|
���
�����ı�����һ�ֽ���״̬���Ƕ�����������Դ�����ö����µġ���������������Ҫ���������漰����ع�����һ�����⡣
һЩ����֪ʶ
Ҫ����SQL Server�е����������õķ�ʽ��ͨ����ȴӸ��������������������˵һ����������Ӿ������������壩���ڵ�·(��Դ)�����ã���ͼ1��ʾ��
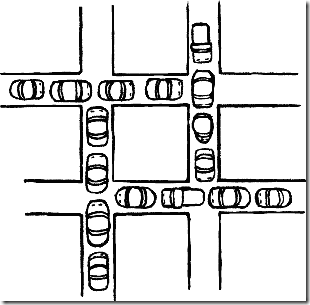
ͼ1.����������ֱ������
��ͼ1�������У�ÿ��������ռ��һ����·��������Ҫ����һ��������ռ�е���һ����·����˻���������˭����ǰ�У�������������������������ӿ��Կ���������������Ҫ�ĸ���Ҫ����������:
1������������
���������Դ�Ƕ�ռ�ģ�ͼ1��ÿ��������ֻ����һ�������������ܵڶ��ӡ�
2)����͵ȴ�����:
ָ�����Ѿ���������һ����Դ������������µ���Դ��������Դ�ѱ���������ռ�У���ʱ�����������������ֶ��Լ��ѻ�õ�������Դ���ֲ��š���ͼ1�У�ÿ�������Ѿ�ռ����һ����������������һ������������ռ�еij��������������
3)����������
ָ���������Ѿ���õ���Դ�������Ŀ��֮ǰ���ܱ��ͷš���ͼ1�У�Ŀ��ָ������������ͨ��������������ָ������������Ŀ��֮ǰ�����Ӳ������ó�����ռ�ij�����
4)��·�ȴ�����
ָ�ڷ�������ʱ����Ȼ����һ�����塪����Դ�Ļ������������弯��{P0��P1��P2����������Pn}�е�P0���ڵȴ�һ��P1ռ�õ���Դ��P1���ڵȴ�P2ռ�õ���Դ��������Pn���ڵȴ��ѱ�P0ռ�õ���Դ����ͼ1�п��Կ����������������Ķ��������÷��Ż�·�ȴ�������������1ϣ����ó���2ռ�еij���������2ϣ����ó���3ռ�еij���������3ϣ����ó���4ռ�еij���,����4��������ϣ����ó���1ռ�еij������γ�һ����·��
�����ڽ����еĶ���
��������������С�����ķ�Χ���ص�����������硣�ڼ�����У�������������Ĵʱ�������Ľ��������������Դ��С���������ʹ�õ���Դ���ڼ�����У�����������������������ڿ�ʼ֮�䣬�������һ�½��̵ļ���״̬���������Ȥ��Ҳ���Բο���֮ǰ��һƪ����:http://www.cnblogs.com/CareySon/archive/2012/05/04/ProcessAndThread.html.
����˵����������֯��Դ����С��λ���������ϵͳ�������������У�ÿһ�����̶���ͼ1��ʾ��������������Ҫǰ������ǰ���Ĺ����У���Ҫ������Դ�Լ�CPU��ͼ2�Dz����ǽ��д������ٵ�״̬���������̵ļ���״̬��

ͼ2.���̵ļ���״̬
�ܶ���Դ�ǿ��Թ����ģ������ڴ档�����ڴ�ӡ������Դ��˵����Ҫ��ռ��ͼ2�еļ���״̬�������ǣ�������û���������Դʱ������˵�ȴ�IO���ȴ���ӡ������ʱ������״̬���������̻������Щ��Դʱ���Ϳ��Ա�Ϊ����״̬���ھ���״̬�Ľ����ٻ��CPUʱ���ͱ�Ϊִ��״̬����ִ�еĹ����У�CPU�������˾ͼ�����Ϊ����״̬�����ǵ���Ҫ������Դʱ���ͻ������Ϊ����״̬���Դ�������
�ڲ���ϵͳ�У���Щ��Դ�����Dz��ɰ�����Դ�������ӡ��������ӡ����һ������ռ��ʱ����һ�����̾ͻᱻ����������һ����Դ��Ҫ�ص�ǿ����,������Դ����ʱ����Դ��������̲������ź���,��Ϣ���������ڵ���Ϣ��������̻��̷߳���������Դʱ������������������SQL
Server�в�����������ʵ������������Դ����ɵġ�
�������������̼�Ȼ���˵�ǰ����Դ������Ҫ�������Դʱ�����������������������ĸ�����ʱ���ͻ����������
������SQL Server�еĶ���
��SQL Server�У�����������Dz�����ʵ�ֲ���֮��ĸ����ԡ�Ϊ��ʹ�ò������������IJ���֮���Ӱ�쵽��ijһ����ֵ������Դ��Ϊ�Ľ��м���(��������ʵ���Կ�����һ����־λ)����һ�����Ӷ��ض�����Դ���в���ʱ����һ������ͬʱ��ͬ������Դ���в����ͻᱻ����(��Ȼ�ˣ������֮��ļ������йأ�����������������۳����˱��ĵķ�Χ�������ⲿ�����ݿ��Կ��ҵ���һƪ����:T-SQL��ѯ���ס�����SQL
Server�е���)�����������������ı�Ҫ������
���棬����ͨ��һ������������������
���ȣ�Ҫ����������һ��Ҫ����ǰ���ᵽ�������ֵ��ĸ���Ҫ������ͼ3�п�������Ŀ�������������(SPID52��SPID55)������������ĸ������ġ�
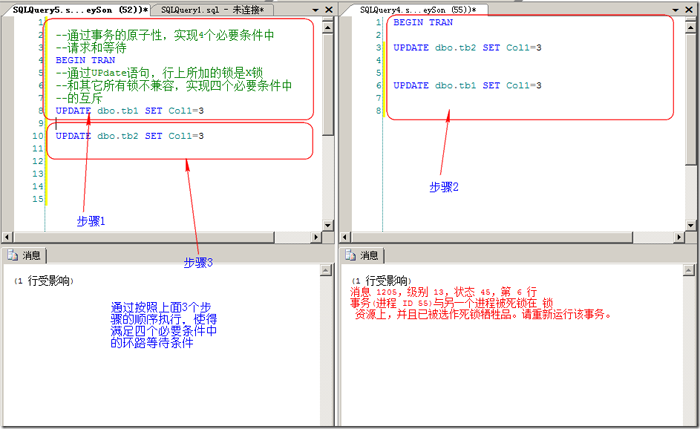
ͼ3.һ������ʾ��
Lock Monitor
ͼ3����������Կ�����SQL Server������������������ȥ������ͨ��һ����Lock
Monitor���̶߳��ڽ��м�⣨Ĭ����5�룩���������������������һ��SPIDռ�е���Դ��������һ��SPIDִ����ȥ�����������һ��SPID����������������:
1.���������ȼ���
2.���������ȼ���ͬ������£����ݿ���������С�����ᱻ����
���棬���Ǹ���ͼ3�е����ӣ����������������ȼ���ʹ����ߵ�������ع�����ͼ4��ʾ��
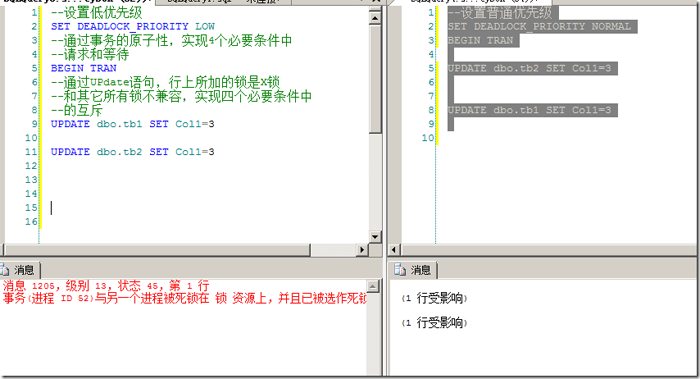
ͼ4.�����������ȼ������ȼ��͵�SPID������
SQL Server�������ļ��
����Ҫ���⣬�ڶಢ���Ļ����У������Dz��ɱ���ģ�ֻ�ܾ�����ͨ�����������ݿ���ƣ����õ��������ʵ��IJ�ѯ����Լ�����ȼ��������ļ��١���ˣ����������Ŀ����֪��������ܻ����������ͨ���Լ����������з����������Ż���ѯ/����/����ȼ����������������Ŀ����ԡ�
�鿴���������ַ�ʽ��һ����ͨ������˵�Trace��������һ����ͨ��SQL
Profiler����������������ͨ��Trace��ץ������
ͨ��Trace��������
������������ͨ������˵�Trace�Ϳ��Խ�������Ϣ������־����SQL
Server 2000ʱ����ֻ��ͨ��Trace flag 1204������������Trace flag 1204�������ṩXML����ͼ����SQL
Server 2005�Լ�֮��İ汾��Trace flag 1222��ȡ����
Ϊ���ڷ����������е�Session����Trace flag 1222������ͨ�������1��ʾ��
DBCC TRACEON(1222,-1)
����1.�������Session����1222���Trace Flag
��ȥ����1֮�⣬������ͨ��������SQL Serverʵ��֮ǰ���Լ���������
�Ct1222������Ͳ���ϸ˵�ˡ�
��ʱ���������������ܴ���־������صļ�¼����ͼ5��ʾ��
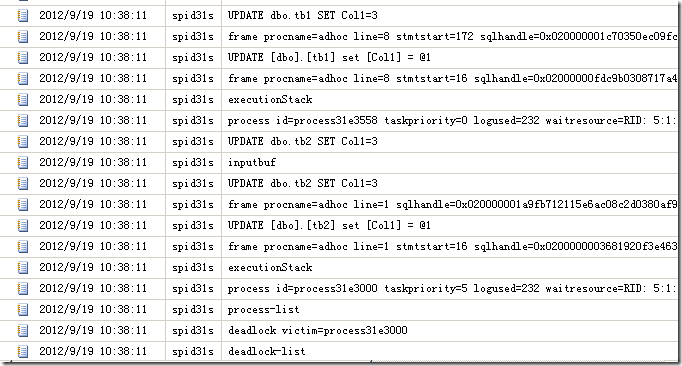
ͼ5.������ļ�¼
ͨ��Profiler���鿴����
��һ�ַ����ǿ���Profiler����,Profiler������ͼʾ������Ϣ���ݾ�ֱ���ˣ�Profiler��������ͼ6��ʾ��
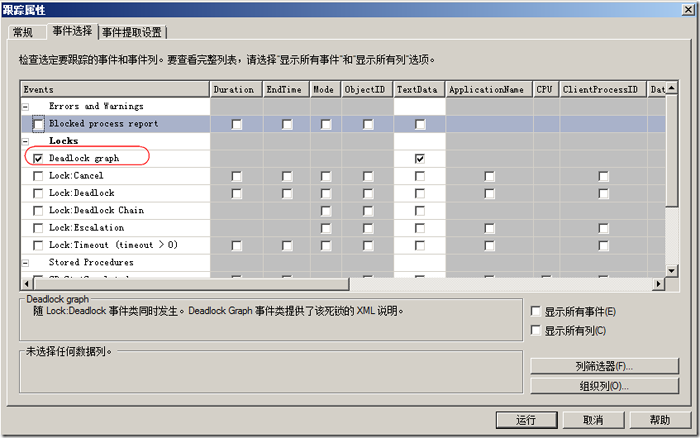
ͼ6.Profiler��ץ����ͼ������
��ץ��������ͼ��ͼ7��ʾ��
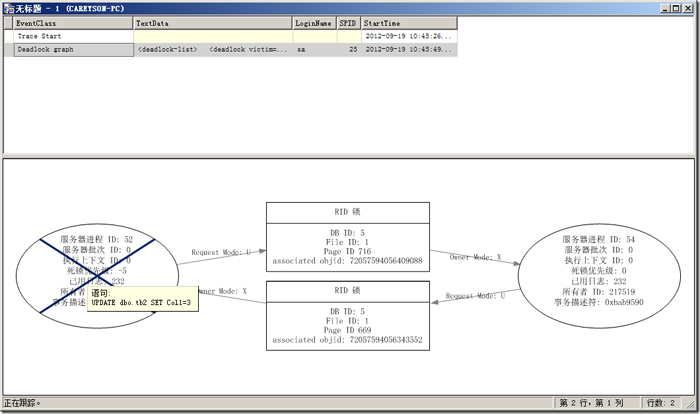
ͼ7.����ͼ
ͨ���������ͼ�����Ը�ֱ�۵Ŀ��������������������Դ����������Ƶ�������ʱ����������ʾ�����������䡣����������Ʒ���̻ᱻ��X�š�
���������ͼ�����Կ��������������Դ��
SQL Server�в���������һЩ���
����ǩ���Ҳ���������
��������������ԭ������ǩ���Һ������ݲ����Ľ���״̬������˵,��������Update���Ի���������X����Ȼ����Ҫ�Ա��ϵ�����Ҳ���и��£������ϵ��������ñ���һ�����ӽ��в��ң�����S������ʱ�ֲ�����ǩ����ȥ����������X�������ݽ�����ǩ���ң���ʱ�γ����������������Դ�ͼ8������
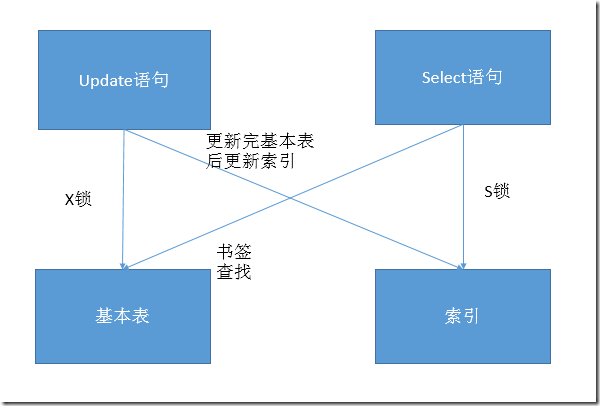
ͼ8.����ǩ���Ҳ���������
������������ͨ��Include����������ǩ���ң��Ӷ����������������������ĸ��ʡ�
���������������
��������������ԭ���������Լ����������(Ҳ���������Ǵӱ�������Ǹ���)��������ʱ����Ҫ�鿴�ӱ�����ȷ���ӱ���������������Լ������ʱ���������ϼ�X�������Ⲣ������ֹͬһʱ�䣬��һ��SPID��ӱ����ӱ��ĵ�����������Ϊ�˽��������⣬SQL
Server�ڽ����������ʱ��ʹ��Range�����������ǵ�����ȼ�Ϊ���л�ʱ���еģ��������ʱ��Ȼ����ȼ�������Ĭ�ϵ����ύ����������Ϊȴ�����л�����ܿ��ܾͻᵼ��������
����취֮һ�������������������ʹ��Range�����������ϣ������DZ��������Ӷ����������������ĸ��ʡ�
�����ƽ�˳������������
��Ҳ��ͼ3��������ԭ���ڶ���������Դ��ʹ��˳�����γ�������·�������ġ���������Ǿ�������Դ��ʹ��˳��һ�¡���Ҳ�����������������һ�������
��������
���������SQL Server�в���������һЩ������������ǴӸ������ĽǶ�������μ���������
�ڲ���ϵͳ�У����̲�������������ԭ��ͬ���������õ�SQL Server�С��ڲ���ϵͳ���ڴ��������İ취���£�
1) Ԥ��������
����һ�ֽϼ�ֱ�۵�����Ԥ���ķ�����������ͨ������ijЩ����������ȥ�ƻ������������ĸ���Ҫ�����е�һ������������Ԥ������������Ԥ��������һ�ֽ���ʵ�ֵķ������ѱ��㷺ʹ�á�����������ʩ�ӵ�������������̫�ϸ��ܻᵼ��ϵͳ��Դ�����ʺ�ϵͳ���������͡�
2) ����������
�÷���ͬ������������Ԥ���IJ��ԣ��������������Ȳ�ȡ�������ƴ�ʩȥ�ƻ����������ĵ��ĸ���Ҫ��������������Դ�Ķ�̬��������У���ij�ַ���ȥ��ֹϵͳ���벻��ȫ״̬���Ӷ����ⷢ��������
3)���������
���ַ������������Ȳ�ȡ�κ������Դ�ʩ��Ҳ���ؼ��ϵͳ�Ƿ��Ѿ����벻��ȫ�����˷�������ϵͳ�����й����з�������������ͨ��ϵͳ�����õļ���������ʱ�ؼ��������ķ���������ȷ��ȷ���������йصĽ��̺���Դ��Ȼ���ȡ�ʵ���ʩ����ϵͳ�н��ѷ����������������
4)���������
������������������һ�ִ�ʩ������ϵͳ���ѷ�������ʱ���뽫���̴�����״̬�н��ѳ��������õ�ʵʩ�����dz��������һЩ���̣��Ա����һЩ��Դ���ٽ���Щ��Դ������Ѵ�������״̬�Ľ��̣�ʹ֮תΪ����״̬���Լ������С������ļ��ͽ����ʩ���п���ʹϵͳ��ýϺõ���Դ�����ʺ�������������ʵ�����Ѷ�Ҳ���
������4�д��������İ취�������м�������ͽ��������Lock Monitor���£���ΪDBA�����ݿ����Ա����������Ҫ����Ԥ���ͱ��������ϡ�
Ԥ������
Ԥ�����������ƻ��ĸ���Ҫ�����е�ijһ���ͼ�����ʹ�䲻���γ������������¼��ְ취
1)�ƻ���������
�ƻ����������бȽ��ϸ������,��SQL Server�У����ҵ��������������������ͨ��������ȼ���Ϊδ�ύ����ʹ��������ʾ������ʹ�ö�ȡ���ü�S�����Ӷ������˺�������ѯ���ӵ���S�������ݵ������⣬�����������������ֵĸ��ʡ�
2)�ƻ�����͵ȴ�����
��������������ԭ���ԣ��Dz����ƻ��ģ���Ϊ����취�Ǿ����ļ�������ij��ȣ�������ִ�е�Խ��Խ�á���Ҳ���Լ����������ֵĸ��ʡ�
3)�ƻ�����������
���������ԭ���Ժ�һ���ԣ�����������ͬ�������ƻ��������ǿ���ͨ��������Դ�ͼ�����Դռ�������Ƕ������ǡ�
������Դ������˵ͨ�������Ǿۼ�������ʹ�����˶������Դ����ѯ�ܶ�ʱ��Ͳ�����Ҫ����������ת�����Ǿۼ���������������ܹ�������(Cover)����ѯ���Ǹ��ò������������Include�в�����������ǩ������������ܣ����ܼ���������������Դ������ͨ��SQL
Server 2005֮����а汾���ƽ��У������ַ�ʽ�����Ƽ����ڴ˲�����ϸ���ۡ�
������Դռ��:����˵��ѯʱ������select col1,col2���ַ�ʽ���Ͳ�Ҫ��select
* .���п��ܴ�������Ҫ����ǩ����
��������
������������������Դ�£�ʹ������������Դ���γɻ�·������˵���͵����м��㷨����������Դ��������£��ڲ�����ֽ������ѵ�����£������ܶ�İ�һ��˳�������Դ��
��˱��������Ĺؼ��ǡ�˳����SQL Server�У�����ʹ��ѯ����Դ��ʹ��˳��һ�¡�����ͼ3����һ�����͵IJ���˳��������Դ�����µ�����������ͼ3��˳���Ϊͼ9��ʾ˳�������β��������ģ�ת�����������Ϊ�ȴ���
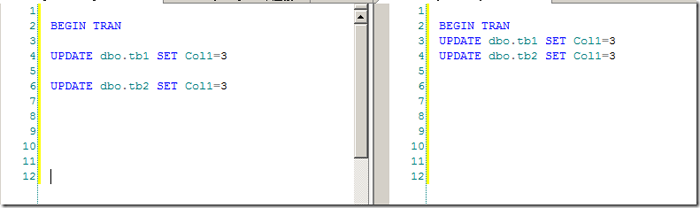
ͼ9.��˳������תΪ�ȴ�
SQL Server�������Ĵ���
�Ǽ�Ȼ���������⣬�ڳ���������ʱ��Ҫ��һ�ִ������ơ���������һ�£������ij�����һ������������վ��������������û������ɵĶ�����RollBack��
��������Ĵ�����SQL Server���Է��������������
��SQL Server���洦������
����Ҫ֪����SQL Server�������Ĵ��������1205����������������������ģ���������ʱ����������������������ͨ�����Լ������������������͵Ĵ��������2��ʾ��
--���Դ���
DECLARE @retry INT
SET @retry = 3
WHILE ( @retry > 0 )
BEGIN
BEGIN TRY
--������ҵ�����
--����ɹ��������Դ�����Ϊ
SET @retry = 0
END TRY
BEGIN CATCH
--�����������������
IF ( ERROR_NUMBER() = 1205 )
SET @retry = @retry
ELSE
BEGIN
--�������������¼����־��..
END
END CATCH
END |
����2.��SQl Server���洦������
�ڳ���㴦������
��SQL Server�д��������ķ�ʽ��ͬС�죬Ҳ��ͨ�������������жϣ�������C#���������ķ�ʽ�����3��ʾ��
int retry = 3;
while (retry > 0)
{
try
{
//ִ��sql���Ĵ���
//�����Դ�����Ϊ0
retry = 0;
}
catch(SqlException e)
{
//����������Ļ�,0.5S������
if(e.Number==1205)
{
System.Threading.Thread.Sleep(500);
retry--;
}
//��������....
else
{
throw;
}
}
} |
����3.����������C#����
�ܽ�
���Ľ����������ĸ�������������ĸ���Ҫ�����������Ĵ�����ʽ����SQL
Server����μ�����ʹ���������������������������ģ��˽��ⲿ�ֻ��������������������Ŵ��Ƿdz���Ҫ�ġ� |


