ժҪ������������־����Ͳ�������ȫ�������ݿ⡱Jay
Kreps˵����Jay Kreps��LinkedIn��˾��ϯ����ʦ�����Ľ��������˶�����־���ĵ���ᣬ������־��ʲô����������ݼ��ɡ�ʵʱ������ϵͳ������ʹ����־�ȡ�
���߰��� Jay Kreps������LinkedIn����ϯ����ʦ������ʾ��־�����ڼ����������ʱ��ʹ��ڣ����˿����ڷֲ�ʽ������߳���ֲ�ʽ����ģ���ڲ�֮�⣬���й㷺����;������������������־��ԭ����ͨ������־��������������ʵ�����ݼ��ɡ�ʵʱ���ݴ����Լ��ֲ�ʽϵͳ��ơ��������ݷdz��ɻ���ֵ��ѧϰ��
��������ǰ��һ�������˷ܵ�ʱ�̼��뵽LinkedIn��˾�����Ǹ�ʱ��ʼ���Ǿ��ƽⵥһ�ġ�����ʽ���ݿ�����ƣ���������������ķֲ�ʽϵͳ����ת��������һ�������˷ܵ����飺���ǹ��������𣬶���ֱ��������Ȼ�����еķֲ�ʽͼ�����ݿ⡢�ֲ�ʽ������ˡ�Hadoop��װ�Լ���һ���͵ڶ�����ֵ���ݴ洢��
����һ����������ᵽ������������������ǹ��������ණ���ĺ����ﶼ����һ���������־����ʱ��Ҳ����Ԥ��д����־�����ύ��־����������־����־�����ڼ����������ʱ��ʹ��ڣ�ͬʱ����������ֲ�ʽ����ϵͳ��ʵʱӦ�ýṹ�ĺ��ġ�
��������־����Ͳ�������ȫ�������ݿ⣬NoSQL�洢����ֵ�洢�����ƣ�paxos,Hadoop,�汾�����Լ��������е�����ϵͳ��Ȼ���������������ʦ�����Dz��Ǻ���Ϥ����Ը��ı�������״������ƪ����������ҽ��������������˽���й���־�����еĶ�����������־��ʲô����������ݼ��ɡ�ʵʱ������ϵͳ������ʹ����־�ȡ�
��һ���֣���־��ʲô��

��־��һ�ּIJ����ټĴ洢��������һ��ֻ�����ӵģ���ȫ����ʱ�������һϵ�м�¼����־���������£�
���ǿ��Ը���־��ĩβ���Ӽ�¼�����ҿ��Դ����Ҷ�ȡ��־��¼��ÿһ����¼��ָ����һ��Ψһ����һ��˳�����־��¼��š�
��־��¼���������ɡ�ʱ�䡱��ȷ���ģ�������Ϊλ����ߵ���־��¼��λ���ұߵ�Ҫ��Щ����־��¼��ſ��Կ�����������־
��¼�ġ�ʱ���������һ��ʼ�Ͱ���������˵���ǰ�ʱ�������Ե��е���� ������ �����κ�һ�����������ʱ����ȣ�ʱ��
�����Ƿdz�����ʹ�õ����ԡ����������ж���ֲ�ʽϵͳ��ʱ��������Ծ��Ե÷dz���Ҫ��
������ƪ���۵�Ŀ����ԣ���־��¼�����ݺ�ʽ����ô��Ҫ����������һ�£�����ȫ�ľ��洢�ռ������£����Dz�����
�ٸ���־���Ӽ�¼���Ժ����ǽ����ᵽ������⡣
��־��������ȫ��ͬ���ļ��������ݱ��ġ��ļ�����һϵ���ֽ���ɣ�������һϵ�м�¼��ɣ�����־ʵ����ֻ�ǰ���ʱ��˳��洢��¼��
һ�����ݱ������ļ���
��ʱ����������ΪʲôҪ������ô�������أ� ��ͬ�����µ�һ��ֻ�����ӵ���һ��˳�����־��¼������������ϵͳ�����������أ�������־�����ض���Ӧ��Ŀ�꣺����¼��ʲôʱ�䷢����ʲô���顣
���Էֲ�ʽ����ϵͳ�������ԣ� �����������������ġ�
�����������ǽ��и������������֮ǰ�������ȳ�����Щ���˻����ĸ��ÿ�������Ա����Ϥ��һ����־��¼-Ӧ��ʹ��syslog����log4j����д�뵽�����ļ����û�нṹ�Ĵ�����Ϣ��������Ϣ��Ϊ�����ֿ��������ǰ��������ε���־��¼��Ϊ��Ӧ����־��¼����Ӧ����־��¼�����������˵����־��һ�ֵͼ��ı��֡����������ǣ��ı���־��ζ����Ҫ�������������Ķ���������˵���ġ���־�����ߡ�������־���Ľ����Ƿ��������ʡ�
��ʵ���ϣ������������������˼������ô���Ƕ�ȡij�������ϵ���־����������Щ��˳Ӧʱ�����������漰���������ͷ�������ʱ�����ַ����ܿ�ͱ��һ�����ڹ����ķ�ʽ������Ϊ����ʶ�����������Ϊ����־��Ŀ��ܿ�ͱ�ɲ�ѯ��ͼ�λ���Щ��Ϊ��������-�Զ��������ijЩ��Ϊ���ԣ��ļ����Ӣ����ʽ���ı�ͬ��������������ֽṹ������־��ȼ����Ͳ��ʺ��ˡ���
���ݿ���־
�Ҳ�֪����־������Դ�ںδ�-�������������������һ������������Ϊ��̫�����ܵ���һ�����������IBM��ϵͳR����ʱ��ͳ����ˡ����ݿ�����÷����ڱ�����ʱ��������ͬ���������ݽṹ��������Ϊ�˱�֤������ԭ���Ժͳ־��ԣ��ڶ����ݿ�ά�������и������ݽṹ������֮ǰ�����ݿ�Ѽ����ĵ���Ϣ��д����־���־��¼�˷�����ʲô���������е�ÿ����������������һЩ���ݽṹ������������ʷӳ�䡣������־�Ǽ������û��ģ�������������������ʱ�����ָ��������������Խṹ�Ŀ���������Դ��
����ʱ������ƣ���־����;��ʵ��ACIDϸ�ڳɳ�Ϊ���ݿ�临�����ݵ�һ�ַ�����������־�Ľ�����Ƿ��������ݿ��ϵĸ���˳����Զ�˸������ݿ��ϵĸ���˳����Ҫ������ȫͬ����
Oracle,MySQL ��PostgreSQL���������ڸ����õĸ������ݿ����־����־����Э�顣Oracle������־��Ʒ��Ϊһ��ͨ�õ����ݶ��Ļ��ƣ�������Oracle���ݶ����û��Ϳ���ʹ��XStreams��GoldenGate���������ˣ�MySQL��PostgreSQL�ϵ����Ƶ�ʵ�����Ϊ�������ݽṹ�Ĺؼ������
����������������Դ��������ʶ�����־�ĸ���ֶ������������ݿ��ڲ�����־�������ݶ��ĵĻ����ƺ���żȻ���ֵģ�����Ҫ������
��������֧���������͵���Ϣ���䡢��������ʵʱ���ݴ����Dz���ʵ�ʵġ�
�ֲ�ʽϵͳ��־
��־������������⣺���Ķ�������������ݵķַ��������������ڷֲ�ʽ����ϵͳ���Ե���Ϊ��Ҫ��Э�̳�һ�µĸ��Ķ�����˳����˵���ָ�����ϵͳ�����������������Խ��д��ڸ����õ����ݿ������Ƿֲ�ʽϵͳ��Ƶĺ�������֮һ��
����־Ϊ����ʵ�ֲַ�ʽϵͳ���ܵ���һ���ľ��鳣ʶ���������Ұ�������鳣ʶ��Ϊ״̬������ԭ�������������ͬ�ġ�ȷ���ԵĽ��̴�ͬһ״̬��ʼ����������ͬ��˳������ͬ�����룬��ô���������̽���������ͬ����������ҽ�������ͬ��״̬��
��Ҳ���е��������⣬�����Ǹ��������̽�֣�Ū�������������塣
ȷ������ζ�Ŵ�����������ʱ���صģ������κ��������ⲿ�ġ����벻��Ӱ�쵽������������磬���һ�������������ܵ��߳�ִ�еľ���˳��Ӱ�죬�����ܵ�gettimeofday���á���������һЩ���ظ����¼���Ӱ�죬��ô�����ij���һ�����п��ܱ���Ϊ�Ƿ�ȷ���Եġ�
����״̬�ǽ��̱����ڻ����ϵ��κ����ݣ��ڽ��̴���������ʱ����Щ����Ҫô�������ڴ��Ҫô�����ڴ����ϡ�
����ͬ��˳������ͬ����ĵط�Ӧ������ע��-�����������־�ĵط��������һ����Ҫ�ij�ʶ�����������ȷ���Դ�����ͬ����־���룬��ô���Ǿͻ�������ͬ�������
�ֲ�ʽ�����ⷽ���Ӧ�þ������ԡ�������ö�̨����һ��ִ��ͬһ���������������Ϊʵ�ֲַ�ʽһ������־Ϊ��Щ������������⡣�����־��Ŀ���ǰ����з�ȷ���ԵĶ����ų���������֮�⣬��ȷ��ÿ�����ƽ����ܹ�ͬ���ش������롣
��������������Ժ�״̬������ԭ���Ͳ��ٸ��ӻ���˵��������ˣ�������ٵ���ζ�š�ȷ���ԵĴ������̾���ȷ���Եġ��������������Ҷ���Ϊ���Ƿֲ�ʽϵͳ�����ϳ��õĹ���֮һ��
���ַ�ʽ��һ������֮��������������־��ʱ�������ʱ��״̬��һ�����������������һ����������������ÿһ������������Ǿ�����������־��ʱ�����ʱ�������־һһ��Ӧ������������״̬��
����д����־�����ݵIJ�ͬ��Ҳ����������ϵͳ��Ӧ�����ԭ��IJ�ͬ��ʽ���ٸ����ӣ����Ǽ�¼һ������������߷����������Ӧ��״̬�仯��������ִ�������ת������������˵��������������Ϊÿһ��������¼һϵ��Ҫִ�еĻ���ָ����ߵ��õķ������Ͳ�����ֻҪ������������ͬ�ķ�ʽ������Щ���룬��Щ���̾ͻᱣ�ָ�����һ���ԡ�
һǧ����������һǧ����־���÷������ݿ����ͨ������������־������־��������־���Ǽ�¼ÿһ�б��ı�����ݡ�����־��¼�IJ��Ǹı���ж�����Щ�����е����ݱ��ı��SQL��䣨insert��update��delete��䣩��
�ֲ�ʽϵͳͨ�����Կ�����Ϊ���ַ������������ݺ������Ӧ����״̬����ģ�͡�ͨ������һ������-������ģ�͡���Ҳ��������Ϊ֮��¼�������Ӧ�Ķ��Դ˽���һ��ϸ�ĸ��ģ���֮Ϊ��Ԥ����ģ�͡�������ѡ��һ��������Ϊleader�������������������ʱ�������д������Ӵ��������������¼��״̬�ı����־�������ĸ�������leader״̬�ı��˳���Ӧ����Щ�ı䣬��������֮��ﵽͬ�������ܹ���leaderʧ�ܵ�ʱ�����leader�Ĺ�����
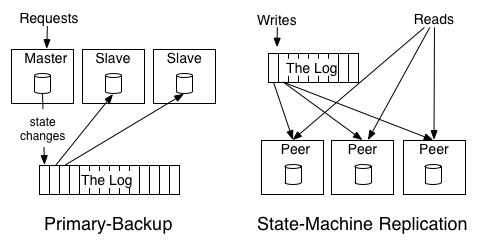
Ϊ���������ַ�ʽ�IJ�ͬ����������һ����̫�Ͻ������ӡ��ٶ���һ���㷨����ĸ���������һ��������������Ϊ����״̬����ʼֵΪ0�����������ֵ���мӷ��ͳ˷����㡣����-������ʽӦ�û���������еı任�����硰+1������*2���ȡ�ÿһ����������Ӧ����Щ�任���Ӷ��õ�ͬ���Ľ⼯������-������ʽ������һ������������ִ����Щ�任����������־�����硰1������3������6���ȡ��������Ҳ�����չʾ��Ϊʲô˵˳���DZ�֤��������һ���ԵĹؼ���һ�μӷ��ͳ˷���˳��ĸı佫�ᵼ�²�ͬ�Ľ����

�ֲ�ʽ��־��������Ϊһ��������ģ�͵����ݽṹ����Ϊ��־�����˺�����ֵ��һϵ�о��ߡ�����Ҫ��������Paxos�㷨�أ�������־ģ�������������Ӧ�á�
��Paxos�㷨�У���ͨ��ͨ��ʹ�ó�֮Ϊ��paxos��Э�飬����Э�齫��־��ģΪһϵ�е����⣬����־��ÿ�����ⶼ�ж�Ӧ�IJ��֡���ZAB��
RAFT��������Э���У���־��������Ϊͻ������ֱ�Ӷ�ά���ֲ�ʽ�ġ�һ���Ե���־�����⽨ģ��
�һ��ɵ��ǣ����Ǿ���ʷ��չ�Ĺ۵�����ƫ��ģ����������ڹ�ȥ�ļ�ʮ���У��ֲ�ʽ���������Զ��������ʵ��Ӧ�á�����ʵ�У���ʶ���������е�̫���ˡ������ϵͳ������Ҫ��������ֵ�����Ǽ������Ǵ��������е����������ļ�¼��������һ���ĵ�ֵ�Ĵ�������Ȼ�Ǹ��ӳ���
���⣬רע���㷨�ڸ��� ����ϵͳ��Ҫ�ĵײ����־���һ��ɣ��������ջ����־�и�ע����Ϊһ����Ʒ���Ļ�ʯ���������Ƿ���ͬ���ķ�ʽ
ʵʩ�ģ����Ǿ���̸��һ����ϣ�������Ǿ������� �õ��Dz��Ǿ���ij��ϸ�ڵĹ�ϣ�����������Ի��ߴ���ʲôʲô���������ϣ������־����Ϊһ�ִ��ڻ��Ľӿڣ�Ϊ������㷨����ʵ�������ṩ��õı�֤����ѵ����ܡ�
�����־101�� �����¼��Ķ����ԡ�
�����Ǽ��������ݿ⡣���ݿ��д����Ŵ��������־�ͱ�֮��Ķ����ԡ���Щ��־�е����ƽ���嵥�����е����̣����ݿ�����ǵ�ǰ��ӯ�����������д����ı����־����Ϳ���ʹ����Щ������Դ�������ǰ״̬�ı������ű�����¼ÿ���ؼ��㣨��־��һ���ر��ʱ��㣩��״̬��Ϣ�������Ϊʲô��־�Ƿdz����������ݽṹ���������ڣ���־������������������Ҳ������������������������ͬʱ��ζ�ſ��Դ洢�ǹ�ϵ�͵Ķ���

�������Ҳ�ǿ���ģ���������ڶ�һ�ű����и��£�����Լ�¼��Щ������������и��µ���־����������״̬��Ϣ�С���Щ�����־����������Ҫ��֧��ʵʱ�Ŀ�¡�����ڴˣ���Ϳ����������������¼��Ķ����ԣ�
��֧���˾�̬���ݶ���־����������־���������������DZ����������¼���������������˱������հ汾�����ݣ�������¼���������ڹ��������汾����Ϣ����־ʵ�����DZ���ʷ״̬��һϵ�б��ݡ�
����ܻ��������Դ����İ汾������Դ������������ݿ�֮�������й�ϵ���汾���������һ����ҷdz���Ϥ�����⣬�Ǿ���ʲô�Ƿֲ�ʽ����ϵͳ��Ҫ����ġ�
ʱʱ�̿��ڱ仯�ŵķֲ�ʽ�������汾����ϵͳͨ���Բ����ķ���Ϊ��������ʵ���Ͽ�����һ����־��������ֱ�ӶԵ�ǰ
�����ڱ��еĴ������������ա����������ע��� �������ֲ�ʽ״̬��ϵͳ���ƣ��汾����ϵͳ �������ʱ�Ḵ����־����ϣ����ֻ�Ǹ��²�����������Ӧ�õ���ĵ�ǰ�����С�
�������Щ�˴�Datomic �Cһ��������־���ݿ�Ĺ�˾�õ���һЩ�뷨����Щ�뷨ʹ���Ƕ���� �����ǵ�ϵͳӦ����Щ�뷨���˿�������ʶ��
��Ȼ��Щ�뷨����ֻ������ϵͳ�����ǻ��Ϊ ʮ����ֲ�ʽϵͳ�����ݿ�����һ���֡�
������ƺ��е�������뻯�����Dz�Ҫ���ۣ����ǻ�ܿ����ʵ�֡�
�ԡ� �Ƽ�������� �ƶ��ǻ��й� ��Ϊ����� �������й��Ƽ����� ����5��20-23���ڱ������һ�������¡�ؾٰ졣��ҵ�۲졢������ѵ��������̳����ҵ���֣����ݷḻ���ɻ�ʮ�㡣Ʊ���Żݣ�����
���� ��
���������Ƚ��� һ�¡����ݼ��ɡ���ʲô��˼������Ϊʲô�Ҿ���������Ҫ��֮��������������������־��ʲô��ϵ��
���ݼ��ɾ��ǽ�������֯������ʹ���������йصķ����ϵͳ�п��Է������ǡ������ݼ��ɡ���data
integration���������Ӧ�ò�ֹ��ô���������Ҳ���һ�����õĽ��͡��������������� ETL ͨ��ֻ�Ǹ��������ݼ��ɵ�һ�������Ӽ�(��ע��ETL��Extraction-Transformation-Loading����д����������ȡ��ת���ͼ���)��������ڹ�ϵ�����ݲֿ⡣���������Ķ����ܴ�̶��Ͽ�������Ϊ����ETL�ƹ���ʵʱϵͳ�ʹ������̡�

��һ�������������ݼ��ɾ���Ȥ��Ȼ��ס�����������컨�����뵽���ڴ����ݵĸ���������������������⡰�����ݿɱ����ʡ�
��һ����֯Ӧ�ù�ע���м�ֵ�����顣
�����ݵĸ�Чʹ����ѭһ�� ��˹�����Ҫ������� ���������Ļ������ְ�����������������ݣ��ܹ�������ȫ���ŵ��ʵ��Ĵ����������Ǹ�����Ӧ����һ�������ʵʱ��ѯϵͳ�����߽������ı��ļ���python�ű�������Щ������Ҫ��ͳһ�ķ�ʽ��ģ�������Ϳ��Է����ȡ�����ݴ��������������ͳһ�ķ�ʽ�������ݵĻ�������õ����㣬��ô�Ϳ����ڻ�����ʩ���������ַ���������Щ���ݡ���ӳ�仯��MapReduce����ʵʱ��ѯϵͳ���ȵȡ�
�����ԣ���һ��ֵ��ע�⣺���û�пɿ��ġ���������������Hadoop��Ⱥ������������ڰ�װ�Ŀռ�ȡů�������ⲻ�������������ˡ�һ�����ݺʹ������ã����Ǿͻ������������ģ�ͺ�һ�µ�������������Щ��ϸ�µ����⡣������DzŻ��ע���Ӹ��Ĵ���-���õĿ��ӻ��������Լ�������Ԥ���㷨��
���ҵľ��飬��������������ݽ������ĵײ����ھ��©��-����ȱ���ɿ��ġ�������������-���Ǵ���ֱ������������ģ�ͼ����ϡ���������ȫ�Ƿ��������ġ���ˣ�������������ι���ͨ����������������ϵͳ�Ŀɿ�����������
���ݼ��ɣ���������֢
��������ʹ���ݼ��ɱ�ø����ѡ�
�¼����ݹܵ�
��һ���������������¼�����(event data)���¼����ݼ�¼���Ƿ��������飬�����Ǵ��ڵĶ�������webϵͳ�У������ζ���û����־������Ϊ�˿ɿ��IJ����Լ�����������ĵĻ�����Ŀ�ģ�����Ҫ��¼�Ļ���������¼���ͳ�����֡��������������Ϊ����־���ݡ�����Ϊ���Ǿ�����д��Ӧ�õ���־�У��������������ʽ�빦�ܡ���������λ���ִ�web�����ģ������ף�Google���ʲ���������һЩ�����ڵ����ӳ�����֮�ϵ���عܵ������ɵġ�����Ҳ�����¼���
��Щ���������ǽ��������繫˾��ֻ�����繫˾�Ѿ���ȫ���ֻ����������Ǹ��������豸��¼����������һֱ�������¼��ġ�RFID(������Ƶʶ��)�����ָ�����������������������Ϊ���������Խ�������������������̵��Ǵ�ͳ���������ֻ���
�������͵��¼����ݼ�¼�·��������飬���������ȴ�ͳ���ݿ�Ӧ��Ҫ��ü���������������ڴ���������ش���ս��
ר�ŵ�����ϵͳ�ı���
�ڶ�������������ר�ŵ�����ϵͳ�ı�����ͨ����Щ����ϵͳ������������п�ʼ������У����ҿ�����ѻ�á�ר�ŵ�����ϵͳ��ΪOLAP,
����, �� ���� �洢, ������, ͼ�����, �� �� �����ڵġ�
����IJ�ͬ�������ݵ���ϣ��Լ�����Щ���ݴ�ŵ������ϵͳ�е�Ը����������һ��������ݼ������⡣
��־�ṹ������
Ϊ�˴���ϵͳ֮�������������־������Ȼ�����ݽṹ�����е��ؾ��ܼ�
��������֯��������ȡ�������������Ƿŵ�һ��������־���Ա�ʵʱ���ġ�
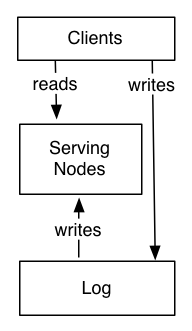
ÿ��������Դ�����Խ�ģΪ���Լ�����־��һ������Դ������һ��Ӧ�ó�����¼���־������������ҳ�����������������һ�������ĵ����ݿ����ÿ��������Ϣ��ϵͳ�������ܿ�Ĵ���־��ȡ��Ϣ����ÿ���µļ�¼���浽�Լ��Ĵ洢����������������־�еĵ�λ�����ķ�����������һ������ϵͳ
���� һ�����棬Hadoop����һ����վ�е���һ�����ݿ⣬һ������ϵͳ���ȵȡ�
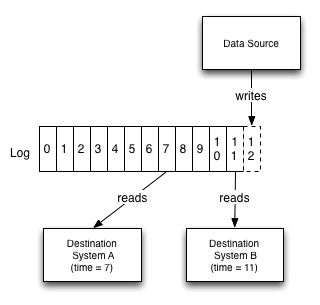
���磬��־���ÿ�����ĸ�������ʱ�ӵĸ���������еĶ��ķ������Ա��������Ƶ���ͬ�Ķ���ϵͳ��״̬Ҳ��˱����ԼĶ࣬��Ϊÿ��ϵͳ����һ����ȡ�����ġ�ʱ��㡱��
Ϊ��������Եø����壬���ǿ���һ���İ�������һ�����ݿ��һ�黺���������Ⱥ����־�ṩ��һ��ͬ������������Щϵͳ�����Ƶ���ÿһ��ϵͳ�ĽӴ�ʱ���ķ��������Ǽ���д��һ����־X��Ȼ����Ҫ�ӻ�����һ�ζ�ȡ����������뱣֤�����IJ��dz¾ɵ����ݣ�����ֻ�豣֤û�д��κ���δ����X�Ļ����ж�ȡ���ɡ�
��־Ҳ��������ã�ʹ��������������������ͬ������������ԭ��������ܺ���Ҫ���ر����ڶ�����ķ��������ݵ��ٶȸ�����ͬ��ʱ������ζ��һ����������ϵͳ����崻�����������ά����֮�����������Ժ��ٸ����������ķ������Լ����ƵĽ������������ݡ�������ϵͳ����Hadoop������һ�����ݲֿ⣬����ֻ��ÿСʱ����ÿ������һ�����ݣ���ʵʱ��ѯϵͳ������Ҫ��ʱ���롣����������ԭʼ����Դ������־����û�и���Ŀ������ϵͳ�����֪ʶ��������ѷ�ϵͳ���Ա����Ӻ�ɾ���������贫��ܵ��ı仯��

ÿ���������ݹܵ���Ƶþ�����һ����־��ÿ�������ݹܵ������Լ��ķ�ʽ������Count
Leo Tolstoy
�ر���Ҫ���ǣ�Ŀ��ϵͳֻ֪����־����֪������Դϵͳ���κ�ϸ�ڡ����ѷ�ϵͳ�������迼�����ݵ�����������һ��RDBMS����ϵ�����ݿ����ϵͳRelational
Database Management System����һ�����͵ļ�ֵ�洢���������������κ���ʽ��ʵʱ��ѯϵͳ�����ɵġ����ƺ���һ��С���⣬��ʵ������������Ҫ�ġ�
������ʹ�������־��ȡ���ˡ���Ϣϵͳ�����ߡ�����-���ġ�����Ϊ���������ϸ���ȷ�����Ҷ�֧�����ݸ��Ƶ�ʵ��ʵ���������������Ÿ��ӽ����������ҷ��֡��������ġ������ȼ��Ѱַ����Ϣ���и���ĺ��塪�������Ƚ��κ���������-���ĵ���Ϣ����ϵͳ�Ļ�����ᷢ�����dz�ŵ������ȫ��ͬ�Ķ��������Ҵ����ģ������һ���������õġ��������Ϊ��־��һ����Ϣϵͳ�������г־��Ա�֤��ǿ��Ķ������塣�ڷֲ�ʽϵͳ�У����ͨ��ģ����ʱ�и�(��Щ���µ�)���ֽ���ԭ�ӹ㲥��
ֵ��ǿ�����ǣ���־��Ȼֻ�ǻ�����ʩ���Ⲣ���ǹ���������������µĽ��������µ����ಿ��Χ����Ԫ���ݣ�ģʽ�������ԣ��Լ��������ݽṹ������ϸ�ڼ����ݻ���������һ�ֿɿ��ģ�һ��ķ����������������������������������Ǵ�Ҫ��ϸ�ڡ�
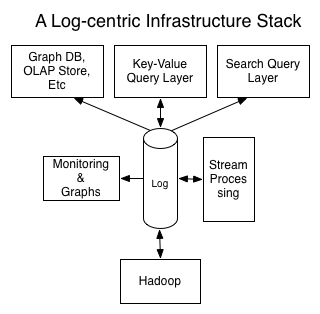
�� LinkedIn��SNS�罻��վ��
��LinkedIn�Ӽ���ʽ��ϵ���ݿ���ֲ�ʽϵͳ����ת���Ĺ����У��ҿ���������ݼ�������Ѹ���ݱ䡣
������Ҫ������ϵͳ������
����
�罻ͼ��
Voldemort (��ֵ�洢)(��ע��һ�ֲַ�ʽ���ݿ�)
Espresso (�ĵ��洢)
�ƾ�����
OLAP��ѯ����(��ע��OLAP������������)
Hadoop
Terradata
Ingraphs (���ͼ����ָ�����)
��Щ����ר�ŵķֲ�ʽϵͳ������רҵ�����ṩ�Ƚ��Ĺ��ܡ�

����ʹ����־��Ϊ��������˼�룬�������ҵ�����֮ǰ���Ѿ���LinkedIn����ˡ����ǿ�����һ������Ļ�����ʩ֮һ����һ�ֳ�Ϊdatabus
�ķ��������������ڵ�Oracle�����ṩ��һ����־������������������ݿ���,�������ǾͿ��Ժܺ�֧�����ǵ��罻���������������
�һ����һЩ��ʷ������һ�������ġ����״β��뵽��Щ��Լ����2008�����ң�������ת�Ƽ�ֵ�洢֮���ҵ���һ����Ŀ����һ�������е�Hadoop�����ݽ�������������һЩ���ǵ��Ƽ����̡�����ȱ���ⷽ��ľ��飬������Ȼ��Ȼ�İ��������ܼƻ������ݵĵ��뵼�����棬ʣ�µ�ʱ��������ʵ�������Ԥ���㷨���������ǾͿ�ʼ�˳�;���档
���DZ����ƻ��ǽ��������ݴ��ִ��Oracle���ݲֿ������롣�����������ȷ��ֽ����ݴ�Oracle��Ѹ��ȡ����һ�ֺڰ�������������ǣ����ݲֿ�Ĵ�������������ΪHadoop���ƻ����������������̲��ʺϡ�����ִ������Dz�����ת�ģ������뼴�����ɵı��������ء��������Dz�ȡ�İ취�ǣ�����ʹ�����ݲֿ⣬ֱ�ӷ���Դ���ݿ����־�ļ����������Ϊ�˼������ݵ���ֵ�洢
�����ɽ����ʵ��������һ�ֹܵ���
������ͨ�����ݸ������ճ�Ϊԭʼ������Ŀ����Ҫ����֮һ�������ǣ����κ�ʱ������ܵ�����һ�����⣬Hadoopϵͳ�ܴ�̶��������õġ����ڴ�������ݻ������������ص��㷨��ֻ���������Ĵ������ݡ�
��Ȼ�����Ѿ���һ��ͨ�õķ�ʽ�����������ÿ������Դ����Ҫ�Զ������ð�װ����Ҳ��֤���Ǿ���������ʧ�ܵĸ�Դ��������Hadoop��ʵ�ֵ���վ�����Ѿ���ʼ����������ͬʱ���Ƿ���������һ��������Ȥ�Ĺ���ʦ��ÿ���û�����������Ҫ���ɵ�һϵ��ϵͳ��������Ҫ��һϵ��������Դ��

��ϣ��ʱ���� ETL����ȡת������Extract Transform and
Load������û��̫��仯��
��Щ����������ǰ��ʼ��������������
���ȣ������ѽ��ɵ�ͨ����Ȼ��һЩ���ң���ʵ���������Ǻ��м�ֵ�ġ��ڲ�������Hadoop���µĴ���ϵͳ���ɿ������ݵĹ��̣��������˴����Ŀ����ԡ�
������Щ���ݹ�ȥ����ʵ�ֵļ��㣬����Ϊ���ܡ� �����µIJ�Ʒ�ͷ�����������Դ�ڰѷ�Ƭ�����ݷ���һ����Щ���ݹ����������ض���ϵͳ�С�
�ڶ��� ������֪���ɿ������ݼ�����Ҫ����ͨ�������֧�֡�������ǿ��Բ�������������Ҫ�Ľṹ���Ҿ;Ϳ���ʹ��Hadoop����ȫ�Զ��ļ��أ������Ͳ���Ҫ����IJ����������µ�����Դ���ߴ���ģʽ����C���ݾͻ��Զ��ij�����HDFS��Hive���ͻ��Զ������ɶ�Ӧ��������Դ��ǡ�����С�
���������ǵ����ݸ�������Ȼ�dz��͡������鿴�洢��Hadoop�еĿ��õ�Linked ���ݵ�ȫ���ٷֱȣ�����Ȼ�Dz������ġ����Ѵ�����Ŭ��ȥʹ�ø����µ�����Դ��ת������ʹ�����ݸ��Ƕ���������һ���������顣
�����������еģ�Ϊÿ������Դ��Ŀ�������ͻ������ݼ��أ����ַ�ʽ����Ȼ�Dz����еġ������д���������ϵͳ�����ݲֿ⡣����Щϵͳ�Ͳֿ���ϵ�������ͻᵼ������һ��ϵͳ�����������ʾ�Ŀͻ���ͨ����
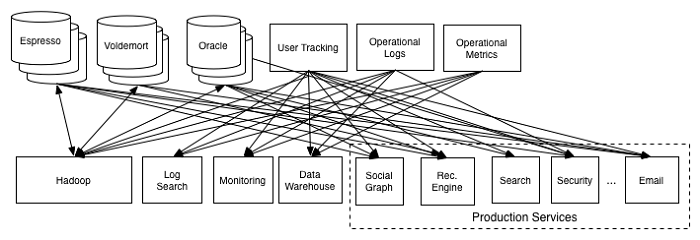
��Ҫע����ǣ�������˫�������ģ���������ϵͳ�������ݿ��Hadoop��������ת������Դ��������ת����Ŀ�ĵء������ζ���������Dz���Ϊÿ��ϵͳ��������ͨ����һ�������������룬һ���������������
����Ȼ��Ҫһ��Ⱥ�ˣ�����Ҳ�����пɲ����ԡ��������ǽӽ���ȫ���ӣ��������ǽ��в��O(N2)���ܵ���
����ģ�������Ҫ������ͨ�õĶ�����

������Ҫ�����ܵĽ�ÿ��������������Դ���롣���������£�����Ӧ��ֻ��һ�����������ݲֿ⼯�ɣ����ɴ��������ܷ��ʵ����ж�����
���˼��������һ���µ�����ϵͳ������������һ������Դ��������һ������Ŀ�ĵء����ü��ɹ���ֻ�����ӵ�һ�������Ĺܵ������������ӵ�ÿ���������ѷ���
���־���ʹ���ҹ�ע����Kafka��������������Ϣϵͳ�����������ݿ�ͷֲ�ʽϵͳ�ں�����������־������ϣ��һЩʵ����Ϊ���ĵ�ͨ���������������еĻ���ݣ�����չ��������;������Hadoop�������ʵʩ�����ݼ�صȡ�
���൱����ʱ���ڣ�Kafka�Ƕ�һ���ĵײ��Ʒ�����Ȳ������ݿ⣬Ҳ������־�ļ��ռ�ϵͳ�������Ǵ�ͳ����Ϣϵͳ���������Amazon�ṩ�˷dz�����Kafka�ķ���֮ΪKinesis.���ƶȰ����˷�Ƭ�����ķ�ʽ�����ݵı��֣�����������Kafka
API�У��е��ر�ĸ߶˺͵Ͷ������߷��ࡣ�Һܿ��Ŀ�����Щ������������Ѿ������˺ܺõĵײ�Э�飬AWS�Ѿ�������Ϊ�����ṩ�����ǶԴ˵��ڴ��������������Ǻϣ�ͨ����ͨ�����еķֲ�ʽϵͳ������DynamoDB,
RedShift, S3�ȣ���ͬʱ��Ϊʹ��EC2���зֲ�ʽ�������Ļ�����
��ETL�����ݲֿ�Ĺ�ϵ
���������������ݲֿ⡣���ݲֿ�����ϴ��һ���ݽṹ����֧�����ݷ����IJֿ⡣����һ��ΰ�������Բ���Ϥ���ݲֿ���������˵�����ݲֿⷽ���۰����ˣ������ԵĴ�����Դ��ȡ���ݣ�������ת��Ϊ���������ʽ��Ȼ����������������ݲֿ⡣�������ݼ��з����ʹ�����ӵ�и߶ȼ��е�λ�ô��ȫ�����ݵ�ԭʼ�����Ƿdz�������ʲ����ڸ߲㼶�ϣ�Ҳ�����ȡ�ͼ������ݵ�˳������������������۲�����̫��仯,������ʹ�ô�ͳ�����ݲֿ�Oracle����Teradata����Hadoop��
���ݲֿ��Ǽ�����Ҫ���ʲ�����������ԭʼ�ĺ��������ݣ�����ʵ�ִ�Ŀ��Ļ����е��ʱ�ˡ�

��������Ϊ���ĵ���֯�ؼ������ǰ�ԭʼ�Ĺ�һ�������ᵽ���ݲֿ⡣���ݲֿ����������Ļ�����ѯ�����������ڸ��౨������ʱ�Է������ر��ǵ���ѯ�����˼ļ������ۺϺ��ˡ��������һ��������ϵͳ����������ԭʼ�����������ݵ����ݲֿ⣬�����ζ����Щ���ݶ���ʵʱ���ݴ���������������ϵͳ��ص�ʵʱ�IJ�ѯ�Dz����õġ�
����֮����ETL���������£����ȣ����dz�ȡ��������ϴ���̨C�ر����ͷű�������֯�ĸ���ϵͳ�е����ݣ��Ƴ�ϵͳר�е�������ڶ����������ݲֿ�IJ�ѯ�ع����ݡ�����ʹ����Ϲ�ϵ���ݿ�����ϵͳ��ǿ��ʹ���Ǻš�ѩ����ģʽ�����߷ֽ�Ϊ�����ܵ���״��ʽ�ȡ��ϲ��������������ѵġ���Щ���������ݼ�Ӧ��������ʵʱ���ʱ�Ӵ����п��ã�Ҳ����������ʵʩ�洢ϵͳ������
���ҿ�����������Ϊ���ԭ�����˶���ô���ʹ�����ݲֿ�ETL��������֯���Ĺ�ģ�����ݲֿ�ľ������������ݲֿ⸺���ռ�����ϴ��֯�и����������ɵ�ȫ�����ݡ�����֯�Ķ����Dz�ͬ�ģ����ݵ������߲���֪�������ݲֿ������ݵ�ʹ����������ղ��������ݺ��ѳ�ȡ��������Ҫ���ѹ�ģ����ת���ſ���ת��Ϊ���õ���ʽ����Ȼ��
�����ŶӲ�����ǡ���ô������չ�ģ��ʹ�����ģ�պ�����֯�������Ŷ���ƥ�䣬������ݵĸ����ʳ������ܴ��������Ǵ�����ͬʱ����ǻ����ġ�
�Ϻõķ�������һ������ͨ������־�������������ݵĶ������õ�API����ͨ�����ɵ����ṩ���õĽṹ���������ļ���ְ�����������ݵ������������ɵ������ļ�������ζ������ƺ�ʵʩ����ϵͳʱӦ���������ݵ�����Լ�������������ת��Ϊ�ṹ���õ���ʽ�����ݸ�����ͨ���������µĴ洢ϵͳ���Dz�����Ϊ���ݲֿ��Ŷ���һ�����Ľ����Ҫ���ɶ���ע���ݲֿ��Ŷӡ����ݲֿ��Ŷӽ��账�������⣬�����������־�м��ؽṹ�������ݣ��������ܱ�ϵͳʵʩ���Ի�������ת���ȡ�
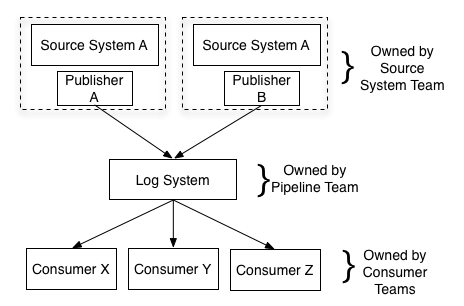
��ͼ��ʾ���������ڴ�ͳ�����ݲֿ�֮�����Ӷ��������ϵͳʱ����֯�ṹ�Ŀ���չ���Ե���Ϊ��Ҫ�����磬���Կ���Ϊ��֯�����������ݼ��ṩ�������ܡ������ṩ���������������ʵʱ�������ƺ澯���������������е���һ������ͳ�����ݲֿ�ܹ�������Hadoop�۴ض��������á�������ǣ�ETL������ͨ����Ŀ�ľ���֧�����ݼ��أ�Ȼ��ETL�ƺ�������������ĸ���ϵͳ��Ҳ��ͨ����������ʹ����Щ��Χ��ϵͳ�ĸ����ܹ���Ϊ���������ݲֿ����Ҫ�ʲ�����Ͳ��ѽ���Ϊʲô��֯�������ɵ�ʹ������ȫ�����ݡ���֮�������֯�ѽ�������һ�ױ��ġ��ṹ���õ����ݣ���ô�κ��µ�ϵͳҪʹ����Щ���ݽ�����Ҫ��ͨ�����мļ��ɾͿ���ʵ�֡�
���ּܹ�����������������ת�����ĸ��ν��еIJ�ͬ�۵㣺
�����ݵ��������ڰ��������ӵ���˾ȫ����־֮ǰ��
����־��ʵʱת���ν��У��⽫�����һ���µ�ת����־��
����Ŀ��ϵͳ��������ʱ����Ϊ���ع��̵�һ���ֽ��С�
�����ģ���ǣ������ݵ��������ڰ����ݷ�������־֮ǰ�����ݽ�����������������ȷ�����ݵ�Ȩ���ԣ�����Ҫά������������������Ϊ���ݲ�����������������ά����Щ���ݵ������Ĵ洢ϵͳ����Щϸ��Ӧ���ɲ������ݵ��Ŷ�����������Ϊ�������˽������Լ������ݡ��������ʹ�õ��κ�����Ӧ��������ĺͿ���ġ�
�κο���ʵʱ��ɵ���ֵת�����Ͷ�Ӧ������ԭʼ��־���к��ڴ�������һ���̰������¼����ݵĻỰ���̣��������Ӵ��ڸ���Ȥ�������ֶΡ�ԭʼ����־��Ȼ�ǿ��õģ���������ʵʱ����������������־�����˲������ݡ�
���գ�ֻ�����Ŀ��ϵͳ�ľۺ���Ҫ���˼������̵�һ���֡��������˰�����ת�����ض������ͻ���ѩ��״ģʽ���Ӷ��������ݲֿ�ķ����ͱ�������Ϊ������Σ�����Ȼ��ӳ�䵽��ͳ��ETL�����У�������������һ�����Ӹɾ����������������ڽ��еģ���������ӵļ�
��־�ļ����¼�
���������������ּܹ������ƣ���֧�ֽ�����¼�������ϵͳ��
��������ҵȡ�û���ݵĵ��ͷ����ǰ�����Ϊ�ı���ʽ����־����Щ�ı��ļ��ǿɷֽ�������ݲֿ����Hadoop�����ھۺϺͲ�ѯ�����ġ��ɴ˲�����������������������ETL����������ͬ�ģ���������������������ݲֿ�ϵͳ�����������̵ĵ��ȡ�
��LinkedIn�У������Ѿ���������־�ķ�ʽ�������¼����ݴ�������������ʹ��Kafka��Ϊ���ĵġ��ඩ�����¼���־�������Ѿ��������������¼����ͣ�ÿ�����Ͷ��Ჶ�������ض����Ͷ����Ķ��ص����ԡ��⽫�Ḳ�ǰ���ҳ����ͼ������ʽ�������Լ�������á�Ӧ���쳣�ȷ������档
Ϊ�˽�һ��������һ���ƣ�����һ��������C����־ҳ����ʾ�ѷ�������־�������־ҳ��Ӧ��ֻ������ʾ��־����Ҫ������Ȼ�������൱��Ķ�̬վ���У���־ҳ�泣����������˺ܶ�����ʾ��־�ص��������磬���ǽ������µ�ϵͳ���м��ɣ�
1.��Ҫ�����ݴ��͵�Hadoop�����ݲֿ��������������ݴ�����
2.��Ҫ����ͼ����ͳ�ƣ�ȷ����ͼ�����߲��ṥ��һЩ����Ƭ�Ρ�
3.��Ҫ�ۺ���Щ��ͼ����ͼ��������ҵ�����ߵķ���ҳ����ʾ��
4.��Ҫ��¼��ͼ��ȷ������Ϊ��ҵ�Ƽ���ʹ�����ṩ��ǡ����ӡ�ǣ����Dz���һ�δε��ظ�ͬ�������顣
5.�Ƽ�ϵͳ��Ҫ��¼��־������ȷ�ĸ�����ҵ���ռ��ȡ�
6.�ȵȡ�
���ã�����ҵ��ʾ����൱�ĸ��ӡ�������������ҵ��ʾ�������ն˨C�ƶ��ն�Ӧ�õȨC��Щ������������ڣ����ӶȲ��ϵ����ӡ��������������Ҫ��֮���ӿڽ�����ϵͳ�����Ǵ��۸��ӵĨC��Ϊ��ʾ����ҵ�������Ĺ���ʦ����Ҫ֪���������ϵͳ�����ǵ��������ſ���ȷ�����DZ���ȷ�ļ����ˡ������������ļ汾����ʵ�ĵ�Ӧ��ϵͳֻ����ӵĸ��ӡ�
���¼���������ģʽ�ṩ��һ�ּ���������Ļ��ơ���ҵ��ʾҳ������ֻ��ʾ��ҵ����¼��������ʾ����ҵ����ҵ��������ص��������ԣ�����������ҵ��ʾ��ص������м�ֵ�����ԡ�ÿ�������ص�����ϵͳ�����Ƽ�ϵͳ����ȫϵͳ����ҵ���ͷ���ϵͳ�����ݲֿ⣬������Щֻ�Ƕ��������ļ������������ǵIJ�������ʾ���벢����Ҫ��ע������ϵͳ��Ҳ����Ҫ��Ϊ���������ݵ������߶���Ӧ�Ľ��б����
��������������־
��Ȼ���ѷ������붩���߷��벻����ʲô�������ˡ������������Ҫȷ���ύ��־����Ϊ������������ʵʱ�ķ�����־������¼��վ������ÿ����ʱ������չ�Ծͻ��Ϊ�������ٵ���Ҫ��ս��������Dz��ܴ������١����Լ۱ȺͿ���չ��������־������ʵ�ʵĿ���չ������־��Ϊͳһ�ļ��ɻ��Ʋ��������õ�����
�����ձ���Ϊ�ֲ�ʽ��־�ǻ����ġ��������ĸ������ͨ������������롰ԭ���ݡ����͵�ʹ����ϵ��������������ʹ��Zookeeper�������ã�����������ʵ�ֲ��ص��ע�����¼���ģ�������������������Dz���ʵ�ʵġ���LinkedIn,
��������ÿ��ͨ��Kafka�����ų���600�ڸ���ͬ����Ϣд���(���ͳ�ƾ�������������֮���д�룬��ô������ֻ�����ǧ�ڡ�)
������Kafk��ʹ����һЩС������֧�����ֿ���չ�ԣ�
��־��Ƭ
ͨ��������������д���Ż�������
������õ����ݸ��ơ�
Ϊ��ȷ��ˮƽ����չ�ԣ����ǰ���־������Ƭ��
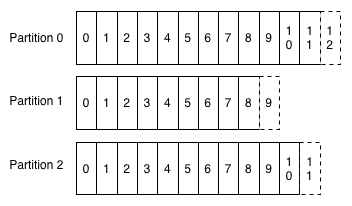
ÿ����Ƭ����һƪ�������־�����Ǹ�Ƭ֮��û��ȫ�ֵĴ�������б�������ܰ�������Ϣ�еĹ���ʱ�䣩������Ϣ���䵽�ض�����־Ƭ��������д���߿��Ƶģ���ʹ����ͨ���û�ID�ȼ�ֵ�����з�Ƭ����Ƭ������־�ӵ�������Э����Ƭ��֮�䣬Ҳ����ʹϵͳ����������Kafka�۴ش�С�����Ա�����ϵ��
ÿ����Ƭ����ͨ�������������ĸ���Ʒ���Ƶģ�ÿ������Ʒ���з�Ƭ��һ����ȫһ�µĿ��������ۺ�ʱ�������е���һ����������Ϊ����Ƭ���������Ƭ�����ˣ��κ�һ������Ʒ�����Խӹܲ���Ϊ����Ƭ��
ȱ�ٿ��Ƭ��ȫ��˳����������Ƶľ����ԣ��������Dz���Ϊ��������Ҫ�ġ���ʵ�ϣ�����־�Ľ�����Ҫ��Դ�ڳɰ���ǧ����ͬ�����̣������ڶ������ǵ���Ϊ��һ�������˳����ûʲô����ġ��෴�����ǿ���ȷ�����������ṩ��ÿ����Ƭ���ǰ�˳�����ġ�Kafka��֤���ӵ��ɵ�һ�������ͳ����ض���Ƭ�ᰴ�շ��͵�˳�����δ�����
��־�������ļ�ϵͳһ�����������Ż������Կɶ���д����ʽ�ġ���־����С�Ķ����д����ϳɴ�ġ����������IJ�����Kafkaһֱ������ʵ����һ�Ż�Ŀ�ꡣ���������Է������ɿͻ�����������˷������ݡ�д�����;�ڷ���������֮�临�ƣ����ݴ��ݸ������ߺ�ȷ���ύ���ݵ����ڡ�
���գ�Kafkaʹ�üĶ�������ʽά���ڴ���־��������־���������ݴ��͡���ʹ�����ǿ���ʹ�ð�����0���ݸ��ƴ��͡����ڵĴ������Ż����ơ�
��Щ�Ż��Ļ���ЧӦ���㳣�����е�д���Ͷ������ݵIJ��������ڴ��̺������ϵõ�֧�֣�������ά���ڴ�����Ĵ������ݼ���
����Ϊֹ����ֻ�������Ӷ˵������ݸ��Ƶ�������ơ������ڴ洢ϵͳ�а����ֽڲ�����Ҫ�������ݵ�ȫ�����������Ƿ�����־��������һ��˵������־���������ĺ��ġ�
���ǣ��ȵȣ�ʲô���������أ�
�������90������ڻ���21���ͳ����ݿ��Ļ��������ݻ����ܹ���Ʒ�İ����ߣ���ô��Ϳ��ܻ���������뽨��SQL������ߴ��������Ӻͼ�ͷ���ӿ������¼������Ĵ�������ϵ������
������ע��Դ���ݿ�ϵͳ�Ĵ������֣���Ϳ��ܰ���������һЩ��Դ���ݿ�ϵͳ������������Щϵͳ�����ˣ�Storm,Akka,S4��Samza.���Ǵ��˻����Щϵͳ��Ϊ�첽��Ϣ����ϵͳ����Щϵͳ��֧��Ⱥ����Զ�̹��̵��ò��Ӧ��ûʲô��𣨶���ʵ���ڿ�Դ���ݿ�ϵͳ����ijЩ����ȷʵ��ˣ���
��Щ��ͼ����һЩ�����ԡ���������SQL���صġ���Ҳ������ʵʱ�����������������ڵ�ԭ�������㲻�ܴ�������Ļ���һ����֮ǰ�������ݣ���ʹ�ö��ֲ�ͬ�����Ա�����㡣

�Ұ���������Ϊ���㷺�ĸ�����������������Ļ����ܹ�������Ϊ����ģ�Ϳ�����MapReduce���߷ֲ�ʽ�����ܹ�һ���ձ飬����������������ʱ�ӵĽ����
����ģ�͵�ʵʱ�����������ռ������������ռ��������Ƿ��������ġ������Dz����ռ��ģ���Ҳ�ǰ�˳�ϴ����ġ�
������ͳ�Ƶ�����dz����ռ����ݵ����õ䷶��ͳ�Ƶ��������ԵĿ�չ��ͨ�����Ű������߷ã�ʹ���������ֺ�ͳ�������Ĺ�����Ϣ��1790��ͳ�Ƶ���ոտ�ʼʱ���ַ�ʽ����Ч�ġ���ʱ�������ռ����������ģ������������������е��н�������Ϣд��ֽ�ϣ�Ȼ��ѳ����ļ�¼���͵�����ͳ�����ݵ�����վ�㡣���ڣ����������ͳ�ƹ���ʱ�������������뵽Ϊʲô���Dz����������������ļ�¼�������Ϳ��Բ����˿�ͳ����Ϣ��Щ��Ϣ���dz����Ļ���������ά�ȵġ�
����һ�����˵����ӣ����Ǵ��������ݴ��ʹ�����Ȼ�����������Ե�ת��������ת���ͼ��ɡ�����������ת����Ψһ�������������Ĵ���������������Щ�������������Ĺ�����ȡ����������Ȼ��Ȼ�Ŀ�ʼ����ϵĴ�����ƽ���Ĵ���������Դ���������ӳ١�
����LinkedIn����û�����������ռ����ֵ����ݻ����ǻ���ݻ��������ݿ����������߶��Dz���Ϸ����ġ���ʵ�ϣ�������뵽���κ���ҵ�����磺Jack
Bauer�������ǵģ��Ͳ�Ļ��ƶ���ʵʱ�����IJ���ϵ������¼��������dz����ռ��ģ������ǻ�������һЩ��Ϊ�IJ��裬����ȱ�����ֻ�������һЩ�Զ����ķ����ֻ����̴�����������Ϣ�������ͺʹ�����Щ���ݵĻ������ʼ������˹��Ĵ���ʱ����һ�����Ƿdz������ġ������Զ������DZ���������Ĵ�����ʽ��������������൱����ʱ�䡣
ÿ�����е�����������ҵ������ģ����һ��һ��Ĵ��ڴ�С�IJ���ϼ��㡣��Ȼ���Ͳ������Ҳ�����仯����LinkedIn,��Щ��˾�ռ���ģ�����ʹ��������Hadoop��ת�Ļ������м��ɵģ���������ʵʩ��һ������������Hadoop�������ļܹ���
�ɴ˿��������������������в�ͬ�Ĺ۵㡣�������������ڵײ����ݴ�����ʱ����������Ҫ���ݵľ�̬���գ������Բ����û��ɿ�Ƶ�ʵ�����������õȴ����ݼ���ȫ�����������Ƕ��Ͻ������������ǹ����ϵ�������������ʵʱ���ݵ����У���������ձ顣
�����Ϊʲô�Ӵ�ͳ���ӽǿ���������������Ӧ�á��Ҹ�����Ϊ����ԭ����ȱ��ʵʱ�����ռ�ʹ�ò���ϵĴ�����Ϊ��ѧ���Եĸ��
����ȱ��ʵʱ�����ռ�����������������ϵͳע�������ˡ����ǵĿͻ���Ȼ��Ҫ���������ļ��ġ�ÿ����������ETL�����ݼ��ɡ���˾����������ϵͳ��ע�����ṩ������ʵʱ�������Ĵ������棬�������յ�ʱ������������ʹ����ʵʱ����������ʵ�ϣ�������LinkedIn�����ij��ڣ���һ�ҹ�˾��ͼ��һ���dz�����������ϵͳ���۸����ǣ�������Ϊ��ʱ���ǵ�ȫ�����ݶ���Сʱ�ռ��ڵ��ļ����ʱ�����������õ�Ӧ�þ�����ÿСʱ��������Щ�ļ����뵽������ϵͳ�С�����ע�����һ���ձ��Ե����⡣��Щ�쳣֤�������¹���������ϵͳҪ�������Ҫ��ҵĿ��֮һ�ǣ�����
����ʵʱ�������Ѿ߱��Ļ��������������Ѿ���Ϊ��ƿ����
��������һ��������������ϵͳ�У���������Ϊһ�ֻ����ܹ���ʵ��Ӧ���������൱�㷺�ġ�����Խ��ʵʱ��������-Ӧ������������������֮��ĺ蹵�����ڵĻ�������˾����Լ25%�Ĵ�����Ի��ֵ���������С�
������Щ��־������������о��ֹؼ��ļ������⡣���ҿ��������������������������ʹ�öඩ���߿��Ի��ʵʱ���ݡ�����Щ����ϸ�ڸ���Ȥ�����ѣ����ǿ����ÿ�Դ��Samza,���ǻ�����Щ������һ��������ϵͳ����ЩӦ�õĸ��༼��ϸ�������ڴ��ĵ�������ϸ��������
������ͼ
����������Ȥ�ĽǶ�������������ϵͳ�ڲ��أ�������֮������ص��������չ������̸�����������ݼ��ɵ����ݻ�ȡ�����������Ҫ�����˻������ݵĻ�ȡ����־�C�¼�����ϵͳִ���в��������ݵȡ������������������ǰ����˼����������ݵ����ݡ���Щ�����������������߿��������Ǽ����ԭʼ����ûʲô�����Щ���������ݿ�������ĸ��ӶȽ���ѹ����
������������һ�������ǵ�Ŀ���ǣ���������ҵ���Զ�ȡ�������־������־д�뵽��־����������ϵͳ�С��������������������־����Щ����������һ�鴦�������С���ʵ�ϣ�ʹ��������ʽ�ļ�����־���������֯ȫ��������ץȡ��ת��������������һϵ�е���־��д�����ǵĴ������̡�
����������������Ҫ����Ŀ�ܣ��������Ƕ�д��־���κδ��������ߴ��������ϣ����Ƕ���Ļ�����ʩ���������ṩ���������������롣
��־���ɵ�Ŀ����˫�صģ�
���ȣ���ȷ��ÿ�����ݼ����ж�������ߺ�����ġ������ǻع�һ��״̬����ԭ������ס˳�����Ҫ�ԡ�Ϊ��ʹ������Ӿ��壬����һ�´����ݿ��и����������C����ڴ������������ǰѶ�ͬһ��¼�����θ������������ܻ��������������
TCP֮������ӽ��������ڵ�һ�ĵ�Ե����ӣ���һ˳��ij־���Ҫ����TCP֮������ӣ������������̴���ʧ�ܺ�����ʱ��Ȼ���ڡ�
�ڶ�����־�ṩ�����̵Ļ��塣���Ƿdz������ġ�������������Ƿ�ͬ���ģ���ô�������������ݵ���ҵ���������������ݵ���ҵ���еĸ��졣�⽫�ᵼ�´����������������������ݣ����߶������ݡ��������ݲ����ǿ��еķ������������ᵼ����������ͼ����ֹͣ��
��־ʵ������һ���dz���Ļ��壬������������������ֹͣ������Ӱ������ͼ�������ֵĴ����ٶȡ����Ҫ����������չ�������ģ����֯�����������ҵ���ɶ����ͬ���Ŷ��ṩ�ģ����ָ������Ǽ����صġ����Dz�������һ���������ҵ������̨��ѹ��������ѹ����ʹ��������������ֹͣ��
Storm��Sama�����߶��ǰ���ͬ����ʽ��Ƶģ�����ʹ��Kafka�����������Ƶ�ϵͳ��Ϊ���ǵ���־��
��״̬��ʵʱ������
һЩʵʱ��������ת��ʱ����״̬�ļ�¼�����������дֵ�Ӧ�û����൱���ӵ�ͳ�ơ��ۺϡ���ͬ����֮��Ĺ�����������ʱ��������������û�������Ϣ���¼�����һϵ�еĵ����������Cʵ���Ϲ������û��ĵ������������û����˻���Ϣ���ݿ⡣������������������ջ���Ҫ�ɴ�����ά����һЩ״̬��Ϣ����������ͳ��ʱ������Ҫͳ�Ƶ�ĿǰΪֹ��Ҫά���ļ��������������������ʧ���ˣ������ȷ��ά����Щ״̬��Ϣ�أ�
����滻�����ǰ���Щ״̬��Ϣ�������ڴ��С�����������̱��������ͻᶪʧ�м�״̬�����״̬�ǰ�����ά���ģ����̾ͻ���˵���־�д��ڿ�ʼ��ʱ����ϡ����ǣ����ͳ���ǰ�Сʱ���еģ���ô���ַ�ʽ�ͻ��ò����С�
��һ���滻�����ǼĴ洢���е�״̬��Ϣ��Զ�̵Ĵ洢ϵͳ��ͨ����������Щ�洢�������������ֻ��Ƶ�������û�б������ݺʹ����������ͨ�š�
�������֧�ִ������̿������һ��������������?
�ع�һ�¹��ڱ�����־�����Ե����ۡ���һ�����ṩ�˹��߰�������ת��Ϊ�봦������Эͬ��λ�ı���ͬʱҲ�ṩ����Щ�����ݴ������Ļ��ơ�
����������������״̬�����ڱ��صı��������Cbdb,����leveldb,������������Lucene ��fastbitһ������������������Щ���ݴ洢�������������У�������ʹ�������ת���������ɵı����־��¼�˱��ص��������������洢�¼������������ȵ�״̬��Ϣ���������ṩ��ͨ�õĻ��������ڱ������������ݵ���������б��湲ͬ��Ƭ��״̬��
����������ʧ��ʱ������ӱ����־�лָ�����������ÿ�α���ʱ����־�ѱ���״̬ת����һϵ�е�������¼��
����״̬�����ķ�����һ�������ǰѴ�������״̬Ҳ��Ϊ��־����ά�������ǿ�����Щ��־���������ݿ�����Ӧ�ı����־����ʵ�ϣ���Щ������ͬʱά������ͬ��Ƭ��һ���ı�����Ϊ��Щ״̬������������־�������Ĵ��������Զ�������������̴�����Ŀ���Ǹ��½������״̬������״̬�������̵��������ô���ַ������Ե���Ϊ��Ҫ��
Ϊ�����ݼ��ɣ����������ݿ����־��������־�����ݿ���Ķ����Ծ��������ˡ������־���Դ����ݿ��г�ȡ��������־�����ɲ�ͬ�����������������������ڹ�����ͬ���¼���������ͬ�ķ�ʽ����������
���ǿ����о���Samza����״̬�����������ĸ���ϸ�ںʹ���ʵ�õ����ӡ�
��־ѹ��
��Ȼ�����Dz�����������ȫ�������������־��������Ҫʹ�����ռ䣬��־��������ȫ�����Ϊ�˳�������������������Kafka��ʵ�֡���Kafka��,����������ѡ����ȡ���������Ƿ�����ؼ����º��¼����ݡ������¼����ݣ�Kafka֧�ֽ�ά��һ�����ڵ����ݡ�ͨ����������ҪһЩʱ�䣬���ڿ���ʱ���ռ䶨�塣��Ȼ���ڹؼ����ݶ��ԣ�������־����Ҫ���������������Դϵͳ��״̬��Ϣ��������������ϵͳ���֡�
����ʱ������ƣ�������������־��ʹ��Խ��Խ��Ŀռ䣬�������ķѵ�ʱ��Խ��Խ������Щ��Kafka��,����֧�ֲ�ͬ���͵ı����������Ƴ��˷����ļ�¼(��Щ��¼������������¹�)�����ǼĶ�������־��������Ȼ��֤��־������Դϵͳ���������ݣ������������Dz�������ԭϵͳ��ȫ��״̬�����ǽ������������״̬�����ǰ���һ������Ϊ��־ѹ����
�������Ҫ���۵�����������ϵͳ�������־�Ľ�ɫ��
�ڷֲ�ʽ���ݿ�����������־�Ľ�ɫ���ڴ�����֯����������������־�Ľ�ɫ�����Ƶġ���������Ӧ�ó����У���־�Ƕ�������Դ�ǿɿ��ģ�һ�µĺͿɻָ��ġ���֯�������һ�����ӵķֲ�ʽ����ϵͳ�أ���������ʲô��
��������Ƕȣ�����Կ�����������֯ϵͳ�������������ǵ�һ�ķֲ�ʽ����ϵͳ����������е��Ӳ�ѯϵͳ������Redis,
SOLR,Hive���ȣ����������ݵ��ض������������Storm��Samzaһ����������ϵͳ�����Ƿ�չ���õĴ���������ͼ���廯���ơ����Ѿ�ע�����ͳ�����ݿ������Ա�dz�ϲ����������ͼ����Ϊ�����ս�������Щ��ͬ������ϵͳ��������ʲô�õĨC����ֻ�Dz�ͬ���������Ͷ��ѡ�
���ɷ����������ݿ�ϵͳ���ڴ����ij��֣�������ʵ�ϣ����ָ�����һֱ�����ڡ���ʹ���ڹ�ϵ���ݿ�ϵͳ�Ķ�ʢʱ�ڣ���֯���д����Ĺ�ϵ���ݿ�ϵͳ�������Դ��ͻ�ʱ����ʼ�����е����ݶ��洢����ͬ��λ�ã������ļ����Ǹ��������ڵġ����ڶ�������������Ҫ�����ݷֽ�ɶ��ϵͳ����Щ���������������ģ���������ء���ȫ�ԣ����ܸ�������������ء���Щ��������һ�����ʵ�ϵͳʵ�֣����磬��֯����ʹ�õ�һ��Hadoop�۴أ���������ȫ�������ݣ����Է����ڴ��͵ĺͶ����ԵĿͻ���
�������ֲ�ʽϵͳ��Ǩ�Ĺ����У��Ѿ�����һ�ִ������ݵļ��ķ������Ѵ����IJ�ͬϵͳ��С��ʵ���ۺϳ�Ϊ��ľ۴ء������ϵͳ��������֧����һ��������Ϊ���Dz�����ȫ���������ܸ����Եò�����֤�����߹�ģ������Ҫ������Щ���ⶼ�ǿ��Խ���ġ�
����֮������ͬϵͳ�������ֵ�ԭ���ǽ���ֲ�ʽ���ݿ�ϵͳ�����ѡ�ͨ����������һ�IJ�ѯ����������ÿ��ϵͳ�����ѹ�ģ���Ƶ�����ʵ�ֵij̶ȡ�����������Щϵͳ�����ĸ��Ӷ���Ȼ�ܸߡ�
δ������������ܵķ�չ���������֣�
��һ�ֿ����DZ�����״��������ϵͳ�����̵ij���һ��ʱ�䡣������Ϊ����ֲ�ʽϵͳ�����Ѻ��ѿ˷���������Ϊ����ϵͳ�Ķ����Ժͱ���Ժ��Ѵﵽ��������Щԭ�����ݼ��ɵĺ���������Ȼ�����ǡ����ʹ�����ݡ���ˣ��������ݵ��ⲿ��־�dz�����Ҫ��
�ڶ��ֿ������ع����߱�ͨ���Եĵ�һ��ϵͳ���ں϶�������γɳ���ϵͳ���������ϵͳ���濴�������ƹ�ϵ���ݿ�ϵͳ����������֯����ʹ��ʱ���IJ�ͬ����ֻ��Ҫһ�����ϵͳ������������Сϵͳ������������������ϵͳ���ѽ����������ⲻ����ʲô���������ݼ������⡣����������Ϊ����������ϵͳ��ʵ�����ѡ�
��Ȼ��һ�ֿ��ܵĽ�����ڹ���ʦ��˵�Ǻ����������ġ���һ�����ݿ�ϵͳ������֮һ����������ȫ��Դ�ġ���Դ�ṩ�˵����ֿ�����
�����ݻ����ܹ����ش���ɷ���������Ӧ�õ�ϵͳ�ӿڡ���Javaջ�У�����Կ�����һ���̶��ϣ�����״���Ѿ������ˡ�
����Ƽ���
Zookeeper���ڴ������ϵͳ֮���Э���������������Helix ����Curator�ȸ���ij����еõ�һЩ������
Mesos��YARN���ڴ������̿��ӻ�����Դ������
Lucene��LevelDB��Ƕ��ʽ�����Ϊ������
Netty,Jetty��Finagle,rest.li�ȷ�װ�ɸ�������ڴ���Զ��ͨ�š�
Avro,Protocol Buffers,Thrift��umpteen
zillion������������ڴ������л���
Kafka��Bookeeper�ṩ֧����־��
��������Щ�ѷ���һ�𣬻����Ƕȿ������е����Ǽ�ķֲ�ʽ���ݿ�ϵͳ���̡��������Щƴװ��һ�𣬴��������Ŀ��ܵ�ϵͳ���Զ���������̽�ֵIJ��������û������ĵ�API�������ʵ�֣������ڲ��϶�������ģ�黯�Ĺ�����������ʵ�ֵ�һϵͳ��;������Ϊ���ſɿ��ġ�����ģ��ij��֣�ʵʩ�ֲ�ʽϵͳ��ʱ��������������Ϊ�ܣ��ۺ��γɴ�������ϵͳ��ѹ������ʧ��
��־�ļ���ϵͳ�ṹ�еĵ�λ
��Щ�ṩ�ⲿ��־��ϵͳ������������˵������������������ӵ���־ϵͳת��ʹ�ù�����־�����ҿ�������־���������������飺
1.ͨ���Խڵ�IJ������µ����������ݵ�һ���ԣ������ڼ�ʱ������������£�
2.�ṩ�ڵ�֮������ݸ���
3.�ṩ��commit�����ֻ�е�д����ȷ�����ݲ��ᶪʧʱ�Ż�д�룩
4.λϵͳ�ṩ�ⲿ�����ݶ�����Դ
5.�ṩ�洢ʧ�ܵĸ��Ʋ����������µĸ��Ʋ���������
6.�����ڵ�������ƽ��
��ʵ������һ�����ݷַ�ϵͳ����Ҫ�IJ��֣�ʣ�µĴ��������ն˵��õ�API������������ء������Dz�ͬϵͳ��IJ������ڣ����磺һ��ȫ�ı���ѯ�����Ҫ��ѯ���еķ�������һ��������ѯֻ��Ҫ��ѯ��������ݵĵ����ڵ�Ϳ����ˡ�
�������������¸�ϵͳ����ι����ġ�ϵͳ����Ϊ������������־�ͷ���㡣��־��˳��״̬�仯������ڵ�洢�����ṩ��ѯ������Ҫ��������Ϣ����-ֵ�Ĵ洢������B-tree��SSTable�ķ�ʽ���У�������ϵͳ���ܴ�����֮�෴����������д��������ֱ�ӷ�����־��������Ҫͨ��������������д����־��ʱ��������ʱ�������log�е������������ϵͳ�Ƿֶ�ʽ�ģ���ô�ͻ���������Ŀ��ͬ��������־�ļ��ͷ���ڵ㣬����������ͻ����������ܻ��нϴ��ࡣ
����ڵ㶩����־��Ϣ����д����������־�洢��˳��Ӧ�õ����ı��������ϡ�
�ͻ���ֻҪ�ڲ�ѯ������ṩ��Ӧ��д������ʱ��������Ϳ��Դ��κνڵ��л�ȡ����д�����塣����ڵ��յ��ò�ѯ����Ὣ���е�ʱ����������������Ƚϣ������Ҫ������ڵ���ӳ�����ֱ����Ӧʱ�������������ϣ������ṩ�����ݡ�
����ڵ������������֪�������ơ���Ͷ��ѡ��leader election�����ĸ���Ժܶ�IJ���������ڵ������ȫ�����쵼��������ṩ������־������Ϣ����Դ��
�ַ�ϵͳ����Ҫ��������һ���Ƚϸ��ӵĹ�����������ʧ�ܽڵ㲢�Ƴ�����֮��ĸ��롣�����������ݲ�����ϸ������ڵ����ݿ�����һ�ֽ�Ϊ���͵����������뱣�����������ݱ��ݲ����������ڻ�����־�����������ȼۡ����ʹ�÷������˺ܶ࣬��־ϵͳҲ��������ԡ�
���������־ϵͳ������Զ��ĵ�API�����API�ṩ�˰�ETL�ṩ������ϵͳ���������ݡ���ʵ�ϣ�����ϵͳ�����Թ�����ͬ����־ͬʱ�ṩ��ͬ��������������ʾ��
����һ������־Ϊ���ĵ�ϵͳ��������������������ṩ����ͬʱ��������ϵͳ�����ݵ��أ���Ϊ���������ȿ������Ѷ�������������������ֿ���ͨ������ϵͳ������������Ϊ�����ṩ����
���ϵͳ����ͼ���������ķֽ��־�Ͳ�ѯAPI,��Ϊ���������ϵͳ�Ŀ����Ժ�һ���ԽǶȷֽ��ѯ������������������Ƕ�ϵͳ���зֽ⣬��������Щ��û�����ַ�ʽ���ʵʩ��ϵͳ��
��ȻKafka��Bookeeper����һ������־�����ⲻ�DZ���ģ�Ҳûʲô���塣��������ɵİ�Dynamo֮������ݹ��ֽ�Ϊһ���Ե�AP��־�ͼ�ֵ�Է���㡣��������־ʹ����������Ϊ���ش��˾���Ϣ����Dynamoһ���������Ĵ���ȡ������Ϣ�Ķ����ߡ�
�ںܶ��˿���������־�����Ᵽ��һ�����ݵ�����������һ���˷ѡ���ʵ�ϣ���Ȼ�кܶ�����ʹ������²������ѡ����ȣ���־������һ����Ч�Ĵ洢���ơ�������Kafka���������ķ������ϴ洢��5
TB�����ݡ�ͬʱ������ķ���ϵͳ��Ҫ������ڴ����ṩ��Ч�����ݷ��������ı���������ͨ�������ڴ��еġ�����ϵͳͬ��Ҳ����Ӳ�̵��Ż������磬���ǵ�ʵʱ����ϵͳ�������ڴ����ṩ�������ʹ�ù�̬Ӳ�̡��෴����־ϵͳֻ��Ҫ���ԵĶ�д����ˣ���������ʹ��TB������Ӳ�̡����գ�����ͼ��ʾ���ɶ��ϵͳ�ṩ�����ݣ���־�ijɱ���̯����������ϣ����־ۺ�ʹ���ⲿ��־�ijɱ���������͵㡣
LinkedIn����ʹ�������ַ�ʽʵ�����Ķ��ʵʱ��ѯϵͳ�ġ���Щϵͳ�ṩ��һ�����ݿ⣨ʹ������������Ϊ��־ժҪ�����ߴ�Kafkaȥ��ר�õ���־������Щϵͳ�ڶ����������ϻ��ṩ������ķ�Ƭ�������Ͳ�ѯ���ܡ���Ҳ������ʵʩ�������罻�����OLAP��ѯϵͳ�ķ�ʽ����ʵ�����ַ�ʽ���൱�ձ�ģ�Ϊ�������ʵʱ����ķ���ϵͳ�ṩ��һ�����ݣ���Щ����Hadoop�����ݻ���ʵʱ�Ļ��������ģ������ַ�ʽ�ѱ�֤ʵ���൱���ġ���Щϵͳ��������Ҫ�ⲿ��д���API��Kafka�����ݿⱻ����ϵͳ�ļ�¼�ͱ������ͨ����־����Բ�ѯϵͳ�������ض���Ƭ�Ľ���ڱ������д��������Щ���äĿ�İ���־�ṩ������ת¼�������Լ��Ĵ洢�ռ��С�ͨ���ط���������־���Իָ�ת¼ʧ�ܵĽ�㡣
��Щϵͳ�ij̶���ȡ������־�Ķ����ԡ�һ����ȫ�ɿ���ϵͳ��������־�������ݷ�Ƭ���洢��㡢���⸺�أ��Լ���������һ���Ժ����ݸ��Ƶȶ�档����һ�����У������ʵ����ֻ������һ�ֻ�����ƣ����ֻ����������ֱ��д����־����������
������
�������ڱ�������̸���Ĺ�����־�Ĵ����ݣ����������������Բο����������ϡ�����ͬһ�������ǻ��ò�ͬ��������������һЩ�������ݿ�ϵͳ���ֲ�ʽϵͳ���Ӹ�����ҵ��Ӧ�������������Ŀ�Դ���硣������Σ��ڴ����ϻ�����һЩ��֮ͬ���� |


