摘要:在 Project REAL
中,我们将使用来自真实公司的大量真实数据和方案,以便使用早期版本的
Microsoft SQL Server
来实现商务智能系统。在该过程中,将开发最佳实施策略并揭露潜在的问题。本文报告了在完成
Project REAL
第一阶段的数据提取、转换和加载
(ETL)
部分的过程中获得的一些经验教训。
本页内容
简介: Project REAL
Project REAL
是一种为了通过创建基于实际客户方案的引用实现来发现基于
Microsoft SQL Server®
创建商务智能应用程序的最佳实施策略所做的努力。这意味着客户数据将被带到企业内部,并用于解决客户在部署过程中面临的相同问题。这些问题包括:
| • |
架构的设计。
|
| • |
数据提取、转换和加载 (ETL)
过程的实现。
|
| • |
用于生产的系统的大小调整。
|
| • |
系统的动态管理和维护。
|
通过处理真实的部署方案,我们可以彻底了解如何使用有关工具。我们的目标是努力解决大型公司在它们自己的实际部署过程中可能面临的全部问题。本文描述了在完成
Project REAL 第 1 阶段的 ETL
部分的过程中获得的一些经验教训。
Project REAL 使用了两个 Microsoft
商务智能客户的数据。该项目的第
1
阶段以一个大型电子设备零售商为原型,该零售商在
Microsoft SQL Server®
数据仓库中保存销售和库存数据。SQL
Server® 数据转换服务 (DTS)
用于管理进入关系数据库、并从那里进入
SQL Server® Analysis Services
多维数据集以便进行报告和交互查询的数据流。该客户在其关系存储中维护大约
200 GB
的数据。随后,所有这些数据都被处理为
Analysis Services 多维数据集。第 1
阶段的实现主要集中于现有 SQL
Server® 客户在执行向 SQL Server®
的迁移时可能关心的问题。我们的结果主要表现了现有功能的迁移,并在适当的时候使用了几个新功能。在
ETL 领域中,要基于现有的 SQL
Server® DTS 软件包通过 SQL Server®
Integration Services (SSIS)
创建软件包,需要完成大量的工作。
注 SQL Server Integration
Services (SSIS) 是指定给原来称为 DTS
的组件的新名称。该产品在 Beta 2
以后被重新命名;因此,本文中的新
SSIS
的很多屏幕截图仍然使用旧名称。
因为 SSIS
基于全新的体系结构,所以很多的
SQL Server® DTS
概念和技术不再适用。处理这些差异的过程是本文的核心焦点之一。
Project REAL 的第 2
阶段基于另一个客户的更大数据集,与第
1 阶段相比,它演示了 SQL Server®2005
的更多新功能。这是因为第 2
阶段主要是 SQL Server®2005
解决方案的一种新实现。请在将来查阅更多关于
Project REAL 的文章。
Project REAL 是由 Microsoft、Unisys、EMC、Scalability
Experts、Panorama、Proclarity 和
Intellinet
共同开发的。本文中描述的工作是由
Microsoft 和 Scalability Experts
完成的。
第 1 阶段的实现
第 1
阶段的客户具有两个流入数据仓库的主要信息源。它们是:
| • |
TLOG
文件,它是商店中的销售点
(POS)
收款机的输出(不要将其与
SQL Server
事务日志文件混淆)。
|
| • |
来自 JDA
系统(一种打包的零售软件应用程序)的平面文件摘录,它用于管理业务。
|
整体数据流(由 SQL Server®2000
DTS 管理)如图 1 所示。
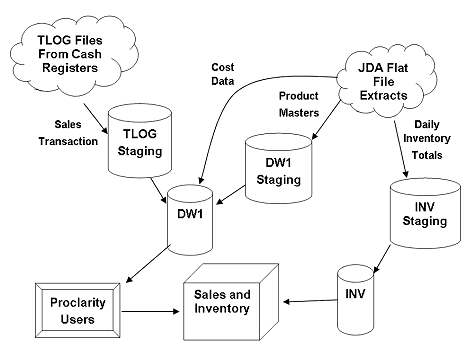
图 1
核心 ETL 处理
为加载该客户的数据仓库而执行的核心
ETL 处理如下所述:
|
1.
|
TLOG 文件从销售点 (POS)
收款机进入,它们采用特殊的高度压缩的格式,并且在加载到数据库之前必须解码。客户的应用程序基于预定义的规范将这些
POS
事务压缩为打包的十进制格式,并且根据每个文件对应的商店编号将它们存储在不同的目录中。
|
|
2.
|
应用程序使用数字序列为每个文件指定一个名称。它根据商店编号将该名称存储到适当的目录中。为了支持存在多日的文件以及每天写入多个文件的情况,使用该命名约定是必要的。
|
|
3.
|
客户使用 Perl 脚本将 TLOG
二进制文件分析为多个文本文件,然后才将数据加载到数据库中。这些脚本使用预定义的模板将数据解包,然后根据
.ini
文件中安排的一组规则来解压缩数据。
|
|
4.
|
这些脚本的输出存储在平面文件中。然后,由
DTS
软件包读取这些平面文件,以便将数据加载到数据库中。这增加了一个分析数据的额外步骤以及一个加载平面文件输出的步骤,只有在执行了这些步骤之后,才能处理数据。
|
为了将 ETL 过程迁移到 SSIS,Scalability
Experts 创建了一个在 SSIS
管道中运行的 TLOG
分析器。这有效地消除了一个代价高昂的额外步骤,并且有助于减少处理
TLOG
文件所需的存储需求。现在,每个
TLOG 文件(包含压缩数据)都通过自定义源组件
直接读取到 SSIS
管道中,并且使用自定义转换组件
进行分析。
注
我们将在另一篇白皮书中说明我们在编写实现
TLOG
分析器所需的自定义转换的过程中获得的经验教训。
为了充分演练该系统,客户不仅提供了数据仓库的初始状态,而且还提供了来自销售和库存系统长达三个月之久的日常增量更新。这使我们可以模拟完整的处理周期(就像随着时间运行一样),包括关系数据库和
OLAP 数据库中的自动分区管理。
除了本文中描述的有关 ETL
的工作以外,该团队还在 Project
REAL 的第 1
阶段执行了各种其他活动,包括:
| • |
将关系数据从 SQL Server®2000
迁移到 SQL Server®2005,同时严格保留架构。
|
| • |
屏蔽客户的数据以保护机密信息。
|
| • |
将 Analysis Services
数据库迁移到 SQL Server
Analysis Services (SSAS)。
|
| • |
使用客户喜欢的前端工具(Excel
和 Proclarity)验证客户端连接性。
|
| • |
使用 SQL Server®2005
Reporting Services (SSRS)
针对新的多维数据集创建示例报表。
|
| • |
在 SSAS
中充分实现了一个新的
Inventory
多维数据集。客户先前在使用半加总措施时由于较大的数据量而遇到了困难。因此,客户已经停止了在该领域的工作。现在,Analysis
Services®
中的新功能使得在给定较大的数据量时使用加总措施变得可行。
|
本文的其余部分说明了我们在将客户的
ETL 处理移动至 SQL Server®2005
Integration Services
的过程中获得的经验教训。本文还重点说明了大量的最佳实施策略。
从 SQL Server DTS 升级
如果您已经是 SQL Server DTS
客户,那么您首先提出的问题之一可能是如何升级到
SSIS。这存在多种不同的选择,包括使用迁移向导、执行手动迁移,甚至还可以将您的软件包保留不动然后使用
Execute Package
任务来运行它们。本部分将简要探讨上述每种选择。
在 Project REAL
的开发过程中,我们了解到,如果客户在
SSIS 中创建 ETL
过程的新实现,则要比试图迁移现有的
DTS
软件包更有可能感到满意。尽管我们在
Project REAL
中成功地使用了一些升级工具 (DTS
迁移向导),但我们的大部分努力涉及到在
SSIS
中重写各种软件包,以便利用这一新软件的增强功能。
使用迁移向导
迁移向导是将软件包从 DTS
升级到 SSIS
的最显而易见的方法。本部分说明如何使用迁移向导,以及该向导使用时机的关键注意事项。
使用迁移向导
|
1.
|
当您在 SQL Server Integration
Services 的 BI Development Studio
中创建新项目(称为 Data
Transformation Project)时,系统将为您创建一个名为
Package.dtsx
的默认新软件包。但是,您可以通过右键单击该软件包并选择
delete 选项,来安全地删除这个新软件包。
|
|
2.
|
右键单击解决方案资源管理器中的
DTS Packages
文件夹,并选择 Migrate DTS
2000 Package
选项。这将启动 Integration
Services Migration Wizard。
|
|
3.
|
单击 Next,然后选择从哪里获取原始软件包(如图
2 所示)。
注
您还可以手动启动迁移向导。默认情况下,它位于
C:\Program Files\Microsoft Sql
Server\90\Dts\binn\Dtsmigrationwizard.exe
中。
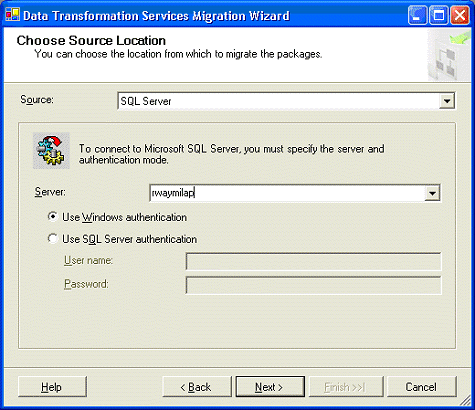
图 2
|
|
4.
|
指定一个存储迁移后的软件包的目标位置(如图
3 所示)。
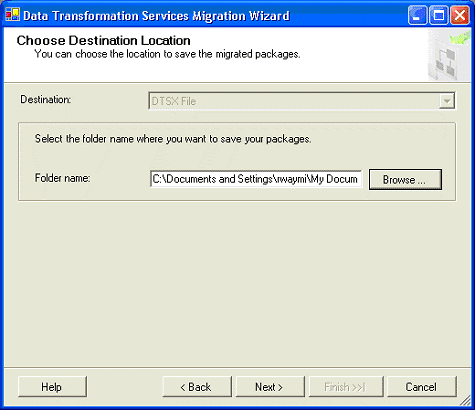
图 3
|
|
5.
|
选择一个要迁移的 DTS
软件包(和版本),如图 4
所示。请注意,软件包可以包含多个版本,因此您可以选择接受默认版本(最新版本),也可以升级该软件包的较早版本。
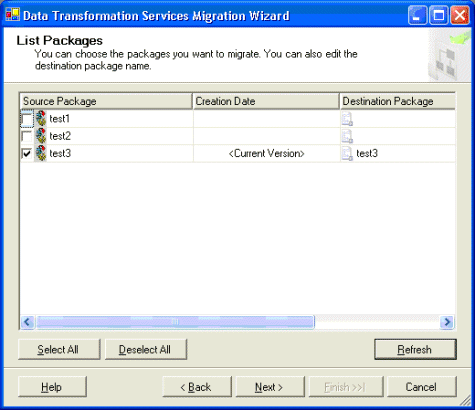
图 4
|
|
6.
|
分配一个日志文件,以捕获该向导在迁移过程中更改的内容的详细信息。完成后,查看该日志文件,以分析在迁移过程中遇到的任何警告或错误。

图 5
|
|
7.
|
单击 Next,查看摘要,然后选择
Finish。您应该看到一个如图
6
所示的对话框,显示该软件包已经迁移。
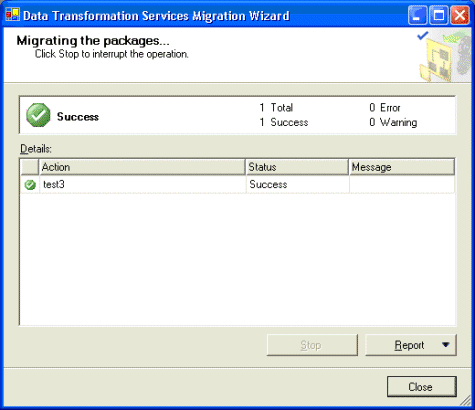
图 6
|
|
8.
|
关闭该向导,然后展开解决方案资源管理器中的
DTS Packages
文件夹。双击迁移后的软件包,以便在编辑器中打开它。
升级后的软件包,而原始软件包显示在SQL
Server®2000 DTS 设计器中。
|
迁移向导注意事项
正如您在上一部分中看到的那样,使用迁移向导的过程并不困难。但是,在使用该向导时,还有其他一些需要铭记的注意事项。
SQL Server®2005 Integration Services
是一种全新的产品。尽管它能够继续运行
SQL Server®2000 DTS
软件包(稍后,我们将对此进行详细说明),但是
SSIS
具有新的设计图面、新的对象模型和新的内部设计。对于可以在
SQL Server®2000 DTS
中设计的所有软件包来说,并不一定存在可用的等效或直接升级途径。迁移向导代表一种尽力而为的迁移尝试。
如果您的软件包包含本部分所述类别中包括的一些任务,则您可能会在迁移向导中看到错误和失败。这些问题是预料之中的,而您将不得不重写该向导无法成功迁移的那些软件包。
SQL Server®2000 DTS
任务可以划分为三个类别。您的迁移体验将取决于您的任务属于哪个类别。
类别 1:简单任务
这些任务可以毫无问题地迁移到
SQL Server®2005 Integration Services
中。它们包括:
| • |
Execute SQL 任务
|
| • |
Bulk Insert 任务
|
| • |
File Transfer Protocol 任务
|
| • |
Execute Process 任务
|
| • |
Send Mail 任务
|
| • |
Copy Objects 任务
|
| • |
Execute Package 任务
|
如果您的软件包只包含这些任务,那么您应该拥有不错的迁移体验。
类别 2:晦涩任务
这些任务可以迁移,但在迁移后可能无法正常工作。对于
ActiveX 和 Dynamic Properties
任务而言,尤其如此。这些任务通常与
SQL Server®2000 DTS
对象模型交互,而 SSIS
对象模型与 SQL Server®2000 DTS
不向后兼容。晦涩任务包括:
| • |
ActiveX Script 任务
|
| • |
Dynamic Properties 任务
|
| • |
Analysis Services DTS Processing
任务
|
您肯定会发现,迁移带有这些任务的软件包起码需要重新开发这些任务组件,并且可能需要对软件包设计进行更为深入的考察。
类别 3:封装任务
这些任务不会被迁移。当迁移向导完成后,它将创建一个包含这些任务的新
DTS 2000 软件包,然后使用 Execute
DTS 2000 Package
任务调入新创建的软件包,以执行这些
SQL Server®2000 DTS
任务。它们包括:
| • |
Custom 任务
|
| • |
Data Pump 任务
|
| • |
Data Driven Query 任务
|
| • |
Transform Data 任务
|
| • |
Parallel Data Pump 任务
|
| • |
Copy Database Wizard 任务
|
对于该类别的任务,您必须重写
SSIS
中的组件(如果您希望迁移它们),或者继续使用
Execute DTS 2000 Package
任务来调用它们。
请注意,如果您计划在带有 SQL
Server®2005
的新服务器安装上运行 SQL Server®2000
DTS
软件包,则必须在安装过程中选择
Advanced 选项来安装 DTS?2000
Run-time
引擎。如果该服务器上尚未安装
SQL Server®2000
管理工具(特别是企业管理器),则在安装过程中,该功能将被视为可选
组件。您必须更改安装过程(如图
9 所示),才能安装该功能。
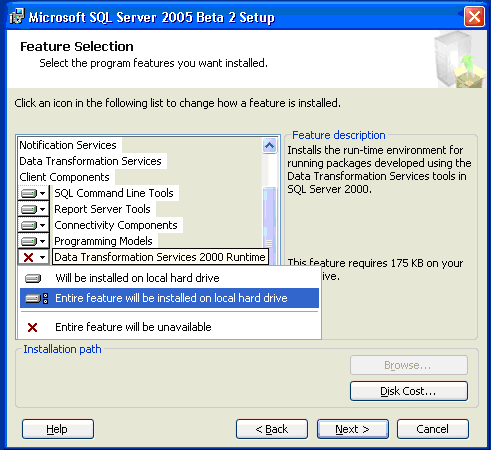
图 9
Beta 2 和大众预览版迁移注意事项
对于 Beta 2 和大众预览版 (IDW9),仍然有一些与迁移向导有关的问题:
| • |
包含 Analysis Services
Processing 任务或 Data Mining
Prediction
任务的软件包将不能升级。
在 Beta 3
中,该问题将会得到解决。
|
| • |
ActiveX Script
任务中的代码在迁移过程中没有进行验证。
用于对对象进行迭代的代码无法转换为循环(这在
SSIS 中可用)。
|
| • |
事务从连接移动至容器。
无法进行任何映射 ―
您必须在 SSIS
中亲自对此进行编码。
|
| • |
自定义转换应该迁移到
SSIS。
如果自定义转换使用 DTS 对象模型,则它们将借助于迁移向导进行迁移。但是,它们将无法在 SSIS 中正常工作。
|
执行手动升级
您可以选择亲自手动升级软件包,而不是使用
DTS 迁移向导。这实际上是从 SQL
Server®2000 DTS 迁移到 SQL Server®2005
Integration Services
的首选办法。尽管您可以选择使用迁移向导并升级一些现有的软件包,但是除非您重写软件包以利用新的服务和功能,否则将不会获得
SSIS 的全部好处。
这是在 Project REAL
中采用的途径。尽管我们选择将某些业务逻辑保存在存储过程中(因此,从表面上看来,软件包在某些方面非常类似),但在其他情况下,我们将相当数量的逻辑从存储过程调用移到
SSIS 软件包中。
这方面的一个示例是我们的第 1
阶段客户用来加载销售数据的过程。这些数据原先是作为一个大型文本字符串使用动态
Bulk Insert 任务加载的,随后又由
select-insert
语句转换为有效的类型化数据集。在进行转换时,记录会从加载的数据中过滤出去。在某些情况下,会过滤掉几乎一半的记录。在
SSIS
中,我们使用平面文件连接打开数据,然后使用原先在动态批量插入操作之后执行的同一逻辑来筛选这些数据。然后,将数据直接加载(正确地类型化和筛选)到目标表中。只是因为
SSIS
中的增强功能,才可以这样做。
在SQL Server Integration Services下运行SQL
Server DTS软件包
您可以使软件包保留 SQL Server®2000
DTS 格式,而只将安装升级到 SQL
Server®2005。在该方案中,SQL
Server®2000 DTS
软件包将继续像以前那样工作。它们是从一个调用
Execute SQL Server®2000 DTS Package
任务的控制 SSIS
软件包中运行的。
图 10
显示该软件包任务中一个指向
DTS?2000
软件包的示例连接。您甚至可以通过选择任务编辑器中的
Edit Package 按钮,在 SQL Server®2005
SSIS
编辑器中编辑这些软件包(起码从
Beta 2 开始可以这样做)。
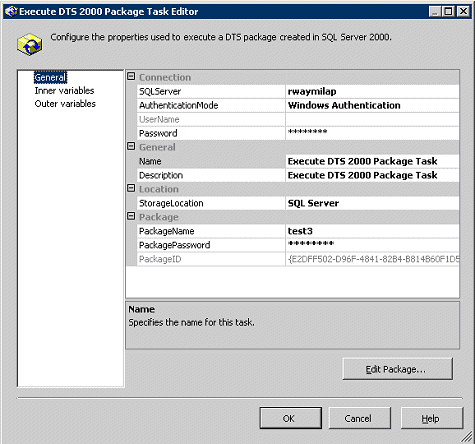
图 10
这可以为软件包加载 SQL Server®2000
DTS
编辑器。需要说明的是,这只能在原先安装了
SQL Server®2000
企业管理器的服务器上起作用。SQL
Server®2005 安装程序没有安装
DTS?2000 编辑器的选项。
对于很多客户而言,这可能是最佳的短期迁移策略。这使您能够将
SQL Server 安装升级到 SQL Server®2005,并继续运行现有的
DTS?2000
软件包。随着时间的推移,您可以迁移每个软件包(使用迁移向导或者重写它们),以利用增强的
SQL Server®2005 功能。
在开发SQL Server Integration Services软件包过程中获得的经验教训
在开发 Project REAL
第一阶段的过程中,我们发现了几个有用的最佳实施策略,以及该产品存在的几个问题。下面对它们进行了说明。
实现最佳实施策略
下面就是我们在开发 Project REAL
第 1
阶段的过程中发现的最佳实施策略。
向软件包中添加日志记录功能
使用 SSIS
软件包内的日志记录功能被视为最佳实施策略。那么,如何添加日志记录功能呢?在
SQL Server®2005 中,这非常容易。
向软件包中添加日志记录功能
|
1.
|
右键单击控制流设计图面上的任何位置,并选择
Logging,如图 12
所示。这将启动 Configure
DTS Logs 对话框。
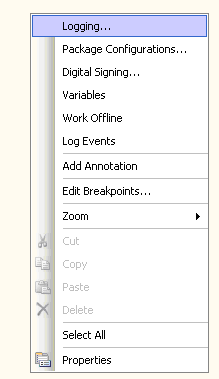
图 12
注 在大众预览版
(IDW9)
中,必须在屏幕左侧的树控件中选中该软件包。然后,单击
Add(位于 provider:
旁边)以添加日志文件。
日志文件类型
除了将结果记录到基本文本文件以外,您还可以根据需要将结果记录到下列位置:
| • |
SQL Server Profiler
|
| • |
SQL Server 表
|
| • |
Windows 2000 Server
事件日志
|
| • |
XML 文件
|
您应该使用哪种类型的日志记录呢?
| • |
SQL Server Profiler
日志使您可以在 SQL
Server Profiler GUI
中打开日志文件。将该功能与加载性能监视器计数器的能力相结合,可以在某些情况下(例如,运行时间出乎意料地长)为您提供强大的分析工具。
|
| • |
SQL Server
表使您可以充分发挥关系语言的威力来分析日志,以及使用
SQL
语句来采取基于日志条目的操作。
|
| • |
如果您要使用操作管理软件(如
Microsoft
操作管理器)来监视服务器,则
Windows
事件日志可能是最佳选择。您可以在软件包中基于日志条目来采取报警和操作。一旦您将应用程序移至生产环境中,这可能是一个值得考虑的好方法。
|
| • |
如果您希望以可视方式浏览日志,则
XML
文件格式十分方便;如果您选择了该格式,则可以编写
XSLT
转换,以便将日志作为
Web 页查看。XML
还提供了一种优秀的中间格式,以便与外部各方共享结果,或者合并来自各种数据源(包括
SQL Server)的日志文件。
|
| • |
文本文件易于查看、易于配置并且易于定义,尤其是在您刚完成软件包的基本测试阶段的时候。
|
|
|
2.
|
单击 Add
按钮以后,请选中 DTS
日志提供程序(如图 13
所示)。在 Configuration
列中单击,即可打开一个列表。选择该列表中的
,如图 13 所示。
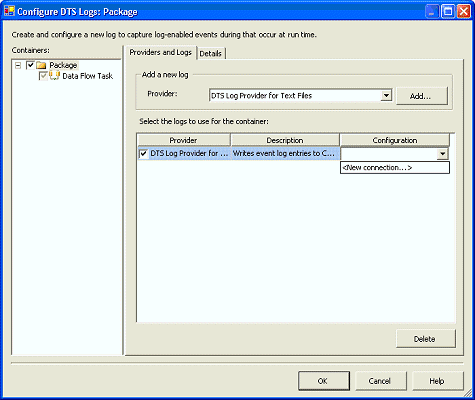
图 13
这会打开 File Connection
Manager Editor
对话框,如图 14 所示。
|
|
3.
|
在该示例中,我打开了 Usage
type: 列表,选择了 Create
File,并且输入了一个文件名以充当我的日志(参见图
14)。
请注意,该对话框与 SQL
Server Profiler
共享一个公共的图形界面,因为二者都基于公共的工作基础结构。这使得日志记录功能更加易于理解,并且在整个
SQL Server 中更加一致。
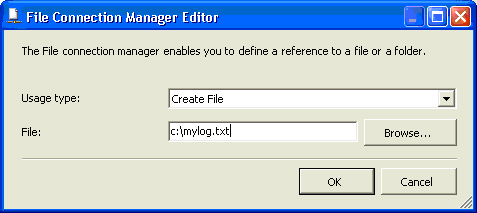
图 14
|
|
4.
|
单击 OK。您已经成功地将日志记录功能添加到
SSIS
软件包中,并且能够在软件包运行之后查看日志。
|
|
5.
|
要配置您希望记录的详细信息,请单击
OK,然后单击 Details
选项卡。这使您可以选择要在日志中捕获的事件类型。
注 如果您单击 Advanced
按钮,则可以在选择记录的事件中获得很高的粒度。
|
使用 Execute SQL 任务
Execute SQL
任务使您可以在查询中设置参数值,并返回单行、多行或者输出到
XML。
要在使用该任务的过程中确保良好的性能,您应该使用传统的查询优化工具来优化查询,因为
SQL Server Integration Services
不会为您优化查询。即使是在从
SQL Server
提取数据的时候,也应该如此。要优化性能,应只在查询中返回绝对必要的列。诸如
Select * from 之类的查询应该避免,因为这会返回不需要的数据。
您可以在 Execute SQL
任务中指定参数化查询。在运行时,存储过程和查询的输入变量被映射到
? 的值。
Select EmployeeName from dbo.EmpTable where EmpID = ?
参数是依赖于顺序的。对于带有多个参数的存储过程,SSIS
引擎遵循输入变量的分配顺序,并且将相应地映射它们。因此,第一个输入变量会映射到第一个
?。
如果查询返回完整的结果集(多于一行),则将
Result Name 设置为 0,以便将该值分配给某个变量,如图
17 所示。
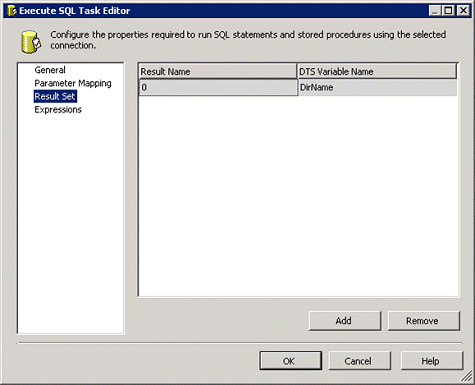
图 17
对于返回单行的情况,请将 Result
Name
的值设置为所返回的列的名称。
对于涉及存储过程的错误处理,请将
Parameter Mapping 中的 ReturnValue
指令映射到某个变量,以便您可以在执行该存储过程之后检查返回代码。
处理“右”侧的列数为变量的文件
某些文件(例如,我们用作
Project REAL
一部分的文本文件)在文件结尾的列数是可变的。有时,可选值出现在数据文件行的结尾;有时不是这样。SSIS
可以使用平面文件连接管理器并借助于
RaggedRight
格式来处理这种类型的文件。但是,在使用该文件格式时存在一个限制。即,只允许
LAST
列可变。换言之,您不能在文件格式中定义多个可选列。
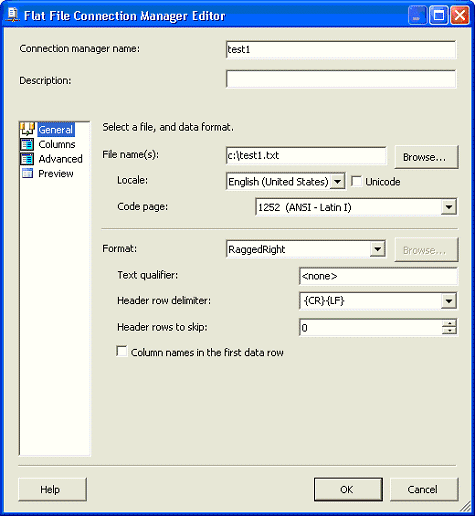
图 18
但是,有一种简单的方法可以解决这一问题
―
您可以将最后一列定义为所有可选列的最大长度,然后使用
Derived Column
编辑器来创建可选列的列定义,以便进一步在您的软件包中使用。图
18
显示了指向一个文件的平面文件连接管理器连接的定义;而在图
19
中,您可以看到我们已经将最后一列
variablecol 定义为 50 个字节。
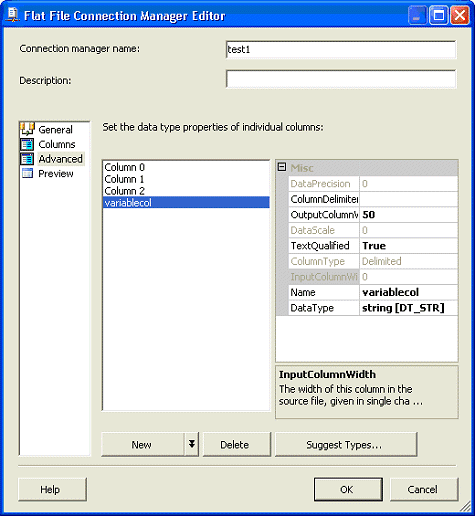
图 19
现在,我们将添加一个平面文件源,以便引用刚才在
connection manager
列表中创建的平面文件连接管理器连接。接下来,我们需要添加
Derived Column
数据流转换,并且将该平面文件源连接到它上面。双击
Derived Column
转换,然后定义可选列(如果存在)的外观。
接下来,添加目标,如 SQL Server
目标。现在,您可以引用所有列,甚至那些可能出现或未出现在该文件每一行中的列。完成的数据流将如图
21 所示。
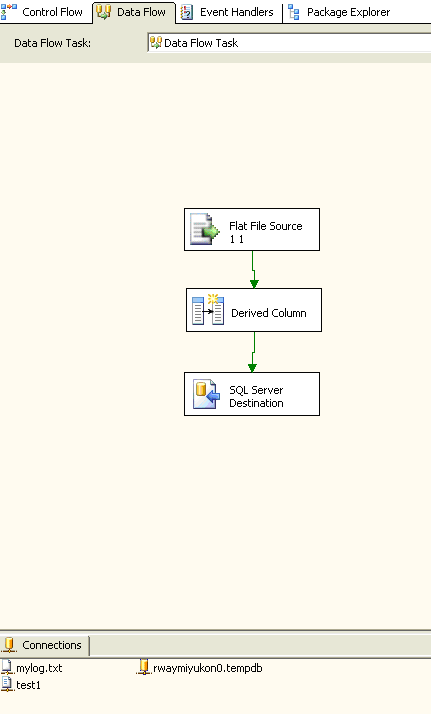
图 21
使用 Derived Column
转换来转换数据
Derived Column
转换使用户可以通过对输入应用表达式来创建新的列。可以将表达式应用于输入和变量。SSIS
定义了它自己的表达式语法集,以便用户可以转换输入。该转换对于下列任务非常有用:
| • |
如果源包含数量可变的列和列长。正如上面讨论的那样,用户可以使用平面文件源中的“右边未对齐”选项,将源数据作为单个列读取,然后应用
Derived Column
转换以便从单个大型列中提取多个列。
|
| • |
当需要基于一个或多个源列来派生新的列以支持下游处理时。
|
| • |
在 ETL
处理过程中,一个很平常的现象是,在将外部数据插入数据库以前,需要对其进行净化。示例:
字符串列:需要去掉前导空字符;只需要提取源列的子字符串。
- 或者 -
整型列:数据需要是绝对值;数据需要是取整的值。
|
这可以使用 Derived Column
转换中的各种字符串或数学函数轻松地完成。因此,Derived
Column
提供了一种方便的方法,以替代传统上用于执行数据净化或转换的复杂存储过程逻辑。
派生列
如图 22
所示,使用单个转换内部定义的多个函数,可以轻松地应用多个复杂表达式。例如,我们的第二个表达式利用了一个依赖于
Substring 函数结果的 Case/Switch
表达式,以便将结果强制转换为所需的数据类型。
注 在 SSIS
内部的该任务和其他任务中使用的表达式语法是一种自定义实现,它既不基于
Transact-SQL,也不基于 Visual Basic。有关表达式语言的完整文档,请参阅
SQL Server 联机图书。
使用 Derived Column 转换
|
1.
|
将 Derived Column 转换拖到“Data
Flow”窗口中,然后双击以打开它。
|
|
2.
|
添加所需的派生列,并定义一个表达式以便为该派生列分配值。可以在输入或变量上编写该表达式。
|
|
3.
|
在 Derived Column
列表中,定义是 还是 。
|
|
4.
|
对于新列,通过长度、精度、小数点后的位数和代码页来指定适当的数据类型。
|
Derived Column
转换使用户可以配置在发生错误或数据被截断时,应该如何处理行级别组件。
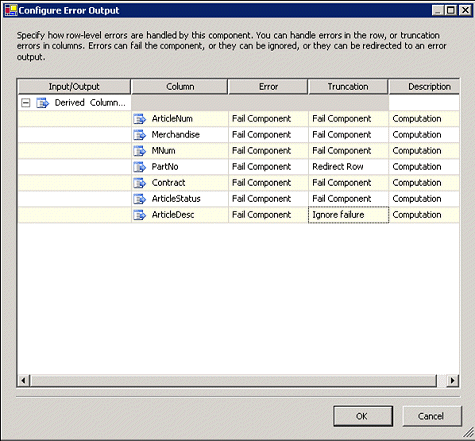
图 23
如图 23
所示,用户可以针对发生的错误或各个列的列数据被截断的情况定义不同的操作。对于
ArticleDesc,我们选择在发生截断时忽略失败;而对于
PartNo,我们决定将该行重定向到错误文件。对于其余的列,如果遇到错误或者数据被截断,则该组件将失败。此时,会生成一个输出
Error
列;该列可以映射到某个下游错误处理组件以进行处理。
使用 Sequence 容器
在 SQL Server DTS
软件包中,经常会见到多个并行运行的任务,如图
24 所示。
通过 SQL Server®2005 Integration
Services,您可以将上述任务包装到一个
Sequence 容器
中,这样您就无需在设计器中保留那么多的工作流连接。此外,您可以拥有在
Sequence
容器中具有依赖项的任务,还可以使工作流中更靠近下游的任务依赖于
Sequence
容器中发生的每件事情(有关使用
Sequence 容器的示例,请参见图 25)。针对输入、输出和错误处理而言,Sequence
容器将充当单个任务。
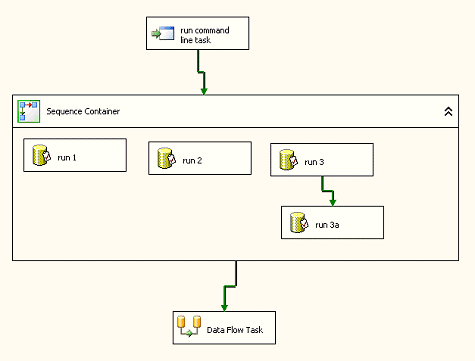
图 25
在 SSIS 中循环
在 DTS 2000
中,要使任务能够循环,开发人员必须实现一种相当于“攻击”的技术以欺骗运行时引擎,使其在任务完成以后,以为该任务仍在等待。令人感到高兴的是,在
SSIS 中,不需要此类“攻击”就可以启用循环。实际上,已经引入了多个循环任务
― ForEach Loop 和 For Loop。
For Loop
For Loop 容器通过使用 for
迭代语句在软件包中定义迭代工作流。For
Loop
容器会计算表达式并重复执行它的工作流,直到该表达式的值为
False。当任务在迭代时,可以在循环中执行多个任务,如下图所示。
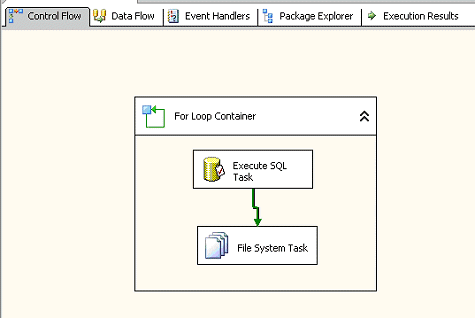
图 26
图 27
ForEach 循环
ForEach Loop 容器通过使用 ForEach
迭代语句在软件包中定义迭代工作流。DTS
提供了下列枚举数类型:
| • |
For Each ADO
枚举数,它可以枚举表中的行。
|
| • |
For Each File
枚举数,它可以枚举文件夹中的文件。
|
| • |
For Each From Variable
枚举数,它可以枚举指定变量所包含的可枚举对象。
|
| • |
For Each SMO
枚举数,它可以枚举 SQL
Server 管理对象 (SMO)。
|
| • |
For Each Nodelist
枚举数,它可以枚举 XML
路径语言 (XPath)
表达式的结果集。
|
在 Beta 3 中,For Each Directory
枚举数将添加到上述列表中。最初没有计划该枚举数。Project
REAL
的其中一个需求是对存储目录进行枚举以访问
TLOG
文件,以便在数据库中处理和插入数据。该需求揭示了使用我们遗漏的
ForEach Directory
枚举数的现实方案。值得庆幸的是,到
Beta 3
的时候,它已经成为一个足够常见的方案,因而我们决定将它包括在
SSIS 中。直到那时,才可以在 DTS
示例中使用 For Each Directory
枚举数自定义任务。
需要说明的是,SSIS
的设计方式使得如果您极其需要的任务不可用,则可以比较容易地创建并包含一个自定义任务,以便在构建
SSIS
软件包的过程中使用。这样的可扩展性受到鼓励,并且您很可能会看到第三方创建自定义任务来扩充
Microsoft 提供的基本集。
使用部署实用工具和配置来简化在服务器之间移动软件包的工作
我们遇到的另一个难题是在环境之间移动软件包(例如,从开发环境移动到测试环境,再移动到生产环境)。指向服务器的连接字符串、硬编码文件位置以及其他信息通常依赖于在软件包开发环境中使用的物理服务器或网络。将软件包移动到不同的服务器或网络时,这些连接字符串可能不再有效。SSIS
中有一个出色的新功能,但要着手使用它有一点儿麻烦。
首先,请确保您希望与实际软件包
(dtsx)
文件一起放置的所有文件都是解决方案资源管理器中项目的一部分(您可以将额外的文件添加到项目中的
Miscellaneous
文件夹)。完成该操作之后,使用
SSIS
配置实用工具来允许输入源(可能是
XML
文件)配置软件包的组成部分。然后,运行
SSIS
部署实用工具来生成可执行的安装程序,以便将该软件包(包括更新后的配置)安装到新的服务器上。
访问 SSIS 配置实用工具
|
1.
|
在生成软件包以后,右键单击控制流的设计图面,然后选择
Package Configurations…。
|
|
2.
|
确保选中了 Enable Package
Configurations,然后单击 Add。
|
|
3.
|
单击 Next
并选择要使用的配置的类型(默认情况下,我们将使用
XML
文件)。为您选择的配置类型指定正确的信息(在我们的示例中,该信息是指向包含配置详细信息的
XML 文件的文件路径)。
您应该看到如图 29
所示的对话框。
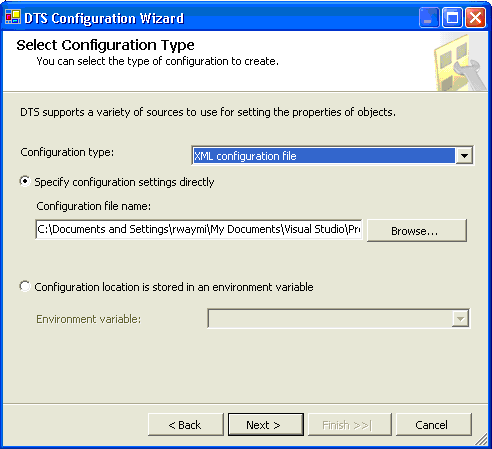
图 29
|
|
4.
|
单击 Next,此时将显示如图
30 所示的 Select Properties to
Export 对话框。
|
|
5.
|
根据需要在 Select
Properties to Export
对话框中设置的属性。这是该过程中最令人困惑的部分。您必须知道在从一个服务器移动到另一个服务器时,哪些内容有可能更改。我选择了指向我的文件的连接和
SQL Server,因为它们在测试系统和生产系统之间可能是不同的。当您浏览可用对象的列表时,我想您一定会为您可以在安装时配置如此之多的内容而留下深刻印象。您最有可能希望配置的项(它们也是为该配置而选择的项)是指向文件和数据库的连接。
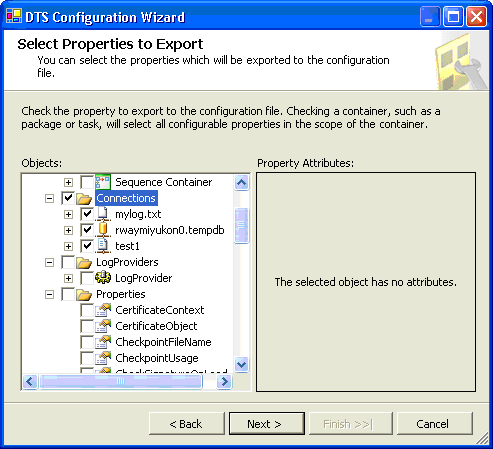
图 30
|
|
6.
|
对于该示例,单击 Next,再单击
Finish,然后单击 Close
the Package Configurations Organizer。保存项目。
|
|
7.
|
右键单击解决方案资源管理器中的项目属性,并选择
Properties。单击位于左侧的树控件的
Deployment Utility
节点,您将看到如图 31
所示的对话框。
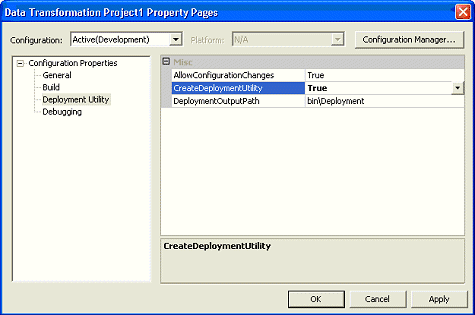
图 31
|
|
8.
|
在该对话框中,将 CreateDeploymentUtility
选项更改为 true。此外,还要确保
AllowConfigurationChanges
属性设置为 true,然后单击
OK。
|
|
9.
|
从菜单中选择 Build →
Build Solution。确保该软件包成功生成。
|
|
10.
|
在 Windows
资源管理器中,导航到生成软件包的目录,然后导航到它下面的
\bin\deployment
目录(在我的项目中,它位于
My Documents → Visual
Studio → Projects →
Data Transformation Project?1
→ Data Transformation Project1
中)。请注意与您的软件包以及可执行的安装程序在一起的配置文件。
|
|
11.
|
将整个目录的内容复制到您打算将软件包移动到的服务器。
|
|
12.
|
双击 DTSInstall.exe。DTS
软件包安装程序将启动。
|
|
13.
|
单击 Next,此时您将看到如图
33 所示的 DTS Package
Installer 对话框。
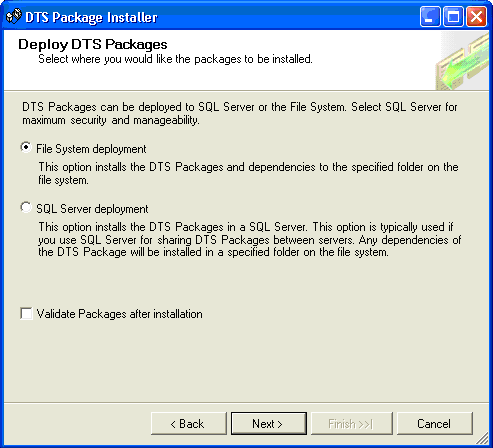
图 33
|
|
14.
|
选择部署的类型(将该软件包复制到文件系统或运行
SQL Server
的服务器中)。对于该示例,我们将选择
File System deployment。
|
|
15.
|
单击 Next,然后选择要部署到的路径,如图
34 所示。
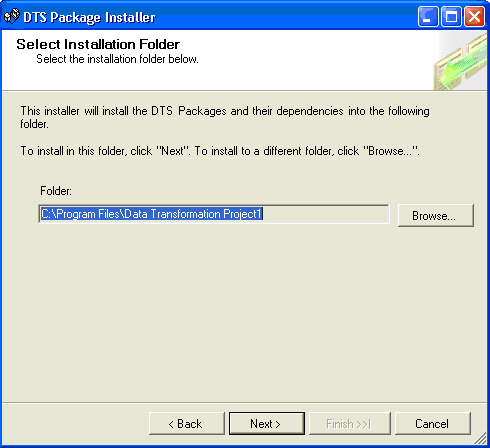
图 34
|
|
16.
|
单击 Next。在该对话框中,您可以更改配置选项,如指向
SQL Server
安装的连接字符串。例如,请注意,我已经将
SQL Server 数据源名称从
rwaymiyukon0 更改为 FRED。
|
|
17.
|
单击 Next,然后单击
Finish。
您的软件包将与您请求
DTS
软件包安装程序对该软件包所作的配置修改一起部署。
|
属性表达式
在执行开始时,配置是一次性加载并应用于软件包的。需要说明的是,配置在执行之前应用,而不是在软件包运行过程中动态应用的。有时,您希望在执行过程中动态更改属性。属性表达式就是为此目的而引入的,它使用户可以使用变量在运行时动态设置组件属性。
通过属性表达式,用户可以在运行时轻松地设置变量值,并使用这些变量将信息从一个组件传递到另一个组件。这样,即使对于非开发人员,也可以轻松地操作变量。每个任务都包含表达式功能,以使用户可以使用不同的表达式来设置组件的属性。属性表达式的
UI 与 Derived Column 任务 UI 类似。
在我们的 SSIS 软件包中,对于
ForEach File
枚举数,我们希望在运行时动态设置文件夹名称属性,但无法在
Expressions
属性列表中找到这些属性。后来,我们发现,可以在
Collection
的属性表达式编辑器中设置枚举配置属性。
图 37 显示了一个设置 Bulk Insert
任务的 DestinationTableName
属性的示例。
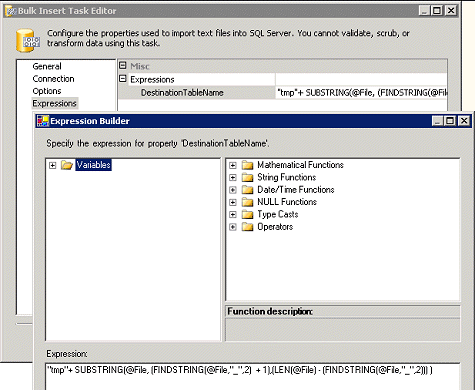
图 37
对于 SQL Server®2000 DTS 中的
Dynamic Properties
任务的狂热爱好者而言,属性表达式功能可能就是针对
SSIS 的答案。
SSIS
中的变量在定义它们的容器内部具有固定的作用范围。在
SQL Server®2000 DTS
中,所有变量都是全局变量,但在
SSIS
中并非如此。因此,当某个变量被指定给属性表达式中的属性时,不能使用子容器中定义的变量。只能使用在容器及以上级别定义的变量来设置属性表达式。即使是在错误处理中,也是如此。另一个需要考虑的重要准则是变量的数据类型。在指定变量之前,需要将变量强制转换为与属性相同的数据类型。
避免在失败后重新启动
在开始测试软件包时,我们遇到了一些令人沮丧的情况,即:数据已经成功加载到分级数据库中,但随后软件包却失败了。值得庆幸的是,可以使用检查点功能来解决这个问题。当检查点功能启用后,SSIS
开始将信息记录到检查点文件中,直至故障点为止。当软件包重新运行时,运行库引擎会使用检查点文件中的信息,从故障点重新启动该文件。
要从故障点重新启动软件包,您需要设置下列属性:
| • |
在 Custom Flow
任务窗口中,将 SaveCheckpoint
属性设置为 True。
|
| • |
在 CheckpointFileName
属性中指定检查点文件的位置。
|
| • |
将 CheckpointUsage
属性设置为以下两个值之一:
Always:
总是从检查点重新启动软件包。
IfExists:
如果检查点存在,则从检查点重新启动软件包。
|
| • |
配置可以从中重新启动软件包的任务和容器。
在该任务或容器上,将 FailPackageOnFailure
属性设置为 True。
|
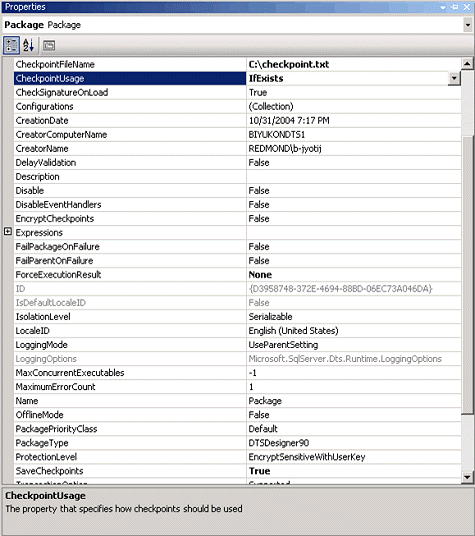
图 38
需要说明的是,ForEach Loop
容器和任何事务处理容器都被视为原子工作单位。检查点文件中不会记录
ForEach
循环中的任何子容器。因此,如果在
ForEach
任务上重新启动软件包,那么
ForEach
循环任务中的所有子容器也会重新启动,即使它们在失败之前可能已经成功完成。例如,请考虑这样一个软件包,它使用
Execute SQL
任务从表中提取文件名,使用
ForEach File
枚举数任务在文件上进行循环,并实现了一个
Bulk Insert
任务以便将所提取的文件数据插入表中。如果该软件包在
Execute SQL
任务中失败,并且被设置为要重新启动的任务,则该软件包会在该任务中启动。但是,如果在使用
ForEach File
枚举数在少数几个文件上循环并使用
Bulk Insert
任务加载数据以后,该任务失败,则在重新启动时,软件包会执行
ForEach 循环容器,并执行该 ForEach
循环任务中包含的 Bulk Insert
任务。
优先级约束编辑器
优先级约束编辑器通过在优先级约束上设置不同的条件和约束,来控制数据向下一个组件的流动。对于条件流(此时,您希望只有在其他某个任务执行之前满足特定条件时,特定任务才能执行)而言,这非常有用。如图
39
所示,我们希望在该流中,只有当上一个任务成功执行,并且变量
@CountPartitions(在运行过程中动态设置)的值等于零时,下一个任务才会执行。这是通过设置约束实现的,如图
39 所示。
如果在某个任务上设置了多个优先级约束,则用户可以指定在下一个任务可以执行之前,是需要满足所有约束,还是只需要满足任何一个条件。在下面的示例中,我们设置了该属性,以便只有当所有优先级约束都计算为
True 时,才能执行任务。
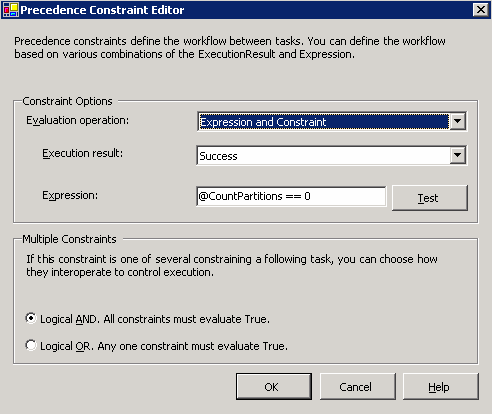
图 39
软件包执行
在运行时,DTS
运行库引擎按照软件包工作流指定的顺序来执行该软件包中的各个任务。您可以通过
Business Intelligence Development Studio 的
DTS 设计器、DTS 导入/导出向导,以及使用
DTS 软件包执行实用工具来运行 DTS
软件包。
在 Business Intelligence Development
Studio
中运行软件包的过程中,您还可以调试该软件包。BI
Development Studio 提供了一个与
Microsoft Visual Studio
环境类似的环境,以便调试软件包。在测试软件包的过程中,我能够通过在特定位置放置断点的方法以及在变量上设置监视点以监视变量的方法来解决很多错误。可以在下列事件上设置断点:
| • |
OnPreExecute
|
| • |
OnPostExecute
|
| • |
OnError
|
| • |
OnWarning
|
| • |
OnInformation
|
| • |
OnTaskFailed
|
| • |
OnProgress
|
| • |
OnQueryCancel
|
| • |
OnVariableValueChanged
|
| • |
OnCustomEvent
|
添加断点
右键单击要设置断点的任务。然后,选择
Edit breakpoints
以选择事件(或者按 F9,这可以在所选对象上快速添加预执行断点)。当该软件包运行时,它将在所选事件上中断运行。
您还应该启用日志记录功能,以便在软件包执行时记录事件。
DTExec
实用工具可用于从命令行执行软件包。DTExec
实用工具提供了对所有软件包配置和执行功能(如连接、属性、变量、日志记录和进度指示)的访问。DTExec
还提供了从以下三个源中加载软件包的能力:Microsoft
SQL Server 数据库、DTS
服务和文件系统。
Analysis Services 分区克隆
对于第 1 阶段,我们收到的 SQL
Server ®DTS 软件包包含了连接到
SQL Server
并且确定(基于要添加的数据的日期)是否需要在
Analysis Services
多维数据集中创建新的每月分区的代码。查询是使用
SQL-DMO 作为 ActiveX Scripting
任务的一部分向 SQL Server
发出的。然后,如果需要创建新的每月分区,则运行
Decision Support Objects (DSO)
代码,以便在 Analysis Services
中生成相应的分区。DSO
代码会生成现有分区的“复本”并赋予其名称,同时基于所加载数据的新年份和月份来设置片段值。
将该功能移动至 SSIS
需要重新考虑如何执行等效任务。一些需要回答的问题包括:
| • |
使其在 SQL-DMO 和 DSO
中保持不变,还是对其进行升级以使用
.NET Scripting 任务?
|
| • |
使用 .NET Scripting
还是使用 SSIS
中的本地任务?
|
| • |
使用现有编程模型,还是使用
SQL Server®2005
等效编程模型?(SQL Server
管理对象 (SMO)/Analysis Services
管理对象 (AMO))
|
我们非常快速地做出了几项决定。第一个决定是使用
.NET Scripting
任务。第二个决定是从 ActiveX
Scripting
任务升级代码。第一个部分涉及调用
SQL-DMO
以确定是否应该创建新分区的代码。由于管理对象模型不应当用于查询访问,因此我们使用
ADO.NET
重写了数据访问代码。这非常容易,因为我们能够轻松地从
Microsoft Developer Network (MSDN)
中剪切并粘贴代码示例,以使修改后的代码能够迅速正常运行。有关代码如下:
Dim sPartition As String
Dim conn As SqlConnection = New SqlConnection("Data Source=servername;" &
"Integrated Security=SSPI;Initial Catalog=DW1")
Dim partCMD As SqlCommand = conn.CreateCommand()
partCMD.CommandText = "select partitionname from partitions where status = 'N'"
conn.Open()
Dim myReader As SqlDataReader = partCMD.ExecuteReader()
myReader.Read()
'if this is not a new month, exit out
If myReader.HasRows = False Then
'update DTSglobal variable
Dts.VariableDispenser.LockOneForWrite("ItemSalesXML", vars)
vars.Item("ItemSalesXML").Value = " "
Exit Sub
'it is a new month, set the partition variable value
Else
sPartition = myReader("partitionname").ToString()
End If
我们的下一个决定是将 DSO
代码升级到 AMO,还是使用另一个选择。我们选择了另一个方式。我们使用
SQL Server Management Studio
中的图形界面,在 SQL Server
Management Studio 的 Analysis Services
数据库中,用脚本生成了一个分区(采用
XML for Analysis
脚本语言),然后在我们的 .NET
Scripting
任务中动态修改分区名称。然后,.NET
Scripting 任务将新形成的 XML for
Analysis 字符串指定给一个 SSIS
全局变量。这样,我们就具有了一个后续任务(新的
Analysis Services Execute DDL
任务),它将按照 SSIS
全局变量中的定义来运行 XML for
Analysis 代码。
这里,另一个选择是用 AMO
编程模型编写更新的代码。但是,该方法需要花费更多的学习时间。尽管
XML for Analysis
方法在技术上不是那么可靠,但可以更快地实现。它可能不是最佳实施策略,但一定能够成功
―
在关键时刻,开发人员通常会采取阻力最小的途径。
使用自定义源和转换组件来扩展 DTS 数据流任务
就像 Core ETL Processing 中描述的那样,要加载的销售数据来自客户的销售点
(POS) 收款机生成的 TLOG 数据。
将软件包迁移到 SSIS
要求重新考虑它们的设计,以便将
TLOG
数据加载到数据库中。我们不能确定是继续使用
Perl
脚本来分析数据,还是将它们的分析器转换为可以在管道内分析数据的自定义数据流组件。后一种方法的性能更高,并且可以提供简化而高效的
ETL。巨大的吸引力在于,这样做可以避免将数据从
TLOG
文件复制到平面文件再复制到数据库中的代价高昂的步骤。而且,该方法更加易于管理。因此,我们决定实现一个自定义任务来加载
TLOG 数据。
TLOG
文件包含经过压缩的打包十进制数据,其中,各个行可能由新的线条或逗号分隔。因此,我们无法轻松地使用可用的数据流源来读取数据文件。在分析数据之前,需要先解压缩打包的十进制数据。出于简单性和可管理性的考虑,我们决定将解包二进制文件的逻辑与基于模板文件分析数据的逻辑分开。因此,我们最后实现了两个自定义管道组件:
| • |
一个用于读取数据的自定义源组件。
|
| • |
一个用于分析数据的自定义转换组件。
|
这两个组件都派生自 PipelineComponent
基类,并且重写了相应的方法。源组件使用
File 连接来连接到外部 TLOG
文件。它接受模板文件作为输入。基于该模板,源组件将打包的十进制字节解包为相应的十六进制字符和
ASCII
字符。示例模板格式如下所示:
"02" => ["H2","H10","H6","H2"],
"99-Data" => ["H2","A4","A99"]
源组件基于模板来解包数据,并输出一个由
DT_TEXT
类型的单个列组成的行。
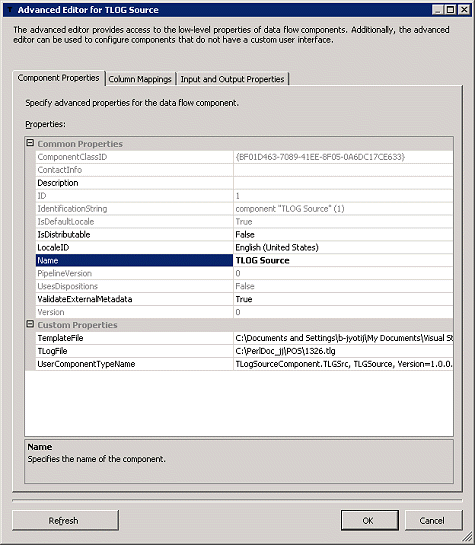
图 41
图 41
显示了源组件的组件属性。
自定义组件从上游数据流中读取解包的数据,基于
.ini
文件分析这些数据,然后向下游生成多个输出。自定义转换接受两个输入:
Config File: .ini 文件的路径
Store Name: 要处理的 TLOG
文件的存储编号
该 .ini
文件的示例部分采用以下格式:
[01]
Filename="Item"
DelimiterCharacter=","
OutputFields="%store,%line,1-0,%term,%tran,%datetime,1-1,1-2,1-3,1-4
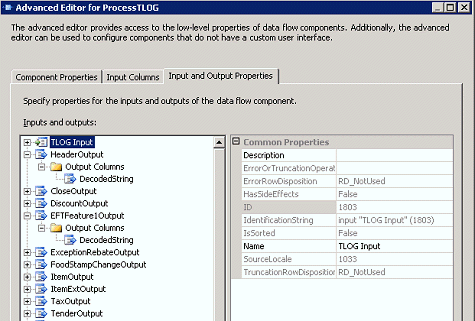
图 42
自定义转换基于 .ini
文件中定义的规则集生成多个
DT_STR 类型的输出,如图 42 所示。
在单独的后续白皮书中,将提供有关自定义数据流组件设计的更多详细信息以及示例代码。
高级编辑器
当您编辑软件包时,您通常会双击某个任务或数据流项来编辑该项的属性。但是,对于某些对象,有两个编辑器
―
默认编辑器和高级编辑器。如果存在高级编辑器,它通常会提供一组显著增强的属性集,以便您可以更改给定的对象。您应该探索在
SSIS
中使用的每种对象的高级编辑器,以确定何时使用高级编辑器而不是默认编辑器。要访问高级编辑器,请右键单击相应的任务、源等,然后选择
Show Advanced Editor 选项(如图
44 所示)。
使用高级编辑器时一定要小心,就像在
SQL Server®2000 DTS 的 Disconnected
Edit
模式下工作时应该小心一样。您可以直接访问多个属性
―
如果它们设置错误,则可能给软件包带来严重的消极后果。但是,有时这是纠正软件包中的问题的最佳方式。
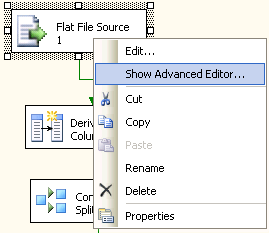
图 44
性能提示和诀窍
| • |
如果软件包在运行目标
SQL Server
关系数据库实例的服务器上运行,请使用
SQL Server Destination
组件而不是针对 SQL Server 的
OLE DB
连接。该组件在进程内运行,因而避免了连接的系统开销。它的速度最高可以比
OLE DB 连接快 25%。
|
| • |
从数据流中移除不需要的列以提高性能。数据流引擎会根据未使用的输出列警告用户。移除这些列可以使引擎免于分配空间和处理未使用的数据。
|
| • |
任务上的 EngineThreads
属性设置了该任务使用的线程数量。默认值是
5,但是在多处理器服务器上,可以将该值设为更高,以提高性能。可以在测试的过程中确定达到最佳性能时的线程数量。
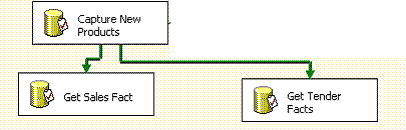
图 45
|
| • |
在多处理器服务器上,以并行方式执行独立任务。例如,对于数据仓库项目,一旦加载了数据仓库中的维表,如果事实表访问不同的维表并且可以同时加载,则您可能会考虑以并行方式加载数据,如图
45 所示。
|
| • |
尽管只有在测试之后才能确定为获得最佳性能而并行执行的任务的正确数量,但您在开始时可以将并行任务的数量设置为与处理器的数量相等。
|
遇到的问题
就像一个仍在开发中的产品通常会遇到的情形一样,我们发现了一些技术问题。如果您使用的是
SQL Server®2005 大众预览版 (IDW9),则也可能会遇到其中一些问题。我们期望这些问题将在
SQL Server®2005 的 Beta 3
中得到解决。
SQL Server
目标无法针对命名实例正常工作
在创建数据流任务时,加载 SQL
Server 表的最有效方式就是使用 SQL
Server 目标。该目标是一个指向 SQL
Server
实例的高度优化的内存中连接,只要有可能,就应该将其用作指向
SQL Server
实例的首选连接(它最高可以比图
46 中所示的方法快 25%;后者使用指向
SQL Server 的 OLE DB
快速加载目标)。
该目标的不利方面是它要求 SQL
Server 实例与 SSIS
软件包位于相同的服务器上。在开发时也是这样,因此您必须在安装有
SQL Server
的计算机上进行开发,以便将该目标类型添加到您的数据流中。如果您必须在另一个服务器上开发,则应该使用
OLE DB 目标,指向 SQL Server
的示例,并确保设置 Data access
mode: 列表中的 fast load
选项,如图 46 所示。
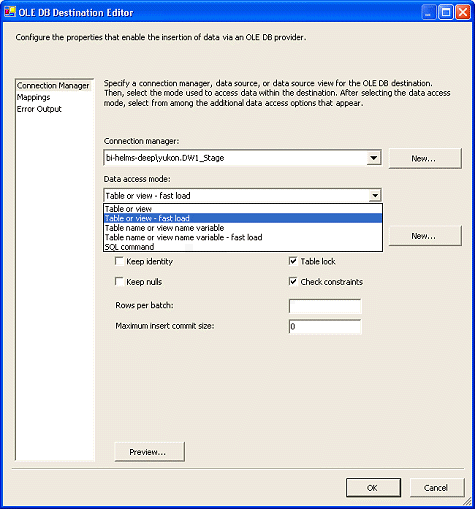
图 46
令人遗憾的是,在 IDW9
大众预览版(用于开发该项目的版本)中,SQL
Server
连接无法针对命名实例正常工作(程序错误
#323570)。该问题将由 SQL Server®2005
的下一个公共更新来解决。
对文件连接对象进行的更改并不总是能够被平面文件源观察到
当您使用平面文件连接管理器创建指向文件的连接时,您通常做的一件事情是定义列和它们的布局。当您在数据流中使用该连接作为平面文件源时,该信息就会被观察到。但是,当您对列布局进行更改时,它未必会被该平面文件源观察到。要实现此类更改,您必须在数据流中编辑该平面文件源,并手动更新此类列定义。特别是在试图更新列的长度属性时,我们注意到了这一问题。另外,我们必须使用该平面文件源上的
Advanced Edit
属性来进行这一更改。双击该平面文件源会调出默认编辑器,如图
47 所示。
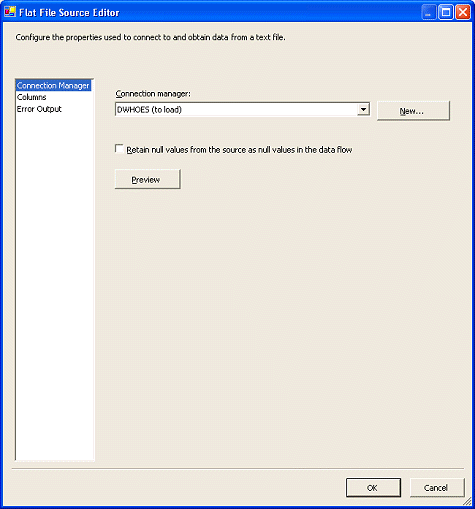
图 47
如果您右键单击该平面文件源,则会看到
Show Advanced Editor…
的选项。选择该选项可以调出该平面文件源的高级编辑器。这使您可以配置单个列属性,以进行无法从默认编辑器中看到的必要更改。例如,您能够管理列映射以及各个列的各种详细属性,如图
48 所示。
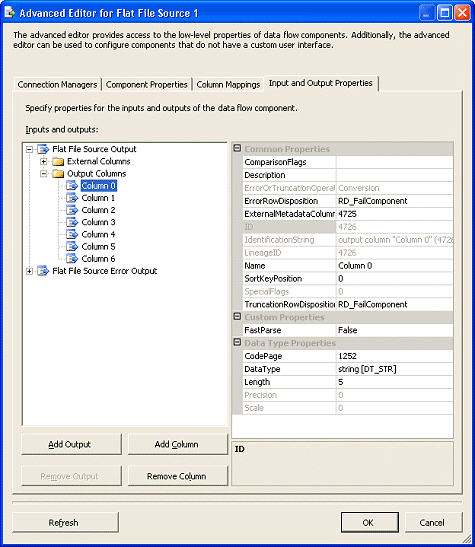
图 48
在调试 SSIS
软件包的过程中最小化 BI
Development Studio 可能会导致 GUI
消失
在调试过程中,BI Development
Studio
中的图形界面多次从我们眼前消失。虽然没有再现这一问题的一致方式,但其影响十分富有戏剧性,因此值得在此指出来。有时,在调试软件包的过程中,当试图最小化调试器时,开发环境却完全消失了。您无法在通常位于屏幕底部的
Windows
任务栏中看到它,并且没有显示任何可见的
GUI ―
它似乎只是消失了。但是,当我们检查任务管理器时,BIENV.EXE(BI
Developer Studio
的可执行文件)仍然作为正在系统中运行的任务列出。解决方法就是使用
ALT-TAB 切换到设计器(它仍然位于
ALT-TAB 列表中,即使不再位于
Windows
任务栏中)。这会将焦点返回到开发环境内部,并且还会将开发环境还原到
Windows 任务栏中。
产品增强请求
在开发 SSIS 第 1
阶段的过程中,产生了几个新的产品增强请求。本部分列举了这些请求。
在加载平面文件的过程中出现“不完整行”问题
在试图执行文件加载的过程中,我们遇到了文件中含有“不完整行”的错误。在记事本中浏览数据时,看不到该“不完整行”。在对此进行疑难解答时,我们在
Visual Studio
中发现了一个方便的功能(我们也将指出该功能)。在打开文件(单击
File,然后依次单击 Open、File)时,可以单击出现在
Open
按钮旁边的向下箭头,如图 49
所示。
图 49
选择 Open With
选项,这样您就可以选择一个二进制编辑器,如图
50 所示。
图 50
请注意出现在该文件结尾处的十六进制“1A”(图
51)。这是 Windows
中的文件尾标记,并且,起码在
Windows Server®2003
中,普通复制命令可以将该值插到文件结尾。在撰写本文时,SSIS
将该行视为数据文件中的新行,但将其视为不完整的行。遗憾的是,在此情况下,SSIS
会停止读取文件,并且将任务状态设置为失败。

图 51
我们提交了一个更改请求
(#323638),以便至少具有一个允许忽略该文件尾标记的选项。该项目的替代方案是更改要执行的复制命令以包含
/B
选项。将该选项添加到复制命令时,文件类型被设置为二进制文件,并且文件没有修改。
Derived Column
编辑器可能在修改列定义时更改数据类型
在创建 Derived Column
转换时,需要更改列定义。当我们进行简单修改时,先前设计为
String (DT_STR)
的数据类型会更改为 Unicode
String (DT_WSTR)。我们更改的对象是现有列上用于定义新列的子字符串语句。该更改很简单,因为我们只是将其从
substring(optional, 1, 8) 更改为 substring(optional,
1, 9)。谁都不会料到,这样一处小小的更改竟然会导致我们的目标派生列的数据类型被重置。在撰写本文时,这被视为“根据设计更改”,因为从技术上说,它是对目标列进行的一项导致目标数据类型重置为默认定义的修改。除非得到解决,否则这无疑是一件需要小心的事情。
平面文件连接不能用作 BULK
INSERT 任务的源
当打开文件以执行记录筛选时,我们使用了“平面文件连接管理器”连接。该连接使我们能够定义列布局和文件位置。在筛选完文本文件以后,我们保存了该文件,并且随后试图重新使用同一连接来供给
BULK INSERT
任务,以加载我们的文件。我们发现,BULK
INSERT 任务只接受来自“文件连接管理器”的连接(请注意在命名方面的微妙却关键的差异)。为了执行
BULK INSERT 操作,我们不得不使用“文件连接管理器”定义了一个指向该文件的冗余连接。我们提交了一个设计更改请求,要求使
BULK INSERT 任务还能够直接从“平面文件连接管理器”对象接受连接。该产品应该使平面文件连接管理器对象在
Beta 3 中得到更广泛的使用。
无法在 File System
任务中指定通配符
Project REAL
所需的一些操作要求在目录结构中执行循环时复制和移动文件。一个示例是将多个文件复制到单个文本文件中,或者在文件加载后将其从“待处理”目录移至“已处理”目录中。在
SQL Server DTS
中,这些任务通常是使用对批处理文件进行调用的
Execute Process
任务完成的。我们希望能够使用
File System
任务完成该工作,而不是继续依赖于批处理文件。
遗憾的是,File System
任务会对某个目录或目录集中的所有文件执行操作。使事情变得更为复杂的是,我们的大多数目录都包含多个类型的文件,而我们只希望针对这些文件的某个子集(例如,只限于
*.txt 文件)执行操作。File System
任务无法按文件扩展名进行筛选,因此我们最后使用了
Execute Process
任务。我们提交了一个设计更改请求,要求添加使用扩展名进行筛选的功能。
Analysis Services Processing
任务进度信息不足
Analysis Services Processing
任务在处理复杂的多维数据集时,生成了很多进度消息,其中包括在
Progress
选项卡中显示完成百分比消息。遗憾的是,在该消息的任何位置上,人们都无法找到所报告的进度是针对哪个特定对象的信息。如果您尝试估计处理进度,则会令人感到沮丧。我们已经提交了一个设计更改请求,要求向该日志记录功能中添加更多的详细信息。在撰写本文时,尚未对我们的请求做出任何决定。
小结
从我们的讨论中可以明显看出,在
SQL Server®2000 DTS 和 SQL Server®2005
的新增 Integration Services
之间存在很多差异。尽管 Microsoft
付出了大量努力,以使客户能够继续运行他们现有的
SQL Server®2000 DTS
软件包,但从这一简短的教程中您应该知道,并不总是能够轻易获得干净、轻松的迁移途径。考虑到
SQL Server®2005 Integration Services
中引入的惊人的体系结构更改和增强,成功迁移现有
DTS 2000
软件包的关键在于分辨哪些任务可以迁移,哪些任务需要重写。在评估完您打算迁移的每个软件包以后,就应该计划足够的时间来重写那些无法迁移的任务,或者计划在
DTS 2000
运行库引擎下运行它们,直到您可以重写它们为止。
另外,SQL Server®2005 中的
Integration Services
还引入了很多新概念。因此,它代表着一种范型变化,现在的
DTS 2000
程序员需要接受这一变化,以便更有效率地工作。您绝对值得花费一些时间来演练所提供的示例,以便熟悉该产品的核心新功能。熟悉
Visual Studio (VS) 语言(如 Visual Basic、Visual
C#
和其他语言)的开发人员可能会发现,新的
SQL Server BI Development Studio
非常友好和亲切。那些不熟悉 VS
的开发人员可以从一些 Visual Studio
培训中获益,或者学习一些 VS
联机教程。 |