| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌ
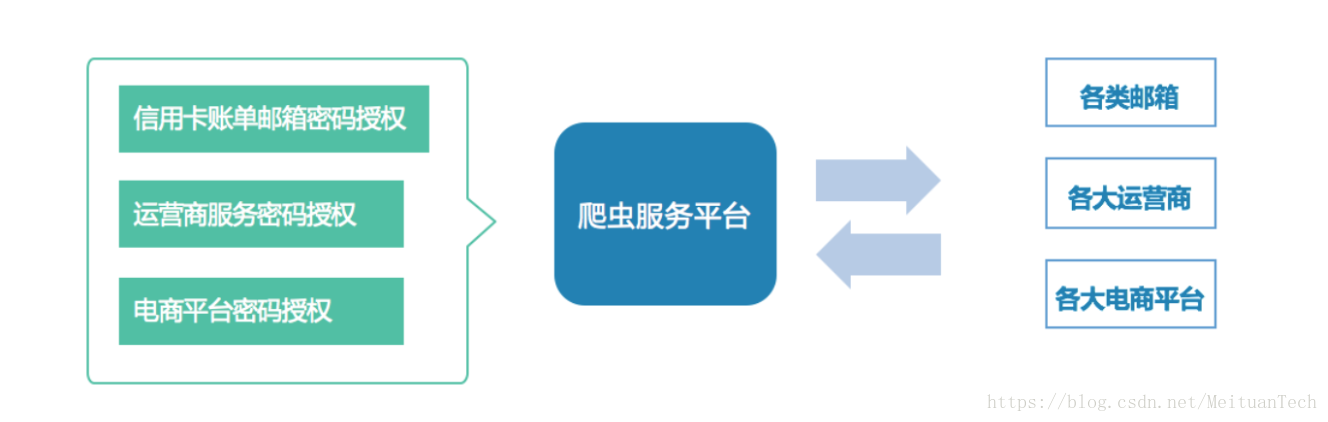
БОЮФжївЊВћЪіСЫУРЭХЕуЦРаХЯЂАВШЋжааФОпЬхВуУцЕФЬНЫїЃЌетаЉЬНЫїгГЩфЕНITЕФВуУцЃЌжївЊАќРЈгІгУЯЕЭГКЭЪ§ОнВжПтЁЃ |
|
БГОА
НќФъРДЃЌЪ§ОнАВШЋаЮЪЦдНЗЂбЯОўЃЌИїжжЪ§ОнАВШЋЪТМўВуГіВЛЧюЁЃдкЕБЧАаЮЪЦЯТЃЌЛЅСЊЭјЙЋЫОвВЛљБОДяГЩСЫвЛИіЙВЪЖЃКЫфШЛЮоЗЈЭъШЋзшжЙЙЅЛїЃЌЕЋЕзЯпЪЧУєИаЪ§ОнВЛФмаЙТЉЁЃвВМДЪЧЫЕЃЌЗўЮёЦїПЩвдБЛЙвТэЃЌЕЋУєИаЪ§ОнВЛФмБЛЭЯзпЁЃЗўЮёЦїЖдгкЛЅСЊЭјЙЋЫОРДЫЕЃЌЪЧПЩвдНгЪмЕФЫ№ЪЇЃЌЕЋУєИаЪ§ОнаЙТЉЃЌдђЛсЖдЙЋЫОВњЩњжиДѓЩљгўЁЂОМУгАЯьЁЃ
дкЛЅСЊЭјЙЋЫОЕФЪ§ОнАВШЋСьгђЃЌЮоТлЪЧДЋЭГРэТлЬсГіЕФЪ§ОнАВШЋЩњУќжмЦкЃЌЛЙЪЧАВШЋГЇЩЬЬсЙЉЕФНтОіЗНАИЃЌЖМУцСйзХТфЕиРЇФбЕФЮЪЬтЁЃЦфКЫаФЕудкгкЖдКЃСПЪ§ОнЁЂИДдггІгУЛЗОГЯТЕФПЩВйзїадВЛМбЁЃ
Р§ШчЪ§ОнАВШЋЩњУќжмЦкЬсГіЃЌЪзЯШвЊЖдЪ§ОнНјааЗжРрЗжМЖЃЌШЛКѓВХЪЧБЃЛЄЁЃЕЋЛЅСЊЭјЙЋЫОЛљБОЩЯЖМЪЧвАТљЩњГЄЃЌЗЂеЙзГДѓвдКѓВХЗЂЯжЪ§ОнАВШЋЕФЮЪЬтЁЃЕЋДцСПЪ§ОнвбОаЮГЩЃЌШевдЭђМЦЕФЪ§ОнБэдкдіГЄЃЌетжжЧщПіЯТШчКЮЪЕЯжЪ§ОнЗжРрЗжМЖЃПШЫЙЄЪсРэЯдШЛВЛЯжЪЕЃЌЪсРэЕФЫйЖШИЯВЛЩЯЪ§ОндіГЄЫйЖШЁЃ
дйР§ШчАВШЋГЇЩЬЬсЙЉЕФЪ§ОнЩѓМЦНтОіЗНАИЃЌвВЖМЪЧЛљгкДЋЭГЙиЯЕаЭЪ§ОнПтЕФгВМўКазгЁЃHadoopЛЗОГЯТЕФЪ§ОнЩѓМЦЗНАИЪЧЪВУДЃПУцЖдКЃСПЪ§ОнЃЌКмЖрГЇЩЬвВТђВЛЦ№етУДЖргВМўКазгАЁЁЃ
вђДЫЃЌЛЅСЊЭјЙЋЫОЦШЧаашвЊвЛаЉЗћКЯздЩэЬиЕуЕФЪжЖЮЃЌРДНјааЪ§ОнАВШЋБЃеЯЁЃ
вЛЁЂгІгУЯЕЭГ
гІгУЯЕЭГЗжЮЊСНПщЃЌвЛЪЧЖдПЙЭтВПЙЅЛїЃЌЪЧЖрЪ§ЙЋЫОЖМгаЕФАВШЋвтЪЖЃЌЕЋвтЪЖВЛЕШгкФмСІЃЌетЪЧвЛИіИКд№ШЮЦѓвЕЕФЛљБОЙІЁЃДЋЭГЮЪЬтАќРЈдНШЈЁЂБщРњЁЂSQLзЂШыЁЂАВШЋХфжУЁЂЕЭАцБОТЉЖДЕШЃЌетвЛРрдкOWASPЕФTop10ЗчЯеЖМгаЬсЕНЃЌдкЪЕМљжажївЊПМТЧSDLЁЂАВШЋдЫЮЌЁЂКьРЖЖдПЙЕШЪжЖЮЃЌЧввдВњЦЗЛЏЕФаЮЪНРДНтОіжївЊЮЪЬтЁЃетРяВЛзіжиЕуНщЩмЁЃ
1.1 ЩЈКХМАХРГц
аТЕФаЮЪЦЯТЃЌЛЙУцСйЩЈКХЁЂХРГцЮЪЬтЁЃЩЈКХЪЧжИзВПтЛђШѕПкСюЃКзВПтЪЧгУвбОаЙТЉЕФеЫКХУмТыРДЪдЬНЃЌГЩЙІКѓЧсдђЧдШЁгУЛЇЪ§ОнЃЌжидђЕСШЁгУЛЇзЪН№ЃЛШѕПкСюдђЪЧМђЕЅУмТыЮЪЬтЁЃЖдгкетРрЮЪЬтЃЌвЕНчВЛЖЯЕФЬНЫїаТЗНЗЈЃЌАќРЈЩшБИжИЮЦММЪѕЁЂИДдгбщжЄТыЁЂШЫЛњЪЖБ№ЁЂIPаХгўЖШЃЌЪдЭМЖрЙмЦыЯТРДЛКНтЃЌЕЋКкВњвВдкВЛЖЯЩ§МЖЖдПЙММЪѕЃЌАќРЈвЛМќаТЛњЁЂФЃФтЦїЁЂIPДњРэЁЂШЫРрааЮЊФЃЗТЃЌвђДЫетЪЧИіВЛЖЯЕФЖдПЙЙ§ГЬЁЃ
ОйИіР§згЃЌгаЙЋЫОдкгУЛЇЕЧТМЪБЃЌХаЖЯМгЫйЕШДЋИаЦїЕФБфЛЏЃЌвђЮЊгУЛЇдкЪжЛњЦСФЛЕуЛїЪБЃЌБиШЛЛсДјРДНЧЖШЁЂжиСІЕФБфЛЏЁЃШчЙћгУЛЇЕуЛїЙ§ГЬжаетаЉДЋИаЦїУЛгаШЮКЮБфЛЏЃЌдђгаЪЙгУНХБОЕФЯгвЩЁЃдйМгЩЯвЛИіЮЌЖШШЅХаЖЯгУЛЇНќЦкЕчСПБфЛЏЃЌОЭПЩвдШЗШЯетЪЧвЛЬЈШЫРрдкгУЕФЪжЛњЃЌЛЙЪЧКкВњЙЄзїЪвЕФЪжЛњЁЃКкВњдкЖдПЙжаЗЂЯжЙЋЫОгУСЫетвЛРрЕФВпТдЃЌдђКмЧсвзЕФНјааСЫЛЏНтЃЌвЛЧаЪ§ОнЖМПЩвдЮБдьГіРДЃЌдкФГБІЩЯПЩвдПДЕНДѓСПЕФДЫРрММЪѕЙЄОпдкГіЪлЁЃ
ХРГцЖдПЙдђЪЧСэвЛИіаТЮЪЬтЃЌжЎЧАгаЮФеТЫЕЃЌФГаЉЙЋЫОЕФЪ§ОнЗУЮЪСїСП75%вдЩЯЖМЪЧХРГцЁЃХРГцВЛДјРДШЮКЮвЕЮёМлжЕЃЌЖјЧвЛЙвЊЮЊДЫИЖГіДѓСПзЪдДЃЌЭЌЪБЛЙУцСйЪ§ОнаЙТЉЕФЮЪЬтЁЃ
дкЛЅСЊЭјН№ШкаЫЦ№КѓЃЌХРГцгжВњЩњСЫаТЕФБфЛЏЃЌДгдРДЕФЮДЪкШЈХРШЁЪ§ОнЃЌБфГЩСЫгУЛЇЪкШЈХРШЁЪ§ОнЁЃОйР§РДЫЕЃЌаЁеХШБЧЎЃЌдкЛЅСЊЭјН№ШкЙЋЫОЭјеОЩъЧыаЁЖюДћПюЃЌЖјЛЅСЊЭјН№ШкЙЋЫОВЂВЛжЊЕРаЁеХФмВЛФмДћЃЌЛЙПюФмСІШчКЮЃЌвђДЫвЊЧѓаЁеХЬсЙЉдкЙКЮяЭјеОЁЂгЪЯфЛђЦфЫћгІгУЕФеЫКХУмТыЃЌХРШЁаЁеХЕФШеГЃЯћЗбЪ§ОнЃЌзїЮЊаХгУЦРЗжВЮПМЁЃаЁеХЮЊСЫЛёШЁДћПюЃЌЬсЙЉСЫеЫКХУмТыЃЌдђЙЙГЩСЫЪкШЈХРШЁЁЃетКЭвдЭљЕФЮДЪкШЈХРШЁВњЩњСЫКмДѓЕФБфЛЏЃЌЛЅСЊЭјН№ШкЙЋЫОПЩвдНјРДЛёШЁИќЖрУєИааХЯЂЃЌВЛЕЋМгжиСЫзЪдДИКЕЃЃЌЛЙДцдкгУЛЇУмТыаЙТЉЕФПЩФмЁЃ
ЖдХРГцЕФЖдПЙЃЌвВЪЧвЛИізлКЯПЮЬтЃЌВЛДцдквЛИіММЪѕНтОіЫљгаЮЪЬтЕФЗНАИЁЃНтОіЫМТЗЩЯГ§СЫжЎЧАЕФЩшБИжИЮЦЁЂIPаХгўЕШЪжЖЮжЎЭтЃЌЛЙАќРЈСЫИїжжЛњЦїбЇЯАЕФЫуЗЈФЃаЭЃЌвдЧјЗжГіе§ГЃааЮЊКЭвьГЃааЮЊЃЌвВПЩвдДгЙиСЊФЃаЭЕШЗНЯђШыЪжЁЃЕЋетвВЪЧИіЖдПЙЙ§ГЬЃЌКкВњвВдкж№НЅУўЫїЪдЬНЃЌДгЖјФЃФтГіШЫРрааЮЊЁЃЮДРДЛсаЮГЩЛњЦїгыЛњЦїЕФЖдПЙЃЌЖјОіЖЈЪфгЎЕФЃЌдђЪЧГЩБОЁЃ
1.2 ЫЎгЁ
НќФъРДвЕНчвВГіЯжСЫвЛаЉНЋФкВПУєИаЮФМўЃЌНиЭМЭтЗЂЕФЪТМўЁЃгааЉЪТМўв§Ц№СЫУНЬхЕФГДзїЃЌЖдЙЋЫОдьГЩСЫгпТлгАЯьЃЌетОЭашвЊФмЙЛЖдетжжЭтЗЂааЮЊНјааЫндДЁЃЖјЫЎгЁдкММЪѕЩЯвЊНтОіЕФПЙТГАєадЮЪЬтЃЌеыЖдЭМЦЌЕФЫЎгЁММЪѕАќРЈПеМфТЫВЈЁЂИЕСЂвЖБфЛЛЁЂМИКЮБфаЮЕШЃЌМђЕЅЕФЫЕЪЧНЋаХЯЂОЙ§БфЛЛЃЌдкЖёСгЬѕМўЯТЛЙдЕФММЪѕЁЃ
1.3 Ъ§ОнУлЙо
ЪЧжИжЦзївЛИіМйЕФЪ§ОнМЏКЯЃЌРДВЖЛёЗУЮЪепЃЌДгЖјЗЂЯжЙЅЛїааЮЊЁЃЙњЭтвбОгаЙЋЫОзіГіСЫЖдгІЕФВњЦЗЃЌЦфЪЕЯжПЩвдДжБЉЕиРэНтЮЊЃЌдквЛИіЪ§ОнЮФМўЩЯМгШыСЫвЛИіЁАФОТэЁБЃЌЫљгаЕФЗУЮЪепдйДђПЊКѓЃЌЛсАбЖдгІМЧТМЗЂЛиЗўЮёЦїЁЃЭЈЙ§етИіЁАФОТэЁБЃЌПЩвдзЗзйЕНЙЅЛїепЯИНкаХЯЂЁЃЮвУЧвВдјзіЙ§РрЫЦЕФЪТЧщЃЌвХКЖЕФЪЧЃЌетИіЪ§ОнЮФМўЗХдкФЧРяКмОУЃЌЖМЮоШЫЗУЮЪЁЃЮоШЫЗУЮЪКЭЮвЮвУЧЖдУлЙоЕФЖЈЮЛгаЙиЃЌЯжНзЖЮЮвУЧИќдИвтАбЫќзїЮЊвЛИіЪЕбщадЕФаЁЭцвтЃЌЖјВЛЪЧДѓЙцФЃВЩгУЃЌвђЮЊЁАФОТэЁББОЩэЃЌПЩФмДјгавЛЖЈЕФЗчЯеЁЃ
1.4 ДѓЪ§ОнааЮЊЩѓМЦ
ДѓЪ§ОнЕФГіЯжЃЌЮЊЙиСЊЩѓМЦЬсЙЉСЫИќЖрЕФПЩФмадЃЌПЩвдЭЈЙ§ИїжжЪ§ОнЙиСЊЦ№РДЗжЮівьГЃааЮЊЁЃетЗНУцЃЌДЋЭГАВШЋЩѓМЦГЇЩЬзіСЫвЛаЉГЂЪдЃЌЕЋДгПЭЙлЕФНЧЖШРДПДЃЌЛЙБШНЯЛљДЁЃЌЮоЗЈгІЖдДѓаЭЛЅСЊЭјЙЋЫОИДдгЧщПіЯТЕФааЮЊЩѓМЦЃЌЕБШЛетВЛФмПСЧѓДЋЭГАВШЋЩѓМЦГЇЩЬЃЌетгыЩњвтгаЙиЃЌЩњвтЪЧвЊзЗЧѓРћШѓЕФЁЃетжжЧщПіЯТЃЌЛЅСЊЭјЙЋЫООЭвЊздМКзіИќЖрЕФЪТЧщЁЃ
Р§ШчЗРЗЖФкЙэЃЌПЩвдЭЈЙ§ЖржжЪ§ОнЙиСЊЗжЮіЃЌЭЈЙ§ЁАгыЛЕШЫЙВгУЙ§вЛИіЩшБИЁБЙцдђЃЌРДЗЂЯжФкЙэЁЃОйвЛЗДШ§ЃЌдђПЩвдЭЈЙ§аХЯЂСїЁЂЮяСїЁЂзЪН№СїЕШМИИіДѓЕФЗНЯђбмЩњГіИќЖрЗћКЯздЩэЪ§ОнЬиЕуЕФзЅФкЙэЙцдђЁЃ
Г§ДЫжЎЭтЃЌЛЙПЩвдЭЈЙ§UEBAЃЈгУЛЇгыЪЕЬхааЮЊЗжЮіЃЉРДЗЂЯжвьГЃЃЌеташвЊдкИїИіЛЗНкШЅТёЕуВЩМЏЪ§ОнЃЌКѓЖЫдђашвЊЖдгІЕФЙцдђв§ЧцЯЕЭГЁЂЪ§ОнЦНЬЈЁЂЫуЗЈЦНЬЈРДжЇГХЁЃ
Р§ШчГЃМћЕФОлРрЫуЗЈЃКФГаЉШЫгыДѓЖрЪ§ШЫааЮЊВЛвЛжТЃЌдђетаЉШЫПЩФмгавьГЃЁЃОпЬхГЁОАПЩвдЪЧЃКе§ГЃгУЛЇааЮЊЪзЯШЪЧДђПЊвГУцЃЌбЁдёВњЦЗЃЌШЛКѓВХЪЧЕЧТМЁЂЯТЕЅЁЃЖјвьГЃааЮЊПЩвдЪЧЃКЯШЕЧТМЃЌШЛКѓаоИФУмТыЃЌзюКѓЯТЕЅбЁСЫвЛИіаТПЊЕФЕъЃЌЪЙгУСЫвЛИіДѓЖюгХЛнШЏЁЃетРяУПвЛИіЪ§ОнзжЖЮЃЌЖМПЩвдбмЩњГіИїжжБфСПЃЌЭЈЙ§етаЉБфСПЃЌзюКѓПЩвдгавЛИівьГЃХаЖЯЁЃ
дйР§ШчЙиСЊФЃаЭЃЌвЛИіЛЕШЫЭХЛяЃЌЭЈГЃЪЧгаСЊЯЕЕФЁЃетаЉЮЌЖШПЩвдАќРЈIPЁЂЩшБИЁЂWiFi
MACЕижЗЁЂGPSЮЛжУЁЂЮяСїЕижЗЁЂзЪН№СїЕШШєИЩЮЌЖШЃЌдйНсКЯздМКЕФЦфЫћЪ§ОнЃЌПЩвдЙиСЊГівЛИіЭХЛяЁЃЖјЭХЛяжаШчЙћгавЛИіШЫБъМЧЮЊКкЃЌдђЙиЯЕШІдђЛсИљОнЙиЯЕЧПШѕНјаааХгўДђЗжНЕМЖЁЃ
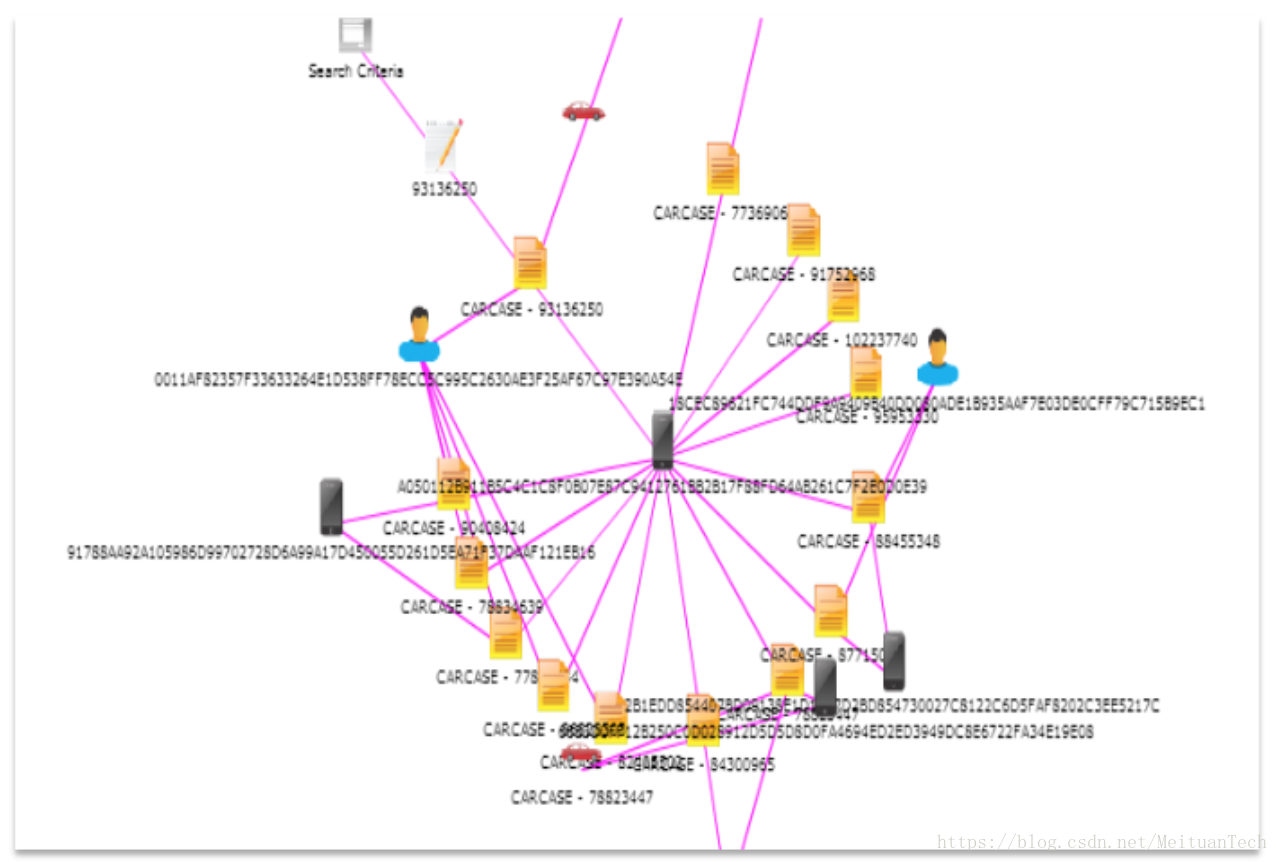
UEBAЕФЛљДЁЪЧгазуЙЛЕФЪ§ОнжЇГХЃЌЪ§ОнПЩвдЪЧЭтВПЕФЪ§ОнЙЉгІЩЬЁЃР§ШчЬкбЖЁЂАЂРяЖМЬсЙЉвЛаЉЖдЭтЪ§ОнЗўЮёЃЌАќРЈЖдIPаХгўЕФХаЖЯЕШЃЌЪЙгУетаЉЪ§ОнЃЌПЩвдЦ№ЕНСЊЗРСЊПиЕФаЇЙћЁЃвВПЩвдЪЧФкВПЕФЃЌЛЅСЊЭјЙЋЫОзмЛсгаШєИЩЬѕвЕЮёЯпЗўЮёвЛИіПЭЛЇЃЌетОЭвЊПДАВШЋШЫдБЕФЪ§ОнУєИаЖШСЫЃЌФФаЉЪ§ОнФмЮЊздМКЫљгУЁЃ
1.5 Ъ§ОнЭбУє
дкгІгУЯЕЭГжаЃЌзмЛсгаКмЖргУЛЇУєИаЪ§ОнЁЃгІгУЯЕЭГЗжЮЊЖдФкКЭЖдЭтЃЌЖдЭтЕФЯЕЭГЭбУєЃЌжївЊЪЧЗРжЙзВКХКЭХРГцЁЃЖдФкЕФЯЕЭГЭбУєЃЌжївЊЪЧЗРжЙФкВПШЫдБаЙТЉаХЯЂЁЃ
ЖдЭтЯЕЭГЕФЭбУєБЃЛЄЃЌПЩвдЗжВуРДЖдД§ЁЃФЌШЯЧщПіЯТЃЌЖдгквјааПЈКХЁЂЩэЗнжЄЁЂЪжЛњКХЁЂЕижЗЕШЙиМќаХЯЂЃЌЧПжЦЭбУєЃЌвд**ЬцЛЛЙиМќЮЛжУЃЌетбљМДЪЙБЛзВПтЛђепХРГцЃЌвВЛёШЁВЛЕНЯрЙиаХЯЂЃЌДгЖјБЃЛЄгУЛЇЪ§ОнАВШЋЁЃЕЋзмгаПЭЛЇашвЊПДЕНздМКЛђаоИФздМКЕФЭъећаХЯЂЃЌетЪБОЭашвЊЗжВуБЃЛЄЃЌжївЊЪЧИљОнГЃгУЩшБИРДХаЖЯЃЌШчЙћЪЧГЃгУЩшБИЃЌдђПЩвдЮоеЯАЕФЕуЛїКѓЯдЪОЁЃШчЙћЗЧГЃгУЩшБИЃЌдђЭЦЫЭвЛИіЧПбщжЄЁЃ
дкШеГЃвЕЮёжаЃЌУРЭХЕуЦРЛЙгавЛИіЬиЕуЁЃЭтТєЦяЪжгыТђМвЕФСЊЯЕЃЌЦяЪжПЩФмевВЛЕНОпЬхЮЛжУЃЌашвЊКЭТђМвНјааЙЕЭЈЃЌетЪБжСЩйАќРЈСЫЕижЗЁЂЪжЛњКХСНЬѕаХЯЂБЉТЖЁЃЖјЖдгкТђМваХЯЂЕФБЃЛЄЃЌЮвУЧвВНјааСЫУўЫїЪдЬНЁЃЪжЛњКХТыаХЯЂЃЌЮвУЧЭЈЙ§вЛИіЁАаЁКХЁБЕФЛњжЦРДНтОіЃЌЦяЪжЕУЕНЕФЪЧвЛИіСйЪБжазЊКХТыЃЌгУетИіКХТыгыТђМвСЊЯЕЃЌЖјецЪЕКХТыдђЪЧВЛПЩМћЕФЁЃЕижЗаХЯЂЃЌЮвУЧдкЯЕЭГжаЪЙгУСЫЭМЦЌЯдЪОЃЌдкЖЉЕЅЭъГЩжЎКѓЃЌЕижЗаХЯЂдђВЛПЩМћЁЃ
ЖдФкЯЕЭГЕФЭбУєБЃЛЄЃЌЪЕМљжаПЩвдЗжЮЊМИИіВНжшзпЁЃЪзЯШЪЧМьВтФкВПЯЕЭГжаЕФУєИааХЯЂЃЌетРяПЩвдбЁдёДгLogжаЛёШЁЃЌЛђепДгJSЧАЖЫЛёШЁЃЌСНИіЗНАИИїгагХСгЁЃДгLogжаЛёШЁЃЌвЊПДЙЋЫОећЬхЩЯЖдШежОЕФЙцЗЖЃЌВЛШЛУПИіЯЕЭГвЛжжШежОЃЌЖдНгжмЦкГЄЙЄзїСПДѓЁЃДгЧАЖЫJSЛёШЁЃЌЗНАИБШНЯЧсСПЛЏЃЌЕЋвЊПМТЧадФмЖдвЕЮёЕФгАЯьЁЃ
МьВтЕФФПЕФЪЧГжајЗЂЯжУєИааХЯЂБфЛЏЃЌвђЮЊдкФкВПИДдгЛЗОГжаЃЌЯЕЭГЛсВЛЖЯЕФИФдьЩ§МЖЃЌШчЙћШБЩйГжајМрПиЕФЪжЖЮЃЌЛсБфГЩдЫЖЏЪНЙЄГЬЃЌЮоЗЈБЃжЄГжајадЁЃ
МьВтжЎКѓвЊзіЕФЪТЧщЃЌдђЪЧНјааЭбУєДІРэЁЃЭбУєЙ§ГЬашвЊгывЕЮёЗНЙЕЭЈУїШЗКУЃЌФФаЉзжЖЮБиаыЧПжЦЭъШЋЭбУєЃЌФФаЉЪЧАыЭбУєЁЃгІгУЯЕЭГШЈЯоНЈЩшБШНЯЙцЗЖЕФЧщПіЯТЃЌПЩвдПМТЧЛљгкНЧЩЋНјааЭбУєЃЌР§ШчЗчПиАИМўШЫдБЃЌЪЧвЛЖЈашвЊгУЛЇЕФвјааПЈЭъећаХЯЂЕФЃЌетЪБКђПЩвдИљОнНЧЩЋИГгшУтвпШЈЯоЁЃЕЋПЭЗўШЫдБдђВЛашвЊВщПДЭъећаХЯЂЃЌдђНјааЧПжЦЭбУєЁЃдкУтвпКЭЭбУєжЎМфЃЌЛЙгавЛВуНазіАыЭбУєЃЌЪЧжИдкашвЊЕФЪБКђЃЌПЩвдЕуЛїВщПДЭъећКХТыЃЌЕуЛїЖЏзїдђЛсБЛМЧТМЁЃ
ОЭЭбУєећЬхЖјбдЃЌгІИУгавЛИіШЋОжЪгЭМЁЃУПЬьгаЖрЩйгУЛЇУєИааХЯЂБЛЗУЮЪЕНЃЌгаЖрЩйаХЯЂЭбУєЃЌЮДЭбУєЕФдвђЪЧЪВУДЁЃетбљПЩвдећЬхзЗзйБфЛЏЃЌФПБъЪЧВЛЖЯНЕЕЭУєИааХЯЂЗУЮЪТЪЃЌЕБЪгЭМГіЯжвьГЃВЈЖЏЃЌдђДњБэвЕЮёВњЩњСЫБфЛЏЃЌашвЊзЗзйЪТМўдвђЁЃ
ЖўЁЂЪ§ОнВжПт
Ъ§ОнВжПтЪЧЙЋЫОЪ§ОнЕФКЫаФЃЌетРяГіСЫЮЪЬтдђУцСйОоДѓЗчЯеЁЃЖјЪ§ОнВжПтЕФжЮРэЃЌЪЧвЛИіГЄЦкНЅНјЕФНЈЩшЙ§ГЬЃЌЦфжаАВШЋЛЗНкжЛЪЧЦфжавЛаЁВПЗжЃЌИќЖрЕФдђЪЧЪ§ОнжЮРэВуУцЁЃБОЮФжївЊЬИМААВШЋЛЗНкжаЕФвЛаЉЙЄОпадНЈЩшЃЌАќРЈЪ§ОнЭбУєЁЂвўЫНБЃЛЄЁЂДѓЪ§ОнааЮЊЩѓМЦЁЂзЪВњЕиЭМЁЂЪ§ОнЩЈУшЦїЁЃ
2.1 Ъ§ОнЭбУє
Ъ§ОнВжПтЕФЭбУєЪЧжИЖдУєИаЪ§ОнНјааБфаЮЃЌДгЖјЦ№ЕНБЃЛЄУєИаЪ§ОнЕФФПЕФЃЌжївЊгУгкЪ§ОнЗжЮіШЫдБКЭПЊЗЂШЫдБЖдЮДжЊЪ§ОнНјааЬНЫїЁЃЭбУєдкЪЕМљЙ§ГЬжагаШєИЩжжаЮЪНЃЌАќРЈЖдЪ§ОнЕФЛьЯ§ЁЂЬцЛЛЃЌдкВЛИФБфЪ§ОнБОЩэБэЪіЕФЧщПіЯТНјааЪ§ОнЪЙгУЁЃЕЋЪ§ОнЛьЯ§вВКУЃЌЬцЛЛвВКУЃЌЪЕМЪЩЯЖМЪЧгаГЩБОЕФЃЌдкДѓаЭЛЅСЊЭјЙЋЫОЕФКЃСПЪ§ОнЧщПіЯТЃЌетжжЪ§ОнЛьЯ§ЬцЛЛДњМлЗЧГЃИпАКЃЌ
ЪЕМљжаГЃгУЕФЗНЪНЃЌдђЪЧНЯЮЊМђЕЅЕФВПЗжекИЧЃЌР§ШчЖдЪжЛњКХЕФекИЧЃЌ139****0011РДеЙЪОЃЌетжжЗНЗЈЙцдђМђЕЅЃЌФмЦ№ЕНвЛЖЈГЬЖШЩЯЕФБЃЛЄаЇЙћЁЃ
ЕЋгааЉГЁОАЯТЃЌМђЕЅЕФекИЧЪЧВЛФмТњзувЕЮёвЊЧѓЕФЃЌетЪБОЭашвЊПМТЧЦфЫћЪжЖЮЃЌР§ШчеыЖдаХгУПЈКХТыЕФЕФTokenizationЃЌеыЖдЗЖЮЇЪ§ОнЕФЗжЖЮЃЌеыЖдВЁР§ЕФЖрбљадЃЌЩѕжСеыЖдЭМЦЌЕФbase64екИЧЁЃвђДЫашвЊИљОнВЛЭЌГЁОАЬсЙЉВЛЭЌЗўЮёЃЌЪЧГЩБОЁЂаЇТЪКЭЪЙгУЕФПМСПНсЙћЃЌ
Ъ§ОнекИЧвЊПМТЧдЪМБэКЭЭбУєКѓЕФБэЁЃдЪМЪ§ОнвЛЖЈвЊгавЛЗнЃЌдкетИіЛљДЁЩЯЪЧСэЭтИДжЦГівЛеХЭбУєБэЛЙЪЧдкдЪМЪ§ОнЩЯзіЪгОѕЭбУєЃЌЪЧСНжжВЛЭЌГЩБОЕФЗНАИЁЃСэЭтИДжЦвЛеХБэЭбУєЃЌЪЧБШНЯГЙЕзЕФЗНЪНЃЌЕЋЕШгкУПеХУєИаЪ§ОнБэЖМвЊИДжЦГіРДвЛЗнЃЌЖдДцДЂЪЧИіГЩБОЮЪЬтЁЃЖјЪгОѕЭбУєЃЌдђЪЧЭЈЙ§ЙцдђЃЌЖЏЬЌЕФЖдЪ§ОнеЙЯжНјааЭбУєЃЌПЩвдНЯЕЭГЩБОЕФЪЕЯжЭбУєаЇЙћЃЌЕЋДцдкБЛШЦЙ§ЕФПЩФмадЁЃ
2.2 вўЫНБЃЛЄ
вўЫНБЃЛЄЩЯбЇЪѕНчвВЬсГіСЫвЛаЉЗНЗЈЃЌАќРЈKФфУћЁЂБпФфУћЁЂВюЗжвўЫНЕШЗНЗЈЃЌЦфФПЕФЪЧНтОіЪ§ОнОлКЯЧщПіЯТЕФвўЫНБЃЛЄЁЃР§ШчгаЕФЙЋЫОЃЌФУГіРДвЛВПЗжШЅГ§УєИааХЯЂКѓЕФЪ§ОнЙЋПЊЃЌНјааЫуЗЈБШШќЁЃетИіЪБКђОЭвЊПМТЧВЛЭЌЕФЪ§ОнОлКЯКѓЃЌПЩвдЙиСЊГіФГИіШЫЕФИіШЫБъжОЁЃФПЧАПДЕНвЕНчдкЩњВњЩЯгІгУЕФЪЧGoogleЕФDLP
APIЃЌЕЋЦфЪЙгУвВНЯЮЊИДдгЃЌеыЖдГЁОАБШНЯЕЅвЛЁЃвўЫНБЃЛЄЕФЗНЗЈЃЌЙиМќЪЧвЊФмЙЛНјааДѓЙцФЃЙЄГЬЛЏЃЌдкДѓЪ§ОнЪБДњЕФБГОАЯТЃЌетаЉЛЙЖМЪЧаТПЮЬтЃЌФПЧАВЂВЛДцдквЛИіЭъећЕФЗНЗЈРДНтОівўЫНБЃЛЄЫљгаЖдПЙЮЪЬтЁЃ
2.3 ДѓЪ§ОнзЪВњЕиЭМ
ЪЧжИЖдДѓЪ§ОнЦНЬЈЕФЪ§ОнзЪВњНјааЗжЮіЁЂЪ§ОнПЩЪгЛЏеЙЯжЕФЦНЬЈЁЃзюГЃМћЕФЫпЧѓЪЧЃЌAВПУХЩъЧыBВПУХЕФЪ§ОнЃЌBзїЮЊЪ§ОнЕФOwnerЃЌЕБШЛЯыжЊЕРЪ§ОнИјЕНAвдКѓЃЌЫћЪЧдѕУДгУЕФЃЌгаУЛгадйДЋИјЦфЫћШЫЪЙгУЁЃетЪБКђдђашвЊгавЛИізЪВњЕиЭМЃЌФмЙЛИњзйЪ§ОнзЪВњЕФСїЯђЁЂЪЙгУЧщПіЁЃЛЛИіНЧЖШЃЌЖдгкАВШЋВПУХРДЫЕЃЌашвЊжЊЕРЕБЧАЪ§ОнЦНЬЈЩЯгаФФаЉИпУєИаЪ§ОнзЪВњЃЌзЪВњЕФЪЙгУЧщПіЃЌвдМАЦНЬЈЩЯФФаЉШЫгЕгаЪВУДШЈЯоЁЃвђДЫЃЌЭЈЙ§дЊЪ§ОнЁЂбЊдЕЙиЯЕЁЂВйзїШежОЃЌаЮГЩСЫвЛИіПЩЪгЛЏЕФзЪВњЕиЭМЁЃаЮГЩЕиЭМВЂВЛЙЛЃЌбгЩьЯТРДЃЌЛЙашвЊФмЙЛМАЪБдЄОЏЁЂЛиЪеШЈЯоЕШИЩдЄДыЪЉЁЃ
2.4 Ъ§ОнПтЩЈУшЦї
ЪЧжИЖдДѓЪ§ОнЦНЬЈЕФЪ§ОнЩЈУшЃЌЦфвтвхдкгкЗЂЯжДѓЪ§ОнЦНЬЈЩЯЕФУєИаЪ§ОнЃЌДгЖјНјааЖдгІЕФБЃЛЄЛњжЦЁЃвЛИіДѓаЭЛЅСЊЭјЙЋЫОЕФЪ§ОнБэЃЌУПЬьПЩФмжБНгВњЩњЖрДяМИЭђеХЃЌЭЈЙ§етаЉБэбмЩњГіРДИќЖрЕФБэЁЃАДееДЋЭГЪ§ОнАВШЋЕФЖЈвхЃЌЪ§ОнАВШЋЕквЛВНЪЧвЊЗжРрЗжМЖЃЌЕЋетвЛВНОЭКмФбНјааЯТШЅЁЃдкКЃСПДцСПБэЕФЧщПіЯТЃЌИУдѕбљНјааЗжРрЗжМЖЃПШЫЙЄЪсРэЯдШЛЪЧВЛЯжЪЕЕФЃЌЪсРэЕФЫйЖШЛЙИЯВЛЩЯаТдіЕФЫйЖШЁЃетЪБКђОЭашвЊвЛаЉздЖЏЛЏЕФЙЄОпРДЖдЪ§ОнНјааДђБъЖЈМЖЁЃвђДЫЃЌЪ§ОнПтЩЈУшЦїПЩвдЭЈЙ§е§дђБэДяЪНЃЌЗЂЯжвЛаЉЛљДЁЕФИпУєИаЪ§ОнЃЌР§ШчЪжЛњКХЁЂвјааПЈЕШетаЉЙцећзжЖЮЁЃЖдгкЗЧЙцећзжЖЮЃЌдђашвЊЭЈЙ§ЛњЦїбЇЯА+ШЫЙЄБъЧЉЕФЗНЗЈРДШЗШЯЁЃ
злЩЯЃЌЪ§ОнАВШЋдквЕЮёЗЂеЙЕНвЛЖЈГЬЖШКѓЃЌЦфживЊаддНЗЂЭЛГіЁЃЮЂЙлВуУцЕФЙЄОпНЈЩшЪЧвЛИіжЇГХЃЌдкОЁСПМѕЩйЖдвЕЮёЕФДђШХЭЌЪБЬсИпаЇТЪЁЃКъЙлВуУцЃЌГ§СЫздЩэЬхЯЕФкЕФЪ§ОнАВШЋЃЌКЯзїЗНЁЂЭЖзЪКѓЕФЙЋЫОЁЂЮяСїЁЂЦяЪжЁЂЩЬМвЁЂЭтАќЕШИїРрзщжЏЕФЪ§ОнАВШЋЧщПіЃЌвВЛсгАЯьЕНздЩэАВШЋЃЌПЩЮНЁАДНЭіГнКЎЁБЁЃЖјдкЕБЧАИїРрзщжЏАВШЋЫЎЦНВЮВюВЛЦыЕФЧщПіЯТЃЌОЭвЊЧѓвбОЗЂеЙЦ№РДЕФЛЅСЊЭјЙЋЫОГаЕЃИќЖрЕФд№ШЮЃЌАяжњКЯзїЗНЬсИпАВШЋЫЎЦНЃЌСЊЗРЙВНЈЁЃ
|








