| 一
Hadoop版本 和 生态圈
1. Hadoop版本
(1) Apache Hadoop版本介绍
Apache的开源项目开发流程 :
-- 主干分支 : 新功能都是在 主干分支(trunk)上开发;
-- 特性独有分支 : 很多新特性稳定性很差, 或者不完善, 在这些分支的独有特定很完善之后, 该分支就会并入主干分支;
-- 候选分支 : 定期从主干分支剥离, 一般候选分支发布, 该分支就会停止更新新功能, 如果候选分支有BUG修复,
就会重新针对该候选分支发布一个新版本;候选分支就是发布的稳定版本;
造成Hadoop版本混乱的原因 :
-- 主要功能在分支版本开发 : 0.20分支发布之后, 主要功能一直在该分支上进行开发, 主干分支并没有合并这个分支,
0.20分支成为了主流;
-- 低版本的后发布 : 0.22版本 发布 要晚于 0.23版本;
-- 版本重命名 : 0.20分支的 0.20.205版本重命名为 1.0版本, 这两个版本是一样的,
只是名字改变了;
Apache Hadoop 版本示意图 :

(2) Apache Hadoop 版本功能介绍
第一代Hadoop特性 :
-- append : 支持文件追加功能, 让用户使用HBase的时候避免数据丢失, 也是使用HBase的前提;
-- raid : 保证数据可靠, 引入校验码校验数据块数目;
-- symlink : 支持HDFS文件链接;
-- security : hadoop安全机制;
-- namenode HA : 为了避免 namenode单点故障情况, HA集群有两台namenode;
第二代Hadoop特性 :
-- HDFS Federation : NameNode制约HDFS扩展, 该功能让多个NameNode分管不同目录,
实现访问隔离和横向扩展;
-- yarn : MapReduce扩展性 和 多框架方面支持不足, yarn 是全新的资源管理框架,
将JobTracker资源管理 和 作业控制功能分开,
ResourceManager负责资源管理, ApplicationMaster负责作业控制;
0.20版本分支 : 只有这个分支是稳定版本, 其它分支都是不稳定版本;
-- 0.20.2版本(稳定版) : 包含所有特性, 经典版;
-- 0.20.203版本(稳定版) : 包含append, 不包含 symlink raid namenodeHA
功能;
-- 0.20.205版本/1.0版本(稳定版) : 包含 append security, 不包含
symlink raid namenodeHA功能;
-- 1.0.1 ~ 1.0.4版本(稳定版) : 修复1.0.0的bug 和 进行一些性能上的改进;
0.21版本分支(不稳定版) : 包含 append raid symlink namenodeHA,
不包含 security ;
0.22版本分支(不稳定版) : 包含 append raid symlink 那么弄得HA, 不包含
mapreduce security;
0.23版本分支 :
-- 0.23.0版本(不稳定版) : 第二代的hadoop, 增加了 HDFS Federation
和 yarn;
-- 0.23.1 ~ 0.23.5 (不稳定版) : 修复 0.23.0 的一些BUG, 以及进行一些优化;
-- 2.0.0-alpha ~ 2.0.2-alpha(不稳定版) : 增加了 namenodeHA
和 Wire-compatiblity 功能;
(3) Cloudera Hadoop对应Apache Hadoop版本.

2. Hadoop生态圈
Apache支持 : Hadoop的核心项目都受Apache支持的, 除了Hadoop之外, 还有下面几个项目,
也是Hadoop不可或缺的一部分;
-- HDFS : 分布式文件系统, 用于可靠的存储海量数据;
-- MapReduce : 分布式处理数据模型, 可以运行于大型的商业云计算集群中;
-- Pig : 数据流语言 和 运行环境, 用来检索海量数据集;
-- HBase : 分布式数据库, 按列存储, HBase使用HDFS作为底层存储, 同时支持MapReduce模型的海量计算
和 随机读取;
-- Zookeeper : 提供Hadoop集群的分布式的协调服务, 用于构建分布式应用, 避免应用执行失败带来的不确定性损失;
-- Sqoop : 该工具可以用于 HBase 和 HDFS 之间的数据传输, 提高数据传输效率;
-- Common : 分布式文件系统, 通用IO组件与接口, 包括 序列化, Java RPC, 和持久化数据结构;
-- Avro : 支持高效 跨语言的RPC 及 永久存储数据的序列化系统;
二. MapReduce模型简介
MapReduce简介 : MapReduce 是一种 数据处理 编程模型;
-- 多语言支持 : MapReduce 可以使用各种语言编写, 例如
Java, Ruby, Python, C ++ ;
-- 并行本质 : MapReduce 本质上可以并行运行的;
1. MapReduce 数据模型解析
MapReduce数据模型 :
-- 两个阶段 : MapReduce 的任务可以分为两个阶段, Map阶段
和 Reduce阶段;
-- 输入输出 : 每个阶段都使用键值对作为输入 和 输出, IO类型可以由程序员进行选择;
-- 两个函数 : map 函数 和 reduce 函数;
MapReduce作业组成 : 一个MapReduce 工作单元, 包括 输入数据, MapReduce
程序 和 配置信息;
作业控制 : 作业控制由 JobTracker(一个) 和 TaskTracker(多个)
进行控制的;
-- JobTracker作用 : JobTracker 控制 TaskTracker
上任务的运行, 进行统一调度;
-- TaskTracker作用 : 执行具体的 MapReduce 程序;
-- 统一调度方式 : TaskTracker 运行的同时将运行进度发送给
JobTracker, JobTracker记录所有的TaskTracker;
-- 任务失败处理 : 如果一个 TaskTracker 任务失败, JobTracker
会调度其它 TaskTracker 上重新执行该MapReduce 作业;
2. Map 数据流
输入分片 : MapReduce 程序执行的时候, 输入的数据会被分成等长的数据块,
这些数据块就是分片;
-- 分片对应任务 : 每个分片都对应着一个 Map 任务, 即MapReduce
中的map函数;
-- 并行处理 : 每个分片 执行 Map 任务要比 一次性处理所有数据
时间要短;
-- 负载均衡 : 集群中的计算机 有的 性能好 有的性能差, 按照性能合理的分配
分片 大小, 比 平均分配效率要高, 充分发挥出集群的效率;
-- 合理分片 : 分片越小负载均衡效率越高, 但是管理分片 和 管理map任务
总时间会增加, 需要确定一个合理的 分片大小, 一般默认为 64M, 与块大小相同;
数据本地优化 : map 任务运行在 本地存储数据的 节点上, 才能获得最好的效率;
-- 分片 = 数据块 : 一个分片只在单个节点上存储, 效率最佳;
-- 分片 > 数据块 : 分片 大于 数据块, 那么一个分片的数据就存储在了多个节点上,
map 任务所需的数据需要从多个节点传输, 会降低效率;
Map任务输出 : Map 任务执行结束后, 将计算结果写入到 本地硬盘,
不是写入到 HDFS 中;
-- 中间过渡 : Map的结果只是用于中间过渡, 这个中间结果要传给
Reduce 任务执行, reduce 任务的结果才是最终结果, map 中间值 最后会被删除;
-- map任务失败 : 如果 map 任务失败, 会在另一个节点重新运行这个map
任务, 再次计算出中间结果;
3. Reduce 数据流
Reduce任务 : map 任务的数量要远远多于 Reduce 任务;
-- 无本地化优势 : Reduce 的任务的输入是 Map 任务的输出,
reduce 任务的绝大多数数据 本地是没有的;
-- 数据合并 : map 任务 输出的结果, 会通过网络传到 reduce
任务节点上, 先进行数据的合并, 然后在输入到reduce 任务中进行处理;
-- 结果输出 : reduce 的输出直接输出到 HDFS中;
-- reduce数量 : reduce数量是特别指定的, 在配置文件中指定;
MapReduce数据流框图解析 :
-- 单个MapReduce的数据流 :

-- 多个MapReduce模型 :
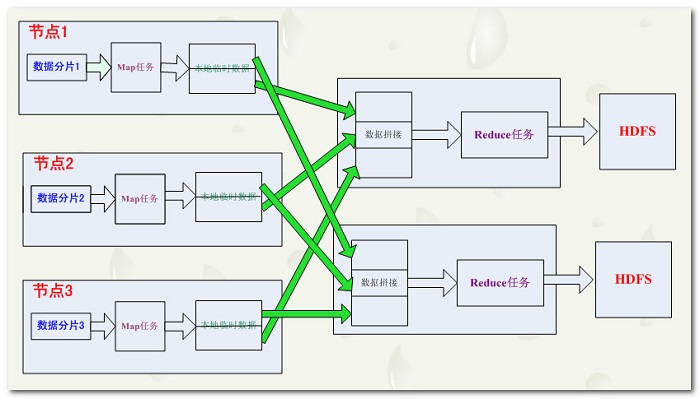
-- 没有Reduce程序的MapReduce数据流 :

Map输出分区 : 多个 reduce 任务, 每个reduce 任务都对应着
一些map任务, 我们将这些map 任务 根据其输入reduce 任务进行分区, 为每个reduce 建立一个分区;
-- 分区标识 : map结果有许多种类键, 相同的键对应的数据 传给
一个reduce, 一个map 可能会给多个reduce输出数据;
-- 分区函数 : 分区函数可以由用户定义, 一般情况下使用系统默认的分区函数
partitioner, 该函数通过哈希函数进行分区;
混洗 : map 任务 和 reduce 任务之间的数据流成为混;
-- reduce数据来源 : 每个 reduce 任务的输入数据来自多个map
-- map 数据去向 : 每个 map 任务的结果都输出到多个 reduce
中;
没有Reduce : 当数据可以完全并行处理的时候, 就可以不适用reduce, 只进行map 任务;
4. Combiner 引入
MapReduce瓶颈 : 带宽限制了 MapReduce 执行任务的数量, Map 和 Reduce
执行过程中需要进行大量的数据传输;\
-- 解决方案 : 合并函数 Combiner, 将 多个 Map 任务输出的结果合并, 将合并后的结果发送给
Reduce 作业;
5. Hadoop Streaming
Hadoop多语言支持 : Java, Python, Ruby, C++;
-- 多语言 : Hadoop 允许使用 其它 语言写 MapReduce
函数;
-- 标准流 : 因为 Hadoop 可以使用 UNIX 标准流 作为
Hadoop 和 应用程序之间的接口, 因此 只要使用标准流, 就可以进行 MapReduce 编程;
Streaming处理文本 : Streaming在文本处理模式下, 有一个数据行视图,
非常适合处理文本;
-- Map函数的输入输出 : 标准流 一行一行 的将数据 输入到 Map
函数, Map函数的计算结果写到 标准输出流中;
-- Map输出格式 : 输出的 键值对 是以制表符 分隔的行, 以这种形式写出的标准输出流中;
-- Reduce函数的输入输出 : 输入数据是 标准输入流中的 通过制表符
分隔的键值对 行, 该输入经过了Hadoop框架排序, 计算结果输出到标准输出流中;
6. Hadoop Pipes
Pipes概念 : Pipes 是 MapReduce 的C++ 接口;
-- 理解误区 : Pipes 不是使用 标准 输入 输出流作为 Map
和 Reduce 之间的Streaming, 也没有使用JNI编程;
-- 工作原理 : Pipes 使用套接字作为 map 和 reduce
函数 进程之间的通信; |


