1 Crash Recovery���� 1
1.1 Crash Recovery���� 1
1.2 Crash Recovery�Ż� 6
1.2.1 Hash Table Size 7
1.2.2 Red Black Tree(RBT) 7
1.2.3 �Ż�Ч�� 8
1.3 rollback segment & Transaction
8
1.3.1 rollback segment 8
1.3.2 Transaction 10
1.3.3 DB_ROLLBACK_PTR 11
1.Crash Recovery����
������Ҫ������InnoDB����crash recovery��Դ�봦�����̣�����ں�����innobase_start_or_create_for_mysql()��InnoDB��crash
recovery���̷dz�����Ҳʮ�ָ��ӣ��������ܽ��˼������⣬�������ܹ��ش����Щ���⣬��ô�Ͳ��ÿ�����������ˡ�
- crash recovery����㣬checkpoint_lsn���ںδ���
- redo������batch redo������single redo�������batch redo����ô�����ʵ�ֵģ�
- redo�������Ƿ���Ҫ��ȡ���������ļ���
- redo���̣���־��������־�طŲ�����Ӧ�ķֱ���ʲô������
- redo�����У���ʱʹ��doublewrite������ҳ�棿
- InnoDB��ϵͳ����ʱ����������Щϵͳ�����ֱ���ʲô���ṹ��
- undo�����������ʲô��
- һ��rollback segment�ܹ�֧�ֵIJ����������Ƕ��٣�
- ��rollback segments�����ʵ�ֵģ�
- ����ҵ�ÿ��rollback segment�е�undo��Ϣ��
- ������undo����ι��������ģ�
- ͬһ����IJ������ǵ�һundo������������Ҫ����insert��update������
- ͬһ�����undo����������������ģ�
- �����crash recovery���̵���Щ�ط�������������ʵ��Percona XtraBackup���Ƶ�ȫ�����ݣ��������ݵĹ��ܣ�
1.Crash Recovery����
����������̣�
|
ha_innodb.cc::innobase_init
// InnoDBCrash Recovery��������ڣ��ڴ˺�����������ж�������open���ݿ�
srv0start.c::innobase_start_or_create_for_mysql();
// �����е�InnoDB�����ļ������һ�ȡ���������ļ��������С
//��flush_lsn����Ϊÿ�������ļ����һ��flush��ʱ����ܲ�һ��
open_or_create_data_files();
// ��ȡ�����ļ���һҳ��FIL_PAGE_FILE_FLUSH_LSN�궨��ָ���flush_lsn
// ϵͳ��֤�����ļ���page_lsnС�ڴ�flush_lsn����ҳ����д������
fil_read_flushed_lsn_and_arch_log_no();
open_or_create_log_files();
// ��ϵͳ���ռ��Ӧ���ļ�+��־�ļ�����ֹ�����ļ�������㵼��
// ϵͳ�ļ����������
fil_open_log_and_system_tablespace_files();
// ���buffer pool�����е�page����Ҫ���¶�ȡ
// ��ʱbuffer pool��Ӧ��ֻ��һ������page
buf_pool_invalidate();
// InnoDB�ָ�Redo��ں���
log0recv.c::recv_recovery_from_checkpoint_start_func();
// �������е�log group��������������checkpoint lsn
// checkpoint��Ϣ������ÿ����־����־�ļ���һҳ֮�У�������
// LOG_CHECKPOINT_1(��һ��LOG_BLOCK_SIZE��)����LOG_CHECKPOINT_2(3)��
recv_find_max_checkpoint();
//
// �������£�
// 1. contiguous_lsn��ʼ��������ǰ��־�顣��lsn��Ϊcheckpoint lsn��
// group_scanned_lsnΪ��ǰ��־���ܹ��ṩ�����lsn��
// 2. ���ݸ�����checkpoint lsn��������log�ļ��е�ƫ��λ��
// 3. ÿ�ζ�ȡRECV_SCAN_SIZE (�궨�壺4) ����־pages������log buf��
recv_group_scan_log_recs(group, contiguous_lsn, group_scanned_lsn);
log_group_read_log_seg();
log_group_calc_lsn_offset();
// avail_memΪcrash recovery�ڼ䣬hash���ܹ�ʹ�õ�buffer pool
// ���ޡ���buffer pool�Ĵ���10MB������ҪԤ��512��free pages��
// ��Щfree pages buffer���ڶ�ȡҳ�浽�ڴ��У����лָ�֮�á�
// hash����bucket����Ϊ buffer pool�Ĵ�С / 512.
// ������־�飬����redo���������£�
// 1. ѭ������buf�е�ÿһ��log block (buf Ϊ4 pages��block = 512)
// 2. ����ÿһ��block����ȡblockͷ����ȡblock����д��־����
// ���ʣ�blockͷ��Ϣ��ʱд�룿block����д��֮�� or ֮ǰ��
// 3. ����ǰblock�����lsn > checkpoint lsn������Ҫ���б����ָ�
// 4. �ݹ鷽ʽ������baseĿ¼�µ�����Ŀ¼���ļ����������е�
// ibd�ļ�(�����ļ�)��������fil_space_struct��chain����֮��
// 5. ��ȡϵͳ���ռ�ĵ����ҳ��(TRX_SYS_PAGE_NO)����ȡ���е�
// doublewrite��Ϣ����ʹ��doublewrite����������ָ���ҳ��
// ����doublewrite��صĶ�ȡ���ָ����������ں�����ϸ����
// 6. ��log block�е�log���ȱ�����recv_sys_struct��buf�У���
// �ռ�һ�ζ�ȡ��4��pages�е�������־֮��ͳһ���н���
// 7. ��־�����IJ������ں���recv_parse_log_recs�����
// 8. �����־����֮�����еĽ�����־��������Ӧ�ã����Ǵ洢
// ��hash��֮�У�hash����С��������ǰ���ᵽ��avail_mem
// Ҳ����buf pool��С �C 512��pages��hash����С���������ƣ�
// ����Ҫ����recv_apply_hashed_log_recs������redo hash���е�
// ��־���˺�������ϸ�������·�������
recv_scan_log_recs(avail_mem, store_to_hash, buf, contigous_lsn);
recv_init_crash_recovery();
fil_load_single_table_tablespaces(); // ����4
fil_load_single_table_tablespace();
fil_node_create();
trx_sys_doublewrite_init_or_restore_pages();// ����5
recv_sys_add_to_parsing_buf(); // ����6
start_offset = LOG_BLOCK_HDR_SIZE;
end_offset=OS_FILE_LOG_BLOCK_SIZE�CLOG_BLOCK_TRL_SIZE;
// ��log block�е�redo��־����copy��recv_sys->buf�У�
// ��Ҫ����log block��ͷ��(12 bytes)��β��(4 bytes)
memcpy(��,log_block+start_offset, end_offset-start_offset);
// ��recv_sys_struct->buf�б������־���н������������
// ����־�洢��hash��֮�У��������£�
// 7.1 ���Ȼ�����־�����ͣ���һ��־(�ļ�������) or ����־
// 7.2 ����һ����־�����ص����ݰ�������־���ȣ���־���ͣ�
// ��־������Ӧ�ı��ռ�ID��Page_no���Լ���־����body
// ������־���ͣ��ɲο�mtr0mtr.h�ļ��еĶ���
// recv_parse_or_apply_log_rec_body��������������־
// ���ͣ�������Ӧ��(crash recoveryʱ�Ȳ�Ӧ�ã���������)
// 7.3 ����־������Ӧ�����ļ���������ôcrash recover������
// ����XtraBackup��Ҫ�����ļ�������־��������Щ��־
// 7.4 ��־������Ӧ�IJ����ļ���������������־����
// hash����hashֵ����(space, page_no)��ϼ��������
// ��ͬ��page������־����hash���б�����һ��ͬʱ
// ������־������˳��������˫������֮�С�
// (���Ծ����ϲ�ͬһ��page�IJ������ط���־���Ӹ�Ч��)
// 7.5 �����ᵽ�����̣�ͬ�������ڶ���־�Ĵ�����Ψһ�IJ�ͬ
// ֮�����ڣ�����־�������ļ��������ļ�����һ���ǵ���
recv_parse_log_recs(); // ����7
recv_parse_log_rec(type, space, page_no, body); // ����7.2
mlog_parse_initial_log_record();
recv_parse_or_apply_log_rec_body();
recv_add_to_hash_table(); // ����7.4
recv_get_fil_addr_struct();
// ��hash���ռ�ռ�����������ޣ���ô��Ӧ��hash���е�
// ������־����Ӧ��page�ϣ������в�����ʹ��Insert Buf
// Ӧ����־���������£�
// 8.1 ����hash���е�ÿһ��bucket���Լ�bucket�е�ÿһ�
// 8.2 ����buf_page_peek�������ж�page�Ƿ��Ѿ���buffer��
// �����ڣ���ֱ�Ӹ���buffer pool�е�ҳ�������־������
// ����(redo)������־���ɵ�˳����У�����־������
// ���ȣ���ȡpage������page_lsn����������־lsn��������
// ������recv_parse_or_apply_log_rec_body��������
// redo����Ҫ��¼redo��־��������page_lsn��
// ������һ��ҳ�棬recv_sys->n_addrs�����C .
// 8.3 ��page��ǰ����buffer pool�У������recv_read_in_area
// ��������������ȡpage(��Щpage������Ҫ�ָ���page)
// ������ȡ��ҳ��������RECV_READ_AHEAD_AREA = 128��
// ������ȡpage֮�������flushǰ��redo��������ҳ��
// 8.4 ��ǰlog hash���е���־redoȫ�����֮�����
// buffer pool�е�����ҳ�棬��ʼ������һ�ֵ�redo����
// 8.5 ��յ�ǰ��log hash����Ϊ��һ��redo����
recv_apply_hashed_log_recs(FALSE); // ����8
// ȡ��Hash����i��bucket�еĵ�һ��ҳ���Ӧ����־��
HASH_GET_FIRST(recv_sys->addr_hash, i);
buf_page_peek();
buf_page_get();
recv_recover_page(); // ����8.2
recv_parse_or_apply_log_rec_body();
recv_read_in_area(); // ����8.3
buf_read_recv_pages();
buf_flush_free_margins();
// ȡ��Hash����i��bucket�е���һ��ҳ���Ӧ����־��
HASH_GET_NEXT(addr_hash, recv_addr);
Buf_pool_invalidate(); // ����8.4
Recv_sys_empty_hash(); // ����8.5
// �ص�recv_recovery_from_checkpoint_start_func��������redo���֮��
// ����ǰ�ж����־�飬��ͬ��������־�鵽һ��״̬��
// recv_recovery_from_checkpoint_start_func�������˽�����
recv_synchronize_groups();
// ��ʼ���������ֵ䣬ͬʱ��ʼ��ϵͳ�������ֵ�ṹ����Ҫ������
// SYS_TABLES; SYS_COLUMNS; SYS_INDEXES; SYS_FIELDS;
dict_boot();
// ǰ���recv_recovery_from_checkpoint_start_func���������crash recovery
// ��redo���ֲ������������trx_sys_init_at_db_start������Ϊ��ʵ��crash
// recovery�ε�undo���ֲ���(����rollback segment�ع��ε�undo)��������
// δ�ɹ�commit������ռ�����������֣�����undo������ǰ������
// undo��Ϣ�ռ��������������£�
// 1. ��ȡTransaction system headerҳ�棬ϵͳ���ռ�ĵ����page
// 2. ��ʼ���ڴ�ع��ζ�����Ҫ���ݰ�����
// 2.1 ��ȡÿ���ع��ζ�Ӧ�Ļع��ζ�ͷҳ(page_no)
// 2.2 ��ȡÿ���ع��ζ�Ӧ�ı��ռ����(space_id)
// 2.3 ����2.1��2.2��ȡ����Ϣ���ع��ع����ڴ�ṹ��
// 2.3.1 ���ع������ӵ�ϵͳ��������ṹ��������(trx_sys->rseg_list)
// 2.3.2 ��ȡ��ǰ�ع��εĶ�ͷҳ(trs_rsegf_get_new())���ṹ�ɼ�trx0rseg.h
// 2.3.3 �����ع��ζ�ͷҳ��ȡ�����е�undo slot (ÿ���ع��ζ�ͷҳ��
// ����ܹ�������TRX_RSEG_N_SLOTS undo slot��page_size / 16 = 1024)
// ÿ��slotռ�� 4 bytes����¼�����ǵ�ǰundo��Ӧ��undo page_no
// ÿ��������Ҫռ������undo slot(insert & update)
// 2.3.4 ����undo slot�м�¼��page_no����ȡ��Ӧ��undo page��Ϣ��
// undo_type�� UNDO_INSERT or UPDATE;
// undo_state�� TRX_UNDO_ACTIVE or TRX_UNDO_PREPARE
// undo_offset�� ��ǰundo���һ��undo��־��ҳ���е�λ��
// trx_id�� ��ȡ���һ��undo��־ͷ�������־��Ӧ����ID
// xid�� ������XA�������ȡXA�����xid
// last_page_no�� ��ǰundo���(����)һ����־д��undo page
// ����Щ��Ϣ��ȡ֮����trx_undo_t��undo�ڴ�ṹ
// 2.3.5 ����last_page_no��undo_offset����ȡ���һ��undo��־����
// 2.3.6 �������һ��undo rec����ȡ���Ӧ��undo ���к�
// 2.3.7 ��ǰundo�����ӵ��ع��ζ�Ӧ��������(insert/update_undo_list)
trx_sys_init_at_db_start();
trx_sysf_get(TRX_SYS_SPACE, TRX_SYS_PAGE_NO);
trx_rseg_list_and_array_init();
trx_rseg_create_instance();
trx_sysf_rseg_get_page_no(); // ����2.1
trx_sysf_rseg_get_space(); // ����2.2
trx_rseg_mem_create(); // ����2.3
trx_undo_lists_init(); // ����2.3.3
trx_undo_mem_create_at_db_start(); // ����2.3.4
trx_undo_mem_create(); // ����
trx_undo_page_get_last_rec(); // ����2.3.5
trx_undo_rec_get_undo_no(); // ����2.3.6
UT_LIST_ADD_LAST(undo_list, undo); // ����2.3.7
// ���undo��Ϣ���ռ������������Ǹ���undo��Ϣ���ؽ�δ�ύ����
// δ�ύ������ؽ��������£�
// 1. ����trx_sys�ṹ�е�rollback segment�ع���������ȡ�����лع���
// 2. ����ÿ���ع��ε�insert_undo_list��update_undo_list��ȡ����undo
// 3. ����undo��־��Ϣ���ؽ������Ҹ�������IJ�ͬ״̬��
// 3.1 undo����״̬ΪTRX_UNDO_ACTIVE��Ϊ��Ծ����TRX_ACTIVE
// 3.2 undo����״̬ΪTRX_UNDO_PREPARED -> TRX_PREPARED
// 4. ��������trx_id��˳������trx_sys->trx_list����
// ע�⣺���ؽ�����ʱ�������start_timeҲΪ�µ�ʱ�䣬������crash
// ǰ��������������ʱ�䡣
trx_lists_init_at_db_start();
trx_create(); // ����3
// trx->undo_no����¼�˵�ǰ�����undo���кţ�Ҳ������ǰ����һ��
// ���˶����м�¼��
rows_to_undo += trx->undo_no;
// ����purge����ϵͳ�ṹ�����ˣ�undo��Ϣ��undo����Ĵ���������
trx_purge_sys_create();
// undo��Ϣ�ع����������֮���뵽crash recovery�����һ������
// ���һ��������������£�
// 1. redo���hash�������һ����log�����һ��hash��δ�����ڴ�ʱredo
// 2. ��ӡInnoDB redo logλ����Ϣ���Լ����һ��commit������binlog��Ϣ
// ������Ϣ��������transaction system header page�С�[0, 5]
// 3. �ع�����ACTIVE״̬��DDL��������ʱ�����ع�DML����
recv_recovery_from_checkpoint_finish();
recv_apply_hashed_log_recs();
trx_rollback_or_clean_recovered(FALSE);
// �ع�DML����ACTIVE�����ڴ˺�������ɣ�������PREPARE״̬��
// �������ع������ǵȴ�MySQL�ϲ��binlog�ж����յĻع�or�ύ
// �ع�DML������ͨ���´���һ���߳���ɣ����������߳���ִ��
recv_recovery_rollback_active();
os_thread_create(trx_rollback_or_clean_all_recovered);
trx_rollback_or_clean_recover(TRUE);
// ����������ʱ����߳�
os_thread_create(&srv_lock_timeout_thread);
// ����InnoDB���̣߳���purge��checkpoint��dirty pages flush����
os_thread_create(&srv_master_thread);
// ���ˣ�innobase_start_or_create_for_mysql����������ϣ�crash recovery
// ����Ҳ������ɣ�InnoDB����ָ��ɹ�������open״̬ |
1.Crash Recovery�Ż�
����crash recovery���̣�������Ա�����������������ܲ���ĵ㣺
- ����redo log hash table�Ĵ�С
redo log hash table��С�����ܳ���available_mem������жϣ�Bug #49535
- redo ��������flush_list
����dirty page�������ʱ�������һ�������ṹ���������fuzzy checkpoint��Bug
#29847
���������������У�����lsn�ǵ������ɣ�������ĵ�pageһ��λ��flush list����ǰ�档������crash
recovery�����У�redo�ǰ���ҳ�����batch��������ͬҳ���oldest_modification��һ���������������ÿ��ҳ�����flush
list������Ҫ����flush list����������cpu���ܡ�
���������˵����������������ɲο�[1][2]�����������IJ��֣���Ҫ�Ǵ�Դ�������������Ľ��������
1.Hash Table Size
ԭ���DZ���hash table�����hash table�е�ҳ��������Ȼ���ж�hash table��size�Ƿ��Ѿ�����ָ����С��
�µ������ǣ��� recs_sys->heap �ṹ�У�����һ��total_size�ֶΣ�ÿ��heap����һ��block������Ӧ��block_size�ӵ�total_size֮�ϡ�
ֻ��Ҫ�ж�total_size��available_memory֮��Ĵ�С���������ж�hash table
size�Ƿ�ָ����С�����㡣
1.Red Black Tree(RBT)
crash recovery�����У�page��oldest_modification��һ���������ɣ���Ҫ��������flush
list������������ȷ�IJ���λ�á�Ϊ�˽������������������ܲ��㣬InnoDB Plugin��crash
recovery�����У��ṩ��һ��Red Black Tree(�������ib_rbt_struct)���ݽṹ�����ڼ���crash
recovery���̡�Դ�������Ҫ������buf_flush_insert_sorted_into_flush_list������
|
buf0flu.c::buf_flush_insert_sorted_into_flush_list();
// 1. ���ʹ��Red Black Tree�������Ƚ�ҳ�����Red Black Tree֮��
// 2. Red Black Tree������<page.oldest_modification, space, offset>����
// 3. �������֮���ҷ��ص�ǰ����ڵ��ǰһ���ڵ�
if (buf_pool->flush_rbt)
prev_b = buf_flush_insert_in_flush_rbt(&block->page); // ����1
cnode = rbt_insert(buf_pool->flush_rbt, &page, &page); // ����2
rbt_prev(buf_pool->flush_rbt, cnode); // ����3
// 4. ����Red Black Tree���ص�ǰһ���ڵ㣬����ǰpage����flush list��
UT_LIST_INSERT_AFTER(list, buf_pool->flush_list, prev_b, &block->page); // ����4 |
crash recovery�����У����ָ������ڴ治�㣬������ȫ��hash table�е�ȫ��redoӦ����ϣ�������ú���������ڴ��е�����dirty
pages�����ͬʱ��Ҳ��Ӧ�����ɾ��Red Black Tree�е�page��
|
buf0flu.cc::buf_flush_remove(bpage);
buf_flush_delete_from_flush_rbt(bpage);
rbt_delete(buf_pool->flush_rbt, &bpage); |
1.�Ż�Ч��
��ͼ�ǽ�����[2]�ĵ�13ҳ�����п��Կ��������Ż�����crash recovery������Ӱ�졣��������������£��ָ�ʱ��Ľ���32���������ǸĽ�2����log
applying�Ľ���35.5����

1.rollback segment & Transaction
��С�ڣ���Ҫ����InnoDB��������Ҫ���ݽṹ�Ĺ�ϵ����һ��rollback segment�������transaction��
1.rollback segment
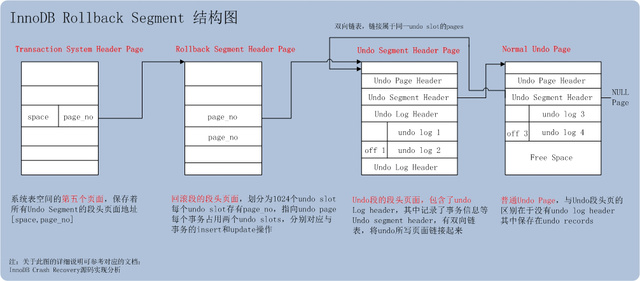
- Transaction System Header Page
ϵͳ���ռ�ĵ����Page [TRX_SYS_SPACE, TRX_SYS_PAGE_NO] ����ҳ���б��������µ�binlog��Ϣ����־��Ϣ�ȡ�ͬʱ��������ÿ��undo
segments�Ļع��ζ�ͷҳ��Ϣ��ÿ���ع�����Ϣ����[space_id, page_no]��ϣ�ָ��ع��ζ�ͷҳ��
- Rollback Segment Header Page
�ع��ζ�ͷҳ����������Ҫ����Ϣ��undo slot��undo�ۡ��ع��ζ�ͷҳ����1024��undo slot��ÿ��slot�д洢����page_no��ָ��Undo
Segment Header Page��
undo slot������ô���⣬һ�������һ�����(insert or update)��undoͨ�����������������γ�һ��undo
slot��
ÿ��������Ҫռ������undo slot��һ��slot���ڴ������������insert��������һ��slot���ڴ��������delete/update�������������еĶ������£�
|
trx_undo_t* insert_undo; /*!< pointer to the insert undo log, or
NULL if no inserts performed yet */
trx_undo_t* update_undo; /*!< pointer to the update undo log, or
NULL if no update performed yet */ |
- Undo Segment Header Page
undo slot�д洢��page_no����Ӧ�ľ���Undo Segment Header Page��Undo
Segment Header Page����Ҫ�����¼���ͷ�ṹ��
1.TRX_UNDO_PAGE_HDR(undoҳͷ)
����������ͣ�page��free�ռ��(trx0undo.h)
2.TRX_UNDO_SEG_HDR(undo��ͷ)
����״̬��undo log headerλ�ã�undo page����(trx0undo.h)
3.undo log header(undo��־ͷ)
��ʼ��ַ��TRX_UNDO_SEG_HDR�б��档���ݰ���������id��xid����һ��undo log
headerλ�õ�(trx0undo.h)
ͨ����ȡundo��ͷ�е�undo page��������ȡ��ǰundoд�����һ��page��Ȼ���ȡ��page�ϵ����һ��undo
record���������һ��undo slot�Ľ���������rollbackʱ������rollback���һ��undo
record��Ȼ����ݴ�undo record��¼����һ��undo��λ�ã������ع���һ��undo��
���ݵ�ǰundo record����λ�ȡ��һ��undo record��ͨ�����ٺ���trx0roll.c::trx_roll_pop_top_rec_of_trx()��������֪һ����
1.undo page�����֣�undo segment header page����ͨundo page��
��ͨundo page������ǰ���ᵽ��undo��־ͷ��
��ͨundo page�У���һ��undo��¼�洢��[TRX_UNDO_PAGE_HDR + TRX_UNDO_PAGE_HDR_SIZE]��
undo segment header page����һ��undo��¼(����undo��־ͷ)�洢��undo��־ͷ�ṹ�е�TRX_UNDO_LOG_START����
��ͨundo page�����һ��undo��¼�洢�ڿ���λ��֮ǰ
undo segment header page�����һ��undo��¼�洢����һ��undo��־ͷ֮ǰ
2.��undo��ǰһ����¼�뵱ǰundo��¼��ͬһҳ��
ǰһ����¼��λ�� = undo_page + mach_read_from_2(rec �C 2);
��ǰundo record��ǰ��2 bytes����¼��ǰһ��undo record��λ��
3.��undo��ǰһ����¼�뵱ǰundo��¼����ͬһҳ��
����ͨ����ǰundo record������undo pageҳ�棬��ȡ��TRX_UNDO_SEG_HDR(undo��ͷ)���ǰһ��undo
page
Ȼ���ȡǰһ��undo page�е����һ��undo record���ɡ�
1.Transaction

��Rollback Segment�Ļ����ϣ����������֡�������Լ���undo��صİ�����
- Transaction System Structure
����ļ��й����ߣ���Ҫ�Ľṹ������
- max_trx_id�� ��һ��δ��������ID
- trx_list�� ���л�Ծ��������
- Transaction Structure
������ڴ�ṹ����undo��صij�Ա������
- undo_no
�����DML���кš���ʶ����ǰ���˶����м�¼��
- update_undo
�������е�update/delete_mark���������������undo�����У�ռ��һ��undo slot
update_undo��Ӧ����trx_undo_struct���ݽṹ�����а���undo slot id��rollback
segment id������һ��undo��¼д��page_no�Լ�page_offset��Ϣ��
- insert_undo
�������е�insert������������һ��undo�����У�ռ��һ��undo slot
��ˣ�һ����������Ȱ���insert������Ҳ����update/delete_mark����������Ҫռ������undo
slot��
1.DB_ROLLBACK_PTR
��InnoDB cluster index�ļ�¼����һ��ϵͳ��DB_ROLLBACK_PTR��7 bytes��������£�
- ���λ2 bytes��ǰһ�汾����undoҳ���ڵ�ƫ�ƣ�
- �м� 4 bytes������undoҳ��page_no��
- ���λ 1 bytes��Ϊ�����֣�
- �� 7 bits�� rollback segment id (128��)��
- ���λ 1 bit����ʶ��ǰ�������ͣ�insert or update��������Ϊinsert��������ֱ�Ӳ���undo��û��ǰһ�汾��
|


