Step
by Step (1)
���ԣ�һֱ�ڴ������ݿ������ƹ�����Ҳ����һЩ�鼮�����������ĵá��ܾ�֮ǰ������Թ�ϵ���ݿ���ƽ����������ܽᣬ����Ϊ����ԭ��ٳ�û�ж��֣���Ҫ���Ƕ���ʹȻ������Ҳ����ʹ�¾��Ŀ�ʼ�������������˷ܵĹ������⽫��һ��ϵ�е����£��ҽ��Խ���ʽ�Ŀ���չ�����ۣ�����͵����������ܽ�ֱ����ȥ��˾��ѵ�����ã���
ϵ�еĵ�һ�����������ش����漸������

���ݿ��Ǵ�¥�ĸ���
���������Ա���ܼ��У����˽��������֮��ϣ���ܿ�Ľ��뵽����Σ�����ֻ�в���������ܷ�ӳ�����������������ݿ����˼���ñȽ��١�
���ϵͳ������������������������ϵͳ�����⣬�磺�����������ݣ����ܲ�����ά�����ӵȣ�����ǰ�����ݿ�����������еĹ�ϵ���������ʱ�����������ݿ���ƻ�����Ż���ͬ���Ʒ�������
�Ҿ������������������������졣��������ᾭ��ͼֽ��ƣ�ģ���������������죬С��������������������������Ȳ��衣�������̻�����ۣ���һ�����ǽ�����ǰһ������ȷ��ǰ�����֮�ϵġ������ͼֽ��ƽη�����һ���©�����ǿ������½���ͼֽ��ƣ����������������η������������ô���Ǿ�Ҫ�Ѵ�ͼֽ��Ƶ���������Ľ�������Խ�����淢������ϵ����⣬�������Ĵ���Խ���ĵ��Ѷ�ҲԽ��
���ݿ�������Ӧ�õĸ�����û�м�ʵ�ĸ���������Ӧ��Ҳ���᧿�Σ�ˡ�
ǿ������ݿ���Բ������Ҳ����Ϊ��
�ִ����ݿ����ϵͳ��DBMS���ṩ�˷����ͼ�λ����湤�ߣ�ͨ����Щ���߿��Ժܷ���Ĵ������������У���������Ƴ��Ľṹ����
��ϵ���ݿ�������dz��õ����ԣ�����Ʋ�����ʹ��Щ���Բ��ֻ���ȫ��ɥʧ��
�������������¼������ݿⲻ�������ɵij�����
1. ����һ���Ե�ɥʧ
һ����������ϵͳ��ά���ſͻ��Ϳͻ��µĶ�����Ϣ��ʹ�ø�ϵͳ���û��ڽӵ��ͻ����ջ���ַ�ĵ绰����ϵͳ�Ŀͻ���Ϣҳ��Ѹÿͻ����ջ���ַ�������ģ���ԭ�ȸÿͻ��Ķ��������ʹ��˵�ַ��
2. ���������Ե�ɥʧ
��˾ս��ת�ƣ�������ij������ϵͳ������Ա˳�ְѸõ�����������Ϣ��ϵͳ�н���ɾ����ϵͳ��ʾɾ���ɹ��������������ˣ��ͷ���Ա���ָõ�������ʷ����ҳ��һ�ͳ�����
3. ���ܵ�ɥʧ
һ��������ϵͳ���ֿ����Աʹ�ø�ϵͳ��¼ÿһ�ʽ�������������ܲ鿴��ǰ������Ŀ���������ϵͳ���м����ºֿ����Ա���ִ�ǰ���ҳ���÷dz�������������������Խ��Խ����
������Щ���������������ݿ���Ʋ�����ɵģ���Դ���������ʱ�����������ֶΣ�û����ƺ�����Լ����������û�н��г�����Ƶȣ����������Ҳֻ�Dz�һ�ڡ�

���ݿ�ƽ̨����
�������ϵ�в��������۵����ݿ���Ʋ�����κ�һ����ϵ���ݿ��Ʒ��������ʹ�õ���Oracle��SQL Server��Sybase������ǿ�Դ���ݿ��磺MySQL��SQLite�ȣ�����������ʵ�������������۵���Ʒ�������������������ϵ�в��ĵĺ��ĺ���ꡣ
ע���������һ�ѡ��һ�����ݿ��Ʒ��������ʾ����ҿ���ѡ���Լ���Ϥ�����ݿ��Ʒ��ʵ�顣�����������һЩ������ݿ��Ʒ�����ӣ���ҿ�������ѧϰ��
һ��ѧϰ��ͬ����
�����������ݿ����ʦ��Ӧ�üܹ�ʦ����������ʦ�����ݿ����Ա��DBA����������Ŀ�������������Թ���ʦ����Ŀ���Ա�����ܴӸ�ϵ�в����������ջ��һ�����ۣ���ͬ������
�����漰����
�Ҷ���һϵ�в������ڵ��������漰���ݿ���Ƶ��������̡������������ʼ�������ݿ⽨ģ���������ݽ�ģ�������з�ʽ����ֱ��ת��ΪSQL��䡣

������һͷ�������ݿ����֮ǰ���������˽�һ�³��˹�ϵ�����ݿ�֮������ݴ洢��ʽ��
ƽ���ļ���Flat File��
������.txt��.ini��β���ļ���
eg: һ��.ini�ļ������ݣ�
------------------------------------------------------------
[WebSites]
MyBlog=http://www.cnblogs.com/DBFocus
[Directorys]
Image=E:\DBFocus Project\Img
Text=E:\DBFocus Project\Documents
Data=E:\DBFocus Project\DB
------------------------------------------------------------
�ŵ㣺
�ļ��Ĵ洢��ʽ�dz�����ͨ�ı༭�����ܶ�����д���
ȱ�㣺
��֧�ָ��ӵIJ�ѯ
û���κ���֤����
��ƽ���ļ��м�����ݽ��в��롢ɾ��������ʵ������������һ�����ļ�
������
���С�����IJ�Ƶ�������ݣ���Ӧ��������Ϣ
Windowsע���
�������Windowsע���������ϵͳ�����ң��ʲ�����Ѻܶ����ݴ����ע����С�
Windowsע���Ϊ���νṹ�������һЩϵͳ������Ϣ��Ӧ��������Ϣ��
ͨ���Ѳ�ͬ�����ô����ע����IJ�ͬ��֧�ϣ�ʹ��Ӧ�ó���������Ϣ���û�����������Ϣ���롣
eg��ij�ĵ��汾����ϵͳ����ͨ�������뱾�����ϰ�װ���ļ��Ƚ����������������ĵ��Ƚϡ�����һ������������Ϣ���ļ��Ƚ���·�����Դ����ע�����HKEY_LOCAL_MACHINE\SOFTWARE��֧�¡�
ͬʱ���ĵ��汾����ϵͳ�ܼ�¼�û������10���ĵ�·���������û�����������Ϣ�����ڲ�ͬ��Windows�û������10���ĵ����Բ�ͬ����Щ������Ϣ�ɴ����ע�����HKEY_CURRENT_USER\Software��֧�¡�
Excel������Spreadsheets��
�ŵ㣺
Excel �dz��ռ����û�����Spreadsheet�ı�����ʽ�dz���Ϥ
���Խ��м�ͳ�ƣ����������ͼ��
ȱ�㣺
������������Spreadsheet֮���ϵ���ӵ����
��Ӧ�Ը��Ӳ�ѯ
������֤������
������
���������Ƿdz���İ칫�Զ�������
XML
XML��һ�ְ�ṹ�������ݡ�����ڳ��ı�������ԣ�HTML�������ǩ�ǿ������ж���ģ�������չ�ġ�
eg��һ��XML�ļ�����
-----------------------------------------------------
<?xml version=��1.0�� encoding=��UTF-8�� ?>
<ClassSchedule>
<Class Name=��Psychology�� Room=��Field 3��>
<Instructor>Richard Storm</Instructor>
<Students>
<Student>
<FirstName>Ben</FirstName>
<LastName>Breaker</LastName>
</Student>
<Student>
<FirstName>Carol</FirstName>
<LastName>Enflame</LastName>
<NickName>Candy</NickName>
</Student>
</Students>
</Class>
</ClassSchedule>
-----------------------------------------------------
XML�ļ��м����ص㡣
���ȣ�XML��ǩҪ���ϸ��Ӧ���Ҳ��ܳ��ֽ���������
��Σ�XML�ļ�������һ�����ڵ㣬�ýڵ������������Ԫ�ء�
������ͬ����IJ�ͬ�ڵ��ڲ��ذ�����ͬ��Ԫ�أ��������еڶ���ѧ��Carol��һ���ر�Ľڵ�NickName���������ʹ����ijЩ������XML�ȹ�ϵ���ݿ����Ӧ�Ա仯��
�ŵ㣺
��Ȼ�IJ���ͽṹ
�ı�����ͨ����ǩ���Խ��͵�
ͨ��XSD��XML Schema���ԣ�������֤XML�Ľṹ
�����ศ���ͼ����磺XPath, XQuery, XSL, XSLT��
һЩ��ҵ���ݿ⣨��Oracle��SQL Server����֧��XML���ݵĴ洢�����
ȱ�㣺
���ݵ�������Ϣ�϶�
��֧�ָ��ӵIJ�ѯ
��֤��������
��XML�м�����ݽ��в��롢ɾ��������ʵ����������һ�����ļ�
������
�ʺϴ�������������в���ͽṹ�����ݣ�������������Ϣ
NoSQL���ݿ�
�ǹ�ϵ�����ݿ��ҽӴ��IJ��Ǻܶ࣬���˸���һЩ��Ʒ����֮�ⲻ���ܶ�չ������������һЩ���£��������Ҳ���������ӹ����ѧϰ���о���
1. Key-Value���ݿ�
Redis, Tokyo Cabinet, Flare
2. �����ĵ������ݿ�
MongoDB, CouchDB
3. ����ֲ�ʽ��������ݿ�
Cassandra, Voldemort
�⼸��NoSQL�dz��ȡ�����ΪNoSQL�����ǡ�����������ijЩSNSӦ�ó�����NoSQL��ʾ������Խ�ԣ������������ҵ�ȶ����ݵ�һ���ԡ������ԡ������ԡ������Ը�Ҫ��ij����£����ڵ�NoSQL��δ�����á�����Ӧ��ַ���Ӧ�õ����dz�������ѡ�����Ͳ�Ʒ��

��Ҫ���ݻع�
1.���ݿ���ƶ���������Ŀ�ɹ��Ĺؼ�����
2.���γ������ݿ��Ʒ�أ���������Ƶ�����ͷ���
3.�������ݴ洢�����õij���
Step by Step (2)
���ԣ����ݿ���� Step by Step (1)�õ���ô�����ѵĹ�ע��ʵ�������ҵ����⡣��Ҳ�ᶨ���Ұ���һϵ�еIJ���д�õľ��ġ����������ϵ�����ȽϷ��أ���֮���������ϵ�е������ܾ����ܵ�ϵͳ����������Ҫ���ܶ�ʱ��������˼�����ݿ���Ƶĸ������ϣ��������µĸ����ٶȿ��ܻ���һЩ��Ҳϣ������ܹ��½⡣
ϵ�еĵڶ������ǽ�վ�ڸߴ����һ�����ݿ���������ڣ��˽����ݿ���Ƶ���������

���ݿ���������
��Ҷ������������ڽ�Ϊ��Ϥ�����ݿ�Ҳ�����������ڣ�����ͼ��ʾ��
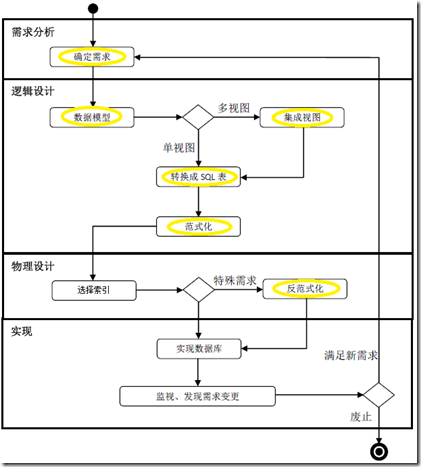
ͼ��1�����ݿ���������
���ݿ������������Ҫ��Ϊ�ĸ��Σ��������������ơ�������ơ�ʵ��ά����
���ϵ�еIJ��Ľ���Ҫ��ע���ݿ����������е�ǰ�����Σ��������������ƣ��������漰����ʽ����Ƶ�һЩ���ݡ���ͼ�и���Ȧ���IJ��֡�
���ݿ��������ƣ�����������ѡ�����Ż������ݷ��������ݡ���Щ����Ҳ�dz��ḻ�����ҿ����Գ���ϵ������Ҳ�кܶ�����£����ڱ�ϵ���в�����Ҫ��ע�����������һЩ���ӹ���Ҳο���
���ݿ��������ڵ��ĸ�������ϸ��Ϊ���С���裬�������ͼ��1��������ÿһС�����������ݡ�
��1 �������
���ݿ�������������һ��������Ҫ�������������
������Ҫ�����ݵĴ����ߺ�ʹ���߽��з�̸���Է�̸��õ���Ϣ������������������д��ʽ�������ĵ���
�����ĵ������������Ҫ���������ݣ����ݵ���Ȼ��ϵ�����ݿ�ʵ�ֵ�Ӳ������������ƽ̨�ȣ�

ͼ��2����1 �������
��2 �����
ʹ��ER��UML��ģ������������������ģ��ͼ��չʾ���������Լ����ݼ��ϵ�����ո�������ģ�ͱ��뱻ת��Ϊ��ʽ���ı���
���ݿ��������Ҫ���������
a) �������ݽ�ģ
�����������ɺ�ʹ��ERͼ��UMLͼ�����ݽ��н�ģ��ʹ��ERͼ��UMLͼ���������е����壬���õ������ݸ���ģ�ͣ�Conceptual
Data Model�������磺��Ԫ��ϵ��ternary relationships�������ࣨsupertypes�������ࣨsubtypes���ȡ�
eg: �������ӽǣ���Ʒ/�ͻ����ݿ��ERģ�ͼ�ͼ
ע��ERͼ�ĺ��壬�Լ���ϸ��Ƿ������ڸ�ϵ�е���һƪ�����н�������
ͼ��3����2(a) �������ݽ�ģ
b) ����ͼ����
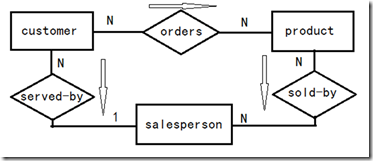
���ڴ�����Ŀ��ƻ���˲�����Ƶ�����£���������ݺ�ϵ�Ķ����ͼ����Щ��ͼ������л����뼯�ɣ�����ģ���е������벻һ�£������γ�һ��ȫ�ֵ�ģ�͡�����ͼ���ɿ���ʹ��ER��ģ�����е�ͬ���(synonyms)���ۺ�(aggregation)������(generalization)�ȷ���������ͼ���������϶��Ӧ�õij�����Ҳ�dz���Ҫ��
eg: ����������ERͼ��ͻ�ERͼ
������ERͼ��ͼ��3����ʾ���ͻ��ӽǣ���Ʒ/�ͻ����ݿ��ERģ�ͼ�ͼ���£�
ͼ��4���Կͻ�Ϊ��ע����Ƶ�ERͼ
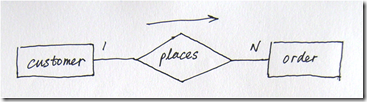
ע�����������������ศ����ģ���߿��Ի���ERͼ��ʹ��Sybase��PowerDesigner������ͼ��4����ͬ�����ERͼ���£�
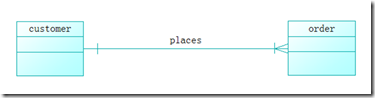
���Ƿ���ͼ��4�������в�ͬ���⽫�ڽ��IJ����м���˵����
������Ҫָ�����Ǹ���������ʹ�ò�����Ƶĺ��ģ���Ҳ�Ҫ����Щ�����Ի����Ժ��������ǽ���Ҫʹ���ֻ档ֻҪ������ERͼ�����壬ʹ����Щ�����������Ǽ����¡�
����������ERͼ��ͻ�ERͼ
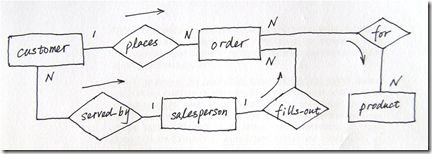
ͼ��5�� ��2(b) ����ͼ����
c) ת����������ģ��ΪSQL��
����ӳ�����ERͼ�е�ʵ�����ϵת��ΪSQL���ṹ������һ���������ǽ�ʶ������ı�����ȥ����Щ����
eg: ��ͼ��5���е�customer, product, salespersonʵ��ת��ΪSQL��

ͼ��6�� ��2(c)ת����������ģ��ΪSQL��
d) ��ʽ��
��ʽ�������ݿ�������е���Ҫһ������ʽ����Ŀ���Ǿ�����ȥ��ģ���е�������Ϣ���Ӷ�������ϵģ���¡����롢ɾ���쳣��anomalies����
������ʽ���ͻ���������������Functional Dependency����һ�����������(FDs)Դ���ڸ�������ģ��ͼ����ӳ����������е����ݹ�ϵ���塣��ͬʵ��֮��ĺ���������ʾ����ʵ��Ψһ��֮���������ʵ���ڲ�Ҳ�к�����������ӳ��ʵ���м�������Ǽ�����֮����������ڱ�֤����������Լ����ǰ���£����ں��������Ժ�ѡ�����з�ʽ�����ֽ⡢�����������ࣩ��
eg: ��ͼ��6���е�Salesperson�����з�ʽ�������������쳣��update anomalies��
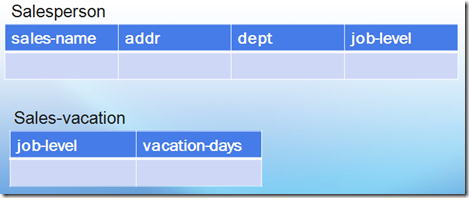
ͼ��7�� ��2(d)��ʽ��
��3 �������
���ݿ�������ư���ѡ�����������ݷ��������ȡ�
����Ʒ���ѧͨ��������Ҫ�������������������˴���ϵ���ݿ����ƣ���Ҳ���������ݿ�������ƽε�ѹ����
1. �������ݽ�ģ�Ͷ���ͼ����ȷ�ط�ӳ����ʵ����
2. ��ʽ����ģ��ת��ΪSQL���Ĺ����б���������������
���ݿ�������Ƶ�Ŀ���Ǿ������Ż����ܡ�
������ƽΣ�ȫ�ֱ��ṹ������Ҫ�����ع������������ϵ������ⱻ��Ϊ����ʽ����
����ʽ���IJ��������
1. ���ؼ������̣���Ƶ�����С��������������ȼ��Ĵ�������
2. ͨ��������������߹ؼ������̵�����
3. ��������ɵĴ��ۣ��Բ�ѯ���ġ��洢��Ӱ�죩�Ϳ�����ʧ������һ����
��4 ���ݿ��ʵ��ά��
��������֮��ʹ�����ݿ����ϵͳ��DBMS���е����ݶ������ԣ�DDL�����������ݽṹ��
���ݿⴴ����ɺ�Ӧ�ó�����û�����ʹ�����ݲ������ԣ�DML����ʹ�ã���ѯ���ĵȣ������ݿ⡣
һ�����ݿʼ���У�����Ҫ�������ܽ��м��ӡ������ݿ�����������Ҫ����û�����µĹ�������ʱ������Ҫ�Ը����ݿ������������ġ����γ���һ��ѭ��������
�C> ����� �C> �� �C> ���ӡ���

�ڽ������ݿ����֮ǰ�������Ȼع�һ�¹�ϵ���ݿ����ػ������
����ֻ��һ���������ļ�飬��ҿ��Ը�����Ӧ������������չ��
��������
��ϵ���ݿ��������ɱ��ļ��ϣ�ÿ�������������С������������һ��Excel workbook���������worksheet����
���ڹ�ϵ�����б���Ϊ��ϵ����Ҳ�ǹ�ϵ���ݿ����Ƶ���Դ����Ҫ���֮��������ϵ��������
���ڹ�ϵ�����б���Ϊ���ԣ�attribute��������������ŵ�ֵ�ļ��ϳ�Ϊ�е���������������������أ���������ȫ��ͬ����
���ڹ�ϵ�����е�ѧ����Ԫ�飨tuple����
��ϵ���ݿ�����ۻ��������ڡ���ϵ�����������ڹ�ϵ�����У�һ�����ϵĸ���Ԫ��û�д���ĸ���ڹ�ϵ���ݿ���Ϊ�˷���ʹ�ã��������еĴ���
��������
����һ��Լ����Ŀ���DZ�֤����������
1. ���ϼ���Compound key�����ɶ����������ɵļ�
2. ������Superkey�����еļ��ϣ������κ����ж�������ȫ��ͬ
3. ��ѡ����Candidate key����������һ��������ͬʱ��������е��κ��е�ȱʧ�����ƻ��е�Ψһ��
4. ������Primary key����ָ����ij����ѡ��
���������ݵ�������֯��ʽ��Ŀ������߲�ѯ������
Լ��
����Լ��
not null constraint, domain constraint
���Լ����Check Constraints��
eg: Salary > 0
����Լ����Primary Key Constraints��
ʵ�������ԣ�entity integrity����û��������¼����ȫ��ͬ�ģ�����������ֶβ���Ϊnull
Ψһ��Լ����Unique Constraints��
���Լ����Foreign Key Constraints��
Ҳ����Ϊ����������Լ����eg:
��ϵ���ݿ����
1.ѡ��Selection��
2.ӳ�䣨Projection��
3.���ϣ�Union��
4.������Intersection��
5.���Difference��
6.�ѿ�������Cartesian Product��
7.���ӣ�Join��
����7����������Ĺ�ϵ���ݿ��������Ӧ�ڼ������еĹ�ϵ���㡣
��Щ�鼮�л�����������Rename��������Divide���ȹ�ϵ������

��Ҫ���ݻع�
1. ���ݿ��������ڵ��ĸ��Σ��������������ơ�������ơ�ʵ��ά����
2. ��ϵ���ݿ�����ۻ����ǹ�ϵ������
Step by Step (3)
���ԣ����ݿ���� Step by Step (2)�������֮���յ���һЩ�ʼ�����������ֱ�ӵ绰��ѯ��Ϊʲô���������ݿ�������Ʒ�������ݡ������������һ�£����ݿ�������������ݿ��Ʒ��������صģ���ϵ�е�רע���ǽ�Ϊͨ�õ����ݿ���������뷽������Ҳ�ǹ���������Ŀ�����ױ����ӵ�һ�顣�������ǽ�ѧϰʵ���ϵ��ER��ģ�����������壬�������ݿ�����ƵĻ��������ݿ�����Щ�����ȴ�dz���Ҫ�����á�
�������ݱȽ϶࣬���ǽ���������ѧϰʵ���ϵģ������
������������ѧϰ����ʵ���ϵģ�͡�

ʵ���ϵ��ER��ģ�͵�Ŀ���Dz�����ʵ��������������Լ�������ķ�ʽ���ֳ�����ERģ�Ϳ�������Ŀ���ڲ��������������û�����ϵͳ��������
ERģ���еĻ���Ԫ��
������ERģ�Ͱ�������Ԫ�أ�ʵ�塢��ϵ������
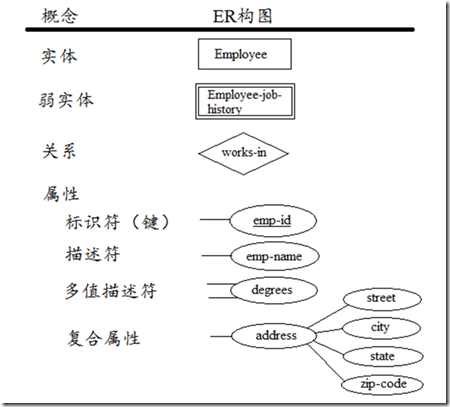
ͼ1 ʵ�塢��ϵ�����Ե�ER��ͼ
ʵ�壨Entities����ʵ������Ҫ�����ݶ������ڱ�ʾһ���ˡ��ط���ij�������ij���¼���һ���ض���ʵ�屻��Ϊʵ��ʵ����entity
instance��entity occurrence����ʵ���ó����ο��ʾ��ʵ������Ʊ�ʶ�ڿ��ڡ�һ�����Ƶ��ʵ�����ĸ��д��
��ϵ��Relationships������ϵ��ʾһ������ʵ��֮�����ϵ����ϵ������ʵ�壬һ��û�����������ϵĴ��ڡ���ϵ�������ʾʵ��֮�䣬һ��һ��һ�Զ࣬��Զ�Ķ�Ӧ����ϵ�Ĺ�ͼ��һ�����Σ���ϵ������һ��Ϊ���ʡ���ϵ�Ķ˵���ϵ�Ž�ɫ��role����һ������½�ɫ������ʡ�ԣ���Ϊʵ������ϵ���Ѿ�������ķ�Ӧ��ɫ�ĸ������Щ���������������ɫ�����������塣
���ԣ�Attributes��������Ϊʵ���ṩ��ϸ��������Ϣ��һ���ض�ʵ���ij�����Ա���Ϊ����ֵ��Employeeʵ������Կ����У�emp-id,
emp-name, emp-address, phone-no����������һ������Բ�α�ʾ������������ʵ�����ӡ����Կɱ���Ϊ���ࣺ��ʶ����identifiers������������descriptors����Identifiers����Ψһ��ʶʵ���һ��ʵ����key���������ɶ��������ɡ�ERͼ��ͨ�����������¼����»�������ʶ����ֵ���ԣ�multivalued
attributes������������ʵ�����ӣ�eg��hobbies���ԣ�һ���˿����ж��hobby����reading��movies�������������ԣ�Complex
attributes�����������������ԡ�
���ǿʵ������ʵ�壺ǿʵ���ڲ���Ψһ�ı�ʶ������ʵ�壨weak entities���ı�ʶ��������һ����������ǿʵ�塣��ʵ����˫�߳����ο��ʾ��������ǿʵ������ڡ�
���������ϵ
��ϵ��ERģ���а����˷dz���Ҫ�Ľ�ɫ��ͨ��ERͼ��������ʵ����ϵ�Ķȡ���ͨ������������Ϣ��
����һһ��������Щ���������������һ�¹�ϵ��ERͼ�еĸ������塣
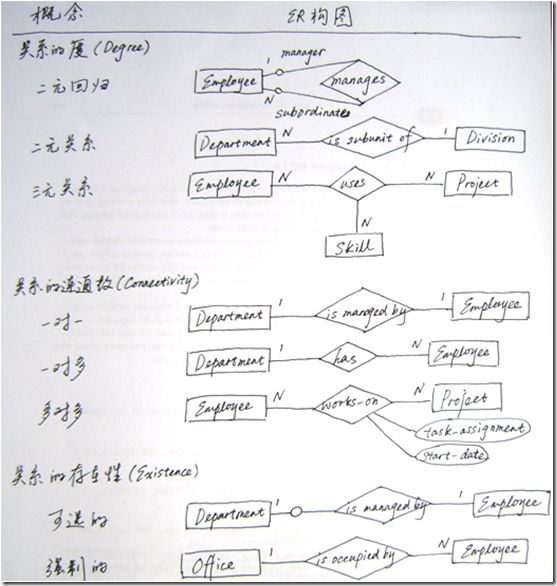
ͼ2 ��ϵ�Ķȡ���ͨ����������
��ϵ�Ķȣ�Degree of a Relationship��
��ʾ��ϵ��������ʵ����������Ԫ��ϵ����Ԫ��ϵ�Ķȷֱ�Ϊ2��3���Դ˿���������nԪ����Ԫ��ϵ������Ĺ�ϵ��
һ��Employee����һ��Employee֮����쵼��ϵ��Ϊ��Ԫ�ع��ϵ����ͼ2����ʾ��Employeeʵ��ͨ����ϵmanages���������ӡ�����Employee����һ��ϵ�а���������ɫ���ʱ���˽�ɫ����manager��subordinate����
��Ԫ��ϵ��ϵ����ʵ�塣����Ԫ��ϵ��ȷ��������������ʱ������Ҫʹ����Ԫ��ϵ��������������������ӣ���ͼ��1���ܷ�ӳ��һ��Employee��ij��Project��ʹ����ʲôSkill����ͼ��2��ֻ�ܿ���Employee��ʲôSkill����������ЩProject������֪����ij��Project��ʹ�õ��ض�Skill��
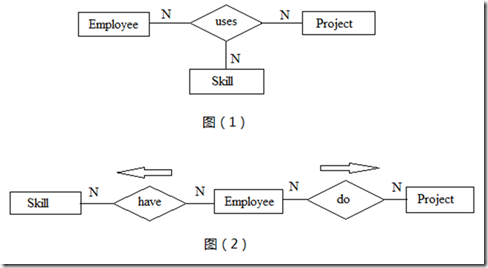
ͼ3 ��Ԫ��ϵ�̺�������
��Ҫע�������Щ����»����Ķ�����Ԫ��ϵ����Щ��Ԫ��ϵ�ɷֽ�Ϊ2����3����Ԫ��ϵ�����ﵽ����������Ĵ������Ժ�IJ����л��һ����ϸ������Ԫ��ϵ��
һ��ʵ����Բ��뵽��������ϵ�С�ÿ����ϵ������ϵ������Ԫ��ʵ�壩����������ʵ��֮��Ҳ������������Ԫ��ϵ��
��ϵ����ͨ����Connectivity of a Relationship��
��ʾ��ϵ��������ʵ��������Լ����
��ͨ����ֵ�����ǡ�һ���ࡱ����һ����һ�ˣ���ERͼ��ͨ����ʵ�����ϵ���ǡ�1����ʾ�����ࡱһ�˱�ǡ�N����ʾ����ͼ2�й�ϵ��ͨ�����֣���һ���ԡ�һ����Department
is managed by Employee����һ���ԡ��ࡱ��Department has Employees�����ࡱ�ԡ��ࡱ��Employee
may work on many Projects and each Project may have
many Employees��
��Щ����������ͨ����ȷ���ģ���������ֵ����N���磺�ᄊ�Ӷ�Ա��12�ˡ�
��ϵ������
��ϵҲ�������ԡ�����ͼ4��ʾ��ijԱ������ij��Ŀ����ʼ���ڣ�ijԱ����ij��Ŀ�б����������ֻ�з��ڹ�ϵworks-on�ϲ������塣
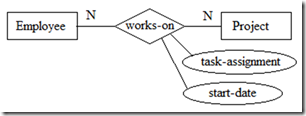
ͼ4 ��ϵ������
��Ҫע����ǹ�ϵ������һ������ڡ��ࡱ�ԡ��ࡱ�Ķ�Ԫ��ϵ����Ԫ��ϵ�ϡ�һ�㡰һ���ԡ�һ����һ���ԡ��ࡱ��ϵ�ϲ�������ԣ����������壩��������Щ���Կ�������һ�˵�ʵ���С�����ͼ5��ʾ�����������Ա����������֮���ǡ�һ���ԡ�һ����ϵ���ڽ�ģ�п��ܰ�start-date��Ϊ��ϵis
managed by�����ԣ���ʾ���ӹܵ�ʱ�䣩��������Կ�������Department��Employeeʵ���С�

ͼ5 �����뾭��֮���һ��һ������ϵ
��ҿ���˼��һ��������ź;���֮���ǡ��ࡱ�ԡ��ࡱ��ϵ����������������ֻ�������
��ϵ��ʵ��Ĵ����ԣ�Existence of an Entity in a Relationship��
��ϵ��ʵ��Ĵ����Կ�����ǿ�ƵĻ��ѡ�ġ�����ϵ�е�ijһ��ʵ�壨�����ǡ�һ���ࡱ�ˣ��������Ǵ��ڣ����ʵ��Ϊǿ�Ƶġ���֮����ʵ��Ϊ��ѡ�ġ�
��ʵ�����ϵ֮����������ϱ�ʶ��0������ʾ��ѡ�����ԡ���������С��ͨ��Ϊ0��
ǿ�ƴ����Ա�ʾ��С��ͨ��Ϊ1���ڴ����Բ�ȷ����֪������£�Ĭ����С��ͨ��Ϊ1��
��ERͼ�������ͨ����ʽ�ر�ʶ��ʵ���Աߡ���ͼ6��ʾ�����̺�������Ϊһ��Department����ֻ��һ��Employee����������һ��Employee������һ��Department�ľ�����Ҳ���ܲ��ǡ�
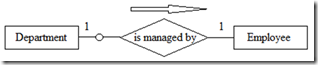
ͼ6 ��ϵ��ʵ��Ĵ�����
������������ģ�ͱ�Ƿ�
ǰ����ʹ�õ�ER��ͼ������Peter Chen 1976������ġ����ִ����ݿ������������������ERģ�ͱ�Ƿ���
��������һ����һ��ʹ�ý϶�ı�Ƿ�����crow��s-foot������β�ƣ���Ƿ�������ǰ����ܵı�Ƿ�����һ���Աȡ�
ѧϰÿһ�ֱ�Ƿ�û�����塣�������֯���ƹ�Ӧ��һ�ֱ�Ƿ���ʹ���Ϊ��ҹ�ͨ�ġ����ԡ���
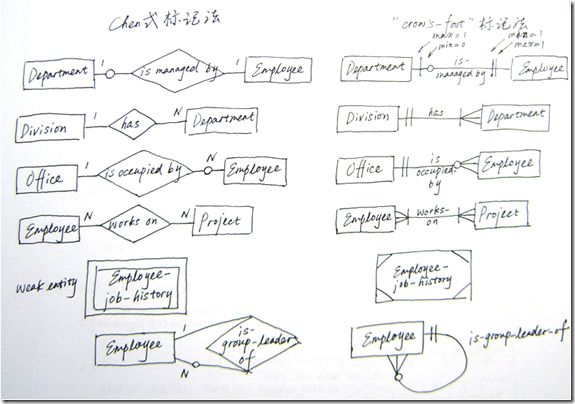
ͼ7 Chenʽ��Ƿ���crow��s-foot��Ƿ�����

��Ҫ���ݻع�
1. ���ERģ�͵Ļ���Ԫ�ذ�����ʵ�塢��ϵ������
2. ���������ϵ�а��������壺��ϵ�Ķȡ���ϵ����ͨ������ϵ�Ĵ�����
3. �˽�ERģ�͵IJ�ͬ��Ƿ�����������һ�ֱ�Ƿ������������Ŀ���ƹ�ʹ��
Step by Step (4)
���ԣ����ݿ���� Step by Step (3)�����������˻���ʵ���ϵģ�����������塣��Щ����dz���Ҫ���ǽ�����һ���Ļ������ڿ�ʼ��������֮ǰ�����ҿ����ٻع�һ����һƪ�����ݡ��������ǽ����۸�ʵ���ϵģ����������һƪһ����ERģ��ͼ�Ĵ����ݡ���Ԫ��ϵ�ǽ�����һ�����ѵ㣬��ҿ����ص��ע��

������Generalization������������������
ԭʼ��ERģ���Ѿ����������������ݺ�ϵ����������Generalization������������ܷ�������������ģ�͵ļ��ɡ�
������ϵ��ָ��ȡ���ʵ��Ĺ�ͬ������Ϊ����ʵ�塣������ι�ϵ�еĵͲ��ʵ�塪�������ͣ��Գ���ʵ���е����Խ��м̳������ӣ����������⻯�˳����͡�
ERģ���еķ���������������еļ̳и������ƣ������Ƿ�����ͼ��ʽ����Щ���졣
��ͼ��ʾԱ���뾭��������ʦ������Ա������֮��ķ�����ϵ��EmployeeΪ����ʵ�壬��������ͬ���ԣ�Manager��Engineer��Technician��Secretary����Employee������ʵ�壬�����ܰ����������е����ԡ�
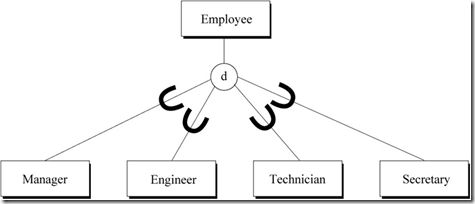
ͼ1 Employee��Manager��Engineer��Technician��Secretary֮��ķ�����ϵ
�������Ա��������͵�������ҪԼ�����ص���Լ����disjointness�����걸��Լ����completeness����
�ص���Լ����ʾ����������֮���Ƿ��������ġ���Ϊ������������ĸ��d����ʶ�������á�o����ʶ��o
-> overlap����ͼ1�и�����ʵ��������������ġ�
��Ա�����ͻ�ʵ����з��������������ʵ����ˣ��õ����¹�ϵͼ�����ڲ���EmployeeҲ������Customer��������ʵ��Employee��Customer֮��������ص��ġ�
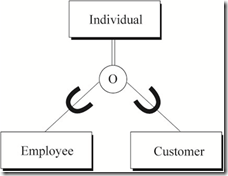
ͼ2 Individual��Employee��Customer֮��ķ�����ϵ
�걸��Լ����ʾ�����������ڵ�ǰϵͳ���Ƿ�����ȫ���dz����͡�������ȫ�������ڳ�������ԲȦ֮����˫�߱�ʶ������˫������Ϊ�Ⱥţ�����ͼ2������ʵ��Employee��Customer����ȫ���dz���Individualʵ�塣
�ۺϣ�Aggregation��
�ۺ����뷺������ͬ����һ�ֳ������������ͼ�ij���
������ʾ��is-a�����壬�ۺϱ�ʾ��part-of�����塣�ۺ����������볬���ͼ�û�м̳й�ϵ��
�ۺϹ�ϵ�ı�Ƿ�����ԲȦ�б�ʶ��ĸ��A������ʾ��
��ͼ��ʾ������Ʒ�ɳ������û��ֲ���ɡ�
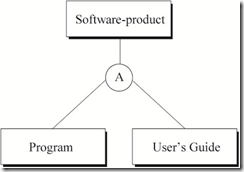
ͼ3 Software-product��Program��User��s Guide֮��ľۺϹ�ϵ
��Ԫ��ϵ��Ternary Relationships��
��ͨ����Ԫ��ϵ��ȷ��������ʵ������ϵʱ��������Ҫʹ����Ԫ��ϵ��
��Ԫ��ϵ�С���ͨ������ȷ��������
a) ����Ԫ��ϵ�е�һ��ʵ����Ϊ���ģ�����������ʵ�嶼ֻ��һ��ʵ��
b) ������ʵ��ֻ��һ��ʵ������������ʵ���һ��ʵ�����й�����������ʵ�����ͨ��Ϊ��һ��
c) ������ʵ���ж���һ��ʵ������������ʵ��ʵ�����й�����������ʵ�����ͨ��Ϊ���ࡱ
ע��ʲôʱ����Ҫʹ����Ԫ��ϵ��ʵ����ο������ݿ���� Step by Step (3)�еġ���ϵ�Ķȣ�Degree
of a Relationship����С�ڡ���ϵ�ġ���ͨ����������ο������ݿ���� Step by Step
(3)�еġ���ϵ����ͨ����Connectivity of a Relationship����С�ڡ�
��������������Ԫ��ϵ��ʵ����ע�����ͼ����ϵ�Ķ������������е����塣
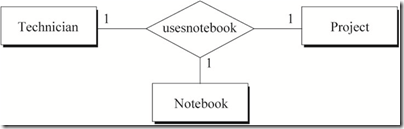
4 ����Ա����Ŀ��ʹ���ֲ�Ĺ�ϵ
ͼ4���̺�������Ϊ��
a) һ������Ա����ÿһ����Ŀʹ��һ���ֲ�
b) ÿһ���ֲ����ÿһ����Ŀ����һ������Ա
c) һ������Ա�������������Ŀ�����ڲ�ͬ����Ŀά����ͬ���ֲ�
����ѧ�еĺ���������ʾͼ4�Ĺ�ϵ��
a) emp-id, project-name -> notebook-no
b) emp-id, notebook-no -> project-name
c) project-name, notebook-no -> emp-id
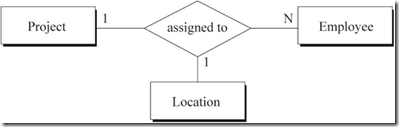
ͼ5 Ա�������䲻ͬ�ص����Ŀ֮��Ĺ�ϵ
ͼ5���̺�������Ϊ��
a) ÿһ��Ա����һ���ص�ֻ�ܱ�����һ����Ŀ���������ڲ�ͬ�ص�����ͬ����Ŀ
b) ��һ���ض��ĵص㣬һ��Ա��ֻ����һ����Ŀ
c) ��һ���ض��ĵص㣬һ����Ŀ�����ɶ��Ա������
����ѧ�еĺ���������ʾͼ5�Ĺ�ϵ��
a) emp-id, loc-name -> project-name
b) emp-id, project-name -> loc-name
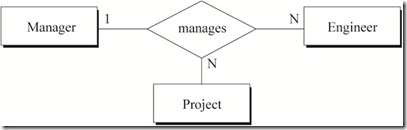
ͼ6 ����������Ŀ�빤��ʦ�Ĺ�ϵ
ͼ6���̺�������Ϊ��
a) һ���������µ�һ������ʦ���ܲ�������Ŀ
b) һ������������һ����Ŀ���ܻ��ж�������ʦ
c) ��ijһ����Ŀ��һ������ʦֻ����һ������
����ѧ�еĺ���������ʾͼ6�Ĺ�ϵ��
a) project-name, emp-id -> mgr-id
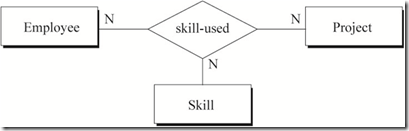
ͼ7 Ա������Ŀ��ʹ�ü��ܵĹ�ϵ
ͼ7���̺�������Ϊ��
a) һ��Ա����һ����Ŀ�п���ʹ�ö��ּ���
b) һ��Ա����һ�ּ��ܿ����ڶ����Ŀ��ʹ��
c) һ�ּ�����һ����Ŀ�п��Ա�����Ա��ʹ��
ͼ7��ʵ��֮��û�к�������
����4����ʽ����Ԫ��ϵ����ͨ��Ϊ��һ����ʵ�����������Ԫ��ϵ��ӳ�ĺ��������������Ŀһ�¡�
��Ԫ��ϵҲ�������ԡ�����ֵ������ʵ��ļ������Ψһȷ����
nԪ��ϵ��General n-ary Relationships��
��Ԫ��ϵ������չ��nԪ��ϵ������n��ʵ��֮��Ĺ�ϵ��
һ����ԣ�nԪ��ϵ��ÿһ����ͨ��Ϊ��һ����ʵ��ļ����������һ��������������ʽ���Ҳࡣ
����nԪ��ϵ��ʹ���������������е�Լ����Խ�Ϊ���ѡ�����ʹ����ѧ��ʽ������������FD�������֡�
nԪ��ϵ�ĺ���������Ŀ�������ϵͼ�С�һ����ʵ���������ͬ��0��n������
nԪ��ϵ�ĺ�����������ʽ����n��Ԫ�أ�n-1��Ԫ�س����ڱ���ʽ��࣬1��Ԫ�س������Ҳࡣ
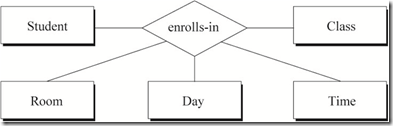
ͼ8 nԪ��ϵͼ��
������Լ����Exclusion Constraint��
һ�㣨Ĭ�ϣ�����£����ֹ�ϵ֮���Ǽ��ݵġ���ϵ�����������������ʵ�������Щ��ϵ��
��ijЩ����£����ֹ�ϵ֮���ǷǼ����ԡ���ϵ���������ϵ��ʵ��ֻ��ѡ������һ�ֹ�ϵ������ͬʱѡ����ֹ�ϵ��
��ͼ��ʾ������Ϊ��һ�������Ҫô����Ϊ�ⲿ��Ŀ�У�Ҫô����Ϊ�ڲ���Ŀ�У�������ͬʱ�����ⲿ��Ŀ���ڲ���Ŀ��

ͼ9 ������Լ����ϵͼ�� | 

