��ϵ�����µĵ�һ���������˸����������ã�������ֽ������о�һ�¸��������ڲ����ơ����Ǵ��Ÿ����������������ɣ�
����������ת�ƣ����ڵ������ѡ�ٵģ��ܷ��ֶ������¼�ijһ̨���ڵ㡣
�ٷ�˵���������������������Ϊʲô��
MongDB�����������ͬ���ģ����ͬ������ʱ�����ʲô����������ֲ�һ���ԣ�
MongDB�Ĺ���ת�ƻ�����Զ�������ʲô�����ᴥ����Ƶ���������ܻ����ϵͳ���ؼ��أ�
Bully�㷨
MongDB����������ת�ƹ��ܵ���������ѡ�ٻ��ơ�ѡ�ٻ��Ʋ�����Bully�㷨�����Ժܷ���ӷֲ�ʽ�ڵ���ѡ�����ڵ㡣һ���ֲ�ʽ��Ⱥ�ܹ���һ�㶼��һ����ν�����ڵ㣬�����кܶ���;�����绺������ڵ�Ԫ���ݣ���Ϊ��Ⱥ�ķ�����ڵȵȡ����ڵ��о��аɣ����Ǹ���ҪʲôBully�㷨��Ҫ������������ȿ��������ּܹ���
1.ָ�����ڵ�ļܹ������ּܹ�һ�㶼������һ���ڵ�Ϊ���ڵ㣬�����ڵ㶼�Ǵӽڵ㣬�����dz��õ�MySQL�������������������ܹ������ڵ�һ��˵��������Ⱥ������ڵ�ҵ��˾͵��ֹ��������ϼ�һ���µ����ڵ���ߴӴӽڵ�ָ����ݣ���̫��
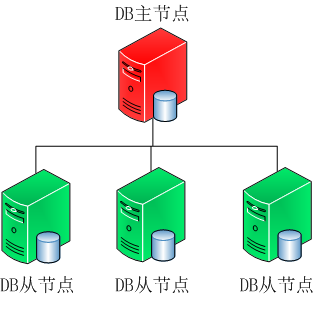
2.��ָ�����ڵ㣬��Ⱥ�е�����ڵ㶼���Գ�Ϊ���ڵ㡣MongoDBҲ���Dz������ּܹ���һ�����ڵ���������ӽڵ��Զ����������ڵ㡣����ͼ��
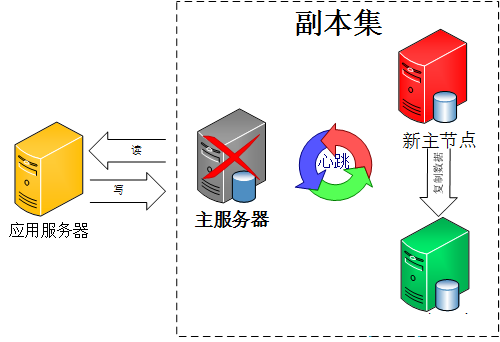
���ˣ������������ط�����Ȼ���нڵ㶼��һ����һ�����ڵ���ˣ���ôȷ����һ�����ڵ㣿�����Bully�㷨��������⡣
��ʲô��Bully�㷨��Bully�㷨��һ��Э���ߣ����ڵ㣩��ѡ�㷨����Ҫ˼���Ǽ�Ⱥ��ÿ����Ա�����������������ڵ㲢֪ͨ�����ڵ㡣��Ľڵ����ѡ�����������ƻ��Ǿܾ����������ڵ㾺�������������нڵ���ܵĽڵ���ܳ�Ϊ���ڵ㡣�ڵ㰴��һЩ�������ж�˭Ӧ��ʤ����������Կ�����һ����̬ID��Ҳ�����Ǹ��µĶ��������һ������ID�����µĽڵ��ʤ������������ο�?NoSQL���ݿ�ֲ�ʽ�㷨��Э���߾�ѡ����ά���ٿƵĽ��͡�
ѡ��
��ô��MongDB��������ѡ�ٵ��أ��ٷ���ô������
1.We use a consensus protocol to pick a primary. Exact details will be spared here but that basic process is:get maxLocalOpOrdinal from each server.
2.if a majority of servers are not up (from this server��s POV), remain in Secondary mode and stop.
3.if the last op time seems very old, stop and await human intervention.
4.else, using a consensus protocol, pick the server with the highest maxLocalOpOrdinal as the Primary.
���·������Ϊʹ��һ��Э��ѡ�����ڵ㡣��������Ϊ��
1.�õ�ÿ���������ڵ��������ʱ�����ÿ��MongDB����oplog���Ƽ�¼��������������������������жԱ������Ƿ�ͬ�����������ڴ���ָ���
2.�����Ⱥ�дַ�����down���ˣ��������ŵĽڵ㶼Ϊsecondary״̬��ֹͣ����ѡ���ˡ�
3.�����Ⱥ��ѡ�ٳ��������ڵ�������дӽڵ����һ��ͬ��ʱ�俴�����ܾɣ�ֹͣѡ�ٵȴ�����������
4.������涼û�������ѡ��������ʱ������£���֤���������µģ��ķ������ڵ���Ϊ���ڵ㡣
�����ᵽ��һ��һ��Э�飨��ʵ����bully�㷨������������ݿ��һ����Э�黹����Щ����һ��Э����Ҫǿ������ͨ��һЩ���Ʊ�֤��Ҵ�ɹ�ʶ����һ����Э��ǿ�����Dz�����˳��һ���ԣ�����ͬʱ��дһ�����ݻ����������ݡ�һ��Э���ڷֲ�ʽ����һ��������㷨�С�Paxos�㷨���������ٽ��ܡ�
�����и����⣬�������дӽڵ��������ʱ�䶼��һ����ô�죿����˭�ȳ�Ϊ���ڵ��ʱ������ѡ˭��
ѡ�ٴ�������
ѡ�ٲ���ʲôʱ�̶��ᱻ�����ģ�������������Դ�����
��ʼ��һ��������ʱ��
�����������ڵ�Ͽ����ӣ��������������⡣
���ڵ�ҵ���
ѡ�ٻ��и�ǰ������������ѡ�ٵĽڵ�����������ڸ������ܽڵ�������һ�룬����Ѿ�С��һ�������нڵ㱣��ֻ��״̬����־������֣�

1. ���ڵ�ҵ��ܷ���Ϊ��Ԥ�����ǿ϶��ġ�
����ͨ��replSetStepDown�����¼����ڵ㡣���������Ե�¼���ڵ�ʹ��

���ɱ��������ʹ��ǿ�ƿ���

����ʹ�� rs.stepDown(120)Ҳ���Դﵽͬ����Ч�����м������ָ������ֹͣ�������ʱ���Ϊ���ڵ㣬��λΪ�롣
2. ����һ���ӽڵ��б����ڵ��и��ߵ����ȼ���
�Ȳ鿴��ǰ��Ⱥ�����ȼ���ͨ��rs.conf()���Ĭ�����ȼ�Ϊ1�Dz���ʾ�ģ������ʾ����
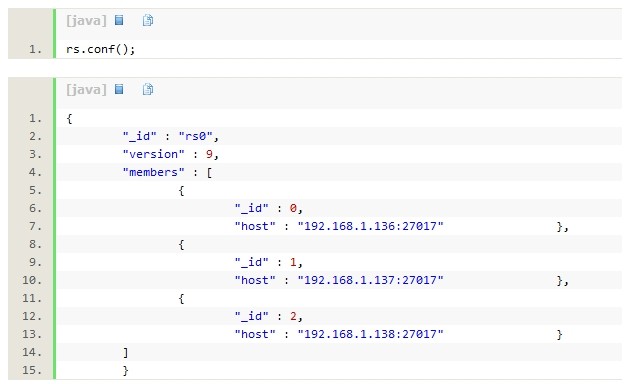
���������һ���ӽڵ��Ϊ���ڵ������ô������
ʹ��rs.freeze(120)����ָ������������ѡ�ٳ�Ϊ���ڵ㡣
������һƪ���ýڵ�ΪNon-Voting���͡�
�����ڵ㲻�ܺʹִӽڵ�ͨѶ���������ڵ����߰ε����ٺ٣���
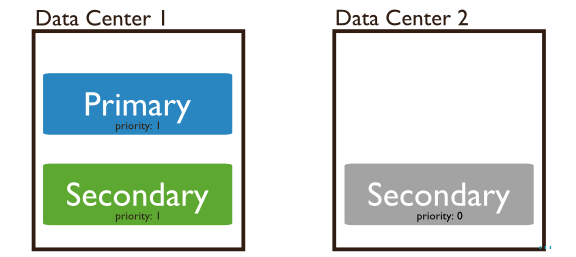
���ȼ���������ô�ã�������Dz�������ʲôhidden�ڵ㣬����secondary������Ϊ���ݽڵ�Ҳ����������Ϊ���ڵ���ô�죿����ͼ���������ڵ�ֲ��������������ģ���������2�Ľڵ��������ȼ�Ϊ0���ܳ�Ϊ���ڵ㣬���ǿ��Բ���ѡ�١����ݸ��ơ��ܹ����Ǻ����ɣ�
����
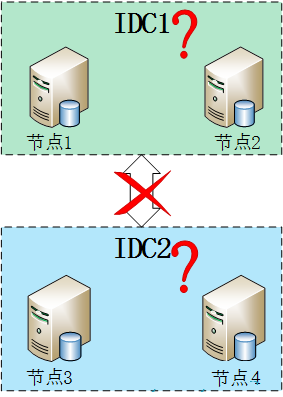
�ٷ��Ƽ��������ij�Ա����Ϊ���������12���������ڵ㣬���7���ڵ����ѡ�١����12���������ڵ�����Ϊû��Ҫһ�����ݸ�����ô��ݣ�����̫�෴�����������縺�غ������˼�Ⱥ���ܣ������7���ڵ����ѡ������Ϊ�ڲ�ѡ�ٻ��ƽڵ�����̫��ͻᵼ��1�����ڻ�ѡ�������ڵ㣬����ֻҪ�ʵ��ͺá������12������7�����ֻ��ã�ͨ�����ǹٷ��������ܲ��Զ�������������⡣���廹����Щ���Ʋο��ٷ��ĵ��� MongoDB Limits and Thresholds ���� ��������һֱû�㶮������ȺΪʲôҪ������ͨ�����Լ�Ⱥ������Ϊż��Ҳ�ǿ������еģ��ο��������http://www.itpub.net/thread-1740982-1-1.html������ͻȻ����һƪstackoverflow���������ڶ����ˣ�mongodb������Ƶľ���һ�����Կ�IDC�ķֲ�ʽ���ݿ⣬��������Ӧ�ð����ŵ���Ļ���������
�����ĸ��ڵ㱻�ֳ�����IDC��ÿ��IDC����̨����������ͼ���������ͳ����˸����⣬�������IDC����ϵ������ڹ������Ϻ����׳��ֵ����⣬������ѡ�����ᵽֻҪ���ڵ�ͼ�Ⱥ�дֽڵ�Ͽ����ӾͻῪʼһ���µ�ѡ�ٲ���������MongoDB���������߶�ֻ�������ڵ㣬����ѡ��Ҫ�����Ľڵ������������һ�룬�������м�Ⱥ�ڵ㶼û�취����ѡ�٣�ֻ�ᴦ��ֻ��״̬����������������ڵ�Ͳ������������⣬����3���ڵ㣬ֻҪ��2���ڵ���žͿ���ѡ�٣�5���е�3����7���е�4������
����
����������������Ⱥ��Ҫ����һ����ͨ�Ų���֪����Щ�ڵ������Щ�ڵ�ҵ���MongoDB�ڵ�������е������ڵ�ÿ����ͻᷢ��һ��pings������������ڵ���10����֮��û�з��ؾͱ�ʾΪ���ܷ��ʡ�ÿ���ڵ��ڲ�����ά��һ��״̬ӳ�����������ǰÿ���ڵ���ʲô��ɫ����־ʱ����ȹؼ���Ϣ����������ڵ㣬����ά��ӳ������Ҫ����Լ��ܷ�ͼ�Ⱥ���ڴֽڵ�ͨѶ�������������Լ�����Ϊsecondaryֻ���ڵ㡣
ͬ��
������ͬ����Ϊ��ʼ��ͬ����keep���ơ���ʼ��ͬ��ָȫ�������ڵ�ͬ�����ݣ�������ڵ��������Ƚϴ�ͬ��ʱ���Ƚϳ�����keep����ָ��ʼ��ͬ�����ڵ�֮���ʵʱͬ��һ��������ͬ������ʼ��ͬ����ֻ���ڵ�һ�βŻᱻ��������������������ᴥ����
1.secondary��һ�μ��룬����ǿ϶��ġ�
2.secondary����������������oplog�Ĵ�С������Ҳ�ᱻȫ�����ơ�
��ʲô��oplog�Ĵ�С��ǰ��˵��oplog���������ݵIJ�����¼��secondary����oplog��������IJ�����secondaryִ��һ�顣����oplogҲ��mongodb��һ�����ϣ�������local.oplog.rs�Ȼ�����oplog��һ��capped collection��Ҳ���ǹ̶���С�ļ��ϣ������ݼ��볬�����ϵĴ�С�Ḳ�ǣ�����������Ҫע�⣬��IDC�ĸ���Ҫ���ú��ʵ�oplogSize������������������������ȫ�����ơ�oplogSize ����ͨ���CoplogSize���ô�С������Linux ��Windows 64λ��oplog sizeĬ��Ϊʣ����̿ռ��5%��
ͬ��Ҳ����ֻ�ܴ����ڵ�ͬ�������輯Ⱥ��3���ڵ㣬�ڵ�1�����ڵ���IDC1���ڵ�2���ڵ�3��IDC2����ʼ���ڵ�2���ڵ�3��ӽڵ�1ͬ�����ݡ�����ڵ�2���ڵ�3��ʹ�þͽ�ԭ��ӵ�ǰIDC�ĸ������н��и��ƣ�ֻҪ��һ���ڵ��IDC1�Ľڵ�1�������ݡ�
����ͬ����Ҫע�����¼��㣺
1.secondary�����delayed��hidden��Ա�ϸ������ݡ�
2.ֻҪ����Ҫͬ����������Ա��buildindexes����Ҫ��ͬ�����Ƿ���true��false��buildindexes��Ҫ���������Ƿ�����ڵ���������ڲ�ѯ��Ĭ��Ϊtrue��
3.���ͬ������30�붼û�з�Ӧ���������ѡ��һ���ڵ����ͬ����
���ˣ�����ǰ���ᵽ������ȫ������ˣ����ò�˵MongoDB����ƻ�����ǿ��
�������������һ���⼸�����⣺
���ڵ�����ܷ��Զ��л����ӣ�Ŀǰ��Ҫ�ֹ��л���
���ڵ�Ķ�дѹ��������ν����
����������������������
�ӽڵ�ÿ����������ݶ��Ƕ����ݿ�ȫ���������ӽڵ�ѹ��������
����ѹ������֧�Ų��˵�ʱ���ܷ������Զ���չ��


