЯЕЭГНгШыESBжаМфМўЪБЃЌНЋМЏГЩESBжаМфМўЬсЙЉИјЫћУЧЕФИїжжПЊЗЂгябдАцБОЕФESB-ClientзщМўЁЃШчЙћЪЙгУЕФЪЧC#гябддђESB-ClientзщМўПЩФмвдDLLЮФМўЕФЗНЪНЬсЙЉЃЛШчЙћЪЙгУЕФЪЧJAVAгябддђESB-ClientзщМўПЩФмвдJarЮФМўЕФЗНЪНЬсЙЉЃЛШчЙћЪЙгУЕФЪЧNODEJSдђПЩФмЪЧвЛИіЃЈЛђЖрИіЃЉJSЮФМўЁЁ
етаЉПЭЛЇЖЫЯЕЭГЕФПЊЗЂШЫдБНЋПЩвдЪЙгУESBжаМфМўЬсЙЉЕФвЛИіЖРСЂЕФСїГЬБрХХ/зЂВсЙЄОпЃЌКѓепдкКмЖрESBжаМфМўЯЕЭГжавЛАуБЛУќУћЮЊЁАЁЁ
StudioЁБЃЌВЂЧветаЉСїГЬБрХХ/зЂВсЙЄОпвЛАувдИїжжIDEВхМўЕФаЮЪНЬсЙЉГіРДЃЌР§ШчжЦзїГЩEclipse-PluginЬсЙЉИјПЊЗЂШЫдБЁЃетаЉЙЄОпЕФжївЊзїгУОЭЪЧШУПЭЛЇЖЫЯЕЭГЕФПЊЗЂШЫдБЃЈПЊЗЂЭХЖгЃЉОпБИЯђESBжїПиЗўЮёНјаадзгЗўЮёзЂВсЕФФмСІЃЌСэЭтЛЙПЩвдШУПЊЗЂШЫдБВщбЏЕНФПЧАЗўЮёЖЫЫљгаПЩгУЕФЦфЫќдзгЗўЮёЃЈРДздгкЦфЫќвЕЮёЯЕЭГЕФЃЉЃЌвдБудкСїГЬБрХХ/зЂВсЙЄОпЩЯЭъГЩаТЕФЗўЮёСїГЬБрХХКЭвбгаЗўЮёСїГЬаТАцБОЕФЗЂВМЁЃетОЭЪЧЩЯЭМжаБъзЂЮЊЁА1ЁБЕФВНжшЁЃ
СэЭтESBжаМфМўЮЊСЫБЃжЄСїГЬБрХХЫљЪЙгУЕФдзгЗўЮёВЛЛсвђЮЊЬсЙЉетИідзгЗўЮёЕФвЕЮёЯЕЭГЕФБфЛЏЖјВњЩњгАЯьЃЌвЛАуРДЫЕдкНјаавЕЮёЯЕЭГзЂВсдзгЗўЮёЪБЖМЛсжИЖЈетИідзгЗўЮёЕФАцБОКЭЕїгУШЈЯоЁЃЕїгУШЈЯовЛАугжЗжЮЊКкУћЕЅШЈЯоКЭАзУћЕЅШЈЯоЁЃвдАзУћЕЅШЈЯоРДЫЕЃЌжЛгаАзУћЕЅжаЫљСаСаОйЕФвЕЮёЯЕЭГгаШЈЯоЕїгУетИідзгЗўЮёЁЃМДЪЙетИідзгЗўЮёВЮгыСЫФГИіESBжаЕФСїГЬБрХХЃЌШчЙћЧыЧѓетИіБрХХКУЕФСїГЬЕФвЕЮёЯЕЭГВЛдкетИіАзУћЕЅжаЃЌЕїгУвВЛсЪЇАмЁЃ
жїПиЗўЮёЮЊСїГЬБрХХ/ЗЂВМЙЄОпЬсЙЉаТЕФдзгЗўЮёзЂВсЧыЧѓЁЂаТЕФСїГЬЗЂВМЧыЧѓЁЂвбгаСїГЬЕФаТАцБОЗЂВМЧыЧѓЁЃзюаТЕФдзгЗўЮёЁЂСїГЬБрХХЕШЪ§ОнНЋЛсБЛжїПиЗўЮёДцДЂдкГжОУЛЏШнЦїжаЃЈР§ШчЙиЯЕаЭЪ§ОнПтЃЉЃЌВЂЧвЯђЁАЗўЮёзДЬЌаЕїФЃПщЁБЗЂЫЭзюаТЕФЪ§ОнБфЛЏЁЃзЂвтЃЌжїПиЗўЮёВЂВЛИКд№жДааБрХХКУЕФСїГЬЃЌжЛЪЧгУгкМЧТМЪ§ОнБрХХЕФБфЛЏКЭЯђЁАЪ§ОнаЕїФЃПщЁБЗЂЫЭетаЉЪ§ОнБфЛЏЃЌетОЭЪЧЩЯЭМжаЫљБъЪОЕФВНжш2ЁЃжїПиЗўЮёЛЙгаСэЭтСНИізїгУЃКИКд№ШЈЯоЙмРэКЭЗўЮёдЫааФЃПщЕФзДЬЌМрПиЁЃ
гЩгкИКд№зюжеЖдСїГЬБрХХНјаажДааЕФЁАЗўЮёдЫааФЃПщЁБДцдкКмЖрНкЕуЃЈЯТЮФГЦЮЊESB-Broker ServerНкЕуЃЉЃЌЧветаЉESB-Broker
ServerНкЕуЕФЪ§СПдкЗўЮёЙ§ГЬжаЛсВЛЖЯБфЛЏЃЈаТдіЛђМѕЩйЃЉЃЌЫљвдЁАжїПиЗўЮёЁБВЂВЛжЊЕРгаФФаЉBokerдкдЫааЁЃЮЊСЫЭЈжЊетаЉдкдЫаазДЬЌЕФBrokerгааТЕФЗўЮёБрХХБЛЗЂВМЃЈЛђепЦфЫќЪТМўаХЯЂЃЉЃЌетаЉДІгкдЫаазДЬЌЕФESB-Broker
ServerНкЕуЖМЛсСЌНгЕНЁАЗўЮёзДЬЌаЕїФЃПщЁБЃЌВЂЧвгЩКѓепЭъГЩЪ§ОнБфЛЏЕФЪТМўЭЈжЊЁЃетОЭЪЧЁАЗўЮёзДЬЌаЕїФЃПщЁБЕФжївЊЙІФмЃЌвВЪЧЩЯЭМжаЫљЪОЕФВНжш3ЁЃдкЮвУЧздМКЩшМЦЕФESBжаМфМўжаЃЌЁАЗўЮёзДЬЌаЕїФЃПщЁБгЩвЛзщzookeeperЗўЮёЙЙГЩЃЈдкЮвСэЭтМИЦЊВЉЮФжазЈУХНщЩмzookeeperЃЌетИізЈЬтОЭВЛЖдzookeeperЕФЛљБОВйзїНјааНВНтСЫЃЉЃЌШчЙћФњдкЪЕМЪЕФЙЄзїжагаЦфЫќЙІФм/ММЪѕашЧѓЃЌвВПЩвдздМКЩшМЦЁАЗўЮёзДЬЌаЕїФЃПщЁБЁЃ
дквЕЮёЯЕЭГМЏГЩЙ§ГЬжаЃЌESBжаМфМўЫљАчбнЕФНЧЩЋОЭЪЧдкИїИівЕЮёЯЕЭГМфНјаадзгЗўЮёЕїгУЁЂзЊЛЛЪ§ОнЁЂдйНјааддђЗўЮёЕїгУЁЂдйзЊЛЛЁЁ.зюКѓЯђжДааЗўЮёБрХХЕФЧыЧѓепЗЕЛиНсЙћЁЃЫљвдESBжаМфМўЗўЮёЭљЭљгаНЯИпЕФадФмвЊЧѓЁЃШчЙћжДааESBЗўЮёБрХХЕФНкЕужЛгавЛИіЃЌЭљЭљОЭДяВЛЕНESBжаМфМўЕФЩшМЦвЊЧѓЩѕжСЛсЪЙESBжаМфМўЗўЮёГЩЮЊећИіШэМўМмЙЙЕФадФмЦПОБЕуЁЃЫљвддкЮвУЧЩшМЦЕФESBжаМфМўжаЃЌеце§жДааESBЗўЮёЕФНкЕуЛсгаЖрИіетжжESB-Broker
ServerНкЕуЁЃ
дкESBдЫааЗўЮёЕФЙ§ГЬжаЪЙгУЖрИіBroker ServerгаКмЖрКУДІЃЌЪзЯШРДЫЕЫќУЧПЩвдБЃжЄдкећИіЯЕЭГГіЯжЧыЧѓКщЗхЕФЧщПіЯТЃЌФмЙЛАбетаЉЧыЧѓбЙСІЦНОљЗжХфЕНетаЉBroker
ServerНкЕуЩЯЃЌзюжеЪЙESBЗўЮёВЛЛсГЩЮЊећИіЖЅВуЩшМЦЕФЦПОБЁЃЧыЧѓбЙСІЕФЗжХфЙЄзїЛсгЩzookeeperМЏШКЭъГЩЁЃСэЭтЃЌЖрИіBroker
ServerПЩвдБЃжЄФГвЛИіЃЈЛђепМИИіЃЉBroker ServerНкЕудкГіЯжвьГЃВЂЭЫГіЗўЮёКѓЃЌећИіESBжаМфМўЕФЗўЮёВЛЛсЭЃжЙЁЊЁЊетЪЧвЛИіЯжГЩЕФШнДэЗНАИЁЃПЊЗЂШЫдБПЩвдЭЈЙ§ЭЫБмЫуЗЈРДОіЖЈESB-ClientЯТвЛДЮЪдЭМЗУЮЪГіЯжДэЮѓЕФBroker
ServerНкЕуЕФЪБМфЃЌвВПЩвдСЂМДЮЊESB-clientжиаТЗжХфвЛИіНЁПЕЕФBroker ServerНкЕуЁЃзюКѓЃЌетИіНтОіЗНАИПЩвддкESBЗўЮёдЫааЕФЙ§ГЬжаБЃжЄЪЕЯжBroker
ServerЕФЖЏЬЌКсЯђРЉеЙЃКЕБESBжїПиЗўЮёФЃПщЗЂЯжећИіBroker ServerЗўЮёзщЕФадФмДяЕНЃЈЛђПьвЊДяЕНЃЉЗхжЕЪБЃЌдЫЮЌШЫдБПЩвдТэЩЯПЊЦєаТЕФBroker
ServerНкЕуЃЌzookeeperМЏШКЛсИКд№НЋЖЈжЦЕФБрХХЁЂЖЈжЦЕФProcessorДІРэЦїЕШЪ§ОнаХЯЂЖЏЬЌМгдиЕНаТЕФBroker
ServerНкЕужаЃЌВЂШУКѓепСЂМДМгШыећИіЗўЮёзщПЊЪМЙЄзїЁЃ
дкESB-ClientЃЈФГИівЕЮёЯЕЭГЃЉЧыЧѓжДааФГИіЗўЮёБрХХЪБЃЌЪзЯШЛсЪЙгУетИіESB-ClientЃЈФГИівЕЮёЯЕЭГЃЉвбОМЏГЩЕФzookeeperПЭЛЇЖЫЧыЧѓESBЕФzookeeperМЏШКЗўЮёЃЌДгжаШЁЕУЕБЧАе§дкдЫааЕФBroker
ServerНкЕуаХЯЂЃЌВЂЭЈЙ§ФГжжЫуЗЈОіЖЈздМКЗУЮЪФФвЛИіBroker ServerНкЕуЃЈЫуЗЈКмЖрЃКТжбЏЫуЗЈЁЂМгШЈЫуЗЈЁЂвЛжТадHashЫуЗЈЕШЕШЃЉЃЌШчЁАЖЅВуЩшМЦЭМЁБжаВНжш4ЁЂВНжш5ЫљЪОЁЃЮЊСЫБЃжЄЩЯЮФжаЬсЕНЕФаТЕФBroker
ServerНкЕуФмЙЛМгШыЗўЮёзщВЂЮЊClientESB-ClientЗўЮёЃЌВНжш4КЭВНжш5ЕФЙ§ГЬПЩвджмЦкадНјааЃЌВЂЪгЧщПіжиаТЮЊESB-ClientЗжХфBroker
ServerНкЕуЁЃ
ЕБESB-ClientШЗЖЈФПБъBroker ServerНкЕуКѓЃЌНЋе§ЪНЯђетИіBroker ServerЗЂЦ№жДааФГИіЗўЮёБрХХЕФЧыЧѓЁЃЕБЭЌвЛИіESB-ClientЕкЖўДЮЧыЧѓжДааЗўЮёБрХХЪБЃЌОЭПЩвддквЛЖЈЪБМфжмЦкФкЃЈгааЇЪБМфФкЃЉВЛдйзпВНжш4ЁЂ5СЫЃЌЖјПЩвджБНгЗЂЦ№ЧыЧѓЕНЭЌвЛИіФПБъBroker
ServerНкЕуЁЃжБЕНетИіBroker ServerВЛдйФмЙЛЯьгІетаЉЧыЧѓЮЊжЙЃЈЛђепгаЦфЫќвРОнШЗЖЈетИіBroker
ServerНкЕувбОВЛФмЬсЙЉЗўЮёЃЉЃЌESB-ClientЛсдйжДааВНжш4ЁЂ5ЃЌвдБуШЗЖЈСэвЛИіаТЕФЁЂе§ГЃЙЄзїЕФBroker
ServerНкЕуЁЃдкЯТЮФБЪепвВЛсжиЕуНщЩмШчКЮНјааBroker ServerНкЕуЕФбЁдёЁЃ
3ЁЂжїПиЗўЮёЕФШежОЪеМЏ
ЩЯвЛНквбОЫЕЕНЃЌдкЮвУЧЩшМЦЕФESBжаМфМўжаАќРЈСНИіФЃПщЃКжїПиЗўЮёФЃПщКЭЗўЮёдЫаазщЃЈФЃПщЃЉЁЃЦфжажїПиЗўЮёФЃПщЕФЦфжавЛИізїгУЃЌЪЧЖдШєИЩЕБЧАДІгкдЫаазДЬЌЕФЗўЮёдЫаазщНкЕуЃЈBroker
ServerЃЉНјааадФмзДЬЌМрПиЁЃадФмзДЬЌМрПиЕФФПЕФЪЧШЗБЃдЫЮЌШЫдБЪЕЪБСЫНтетаЉBroker ServerЕФдЫаазДЬЌЃЌВЂЧвФмдкећИіЗўЮёдЫаазщПьвЊДяЕНадФмЦПОБЪБФмЙЛЦєЖЏаТЕФBroker
ServerЗжЕЃбЙСІЛђепдкећИіЗўЮёдЫаазщУЛгаЪВУДЧыЧѓИКЕЃЪБЃЌЭЃжЙвЛаЉBroker ServerЁЃ
ФЧУДжїПиНкЕуШчКЮжЊЕРећИіBroker ServerзщжаЖрИіЗўЮёНкЕуЕФадФмзДЬЌФиЃПвЊжЊЕРЃЌBroker
ServerНкЕуЪЧПЩвдЖЏЬЌРЉеЙЕФЁЃЩЯЮФвВвбОЫЕЕНЃКжїПиНкЕуВЂВЛжЊЕРЕБЧАгаФФаЉBroker ServerНкЕуДІгкдЫаазДЬЌЁЃФЧУДЛљгкKafkaЯћЯЂЖгСаЕФШежОЪеМЏОЭЪЧвЛИіНтОіЗНАИЃЌЩшМЦШЫдБЛЙПЩвдЪЙгУFlume
+ StormЕФНтОіЗНАИНјааШежОздЖЏЪеМЏКЭМДЪБЗжЮіЁЃЯТУцЮвУЧЖдетСНжжШежОЪеМЏЗНАИНјааНщЩмЁЃзЂвтЃЌЙигкKafkaЁЂFlumeдкетИізЈЬтжЎЧАЕФЮФеТжавбОзіСЫЯъЯИНщЩмЃЌЫљвдБОаЁНкжаЩцМАKafkaЁЂFlumeММЪѕЕФВПЗжОЭВЛдйЖдЩшМЦЗНАИЕФЪЕЪЉНјааНщЩмСЫЁЃ
3-1ЁЂЪЙгУKafkaЪеМЏадФмЪ§Он
Kafka ServerЕФЬиЕуОЭЪЧПьЃЌЫфШЛдкЬиЖЈЕФЧщПіЯТKafka ServerЛсГіЯжЯћЯЂЖЊЪЇЛђжиИДЗЂЫЭЕФЮЪЬтЃЌЕЋЪЧетИіЮЪЬтеыЖдШежОЪ§ОнЪеМЏГЁОАРДЫЕВЛЫуДѓЮЪЬтЁЃЪЙгУЯћЯЂЖгСаЪеМЏИїBroker
ServerНкЕуЕФадФмШежОвВЪЧКЭESBжаИїФЃПщЕФвРРЕЬиадЯрЪЪгІЕФЃКгЩгкдкЮвУЧЩшМЦЕФESBжаМфМўжаЃЌжїПиЗўЮёФЃПщВЂВЛжЊЕРгаЖрЩйBroker
ServerНкЕуДІгкдЫаазДЬЌЃЌвВВЛжЊЕРетаЉBroker ServerНкЕуЕФIPЮЛжУЁЃвВОЭЪЧЫЕжїПиЗўЮёФЃПщЮоЗЈжїЖЏШЅетаЉBroker
ServerНкЕуЩЯЪеМЏадФмЪ§ОнЁЃзюКУЕФАьЗЈОЭЪЧгЩетаЉЛюЖЏЕФBroker ServerНкЕужїЖЏЗЂЫЭШежОЪ§ОнЁЃ
3-1-1ЁЂЩшМЦЫМТЗ
ЯТЭМЪЧЪЙгУKafkaзщМўЪеМЏBroker ServerНкЕуЩЯадФмЪ§ОнВЂНјааадФмЪ§ОнДІРэЁЂНсЙћДцДЂЕФЩшМЦЪОР§ЭМЃК
ЩЯЭМжаЃЌУПвЛИіBroker ServerНкЕуЩЯГ§СЫЦєЖЏвЛИіCamel ContextЪЕР§вдЭтЃЈКѓЮФНјааЯъЯИЫЕУїЃЉЃЌЛЙашвЊХфжУвЛИіKafkaЕФProducerЖЫгУгкЗЂЫЭЪ§ОнЁЃKafka-ProducerЖЫЪеМЏЕФадФмЪ§ОнПЩФмАќРЈЃКCPUЪЙгУЧщПіЁЂФкДцЪЙгУЧщПіЁЂБОЕиI/OЫйЖШЁЂВйзїЯЕЭГЯпГЬЧщПіЁЂCamel
ContextжаЕФТЗгЩЪЕР§зДЬЌЁЂEndpointдкCacheжаЕФУќжаЧщПіЁЂПЭЛЇЖЫЖдBroker ServerжавдБрХХТЗгЩЕФЕїгУЧщПіЕШЕШЁЊЁЊвЕЮёЪ§ОнКЭЗЧвЕЮёЪ§ОнЖМПЩвдЭЈЙ§етжжЗНЪННјааМрПиЃЌВЂЧввдвЕЮёЪ§ОнЮЊжїЁЃ
Kafka ServersжаВПЪ№СЫШ§ИіKafka Broker ServerНкЕуЃЈНЈвщЕФжЕЃЉЃЌгУгкНгЪеШєИЩESB
Broker ServerНкЕуЩЯИїИіKafka-ProducerЗЂЫЭРДЕФадФмШежОЪ§ОнЁЃЮЊСЫБЃжЄећИіKafkaМЏШКЕФадФмЃЌУПвЛИіKafka
Broker ServerЖМгажСЩйСНИіЗжЧјЃЈpartitionЃЌЛЙЪЧНЈвщжЕЃЉЁЃетРяЖрЫЕвЛОфЃЌЮЊСЫНкдМЗўЮёзЪдДФњПЩвдНЋKafka
Broker ServerКЭKafka-ConsumerЗХдквЛЬЈЗўЮёНкЕуЩЯЃЌЩѕжСПЩвдНЋЫќУЧКЭжїПиЗўЮёНкЕуЗХдквЛЦ№ЁЃ
Kafka-ConsumerИКд№НјааадФмШежОЪ§ОнЕФДІРэЁЃгаЕФЖСепПЩФмОЭвЊЮЪСЫЃЌМШШЛConsumerНгЪеЕНЕФЖМЪЧПЩвдЖРСЂДцДЂадФмШежОЪ§ОнЃЌФЧУДжЛашвЊНЋетаЉШежОевЕНвЛИіКЯЪЪЕФДцДЂЗНАИЃЈР§ШчHBaseЃЉДцЗХЦ№РДОЭПЩвдСЫЃЌЛЙашвЊConsumerзіЪВУДДІРэФиЃПетЪЧвђЮЊПЊЗЂЭХЖгЭъГЩЕФProducerВЩбљЦЕТЪПЩФмКЭдЫЮЌЭХЖгвЊЧѓЕФМрПиВЩгУЦЕТЪВЛвЛбљЁЃ
ЮЊСЫБЃжЄадФмМрПиЪ§ОнЕФОЋзМадЃЌПЊЗЂЭХЖгРћгУЛљгкKafkaМЏШКЬсЙЉЕФЭЬЭТСПгХЪЦЃЌПЩвддкИїИіESB Broker
ServerНкЕуЫљМЏГЩЕФKafka-ProducerЩЯЩшжУвЛИіНЯИпЕФВЩбљТЪЃЈЕБШЛЛЙЪЧвЊЙЫМЩНкЕуБОЩэЕФзЪдДЯћКФЃЉЃЌР§ШчУПУыЖдЙЬЖЈЕФвЕЮёжИБъКЭЗЧвЕЮёжИБъЭъГЩ10ДЮВЩбљЁЃЕЋЪЧдЫЮЌЭХЖгЭЈЙ§жїПиЗўЮёМрПиИїИіESB
Broker ServerНкЕуЪЧЃЌЭљЭљВЛашвЊетУДИпЕФВЩбљТЪЃЈетРяПЩвдЬсЙЉвЛИіЩшжУбЁЯюЙЉдЫЮЌЭХЖгЫцЪБНјааЕїећЃЉЃЌДѓИХвВОЭЪЧУПУыИќаТ1ДЮЕФбљзгОЭВюВЛЖрСЫЁЃ

ФЧУДConsumerШчКЮДІРэУПУыжгЖрГіРДЕФ9ДЮВЩбљЪ§ОнФиЃППЩвдУїШЗЯыЕНЕФгаСНжжДІРэЗНЪНЃКвЛжжДІРэЗНЪНЪЧЮоТлжїПиЗўЮёЕФМрПиЬЈЩЯЕФадФмжИБъвдКЮжжЦЕТЪНјааЯдЪОЃЌConsumerЖМНЋЪеЕНЕФЪ§ОнаДГіДцДЂЯЕЭГжаЃЛСэвЛжжДІРэЗНЪНЪЧConsumerНЋЪеЕНЕФЖргрЪ§ОнЖЊЦњЃЌжЛАДеедЫЮЌЭХЖгЩшжУЕФВЩбљЦЕТЪНЋЪ§ОнаДШыГжОУЛЏДцДЂЯЕЭГЁЃдкЕкЖўжаДІРэЗНЪНжагавЛИіЧщПіашвЊЬиБ№зЂвтЃКШчЙћНЋвЊБЛЖЊЦњЕФадФмЪ§ОнДяЕНСЫадФмЗЇжЕЃЈР§ШчБОДЮВЩМЏЕФФкДцЪЙгУТЪГЌЖрСЫ2GBЃЉЃЌдђетЬѕШежОЪ§ОнЛЙЪЧашвЊНјааБЃСєЁЃЕквЛжжДІРэЛљБОЩЯУЛгаЪВУДашвЊНщЩмЕФЃЌгХЕуКЭШБЕувВЪЧКмУїШЗЕФЃКгХЕуЪЧПЩвддкКѓЦкНјааЭъећЕФадФмРњЪЗЛиЫнЃЌШБЕуОЭЪЧЛсеМгУНЯДѓЕФДцДЂПеМфЁЊЁЊЫфШЛФПЧАПЩвдЪЙгУЕФГЌДѓДцДЂЗНАИгаКмЖрЖјЧвЖМКмГЩЪьЮШЖЈЃЌЕЋЫќУЧЖМашвЊБШНЯЧПДѓЕФзЪН№дЄЫужЇГжЁЃ
3-1-2ЁЂConsumerЕФЪЕЯж
етРяБЪепжївЊЬжТлвЛЯТConsumerЕФЕкЖўжжДІРэЗНЪНЃКЖЊЦњЖргрЕФЪ§ОнЁЃЮвУЧПЩвдЪЙгУжЎЧАЮФеТНщЩмЙ§ЕФConcurrentLinkedHashMapзїЮЊConsumerжаДцДЂадФмЯћЯЂШежОЕФCacheЃЌCacheЕФЙЬЖЈДѓаЁЩшжУЮЊ200ЃЈЛђепЦфЫќвЛИіНЯДѓЕФжЕЃЉЁЃетИіCacheНсЙЙПЩвдАяжњЮвУЧЭъГЩКмЖрЙЄзїЃКЪзЯШЫќПЩППЕФадФмФмЙЛБЃжЄЙ§ИіConsumerВЛЛсГЩЮЊећИіадФмШежОЪеМЏЗНАИЕФЦПОБЁЊЁЊЫфШЛConcurrentLinkedHashMapЕФадФмВЂВЛЪЧзюПьЕФЃЛЦфДЮетИіCacheНсЙЙФмЙЛАяжњЮвУЧздЖЏЭъГЩЖрградФмШежОЕФЧхГ§ЙЄзїЃЌвђЮЊдкЕк201ЬѕШежОМЧТМБЛЭЦШыCacheЪБЃЌдкLRUЖгСаЮВВПЕФзюГѕвЛЬѕМЧТМНЋздЖЏБЛХХГ§ЖгСаЃЌзюжеБЛРЌЛјЛиЪеВпТдЛиЪеЕєЃЛзюКѓЃЌConsumerАДеедЫЮЌЭХЖгЩшжУЕФВЩбљжмЦкЃЌЖдCacheжаЕФадФмШежОЪ§ОнНјааГжОУЛЏБЃДцЪБЃЌЪМжежЛашвЊШЁГіЕБЧАдкCacheНЋБЛЬоГ§ЕФФЧЬѕМЧТМЃЌетбљОЭЪЁЕєСЫБраДГЬађЃЌдкСНИіжмЦкЕФЪБМфВюжЎМфХаЖЯЁАвЊЖдФФЬѕадФмШежОЪ§ОнЁБНјааГжОУЛЏБЃДцЕФЖЈЮЛЙЄзїЁЃ
ЫГБуЫЕвЛОфЃЌШчЙћФњашвЊдкЙЄГЬжаЪЙгУGoogleЬсЙЉЕФConcurrentLinkedHashMapЪ§ОнНсЙЙЙЄОпЃЌФЧУДФњашвЊЪзЯШдкpomЮФМўжаЬэМгЯргІЕФзщМўвРРЕаХЯЂЃК
<dependency>
<groupId>com.googlecode.concurrentlinkedhashmap</groupId>
<artifactId>concurrentlinkedhashmap-lru</artifactId>
<version>1.4.2</version>
</dependency> |
вдЯТЪЧConsumerжагУгкДІРэLRUЖгСаЬэМгЁЂLRUжмЦкадЖСШЁЁЂLRUЩОГ§ЪТМўЕФДњТыЦЌЖЮЃК
......
/**
* етОЭЪЧадФмЪ§ОнЕФLRUЖгСа
*/
private static final ConcurrentLinkedHashMap<Long,
String> PERFORMANCE_CACHE =
new ConcurrentLinkedHashMap.Builder<Long, String>()
.initialCapacity(200)
.maximumWeightedCapacity(200)
.listener(new EvictionListenerImpl())
.build();
......
/**
* етИіМрЬ§ЦїгУгкдкЪ§ОнБЛДгLRUЖгСаЬоГ§ЪБ<br>
* АДееЙІФмашЧѓМьВщетЬѕМЧТМЪЧЗёашвЊБЛГжОУЛЏДцДЂЦ№РДЁЃ
* @author yinwenjie
*/
public static class EvictionListenerImpl implements
EvictionListener<Long, String> {
// ЩЯвЛДЮНјааЪ§ОнВЩМЏЕФЪБМфЃЌГѕЪМЮЊ-1
private Long lastTime = -1l;
// етЪЧгЩдЫЮЌЭХЖгЩшжУЕФЪ§ОнВЩМЏжмЦкЃЌ1000БэЪО1000КСУы
// е§ЪНЯЕЭГжаЃЌетИіжЕНЋгаЭтВПЖСШЁ
private Long period = 1000l;
@Override
public void onEviction(Long key, String jsonValue)
{
/*
* вдЯТЬѕМўШЮвтГЩСЂЪБЃЌОЭашвЊЖдетЬѕЪ§ОнНјааВЩМЏСЫЃК
* 1ЁЂlastTimeЮЊ-1ЕФЧщПіЃЈЫЕУїЪЧГЬађЕквЛДЮВЩМЏЃЉ
*
* 2ЁЂЕБЧАЪТМў - lastTime >= period(ВЩМЏжмЦк)
*
* 3ЁЂЕБМрПиЪ§ОнДѓгкЩшжУЕФОЏИцЗЇжЕЃЌдкетИіЪОР§ДњТыжа
* етИіОЏИцЗЇжЕЮЊ80ЃЌе§ЪНЯЕЭГжаЃЌетИіЗЇжЕгІДгЭтВПЖСШЁ
* вдЯТЕФthresholdБфСПОЭДњБэетИіжЕ
* */
Long threshold = 80L;
Long nowtime = new Date().getTime();
// ЛёШЁадФмЪ§ОнжаЕФCPUЪЙгУТЪ
// зЂвтЃЌе§ЪНЯЕЭГ жазюКУВЛвЊДЋЕнjsonНсЙЙЃЌЮФБОНсЙЙЕФЪ§ОнОЭКУСЫ
JSONObject jsonData = JSONObject.fromObject(jsonValue);
Long cpuRate = jsonData.getLong("cpu");
boolean mustCollecting = false;
if(this.lastTime == -1 ||
nowtime - lastTime >= this.period ||
cpuRate >= threshold) {
mustCollecting = true;
this.lastTime = nowtime;
}
// ШчЙћВЛашвЊзіЪ§ОнЕФГжОУЛЏДцДЂЃЌОЭжежЙБОДЮМрЬ§ЕФВйзїМДПЩ
if(!mustCollecting) {
return;
}
// ********************
// етРяПЩвдзіГжОУЛЏЪ§ОнДцДЂЕФВйзїСЫ
// ********************
LRUConsumer.LOGGER.info(key + ":"
+ jsonValue + " ЭъГЩЪ§ОнГжОУДцДЂВйзї=======");
}
}
......
// вдЯТДњТыОЭЪЧЕБKafka-ConsumerЪеЕНадФмШежОЪ§ОнЕФВйзї
// НЋетИіЪ§ОнДцЗХЕНPERFORMANCE_CACHEМДПЩ
Long key = new Date().getTime();
// ПЩЪЙгУЪБМфЕФКСУыЪ§зїЮЊkeyжЕЃЈе§ЪНгІгУГЁОАЯТЃЌПМТЧЖрИіconsumerНкЕуЃЌKeyЕФШЗЖЈЛсгавЛИіИќЙцЗЖЕФЙцдђЃЉ
LRUConsumer.PERFORMANCE_CACHE.put(key, performanceData);
...... |
вдЩЯДњТыжаЃЌЮвУЧЪЙгУжЎЧАвбОНщЩмЙ§ЕФLRUЪ§ОнНсЙЙдкConsumerЖЫБЃДцЗЂЫЭЙ§РДЕФЪ§ОнЁЃШчЙћЖСепЖдLRUЛЙВЛЧхГўПЩвдВщПДЮвСэЭтЕФвЛЦЊЮФеТжаЕФНщЩмЃЈЁЖМмЙЙЩшМЦЃКЯЕЭГМфЭЈаХЃЈ39ЃЉЁЊЁЊApache
CamelПьЫйШыУХЃЈЯТ2ЃЉЁЗЃЉЁЃгЩGoogleЬсЙЉЕФConcurrentLinkedHashMapНсЙЙОЭПЩвдЯђЮвУЧЬсЙЉвЛИіЯжГЩЕФLRUЖгСаЃЌетбљвЛРДЕБLRUЖгСаДцДЂТњКѓЃЌзюЯШБЛНгЪеЕНЕФадФмШежОЪ§ОнОЭЛсДгЖгСаЮВВПБЛЩОГ§ЁЃзюЙиМќЕФДІРэЙЄзїЖМНЋдкEvictionListenerНгПкЕФЪЕЯжРржаЭъГЩЃЌдкЪЕМЪгІгУжаПЊЗЂШЫдБЛЙПЩвддкШЗЖЈвЛЬѕадФмШежОашвЊБЛГжОУЛЏДцДЂжЎКѓзЈУХЦєЖЏвЛИіЯпГЬНјааВйзїЃЌР§ШчЪЙгУвЛИізЈУХЕФЯпГЬГиЃЈThreadPoolExecutorЃЉЁЃетбљвЛРДLRUЖгСаОЭеце§ВЛЪмГжОУЛЏДцДЂВйзїбгГйЪБМфЕФгАЯьСЫЁЃ
3-2ЁЂЪЙгУFlume + StormЪеМЏадФмЪ§Он
вдЩЯЪЙгУKafkaЪеМЏBroker ServerНкЕуЕФадФмЪ§ОнЕФЗНАИжаЃЌашвЊдкУПИіБраДЕФBroker
ServerНкЕуЩЯдіМгЖюЭтЕФДњТыЯђKafka Broker ServerЗЂЫЭЪ§ОнЁЃЪЕМЪЩЯетжжЙІФмашЧѓЧщПіЪЙгУApache
FlumeЪеМЏЪ§ОнЛсЪЙММЪѕЗНАИИќШнвзЪЕЯжКЭЮЌЛЄЃЌЯТУцЮвУЧОЭДѓжТНщЩмвЛЯТетИіММЪѕЗНАИЪЕЯжЁЃгЩгкдкжЎЧАЕФЮФеТжаБЪепвбОНЯЯъЯИЕФНщЩмСЫШчКЮЪЙгУApache
FlumeНјааЛљБОХфжУСЫЃЌЫљвдетРяЮвУЧжиЕуЬжТлСНИіЮЪЬтApache FlumeЕФЪ§ОнРДдДКЭStorm
ServerдкНгЪеЕНFlume ServerЗЂЫЭРДЕФЪ§ОнКѓШчКЮНјааДІРэЁЃ
3-2-1ЁЂЩшМЦЫМТЗ
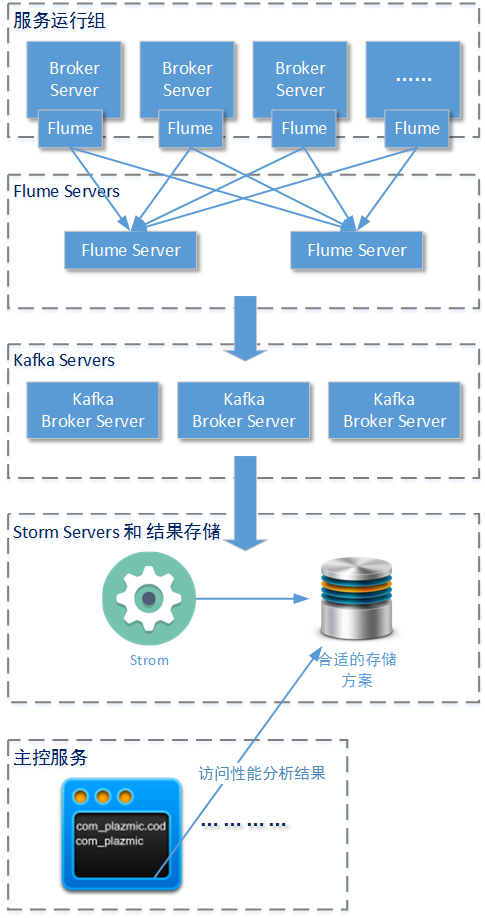
ЩЯЭМеЙЪОСЫећИіЙІФмашЧѓЕФЩшМЦНсЙЙЁЃАВзАдкESB Broker ServerНкЕуЕФFlumeГЬађИКд№ЪеМЏетИіНкЕуЩЯЕФИїжжЙІФмаджИБъКЭЗЧЙІФмаджИБъЃЌетбљБмУтСЫдкESC
Broker ServerЗўЮёЩЯБраДЖюЭтЕФДњТыВЩМЏЗЧЙІФмаджИБъЃЌвВМѕЩйСЫБраДДњТыВЩМЏЙІФмаджИБъЕФИДдгЖШЁЃШЛКѓНЋетаЉадФмШежОЪ§ОнАДееИКдиОљКтФЃЪНДЋЕнЕНШєИЩжаМЬFlume
ServerНкЕуЩЯЃЌКѓепзЈУХгУгкГади/ЛузмЖрИіESB Broker ServerНкЕуДЋРДЕФадФмШежОЪ§ОнЃЌВЂЧвзюжеНЋЪ§ОнаДШыStorm
ServerЁЃдкFlume ServerКЭStorm ServerжЎМфЮвУЧЛЙЪЧашвЊЪЙгУKafka ServerзїЮЊЛКДцЃЌетЪЧвђЮЊApache
KafkaЭЈЙ§Storm-KafkaзщМўКЭStorm ServerЪЕЯжЮоЗьМЏГЩЁЃ
ЪзЯШЧызЂвтАВзАдкESB Broker ServerНкЕуЕФFlumeГЬађЃЌдк3-1аЁНкжаВЩМЏНкЕуЙІФмаджИБъКЭЗЧЙІФмаджИБъЖМЪЧвРПППЊЗЂШЫдББраДГЬађЭъГЩЃЌВЂЗЂЫЭИјKafka-BrokerЁЃЕЋетбљзіШДецЕФШЦСЫКмДѓвЛИіЭфТЗЃЌвђЮЊLinuxВйзїЯЕЭГЩЯвбОЬсЙЉСЫКмЖрВЩМЏНкЕуЗЧЙІФмаджИБъЕФЗНЪНЃЈР§ШчВЩМЏI/OаХЯЂЁЂФкДцЪЙгУаХЯЂЁЂФкДцЗжвГаХЯЂЁЂCPUЪЙгУаХЯЂЁЂЭјТчСїСПаХЯЂЕШЃЉЃЌПЊЗЂШЫдБжЛашвЊвЛаЉНХБООЭПЩвдЭъГЩВЩМЏЙЄзїЁЃР§ШчЃЌЮвУЧВЩМЏCPUаХЯЂЭъШЋВЛашвЊЮвУЧдкESB-Broker
ServerжаБраДГЬађЃЈВЩМЏCPUаХЯЂвВВЛгІИУЪЧESB-Broker ServerЕФвЛЯюЙЄзїШЮЮёЃЉЃЌЖјВЩгУШчЯТЕФНХБОМДПЩЃК
| top -d 0.1 |
grep Cpu >> cpu.rel
#аДЗЈЛЙгаКмЖрЃЌЛЙПЩвдДг/proc/statЮФМўжаЛёШЁCPUзДЬЌ |
вдЩЯНХБОПЩвдАДее100КСУыЮЊжмЦкЃЌЛёШЁCPUЕФаХЯЂЁЃВЂНЋетЬѕаХЯЂзїЮЊвЛЬѕаТЕФМЧТМДцДЂЕНcpu.relЮФМўжаЁЃетбљApache
FlumeОЭПЩвдЖСШЁcpu.relЮФМўжаЕФБфЛЏЃЌзїЮЊадФмШежОЪ§ОнЕФРДдДЃК
#flume ХфжУЮФМўжаЕФЦЌЖЮ
......
agent.sources.s1.type = exec
agent.sources.s1.channels = c1
agent.sources.s1.command = tail -f -n 0 /root/cpu.rel
...... |
дкESB-Broker ServerНкЕужаЃЌЮвУЧПЩвдЪЙгУетбљЕФЗНЪНДгВЛЭЌЮФМўжаЖСШЁИїжжВЛЭЌЕФШежОаХЯЂЃЌШчЯТЭМЫљЪОЃК

ЧыПДЯТЮФ
|





