|
在网上看到一篇介绍使用统计信息出现的问题已经解决方案,感觉写的非常全面。在自己看的过程中顺便做了翻译。由于本人英文水平有限,可能中间有一些错误。如果有哪里有问题欢迎大家批评指正。建议英文好的直接看原文:SQL
Server Statistics: Problems and Solutions
正文:
SQL Server统计信息协助查询优化器计算运行查询的最优方式. Holger描述了常见的统计信息出错的事情,并且如何改善
通常你不需要太担心执行SQL查询的方式.他们被传送到查询优化器,首先检查是否有可用的执行计划.如果没有,就编译一个计划.为了做的有效率,他需要能够从各种替代策略的结果中评估中间行数.
数据库引擎保存了表中每个索引键值的分布统计信息,并且用这些统计信息确定哪些索引用于编译执行计划.然而如果这些统计信息存在问题,性能就受到影响.统计信息会出什么问题?如何修正?我们将通过最常见的问题解释它如何发生和如何处理。
There is no statistics object at all
没有统计信息
如果没有统计信息,查询优化器只能猜行数而不能估计他们,相信我这不是你要的。
有几种方法可以在估计和实际的执行计划中找到查询优化器是否丢失了统计信息。在这种情况下在计划中会看到警告。图形显示的执行计划会中有一个感叹号,并且在扩展的属性有警告如图1。你不会看到关于表变量的警告,所以小心表变量的表扫描和行估计。

Picture 1: Missing statistics
warning
如果你想查看当前语句的执行计划,可以用DMV sys.dm_exec_cached_plans。
SQL Server profiler提供了另外一种选项。如果你在Profiler中使用Event
Errors/Warings/Missing Column Statists等事件,当优化器检测到丢失统计信息,你可以观察到日志。注意如果数据库或者表启用了AUTO
CREATE STATISTICS选项,这个事件不会被触发。
有几种情况,你会经历丢失统计信息:
1、自动创建统计信息关闭
问题:
如果你关闭了 AUTO CREATE STATISTICS OFF选项,并且忽视了手工创建统计信息,优化器会遭受丢失统计信息之苦。
解决方案:
依赖自动创建统计信息,将AUTO CREATE STATISTICS选项设置为ON。
2、表变量
问题:
对于表变量,从来不维护统计信息。记住:关于表变量没有统计信息。当从表变量查询,估计的行数实始终是1,除非断定的求值结果为false和表变量没有关系(比如where
1=0),在这种情况下,估计返回的行数为0.
解决办法:
如果临时表包含多行数据,不要指望表变量为临时表。作为一个经验法则,对于超过100行的临时表使用临时表(#为表名称的第一个字符)而不是表变量。
3、XML和空间数据
问题:
SQL Server不维护XML和空间数据的统计信息,这是一个事实而不是问题。所以不要尝试找到这些列的统计信息,因为他们不存在。
解决办法:
如果使用的查询在搜索XML数据或者过滤空间列时遇到性能问题,XML或者空间索引可能会有帮助。但是这是另外一个故事超出了本文的范围。
4、Remote queries 远程查询
问题:
假设你通过Linked Server从Oracle数据库查询一张表并跟本地表关联。SQL
Server并不知道远程表返回的行数,这是可以完全理解的,因为这些数据存在Oralce数据库。如果你使用OPENROWSET或者OPENQUERY远程数据访问,也可能发生。
但是你使用DMV的时候可能也遇到这个问题。一定数量的SQL Server
DMV只不过是从内部表中查询数据的壳。你可能在2005中看到远程扫描操作或者2008中看到表值函数操作符。这些操作默认绑定基数估计(取决于服务器版本和操作符,他们是1,1000,10000)
看一下下面的查询:
select * from sys.dm_tran_current_transaction |
这是BOL的声明: “返回一行显示当前回话事务的状态信息”
但是看图2的执行计划,估计行数不是1。显然优化器在生成计划的时候没有考虑BOL的内容。你可以看到内部表DM_TRAN_CURRENT_TRANSACTION通过OPENROWSET被调用而且估计行数为1000,远离事实。
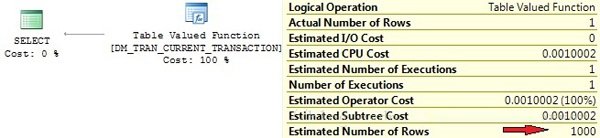
Picture 2: Row-count
estimation for TVF
解决办法:
如果可能的话,通过TOP(N)字句制定返回行数给优化器一些支持。它只会在N
小于估计行数的情况下有效果,比如 1000在我们的例子。因此如果你能猜测Oracle查询返回多少行,只需要在OPENQUERY语句添加TOP(n)。这将有助于更好的基数估计和你使用OPENROWSET结果集进一步关连或者过滤。但这种做法有点危险。如果你指定的n值过低,就会使结果集丢失行,这将是一场灾难。
我们使用sys.dm_tran_current_transaction的例子,可以写出更好的查询如下:
select top 1 * from sys.dm_tran_current_transaction |
通常来说这不是必要的,因为简单的查询单独使用足够快。但是如果你进一步的处理结果集,在连接中使用,那么TOP
1是有用的。
如果你发现你是在更复杂的查询中使用OPENQUERY的结果集进行连接或者过滤操作,先将OPENQUERY的结果导入临时表是明智的。统计信息和索引在本地表可以适当的维护,所以优化器有足够的信息评估行数。
数据库只读
问题:
如果你的数据库设置为只读,优化器不能增加丢失的统计信息即使AUTO CREATE
STATISTICS被开启,因为制度数据库不允许更改。当心有一种特殊用途的只读数据库。是的,我说的是快照。如果优化器丢失了统计信息,在数据库快照中无法自动创建。这有可能发生快照被应用于报表应用。我经常读到建议为报表目的创建快照一边避免在底层的OLTP系统中运行长时间的资源密集性的报表查询。在一定程度上可能好一点,但是报表查询时高度不可预测的通常不同于正常的OLTP查询。因此,你的报表查询有机会因为丢失统计信息或者更糟糕的丢失索引而影响性能。
解决方法:
如果你将数据库设置为只读,你需要在做之前手动创建统计信息。
有合适的统计信息,但是没有被正确使用:
经常有这种可能性优化器无法使用统计信息,尽管统计信息存在并且是最新的.这可能是由于拙略的T-SQL代码导致的。正如本节看到的:
在SQL代码中使用本地变量
问题:
我们再看一下下面例子中的查询:
create table T0(C1INT,C2INT)
INSERT INTO T0VALUES(2000,2000)
INSERT INTO T0VALUES(1000,1000)
GO 100000
declare @x int
set @x = 2000
select c1,c2from T0
where c1 = @x
|
图片5执行计划的第一部分,揭示了实际和估计的行数存在很大差异。造成这种差距的原因是什么?如果你熟悉查询执行的各个步骤,你会意识到这个问题的答案.在查询被执行前,计划需要被生成,并且在计划被编译的时候,SQL
Server不知道变量@x的值.当然在我们的例子中,可以很容易断定@x的值,但是可能有更复杂的表达式会阻止编译期间计算@x的值.优化器没有足够的知识知道真实的@x值,因此没有办法从直方图中合理评估基数.
但是等等。至少列C1是有统计信息的,所以如果优化器不能浏览直方图,它可能转向其他的更一般的数量。正如这个例子中发生的。如果优化器不能利用统计直方图,基数的预测可以通过检查平均密度,表的总行数也可能和谓词操作符。如果你看例子的第一部分,你可以看到我们插入了100001条记录到测试表,在c1值2000只有一行,一个1000的值100000行。你可以通过执行DBCC
SHOW_STATISTICS查看统计信息平均密度,但是记住值计算式1/不同数量的值,在我们例子中计算结果为1/2=0.5。因此优化器为每个不同值计算的平均行数为100001行*0.5=50000.5。有了这个值,谓词操作符进场,在我们的例子中就是“=”。
为准确比较,优化器假设返回C1一个值的平均行数,因此预期是50000.5(再次看图5的第一部分)
其他运算符可能导致不同的选择估计,平均密度可能会或者不会被考虑。如果“大于”或者“小于”运算符被应用,它只会假设返回30%的表数据。你可以很容易的通过我们的测试脚本验证。
解决方法:
如果可能的话,避免在TSQL脚本中使用本地变量。因为这并不总是可行的,有其他选项可用。
首先,你可以考虑引入存储过程。他们被完美的设计为通过参数嗅探技术使用参数。首次调用存储过程,优化器将会找出任何提供的参数并且根据这些参数调整生成计划(当然还有基数估计)。尽管你可能面临其他问题(见下文),在我们这个例子中是完美的解决方案。
create procedure getT0Values(@xint)as
select c1,c2from T0
where c1 = @x
|
然后通过程序调用执行这个存储过程
这个执行计划将会显示索引查找。这是因为优化器必须为@x=2000的值产生计划。
图3显示了这个执行计划,将这个跟图5中原始计划的一部分比较。
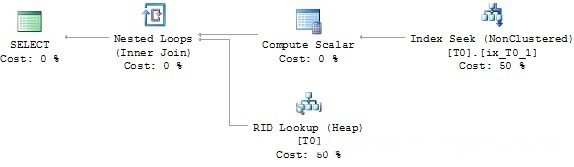
Picture 3: Execution
plan of stored procedure
其次,你可以考虑用动态SQL解决这个问题。好的只是为了澄清一下,我不建议通常广泛使用动态SQL。这样绝不是合适的。动态SQL已经有一些副作用比如可能计划缓存污染,容易遭到SQL注入攻击,可能增加CPU和内存使用。但是看看这个:
declare @x int
,@cmd nvarchar(300)
set @x = 2000
set @cmd = 'select c1,c2 from T0 where c1='
+ cast(@xasnvarchar(8))
exec (@cmd)
|
这个执行计划现在是完美的(跟图3一样),因为他是在执行EXEC命令的时候创建并且提供的命令字符串被当作参数传递这个命令。事实上,你不需要平衡结果决定是否使用动态SQL.但是你看到,只要精心挑选选择性的应用,动态SQL在所有情况下还是不错的。总之很简单:知道你要做什么。
通常扩展存储过程sp_executesql可以帮助你使用动态SQL,同时排除了动态SQL的一些弊端。这是我们的例子,这次用sp_executesql重写:
exec sp_executesqlN'select c1,c2 from T0 where c1=@x'
,N'@x int'
,@x = 2000 |
再一次执行计划看起来想图3展现的。
在谓词使用表达式。
问题:
在谓词中使用表达式也会阻止优化器使用直方图,看下面的例子:
select c1,c2from T0
where sqrt(c1) = 100 |
执行计划在图4显示。
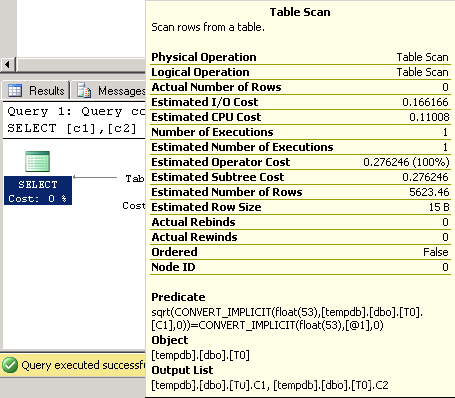
Picture 4: Bad cardinality
estimation because of expression in predicate
因此,尽管字段C1的统计信息存在,但是优化器不知道如何在表达式POWER(c1,1)应用这些统计信息,因此只能猜行数。这非常类似我们上文提到的丢失统计索引的问题,因为表达式POWER(c1,1)根本没有统计信息。对优化器来说,POWER(c1,1)是一个non-foldable表达式。更多信息可以参考这篇文章
解决办法
如果有可能重写SQL代码以便比较只在“纯粹”列上做。例如不是指定:
这样写更好:
幸运的是优化器在评估表达式的时候足够聪明,某些情况下会在内部重写(看这篇文章获得更多信息)
如果不能重写查询,我建议向其他同事同事寻求帮助。如果还是不行,你可能考虑计算列。计算列可以解决这个问题,因为计算列维护统计信息。此外你还可以在计算列上创建索引,这些在表达式上无法实现。
参数化问题
问题:
如果你使用参数化查询比如前面事例的存储过程,你可能面临另外一个问题。你们记住查询计划是在存储过程第一次执行的时候产生而不是执行CREATE
PROCEDURE语句。这是参数嗅探的工作方式。
计划的生成是利用了第一次调用时提供的参数值评估行数。问题很明显。如果第一次调用的参数值异常,基数评估会利用这些值生成执行计划并存储到计划缓存。计划估计的行数比较差,因此后续计划重用使用通常的参数值可能导致性能不佳。
看一下下面的存储过程:
如果这是第一次调用存储过程,为过滤器生成的计划是WHERE c1=2000。因为只有对于c1=2000只有一行,所以索引查找被执行。如果我们像这样第二次调用:
缓存的计划被重用,索引查找被执行。这是非常糟糕的选择,因为这个查询要返回100000行。估计和实际的行数有很大区别,这里表扫描更有效。
使用参数有另外一个问题,非常类似我们前写过的在TSQL脚本中使用本地变量。考虑一下这个存储过程:
create procedure getT0Values(@xint)as
set @x = @x* 2
select c1,c2from T0
where c1 = @x |
修改@x的值不是理想的。参数嗅探技术不会跟踪任何@x的修改,所以执行计划只会根据提供的@x值调整,而不是使用查询内部的实际值。如果你像这样调用上面的存储过程:
然后执行计划为c=1000的过滤做优化而不是c1=2000.你通过这种做法愚弄了优化器,不满意的基数预测很可能发生。
解决办法:
如果你遇到参数嗅探导致的问题,可以考虑使用查询提示比如OPTIMIZE
FOR或者WITH RECOMPILE。这个话题超出了我们这批文章讨论的范围。
尝试不要在存储过程内修改参数的值。这样将击败参数嗅探。如果为了进一步处理需要修改参数的值,你可以考虑将存储过程拆分成多个小的存储过程,采用存储过程的子程序。在主存储过程中修改参数的值,调用子程序时使用改变的值。因为对于每个存储过程,会生成单独的存储过程:这种做法将规避这个问题。
统计信息不准确
通常我们必须接受一定数量的不确定性分布统计信息。毕竟,统计信息执行一些数据精简,信息
损失不可避免。但是如果我们损失的信息对优化器做出合适的基数估计至关重要,我们需要找到一些解决办法。统计对象如何会变成不精确无法使用呢?
样本不足
问题:
想像一张表有数百万行。当SQL Server自动为这张表的一列自动创建或者更新统计信息,它不会考虑表的所有行。为了避免过多的资源消耗比如CPU和IO,通常只有一些示例行处理护统计信息。这样可能导致直方图不能准确代表整体的数据分布。如果优化器估计基数,它可能无法获得足够的信息产生高效执行计划。
解决办法:
一般的解决办法很简单。你将不得不通过手动更新或者创建索引干预自动创建很更新。
记住你可以指定样本大小甚至执行CREATE STATISTICS或者UPDATE
STATISTICS全扫描。记住索引重建总是迫使统计信息用全扫描产生。需要意识到,索引重建只会影响到跟索引相关的统计信息不对列统计有影响。
统计力度太广泛
问题:
让我们再次回到几百万行的表。虽然直方图最大限制为200个条目,我们知道对于400W数据表只有200
step估计行数。对于直方图的每个step平均40000000行/200 step=20000行。如列的值平均分布到各行,这不是一个问题,但如果不是呢?这些统计信息可能太粗导致错误的基数估计。
解决办法:
表面上看增加直方图会很有帮助,但是我们不能这样做。没有办法可以扩大直方图超过200条目。但是如果我们不能包含更多的列形成直方图,简单的使用多个直方图怎么样?当然通过筛选统计我们可以做到。由于直方图绑定单一的统计,对于同样列使用筛选统计,可以有多个直方图。
你需要手动创建那些筛选统计信息,同时要注意后果,我后面会做解释。
让我们回到之前的例子,假设我们有一张表包含90%的历史数据(从来不被更改)10%的活跃数据.我们乐意创建两个筛选统计,通过应用时间列过滤将两个统计对象分开.(你可能倾向于两个筛选索引,对这个例子,使用筛选索引或者筛选统计没有关系).另外,我们对于只展现的历史数据(90%部分)禁用统计信息自动更新。因为只有(10%)的活跃部分,统计信息需要要定期刷新。
现在我们遇到一个问题:通过设置CREATE AUTO STATISTICS
ON,优化器会增加一个未过滤的统计对象,尽管这列的筛选统计信息已经存在。这个自动增加的统计信息也会启动“自动更新”选项。因此,尽管你看起来只有两个筛选统计信息,历史和活跃部分,但最终你会有三个统计信息。另外一个(无过滤)会自动添加。我们不仅有多余的未经过滤的统计信息,而且会无意义的自动更新。当然我们可以对整个表禁用自动创建统计信息,但是这样需要我们创建合适的统计信息。我非常不喜欢这个主意。如果有一个自动的选项,为什么不依赖它。
我想克服这个问题的最佳办法是手动创建筛选统计信息的时候指定NORECOMPUTE选项。这将防止优化器添加这个统计对象并且自动更新。
下面是必须的步骤:
1.使用NORECOMPUTE选项创建一个未过滤的统计信息为了防止自动更新。这个统计知识为了“误导”优化器。
2.为10%的活跃数据创建另外一个筛选统计信息,这次启用自动更新。
3.如果需要的话,为90%的历史数据创建另一个筛选统计,禁用自动更新。
4.如果你遵守上面的步骤,表中活跃的部分会获得相当好的统计信息。但不幸的是这个解决方案不是免费的,下一章将展示。
过时的统计信息
我已经在前面提到,统计信息的同步一直落后于真实数据的更改。因此在某种层面上每个统计对象都是过时的。在大部分情况下这种行为完全可以接受,但也有情况源数据和统计信息偏差太大。
问题:
我们都知道,对于超过500行的表,只有超过20%的列数据被更改,与之相关的统计信息才会无效,所以这些统计信息在下次被使用时才接收更新。在一些情况下,这个“至少20%“的门槛可能太大了。通过另外一个例子可以最好的解释:
假设我们有一个产品表如下:
if (object_id('Product','U')is not null)
drop table Product
go
create table Product
(
ProductId int identity(1,1)notnull
,ListPrice decimal(8,2)notnull
,LastUpdate date not nulldefaultcurrent_timestamp
,filler nchar(500)notnull default '#'
)
Go
alter table Productaddconstraint PK_Product
primary key clustered (ProductId) |
包含主键和其他一些列,有一个列记录最后产品的修改时间。之后,我们搜索单个时间或者时间区间的产品。因此我们在LastUpdate列上创建非聚集索引。
create nonclusteredindex ix_Product_LastUpdateon Product(LastUpdate) |
现在我们增加500000产品到表:
insert Product(LastUpdate, ListPrice)
select dateadd(day,abs(checksum(newid()))% 3250,'20000101')
,0.01*(abs(checksum(newid()))% 20000)
from Numbers where n <= 500000
go
update statistics Productwithfullscan |
我们使用了一些随机值生成LastUpdate和ListPrice,并且在插入完成后更新了所有统计信息。
精彩的一天,经过艰苦谈判,我们高兴的宣布在2010年1月之前收购我们的主要竞争对手。很高兴,我们要添加他们的100000产品。
insert Product(LastUpdate,ListPrice)
select '20100101', 100from Numberswhere n<= 100000 |
确认一下,那些产品被添加,我们通过下面的语句检查所有新插入的行:
select * from Product where LastUpdate = '20100101' |
在图5中看一下上面语句真实的执行过程
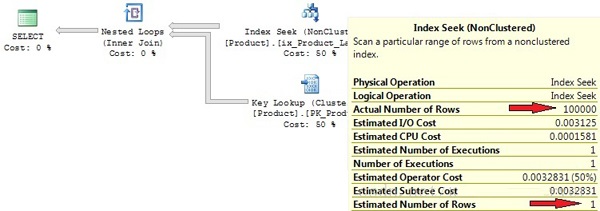
Picture 5: Execution plan created by
use of stale statistics
由于过时的统计信息,真实行数和预测行数有很大差异。我们加入的100000数据没有超过20%的修改阀值,也就意味着自动更新没有执行。使用的索引查找对于获取100000行数据不是最好的选择,除此之外对于索引查找返回的值还要键查找。这个语句在我的PC机上话费了大概300000逻辑读。表扫描或者聚集索引扫描时一个更好的选择。
解决办法:
当然我们有机会提供知识给优化器通过查询提示。在我们的例子中,如果我们知道聚集索引扫描是最好的选择,我们可以指定一个查询提示,如下:
select *from Productwith (index=0)
where LastUpdate = '20100101' |
尽管查询提示可以做,但是指定查询提示存在风险。有可能查询参数被更改或者底层数据被更改。当这些发生了,你之前有用的查询提示可能对性能有负面影响。执行更新统计信息室一个更好的选择:
update statistics Productwithfullscan |
之后,聚集索引扫描被执行,我们可以看到只有大概86000逻辑读。所以,不要仅仅依赖自动更新。开启自动更新,但是准备着通过手动更新支持自动更新,很可能在你维护窗口的非高峰时间。对于持续增长的列比如IDENTIY列统计信息尤其重要。每添加一行都高于直方图的最大值,造成优化器很难或者不可能获得合适的估计行数。通常你需要更频繁的更新这些列上的统计信息,而不是等到20%的数据更改。
问题
筛选统计信息自动更新造成两种特别的问题。
首先任何数据的修改改变了过滤器的选择性,不会考虑现有统计信息的有效性。
第二也是最重要的,“20%规则“被应用到表的所有行,不只是过滤的数据集。这一事实可以使你的筛选统计信息快速过时。让我再次回到我们的例子里面有10%的活跃数据和一个筛选统计。如果所有的统计数据集被缸盖了,尽管对过滤结果集是100%(活跃数据),但是对于整个表只有10%。即使我们再次修改全部10%的部分,对这个表来说也只有20%的数据更改。我们筛选统计信息还是过时的,虽然我们已经修改了200%的数据!请记住,这个也同样适用于筛选索引的筛选统计信息。
Solution 解决方案
对于目前大部分我提到的问题,一个合理的解决方案包设计手动更新或者创建统计信息。如果你采用了筛选索引或者筛选统计,那么手动更新变得更重要。你不应该仅仅依赖于筛选统计的自动更新,而是应该更频繁的额外执行手动更新。
多列统计信息不会自动生成
问题:
如果我们依赖自动创建统计信息,你需要记住那些统计信息都是单列的统计数据。在很多情况下,如果多列统计信息存在,优化器能够利用多列统计信息获得更准确的行估计。
解决方案:
你必须手动添加多列统计。作为一些查询分析的结果,如果你怀疑到多列统计信息会帮助增加他们。找到支持的多列统计信息可能非常困难,但是数据库优化顾问(DTA)可以帮助你完成这个任务。
统计信息不支持相关列
有一个特定的变化统计信息并不像预期的那样工作,因为他们的目的不是:相关列。相关列我们指列包含的数据相关。有时候你会遇到两个或多个列的值不是相互独立的,这样的例子包括小孩的年龄和鞋码或者性别和身高。
问题:
为了显示为什么这可能导致一个问题,我们将尝试一个简单的实验。让我们创建下面的测试表,包含租赁车。
create table RentalCar
(
RentalCarID int not null identity(1,1)
primary key clustered
,CarType nvarchar(20)notnull
,DailyRate decimal(6,2)
,MoreColumns nchar(200)notnull default '#'
) |
这张表有两列,一个是车型另外一辆是每日租金,以及一些其他的数据跟我们这次的实验没特殊关系。
我们知道应用程序要查询车型和日租金,所以最好在这两列创建索引:
create nonclusteredindex Ix_RentalCar_CarType_DailyRate
on RentalCar(CarType, DailyRate) |
现在我们添加一些测试数据。我们会包含四个不同的车型与每日租金,当然车越好租金越贵。用下面的脚步实现:
with CarTypes(minRate, maxRate, carType)as
(
select 20, 39,'Compact'
union allselect 40, 59,'Medium'
union allselect 60, 89,'FullSize'
union allselect 90, 140,'Luxory'
)
insert RentalCar(CarType, DailyRate)
select carType, minRate+abs(checksum(newid()))%(maxRate-minRate)
from CarTypes
inner join Numberson n<= 25000
go
update statistics RentalCarwithfullscan |
如你所见,豪华车日租金结余90美元和140美元,小型车介于20和39美元,我们添加100000行到表中。
现在假设客户想要一辆豪华车。因为客户要求价格非常地,它不想这辆车日花费超过90美元。下面是查询:
select *from RentalCar
where CarType='Luxory'
and DailyRate < 90 |
我们知道在我们数据库中没有这样的车,所以查询会返回0行。但是看一下实际的执行计划(图6)

Picture 6: Correlated columns and Clustered
Index Scan
为什么这里我们的索引没有被使用?统计信息是最新的,因为我们在插入100000行后显示执行了UPDATE
STATISTICS 命令。查询返回0行,因此索引的选择性应该被使用,对吗?看一下索引的估计行数会给我们答案。图7显示了聚集索引扫描的操作符信息。
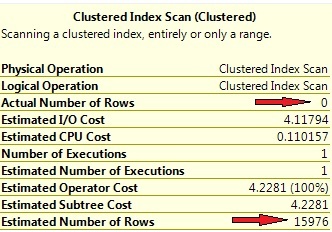
Picture 7: Wrong row-count estimations
for correlated columns
看看估计和实际行数存在巨大的偏差。优化器预计会返回16000行数据,从这个角度看,使用聚集索引扫描是完全可以理解的。
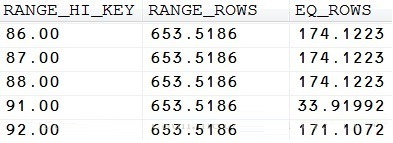
因此,这个奇怪的行为的原因是什么?为了弄清楚答案,我们需要检查统计信息。如果你在对象管理器内打开“统计信息“文件夹,你可能注意的第一件事情是自动为非聚集索引DailyRate生成的统计信息。根据条件”DailyRate<90“,你可以根据统计信息的直方图轻松计算预期的返回行数。
Picture 8: Excerpt from the statistics
for the DailyRate column
只需要汇总RANGE_HI_KEY < 90的RANGE_ROWS和 EQ_ROWS的值,就可以得到‘DailyRate
< 90’的行数。实际上,对于‘DailyRate=89’需要一些特殊的对待,因为这个值没有被包含在直方图的step中。因此计算值不会百分百的准确,但是它会让你了解优化器使用直方图的方式。因此,我们可能简单计算行数通过下面的查询:
select count(*)from RentalCarwhere DailyRate< 90 |
看一下执行计划中估计的行数,在我这里是62949.8(你的数字可能不同,因为我为日租金增加了随机值)。
现在我们对索引列CarType的统计信息做同样的事情(看图片9直方图)
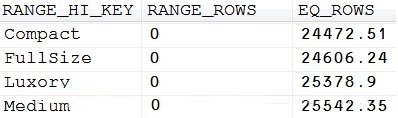
Picture 9: Histogram for the CarType
column
显然,估计在我们的表中有25378.9豪华车。(这是一个有趣的统计数据!他们使用两位小数位显示估计值)
下面是优化器如何为我们的SELECT语句计算基数:DailyRate<90估计62949.8行,表中总共100000行,对这个过滤计算的密度是62949.8/100000=0.629498.
对第二个过滤条件CarType=’Luxory’应用同样的计算。这次,估计的密度为25378.9/100000=0.253789.
为了确定整体过滤条件返回的总行数,需要两个密度相乘。这样做,我们得到0.629498*0.253789=0.15976。查询优化器将这个值与表总行数结合确定估计的行数,最后计算得到0.15976*100000=15976.这正是图7显示的值。
要理解这个问题,你需要回忆一些学校的数学。查询优化器假设参与的两列值相互独立,仅通过两个不同密度计算相乘,这显然并非如此。一个列的值对于第二个列的值不是均匀分布的。因此只是对两列密度相乘在数学上是不正确的。它错误的推断‘DailyRate<90’的总密度对于CarType列的所有值和“CarType=’Luxory’
同样合理。目前,优化器不考虑这样的依赖关系,但是我们有一些选项来处理类似问题,你将会看到以下解决方案:
解决方案
1)使用索引提示
当然,我们知道执行计划不满意,而且很容易证明如果我们强制优化器使用现有的索引(CarType, DailyRate).。我们可以简单的通过添加一个查询提示如下:
select *from RentalCarwith (index=Ix_RentalCar_CarType_DailyRate)
where CarType='Luxory'
and DailyRate < 90 |
执行计划现在显示索引查找。不过注意预计的行数没有改变。因为执行计划生成在查询执行之前,在两个实验中基数估计是一样的。
然后,必要的读此时(通过SET STATISTICS IO ON监控)已经大幅减少。在我的环境中聚集索引扫描需要5578逻辑读,如果索引查找被使用,只需要四个逻辑读。这个改进系数达到1400.
当然这个解决方案也暴漏了一个缺点。尽管事实上索引提示在这种情况下非常有用,但是你通常应该避免使用索引提示(或者查询提示)。索引提示减少优化器的潜在选项,当数据被更改,索引已经不再有用时,可以导致不满意的执行计划。更糟糕的是,查询可能变的无效,如果该索引已经被删除或者重命名。
有更优秀的解决方法,在下面的段落中提出。
2) 使用筛选索引
在SQL Server 2008我们有机会使用筛选索引,在我们这个查询很适合。因为对于CarType列只有四个不同值,我们可以创建四个不同的筛选索引对应每个车型。CarType=’Luxory’的特殊索引看起来如下:
create nonclusteredindex Ix_RentalCar_LuxoryCar_DailyRate
on RentalCar(DailyRate)
where CarType='Luxory' |
其余的三个值我们调整过滤条件创建相同的索引。
我们最终得到四个索引和四个统计信息,适应我们的查询。在图10种你可以看到完美的基数估记和完美的执行计划。

Picture 10: Improved
execution plan with filtered indexes
筛选索引对不超过两列的关联列提供了优雅的解决方案,对于其中起作用的列只有少量数据机。以防你需要多列或者你的列值相差非常大并且不可预见,你在检测正确的过滤条件时会遇到困难。同时,你需要确保过滤的条件不能重叠,这可能给优化器造成难题。
3) Using filtered statistics 使用过滤的统计信息。
我想让考虑上一节。通过创建筛选索引,查询优化去能够创建一个最佳执行计划。最后它就是这样做的,因为我们为它提供了很多改进的基数估计。但是等等。基数估计不是从索引中获得。实际上,跟索引关联的统计信息做了估计。
所以,为什么我们不离开原始的索引而创建筛选统计信息?事实上我们正要这样做。我们删除之前的筛选统计索引创建筛选统计信息作为一种替代方法:
drop index Ix_RentalCar_LuxoryCar_DailyRateon RentalCar
go
create statistics sfon RentalCar(DailyRate)
where CarType='Luxory' |
如果我们为CarType列其他三个值做同样的动作,这样会产生四个不同的直方图,每一个对应这个列的不同值。再次执行我们上面的测试语句,我们可以看到执行计划正如图10展示。
请注意面对同样的障碍,就像上一节提到的关于筛选索引,你可能在决定合适的过滤条件遇到问题。
4)使用覆盖索引
我已经提到在决定最佳的筛选索引或者过滤你可能遇到问题。显示情况可能不会像我们例子那么容易,如果你无法找到微妙的筛选表达式,有一个其他的选项,你可以考虑:覆盖索引。
如果优化器发现索引包含所有需要的列和行不需要关联相关表,这个索引覆盖了查询,那么索引会被使用,不考虑基数估记。
让我们构建一个索引。首先移除筛选统计信息确保优化器不依赖它。之后我们构造一个覆盖索引,优化器从中受益:
drop statistics RentalCar.sf
go
create index IxRentalCar_Covering
on RentalCar(CarType, DailyRate)
include(MoreColumns) |
如果再次执行测试查询,你会看到覆盖索引被使用。图11显示了执行计划:
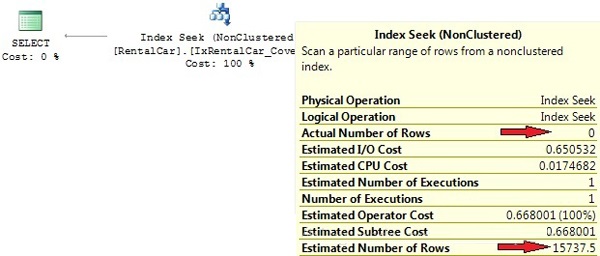
Picture 11: Index Seek
with covering index
你可能会问为什么不包含RentalCarID列,原因是我门已经在聚集索引中包含这列,所以她会被包含在每个非聚集索引).
注意尽管行预测跟真事偏差很大。行预测在这里并不重要。因为我们使用了索引,查询在第一列使用了搜索并且索引覆盖了查询。
也请注意覆盖索引也有特殊性。我说的是每个表都可以有(实际应该有)聚集索引.如果你的查询设计为搜索聚集索引的前面列,那么会使用聚集索引,而不考虑行估计。
更新统计信息也有代价
问题:
实际上这不是一个问题,只是一个事实,你要在规划数据库维护计划考虑:对于500万的表执行OLTP操作期间,最好避免开启自动更新统计信息。
解决方案
同样,自动更新的补充方案是手动更新。你应该添加手动更新任务到你的数据库维护计划任务列表。记住,更新统计信息会导致缓存的秩序计划重新编译,所以你不能更新的太频繁。如果你仍然遇到在正常操作时自动更新代价昂贵的问题,你可以切换到异步更新。
内存分配问题
每个查询都需要一定的内存执行。优化器评估行数和行的大小计算和申请内存大小。如果这两个信息都是错的,优化器会过多或过少估计内存。对于排序和HASH连接是一个问题。内存分配问题可以分为以下两个问题:
内存需求估计过高
问题:
估计的行数太大,分配的内存会太高。这只是浪费内存,因为分配的这部分内存在查询期间不会被用到。如果系统已经遇到内存分配竞争,这回导致等待时间增加。
解决方案:
当然最好的办法是调整统计信息或重写代码。如果都不可能,你可以使用查询提是(比如OPTIMIZE FOR)告诉优化器更好的基数估计。
内存需求低估
问题:
这个问题更严重。如果需要的内存被低估,在执行期间不能立即获得额外内醋。记过,查询将中间结果交换到tempdb导致性能降低8-10倍。
解决办法:
每次查询或者Hash连接使用tempdb,SQL Server profiler事件 Errors and
Warnings/Sort Warnings and Errors and Warnings/Hash
Warnings能够知道。当你看到这一点,可能值得进一步调查。如果你怀疑行估计造成tempdb交换,更新统计信息或者检查修改代码会有帮助。如果不能,考虑查询提示解决这个问题。
另外,你也可以增加查询最低内存分配,通过调整min memory per query (KB)。默认的是1MB。请确保这是在没有其他解决方案之前。每次修改选项,最好知道你在做什么。修改配置选项应该是你解决问题的最后一个选择。
最佳实践
目前我提取所有给出的建议,并将它们放入下面的最佳实践列表。你可以认为这是一个特殊的总结:
做懒人。如果有自动创建和更新统计信息的进程,使用它们。让SQL Server做大部分的工作。在大部分情况下,自动创建和更新统计信息工作的很好。
如果你遇到一个查询性能问题,这通常是由于过时或者质量差的查询统计信息导致。在大部分情况下,你没有时间做更深层次的分析,所以简单的直线一下统计信息更新。一定不要更新所有表的统计信息,只是更新参与的表或者索引。如果这没有帮助,你可能找个时间使用full
scan更新统计信息。注意执行计划中估计和实际的行数差异。优化器应该估计而不是猜测。如果你看到相当大的差异,这通常是不良的统计信息或者差的TSQL
代码导致。
使用内置的自动机制,但是不仅仅依赖这些。对于更新尤其如此。如果需要,可以通过手动更新支持自动更新。必要时重建碎片索引。这样可以使用full
scan更新与索引关联的统计信息.千万不要在重建索引之后再去更新这些索引的统计信息。这不仅是不必要的,甚至会降低统计信息的质量,如果默认的采样被使用。
仔细检查,如果你的查询可以使用到多列统计。如果是这样,手动创建他们。你可以利用数据库引擎优化顾问(DTA)进行相关分析。用筛选统计如果你需要不止200直方图条目。当引入筛选统计,你需要执行手动更新,否则你的筛选统计信息会很快变得过时。
不要再一列上创建多个统计信息除非他们是筛选统计。SQL Server不会阻止你在一列上创建多列统计信息。同样你也可以在一列上有相同的索引。这不光增加维护工作,也增加了优化器的负载。此外,因为优化器始终使用一个特定的统计信息作基数估计,它需要选择其中的一个。他通过评价这些统计信息选择最好的一个。这可能是最新更新的或者具有更大样本。最后但是不最重要的:提升你的TSQL代码。避免在TSQL代码使用本地变量或者在存储过程中覆盖参数。不要在where
/join/比较上使用表达式。
|





