1��ȷ���Ƿ���Ҫִ�лָ�
2�����ʲ�ͬ�Ľ��棨��Enterprise Manager �������У�
3��������ʹ�ÿ��õķ�������Recovery Manager (RMAN)
�����ݻָ�ָ��
4���������ļ�ִ�лָ���
�C �����ļ�
�C ������־�ļ�
�C �����ļ�
�����ݿ�
Ҫ�����ݿ⣬������������������
1.���п����ļ��������������ͬ��
2.�������������ļ��������������ͬ��
3.ÿ��������־�����������һ����Ա����
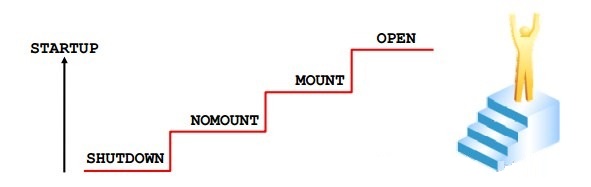
�����ݿ�
�����ݿ�ӹرս�תΪ��ȫ��ʱ�����ݿ������½�ִ���ڲ�һ���Լ�飺
1.NOMOUNT��ʵ��Ҫ�ﵽNOMOUNT���ֳ�STARTED��״̬���ͱ����ȡ��ʼ�������ļ���ʵ������NOMOUNT״̬ʱ���������κ����ݿ��ļ���
2.MOUNT��ʵ������MOUNT״̬ʱ�������ʼ�������ļ����г������п����ļ��Ƿ�������ͬ������ʹ��һ�������ļ�ȱʧ����ʵ��Ҳ�������Ա���ش���
��ָ�������ļ�ȱʧ��������NOMOUNT״̬��
3.OPEN��ʵ����MOUNT״̬תΪOPEN״̬ʱ������ִ�����²�����
- �������ļ���֪������������־���Ƿ�������һ����Ա���ڡ��κ�ȱʧ�ij�Ա���¼��Ԥ����־�С�
- ��֤�����ļ���֪�����������ļ��Ƿ���ڣ�������֤�ѻ��ļ���
�ڹ���Ա����ʹ�ѻ����ļ�����֮ǰ����������Щ�ļ�����������ļ�������SYSTEM��UNDO���ռ䣬����Ա�Ϳ�ʹ�����ļ��ѻ�����ʵ�������ȱʧ���κ��ļ����������Ա����һ������ָ����һ��ȱʧ���ļ�����ʱʵ������MOUNT״̬����ʵ������ȱʧ�ļ�ʱ��������Ϣ��ֻ��ʾ��������ĵ�һ���ļ���Ҫ������Ҫ�ָ��������ļ�������Ա��ͨ�����v$recover_file��̬������ͼ����ȡ��Ҫע����ļ��������б���
SQL> startup
ORACLE instance started.
Total System Global Area 171966464 bytes
Fixed Size 775608 bytes
Variable Size 145762888 bytes
Database Buffers 25165824 bytes
Redo Buffers 262144 bytes
Database mounted.
ORA-01157: cannot identify/lock data file 4 - see DBWR trace file
ORA-01110: data file 4: '/oracle/oradata/orcl/users01.dbf'
SQL> SELECT name, error FROM v$datafile JOIN v$recover_file USING (file#);
NAME ERROR
----------------------------------- ------------------
/oracle/oradata/orcl/users01.dbf FILE NOT FOUND
/oracle/oradata/orcl/example01.dbf FILE NOT FOUND |
- ��֤����δ�ѻ������ļ���ֻ�������ļ��Ƿ�������ļ�ͬ������Ҫʱ��ʵ�����Զ�ִ�лָ������ǣ����ij���ļ���ͬ����������ͨ��ʹ������������
־����лָ�������Ա����ִ�н��ʻָ�������κ��ļ���Ҫ���н��ʻָ����������Ա����һ��������Ϣ��ָ����һ����Ҫ�ָ����ļ�����ʱʵ������MOUNT״̬��
ORA-01113: file 4 needs media recovery
ORA-01110: data file 4: '/oracle/oradata/orcl/users01.dbf' |
���⣬v$recover_file���ṩ��Ҫע����ļ��������б��������г��˴��ڵ�����Ҫ���н��ʻָ����ļ���������ʾ������Ϣ��
ʹ���ݿⱣ���ڴ�״̬
�����ݿ������������ʧ�����ݿ��ʧ�ܣ�
1.�κο����ļ�
2.����ϵͳ���ռ��ԭ���ռ�������ļ�
3.����������־�飨ֻҪ����������һ����Ա���ã�ʵ���ͻᱣ�ִ�״̬����
ʹ���ݿⱣ���ڴ�״̬
�����ݿ�����½��ʹ��Ͽ��ܻᵼ��ʵ��ʧ�ܣ���ʧ�˿����ļ�����ʧ������������־�飬���߶�ʧ������SYSTEM��UNDO���ռ�������ļ�����ʹ�Ƕ�ʧ��һ���ǻ��������־�飬���ݿ�Ҳ����Ϊ��־�л�������ʧ�ܡ�
����������£�ʧ�ܵ�ʵ����û����ȫ�رգ����Dz��ܼ��������������ڹر������ݿ������´���Щ���͵Ľ��ʹ��Ͻ��лָ�����ˣ�����Ա������ִ��SHUTDOWN
ABORT���Ȼ����ܿ�ʼ�ָ�������
��ʧ�������������ռ�������ļ����ᵼ��ʵ��ʧ�ܣ����ҿ��������ݿ�ڴ�״̬ʱ�ָ����ݿ⣬��ʱ�������ռ��еĹ������Լ������С�
ͨ�����Ԥ����־�ļ���ʹ�����ݻָ�ָ�����ɼ���Щ����
Data Recovery Advisor�����ݻָ�ָ����
1.���ټ�⡢������������
2.ͣ��������ʱ�Ĺ���
3.�����û��ĸ��Ž������
4.�û����棺
�C Enterprise ManagerGUI�����·����
�C RMAN ������
5.֧�ֵ����ݿ����ã�
�C ��ʵ��
�C ��RAC
�C ֧�ֹ���ת�Ƶ��������ݿ⣬����֧�ַ��������������ݿ�
Data Recovery Advisor�����ݻָ�ָ����
�ڷ�������ʱ�����ݻָ�ָ�����Զ��ռ����ݹ�����Ϣ�����⣬�����������������ϡ�������ģʽ�£����п��������ݿ���̷�����ָ������֮ǰ�ͼ��ͷ������ݹ��ϡ�����ע�⣬��ʼ������Ϊ����֮�£���
���ݹ��Ͽ��ܻ�����ء����磬�����ǰ��־�ļ���ʧ�����ܴ����ݿ⡣��Щ���ݹ��ϣ��������ļ��еĿ��������������Եģ���Ϊ���Dz��ᵼ�����ݿ������Oracle
���ݿ�����
���ݻָ�ָ���ɴ����������������һ�������������ݿ��ļ�ȱʧ����һ�»������������ݿ⣬��һ����������ʱ�����ļ���
����������ݹ��ϵ���ѡ����������ʾ��
1. �������Data Guard �����У������ת�Ƶ��������ݿ⡣��ʹ�û����Ծ���ػָ�������
2. �������ݹ��ϵ���Ҫԭ�����˵��ǣ��ⲻ����û����Ӱ�죩��
�û�����
�ɴ�Enterprise Manager (EM) Database Control ��Grid Control
ʹ�����ݻָ�ָ�������ֹ���ʱ����ʹ�ö��ַ����������ݻָ�ָ��������ʾ�����Ǵӡ�Database Instance�����ݿ�ʵ��������ҳ��ʼ�ģ�
1.��Availability�������ԣ���ѡ�ҳ> Perform
Recover��ִ�лָ���> Advise and Recover������ͻָ���
2.������Active Incidents��������¼��������ӷ��ʡ�Support
Workbench��֧�ֹ���̨�����ϵġ�Problems�����⣩��ҳ����Checker Findings����������ҽ������ѡ��
��ҳ> Launch Recovery Advisor�������ָ�ָ����
3.��λ����Database Instance Health�����ݿ�ʵ������״��������Ȼ����Incidents�������¼����������е��ض����ӣ���ORA
1578�������ʡ�Support Workbench
��֧�ֹ���̨�����ġ�Problems Detail��������ϸ���ϣ���ҳ��Ȼ����Data Recovery
Advisor�����ݻָ�ָ������
4.Database Instance Health�����ݿ�ʵ������״����>��Related
Links��������ӣ������֣�Support Workbench��֧�ֹ���̨��>��Checker
Findings����������ҽ������ѡ�ҳ��Launch Recovery Advisor�������ָ�ָ����
5.Related Link��������ӣ���Advisor Central��ָ�����ģ�>��Advisors��ָ������ѡ�ҳ��Data
Recovery Advisor�����ݻָ�ָ����
6.Related Link��������ӣ���Advisor Central��ָ�����ģ�>��Checkers�����������ѡ�ҳ��Details����ϸ���ϣ�>��Run
Detail��������ϸ���ϣ���ѡ�ҳ��Launch Recovery Advisor�������ָ�ָ����
Ҳ����ͨ��RMAN ������ʹ�����ݻָ�ָ����
rman target /
rman> list failure all; |
֧�ֵ����ݿ�����
�ڵ�ǰ�汾�У����ݻָ�ָ��֧�ֵ�ʵ�����ݿ⣬��֧��Oracle Real Application Cluster���ݿ⡣
���ݻָ�ָ������ʹ�ôӱ������ݿ�Ͷ����Ŀ���ļ��������ݿ��еĹ��ϡ����⣬���ݻָ�ָ��Ҳ����������Ϻ����������ݿ��еĹ��ϡ����ǣ����ݻָ�ָ��ȷʵ֧�ֹ���ת�Ƶ��������ݿ⣨��Ϊ��������������������
��ʧ�˿����ļ�
��ʧ�����ļ����Իָ��ο���http://blog.csdn.net/rlhua/article/details/12625067
��������ļ���ʧ������ʵ��ͨ������ֹ��
1.��������ļ��洢��ASM �������У���ָ��������£�
�C ʹ��Enterprise Manager ִ��ָ��ʽ�ָ���
�C �����ݿ�����NOMOUNTģʽ��Ȼ��ʹ��RMAN ��������п����ļ��ָ������ļ���
2.��������ļ��洢Ϊ�����ļ�ϵͳ�ļ�����
�C �ر����ݿ⡣
�C �������еĿ����ļ��������ʧ�Ŀ����ļ���
�ɹ��ָ������ļ������ݿ⡣
RMAN> restore controlfile from '+DATA/orcl/controlfile/current.260.695209463'; |
��ʧ�˿����ļ�
��ʧ�˿����ļ���ѡ�Ļָ�����ȡ���ڿ����ļ��Ĵ洢�����Լ������ٻ���һ�������ļ����Ƕ�ʧ�������ļ���
���ʹ��ASM �洢���������ٻ���һ�������ļ�����������ʹ��Enterprise Manager ִ��ָ��ʽ�ָ�������ʹ��RMAN
ִ���ֶ��ָ���������ʾ��
1. �����ݿ�����NOMOUNTģʽ��
2. ���ӵ�RMAN ������restore controlfile�����������еĿ����ļ��ָ������ļ������磺restore
controlfile from '+DATA/orcl/controlfile/current.260.695209463';
3. �ɹ��ָ������ļ������ݿ⡣
��������ļ��洢Ϊ�����ļ�ϵͳ�ļ��������ٻ���һ�������ļ������������������ݿ�ڹر�״̬ʱ��ֻ�轫ʣ��Ŀ����ļ��е�һ�����Ƶ���ʧ�ļ���λ�á�������ʹ��������ڴ����������������ȱʧ����ɵģ���ʣ��Ŀ����ļ��е�һ�����Ƶ�����ij��λ�ã�Ȼ��ͨ������ʵ���IJ����ļ���ָ����λ�á����ߣ��ɴӳ�ʼ�������ļ���ɾ���Զ�ʧ�Ŀ����ļ������á���ע�⣺Oracle
����ʼ�����ٱ������������ļ���
��ʧ��������־�ļ�
�����ʧ��������־�ļ����е�ij����Ա�������������ٻ���һ����Ա��ע���������£�
1.����Ӱ��ʵ��������������
2.Ԥ����־�л��յ�һ����Ϣ��֪ͨ���ҵ�ij����Ա��
3.����ͨ��ɾ����ʧ��������־��Ա�������³�Ա���ָ���ʧ����־�ļ���
4.���������ʧ��־�ļ������ѹ鵵�����������־�������´�����ʧ���ļ���
��ʧ��������־�ļ�
�����ʧ�˵���������־���Ա�����ڽ��лָ�ʱ����Ӱ���������е�ʵ����
Ҫִ�����ָֻ�����ִ�����²�����
1. ͨ�����Ԥ����־��ȷ���Ƿ���ȱʧ����־�ļ���
2. �ָ���ʧ���ļ�ʱ������ɾ����ʧ��������־��Ա��
SQL> ALTER DATABASE DROP LOGFILE MEMBER '+DATA/orcl/onlinelog/group_1.261.691672257'; |
Ȼ�������³�Ա�������ʧ�ĺ�ɫ��־��Ա��
SQL> ALTER DATABASE ADD LOGFILE MEMBER '+DATA'TO GROUP 2; |
Ҳ��ʹ��Enterprise Manager ��ɾ�������´�����־�ļ���Ա��
ע�����������־�ļ�ʹ����OMF������ʹ�����������µ�������־��Ա���ӵ��������У����µ�������־��Ա�ļ�������OMF
�ļ��������ȷ���µ�������־��Ա�ļ���OMF �ļ��������Ļָ������Ǵ���һ���µ�������־�飬Ȼ��ɾ��������ʧ��������־��Ա��������־�顣
3. ������ʹ��������ڴ����������������ȱʧ����ɵģ���������ȱʧ�ļ���
4. ���������־���ѹ鵵�����ߴ���NOARCHIVELOGģʽ�£����ѡ���������־������´���ȱʧ�ļ���������⡣ѡ����Ӧ���飬Ȼ��ѡ��Clear
Logfile�������־�ļ�����������������ʹ�����������ֶ������Ӱ����飺
SQL> ALTER DATABASE CLEAR LOGFILE GROUP #; |
ע��Database Control �����������δ�鵵����־�顣���������ƻ�������Ϣ��������������δ�鵵����־�飬��Ӧ�������������ݿ�ִ����ȫ���ݡ������ڷ����������ϵ�����£��ᵼ�����ݶ�ʧ��Ҫ���δ�鵵����־�飬��ʹ���������
SQL> ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP #; |
��NOARCHIVELOGģʽ�¶�ʧ�������ļ�
���ݿ��NOARCHIVELOGģʽʱ�������ʧ���κ������ļ�����ִ����������
1. ���ʵ����δ�رգ���ر�ʵ����
2. �ӱ��ݻ�ԭ�������ݿ⣬�������������ļ��Ϳ����ļ���
3. �����ݿ⡣
4. ���û������������ϴα����������������и��ġ�
��NOARCHIVELOGģʽ�¶�ʧ�������ļ�
�����NOARCHIVELOGģʽ�¶�ʧ�����ݿ��е��κ������ļ�������Ҫ��ȫ��ԭ���ݿ⣬���������ļ������������ļ���
�����ݿ��NOARCHIVELOGģʽʱ��ֻ�ָܻ�����һ�α���ʱ��״̬����ˣ��û�����������������һ�α����������������и��ġ�
Ҫִ���������͵Ļָ�����ִ�����²�����
1. ���ʵ����δ�رգ���ر�ʵ����
2. �ڡ�Maintenance��ά����������ҳ�ϵ�����Perform Recovery��ִ�лָ�������
3. ѡ��Whole Database���������ݿ⣩����Ϊ�ָ����͡�
�������NOARCHIVELOGģʽ�����ݿ�����������ݲ��ԣ���RMAN
���Ȼ�ԭ�����0 �����ݣ�Ȼ��RMAN �ָ�������Ӧ���������ݡ�
��ARCHIVELOGģʽ�¶�ʧ�˷ǹؼ������ļ�
���ij�������ļ���ʧ�����Ҹ��ļ�������SYSTEM��UNDO���ռ䣬��ֻ��ԭ���ָ�ȱʧ�������ļ���
��ARCHIVELOGģʽ�¶�ʧ�˷ǹؼ������ļ�
���ݿ��ARCHIVELOGģʽʱ�������ʧ���κβ�����SYSTEM��UNDO���ռ�������ļ�����ֻ��Ӱ��ȱʧ�ļ��еĶ����û��Կ�ʹ�����ݿ�����ಿ�ּ���������Ҫ��ԭ���ָ�ȱʧ�������ļ�����ִ�����²�����
1. �ڡ�Maintenance��ά����������ҳ�ϵ�����Perform Recovery��ִ�лָ�������
2. ѡ��Datafiles�������ļ�������Ϊ�ָ����ͣ�Ȼ��ѡ��Restore to current
time����ԭ����ǰʱ�䣩����
3. ����������Ҫ�ָ��������ļ���
4. ȷ���ǽ��ļ���ԭ��Ĭ��λ�û�����λ�ã�������̻������ȱʧ����
5. �ύRMAN ��ҵ����ԭ���ָ�ȱʧ���ļ���
�������ݿ��ARCHIVELOGģʽ����˿ɻָ�������ύ��ʱ�䣬�����û�����Ҫ���������κ����ݡ�
ʹ�ýű���
contents of repair script:
# restore and recover datafile
sql 'alter database datafile 10 offline';
restore datafile 10;
recover datafile 10;
sql 'alter database datafile 10 online'; |
��ARCHIVELOGģʽ�¶�ʧ��ϵͳ�ؼ������ļ�
���ij�������ļ���ʧ�����Ҹ��ļ�����SYSTEM��UNDO���ռ䣬��ִ����������
1. ʵ�����ܻ�Ҳ���ܲ����Զ��رա����δ�Զ��رգ���ʹ��SHUTDOWN ABORT�ر�ʵ����
2. װ�����ݿ⡣
3. ��ԭ���ָ�ȱʧ�������ļ���
4. �����ݿ⡣
��ARCHIVELOGģʽ�¶�ʧ��ϵͳ�ؼ������ļ�
����SYSTEM���ռ�����UNDO���ݵ������ļ�����Ϊ��ϵͳ�ؼ������ļ��������ʧ������һ���ļ�������Ҫ��MOUNT״̬��ԭ���ݿ⣨��ͬ�������ݿ�ڴ�״̬ʱ��ԭ���������ļ�����
Ҫִ�����ָֻ�����ִ�����²�����
1. ���ʵ����δ�رգ���ر�ʵ����
2. װ�����ݿ⡣
3. �ڡ�Maintenance��ά����������ҳ�ϵ�����Perform Recovery��ִ�лָ�������
4. ѡ��Datafiles�������ļ�������Ϊ�ָ����ͣ�Ȼ��ѡ��Restore to current
time����ԭ����ǰʱ�䣩����
5. ����������Ҫ�ָ��������ļ���
6. ȷ���ǽ��ļ���ԭ��Ĭ��λ�û�����λ�ã�������̻������ȱʧ����
7. �ύRMAN ��ҵ����ԭ���ָ�ȱʧ���ļ���
8. �����ݿ⡣��Ϊ��ָ�����һ���ύʱ�������û����������������ݡ�
���ݹ��ϣ�ʾ��
1.��������ʣ�ȱ�ٲ���ϵͳ����������ļ�������Ȩ����ȷ�����ռ��ѻ�
2.��������У��ʹ���ͷ�ֶ�ֵ��Ч
3.����Ŀ¼��һ�£���Ƭ�Ρ�������Ŀ����������
4.��һ�£������ļ����ڻ����������ļ�������������־
5.I/O ���ϣ��������ļ������ơ�ͨ�������ʡ������I/O ����
���ݻָ�ָ�����Է������ϣ�����Բ��������������б��ṩ���������顣
���ݻָ�ָ��
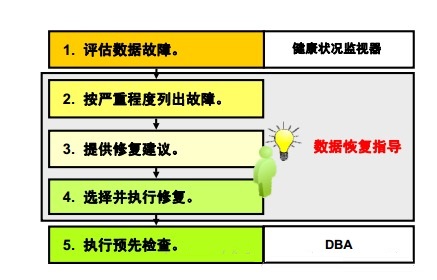
Oracle Database 11g�е��Զ���Ϲ�������Ϊ��ִ�й��������衣�������ݻָ�ָ����ֻ����������������ɡ�
1. ����״���������Զ�ִ�м�鲢�ԡ�������������ʽ�����ϼ���֢״��¼���Զ�������ϵ�����(ADR)
�С�
2. ���ݻָ�ָ��������������Ϻϲ���һ�𣬲����������س̶ȣ����ػ�ߣ��г���ǰִ�е����������
3. �����ṩ�йع��ϵ�������ʱ�����ݻָ�ָ���Ὣ���϶�Ӧ���Զ����ֶ��������������������ԣ�Ȼ���ṩ�����顣
4. �����ֶ�ִ������Ҳ���������ݻָ�ָ��ִ������
5. ���˽���״�����������Զ���飨�����ǡ�����ʽ����飩�Լ����ݻָ�ָ��֮�⣬Oracle ������ʹ��VALIDATE����ִ�С�Ԥ�ȡ���顣
�������ݹ���
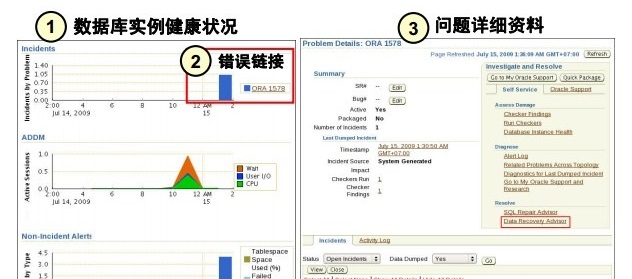
ʾ����ʾ�˶��ֿ��ܷ�ʽ�е�һ�֣��������˽��뽡��״�������������ݻָ�ָ���Ľ��������
���ݹ���
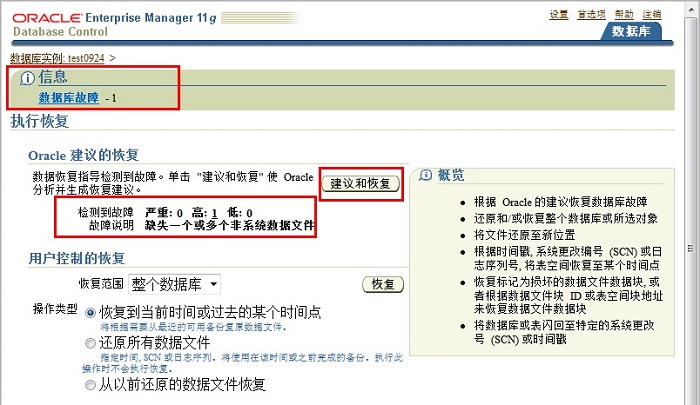
��ͨ�������������ݹ��ϣ�������������ݿ�����������״������Ϲ��̡�ÿ����鶼�����һ���������ϣ�Ȼ����ӳ�䵽����
�������DZ�����飬Ҳ������Ԥ�ȼ�顣���ݿ��з�������ʱ��ϵͳ���Զ�ִ�б���ʽ��顣���⣬Ҳ��������Ԥ�ȼ�飨���磬ִ��VALIDATE
DATABASE�����
��Enterprise Manager �У�ѡ��Availability > Perform
Recovery��������> ִ�лָ����������������ݿ�ڡ��رա�����װ�ء�״̬ʱ������Perform
Recovery��ִ�лָ�������ť��������Advise and Recover������ͻָ�������Enterprise
Manager ���������ɻָ����顣
�г����ݹ���
�ˡ�View and Manage Failures���鿴�������ϣ���ҳ�����ݻָ�ָ������ҳ����Ļ�����е�ʾ����ʾ�����ݻָ�ָ������г����ݹ��Ϻ���ϸ���ϡ��������������Ļ������������顢�������ȼ��Լ��رչ��ϡ�
RMAN ��������LIST FAILUREҲ������ʾ���ݹ��Ϻ���ϸ���ϡ��˴�������������������ADR
��ִ�кʹ洢��һ������
���ϰ��������ȼ�����˳���г���CRITICAL��HIGH��LOW�����ȼ���ͬ�Ĺ��Ͻ���ʱ����������г���
�ṩ������
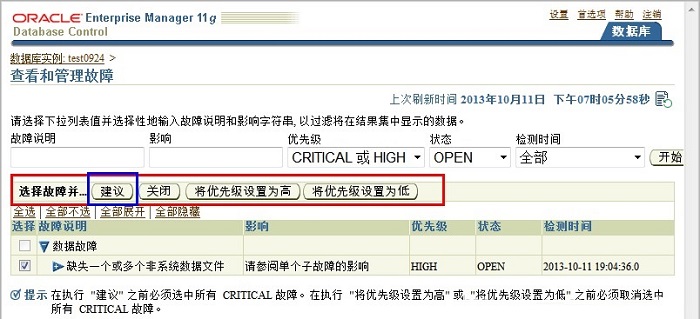
�ڡ�View and Manage Failures���鿴�������ϣ���ҳ�ϵ�����Advise�����飩����ť�����ݻָ�ָ��������һ���ֶ��˶��嵥������ʾ�������͵Ĺ��ϡ�
1.��Ҫ�˹���Ԥ�Ĺ��ϣ����磬δ������̵��µ����ӹ��ϡ�
2.��ͨ��������ǰ�Ĵ�������������Ĺ��ϣ����磬���������������������ļ�������ӱ�������RMAN
��ԭ��ȣ������ļ�����������ǰ�����ƿ��Ը���ؽ�������
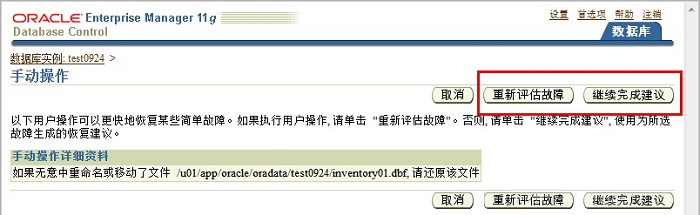
���������²�����
3.��ִ���ֶ���������Re-assess Failures�������������ϣ������ѽ���Ĺ��Ͻ���ʽ�رգ���View
and Manage Failures���鿴�������ϣ���ҳ�ϻ���ʾ����ʣ����ϡ�
4.������Continue with Advise������ʹ�ý��飩�������Զ��������ݻָ�ָ�������Զ�������ʱ��������һ���ű���������ʾRMAN
�ƻ����ù��ϵķ��������Ҫִ���Զ���������Continue�����������������ϣ�����ݻָ�ָ���Զ������ϣ�����ԴӴ˽ű���ʼ�����ֶ�����
ִ����
��ҳ���������ɽ��������rman�ű�
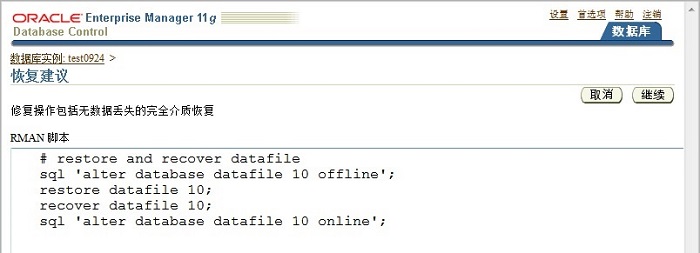
# restore and recover datafile
sql 'alter database datafile 10 offline';
restore datafile 10;
recover datafile 10;
sql 'alter database datafile 10 online'; |
�ύ�ָ���ҵ�������Զ�ִ�С�
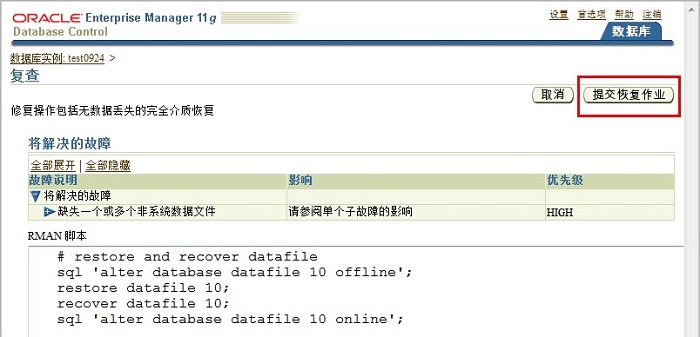
�鿴���е���ҵ
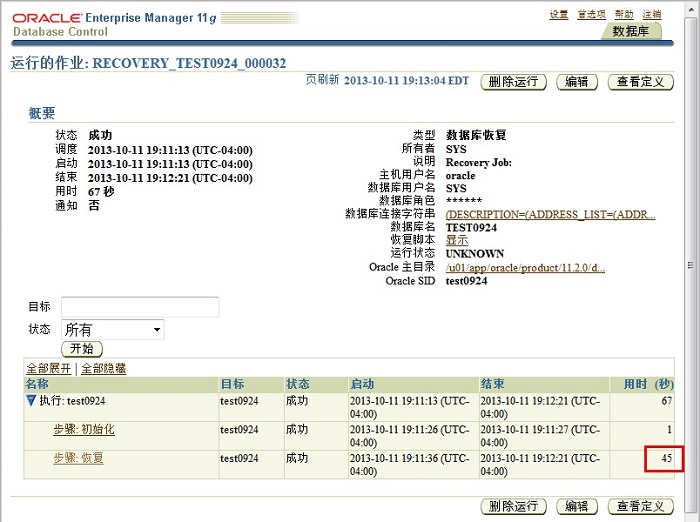
���ݻָ�ָ������ʾ��Щҳ�档�ڸ�ʾ���У�45��ͳɹ������������
���ݻָ�ָ����ͼ
��ѯ��̬�����ֵ���ͼ
1.V$IR_FAILURE���г����й��ϣ����а����ѹرյĹ��ϣ�LIST
FAILURE����Ľ����
2.V$IR_MANUAL_CHECKLIST���г��ֶ����飨ADVISE
FAILURE����Ľ����
3.V$IR_REPAIR���г�����ADVISE FAILURE����Ľ����
4.V$IR_FAILURE_SET���������ù��Ϻͽ����ʶ��
�÷�ʾ��
������Ҫ��ʾ��2007 ��6 ��21 �ռ������й��ϡ�
SELECT * FROM v$ir_failure WHERE trunc (time_detected) = '21-JUN-2007'; |
|


