◆第三章 工程数据库管理系统
◇ 课前索引
内容简介:
工程数据库管理系统是在传统的数据库管理系统基础上,针对计算机辅助设计/制造/系统集成等工程应用的需求,通过扩展数据库管理系统的数据模型使之更具有工程语义、增加一些新的功能或模块而发展起来的。所以本章首先着重讨论满足工程应用的几种数据模型,然后介绍工程数据库管理系统的结构及其实现方法、典型的工程数据库管理系统。最后,介绍商品化的数据库管理系统支持最好的数据库语言SQL,为第四章工程数据库设计与应用奠定数据库技术基础。
学习目标:
本章主要介绍工程数据模型及工程数据库管理系统的体系结构和实现方法,使学生掌握工程数据库管理系统的基本概念。但由于到目前为止,还没有商品化的工程数据库管理系统,我们就以目前商品化的DBMS支持的SQL语言介绍数据库语言。另外希望学生课后选择结合某个DBMS学习第二章和本章的内容,其目的是希望学生掌握某种数据库,为后面的工程数据库设计与应用的学习打下良好的基础。另外,在后续章节中,有关工程数据库的基本概念不再单独讲解,主要通过工程应用的例子讲解一些工程数据库技术。
学生要求:
1、 学生必须学完传统的数据模型(层次、网状、关系、对象)
2、 对面向对象的技术、SQL语言、关系数据库有所了解。
3、 有商品化的DBMS实验环境。
学习要求:
通过本章的学习,学生要掌握工程数据的几种数据模型。通过这些数据模型的学习,理解和掌握传统数据模型在表达工程应用中的不足,另外对于课堂上介绍的这些数据模型的定义,它们的数据结构、数据操纵以及数据的完整性约束等要能理解和掌握,并能比较它们的优缺点。
在工程数据库研究的初期,人们希望能开发出满足工程应用需求的工程数据库管理系统EDBMS(Engineering Database
Management System),所以本章也介绍了工程数据库管理系统的体系结构、常用的工程数据库管理系统实现方法和已实现的典型工程数据库管理系统。通过本小节的学习希望学生理解工程数据库系统的体系结构及其实现方式。
由于目前的工程应用都是建立在商业化的数据库管理系统上。所以希望学生通过课堂学习和课后大作业掌握一个数据库管理系统和数据库语言SQL。
学习安排
总共九个学时。
◇ 第一节 引言
我们知道,工程数据库管理是在20世纪70年代末期,数据库技术在商务数据管理上取得明显的进展,逐步走向成熟的条件下研究与开发起来的。人们从研究与开发的实践中,深刻认识到一般的商务数据库管理系统不适合于工程数据管理,必须重新开发适合于工程数据管理所需要的那种工程数据库管理系统。工程数据管理有其特殊的要求,因此开发的工程数据库管理系统EDBMS(Engineering
Database Management System)应具有以下的功能和特点:
1、支持多个工程应用程序
2、支持动态模式的修改和扩充
3、支持反复的试探性设计
4、支持在数据库中嵌入语义信息
5、支持存储和管理各种设计结果版本
6、支持复杂的抽象层次表示
7、支持多CPU/分布式处理环境
8、支持建立和临时存取数据库
9、支持交互式和多用户工作以及并行设计
10、支持多种表示处理
11、支持数据库与应用程序的接口
12、支持工程事务处理
1、支持多个工程应用程序
一个工程数据库必须适应多个工程应用程序,以支持不断发展的新的应用环境。最初的概念设计、详细设计、工艺设计、制造设计和生产计划都需要直接进入到工程数据库中去,因为设计后期所进行的操作,像生产控制、质量控制和服务等,都需要利用在产品设计和制造阶段的一些公用信息。
2、支持动态模式的修改和扩充
数据库的结构确定了工程应用中实体在数据库中建模的关系。一个工程必须经过计划分析、设计、施工、调试、生产等阶段,相应的工程数据也是通过各阶段逐步明确,逐步详细,最后得到满意的结果。为此,必须记载整个工程过程的全部图形和及相关数据的数据结构,作为文档保存,以便在工程中修改,以及在工程建成后的扩充和改建。
例如,产品的计算机辅助设计(CAD)是一个变化频繁的动态过程,不仅数据变化频繁,而且数据的结构也会有所改变,这就要求工程数据库具有动态修改和易于改变数据结构的能力。修改结构的功能应当"在空中"操作,而不需要结构的再编辑或者数据库的再装配。因此为CAD/CAM应用设计的数据模型必须支持各种工程数据类型和工程应用中复杂的物理模型的修改和管理。
3、支持反复的试探性设计
在工程中解决一个问题往往是一个多次重复、反复修改的过程,而不同于一般事务处理。面向CAD/CAM数据库必须适合设计过程中的试凑、重复和发展的特点。即在一般情况下,数据库必须保持数据的一致性,在特殊情况下,工程数据库应允许暂时的、不一致数据存在,并能加以管理。这就要求对工程数据库实行分级和综合管理的要求。
4、支持在数据库中嵌入语义信息
语义信息是用来描述在数据库中存储数据,它包括实体和关系的建模方法,有关实体和关系的信息在数据库中是怎样表示的,怎样获得和使用这些信息等。一个集成语义的工程数据词典/字典系统是用来记录指定含义的,并是使用数据库中数据记录的工具。这个功能一般不仅仅是资料程序员利用,并且也是文件的主要来源。更多的语义信息被机器占用,成为数据库中一个集成部分,可用于人和机器直接相互作用及数据库的修改。
5、支持存储和管理各种设计结果版本
在人工设计中,存在几种设计版本的情况是经常发生的,每一个设计版本尽管不同,但均满足设计所要求的全部功能,它们可供选择。设计问题很少只有唯一的方案解,当在设计中对重要条件强调的重点不同时,一般有几种可供选择的方案。理想情况下,一个支持工程设计的数据库管理系统应当具有一个设计任务多个版本管理的能力。
6、支持复杂的抽象层次表示
设计单元之间的许多复杂关系可以在抽象层次中模型化。设计过程常被看成自顶向下的工作方式,即将复杂的问题不断分解到子问题层中,这些子问题概念简单,可以组合起来解决原问题。例如,工程所涉及的工程图很少是仅由一张图来表示,通常采用分层表示法,即上层工程图中的一个符号表示下层某一张子工程图(即上层的一个抽象部件符号代表下层若干个部件的组合),这些子工程图中的一个符号又能表示更下一层的某一张子工程图等。所以面向工程的数据库管理系统应支持自顶向下逐层表示的数据模型,直至最下层为止的基本原子数据对象。
7、支持多CPU/分布式处理环境
通常支持CAD/CAM一体化系统的硬件是由异种机组成的计算机网络系统。因此,要求工程数据库管理系统应是一个分布式的数据库管理系统,并为所有基本单元系统存取全局数据提供统一的接口标准。
8、支持建立和临时存取数据库
在设计和制造过程中,存在许多临时性数据,这些不需长期保存的数据可存入临时数据库中,使用完毕即可删除。
9、支持交互式和多用户工作以及并行设计
工程设计时,为了及时传达设计人员的思想和意图,需要进行交互式工作。而且现代设计工作决不是一人能胜任的,为提高工程设计质量,加快进度,必须开展并行作业,使若干名设计人员既能同时工作,又可达到资源共享。为此,要求工程数据库能随时提供数据并存储数据,提供多用户使用和进行并行设计。
10、支持多种表示处理
在设计和制造过程中,应用程序往往要利用同一物体的不同表示形式来实现不同的目的和要求。例如,在几何造型中,可以使用CSC树、边界表示、八叉树法等多种表示形式来表示同一形体。因此,工程数据库要有存储和管理同一形体的多种表示形式的功能,而且要保持这些表示形式之间的一致性。
11、支持数据库与应用程序的接口
为了支持工程数据库的应用过程,数据库必须与多种程序语言交互。数据库与应用程序的接口有两类:子语句方式(嵌入式编程)和CALL方式(调用式编程)。子语句方式将数据库的DML语句看成特殊的应用程序语句。CALL方式将数据库的DML语句设计成宿主语言的一个过程或函数,应用程序通过CALL语句调用它们。
目前,基于开放的互联数据库接口技术(ODBC)已成为数据库应用程序接口的标准,今后开发的工程数据库管理系统只要支持这个标准就能满足大多数工程应用的需要。
12、支持工程事务处理
在工程应用中,解决一个工程问题需要花费很长时间,涉及的数据量也很多,这种解决工程问题的过程称为工程事务。由于这类问题工作时间很长,中间出现意外错误或认为中断的可能性较高。因此,商业数据库系统中处理事务的方法在此已不适用。工程数据库系统应具备处理工程事务的能力。
数据模型是数据库管理系统的核心,传统的数据模型不能满足上述功能,我们必须研究新的数据模型来满足上述的各种要求。在面向对象技术出现以前,人们着重在传统的数据结构模型上面增加模型的语义表示或为了满足某种工程应用提出一些特殊的数据模型。因此人们在20世纪80年年代提出了很多工程数据模型。
◇ 第二节 工程数据库的数据模型
数据模型是数据库技术的重要组成内容。早期的数据模型主要是围绕数据管理提供概念结构,为数据处理提供大量格式化数据共享存取,提高数据独立性。在工程和理论不断发展的过程中,今天人们更深入更全面认识了数据模型,开始运用它来解决工程数据库中性质完全不同的数据模型问题。
上一章我们就数据模型定义的三个方面分别分析了层次数据模型、网状数据模型、关系数据模型和对象模型的数据结构、数据操纵、一致性和完整性约束以及它们的优缺点等。除了以上面向数据库管理系的结构数据模型外,人们在工程数据、演绎数据库等新型数据库的数据模型研究中还提出了其他几十种数据模型,以便能够反映或者说适合工程数据库的这些特点。
实践证明,这些模型用来表示工程数据的能力和效果,确实比传统的数据模型方便,问题的关键是要有一个好的工程数据库管理系统(EDBMS)来支持这些工程数据模型。
从分类学观点剖析来看,我们可以将所有的数据模型分为以下四种:
1) 原始(文件)数据模型;
2) 传统数据模型(层次、网状和关系);
3) 语义数据模型(如SAM*,OSAM*);
4) 特殊目的(如面向对象、面向应用)的数据模型。
通过第二章的介绍我们知道,传统的层次、网状和关系数据模型没有足够的能力来表达工程数据的全部语义结构。我们需要研究新的满足工程数据库的数据模型。工程数据模型的研究要借助于前三种数据模型研究的丰富经验,并且要用迄今最好的概念模式技术和数据库技术来实现。
纵观各种用于工程数据库的数据模型,我们可按下列方法进行分类:
1) 扩充传统的数据库模型,包括扩充网状数据模型、扩充关系数据模型(如XSQL、NF2扩充关系数据模型)、对象-关系模型。
2) 专用的工程数据模型如函数数据模型、版本模型等。
3) 语义数据模型:包括一般的面向对象模型和专用的语义数据模型(如面向统计的SAM*模型、面向CAD/CAM集成的对象模型)。
3.2.1扩充传统的数据模型
一、扩充的网状数据模型
在工程设计活动中,数据模型是复杂的,它不仅要处理几何模型的塑造面,而且还要充分表示几何实体的细节,即要处理CAD设计中的GPM(几何产品模型)模型,又要表示这些几何模型与相关文档的依赖关系等。这种面向工程的技术实体信息要求,必然是网状数据结构。但是在GPM模型中,连接实体类型之间不仅有1对多的关系,而且有大量多对多的关系,还有同构和递归的关系。这样,CODASYL的DBTG报告提出的网状数据模型不太适合描述像GPM这样工程设计的几何模型的复杂数据结构。为了反映几何实体的复杂的数据结构关系,构造超出CODASYL建议很多的一种扩充网状数据模型,使它允许实体和系(set)可以用任何组合方式组合,包括同构组合、递归关系。
扩充网状数据模型的构造可以为:
(1)系可由一单环或双环来联结,并且每个从属记录可设指向主记录指针,以加快查找速度;
(2)一个实体可以是多个系的属记录;
(3)任何实体可以为任意个系的主记录;
(4)任何实体可以为任意系的主记录,同时又可以是任何系的属记录;
(5)不同实体型的实体可以是同一系型的主记录或属记录;
(6)一个系的主记录和属记录可以为同一类型(自合型或递归型);
(7)两个实体型之间可以出现多个系的关系;
(8)一个实体可以不必是系的主记录或属记录,而仅通过名字对它们进行存取。
(9)能遍历树结构的特殊功能--对几何产品尤其要提高某类操作的执行速度,其典型的图形操作是;
·遍历分层结构中任意个层次,以显示图形的细节;
·从顶到底遍历分层结构,如搜索线、平面或共用一组节点的若干物体;
·跨越任意个中间层次的遍历,借此对用户隐藏不必要的结构细节;
·不但能遍历简单层次(即每个实体仅是一个系的主记录),而且能遍历层次复杂的系型;
(10)直接处理混合实体种类。
一个实体在几何设计中,例如作为"表面"实体型,它可以是平面,也可以是扭曲面。在有限元(FEM)计算中也可以是网格组,这样就产生了混合实体型。直接处理混合实体型,是GPM模型中非常重要的,不需要应用程序员在程序上做复杂的转换工作。
在我国开发的面向航天的工程数据库管理系统HEDBMS中就成功的实现了这种模型。在此模型支持下,用户可方便地在HEDBMS支持下,设计产品的几何信息,设计的产品几何信息可直接与有限元系统PSDAS进行对接,从而进行有限元的动、静力学分析计算。
注:
有关这方面的数据模型及其应用请参看宛延垲教授主编的《工程数据库管理系统》,清华大学出版社,1999年。
二、 扩展的关系数据模型
为了适合工程设计应用,把关系模型进行扩展,以支持对象模型的聚合、概括、引用等各种语义和复杂对象,是当前工程数据库研究的另一个方面。
扩展的关系数据模型是表达能力超过E.F.Codd先生所定义的关系13条规则,但由于嵌套关系模型已形成了独立的体系,所以习惯上并不把其列入扩展的关系模型之列。扩展的关系模型,不仅仅保持了第一范式的限制,还允许属性可以是过程类型和抽象数据类型。这样不仅可以模拟嵌套关系的部分功能,而且还可以模拟面向对象模型的部分功能,从而大大提高了关系模型的表达能力。
至今,扩展的关系模型已有很多,如XSQL中的层次结构的对象模型,嵌套关系模型NF2、、对象-关系模型等。
在目前的数据库市场中,虽然面向对象的数据库管理系统在复杂对象的建模、模型的扩展、对象的语义表达(方法)等方面,满足了工程应用的需求,但由于它的使用效率、支持的开发工具等与工程应用相差较远,特别是对象数据库管理系统没有关系数据库管理系统那样通用的数据库查询语言,所以面向对象数据库管理系统没有在工程界得到认可。90年代后期,由于传统的商品化的关系数据库厂商都对关系进行了扩展,支持对象的概念,以关系数据库为基础的对象-关系数据库已成功目前市场上的主流产品。国际SQL标准也开始支持对象的操作与查询标准:SQL3。
1、XSQL扩展关系模型
1)复杂对象
2)引用关系属性
3)复杂对象的操作
4) 版本管理
XSQL是IBM公司对SYSTEM R关系数据库管理系统进行的扩充,以适应支持工程应用中复杂对象数据的管理。主要的扩充在于:
- 层次结构的复杂对象
- 长域和
- 对话式事务。
长域(即变长字段)用于存储变长的结构化或非结构化的数据,如几何造型中的CSG表示或Brep表示、图像数据、声音、文本等。对话式事务用于解决工程中的长事务处理。
1)复杂对象
在XSQL系统中,把复杂对象看作一个单个实体。一个复杂对象由多个子实体按层次结构组织起来的,子实体本身还可以是由其它的按层次关系组织的子实体构成,如此形成层次结构的复杂实体关系。
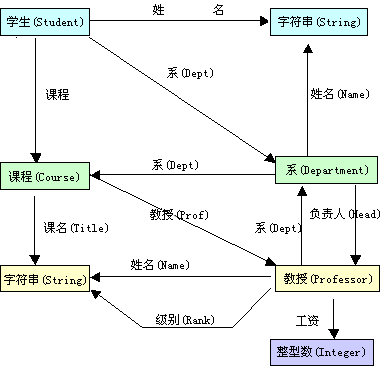
在复杂实体的层次关系中,每个对象有一个根元组和若干相关的子元组组成。相关的子元组可以来自于不同的多个关系表中,按层次组织这些元组的集合,构成复杂对象。图3-1是复杂对象的表结构示例。其中TA是复杂对象结构的根表,该结构有四个表TA、TB、TC和TD。TA是TB和TC表的父表,TB是TD表的父表。
图3-1 一个复杂对象的结构
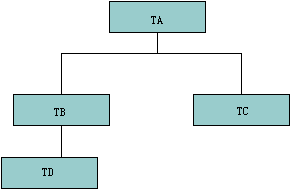
在传统的关系数据模型中,首先不允许定义非原子属性域,其次是每个元组没有系统形成的唯一标识。为了构造层次结构的复杂对象,在XSQL中,增加了两个属性域:标识符域(IDENTIFIER)和父子关系域(COMPONENT_OF)。这两个域的值都是存放某元组的标识符。
标识符域用于存放元组的唯一标识符,它是该元组创建时由系统自动产生的,并作为标识符域的值保存起来。元组的标识符有如下特性:
1) 该标识符与对象的内容和对象存放的位置无关;
2) 该标识符与对象的生命周期也无关,即当该元组删除以后,它的标识符也不可再用。所以,元组的标识符不能更新和修改;
3) 使用标识符可以唯一的访问该元组对象。
注:
标识符的产生方法可由两部分组成,即元组产生时的处理器标识号和它产生的日期与时间,即处理器标识_日期_时间。用这种方法产生的标识符在"全世界范围内"都保证唯一的。就像WINDOWS中的资源标识符一样。
父子关系域用于描述双亲元组和子元组之间的关系,即存放父元组的标识符。父子元组之间的关系便于描述1:N的关系。
使用父子关系域构造元组层次结构的方法是:
1) 一个复杂对象由一个根元组和若干其它关系的元组组成。根元组存放于根关系表,其它关系称为根关系表的子关系。
2) 参与复杂对象的每个关系都有一个标识(IDENTIFIER)列,根关系中的标识列的值就作为该复杂对象的唯一标识符。
3) 每个非根关系要有一个双亲(COMPONENT_OF)列,该列中的值存放这个子元组的父元组的标识符。每个孩子元组恰有一个父元组,多个孩子元组可有相同的父元组,从而保证了元组之间严格的层次关系。实际上是用指针实现了元组之间的链接。也可以采用双链结构,即在父元组中再增加多个指向孩子元组的孩子(CHILD)属性列,存放子元组的标识符。
4) 组成一个复杂对象的每个元组都包含两部分内容:第一部分是由用户定义的正规的元组字段,是用户可见的。第二部分是用来实现复杂对象结构的附加字段:标识符字段、双亲字段和孩子字段。
2)引用关系属性
引用关系是用来描述复杂对象之间的非层次结构和复杂对象之间的相互引用关系,以便支持工程中的多对多关系的描述。为此,XSQL在元组中再增加一个引用(REFERENCE)字段,用来指向其它元组。在元组中的引用(REFERENCE)字段列存放它所引用元组的唯一标识符(IDENTIFIER)。有两种引用类型:内部引用INTERNAL_REFERENCE和外部引用EXTERAL_REFERENCE。外部引用是指引用与该复杂对象不同类型的其它关系的复杂对象;内部引用是指引用同一复杂对象关系中的其它元组。
在引用关系中,要处理的问题有:
1) 一个元组可由多个元组引用。
2) 引用元组的存在性。即要引用的元组必须事先存在,而且一旦一个元组被其它元组所引用,无论该元组是否与引用它的元组在同一个数据库中,被引用的元组就不能被删除。只有不被引用的元组才能被删除。为了标明一个元组是否被其它元组所引用,最简单的方法是在元组中增加一个引用次数列。引用次数列的初始值为零,每增加一次引用,次数加一,每删除一次引用,次数减一。只有引用次数等于零的元组才可以被删除。
3) 避免循环递归引用。但是,有时元组的递归引用是难于避免的。要解决这种情况下元组的删除只能允许引用的元组可为空值。
4) 假如允许引用的元组为空值,就可以删除正在被引用的元组,但必须确保被删除元组的标识符不变,且不可再用。
XSQL支持引用属性的能力是很有限的。例如,XSQL能提取具有父子关系结构的整个复杂对象,但对于包含引用属性关系的对象,需要通过纯关系模型的联结重新构造。
3)复杂对象的操作
在XSQL中,提供了对复杂对象的描述和操作。对复杂对象的描述包括层次结构复杂对象的描述和具有引用属性的复杂对象的描述。图3-2是描述一个电路设计板复杂对象的例子。它说明如何把一个单元对象按层次分解成预先定义的其它单元的实例和通路,以及如何把一个通路分解为矩形,把实例和通路元组作为根元组单元的孩子,把矩形作为通路元组的孩子构成元组之间的层次关系。与一个原型元件相关的实例是通过外部引用关系表示的,即一个复杂对象的实例元组为另外一个不同的复杂对象的一个单元元组所引用。图中实线箭头表示组成COMPONENT_OF属性;虚线箭头表示IS_A关系,并指明是外部引用REFERENCE属性,图中省略了元组的其它属性数据,其中图a为模式,b为相应的数据库。
图3-2 一个扩展关系数据库的结构
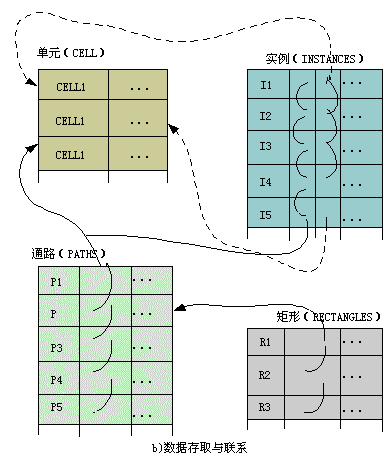
在图3-2中,各父子元组之间是1:N的层次结构关系。引用关系是IS_A类型,所以图3-2 a 模式映射到XSQL关系模式的描述如下:
Create Table CELL(
CID : String,
CDATA:…)
Create Table PATHS(
PID: String,
P_FATHER: Component-of (CELL),
PDATA: …)
Create Table RECTANGLES(
RID: String,
R_FATHER: Component-of (PATHS),
RDATA: …)
Create Table INSTANCES(
IID: String,
I_FATHER: Component-of (CELL),
IS_A: reference (CELL),
IDATA: …)
对于M:N的关系类型,XSQL只提供有限的支持能力,实际是增加了联结关系。设A和B之间是一般的M:N的引用关系,要想通过引用属性来维持不同元组之间的引用关系,必须定义连接关系RAB:
Create Table A(
AID: String,
ADATA: …)
Create Table B(
BID: String,
BDATA: …)
Create Table RAB(
RID: String,
RA: Reference (A),
RB: Reference (B))
复杂对象的操作涉及到整个复杂对象及其引用的子对象:
1) 删除一个根元组,要自动地删除它的直接的和间接的子元组。假如不把引用关系作为隐含的一致性控制目标,就可以不检查引用列指向的对象(元组)是否已被删除。
2) 提取一个复杂对象,允许提取一个复杂对象的某些元组子集,如提取某些指定的属性或属性值。提取元组层次上的有限层次,或从指定的构成关系中提取某些元组。
3) 存储一个复杂对象也允许存储某些有关的子集,相同的操作规则可用于复杂对象的拷贝、移动、封锁或读一个对象到内存。假如不能提供对复杂对象的交互查询,可以使用纯关系的概念一个元组一个元组的提取数据。
从上述的描述可知,XSQL扩展关系模型的出发点是对现有的关系模型进行扩充和修改,通过增加指针和相应的操作扩展到满足工程应用中复杂对象的数据库表达。这类模型也称关系和网状混合的数据模型。对这类混合模型,关键是要实现系统的操作和查询优化,这必须要了解复杂对象的结构,以便实现有效的操作处理。
4) 版本管理
为了适应工程设计应用,扩展的关系模型还要提供支持基本的版本概念。版本化的对象称为设计对象,它由两部分组成:
1) 一个表示所有版本共同信息的部分,叫做普通部分;
2) 另一部分是每个版本特有的信息。一般对应一个复杂对象。通过版本集来管理设计对象的特有信息。版本集有相同的类型。
每个版本是单独产生的,或是新生成的或者是拷贝一个以前的版本修改而得,在XSQL中,一个设计对象的所有版本是顺序编号的。
考虑到在设计环境中面向对象的工作方法,XSQL中的版本概念是一个纯操作性的界面,就是说版本不能在模式中定义。因此,在数据库设计时,用户为了描述所要的设计对象版本,需要定义相应的复杂对象类型,如同定义一个其它的复杂对象类型一样。运行时,要产生一个设计对象,就要为它的版本选择一个现存的复杂对象类型。在一个设计对象内,可以通过版本编号选择版本进行提取、更新或删除。
XSQL中版本的实现完全处在XSQL界面的顶部。因此,版本的操作没有集成到查询语言中。在大多数情况下,不会给用户引起麻烦:用户应当选择所希望要的版本,而后再使用XSQL查询或操纵命令操作该版本,如同操作其它的复杂对象一样。
其实,XSQL扩展关系模型的很多概念与对象的概念类似,在XSQL中没有使用对象、对象之间的关联(引用)主要是当时有关对象的术语还没有出现。
2、NF2关系数据模型
1)嵌套关系的描述结构
2) NF2关系的表示
3) NF2数据库
4) NF2数据库的操作
5)NF2数据模型在工程中的应用
标准的关系数据模型都满足第一范式(1NF)要求,即一个关系的所有属性,从数据库管理系统的观点来看都是原子的。Codd先生在提出关系模式概念后就认识到第一范式(1NF)的不足,特别是1977年日本学者对非第一范式的需求作了进一步的描述。
假如允许非第一范式(Non First Normal Form)或嵌套的关系,一个属性本身可以是有值的关系,这样就可以组织嵌套关系的复杂对象,表示"表中表"。这就是NF2关系模型。
1)嵌套关系的描述结构
在标准关系模型中,关系是相同结构的元组集合,每个元组是具有原子类型值的聚合。在这类关系中,集合、聚合只使用了一次。NF2嵌套关系模型是要把这种集合概念和聚合概念嵌套使用多次,而且是有限的、预先定义好的次数。即元组的某个属性值是一个关系,关系的元组又是具有原子值和关系值的聚合体,如此嵌套若干次,直到元组的所有属性都是原子值域为止。
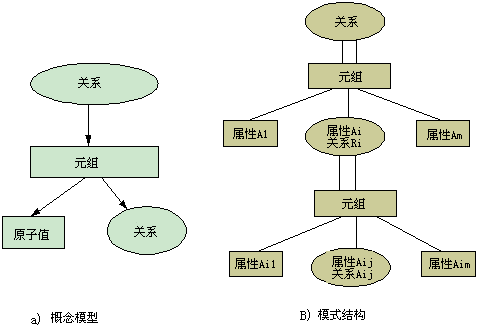
图3-3 是这种嵌套关系的结构概念图和模式图。椭圆表示为关系表,关系表是元组的集合,元组由原子值属性和关系值属性组成,它们分别用矩形和椭圆形表示。
图3-3 嵌套关系结构图
2) NF2关系的表示
在NF2关系中,属性值域为原子类型的属性,称为原子属性,属性的值域为复杂域类型的属性,称为复杂属性。复杂域是由原子域经过多次应用笛卡尔积和幂操作形成的。
NF2关系由多个二维关系表组成,二维关系表之间通过对象标识符OID(Object Identifier)相连接。
二维关系表嵌套的表示形成有多种,通常可用三种方式表示出来。
a) 嵌套关系的线性列表表示形式
线性列表是嵌套的表结构。例如,具有四个属性的关系表,其表示形式为:
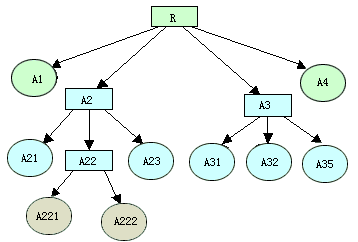
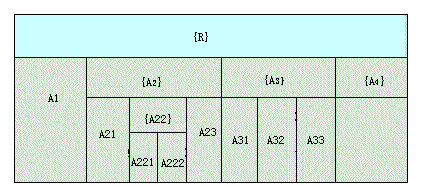
R(A1,A2(A21,A22(A221,A222),A23),A3(A31,A32,A33),A4)
其中A1和A4是原子属性,A2和A3是子关系表,A3是有三个属性A31、A32和A33的子关系表。A2有原子属性A21、A23和子关系属性A22,而A22又是有两个原子属性A221和A222的子关系表。
b) 树型表示形式
在树型表示中,用椭圆框作为叶子结点表示原子属性,用方框作为树的中间结点表示复杂关系属性。前面的例子可以表示成如图3-4所示的树状。
图 3-4 NF2关系的树型表示
c) 表格表示形式
表格表示形式直观,是嵌套关系表的较好的表示方法。在表格表示中,子关系属性用{}括起属性名,如{A2}、{A3}等。其中的子关系表包含在父关系表中,子关系由属性名标识。前面的例子用表格表示如下:
图 3-5 NF2关系的嵌套表格表示
3) NF2数据库
图3-6是对应图3-2层次结构的NF2数据库。库的组织借助于嵌套关系实现。嵌套关系采用表格表示形式。把图3-5中的R对应于单元CELL,属性A1、A2、A3和A4分别对应于CID、PATHS、INSTANCES和CDATA,就形成对应图3-6的数据库模式结构。
图3-6 基于图3-2层次关系的NF2数据库
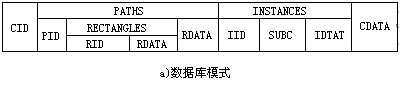
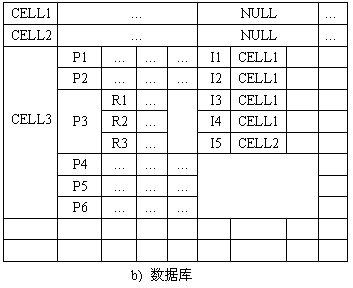
在图3-6中,其中图a)是模式,图b)是对应的数据库。数据库中的IS_A引用关系借助于单元CELL的标识符CID实现,它对应于INSTANCE中的属性SUBC的值。其中CELL关系中的CID和CDATA是原子类型属性,PATHS和INSTANCES是复杂属性,其本身是赋了值的关系。这样、一个CELL元组包含着一个完整的子关系作为它的INSTANCES属性的值。由PATHS属性可以看到,关系可以交叉嵌套多重层次。
该数据库中列出了三个元组CELL1、CELL2和CELL3。CELL3的PATHS属性值是由P1~P6的六个通路组成的一个集合。通道P3的RECTANGLES属性值又是由矩形R1、R2和R3组成的集合。它的INSTANCES属性值是由元件实例I1~I5组成的集合。但它的CID和CDATA属性只赋予一个值。
NF2数据模型已用到对象-关系数据库系统中,与XSQL一样,它的缺点是非层次的部分必须用与层次不同的方法表示。二者的优点是或多或少处在关系模型世界中。NF2模型中,赋值的关系属性可以按同样的方法处理成关系。从而,只要对现存的关系查询语言SQL稍做修改,考虑处理嵌套查询,就可在NF2中使用标准的SQL语言进行查询。NF2关系属性很容易转换成平常的关系属性,反之亦然。
4) NF2数据库的操作
实现NF2数据模型的原型系统之一是AIM原型系统,是由在Heidelberg的IBM科学中心开发的。他们使用了扩充的SQL语言HDBL(Heidelberg
Data Base Languange)。该数据库系统是关系型的,它支持表和多重集合作为属性。
HDBL语言仍然使用基本的SQL语句格式。下面给出对图3-6中嵌套关系模式的定义
Create table CELL(
CID: Char(10),
PATHS:
(PID: Char(10),
RECTANGLES:
(RID: char(10),
RDATA: Read)
PDATA: real)
INSTANCES:
(IID: Int,
SUBC: Char(10),
IDATA: Real)
CDATA: real)
HDBL语言提供的操作功能包括:
a) 元组专用的操作:即基本的关系数据操作。
b) 表专用的操作:指表的连结、子表截断、按下标访问表中的元素等。
c) 集合的专用操作:包括集合的相交、集合差和联合,以及集合约束等。
d) 转换操作:多重集合/表的排序、表与多重集合的转换、INF与INF2的相互转换。
e) 算术的和关系的聚合运算函数。
f) 对表、对多重集合以及其它的比较操作。
g) 对元组、表及多重集合的构造器等。
AIM中HDBL语言的实现也需要提供基于指针的应用程序设计界面。AIM包括版本支持机制,维持表和子表的历史状态,并且可以替换和更新。因此,也可通过查询提取过去某个时间的状态。
5)NF2数据模型在工程中的应用
由于NF2数据模型支持层次结构对象的定义和操纵,对于工程设计提供了许多方便。由图3-6的例子中可看到,如用标准的关系模型描述图3-2
CELL结构,要把信息分散地存于几个表中,检索时要对所有关系表进行联结操作,又麻烦又费时间。
使用NF2数据模型,可以把层次结构的对象作为一个整体存储于数据库中。外部对象用嵌套的NF2数据模型形式构成。这为复杂工程对象的存储、操纵提供了很大方便。NF2数据模型还支持隐含的向前引用和后向引用,向前引用就是若一个对象是另一对象的子关系则在选择所有的子结构信息时,不再需要连接(Join)操作。
下面的语句体现了对关系数据模型的不断扩充。
(1) CREATE TABLE Employee(name CHAR(20),Job CHAR(20),Salary FLOAT,Hobby
CHAR(20),Manager CHAR(20));
(2) CREATE TABLE Employee(name CHAR(20),Job CHAR(20),Salary FLOAT,Hobby
Activity,Manager Employee);
CREATE TABLE Activity(name CHAR(20),Numplayers,INTEGER,origin
CHAR(20));
(3) CREATE TABLE Employee(name CHAR(20),job CHAR(20),Salary FLOAT,Hobby
Activity,Manager Employee);
PROCEDURE Retirement Benefits FLOAT;
(4) CREATE TABLE Employee(name CHAR(20),Job CHAR(20),Salary FLOAT,Hobby
Activity,Manager Employee)
PROCEDURE Retirement Benefits FLOAT
AS CHILD OF Person;
CREATE TABLE Person
(name CHAR(20),SSN CHAR(9),Age INTEGER);
(5) CREATE TABLE Employee(name CHAR(20),Job CHAR(20),Salary FLOAT,Hobby
set-of Activity,Manager Employee)
第一个CREATE TABLE语句中,显示了在关系模型下对Employee这个数据库表的定义方式,其中Hobby和Manager两个属性被限制为字符型。第二个CREATETABLE语句中,则明确地显示了对数据库表的属性类型(原子类型)的扩充:Hobby这个属性不再限制为字符型,它现在可以是用户定义的一个数据库表Activity。与此类似,Manager这个属性的数据类型甚至可以是Employee这个表本身。
允许数据库表的属性是另一个数据库表(即随机数据类型),就可以导致嵌套数据库表,即表中表,如此逐层下去,这个在概念上的简单突破可以导致数据检索效率的大大提高,并使数据库系统有能力支持多媒体应用(管理图象、声音、图形、正文数据以及由这些数据组成的文件)、处理科学数据(管理向量、矩阵等)、工程及设计系统(与复杂的嵌套数据打交道)和其他类似的系统。
扩展关系模型还体现在封装概念上,即允许将数据及对数据进行处理的程序(过程)结合起来,其方式是允许用户将过程附加到表上,并允许过程对属性值做运算。上面第三个CREATE
TABLE语句中带有PROCEDURE子句,用来定义一个过程Retirement Benefits,此过程计算给定雇员的退休待遇,并返回一个浮点值。这种方式使表的组成由状态(state,即属性值)和过程(procedure,即对属性值的处理)两部分构成。用户可以编写任何过程附到表上,对表的值进行处理。过程的应用几乎不受到任何限制。
第三个扩充体现在支持继承概念上,即允许用户将数据库表按等级进行组织。如两个表P和C,P是C的父表,则C除了自己定义的属性和过程外,同时还继承了P的所有属性及过程。此模型允许子表有多个父表,即所谓多重继承。表的等级属于带有系统定义的根(root)的有向无循环圈(directed
acyclic graph)。此外,在子表和父表之间存在IS-A(1对多)关系。在上述语句第四个CREATE TABLE中,Employee表被定义为另一个表
Person的子表(CHILD OF)。Employee表因而自动继承了表Person的三个原子类型,即Employee表有Name,SSN,Age三个属性,虽然这三个属性并未在Employee表中被定义。
第四个扩充是允许表的某个属性值可以不只是一个,而是一组(即任意数量的值);同时,这组值又可以是多个随机数据类型。上述语句中第五个CREATE
TABLE中,Hobby属性的数据类型是一组(set-of)Activity。这就是说,Hobby属性值可以是一组Activity表的记录。在传统的关系数据库中,需另建一数据库表,或多加几个可能冗余的属性来实现此功能。例如,再建立一个名为Employee-Hobby的表存放雇员的嗜好,并为Employee和Employee-Hobby建立关联关系,以便检索。
3、对象-关系数据模型
随着面向对象语言的成熟,人们开始研究面向对象的数据库管理系统(OODBMS),但是进展比预期的要缓慢的多,究其原因:主要是OODBMS在以下几个方面的不足:
a) 缺乏标准:面向对象数据库产品在程序设计接口、实现方法、对查询的支持等方面存在许多差异。
b) 在一些方面无法与RDBMS匹敌。由于底层实现仍然采用面向对象的编程方法,导致了:对于视图的支持不足;模式演化艰难;与应用程序语言结合很紧密;在鲁棒性、可伸缩性、容错性、性能等方面也不如RDBMS。
c)应用开发工具很少,对客户机/服务器计算环境的支持不够。
在这样的情况下,各大数据库厂商在20世纪90年代后期纷纷推出相应的对象-关系数据库管理系统(ORDBMS):既具备关系数据库管理系统的功能,同时又支持面向对象的特征:抽象数据类型(ADT),对象之间的继承(概括)关系、包含(聚集)关系,对象的封装,对象(包括方法和成员变量)在数据库中的可持续性,对象的消息驱动特性,对象的多态性等。由于它是关系数据库技术和对象数据库技术的结合,它具有另外一些特性:面向对象的视图、触发器、权限设置等特性。
ORDBMS的优点:
a) 相对于OODBMS有比较高的性能,可以利用RDBMS的研究成果。
b) 支持RDBMS,具有RDBMS的优点:透明的存储路径、表、视图、非过程性查询语言、事务、恢复、数据完整性。
c) 具有OODBMS的优点:容易表达对象间的各种关系(包括继承、包含等)、对象的封装、方法与数据在数据库中的关联,对象的标识、对象的多态性和覆盖性等等。
对象-关系模型主要在关系模型的基础上增加了一下特征:
1) Collection对象:包括Set、Array、List、MultiSet等对象,在定义复杂对象的组成关系是通过使用它们来管理对象之间的关系,通过这些对象的方法也可操作所管理的对象;
2) 对象标识符(OID):类似于XSQL的IDENTIFIER,用来管理具体的对象。由系统产生,用户不能修改。
3) 对象引用(References):用于描述对象之间的引用关系。一个对象可被多个对象引用。对象引用的定义在SQL3中通过如下语句定义
CREATE TABLE PropertyForRent (
propertyNo PropertyNumber NOT NULL,
street Street NOT NULL,
….
staffID REF(StaffType) SCOPE Staff REFERENCES ARE CHECKED
ON DELETE CASCADE,
PRIMARY KEY (propertyNo));
4) 用户自定义数据类型:包括Distinct Types、Row Types、Abstract Data Type等数据类型的定义与使用
5) 对象继承关系的定义:SubType和Supertypes
6) 用户自定义过程等(User-Defined Routines)
ORDBMS实现的体系结构主要有以下几种:
a) 在RDBMS上增加一层软件,用于将有关OODBMS的特点转化成RDBMS所能管理的形式,以模拟ORDBMS的功能。这种方法实现的ORDBMS的功能很大程度上受制于底层的RDBMS,且在性能上可能会差一点。
b) 修改RDBMS,扩充原来系统中不适合于ORDBMS的地方(比如放宽要求符合1NF的要求,对象的标识在底层的实现),增加OODBMS的特性。
c) 重新构建ORDBMS,这种模式的工作量太大。与某一种面向对象的编程语言相结合,由该语言提供ORDBMS的标准类库定义,共同提供ORDBMS的功能。
目前商品化的关系数据库管理都支持对象-关系功能。国际标准化组织定义的SQL-3就是在SQL-92上面增加了对象的功能。有关SQL-4的标准(也称后SQL-99)正在制定中。
3.2.2函数数据模型
函数数据模型最基本的结构是实体与函数,用它们描述概念对象和对象的特性。一个对象与其特性之间的联系可用函数映射关系来实现。例如,描述一个特殊的学生和他所选学的课程,可定义一个函数course(student),实现由学生到课程的映射。
数据库的表示是相当复杂的,不可能用一个模型就能满足所有用户的要求。对象和对象的特性是相对的,有时它们依赖于不同的观察方法。DAPLEX利用导出函数可为用户提供不同的数据库视图结构,处理不同视图间复杂的相互联系。
1、函数和对象
2、导出数据和导出函数
3、数据操纵
4、数据库系统的组织
函数数据模型是伴随着数据定义语言DAPLEX而构造出来的。1981年,D.W.SHIPMAN提出的概念模型:"The
Functional Data Model and the Data Language DAPLEX",ACM Transactions
on Database Systems,其目的是提供一种概念上自然的数据库界面语言,能简单而直观地定义和操作应用数据。所以,DAPLEX是为数据库系统提供的一种数据定义和操纵语言,用这种概念构造的模型称为函数数据模型。
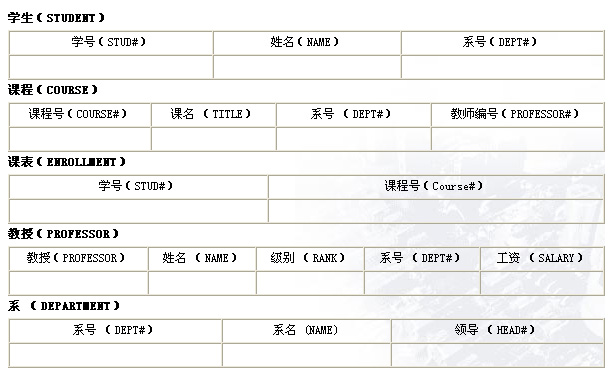
本节以简单的一个系的学生、教授、课程的数据库为例,说明函数数据模型对数据库的描述。图3-7说明实体间的联系,单箭头表示1:1的联系;双箭头表示1:N的联系。每个方框表示一种实体类型。
图 3-7 大学数据库
1、 函数和对象
在函数数据模型中,要建立一系列函数,用函数来表示实体类型以及一个实体的属性。
一个函数由两部分组成:函数名和它把自变量类型的实体映射为结果类型实体的说明,并用前头说明这种映射关系。 例如,函数说明语句:
DECLARE Name(Student)=>STRING
其中"Name"是一个函数,它把"Student"类型的实体映射到STRING类型的实体。
在函数数据模型中,实体分为原子类型和用户定义的实体类型。函数数据模型提供原子类型的实体,它们包括整数、实数、字符串、数组等。系统还为所有实体提供预定义的类型ENTITY,用它可以定义用户想要的任何实体类型。例如:
DECLARE Course()=>>ENTITY
把函数"Course"赋值到一个实体集合。
对象是数据库中所描述的实体及其关系的抽象表示。使用函数可以定义对象类型及对象类型间的映射关系。定义对象的函数可以返回对象类型的实例值、或对象集合。根据函数返回结果的情况以及函数间关系,可分为:
1) 单值函数
2) 多值函数
3) 逆向函数
有关函数的几个概念
a) 单值函数:单值函数表达对象间一对一的映射关系,它们总是返回一个单个实体。单值函数在函数定义时用单箭头(=>)表示。例如,一个学生实例的名字是唯一的一个字符串:
DECLARE Name(Student)=>STRING
b) 多值函数:多值函数表达对象间一对多的映射关系。多值函数返回的是相应类型的实体集合。多值函数可以返回空集合。根据数学上的定义,应用多值函数得到的实体集合,集合中的元素认为是无序的而且是不包含重值的。多值函数在函数定义时用双箭头(=>>)表示。例如,定义函数"Course"为学生选课:
DECLARE Course(Student)=>>Course
它回送Course类型的一个实体集合。
c) 逆值函数:在DAPLEX中,函数的映射可以是双向的,即可以定义一个函数的逆向函数。例如,给定一个教授(Prof)实体,要确定他所教的课程可定义"Course"函数的逆映射函数:
DEFINE Course(Prof)=>INVERSE OF Prof(Course)
d) 函数的自变量个数:函数的自变量个数可为零个或任意多个。零个自变量的函数定义实体类型。例如定义函数:
DECLARE Course()=>>Entity
这样的函数定义语句有两个目的:它定义了函数"Course",同时又定义了实体类型"Course"。由该函数返回的所有实体(也只有这些实体)才是类型"Course"。
多个自变量函数的例子如函数"Grade",返回修某门课程的学生的成绩:
DECLARE Grade (Student, Course) =>INTEGER
其中的自变量Course实际是学生修学的课程名称,即Cource(Stendent)的返回值,所以该函数的定义也可写成:
DECLARE Grade (Student, Course(Student)) =>INTEGER
e) 超类型和子类型:主要用于工程应用中对象之间继承关系的描述。
下面的描述定义了实体类型Person,把Designer定义为Employee,把User和Employee都定义为Person,实际上User和Designer都是Person。在他们之间隐含着超类型和子类型的联系。
DECLARE Person()=>>Entity
DECLARE Name(Person)=>String
DECLARE Designer()=>>Employee
DECLARE Dept(Designer)=>Department
DECLARE Employee()=>>Person
DECLARE Salary(Employee)=>Integer
DECLARE User()=>>Person
DECLARE ID(User)=>String
根据上面的定义,函数User要返回Person实体的一个集合。User实体的集合是Person实体集合的子集。这意味着,任何一个User实体都有一个Name函数定义在它上面,因为User也是一个Person实体。同样的规范原则也适用于Employee,以及作为Employee子类型的Designer。一个Designer同样要继承它的超类型的所有属性,定义在Designer上的函数应当有Name、salary和Dept。
这样的继承机制把类型组织成层次。Person是User和Employee的超类型,Designer的超类型是Employee。所以,函数数据模型可以描述实体之间的继承关系。
2、导出数据和导出函数
通常,一个对象的某些特性是由相关的其它对象的特性中推导出来的。例如,课程有一个讲课教授特性"Prof(Course)",还可以认为该特性把学生与其导师建立了联系"Prof(Student)"。因而,这个特性应当看作是学生所选课程的特性"Prof(Course(Student))",这种表示方法称为导出函数表示法。
处理导出特性如同处理基本特性一样。而且在一个数据库中的导出特性,在另一个数据库中可能是基本特性,甚至表示相同的现实世界情况。
使用导出函数可极大地扩展一个数据库系统的自然表达能力和实用性。在函数数据模型中,导出数据看作是"导出函数定义"。相当于根据其它对象的某些属性值定义新的函数。例如o,在Student实体上定义函数Prof,该函数返回学生所选课程的教授,用如下语句实现:
DEFINE Prof(Student)=>>Prof(Course(Student))
这样定义的函数在查询时可象一个基本函数一样使用。对用户是完全透明的,用户无需关心它是否是导出函数。根据需要,用户还可以定义更复杂的导出函数。例如,定义函数Grade_Averge,计算学生所学课程的平均成绩,函数定义为:
DEFINE Grade_Averge (Student) =>
AVERGER (Grade (Student,Course)
OVER Course (Student))
其中学生Student是形式参数,当计算函数值时,要用实在参数赋予形式变量。在这个函数中,Student可取相同类型的整个实体集合中的任一个实例值。根据集合运算方式,还可以定义一个布尔函数,比较两个学生的平均成绩:
DEFINE Compare_Grade (s1 IN Student, s2 in Student)=>
Grade_Averge (s1)>Grade_Averge(S2)
使用导出函数,可以定义用户视图以及实现对实体类型的约束。
1) 定义用户视图
在DAPLEX语言中,利用导出函数的定义,用户可以定义自己的数据库视图。例如,学生的名字、学生所在系的名字和学生所选课程的名字,所有名字都是字符串类型的。满足该 用户视图的导出函数的定义如下:
DEFINE StudentName()=>>Name(Student())
DEFINE DeptName(StudentName AS 课程名(CourseName) STRING)=>Name(Dept(The
Student (StudentName)))
DEFINE CourseName (StudentName AS STRING)=>>title (Course
(The STUDENT(StudentName)))
定义用户视图,不仅有利于数据库保密,而且使用户能直接访问新定义的函数,不必调用底层的基本函数。为此,用户视图中的函数名字应当与表视图中的函数名不同。在一个安全好的系统中,允许用户访问在新视图中定义的名字。
2)定义约束
在DAPLEX中,提供了对函数、以及对整个数据库的约束能力。在定义函数时,可以设置约束表达式,并通过使用关键字CONSTRAINT通知系统,当任何一个更新事务不满足约束表达式时,就流产该事务。例如,为了保证每个系的领导必须是本系的成员,可定义约束函数如下:
DEFINE CONSTRAINT NativeHead(Department)=>Dept(Head (Department))=Department
触发功能是与约束有关的。在函数定义时说明一个触发,每当函数由FALSE改变到TRUE,要强迫执行一个指令的命令。下面的例子说明,每当编入一个班的学生人数超过45人时,就要执行SendMessage过程通知系统的领导。过程SendMessage是用其它高级程序设计语言写的:
DEFINE Student (Class) =>INVERSE OF Class(Student)
DEFINE TRIGGER OverBooked (Class) => COUNT(Student(Class)
> 45
SendMessage (Head (Dept (Class)),"OverFlow", Name(Class))
3、 数据操纵
DAPLEX数据库语言,它的语法基本元素是语句和表达式:
1) 语句包括数据定义语句和FOR循环语句,它们通知系统完成某些动作;
2) 表达式出现在语句中间,对实体集合进行计算。表达式中可包含限定条件、数量词、逻辑运算和比较运算符。
例子1:
要查询选修电子工程系(EE)课程、授课教授为李教授(LI)的所有学生的名字,查询语句可用如下形式:
FOR EACH Student
SUCH THAT FOR SOME Course (Student)
Name (Dept (Course)) = "EE" AND
Name (Prof (Course)) = "LI"
PRINT Name(Student)
在这个查询语句中, FOR EACH是重述对Student类型的整个实体集合,通过限定条件SUCH THAT子句选择符合条件的子集,对子集中的每个成员执行PRINT语句。由该查询语句可以看到,DAPLEX允许嵌套的函数表示方法,和隐含的循环变量形式。从而使DAPLEX具有概念性的自然表达能力。而且省略许多附加变量的说明,使得语言显得结构紧凑、简明扼要,且可读性强。
例子2:
使用IN操作符,允许用户显式地指定引用变量。例如,查询哪个雇员的工资比他的领导工资多,可如下表示
FOR EACH X IN Employee
SUCH THAT FOR SOME Y IN Employee
Y=Head(X) and Salary(X) > Salary(Y)
PRINT Name(X)
例子3:
使用显式变量看起来很麻烦,但其优点是对数据库的前端处理很容易;其次是,当对同一个实体集合需要安排多个变量时,避免了在隐式变量说明中必须用相同的名字,进而容易混淆的问题。
在DAPLEX中,通过对一个特殊的实体作用,用指定函数的返回值实现更新操作。例如,要加入一个新生"张三"到电子工程系,并把他编入"System
Analysis"和"SemiConductor Physics"课程的班级中,如下描述:
FOR A NEW Student
BEGIN
LET Name (Student) = "张三"
LET Dept (Student) = THE Department SUCH THAT Name (Department)
= "EE"
LET Course (Student) = (THE Course SUCH THAT Name(Course)
= "System Analysis",
THE Course SUCH THAT Name (Course) = "SemiConductor Physics")
END
例子4:
更新多值函数,把"马利"的物理化学课程取消,增加有机化学,描述如下:
FOR THE Student SUCH THAT Name (Student) = "马利"
BEGIN
EXCLUDE Course (Student) = THE Course SUCH THAT Name (Course)="物理化学"
INCLUDE Course (Student) = THE Course SUCH THAT Name (Course)="有机化学"
END
例子5:
对导出函数的更新语句要通过PERFORM … USING结构由用户明确地指出。PERFORM … USING语句通知系统实现更新操作的语句体,作为用户更新导出函数的范式。更新是针对已经定义的视图做的。例如,对导出函?quot;CourseName"的更新可定义下述更新语句体:
PERFORM
INCLUDE CourseName (StudentName) = Title
USING
INCLUDE Course ( THE Student (StudentName)) = THE Course (Title)
PERFORM
EXCLUDE CourseName (StudentName) = Title
USING
EXCLUDE Course ( THE Student (StudentName)) = THE Course (Title)
使用该更新语句范式,要把"马利"的物理化学更改为有机化学比前面的描述更简明明了:
EXCLUDE CourseName ("马利") = "物理化学"
INCLUDE Course ("马利") = "有机化学"
4、数据库系统的组织
DAPLEX的数据模型能力与层次、网状和关系模型相配合,是当今数据库系统设计中使用的主要模型之一。所以DAPLEX数据模型也可用作现有数据库系统的抽象的前端模型。
以图3-7的大学生数据库模型作为一个例子,分别说明关系数据库模型和同构的DAPLEX的描述。图3-8 给出关系模型描述
DECLARE Student() =>>ENTITY
DECLARE Stud# (Student) =>INTEGER
DECLARE Name (Student) => STRING
DECLARE Dept# (Student) => INTEGER
DECLARE Course() =>> ENTITY
DECLARE Course#(Course) => INTEGER
DECLARE Title (Course) => STRING
DECLARE Dept#(Course) => INTEGER
DECLARE Professor# (Course) => INTEGER
DECLARE Enrollment() =>> ENTITY
DECLARE Stud# (Enrollment) => INTEGER
DECLARE Course# (Enrollment) => INTEGER
DECLARE Professor() =>> ENTITY
DECLARE Professor# (Professor) => INTEGER
DECLARE Name (Professor) => STRING
DECLARE Rank (Professor) => STRING
DECLARE Dept# (Professor) => INTEGER
DECLARE Salary (Professor) => INTEGER
DECLARE Department =>> ENTITY
DECLARE Dept# (Department) => INTEGER
DECLARE Name(Department) => STRING
DECLARE Head (Department) => INTEGER
图 3-8 关系模型描述
对比图3-8中关系表和DAPLEX描述可以看到,关系模型是函数模型的子集。因为对任何关系数据库的同构的DAPLEX的描述受到如下的限制:
1) 不允许多值函数
2) 函数不能返回用户定义的实体
3) 不允许多变量的函数
4) 不存在超类型和子类型的层次结构。
由于关系模型的限制,函数数据模型的许多优点不能得到充分地发挥。例如。要想用DAPLEX语言对关系数据库进行查询,需要先用导出函数定义数据视图。对用户视图用DAPLEX写查询语句就如同用DAPLEX数据一样处理。在用户视图中增加的导出函数表示的语义信息,在关系数据库模型中是不可表示的。
3.2.3语义数据模型
语义数据模型是适应更强表达能力的概念数据模型的需要而产生的。通常语义模型提供预定义的语义标准体系,包括相应的操作和约束,并提供访问和存储策略,用户只需选择并结合这些联系,就能描述现实世界。
语义数据模型包括以下几个概念:
1 语义网络表达
2 语义约束
3 语义模型的特点
4、语义模型的设计
5、工程应用对语义模型的要求
6、语义数据模型的分类
语义网络以结点>和弧模拟客观世界的静态和动态特性。其中结点表示对象、概念、事件等,弧表示结点间的各种联系。作为数据模型,语义网络是高层次的,独立于具体实现的方法。
使用语义模型,在产生和操作数据库时,可以对数据库的语义特性进行明确地、完整地和直接地描述,这对数据库用户或设计者都是很方便的。
1 语义网络表达
在工程数据库的环境之中,语义网络着重用于描述内涵性的信息,而将大量的外延数据通过链引开。语义网络的基本构成部分是结点以及连接结点的弧,与层次或层次模型的根本区别在于结点和弧均有丰富的内涵。结点可用于描述概念、事件、属性或值,弧则可用于描述结点间各种不同的联系,而不仅仅是有或无联系。利用语义网络可从一个概念过渡到另一概念,可从实例对象过渡到类型,并可继而过渡到同类型的其他个体,可从事件的起因过渡到事件的结果等。与实体一联系数据模型(ER模型)相比,语义网络模型在描述数据内涵方面更为丰富和精细。
语义网络模型的主要特征:
(1) 区分对象型和对象实例
在语义网络中,型和实例对象是分别处理的。型的性质以及和其他型的联系反映了该型所有实例对象的共性,从而提供了分析和推理的可能方向。譬如,"汽车"可作为一个型"具有两组轮子"。即只表示"一辆汽车具有两组轮子",而不是表示"一辆汽车一定具有两组轮子"。在具体到一汽车的实例,可能有也可能没有上述特点。型和实例的分离是大多数数据模型所没有的特点。一个型与一个属于该型的实例对象的联系为聚类和实例化,前者表示一实例对象所属的型或类,后者表示一个型或类所具有的实例对象。
(2) 语义距离
在一般数据模型中,对象间的联系不存在程度上的差别,两对象的联系只是有或无的问题,而不涉及到松散或紧密的程度。在语义模型中,概念之间的关联的程度是重要的,用于引导搜索的首要目标。譬如在工厂安全管理中,由烟雾报警器产生的火灾信号可能与多个事物相关联,但其中必有一部分是更加密切相关的,如切断某些动力电源等。联系的紧密程度可用不同形式定义,如采用加权弧等。
(3) 分割
语义网络在应用时可根据所面向的问题域而加以分割,每次只取有关的一部分从而缩小搜索范围。在大多数数据模型中,类似的分割是通过定义子模式实现的,而子模式只涉及到数据的型而不是数据的实例值。假如在语义网络中将一个车间及该车间的全部机器和人员作为一个分割,而在层次或网状数据模型中却无法定义这样的子模式,包含上述信息的最小子模式也涉及到所有的车间及从属的机器和人员。
(4) 支持型的层次与性质继承
型的层次描述超型和次型的关系。超型和次型在概念上联系反映在性质继承方面。如对于"微电机"来讲,"电机"可看作超型,其一般性质可为不同类型的电机(包括微电机)所继承;某一型号的微电机又可视为微电机的次型。在继承关系中不仅包括类型本身的性质,而且包括类型之间的联系。如"计算机"可作为一个一般化的型,具有某些属性及基本构成,且通过局部网相互联系。某一型号如COMPAQ计算机作为"计算机"这一型的子型继承上述属性、基本构成以及与其他计算机经由局域网的联系
在语义网络数据模型中,结点之间的联系可分成两大类:一类与实际模拟语义直接相关;另一类用于描述典型的结构关系,适用于各种采用这些结构的语义网络,而独立于某一特定的模拟语义。后者可归纳如下几种典型情况:
1)分类:用于建立在类型与实例值之间、
2)聚合:用于建立在对象(或型)与其构成部分之间和
3)概括(泛化):用于建立在概念上较抽象的超型和较具体的次型之间。
2 语义约束
在语义网络数据模型中,语义约束和网络结构合为一体且无需分离,一约束描述与一对象或一类型有关的事实。大部分语义网络数据模型采用一阶谓词来表达约束条件,以及类与类之间的二元关系。
约束在语义网络中的表达可取多种形式:
- 一约束条件可直接针对某一实例对象而设立;
- 也可针对某一类型而设立,并由此作用于该类型的全部实例对象;
- 还可针对某一超类而设立,并为所有次类的对象所继承。
从语义网络数据模型的定义也可看出语义网络本身的结构中也隐含着约束条件。例如分类、聚合和概括本身就是结构约束和性质约束。
又如,对于类型A, p为A型对象必须遵循的约束条件, 则有
( a ∈ A)p(a)
如果B是A的次型,则有
( b ∈ B)p(b)
具有固定值的属性本身也隐含有约束条件。如果将"金额100万元"作为银行转账类的"最大金额"属性值,则隐含了对全体转账实例值的约束。
由此可见,语义约束在语义网络模型中是从很自然的方式表达的,并可经由概括链继承。对于语义约束的处理和对于以结点和弧所表达的其他信息的处理是一致的。概括和聚合等多种语义关联,使其能更自然地表达工程设计中实体间的不同联系。
综上所述,语义网络数据模型提供了表达数据、数据范畴、性质和操作的统一环境,数据和数据型被统一地视为对象并以结点及弧表达,对程序的组织也沿用了同样的机理,具有类别、性质继承等特征,整个模拟语义不仅涉及到系统的静态行为,而且涉及到系统的动态行为。这些特性对于模拟复杂工程设计环境是十分重要和有益的。
3 语义模型的特点
语义模型利用实体、联系和约束描述现实世界的静态、动态和时态特征。
不注重数据的物理组织结构,着重表示数据模型的语义,使数据模型便于用户理解。
另外,语义数据模型具有下列特点:
1) 有高度的标准抽象概念:语义模型数据库中最常用的抽象概念是分类、概括、聚合与组合。所以,语义模型是在更高层次上表达数据模拟的语义,不同于传统的结构数据模型。
2) 定义非结构的原子对象:原子对象是非结构的数据类型,而且是最基本的类型,不可再分的。
3) 联系的表示:从概念上说,联系在模型中可用属性、实体、或者函数的形式出现。一个属性体现的联系是:其中某一对象的属性连接到或指向另一对象,或者是由另一对象派生出来的。
4) 用继承方法消除数据模式的重复信息:对象类型之间的重复描述用继承来处理,使某对象的属性描述来自于对其他对象的描述,就是把一般对象的属性传递给特殊的对象的一种方法。
5) 插入、删除、修改约束:插入和删除约束用于维持语义数据库的完整性是其最重要的特征之一,约束的说明是对这个模型语义的物理解释和操作解释。如果对象通过联系连接起来,一个对象的插入、删除和修改将会影响到所有与其连接的其他对象的存在状态。对于数据库设计者和终端用户来说,模型的联系要清晰地反映数据库联系的语义是至关重要的,即所有的用户应该对数据库操作的结果有了清晰的了解。甚至有些模型允许设计者说明联系的插入/删除/修改语义。
6) 语义模型中网状和层次联系:几乎所有的语义数据模型都为模式的概念化提供了图示结构,在大多数这类模型中,用图来表示模型的基本建模概念,例如概括/特化图、聚合层次图、实体联系模型图等。
7) 有精确的建模规则和表达语义联系的能力:实体之间的联系是用户从现实世界中通过分析抽象出来的。语义模型通过抽象概念,允许用户在多个层次上建立模型和处理数据,有的模型给语义表达式赋予主值、空值或缺省值等,这使设计者有更多的灵活性。
4、语义模型的设计
语义模型的设计要考虑诸多因素,例如:
- 系统的基本元素必须安排的富有语义;
- 当用基本元素表示模型时,语义信息必须是明确的、无二义性的;
- 由外部模型到内部模型的转换必须是简单的;
- 模型必须是稳定,即外部或内部数据的变动不影响模型的稳定性,对基本元素进行模型操作时必须保持模型的稳定性。
5、工程应用对语义模型的要求
1) 支持复杂对象:数据模型必须是面向对象的,就是把复杂的结构化的设计对象的模型化和处理作为逻辑单位。为了使数据库管理系统了解设计对象的复杂结构,以便能控制该结构的一致性,并有效地处理它,数据的模型必须包括表示对象和子对象关系的概念
2) 支持版本:数据模型应当提供灵活的版本机制,这种机制可允许用户描述所需要的各种版本语义。
3) 支持一般关系:复杂的对象和版本可看作是在对象之间建立的特殊关系。在工程当中,除了这些特殊关系外,还有大量一般的关系,如概括、分类等,语义模型必须具有表示对象间一般关系的机制。
4) 扩展的属性域:属性反映了与一个整体对象相关的特性。除了基本的数据类型外,工程应用中需要有表、矩阵、集合、数组等作为属性,同时需要有变长的属性域或文件作属性支持。
6、语义数据模型的分类
在工程数据库分析、设计、建模和应用中,常用的具有语义的数据模型有以下几种:
- 实体-关系模型
- 扩展实体-关系模型
- IDEF模型::IDEF0、IDEF1、IDEF4
- 面向对象的模型
- 语义关联模型SAM
- 函数数据模型
- 版本模型
- 面向应用的语义模型等
根据语义模型的用途我们可将上述模型分为以下几大类:
1) 通用的语义数据模型:
如实体关系数据模型、扩展的实体关系数据模型、面向对象的数据模型;
2) 面向应用的语义数据模型:
如面向CAD/CAM的对象模型、面向统计分析的语义模型、IDEF数据模型等;
3) 专用的数据模型:
如函数数据模型、版本模型。
实体-关系模型和扩展的实体关系模型在第四章的工程数据库设计中我们将结合具体的例子进行讲解。第一章中我们介绍了IDEF0分析模型,有关IDEF的其它模型的讲解已超出本书的范畴。下面介绍我们两种在工程应用中较多的语义模型:面向CAD/CAM的对象模型和面向统计分析的语义模型SAM*。
一、面向 CAD/CAPP/CAM集成的对象模型
建立一个面向CAD/CAPP/CAM共享的数据模型的目的是,要建立面向领域的、工程师能够使用的、覆盖产品生命周期各活动(设计、工艺、生产准备、计划、制造、销售、维护等阶段)之间的实在联系,而不仅是用传统的数据格式转换的形式,将已有的计算机辅助单元技术简单地连接在一起。用面向对象方法建立CAD/CAPP/CAM的统一的产品数据模型是一种比较好的途径,也是解决面向工程应用目的工程数据库的数据模型的一种方法。
1、面向对象模型的方法
2 建立面向CAD/CAPP/CAM集成的对象模型
1、面向对象模型的方法
设计和制造活动,在传统上是由企业不同的职能部门来执行的:设计部门的人员只管设计、设计好的图纸交给工艺部门进行工艺过程的设计,制造部门根据产品的设计图纸和工艺过程安排生产。这种设计与制造的分离是历史上的缺憾,致使计算机辅助设计(CAD)和计算机辅助制造(CAM)形成了两支彼此独立的分叉,阻碍了计算机集成制造系统CIMS的发展。
从70年代开始,国外对计算机与计算机之间、人和计算机之间的信息交换,和有关标准进行了广泛的研究,但均是把设计、制造的对象孤立地进行,例如在计算机辅助设计领域使用DXF、IGES实现不同CAD系统间的数据交换,在CAD/CAE/CAPP/CAM等系统间使用STEP标准来实现信息的交换和共享。但这样建立的集成系统(CIMS)只能称之为界面化系统。要在计算机集成理念的指导下建立真正集成化系统,必须从本质入手,运用面向对象方法理论深刻分析领域里的知识,使设计和制造活动的各环节之间建立更本质性的联系面向对象的集成数据模型就是实现该方法的信息载体。
2 建立面向CAD/CAPP/CAM集成的对象模型
从面向对象的数据模型出发,把数据和它的运用(运算)结合起来,我们就可建立面向对象的CAD/CAPP/CAM集成的数据模型。
从制造的实践经验来看,往往出现这样的情况(设计试探过程中发生的):如果将零件的设计稍加改进,使得可以用另一种材料或者另一种加工方法来加工它,会带来意想不到的好的效果。但这种改进(或改善)必须在设计早期才是有效的。到了设计的后期,这种改进很难实施,到了数控(NC)和柔性制造系统(FMS)之时,这种矛盾更加尖锐。尽管这些技术提供了实现高效率的可能性,但在旧的设计活动环境中,新的技术优势无法施展和发挥,因为现有的机械设计理论仍然按照传统的工艺路线来进行的,信息是按设计-工艺-制造-管理路线传递的,所以有关制造的信息无法反映到设计活动中来,即设计与制造是相互脱节的。为此,我们需要运用并行工程的技术,把设计和工艺规划等相关的制造活动作为一个整体来考虑,改变过去先设计后工艺的作法,在设计的早期就充分考虑到CIMS生产环境的限制和特点,使产品的可靠性和制造的经济性得到根本性的改善。同时,在分析建立有关的数据模型之时,把设计与工艺规划等相关的制造活动一并加以考虑,成为一个既有几何数据,又有制造信息(如工艺路线),既有设计对象又有设计意图的有机整体。
为此,我国的宛延闿教授将CAD/CAM中的特征建模概念运用到工程数据库管理系统的模型上,建立了一套比较实用的面向CAD/CAM工程数据库集成模型:把产品设计/制造等特征信息存入工程数据库,在EDBMS支持下,直接用设计/制造特征概念来思考,来产生零件的图形,充分把人和计算机的能力有机统一起来。
该方法的要点是:
1) 把制造中对应于某一特征的机械加工过程称之为"特征工艺段",把它参数化后,作为产生整个零件工艺计划的基本单位。
2) 把以数控机床为主的生产环境中对应于特征工艺段的数控程序段称之为"特征数控段"。
3) 在应用之时,首先把设计对象用成组技术(GT技术)的原理进行分类以后,建立基本的设计、制造特征库,以及与之相对应的特征工艺库和特征数控库。这样,在设计时,一旦复杂的零件由这些基本特征复合而成时,其工艺规划和数控加工指令也同步产生了
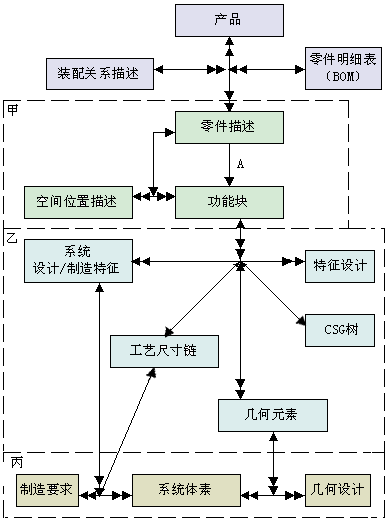
按照这种新的设计方法,把设计、工艺规划和制造等活动,从内容到形式上都在设计/制造特征的基础上统一起来了,从而建立了设计、制造和部分管理的较完整的CIMS全局数据模型。例如基于设计活动的对象模型如图3-9所示。
此子模式可以看出,设计活动一开始,就建立了设计和制造活动的有机联系,实现了几何信息和制造信息的集成和分离的对立统一。图中甲部分的对象是设计活动的主要数据:零件由功能块组成,功能块又是由几何元素发展而来的,几何元素则是由最基本的体素组成的。乙部分和丙部分是有关制造的信息,从制造的角度来看,用户体素也是构成特征的基本几何要素,加上制造要求就成了上述设计/制造特征。几何信息和制造信息得到了统一,但又与面向图形的和显示的纯几何数据的细节是分离开来的。
图3-9 CIMS全局数据模型之一:设计活动子模式
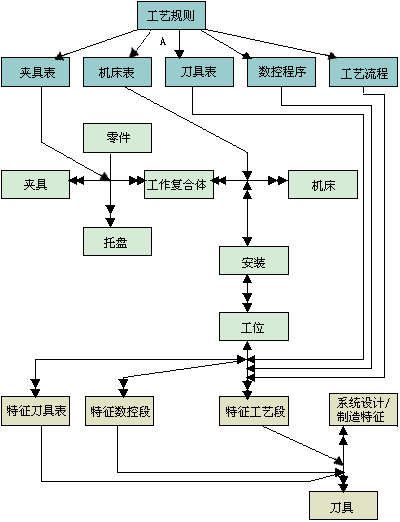
基于工艺规划子模式的对象模型图3-10所示,此模型是面向CIMS生产环境,根据加工中心的特点,按照面向CIMS工艺规划理论,以工件复合体为编制工艺计划的最小物理单位,以特征工艺段为编制工艺计划的最小逻辑单位。工件复合体由托盘、工件和夹具组成,在柔性制造系统中作为一个整体考虑。正如图3-10所示,通过工件复合体的概念,许多与制造相关的,如机床、夹具、定位和夹紧方法都分别加以相应的考虑,进而还可以把管理的因素,如柔性制造系统的调度、物料管理等,加以考虑。
图3-10 CIMS全局数据模型之二:工艺规划子模式
从上述的对象模型可知,面向对象的概念分析设计工程应用可以使用户与具体实现环境无关,从概念的高度,把握事物之间内在的实质性联系。面向对象的数据模型的柔性好,表达力强。采用面向对象的数据模型可以描述很复杂的事物,并能在统一概念化的基础上处理有关数据。这使我们有可能把对象数据模型的研究和对设计理论与方法学的研究结合起来进行,改变了过去两者分离的状况,从而使得CAD/CAPP/CAM/CAE集成可以从更本质的基础上建立起来。
对象模型的规范化
如同关系模型规范化一样,对象模型到数据库的实现也存在规范化。规范化的目的是去除数据的冗余性和不一致性。对象模型的规范化包括两个方面的内容:
1) 关于如何建立对象从而使得数据的冗余性和不一致性能减到最小;
2) 如何建立对象和对象之间的关系,使数据模型既要实反映技术世界,又要遵循数据库系统的规范要求。
对象规范化准则有三条:
1) 属于该对象的每个实例对象的每个属性只能取一个简单值;
2) 如果对象的标识符属性是由多个属性组成的复合标识符,其属性的取值必须和对象标识符的全体唯一对应;
3) 每个非标识属性必须是反映该对象的一个独立的方面,而与其他非标识属性无关的这样互相依赖的关系。
通过如此处理,上述模型满足于第三范式(3NF)要求。
总结:
本节只从应用的角度讨论了对象技术在工程中的应用。有关对象模型的基本概念我们在第二章讲解过,但如何将工程应用中的数据、信息、实体、业务流程等对象化需要工程界的知识。只有正确建立了工程应用的对象模型并赋予了语义后,才能真正发挥对象模型的优点。
二、语义关联模型SAM*
语义关联模型SAM*(Semantic Association Model)原为科学统计数据库SSD (Scientific-Statistical
Database)而设计的语义模型。它包括大量的语义描述结构特别适合科学统计的应用,因为在SSD中需要处理大量复杂的数据模型,如变长文本、矩阵、向量、集合、时间序列、有序集等。后来发展为支持计算机集成制造的应用。因为在工程设计领域,各种设计对象之间除了几何的、拓扑的关系外,还有大量的语义关系需要维护。
语义关联模型涉及到下面几个概念:
1 概念和关联
2 用关联类型描述数据库
3 面向对象的语义关联模型OSAM*
语义关联模型SAM*用:
"概念(Concept)"
和这些概念的
""关联(Association)"
描述要管理的现实世界的信息。
它定义了7种关联类型来描述数据库中复杂语义关系的基本结构,并根据结构特性、操作特性和语义约束加以区分。该模型的特点是:
1) 由7个语义模型结构以及这些结构的循环利用和递归构造描述现实世界。
2) 把复杂的数据类型,如文本、有序集、矩阵、时间序列、向量、集合以及时间看作基本的数据类型,这些类型可由用户直接使用DML进行操作。
3) SAM*支持相对性原则:相同数据对象的不同解释对应和表示相同的情况。SAM*允许多重标识同一个数据对象,以便说明对象所属语义特性的不同范畴。
4) 它区分表征对象的属性和对一个对象集合的综合统计的属性,同时支持统计操作。
1、 概念和关联
一个现实世界可用相互关联的概念网进行描述。有两类基本的概念:原子概念和非原子概念。简单原子概念可用一个简单的数据类型表示,如整型数、实型数、字符、布尔型或复杂的数据类型。一个复杂的数据类型是一种结构化的数据类型,它对应于数据库用户视图中的一个抽象数据元素。复杂数据类型如集合、向量、有序集合、矩阵、时间序列、文本等。
概念的定义
原子概念是不可分割的,可观察的实际对象、抽象对象、事件,或者是数据库用户作为基本信息单位的任何数据,这些数据是可理解的,不需要定义的。
非原字的概念是一个实际的对象、一个抽象事情、或者是由其他的原子的和非原子的概念描述的一个事件。例如:可用性名、年龄、工资收入等描述一个职工。用一组原子或非原子概念描述其他的非原子概念称为一个关联。不同类型的关联是基于不同结构的特性、操作特性以及语义约束,这些都是用户或DBA关心的概念。
在传统的数据库系统中,定义的数据域是简单的数据类型,如整数、实数、字符、布尔型和位(bit)等,这些简单的数据类型由DBMS承认和支持对它们的操作。复杂的数据类型在传统的DBMS中不予承认和支持,必须在应用程序中用高程序设计语言进行定义和使用。由程序设计语言承认和支持的数据类型与由DBMS支持的数据类型之间的差别完全是任意的。因而这就为用户增加了负担,必须定义适当的数据结构并写程序处理它们。如果把这些复杂的数据类型建立到数据模型中并在操纵语言中包含有对复杂数据的操作,该DBMS就是面向应用的,这些复杂的数据元素就可以作为不可再分的数据元素进行提取和操纵。这既减少用户写程序的麻烦,又提高应用数据库的效率。但DBMS必须要检查在这些数据元素上实现的操作是否合乎语义。
关联的分类
SAM*模型定义了七种关联类型:
1)、成员关系(Membership Association)
2)、聚合关联(Aggregation Association)
3)、概括关联(Generalization Association)
4)、交互关联(Interaction Association)
5)、组合关联(Composition Association)
6)、叉积关联(Cross-product Association)
7)、总计关联(Summarization Association)
下面分别介绍依照数据模型的结构特性、操作特性以及语义约束来分别介绍每种关联类型。在下面的表示中,使用带标识的结点和箭头描述各种关联类型。一个关联类型中的非原子概念由关联类型名明显地标出。假如同一个非原子概念由不同的用户看作有不同的语义特性,这个概念就要用多个关联类型名标识。根据数据库语义的复杂性,对数据库的概念描述可用任意多的数据项和这些关联类型的结构来描述。图形中只说明了最重要的关联类型特性,而不是数据库定义的所有信息。
1)、成员关系(Membership Association)
由同类原子概念组成的集合S,集合的成员具有相同的数据类型,形成一个值域,表示
某种属性类型,称为成员关联。集合的成员si∈S称为属性事件。这种关联类型由M(Membership)表示。
(1) 结构特性
这种概念类型分组的结果是一个集合,集合中的所有成员是不同的。例如,职工的年龄集合是20~65岁。
一个属性类型本身是一个概念。作为一个概念它又可以是其他概念的成员,形成成员层 次结构。例如,一年四季分为春、夏、秋、冬。每个季度又有三个月份。
在属性类型的说明中必须指定数据类型,如整数、实数、集合或矩阵等。一个属性类型的所有成员必须是相同的数据类型。图3-11给出成员关联的例子。
图3-11 成员关联
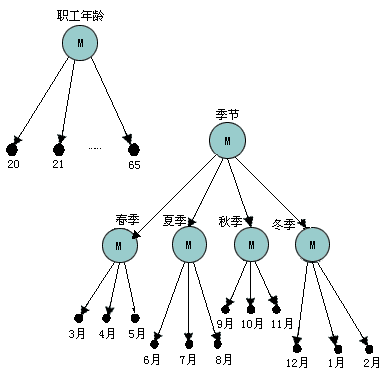
(2) 操作特性
在属性事件上实现的操作依赖于该属性的数据类型。在属性类型上可以实现传统的集合操作,如并、交、差运算,以便产生和修改集合。
(3) 语义约束
可使用规则约束属性类型的成员。例如,职工的年龄必须在20~65岁之间。成员关联约束属性类型的组成。所以,具有不同成员约束的属性类型就是不同的属性类型。例如,小孩的年龄是1~16岁,不同于职工的年龄。
成员关联类型用于控制和定义可比较的属性。不同的属性类型的成员不能进行比较。例如名字和年龄无法进行比较。
下一页
|