| dz̸SQL Server�е�������־(һ)----������־��������������
���
SQL Server�е�������־������SQL Server������Ҫ�IJ���֮һ����ΪSQL SERVER����������־��ȷ���־���(Durability)������ع�(Rollback)���Ӷ�������ȷ���������ACID����.��SQL Server����ʱ��DBA������ͨ��������־�����ݻָ���ָ����ʱ��㡣��SQL Server��ת����ʱ�����˽�һЩ������־��ԭ�������Եò�������ô��Ҫ�����ǣ�һ��SQL SERVER��������ʱ���˽�������־��ԭ��������ڿ���������ȷ�ľ������ָ������Ե���Ϊ��Ҫ.��ϵ�����½����������־�ĸ��ԭ����SQL Server���ʹ����־��ȷ���־������Եȷ�����̸SQL Server��������־.
������־��������֯����
������־�����Ǽ�¼�����Ӧ���ݿ��ϵ�������Ϊ�Ͷ����ݿ��ĵ���־�ļ�.�����½����ݿ�ʱ�����������ݿ��ļ�������һ��Ĭ����ldfΪ��չ����������־�ļ�. ��Ȼ��һ�����ݿ�Ҳ�������ж����־�ļ������������ϣ����ǿ��Կ���һ��.
��SQL Server������־�ļ��Ĺ������ǽ�����һ��ldf�ļ����ֳɶ�����ϵ�������־�ļ�(virtual log files,���VLFs).�Ա��ڹ������ø���ȷ�����������־�ļ�(ldf)�ñ�һ�˻�ÿһ�ڳ��ᶼ��һ��������־�ļ�(VLFs):

��ΪʲôSQL ServerҪ����־�ļ����ֳ����VLFS�أ���ΪSQL Serverͨ�����ַ�ʽʹ�ô洢�������������־������Ч.���Ҷ�����־�ռ���ظ�����Ҳ����Ӹ�Ч��ʹ��VLF��Ϊ�������ݿ����С��λ��ʹ��ldf�ļ���Ϊ��С��λ�����Ǹ��Ӹ�Ч��.
VLFS�ĸ����ʹ�С��ͨ�����ý����趨,������SQL Server���й���.��Create��Alter���ݿ�ʱ,SQL Serverͨ��ldf�ļ��Ĵ�С������VLFS�Ĵ�С������������־�ļ�����ʱ��SQL ServerҲ�����¹滮VLFS������.
ע�⣺�������ԭ�����ѿ��飬���������־�ļ���������С�������������VLFS,Ҳ������־�ļ���Ƭ���������־�ļ���Ƭ������SQL Server����.
SQL Server�������ݿ�ʱ��������־�ļ�(ldf)�Ĵ�С������VLF��������ʽ����:

������������һ������:
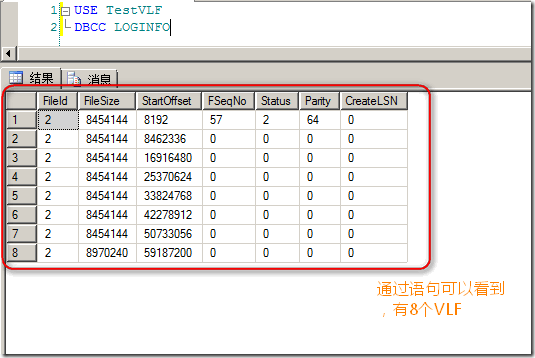
�������ݿ⣬ָ����־��СΪ65M

ͨ��DBCC�����ǿ��Կ�������Ӧ����8��VLFs:
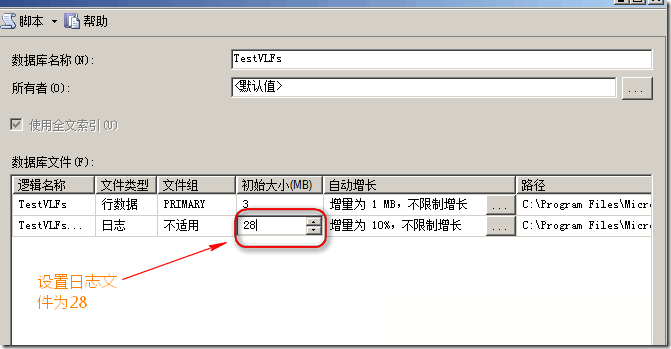
�ٴδ������ݿ⣬ָ����־��ʼ��СΪ28M:
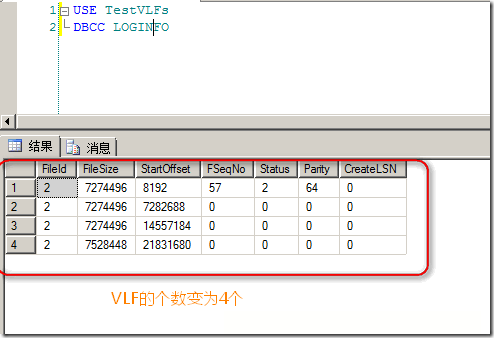
���Կ�������Ӧ�ģ�VLF��������Ϊ4:
��������־�ļ���������SQL Serverʹ���˺ʹ������ݿ�ʱ��ͬ�Ĺ�ʽ��Ҳ����ÿ����������Ϊ2M�����չ�ʽÿ������4��VLFs.
���Ǵ���һ��TestGrow���ݿ⣬ָ����־�ļ�Ϊ2M����ʱ��4��VLFS:
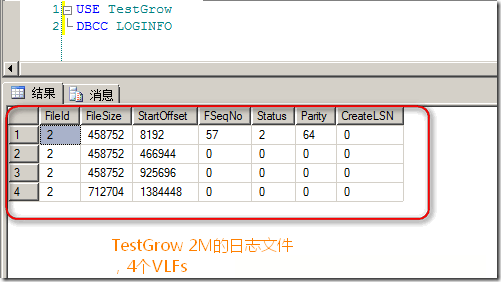
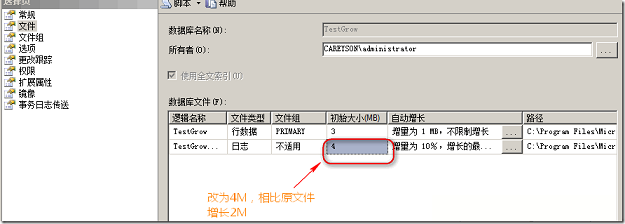
����������2Mʱ�����2M���ǰ��չ�ʽ���ٴη���4��VLFs:
��ʱ����ʱ�ܿ�����VLFs����Ӧ��Ϊ4+4=8��:
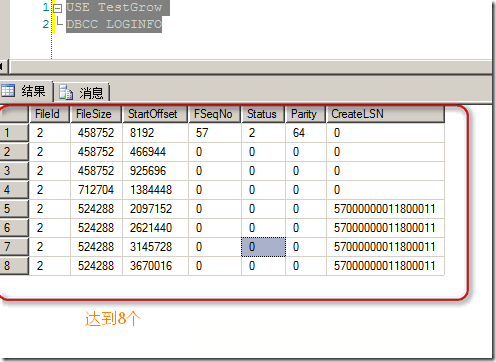
�ɴ˿��Կ�����ָ�����ʵ���־�ļ���ʼ��С���������Ǽ�����־��Ƭ��ؼ��IJ���.
������־������֯����
��������ݿ�����������κ��ı��浽���ݿ�֮ǰ����Ӧ����־���Ȼᱻ��¼����־�ļ��������¼�ᱻ�����Ⱥ�˳���¼����־�ļ�����ĩβ��������һ��ȫ��Ψһ����־���к�(log sequence number,���LSN��,������к���ȫ�ǰ���˳�����ģ������־���������к�LSN2>LSN1,��˵��LSN2����LSN1֮������.
�ɴ˿��Կ���������־�ļ���Ϊ����ļ����˴��̿ռ�Ŀ���֮�⡣��ȫ�����������������Բ��з��ʣ����Խ���־�ļ���Ϊ�����ȫ�����������ϵ�����.
LSN�ſ��Կ����ǽ���־�ļ������¼����֮���Ŧ��.ÿһ����־������LSN�ţ��������Ӧ�����������־:
һ����ͼƬʾ������:
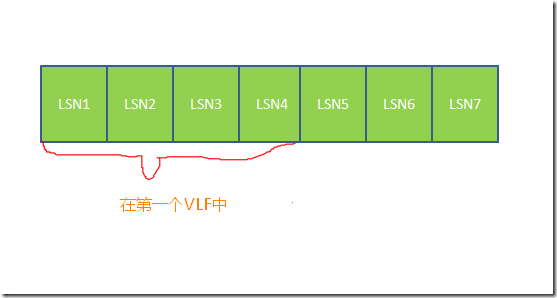
�������͵IJ�������¼��������־�С���Щ����������
- ÿ������Ŀ�ʼ�ͽ�����
- ÿ�������ģ����롢���»�ɾ�����������ϵͳ�洢���̻����ݶ������� (DDL) ������ϵͳ�����ڵ��κα������ĸ��ġ�
- ÿ�η�����ͷ�����ҳ��
- ������ɾ������������
����LSN�����ROLLBACK������ROLL FORWARD���Լ��ڱ��ݻָ������������ã����ں����������ᵽ
�ܽ�
��ƪ���´�������־�������������ܼ�����������־�Ĺ���.��������SQL Server���������־��֤�־��Ժ����ݱ��ݻָ��Ļ�������һƪ���½������SQL Server�ڲ����л����ʹ�õ���־�ļ���
dz̸SQL Server�е�������־(��)----������־��������ʱ�Ľ�ɫ
���
ÿһ��SQL Server�����ݿⶼ�ᰴ����������(insert,update,delete)��˳��Ӧ����־��¼����־�ļ�.SQL Serverʹ����Write-Ahead logging��������֤��������־��ԭ���Ժͳ־���.���������������֤��ACID�е�ԭ����(A)�ͳ־���(D),����������IO�������Ѷ����ݵ����ύ�����̵Ĺ�������lazy-writer��checkpoint.������Ҫ������SQL Server������ʱ�Ĺ����Լ���صļ�����
Ԥдʽ��־��Write-Ahead Logging (WAL)��
SQL Serverʹ����WAL��ȷ���������ԭ���Ժͳ־���.ʵ���ϣ�������SQL Server,�����������Ĺ�ϵ���ݿ����oracle,mysql,db2��ʹ����WAL����.
WAL�ĺ���˼����:������д�뵽���ݿ�֮ǰ����д�뵽��־.
��Ϊ�������ݵ�ÿ���Ķ���¼����־�У����Խ��������ݵ���ʵʱд�뵽���̲�û��̫�����壬��ʹ��SQL Server�����������ʱ���ڻָ�(recovery)��������Щ����д���Ѿ�д�뵽���̵����ݻᱻ�ع�(RollBack),����ЩӦ��д�����ȴû��д������ݻᱻ����(Redo)���Ӷ���֤�˳־���(Durability)
��WAL�������DZ�֤��ԭ���Ժͳ־��ԡ������������.
Ӳ����ͨ����ת����ȡ����,ͨ��WAL������ÿ���ύ�������ݵ����������Ϸ�ӳ�����ݿ��У������ȼ�¼����־.������CheckPoint��lazy Writer��һ���ύ,���û��WAL��������Ҫÿ���ύ����ʱд�����ݿ�:
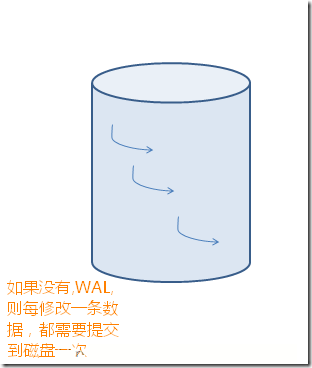
��ʹ��WAL�ϲ�д�룬������ٴ���IO��
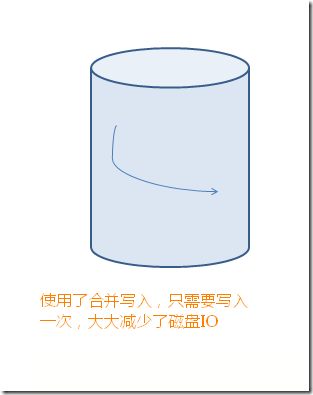
Ҳ����������ʣ���ÿ�ζ����ĵ����ݻ��ǻ�д����־�ļ�.ͬ�����Ĵ���IO����ƪ���½�����ÿһ��д����־�ļ�¼���ǰ����Ⱥ�˳����˳���ŵ�LSN����д��ģ���־ֻ��д�뵽��־�ļ�����ĩ�ˡ��������������������ܻ�д�����̵ĸ����ط�.���ԣ�д����־�Ŀ������д�����ݵĿ���С�ܶࡣ
SQL Server�����ݵIJ���
SQL Server�������ݵ���,���Ϊ���¼�������˳��ִ��:
1.��SQL Server�Ļ���������־��д�롱Begin Tran����¼
2.��SQL Server�Ļ���������־ҳд��Ҫ�ĵ���Ϣ
3.��SQL Server�Ļ�������Ҫ�ĵ�����д������ҳ
4.��SQL Server�Ļ���������־��д�롱Commit����¼
5.������������־д����־�ļ�
6.����ȷ����Ϣ(ACK)���ͻ���(SMSS,ODBC�ȣ�
���Կ���,������־������һ����д�����.��������д�뻺������һ����д����־������.������������־д�����������IO�����ܱ�֤��־LSN��˳��.
����IJ�����Կ�������ʹ�����Ѿ�����Commit�Σ�Ҳ����ֻ�ǰѻ���������־ҳд����־����û�а�����д�����ݿ�.�ǽ�Ҫ�ĵ�����ҳд�����ݿ����ں�ʱ��������?
Lazy Writer��CheckPoint
�����ᵽ��SQL Server�����ݵIJ����в�û�а���������ʵ��д�뵽���̵Ĺ���.ʵ���ϣ����������ڵ�ҳд�뵽������ͨ�����������е�һ��ʵ�֣�
���������̷ֱ�Ϊ:
1.CheckPoint
2.Lazy Writer
�κ��ڻ��������ĵ�ҳ���ᱻ���Ϊ���ࡱҳ���������ҳд�뵽���ݴ��̾���CheckPoint����Lazy Writer�Ĺ���.
����������Commitʱ�������ǽ���������������־ҳд������е���־�ļ�:
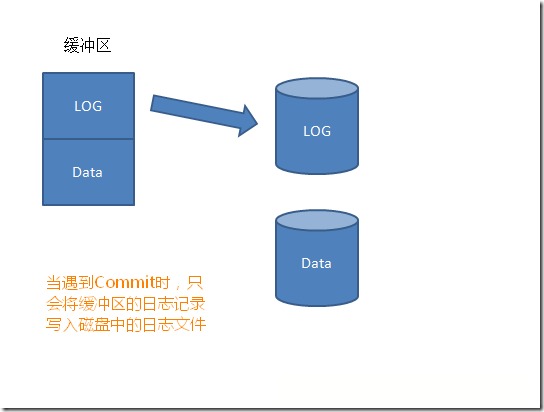
��ֱ��Lazy Writer��CheckPointʱ����������������������ҳд������ļ�:
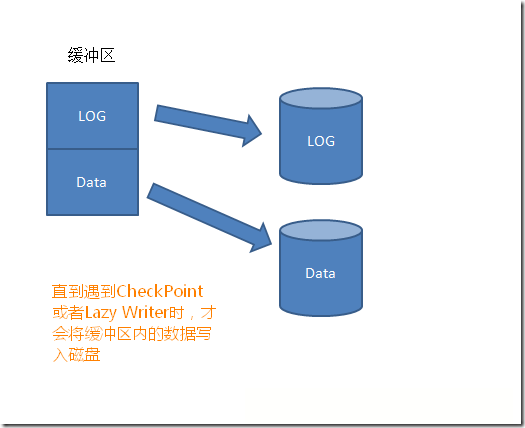
ǰ��˵������־�ļ��е�LSN���ǿ��ԱȽϵģ����LSN2>LSN1,��˵��LSN2�ķ���ʱ������LSN1�ķ���ʱ�䡣CheckPoint��Lazy Writerͨ������־�ļ�ĩβ��LSN�źͻ������������ļ���LSN���жԱȣ�ֻ�л�������LSN��С����־�ļ�ĩβ��LSN�ŵ����ݲŻᱻд�뵽�����е����ݿ⡣���ȷ����WAL��������д�뵽���ݿ�֮ǰ����д����־)��
Lazy Writer��CheckPoint������
Lazy Writer��CheckPoint��������������ΪLazy Writer��CheckPoint���ǽ��������ڵġ��ࡱҳд�뵽�����ļ����С�����Ҳ����������Ψһ����ͬ���ˡ�
Lazy Writer���ڵ�Ŀ���ǶԻ��������й��������������ﵽijһ�ٽ�ֵʱ��Lazy Writer�Ὣ�������ڵ���ҳ��������ļ��У�����δ�ĵ�ҳ�ͷŲ�������Դ��
��CheckPoint���ڵ������Ǽ��ٷ������Ļָ�ʱ��(Recovery Time).CheckPoint������������ָʾ����������һ���浵��.CheckPoint�ᶨ�ڷ���.�����������ڵġ��ࡱҳд����̡�������Lazy Writer,Checkpoint��SQL Server���ڴ����������Ȥ������CheckPointҲ����ζ���������֮ǰ�������Ķ��Ѿ����浽�˴���.����Ҫע����ǣ�CheckPoint�Ὣ���л���������ҳд����̣�������ҳ�е������Ƿ��Ѿ�Commit������ζ���п����Ѿ�д����̵ġ���ҳ������֮��ع���RollBack).�������õ��ģ�������ݻع���SQL Server�Ὣ�������ڵ�ҳ�ٴ��ģ���д����̡�
ͨ��CheckPoint���������ƿ��Կ�����CheckPoint�ļ�Ъ(Recovery Interval)�����п��ܻ�����ܲ���Ӱ�졣���CheckPoint�ļ�Ъ��һ������������IJ���������ͨ��sp_config�������ã�Ҳ������SSMS�н�������:
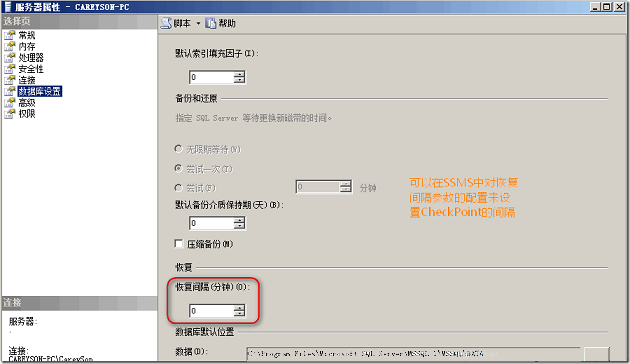
�ָ���Ъ��Ĭ�ϲ�����0����ζ����SQL Server����������ظ���������Լ����ûָ����Ҳ����Ҫ���ݾ�����������н綨�����̵Ļָ���Ъ��ζ����̵Ļָ�ʱ�����Ĵ���IO���������Ļָ���Ъ��������ٵĴ���IOռ�ú����Ļָ�ʱ��.
�����Զ�CheckPoint֮�⣬CheckPoint���ᷢ����Alter DataBase�Լ��ر�SQL Server������ʱ��sysadmin��db_backupoperator��ij�Ա�Լ�db_ownerҲ����ʹ��CheckPointָ�����ֶ�����CheckPoint:
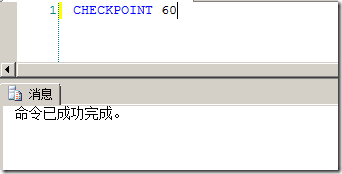
ͨ��ָ��CheckPoint��IJ�����SQL Server�ᰴ�����ʱ�������CheckPoint���̣����ʱ��ָ���Ķ̣���SQL Server��ʹ�ø������Դ�������CheckPoint���̡�
ͨ������£������ࡱҳд����̵Ĺ�����Lazy WriterҪ���ı�CheckPoint�������ࡣ
�ܽ�
���ļ�����WAL�ĸ���������ݿ����ʱ����־�����ݵĽ�ɫ�����ֱ������CheckPoint��Lazy Writer,������Щ���������������SQL Server DBA�����Ļ�������ƪ���½��ὲ���ڼָ�ģʽ����־�Ļ��ơ�
dz̸SQL Server�е�������־(��)----�ڼָ�ģʽ����־�Ľ�ɫ
���
�ڼָ�ģʽ�£���־�ļ������ý����DZ�֤��SQL Server�����ACID���ԡ������е�����Ļָ����ݵĽ�ɫ�����硱������ʵ�������˼һ�������ݵı��ݺͻָ��������������ֶ����ݺͻָ�.�ڿ�ʼ����֮ǰ������Ҫ�˽�SQL Server�ṩ�ļ��ֲ�ͬ�������͡�
SQL Server�ṩ�ļ��ֱ�������
SQL Server���ṩ�ļ��ֱ������ͻ������Է�Ϊ�������֣��ļ����ļ��鱸���Լ����ֱ��ݲ��ڱ�������֮��):
1.����(Full)����:ֱ�ӽ������ݵ����ݵ�������(Extent)���и��ơ�����ֵ��ע�����2��:
- �������ݲ����������֡������������������в��֣����ǽ��������ݿⱾ��������������־(��Ȼ��������������־����ͬ����
- ���������ڱ����ڼ䣬���ݿ��ǿ��õġ��������ݻ��¼��ʼ����ʱ��MinLSN�ţ���������ʱ��LSN�ţ�������������־���б��ݣ��ڻָ�ʱӦ�õ����ָ������ݿ�(���ᆳ���ģ���лħ������ָ��)
2.����(Differential)����:ֻ�����ϴ��������ݺ����ĵIJ��֡����ݵ�λ����(Extent)����ζ��ij�����ڼ�ʹֻ��һҳ���˱䶯�����ڲ��챸����ᱻ����.���챸������һ��BitMap����ά����һ��Bit��Ӧһ���������ϴ��������ݺ��ĵ����ᱻ��Ϊ1����BitMap�б���Ϊ1��Ӧ�����ᱻ���챸�������ݡ�������һ���������ݺ�BitMap�����е�Bit���ᱻ����Ϊ0��
3.��־(Log)����:�����������ϴ��������ݻ���־����֮��ļ�¼���ڼ�ģʽ�£���־���ݺ�������(SQL Server�������ڼָ�ģʽ�±�����־)�����Ļ�˵���ڼָ�ģʽ�£�Ϊʲô��־����û�����塣
�ָ�ģʽ(Simple Recovery Mode)
�ڼָ�ģʽ�£���־������Ϊ�˱�֤SQL Server�����ACID����û�лָ����ݵĹ���.
���磬������һ�����ݼƻ�������:

������ÿ��һ0����һ���������ݣ�������0�������0��ֱ������챸�ݡ��ڼָ�ģʽ�£�����������ݿ���������ǵĻָ��ƻ�ֻ�и�����һ0��������������ݻָ�������������0��IJ��챸�ݽ��лָ�.������0��֮�����������ڼ����е����ݽ��ᶪʧ��
���硱������������ǵ���˼���ڼָ�ģʽ�£���־������ȫ���ù����������ݺͻָ���ȫ�����������Լ��������Ͳ��챸��.
�ָ�ģʽ��һ�����ݿ⼶��IJ���������ͨ����SSMS���ͨ��SQL����������:
�ָ�ģʽ����־�Ŀռ�ʹ��
�ڱ�ϵ�����µĵ�һƪ�����ᵽ������־�ļ��Ữ�ֳɶ��VLF���й����������ϼ�¼�����Եģ���ÿ����¼һ��˳��ģ�Ψһ��LSN��
���ڼָ�ģʽ��,Ϊ�˱�֤����ij־��ԣ���Щ�п��ܻع������ݻᱻд����־����Щ��־��Ҫ����ʱ��������־��ȷ�����ض��������������˳���ع�������漰����һ�������С�ָ�LSN��Minimum Recovery LSN��MinLSN�� ��
MinLsn���ڻ�δ�����������¼����־����С��LSN��,MinLSN����������֮һ����Сֵ:
- CheckPoint�Ŀ�ʼLSN
- ��δ��������������־����СLSN
- ��δ���ݸ��ַ����ݿ������ĸ����������� LSN.
��ͼ��һ����־��Ƭ�Σ�

(ͼƬժ��MSDN��
���Կ��������µ�LSN��148��147��CheckPoint,�����CheckPoint֮ǰ����1�Ѿ���ɣ�������2��δ��ɣ����Զ�Ӧ��MinLSNӦ��������2�Ŀ�ʼ��Ҳ����142.
����MinLSN����־������β�������Ϊ���־(Active Log)��
�����־�ֲ�������VLF�ϵĹ�ϵ��������ͼ��ʾ:
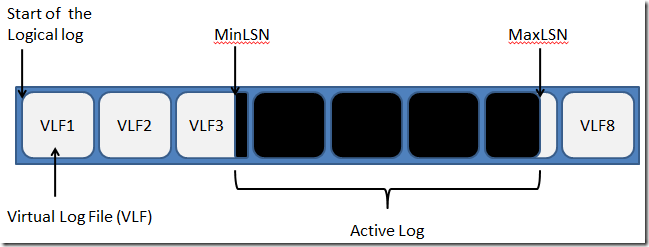
��ˣ�VLF��״̬��Դ�����������е�LSN��״̬�����Է�Ϊ������:�VLF�Ͳ��VLF
������ϸ�ֿ��Խ�VLF��״̬��Ϊ��������:
1.�(Active) �C��VLF �ϴ洢������һ��LSN�ǻ��ʱ����VLF��Ϊ�״̬����ʹһ��200M��VLFֻ������һ��LSN������ͼ��VLF3
2.�ɻָ�(Recoverable) �C VLF�Dz���ģ�VLF�ϲ������LSN,����δ���ض�(truncated)
3.������(Reusable) �C VLF�Dz���ģ�VLF�ϲ������LSN,�Ѿ����ض�(truncated)����������
4.δʹ��(Unused) �C VLF�Dz����,���һ�δ��ʹ�ù�
��������ͼ:
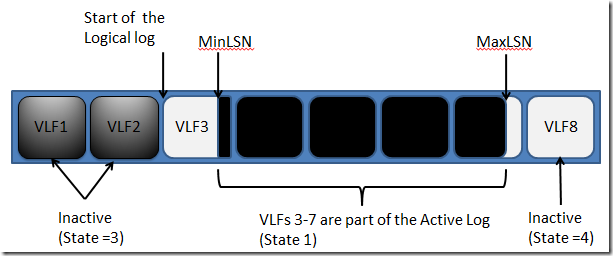
����ν�Ľض�(truncated)ֻ�ǽ��ɻָ�״̬��VLFת����������״̬���ڼָ�ģʽ�£�ÿһ��CheckPoint������ȥ����Ƿ�����־���Խض�.�����inactive��VLFʱ��CheckPoint���Ὣ�ɽضϲ��ֽ��нضϣ�����MinLSN�����.
����־�ﵽ��־�ļ�(ldf�ļ���ĩβʱ��Ҳ������ͼ��VLF8ʱ��������ѭ����VLF1��ʼ���Ա��ÿռ�����ظ�����.������־��Ȼ���Դ�����˳�����Ǵ�VLF1��VLF8������˳������Ǵ�VLF6��ʼ��VLF2����:
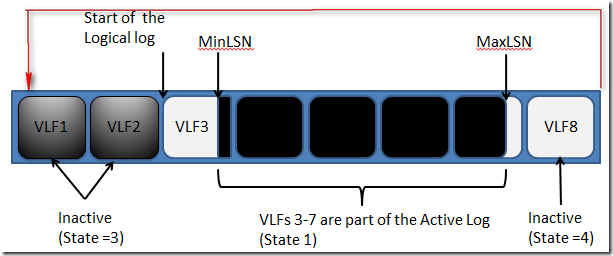
��˿��Կ������ָ�ģʽ����־�Dz�����ģ��������������صĻᱻ�ضϣ������������ڱ�֤����ع��ͱ����ָ�����;.���Ա�����־Ҳ����̸�𣬸�����������־���ָ����ݿ⡣
�ܽ�
���Ľ����˼ָ�ģʽ����־��ԭ��������������һЩ���ݻ��ָ����ݵĻ�������ʵ���ϣ������ڿ�������Ի����¡�ʹ�üָ�ģʽ�ij��������࣬��Ϊ����ʵ�����У�������������������Сʱ�����ݶ�ʧ�ij�������û��.��ƪ���½��ὲ���������ָ�ģʽ�£���־�����á�
| 

