|
前几篇文章介绍了Spark SQL的Catalyst的核心运行流程、SqlParser,和Analyzer
以及核心类库TreeNode,本文将详细讲解Spark SQL的Optimizer的优化思想以及Optimizer在Catalyst里的表现方式,并加上自己的实践,对Optimizer有一个直观的认识。
Optimizer的主要职责是将Analyzer给Resolved的Logical
Plan根据不同的优化策略Batch,来对语法树进行优化,优化逻辑计划节点(Logical Plan)以及表达式(Expression),也是转换成物理执行计划的前置。如下图:
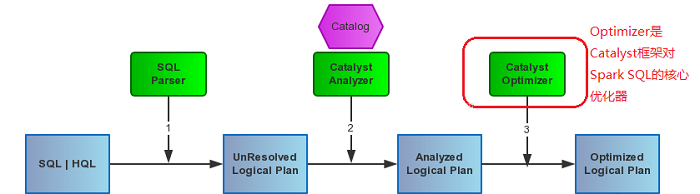
一、Optimizer
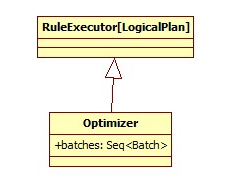
Optimizer这个类是在catalyst里的optimizer包下的唯一一个类,Optimizer的工作方式其实类似Analyzer,因为它们都继承自RuleExecutor[LogicalPlan],都是执行一系列的Batch操作:
Optimizer里的batches包含了3类优化策略:1、Combine
Limits 合并Limits 2、ConstantFolding 常量合并 3、Filter Pushdown
过滤器下推,每个Batch里定义的优化伴随对象都定义在Optimizer里了:
object Optimizer extends RuleExecutor[LogicalPlan] {
val batches =
Batch("Combine Limits", FixedPoint(100),
CombineLimits) ::
Batch("ConstantFolding", FixedPoint(100),
NullPropagation,
ConstantFolding,
BooleanSimplification,
SimplifyFilters,
SimplifyCasts,
SimplifyCaseConversionExpressions) ::
Batch("Filter Pushdown", FixedPoint(100),
CombineFilters,
PushPredicateThroughProject,
PushPredicateThroughJoin,
ColumnPruning) :: Nil
} |
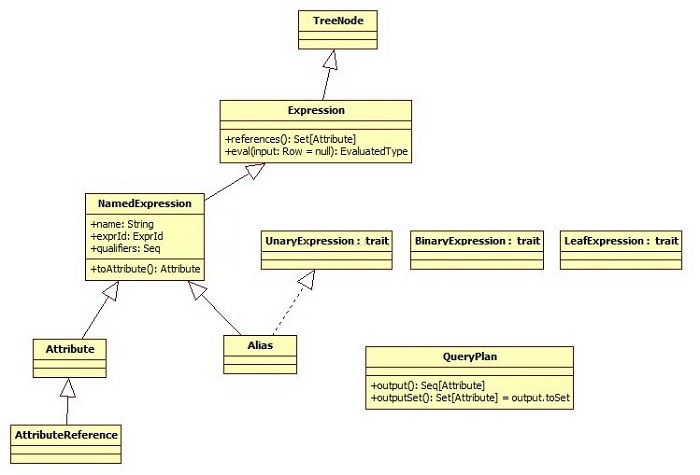
另外提一点,Optimizer里不但对Logical Plan进行了优化,而且对Logical Plan中的Expression也进行了优化,所以有必要了解一下Expression相关类,主要是用到了references和outputSet,references主要是Logical
Plan或Expression节点的所依赖的那些Expressions,而outputSet是Logical
Plan所有的Attribute的输出:
如:Aggregate是一个Logical Plan, 它的references就是group by的表达式
和 aggreagate的表达式的并集去重。
case class Aggregate(
groupingExpressions: Seq[Expression],
aggregateExpressions: Seq[NamedExpression],
child: LogicalPlan)
extends UnaryNode {
override def output = aggregateExpressions.map(_.toAttribute)
override def references =
(groupingExpressions ++ aggregateExpressions).flatMap(_.references).toSet
} |
二、优化策略详解
Optimizer的优化策略不仅有对plan进行transform的,也有对expression进行transform的,究其原理就是遍历树,然后应用优化的Rule,但是注意一点,对Logical
Plantransfrom的是先序遍历(pre-order),而对Expression transfrom的时候是后序遍历(post-order):
2.1、Batch: Combine Limits
如果出现了2个Limit,则将2个Limit合并为一个,这个要求一个Limit是另一个Limit的grandChild。
/**
* Combines two adjacent [[Limit]] operators into one, merging the
* expressions into one single expression.
*/
object CombineLimits extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
case ll @ Limit(le, nl @ Limit(ne, grandChild)) => //ll为当前Limit,le为其expression, nl是ll的grandChild,ne是nl的expression
Limit(If(LessThan(ne, le), ne, le), grandChild) //expression比较,如果ne比le小则表达式为ne,否则为le
}
} |
给定SQL:val query = sql("select * from (select *
from temp_shengli limit 100)a limit 10 ")
scala> query.queryExecution.analyzed
res12: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Limit 10
Project [key#13,value#14]
Limit 100
Project [key#13,value#14]
MetastoreRelation default, temp_shengli, None |
子查询里limit100,外层查询limit10,这里我们当然可以在子查询里不必查那么多,因为外层只需要10个,所以这里会合并Limit10,和Limit100
为 Limit 10。
2.2、Batch: ConstantFolding
这个Batch里包含了Rules:NullPropagation,ConstantFolding,BooleanSimplification,SimplifyFilters,SimplifyCasts,SimplifyCaseConversionExpressions。
2.2.1、Rule:NullPropagation
这里先提一下Literal字面量,它其实是一个能匹配任意基本类型的类。(为下文做铺垫)
object Literal {
def apply(v: Any): Literal = v match {
case i: Int => Literal(i, IntegerType)
case l: Long => Literal(l, LongType)
case d: Double => Literal(d, DoubleType)
case f: Float => Literal(f, FloatType)
case b: Byte => Literal(b, ByteType)
case s: Short => Literal(s, ShortType)
case s: String => Literal(s, StringType)
case b: Boolean => Literal(b, BooleanType)
case d: BigDecimal => Literal(d, DecimalType)
case t: Timestamp => Literal(t, TimestampType)
case a: Array[Byte] => Literal(a, BinaryType)
case null => Literal(null, NullType)
}
} |
注意Literal是一个LeafExpression,核心方法是eval,给定Row,计算表达式返回值:
case class Literal(value: Any, dataType: DataType) extends LeafExpression {
override def foldable = true
def nullable = value == null
def references = Set.empty
override def toString = if (value != null) value.toString else "null"
type EvaluatedType = Any
override def eval(input: Row):Any = value
} |
现在来看一下NullPropagation都做了什么。
NullPropagation是一个能将Expression Expressions替换为等价的Literal值的优化,并且能够避免NULL值在SQL语法树的传播。
/**
* Replaces [[Expression Expressions]] that can be statically evaluated with
* equivalent [[Literal]] values. This rule is more specific with
* Null value propagation from bottom to top of the expression tree.
*/
object NullPropagation extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
case q: LogicalPlan => q transformExpressionsUp {
case e @ Count(Literal(null, _)) => Cast(Literal(0L), e.dataType) //如果count(null)则转化为count(0)
case e @ Sum(Literal(c, _)) if c == 0 => Cast(Literal(0L), e.dataType)
<span style="font-family: Arial;">//如果sum(null)则转化为sum(0)</span>
case e @ Average(Literal(c, _)) if c == 0 => Literal(0.0, e.dataType)
case e @ IsNull(c) if !c.nullable => Literal(false, BooleanType)
case e @ IsNotNull(c) if !c.nullable => Literal(true, BooleanType)
case e @ GetItem(Literal(null, _), _) => Literal(null, e.dataType)
case e @ GetItem(_, Literal(null, _)) => Literal(null, e.dataType)
case e @ GetField(Literal(null, _), _) => Literal(null, e.dataType)
case e @ Coalesce(children) => {
val newChildren = children.filter(c => c match {
case Literal(null, _) => false
case _ => true
})
if (newChildren.length == 0) {
Literal(null, e.dataType)
} else if (newChildren.length == 1) {
newChildren(0)
} else {
Coalesce(newChildren)
}
}
case e @ If(Literal(v, _), trueValue, falseValue) => if (v == true) trueValue else falseValue
case e @ In(Literal(v, _), list) if (list.exists(c => c match {
case Literal(candidate, _) if candidate == v => true
case _ => false
})) => Literal(true, BooleanType)
// Put exceptional cases above if any
case e: BinaryArithmetic => e.children match {
case Literal(null, _) :: right :: Nil => Literal(null, e.dataType)
case left :: Literal(null, _) :: Nil => Literal(null, e.dataType)
case _ => e
}
case e: BinaryComparison => e.children match {
case Literal(null, _) :: right :: Nil => Literal(null, e.dataType)
case left :: Literal(null, _) :: Nil => Literal(null, e.dataType)
case _ => e
}
case e: StringRegexExpression => e.children match {
case Literal(null, _) :: right :: Nil => Literal(null, e.dataType)
case left :: Literal(null, _) :: Nil => Literal(null, e.dataType)
case _ => e
}
}
}
} |
给定SQL: val query = sql("select count(null) from
temp_shengli where key is not null")
scala> query.queryExecution.analyzed
res6: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Aggregate [], [COUNT(null) AS c0#5L] //这里count的是null
Filter IS NOT NULL key#7
MetastoreRelation default, temp_shengli, None |
调用NullPropagation
scala> NullPropagation(query.queryExecution.analyzed)
res7: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Aggregate [], [CAST(0, LongType) AS c0#5L] //优化后为0了
Filter IS NOT NULL key#7
MetastoreRelation default, temp_shengli, None |
2.2.2、Rule:ConstantFolding
常量合并是属于Expression优化的一种,对于可以直接计算的常量,不用放到物理执行里去生成对象来计算了,直接可以在计划里就计算出来:
object ConstantFolding extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform { //先对plan进行transform
case q: LogicalPlan => q transformExpressionsDown { //对每个plan的expression进行transform
// Skip redundant folding of literals.
case l: Literal => l
case e if e.foldable => Literal(e.eval(null), e.dataType) //调用eval方法计算结果
}
}
} |
给定SQL: val query = sql("select 1+2+3+4 from temp_shengli")
scala> query.queryExecution.analyzed
res23: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Project [(((1 + 2) + 3) + 4) AS c0#21] //这里还是常量表达式
MetastoreRelation default, src, None |
优化后:
scala> query.queryExecution.optimizedPlan
res24: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Project [10 AS c0#21] //优化后,直接合并为10
MetastoreRelation default, src, None |
2.2.3、BooleanSimplification
这个是对布尔表达式的优化,有点像java布尔表达式中的短路判断,不过这个写的倒是很优雅。
看看布尔表达式2边能不能通过只计算1边,而省去计算另一边而提高效率,称为简化布尔表达式。
解释请看我写的注释:
/**
* Simplifies boolean expressions where the answer can be determined without evaluating both sides.
* Note that this rule can eliminate expressions that might otherwise have been evaluated and thus
* is only safe when evaluations of expressions does not result in side effects.
*/
object BooleanSimplification extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
case q: LogicalPlan => q transformExpressionsUp {
case and @ And(left, right) => //如果布尔表达式是AND操作,即exp1 and exp2
(left, right) match { //(左边表达式,右边表达式)
case (Literal(true, BooleanType), r) => r
// 左边true,返回右边的<span style="font-family: Arial;">bool</span><span style="font-family: Arial;">值</span>
case (l, Literal(true, BooleanType)) => l //右边true,返回左边的bool值
case (Literal(false, BooleanType), _) => Literal(false)//左边都false,右边随便,反正是返回false
case (_, Literal(false, BooleanType)) => Literal(false)//只要有1边是false了,都是false
case (_, _) => and
}
case or @ Or(left, right) =>
(left, right) match {
case (Literal(true, BooleanType), _) => Literal(true) //只要左边是true了,不用判断右边都是true
case (_, Literal(true, BooleanType)) => Literal(true) //只要有一边是true,都返回true
case (Literal(false, BooleanType), r) => r //希望右边r是true
case (l, Literal(false, BooleanType)) => l
case (_, _) => or
}
}
}
} |
2.3 Batch: Filter Pushdown
Filter Pushdown下包含了CombineFilters、PushPredicateThroughProject、PushPredicateThroughJoin、ColumnPruning
Ps:感觉Filter Pushdown的名字起的有点不能涵盖全部比如ColumnPruning列裁剪。
2.3.1、Combine Filters
合并两个相邻的Filter,这个和上述Combine Limit差不多。合并2个节点,就可以减少树的深度从而减少重复执行过滤的代价。
/**
* Combines two adjacent [[Filter]] operators into one, merging the
* conditions into one conjunctive predicate.
*/
object CombineFilters extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
case ff @ Filter(fc, nf @ Filter(nc, grandChild)) => Filter(And(nc, fc), grandChild)
}
} |
给定SQL:val query = sql("select key from (select
key from temp_shengli where key >100)a where key
> 80 ")
优化前:我们看到一个filter 是另一个filter的grandChild
scala> query.queryExecution.analyzed
res25: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Project [key#27]
Filter (key#27 > 80) //filter>80
Project [key#27]
Filter (key#27 > 100) //filter>100
MetastoreRelation default, src, None |
优化后:其实filter也可以表达为一个复杂的boolean表达式
scala> query.queryExecution.optimizedPlan
res26: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Project [key#27]
Filter ((key#27 > 100) && (key#27 > 80)) //合并为1个
MetastoreRelation default, src, None |
2.3.2 Filter Pushdown
Filter Pushdown,过滤器下推。
原理就是更早的过滤掉不需要的元素来减少开销。
给定SQL:val query = sql("select key
from (select * from temp_shengli)a where key>100")
生成的逻辑计划为:
scala> scala> query.queryExecution.analyzed
res29: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Project [key#31]
Filter (key#31 > 100) //先select key, value,然后再Filter
Project [key#31,value#32]
MetastoreRelation default, src, None |
优化后的计划为:
query.queryExecution.optimizedPlan
res30: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Project [key#31]
Filter (key#31 > 100) //先filter,然后再select
MetastoreRelation default, src, None |
2.3.3、ColumnPruning
列裁剪用的比较多,就是减少不必要select的某些列。
列裁剪在3种地方可以用:
1、在聚合操作中,可以做列裁剪
2、在join操作中,左右孩子可以做列裁剪
3、合并相邻的Project的列
object ColumnPruning extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
// Eliminate attributes that are not needed to calculate the specified aggregates.
case a @ Aggregate(_, _, child) if (child.outputSet -- a.references).nonEmpty =>
////如果project的outputSet中减去a.references的元素如果不同,那么就将Aggreagte的child替换为a.references
a.copy(child = Project(a.references.toSeq, child))
// Eliminate unneeded attributes from either side of a Join.
case Project(projectList, Join(left, right, joinType, condition)) =>
// 消除join的left 和 right孩子的不必要属性,将join的左右子树的列进行裁剪
// Collect the list of off references required either above or to evaluate the condition.
val allReferences: Set[Attribute] =
projectList.flatMap(_.references).toSet ++ condition.map(_.references).getOrElse(Set.empty)
/** Applies a projection only when the child is producing unnecessary attributes */
def prunedChild(c: LogicalPlan) =
if ((c.outputSet -- allReferences.filter(c.outputSet.contains)).nonEmpty) {
Project(allReferences.filter(c.outputSet.contains).toSeq, c)
} else {
c
}
Project(projectList, Join(prunedChild(left), prunedChild(right), joinType, condition))
// Combine adjacent Projects.
case Project(projectList1, Project(projectList2, child)) => //合并相邻Project的列
// Create a map of Aliases to their values from the child projection.
// e.g., 'SELECT ... FROM (SELECT a + b AS c, d ...)' produces Map(c -> Alias(a + b, c)).
val aliasMap = projectList2.collect {
case a @ Alias(e, _) => (a.toAttribute: Expression, a)
}.toMap
// Substitute any attributes that are produced by the child projection, so that we safely
// eliminate it.
// e.g., 'SELECT c + 1 FROM (SELECT a + b AS C ...' produces 'SELECT a + b + 1 ...'
// TODO: Fix TransformBase to avoid the cast below.
val substitutedProjection = projectList1.map(_.transform {
case a if aliasMap.contains(a) => aliasMap(a)
}).asInstanceOf[Seq[NamedExpression]]
Project(substitutedProjection, child)
// Eliminate no-op Projects
case Project(projectList, child) if child.output == projectList => child
}
} |
分别举三个例子来对应三种情况进行说明:
1、在聚合操作中,可以做列裁剪
给定SQL:val query = sql("SELECT 1+1
as shengli, key from (select key, value from temp_shengli)a
group by key")
优化前:
res57: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Aggregate [key#51], [(1 + 1) AS shengli#49,key#51]
Project [key#51,value#52] //优化前默认select key 和 value两列
MetastoreRelation default, temp_shengli, None |
优化后:
scala> ColumnPruning1(query.queryExecution.analyzed)
MetastoreRelation default, temp_shengli, None
res59: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Aggregate [key#51], [(1 + 1) AS shengli#49,key#51]
Project [key#51] //优化后,列裁剪掉了value,只select key
MetastoreRelation default, temp_shengli, None |
2、在join操作中,左右孩子可以做列裁剪
给定SQL:val query = sql("select a.value
qween from (select * from temp_shengli) a join (select
* from temp_shengli)b on a.key =b.key ")
没有优化之前:
scala> query.queryExecution.analyzed
res51: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Project [value#42 AS qween#39]
Join Inner, Some((key#41 = key#43))
Project [key#41,value#42] //这里多select了一列,即value
MetastoreRelation default, temp_shengli, None
Project [key#43,value#44] //这里多select了一列,即value
MetastoreRelation default, temp_shengli, None |
优化后:(ColumnPruning2是我自己调试用的)
scala> ColumnPruning2(query.queryExecution.analyzed)
allReferences is -> Set(key#35, key#37)
MetastoreRelation default, temp_shengli, None
MetastoreRelation default, temp_shengli, None
res47: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Project [key#35 AS qween#33]
Join Inner, Some((key#35 = key#37))
Project [key#35] //经过列裁剪之后,left Child只需要select key这一个列
MetastoreRelation default, temp_shengli, None
Project [key#37] //经过列裁剪之后,right Child只需要select key这一个列
MetastoreRelation default, temp_shengli, None |
3、合并相邻的Project的列,裁剪
给定SQL:val query = sql("SELECT c
+ 1 FROM (SELECT 1 + 1 as c from temp_shengli ) a ")
优化前:
scala> query.queryExecution.analyzed
res61: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Project [(c#56 + 1) AS c0#57]
Project [(1 + 1) AS c#56]
MetastoreRelation default, temp_shengli, None |
优化后:
scala> query.queryExecution.optimizedPlan
res62: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Project [(2 AS c#56 + 1) AS c0#57] //将子查询里的c 代入到 外层select里的c,直接计算结果
MetastoreRelation default, temp_shengli, None |
三、总结:
本文介绍了Optimizer在Catalyst里的作用即将Analyzed Logical Plan
经过对Logical Plan和Expression进行Rule的应用transfrom,从而达到树的节点进行合并和优化。其中主要的优化的策略总结起来是合并、列裁剪、过滤器下推几大类。
Catalyst应该在不断迭代中,本文只是基于spark1.0.0进行研究,后续如果新加入的优化策略也会在后续补充进来。
欢迎大家讨论,共同进步!
|





