| 编辑推荐: |
| 本文来自于网络,
本文主要从可用性、可靠性、可控性、监控熔断等角度做的架构设计与框架设计,分享的产品研发思路。 |
|
背景
近年来,互联网上安全事件频发,企业信息安全越来越受到重视,而IDC服务器安全又是纵深防御体系中的重要一环。保障IDC安全,常用的是基于主机型入侵检测系统Host-based
Intrusion Detection System,即HIDS。在HIDS面对几十万台甚至上百万台规模的IDC环境时,系统架构该如何设计呢?复杂的服务器环境,网络环境,巨大的数据量给我们带来了哪些技术挑战呢?
需求描述
对于HIDS产品,我们安全部门的产品经理提出了以下需求:
1.满足50W-100W服务器量级的IDC规模。
2.部署在高并发服务器生产环境,要求Agent低性能低损耗。
3.广泛的部署兼容性。
4.偏向应用层和用户态入侵检测(可以和内核态检测部分解耦)。
5.针对利用主机Agent排查漏洞的最急需场景提供基本的能力,可以实现海量环境下快速查找系统漏洞。
6.Agent跟Server的配置下发通道安全。
7.配置信息读取写入需要鉴权。
8.配置变更历史记录。
9.Agent插件具备自更新功能。
分析需求
首先,服务器业务进程优先级高,HIDS Agent进程自己可以终止,但不能影响宿主机的主要业务,这是第一要点,那么业务需要具备熔断功能,并具备自我恢复能力。
其次,进程保活、维持心跳、实时获取新指令能力,百万台Agent的全量控制时间一定要短。举个极端的例子,当Agent出现紧急情况,需要全量停止时,那么全量停止的命令下发,需要在1-2分钟内完成,甚至30秒、20秒内完成。这些将会是很大的技术挑战。
还有对配置动态更新,日志级别控制,细分精确控制到每个Agent上的每个HIDS子进程,能自由地控制每个进程的启停,每个Agent的参数,也能精确的感知每台Agent的上线、下线情况。
同时,Agent本身是安全Agent,安全的因素也要考虑进去,包括通信通道的安全性,配置管理的安全性等等。
最后,服务端也要有一致性保障、可用性保障,对于大量Agent的管理,必须能实现任务分摊,并行处理任务,且保证数据的一致性。考虑到公司规模不断地扩大,业务不断地增多,特别是美团和大众点评合并后,面对的各种操作系统问题,产品还要具备良好的兼容性、可维护性等。
总结下来,产品架构要符合以下特性:
1.集群高可用。
2.分布式,去中心化。
3.配置一致性,配置多版本可追溯。
4.分治与汇总。
5.兼容部署各种Linux 服务器,只维护一个版本。
6.节省资源,占用较少的CPU、内存。
7.精确的熔断限流。
8.服务器数量规模达到百万级的集群负载能力。
技术难点
在列出产品需要实现的功能点、技术点后,再来分析下遇到的技术挑战,包括不限于以下几点:
1.资源限制,较小的CPU、内存。
2.五十万甚至一百万台服务器的Agent处理控制问题。
3.量级大了后,集群控制带来的控制效率,响应延迟,数据一致性问题。
4.量级大了后,数据传输对整个服务器内网带来的流量冲击问题。
5.量级大了后,运行环境更复杂,Agent异常表现的感知问题。
6.量级大了后,业务日志、程序运行日志的传输、存储问题,被监控业务访问量突增带来监控数据联动突增,对内网带宽,存储集群的爆发压力问题。
我们可以看到,技术难点几乎都是服务器到达一定量级带来的,对于大量的服务,集群分布式是业界常见的解决方案。
架构设计与技术选型
对于管理Agent的服务端来说,要实现高可用、容灾设计,那么一定要做多机房部署,就一定会遇到数据一致性问题。那么数据的存储,就要考虑分布式存储组件。
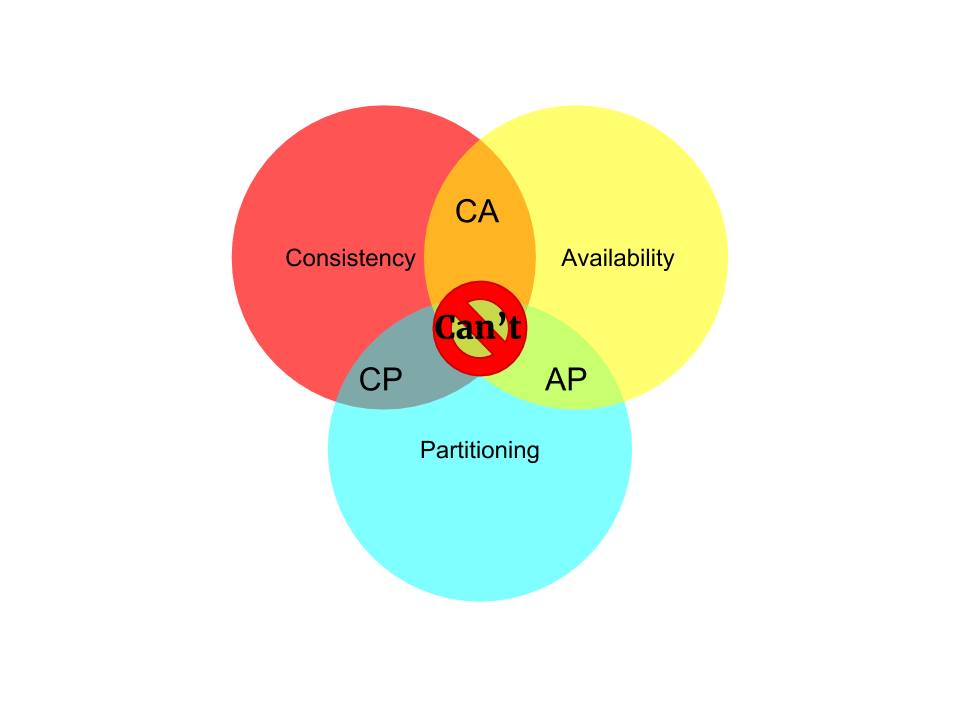
分布式数据存储中,存在一个定理叫CAP定理:
CAP的解释
关于CAP定理,分为以下三点:
1.一致性(Consistency):分布式数据库的数据保持一致。
2.可用性(Availability):任何一个节点宕机,其他节点可以继续对外提供服务。
3.分区容错性(网络分区)Partition Tolerance:一个数据库所在的机器坏了,如硬盘坏了,数据丢失了,可以添加一台机器,然后从其他正常的机器把备份的数据同步过来。
根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项。理解CAP定理的最简单方式是想象两个节点分处分区两侧。允许至少一个节点更新状态会导致数据不一致,即丧失了Consistency。如果为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了Availability。除非两个节点可以互相通信,才能既保证Consistency又保证Availability,这又会导致丧失Partition
Tolerance。
CAP的选择
为了容灾上设计,集群节点的部署,会选择的异地多机房,所以 「Partition tolerance」是不可能避免的。那么可选的是
AP 与 CP。
在HIDS集群的场景里,各个Agent对集群持续可用性没有非常强的要求,在短暂时间内,是可以出现异常,出现无法通讯的情况。但最终状态必须要一致,不能存在集群下发关停指令,而出现个别Agent不听从集群控制的情况出现。所以,我们需要一个满足
CP 的产品。
满足CP的产品选择
在开源社区中,比较出名的几款满足CP的产品,比如etcd、ZooKeeper、Consul等。我们需要根据几款产品的特点,根据我们需求来选择符合我们需求的产品。
插一句,网上很多人说Consul是AP产品,这是个错误的描述。既然Consul支持分布式部署,那么一定会出现「网络分区」的问题,
那么一定要支持「Partition tolerance」。另外,在consul的官网上自己也提到了这点
| Consul
is opinionated in its usage while Serf is a
more flexible and general purpose tool. In CAP
terms, Consul uses a CP architecture, favoring
consistency over availability. Serf is an AP
system and sacrifices consistency for availability.
This means Consul cannot operate if the central
servers cannot form a quorum while Serf will
continue to function under almost all circumstances.
|
etcd、ZooKeeper、Consul对比
借用etcd官网上etcd与ZooKeeper和Consul的比较图。
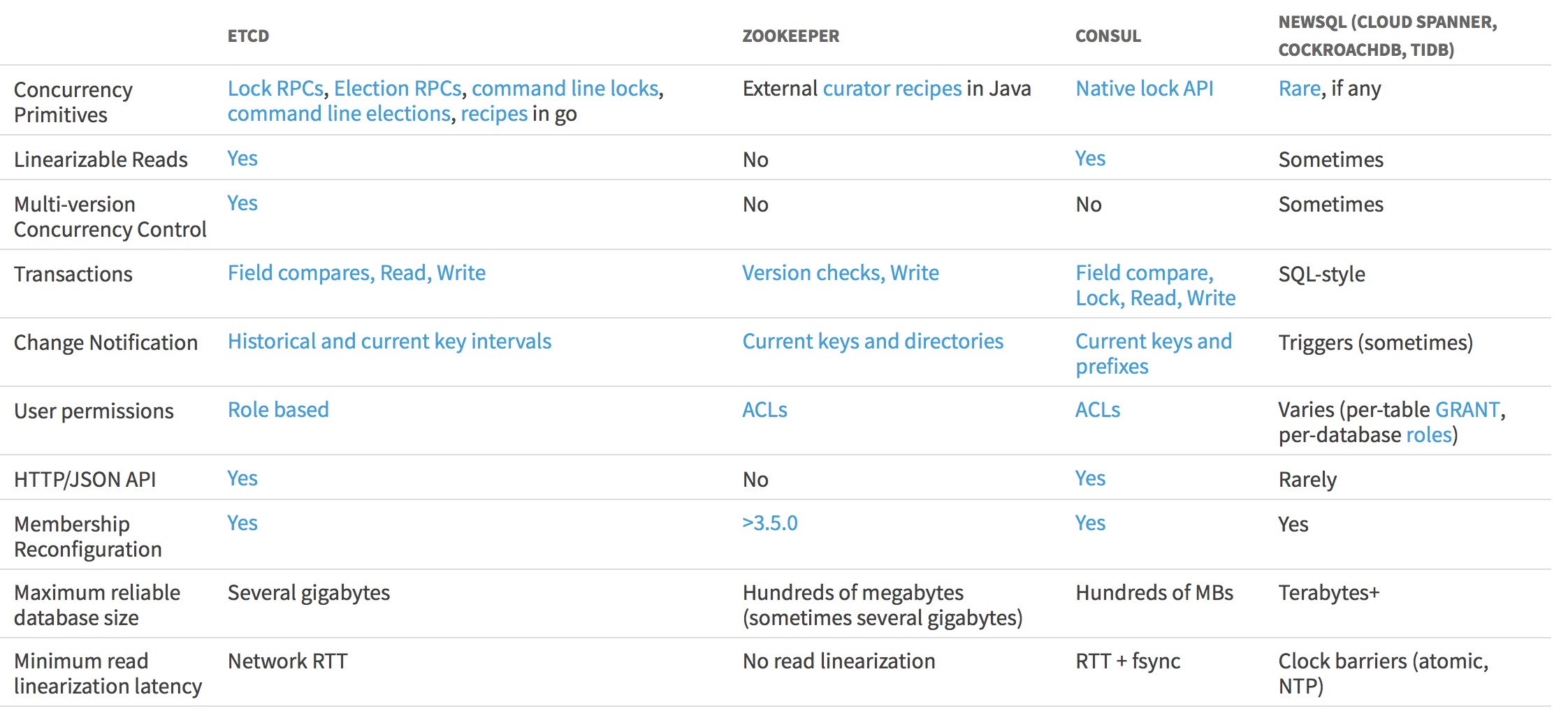
在我们HIDS Agent的需求中,除了基本的服务发现 、配置同步 、配置多版本控制 、变更通知等基本需求外,我们还有基于产品安全性上的考虑,比如传输通道加密、用户权限控制、角色管理、基于Key的权限设定等,这点
etcd比较符合我们要求。很多大型公司都在使用,比如Kubernetes、AWS、OpenStack、Azure、Google
Cloud、Huawei Cloud等,并且etcd的社区支持非常好。基于这几点因素,我们选择etcd作为HIDS的分布式集群管理。
选择etcd
对于etcd在项目中的应用,我们分别使用不同的API接口实现对应的业务需求,按照业务划分如下:
1.Watch机制来实现配置变更下发,任务下发的实时获取机制。
2.脑裂问题在etcd中不存在,etcd集群的选举,只有投票达到
N/2+1 以上,才会选做Leader,来保证数据一致性。另外一个网络分区的Member节点将无主。
3.语言亲和性,也是Golang开发的,Client SDK库稳定可用。
4.Key存储的数据结构支持范围性的Key操作。
5.User、Role权限设定不同读写权限,来控制Key操作,避免其他客户端修改其他Key的信息。
6.TLS来保证通道信息传递安全。
7.Txn分布式事务API配合Compare API来确定主机上线的Key唯一性。
8.Lease租约机制,过期Key释放,更好的感知主机下线信息。
9.etcd底层Key的存储为BTree结构,查找时间复杂度为O(㏒n),百万级甚至千万级Key的查找耗时区别不大。
etcd Key的设计
前缀按角色设定:
1.Server配置下发使用 /hids/server/config/{hostname}/master。
2.Agent注册上线使用 /hids/agent/master/{hostname}。
3.Plugin配置获取使用 /hids/agent/config/{hostname}/plugin/ID/conf_name。
Server Watch /hids/server/config/{hostname}/master,实现Agent主机上线的瞬间感知。Agent
Watch /hids/server/config/{hostname}/来获取配置变更,任务下发。Agent注册的Key带有Lease
Id,并启用keepalive,下线后瞬间感知。 (异常下线,会有1/3的keepalive时间延迟)
关于Key的权限,根据不同前缀,设定不同Role权限。赋值给不同的User,来实现对Key的权限控制。
etcd集群管理
在etcd节点容灾考虑,考虑DNS故障时,节点会选择部署在多个城市,多个机房,以我们服务器机房选择来看,在大部分机房都有一个节点,综合承载需求,我们选择了N台服务器部署在个别重要机房,来满足负载、容灾需求。但对于etcd这种分布式一致性强的组件来说,每个写操作都需要N/2-1的节点确认变更,才会将写请求写入数据库中,再同步到各个节点,那么意味着节点越多,需要确认的网络请求越多,耗时越多,反而会影响集群节点性能。这点,我们后续将提升单个服务器性能,以及牺牲部分容灾性来提升集群处理速度。
客户端填写的IP列表,包含域名、IP。IP用来规避DNS故障,域名用来做Member节点更新。最好不要使用Discover方案,避免对内网DNS服务器产生较大压力。
同时,在配置etcd节点的地址时,也要考虑到内网DNS故障的场景,地址填写会混合IP、域名两种形式。
1.IP的地址,便于规避内网DNS故障。
2.域名形式,便于做个别节点更替或扩容。
我们在设计产品架构时,为了安全性,开启了TLS证书认证,当节点变更时,证书的生成也同样要考虑到上面两种方案的影响,证书里需要包含固定IP,以及DNS域名范围的两种格式。
etcd Cluster节点扩容
节点扩容,官方手册上也有完整的方案,etcd的Client里实现了健康检测与故障迁移,能自动的迁移到节点IP列表中的其他可用IP。也能定时更新etcd
Node List,对于etcd Cluster的集群节点变更来说,不存在问题。需要我们注意的是,TLS证书的兼容。
分布式HIDS集群架构图
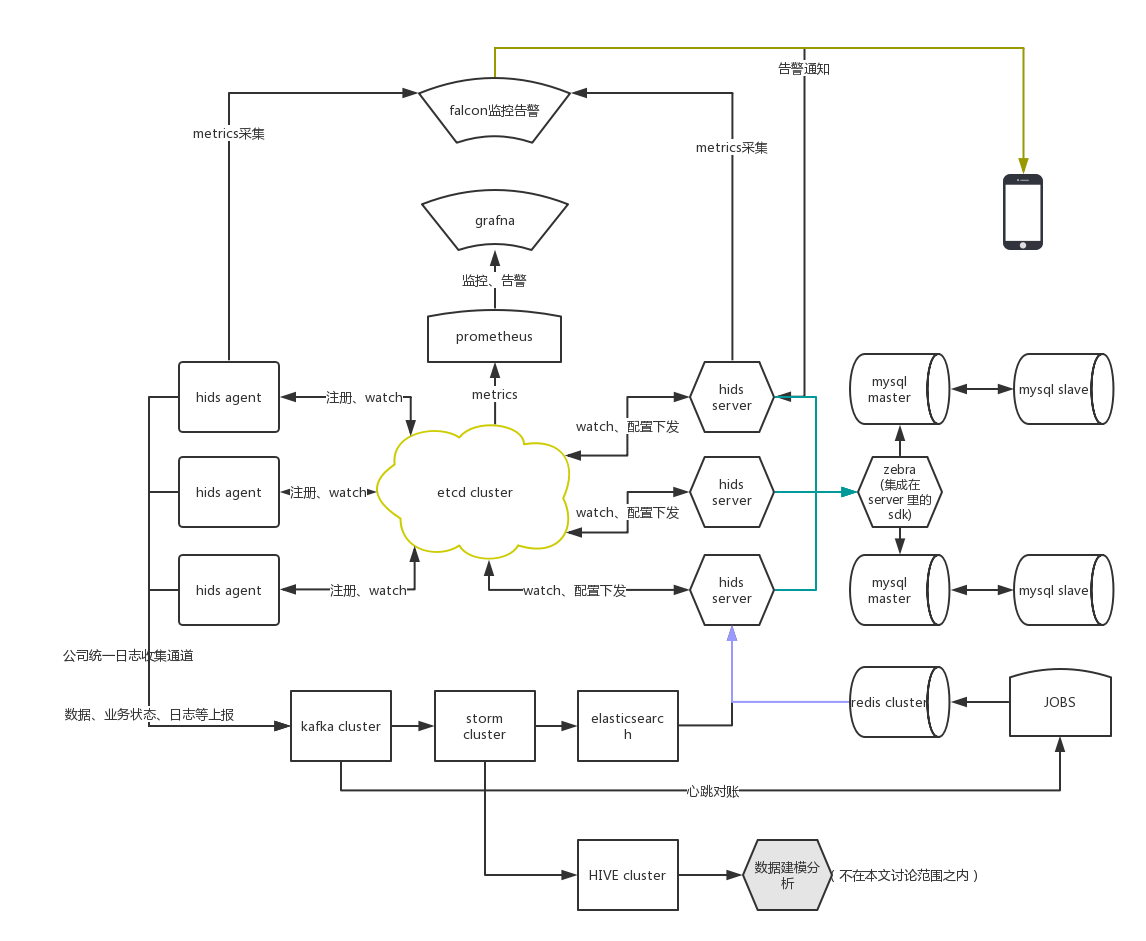
集群核心组件高可用,所有Agent、Server都依赖集群,都可以无缝扩展,且不影响整个集群的稳定性。即使Server全部宕机,也不影响所有Agent的继续工作。
在以后Server版本升级时,Agent不会中断,也不会带来雪崩式的影响。etcd集群可以做到单节点升级,一直到整个集群升级,各个组件全都解耦。
编程语言选择
考虑到公司服务器量大,业务复杂,需求环境多变,操作系统可能包括各种Linux以及Windows等。为了保证系统的兼容性,我们选择了Golang作为开发语言,它具备以下特点:
1.可以静态编译,直接通过syscall来运行,不依赖libc,兼容性高,可以在所有Linux上执行,部署便捷。
2.静态编译语言,能将简单的错误在编译前就发现。
3.具备良好的GC机制,占用系统资源少,开发成本低。
4.容器化的很多产品都是Golang编写,比如Kubernetes、Docker等。
5.etcd项目也是Golang编写,类库、测试用例可以直接用,SDK支持快速。
6.良好的CSP并发模型支持,高效的协程调度机制。
产品架构大方向
HIDS产品研发完成后,部署的服务都运行着各种业务的服务器,业务的重要性排在第一,我们产品的功能排在后面。为此,确定了几个产品的大方向:
高可用,数据一致,可横向扩展。
容灾性好,能应对机房级的网络故障。
兼容性好,只维护一个版本的Agent。
依赖低,不依赖任何动态链接库。
侵入性低,不做Hook,不做系统类库更改。
熔断降级可靠,宁可自己挂掉,也不影响业务 。
产品实现
篇幅限制,仅讨论框架设计、熔断限流、监控告警、自我恢复以及产品实现上的主进程与进程监控。
框架设计 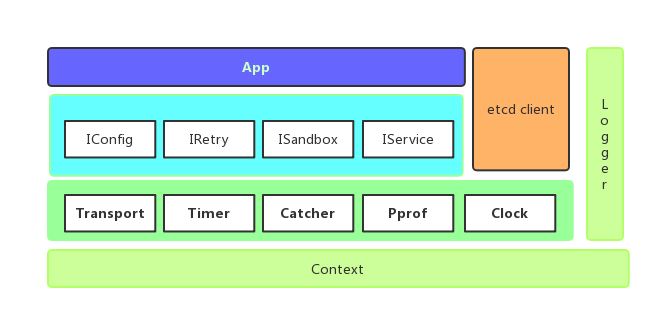
如上图,在框架的设计上,封装常用类库,抽象化定义Interface,剥离etcd Client,全局化Logger,抽象化App的启动、退出方法。使得各模块(以下简称App)只需要实现自己的业务即可,可以方便快捷的进行逻辑编写,无需关心底层实现、配置来源、重试次数、熔断方案等等。
沙箱隔离
考虑到子进程不能无限的增长下去,那么必然有一个进程包含多个模块的功能,各App之间既能使用公用底层组件(Logger、etcd
Client等),又能让彼此之间互不影响,这里进行了沙箱化处理,各个属性对象仅在各App的sandbox里生效。同样能实现了App进程的性能熔断,停止所有的业务逻辑功能,但又能具有基本的自我恢复功能。
IConfig
对各App的配置抽象化处理,实现IConfig的共有方法接口,用于对配置的函数调用,比如Check的检测方法,检测配置合法性,检测配置的最大值、最小值范围,规避使用人员配置不在合理范围内的情况,从而避免带来的风险。
框架底层用Reflect来处理JSON配置,解析读取填写的配置项,跟Config对象对比,填充到对应Struct的属性上,允许JSON配置里只填写变化的配置,没填写的配置项,则使用Config对应Struct的默认配置。便于灵活处理配置信息。
| type
IConfig interface {
Check() error //检测配置合法性
}
func ConfigLoad(confByte []byte, config IConfig)
(IConfig, error) {
...
//反射生成临时的IConfig
var confTmp IConfig
confTmp = reflect.New(reflect.ValueOf(config).Elem().Type()).
Interface().(IConfig)
...
//反射 confTmp 的属性
confTmpReflect := reflect.TypeOf(confTmp).Elem()
confTmpReflectV := reflect.ValueOf(confTmp).Elem()
//反射config IConfig
configReflect := reflect.TypeOf(config).Elem()
configReflectV := reflect.ValueOf(config).Elem()
...
for i = 0; i < num; i++ {
//遍历处理每个Field
envStructTmp := configReflect.Field(i)
//根据配置中的项,来覆盖默认值
if envStructTmp.Type == confStructTmp.Type {
configReflectV.FieldByName(envStructTmp.Name).
Set(confTmpReflectV.Field(i))
|
Timer、Clock调度
在业务数据产生时,很多地方需要记录时间,时间的获取也会产生很多系统调用。尤其是在每秒钟产生成千上万个事件,这些事件都需要调用获取时间接口,进行clock_gettime等系统调用,会大大增加系统CPU负载。
而很多事件产生时间的准确性要求不高,精确到秒,或者几百个毫秒即可,那么框架里实现了一个颗粒度符合需求的(比如100ms、200ms、或者1s等)间隔时间更新的时钟,即满足事件对时间的需求,又减少了系统调用。
同样,在有些Ticker场景中,Ticker的间隔颗粒要求不高时,也可以合并成一个Ticker,减少对CPU时钟的调用。
Catcher
在多协程场景下,会用到很多协程来处理程序,对于个别协程的panic错误,上层线程要有一个良好的捕获机制,能将协程错误抛出去,并能恢复运行,不要让进程崩溃退出,提高程序的稳定性。
抽象接口
框架底层抽象化封装Sandbox的Init、Run、Shutdown接口,规范各App的对外接口,让App的初始化、运行、停止等操作都标准化。App的模块业务逻辑,不需要关注PID文件管理,不关注与集群通讯,不关心与父进程通讯等通用操作,只需要实现自己的业务逻辑即可。App与框架的统一控制,采用Context包以及Sync.Cond等条件锁作为同步控制条件,来同步App与框架的生命周期,同步多协程之间同步,并实现App的安全退出,保证数据不丢失。
限流
网络IO
1.限制数据上报速度。
2.队列存储数据任务列表。
3.大于队列长度数据丢弃。
4.丢弃数据总数计数。
5.计数信息作为心跳状态数据上报到日志中心,用于数据对账。
磁盘IO
程序运行日志,对日志级别划分,参考 /usr/include/sys/syslog.h:
1.LOG_EMERG
2.LOG_ALERT
3.LOG_CRIT
4.LOG_ERR
5.LOG_WARNING
6.LOG_NOTICE
7.LOG_INFO
8.LOG_DEBUG
在代码编写时,根据需求选用级别。级别越低日志量越大,重要程度越低,越不需要发送至日志中心,写入本地磁盘。那么在异常情况排查时,方便参考。
日志文件大小控制,分2个文件,每个文件不超过固定大小,比如20M、50M等。并且,对两个文件进行来回写,避免日志写满磁盘的情况。
IRetry
为了加强Agent的鲁棒性,不能因为某些RPC动作失败后导致整体功能不可用,一般会有重试功能。Agent跟etcd
Cluster也是TCP长连接(HTTP2),当节点重启更换或网络卡顿等异常时,Agent会重连,那么重连的频率控制,不能是死循环般的重试。假设服务器内网交换机因内网流量较大产生抖动,触发了Agent重连机制,不断的重连又加重了交换机的负担,造成雪崩效应,这种设计必须要避免。
在每次重试后,需要做一定的回退机制,常见的指数级回退,比如如下设计,在规避雪崩场景下,又能保障Agent的鲁棒性,设定最大重试间隔,也避免了Agent失控的问题。
| //网络库重试Interface
type INetRetry interface {
//开始连接函数
Connect() error
String() string
//获取最大重试次数
GetMaxRetry() uint
...
}
// 底层实现
func (this *Context) Retry(netRetry INetRetry)
error {
...
maxRetries = netRetry.GetMaxRetry() //最大重试次数
hashMod = netRetry.GetHashMod()
for {
if c.shutting {
return errors.New("c.shutting is true...")
}
if maxRetries > 0 && retries >=
maxRetries {
c.logger.Debug("Abandoning %s after %d
retries.", netRetry.String(), retries)
return errors.New("超过最大重试次数")
}
...
if e := netRetry.Connect(); e != nil {
delay = 1 << retries
if delay == 0 {
delay = 1
}
delay = delay * hashInterval
...
c.logger.Emerg("Trying %s after %d seconds
, retries:%d,error:%v", netRetry.String(),
delay, retries, e)
time.Sleep(time.Second * time.Duration(delay))
}
...
}
|
事件拆分
百万台IDC规模的Agent部署,在任务执行、集群通讯或对宿主机产生资源影响时,务必要错峰进行,根据每台主机的唯一特征取模,拆分执行,避免造成雪崩效应。
监控告警
古时候,行军打仗时,提倡「兵马未动,粮草先行」,无疑是冷兵器时代决定胜负走向的重要因素。做产品也是,尤其是大型产品,要对自己运行状况有详细的掌控,做好监控告警,才能确保产品的成功。
对于etcd集群的监控,组件本身提供了Metrics数据输出接口,官方推荐了Prometheus来采集数据,使用Grafana来做聚合计算、图标绘制,我们做了Alert的接口开发,对接了公司的告警系统,实现IM、短信、电话告警。
Agent数量感知,依赖Watch数字,实时准确感知。
如下图,来自产品刚开始灰度时的某一时刻截图,Active Streams(即etcd Watch的Key数量)即为对应Agent数量,每次灰度的产品数量。因为该操作,是Agent直接与集群通讯,并且每个Agent只Watch一个Key。且集群数据具备唯一性、一致性,远比心跳日志的处理要准确的多。
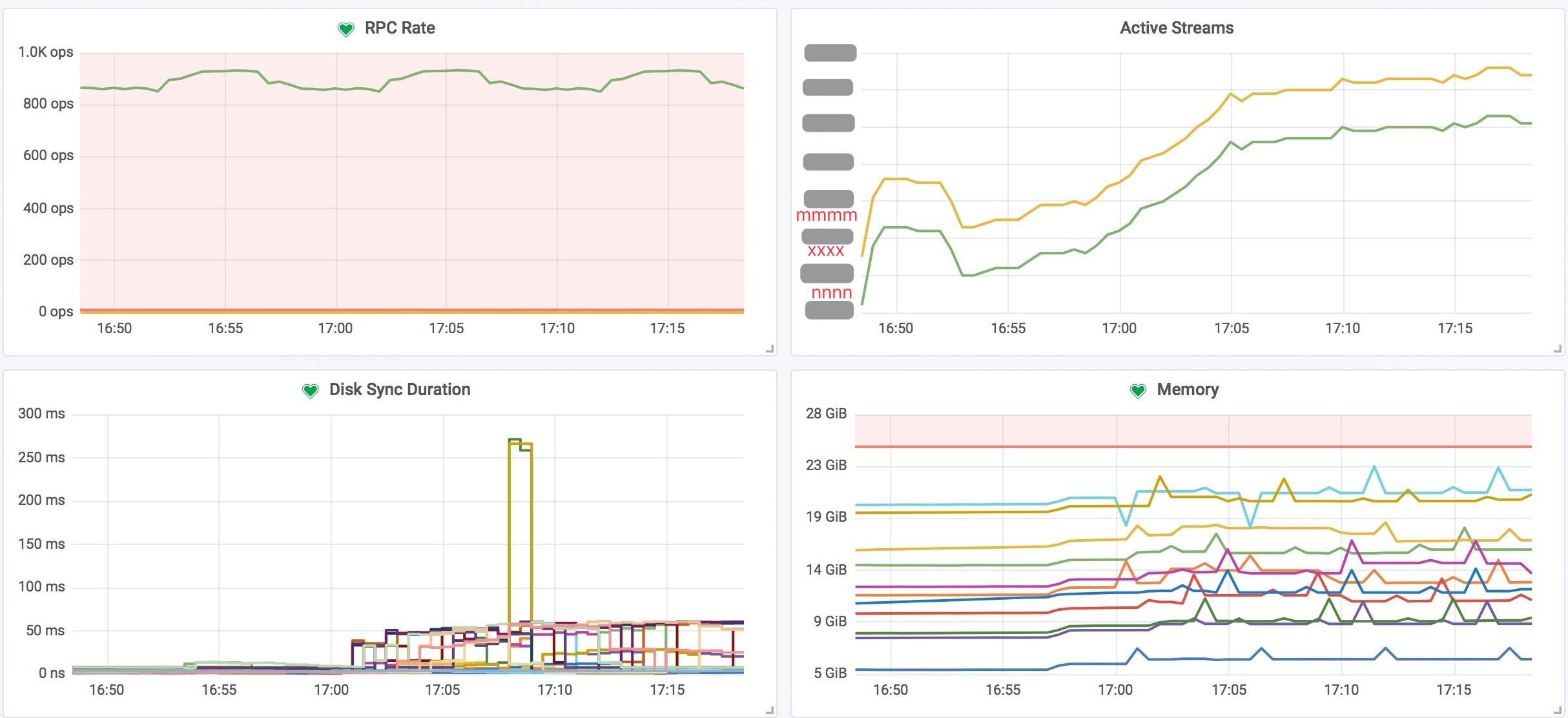
etcd集群Members之间健康状况监控
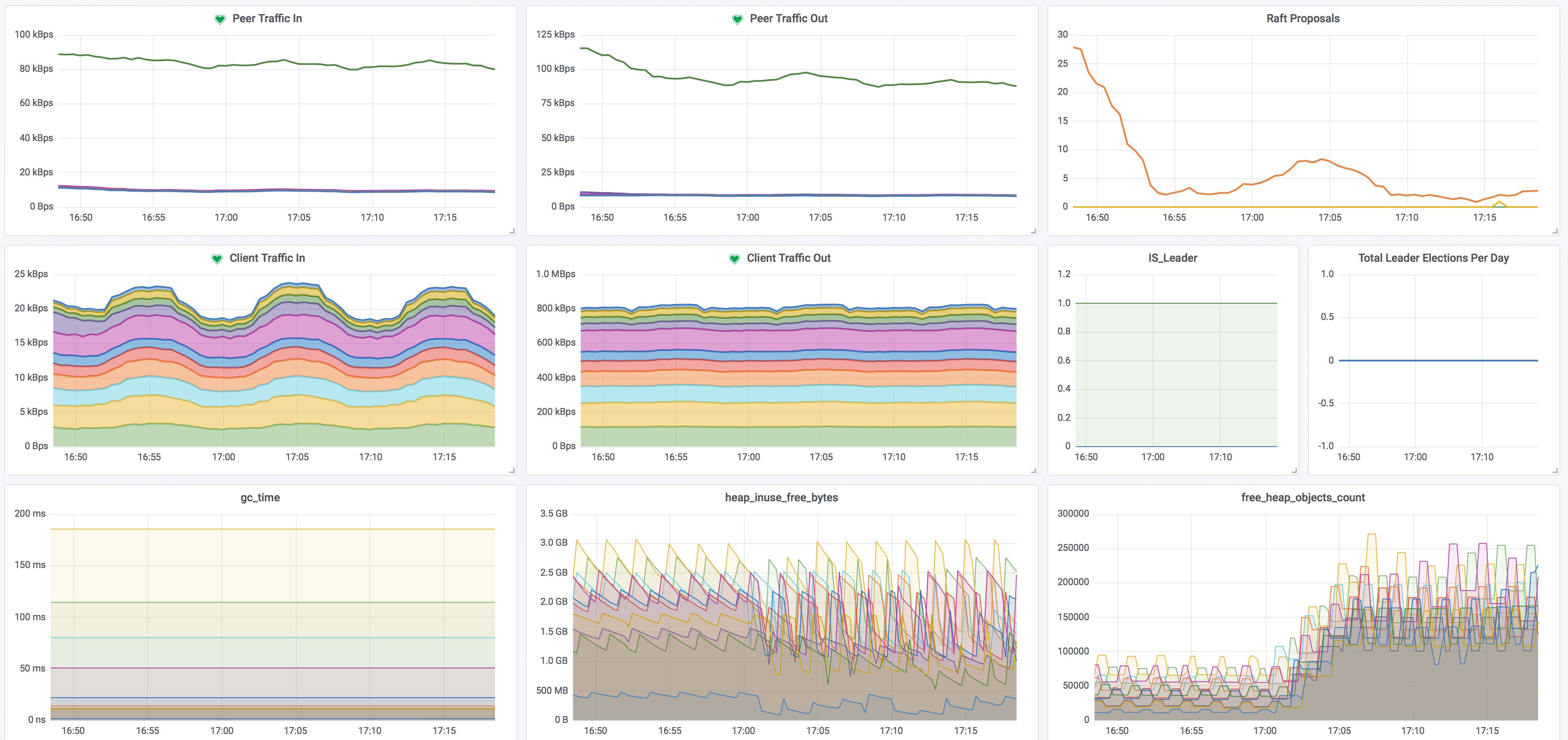
用于监控管理etcd集群的状况,包括Member节点之间数据同步,Leader选举次数,投票发起次数,各节点的内存申请状况,GC情况等,对集群的健康状况做全面掌控。
程序运行状态监控告警
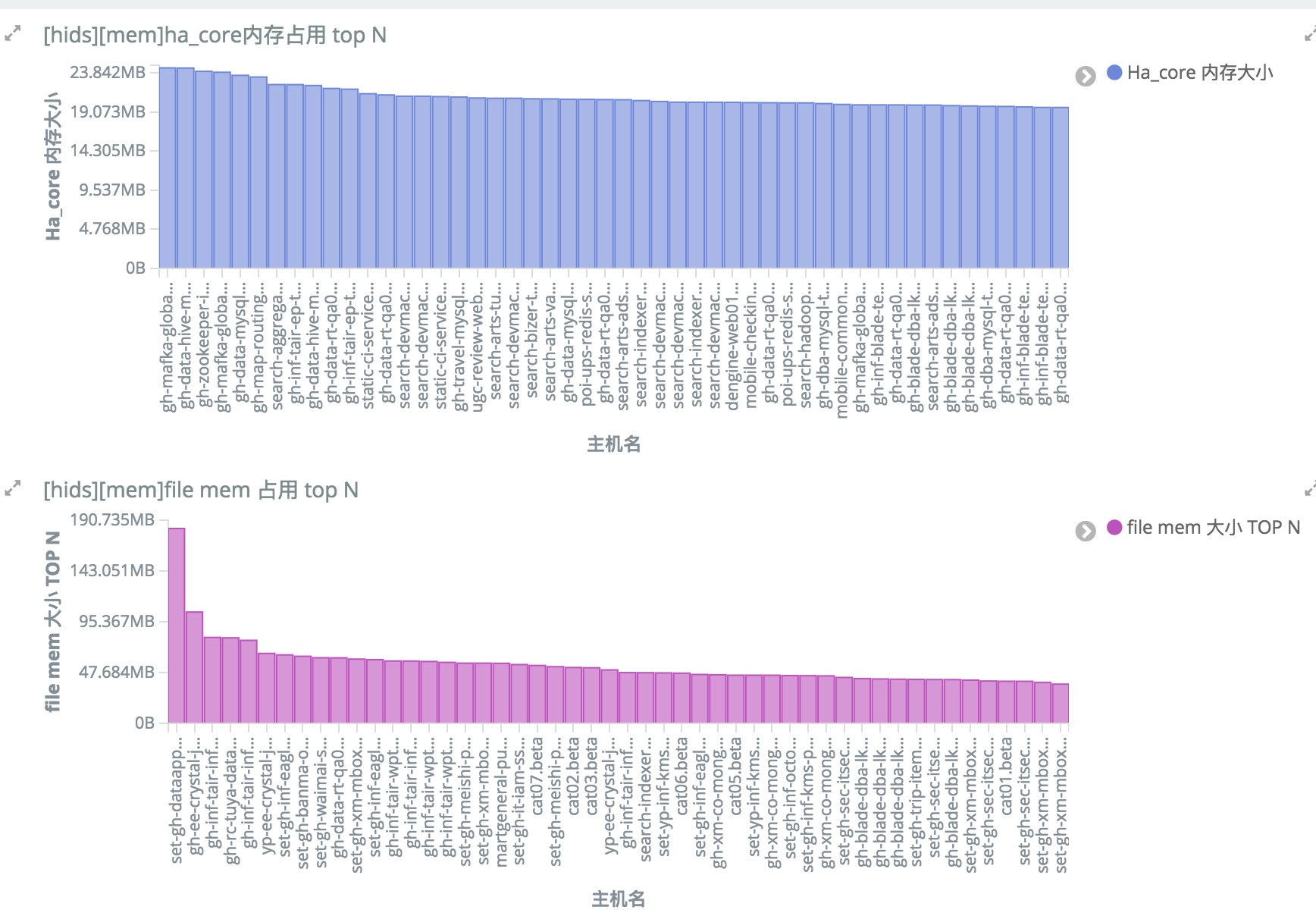
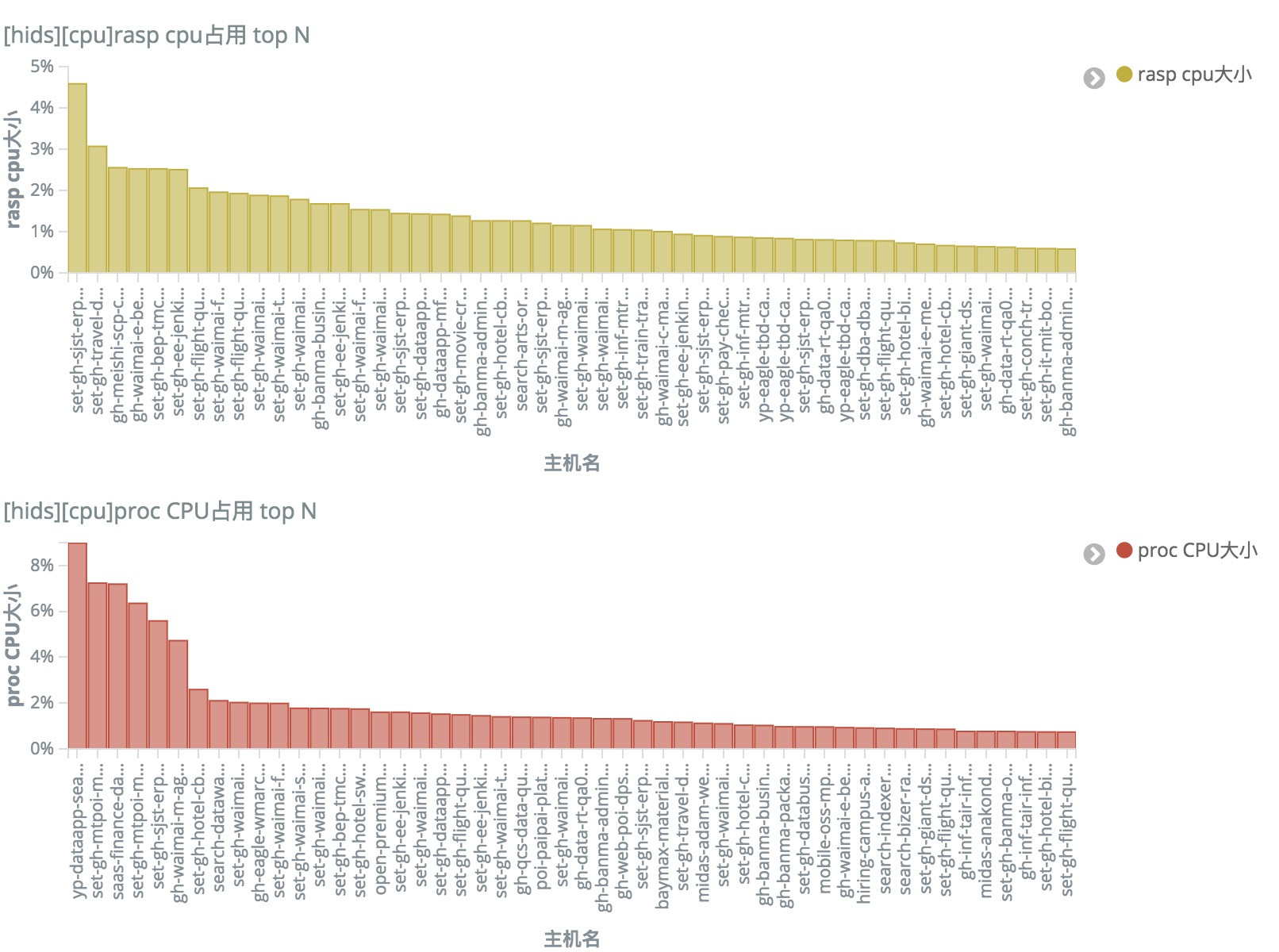
全量监控Aagent的资源占用情况,统计每天使用最大CPU\内存的主机Agent,确定问题的影响范围,及时做策略调整,避免影响到业务服务的运行。并在后续版本上逐步做调整优化。
百万台服务器,日志告警量非常大,这个级别的告警信息的筛选、聚合是必不可少的。减少无用告警,让研发运维人员疲于奔命,也避免无用告警导致研发人员放松了警惕,前期忽略个例告警,先解决主要矛盾。
1.告警信息分级,告警信息细分ID。
2.根据告警级别过滤,根据告警ID聚合告警,来发现同类型错误。
3.根据告警信息的所在机房、项目组、产品线等维度来聚合告警,来发现同类型错误。
数据采集告警
单机数据数据大小、总量的历史数据对比告警。
按机房、项目组、产品线等维度的大小、总量等维度的历史数据对比告警。
数据采集大小、总量的对账功能,判断经过一系列处理流程的日志是否丢失的监控告警。
熔断
1.针对单机Agent使用资源大小的阈值熔断,CPU使用率,连续N次触发大于等于5%,则进行保护性熔断,退出所有业务逻辑,以保护主机的业务程序优先。
2.Master进程进入空闲状态,等待第二次时间Ticker到来,决定是否恢复运行。
3.各个App基于业务层面的监控熔断策略。
灰度管理
在前面的配置管理中的etcd Key设计里,已经细分到每个主机(即每个Agent)一个Key。那么,服务端的管理,只要区分该主机所属机房、环境、群组、产品线即可,那么,我们的管理Agent的颗粒度可以精确到每个主机,也就是支持任意纬度的灰度发布管理与命令下发。
数据上报通道
组件名为 log_agent ,是公司内部统一日志上报组件,会部署在每一台VM、Docker上。主机上所有业务均可将日志发送至该组件。
log_agent会将日志上报到Kafka集群中,经过处理后,落入Hive集群中。(细节不在本篇讨论范围)
主进程
主进程实现跟etcd集群通信,管理整个Agent的配置下发与命令下发;管理各个子模块的启动与停止;管理各个子模块的CPU、内存占用情况,对资源超标进行进行熔断处理,让出资源,保证业务进程的运行。
插件化管理其他模块,多进程模式,便于提高产品灵活性,可更简便的更新启动子模块,不会因为个别模块插件的功能、BUG导致整个Agent崩溃。
进程监控
方案选择
我们在研发这产品时,做了很多关于linux进程创建监控的调研,不限于安全产品,大约有下面三种技术方案:

对于公司的所有服务器来说,几十万台都是已经在运行的服务器,新上的任何产品,都尽量避免对服务器有影响,更何况是所有服务器都要部署的Agent。
意味着我们在选择系统侵入性来说,优先选择最小侵入性的方案。
对于Netlink的方案原理,可以参考这张图
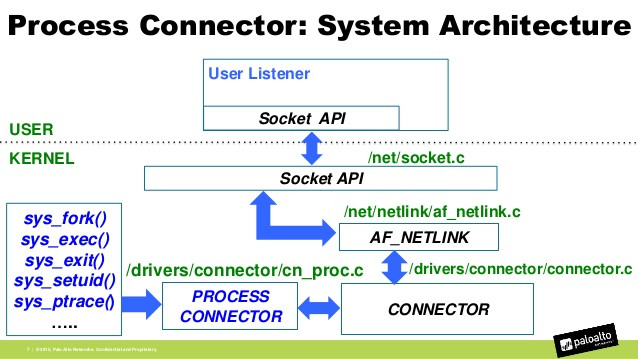
系统侵入性比较
cn_proc跟Autid在「系统侵入性」和「数据准确性」来说,cn_proc方案更好,而且使用CPU、内存等资源情况,更可控。
Hook的方案,对系统侵入性太高了,尤其是这种最底层做HOOK syscall的做法,万一测试不充分,在特定环境下,有一定的概率会出现Bug,而在百万IDC的规模下,这将成为大面积事件,可能会造成重大事故。
兼容性上比较
cn_proc不兼容Docker,这个可以在宿主机上部署来解决。
Hook的方案,需要针对每种Linux的发行版做定制,维护成本较高,且不符合长远目标(收购外部公司时遇到各式各样操作系统问题)
数据准确性比较
在大量PID创建的场景,比如Docker的宿主机上,内核返回PID时,因为PID返回非常多非常快,很多进程启动后,立刻消失了,另外一个线程都还没去读取/proc/,进程都丢失了,场景常出现在Bash执行某些命令。
最终,我们选择Linux Kernel Netlink接口的cn_proc指令作为我们进程监控方案,借助对Bash命令的收集,作为该方案的补充。当然,仍然存在丢数据的情况,但我们为了系统稳定性,产品侵入性低等业务需求,牺牲了一些安全性上的保障。
对于Docker的场景,采用宿主机运行,捕获数据,关联到Docker容器,上报到日志中心的做法来实现。
遇到的问题
内核Netlink发送数据卡住
内核返回数据太快,用户态ParseNetlinkMessage解析读取太慢,导致用户态网络Buff占满,内核不再发送数据给用户态,进程空闲。对于这个问题,我们在用户态做了队列控制,确保解析时间的问题不会影响到内核发送数据。对于队列的长度,我们做了定值限制,生产速度大于消费速度的话,可以丢弃一些数据,来保证业务正常运行,并且来控制进程的内存增长问题。
疑似“内存泄露”问题
在一台Docker的宿主机上,运行了50个Docker实例,每个Docker都运行了复杂的业务场景,频繁的创建进程,在最初的产品实现上,启动时大约10M内存占用,一天后达到200M的情况。
经过我们Debug分析发现,在ParseNetlinkMessage处理内核发出的消息时,PID频繁创建带来内存频繁申请,对象频繁实例化,占用大量内存。同时,在Golang
GC时,扫描、清理动作带来大量CPU消耗。在代码中,发现对于linux/connector.h里的struct
cb_msg、linux/cn_proc.h里的struct proc_event结构体频繁创建,带来内存申请等问题,以及Golang的GC特性,内存申请后,不会在GC时立刻归还操作系统,而是在后台任务里,逐渐的归还到操作系统,见:debug.FreeOSMemory
| FreeOSMemory
forces a garbage collection followed by an attempt
to return as much memory to the operating system
as possible. (Even if this is not called, the
runtime gradually returns memory to the operating
system in a background task.)
|
但在这个业务场景里,大量频繁的创建PID,频繁的申请内存,创建对象,那么申请速度远远大于释放速度,自然内存就一直堆积。
从文档中可以看出,FreeOSMemory的方法可以将内存归还给操作系统,但我们并没有采用这种方案,因为它治标不治本,没法解决内存频繁申请频繁创建的问题,也不能降低CPU使用率。
为了解决这个问题,我们采用了sync.Pool的内置对象池方式,来复用回收对象,避免对象频繁创建,减少内存占用情况,在针对几个频繁创建的对象做对象池化后,同样的测试环境,内存稳定控制在15M左右。
大量对象的复用,也减少了对象的数量,同样的,在Golang GC运行时,也减少了对象的扫描数量、回收数量,降低了CPU使用率。
项目进展
在产品的研发过程中,也遇到了一些问题,比如:
1.etcd Client Lease Keepalive的Bug。
2.Agent进程资源限制的Cgroup触发几次内核Bug。
3.Docker宿主机上瞬时大量进程创建的性能问题。
4.网络监控模块在处理Nginx反向代理时,动辄几十万TCP链接的网络数据获取压力。
5.个别进程打开了10W以上的fd。
方法一定比困难多,但方法不是拍脑袋想出来的,一定要深入探索问题的根本原因,找到系统性的修复方法,具备高可用、高性能、监控告警、熔断限流等功能后,对于出现的问题,能够提前发现,将故障影响最小化,提前做处理。在应对产品运营过程中遇到的各种问题时,逢山开路,遇水搭桥,都可以从容的应对。
经过我们一年的努力,已经部署了除了个别特殊业务线之外的其他所有服务器,数量达几十万台,产品稳定运行。在数据完整性、准确性上,还有待提高,在精细化运营上,需要多做改进。
本篇更多的是研发角度上软件架构上的设计,关于安全事件分析、数据建模、运营策略等方面的经验和技巧,未来将会由其他同学进行分享,敬请期待。
总结
我们在研发这款产品过程中,也看到了网上开源了几款同类产品,也了解了他们的设计思路,发现很多产品都是把主要方向放在了单个模块的实现上,而忽略了产品架构上的重要性。
比如,有的产品使用了syscall hook这种侵入性高的方案来保障数据完整性,使得对系统侵入性非常高,Hook代码的稳定性,也严重影响了操作系统内核的稳定。同时,Hook代码也缺少了监控熔断的措施,在几十万服务器规模的场景下部署,潜在的风险可能让安全部门无法接受,甚至是致命的。
这种设计,可能在服务器量级小时,对于出现的问题多花点时间也能逐个进行维护,但应对几十万甚至上百万台服务器时,对维护成本、稳定性、监控熔断等都是很大的技术挑战。同时,在研发上,也很难实现产品的快速迭代,而这种方式带来的影响,几乎都会导致内核宕机之类致命问题。这种事故,使用服务器的业务方很难进行接受,势必会影响产品的研发速度、推进速度;影响同事(SRE运维等)对产品的信心,进而对后续产品的推进带来很大的阻力。
|








