�ܶ��˶�֪��SQLע�룬Ҳ֪��SQL��������ѯ���Է�ֹSQLע�룬��Ϊʲô�ܷ�ֹע��ȴ�����Ǻܶ��˶�֪���ġ�
������Ҫ��������������⣬Ҳ�����ڲ��������п�����������ݣ���Ȼ�˿���Ҳ����
���ȣ�����Ҫ�˽�SQL�յ�һ��ָ������������飺
����ϸ�ڿ��Բ鿴���£�Sql Server ���롢�ر�����ִ�мƻ�����ԭ��
������Ҽı�ʾΪ���յ�ָ�� -> ����SQL����ִ�мƻ� ->ѡ��ִ�мƻ�
->ִ��ִ�мƻ���
��������е㲻һ���������µIJ���������ʾ��
��������������Ϊʲôƴ��SQL �ַ����ᵼ��SQLע��ķ����أ�
���ȴ���һ�ű�Users:
CREATE TABLE [dbo].[Users](
[Id] [uniqueidentifier] NOT NULL,
[UserId] [int] NOT NULL,
[UserName] [varchar](50) NULL,
[Password] [varchar](50) NOT NULL,
CONSTRAINT [PK_Users] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] |

����һЩ���ݣ�
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),1,'name1','pwd1');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),2,'name2','pwd2');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),3,'name3','pwd3');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),4,'name4','pwd4');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),5,'name5','pwd5');
|
���������и��û���¼��ҳ�棬�������£�
��֤�û���¼��sql ���£� select COUNT(*) from
Users where Password = 'a' and UserName = 'b'
��δ��뷵��Password ��UserName��ƥ����û��������������1�Ļ�����ô�ʹ����û����ڡ�
���IJ�����SQL �е�������ԣ�Ҳ�����۴���淶����Ҫ�ǽ�Ϊʲô�ܹ���ֹSQLע�룬��һЩͬѧ��Ҫ������ijЩ���룬���ߺ�SQLע���ص����⡣
���Կ���ִ�н����

�����SQL profile ���ٵ�SQL ��䡣

ע��Ĵ������£�
select COUNT(*) from Users where Password = 'a' and
UserName = 'b' or 1=1��' �������˽�UserName����Ϊ�� ��b' or 1=1
�C��
ʵ��ִ�е�SQL�ͱ�������£�


���Ժ����ԵĿ���SQLע��ɹ��ˡ�
�ܶ��˶�֪����������ѯ���Ա���������ֵ�ע�����⣬��������Ĵ��룺
class Program
{
private static string connectionString = "Data Source=.;Initial Catalog=Test;Integrated Security=True";
static void Main(string[] args)
{
Login("b", "a");
Login("b' or 1=1--", "a");
}
private static void Login(string userName, string password)
{
using (SqlConnection conn = new SqlConnection(connectionString))
{
conn.Open();
SqlCommand comm = new SqlCommand();
comm.Connection = conn;
//Ϊÿһ����������һ������
comm.CommandText = "select COUNT(*) from Users where Password = @Password and UserName = @UserName";
comm.Parameters.AddRange(
new SqlParameter[]{
new SqlParameter("@Password", SqlDbType.VarChar) { Value = password},
new SqlParameter("@UserName", SqlDbType.VarChar) { Value = userName},
});
comm.ExecuteNonQuery();
}
}
} |
ʵ��ִ�е�SQL ������ʾ��
exec sp_executesql N'select COUNT(*) from Users where
Password = @Password and UserName = @UserName',
N'@Password varchar(1),@UserName varchar(1)',@Password='a',@UserName='b'exec sp_executesql N'select COUNT(*)
from Users where Password = @Password and UserName
= @UserName',N'@Password varchar(1),@UserName varchar(11)',@Password='a',@UserName='b'' or 1=1��'
|
���Կ�����������ѯ��Ҫ������Щ���飺
1���������ˣ����Կ��� @UserName='b'' or 1=1��'
2��ִ�мƻ�����
��Ϊִ�мƻ������ã����Կ��Է�ֹSQLע��
���ȷ���SQLע��ı��ʣ�
�û�д��һ��SQL ������ʾ����������a�ģ��û�����b�������û���������
ͨ��ע��SQL�����SQL���ڱ�ʾ�ĺ����Dz���(������a�ģ������û�����b�ģ�) ����1=1 �������û���������
���Կ���SQL�����ⷢ���˸ı䣬Ϊʲô�����˸ı��أ�����Ϊû��������ǰ��ִ�мƻ�����Ϊ��ע����SQL������½����˱��룬��Ϊ����ִ���������������Ҫ��֤SQL���岻�䣬������Ҫ����SQL��������������˼�����DZ��ע������˼����Ӧ������ִ�мƻ���
������ܹ�����ִ�мƻ�����ô����SQLע��ķ��գ���ΪSQL�������п��ܻ�仯��������IJ�ѯ�Ϳ��ܱ仯��
��SQL Server �в�ѯִ�мƻ�����ʹ������Ľű���
DBCC FreeProccache
select total_elapsed_time / execution_count ƽ��ʱ��,total_logical_reads/execution_count ����,
usecounts ����,SUBSTRING(d.text, (statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(text)
ELSE statement_end_offset END
- statement_start_offset)/2) + 1) ���ִ�� from sys.dm_exec_cached_plans a
cross apply sys.dm_exec_query_plan(a.plan_handle) c
,sys.dm_exec_query_stats b
cross apply sys.dm_exec_sql_text(b.sql_handle) d
--where a.plan_handle=b.plan_handle and total_logical_reads/execution_count>4000
ORDER BY total_elapsed_time / execution_count DESC; |

������ƪ���£� Sql Server��������ѯ֮where in��likeʵ�����
����ƪ����������ôһ�Σ�

����������һ�仰������������д����ֱ��ƴSQLִ��ûɶʵ���Ե�����
�κ�ƴ��SQL�ķ�ʽ����SQLע��ķ��գ��������û��ʵ���Ե�����Ļ�����ôʹ��exec
��ִ̬��SQL�Dz��ܷ�ֹSQLע��ġ���������Ĵ��룺
private static void TestMethod()
{
using (SqlConnection conn = new SqlConnection(connectionString))
{
conn.Open();
SqlCommand comm = new SqlCommand();
comm.Connection = conn;
//ʹ��exec��ִ̬��SQL��
//ʵ��ִ�еIJ�ѯ�ƻ�Ϊ(@UserID varchar(max))select * from Users(nolock) where UserID in (1,2,3,4)����
//����Ԥ�ڵ�(@UserID varchar(max))exec('select * from Users(nolock) where UserID in ('+@UserID+')')
comm.CommandText = "exec('select * from Users(nolock) where UserID in ('+@UserID+')')";
comm.Parameters.Add(new SqlParameter("@UserID", SqlDbType.VarChar, -1) { Value = "1,2,3,4" });
//comm.Parameters.Add(new SqlParameter("@UserID", SqlDbType.VarChar, -1) { Value = "1,2,3,4); delete from Users;--" });
comm.ExecuteNonQuery();
}
} |
ִ�е�SQL ���£�
exec sp_executesql N'exec(''select
* from Users(nolock) where UserID in (''+@UserID+'')'')'N'@UserID
varchar(max) ',@UserID='1,2,3,4' ���Կ���SQL��䲢û�в�������ѯ��
����㽫UserID����Ϊ��
1,2,3,4); delete from Users;��-
��,��ôִ�е�SQL��������������exec sp_executesql N'exec(''select
* from Users(nolock) where UserID in (''+@UserID+'')'')',N'@UserID
varchar(max) ',@UserID='1,2,3,4); delete from Users;--'
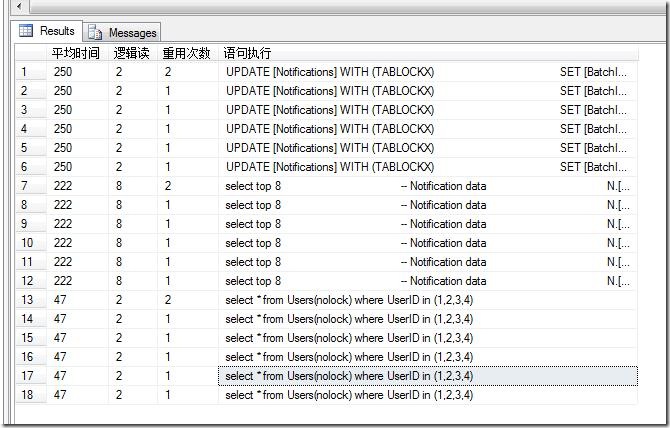
��Ҫ��Ϊ���˸�@UserID �ʹ����ܹ���ֹSQLע�룬ʵ��ִ�е�SQL ���£�

�κζ�̬��ִ��SQL ����ע��ķ��գ���Ϊ��̬��ζ�Ų�����ִ�мƻ��������������ִ�мƻ��Ļ�����ô�ͻ���������֤��д��SQL����ʾ����˼������Ҫ�������˼��
��ͺ���Сʱ�������⣬����������(____) �����û�����(____)���û��������������ʲôֵ����������ľ��������˼.
������ܽ�һ�䣺��Ϊ��������ѯ��������ִ�мƻ��������������ִ�мƻ��Ļ���SQL��Ҫ���������Ͳ���仯�����Ծ��Է�ֹSQLע��,�����������ִ�мƻ������п��ܳ���SQLע�룬�洢����Ҳ��һ���ĵ�������Ϊ��������ִ�мƻ��� |


