| БрМЭЦМі: |
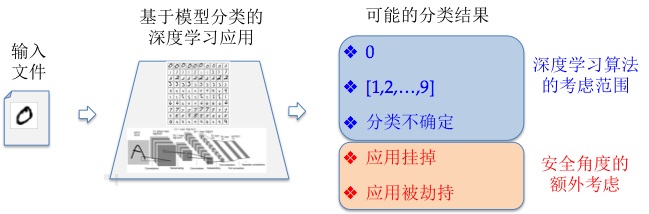
БОЮФвдФПЧАСїааЕФЭМЯёЪЖБ№AIЯЕЭГЮЊР§ЃЌAIЯЕЭГЕФАВШЋЮЪЬтжївЊАќРЈФЃаЭАВШЋЁЂЪ§ОнАВШЋвдМАДњТыАВШЋЁЃ
НщЩмAIЯЕЭГдкетаЉЗНУцУцСйЕФАВШЋЭўаВЃЌЯЃЭћЖдФњгаЫљАяжњ
БОЮФРДздгкfreebufЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
I. ЩюЖШбЇЯАШэМўЪЕЯжжаЕФАВШЋЮЪЬт
ШЫЙЄжЧФмгІгУУцСйРДздЖрИіЗНУцЕФЭўаВЃКАќРЈЩюЖШбЇЯАПђМмжаЕФШэМўЪЕЯжТЉЖДЁЂЖдПЙЛњЦїбЇЯАЕФЖёвтбљБОЩњГЩЁЂбЕСЗЪ§ОнЕФЮлШОЕШЕШЁЃ етаЉЭўаВПЩФмЕМжТШЫЙЄжЧФмЫљЧ§ЖЏЕФЪЖБ№ЯЕЭГГіЯжЛьТвЃЌаЮГЩТЉХаЛђепЮѓХаЃЌЩѕжСЕМжТЯЕЭГБРРЃЛђБЛНйГжЃЌВЂПЩвдЪЙжЧФмЩшБИБфГЩНЉЪЌЙЅЛїЙЄОпЁЃ
дкЭЦНјШЫЙЄжЧФмгІгУЕФЭЌЪБЃЌЮвУЧЦШЧаашвЊЙизЂВЂНтОіетаЉАВШЋЮЪЬтЁЃБОеТЪзЯШНщЩмЮвУЧдкЩюЖШбЇЯАПђМмжаЗЂЯжЕФАВШЋЮЪЬтЁЃ
1. ШЫЙЄжЧФмЬжТлжаЕФАВШЋУЄЕу
ФПЧАЙЋжкЖдШЫЙЄжЧФмЕФЙизЂЃЌгШЦфЪЧЩюЖШбЇЯАЗНУцЃЌ ШБЩйЖдАВШЋЕФПМТЧЁЃЮвУЧАбетИіЯжЯѓГЦЮЊШЫЙЄжЧФмЕФАВШЋУЄЕуЁЃ ЕМжТетИіУЄЕуЕФжївЊдвђЪЧгЩгкЫуЗЈгыЪЕЯжЕФОрРыЁЃ НќЦкЖдгкЩюЖШбЇЯАЕФЬжТлжївЊЭЃСєдкЫуЗЈКЭЧАОАеЙЭћЕФВуУцЃЌЖдгІгУГЁОАКЭГЬађЪфШыгаКмЖрМйЩшЁЃ
ЪмЕНЙизЂЕФгІгУЭљЭљМйЖЈДІгкЩЦвтЕФЛђЗтБеЕФГЁОАЁЃР§ШчИпзМШЗТЪЕФгявєЪЖБ№жаЕФЪфШыЖМЪЧздШЛВЩМЏЖјГЩЃЌЭМЦЌЪЖБ№жаЕФЪфШывВЖМРДзде§ГЃХФЩуЕФееЦЌЁЃетаЉЬжТлУЛгаПМТЧШЫЮЊЖёвтЙЙдьЛђКЯГЩЕФГЁОАЁЃ
ШЫЙЄжЧФмЬжТлжаЕФАВШЋУЄЕуПЩвдЭЈЙ§зюЕфаЭЕФЪжаДЪ§зжЪЖБ№АИР§РДЫЕУїЁЃЛљгкMNISTЪ§ОнМЏЕФЪжаДЪ§зжЪЖБ№гІгУЪЧЩюЖШбЇЯАЕФвЛИіЗЧГЃЕфаЭЕФР§згЃЌ зюаТЕФЩюЖШбЇЯАНЬГЬМИКѕЖМВЩгУетИігІгУзїЮЊЪЕР§бнЪОЁЃдкетаЉНЬГЬжаЃЈШчЯТЭМЫљЪОЃЉЫуЗЈВуЕФЬжТлЫљПМТЧЕФЗжРрНсЙћжЛЙиаФЬиЖЈРрБ№ЕФНќЫЦЖШКЭжУаХИХТЪЧјМфЁЃЫуЗЈВуЕФЬжТлУЛгаПМТЧЪфШыЛсЕМжТГЬађБРРЃЩѕжСБЛЙЅЛїепНйГжПижЦСїЁЃетЦфжаБЛКіТдЕєЕФЪфГіНсЙћЗДгГГіЫуЗЈКЭЪЕЯжЩЯПМТЧЮЪЬтЕФВюОрЃЌвВОЭЪЧФПЧАШЫЙЄжЧФмЬжТлжаЕФАВШЋУЄЕуЁЃ
ЭМI-1. ЩюЖШбЇЯАЫуЗЈгыАВШЋЫљПМТЧЕФВЛЭЌЪфГіГЁОА
ЯжЪЕжаЕФПЊЗХгІгУашвЊДІРэЕФЪфШыВЛНіРДдДгке§ГЃгУЛЇЃЌвВПЩвдЪЧРДздКкВњЕШЖёвтгУЛЇЁЃ ШЫЙЄжЧФмЕФгІгУБиаыПМТЧЕНгІгУЫљУцСйЕФЯжЪЕЭўаВЁЃГЬађЩшМЦШЫдБашвЊПМТЧЪфШыЪ§ОнЪЧЗёПЩПиЃЌМрВтГЬађЪЧЗёе§ГЃжДааЃЌВЂбщжЄГЬађжДааНсЙћЪЧЗёецЪЕЗДгГгІгУЕФБОРДФПЕФЁЃ
2. ЩюЖШбЇЯАЯЕЭГЕФЪЕЯжМАвРРЕИДдгЖШ
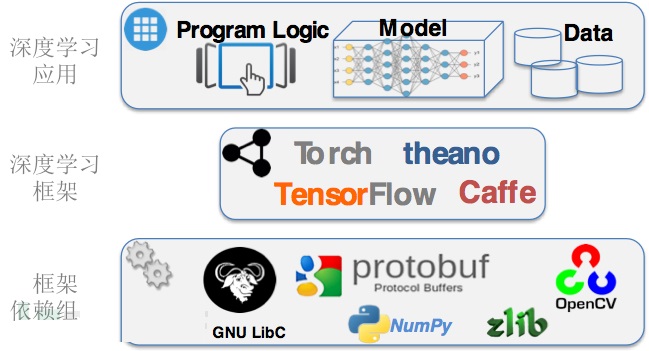
ЩюЖШбЇЯАШэМўКмЖрЪЧЪЕЯждкЩюЖШбЇЯАПђМмЩЯЁЃФПЧАЛљгкЩюЖШбЇЯАЯЕЭГПђМмЗЧГЃЖрЃЌжїСїЕФАќРЈTensorFlowЁЂTorchЃЌвдМАCaffe ЕШЁЃ
ЩюЖШбЇЯАПђМмЕФЪЙгУПЩвдШУгІгУПЊЗЂШЫдБЮоашЙиаФЩёОдЊЭјТчЗжВувдМАХрбЕЗжРрЕФЪЕЯжЯИНкЃЌИќЖрЙизЂгІгУБОЩэЕФвЕЮёТпМЁЃ ПЊЗЂШЫдБПЩвддкПђМмЩЯжБНгЙЙНЈздМКЕФЩёОдЊЭјТчФЃаЭЃЌВЂРћгУПђМмЬсЙЉЕФНгПкЖдФЃаЭНјаабЕСЗЁЃетаЉПђМмМђЛЏСЫЩюЖШбЇЯАгІгУЕФЩшМЦКЭПЊЗЂФбЖШЃЌвЛИіЩюЖШбЇЯАЕФФЃаЭПЩвдгУМИЪЎааДњТыОЭПЩвдаДГіРДЁЃ
ЭМI-2. ЩюЖШбЇЯАПђМмвдМАПђМмзщМўвРРЕ
ЩюЖШбЇЯАПђМмбкИЧСЫЫќЫљЪЙгУЕФзщМўвРРЕЃЌЭЌЪБвВвўВиСЫЯЕЭГЕФИДдгГЬЖШЁЃ УПжжЩюЖШбЇЯАПђМмгжЖМЪЧЪЕЯждкжкЖрЛљДЁПтКЭзщМўжЎЩЯЃЌКмЖрЩюЖШбЇЯАПђМмРяЛЙАќРЈЭМЯёДІРэЁЂОиеѓМЦЫуЁЂЪ§ОнДІРэЁЂGPUМгЫйЕШЙІФмЁЃ ЭМ2еЙЪОСЫЕфаЭЕФЩюЖШбЇЯАгІгУзщМўКЭЫќУЧЕФвРРЕЙиЯЕЁЃР§ШчCaffeГ§СЫздЩэЩёОдЊЭјТчФЃПщЪЕЯжвдЭтЃЌЛЙАќРЈ137ИіЕкШ§ЗНЖЏЬЌПтЃЌР§Шчlibprotobuf, libopencv, libzЕШЁЃ ЙШИшЕФTensorFlow ПђМмвВАќКЌЖдЖрДя97ИіpythonФЃПщЕФвРРЕЃЌАќРЈlibrosa,numpy ЕШЁЃ
ЯЕЭГдНИДдгЃЌОЭдНгаПЩФмАќКЌАВШЋвўЛМЁЃШЮКЮдкЩюЖШбЇЯАПђМмвдМАЫќЫљвРРЕЕФзщМўжаЕФАВШЋЮЪЬтЖМЛсЭўаВЕНПђМмжЎЩЯЕФгІгУЯЕЭГЁЃСэЭтФЃПщЭљЭљРДздВЛЭЌЕФПЊЗЂепЃЌЖдФЃПщМфЕФНгПкОГЃгаВЛЭЌЕФРэНтЁЃЕБетжжВЛвЛжТЕМжТАВШЋЮЪЬтЪБЃЌФЃПщПЊЗЂепЩѕжСЛсШЯЮЊЪЧЦфЫќФЃПщЕїгУВЛЗћКЯЙцЗЖЖјВЛЪЧздМКЕФЮЪЬтЁЃдкЮвУЧЕФЗЂЯжЕФЕМжТЩюЖШбЇЯАПђМмБРРЃЕФТЉЖДжаОЭгіЕНЙ§етжжЧщПіЁЃ
3. ЩюЖШбЇЯАШэМўЪЕЯжЯИНкжаЕФАВШЋЮЪЬт
е§ШчАВШЋШЫдБГЃЫЕЕФЃЌ ФЇЙэвўВигкЯИНкжЎжа ЃЈThe Devil is In the DetailЃЉЁЃШЮКЮвЛИіДѓаЭШэМўЯЕЭГЖМЛсгаЪЕЯжТЉЖДЁЃ ПМТЧЕНЩюЖШбЇЯАПђМмЕФИДдгадЃЌ ЩюЖШбЇЯАгІгУвВВЛР§ЭтЁЃ
360 Team Seri0us ЭХЖгдквЛИідТЕФЪБМфРяУцЗЂЯжСЫЪ§ЪЎИіЩюЖШбЇЯАПђМмМАЦфвРРЕПтжаЕФШэМўТЉЖДЁЃЗЂЯжЕФТЉЖДАќРЈСЫМИКѕЫљгаГЃМћЕФРраЭЃЌР§ШчФкДцЗУЮЪдННчЃЌПежИеыв§гУЃЌећЪ§вчГіЃЌГ§СувьГЃЕШЁЃ етаЉТЉЖДЧБдкДјРДЕФЮЃКІПЩвдЕМжТЖдЩюЖШбЇЯАгІгУЕФОмОјЗўЮёЙЅЛїЃЌПижЦСїНйГжЃЌЗжРрЬгвнЃЌвдМАЧБдкЕФЪ§ОнЮлШОЙЅЛїЁЃ
вдЯТЮвУЧЭЈЙ§СНИіМђЕЅЕФР§згРДНщЩмЩюЖШбЇЯАПђМмжаЕФТЉЖДвдМАЖдгІгУЕФгАЯьЁЃСНИіР§згЖМРДдДгкПђМмЕФвРРЕПтЃЌвЛИіЪЧTensorFlowПђМмЫљвРРЕЕФnumpyАќЃЌСэвЛИіЪЧCaffeдкДІРэЭМЯёЪЖБ№ЫљЪЙгУЕФlibjasperПтЁЃ
АИР§1ЃК ЖдЛљгкTensorFlowЕФгявєЪЖБ№гІгУНјааОмОјЗўЮёЙЅЛї

ЭМI-3. Numpy ОмОјЗўЮёЙЅЛїТЉЖДМАЙйЗНВЙЖЁ
ЮвУЧбЁдёСЫЛљгкTensorFlowЕФгявєЪЖБ№гІгУРДбнЪОЛљгкетИіТЉЖДДЅЗЂЕФЙЅЛїЁЃЙЅЛїепЭЈЙ§ЙЙдьгявєЮФМўЃЌЛсЕМжТЩЯЭМжаЯдЪОЕФбЛЗЮоЗЈНсЪјЃЌЪЙгІгУГЬађГЄЪБМфеМгУCPUЖјВЛЗЕЛиНсЙћЃЌДгЖјЕМжТОмОјЗўЮёЙЅЛїЁЃ
ЮвУЧбЁШЁСЫвЛИіЛљгкTensoFlowНјааЩљвєЗжРрЕФгІгУРДбнЪОетИіЮЪЬтЁЃетИігІгУЪЧвЛИіTensorFlowГЬађбнЪОЃЌгІгУНХБОдДТыПЩвдДгвдЯТЭјеОЯТдиЃК[ ЁАUrbanSound ClassificationЁБЃК https://aqibsaeed.github.io/2016-09-03-urban-sound-classification-part-1/ ]
ЕБИјЖЈвЛИіе§ГЃЕФЙЗНаЕФвєЦЕЮФМўЃЌгІгУПЩвдЪЖБ№ЩљвєФкШнЮЊЁБdog barkЁБЃЌЦфЙ§ГЬШчЯТЃК
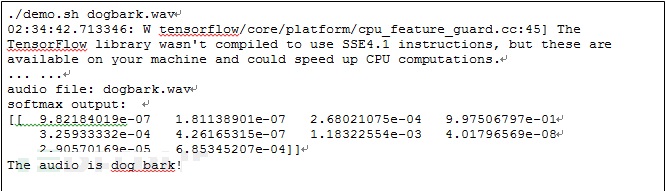
ЕБИјЖЈвЛИіЛћаЮЕФЩљвєЮФМўПЩЕМжТОмОјЗўЮёЃЌ ГЬађЮоЗЈе§ГЃНсЪјЃК
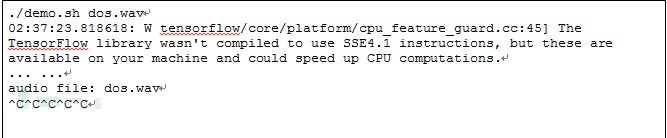
дкЧАУцЙигкФЃПщвРРЕИДдгЕМжТТЉЖДЕФЬжТлжаЃЌЮвУЧЬсЕНЙ§ЖдФЃПщНгПкЕФРэНтВЛвЛжТЛсЕМжТЮЪЬтЁЃжЕЕУвЛЬсЕФЪЧNumpyетИіТЉЖДЕФаоИДЙ§ГЬе§КУЗДгГСЫетИіЮЪЬтЁЃдкЮвУЧзюГѕЭЈжЊNumpyПЊЗЂепЕФЪБКђЃЌЫћУЧШЯЮЊЮЪЬтЪЧгЩгкЕїгУепlibrosaПтЕФПЊЗЂШЫдБУЛгаЖдЪ§ОнНјаабЯИёМьВтЃЌЕМжТПеСаБэЕФЪЙгУЁЃЫљвдОЁЙмгагІгУЛсвђЮЊДЫЮЪЬтЪмЕНОмОјЗўЮёЙЅЛїЃЌ NumpyПЊЗЂепзюГѕШЯЮЊВЛашвЊаоИДетИіЮЪЬтЁЃЕЋКѓРДЗЂЯжгаЖрИіЦфЫќПтЖдnumpyЕФЯрЙиКЏЪ§вВгаЦЕЗБЕФРрЫЦЕїгУЃЌЫљвдзюжеЖдетИіТЉЖДНјааСЫаоИДЁЃЭЌЪБ librosa ПЊЗЂепвВЖдЯрЙиЕїгУЬэМгСЫЪфШыМьВщЁЃ
АИР§2ЃКЖёвтЭМЦЌЕМжТЛљгкCaffeЕФЭМЯёЪЖБ№гІгУГіЯжФкДцЗУЮЪдННч
КмЖрЩюЖШбЇЯАЕФгІгУЪЧдкЭМЯёКЭЪгОѕДІРэСьгђЁЃЮвУЧЗЂЯжЕБЪЙгУЩюЖШбЇЯАПђМмCaffeРДНјааЭМЦЌЪЖБ№ЪБЃЌCaffeЛсвРРЕlibjasperЕШЭМЯёЪгОѕПтРДДІРэЪфШыЁЃ libjasperЖдЭМЯёНјааЪЖБ№ДІРэЪБЃЌШчЙћДцдкТЉЖДЃЌР§ШчФкДцдННчЃЌОЭПЩФмЕМжТећИігІгУГЬађГіЯжБРРЃЃЌЩѕжСЪ§ОнСїБЛДлИФЁЃЯТУцЕФР§згЪЧгУеЙЪОЕФЪЧгУCaffeЫљздДјЕФР§згЭМЯёЪЖБ№ГЬађРДДІРэЮвУЧЬсЙЉЕФЛћаЮЭМЦЌЫљГіЯжЕФБРРЃГЁОАЁЃ
ЕБРћгУCaffeРДЖде§ГЃЭМЦЌНјааЗжРрЪБЃЌе§ГЃЕФЪЙгУЧщПіШчЯТЃК

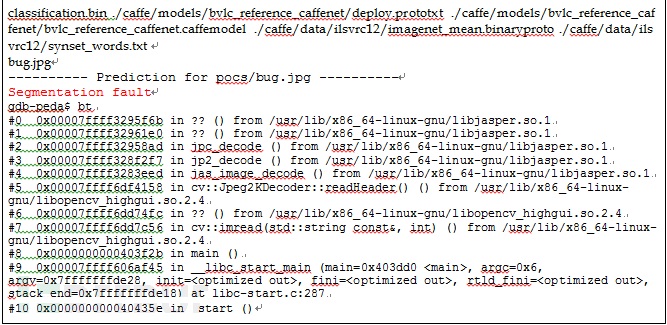
вдЩЯНіНіЪЧЮвУЧЗЂЯжЕФжкЖрЮЪЬтжаЕФСНИіеЙЪОЁЃ 360 Team Seri0s ЭХЖгвбЗЂЯжВЂЙЋВМСЫЪ§ЪЎИіЕМжТЩюЖШбЇЯАПђМмГіЯжЮЪЬтЕФТЉЖДЃЌЦфжаАќКЌвбЖдЭтЙЋПЊЕФ15ИіCVEЁЃ дкЩЯИідТОйааЕФISCАВШЋДѓЛсЩЯЃЌTeam Seri0sГЩдБвбОеЙЪОСЫСљИіЙЅЛїЪЕР§ЁЃИќЖрЯИНкЧыВЮПМISC 2017ДѓЛсШЫЙЄжЧФмгыАВШЋТлЬГЫљЗЂВМЕФФкШнЁЃ
4. аЁНс
БОеТНкЕФФПЕФЪЧНщЩмБЛДѓжкЫљКіЪгЕФШЫЙЄжЧФмАВШЋЮЪЬтЃЌгШЦфЪЧЩюЖШбЇЯАШэМўЪЕЯжжаЕФТЉЖДвдМАПЩФмдьГЩЕФвўЛМЁЃФПЧАдкУНЬхжаеЙЪОЕФЩюЖШбЇЯАгІгУжаЃЌаэЖрВЂВЛгыЭтНчжБНгНЛЛЅЃЌР§ШчAlphaGoЃЛЛђепЪЧдкЗтБеЕФЛЗОГЯТЙЄзїЃЌР§ШчЭЈЙ§гУЛЇааЮЊШежОЖдгУЛЇЗжРрЛЯёВЂНјаавьГЃМьВтЁЃетаЉЯЕЭГЕФЙЅЛїУцЯрЖдНЯаЁЃЌЫќУЧВЂВЛШнвзЪмЕНБОЮФжаЫљЬсЕНЕФТЉЖДЕФжБНггАЯьЁЃ ЕЋЪЧЫцзХШЫЙЄжЧФмгІгУЕФЦеМАЃЌАВШЋЭўаВЛсВЛЖЯдіМгЁЃ ИќЖрЕФгІгУЛсАбгІгУЕФЪфШыНгПкжБНгЛђМђНщБЉТЖГіРДЁЃЭЌЪБЗтБеЯЕЭГЕФЙЅЛїУцвВЛсЫцзХЪБМфКЭЛЗОГЖјзЊЛЏЁЃ СэЭтГ§СЫДЋЭГЕФЛљгкШэМўТЉЖДЕФЙЅЛїЃЌЩюЖШбЇЯАЛЙУцСйЖдПЙЩёОдЊЭјТчвдМАЦфЫќИїжжЬгвнЙЅЛїЁЃ
II. ЩюЖШбЇЯАФЃаЭЯрЙиЕФАВШЋЮЪЬт
ЩюЖШбЇЯАв§СьзХаТвЛТжЕФШЫЙЄжЧФмРЫГБЁЃ дкЪмЕНШЋЩчЛсЙуЗКЙизЂЕФЭЌЪБЃЌШЫЙЄжЧФмгІгУвВУцСйРДздЖрИіЗНУцЕФЭўаВЃКАќРЈЩюЖШбЇЯАПђМмжаЕФШэМўЪЕЯжТЉЖДЁЂЖдПЙЛњЦїбЇЯАЕФЖёвтбљБОЩњГЩЁЂбЕСЗЪ§ОнЕФЮлШОЕШЕШЁЃ етаЉЭўаВПЩФмЕМжТШЫЙЄжЧФмЫљЧ§ЖЏЕФЪЖБ№ЯЕЭГГіЯжЛьТвЃЌаЮГЩТЉХаЛђепЮѓХаЃЌЩѕжСЕМжТЯЕЭГБРРЃЛђБЛНйГжЃЌВЂПЩвдЪЙжЧФмЩшБИБфГЩНЉЪЌЙЅЛїЙЄОпЁЃдкЭЦНјШЫЙЄжЧФмгІгУЕФЭЌЪБЃЌЮвУЧЦШЧаашвЊЙизЂВЂНтОіетаЉАВШЋЮЪЬтЁЃБОЮФНщЩмдкЩюЖШбЇЯАЬгвнЗНУцЕФвЛаЉЪЕР§КЭбаОПЙЄзїЁЃ
1. ЬгвнЙЅЛїМђНщ
ЬгвнЪЧжИЙЅЛїепдкВЛИФБфФПБъЛњЦїбЇЯАЯЕЭГЕФЧщПіЯТЃЌЭЈЙ§ЙЙдьЬиЖЈЪфШыбљБОвдЭъГЩЦлЦФПБъЯЕЭГЕФЙЅЛїЁЃР§ШчЃЌЙЅЛїепПЩвдаоИФвЛИіЖёвтШэМўбљБОЕФЗЧЙиМќЬиеїЃЌЪЙЕУЫќБЛвЛИіЗДВЁЖОЯЕЭГХаЖЈЮЊСМадбљБОЃЌДгЖјШЦЙ§МьВтЁЃЙЅЛїепЮЊЪЕЪЉЬгвнЙЅЛїЖјЬивтЙЙдьЕФбљБОЭЈГЃБЛГЦЮЊЁАЖдПЙбљБОЁБЁЃжЛвЊвЛИіЛњЦїбЇЯАФЃаЭУЛгаЭъУРЕибЇЕНХаБ№ЙцдђЃЌЙЅЛїепОЭгаПЩФмЙЙдьЖдПЙбљБОгУвдЦлЦЛњЦїбЇЯАЯЕЭГЁЃР§ШчЃЌбаОПепвЛжБЪдЭМдкМЦЫуЛњЩЯФЃЗТШЫРрЪгОѕЙІФмЃЌЕЋгЩгкШЫРрЪгОѕЛњРэЙ§гкИДдгЃЌСНИіЯЕЭГдкХаБ№ЮяЬхЪБвРРЕЕФЙцдђДцдквЛЖЈВювьЁЃЖдПЙЭМЦЌЧЁКУРћгУетаЉВювьЪЙЕУЛњЦїбЇЯАФЃаЭЕУГіКЭШЫРрЪгОѕНиШЛВЛЭЌЕФНсЙћЃЌШчЭМ1ЫљЪО[1]ЁЃ
ЭМII-1: ЙЅЛїепЩњГЩЖдПЙбљБОЪЙЯЕЭГгыШЫРргаВЛЭЌЕФХаЖЯ
вЛИіжјУћЕФЬгвнбљБОЪЧIan Goodfellow[2]дк2015ФъICLRЛсвщЩЯгУЙ§ЕФамУЈгыГЄБлдГЗжРрЕФР§згЁЃ БЛЙЅЛїФПБъЪЧвЛИіРДЙШИшЕФЩюЖШбЇЯАбаОПЯЕЭГЁЃИУЯЕЭГРћгУОэЛ§ЩёОдЊЭјТчФмЙЛОЋШЗЧјЗжамУЈгыГЄБлдГЕШЭМЦЌЁЃЕЋЪЧЙЅЛїепПЩвдЖдамУЈЭМЦЌдіМгЩйСПИЩШХЃЌЩњГЩЕФЭМЦЌЖдШЫРДНВШдШЛПЩвдЧхЮњЕиХаЖЯЮЊамУЈЃЌЕЋЩюЖШбЇЯАЯЕЭГЛсЮѓШЯЮЊГЄБлдГЁЃ ЭМ2ЯдЪОСЫамУЈдЭМвдМАОЙ§ШХЖЏЩњГЩКѓЕФЭМЦЌЁЃ
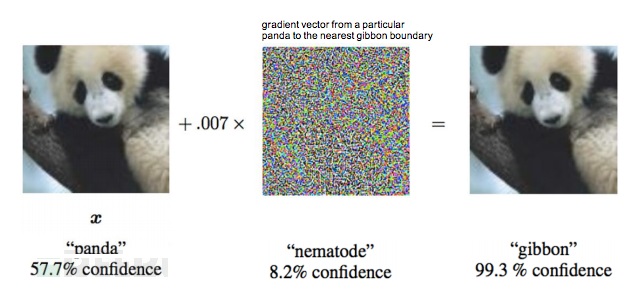
ЭМII-2: дкЭМЦЌжаЬэМгШХЖЏЕМжТЩюЖШбЇЯАЯЕЭГЕФДэЮѓЪЖБ№ЪЕР§
ЯТУцЮвУЧДгЙЅЛїепЕФНЧЖШНщЩмШчКЮЯЕЭГЩњГЩЖдПЙбљБОРДДяЕНЮШЖЈЕФЬгвнЙЅЛїЁЃВЛЙиаФММЪѕЯИНкЕФЖСепПЩКіТдетаЉФкШнЃЌжБНгЬјЕНЮФеТНсЮВЕФзмНсВПЗжЁЃ
2. ЛљгкЛњЦїбЇЯАЕФЖдПЙбљБОЩњГЩ
ЛљгкЛњЦїбЇЯАЕФЬгвнЙЅЛїПЩЗжЮЊАзКаЙЅЛїКЭКкКаЙЅЛїЁЃАзКаЙЅЛїашвЊЛёШЁЛњЦїбЇЯАФЃаЭФкВПЕФЫљгааХЯЂЃЌШЛКѓжБНгМЦЫуЕУЕНЖдПЙбљБОЃЛКкКаЙЅЛїдђжЛашвЊжЊЕРФЃаЭЕФЪфШыКЭЪфГіЃЌЭЈЙ§ЙлВьФЃаЭЪфГіЕФБфЛЏРДЩњГЩЖдПЙбљБОЁЃ
2.1АзКаЙЅЛї
ЩюЖШЩёОЭјТчЪЧЪ§бЇЩЯПЩЮЂЕФФЃаЭЃЌдкбЕСЗЙ§ГЬжаЭЈГЃЪЙгУЗДЯђДЋВЅЫуЗЈЕУЕНУПВуЕФЬнЖШРДЕїећЭјТчВЮЪ§ЁЃМйЩшЩёОЭјТчЕФЪфШыЪЧXЃЌРрБ№БъЧЉЪЧYЃЌ ЭјТчВЮЪ§ЪЧWЃЌЪфГіЪЧF(X)=W*XЁЃбЕСЗЩёОЭјТчЪБЃЌЖдгкУПИіШЗЖЈЕФЪфШыбљБОXЃЌЮвУЧЗДИДЕїећЭјТчВЮЪ§WЪЙЕУЪфГіжЕF(X)ЧїЯђгкИУбљБОЕФРрБ№БъЧЉYЁЃАзКаЙЅЛїЪЙгУЭЌбљЕФЗНЗЈЃЌЧјБ№жЛЪЧЮвУЧЙЬЖЈЭјТчВЮЪ§WЃЌЗДИДаоИФЪфШыбљБОXЪЙЕУЪфГіжЕF(X)ЧїЯђгкЙЅЛїФПБъYЁЏЁЃетвтЮЖзХЮвУЧжЛашвЊаоИФФПБъКЏЪ§вдМАдМЪјЬѕМўЃЌОЭПЩвдЪЙгУгыбЕСЗЩёОЭјТчЭЌбљЕФЗНЗЈМЦЫуЕУЕНЖдПЙадбљБОЁЃ
АзКаЙЅЛїЕФдМЪјЬѕМўЪЧвЛИіЙиМќВПЗжЁЃДгXЦ№ЪМЧѓНтXЁЏЪЙЕУF(XЁЏ)=YЁЏЕФЙ§ГЬжаЃЌЮвУЧБиаыБЃжЄXЁЏЕФБъЧЉВЛЪЧYЁЏЁЃР§ШчЃЌЖдгквЛИіЪжаДЬхЪфШыЁА1ЁБЃЌШчЙћЮвУЧАбЫќИФГЩЁА2ЁБЪЙЕУФЃаЭХаБ№ЪЧЁА2ЁБЃЌФЧОЭВЛЫуЪЧЙЅЛїЁЃдкМЦЫуЛњЪгОѕСьгђЃЌЮвУЧВЛЬЋПЩФмЪЙгУШЫСІХаЖЈЙЅЛїЗНЗЈЩњГЩЕФУПвЛИібљБОXЁЏЃЌвђДЫв§ШыСЫОрРыКЏЪ§ІЄ(X, XЁЏ)ЁЃЮвУЧМйЩшдквЛЖЈЕФОрРыФкЃЌXЁЏЕФ КЌвхКЭБъЧЉгыXЪЧвЛжТЕФЁЃОрРыКЏЪ§ПЩвдбЁдёВЛЭЌЕФNormРДБэЪОЃЌБШШчL2, LЁо, КЭL0 ЁЃ
L-BFGSЪЧЕквЛжжЙЅЛїЩюЖШбЇЯАФЃаЭЕФЗНЗЈЃЌЫќЪЙгУL2-NormЯожЦXЁЏЕФЗЖЮЇЃЌВЂЪЙгУзюгХЛЏЗНЗЈL-BFGSМЦЫуЕУЕНXЁЏЁЃКѓРДЛљгкФЃаЭЕФЯпадМйЩшЃЌбаОПепгжЬсГіСЫFastGradient Sign Method (FGSM)[3] КЭDeepFool[4]ЕШвЛаЉаТЗНЗЈЁЃШчЙћвдОрРыІЄ(X, XЁЏ)зюаЁЮЊФПБъЃЌФПЧАзюЯШНјЕФЗНЗЈЪЧCarlini-WagnerЃЌЫќЗжБ№ЖдЖржжОрРыКЏЪ§зіСЫЧѓНтгХЛЏЁЃ
2.2 КкКаЙЅЛї
КкКаЙЅЛїжЛвРРЕгкЛњЦїбЇЯАФЃаЭЕФЪфГіЃЌЖјВЛашвЊСЫНтФЃаЭФкВПЕФЙЙдьКЭзДЬЌЁЃвХДЋЃЈНјЛЏЃЉЫуЗЈМДЪЧвЛИігааЇЕФКкКаЙЅЛїЗНЗЈЁЃ
вХДЋЫуЗЈЪЧдкМЦЫуЛњЩЯФЃЗТДяЖћЮФЩњЮяНјЛЏТлЕФвЛжжзюгХЛЏЧѓНтЗНЗЈЁЃЫќжївЊЗжЮЊСНИіЙ§ГЬЃКЪзЯШЭЈЙ§ЛљвђЭЛБфЛђдгНЛЕУЕНаТвЛДњЕФБфжжЃЌШЛКѓвдгХЪЄСгЬЕФЗНЪНбЁдёгХЪЦБфжжЁЃетИіЙ§ГЬПЩвджмЖјИДЪМЃЌвЛДњвЛДњЕибнЛЏЃЌзюжеЕУЕНЮвУЧашвЊЕФбљБОЁЃ
АбвХДЋЫуЗЈгУгкКкКаЬгвнЙЅЛїЪБЃЌЮвУЧРћгУФЃаЭЕФЪфГіИјУПвЛИіБфжжДђЗжЃЌF(XЁЏ)дННгНќФПБъБъЧЉYЁЏдђЕУЗждНИпЃЌАбИпЗжБфжжСєЯТРДМЬајбнЛЏЃЌзюжеПЩвдЕУЕНF(XЁЏ)=YЁЏЁЃетжжЗНЗЈвбОГЩЙІгУгкЦлЦЛљгкЛњЦїбЇЯАЕФМЦЫуЛњЪгОѕФЃаЭвдМАЖёвтШэМўМьВтЦїЁЃ
3.ЛљгквХДЋЫуЗЈЕФЖдПЙбљБОЩњГЩ
3.1 ЖдGmail PDFЙ§ТЫЕФЬгвнЙЅЛї
БОЮФКЯзїепаэЮАСжвЛФъЧАдкNDSSДѓЛсЩЯЗЂБэСЫУћЮЊAutomatically EvadingClassifiersЕФТлЮФ[5]ЁЃбаОПЙЄзїВЩгУвХДЋБрГЬЃЈGeneticProgrammingЃЉЫцЛњаоИФЖёвтШэМўЕФЗНЗЈЃЌГЩЙІЙЅЛїСЫСНИіКХГЦзМШЗТЪМЋИпЕФЖёвтPDFЮФМўЗжРрЦїЃКPDFrate КЭHidost ЁЃетаЉЬгвнМьВтЕФЖёвтЮФМўЖМЪЧЫуЗЈздЖЏаоИФГіРДЕФЃЌВЂВЛашвЊPDFАВШЋзЈМвНщШыЁЃЭМ3ЯдЪОСЫЖдПЙбљБОЩњГЩЕФЛљБОСїГЬЁЃ
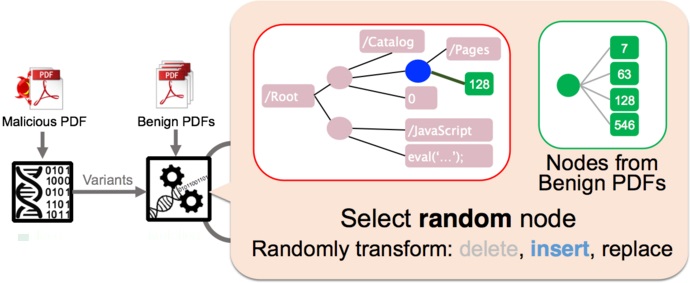
ЭМII-3: РћгУНјЛЏЫуЗЈЩњГЩЖёвтPDFЖдПЙБфжж
ЭЌбљЕФЫуЗЈПЩвдгУРДЖдЪЕМЪгІгУЕФЛњЦїбЇЯАЯЕЭГНјааЬгвнЙЅЛїЁЃЩЯУцЬсЕНЕФЙЄзїПЩвдЖд GmailФкЧЖЕФЖёвтШэМўЗжРрЦїНјааЙЅЛїЃЌ ВЂЧвжЛаы4ааДњТыаоИФвбжЊЖёвтPDFбљБООЭПЩвдДяЕННќ50%ЕФЬгвнТЪЃЌ10вкGmailгУЛЇЖМЪмЕНгАЯьЁЃ
3.2 РћгУFuzzingВтЪдЕФЖдПЙбљБОЩњГЩ
Г§СЫЖдФЃаЭКЭЫуЗЈЕФШѕЕуНјааЗжЮіЃЌКкКаЙЅЛїЛЙПЩвдНшМјФЃК§ВтЪдЕФЗНЗЈРДЪЕЯжЖдПЙбљБОЕФЩњГЩЁЃЯТУцвдЪжаДЪ§зжЭМЯёЪЖБ№ЮЊР§ЃЌЮвУЧЕФФПБъЪЧВњЩњЖдПЙЭМЦЌЃЌЪЙЦфПДЦ№РДЪЧЁА1ЁБЃЌЖјШЫЙЄжЧФмЯЕЭГШДЪЖБ№ЮЊЁА2ЁБЁЃЮвУЧЕФжївЊЫМТЗЪЧНЋетбљвЛИіЖдПЙбљБОЩњГЩЕФЮЪЬтЃЌзЊЛЛЮЊвЛИіТЉЖДЭкОђЕФЮЪЬтЃЌШчЯТЭМ4ЫљЪОЁЃ
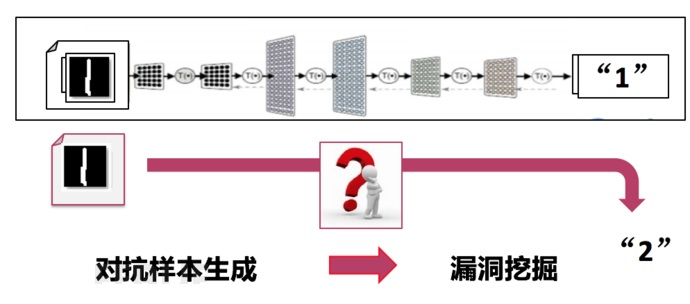
ЭМII-4ЃКеыЖдЪжаДЪ§зжЭМЯёЪЖБ№ЕФЖдПЙбљБОЩњГЩ
ЮвУЧжївЊЪЧРћгУЛвКаfuzzingВтЪдЕФЗНЗЈРДЪЕЯжЃЌЪзЯШИјЖЈЪ§зжЁА1ЁБЕФЭМЦЌзїЮЊжжзгЃЌШЛКѓЭЈЙ§ЖджжзгЭМЦЌНјааБфвьЃЌШчЙћЛњЦїбЇЯАЯЕЭГНЋБфвьКѓЕФЭМЦЌЪЖБ№ЮЊЁА2ЁБЃЌФЧУДЮвУЧШЯЮЊетбљвЛИіЭМЦЌОЭЪЧЖдПЙбљБОЁЃ
РћгУFuzzingВтЪдЕФЖдПЙбљБОЩњГЩЪЧЛљгкAFLРДЪЕЯжЕФЃЌжївЊзіСЫвдЯТМИЗНУцЕФИФНјЃК
1. ЪЧТЉЖДзЂШыЃЌЮвУЧдкЛњЦїбЇЯАЯЕЭГжаЬэМгвЛИіХаЖЯЃЌЕБЭМЦЌБЛЪЖБ№ЮЊ2ЪБЃЌдђШЫЮЊВњЩњвЛИіcrashЃЛ
2. ЪЧдкЪ§ОнБфвьЕФЙ§ГЬжаЃЌЮвУЧПМТЧЮФМўИёЪНЕФФкШнЃЌгХЯШЖдвЛаЉЭМЯёФкШнЯрЙиЕФЪ§ОнНјааБфвьЃЛ
3. ЪЧдкAFLвбгаЕФТЗОЖЕМЯђЕФЛљДЁЩЯЃЌдіМгвЛаЉЙиМќЪ§ОнЕФЕМЯђЁЃ
ЯТЭМ5ЪЧЮвУЧЩњГЩЕФвЛаЉЖдПЙбљБОЕФР§згЁЃ

ЭМII-5ЃКеыЖдЪжаДЪ§зжЭМЯёЕФЖдПЙбљБОЩњГЩНсЙћ
ЛљгкFuzzingВтЪдЕФЖдПЙбљБОЩњГЩЗНЗЈвВПЩвдПьЫйЕФгІгУЕНЦфЫћAIгІгУЯЕЭГжаЃЌШчШЫСГЪЖБ№ЯЕЭГЁЃ
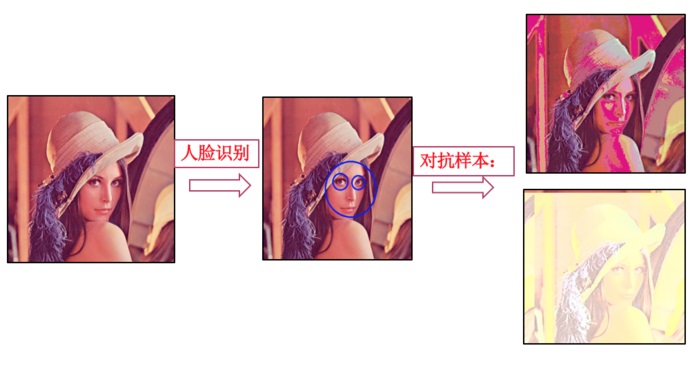
ЭМII-6ЃКеыЖдШЫСГЪЖБ№ЯЕЭГЕФЖдПЙбљБОЩњГЩ
4. ЛљгкШэМўТЉЖДНјааЬгвнЙЅЛї
еыЖдAIЯЕЭГЕФЖдПЙадЙЅЛїЃЌОЭЪЧШУШЫЙЄжЧФмЯЕЭГЪфГіДэЮѓЕФНсЙћЁЃ ЛЙЪЧвдЪжаДЭМЯёЪЖБ№ЮЊР§ЃЌЙЅЛїепПЩвдЙЙдьЖёвтЕФЭМЦЌЃЌЪЙЕУШЫЙЄжЧФмЯЕЭГдкЗжРрЪЖБ№ЭМЦЌЕФЙ§ГЬжаДЅЗЂЯргІЕФАВШЋТЉЖДЃЌ ИФБфГЬађе§ГЃжДааЕФПижЦСїЛђЪ§ОнСїЃЌЪЙЕУШЫЙЄжЧФмЯЕЭГЪфГіЙЅЛїепжИЖЈЕФНсЙћЁЃ ЙЅЛїЫМТЗЛљБОЗжЮЊСНжжЃК
1.ЛљгкЪ§ОнСїДлИФПЩвдРћгУШЮвтаДФкДцТЉЖДЃЌжБНгНЋAIЯЕЭГжаЕФвЛаЉЙиМќЪ§ОнНјаааоИФ(ШчБъЧЉЁЂЫїв§ЕШ)ЃЌ ЪЙЕУAIЯЕЭГЪфГіДэЮѓЕФНсЙћЁЃ2.СэвЛжждђЪЧЭЈЙ§ГЃЙцЕФПижЦСїНйГж(ШчЖбвчГіЁЂеЛвчГіЕШТЉЖД)РДЭъГЩЖдПЙЙЅЛїЃЌгЩгкПижЦСїНйГжТЉЖДПЩвдЭЈЙ§ТЉЖДЪЕЯжШЮвтДњТыЕФжДааЃЌвђДЫБиШЛПЩвдПижЦAIЯЕЭГЪфГіЙЅЛїепдЄЦкЕФНсЙћЁЃ
ЙигкШэМўТЉЖДдьГЩЕФЮЪЬтЮвУЧдкЕквЛеТРявбгаЯъЯИНщЩмЁЃ етРяжЛзіСЫвЛИіМђЕЅНщЩм, ИќЖрЯИНкЧыВЮПМISC 2017ДѓЛсШЫЙЄжЧФмгыАВШЋТлЬГЫљЗЂВМЕФФкШнЁЃ
5. аЁНс
БОЮФЕФФПЕФЪЧМЬајНщЩмБЛДѓжкЫљКіЪгЕФШЫЙЄжЧФмАВШЋЮЪЬтЁЃЫфШЛЩюЖШбЇЯАдкДІРэздШЛЩњГЩЕФгявєЭМЯёЕШвдДяЕНЯрЕБИпЕФзМШЗТЪЃЌЕЋЪЧЖдЖёвтЙЙдьЕФЪфШыШдШЛгаОоДѓЕФЬсЩ§ПеМфЁЃЫфШЛЩюЖШбЇЯАЯЕЭГОЙ§бЕСЗПЩвдЖде§ГЃЪфШыДяЕНКмЕЭЕФЮѓХаТЪЃЌЕЋЪЧЕБЙЅЛїепгУЯЕЭГЛЏЕФЗНЗЈФмЙЛЩњГЩЮѓХабљБОЕФЪБКђЃЌЙЅЛїЕФаЇТЪОЭПЩвдНгНќ100%ЃЌ ДгЖјЪЕЯжЮШЖЈЕФЬгвнЙЅЛїЁЃ ЫцзХШЫЙЄжЧФмгІгУЕФЦеМАЃЌЯраХЖдЬгвнЙЅЛїЕФбаОПвВЛсдНРДдНЩюШыЁЃ
III. ЩюЖШбЇЯАЪ§ОнСїДІРэжаЕФАВШЋЗчЯе
ЩюЖШбЇЯАдкКмЖрСьгђЪмЕНЙуЗКЙизЂЁЃ гШЦфдкЭМаЮЭМЯёСьгђРяЃЌШЫСГЪЖБ№КЭздЖЏМнЪЛЕШгІгУе§дкж№НЅНјШыЮвУЧЕФЩњЛюЁЃ ЩюЖШбЇЯАЕФСїаагыЦеМАвВздШЛДјРДСЫАВШЋЗНУцЕФПМТЧЁЃ ФПЧАЖдЩюЖШбЇЯАЕФАВШЋЬжТлАќРЈЩюЖШбЇЯАЦНЬЈжаЗЂЯжЕФТЉЖДЃЌЩюЖШбЇЯАФЃаЭжавўВиЕФДэЮѓЃЌЛЙгаЖдЩюЖШбЇЯАЯЕЭГЕФЬгвнЙЅЛїЁЃ
360 АВШЋЭХЖгЗЂЯждкЩюЖШбЇЯАЕФЪ§ОнДІРэСїГЬжаЃЌЭЌбљДцдкАВШЋЗчЯеЁЃЙЅЛїепдкВЛРћгУЦНЬЈШэМўЪЕЯжТЉЖДЛђЛњЦїбЇЯАФЃаЭШѕЕуЕФЧщПіЯТЃЌжЛРћгУЩюЖШбЇЯАЪ§ОнСїжаЕФДІРэЮЪЬтЃЌОЭПЩвдЪЕЯжЬгвнЛђЪ§ОнЮлШОЙЅЛїЁЃ
1. ЙЅЛїЪЕР§
вдЩюЖШбЇЯАЭМЦЌЪЖБ№гІгУЮЊЙЅЛїФПБъЃЌ ЮвУЧгУМИИіР§згРДНщЩмНЕЮЌЙЅЛїЕФаЇЙћЁЃ

етРяЮвУЧгУЕФГЬађРДздCaffeЦНЬЈздДјЕФОЕфЭМЦЌЪЖБ№гІгУР§згЃЌЪЖБ№ЫљгУЕФЩёОдЊЭјТчЪЧгЩЙШИшЗЂВМЕФGoogleNetЃЌЪ§ОнРДзджјУћЕФImageNet БШШќЃЌФЃаЭЪЧгЩВЎПЫРћгУЙШИшЕФФЃаЭМгЩЯImageNetЕФЪ§ОнХрбЕЕФЁЃетИіЦНЬЈЕФЪЖБ№ФмСІДѓМвУЛгавЩЮЪАЩЁЃ
CaffeЕФЩюЖШбЇЯАгІгУШЯЮЊЩЯУцЕФЭМЦЌЪЧ РЧ ЃЁ ЃЈЭМЦЌЪЖБ№ГЬађЪфГіШчЯТЁЃ TensorFlowЕФР§згНсЙћвВЪЧРЧЃЁЃЉ
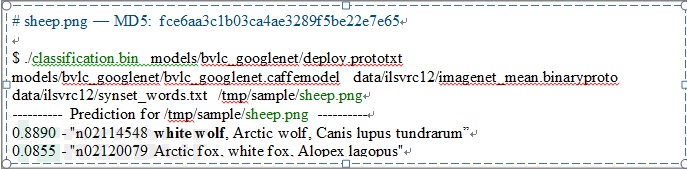

ФЧУДдкЛњЦїбЇЯАЯЕЭГРяЫќЛсБЛШЯГЩЪВУДФиЃП CaffeЕФЛњЦїбЇЯАгІгУЛсАбетвЛеХШЯЮЊЪЧУЈЃЌОпЬхНВЪєгкImageNetРяЕФтІсћУЈЃЁЦфЫќЦНЬЈTensorFlowЃЌTorchЕШСїааЕФЭМЦЌЪЖБ№гІгУвВЪЧетбљЁЃ
ЮЊЪВУДЛсЪЧетбљЃП ЩюЖШбЇЯАЕФбЕСЗФЃаЭУЛгаДэЁЃЮЪЬтГідкЩюЖШбЇЯАгІгУЕФЪ§ОнСїДІРэЩЯЁЃ
2. НЕЮЌЙЅЛїдРэ
ЮвУЧдкЧАвЛЖЮЪБМфЬжТлЙ§ЙигкЩюЖШбЇЯАЕФЬгвнЙЅЛїЃЌжївЊНщЩмСЫИїжжШУЛњЦїбЇЯАЯЕЭГзіГіДэЮѓХаБ№ЕФЗНЗЈЁЃ ФПЧАбЇЪѕНчЖдЩюЖШбЇЯАЬгвнЙЅЛїЕФбаОПДѓЖрМЏжадкЖдПЙбљБОЩњГЩЕФЗНЗЈЃЌЭЈЙ§ИїжжЫуЗЈдкЭМЦЌЩЯЩњГЩШХЖЏЃЌДгЖјЕМжТЩюЖШбЇЯАЯЕЭГЕФЮѓХаЁЃ етЦЊЮФеТЬсЕНЕФНЕЮЌЙЅЛїУЛгаЪЙгУДЋЭГЕФЖдПЙбљБОЩњГЩВпТдЁЃ НЕЮЌЙЅЛїЪЧЖдЩюЖШбЇЯАгІгУЕФЪ§ОнСїДІРэНјааСЫЙЅЛїЁЃ
ЩюЖШбЇЯАЯЕЭГЕФКЫаФЪЧЩёОдЊЭјТчЁЃ ЩюЖШбЇЯАЫљЪЙгУЕФОВЬЌЩёОдЊЭјТчЭљЭљМйЖЈЫќЕФЪфШыЪЧвЛИіЙЬЖЈЕФЮЌЖШЃЌетбљБугкЩшМЦЩюЖШЩёОдЊЭјТчЁЃ ЙЬЖЈЕФЮЌЖШДјРДЕФЮЪЬтЪЧЃКЪЕМЪЕФЪфШыВЂВЛвЛЖЈгыЩёОдЊЭјТчФЃаЭЪфШыгУЯрЭЌЕФЮЌЖШЁЃ НтОіетжжЮЌЖШВЛЦЅХфЕФЗНЗЈгаСНИіЃЌвЛИіЪЧвЊЧѓЫљгаЕФЪфШыЖМБиаыЪЧФЃаЭЪЙгУЕФЮЌЖШЃЌЦфЫќЪфШывЛИХШгЕєЁЃ СэЭтвЛИібЁдёЪЧЖдЪфШыНјааЮЌЖШЕїећЁЃЖдгкЪдЭМЖдЙуЗКЭМЦЌНјааЪЖБ№ЕФгІгУРяЃЌДѓЖрВЩгУСЫЕкЖўжжЗНЗЈЁЃдкОпЬхЭМЯёЪЖБ№гІгУРяЃЌОЭЪЧАбДѓЕФЪфШыЭМЦЌНјааЮЌЖШЫѕМѕЃЌаЁЕФЭМЦЌНјааЮЌЖШЗХДѓЁЃ

ЮЌЖШБфЛЏЕФНсЙћЪЧЃЌЩюЖШбЇЯАФЃаЭеце§гУЕНЕФЪ§ОнЪЧЮЌЖШБфЛЏЙ§ЕФЭМЦЌЁЃ
ЮЌЖШБфЛЏЕФЫуЗЈгаКмЖржжЃЌГЃгУЕФАќРЈзюНќЕуГщШЁЃЌЫЋЯпадВхжЕЕШЁЃетаЉЫуЗЈЕФФПЕФЪЧдкЖдЭМЦЌНЕЮЌЕФЭЌЪБОЁСПБЃГжЭМЦЌдгаЕФбљзгЁЃ

ЭМЦЌзѓБпЪЧЖдЩюЖШбЇЯАгІгУЕФЪфШыЭМЦЌЃЌгвБпЪЧНЕЮЌКѓЕФЭМЦЌЁЃ бђШКЭМЦЌОЙ§ЫѕМѕЃЌОЭЛсБфГЩвЛжЛбЉЕиРяЕФАзРЧЁЃ ПЈЭЈаЁбђЕФЭМЦЌвВОЭБфГЩСЫПЩАЎаЁУЈЕФЭМЦЌЁЃ ЕБШЛетаЉЪфШыЭМЦЌЪЧОЙ§ЬиЪтДІРэЙЙдьЕФЃЌзЈУХШУНЕЮЌКЏЪ§ГіЯжетжжвьГЃЕФНсЙћЁЃ
ЛљгкетИіЙЅЛїЫМТЗЃЌЮвУЧвВЖдЦфЫќЩюЖШбЇЯАгІгУНјааСЫВтЪдЁЃ Р§ШчжјУћЕФЩюЖШбЇЯАНЬПЦЪщАИР§ MINST ЪжаДЪ§зжЪЖБ№ЃЌЮвУЧПЩвдГЩЙІЩњГЩЖдШЫКмЧхГўЕФЪ§зжЃЌЕЋЛсБЛЩюЖШбЇЯАЯЕЭГЮѓЪЖБ№ЕФЭМЦЌЁЃЯТУцЯдЪОСЫЫФзщЭМЦЌЁЃ УПвЛзщжаЃЌзѓБпЪЧЖдгІгУЕФЪфШыЃЌвВОЭЪЧШЫПДЕНЕФЭМЦЌЃЛгвБпЪЧШЫПДВЛЕНЃЌЕЋЪЧБЛЛњЦїбЇЯАФЃаЭзюКѓДІРэЕФЭМЦЌЁЃ етбљЕФЭМЦЌБфЛЏЃЌдьГЩЩюЖШбЇЯАЯЕЭГГіЯжДэЮѓЪЖБ№гІИУВЛФбРэНтЁЃ

3. НЕЮЌЙЅЛїгАЯьЗЖЮЇМАЗРЗЖЪжЖЮ
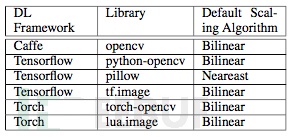
ИљОнЮвУЧЕФГѕВНЗжЮіЃЌМИКѕЫљгаЭјЩЯСїааЕФЩюЖШбЇЯАЭМЦЌЪЖБ№ГЬађЖМгаБЛНЕЮЌЙЅЛїЕФЗчЯеЁЃ
ЖдгкНЕЮЌЙЅЛїЕФЗРЗЖЃЌгУЛЇПЩвдВЩгУЖдГЌГівьГЃЕФЭМЦЌНјааЙ§ТЫЃЌЖдНЕЮЌЧАКѓЕФЭМЦЌНјааБШЖдЃЌвдМАВЩгУИќМгНЁзГЕФНЕЮЌЫуЗЈЕШЁЃ
4. аЁНс
БОЮФЕФФПЕФЪЧМЬајНщЩмБЛДѓжкЫљКіЪгЕФШЫЙЄжЧФмАВШЋЮЪЬтЁЃНЕЮЌЙЅЛїЪЧЖдЩюЖШбЇЯАЕФЪ§ОнСїНјааЙЅЛїЕФвЛжжаТаЭЙЅЛїЗНЗЈЃЌжївЊгАЯьЖдШЮвтЭМЦЌНјааЪЖБ№ЕФЩюЖШбЇЯАгІгУГЬађЁЃ ЮвУЧЯЃЭћЭЈЙ§етаЉЙЄзїЬсабЙЋжкЃЌдкгЕБЇШЫЙЄжЧФмШШГБЕФЭЌЪБЃЌашвЊГжајЙизЂЩюЖШбЇЯАЯЕЭГжаЕФАВШЋЮЪЬтЁЃ
|








