北京火龙果软件工程技术中心 |
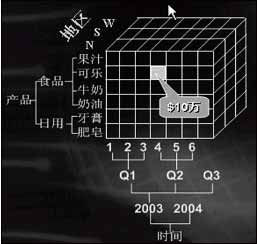
| 经过几年的积累,大部分中大型的企事业单位已经建立了比较完善的CRM、ERP、OA等基础信息化系统。这些系统的统一特点都是:通过业务人员或者用户的操作,最终对数据库进行增加、修改、删除等操作。上述系统可统一称为OLTP(Online TranSAction ProcESs,在线事务处理),指的就是系统运行了一段时间以后,必然帮助企事业单位收集大量的历史数据。但是,在数据库中分散、独立存在的大量数据对于业务人员来说,只是一些无法看懂的天书。业务人员所需要的是信息,是他们能够看懂、理解并从中受益的抽象信息。此时,如何把数据转化为信息,使得业务人员(包括管理者)能够充分掌握、利用这些信息,并且辅助决策,就是商业智能主要解决的问题。 如何把数据库中存在的数据转变为业务人员需要的信息?大部分的答案是报表系统。简单说,报表系统已经可以称作是BI了,它是BI的低端实现。 现在国外的企业,大部分已经进入了中端BI,叫做数据分析。有一些企业已经开始进入高端BI,叫做数据挖掘。而我国的企业,目前大部分还停留在报表阶段。 数据报表不可取代 传统的报表系统技术上已经相当成熟,大家熟悉的Excel、水晶报表、Reporting Service等都已经被广泛使用。但是,随着数据的增多,需求的提高,传统报表系统面临的挑战也越来越多。 1. 数据太多,信息太少 密密麻麻的表格堆砌了大量数据,到底有多少业务人员仔细看每一个数据?到底这些数据代表了什么信息、什么趋势?级别越高的领导,越需要简明的信息。如果我是董事长,我可能只需要一句话:目前我们的情况是好、中还是差? 2. 难以交互分析、了解各种组合 定制好的报表过于死板。例如,我们可以在一张表中列出不同地区、不同产品的销量,另一张表中列出不同地区、不同年龄段顾客的销量。但是,这两张表无法回答诸如“华北地区中青年顾客购买数码相机类型产品的情况”等问题。业务问题经常需要多个角度的交互分析。 3. 难以挖掘出潜在的规则 报表系统列出的往往是表面上的数据信息,但是海量数据深处潜在含有哪些规则呢?什么客户对我们价值最大,产品之间相互关联的程度如何?越是深层的规则,对于决策支持的价值越大,但是,也越难挖掘出来。 4. 难以追溯历史,数据形成孤岛 业务系统很多,数据存在于不同地方。太旧的数据(例如一年前的数据)往往被业务系统备份出去,导致宏观分析、长期历史分析难度很大。 因此,随着时代的发展,传统报表系统已经不能满足日益增长的业务需求了,企业期待着新的技术。数据分析和数据挖掘的时代正在来临。值得注意的是,数据分析和数据挖掘系统的目的是带给我们更多的决策支持价值,并不是取代数据报表。报表系统依然有其不可取代的优势,并且将会长期与数据分析、挖掘系统一起并存下去。 八维以上的数据分析 如果说OLTP侧重于对数据库进行增加、修改、删除等日常事务操作,OLAP(Online Analytics Process,在线分析系统)则侧重于针对宏观问题,全面分析数据,获得有价值的信息。 为了达到OLAP的目的,传统的关系型数据库已经不够了,需要一种新的技术叫做多维数据库。 多维数据库的概念并不复杂。举一个例子,我们想描述2003年4月份可乐在北部地区销售额10万元时,牵扯到几个角度:时间、产品、地区。这些叫做维度。至于销售额,叫做度量值。当然,还有成本、利润等。 如图2,每个维度分别代表了时间、产品和地区,立方体上的单元代表了度量值。进一步,维度可以分为不同的层次。
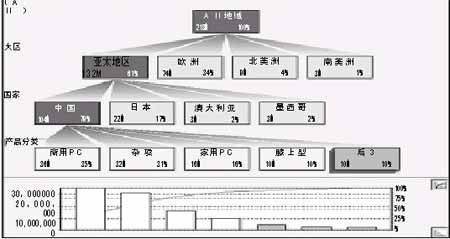
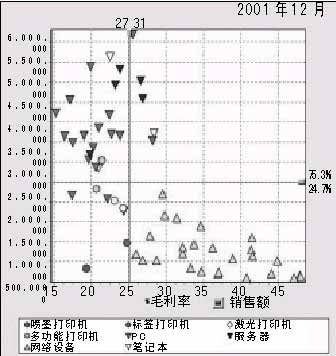
除了时间、产品和地区,我们还可以有很多维度,例如客户的性别、职业、销售部门、促销方式等等。实际上,使用中的多维数据库可能是一个8维或者15维的立方体。 虽然结构上15维的立方体很复杂,但是概念上非常简单。 数据分析系统的总体架构分为四个部分:源系统、数据仓库、多维数据库、客户端。 ・源系统:包括现有的所有OLTP系统,搭建BI系统并不需要更改现有系统。 ・数据仓库:数据大集中,通过数据抽取,把数据从源系统源源不断地抽取出来,可能每天一次,或者每3个小时一次,当然是自动的。数据仓库依然建立在关系型数据库上,往往符合叫做“星型结构”的模型。 ・多维数据库:数据仓库的数据经过多维建模,形成了立方体结构。每一个立方体描述了一个业务主题,例如销售、库存或者财务。 ・客户端:好的客户端软件可以把多维立方体中的信息丰富多彩地展现给用户。 数据分析案例: 在实际的案例中,我们利用ORACLE 9i搭建了数据仓库,MicrOSoft Analysis Service 2000搭建了多维数据库,ProClarity 6.0 作为客户端分析软件。 分解树好像一个组织图。分解树在回答以下问题时很有效: ・在指定的产品组内,哪种产品有最高的销售额? ・在特定的产品种类内,各种产品间的销售额分布如何? ・哪个销售人员完成了最高百分比的销售额? 在图1中,可以对PC机在各个地域的销售额和所占百分比一目了然。任意一层分解树都可以根据不同维度随意展开。在该分解树中,在大区这一层是按国家展开,在国家这一层是按产品分类展开。 投影图(图3)使用散点图的格式,显示两个或三个度量值之间的关系。数据点的集中预示两个变量之间存在强的相关关系,而稀疏分布的数据点可能显示不明显的关系。 投影图很适合分析大量的数据。在显示因果关系方面有明显效果,比如例外的数据点就可以考虑进一步研究,因为它们落在“正常”的点群范围之外。 数据挖掘看穿你的需求 广义上说,任何从数据库中挖掘信息的过程都叫做数据挖掘。从这点看来,数据挖掘就是BI。但从技术术语上说,数据挖掘(Data Mining)特指的是:源数据经过清洗和转换等成为适合于挖掘的数据集。数据挖掘在这种具有固定形式的数据集上完成知识的提炼,最后以合适的知识模式用于进一步分析决策工作。从这种狭义的观点上,我们可以定义:数据挖掘是从特定形式的数据集中提炼知识的过程。数据挖掘往往针对特定的数据、特定的问题,选择一种或者多种挖掘算法,找到数据下面隐藏的规律,这些规律往往被用来预测、支持决策。 关联销售案例: 美国的超市有这样的系统:当你采购了一车商品结账时,售货员小姐扫描完了你的产品后,计算机上会显示出一些信息,然后售货员会友好地问你:我们有一种一次性纸杯正在促销,位于F6货架上,您要购买吗? 这句话决不是一般的促销。因为计算机系统早就算好了,如果你的购物车中有餐巾纸、大瓶可乐和沙拉,则86%的可能性你要买一次性纸杯。结果是,你说,啊,谢谢你,我刚才一直没找到纸杯。 这不是什么神奇的科学算命,而是利用数据挖掘中的关联规则算法实现的系统。 每天,新的销售数据会进入挖掘模型,与过去N天的历史数据一起,被挖掘模型处理,得到当前最有价值的关联规则。同样的算法,分析网上书店的销售业绩,计算机可以发现产品之间的关联以及关联的强弱。 数据报表、数据分析、数据挖掘是BI的三个层面。我们相信未来几年的趋势是:越来越多的企业在数据报表的基础上,会进入数据分析与数据挖掘的领域。商业智能所带来的决策支持功能,会给我们带来越来越明显的效益。 |
版权所有:UML软件工程组织