| ������֯���������ݱ�ը����������GB��TB����TB��PB����ͳ�����ݿ��Ѿ���ͨ����ֱ��չ���������֮�����ݡ���ͳ�����洢�ʹ������ݵijɱ����������������������������ӡ���ʹ�úܶ���֯����Ѱ��һ�־��õĽ������������NoSQL���ݿ⣬���ṩ����������ݴ洢�ʹ�����������չ�Ժͳɱ�Ч�ʡ�NoSQL���ݿⲻʹ��SQL��Ϊ��ѯ���ԡ��������ݿ��ж��ֲ�ͬ�����ͣ������ĵ��ṹ�洢����ֵ�ṹ�洢��ͼ�ṹ���������ݿ�ȵȡ�
����NoSQL���ݿ���и��ٵĶ�д������������ĵĵ���Ӧ�ð����鵵��ʷ��־���¼���־������������־����Ϸ���ݡ��罻���ݵȣ��洢������������Ϊ�˽��к����������Եõ������û��Լ�����ʹ�������������Ϣ��
�����ڱ�����ʹ�õ�NoSQL��MongoDB������һ�ֿ�Դ���ĵ����ݿ�ϵͳ����������ΪC++�����ṩ��һ�ָ�Ч�������ĵ��Ĵ洢�ṹ��ͬʱ֧��ͨ��MapReduce�������������洢���ĵ���������չ�Ժܺã�����֧���Զ�������Mapreduce��������ʵ�����ݾۺϡ�����������BSON��������JSON����ʽ�洢���ڴ洢�ṹ��֧�ֶ�̬schema������������̬��ѯ����RDBMS��SQL��ѯ��ͬ��Mongo��ѯ������JSON��ʾ��
MongoDB�ṩ��һ���ۺϿ�ܣ����а������ù��ܣ�����count��distinct��group��Ȼ������ĸ��ۺϺ���������sum��average��max��min��variance�������standard
deviation���������Ҫͨ��MapReduce��ʵ�֡�
��ƪ������������MongoDB�洢���ĵ���ʹ��MapReduce��ʵ��ͨ�õľۺϺ�������sum��average��max��min��variance��standard
deviation���ۺϵĵ���Ӧ�ð����������ݵ�ҵ�������罫�����������ݷ������������ܺ͡������ȡ�
���Ǵӱ���ʾ��Ӧ�����������İ�װ��ʼ��
������װ
�����ڱ��ػ����ϰ�װ������MongoDB����
- ��Mongo��վ������MongoDB����ѹ������Ŀ¼������C:>Mongo
- ����һ���ļ����ڴ�������Ŀ¼�����磺C:\Mongo\Data ?��������ļ�����������ط�����ô����mongod.exe��������MongoDBʱ����Ҫ�������мӲ�����-dbpath
- �������� ?MongoDB�ṩ�����ַ�ʽ��mongod.exe�Ժ�̨����������mongo.exe���������н��棬����������������������ִ���ļ���λ��Mongo\binĿ¼�£�
- ����Mongo��װĿ¼��binĿ¼�£����磺C:> cd Mongo\bin
- ������������ʽ�����£�
mongod.exe �Cdbpath C:\Mongo\data
���� mongod.exe �Cconfig mongodb.config
mongodb.config��Mongo\binĿ¼�µ������ļ�����Ҫ�ڴ������ļ���ָ������Ŀ¼�����磬dbpath=
C:\Mongo\Data����λ�á�
- ���ӵ�MongoDB������һ����mongo��̨�����Ѿ�����������ͨ��http://localhost:27017�鿴��
MongoDB�������к����ǽ����������ľۺϺ�����
ʵ�־ۺϺ���
�ڹ�ϵ���ݿ��У����ǿ�������ֵ���ֶ���ִ�а���Ԥ����ۺϺ�����SQL��䣬���磬SUM()��COUNT()��MAX()��MIN()��������MongoDB�У���Ҫͨ��MapReduce������ʵ�־ۺ��Լ�������������SQL������ʵ�־ۺϵ�GROUP
BY�Ӿ�Ƚ����ơ���һ�ڽ�������ϵ���ݿ���SQL��ʽʵ�ֵľۺϺ���Ӧ��ͨ��MongoDB�ṩ��MapReduceʵ�ֵľۺϡ�
Ϊ������������⣬���ǿ���������ʾ��Sales��������MongoDB�еķ���ʽ��ʽ���֡�
Sales��
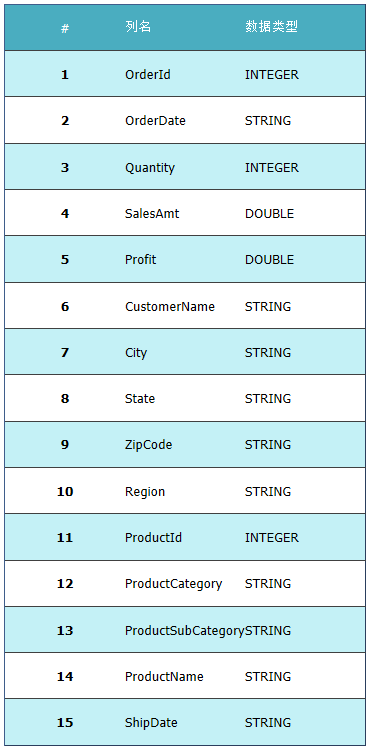
����SQL��MapReduce��ʵ��
�����ṩ��һ����ѯ������������Щ��ѯʹ�þۺϺ��������������ͷ���Ӿ䣬�����Ч��MapReduceʵ�֣���MongoDBʵ��SQL��GROUP
BY�ĵ�Ч��ʽ����MongoDB�洢���ĵ���ִ�оۺϲ����dz����ã����ַ�ʽ��һ�������ǾۺϺ��������磬SUM��AVG��MIN��MAX����Ҫͨ��mapper��reducer���������ƻ�ʵ�֡�
MongoDBû��ԭ��̬���û��Զ��庯����UDFs��֧�֡�����������ʹ��db.system.js.save����������������JavaScript������JavaScript����������MapReduce�и��á��±���һЩ���õľۺϺ�����ʵ�֡��Ժ����ǻ�������Щ������MapReduce�����е�ʹ�á�
| �ۺϺ��� |
Javascript ���� |
| SUM |
db.system.js.save( { _id : "Sum" ,
value : function(key,values)
{
var total = 0;
for(var i = 0; i < values.length; i++)
total += values[i];
return total;
}}); |
| AVERAGE |
db.system.js.save( { _id : "Avg" ,
value : function(key,values)
{
var total = Sum(key,values);
var mean = total/values.length;
return mean;
}}); |
| MAX |
db.system.js.save( { _id : "Max" ,
value : function(key,values)
{
var maxValue=values[0];
for(var i=1;i |
| MIN |
db.system.js.save( { _id : "Min" ,
value : function(key,values)
{
var minValue=values[0];
for(var i=1;i |
| VARIANCE |
db.system.js.save( { _id : "Variance" ,
value : function(key,values)
{
var squared_Diff = 0;
var mean = Avg(key,values);
for(var i = 0; i < values.length; i++)
{
var deviation = values[i] - mean;
squared_Diff += deviation * deviation;
}
var variance = squared_Diff/(values.length);
return variance;
}}); |
| STD DEVIATION |
db.system.js.save( { _id : "Standard_Deviation"
, value : function(key,values)
{
var variance = Variance(key,values);
return Math.sqrt(variance);
}}); |
SQL��MapReduce�ű������ֲ�ͬ������������ʵ�־ۺϺ����Ĵ���Ƭ�����±���ʾ��
1.��������ƽ��������
����IJ�ѯ��������ȡ��ͬ������ƽ����������
| SQL Query |
MapReduce Functions |
| SELECT |
db.sales.runCommand(
{
mapreduce : "sales" , |
City,
State,
Region,
|
map:function()
{ // emit function handles the group by
emit( {
// Key
city:this.City,
state:this.State,
region:this.Region},
// Values
this.Quantity);
}, |
| AVG(Quantity) |
reduce:function(key,values)
{
var result = Avg(key, values);
return result;
} |
| FROM sales |
trx_undo_t* insert_undo; |
| GROUP BY City, State,
Region |
// Group By is handled by the emit(keys, values)
line in the map() function above |
|
out : { inline : 1 } }); |
2.��Ʒ�ķ��������ܶ�
����IJ�ѯ��������ȡ��Ʒ�ķ������۶���ݲ�Ʒ���IJ㼶���顣�����������У���ͬ�IJ�Ʒ�����Ϊ����ά�ȣ�����Ҳ���Ա���Ϊ�����ӵĻ��ڲ�ε�ά�ȡ�
| SQL ��ѯ |
MapReduce ���� |
| SELECT |
db.sales.runCommand(
{
mapreduce : "sales" , |
ProductCategory,
ProductSubCategory, ProductName,
|
map:function()
{
emit(
// Key
{key0:this.ProductCategory,
key1:this.ProductSubCategory,
key2:this.ProductName},
// Values
this.SalesAmt);
}, |
| SUM(SalesAmt) |
reduce:function(key,values)
{
var result = Sum(key, values);
return result;
} |
| FROM sales |
|
| GROUP BY ProductCategory,
ProductSubCategory, ProductName |
// Group By is handled by the emit(keys, values)
line in the map() function above |
|
out : { inline : 1 } }); |
3. һ�ֲ�Ʒ���������
����IJ�ѯ��������ȡһ��������Ʒ���ڹ����������������
| SQL��ѯ |
MapReduce ���� |
| SELECT |
db.sales.runCommand(
{
mapreduce : "sales" , |
ProductId, ProductName,
|
map:function()
{
if(this.ProductId==1)
emit( {
key0:this.ProductId,
key1:this.ProductName},
this.Profit);
}, |
| MAX(SalesAmt) |
reduce:function(key,values)
{
var maxValue=Max(key,values);
return maxValue;
} |
| FROM sales |
|
| WHERE ProductId=��1�� |
// WHERE condition implementation is provided in
map() function |
| GROUP BY ProductId, ProductName |
// Group By is handled by the emit(keys, values)
line in the map() function above |
|
out : { inline : 1 } }); |
4. �����������۶ƽ������
��������������Ǽ��㶩���������������۶��ƽ��������ID��1��10֮�䣬����ʱ����2011���1��1�յ�12��31��֮�䡣����IJ�ѯ������ִ�ж���ۺϣ����磬��ָ������Լ�ָ���IJ�ͬ����Ͳ�Ʒ���Χ�ﶩ���������������۶��ƽ������
| SQL��ѯ |
MapReduce ���� |
| SELECT |
db.sales.runCommand(
{ mapreduce : "sales" , |
Region,
ProductCategory,
ProductId,
|
map:function()
{
emit( {
// Keys
region:this.Region,
productCategory:this.ProductCategory,
productid:this.ProductId},
// Values
{quantSum:this.Quantity,
salesSum:this.SalesAmt,
avgProfit:this.Profit} );
} |
Sum(Quantity),
Sum(Sales),
Avg(Profit)
|
reduce:function(key,values)
{
var result=
{quantSum:0,salesSum:0,avgProfit:0};
var count = 0;
values.forEach(function(value)
{
// Calculation of Sum(Quantity)
result.quantSum += values[i].quantSum;
// Calculation of Sum(Sales)
result.salesSum += values[i].salesSum;
result.avgProfit += values[i].avgProfit;
count++;
}
// Calculation of Avg(Profit)
result.avgProfit = result.avgProfit / count;
return result;
}, |
| FROM Sales |
|
| WHERE |
|
Orderid between
1 and 10
AND Shipdate BETWEEN
��01/01/2011�� and
��12/31/2011��
|
query : {
"OrderId" : { "$gt" : 1 },
"OrderId" : { "$lt" : 10 },
"ShipDate" : { "$gt" : "01/01/2011" },
"ShipDate" : { "$lt" : "31/12/2011" },
}, |
GROUP BY
Region, ProductCategory, ProductId
|
// Group By is handled by the emit(keys, values)
line in the map() function above |
| LIMIT 3; |
limit : 3, |
|
out : { inline : 1 } }); |
��Ȼ�����Ѿ������ڲ�ͬҵ���µľۺϺ����Ĵ���ʾ������������������������Щ������
���ԾۺϺ���
MongoDB��MapReduce����ͨ�����ݿ����������á�Map��Reduce������ǰ���½����Ѿ�ʹ��JavaScriptʵ�֡�������ִ��MapReduce���������
db.runCommand(
{ mapreduce : <collection>,
map : <mapfunction>,
reduce : <reducefunction>
[, query : <query filter object>]
[, sort : <sorts the input objects using this key. Useful for
optimization, like sorting by the emit key for fewer reduces>]
[, limit : <number of objects to return from collection>]
[, out : <see output options below>]
[, keeptemp: <true|false>]
[, finalize : <finalizefunction>]
[, scope : <object where fields go into javascript global scope >]
[, jsMode : true]
[, verbose : true]
}
)
Where the Output Options include:
{ replace : "collectionName" }
{ merge : "collectionName"
{ reduce : "collectionName" }
{ inline : 1} |
��������������ۺϺ�������MapReduce��ʹ�õ����
����Mongo�����в����ñ�
- ȷ��Mongo��̨���������У�Ȼ��ִ��mongo.exe����Mongo�����С�
- ʹ�������л����ݿ⣺use mydb
- ʹ������鿴Sales�������ݣ�db.sales.find()
find�����������£�
{ "_id" : ObjectId("4f7be0d3e37b457077c4b13e"), "_class" : "com.infosys.mongo.Sales", "orderId" : 1,
"orderDate" : "26/03/2011","quantity" : 20, "salesAmt" : 200, "profit" : 150, "customerName" : "CUST1",
"productCategory" : "IT", "productSubCategory" : "software", "productName" : "Grad", "productId" : 1 }
{ "_id" : ObjectId("4f7be0d3e37b457077c4b13f"), "_class" : "com.infosys.mongo.Sales", "orderId" : 2,
"orderDate" : "23/05/2011", "quantity" : 30, "salesAmt" : 200, "profit" : 40, "customerName" : "CUST2",
"productCategory" : "IT", "productSubCategory" : "hardware", "productName" : "HIM", "productId" : 1 }
{ "_id" : ObjectId("4f7be0d3e37b457077c4b140"), "_class" : "com.infosys.mongo.Sales", "orderId" : 3,
"orderDate" : "22/09/2011","quantity" : 40, "salesAmt" : 200, "profit" : 80, "customerName" : "CUST1",
"productCategory" : "BT", "productSubCategory" : "services", "productName" : "VOCI", "productId" : 2 }
{ "_id" : ObjectId("4f7be0d3e37b457077c4b141"), "_class" : "com.infosys.mongo.Sales", "orderId" : 4,
"orderDate" : "21/10/2011", "quantity" : 30, "salesAmt" : 200, "profit" : 20, "customerName" : "CUST3",
"productCategory" : "BT", "productSubCategory" : "hardware", "productName" : "CRUD", "productId" : 2 }
{ "_id" : ObjectId("4f7be0d3e37b457077c4b142"), "_class" : "com.infosys.mongo.Sales", "orderId" : 5,
"orderDate" : "21/06/2011", "quantity" : 50, "salesAmt" : 200, "profit" : 20, "customerName" : "CUST3",
"productCategory" : "BT", "productSubCategory" : "hardware", "productName" : "CRUD", "productId" : 1 } |
����������ۺϺ���
ͨ��MongoDB�����д���ִ���������
> db.system.js.save( { _id : "Sum" ,
value : function(key,values)
{
var total = 0;
for(var i = 0; i < values.length; i++)
total += values[i];
return total;
}}); |
��ʾ����Sales����ִ��MapReduce����
> db.sales.runCommand(
{
mapreduce : "sales" ,
map:function()
{
emit(
{key0:this.ProductCategory,
key1:this.ProductSubCategory,
key2:this.ProductName},
this.SalesAmt);
},
reduce:function(key,values)
{
var result = Sum(key, values);
return result;
}
out : { inline : 1 } }); |
������£�
"results" : [
{
"_id" : {
"key0" : "BT",
"key1" : "hardware",
"key2" : "CRUD"
},
"value" : 400
},
{
"_id" : {
"key0" : "BT",
"key1" : "services",
"key2" : "VOCI"
},
"value" : 200
},
{
"_id" : {
"key0" : "IT",
"key1" : "hardware",
"key2" : "HIM"
},
"value" : 200
},
{
"_id" : {
"key0" : "IT",
"key1" : "software",
"key2" : "Grad"
},
"value" : 200
}
],
"timeMillis" : 1,
"timing" : {
"mapTime" : NumberLong(1),
"emitLoop" : 1,
"total" : 1
},
"counts" : {
"input" : 5,
"emit" : 5,
"output" : 4
},
"ok" : 1 |
�ܽ�
MongoDB�ṩ�������ĵ��Ĵ洢�ṹ�����Ժ�������չ֧��TB�����ݡ�ͬʱҲ�ṩ��Map
Reduce���ܣ�����ͨ����������ʽʹ����SQL������ʵ�����ݾۺϡ�����ƪ�����У����������˰�װMongoDB��ʹ��MapReduce����ִ�оۺϺ����Ĺ��̣�Ҳ�ṩ�˼�SQL�ۺϵ�MapReduceʾ��ʵ�֡���MongoDB�У������ӵľۺϺ���Ҳ����ͨ��ʹ��MapReduce����ʵ�֡� |


