1
RPC
RPC(Remote Procedure Call)――远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
2 hadoop.ipc
2.1 Server
RPC Server实现了一种抽象的RPC服务,同时提供Call队列。
RPC Server结构
| 结构 |
功能 |
| Server.Listener |
RPC Server的监听者,用来接收RPC Client的连接请求和数据,其中数据封装成Call后PUSH到Call队列。 |
| Server.Handler |
RPC Server的Call处理者,和Server.Listener通过Call队列交互。 |
| Server.Responder |
RPC Server的响应者。Server.Handler按照异步非阻塞的方式向RPC
Client发送响应,如果有未发送出的数据,交由Server.Responder来完成。 |
| Server.Connection |
RPC Server数据接收者。提供接收数据,解析数据包的功能。 |
| Server.Call |
持有客户端的Call信息。 |
RPC Server主要流程
RPC Server作为服务提供者由两个部分组成:接收Call调用和处理Call调用。
接收Call调用负责接收来自RPC Client的调用请求,编码成Call对象后放入到Call队列中。这一过程由Listener线程完成。具体步骤:
- Listener线程监视RPC Client发送过来的数据。
- 当有数据可以接收时,调用Connection的readAndProcess方法。
- Connection边接收边对数据进行处理,如果接收到一个完整的Call包,则构建一个Call对象PUSH到Call队列中,由Handler线程来处理Call队列中的所有Call。
处理Call调用负责处理Call队列中的每个调用请求,由Handler线程完成:
- Handler线程监听Call队列,如果Call队列非空,按FIFO规则从Call队列取出Call。
- 将Call交给RPC.Server处理。
- 借助JDK提供的Method,完成对目标方法的调用,目标方法由具体的业务逻辑实现。
- 返回响应。Server.Handler按照异步非阻塞的方式向RPC Client发送响应,如果有未发送出的数据,则交由Server.Responder来完成。
交互过程如下图所示:
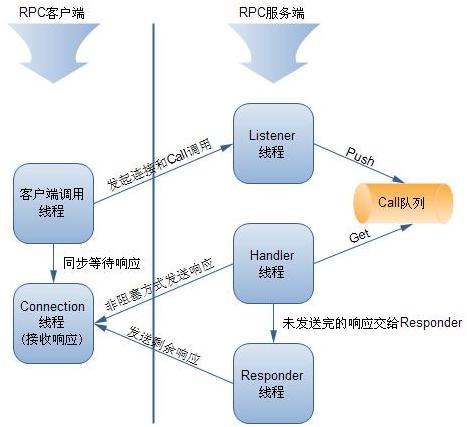
图 RPC交互过程图
这里还需要提到的是,在namenode的高负荷运行的环境下,单线程的Listener线程在读取rpc
call中带来的参数时,如果该rpc call的调用所带的参数非常的大(如BlockReport),那么Listener在读取这种rpc
call的调用参数时就会花费很多的时间,那么此时单线程的Listener就成了namenode服务的瓶颈。所以后来对这种机制进行了优化,将对rpc
call的参数读取的方式也换成异步的方式,在Listener中增加了一个reader pool,将需要读取参数的rpc
call的read请求放入pool中,然后利用多个reader并行的读取,这样就能将listener线程给解放出来。reader读取参数后,构造出Call变量,放入Call队列中。因此,后续的hadoop版本中都会增加一个配置参数:ipc.server.read.threadpool.size,以达到优化rpc接收rpc
call参数的效率。
2.2 Client
RPC Client是Client的实现和入口类。
RPC Client结构
| 结构 |
功能 |
| Client.ConnectionId |
到RPC Server对象连接的标识。 |
| Client.Call |
Call调用信息。 |
| Client.ParallelResults |
Call响应。 |
| RPC.Invoker |
对InvocationHandler的实现,提供invoke方法,实现RPC Client对RPC
Server对象的调用。 |
| RPC.Invocation |
用来序列化和反序列化RPC Client的调用信息。(主要应用JAVA的反射机制和InputStream/OutputStream) |
RPC Client主要流程
每一个Call都是由RPC Client发起。步骤说明:
- RPC Client发起RPC Call,通过JAVA反射机制转化为对Client.call调用。
- 调用getConnection得到与RPC Server的连接。每一个RPC Client都维护一个HashMap结构的到RPC
Server的连接池。具体建立连接的流程见下图。

图 RPC Client建立连接流程
- 通过Connection将序列化后的参数发送到RPC服务端。
- 阻塞方式等待RPC服务端返回响应。
2.3 同步
客户端发起的RPC调用是同步的,而服务端处理RPC调用是异步的。客户端调用线程以阻塞同步的方式发起RPC连接及RPC调用,将参数等信息发送给Listener,然后等待Connection接收响应返回。
Listener负责接收RPC连接和RPC数据,当一个Call的数据接收完后,组装成Call,并将Call放入由Handler提供的Call队列中。
Handler线程监听Call队列,如果Call队列不为空,则按FIFO方式取出Call,并转为实际调用,以非阻塞方式将响应发回给Connection,未发送完毕的响应交给Responder处理。
3 Avro
关于Avro与Thrift的比较,http://www.tbdata.org/archives/1307中做了详细的分析,本节主要介绍avro的一些细节。
3.1 综述
Avro完全依赖模式(Schema),通过Schema定义各种数据结构,只有确定了Schema才能对数据进行解释,所以在数据的序列化和反序列化之前,必须先确定Schema的结构。正是Schema的引入,使得数据具有了自描述的功能,同时能够实现动态加载,另外与其他的数据序列化系统如Thrift相比,数据之间不存在其他的任何标识,有利于提高数据处理的效率。Avro的诸多优势,使得Avro将成为代替Hadoop现有RPC的下一代通讯中间件系统。
Schema通过JSON对象表示。Schema定义了简单数据类型和复杂数据类型,其中复杂数据类型包含不同属性。通过各种数据类型用户可以自定义丰富的数据结构。
Schema由下列JSON对象之一定义:
1. JSON字符串:命名
2. JSON对象:{“type”: “typeName” …attributes…}
3. JSON数组:Avro中Union的定义
3.2 数据类型
数据类型标准化的意义:一方面使不同系统对相同的数据能够正确解析,另一方面,数据类型的标准定义有利于数据序列化/反序列化。
简单数据类型
Avro定义了几种简单数据类型,下表是其简单说明。
| avro type |
json type |
default |
| Null |
Null |
Null |
| Boolean |
Boolean |
True |
| int,long |
Integer |
1 |
| float,double |
Number |
1.1 |
| Bytes |
String |
“\u00FF” |
| String |
String |
“foo” |
| Record |
Object |
{“a”: 1} |
| Enum |
String |
“FOO” |
| Array |
Array |
[1] |
| Map |
Object |
{“a”: 1} |
| Fixed |
String |
“\u00ff” |
简单数据类型由类型名称定义,不包含属性信息,例如字符串定义如下:
{“type”: “string”}
复杂数据类型
Avro定义了六种复杂数据类型,每一种复杂数据类型都具有独特的属性,下表就每一种复杂数据类型进行说明。
| 类型 |
属性 |
说明 |
| records |
type name |
Record |
| name |
a JSON string
providing the name of the record (required). |
| namespace |
a JSON string
that qualifies the name(optional). |
| doc |
a JSON string
providing documentation to the user of this schema
(optional). |
| aliases |
a JSON array
of strings, providing alternate names for this
record (optional). |
| fields |
a JSON array,
listing fields (required). |
| name |
a JSON string. |
| type |
a schema/a string of defined record. |
| default |
a default value for field when
lack. |
| order |
ordering of this field. |
| Enums |
type name |
Enum |
| name |
a JSON string
providing the name of the enum (required). |
| namespace |
a JSON string
that qualifies the name. |
| doc |
a JSON string
providing documentation to the user of this schema
(optional). |
| aliases |
a JSON array
of strings, providing alternate names for this
enum (optional) |
| symbols |
a JSON array,
listing symbols, as JSON strings (required). All
symbols in an enum must be unique. |
| Arrays |
type name |
Array |
| items |
the schema of
the array’s items. |
| Maps |
type name |
Map |
| values |
the schema of
the map’s values. |
| Fixed |
type name |
Fixed |
| name |
a string naming
this fixed (required). |
| namespace |
a string that
qualifies the name. |
| aliases |
a JSON array
of strings, providing alternate names for this
enum (optional). |
| size |
an integer, specifying
the number of bytes per value (required). |
| Unions |
a JSON arrays |
| P.S.: may not
contain more than one schema with the same type,
except for the named types record, fixed and enum |
每一种复杂数据类型都含有各自的一些属性,其中部分属性是必需的,部分是可选的。例如:下图示为链表的Schema结构。其他类型的Schema结构实例以此类推这里就不一一列举。
这里需要说明Record类型中field属性的默认值,当Record Schema实例数据中某个field属性没有提供实例数据时,则由默认值提供,具体值见下表。Union的field默认值由Union定义中的第一个Schema决定。
| avro type |
json type |
default |
| Null |
Null |
Null |
| Boolean |
Boolean |
True |
| int,long |
Integer |
1 |
| float,double |
Number |
1.1 |
| Bytes |
String |
“\u00FF” |
| String |
String |
“foo” |
| Record |
Object |
{“a”: 1} |
| Enum |
String |
“FOO” |
| Array |
Array |
[1] |
| Map |
Object |
{“a”: 1} |
| Fixed |
String |
“\u00ff” |
3.3 数据序列化
Avro指定两种数据序列化编码方式:binary encoding和JSON
encoding。其中各种数据类型的binary encoding规则如下所述:
简单数据类型
| Type |
Encoding |
Example |
| Null |
zero byte |
null |
| Boolean |
a sigle byte |
{true: 1,false:0} |
| int/long |
variable-length |
| Float |
4 bytes |
Java’s floatToIntBits |
| Double |
8 bytes |
Java’s doubleToLongBits |
| Bytes |
a long followed by that
many bytes of data |
|
| String |
a long followed by that
many bytes of UTF-8 encoded character data |
”foo”:{3,f,o,o}
06 66 6f 6f |
复杂数据类型
| Type |
Encoding |
| Records |
encoded as just the concatenation of the encodings
of its fields |
| Enums |
int representing the zero-based position of
the symbol in the schema |
| Arrays |
encoded as series of blocks. A block with
count 0 indicates the end of the array. block:{long,items} |
| maps |
encoded as series of blocks. A block with
count 0 indicates the end of the map. block:{long,key/value
pairs}. |
| Unions |
encoded by first writing a long value indicating
the zero-based position within the union of the
schema of its value. The value is then encoded
per the indicated schema within the union. |
| fixed |
encoded using number of bytes declared in
the schema. |
下面就各种复杂数据类型的binary encoding举例说明。
例1:records
设:a = 27, b = “foo” ( enc:36(27), 06(3),
66(“f”), 6f(“o”) )
BC:36 06 66 6f 6f
例2:enums
设:”D”( enc:06(3) )
BC:06
例3:arrays
设:{ 3, 27 } (enc:04(2), 06(3), 36(27)
)
BC:04 06 36 00
例4:maps
设:{ (“a”:1), (“b”:2) }
BC:02 61 02 02 62 04
例5:unions
设:(1) null; (2) “a”
BC:
(1) 02;说明:02代表null在union定义中的位置1;
(2) 00 02 61;说明:00为string在union定义的位置,02
61为”a”的编码。
3.4 排序
Avro为数据定义了一个标准的排列顺序。比较在很多时候是经常被使用到的对象之间的操作,标准定义方便有效的比较和排序。同时标准的定义可以方便对Avro的二进制编码数据直接进行排序而不需要反序列化。
只有当数据项包含相同的Schema的时候,数据之间的比较才有意义。数据的比较按照Schema深度优先,从左至右的顺序递归的进行。找到第一个不匹配即可终止比较。
两个拥有相同的模式的项的比较按照以下规则进行:
- null总是相等。
- int,long,float按照数值大小比较。
- boolean是false在true之前。
- string按照字典序进行比较。
- bytes,fixed按照byte的字典序进行比较。
- array按照元素的字典序进行比较。
- enum按照符号在枚举中的位置比较。
record按照域的字典序排序,如果指定了以下属性:
- “ascending”,域值的顺序不变。
- “descending”,域值的顺序颠倒。
- “ignore”,排序的时候忽略域值。
- map不可进行比较。
3.5 对象容器文件
Avro定义了一个简单的对象容器文件格式。一个文件对应一个模式,所有存储在文件中的对象都是根据模式写入的。对象按照块进行存储,块可以采用压缩的方式存储。为了在进行mapreduce处理的时候有效的切分文件,在块之间采用了同步记号。一个文件可以包含任意用户定义的元数据。
一个文件由两部分组成:文件头和一个或者多个文件数据块。
文件头
- 四个字节,ASCII ‘O’, ‘b’, ‘j’, 1。
- 文件元数据,用于描述Schema。
- 16字节的文件同步记号。
其中,文件元数据的格式为:
- 值为-1的长整型,表明这是一个元数据块。
- 标识块长度的长整型。
- 标识块中key/value对数目的长整型。
- 每一个key/value对的string key和bytes value。
- 标识块中字节总数的4字节长的整数。
文件数据块
数据是以块结构进行组织的,一个文件可以包含一个或者多个文件数据块。
- 表示文件中块中对象数目的长整型。
- 表示块中数据序列化后的字节数长度的长整型。
- 序列化的对象。
- 16字节的文件同步记号。
当数据块的长度为0时即为文件数据块的最后一个数据,此后的所有数据被自动忽略。
下图示对象容器文件的结构分解及说明:
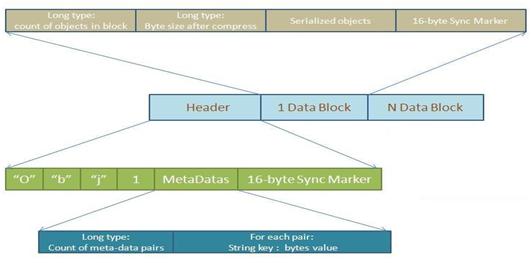
图 对象容器文件分解
4 Avro RPC服务
对象容器文件是Avro的数据存储的具体实现,数据交换则由RPC服务提供,与对象容器文件类似,数据交换也完全依赖Schema,所以与Hadoop目前的RPC不同,Avro在数据交换之前需要通过握手过程先交换Schema。
握手过程
握手的过程是确保Server和Client获得对方的Schema定义,从而使Server能够正确反序列化请求信息,Client能够正确反序列化响应信息。一般的,Server/Client会缓存最近使用到的一些协议格式,所以,大多数情况下,握手过程不需要交换整个Schema文本。
所有的RPC请求和响应处理都建立在已经完成握手的基础上。对于无状态的连接,所有的请求响应之前都附有一次握手过程;对于有状态的连接,一次握手完成,整个连接的生命期内都有效。
具体过程:
Client发起HandshakeRequest,其中含有Client本身Schema
Hash值和对应Server端的Schema Hash值(clientHash!=null, clientProtocol=null,
serverHash!=null)。如果本地缓存有serverHash值则直接填充,如果没有则通过猜测填充。
Server用如下之一HandshakeResponse响应Client请求:
- (match=BOTH, serverProtocol=null, serverHash=null):当Client发送正确的serverHash值且Server缓存相应的clientHash。握手过程完成,之后的数据交换都遵守本次握手结果。
- (match=CLIENT, serverProtocol!=null, serverHash!=null):当Server缓存有Client的Schema,但是Client请求中Server
Hash值不正确。此时Server发送Server端的Schema数据和相应的Hash值,此次握手完成,之后的数据交换都遵守本次握手结果。
- (match=NONE):当Client发送的ServerHash不正确且Server端没有Client
Schema的缓存。这种情况下Client需要重新提交请求信息 (clientHash!=null,
clientProtocol!=null, serverHash!=null),Server响应 (match=BOTH,
serverProtocol=null, serverHash=null),此次握手过程完成,之后的数据交换都遵守本次握手结果。
握手过程使用的Schema结构如下图示。

图 握手过程使用的Schema
消息帧格式
消息从客户端发送到服务器端需要经过传输层,它发送请求并接收服务器端的响应。到达传输层的数据就是二进制数据。通常以HTTP作为传输模型,数据以POST方式发送到对方去。在
Avro中消息首先分帧后被封装成为一组缓冲区(Buffer)。
数据帧的格式如下:
一系列Buffer:
长度为0的Buffer结束数据帧
Call格式
一个调用由请求消息,结果响应消息或者错误消息组成。请求和响应包含可扩展的元数据,两种消息都按照之前提出的方法分帧。
调用的请求格式为:
- 请求元数据,一个类型值的映射。
- 消息名,一个Avro字符串。
- 消息参数。参数根据消息的请求定义序列化。
调用的响应格式为:
- 响应的元数据,一个类型值的映射。
- 一字节的错误标志位。
- 如果错误标志为false,响应消息,根据响应的模式序列化。
如果错误标志位true,错误消息,根据消息的错误联合模式序列化。 |


