| 简介
在众多不同的数据模型里,关系数据模型自80年代就处于统治地位,而且有不少实现,如Oracle、MySQL和MSSQL,它们也被称为关系数据库管理系统(RDBMS)。然而,最近随着关系数据库使用案例的不断增加,一些问题也暴露了出来,这主要是因为两个原因:数据建模中的一些缺陷和问题,以及在大数据量和多服务器之上进行水平伸缩的限制。两个趋势让这些问题引起了全球软件社区的重视:
用户、系统和传感器产生的数据量呈指数增长,其增长速度因大部分数据量集中在象Amazon、Google和其他云服务这样的分布式系统上而进一步加快。
数据内部依赖和复杂度的增加,这一问题因互联网、Web2.0、社交网络,以及对大量不同系统的数据源开放和标准化的访问而加剧。
在应对这些趋势时,关系数据库产生了更多的问题。这导致大量解决这些问题某些特定方面的不同技术的出现,它们可以与现有RDBMS相互配合或代替它们 - 亦被称为混合持久化(Polyglot Persistence)。数据库替代品并不是新鲜事物,它们已经以对象数据库(OODBMS)、层次数据库(如LDAP)等形式存在很长时间了。但是,过去几年间,出现了大量新项目,它们被统称为NOSQL数据库(NOSQL-databases)
本文旨在介绍图形数据库(Graph Database)在NOSQL运动里的地位,第二部分则是对Neo4j(一种基于Java的图形数据库)的简介。
NOSQL环境
NOSQL(Not Only SQL,不限于SQL)是一类范围非常广泛的持久化解决方案,它们不遵循关系数据库模型,也不使用SQL作为查询语言。
简单地讲,NOSQL数据库可以按照它们的数据模型分成4类:
- 键-值存储库(Key-Value-stores)
- BigTable实现(BigTable-implementations)
- 文档库(Document-stores)
- 图形数据库(Graph Database)
就Voldemort或Tokyo Cabinet这类键/值系统而言,最小的建模单元是键-值对。对BigTable的克隆品来讲,最小建模单元则是包含不同个数属性的元组,至于象CouchDB和MongoDB这样的文档库,最小单元是文档。图形数据库则干脆把整个数据集建模成一个大型稠密的网络结构。
在此,让我们深入检阅NOSQL数据库的两个有意思的方面:伸缩性和复杂度。
1. 伸缩性
CAP: ACID vs. BASE
为了保证数据完整性,大多数经典数据库系统都是以事务为基础的。这全方位保证了数据管理中数据的一致性。这些事务特性也被称为ACID(A代表原子性、C表示一致性、I是隔离性、D则为持久性)。然而,ACID兼容系统的向外扩展已经表现为一个问题。在分布式系统中,高可用性不同方面之间产生的冲突没有完全得到解决 - 亦称CAP法则:
- 强一致性(C):所有客户端看到的数据是同一个版本,即使是数据集发生了更新 - 如利用两阶段提交协议(XA事务),和ACID,
- 高可用性(A):所有客户端总能找到所请求数据的至少一个版本,即使集群中某些机器已经宕机,
- 分区容忍性(P):整个系统保持自己的特征,即使是被部署到不同服务器上的时候,这对客户端来讲是透明的。
CAP法则假定向外扩展的3个不同方面中只有两个可以同时完全实现。

为了能处理大型分布式系统,让我们深入了解所采用的不同CAP特征。
很多NOSQL数据库首先已经放宽了对于一致性(C)的要求,以期得到更好的可用性(A)和分区容忍性(P)。这产生了被称为BASE(基本(B)可用性(A)、软状态(S)、最终一致性(E))的系统。它们没有经典意义上的事务,并且在数据模型上引入了约束,以支持更好的分区模式(如Dynamo系统等)。关于CAP、ACID和BASE的更深入讨论可以在这篇介绍里找到。
2. 复杂度

数据和系统的互联性增加产生了一种无法用简单明了或领域无关(domain-independent)方式进行伸缩和自动分区的稠密数据集,甚至连Todd Hoff也提到了这一问题。关于大型复杂数据集的可视化内容可以访问可视化复杂度(Visual Complexity)。
关系模型
在把关系数据模型扔进故纸堆之前,我们不应该忘记关系数据库系统成功的一个原因是遵照E.F. Codd的想法,关系数据模型通过规范化的手段原则上能够建模任何数据结构且没有信息冗余和丢失。建模完成之后,就可以使用SQL以一种非常强大的方式插入、修改和查询数据。甚至有些数据库,为了插入速度或针对不同使用情况(如OLTP、OLAP、Web应用或报表)的多维查询(星形模式),对模式实现了优化。
这只是理论。然而在实践中,RDBM遇到了前面提到的CAP问题的限制,以及由高性能查询实现而产生的问题:联结大量表、深度嵌套的SQL查询。其他问题包括伸缩性、随时间的模式演变,树形结构的建模,半结构化数据,层级和网络等。
关系模型也很难适应当前软件开发的方法,如面向对象和动态语言,这被称为对象-关系阻抗失配。由此,象Java的Hibernate这样的ORM层被开发了出来,而且被应用到这种混合环境里。它们固然简化了把对象模型映射到关系数据模型的任务,但是没有优化查询的性能。尤其是半结构化数据往往被建模成具有许多列的大型表,其中很多行的许多列是空的(稀疏表),这导致了拙劣的性能。甚至作为替代方法,把这些结构建模成大量的联结表,也有问题。因为RDBMS中的联结是一种非常昂贵的集合操作。
图形是关系规范化的一种替代技术
看看领域模型在数据结构上的方案,有两个主流学派 - RDBMS采用的关系方法和图 - 即网络结构,如语义网用到的。
尽管图结构在理论上甚至可以用RDBMS规范化,但由于关系数据库的实现特点,对于象文件树这样的递归结构和象社交图这样的网络结构有严重的查询性能影响。网络关系上的每次操作都会导致RDBMS上的一次"联结"操作,以两个表的主键集合间的集合操作来实现 ,这种操作不仅缓慢并且无法随着这些表中元组数量的增加而伸缩。
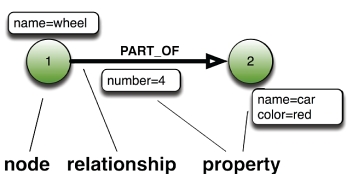
属性图形(Property Graph)的基本术语
在图的领域,并没有一套被广泛接受的术语,存在着很多不同类型的图模型。但是,有人致力于创建一种属性图形模型(Property Graph Model),以期统一大多数不同的图实现。按照该模型,属性图里信息的建模使用3种构造单元:
- 节点(即顶点)
- 关系(即边) - 具有方向和类型(标记和标向)
- 节点和关系上面的属性(即特性)
更特殊的是,这个模型是一个被标记和标向的属性多重图(multigraph)。被标记的图每条边都有一个标签,它被用来作为那条边的类型。有向图允许边有一个固定的方向,从末或源节点到首或目标节点。属性图允许每个节点和边有一组可变的属性列表,其中的属性是关联某个名字的值,简化了图形结构。多重图允许两个节点之间存在多条边。这意味着两个节点可以由不同边连接多次,即使两条边有相同的尾、头和标记。
下图显示了一个被标记的小型属性图。

TinkerPop有关的小型人员图
图论的巨大用途被得到了认可,它跟不同领域的很多问题都有关联。最常用的图论算法包括各种类型的最短路径计算、测地线(Geodesic Path)、集中度测量(如PageRank、特征向量集中度、亲密度、关系度、HITS等)。然而,在很多情况下,这些算法的应用仅限制于研究,因为实际中没有任何可用于产品环境下的高性能图形数据库实现。幸运的是,近些年情况有所改观。有几个项目已经被开发出来,而且目标直指24/7的产品环境:
- Neo4j - 开源的Java属性图形模型
- AllegroGraph,闭源,RDF-QuadStore
- Sones - 闭源,关注于.NET
- Virtuoso - 闭源,关注于RDF
- HyergraphDB - 开源的Java超图模型
- Others like InfoGrid、Filament、FlockDB等。
下图展示了在复杂度和伸缩性方面背景下的主要NOSQL分类的位置。

关于“规模扩展和复杂度扩展的比较”的更多内容,请阅读Emil Eifrem的博文。
Neo4j - 基于Java的图形数据库
Neo4j是一个用Java实现、完全兼容ACID的图形数据库。数据以一种针对图形网络进行过优化的格式保存在磁盘上。Neo4j的内核是一种极快的图形引擎,具有数据库产品期望的所有特性,如恢复、两阶段提交、符合XA等。自2003年起,Neo4j就已经被作为24/7的产品使用。该项目刚刚发布了1.0版 - 关于伸缩性和社区测试的一个主要里程碑。通过联机备份实现的高可用性和主从复制目前处于测试阶段,预计在下一版本中发布。Neo4j既可作为无需任何管理开销的内嵌数据库使用;也可以作为单独的服务器使用,在这种使用场景下,它提供了广泛使用的REST接口,能够方便地集成到基于PHP、.NET和JavaScript的环境里。但本文的重点主要在于讨论Neo4j的直接使用。
开发者可以通过Java-API直接与图形模型交互,这个API暴露了非常灵活的数据结构。至于象JRuby/Ruby、Scala、Python、Clojure等其他语言,社区也贡献了优秀的绑定库。Neo4j的典型数据特征:
数据结构不是必须的,甚至可以完全没有,这可以简化模式变更和延迟数据迁移。
可以方便建模常见的复杂领域数据集,如CMS里的访问控制可被建模成细粒度的访问控制表,类对象数据库的用例、TripleStores以及其他例子。
典型使用的领域如语义网和RDF、LinkedData、GIS、基因分析、社交网络数据建模、深度推荐算法以及其他领域。
甚至“传统”RDBMS应用往往也会包含一些具有挑战性、非常适合用图来处理的数据集,如文件夹结构、产品配置、产品组装和分类、媒体元数据、金融领域的语义交易和欺诈检测等。
围绕内核,Neo4j提供了一组可选的组件。其中有支持通过元模型构造图形结构、SAIL - 一种SparQL兼容的RDF TripleStore实现或一组公共图形算法的实现。
要是你想将Neo4j作为单独的服务器运行,还可以找到REST包装器。这非常适合使用LAMP软件搭建的架构。通过memcached、e-tag和基于Apache的缓存和Web层,REST甚至简化了大规模读负荷的伸缩。
高性能?
要给出确切的性能基准数据很难,因为它们跟底层的硬件、使用的数据集和其他因素关联很大。自适应规模的Neo4j无需任何额外的工作便可以处理包含数十亿节点、关系和属性的图。它的读性能可以很轻松地实现每毫秒(大约每秒1-2百万遍历步骤)遍历2000关系,这完全是事务性的,每个线程都有热缓存。使用最短路径计算,Neo4j在处理包含数千个节点的小型图时,甚至比MySQL快1000倍,随着图规模的增加,差距也越来越大。
这其中的原因在于,在Neo4j里,图遍历执行的速度是常数,跟图的规模大小无关。不象在RDBMS里常见的联结操作那样,这里不涉及降低性能的集合操作。Neo4j以一种延迟风格遍历图 - 节点和关系只有在结果迭代器需要访问它们的时候才会被遍历并返回,对于大规模深度遍历而言,这极大地提高了性能。
写速度跟文件系统的查找时间和硬件有很大关系。Ext3文件系统和SSD磁盘是不错的组合,这会导致每秒大约100,000写事务操作。
示例 - 黑客帝国
前面已经说过,社交网络只是代表了图形数据库应用的冰山一角,但用它们来作为例子可以让人很容易理解。为了阐述Neo4j的基本功能,下面这个小型图来自黑客帝国这部电影。该图是用Neo4j的Neoclipse产生的,该插件基于Eclipse RCP:
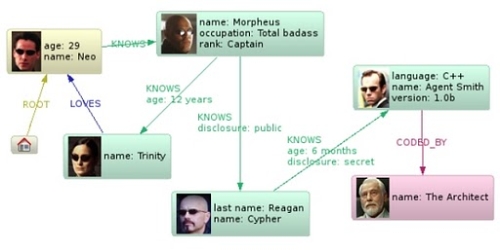
这个图链接到一个已知的引用节点(id=0),这是为了方便的从一个已知起点找到条路进入这个网络。这个节点不是必须的,但实践证明它非常有用。
Java的实现看上去大概是这个样子:
在“target/neo”目录创建一个新的图形数据库
EmbeddedGraphDatabase graphdb = new EmbeddedGraphDatabase("target/neo");关系类型可以动态创建:
RelationshipType KNOWS = DynamicRelationshipType.withName("KNOWS");或通过类型安全的Java Enum:
enum Relationships implements RelationshipType { KNOWS, INLOVE, HAS_CODED, MATRIX }现在,创建2个节点,给每个节点加上“name”属性。接着,把两个节点用一个“KNOWS”关系联系起来:
Node neo = graphdb.createNode(); node.setProperty("name", "Neo");
Node morpheus = graphdb.createNode(); morpheus.setProperty("name", "Morpheus");
neo.createRelationshipTo(morpheus, KNOWS);任何修改图或需要数据隔离级别的操作要包在事务中,这样可以利用内置的回滚和恢复功能:
Transaction tx = graphdb.beginTx();
try {
Node neo = graphdb.createNode();
...
tx.success();
} catch (Exception e) {
tx.failure();
} finally {
tx.finish();
}创建“黑客帝国”图的完整代码:
graphdb = new EmbeddedGraphDatabase("target/neo4j");
index = new LuceneIndexService(graphdb);
Transaction tx = graphdb.beginTx();
try {
Node root = graphdb.getReferenceNode();
// we connect Neo with the root node, to gain an entry point to the graph
// not neccessary but practical. neo = createAndConnectNode("Neo", root, MATRIX); Node morpheus = createAndConnectNode("Morpheus", neo, KNOWS); Node cypher = createAndConnectNode("Cypher", morpheus, KNOWS); Node trinity = createAndConnectNode("Trinity", morpheus, KNOWS); Node agentSmith = createAndConnectNode("Agent Smith", cypher, KNOWS); architect = createAndConnectNode("The Architect", agentSmith, HAS_CODED);
// Trinity loves Neo. But he doesn't know.
trinity.createRelationshipTo(neo, LOVES);
tx.success();
} catch (Exception e) {
tx.failure();
} finally {
tx.finish();
}以及创建节点和关系的成员函数
private Node createAndConnectNode(String name, Node otherNode,
RelationshipType relationshipType) {
Node node = graphdb.createNode(); node.setProperty("name", name);
node.createRelationshipTo(otherNode, relationshipType); index.index(node, "name", name);
return node;
}谁是Neo的朋友?
Neo4j的API有一组面向Java集合的方法可轻易地完成查询。这里,只消看看“Neo”节点的关系便足以找出他的朋友:
for (Relationship rel : neo.getRelationships(KNOWS)) {
Node friend = rel.getOtherNode(neo); System.out.println(friend.getProperty("name"));
} returns "Morpheus" as the only friend.但是,Neo4j的真正威力源自Traverser-API的使用,它可以完成非常复杂的遍历描述和过滤器。它由Traverser和ReturnableEvaluator组成,前者计算StopEvaluator来获知何时停止,后者则用于在结果中包含哪些节点。此外,你还可以指定要遍历关系的类型和方向。Traverser实现了Java的Iterator接口,负责延迟加载和遍历整个图,在节点被首次要求访问(如for{...}循环)时进行。它还内置了一些常用的Evaluator和缺省值:
Traverser friends = neo.traverse(Order.BREADTH_FIRST,
StopEvaluator.DEPTH_ONE,
ReturnableEvaluator.ALL_BUT_START_NODE, KNOWS, Direction.BOTH);
for (Node friend : friends) { System.out.println(friend.getProperty("name")); }
我们在继续访问更深一级的节点之前首先从起点访问处于同一深度的所有节点(Order.BREADTH_FIRST),在深度为1的一次遍历后停止(StopEvaluator.DEPTH_ONE),然后返回除了起点("Neo")之外的所有节点(ReturnableEvaluator.ALL_BUT_START_NODE)。我们在两个方向只遍历类型为KNOWS的关系。这个遍历器再次返回Morpheus是Neo仅有的直接朋友。
朋友的朋友?
为了调查谁是Neo朋友的朋友,KNOWS网络需要再进行深度为2的步骤,由Neo开始,返回Trinity和Cypher。实际编程中,这可以通过调整我们的Traverser的StopEvaluator,限制遍历深度为2来实现:
StopEvaluator twoSteps = new StopEvaluator() {
@Override
public boolean isStopNode(TraversalPosition position) {
return position.depth() == 2;
}
};还要定制ReturnableEvaluator,只返回在深度2找到的节点:
ReturnableEvaluator nodesAtDepthTwo = new ReturnableEvaluator() {
@Override
public boolean isReturnableNode(TraversalPosition position) {
return position.depth() == 2;
}
};现在“朋友的朋友”遍历器就成了:
Traverser friendsOfFriends = neo.traverse(Order.BREADTH_FIRST,
twoSteps, nodesAtDepthTwo, KNOWS, Direction.BOTH);
for (Node friend : friendsOfFriends) { System.out.println(friend.getProperty("name"));
}它的结果是Cypher和Trinity。
谁在恋爱?
另一个有趣的问题是,这个图上是否有人正在热恋,比方说从架构师(Architect)开始。
这次,整个图需要沿着由架构师(假定他的节点ID是已知的,但要到很晚才知道)开始的任何关系开始检查,返回拥有向外LOVE关系的节点。一个定制的ReturnableEvaluator可以完成这件事:
ReturnableEvaluator findLove = new ReturnableEvaluator() {
@Override
public boolean isReturnableNode(TraversalPosition position) {
return position.currentNode().hasRelationship(LOVES, Direction.OUTGOING);
}
};为了遍历所有关系,需要知道整个图的所有关系类型:
List<Object> types = new ArrayList<Object>();
// we have to consider all relationship types of the whole graph
// (in both directions)
for(RelationshipType type : graphdb.getRelationshipTypes()) {
types.add(type);
types.add(Direction.BOTH);
}
//let's go!
Traverser inLove = architect.traverse(Order.BREADTH_FIRST,
StopEvaluator.END_OF_GRAPH, findLove, types.toArray());
for (Node lover : inLove) { System.out.println(lover.getProperty("name"));
}上述代码的返回结果只有一个节点:Trinity,因为我们只返回拥有向外LOVE关系的节点。
给图建立索引
尽管沿着所有关系的遍历操作是Neo4j的亮点之一,但也需要在整个图之上进行面向集合的操作。所有节点属性的全文检索就是一个典型的例子。为了不重新发明轮子,Neo4j在这里使用了外部索引系统。针对常见的基于文本的搜索,Neo4j已经跟Lucene和Solr进行了深度集成,在Lucene/Solr里增加了给具有事务语义的任意节点属性创建索引的功能。
在黑客帝国的例子里,如给“name”属性创建索引:
GraphDatabaseService graphDb = // a GraphDatabaseService instance
IndexService index = new LuceneIndexService( graphDb );
//create a new node and index the "name" property
Node neo = graphDb.createNode(); neo.setProperty( "name", "Neo" ); index.index( neo, "name", neo.getProperty( "name" ) );
//search for the first node with "name=Neo" Node node = index.getSingleNode( "name", "Neo" );Lucene是图的外部索引的一个例子。但是,作为一个快速图形引擎,有大量的策略来构建图本身内部的索引结构,针对特殊数据集和领域缩短遍历模式。例如,有针对一维数据的timeline和B树,给二维数据(在空间和GIS社区非常普遍)建立索引的RTrees和QuadTrees等。另一个常见的有用模式是将重要的子图直接连接到根节点,以创建重要开始节点的快捷路径。
Java太麻烦了。拜托,有没有简短点的?
Neo4j甚至还提供了一组优秀的语言绑定来简化图结构操作。这个例子使用了优秀的Neo4j-JRuby-绑定,它极大地减少了整个代码量:
先安装neo4j gem
>gem install neo4j这时,整个黑客帝国的图和前面提到的查询,用JRuby代码编写就成了这个样子:
require "rubygems"
require "neo4j"
class Person
include Neo4j::NodeMixin
#the properties on the nodes
property :name
#the relationship types
has_n :friends
# Lucene index for some properties
index :name
end
#the players
neo = Person.new :name => 'Neo' morpheus = Person.new :name => 'Morpheus' trinity = Person.new :name => 'Trinity' cypher = Person.new :name => 'Cypher' smith = Person.new :name => 'Agent Smith' architect = Person.new :name => 'Architect'
#the connections
cypher.friends << morpheus cypher.friends << smith neo.friends << morpheus morpheus.friends << trinity trinity.rels.outgoing(:loves) << neo
architect.rels.outgoing(:has_coded) << smith
#Neos friends
neo.friends.each { |n| puts n }
#Neos friends-of-friends
neo.friends.depth(2).each { |n| puts n }
#Who is in love?
architect.traverse.both(:friends, :has_coded, :loves).depth(:all).filter do outgoing(:loves).to_a.size > 0
end.each do |n|
puts 'In love: ' + n.name
end图编程语言 - Gremlin

直到最近,还没有任何查询语言涉及大型的图领域和图相关项目。在语义网/RDF领域,有SPARQL,受SQL启发的查询语言,专注于描述用来匹配元组集合的样本图。但是,大量的图并不兼容RDF,而且采用不同或更侧重于更实用的方式进行数据建模,象本文中的黑客帝国例子,以及其他领域特定的数据集。其他查询语言都是面向JSON的,如MQL,一种用于Freebase的查询语言。这些语言只工作于它们自己定义的数据模型,完全不支持或只非常有限地支持深度图算法和启发式分析方法,而这又是当今大型图里不可或缺的内容。
至于针对各种图数据模型(如RDF)的更复杂有趣的查询,Gremlin - 一种面向XPath,图灵完备的图形编程语言 - 正由TinkerPop团队开发,主要由Marko A. Rodriguez推动。借助引入属性图模型,它创造了一个针对现有大多数模型的超集,以及最小的公共操作集合。此外,它允许连接其他图形框架(如Gremlin使用JUNG),同时支持在不同的图实现上都能表达图的遍历。已支持的一组实现包括,从简单的如内存中的TinkerGraph,到其他通过针对AllegroGraph、Sesame和ThinkerPop LinkedData SAIL(最开始由Josh Shinavier为Ripple编程语言开发)的RDF-SAIL适配器,一直到Neo4j。
Gremlin的语法建立在XPath基础之上,这是为了可以简单地表达整个图的深度路径描述。很多简单的例子几乎就像普通的XPath。
在安装Gremlin或在线试用之后,黑客帝国例子里的图的Gremlin会话大致是:
peterneubauer$ ~/code/gremlin/gremlin.sh
\,,,/
(o o)
-----oOOo-(_)-oOOo----- gremlin> #open a new neo4j graph as the default graph ($_g) gremlin> $_g := neo4j:open('tmp/matrix') ==>neo4jgraph[tmp/matrix] gremlin> #the vertices gremlin> $neo := g:add-v(g:map('name','Neo')) ==>v[1] gremlin> $morpheus := g:add-v(g:map('name','Morpheus')) ==>v[2] gremlin> $trinity := g:add-v(g:map('name','Trinity')) ==>v[3] gremlin> $cypher := g:add-v(g:map('name','Cypher')) ==>v[4] gremlin> $smith := g:add-v(g:map('name','Agent Smith')) ==>v[5] gremlin> $architect := g:add-v(g:map('name','The Architect')) ==>v[6] gremlin> #the edges gremlin> g:list($cypher,$neo,$trinity)[g:add-e($morpheus,'KNOWS',.)] ==>v[4] ==>v[1] ==>v[3] gremlin> g:add-e($cypher,'KNOWS',$smith) ==>e[3][4-KNOWS->5] gremlin> g:add-e($trinity,'LOVES',$neo) ==>e[4][3-LOVES->1] gremlin> g:add-e($architect,'HAS_CODED',$smith) ==>e[5][6-HAS_CODED->5] gremlin> #go to Neo as the current root ($_) via a full-text index search gremlin> $_ := g:key('name','Neo') ==>v[1] gremlin> #is this Neo? gremlin> ./@name ==>Neo gremlin> #what links to here and from here? gremlin> ./bothE ==>e[0][1-KNOWS->2] ==>e[4][3-LOVES->1] gremlin> #only take the KNOWS-edges gremlin> ./bothE[@label='KNOWS'] ==>e[0][1-KNOWS->2] gremlin> #Neo's friend's names gremlin> ./bothE[@label='KNOWS']/inV/@name ==>Morpheus gremlin>
gremlin> #Neo's Friends of friends, 2 steps gremlin> repeat 2
$_ := ./outE[@label='KNOWS']/inV
end ==>v[4] ==>v[3] gremlin> #What are their names? gremlin> ./@name ==>Cypher ==>Trinity gremlin> #every node in the whole graph with an outgoing LOVES edge gremlin> $_g/V/outE[@label='LOVES']/../@name ==>
Trinity深度图算法 - 关系的价值
鉴于Gremlin的能力,黑客帝国的例子显得相当幼稚。更有趣的是开发和测试大型图上的算法。象特征向量集中度和Dijkstra这类穷举算法并不会扩展到这些图上,因为它们需要了解网络里的每个顶点。对于针对这些问题的如基于语法的随机访问器和扩散激活(Marko Rodriguez和这里有更深入的解释)这类概念,启发式方法更合适。Google PageRank算法就是启发式的,而且可以用Gremlin建模,代码如下(Greatful Dead的歌曲、演唱会和相册图的一个例子,图从这里装入,2500个循环,每次重复能量损失15%):

$_g := tg:open()
g:load('data/graph-example-2.xml')
$m := g:map()
$_ := g:key('type', 'song')[g:rand-nat()]
repeat 2500
$_ := ./outE[@label='followed_by'][g:rand-nat()]/inV
if count($_) > 0
g:op-value('+',$m,$_[1]/@name, 1.0)
end
if g:rand-real() > 0.85 or count($_) = 0
$_ := g:key('type', 'song')[g:rand-nat()]
end
end
g:sort($m,'value',true())它返回如下的歌曲权重列表:
==>DRUMS=44.0 ==>PLAYING IN THE BAND=38.0 ==>ME AND MY UNCLE=32.0 ==>TRUCKING=31.0 ==>CUMBERLAND BLUES=29.0 ==>PROMISED LAND=29.0 ==>THE MUSIC NEVER STOPPED=29.0 ==>CASSIDY=26.0 ==>DARK STAR=26.0 ==>NOT FADE AWAY=26.0 ==>CHINA CAT SUNFLOWER=25.0 ==>JACK STRAW=25.0 ==>TOUCH OF GREY=24.0 ==>BEAT IT ON DOWN THE LINE=23.0 ==>BERTHA=23.0其底层图的另一个有趣的例子是LinkedData图,在互联网上可在线了解:LinkedData和DBPedia的音乐推荐算法。
总结
就像RDBMS和其他持久化解决方案一样,图不是解决所有问题的银弹。数据才是最重要的东西,它是关键,然后是查询类型、要处理的操作结构,以及什么需求要考虑伸缩性和CAP。
将采用NOSQL数据库的高伸缩性方面作为使用非关系解决方案的唯一考量往往是不必要的,而且也不符合预期。使用Neo4j和当今的硬件,大多数情况下,完全可以在单实例里容纳整个领域模型和查询数十亿领域对象。
如果那还不够,总是有办法引入针对领域优化过的数据分区概念,无需引入文档或键/值系统的硬数据建模限制。最终导致的结果是一个文档模型、或领域特定的“对象数据库”还是其他模型则取决于领域上下文和应用场景。
| 

