| 分布式数据库计算涉及到分布式事务、数据分布、数据收敛计算等等要求
分布式数据库能实现高安全、高性能、高可用等特征,当然也带来了高成本(固定成本及运营成本),我们通过MongoDB及MySQL
Cluster从实现上来分析其中的设计思路,用以抽象我们在设计数据库时,可以引用的部分设计方法,应用于我们的生产系统
首先说说关系及非关系数据库的特征
MySQL的Innodb及Cluster拥有完整的ACID属性
A 原子性 整个事务将作为一个整体,要么完成,要么回滚
C 一致性 事务开始之前和事务结束以后,数据库的完整性限制没有被破坏
I 隔离性 两个事务的执行是互不干扰的,两个事务时间不会互相影响
D 持久性 在事务完成以后,该事务对数据库所作的更改便持久地保存在数据库之中,并且是完全的
为了实现ACID,引入了诸如Undo、Redo、MVCC、TAS、信号、两阶段封锁、两阶段提交、封锁等实现,并引入数据存取路径,整个事情变得将极其复杂
MySQL遵循SQL标准、使用SQL标准的情况下,可以做到RDBMS之间的无缝迁移
其丰富的数据类型、完整的业务逻辑控制及表达能力一直作为商业应用的首选
MongoDB使用集合表示数据,不拥有ACID属性,其无类型、快速部署及快速开发得到了普遍的认可
不管是RDBMS还是MongoDB,无一都使用了索引结构,MongoDB支持B树索引,索引根据用户需要进行建立,可以嵌套在各个层次的各个容器之间构建
在数据库中,有两种数据存放方法:
1、堆:数据按照向后插入的方法,一直堆积在文件末尾,使用索引结构访问数据时,将在索引中得到数据指针,然后获取数据,当有数据删除时,将其从对应位置删除,对于频繁更新的堆表,需要定期进行优化,使用堆表,会导致数据顺序访问原则被打破(在DBMS中做了访问优化,性能得到部分提升),由于没有填充因子,在相同压缩算法下,空间能得到很大的节省,堆表很适合于顺序范围访问,如数据仓库等业务场景
2、索引组织:一般索引组织表使用B+作为构造方法,整个结构如同一个倒挂的树(从数据访问流来看),路由信息存放在树枝上,所有的数据存放在叶子节点,通过双向指针将所有叶子根据顺序方式串联起来,由于时空访问局限特性,这能很大提升数据性能,DBMS根据访问存取路径访问及构造数据,访问路径深度直接影响了性能,一般建议访问路径控制在4以内(小于或等于3),原因由于访问多层路径需要消耗更高的代价及维护索引树代价越来越昂贵
我们常见的Innodb、MySQL Cluster等都是索引组织表、MyISAM为堆表,MongoDB的组织结构为堆
拥有AICD属性的数据库拥有索引维护功能,MyISAM存储引擎及MongoDB由于是堆组织结构,且没有ACID的控制,会导致元数据与索引不一致问题,直接导致数据存取失效,造成数据不一致,但由于没有ACID的要求,更新(本文所阐述的更新包括包括所有的写入操作)速度将得到很大的提升,MyISAM存储引擎需要定期进行一致性check,正是因为不具有ACID属性,MyISAM存储引擎需要为数据更新锁定表,造成大并发下更新的低性能
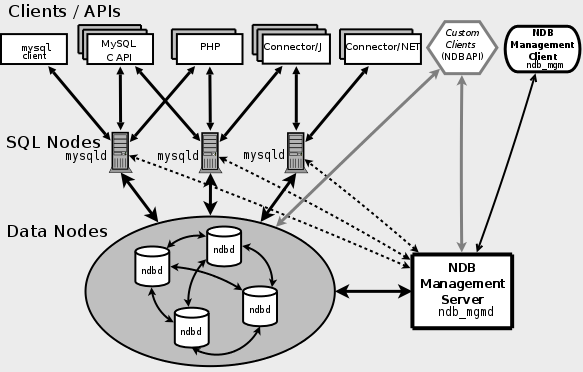
MySQL Cluster 架构
Cluster分为SQL节点、数据节点、管理节点(MySQL Cluster提供了API供内部调用,外部应用程序可以通过API借口访问任意层方法)
SQL节点提供用户SQL指令请求,解析、连接管理,query优化和响、cache管理等、数据merge、sort,裁剪等功能,当SQL节点启动时,将向管理节点同步架构信息,用以数据查询路由
数据节点提供数据存取,持久化、API数据存取访问等功能
管理节点维护着节点活动信息,以及实施数据的备份和恢复等。管理节点会获取整个cluster环境中节点的状态和错误信息,并将各个cluster集群中各个节点的信息反馈给整个集群中其他的所有节点,这对于SQL节点的数据路由规则至关重要,当节扩容时,数据将会被rebuild
数据节点使用分片及多份数据存储,至少存放2份,数据存放于内存中,根据管理节点的规则进行持久化,作为数据存取地,需要大量内存支持
SQL节点作为查询入口,需要消耗大量cpu及内存资源,可使用分布式管理节点,并在SQL节点外封装一层请求分发及HA控制机制可解决单点及性能问题,其提供了线性扩展功能
管理节点维护着全局规则信息,当节点发生故障时,将会发生故障通告
在整个Cluster体系中,任何一个组建都支持动态扩展,线性扩展,提供了高可用,高性能的解决方案
问题:
当新增数据节点时,需要重构存取路径信息,对管理节点将造成数据重构压力,该操作建议在非业务高峰时进行
Cluster使用自动键值识别数据分片方案,用户无需关心数据切片方案(在5.1及以后提供了分区键规则),透明实现分布式数据库,数据分片规则根据1、主键、2唯一索引、3自动行标识rowid完成,再集群个数进行分布,其访问数据犹如RAID访问机制一样,能并行从各个节点抽取数据,散列数据,当使用非主键或分区键访问时,将导致所有簇节点扫描,影响性能(这是Cluster面对的核心挑战)
MySQL Cluster架构
MongoDB 复制集架构,基于MongoDB复制,构造出的分布式数据库解决方案:
MongoDB提供了和MySQL Cluster类似的架构,在configre
server、mongos、mongo中,包含:
configure server: 提供集群元数据,其中包含基本信息,每个replica
set,trunk及trunk大小等信息
Mongs: 数据访问路由、查询优化、数据merge、sort,裁剪等功能,请求推送等
mongo+replica set:数据存取(使用mongo协议还提供直接数据访问)
MongoDB Shard架构
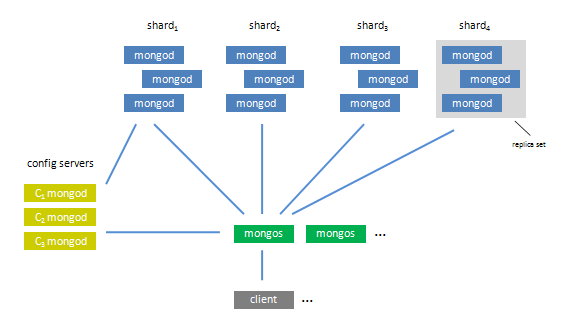
MongoDB在构建集合时,需要提供数据分片规则,该规则将被记录在mongoDB中,查询请求mongos发起请求,mongos根据存取路径在Replica中访问数据
由于MongoDB为用户提供了一个选择性,将数据如何进行切片,在对用户访问透明的情况下,快速存取数据
MongoDB面临的问题:
以非分片规则访问数据时(索引可以建立在各个分片),将导致所有Mongo簇节点全扫描(可以通过多份冗余拷贝并进行不同的分片规则实现,这也是当前数据分片应用常用的手段)
当新增数据簇时,将导致所有数据节点重构,直接影响性能
总结:
MongoDB使用堆存取路径方法组织数据、不包含ACID特性对于数据大量数据更新及查询(对于拥有MVCC的架构,将降低在高并发、大数据集的响应速度)有很大的提升,但没有ACID保证关键数据的稳定、安全
MongoDB解决了MySQL Cluster的自动分片规则(5.1以后提供了用户定义功能),将MySQL
Cluster的SQL节点数据处理工作移交给mongos,MySQL Cluster使用SQL->节点->SQL的访问路径,MongoDB使用
Mongos-> replica set ->Mongos 的访问路径,从架构上来说,MySQL
Cluster和MongoDB的架构类似(MongoDB Replica set模式使用两阶段提交,性能将被大大降低)
MySQL Cluster拥有完整的商业支持及通用标准支持,相对丰富的管理工具,MongoDB拥有相对局部的性能优势,但缺少强大的稳定及安全支撑,丰富的管理工具,两者有各自的优势,但有差不多相同的致命弱点。
MySQL Cluster可以实现基于复制的拓扑架构,在不改变内部拓扑架构的情况下将数据同步至异地,形成星形拓扑,MongoDB在这方面还缺少相关的技术解决方案(当然可以是复制方案,但MySQL
Cluster在较高的层次实现,MongoDB在较低层的方面实现,对于管理来说,将面临很大的挑战)
从商业上来说,MySQL Cluster拥有足够的商业使用价值,但缺陷也很明显,MongoDB对MySQL
Cluster的改进很值得思考及在日常数据架构设计,模式设计中引入,但作为大面积商业应用,MySQL Cluster和MongoDB都还有很长一段路要走,不管是固有的缺陷还是管理模式上。 |


