| MapReduce的大体流程是这样的,如图所示:

由图片可以看到mapreduce执行下来主要包含这样几个步骤
1.首先对输入数据源进行切片
2.master调度worker执行map任务
3.worker读取输入源片段
4.worker执行map任务,将任务输出保存在本地
5.master调度worker执行reduce任务,reduce worker读取map任务的输出文件
6.执行reduce任务,将任务输出保存到HDFS
若对流程细节进行深究,可以得到这样一张流程图
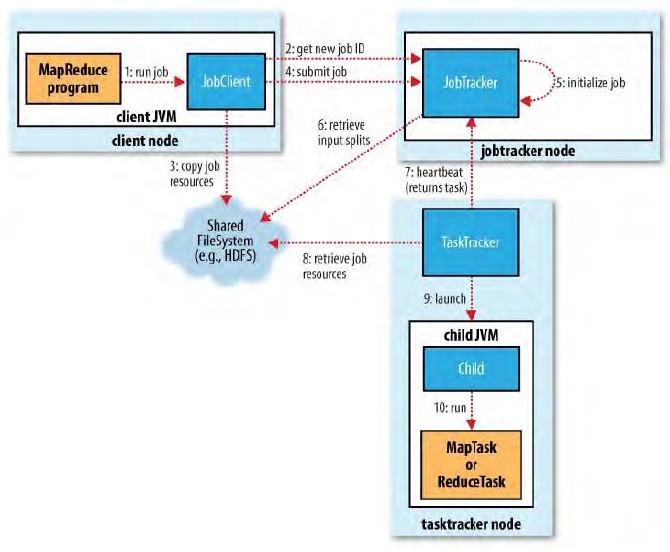
角色描述:
- JobClient:执行任务的客户端
- JobTracker:任务调度器
- TaskTracker:任务跟踪器
- Task:具体的任务(Map OR Reduce)
从生命周期的角度来看,mapreduce流程大概经历这样几个阶段:初始化、分配、执行、反馈、成功与失败的后续处理
每个阶段所做的事情大致如下
任务初始化
1.JobClient对数据源进行切片
切片信息由InputSplit对象封装,接口定义如下:
[public interface InputSplit extends Writable {
long getLength() throws IOException;
String[] getLocations() throws IOException;
} |
可以看到split并不包含具体的数据信息,而只是包含数据的引用,map任务会根据引用地址去加载数据InputSplit是由InputFormat来负责创建的
[public interface InputFormat<K, V> {
InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
RecordReader<K, V> getRecordReader(InputSplit split,JobConf job,Reporter reporter) throws IOException;
} |
JobClient通过getSplits方法来计算切片信息,切片默认大小和HDFS的块大小相同(64M),这样有利于map任务的本地化执行,无需通过网络传递数据
切片成功后,JobClient会将切片信息传送至JobTracker
2.通过jobTracker生成jobIdJobTracker.getNewJobId()
3.检查输出目录和输入数据源是否存在
输出目录已存在,系统抛出异常
输入源目录不存在,系统抛出异常
4.拷贝任务资源到jobTracker机器上(封装任务的jar包、集群配置文件、输入源切片信息)
任务分配
JobTracker遍历每一个InputSplit,根据其记录的引用地址选择距离最近的TaskTracker去执行,理想情况下切片信息就在TaskTracker的本地,这样节省了网络数据传输的时间
JobTracker和TaskTracker之间是有心跳通信的逻辑的,通过彼此间不停的通信,JobTracker可以判断出哪些TaskTracker正在执行任务,哪些TaskTracker处于空闲状态,以此来合理分配任务
任务执行
TaskTracker接到任务后开始执行如下操作:
1.将任务jar包从HDFS拷贝到本地并进行解压
2.创建一个新的JVM来执行具体的任务,这样做的好处是即使所执行的任务出现了异常,也不会影响TaskTracker的运行使用
如果所执行的任务是map任务,则处理流程大致如下:
首先加载InputSplit记录的数据源切片,通过InputFormat的getRecordReader()方法获取到Reader后,执行如下操作:
K key = reader.createKey();
V value = reader.createValue();
while (reader.next(key, value)) {//遍历split中的每一条记录,执行map功能函数
mapper.map(key, value, output, reporter);
}
|
执行反馈
mapreduce的执行是一个漫长的过程,执行期间会将任务的进度反馈给用户任务结束后,控制台会打印Counter信息,方便用户以全局的视角来审查任务
执行成功
清理MapReduce本地存储(mapred.local.dir属性指定的目录)清理map任务的输出文件
执行失败
1.如果task出现问题(map或者reduce)
错误可能原因:用户代码出现异常;任务超过mapred.task.timeout指定的时间依然没有返回
错误处理:
首先将错误信息写入日志
然后jobtracker会调度其他tasktracker来重新执行次任务,如果失败次数超过4次(通过mapred.map.max.attempts
mapred.reduce.max.attempts属性来设置,默认为4),则job以失败告终
如果系统不想以这种方式结束退出,而是想通过Task成功数的百分比来决定job是否通过,则可以指定如下两个属性
mapred.max.map.failures.percent map任务最大失败率=
mapred.max.reduce.failures.percent reduce任务最大失败率
如果失败比率超过指定的值,则job以失败告终
2.如果是tasktracker出现问题
判断问题的依据:和jobtracker不再心跳通信
jobtracker将该tasktracker从资源池中移除,以后不在调度它
3.jobtracker出现问题
jobtracker作为系统的单点如果出现问题也是最为严重的问题,系统将处于瘫痪
|


