(1)-概述
一. 前言
近期计划写一点有关SQL Server性能调校方面的想法, 就是太繁杂没有整理出来头绪.在我们写SQL,设计Table或者做DBA,
或者做项目时,会有好多性能方面的考量,好多论坛里面也会常常提问到: 为何我这个SQL运行的这么慢或者效率很低,如果做性能方面的调优?
如果管理的数据库比较大(maybe >50GB),性能方面的考量就显得非常重要了. 在业务逻辑层面上当然希望后台的数据能够快速的处理,提交一个请求能够得到快速的回应.
如果后台数据处理太慢的话,前台的页面就会出现假死的现象,容易给User造成错觉,还以为是程序死掉了.
SQL Server是当前使用最广泛的大型数据库系统之一,大型数据库系统运行一段时间后就会出现运行缓慢、性能下降、故障增多等问题,为了使系统维持正常运行,必须对系统不断进行"调校"。这样才能够使我们的前台页面或后台数据处理能够高效的执行.
性能调校不是一件简单的事,一般来说需要有广泛的经验与知识,不单单是数据库的经验,还要对商业逻辑、系统架构设计、编写应用程序、操作系统、架设网络环境、使用各种侦测与监控工具程序、安全与防毒等,都有基本的了解,才能在复杂的系统中,找到症结所在。
我不是性能调校方面的专家,只能提出自己的一点浅见与想法,分享出来. 请各位博友专家学者指教,也欢迎一起交流!
二. 性能调校理论
运用80/20原则,找到最影响效率的20%进行优化,就能够取得80%甚至更多的效果.
1. 调校的五个基本原理
(1). 全局考虑,局部休整.
正确的找到问题,对数据库的干涉减到最小,才能有效的调优.在做一些局部的调整时,一定要考虑全局性的因素.
(2). 划分打破瓶颈.
大多数情况系统运行缓慢,是由于系统中的某个模块占用的大量的资源,阻碍的其他进程的访问,进一步限制系统的性能,造成瓶颈.
(3). 启动成本高,运行成本低.
启动的开销,比运行的开销低. 应该用尽可能少的启动次数来获取最好的性能.
(4). 服务器和客户端之间合 /script> 理的任务分配,loading均衡.
把loading均衡,如果有多个server, 可以平分loading,以提高整体的性能.
(5). 性能价格比.
SQL Server的高速度需要搞配置的硬件做支撑 , 所以在性能与价格之间需要一个权衡点.
2. 调校就是要找出系统的瓶颈, 做优化以消除瓶颈,提高系统运行效率.刚开始做时,可以从以下几个方面考虑.
(1). Server硬件(CPU,IO,ROM, 如果存在瓶颈可以考虑硬件升级)
(2). RAID
(3). SQL Server配置
(4). Table结构设计(包括Index的有效使用)
(5). 定期的维护计划(包括Backup History Data,Rebuild Index,Reorganize
Index,Shrink Database等)
(6). T-SQL编程(找出运行效率比较低的SQL语句,做优化)
三. 性能调校方法及优化技巧
1.用Server性能监视器做监测(介绍Performance Monitor, PowerShell
Get-Counter两个工具)
2. Profile,做trace追踪SQL的执行,找出耗费资源比较大的SQL语句或SP
3. SQL Server Configuration
4. Index and T-SQL Program
.
.
.
......
(2)--Server Performance Monitor(Perfmon)
性能监视的工具有很多,首先介绍Microsoft Windows Server自带的Performance
Monitor. Windows性能监视器是一个很好用的工具,可以实时检查运行程序影响计算机性能的方式(CPU,ROM,IO等),并通过收集日志数据供以后分析使用.
通过性能监视能了解系统loading以及这种loading对系统资源的影响, 分析性能或者资源使用率的变化趋势,
有效的对系统做出调整, 优化或者升级. 诊断系统故障或确定优化的组件或升级的步骤, 也可以找出性能瓶颈.
Performance Monitor是一个系统内置的MMC控制台: 包括系统监视器(System
Monitor)和性能日志和警报(Performance Logs and Alerts)两个部分. 通过实时和日志的方式来记录服务器性能.
使用系统监视器可以取现, 曲方图或者报表的方式实时查看内存, 硬盘, 处理器, 网络等各种对象的性能数据.
使用性能日志也警报可以对计数器日志进行配置, 记录性能数据, 设置性能警报, 通过设定性能警报, 可以使系统在某一特定的计数器值低于或高于指定的值时及时通知系统管理员.
下面简单介绍Windows Server 2003下的Performance Monitor, 通过日志记录性能数据,
之后分析.
1. 打开:Administrative Tools->Performance,
或SQL Server Profiler->Tools->Performance Monitor,
或在运行中输入"perfmon"
2.重要的性能计数器
(1). Processor
(2). PhysicalDisk
(3). Memory
(4). Network Interface
(5). SQL Server Access Methods
(6). SQL Server: SQL Statistics
(7). SQL Server: Databases
(8). SQL Server General Statistics
(9). SQL Server Locks
(10). SQL Server Buffer Manager
下表对重要的性能计数器做一个简要的说明:
| 性能计数器: |
|
|
| Performance Object |
Counter |
Description |
| Processor |
%processor Time |
指处理器执行非闲置线程时间的百分比,测量处理器繁忙的时间 这个计数器设计成用来作为处理器活动的主要指示器,可以选择单个CPU实例,也可以选择Total |
| Interrupts/sec |
处理器正在处理的来自应用程序或硬件的中断的数量 |
| PhysicalDisk |
% Disk Time |
计数器监视磁盘忙于读/写活动所用时间的百分比.在系统监视器中,PhysicalDisk:
% Disk Time 计数器监视磁盘忙于读/写活动所用时间的百分比。
如果 PhysicalDisk: % Disk Time 计数器的值较高(大于 90%),请检查
PhysicalDisk: Current Disk Queue Length 计数器了解等待进行磁
盘访问的系统请求数量。等待 I/O 请求的数量应该保持在不超过组成物理磁盘的轴数的 1.5 到
2 倍。大多数磁盘只有一个轴,但独立磁盘冗余阵列
(RAID) 设备通常有多个轴。硬件 RAID 设备在系统监视器中显示为一个物理磁盘。通过软件创建的多个
RAID 设备在系统监视器中显示为多个实例。
可以使用 Current Disk Queue Length 和 % Disk Time 计数器的值检测磁盘子系统中的瓶颈。如果
Current Disk Queue Length 和 % Disk Time 计数器的值一直很高,则考虑下列事项:
1.使用速度更快的磁盘驱动器。
2.将某些文件移至其他磁盘或服务器。
3.如果正在使用一个 RAID 阵列,则在该阵列中添加磁盘。 |
| Avg.Disk Queue Length |
指读取和写入请求(为所选磁盘在实例间隔中列队的)的平均数 |
| Current Disk Queue Length |
指示被挂起的磁盘 I/O 请求的数量。如果这个值始终高于 2, 就表示产生了拥塞 |
| Avg.Disk Bytes/Transfer |
写入或读取操作时向磁盘传送或从磁盘传出字节的平均数 |
| Disk Bytes/sec |
在读写操作中,从磁盘传出或传送到磁盘的字节速率 |
| |
|
|
| Memory |
Pages/sec |
被请求页面的数量. |
| Available Bytes |
可用物理内存的数量 |
| Committed Bytes |
已分配给物理 RAM 用于存储或分配给页面文件的虚拟内存 |
| Pool Nonpaged Bytes |
未分页池系统内存区域中的 RAM 数量 |
| Page Faults/sec |
是每秒钟出错页面的平均数量 |
| |
|
|
| Network Interface |
Bytes Received/sec |
使用本网络适配器接收的字节数 |
| Bytes Sent/sec |
使用本网络适配器发送的字节数 |
| Bytes Total/sec |
使用本网络适配器发送和接收的字节数 |
| Server |
Bytes Received/sec |
把此计数器与网络适配器的总带宽相比较,确定网络连接是否产生瓶颈 |
| |
|
|
| SQL Server Access Methods |
Page Splits/sec |
每秒由于索引页溢出而发生的页拆分数.如果发现页分裂的次数很多,考虑提高Index的填充因子.数据页将会有更多的空间保留用于做数据的填充,从而减少页拆分 |
| Pages Allocated/sec |
在此 SQL Server 实例的所有数据库中每秒分配的页数。这些页包括从混合区和统一区中分配的页 |
| Full Scans/sec |
每秒不受限制的完全扫描数. 这些扫描可以是基表扫描,也可以是全文索引扫描 |
| |
|
|
| SQL Server: SQL Statistics |
Batch Requests/Sec |
每秒收到的 Transact-SQL 命令批数。这一统计信息受所有约束(如 I/O、用户数、高速缓存大小、请求的复杂程度等)影响。
批处理请求数值高意味着吞吐量 |
| SQL Compilations/Sec |
每秒的编译数。表示编译代码路径被进入的次数。包括 SQL Server 中语句级重新编译导致的编译。当
SQL Server 用户活动稳定后,
该值将达到稳定状态 |
| Re-Compilations/Sec |
每秒语句重新编译的次数。计算语句重新编译被触发的次数。一般来说,这个数最好较小,存储过程在理想情况下应该只编译一次,
然后执行计划被重复使用. 如果该计数器的值较高,或许需要换个方式编写存储过程,从而减少重编译的次数 |
| |
|
|
| SQL Server: Databases |
Log Flushes/sec |
每秒日志刷新数目 |
| Active Transactions |
数据库的活动事务数 |
| Backup/Restore Throughput/sec |
每秒数据库的备份和还原操作的读取/写入吞吐量。例如,并行使用多个备份设备或使用更快的设备时,可以测量数据库备份操作性能的变化情况。
数据库的备份或还原操作的吞吐量可以确定备份和还原操作的进程和性能 |
| |
|
|
| SQL Server General Statistics |
User Connections |
系统中活动的SQL连接数. 该计数器的信息可以用于找出系统的最大并发用户数 |
| Temp Tables Creation Rate |
每秒创建的临时表/表变量的数目 |
| Temp Tables For Destruction |
等待被清除系统线程破坏的临时表/表变量数 |
| |
|
|
SQL Server Locks |
Number of Deadlocks/sec |
指每秒导致死锁的锁请求数. 死锁对于应用程序的可伸缩性非常有害, 并且会导致恶劣的用户体验.
该计数器必须为0 |
| Average Wait Time (ms) |
每个导致等待的锁请求的平均等待时间 |
| Lock requests/sec |
锁管理器每秒请求的新锁和锁转换数. 通过优化查询来减少读取次数, 可以减少该计数器的值 |
| |
|
|
| SQL Server:Memory Manager |
Total Server Memory (KB) |
从缓冲池提交的内存(这不是 SQL Server 使用的总内存) |
| Target Server Memory (KB) |
服务器能够使用的动态内存总量 |
| SQL Cache Memory(KB) |
服务器正在用于动态 SQL 高速缓存的动态内存总数 |
| Memory Grants Pending |
指每秒等待工作空间内存授权的进程数. 该计数器应该尽可能接近0,否则预示可能存在着内存瓶颈 |
| SQL Server Buffer Manager |
Buffer Cache Hit Ratio |
缓存命中率,在缓冲区高速缓存中找到而不需要从磁盘中读取(物理I/O)的页的百分比. 如果该值较低则可能存在内存不足或不正确的索引 |
|
Page Reads/sec |
每秒发出的物理数据库页读取数。此统计信息显示的是所有数据库间的物理页读取总数。由于物理 I/O
的开销大,可以通过使用更大的数据缓存、智能索引、更有效的查询或更改数据库设计等方法,将开销降到最低 |
| Page Writes/sec |
每秒执行的物理数据库页写入数 |
| Page Life Expectancy |
页若不被引用将在缓冲池中停留的秒数 |
| Lazy Writes/Sec |
每秒被缓冲区管理器的惰性编写器写入的缓冲区数 |
| Checkpoint Pages/Sec |
由要求刷新所有脏页的检查点或其他操作每秒刷新到磁盘的页数 |
提示:
当监视Windows Server或SQL Server以调查与性能有关的问题时,请首选关注一下硬件的三方面:
(1) CPU(处理器使用率)
(2) RAM(内存使用率)
(3) HDD(磁盘活动即IO)
3.建立监视
下面要建立监视(我监视的HP Server配置为:Intel 4x4 x 3.0 GHz/RAM 16.0G,业务系统为OLTP).
(1) 在performance->Performance Logs and Alerts->New
Log Setting...
(2) General Tab->Add Counters,添加需要监测的计数器(可参考如上的计数器列表)
(3) General Tab->Interval,设置监测的时间间隔(默认是15s)
(4) Log Files Tab->Log file type,选择Log File保存的方式(text
File,Binary File,SQL Database),这里我选择text File(Tab delimited).
(5) Schedule Tab,设置监测的开始时间及结束时间.
4.分析(我做测试监测的时间段(2010/7/7 10:30-23:59))
在监测一段时间之后,你就会得到Server重要的性能计数器信息,接下来就可以分析Server的性能.
我是借助数据透视图来做的,看起来会比较直观.
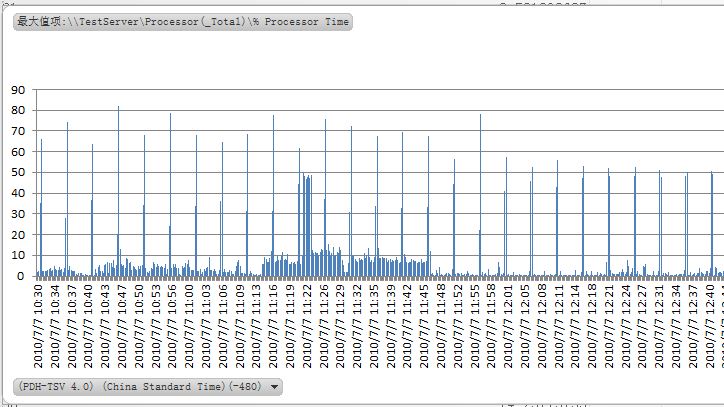
4.1 CPU使用率.分析%Processor Time(_Total)(所用时间的百分比,横轴取时间,竖轴取%Processor
Time)
如下图在2010/7/7 10:30-12:40和2010/7/7 16:44-18:48这两段时间内CPU的使用率很高基本上都在50%以上.尤其在17:00-17:12,17:53-18:00CPU很繁忙,在这段时间会有大量的事务需要处理(T-SQL查询,SP,后台job,
User操作等等).
如果CUP使用率一直居高不下(持续80%到90%的状态),就要考虑升级CPU, 增加更多的处理器或者系统调优(建议先做系统调优,升级硬件需要增加额外的成本).

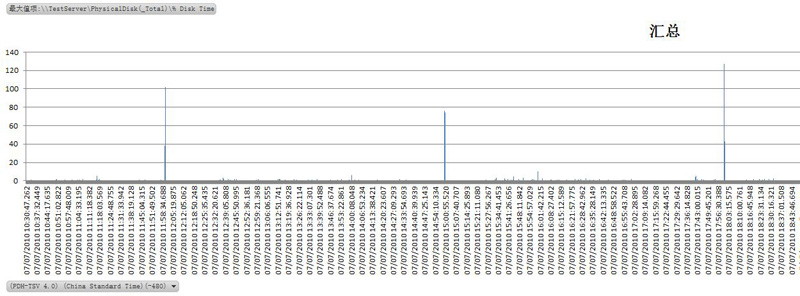
4.2 磁盘I/O(%Disk Time,磁盘忙于读/写活动所用时间的百分比)
监视磁盘活动涉及到两个主要方面:
(1)监视磁盘I/O及检测是否有过度换页
(2)隔离SQL Server产生的磁盘活动
从做的数据透视图来看,磁盘I/O的读写很清闲,只在11:58,15:00,18:00,23:45左右(图上没有截出来)会有较大的IO.
如果磁盘I/O很高(>90%),则考虑更换快速磁盘(如固态硬盘等).
请参考微软给出的解决方案:
监视磁盘 I/O 及检测过度换页
可以对下面两个计数器进行监视以确定磁盘活动:
- PhysicalDisk: % Disk Time
- PhysicalDisk: Avg. Disk Queue Length
在系统监视器中,PhysicalDisk: % Disk Time 计数器监视磁盘忙于读/写活动所用时间的百分比。如果
PhysicalDisk: % Disk Time 计数器的值较高(大于 90%),请检查PhysicalDisk:
Current Disk Queue Length 计数器了解等待进行磁盘访问的系统请求数量。等待 I/O
请求的数量应该保持在不超过组成物理磁盘的轴数的 1.5 到 2 倍。大多数磁盘只有一个轴,但独立磁盘冗余阵列
(RAID) 设备通常有多个轴。硬件 RAID 设备在系统监视器中显示为一个物理磁盘。通过软件创建的多个
RAID 设备在系统监视器中显示为多个实例。
可以使用 Current Disk Queue Length 和 % Disk Time 计数器的值检测磁盘子系统中的瓶颈。如果
Current Disk Queue Length 和 % Disk Time 计数器的值一直很高,则考虑下列事项:
- 使用速度更快的磁盘驱动器。
- 将某些文件移至其他磁盘或服务器。
- 如果正在使用一个 RAID 阵列,则在该阵列中添加磁盘。
如果使用 RAID 设备,% Disk Time 计数器会指示大于 100% 的值。如果出现这种情况,则使用
PhysicalDisk: Avg.Disk Queue Length 计数器来确定等待进行磁盘访问的平均系统请求数量。
I/O 依赖的应用程序或系统可能会使磁盘持续处于活动状态。
监视 Memory: Page Faults/sec 计数器可以确保磁盘活动不是由分页导致的。在 Windows
中,换页的原因包括:
如果在同一硬盘上有多个逻辑分区,请使用 Logical Disk 计数器而非 Physical Disk
计数器。查看逻辑磁盘计数器有助于确定哪些文件被频繁访问。当发现磁盘有大量读/写活动时,请查看读写专用计数器以确定导致每个逻辑卷负荷增加的磁盘活动类型,例如,Logical
Disk: Disk Write Bytes/sec。
隔离 SQL Server 产生的磁盘活动
可以进行监视以确定由 SQL Server 组件生成的 I/O 活动量的两个计数器为:
- SQL Server:Buffer Manager:Page reads/sec
- SQL Server:Buffer Manager:Page writes/sec
在系统监视器中,这些计数器通过检查以下操作的性能监视由 SQL Server 组件生成的 I/O 活动量。
如果这些计数器的值达到硬件 I/O 子系统的容量限制,则需要减小这些值,方法是调整应用程序或数据库以减少
I/O 操作(如索引覆盖、索引优化或规范化),增加硬件的 I/O 容量或添加内存
4.3 缓存命中率(Buffer Cache Hit Ratio)
根据检测的数据来看,缓存命中率基本上在99.99%-100%之间,表示数据缓存几乎满足所有的数据请求.
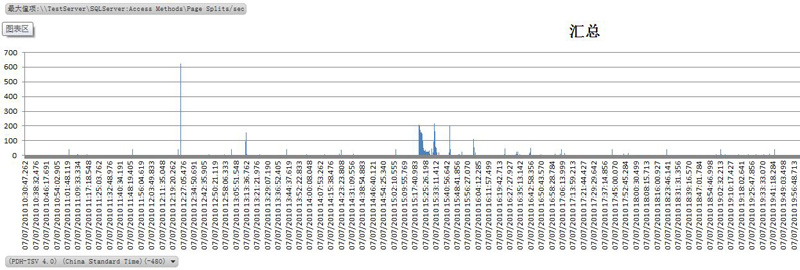
4.4 页拆分(Page Splits/sec,每秒由于索引页益处而发生的页拆分数)
如果页拆分很频繁,可以考虑增加填充因子(我设置的Index fill factor为85,也就是每个页会留有15%的空间做数据填充).
从我做的检测来看,只有在很少的时间段内会有较大的页拆分,此时可能会有大量的数据事务操作.总体来看性能还好.
4.5 每秒日志刷新数目(Log Flushes/sec)
日志刷新发生在当transaction提交, 数据从日志缓存写入磁盘日志文件时. 应该尽可能的减少日志刷新.
如果检测到数值一直很高的话,说明transaction非常活跃,就要减少transaction数.
这里有一个简单的示例来说明:
比如说要向Table中Insert 1w条数据
做法1: 一条一条的Insert,一个transaction一条. 会产生1w个log flushes
做法2: 1w条数据在一个transaction Insert.只产生1个log flushes
明显的第二种产生的日志刷新会大大减少,相应的磁盘I/O也大大减少.从而有助于提高性能.
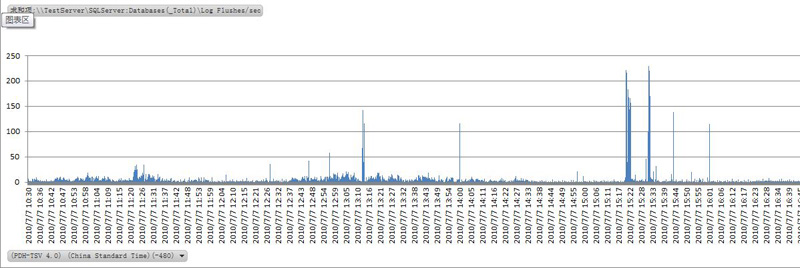
总结:
(1). 还有很多的日志记录没有做一一的简单分析.
(2). Performance Monitor只是提供一个方法来帮助发现问题,提供一个性能优化的方向.
一旦影响性能的问题找到了,就可以从这个方向来着手处理.
(3). 网上有很多性能检测的工具,大抵应该是把如上所做的工作封装起来,并且UI上面已经分析好,更加的直观.
(4). 如果写的有不当之处,欢迎指出指正,谢谢!
另:
参考文章:http://www.sql-server-performance.com/tips/sql_server_performance_monitor_coutners_p1.aspx
微软对计数器更详细的描述:http://technet.microsoft.com/en-us/library/ms190382.aspx
| 

