摘要:
您在本文中看到,一个小型数据仓库可以仅包含一个多维数据集和少数几个维度,这些维度构成了该多维数据集的边缘。具体来说,您观察了一个示例,了解了如何将流量统计数据组织为多维数据集,而该多维数据集的边缘包括
...
上学时,我们知道,尽管大多数数学题都有清晰明了的公式,但我们仍须用未知数
x 来列方程,有时还要用 x、y 甚至更多未知数来列出方程组,以便求解。类似地,在决策支持系统中,我们须根据清晰表述的业务问题来设计一组数据对象,例如维度和多维数据集,以便解答这些问题。
本文着重介绍如何构建一个维度环境以解答业务问题。具体来说,本文将介绍如何将某些分析问题转化为获得答案所需的一组数据对象,使用
Oracle Warehouse Builder 作为开发工具。最好的学习方式是通过示例,因此本文将指导您构建一个简单的数据仓库。
从问题到答案
一般数据仓库主要针对销售,旨在利用基于时间、产品或客户条件从销售多维数据集中检索的结果,帮助用户找到有关业务状况的问题的答案。而本文中的示例不同于一般情况。在这里,您将观察一个示例,了解如何利用基于地理、资源和时间条件从一个流量多维数据集中检索的信息,分析特定网站的相关传出流量。
假设您拥有一个网站,其资源托管在多台服务器上,每台服务器存储流量统计信息的方式都各不相同。从关系数据库到平面文件,它们使用的存储类型多种多样。您需要整合所有这些服务器上的流量统计信息,以便分析用户活动,包括所访问的资源、日期和时间以及地理位置,从而解答如下问题:
1、在我们的站点中,哪五种资源最具吸引力?
2、在过去一年中,来自哪个国家的用户加载该资源的次数最多?
3、在过去三个月中,来自哪个地区的连接产生的站点传出流量最多?
乍一看,似乎只要使用 SQL 即可解答这些问题。毕竟 SQL 的 CUBE、ROLLUP
和 GROUPING SETS 扩展都是专门为聚合多维数据而设计的。但请不要忘记,此处的某些数据存储在平面文件中,因此基于
SQL 的方法是不可行的。除此之外,观察上述问题,您会注意到个别问题的解答需要利用一年的历史数据。在实践中,这意味着您还需要访问包含历史数据的存档,这些历史数据源于事务数据,存储在各个不同的源中。在
SQL 中,管理所有这些数据源,以及将各数据源中的数据转为一致格式以支持统一的查询操作,这些工作费力且易于出错。
简而言之,这里的主要工作是:
1、将存储在不同源中的数据整合成一致的格式。
2、使用源于事务数据的历史数据。
3、使用预先加载的数据来加快查询速度。
4、以便于维度分析的方式组织数据。
数据仓库正是为执行这些任务而设计的。我们简要概括一下,数据仓库是一个专为处理分析查询(而非事务处理)而调优的关系数据库,通过定期刷新和更新保持是最新的,定期刷新和更新通过
ETL(提取、转换和加载)流程从源下载数据子集(通常在一周的某一天或白天、夜晚的一个预定时间调度执行)。要加载的数据转换为一致的格式,然后加载到数据仓库的目标对象中。填充数据仓库之后,一般可以通过多维数据集和维度等维度对象来查询该数据仓库。其示意图如下所示:
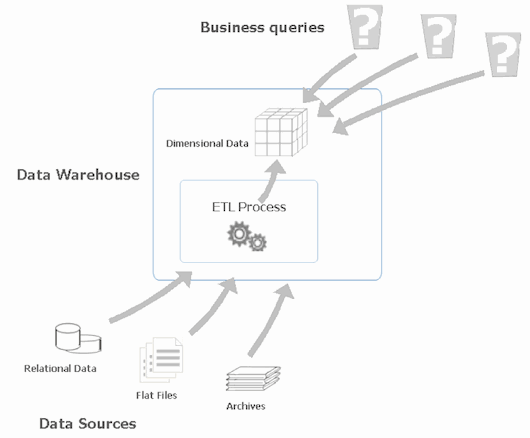
图 1 从不同源收集数据,将其转换为可供业务用户使用的有用信息。
具体来说,在本例中,合适的解决方案是一个简单的数据仓库,其中包含一个有几个维度的多维数据集。由于流量是这里的重点,您可能希望将传出流量定义为多维数据集的量度。为简单起见,本例中我们将根据所访问资源的大小测量传出流量。例如,若有人从您的站点下载一个
1MB 的文件,那么我们认为将产生 1MB 的传出流量。这类似于购买金额取决于所选产品的价格。金额通常是销售多维数据集的一个量度,而价格是产品的一个属性,产品通常用作该多维数据集中一个维度。与之相似的是,传出流量是我们的流量多维数据集的量度,而资源大小是资源的一个属性,资源将用作一个维度。
现在来看看维度,通过分析要回答的系列问题可以确定本示例中多维数据集所用的一组维度。因此,请仔细观察本节开始处列出的问题,您可能希望使用以下维度来组织多维数据集中的数据:
1、地理,将站点用户所来自的地理位置的相关数据组织在一起
2、资源,对站点资源的相关数据进行分类
3、时间,用于聚合一段时间的流量数据
每条流量记录都将具有针对地理位置、资源以及日期和时间的具体值。说明一下,流量记录中的时间值指的是是访问资源的时间。
下一个关键步骤是定义为各维度聚合数据的级别,并将这些级别组织为层次结构。就地理维度而言,您可能会定义包含以下级别的层次结构(最先列出的是最高的级别):
1、地区
2、国家
资源维度的级别层次结构可能如下所示:
1、组
2、资源
时间维度可能包含以下层次结构:
1、年
2、月
3、日
在更加复杂、现实的场景中,一个维度可能包含多个层次结构,例如,财年和日历年。但在这个特定的示例中,每个维度仅有一个层次结构。
使用 Oracle Warehouse Builder 实现数据仓库
您已确定了仓库中所需的对象,接下来就可以设计和构建这些对象了。这个任务可以使用
Oracle Warehouse Builder 来完成,从 Oracle Database 11g 第
1 版开始,这个工具就已经成为 Oracle Database 标准安装的一部分。但要启用它,您必须完成一些准备工作:
首先,需要解锁 Oracle Warehouse Builder 使用的数据库模式。Oracle
Warehouse Builder 11g 第 1 版中使用的是 OWBSYS 模式,11g第 2 版则同时使用了
OWBSYS 和 OWBSYS_AUDIT 模式。这些模式包含 OWB 设计和运行时元数据。可以作为 SYS
或 SYSDBA 连接到 SQL*Plus,然后使用以下命令完成此任务:
ALTER USER OWBSYS IDENTIFIED BY owbsyspwd ACCOUNT UNLOCK;
ALTER USER OWBSYS_AUDIT IDENTIFIED BY owbsys_auditpwd ACCOUNT UNLOCK; |
接下来,必须创建一个 Warehouse Builder 工作区。工作区包含一个或多个数据仓储项目的对象,在复杂环境中,可能要使用多个工作区。(面向
Windows 和 Linux 的 Oracle Warehouse Builder 安装和管理指南 提供了有关如何创建工作区的说明。可按照其中的说明新建一个工作区,将新用户作为工作区的所有者。)
现在,您可以启动 Warehouse Builder Design Center,这是 Oracle
Warehouse Builder 的主要图形用户界面。单击 Show Details,用新建的工作区用户连接到
Design Center,提供必要的主机/端口/服务名称或网络服务名称。
我们先概述一下需要完成的任务,然后再继续解读。大致来说,本示例要完成的任务包括:
1、定义一个数据仓库来容纳上述维度对象
2、整合来自不同数据源的数据
3、实现维度对象:维度和多维数据集
4、将从数据源提取的数据加载到维度对象中
下面几节介绍如何完成上述任务,实现本文讨论的维度解决方案。在继续操作之前,必须先确定要使用哪种实现模型。实际上,您有两种选择:在关系表中存储实际数据的关系目标仓库,或者多维数据仓库。在后一种情况下,维度数据存储在
Oracle OLAP 分析工作区中。此特性在 Oracle Database 10g 和 Oracle
Database 11g 中可用。就本示例而言,维度模型将作为关系目标数据仓库实现。
定义目标模式
在这个初始步骤中,首先要创建一个新项目,或指责配置 OWB Design
Center 中的默认项目。随后,您可以确定目标模式,该目标模式将用于包含目标数据对象:本文前面介绍的维度和多维数据集。
假设您已经决定使用默认项目 MY_PROJECT,让我们来继续创建目标模式。下面的步骤展示了创建目标模式的过程,随后还在
Design Center 中根据该模式创建目标模块:
1、在 Globals Navigator 中,右键单击 Security->Users
节点,然后从弹出菜单中选择 New User 启动 Create User 向导。
2、在 Select DB user to register 屏幕中,单击
Create DB User… 打开 Create Database User 对话框。
3、在 Create Database User 对话框中,输入 system
用户的口令,然后指定用户名,例如 owbtarget,指定新数据库用户的口令。然后,单击 OK。
4、此时已返回 Select DB user to register 屏幕,新建的
owbtarget 用户会出现在 Selected Users 窗格中。单击 Next 继续。
5、在 Check to create a location 屏幕中,确保为
owbtarget 用户选中了 To Create a location 复选框,随后单击 Next。
6、在 Summary 屏幕中,单击 Finish 完成此过程。
完成上述步骤后,即在数据库中创建了 owbtarget 模式。(此外,owbtarget
用户还会出现在 Globals Navigator 的 Security->Users 节点下。)下一步是基于新建的数据库模式创建目标模块。简单说来,您将在
Warehouse Builder 中使用模块将要处理的对象组织为面向主题的组。以下步骤将说明如何基于
owbtarget 数据库模式构建 Oracle 模块:
1、在 Projects Navigator 中,展开 MY_PROJECT->Databases
节点,然后右键单击 Oracle 节点。
2、在弹出菜单中,选择 New Oracle Module 启动向导。
3、在向导的 Name and Description 屏幕中,为所创建的模块指定名称,例如
target_mdl。对于模块状态,可保留为 Development。
4、在 Connection Information 屏幕上,首先确保选定的位置是与所创建的
target_mdl 模块相关联的位置(可能会出现在 TARGET_MDL_LOCATION1 名称下)。随后,需要提供此位置的连接信息。单击
Edit… 按钮,提供 Oracle 数据库位置的详细信息,指定 owbtarget 作为用户名。完成上述操作之后,您可能希望确认一切正确,此时可单击
Test Connection 按钮来测试连接。单击 OK 关闭所有打开的对话框,返回 Connection
Information 屏幕。单击 Next 继续。
5、在 Summary 屏幕中,单击 Finish。
6、在 Design Center 中,选择 File->Save
All 保存刚创建的模块。
完成上述步骤之后,TARGET_MDL 模块会出现在 Projects
Navigator 的 MY_PROJECT->Databases->Oracle 节点下。如果展开该模块节点,您会看到可在其中创建的对象的类型。其中包括用于保存以下内容的节点:多维数据集、维度、表和外部表。
整合来自不同数据源的数据
此时,您不仅需要从不同源中提取数据,还需要将提取的数据转换为可整合到单个数据源中的形式。因此,此任务通常包含以下阶段:
1、将元数据导入 OracleWarehouse Builder 中。
2、设计 ETL 操作。
3、将源数据加载到数据仓库中。
您首先需要制定一个提取源数据、转换数据并将其加载到数据仓库中的通用战略。也就是说,您必须首先制定战略决策,确定如何以最佳方式实现从数据源整合数据的任务。
就平面文件而言,您要制定的第一项决策或许就是如何将数据从这些源移至数据仓库中。下面是可供选择的方法:利用
SQL*Loader 或通过外部表。在这个具体示例中,使用外部表应该是更为可取的选择,因为从平面文件中提取的数据必须与关系数据相联接。回忆一下,本例假设将从数据库表和平面文件中提取源数据。
接下来,您需要决定是否为将使用的源数据对象定义一个源模块。尽管将源对象和目标对象分别放在不同的模块中通常被视为一种良好的习惯,但对于这个简单的示例来说,我们将在一个数据库模块中创建所有对象。
现在,让我们来进一步观察要访问的数据源。
如前所述,我们拥有一个网站,其资源托管在多台服务器上,每台服务器存储流量统计信息的方式各不相同。例如,一台服务器将其存储为平面文件,另一台服务器则将其存储在数据库中。举例来说,一个包含实时数据的名为
access.csv 的平面文件的内容可能如下所示:
User IP,Date Time,Site Resource
67.212.160.0,5-Jan-2011 20:04:00,/rdbms/demo/demo.zip
85.172.23.0,8-Jan-2011 12:54:28,/articles/vasiliev_owb.html
80.247.139.0,10-Jan-2011 19:43:31,/tutorials/owb_oracle11gr2.html |
可以看到,上述文件包含有关用户访问资源的信息,并且这些信息以逗号分隔 (CSV)
格式存储。 而使用数据库代替平面文件的服务器可能会将相同的信息存储在结构如下的 accesslog 表中:
USERIP VARCHAR2(15)
DATETIME DATE
SITERESOURCE VARCHAR2(200) |
您可能已经猜到了,在本例中,为了确定访问资源的用户的地理位置,IP 地址数据必不可少。具体来说,这使您能够推断出
IP 地址所属的地区、国家、城市乃至组织的地理位置。为了通过 IP 地址获得这样的信息,您可以利用一个免费或付费使用的地理位置数据库,现在有很多这样的数据库。此外,还可以利用用户在注册过程中提供的地理位置信息,也就是依靠您自己的数据库中存储的信息。但在这种情况下,您可能需要依靠用户的
ID 而非 IP 地址。
就本示例而言,我们将使用一个免费的地理位置数据库,该数据库可确定国家一级的 IP 地址范围,例如 MaxMind
的 GeoLite Country 数据库。(Maxmind 还提供了更精确的付费数据库,这些数据库包含国家级和城市级地理位置数据。)有关更多详细信息,可访问
MaxMind 网站。
GeoLite Country 数据库存储为一个 CSV 文件,其中包含公开分配的 IPv4 地址的地理数据,这样您能够根据
IP 地址确定用户所在的国家。为了利用此数据库,您需要下载压缩的 CSV 文件,进行解压缩,然后将其数据导入到您的数据仓库中。导入的数据将与通过本节前述的平面文件和数据库获得的
Web 流量统计数据相联接。
查看 GeoLite Country CSV 文件的结构,您可能会注意到,除了分配给特定国家的,由点分十进制表示的起始和结束
IP 地址定义的 IP 地址范围之外,还包括借助以下公式根据这些 IP 地址得出的相应 IP 编号:
IP Number = 16777216*w + 65536*x + 256*y + z |
其中
与使用直接 IP 地址相比,使用 IP 编号有个明显的好处,那就是,IP 编号是普通十进制数字,易于对比,这简化了确定相应
IP 地址属于哪个国家的任务。然而,问题在于我们的流量统计数据源存储的是直接 IP 地址,而非据此得出的编号。您需要转换
Web 流量数据,使转换的结果包含 IP 编号,而非 IP 地址。
下面是数据转换和联接的示意图:
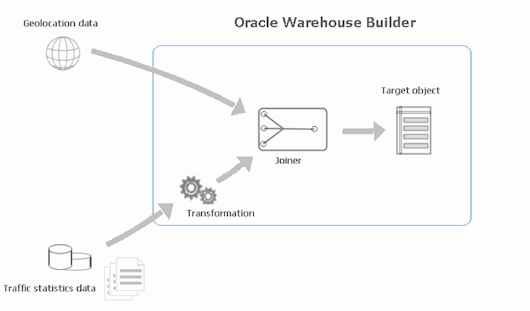
图 2 Oracle Warehouse
Builder 提取、转换和联接源数据。
我们记得,维度和多维数据集数据通常来自多个数据源。就本例而言,除了流量统计信息和地理位置数据之外,您还需要包含资源和地区信息的数据源。为此,可以假设您有两个数据库表:RESOURCES
和 REGIONS。假设 RESOURCES 表的结构如下:
SITERESOURCE VARCHAR2(200) PRIMARY KEY
RESOURCESIZE NUMBER(12)
RESOURCEGROUP VARCHAR2(10) |
假设 REGIONS 表的定义如下:
COUNTRYID VARCHAR2(2) PRIMARY KEY
REGION VARCHAR2(2) |
上述表中的数据将与 Web 流量统计信息和地理位置数据相联接。
现在您已了解了源数据的结构和含义,我们将继续操作,在 Warehouse Builder 中定义所有必要的数据对象。我们首先为平面文件创建所需的对象。一般执行步骤如下:
1、在项目中创建一个新的平面文件模块,将其与您的源平面文件所在的位置关联。
2、在新建的平面文件模块中,定义所需的平面文件并指定其结构。
3、在上一节中定义的目标仓库模块中添加外部表,将这些表与上一步中创建的平面文件关联。
4、将 accesslog、resources 和 regions 数据库表导入目标仓库模块。
要创建平面文件模块,请在 Design Center 中执行以下步骤:
1、在 Projects Navigator 中,右键单击 MY_PROJECT->Files
节点,然后从弹出菜单中选择 New Flat File Module。
2、在向导的 Name and Description 屏幕中,为所创建的模块指定名称,或者保留默认名称。然后单击
Next。
3、在 Connection Information 屏幕中,单击 Location
选择框右侧的 Edit… 按钮。
4、在 Edit File System Location 对话框中,指定能够找到您希望从中提取数据的平面文件的位置。单击
OK 返回向导。
5、在 Summary 屏幕中,单击 Finish 完成此向导。
现在,可在新建的平面文件模块中定义一个新的平面文件。首先,我们为本节前面提到的
access.csv 文件创建一个平面文件对象:
1、在 Projects Navigator 中,右键单击 MY_PROJECT->Files->FLAT_FILE_MODULE_1
节点,然后选择 New Flat File 启动 Create Flat File 向导。
2、在向导的 Name and Description 屏幕中,为所创建的平面文件对象指定名称,例如
ACCESS_CSV_FF。随后,确保指定物理文件名称。在这个页面中,您还可以更改字符集,或者接受向导中显示的默认字符集。
3、在 File Properties 屏幕中,确保记录分隔符已设置为回车:<CR>,字段分隔符已设置为
(,)。
4、在 Record Type Properties 屏幕中,确保选择了
Single Record。
5、在 Field Properties 屏幕中,您需要定义 access.csv
文件记录的结构,为各字段设置 SQL 属性。请注意,Name 属性后的第一组属性是 SQL*Loader
属性。但您不必定义这些属性,因为您将使用外部表选项,而非 SQL*Loader 实用工具。外部表是将平面文件数据载入
Oracle 数据仓库的最高效的方法。因此,您需要向右滚动到第二组属性:SQL 属性。按如下所示定义这些属性:
Name SQL Type SQL Length
USERIP VARCHAR2 15
DATETIME DATE
SITERESOURCE VARCHAR2 200 |
6、在 Summary 屏幕中,单击 Finish 完成此向导。
此时,您可能希望将更改提交到信息库。选择 File->Save All
提交您的更改。
对包含地理位置数据的 GeoIPCountryWhois.csv 文件重复上述步骤,在向导的 Field
Properties 屏幕中定义以下属性:
Name SQL Type SQL Length
STARTIP VARCHAR2 15
ENDIP VARCHAR2 15
STARTNUM VARCHAR2 10
ENDNUM VARCHAR2 10
COUNTRYID VARCHAR2 2
COUNTRYNAME VARCHAR2 100 |
完成这些操作之后,在目标模块中定义外部表对象。这将在数据库中以表的形式提供平面文件数据。要根据此前创建的
ACCESS_CSV_FF 平面文件对象定义外部表,请执行以下步骤:
1、在 Projects Navigator 中,展开 MY_PROJECT->Databases->Oracle->TARGET_MDL
节点,右键单击 External Tables 并选择 New External Table。
2、在向导的 Name and Description 屏幕中,为外部表指定名称,例如
ACCESS_CSV_EXT。
3、在 File Selection 屏幕中,选择应可在 FLAT_FILE_MODULE1
下找到的 ACCESS_CSV_FF。
4、在 Locations 屏幕中,选择外部表将要部署到的位置。
5、在 Summary 屏幕中,单击 Finish 完成此向导。
对 GEOLOCATION_CSV_FF 平面文件对象重复上述步骤。
现在,您已创建了所有必需的对象定义,接下来就需要将其部署到目标模式,之后才能使用它们。另外一个准备步骤是确保数据库中的目标模式具有创建和删除目录的权限。为此,可以作为
sysdba 连接到 SQL*Plus,并执行以下命令:
GRANT CREATE ANY DIRECTORY TO owbtarget;
GRANT DROP ANY DIRECTORY TO owbtarget; |
之后,您可以返回 Design Center 继续部署。以下步骤说明如何部署外部表:
1、在 Projects Navigator 中,展开 MY_PROJECT->Databases->Oracle->TARGET_MDL->External
Tables 节点,然后选择 ACCESS_CSV_EXT 和 GEOLOCATION_CSV_ EXT
节点。
2、右键单击所选内容,选择 Deploy …。此过程首先将编译选定的对象,然后继续部署,可能需要花一些时间才能完成。
如果部署成功完成,也就意味着您已经在数据库的目标模式中创建了外部表的定义,因此可以查询这些表。为确保到目前为止一切均如期实现,最好看看可通过新部署的表访问的数据。最简单的方法是在
Project Navigator 中右键单击一个外部表节点,然后从弹出菜单中选择Data… 命令。
GEOLOCATION_CSV_ EXT 表不会有任何问题,该表包含大约
140,000 行记录,但对于 ACCESS_CSV_EXT 数据,您可能不会看到任何内容。为了确定问题出在哪里,您可能希望检查的第一个方面就是
ACCESS_CSV_EXT 的访问参数,可通过 ALL_EXTERNAL_TABLES 数据字典视图访问这些参数。这样,作为
sysdba 连接到 SQL*Plus 后,您可以执行以下查询:
SELECT access_parameters FROM all_external_tables
WHERE table_name ='ACCESS_CSV_EXT'; |
使用多维数据集跨维度聚合数据
创建并部署了源对象定义之后,我们来构建目标结构。具体来说,您需要构建一个
Traffic 多维数据集,用于存储聚合的流量数据。在继续构建多维数据集之前,您必须先构建构成其边缘的维度。
记得本文开始时讲过,您需要定义以下三个维度来组织多维数据集内的数据:地理、资源和时间。以下步骤说明如何构建地理维度并为其加载数据:
1、在 Projects Navigator 中,右键单击 MY_PROJECT->Databases->Oracle->
TARGET_MDL->Dimensions 节点,然后从弹出菜单中选择 New Dimension
启动 Create Dimension 向导。
2、在向导的 Name and Description 屏幕中,在 Name
域中键入 GEOGRAPHY_DM。
3、在 Storage Type 屏幕中,选择 ROLAP。
4、在 Levels 屏幕中输入以下级别:Region Country
5、在 Level Attributes 屏幕中,确保选中 Region
和 Country 级别的所有级别属性。
6、在 Slowly Changing Dimension 屏幕中,选择
Type1:Do not keep history。
完成向导之后,会在 Project Navigator 的 MY_PROJECT->Databases->Oracle->
TARGET_MDL->Dimensions 节点下看到GEOGRAPHY_DM 对象。现在,右键单击此对象并选择
Bind。此时,GEOGRAPHY_DM_TAB 表会出现在 MY_PROJECT->Databases->Oracle->TARGET_MDL->Tables
节点下。右键单击并选择 Deploy…。同样,GEOGRAPHY_DM_SEQ 会出现在 MY_PROJECT->Databases->Oracle->TARGET_MDL->Sequences
节点下,同样也需要部署。在两个部署都完成后,返回 GEOGRAPHY_DM 并进行部署。
现在,您将定义一个 ETL 映射,以便从源数据载入 GEOGRAPHY_DM
维度。步骤如下所示:
1、在 Projects Navigator 中,展开 MY_PROJECT->Databases->Oracle->TARGET_MDL
节点,然后右键单击 Mappings。在弹出菜单中,选择 New Mapping 启动 Create Mapping
对话框。在这个对话框中,指定映射名称,例如 GEOGRAPHY_DM_MAP。单击 OK 后,会显示 Mapping
Editor 画布。
2、在 Projects Navigator 中,展开 MY_PROJECT->Databases->Oracle->TARGET_MDL->Tables
节点,随后在 Mapping Editor 中将 REGIONS 表拖放到 GEOGRAPHY_DM_MAP
的映射画布中。
3、然后,展开 MY_PROJECT->Databases->Oracle->TARGET_MDL->Dimensions
节点,将 GEOGRAPHY_DM 维度拖放到映射画布中 REGIONS 表操作符右侧的位置。
4、在映射画布中,将 REGIONS 操作符的 COUNTRYID 属性连接到
GEOGRAPHY_DM 的 COUNTRY.NAME 属性,随后将 REGIONS 操作符的 COUNTRYID
属性连接到 GEOGRAPHY_DM 的 COUNTRY.DESCRIPTION 属性。
5、类似地,将 REGIONS 操作符的 REGION 属性连接到 GEOGRAPHY_DM
的 REGION.NAME、COUNTRY.REGION_NAME 和 REGION.DESCRIPTION
属性。
6、在 Projects Navigator 中,展开 MY_PROJECT->Databases->Oracle->TARGET_MDL->Mappings
节点。右键单击GEOGRAPHY_DM_MAP 并从弹出菜单中选择 Deploy…。
7、最后一步是加载 GEOGRAPHY_DM 维度。为此,您需要执行 GEOGRAPHY_DM_MAP
映射。因此,右键单击GEOGRAPHY_DM_MAP,选择 Start…
8、同样,您应创建并部署 RESOURCE_DM 和 RESOURCE_DM_MAP
对象,使用 resources 表作为源,并在 RESOURCE_DM 维度中指定以下级别:Group、Resource
9、定义 RESOURCE_DM 维度属性时,不要忘记将 NAME 和
DESCRIPTION 属性的长度增加到 200,使它们能够与 RESOURCES 操作符的 SITERESOURCE
属性连接。
最后,您需要创建一个时间维度。最简单的方法就是使用 Create Time
Dimension 向导,该向导将为您定义一个时间维度对象以及用于加载此对象的 ETL 映射。有关如何创建和填充时间维度的详细信息,可参考“Oracle
Warehouse Builder 数据建模、ETL 和数据质量指南”中的“创建时间维度”一节。
建立了维度之后,可执行以下步骤来定义多维数据集:
1、在 Projects Navigator 中,右键单击 MY_PROJECT->Databases->Oracle->TARGET_MDL->Cubes
节点,然后从弹出菜单中选择 New Cube。
2、在向导的 Name and Description 屏幕中,在 Name
域中输入多维数据集的名称:TRAFFIC。
3、在 Storage Type 屏幕中,选择 ROLAP:Relational
storage。
4、在 Dimensions 屏幕中,将所有可用维度从 Available
Dimensions 窗格移至 Selected Dimensions 窗格,从而选定以下维度:
RESOURCE_DM
GEOGRAPHY_DM
TIME_DM |
5、在 Measures 屏幕中输入以下量度:
OUT_TRAFFIC with the data type NUMBER |
6、在向导完成后,TRAFFIC 多维数据集和 TRAFFIC_TAB
表会出现在 Project Navigator 中。您必须先部署它们,然后才能继续其他操作。
对于维度,下一步要做的是创建一个映射,定义如何将源数据加载到多维数据集中。
为加载多维数据集转换源数据
现在,您需要设计 ETL 映射,以便转换源数据并将其载入多维数据集中。下面是需要设计的转换操作的列表:
1、将 access_csv_ext 外部表和 accesslog 数据库表的行合并为一个行集,以整合流量统计数据。
2、将流量统计数据内的 IP 地址转换为 IP 编号,以便简化确定所关注的
IP 地址属于哪个地址范围的任务。
3、联接流量统计数据与地理数据。
4、聚合联接后的数据,将输出数据集加载到多维数据集中。
如前所述,上述操作必须在一个映射中进行描述。在继续创建映射之前,我们首先来定义上述第二步所述的转换。这个转换将实现为一个
PL/SQL 函数。以下步骤描述如何不必离开 Design Center 即可完成此任务:
1、在 Projects Navigator 中,展开 MY_PROJECT->Databases->Oracle->TARGET_MDL->Transformations
节点,然后右键单击Functions。在弹出菜单中,选择 New Function。
2、在 Create Function 对话框中,指定该函数的名称,例如
IpToNum,然后单击 OK。此时将显示与所创建的函数相关联的 Function Editor。
3、在 Function Editor 中,转到 Parameters
选项卡,添加 IPADD 参数,将数据类型设置为 VARCHAR2,将 I/O 设置为 Input。
4、在 Function Editor 中,转到 Implementation
选项卡,编辑函数代码如下:
p NUMBER;
ipnum NUMBER;
ipstr VARCHAR2(15);
BEGIN
ipnum := 0;
ipstr:=ipadd;
FOR i IN 1..3 LOOP
p:= INSTR(ipstr, '.', 1, 1);
ipnum := TO_NUMBER(SUBSTR(ipstr, 1, p - 1))*POWER(256,4-i) + ipnum;
ipstr := SUBSTR(ipstr, p + 1);
END LOOP;
ipnum := ipnum + TO_NUMBER(ipstr);
RETURN ipnum;
END; |
5、在 Projects Navigator 中,右键单击新建的 IPTONUM
节点,然后选择 Deploy…
现在,您可以创建一个映射,随后可在其中定义如何将源对象中的数据加载到多维数据集:
1、在 Projects Navigator 中,展开 MY_PROJECT->Databases->Oracle->TARGET_MDL
节点,然后右键单击 Mappings。在弹出菜单中,选择 New Mapping 启动 Create Mapping
对话框。在这个对话框中,指定映射名称:TRAFFIC_MAP。单击 OK 后,会显示 Mapping Editor
画布。
2、为了完成合并 access_csv_ext 和 accesslog
表的行记录这一任务,首先将 ACCESS_CSV_EXT 和 ACCESSLOG 表对象从 Project
Navigator 中拖放到 Mapping Editor 画布。此时,代表上述各表的操作符会出现在画布中。
3、从 Component Palette 中,将 Set Operation
操作符拖放到映射画布上。随后,在 Property Inspector 中,将操作符的 Set 操作属性设置为
UNION。
4、在映射画布中,将 ACCESSLOG 操作符的 INOUTGRP1
组连接到 SET OPERATION 操作符的 INGRP1 组。结果将使这些组下的所有相应属性自动相连。
5、接下来,将 ACCESS_CSV_EXT 操作符的 OUTGRP1
组连接到 SET OPERATION 操作符的 INGRP2 组。
6、接下来要完成的任务是将流量统计数据与地理数据相联接。首先,将 GEOLOCATION_CSV_EXT
表对象从 Project Navigator 拖放到映射画布。
7、从 Component Palette 中,将 Joiner 操作符拖放到映射画布上。随后,将
GEOLOCATION_CSV_EXT 操作符的 OUTGRP1 组连接到 JOINER 操作符的 INGRP1
组。接下来,将 SET OPERATION 操作符的 OUTGRP1 组连接到 JOINER 操作符的
INGRP2 组。
8、在 Projects Navigator 中,展开 MY_PROJECT->Databases->Oracle->TARGET_MDL->Transformations->Functions
节点,将 IPTONUM 函数拖放到映射画布上。
9、在映射画布中,选择并删除连接 SET OPERATION 操作符的
USERIP 输出属性与 JOINER 操作符的 USERIP 输入属性的线。将 SET OPERATION
操作符的 USERIP 输出属性连接到 IPTONUM 操作符的 IPADD 输入属性。然后,将 IPTONUM
操作符的输出属性连接到 JOINER 操作符的 USERIP 输入属性。您还需要将 JOINER 的 USERIP
输入属性的数据类型更改为 NUMERIC。可以在 Joiner Editor 对话框的 Input Attributes
选项卡中完成此任务,双击 JOINER 操作符的标题即可打开此对话框。
10、在 Joiner Editor 对话框中,转到 Groups 选项卡,添加一个输入组
INGRP3。然后单击 OK 关闭该对话框。
11、在 Project Navigator 中,将 RESOURCES
表对象拖放到 Mapping Editor 画布上。随后将 RESOURCES 操作符的 INOUTGRP1
组连接到 JOINER 操作符的 INGRP3 组。
12、单击 JOINER 操作符的标题。随后转到 JOINER Property
Inspector,在其中单击 Join Condition 按钮。结果将打开 Expression Builder
对话框,在其中构建以下联接条件:
(INGRP2.USERIP BETWEEN INGRP1.STARTNUM AND INGRP1.ENDNUM)
AND
(INGRP2.SITERESOURCE = INGRP3.SITERESOURCE) |
13、接下来,您需要添加一个 Aggregator,以便聚合 Joiner
操作符的输出。从 Component Palette 中,将 Aggregator 操作符拖放到映射画布上。
14、将 JOINER 操作符的 OUTGRP1 组连接到 AGGREGATOR
操作符的 INGRP1 组。随后,单击 AGGREGATOR 操作符的标题,进入 Property Inspector,单击其中
Group By Clause 域右侧的省略号按钮,调用 Expression builder 对话框。在这个对话框中,为聚合器指定以下
group by 子句:
INGRP1.COUNTRYID,INGRP1.SITERESOURCE,INGRP1.DATETIME |
15、双击 AGGREGATOR 操作符的标题,转到对话框的 Output
选项卡,添加 RESOURCESIZE 属性,并为其指定以下表达式:SUM(INGRP1.RESOURCESIZE)。
16、从 Component Palette 中,将 Expression
操作符拖放到映射画布上。随后,双击 EXPRESSION 操作符的标题,转到对话框的 Input Attributes
选项卡,在其中定义类型为 DATE 的 DATETIME 属性。随后,转到 Output Attributes
选项卡,定义类型为 DATE 的 DAY_START_DAY 属性,指定以下表达式:
TRUNC(INGRP1.DATETIME, 'DD') |
17、删除连接 JOINER 操作符的 DATETIME 属性与 AGGREGATOR
操作符的 DATETIME 属性的线。随后,将 JOINER 的 DATETIME 连接到 EXPRESSION
的 DATETIME,并将 EXPRESSION 的 DAY_START_DAY 连接到 AGGREGATOR
的 DATETIME。
18、在 Projects Navigator 中,展开 MY_PROJECT->Databases->Oracle->TARGET_MDL->Cubes
节点,将 TRAFFIC 多维数据集对象拖放到画布上。
19、将 AGGREGATOR 操作符的 OUTGRP1 组中的属性连接到
TRAFFIC 操作符的属性,如下所示:
RESOURCESIZE to OUT_TRAFFIC
COUNTRYID to GEOGRAPHY_DM_NAME
DATETIME to TIME_DM_DAY_START_DATE
SITERESOURCE to RESOURCE_DM_NAME |
至此,映射画布应如下图所示:
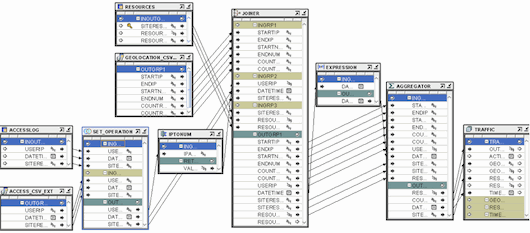
图 3 映射画布,显示了将源对象中的数据加载到多维数据集的
TRAFFIC_MAP 映射。
20、现在可以部署该映射。在 Project Navigator 中,右键单击
MY_PROJECT->Databases->Oracle->TARGET_MDL->Mapping
节点下的TRAFFIC_MAP 对象,然后选择 Deploy…。这将实际生成该映射。
21、在成功完成部署后,您可以执行该映射,启动已定义的 ETL 逻辑的作业。为此,右键单击
TRAFFIC_MAP 对象,然后选择 Start…
完成上述步骤后,也就按照映射中实现的逻辑使用来自源的数据填充了 TRAFFIC
多维数据集。然而,从实践的角度来讲,您更希望为事实表(也就是本例中的 TRAFFIC_TAB 表)填充数据。换句话说,多维数据集记录存储在事实表中。多维数据集本身仅仅是这里使用的维度数据的逻辑表示或可视化表示。
类似地,维度以物理的方式绑定到相应的维度表,这些维度表将维度数据存储在数据库中。维度表使用外键联接到事实表,构成了一种称为星型模式的模型(因为这种模式的示图类似于星型)。Oracle
Database 的查询优化器能够为星型查询(对事实表和与之联接的维度表所发出的联接查询)应用强大的优化技术,从而为解答业务问题的查询提供了高效的查询性能。 |


