摘要:
探查大数据和传统企业数据是许多组织的共同需求。在本文中,我们概述了为通过基于 Hadoop 的平台管理的大数据建立索引的方法和指南,以便将这些数据用于数据发现解决方案
IBM 的大数据平台概述
IBM 的大数据平台旨在帮助组织探查、分析和管理丰富的数据,包括流数据、传统业务数据,以及以前很难合并到企业的商业智能和分析平台中的
“非传统” 数据或辅助数据。首先让我们简要了解一下这个平台,然后再重点介绍两个重要组件:InfoSphere
Data Explorer 和 InfoSphere BigInsights。
图 1 描绘了 IBM 的大数据平台的架构,它在功能的丰富性上不同于其他商用产品。从上到下,您会看到
IBM 的这个平台包含丰富的功能和技术,能够可视化和发现各种数据源中的洞察,开发分析应用程序,管理您的环境。Data
Explorer 提供了 IBM 的大数据平台的重要可视化和发现功能,所以稍后我们会更详细地讨论该组件。图
1 中所示的加速器是 IBM 提供的工具包,包含数十个预先构建的软件工件,以帮助公司快速部署分析社交媒体和机器数据(比如日志记录)的解决方案。3
个数据处理引擎使组织能够有效地应对大数据内在的多样性、大量性和高速性。这些引擎包含一个基于 Hadoop
的系统(BigInsights,我们稍后将详细探讨它)、一个流计算平台 (InfoSphere Streams)
和一个数据仓库平台(比如 PureData? for Analytics 或 DB2?)。最后,IBM
的大数据平台还包含与其他流行企业软件的连接,包括关系 DBMS、提取/转换/加载平台、商业智能工具、内容管理系统等。
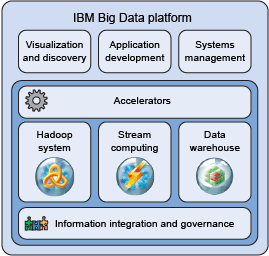
图 1. IBM 的大数据平台架构
InfoSphere BigInsights 概述
InfoSphere BigInsights 是 IBM 持久化和分析众多形式的大数据的平台。基于开源
Apache Hadoop 项目,BigInsights 旨在帮助公司发现和分析隐藏在海量数据中的业务洞察,这些数据在平时可能被忽略或丢弃,因为使用传统方法来处理这些数据有些不切实际或太困难。这些数据的示例包括日志记录、单击流、社交媒体数据、新闻源、电子邮件、电子传感器输出,甚至一些事务数据。
为了帮助企业高效地从这些类型的数据获取价值,BigInsights Enterprise
Edition 包含一些来自 Hadoop 生态系统的开源项目,以及 IBM 开发的一些增强和扩展了这个开源软件的价值的技术。如
图 2 所示,这些技术涵盖范围从应用程序加速器到分析工具、开发工具、平台改进和企业软件集成。例如,BigInsights
客户可使用复杂的文本分析功能从文档、电子邮件和消息中提取内容和上下文。应用程序开发人员可采用基于 Eclipse
的向导来加速自定义 Java?
MapReduce、Jaql、Hive、Pig 和文本分析应用程序的开发。管理员可通过一个集成的
Web 控制台管理和监视其 BigInsights 环境,业务用户可通过基于 Web 的目录来启动 IBM
提供的或自行开发的应用程序。
在本文中,我们将重点介绍 BigInsights 特性的一个子集,比如文本分析和应用程序生命周期工具。有关
BigInsights 的更多信息,请参阅 参考资料。

图 2. InfoSphere BigInsights
架构
InfoSphere Data Explorer 概述
InfoSphere Data Explorer 允许您为来自不同数据来源的大量结构化、非结构化和半结构化数据建立索引。它还提供了构建大数据探查应用程序和
360 度信息应用程序的能力。InfoSphere Data Explorer 允许用户根据存储在不同的内部和外部数据存储库中的庞大数据集合,创建不同实体(比如客户、产品、事件、合作伙伴等)的相关信息的视图,而无需移动数据。
当今企业的一个重要挑战是,用户无法快速找到解决业务问题或完成一项任务所需的信息。通常,数据分散在不同的系统中,以便支持不同组织管理的具体应用程序。此外,新数据来源逐渐成为关键的资源,人们可能需要在日常工作和制定重要决策时考虑它们,比如社交媒体、来自移动设备的源、Twitter
等。
这方面的一个示例是,联系人信息、购买的产品、开具的服务票据和保修信息等客户信息都存储在不同的业务应用程序中,比如
CRM、支持票据系统、市场门户等。想象一位希望联系客户以进行追加销售的销售人员。他必须先登录 10 个应用程序来汇总客户的信息,或者与
5 个人沟通来理解所有这些信息。
Data Explorer 解决了这个重要难题。信息存储在许多不同的系统和筒仓中,而用户需要采用一致的方式来查看所有数据,快速导航到与他们最相关的信息。这里的挑战是:在员工最需要制定决策的信息地方提供该信息。

图 3. InfoSphere Data
Explorer 架构
BigInsights 和 Data Explorer 的集成
BigInsights 和 Data Explorer 彼此互补,使组织能够拓宽他们能以一种一致、连贯的方式分析的信息范围。例如,BigInsights
常常用于存储非结构化和半结构化内容。此外,探查和导航内容的需求变得更为紧迫,这常常表现在搜索式界面中。这使得信息更容易让业务线用户使用。例如,如果您存储了机器数据,最终用户可能希望导航内容日期,寻找特定的机器故障类型,等等。另一方面,如果存储社交数据,最终用户可能希望搜索与产品相关的用户态度。所有这些都需要一种富索引功能。除了索引之外,Data
Explorer 还可提供了一种富用户体验,合并来自 BigInsights 的内容和其他企业内容,以实现全面的大数据探查。
示例场景
要实现这一架构,我们需要执行一些步骤。这里总结了这些步骤,稍后会更详细地分析它们:
收集和准备您的社交媒体数据以供分析
BigInsights 通过预先构建的应用程序提供各种不同的数据收集机制。当基于文本的社交媒体帖子位于
BigInsights 中时,您需要提取感兴趣的信息,以便可在以后轻松地为它们建立索引和探查它们。BigInsights
提供了复杂的文本分析功能,帮助您提取感兴趣的实体,包括产品、人员和对产品的态度。
建模感兴趣的业务实体和关系
一个应用程序可快速启动此过程,为 Data Explorer 指定一种实体模型来帮助设置我们稍后将展示的各种配置选项。此实体模型对您的应用程序场景的总体成功至关重要。
该实体模型将捕获一组重要的业务实体和关系,您的业务分析师将有兴趣在 Data
Explorer 中搜索、发现和探查它们。因此,一种有效的实体模型设计是理解业务分析师希望如何搜索和探查哪些信息的前提。
该实体模型将捕获您的 Data Explorer 集群的一组重要配置,以反映您的容量和部署计划。稍后,您将看到我们如何捕获产品和
tweet 作为感兴趣的关键业务实体,进一步指定这些实体之间的关系,并提供 Data Explorer
集群的拓扑结构部署信息。
开发您的第一个索引应用程序,在 Data Explorer 中为提取的社交数据建立索引
您可以利用 BigInsights 应用程序开发生命周期开发您的索引应用程序,该生命周期使您能够以极少的工作创建、发布和部署您的应用程序。部署之后,从您的社交数据中提取的实体信息将被推送到一个
Data Explorer 搜索集合中,可使用 Data Explorer 分面搜索 (faceted
search) 特性进一步探查这些信息,使用它们构建一个 360 度视图应用程序。
使用 Data Explorer 实现可视化
Data Explorer Application Builder 提供了一种途径来构建一个应用程序,将分散在不同系统中的数据的相关信息集中在一起。在我们的示例场景中,一位产品计划主管可能关心一个产品或产品家族,所以一个
360 度视图应用程序可能包含反馈、产品问题和过去的客户交互。
在 BigInsights 中收集和准备您的社交媒体数据以供分析
BigInsights 通过预先构建的应用程序(比如 Boardreader
应用程序)提供了众多数据收集机制。

图 4. Boardreader 应用程序
您看收集社交数据,利用众多存储选项将其存储在 BigInsights 中,包括分布式文件系统和存储引擎,比如
HBase。

图 5. BigInsights 分布式文件系统和存储引擎
基于文本的社交媒体帖子存储在 BigInsights 中后,您需要提取感兴趣的信息,以便可在以后轻松地为其建立索引和探查。BigInsights
提供了复杂的文本分析功能,帮助您提取与产品相关的态度和提取社交媒体用户概要信息。下图显示了从社交媒体提取实体和态度的输出片段,突出显示了这次实体提取的一些重要字段,包括
Category、Brand、Product、Source、IsSentiment、IsCustomerOf、Polarity、Created
Time、FullName、Screenname、UserID 和 Text。

图 6. Tweet 上的产品态度
设计和管理您的应用程序实体模型
拥有从上一节的 BigInsights 文本分析中提取的实体信息后,您就可以设计
Data Explorer 实体模型了。
这一节介绍将在解决方案中考虑并设计到您的实体模型中的一组元素。此过程将确保您的应用程序解决方案能够满足您的业务分析师的需求,提供可扩展的大数据搜索环境所需的访问和探查模式。我们将简要介绍一下这个设计过程中的步骤,稍后将更详细地分析它们:
确定您感兴趣的一组重要的业务实体和关系,以支持 Data Explorer
中的进一步搜索和探查,并在这些业务实体分散在各处时识别各种来源。
在您场景的实体模型中捕获这些实体和关系。
确定您的 Data Explorer 集群的可伸缩性,将这些规范设计到您的实体模型中。这些规范将确定您的
Data Explorer 部署的可伸缩性。
将您的实体模型部署到 Zookeeper 集群中,以实现配置设置的集中化管理。
确定一组重要的业务实体和关系,以构建上下文信息
在我们的示例场景中,我们积累了关于现有客户和我们的产品的内部数据。这些数据存储在一个关系
DBMS 中。此外,我们还收集了一些社交 tweet,使用 BigInsights 文本分析提取了用户对我们的产品的态度。我们的业务分析师可能希望获取一个更全面的视图,以便了解客户如何认知我们的产品和我们的产品在整体市场中的知名度。将企业和社交媒体数据相结合,可为我们的业务分析提供更有用的洞察。我们发现,业务分析师将对以下实体很感兴趣:
从 BigInsights 中的社交数据提取的用户对产品的态度
存储在一个关系数据库中的产品数据
存储在一个关系数据库中的在线客户
同样重要的是,需要为业务分析师提供正确的上下文信息。为实现此目标,您需要定义实体之间的一组关系。关系是一个重要元素,Data
Explorer Application Builder 使用它链接实体之间的交互,提供了构建上下文信息的重要好处。例如,在我们的场景中,我们需要捕获
tweet 与特定用户(客户)有关联以及一些 tweet 可能与产品相关的事实。
在实体模型中捕获这些实体和任何重要关系
Data Explorer 实体模型为 XML 格式。可使用您选择的 XML
编辑器来为该实体模型创建一个新文件:
添加实体 sentiment:
将 sentiment 实体添加到实体模型中的代码段类似于下面的清单。它包含一些字段的附加信息,我们希望捕获这些信息,让它们可用在
Data Explorer Application Builder 可构建的搜索应用程序中。
清单 1. 实体 sentiment 的定义
<entity-definition default-searchable="true" identifier="@hash"
name="tweet" store-name="tweet-search-store">
<field external-name="Category" name="Category"/>
<field external-name="Brand" name="Brand"/>
<field external-name="Product" name="Product"/>
<field external-name="IsSentiment" name="IsSentiment"/>
<field external-name="Polarity" name="Polarity"/>
<field external-name="CreatedTime" name="CreatedTime"/>
<field external-name="Screenname" name="Screenname"/>
</entity-definition> |
添加实体 products:
将 product 实体和相关字段添加到实体模型中的代码段类似于下面的清单:
清单 2. 实体 product 的定义
<entity-definition default-searchable="true" identifier="@hash"
name="product" store-name="product">
<field external-name="BRAND" name="BRAND"/>
<field external-name="PRODUCT_NUMBER" name="PRODUCT_NUMBER"/>
<field external-name="PRODUCT_BRAND_CODE" name="PRODUCT_BRAND_CODE"/>
<field external-name="PRODUCT_DESCRIPTION" name="PRODUCT_DESCRIPTION"/>
</entity-definition> |
添加我们的实体之间的必要关系:
关系是一个重要的元素,Data Explorer Application
Builder 使用它链接实体之间的交互,并提供构建上下文信息的重要好处。以我们的场景为例,我们可能希望捕获一些
tweet 与产品相关的事实。关系定义可能类似于下面的清单:
清单 3. 关系的定义
<entity-definition default-searchable="true" identifier="@hash"
name="product" store-name="product">
...
<association-definition name="feedback" to="FEEDBACK_TYPE">
<link from-field="BRAND" fuzzy="false" to-field="Brand"/>
</association-definition>
</entity-definition> |
提供您的 Data Explorer 集群的拓扑结构规范
指定 Data Explorer 的集群集合存储:
识别感兴趣的实体和关系后,需要构建一个索引来支持搜索、发现和分析。为此,您需要为此索引指定一种存储机制,即一个集合存储。对于涉及
BigInsights 的用例,比如我们的场景,我们希望使用一个集群集合存储。它是 Data Explorer
支持的集中集合存储类型之一。选择该集群集合存储类型,将使 Data Explorer 引擎能够利用一个机器集群来水平扩展,从而处理
BigInsights 数据的更大规模索引。
下面的代码段展示了如何指定集群集合存储,以便为来自 BigInsights
的社交数据建立索引。另一个表示来自关系 DBMS 的数据的实体将使用更加典型的单一集合。
清单 4. BigInsights 数据的集群集合存储
<cluster-collection-store activity-collection="false"
collection-name="tweet-search-store"
monitor-activities="false"
name="tweet-search-store"
base-collection="default-push"
n-shards="2"/>
<collection-store activity-collection="false"
collection-name="gssdb-product"
monitor-activities="false"
name="product"/> |
指定您的 Data Explorer 集群的可伸缩性:
向搜索应用程序添加分片 (shard),允许对数据进行水平分区,尤其是在这些分片分散在多个物理
Data Explorer 实例上时。在处理大量数据时,总体性能将会提升,因为索引和搜索操作分布在一个集群环境中。我们重用了上面的实体模型示例,在集群集合存储中指定一些分片,将它们分散在两个不同的物理
Data Explorer 实例上。
清单 5. 指定 BigInsights 数据的可伸缩性
<velocity-instance url="http://velocity1.domain.com:9080/vivisimo/cgibin/
velocity?v.app=api-soap&wsdl=1&use-types=true&"
username="api-user"
password="password">
<serves name="tweet-search-store"
shard="1"
n-shards="2"
port="9081"/>
<serves name="tweet-search-store"
shard="2"
n-shards="2"
port="9082"/>
</velocity-instance>
<velocity-instance url="http://velocity2.domain.com:9080/vivisimo/cgibin/
velocity?v.app=api-soap&wsdl=1&use-types=true&"
username="api-user"
password="password">
<serves name="tweet-search-store"
shard="1"
n-shards="2"
port="9081"/>
<serves name="tweet-search-store"
shard="2"
n-shards="2"
port="9082"/>
</velocity-instance> |
使用 ZooKeeper 管理您的 Data Explorer 实体模型
Data Explorer 使用 ZooKeeper 管理您应用程序的实体模型。Zookeeper
是一个集中化的服务,用于维护配置信息,提供分布式同步功能,以及提供分组服务。现在我们已经定义了我们的应用程序实体模型,我们需要通过上传到
ZooKeeper 集群将它提供给应用程序。应用程序将使用这个集群配置来发现所使用的部署拓扑结构:
将您的实体模型上传到 ZooKeeper 集群:
设置您的 ZooKeeper 集群后,您可以将您的 Data Explorer
应用程序实体模型 上传到这个 ZooKeeper 集群并使用它进行管理。Data Explorer BigIndex
API ZIP 文件的 lib 文件夹中包含的 bigindex JAR 是一个可执行文件,可用作一个基本的命令行工具,在
ZooKeeper 中上传和管理实体模型。该命令行的用法如下所示。
清单 6. 将实体模型上传到 ZooKeeper 集群
java -jar bigindex-2.0.0.jar
--properties-file zookeeper.properties
--import-file scenario_entity_model.xml
--export-to-screen --legacy-model |
请注意,如果使用 Data Explorer Application Builder
管理 UI 来管理应用程序实体模型,可以跳过上面的步骤,将您的应用程序指向 Data Explorer
Application Builder 所使用的相同的 ZooKeeper 服务器实例和命名空间。您可以在
IBM/IDE/AppBuilder/wlp/usr/servers/AppBuilder/apps/AppBuilder/WEB-INF/config
的 zookeeper.yml 中找到所使用的 ZooKeeper 配置的更多细节。
使用 Data Explorer 开发您的第一个 BigInsights
索引应用程序
完成 Data Explorer 实体模型的设计后,您就可以利用 BigInsights
应用程序开发生命周期来开发您的第一个索引应用程序,以便将社交数据推送到 Data Explorer 的一个搜索集合中。BigInsights
应用程序框架使您能够以极少的工作创建、发布和部署您的第一个索引应用程序。
创建一个 BigInsights 项目并创建一个新 Java 类
您需要为应用程序创建一个适当的项目,就像您期望在任何基于 Eclipse
的应用程序开发工作中看到的一样,请查阅文章 “使用 InfoSphere BigInsights 开发、发布并部署您的第一个大数据应用程序”,了解创建一个
BigInsight 项目的快捷步骤(请参阅 参考资料)。创建 BigInsights 项目后,您需要向项目添加一个新
Java 类。为此,从 Eclipse 环境中选择 File > New > Java >
Class。填入您的类的信息(包名称等),完成后单击 Finish。
使用新 BigIndex API 在 Data Explorer 中对
BigInsight 数据建立索引
您的应用程序将调用 Data Explorer 所提供的一组索引 Java
API (BigIndex API) 来推送来自 BigInsights 的数据。后续步骤将给出完成此目标所需的各种重要的
API 部分:
检索 Data Explorer 部署拓扑结构以建立索引:
回想一下前面介绍实体模型的一节,Data Explorer 集群拓扑结构捕获在上传到
ZooKeeper 的实体模型中。您的索引应用程序将需要建立与此 ZooKeeper 集群的一个连接,以检索该拓扑结构并找到
Data Explorer 集群来建立索引。下面的清单是实现此任务的代码段。
清单 7. 建立与 ZooKeeper 集群的连接
ZookeeperConfiguration zookeeperConfiguration =
new ZookeeperConfiguration("namespace_sample_big_data_app",
new ZookeeperEndpoint("zkhost1.domain.com", 2181)); |
发布和部署您的索引应用程序
开发索引应用程序后,就可以将其发布到 BigInsights 应用程序目录中。通过打包和发布索引应用程序,您能够定义应用程序的工作流,指定输入数据(您的社交媒体数据)等参数,并指定您的
Data Explorer ZooKeeper 端点。请查阅文章 “使用 InfoSphere BigInsights
开发、发布并部署您的第一个大数据应用程序”,了解创建一个 BigInsight 项目的快捷步骤(请参阅
参考资料),大体了解发布 BigInsights 应用程序的步骤。在这个发布过程中,您将为索引应用程序指定以下信息:
应用程序类型:
选择应用程序类型 workflow,如下图所示。

图 7. 应用程序类型
Oozie 工作流定义:
BigInsights Web 控制台生成一个 Oozie 工作流来帮助管理
MapReduce 作业。 在Workflow 选项卡中,接受允许向导创建一个新操作 workflow.xml
文件的默认设置。在下拉菜单中,将工作流类型更改为 Java,如下所示。

图 8. Oozie 工作流操作类型
索引应用程序参数:
在 Parameters 页面上,指定您的索引应用程序的参数,包括输入目录。此外,您也可提供
ZooKeeper 端点信息作为索引应用程序的输入参数,而不是将它硬编码到应用程序中。最终的工作流可能类似于下图。

图 9. Oozie 工作流示例
在 BigInsights 集群中设置 Data Explorer 客户端库
运行您的索引应用程序之前,您需要在 BigInsights 集群中设置一些
Data Explorer 客户端库。
将 install-dir/AppBuilder/bigindex.zip
文件夹从您的 Data Explorer 集群的安装中复制到 BigInsights 集群的本地文件系统中。
解压 bigindex.zip 文件。您会看到一组 Data Explorer
依赖性 JAR 文件。
创建一个 HDFS 目录,比如 /biginsights/oozie/sharedLibraries/DataExplorer。
使用 Hadoop copy 命令将 Data Explorer 依赖性
JAR 文件复制到目录
/biginsights/oozie/sharedLibraries/DataExplorer(比如
hadoop fs -copyFromLocal *jar
/biginsights/oozie/sharedLibraries/DataExplorer/),或者使用
BigInsights Console 将这些文件上传到 HDFS 目录。
监视您的索引应用程序
部署应用程序后,该程序将出现在 BigInsights Web 控制台中,如下图所示。您可以使用此
Web 控制台检查应用程序的详细信息并运行它。要了解监视您的工作流的 BigInsights Web 控制台的更多信息,请查阅文章
“探索 InfoSphere BigInsights 集群和样例应用程序”(参见 参考资料)。

图 10. BigInsights 索引应用程序
使用 Data Explorer 进行可视化
在 Data Explorer 索引中验证您的社交数据
您的社交数据从 BigInsights 推送到 Data Explorer
中的一个搜索集合中后,您应能够使用 Data Explorer Engine 管理 UI 检查建立了索引的数据。例如,您可以直观地验证您关注的各个字段是否已相应地建立了索引。要访问管理员
UI,请执行以下步骤:
登录到 Data Explorer Engine 管理 UI。
从左侧菜单选择 Search Collection。
查找您的实体模型中指定的社交数据的集合存储。
打开搜索集合,单击左侧面板上的 Search 按钮。

图 11. Data Explorer Engine
管理 UI
搜索关于产品的用户 tweet:
在搜索框中,用户可以键入关键词(比如 golf),使用现有的界面执行文本搜索,如下图所示。

图 12. 对与高尔夫相关的用户 tweet
的文本搜索
利用 Data Explorer Application Builder
Data Explorer 中新增了 Application Builder,它为构建富有吸引力的数据探查应用程序提供了框架,比如分面搜索以及
360 度信息应用程序,这些应用程序可将分散在各个系统中的数据的相关信息集中在一起。
分面搜索:
下图给出了一个可使用 Application Builder 构建的搜索小部件,它为用户提供一个直观的分面搜索应用程序来探查其社交数据。分面搜索使您能够使用一组细化操作轻松地导航某个特定主题上的结果集。在此示例中,我们探查了关于产品(比如高尔夫球)的用户
tweet,如下所示。

图 13. 与高尔夫球相关的用户 tweet
的分面搜索
360 度信息应用程序:
探查社交数据的各个方面后,您还可以将它与更多可从其他系统提取的数据类型相关联,比如客户或产品数据。Data
Explorer 提供了对各种关系数据库、企业 CRM 系统、文件共享等的连接和爬网功能。Data Explorer
Application Builder 提供了一种方式来构建一个 360 度视图应用程序,将分散在这些不同系统中的数据的相关信息集中在一起,同时将数据保留在原始位置。

图 14. 360 度视图应用程序
在我们的示例场景中,一位市场分析师关心某个产品或产品家族,所以一个 360
度视图应用程序可能包含用户反馈和产品细节。下图演示了一个产品页面,其中多个小部件被集中在一起,显示产品信息和相关用户评论。有关使用所示小部件构建实体页面的更多信息,请参阅
参考资料。

图 15. 360 度视图应用程序 ― 实体页面
请注意,图 14 和图 15 给出了一个 360 度应用程序,涉及到来自本文未提及的不同系统的数据。
|


