| 编辑推荐: |
| 本文来源infoq,本文简单谈一谈苏宁传统企业架构到互联网微服务架构的转型。 |
|
现代互联网企业,随着业务的井喷,对系统的可维护性、可用性和并发性三个方面都提出了相当高的要求。在这三个维度的要求下,互联网企业的架构都会走上从单体应用拆分到多应用、多系统、多环境、多主机、多机房的大规模分布模式。
系统的拆分往往伴随着研发团队的快速膨胀和组织扩容。以苏宁易购举例,苏宁 IT 序列的研发人员在最近几年呈指数级的增加,目前已突破
8000 人,今年有望达到一万人的规模。
与很多同时代发展起来的互联网企业相比,除了都具备系统复杂度井喷式增长这个共性之外,苏宁易购也有不同于其他纯电商企业的特殊之处,那就是有大量的传统
IT 历史资产。
苏宁从发展之初就很重视 IT 信息化的建设,从 1994 年开始用电子化记账,发展到 2000 年启用
ERP 系统,到 2006 年大规模上线 SAP,最后到 08 年开始转型互联网化。和很多同行业的互联网公司从一张白纸出发不同,苏宁走过的是边开飞机边换引擎的一条艰辛的道路。
面对这种一边是一团乱麻的历史资产,一边是开疆扩土的业务倒逼,苏宁在早期经常会遇到各种因为缺乏企业架构全面治理导致的各种问题。比如,服务上线时缺乏版本向下兼容导致关联系统异常;比如部署环境更新版本时,导致完全没有预料的周边中间件异常崩溃。
如果我们尝试用如下的信息熵公式来描述苏宁 IT 企业架构的复杂度:
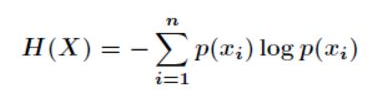
公式中的 Xi 的含义是一组对立的随机变量,对应到苏宁的 IT 环境中,可以理解成:人,机器,系统,应用,而
p(Xi) 就是这些人 / 机器 / 系统 / 应用出故障的概率。根据信息熵理论可以如下图推导,信息熵在
p(Xi)=0.5 的时候,取值最高。
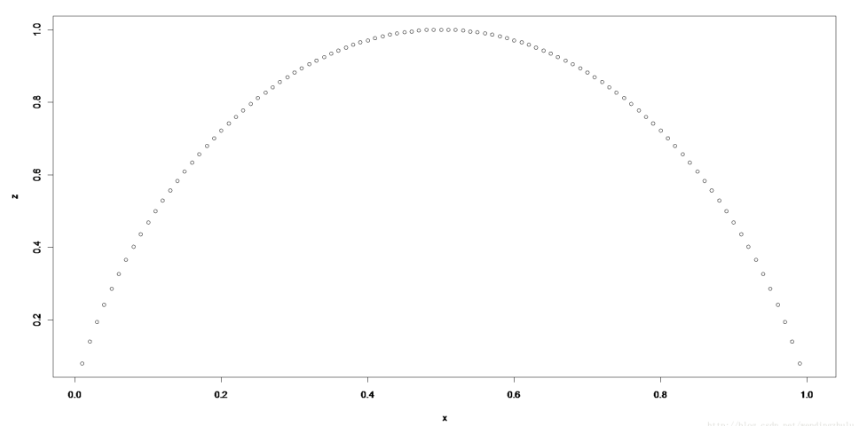
所以如果想降低整体系统的熵,那么就要降低各种变量的概率不确定性,让每个变量的概率逼近曲线的两端。如何做到呢?唯一解就是将所有独立变量关联起来做高维度治理。
通过这个理论引申,结合苏宁这么多年的互联网化转型和实践中的摸爬滚打,总结实践出了一套大规模分布式下企业架构治理系统,我们内部将其取名为
苏宁架构云。
企业架构的演变
企业架构 (Enterprise Architecture ) 这一概念由 Zachman 在 1984
年提出,伴随着 80 年代的主机发展浪潮,90 年代的信息化和互联网化浪潮,21 世纪初的移动互联网浪潮,一直到今天的云计算、物联网,大数据、人工智能、区块链时代。企业架构涌现了一大批专家模型和方法论。
比如典型的 TOGAF 方法论中,将企业架构分成如下几层。

从最上层的业务产品线开始,第二层是整体企业的业务战略,包括业务的经营模式推广模式收费模式盈利模式。接下一层是应用架构,包括应用,系统,服务,接口多个维度的系统拆分和组织编排。再往下一层是数据架构,包括数据结构,数据持久化模式,数据分析模型。到最后一层的基础架构,包括主机,虚拟机,机房,IDC
等等。可以说,整个企业架构模型本质就是一家公司的数字资产库。
对于没有重资产的互联网企业而言,产品,流量,用户,数据,代码,机器,这些就是公司的全部资产。所以我们可以断言,一家科技公司,如果没有企业架构的数字化管理,就等于一家会计事务所没有财务系统一样荒唐可笑。
苏宁的架构哲学
正是因为企业架构对于公司的发展有如此巨大的重要性,所以苏宁很早就重视总结,在综合行业内主流的企业架构模型之后,提出了自己的架构哲学。
苏宁认为企业架构是人,物,事三者的数字化模型。
我们不光要架构层面加入静态的物,比如系统,应用,服务,接口。我们还要在架构模型中加入动态的事,比如各种日志时间序列,各种营销规划动作。最后我们还要在模型中加入人,将外部的客户,供应商,内部的员工都纳入全局的架构视图。
从人的角度:我们认为任何商业活动,组织行为都要以人为本,以人为核心。人是一切商业活动的根本。用学术的话来说,架构的本质就是识别商业活动中的利益相关人,把人的描述升高到架构识别的第一要素。在落地过程中,我们识别出人,然后对人进行画像,接着将人与人的利害关系梳理组织出来。在苏宁架构云的产品中,我们运用了自然语言识别方式和在线思维导图,辅助企业架构师完成本工作。
从物的角度:我们认为万物互联,我们将整个企业活动中涉及的方方面面的物理设备都纳入到架构的设计范畴。不光聚焦传统
IT 架构中的机房,服务器,交换机等,我们还将眼光放宽泛一点,比如在物流架构规划中,我们会将卡车,仓储乃至高速公路都纳入架构的视野,对其进行分析和建模。在苏宁架构云的产品中,我们打通物联网平台,建立所有物理设备的逻辑拓扑关系,辅助企业架构师工作。
从事的角度:我们认为,商业活动中所有动态的行为都是数据的纽带,是企业架构的灵魂。商业规划,业务拓展,大促活动,这些事件,围绕着人和物组织编排,我们在架构中的工作就是要将事件活动抽象出来,将流程与组织解耦,关注流程本身的泛型和价值重构。在苏宁架构云的产品中,我们引入流程引擎,根据苏宁历史沉淀,建立若干基础商业事件的逻辑模型,辅助企业架构师设计。
企业架构的数字化
如果想在苏宁这样一个巨大的体量下实时的治理企业架构,我们首先干的就是识别企业架构模型中的领域模型,寻找数据建模的依据。
比如如下,我们根据苏宁的业务场景结合,识别出以下若干核心领域。

应用
一组同类型的或紧密耦合的、实现同一业务目标的功能逻辑组合
系统
由计算机硬件和软件所共同组成,是应用功能的具体实现,系统的划分应考虑非功能需求以及具体实现技术
服务
一组接口的逻辑组合
接口
指的是一个服务中的一个调用接口,包括接口名,接口入参,接口出参,接口暴露模式
接下来,我们根据领域模型,识别出周边的关联系统,对于苏宁而言,我们需要考虑从自研的项目管理平台中获取产品线和项目数据,从服务调用链中获取微服务实时调用数据,从
CMDB 中获得主机和虚拟机的静态部署数据,从统一配置中心中获取主机中的配置更改记录等等。
接下来,我们根据领域模型,识别出周边的关联系统,对于苏宁而言,我们需要考虑从自研的项目管理平台中获取产品线和项目数据,从服务调用链中获取微服务实时调用数据,从
CMDB 中获得主机和虚拟机的静态部署数据,从统一配置中心中获取主机中的配置更改记录等等。
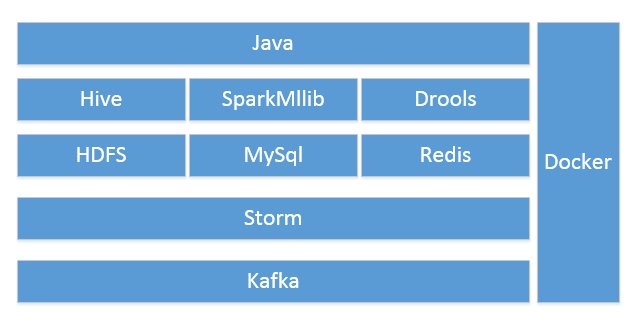
然后我们采用 Kafka 接入所有这些数据通道,通过 Storm 做数据消费和清洗,将数据拆分成结构化和非结构化两种,结构化存入
RDMBS,非结构化存入 BigData。通过数据模型对上支撑各种治理业务。
如下图是一个简化版的技术架构图。
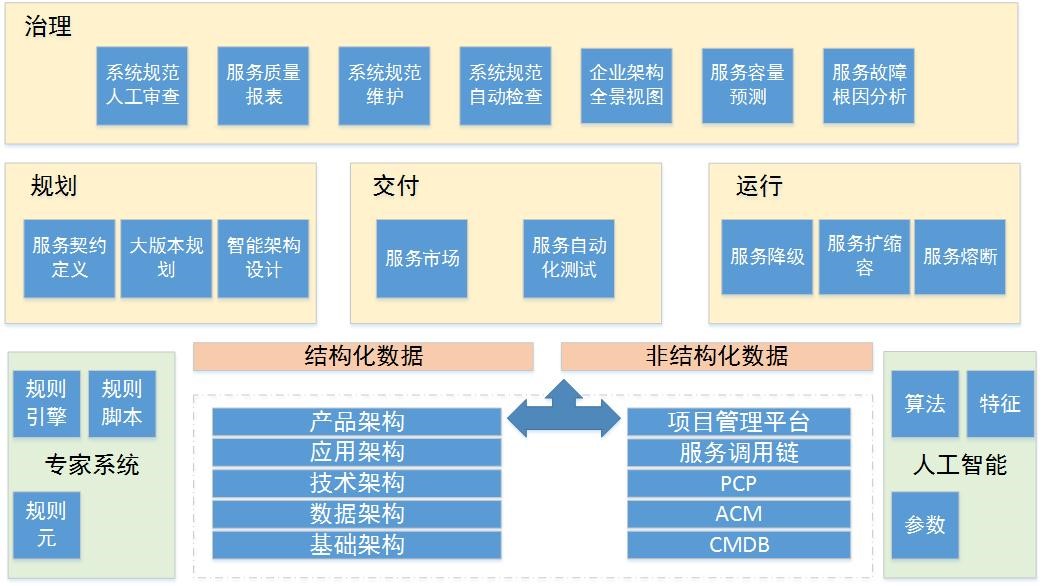
在建模之后,我们就可以通过专家系统和人工智能引擎的支撑,对外提供多维度的治理能力,如下图的简要产品架构。
企业架构的专家治理
有了数字化的企业架构模型之后,我们就可以在这个模型上进行治理。
第一个问题,治理什么?
根据苏宁的经验,我们将企业架构从生命周期上分成规划,交付,运行和过程改进四个阶段。
在规划阶段,我们主要关注于服务 / 接口的契约管理,服务依赖版本的规划,在线的企业架构设计。在交付阶段,我们关注于服务
/ 接口的交付市场,服务 / 接口的自动化测试落地。在运行阶段,我们提供服务流控,服务扩缩容,服务熔断。在过程改进中,我们提供服务
/ 接口的质量报表,企业架构的整体视图等功能。
第二个问题,用什么治理?
每个公司都会有经过大并发大规模分布式下积累的历史经验和教训,我们采取的做法是,将苏宁的经验和教训用规则化逻辑表达出来,在专家系统中落地。贯穿整个企业架构数字化模型,将我们用血和泪换来的经验和教训,实时快速准确的扫描和落地。具体落地实践中,我们深度改造了
Drools 规则引擎,接入本系统。
深度学习下的自治理
专家治理本质还是根据人工经验的提取进行治理。人会犯错,人发现的规则也会失效。
有没有能够自治理,自发现,自解决的办法呢?
本质上,我们经过研究觉得这就是一个 AIOps 的应用场景,通过引入深度学习机制我们现在初步规划了以下几个落地方向。
通过回归算法做线上系统 / 服务 / 接口的流量预测
对于电商这种周期性特点很强的行业,在预测上需要平滑周期性干扰,达成更准确的预估。这点上我们参考了
Twitter 的论文《Forecasting at scale》,如下公式我们将周期效应看成是一个奇三角函数和一个偶三角函数的和。
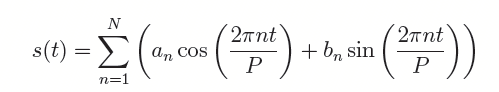
上图中的 P 代表时间周期,比如以年为周期的话 P=365.25。如上图所见,周期效应本身就是一个傅里叶级数,那么我们就可以用傅里叶变换来定积分求解,于是我们就把问题转换为求解如下一个向量的值。
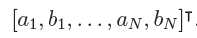
根据归纳可以发现,该向量满足正态分布模型,工程落地钟可以用 Normal 函数做解,需要注意的是此向量的
N 的取值需要根据各自的业务形态调整。
比如下图就是平滑大促周期之后的某接口的日 PV 部分拟合。
s
通过聚类算法做线上运行状态的自检
我们将大规模时间序列数据抽取出来,进行离线学习,学习出常见的系统异常时间序列模型。然后将线上时间序列数据的学习结果和离线模型通过聚类算法比较,分析诊断现在生产状态。
总结
大型分布式环境下的企业架构治理是个大命题,有各种维度的管理。比如有专注于服务监控的服务调用链,有专注于主机和
OS 的系统监控平台,有专注于流量的流控平台。
但是从整个企业架构的维度上,打通各个环节,采集建模分析机器学习的平台还很少。
|





