| 很久没写博客了,也不是没时间,总觉得缺少积累。开了个独立博客
foocoder.com,用octopress搭在github上的。以后可能就只在这上面更新博客。(csdn,cnblog,51cto每个都去写很累。。。)
要使用索引对数据库的数据操作进行优化,那必须明确几个问题:
1. 什么是索引
2. 索引的原理
3. 索引的优缺点
4. 什么时候需要使用索引,如何使用
围绕这几个问题,来探究索引在数据库操作中所起到的作用。
1.数据库索引简介
回忆一下小时候查字典的步骤,索引和字典目录的概念是一致的。字典目录可以让我们不用翻整本字典就找到我们需要的内容页数,然后翻到那一页就可以。索引也是一样,索引是对记录按照多个字段进行排序的一种展现。对表中的某个字段建立索引会创建另一种数据结构,其中保存着字段的值,每个值还包括指向与它相关记录的指针。这样,就不必要查询整个数据库,自然提升了查询效率。同时,索引的数据结构是经过排序的,因而可以对其执行二分查找,那就更快了。
2. B-树与索引
大多数的数据库都是以B-树或者B+树作为存储结构的,B树索引也是最常见的索引。先简单介绍下B-树,可以增强对索引的理解。
B-树是为磁盘设计的一种多叉平衡树,B树的真正最准确的定义为:一棵含有t(t>=2)个关键字的平衡多路查找树。一棵M阶的B树满足以下条件:
1) 每个结点至多有M个孩子;
2) 除根结点和叶结点外,其它每个结点至少有M/2个孩子;
3) 根结点至少有两个孩子(除非该树仅包含一个结点);
4) 所有叶结点在同一层,叶结点不包含任何关键字信息,可以看作一种外部节点;
5) 有K个关键字的非叶结点恰好包含K+1个孩子;
B-树中的每个结点根据实际情况可以包含大量的关键字信息和分支(当然是不能超过磁盘块的大小,根据磁盘驱动(disk
drives)的不同,一般块的大小在1k~4k左右);这样树的深度降低了,这就意味着查找一个元素只要很少结点从外存磁盘中读入内存,很快访问到要查找的数据。B-树上操作的时间通常由存取磁盘的时间和CPU计算时间这两部分构成。而相对于磁盘的io速度,cpu的计算时间可以忽略不计,所以B树的意义就显现出来了,树的深度降低,而深度决定了io的读写次数。
B-树索引是一个典型的树结构,其包含的组件主要是:
1) 叶子节点(Leaf node):包含条目直接指向表里的数据行。
2) 分支节点(Branch node):包含的条目指向索引里其他的分支节点或者是叶子节点。
3) 根节点(Root node):一个B树索引只有一个根节点,它实际就是位于树的最顶端的分支节点。
如下图所示:
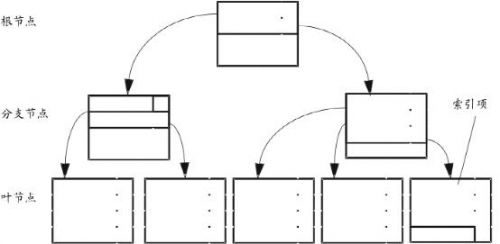
每个索引都包含两部分内容,一部分是索引本身的值,第二部分即指向数据页或者另一个索引也的指针。每个节点即为一个索引页,包含了多个索引。
当你为一个空表建立一个索引,数据库会分配一个空的索引页,这个索引页即代表根节点,在你插入数据之前,这个索引页都是空的。每当你插入数据,数据库就会在根节点创建索引条目,。当根节点插满的时候,再插入数据时,根节点就会分裂。举个例子,根节点插入了如图所示的数据。(超过4个就分裂),这时候插入H,就会分裂成2个节点,移动G到新的根节点,把H和N放在新的右孩子节点中。如图所示:
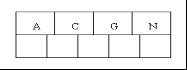
根节点插满4个节点
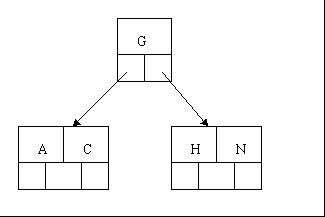
插入H,进行分裂。
大致的分裂步骤如下:
1) 创建两个儿子节点
2) 将原节点中的数据近似分为两半,写入两个新的孩子节点中。
3) 在跟节点中放置指向页节点的指针
当你不断向表中插入数据,根节点中指向叶节点的指针也被插满,当叶子还需要分裂的时候,根节点没有空间再创建指向新的叶节点的指针。那么数据库就会创建分支节点。随着叶子节点的分裂,根节点中的指针都指向了这些分支节点。随着数据的不断插入,索引会增加更多的分支节点,使树结构变成这样的一个多级结构。
3. 索引的种类
1) 聚集索引:表中行的物理顺序与键值的逻辑(索引)顺序相同。因为数据的物理顺序只能有一种,所以一张表只能有一个聚集索引。如果一张表没有聚集索引,那么这张表就没有顺序的概念,所有的新行都会插入到表的末尾。对于聚集索引,叶节点即存储了数据行,不再有单独的数据页。就比如说我小时候查字典从来不看目录,我觉得字典本身就是一个目录,比如查裴字,只需要翻到p字母开头的,再按顺序找到e。通过这个方法我每次都能最快的查到老师说的那个字,得到老师的表扬。
2) 非聚集索引:表中行的物理顺序与索引顺序无关。对于非聚集索引,叶节点存储了索引字段值以及指向相应数据页的指针。叶节点紧邻在数据之上,对数据页的每一行都有相应的索引行与之对应。有时候查字典,我并不知道这个字读什么,那我就不得不通过字典目录的“部首”来查找了。这时候我会发现,目录中的排序和实际正文的排序是不一样的,这对我来说很苦恼,因为我不能比别人快了,我需要先再目录中找到这个字,再根据页数去找到正文中的字。
4.索引与数据的查询,插入与删除
1) 查询。查询操作就和查字典是一样的。当我们去查找指定记录时,数据库会先查找根节点,将待查数据与根节点的数据进行比较,再通过根节点的指针查询下一个记录,直到找到这个记录。这是一个简单的平衡树的二分搜索的过程,我就不赘述了。在聚集索引中,找到页节点即找到了数据行,而在非聚集索引中,我们还需要再去读取数据页。
2) 插入。聚集索引的插入操作比较复杂,最简单的情况,插入操作会找到对于的数据页,然后为新数据腾出空间,执行插入操作。如果该数据页已经没有空间,那就需要拆分数据页,这是一个非常耗费资源的操作。对于仅有非聚集索引的表,插入只需在表的末尾插入即可。如果也包含了聚集索引,那么也会执行聚集索引需要的插入操作。
3) 删除。删除行后下方的数据会向上移动以填补空缺。如果删除的数据是该数据页的最后一行,那么这个数据页会被回收,它的前后一页的指针会被改变,被回收的数据页也会在特定的情况被重新使用。与此同时,对于聚集索引,如果索引页只剩一条记录,那么该记录可能会移动到邻近的索引表中,原来的索引页也会被回收。而非聚集索引没办法做到这一点,这就会导致出现多个数据页都只有少量数据的情况。
5. 索引的优缺点
其实通过前面的介绍,索引的优缺点已经一目了然。
先说优点:
1) 大大加快数据的检索速度,这也是创建索引的最主要的原因
2) 加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
3) 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
再说缺点:
1) 创建索引需要耗费一定的时间,但是问题不大,一般索引只要build一次
2) 索引需要占用物理空间,特别是聚集索引,需要较大的空间
3) 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度,这个是比较大的问题。
6.索引的使用
根据上文的分析,我们大致对什么时候使用索引有了自己的想法(如果你没有,回头再看一遍。。。)。一般我们需要在这些列上建立索引:
1)在经常需要搜索的列上,这是毋庸置疑的;
2)经常同时对多列进行查询,且每列都含有重复值可以建立组合索引,组合索引尽量要使常用查询形成索引覆盖(查询中包含的所需字段皆包含于一个索引中,我们只需要搜索索引页即可完成查询)。
同时,该组合索引的前导列一定要是使用最频繁的列。对于前导列的问题,在后面sqlite的索引使用介绍中还会做讨论。
3)在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度,连接条件要充分考虑带有索引的表。;
4)在经常需要对范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的,同样,在经常需要排序的列上最好也创建索引。
6)在经常放到where子句中的列上面创建索引,加快条件的判断速度。要注意的是where字句中对列的任何操作(如计算表达式,函数)都需要对表进行整表搜索,而没有使用该列的索引。所以查询时尽量把操作移到等号右边。
对于以下的列我们不应该创建索引:
1)很少在查询中使用的列
2)含有很少非重复数据值的列,比如只有0,1,这时候扫描整表通常会更有效
3)对于定义为TEXT,IMAGE的数据不应该创建索引。这些字段长度不固定,或许很长,或许为空。
当然,对于更新操作远大于查询操作时,不建立索引。也可以考虑在大规模的更新操作前drop索引,之后重新创建,不过这就需要把创建索引对资源的消耗考虑在内。总之,使用索引需要平衡投入与产出,找到一个产出最好的点。
7. 在sqlite中使用索引
1)Sqlite不支持聚集索引,android默认需要一个_id字段,这保证了你插入的数据会按“_id”的整数顺序插入,这个integer类型的主键就会扮演和聚集索引一样的角色。所以不要再在对于声明为:INTEGER
PRIMARY KEY的主键上创建索引。
2)很多对索引不熟悉的朋友在表中创建了索引,却发现没有生效,其实这大多数和我接下来讲的有关。对于where子句中出现的列要想索引生效,会有一些限制,这就和前导列有关。所谓前导列,就是在创建复合索引语句的第一列或者连续的多列。比如通过:CREATE
INDEX comp_ind ON table1(x, y, z)创建索引,那么x,xy,xyz都是前导列,而yz,y,z这样的就不是。下面讲的这些,对于其他数据库或许会有一些小的差别,这里以sqlite为标准。在where子句中,前导列必须使用等于或者in操作,最右边的列可以使用不等式,这样索引才可以完全生效。同时,where子句中的列不需要全建立了索引,但是必须保证建立索引的列之间没有间隙。举几个例子来看吧:
用如下语句创建索引:
CREATE INDEX idx_ex1 ON ex1(a,b,c,d,e,...,y,z);
这里是一个查询语句:
...WHERE a=5 AND b IN (1,2,3) AND c
IS NULL AND d='hello'
这显然对于abcd四列都是有效的,因为只有等于和in操作,并且是前导列。
再看一个查询语句:
... WHERE a=5 AND b IN (1,2,3) AND c>12
AND d='hello'
那这里只有a,b和c的索引会是有效的,d列的索引会失效,因为它在c列的右边,而c列使用了不等式,根据使用不等式的限制,c列已经属于最右边。
最后再看一条:
... WHERE b IN (1,2,3) AND c NOT NULL
AND d='hello'
索引将不会被使用,因为没有使用前导列,这个查询会是一个全表查询。
其实除了索引,对查询性能的影响因素还有很多,比如表的连接,是否排序等。影响数据库操作的整体性能就需要考虑更多因素,使用更对的技巧,不得不说这是一个很大的学问。
最后在android上使用sqlite写一个简单的例子,看下索引对数据库操作的影响。
创建如下表和索引:
db.execSQL("create table if not
exists t1(a,b)");
db.execSQL("create index if not
exists ia on t1(a,b)");
插入10万条数据,分别对表进行如下操作:
select * from t1 where a='90012'
插入:insert into t1(a,b) values('10008','name1.6982235534984673')
更新:update t1 set b='name1.999999' where
a = '887'
删除:delete from t1 where a = '1010'
数据如下(5次不同的操作取平均值):
| 操作 |
无索引 |
有索引 |
| 查询 |
170ms |
5ms |
| 插入 |
65ms |
75ms |
| 更新 |
240ms |
52ms |
| 删除 |
234ms |
78ms |
可以看到显著提升了查询的速度,稍稍减慢了插入速度,还稍稍提升了更新数据和删除数据的速度。如果把更新和删除中的where子句中的列换成b,速度就和没有索引一样了,因为索引失效。所以索引能大幅度提升查询速度,对于删除和更新操作,如果where子句中的列使用了索引,即使需要重新build索引,有可能速度还是比不使用索引要快的。对与插入操作,索引显然是个负担。同时,索引让db的大小增加了2倍多。
还有个要吐槽的是,android中的rawQurey方法,执行完sql语句后返回一个cursor,其实并没有完成一个查询操作,我在rawquery之前和之后计算查询时间,永远是1ms...这让我无比苦闷。看了下源码,在对cursor调用moveToNext这些移动游标方法时,都会最终先调用getCount方法,而getCount方法才会调用native方法调用真正的查询操作。这种设计显然更加合理。 |


