|
1 引言
中国本土程序员马根峰推出的个人作品----万能数据库查询分析器,中文版本《DB 查询分析器》、英文版本《DB
Query Analyzer》。
万能数据库查询分析器集哈希技术、链表等多种数据结构于一体,使用先进系统开发技术,经历4年的研究、开发、测试周期后在2006年面世。之后7年来一直在进行不断地完善、升级,到目前为止,最新版本为5.04
。“万能数据库查询分析器”核心部分就具有长达5万多行代码的工作量,使得其具有强大的功能、友好的操作界面、良好的操作性、跨越各种数据库平台乃至于EXCEL和文本文件。
你可以通过它查询ODBC数据源(包括世面上所有的数据库、TXT/CSV文件、EXCEL文件)的数据。你可以同时执行多条DML语句乃至存贮过程,结果会以你设定的表格、文本框、文件来返回。从数据库导出千万条数据时,效率与DBMS没有什么区别。
本文将以5.04版本为例,详细阐述“万能数据库查询分析器”中文版本《DB
查询分析器》在 文本文件 处理方面非常强大的功能,你可以直接用SQL语句来访问这些文本文件,访问250万条记录的文件的复杂的关联操作,也不过用时59秒钟。要注意的是,文本文件的第一行需要有列名。
2 产品获得的成就及发展历程
中文版本《DB 查询分析器》在中关村在线 下载量超过10万 多次,位居整个数据库类排行榜中前20位。
在《程序员》2007第2期的“新产品&工具点评”部分,编辑“特别推荐”了“万能数据库查询分析器”发布。本期只点评了5个工具,分别是“Adobe
Acrobat 8 中文版”、“迅雷搜索 1.7 新版上线”、“Google 桌面搜索 5.0 中文发布”、“BEA
发布 WebLogic SIPServer 3.0”和特别推荐“万能数据库查询分析器”发布。前面4个都是国内外大型软件公司的产品,只有“万能数据库查询分析器”是个人创作的软件。
截止到2013年4月17日,在Baidu上搜索关键字"万能数据库查询分析器",搜索结果达318万。在Baidu上搜索关键字"DB查询分析器"、"DBQuery
Analyzer",搜索结果分别在104万、16万左右;在Google上搜索“DB 查询分析器”、“DBQuery
Analyzer”,结果分别达104万、44万之多。
本人撰写了关于“万能数据库查询分析器”有关技术的64篇文章,发布在《电脑编程技巧与维护》、《软件》、《计算机时代》、《电脑编程技巧与维护》、百度文库、CSDN资源、和本人的四大博客上(CSDN博客、新浪博客、QQ空间和搜狐博客上)。
3 为何用《DB 查询分析器》来访问文本文件来解决实际问题
在广东联合电子服务股份有限公司实施一张网的过程中,由于路段上传的流水存在大量的异常,导致按照正常的结算流程无法快速地进行路段的结算。因此,为了进行及时的结算,广东省高速公路公司授权先将异常流水进行忽略,后期再将这些流水进行上传、修改、拆分结算。
最近,为了实施忽略流水的回传,本人做的第一步就是从忽略的流水中按照(流水只有在管理点存在、中心和管理点都存在)这两种情况,再按照流水金额小于0、等于0、大于0三类进行统计成台账(6个文件),然后业务组,再从这些分类批次(6个文件)中确认哪些批次需要回传(形成2
个文件, 流水大于0.csv 和 流水小于0.csv )。
最终,本人还要根据这些这两个文件中是否“回传”,再从结算系统中根据复杂的逻辑,找出要回传的流水号并按照区域分成4个文件。
在本次处理中,
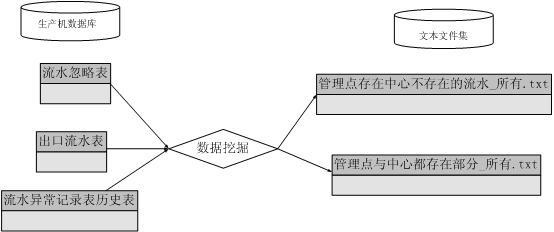
源处理文件:流水大于0.csv 、 流水小于0.csv 、tb_road、 管理点存在中心不存在的流水_所有.txt
和 管理点与中心都存在的部分_所有.txt 这5个文件。
后两个文件是从结算系统数据库服务器中通过复杂的逻辑处理生成的中间结果文件。
输出结果:要回传的流水号并按照区域分成4个文件。
解决方案:因此,输入条件决定要么在结算数据库系统中建立 数据表 来完成条件的判断;要么将结果全部忽略的流水、需要关联的数据表(tb_road)导出成.CSV/.TXT
文件,再使用《DB 查询分析器》强大、高效的.CSV/.TXT 访问功能来实施整个回传流水文件的生成。
tb_road 表只是从生产机数据库中导出tb_road表就行了。
图2 数据挖掘生成文本文件“管理点与中心都存在部分_所有.txt”
4 5.04中文版本《DB 查询分析器》为例
下面我们就以“万能数据库查询分析器”的中文版本《DB 查询分析器》 5.04为例,以Windows
2000Server操作系统为平台,先创建基于目录 “D:\ODBC_TXT_CSV”中 .TXT/.CSV
文件的ODBC数据源 “odbc_txt_csv”,然后再通过 DB 查询分析器 5.04来访问这些目录下的文件。
操作系统: Windows2000 Server操作系统
CPU:2.8 GHZ 单核
内存:1GB
前台程序: DB 查询分析器 5.04
后台文件: .TXT/.CSV
图3 创建基于 .CSV/.TXT 文件的ODBC数据源(一)
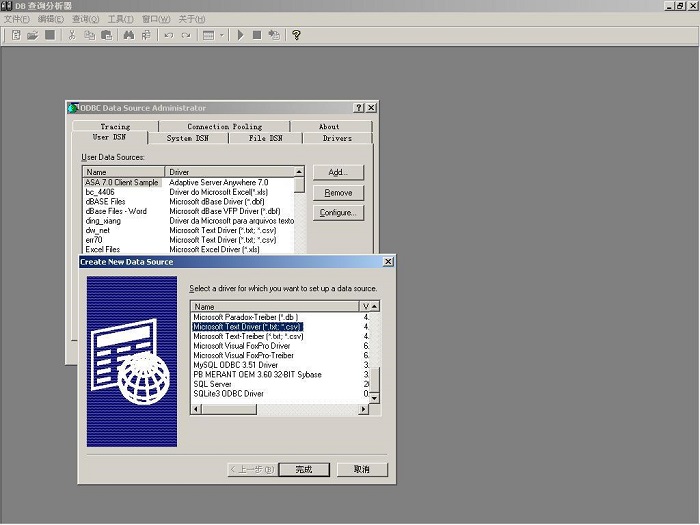
图4 创建基于 .CSV/.TXT 文件的ODBC数据源(二)
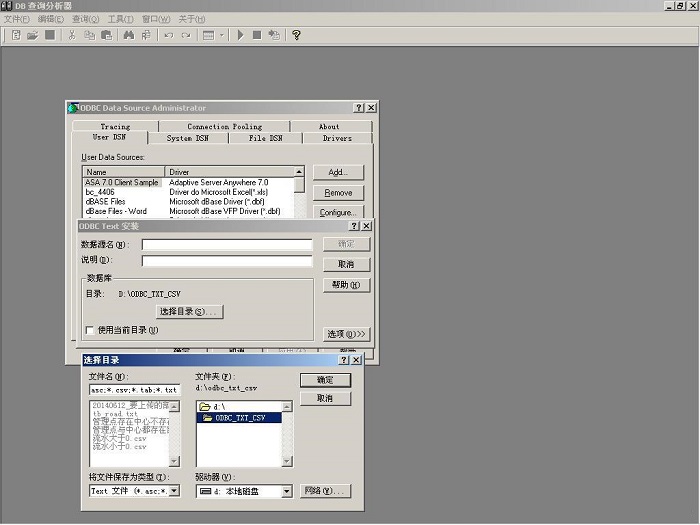
图5 登录odbc_txt_csv,不用输入用户名和口令
图6 对象浏览器来查看数据源 odbc_txt_csv
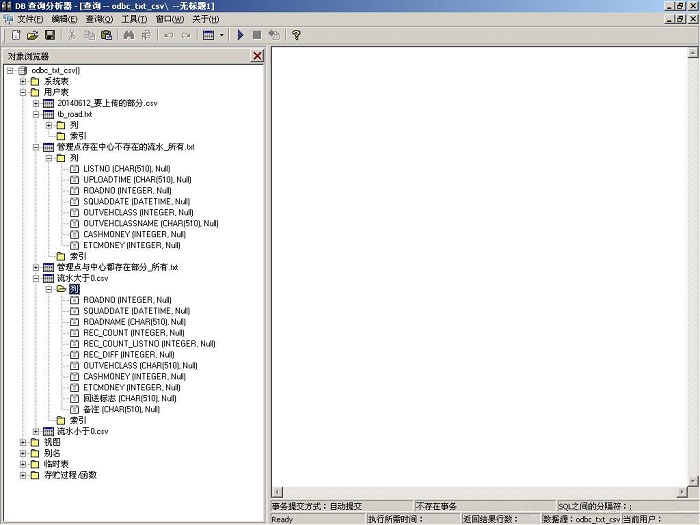
图7 Windows资源管理器中,ODBC数据源odbc_txt_csv对应的目录下所有的文件
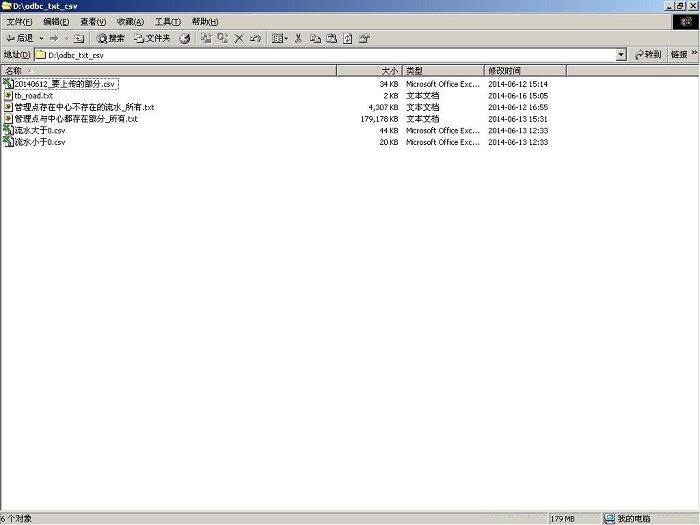
图8 用SQL语句来访问 .txt和 .csv文件,来生成各区域需要回传的流水
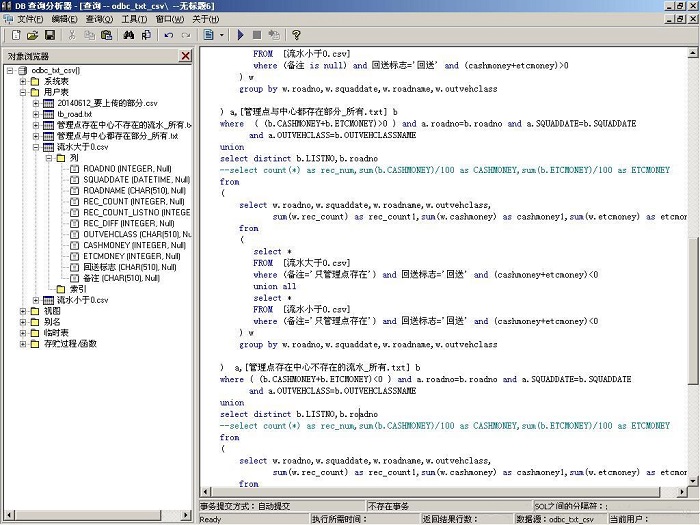
图8中的复杂的SQL语句如下:
select listno,'2014-06-16'
from
(
select distinct b.LISTNO,b.roadno
--select count(*) asrec_num,sum(b.CASHMONEY)/100 as CASHMONEY,sum(b.ETCMONEY)/100 as ETCMONEY
from
(
selectw.roadno,w.squaddate,w.roadname,w.outvehclass,
sum(w.rec_count) as rec_count1,sum(w.cashmoney) as cashmoney1,sum(w.etcmoney) as etcmoney1
from
(
select *
FROM [流水大于0.csv]
where (备注 is null) and 回送标志='回送' and(cashmoney+etcmoney)<0
union all
select *
FROM [流水小于0.csv]
where (备注 is null) and 回送标志='回送' and(cashmoney+etcmoney)<0
) w
group byw.roadno,w.squaddate,w.roadname,w.outvehclass
) a,[管理点与中心都存在部分_所有.txt] b
where ( (b.CASHMONEY+b.ETCMONEY)<0 ) and a.roadno=b.roadno anda.SQUADDATE=b.SQUADDATE
anda.OUTVEHCLASS=b.OUTVEHCLASSNAME
union
select distinct b.LISTNO,b.roadno
--select count(*) asrec_num,sum(b.CASHMONEY)/100 as CASHMONEY,sum(b.ETCMONEY)/100 as ETCMONEY
from
(
selectw.roadno,w.squaddate,w.roadname,w.outvehclass,
sum(w.rec_count) as rec_count1,sum(w.cashmoney) as cashmoney1,sum(w.etcmoney) as etcmoney1
from
(
select *
FROM [流水大于0.csv]
where (备注 is null) and 回送标志='回送' and(cashmoney+etcmoney)>0
union all
select *
FROM [流水小于0.csv]
where (备注 is null) and 回送标志='回送' and(cashmoney+etcmoney)>0
) w
group byw.roadno,w.squaddate,w.roadname,w.outvehclass
) a,[管理点与中心都存在部分_所有.txt] b
where ( (b.CASHMONEY+b.ETCMONEY)>0 ) and a.roadno=b.roadno anda.SQUADDATE=b.SQUADDATE
anda.OUTVEHCLASS=b.OUTVEHCLASSNAME
union
select distinct b.LISTNO,b.roadno
--select count(*) asrec_num,sum(b.CASHMONEY)/100 as CASHMONEY,sum(b.ETCMONEY)/100 as ETCMONEY
from
(
selectw.roadno,w.squaddate,w.roadname,w.outvehclass,
sum(w.rec_count) as rec_count1,sum(w.cashmoney) as cashmoney1,sum(w.etcmoney) as etcmoney1
from
(
select *
FROM [流水大于0.csv]
where (备注='只管理点存在') and 回送标志='回送' and(cashmoney+etcmoney)<0
union all
select *
FROM [流水小于0.csv]
where (备注='只管理点存在') and 回送标志='回送' and(cashmoney+etcmoney)<0
) w
group byw.roadno,w.squaddate,w.roadname,w.outvehclass
) a,[管理点存在中心不存在的流水_所有.txt] b
where ((b.CASHMONEY+b.ETCMONEY)<0 ) and a.roadno=b.roadno anda.SQUADDATE=b.SQUADDATE
anda.OUTVEHCLASS=b.OUTVEHCLASSNAME
union
select distinct b.LISTNO,b.roadno
--select count(*) asrec_num,sum(b.CASHMONEY)/100 as CASHMONEY,sum(b.ETCMONEY)/100 as ETCMONEY
from
(
selectw.roadno,w.squaddate,w.roadname,w.outvehclass,
sum(w.rec_count) as rec_count1,sum(w.cashmoney) as cashmoney1,sum(w.etcmoney) as etcmoney1
from
(
select *
FROM [流水大于0.csv]
where (备注='只管理点存在') and 回送标志='回送' and(cashmoney+etcmoney)>0
union all
select *
FROM [流水小于0.csv]
where (备注='只管理点存在') and 回送标志='回送' and(cashmoney+etcmoney)>0
) w
group byw.roadno,w.squaddate,w.roadname,w.outvehclass
) a,[管理点存在中心不存在的流水_所有.txt] b
where ((b.CASHMONEY+b.ETCMONEY)>0 ) and a.roadno=b.roadno anda.SQUADDATE=b.SQUADDATE
anda.OUTVEHCLASS=b.OUTVEHCLASSNAME
) www
where roadno in (select roadno from [tb_road.txt] where areano=4407)
|
图9 一开始执行图8中的SQL语句时,本机CPU使用率立刻攀升至97%
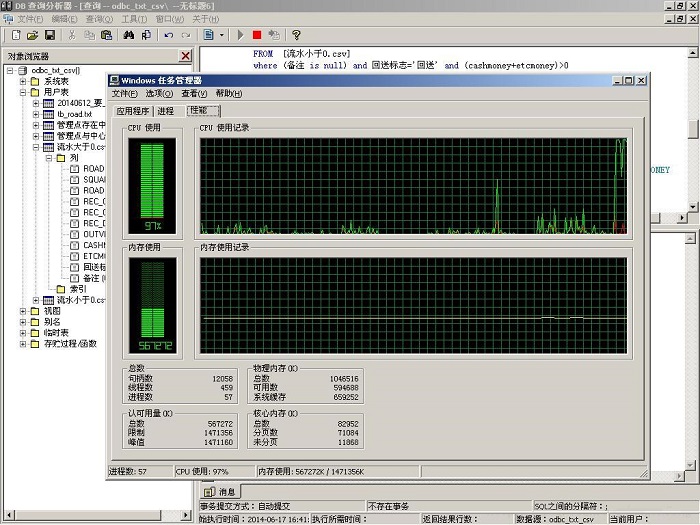
图10 生成中片区需要回传的流水文件,共有6万多条记录
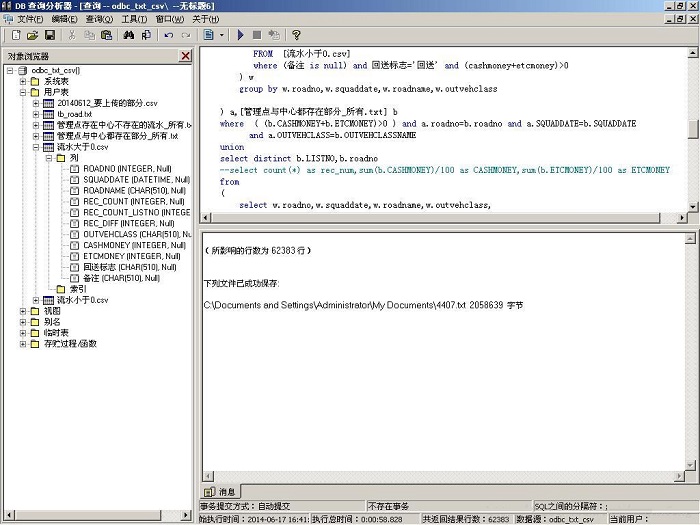
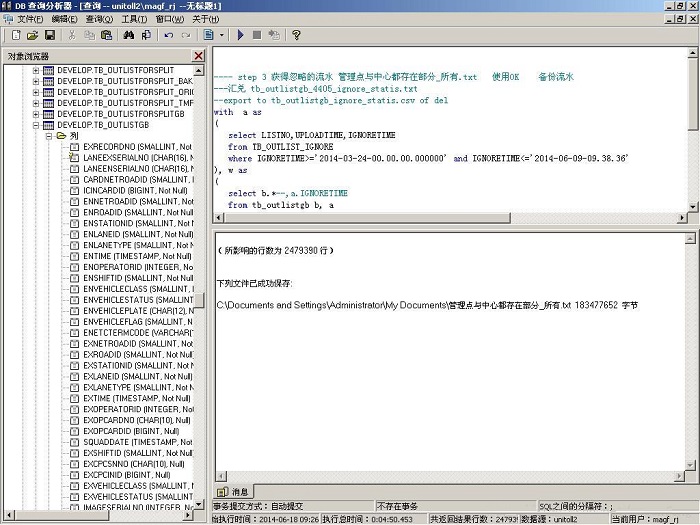
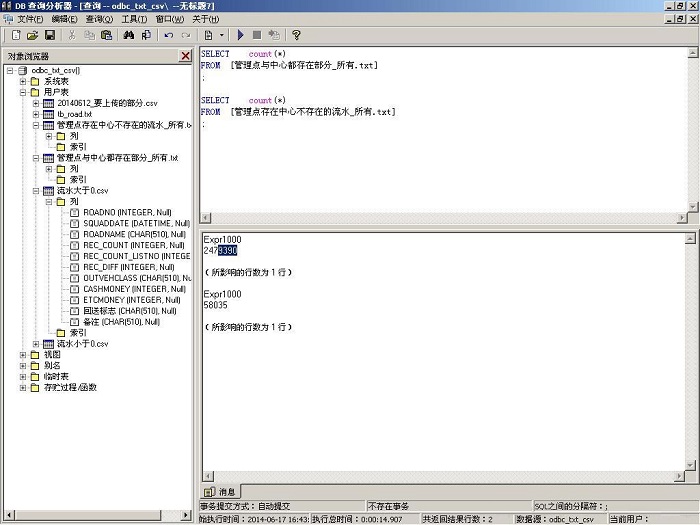
图11 从结算中心数据库中用挖掘生成的所有忽略的流水,两个文件共250多万条记录
结论:
对于“交互式”这种数据处理的方式来说,将结果导出,用《DB 查询分析器》的强大、高效的文本文件的处理功能来分析处理,也是一种不错的选择。并且《DB
查询分析器》的效率非常之高、处理非常方便,可以将源文件当成一个数据库中的数据表一样用标准SQL语句来进行访问。
本人的PC机只不过内存1GB的2005年的DELL 台式PC机,对250万条记录的文件进行关联访问的时候,也只是用不到59秒的时间就生成了一个区域的结果文件,期间CPU使用率高达97%
。 |





