������
�Ż�����SQL��䴦��
�û���SQL������ʽ�������ݿ⡣һ��SQL�������кܶ���ִ�з�ʽ�������յ�ִ�мƻ����Ż����������Ż������SQL����������ͷ��룬�����������ֵ�����Ϣ����SQL��������ִ�мƻ����˽��Ż�����SQL�����Ż��ͷ������̣��������û�д����Ч�ʵ�SQL��䡢������ά���Ϳ����Ż����Ĵ�����
���½������Ż������Ż����̡��Ż�����SQL���Ĵ�����ʽ���ڴ˻��������������������SQL�����д��һ����ԭ�����Ż������������ı�֤��ʩ�����˽��⡣���������Գ������ݿ�ϵͳ���Ż������������˼��ܡ�
5.1 SQL���Ը���
SQL�ǽṹ����ѯ���ԣ�structured query language������д���ǹ�ϵ���ݿ�ϵͳ�ı����ԡ����ṩ���û�һ�ֱ�ʾ������˵��Ҫ��ѯ�Ľ�����ԣ�������β�ѯ���Լ���ѯ�������ʽ�������ݿ�ϵͳ����ɡ��������������书�ܷḻ��������ѧ���ܵ��û��Ĺ㷺��ӭ��1986�����������ұ��֣�ANSI�������ʻ�����֯��ISO����������Ϊ��ϵ���ݿ�ϵͳ�ı����ԡ�
Ŀǰ�㷺ʹ�õ�SQL����1992���ƶ���SQL-92�����ΪSQL2����SQL3�����µ�SQL���Ա�����SQL2�Ļ����������������µ�������SQL�����ƶ�ʹ�ü������е����ݿ⳧�Ҷ�����SQL������Ϊ�����ݿ����ԣ����������ݿ⳧���ֽ��������Ҫ��SQL���Ļ����Ͻ��������䡣
SQL��Ϊ�ṹ����ѯ���ԣ�ʵ�ʹ��ܰ������ݶ��塢���ݲ��ݺ����ݿ��ơ�������˵���������¼��������ݣ�
��1������ģʽ�������ԣ�data definition language��DDL�����������塢�Ļ���ɾ��������ϵ������ͼ��������������Լ�������ݿ����
��2�����ݲ������ԣ�data manipulation language��DML����������ѯ�����롢ɾ�����������ݱ��еļ�¼��
��3��Ƕ��ʽSQL���ԣ���Ƕ�������������У�ִ��SQL��䴦����
��4��Ȩ���������������Ϳ��ƶ����ݿ����ķ��ʡ�
�й�SQL���Ե���ϸ���������Բο����������ݿ��鼮�����ﲻ�ٽ�һ�����ܡ��Ծ�������ݿ�ϵͳ����ʹ��ʱ�����Ķ���ϵͳ��������ϣ��˽���SQL���Եľ���ʹ�÷�����
5.2 �Ż�������
�û���SQL������ʽ�������ݿ�ϵͳ��������ϵͳ�ڽ��յ��û���SQL�����������Ż���������������Ż����ҳ�SQL����ִ�мƻ���Ȼ���մ�ִ�мƻ����У��������������û���
һ��SQL�������кܶ��ֵȼ۵�ִ�з�ʽ���Ż�����Ҫ�����е�ִ�з�ʽ���з�����ѡ�������͵�ִ�з�ʽ����Ϊ��SQL������յ�ִ�мƻ���
5.2.1 ΪʲôҪʹ���Ż���
����֪�������ݵĴ洢���������������Σ��˹������Ρ��ļ�ϵͳ�κ����ݿ�ϵͳ�Ρ����˹��������ļ�ϵͳ�Σ�Ӧ�ó�������ݽ��ܽ�ϣ�Ӧ�ó����������ݽṹ�ĸı���ı䣬�Ӷ��������ݵ������ʲ��ߣ����ݲ�����������һ���Ժ���ά�������⡣
�������ݿ�ϵͳ�Σ����ݿ�ϵͳ��������ģʽ�ṹ�����������Ϊ����ģʽ��ģʽ����ģʽ������ģʽ��ģʽ��ģʽ����ģʽ֮�佨��ӳ���ϵ������һ�������ģʽ�����ı䣬ֻ��Ҫ�ı���ģʽ��ģʽ֮���ӳ����ģʽ����Ҫ�ı䡣ͬ���������ģʽ�����ı䣬��Ҫ�ı��ֻ��ģʽ����ģʽ֮���ӳ��
���ֶ�ģʽ�ṹ����֤�����ݵ��������������ԣ��������������࣬��������������ʡ�ͬʱ��Ҳʹ�û�����ʹ��ͳһ�Ľӿڷ������ݿ��е����ݣ������ݿ�ϵͳ���������ݵĴ�����ʽ���û����á�Ҳ�����˽����������ݿ���δ�ţ��Ӷ�����ط������û���ʹ�á�
���ݿ⼼���ķ�չ�����˲�����ݿ�ϵͳ����״���ݿ�ϵͳ����ϵ���ݿ�ϵͳ�����Ρ�������ݿ�ϵͳʹ�ò������ģ�ͣ�ϵͳ���û�����Ĵ��������Ǵ��������ݵĶ��㿪ʼ���ң�һֱ�ҵ�Ҫ����������Ϊֹ����������ģ�͵�ʵ���Ѿ����������ݵĴ�����ʽ��
��״���ݿ�ϵͳʹ����״����ģ�ͣ��κ������������֮�䶼Ҫ������ϵ��ϵͳ���û�����Ĵ�����ֻҪ������Щ��ϵ�ҵ�Ҫ���������ݾͿ����ˡ�������ģ�͵�ʵ��Ҳָ�������ݵĴ�����ʽ��
�Ͳ�����ݿ�ϵͳ����״���ݿ�ϵͳ��ͬ����ϵ���ݿ�ϵͳʹ�ù�ϵ����ģ�ͣ�����ʹ�ö�ά�����ʾ�����Լ�����֮�����ϵ����������ģ��û�и������ݵĴ�����ʽ�����û�����Ĵ�����������ϵͳ���������ֵ���Ϣ�������䴦����ʽ��������Ż����Ĺ�����
һ���û���SQL�����������кܶ��ֵȼ۵�ִ�з�ʽ���Ż���Ҫ����SQL��������ִ�мƻ���Ȼ���ɲ��������û�������SQL����ִ�мƻ��أ�
���ǿ϶��ġ����������ݿ��е����ݴ��ڲ��ϵر䶯֮�У���һ��SQL��䣬�û��ṩ��ִ�мƻ���ֻ�ܷ�ӳ���ݼ����ṹ�ĵ�ǰ������ھ���һ��ʱ�������֮�����������������ṹ�ı仯����ִ�мƻ��Ͳ��ٺ��ʣ��������ܺ���⡣���Ż�����̬�ء��������ݿǰͳ����Ϣ�����ɵ�ִ�мƻ������ܹ���Ч����Ӧ�����������ṹ�����ֱ仯�����û���˵��Ҳ����Ϊָ��SQL����ִ�мƻ�����ϸ��ȥ�˽����ݿ����Ķ��塢���ݵķֲ��������Ϣ��
5.2.2 �Ż����Ĵ�������
�ڵ�2.2.7һ���У������Ѿ����Ż����Ĵ������������˽⣬�������ǽ�����һ���Ľ��ܡ�
���ݿ�ϵͳ��SQL���Ĵ�����Ҫ���������������裺
��1��������뷭��
��2���Ż�
��3��ִ��
�����ִ�й��̿ɼ�ͼ5-1�����У�������뷭�롢�Ż��������Ż���������ɣ���SQL����ִ���ɴ�������ʵ�֡���һ��SQL��䣬���ϵͳ�ܹ����ڴ����ҵ���������ִ�мƻ�����ֱ��ʹ�ã�������ȥ�������Ż���
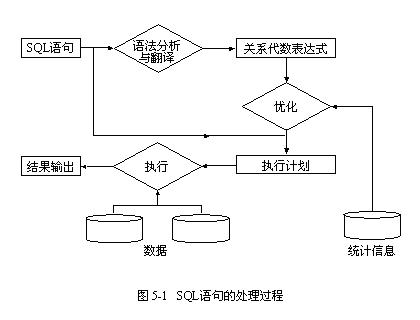
1. ������뷭��
�Ż�����SQL��������������ǹ����SQL�������������ʾ����֤SQL����Ƿ�����������������û��Ƿ���ִ��Ȩ�ȡ�Ȼ����������������SQL��䷭���һ����ϵ��������ʽ����������ϵ��������ʽʹ�õȼ�ת�������ҳ�SQL������еȼ۵Ĺ�ϵ��������ʽ��ÿһ����ϵ��������ʽ�Ͷ�ӦSQL����һ��ִ�з�ʽ��
2. �Ż�
�Ա������ݵķ��ʣ�����ʹ�ñ�ɨ�裬Ҳ����ʹ���������ڴӶ�����з��ؽ��ʱ��Ҫִ�б������ӣ����Բ���Ƕ��ѭ�����ӣ�Ҳ����ʹ������鲢���ӡ�ɢ�����ӣ����ұ��ͱ�֮�������˳�����������ġ�SQL����һ��ִ�з�ʽ�����Ǹ��ֿ���ִ��;����һ����Ϻͱ��ŷ�ʽ����ȷָ�������ִ�еķ���·�������ӷ�ʽ�Լ�����˳��ȵȡ�
SQL���IJ�ִͬ�мƻ��������ܡ���Դʹ���Ͽ��ܻ��зdz���IJ��졣�Ż�����SQL�����Ż�����������Ҫ��SQL������е�ִ�з�ʽ���ҳ�������͵�һ������ΪSQL������յ�ִ�мƻ�������νSQL����ִ�з��ã�����ִ��SQL���ʱ������ִ��ʱ�䡢CPUʹ�á��ڴ�ռ�ʹ�á�I/O�������������ɵ��м����������ȶ�����ص��ۺϡ���������I/O�����Ƚ�������Ӱ��SQL������еĹؼ����ء�һЩϵͳ���Ż����͵�����I/O����������������SQL���ķ��á�
Ϊ���ҳ�������͵�ִ�мƻ����������е�ִ�мƻ���ִ��һ�飬���Dz���ȡ��Ҳ�Dz���ʵ�ġ��Ż����Ǹ��������ֵ��е������Ϣ��ͨ������������ÿһ��ִ�мƻ���ִ�з��ã��������ֹ�����ʱ����ȫ��ȷ��
�Ż�����SQL�����Ż�����������������������ɣ�
��1�����ݹ�ϵ��������ʽ��ʹ�õȼ�ת�������ҳ����еȼ۵�ִ�мƻ���
��2�����������ֵ��б��������Ľṹ�������ص�ͳ����Ϣ���ֱ����ÿһ��ִ�мƻ��ķ��á�
��3���Ƚ�����ִ�мƻ��ķ��ã�������͵���һ������SQL������յ�ִ�мƻ���
3. �Ż���Ҫʹ�õ������ֵ���Ϣ
�������ֵ��У����Ż������յı���������Ϣ�����Է�Ϊ�����ࣺ�ṹ���塢���ݿ����ͳ����Ϣ���Ա��������Ľṹ���壬������˵�����������Щ��
��1�����е��ֶζ��壨���ͣ����ȵȣ����ֶε������Զ��塢�����Ƿ��������������������Ƿ�����������ȵȡ�
��2��������������Щ�ֶ��ϡ��������ֶε�˳�Ը����������ԣ������������ͣ�Ψһ��������Ψһ�������ۼ����������ȵȡ�
���Ա���������ͳ����Ϣ���û����Ը����Լ�����Ҫ����ѡ���ռ���������˵�������µ����ݣ�
��1����һ������˵������ͳ�ƣ����е��ֶθ��������м�¼�ij��ȡ����еļ�¼�������Ŀ����ӣ���һ�����ݿ�����ݿ���Դ�ŵļ�¼��������ʹ�õ�����ҳ�����ȵȡ�
��2���Ա��еĵ����ֶ���˵������ͳ����ȡֵ�����ֵ����Сֵ����ͬȡֵ�ĸ����������趨�ֶ�ȡֵ����ĸ����������в�ͬȡֵ�ĸ�������������ͳ������ÿһ��ȡֵ�������������ļ�¼������Ҳ���Խ�����ֶκϲ���һ�����ͳ�ƣ��ȵȡ�
��3����������˵������ͳ�ƣ������ĸ߶ȡ�Ҷ����ҳ����Ŀ�������м�¼�ij��ȡ������Ŀ����ӣ��ȵȡ�
����������Щ�ṹ�����ͳ����Ϣ���Ż����ܹ������SQL���һ��ִ�мƻ���ִ�гɱ������磺����һ����ѯ�������Ż������Լ����Ӧ�ֶε�ͳ����Ϣ�������ѯ�����е���ֵ�����ֶ����ֵ������С���ֶ���Сֵ���Ż����Ϳ����жϷ��������ļ�¼��Ϊ�㣻�����ѯ�����е���ֵ���ֶε�ij��ȡֵ����֮�У��Ż������ݸ�ȡֵ�����в�ͬȡֵ�ĸ������������ļ�¼��������������������ļ�¼�����ٸ��ݱ��Ŀ����ӣ���������Щ��¼��Ҫ��������ҳ�������ڴ���Ҫ���ٴε�I/O�����������������ҪCPU���ڴ���Դ���������ȵȡ�
�Ż�����������������Ǹ��ӡ���ʱ�ģ��ر��Ƕ�һЩ���ӵ�SQL��䣬�磺���������ѯ��������Ҫ�����֮������ӡ���Ҫ�����м���������Ҫ���������ȣ����ķѸ����ʱ���ϵͳ��Դ�����ݿ�ϵͳ���ȡһЩ��ʩ���������Ż�����SQL���Ĺ��㡢�Ż���������һ�����ǻ������潲����
5.2.3 �˽��Ż����������̵�����
SQL�������û��������ݿ����ݵ�ͨ�ýӿڡ�Ҫ�ﵽͬ����Ŀ�ģ������кܶ��ֲ�ͬ��SQL�����д��ʽ����ͬ��SQL��䣬���ܻ������ͬ�Ľ��������ִ�й��̡�ִ��Ч�ʽ��������Ե�����
���磬Ҫ��Ա����employee�з�������Ա����������ʹ�������SQL��䣺
SELECT *
FROM employee
�Ż�����ѡ�ñ�ɨ����Ϊִ�з�ʽ��ͨ��ɨ�����������ؽ��������Ա����employee���Ƿ������������ʹ�������SQL��䣺
SELECT empy_name
FROM employee
�����empy_name�ϴ����������Ż�����ѡ������ɨ����Ϊ������ִ�з�ʽ�����ַ�ʽ����Ϊ�������ǡ�����������ÿ����¼�������ٵ��ֶΣ�һ������ҳ��������ļ�¼��ʹ������ɨ�裬��ʹ�ø��ٵĴ���I/O������
�Գ���Ա�����ݿ����Ա��˵������Ż�����SQL�����Ż��������̣��ܹ��������жϳ�һ��SQL����ִ�мƻ�������������д���õġ�Ч�ʸߵ�SQL��䣬�����ܹ��ҳ�����ϵͳ����ƿ����SQL��䣬�Ӷ���֤ϵͳ���������ȶ����С�
5.3 �Ż�����SQL���Ĵ���
�����ҳ���С�ɱ���ִ�мƻ����Ż�����ְ�𣬵���������SQL��䣬�Ż���Ҳ����Ϊ���������˽��Ż�����SQL�����Ż��������ܹ������û�д����Ч��SQL��䡣
�Ż�����ȷ��SQL�����С���۵�ִ�мƻ�ʱ�����������ȷ�����ݵķ���·�����������ʻ��߱�ɨ�裩�������ӵķ�ʽ��˳���Լ�����������ʱ�Ƿ��������ȡ��������Ǿʹ��⼸������������ۡ�
5.3.1 ������
ϵͳ��SQL���Ĵ���������Ҫ������������Ҫ��������������ԭ������ģ�
��1����SQL����У�ָ��Ҫ�Խ�������������߰�����Ҫ����Ĺؼ��֡�
��2�����б�����ʱ��ϵͳѡ������鲢���ӡ�ɢ�����ӣ�����ϵͳ��Ȼѡ��Ƕ��ѭ�����ӣ���������Ϊ����ı������������ʵ��Ч�ʻ���ߡ��йر����ӵ���ϸ��Ϣ���ɲμ���5.3.2һ�ڡ�
�����Ҫ������ֶ��ϴ���������ϵͳ��ֱ��ʹ�ø�������˳���ȡ�����Ӷ�������������Ҫ������ֶ��ϲ��������������߾��ܴ�������������������������Ҫ�����ϵͳ����ʱ��ϵͳ�Ͳ���ʹ��������ֻ��������ڴ��ֶζԽ������������
���Ҫ��������ݣ�����һ�����ڴ�����ɣ���������ͳ�Ϊ��������������ڴ�ռ����ƣ���һ��������ݵ�����ϵͳ�Ͱ��տ����ڴ�Ŀռ��С����Ҫ�������ݷֳɶ�����֡��ֱ������м���������ڴ����ϣ����������������ϲ����γ����յĽ���������������Ϊ������
����Ȼ���������ִ��Ч�ʺܸߡ�������ݿ��д���������������ǵ�Ȼϣ�����е�������ܹ�һ�����ڴ�����ɡ�
��SQL����г������еĹؼ��ֺ�����Ż���û��ѡ����ص���������һ����������������
1. order by
�ùؼ���Ҫ��Խ������������������е�ijЩ�ֶξ�����order by��ʹ�ã�����Щ�ֶ��Ͻ��������������ڱ������ݿ��е����������
2. group by
�ùؼ���Ҫ��Խ�������з��顣ϵͳ�Է���Ĵ����������Ȼ���Ҫ������ֶν�������Ȼ���������ļ�¼���ݣ����ϵ��²�ȡ���µĴ������裬�γɽ������
��1��ȡ����һ����¼������������
��2��ȡ����һ����¼�����������¼�ͽ���������һ����¼��Ҫ�����ֶ���ȡֵ��ȣ��ͽ�������¼�����һ����¼�ϲ����������ȣ��ͽ��ü�¼���ڽ����������档
��3������������ֱ�����еļ�¼��������ɡ�
���磬����SQL��䷵�ظ�������Ա�����¹����ܶ
SELECT dept_no, sum(empy_salary)
FROM employee group by dept_no
ϵͳ���ȶ�Ա����employee���ڲ��ź�dept_no��������Ȼ����Ѿ�����ļ�¼���������ֶ�dept_no��ֵ�����ֶ�empy_salary�е�ֵ��ӡ�
3. distinct
�ùؼ���Ҫ�������в������ظ��ļ�¼��ϵͳ��distinct�Ĵ����������ڶ�group by�Ĵ�����ϵͳ���Ȱ��ս������Ҫ����ֶν�������Ȼ�������²������ظ��ļ�¼��
��1��ȡ����һ����¼������������
��2��ȡ����һ����¼�����������¼�ͽ���������һ����¼��ͬ���ͷ���������¼���������ͬ���ͽ��ü�¼���ڽ����������档
��3������������ֱ�����еļ�¼��������ɡ�
���磬����SQL����Ա����employee�з������еIJ��źţ�
SELECT distinct dept_no
FROM employee
ϵͳ���ȶ�ȡ��employee�е����м�¼�������ֶ�dept_no��������Ȼ����Ѿ�����ļ�¼���������ֶ�dept_no��ֵ��ɾ���ظ��ļ�¼��
4. ���ϲ�����union��intersect��minus
���ϲ�����union��intersect��minus������ʵ����������¼��֮��IJ������������㣬���У�
��1��union���ϲ�������¼����������в������ظ��ļ�¼��
��2��intersect������ͬʱ������������¼���еļ�¼��
��3��minus�����س����ڵ�һ����¼���������ڵڶ�����¼�������м�¼��
������Щ�������㣬ϵͳ���Ƚ�������¼��������ͬ���ֶλ����ֶ���ϣ��ֱ�����ͬ�ķ�������Ȼ���������Ѿ�����ļ�¼���ϴ��ϵ��½��бȽϣ��Ӷ��ҵ����յĽ������
���������Ҫע��ؼ���union��union all������union all��������������ظ��ļ�¼������Ż�������Ҫ��Լ�¼����������
5.3.2 �����ӵĴ���
��SQL���IJ�ѯ�����У�������Ҫ�Ӷ�����з������ݣ������Ҫ�������ӡ��ڱ�������ʱ��ϵͳ��Ҫ���ǵ������У�
��1�������֮�䣬����ʲô����˳��ִ�б������ӡ�
��2������ʲô���ķ�ʽ��ʵ��������֮������ӡ�
���磬����SQL��䷵�ز���������Ա�����ʻ���
SELECT b.dept_company,a.empy_name,c.acct_balance
FROM employee a, department b, account c
WHERE a.dept_no=b.dept_no and a.empy_no=c.empy_no
��ִ�б�������ʱ������ʹ�����°��ֱ�����˳��
((employee,department),account)��(account,(employee,department))
((department,employee),account)��(account,(department,employee))
((employee,account),department)��(department,(employee,account))
((account,employee),department)��(department,(account,employee))
���⣬������֮������ӿ���ʹ�����µ����ӷ�ʽ��Ƕ��ѭ�����ӡ�����ϲ����ӡ�ɢ�����ӡ������SQL��䣬�Ż���Ӧ��ѡ�����ֱ�����˳���ͱ�֮��ʹ��ʲô�������ӷ�ʽ�أ�
����֪����һ��SQL����кܶ��ֲ�ͬ��ִ�з�ʽ����Щ������˳�����ӷ�ʽ�IJ�ͬ���ź���ϣ��Ͱ����ڲ�ͬ��ִ�з�ʽ�С��Ż���ͨ�������ȡ������ִ�мƻ��������˸�SQL�������ʵı�����˳������ӷ�ʽ�������������ϵı����ӣ�����Ҫ�����м��������Ż����ڹ���ʱ��Ҫ�����������ĵ��ڴ桢���̿ռ���Դ��
�������ǽ��Ա��ͱ�֮������ӷ�ʽ���м��ܡ�
1. Ƕ��ѭ������
Ƕ��ѭ�����ӣ�������Ƕ��ѭ�������ɡ��������ѭ���еı���Ϊ�����������ڲ�ѭ���еı���Ϊ�ڲ����ϵͳ˳��ض�ȡ�����е�ÿһ����¼���������ڲ���е�ÿһ����¼���бȽϣ�������������ͷ����������������ӵĴ������̼�ͼ5-2��
for
��1�е�ÿһ����¼
do
begin
for
��2�е�ÿһ����¼
do
begin
���Ա�1�ͱ�2��ǰ�ļ�¼�Ƿ�������������
������㣬�ͼ�������
end
end
ͼ
5-2
Ƕ��ѭ������
|
|
|
|
Ƕ��ѭ�����Ӳ�Ҫ����д������������Ҳ�����ʲô���������㷨������ʹ�á�Ȼ��Ƕ��ѭ�������㷨�Ĵ��ۺܴ���Ϊ���㷨Ҫ��һ����������е�ÿһ����¼������������һ��¼�Ĵ�������Ҫ���ڲ��ɨ��һ�Ρ�����ڲ���ܹ�������ڴ��У�������ؼ��ٴ��̵IJ����������Ż�����ʹ��Ƕ��ѭ������ʱ���ῼ�DZ��еļ�¼��������¼����С�ı���Ϊ�ڲ��ʹ�á�
����Ƕ��ѭ�����ӵĴ���Ч�ʱȽϵͣ������Ѿ��Դ��㷨�����˸Ľ�������ǣ���Ƕ��ѭ�����Ӻ�����Ƕ��ѭ�����ӡ�
2. ��Ƕ��ѭ������
���ڿ�Ƕ��ѭ�����ӣ�ϵͳ�Կ�ķ�ʽ�������Լ�¼�ķ�ʽ�����������ӣ���ν�飬�������ݿ�ϵͳ������ҳ���ǶԴ���I/O��������С��λ����ϵͳ˳��ض�ȡ�����е�ÿһ�����ݿ飬������ÿһ����¼���������п��е�ÿһ����¼���бȽϣ�������������ͷ����������������ӵĴ������̼�ͼ5-3��
for
��1�е�ÿһ���ݿ�
do
begin
for
��2�е�ÿһ���ݿ�
do
begin
for
��1��ǰ���е�ÿһ����¼
do
begin
for
��2��ǰ���е�ÿһ����¼
do
begin
���Ա�1�ͱ�2��ǰ�ļ�¼�Ƿ�������������
������㣬�ͼ�������
end
end
end
end
ͼ
5-3
��Ƕ��ѭ������
|
|
|
|
��Ҫ���ӵ������������ܷ����ڴ�ʱ�������ӵĴ������ɱ���Ҫ��ͣ���Կ�Ϊ��λ���д��̵Ķ�д��ʹ�ÿ�Ƕ��ѭ�����ӣ�������ؼ��ٶԴ��̵�I/O������
3. ����Ƕ��ѭ������
��Ƕ��ѭ�������У�����ڲ�����������ԣ���������Ҳ���DZ����ֶΣ��ϴ���������ϵͳ�Ϳ���ʹ�ô����������ڲ�����Ӷ�ȡ���ڲ�ѭ�����ڲ����ɨ�裬���ַ����ͳ�Ϊ����Ƕ��ѭ�����ӡ�
ʹ�ñ��ϵ���������Ƕ��ѭ�����ӣ�һ����˵����ڱ���ɨ�衣�Ż������Ż�����ʱ�����ѡ����Ƕ��ѭ�����ӣ�һ�������������ϴ��������ı���Ϊ�ڲ�����������Ӷ��������SQL���Ĵ������ܡ�
����ڲ�������������ϲ����������������Ż�������������������������Ͻ�����ʱ���������ή��SQL����ִ�гɱ�������������£��Ż������ڸ�SQL��������ִ�мƻ��У�Ҫ�����Ƚ����ڲ�����������ϵ�������Ȼ���ٽ�������Ƕ��ѭ�����ӡ�
4. ����鲢����
���������ӵ������������������ԣ��ֱ�����ͬ�ķ����Ͻ�������Ȼ�������������ļ�¼���ϵ��£�һһ���бȽϣ������������ļ�¼��ŵ�������У��������ӷ�ʽ�ͳ�Ϊ����鲢���ӡ�
����������ӵı��Ѿ�������������������ñ��Ͳ������������������������ϴ�������ʱ����Щ�������ܻ�������鲢�����б�ʹ�á�
5. ɢ������
ɢ������Ҫʹ��ɢ�к��������һ�����еļ�¼����һ�����еļ�¼����������������ô��������������������ͬ��ȡֵ����ͬ��ɢ��ֵ�����ڴ�ԭ����ɢ�����ӵĻ���˼����ʹ��ɢ�к��������������ֱ����������ԣ����ֳ�һϵ������ͬɢ��ֵ�ļ�¼���ϡ�Ȼ��Ѿ�����ͬɢ��ֵ�ļ�¼���ϣ���������鲢���ӣ�������е��м��������кϲ����γ����Ľ������
����֪�����Դ���������������������������ȫ��װ���ڴ棬�������ڴ�������������������������̷ֽν��У���Ҫ���̿ռ���������м����������������Ч�ʡ����������������������������Ч�ʽ�������½�����˶Դ���������֮������ӣ�ֱ��ʹ������鲢���ӣ�������Ч�ʻ�ܵ͡�
���������鲢���ӣ�ɢ���������Ƚ��������������ֳ�����С������ЩС��������������ڴ�����ɣ�Ȼ����ִ������鲢���ӣ������ӵ�Ч�ʻ�õ���ߡ����ɢ�������ʺ��ڴ���������֮������Ӵ�����
5.3.3 ����·����ѡ��
�Ա������ݵķ��ʣ�����ʹ�ñ�ɨ�裬Ҳ����ʹ���������ʡ���һ��SQL�����˵�����������������ݷ���·�����������Ż���������
ʹ���������ʱ�������ʱ��ϵͳ����Ҫ������ҳ�����ڴ棬����������¼�е�ָ�룬�ҵ��������ڱ��е�����ҳ��Ȼ���ٽ�����ҳ�����ڴ棬�����ҵ��������ݡ�ʹ���������ʱ��е�һ����¼��������Ҫ���ε�I/O������
�Ż���ͨ������I/O�����Ķ��٣����������ķ���·�����Խ��������ı����Ż����������ǰ����������ʱ��е����ݡ���ʱ��ʹ�������ҵ��������ݣ���ȵ����ı�ɨ����Ҫ�����I/O����������������£��Ż�����ʹ�ñ�ɨ�������ѡ������������Ϊ���ݵķ���·����
��1�����еļ�¼���٣�ֻʹ�ú��ٵ�����ҳ��
����������£��Ż������ñ�ɨ�跽ʽ�������ݡ������������ʣ����������Ӵ��̵�I/O������ͬʱ����Ҳ���Կ�����������С�������ı��Ͻ��������������ݵIJ�ѯ������������������Ӱ�쵽���ĸ��²�����
��2����ѯ�����Ҫ���ش����ļ�¼��
���һ����ѯ�����Ҫ�ӱ��з��ش����ļ�¼�����磺���ؼ�¼ռ�����ܼ�¼��30%���ϣ�ʹ����������Ҫ�����I/O��������ʱ��ɨ����Ǹ��õ����ݷ���·����
��3����ѯ��������ѡ���а������������
�����ѯ����еĶ�������ǻ�Ĺ�ϵ�����߿���ʹ�������IJ�ѯ����������Ч�ؽ��ͼ�¼����Ŀ�������������ϵͳ��ʹ��һ�α�ɨ�裬ͬʱ������еIJ�ѯ����������������ֿ���ʹ��������ѯ���ٽ��м�¼���ϲ�������Ҫ�����I/O������
��4������û������������������������ʹ�á�
Ϊ������Ҫ���ʵı����������������Ĵ�����Ӧ���Ӧ�ó����ݲ�ѯ�������ֶε�ʹ��Ƶ�ȣ���������Щ�ֶ��Ͻ�������������������������Ҫ��ѭ��һЩԭ�ɼ���5.6.1һ�ڡ�
��5��SQL����д���������⡣
�������д��SQL��䣬���ǽ��ڵ�5.6.2һ����˵����
5.4 �Ż����Ż����̵ĸĽ�
�Ż������Ż�������Ҫʱ�䣬��Ҫ�ķ�CPU���ڴ��ϵͳ��Դ���ر��Ǹ��ӵ�SQL��䣬����ʱ�估�ķѵ�ϵͳ��Դ����ࡣ�Դ��ڳ�ǧ�����ִ�мƻ���SQL��䣬��ÿһ��ִ�мƻ������й����Dz����еġ����ݿ�ϵͳ��Ҫ��ȡ���ִ�ʩ��������Ҫ�����ִ�мƻ��������Ӷ������Ż�������ϵͳ��Դ�����ġ�
5.4.1 ����ʽ�Ż�����
����ǰ���������Ż���������ͨ������������ִ�мƻ��ijɱ�����һ�ֻ��ڴ��۵��Ż�������Ҳ�����ݿ�ϵͳ�������ʹ�õ�һ���Ż�������������Ҫȱ�����Ż�����Ҳ��Ҫʱ�䡢��Ҫ������Դ���Ż�������ʹ�õ�����һ���Ż�������Ϊ����ʽ�Ż���
����ʽ�Ż���������һ�ֻ��ڹ�����Ż��������������������ݿ�ϵͳ�ж���һϵ�еĹ���ÿ�������в�ͬ�����ȼ��𣬹涨���Ż�����SQL���Ĵ�����ʽ���Ż���������Щ���������ȼ��ĸߵͣ���SQL�����й�ϵ�����ĵȼ�ת�����Ӷ��ҵ�SQL������յ�ִ�мƻ���
������Щ���ȶ���Ĺ���������ʽ�ģ�����������Ч���������ʽ�Ż���������Ҫȱ�����Ż��������������ҵ����ŵ�ִ�мƻ�����ʱ�����Ƿdz�����ִ�мƻ�����Ϊ�������Ż�������˵��������������������ʹ�õ�������ʽ����
��1������ִ��ѡ������
��������ʽ����Ҫ���SQL����ִ�У�Ӧ���������ʹ�ò�ѯ������ȥ�������������ļ�¼���Ӷ�����Ҫ�����ļ�¼��Ŀ���������Ż�����ִ�мƻ�ѡ���ϣ�����ʹ�õȼ�ת������ѡ�����������ִ�мƻ���������λ���ϡ�
��2������ִ��ͶӰ����
��������ʽ����Ҫ���SQL����ִ�У�Ӧ���������ʹ��ͶӰ���㣬�����ݱ���ѡ����������Ҫ���ֶΡ�����ִ��ͶӰ���㣬�ر��Ƕ�Ҫ�����м�������SQL��䣬��������ڴ�ռ��ʹ��������
5.4.2 �����Ż������Ĵ�ʩ
����һ�����ӵIJ�ѯ���ȼ��ڸ���SQL���IJ�ִͬ�мƻ���ܶࡣһ����ԣ�����n���������ӣ���(2 (n
�C 1))! / (n �C 1)!����ͬ����˳��n = 3ʱ����12�ֲ�ͬ������˳��n = 5ʱ����1680�ֲ�ͬ������˳���ɴ����ǿ��Կ�������һ����ġ����ӵ�SQL��䣬Ҫ�������п��ܵ�ִ�мƻ��������ҳ�������С����һ�������Dz����ܵ����顣
���ݿ�ϵͳͨ��ʹ�û��ڴ��۵��Ż�������Ϊ�˼����Ż����Ĺ�����������ٶ�ϵͳ��Դ�����ģ����ݿ�ϵͳ��ȡ�������ʩ����Щ��ʩ�����ϰ���������Щ��
��1���������ʽ���������ҵ�����ܾ�����С���۵�ִ�мƻ���Ȼ���������ۣ����ͬʱ�ų�����ܵ�ִ�мƻ���
��2���ڶ�����ִ�мƻ����й���ʱ������ʹ�����¼�����һ�����ٻ����ų�Ҫ������ִ�мƻ���
�� �Ҷ�������������˳��ʱ�����Ǽؿ������п��ܵ�����˳��������Ϊ�������ÿ���Ӽ��ҳ��������˳��һ���Ӽ���˵�������а�������Ӽ���ִ�мƻ��У�ֻ��ʹ��������Ӽ��������˳���ִ�мƻ�������Ҫ�����㣬�����ִ�мƻ������Ա��ų���ʹ�����ַ����ܹ���������Ҫ��������˳��������
�� ������һ��ִ�мƻ���ij���ֺ�����һ���ֵ�ִ�д����Ѿ�����ǰ�Ѽ���������ִ�мƻ�����С����Ҫ���������ֹ�����ִ�мƻ��ļ�顣
�� �������һ���ӱ���ʽ����С���ۣ�����ǰ�Ѽ���������ִ�мƻ�����С���ۻ�����û�б�Ҫ�������ӱ���ʽ���κ�ִ�мƻ����м�顣
��3��ϵͳ��SQL��侭�Ż����ִ�мƻ�������ڴ���������ֵ��С���������SQL����ٴα�����ʱ��ϵͳ��ֱ��ʹ�ã����ٽ����Ż���������һ�������Ѿ��ڵ�3.2.4һ�������˽��ܡ��Գ���Ա���ԣ�Ӧ��������Ӧ�ó���֮������SQL���Ĺ����������Ż�����������
5.5 �й��Ż������ճ�ά��
�Ż�����SQL���ִ�мƻ��ijɱ����㣬��Ҫʹ�������ֵ���Ϣ�����е����ݿ����ͳ����Ϣ��ӳ�����ݿ����û����ݵ�ʹ�úͷֲ�״������Щ��Ϣ��ȷ�Ծ�����SQL�������ִ�мƻ�����ȷ�ԡ�
���ݿ�ϵͳ�����Զ�ά����Щͳ����Ϣ��������ά�������ݿ����Ա��ְ��
1. ����ִ��ͳ����Ϣ���ռ�
���ݿ�ϵͳ�����У�Ҫ���ϵظı���������еļ�¼�����������Ĵ��̿ռ�ʹ��Ҳ���ϵط����仯����һ��ʱ��֮������ͳ����Ϣ�Ѳ�����ȷ��ӳ���������е�����״�����Ż���ʹ����Щͳ����Ϣ��������ȷ�ҳ�SQL������С����ִ�мƻ���������ݿ����ԱӦ�������ռ�����������ͳ����Ϣ���Է�ӳ�������������ݵ�ʵ�������
����Ա������˴������������ӡ�ɾ�����߸��IJ�������Ӧ����������ͳ����Ϣ���ռ���
2. ������Ҫ����ͳ����Ϣ�ռ����ֶλ����ֶ����
һ�������ܰ����ܶ��ֶΣ�һ������Ҳ���ܽ����ڶ���ֶ��ϡ��Dz��DZ��������е������ֶζ���Ҫͳ����Ϣ���ռ��أ�
����֪�����Ż���ʹ�ò�ѯ���������������ֶμ������ǵ�ͳ����Ϣ������SQL���ִ�мƻ��ķ���·������ɨ���������ɨ�裩�������ӵķ�ʽ��˳����ˣ�����ֻҪ����Щ�ֶν���ͳ����Ϣ���ռ������ܹ���֤�Ż�������������ѡ�������ֶε���Ϣ�ռ����Dz���Ҫ�ġ�
һ����˵������Ӧ�����Ӧ�ó���ѡ�������ֶν���ͳ����Ϣ���ռ���
��1������������ѯ�������ֶΡ�
��2���������������ӵ��ֶΡ�
��3��������ʹ���ֶΡ�
��4��������ж���ֶξ���һ������ڲ�ѯ�����У����ұ�������������ô���Խ����Ƿ���һ�������Ϣͳ�ơ�
��5����������Ǹ������������������м�¼���ܶ࣬��ô���Ը�����Ҫ���������ĵ�һ���ֶκ������ֶ��е�һЩ������ϣ�����ͳ����Ϣ���ռ���
�ھ���Ҫ������Ϣ�ռ����ֶ�֮��������Ҫȷ����Ϣ���ռ���ʽ��ȷ�̶ȡ����ֶε���Ϣ�ռ�������ͳ����ȡֵ�����ֵ����Сֵ����ͬȡֵ�ĸ����������趨�ֶ�ȡֵ���䣬ͳ��ÿһ��ȡֵ�������������ļ�¼�������ȵȡ�
��Щͳ����Ϣ��ȷ�̶��봦�����������йأ�ͳ�ƿ��Ի����������������е����ݣ�Ҳ����ֻ�ڲ��ֲ��������Ͻ��С����ʹ�����ݲ�����������������Խ����ϢԽȷ��
������Щ����Ӧ����Ӧ��ϵͳ������ɺ���ϵͳ��ʹ�������������
3. �ڿ���״̬�½���ͳ����Ϣ���ռ�
�Ż�������SQL����ִ�мƻ���Ҫ������ڴ滺�����С���SQL����ٴα�ʹ��ʱ���Ϳ���ֱ��ʹ�ã��Ӷ������SQL����ִ���ٶȡ�
Ȼ����SQL����ִ�мƻ��������ֵ���Ϣ������ء�һ�������ݿ�ϵͳ������ά�������������ֵ���Ϣ���磺�����˱��������Ľṹ�������ռ���ͳ����Ϣ��������ڴ滺�����С������ص�ִ�мƻ���ʧЧ���Ż��������ٴζ�SQL�������Ż���
���⣬��ҵ��߷��ڶ�ϵͳ����ά��������Ҫ���Ѵ���ʱ�䡢ռ�ô�����Դ��������������ʹ�ã�Ӱ����ϵͳ�IJ����������Ӷ���ҵ��ϵͳ�����в����dz����Ӱ�졣
���Ϊ�˱���ִ�мƻ���ʧЧ�Լ���ҵ��ϵͳ��Ӱ�죬���ݿ����Ա��Ҫ��ҵ��߷��ڶ�ϵͳ����ά����ά������������ϵͳ���ڿ���״̬�½��У��磺�°�����ҹ�䡣
5.6 �����Ż���������ʵ��Ӧ��
�����������������Ż����Ĵ��������Լ���SQL���Ĵ�����ʽ�����ڶ���Щ֪ʶ�����գ��û��Ϳ����ж�SQL���ִ��Ч�ʵĸߵͣ��Ϳ����ж��Ƿ���ҪΪ��������������������δ����ȵȡ��������ǽ�����δ������������д��SQL�������һЩ����Ϳ�����
5.6.1 �����Ĵ���ԭ��
���ں��������ݿ���ƣ�������˼���Ǻ�Ϊ�������������ǻ�ø��������ݿ�ϵͳ�Ļ�������δ������������������������ή��ϵͳ���������ܡ�������Ȼ˵��������ݵķ����ٶȣ���ͬʱҲ�����˲��롢���º�ɾ�������Ĵ���ʱ�䡣
�Ƿ�ҪΪ������������������������Щ�ֶ��ϣ��Ǵ�������ǰ����Ҫ���ǵ����⡣����������һ���ȽϺõķ��������Ƿ���Ӧ�ó����ҵ����������ʹ�ã�Ϊ������������ѯ���������߱�Ҫ��������ֶν��������������Ż�����SQL�����Ż������������ڴ�������ʱ������ѭ�����һ����ԭ��
��1��Ϊ���������ڹؼ���order by��group by��distinct������ֶΣ�����������
����Щ�ֶ��Ͻ���������������Ч�ر����������������������Ǹ����������������ֶ�˳��Ҫ����Щ�ؼ��ֺ�����ֶ�˳��һ�£������������ᱻʹ�á�
��2����union�ȼ��ϲ����Ľ�����ֶ��ϣ������������佨��������Ŀ��ͬ�ϡ�
��3��Ϊ����������ѯѡ����ֶΣ�����������
��4���ھ������������ӵ������ϣ�����������
��5������ʹ���������ǡ������ݺ��ٱ����µı�������û�����ֻ��ѯ���еļ����ֶΣ����Կ������⼸���ֶ��Ͻ����������Ӷ�������ɨ��ı�Ϊ������ɨ�衣
��������ԭ���ڴ�������ʱ�����ǻ�Ӧ��ע�����µ����ƣ�
��1�����Ʊ��ϵ�������Ŀ��
��һ�����ڴ������²����ı���������������Ŀһ�㲻Ҫ����3������Ҫ����5����������˵����˷����ٶȣ���̫��������Ӱ�����ݵĸ��²�����
��2����Ҫ���д�����ͬȡֵ���ֶ��ϣ�����������
���������ֶΣ����磺�Ա��Ͻ����������ֶ���Ϊѡ������ʱ�����ش������������ļ�¼���Ż�������ʹ�ø�������Ϊ����·����
��3��������ȡֵ��һ�������������ֶΣ����磺�������͵��ֶΣ��ϣ������������Ը������������⽫�������͵��ֶη�������ǰ�档
�����ֶε�ȡֵ���dz�һ�������������¼�¼���Ǵ�������������һ��Ҷҳ�У��Ӷ����ϵ������Ҷҳ�ķ��ʾ�������Ҷҳ�ķ��䡢�м��֧ҳ�IJ�֡����⣬������������Ǿۼ��������������ݰ�������������˳���ţ����еIJ�����������������һ������ҳ�Ͻ��У��Ӷ�������롰�ȵ㡱��
��4���Ը��������������ֶ��ڲ�ѯ�����г��ֵ�Ƶ�Ƚ���������
�ڸ��������У���¼���Ȱ��յ�һ���ֶ��������ڵ�һ���ֶ���ȡֵ��ͬ�ļ�¼��ϵͳ�ٰ��յڶ����ֶε�ȡֵ�����Դ����ơ����ֻ�и��������ĵ�һ���ֶγ����ڲ�ѯ�����У��������ſ��ܱ�ʹ�á�
��˽�Ӧ��Ƶ�ȸߵ��ֶΣ������ڸ���������ǰ�棬��ʹϵͳ�����ܵ�ʹ�ô��������������������á�
��5��ɾ������ʹ�ã����ߺ��ٱ�ʹ�õ�������
���е����ݱ��������£��������ݵ�ʹ�÷�ʽ���ı��ԭ�е�һЩ�������ܲ��ٱ���Ҫ�����ݿ����ԱӦ�������ҳ���Щ������������ɾ�����Ӷ����������Ը��²�����Ӱ�졣
5.6.2 ����SQL���
����Ա�ڱ�дSQL���ʱ�����ܽ���������������ȷ�ԡ�SQL����ִ��Ч�ʣ����������ݿ�ϵͳ�����ܣ�Ӱ����Ӧ��ϵͳ���������С������Ż�����SQL�����Ż�������Ϊ�˱�д����Ч��SQL��䣬����Ӧ����ѭ�����ԭ��
1. ��Ҫ���ز���Ҫ���ֶ�����
��SQL����з��ز���Ҫ�����ݣ����˷�ϵͳ��Դ���������ܵĽ��͡�����Ҫ�����ڣ�
��1�����Ӵ��̵�I/O������
��2����������ظ��ͻ��ˣ�����������������
��3�������˱�����ʱ�䣬Ӱ���������û��ķ��ʣ�����ϵͳ�IJ���������
���⣬���ز���Ҫ���ֶ����ݻ�����Ӱ�쵽�Ż������Ż��������籾�µ�5.2.3һ������������Ҫ���ֶ����ݵ����Ż���ʹ�ñ�ɨ�裬�������������ǡ�
Ϊ���ⷵ�ز���Ҫ���ֶ����ݣ��ڲ�ѯ����У������ܽ����������Ҫ���ֶ��г�������Ҫ��ͳ��ʹ�á�*�����档
2. ����дһЩ���ӵ�SQL���
���ڸ��ӵ�SQL��䣬�Ż��������Ѻܳ���ʱ������Ż�������������ִ�мƻ�Ҳ�����ڶ��Ӧ�ó���֮�乲����������SQL��������Ӱ��ϵͳ���ܣ���Ӧ�ó�����Ӧ������⡣
���ǿ��Խ����ӵ�SQL��仮�ֳɶ������䣬�ֿ������������Ҫ�Ļ������Կ���ʹ����ʱ������м�����
3. ��дSQL���Ҫ�淶
����һ���Ĺ淶��дSQL��䣬��Ҫ��ϣ��SQL����ܹ��ڶ��Ӧ�ó���֮��ʵ�ֹ���������һ����SQL����ִ�мƻ��Ϳ���Ϊ���Ӧ�ó�����ʹ�ã��Ӷ������Ż������Ż�������
4. �����ڲ�ѯ�����ж��ֶ�ʹ�ú������߽��м���
���ݿ��е����������ո�ҳ����֧ҳ��Ҷҳ�IJ�ηּ���š�ʹ���������Ҽ�ֵʱ�����ݿ�ϵͳ�Ӹ�ҳ��ʼ��ͨ����ֵ��ƥ��ͱȽϣ����ٵ��ҵ���ֵ���ڵ�Ҷҳ�������ҵ����е�����ҳ��
����ڲ�ѯ�����ж��ֶ�ʹ�ú������߽��м��㣬ϵͳ����ִ�м�ֵ��ƥ��ͱȽϡ���ʹ��Щ�ֶ��ϴ���������ϵͳҲ����ʹ�������������ݵķ��ʡ�
Ҫ������ʹ�����������DZ�ɨ��������ݣ��Ͳ����ڲ�ѯ�����ж��ֶ�ʹ�ú������߽��м��㡣��ʵ�����������£�����ͨ����д��ѯ��������ȫ����������һ�㡣�����������Щ���ӣ�
��1��Ҫ���ֶ�ȡֵ��ǰ���һ���ַ�Ϊ��m����substring(col1,1,1) = ��m��
�����滻Ϊ��col1 like ��m%��
��2�����ֶ�ȡֵ������ֵ���㣺col1 �C1 = 5
�����滻Ϊ��col1 = 5 �C1
��3�����ֶ�ȡֵСдת������бȽϣ�lower(col1) = ��tom��
�����滻Ϊ��col1 = ��tom�� or col1 = ��TOM��
��4�����ֶ�ȡֵ���з�����not col1 > 5
�����滻Ϊ��col1 <=5
��5��Ҫ���ֶ�ȡֵ��2007��֮ǰ��year(col1) < 2007
�����滻Ϊ��col1 < '2007-01-01'
��Ҫ˵�����ǣ���������������Ӧ��ϵͳͶ��ʹ��֮������Ҫ�������ӣ������Ӧ�ó���ʱ����Ӧ���淶��ѯ������д���������ܽ��ֶκ���ֵ�����������ֿ������ڱ���ʽ�����ߡ�
5. ֻ�б�Ҫʱ����ʹ����������Ĺؼ���
�û������ݽ����ʲôҪ��ϵͳ��֪���������Ǹ���SQL��䱾������������ִ�мƻ������ؽ������ˣ�ֻ���ڱ�Ҫʱ���û���Ӧ����SQL�����ʹ����������Ĺؼ��֡�����������Ч�ر���ϵͳ�г��ֲ���Ҫ����������
����֪����distinct��union�ؼ���Ҫ�������в������ظ��ļ�¼��order by�ؼ���Ҫ��������������Щ����������ϵͳ��������������û���Ҫ��Խ�����������������ظ���¼�Ĵ��ڣ��Ϳ�����SQL����У�
��1����ʹ��distinct��order by�ؼ��֡�
��2��ʹ��union all����union��
���⣬��ʹ�������Ҫ��������߲������ظ���¼�����û�֪����
��1��������Ѿ�������SQL����У��Ϳ��Բ�ʹ��order by�ؼ��֡�
��2����������ظ��ļ�¼����SQL����У��Ϳ��Բ�ʹ��distinct�ؼ��֣�����ʹ��union all����union��
6. ʹ��top��first�ȹؼ��֣����ز�������
�����ѯֻ���ҵ�����������һ�����߲��ּ�¼���ɣ�����Ҫ���������������ļ�¼������������£�������SQL����У�ʹ��top��first�ؼ��֣��Բ�ͬ�����ݿ�ϵͳ����Щ�ؼ��ֿ��ܲ�����ͬ�����Ż�����ʹ������ִ�мƻ������ҵ�����ļ�¼�������жϸò������Ӷ���ʡ��ϵͳ��Դ��
7. ���������ԡ���ѯ�����У�ʹ����ͬ�������͵��ֶ�
�������������������Ի�����Ҫ���бȽϵ��ֶΣ�������в����ݵ��������ͣ����ݿ�ϵͳ�ڴ���ʱ���Զ�ʹ�ú�����ʵ���������͵�ת������ʹ�����ֶξ��м��ݵ��������ͣ����磺�����ͺ����ͣ��������ڼ�����д洢��ʽ�IJ�ͬ�����ݿ�ϵͳ�Ծ���Ҫ�����ڲ��Ĵ�����
�����ϵ�����£����ݿ�ϵͳ�Ͳ���ʹ��������Ϊ�˱�����������ķ����������ݿ����ʱ����Ӧ������Ӧ�ó����ʹ�ã�ʹ�������������������Ի�����Ҫ���бȽϵ��ֶΣ�������ͬ���������͡�
8. ѡ����ʵIJ�����
��SQL����У������ܱ���ʹ��������Щ��������
��!=������< >������!>������!<������not������not exists������not
in������not like��
������Щ��������ʹ���˷�����ϵͳ��֪�����������ļ�ֵ������ʲô����֮�ڣ��Ӷ���ʹ���������ڴ�����£�ϵͳֻ��ʹ�ñ�ɨ�裬������ÿһ��¼���м�顢�Ƚϡ�
��ʵ���������£���Щ�������Ա��滻�����ǿ���ʹ�����в������������ǵ���ϣ����������
��>������>=������<������<=������like������in��
5.6.3 �Ż������Ż�����
�Ż������������ֵ���Ϣ��ͨ�������ҳ�SQL��������͵�ִ�мƻ������ֹ��㷽ʽ�������ܱ�֤�Ż����ҳ���ִ�мƻ��������ŵġ�����������£��Ż���ѡ���ִ�мƻ����ܻ����⣺
��1��SQL���dz�����
��2��SQL�������������
��3�������ֵ���û���㹻��ͳ����Ϣ
Ϊ�˱�����������ķ���������ϣ��ͨ��һЩ���ã�Ӱ���Ż����Ķ�������������ִ�мƻ���ѡ�Ͼ��û������ݿ��б��������Ľṹ�dz��˽⣬������֪��SQL���Ӧ��������ִ�С������ͨ����SQL����м���ָʾ��Ϣ��directive����ʵ�֡�
����SQL����ָʾ��Ϣ������SQL����һ���֣������൱��һЩע�ͣ������Ż���Ӧ������ʲô���Ķ���������ʲô����ѡ������˵��һЩ���õġ��ȽϹؼ���ָʾ��Ϣ��������Щ��
��1���Ƿ�ʹ�ñ�ɨ��
��2���Ƿ�ʹ�������Լ�ʹ����һ������
��3���趨��������˳���Լ����ӷ�ʽ
���磬����ʹ������SQL��䣬��Ա����employee�з�������Ա����������
SELECT empy_name
FROM employee
����û�ϣ���Ż���ͨ��Ա��������empy_ind�������ݷ��ʣ�������SQL����м���indexָʾ��
SELECT --+index(empy_ind) empy_name
FROM employee
���磬����ʹ������SQL��䣬�����¹��ʳ���5000������Ա�����������ڲ��ţ�
SELECT a.empy_name,b.dept_name
FROM employee a, department b
WHERE a.dept_no = b.dept_no AND a.salary > 5000
�û�������SQL����м���avoid_fullָʾ��ϣ���Ż�����Ҫʹ�ñ�ɨ�����Ա����employee������orderedָʾ�����Ż�������Ա����employee�����ű�department��SQL����е�˳��ִ�б������ӣ�
SELECT --+ordered, avoid_full(a) a.empy_name,b.dept_name
FROM employee a, department b
WHERE a.dept_no = b.dept_no AND a.salary > 5000
SQL����е�ָʾ��Ϣ����Ӱ���Ż����������̵�ͬʱ���������Ż���������Ҫ�Ĺ���������һ��ֵ�ó��Ե����ù��ߡ�Ȼ�����û���˵����SQL�����ʹ��ָʾ��Ϣ���������ӹ�������Ҫ��Ա��������Ľṹ�Լ����е����ݴ����������˽�֮�⣬��Ҫ����������ϵͳ��SQL���Ĵ�����ִ�з�ʽ��ʹ���������൱����Ѷȡ�
��Ҫ˵�����ǣ�ָʾ��Ϣ���������ܴ����õĽ���������ָʾ��Ϣֻ��ʹ�Ż������������ѡ����Ӱ��SQL����ִ�С����⣬�ڶԱ����д��������ݴ��������е����ݴ���Ѿ������˽ϴ�ı仯֮������Ҫ����ָʾ��Ϣ���Ե���SQL����ִ�з�ʽ��
һ����˵���û�Ӧ���˽�SQL����ָʾ��Ϣ����������ֱ����SQL�����ʹ�á��û�����ͨ�����Ż�SQL��䡢���ڵ�ά���Լ��ռ�ͳ����Ϣ�ȸ����㡢����Ч�ķ�ʽ�������Ż�����������ȷ��ѡ��
5.6.4 SQL����ִ�мƻ�����
����SQL����ִ�мƻ����Ż������ɣ�������ϵͳִ�У����û����Զ�SQL����ִ�мƻ����в鿴�ͷ�����
ÿһ�����ݿ�ϵͳ�����ṩһЩ���ߣ����������Ż������Ż����̣���ʾSQL����ִ�мƻ����û�ͨ����������̵ĸ��١���SQL�������ִ�мƻ��ķ��������Խ������ϵͳ�е����⣺
��1���ڱ�д��SQL���ʱ��ͨ����ʾ����ִ�мƻ�������SQL�����д�ϴ��ڵ����⣬�����Ƿ���Ҫ�������ݵĽṹ���塣
��2����ϵͳ���й����У������Ĵ�����Դ��SQL�����з���������ϵͳ����ƿ���������Ƿ�Ҫ����ͳ����Ϣ���ռ������ݴ洢�������ȵȡ�
5.7 �������ݿ�ϵͳ���Ż�������
ÿһ����ϵ���ݿ�ϵͳ�����Լ����Ż�������������SQL����ִ�мƻ�����Щ�Ż��������û��ڴ��۵��Ż��������������Ǿͳ������ݿ�ϵͳ���Ż����������м��ܡ�
Ϊ�˰����û�����SQL���Ĵ������̣����ݿ�ϵͳ�����ṩһЩ���ߣ�������ʾ�ͷ���SQL����ִ�мƻ����������ﲻ����Щ���ߵ�ʹ�ú��������н��ܣ�����Ȥ���û����Բο��������ݿ�ϵͳ������ĵ���
5.7.1 DB2���ݿ�ϵͳ
DB2ϵͳʹ�û��ڴ��۵��Ż��������ڶ�һ��SQL��������ִ�мƻ����з��ù���ʱ���������ݿ��е�ͳ����Ϣ��ϵͳ�������ã�����ÿһ��ִ�мƻ���I/O����������CPU����������Ҫ���ڴ�ռ����Դ������֮�⣬��Ҫ��ϼ������CPU�ĸ����ʹ����ٶȡ�����ͨѶ���������Ӳ����Դ�����վ���ÿһ��ִ�мƻ���ִ�з��á�
DB2ϵͳ���Ż��������൱ǿ��ҲҪ���ĸ����ϵͳ��Դ��Ϊ�˽���ϵͳ���й������Ż����Ż����������ĵ�ϵͳ��Դ��ϵͳ��Ӧ�ó������ʱ�����ɳ����о�̬SQL����ִ�мƻ���������������ֵ��С�������Ӧ�ó���������ʱ�Ϳ���ֱ��ʹ����Щ�Ѿ������ɵ�ִ�мƻ�������Ҫ�����Ż���Ȼ����Ҫע����ǣ�����û����������ݿ�ṹ�������ռ������ݿ�����ͳ����Ϣ������Ҫ��ϵͳ��������Ӧ�ó�����SQL����ִ�мƻ���
�Ժ��Ż����йص�ϵͳ���ã����Բο���2.6.1һ�ڡ�
5.7.2 ORACLE���ݿ�ϵͳ
ORACLEϵͳ֧�ֻ��ڴ��ۺͻ��ڹ�����Ż����������ڵ�ORACLEϵͳ�汾��ֻ�ṩ���ڹ�����Ż�����������ϵͳ�汾�Ի��ڹ����Ż�������֧�֣���Ϊ�˼�����ǰ��Ӧ��ϵͳ�����Ż��ڴ����Ż������Ĺ������ƺ���ǿ��ORACLEϵͳ���ս�����ȫ�������ڹ����Ż�������
ORACLEϵͳ���ڴ��۵��Ż�������Ҳ���������ݿ�ϵͳһ�����������ݿ��е�ͳ����Ϣ��ϵͳ�������ã�����һ��SQL�������ִ�мƻ���I/O��CPU���ڴ��ϵͳ��Դ�ϵ�ʹ�ã����������ִ�з��ã��ҳ���С���õ�ִ�мƻ���
�Ժ��Ż����йص�ϵͳ���ã����Բο���2.6.2һ�ڡ�
5.7.3 INFORMIX���ݿ�ϵͳ
INFORMIXϵͳʹ�û��ڴ��۵��Ż���������һ��SQL��䣬�Ż��������¼�����������������ִ�мƻ��ķ��ã�
��1����Ҫ���е�I/O��������
��2���ҳ��������������м�¼����Ҫ��CPU������
��3������ͷ���������Ҫ�����Դ
��4����ѯ��������ʹ�õ��ڴ�����
�ھ�������ʱ��ϵͳ�������ݿ��е�ͳ����Ϣ��ϵͳ�������ã��ҳ�ÿһ������Ĺ���ֵ��Ȼ������ϵͳ���úõ�Ȩ�أ������ִ�мƻ��ķ��á�
�Ժ��Ż����йص�ϵͳ���ã����Բο���2.6.3һ�ڡ�
5.7.4 SYBASE���ݿ�ϵͳ
SYBASEϵͳʹ�û��ڴ��۵��Ż�����������I/O����������ϵͳ������ƿ����SYBASEϵͳ�Ż�����ʹ��I/O�����Ķ���������ִ�мƻ��ķ��á���SQL����һ��ִ�мƻ����Ż�����������Ҫ������I/O����I/O����������I/O���ǴӴ��̶����ݵ��ڴ��н��д���������I/O�Ǵ��ڴ����ҵ��������ݣ���������I/O����I/O��ϵͳ�ֱ�������Ȩ��Ϊ18��2������һ��ִ�мƻ��ķ��þͿ���ͨ�����¹�ʽ���������
ִ�з��� = ����I/O���� * 18 + ��I/O���� * 2
�����˵��SYBASEϵͳ�ķ��ù����㷨��Щ����Ҳ��Ч�ؽ������Ż��������������ѵ�ϵͳ��Դ��
�Ժ��Ż����йص�ϵͳ���ã����Բο���2.6.4һ�ڡ�
5.8 ������
SQL�������û��������ݿ����ݵ�ͨ�ýӿڣ��û���SQL������ʽ�������ݿ�ϵͳ�����������ݿ�ϵͳ�ڽ��յ��û���SQL��������Ż���������������Ż��������п��ܡ��ȼ۵�ִ�з�ʽ�У��ҳ����յ�ִ�мƻ���Ȼ���մ�ִ�мƻ����У��������������û���
���ݵ��������������ԡ����ݵIJ��ϸ��ºͱ仯������SQL��������ִ�мƻ����Ż�������ɡ�һ��SQL��������ִ�мƻ���������ִ�з�ʽ��ִ�з�����͵���һ������νSQL����ִ�з��ã�����ִ��SQL���ʱ������ִ��ʱ�䡢CPUʹ�á��ڴ�ռ�ʹ�á�I/O�������������ɵ��м����������ȶ�����ص��ۺϡ�
Ϊ���ҳ�������͵�ִ�мƻ����Ż������������ֵ��е������Ϣ��ͨ������SQL���ÿһ��ִ�мƻ��ķ��ã�Ȼ����бȽ϶��ó����Ż��������յ������ֵ���Ϣ�����Է�Ϊ�����ࣺ�ṹ���塢���ݿ����ͳ����Ϣ���û����Ը����Լ�����Ҫѡ��Ҫ�ռ��ı�������ͳ����Ϣ��
�Ż���ѡ��SQL����ִ�мƻ������������ȷ�����ݵķ���·�����������ʻ��߱�ɨ�裩�������ӵķ�ʽ��˳���Լ�����������ʱ�Ƿ��������ȡ�SQL����е����йؼ��ֻ��������������order
by��group by��distinct��union��intersect��minus��
�û�Ӧ�����Լ�����Ҫ�������Ƿ�ʹ����Щ�ؼ��֡��Զ����֮��Ĺ����������Ż�����Ҫ������֮�������˳������ӷ�ʽ��������֮������ӣ�����ʹ�õ����ӷ�ʽ�У�Ƕ��ѭ�����ӡ�����ϲ����ӡ�ɢ�����ӡ�
���ڶ��Ż����������̺ͷ�ʽ���˽⣬�û�Ӧ�ܹ������Ƿ�ҪΪ����������������Ӧ��������Щ�ֶ��ϣ�Ӧ�ܹ���д����Ч��SQL��䣬���¾���Щ����ָ����һЩָ����ԭ���û�������ϵͳ���й�����ͨ�����SQL����ִ�мƻ�������ϵͳ���ڵ����⡣
Ϊ�����Ż���������ϵͳ��Դ�����ģ����ݿ�ϵͳ���ȡһЩ��ʩ���磺����ʽ�Ż���������SQL��������ִ�мƻ�������ڴ��еȣ������Ż������Ż�������Ϊ��֤�Ż������������У����ݿ����ԱӦ���������µ�ԭ����ִ��ͳ����Ϣ���ռ�����ϵͳ����״̬�½���ϵͳ��ά����
���������ݿ�ϵͳ��ʹ�û��ڴ��۵��Ż�����������ORACLEϵͳ�汾��֧�ֻ��ڹ�����Ż������������˵��DB2ϵͳ���Ż������ܱȽ�ǿ��SYBASEϵͳ�ķ��ù����㷨��Щ�� | 