|
摘要: BigSheets 使得可视化数据变成一项非常简单的工作,您不再需要
Hadoop 专家甚至 Excel 向导,就可以根据您的数据生成漂亮的图表和信息。无论数据是原始信息还是以前处理的信息,BigSheets
都会为您提供您所需的视觉 ...
将数据载入 BigSheets 中
InfoSphere BigInsights Quick Start
Edition
InfoSphere BigInsights Quick Start Edition
是 IBM 基于 Hadoop 的 InfoSphere BigInsights 产品的一个可下载的免费版本。使用
Quick Start Edition,您可尝试 IBM 构建的功能来提高开源 Hadoop 的价值,比如
Big SQL、文本分析和 BigSheets。引导式学习可让您的学习体验非常顺利,包括循序渐进、自订进度的教程和视频,可帮助您让
Hadoop 为您工作。没有时间和数据限制,您可以在自己的时间里试验大量数据。
BigSheets 是 InfoSphere BigInsights 的一部分,它基于
Web 的电子表格式界面使得用户能够轻松地分析大量数据。它包含内置的功能来提取名称、地址、组织、电子邮件、位置和电话号码。BigSheets
与典型的电子表格应用程序有许多相似之处,比如 Microsoft? Excel?。它的好处是使您能够使用它轻松地打开、浏览并最终以图表和标记云形式创建数据的图形视图。作为一个执行数据查看和分析流程的完全基于
Web 的界面,它很容易使用,但也有一定的复杂性。
将数据载入 BigSheets 环境中是生产流程中的一个必要步骤。在更加传统的
Hadoop 系统中,可以在完成初始设置之后传入数据,与这些系统不同,在使用 BigSheets 时,您可以打开预先加载的数据,并将使用它们来处理实际内容。
BigSheets 获取您提供的数据,并以图表形式构建该数据的可视化版本,或者它处理原始信息,以便提供数据的摘要视图。除了它的核心可视化作用之外,这还使得
BigSheets 能够支持一些基本的处理。
将原始数据文件载入 BigSheets 中与其他任何 InfoSphere
BigInsights 流程相同。您可以通过 Files 选项卡上传文件,通过一个内置的应用程序处理数据,或者在其他载入系统中的数据上运行
MapReduce 流程。
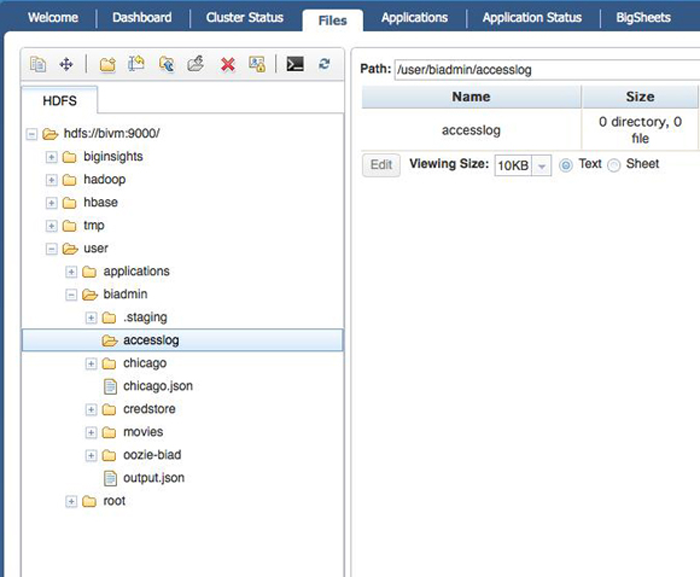
图 1. 通过 Files 选项卡上传文件
例如,使用文件系统,您可以通过选择一个本地文件,通过浏览器界面发送该文件,以这种方式上传数据。这很方便,但有时可能导致加载过程出现问题,导致文件被截断。
上传或从以前的处理流程中生成原始数据后,您需要在 BigSheets 内打开该文件,然后确定应该如何提取内容和数据。
BigSheets 中的项目按工作簿 进行组织,工作簿可定义数据的不同分析、关系和可视化集合来实现其目的。
选择一种适合数据格式的可视化技术
要创建一个新 BigSheets 工作簿并识别您想要构建的数据,您需要考虑数据和可用的可视化技术。
通过您的浏览器打开 InfoSphere BigInsights 应用程序(主机名:8080),单击
BigSheets 选项卡,然后单击 New Workbook。您将看到一个浏览器对话框,用于选择源数据文件的位置。例如,在
Chicago 目录中选择 chicago.csv 数据,如图 2 所示。在默认情况下,BigSheets
将数据读取为单行信息。
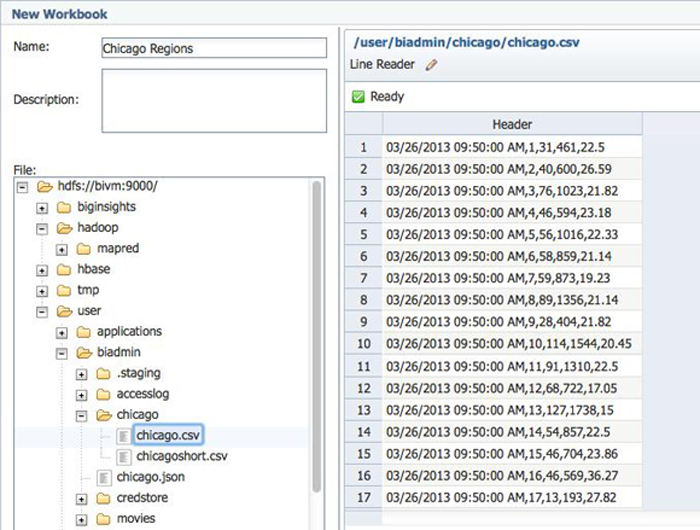
图 2. 选择源数据文件的位置
数据可能具有多种格式。Chicago 数据为逗号分隔值 (CSV) 格式,所以单击
Pencil 图标选择该数据文件类型。支持以下类型(如图 3 所示):
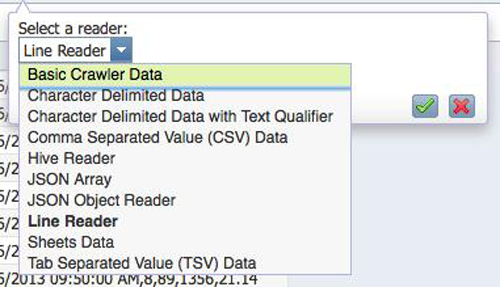
图 3. 支持的类型
1.基本的爬网工具数据― 使用 BigInsights Web 爬网工具从网页提取的信息。
2.字符分隔的数据― 基于制表符、波浪字符或其他字段的、用字符分隔的信息。
3.包含文本修饰符的字符分隔数据― 分隔的数据,其中字段包含在引号或其他字符内,以包含该数据。
4.逗号分隔值 (CSV) 数据― 标准的 CSV 格式,包含符合条件的字段(引号或转义字符),具有或没有标题行。
5.Hive 读取― 从一个现有的 Hive 数据表中读取的数据。
6.JSON 数组― 一个 JSON 数据数组。
7.JSON 对象读取― 多行 JSON 对象数据。
8.行读取器― 每一行作为一个离散数据数组。在一个单独的作业输出了一个惟一词汇列表时,此格式很有用。
9.表格数据― 一个之前的表格的处理作业生成的数据。
10.制表符分隔值 (TSV) 数据― 用制表符分隔的基于字段的信息,包含或不包含标题行。
支持的不同数据类型会影响可视化或分析信息的不同方式。
要处理 CSV 数据,可选择 CSV 数据类型并禁用标题行,因为数据文件中未包含它。系统会显示数据的结构和格式,以确认您挑选了正确的解析方法。
数据具有正确的格式后,单击导入页面底部的复选框。BigSheets 然后解析并显示数据文件。
在识别数据的基本结构以便将可解析为各列后,您可以使用内嵌浏览器来选择信息的数据类型和格式。单击每列旁边的数组来选择字段类型。BigSheets
会尝试自动确定类型,但您可能希望相应地调整结构。类型识别很重要,因为它会影响数据的分析和汇总方式。
使用浏览器手动分析数据,查看提取的行、字段和其他数据。您可以检查整个数据集,找到您需要的信息或更好地理解数据范围。
BigSheets 的用途是转换典型的 Hadoop 集群中存储或生成的大量数据。
将工作表数据转换为图表
基本分析流程是将您导入 BigSheets 中的工作表数据转换为一个图表,以简化信息。有各种各样的图表类型,每种类型对一种特定的数据类型特别有用和适合。
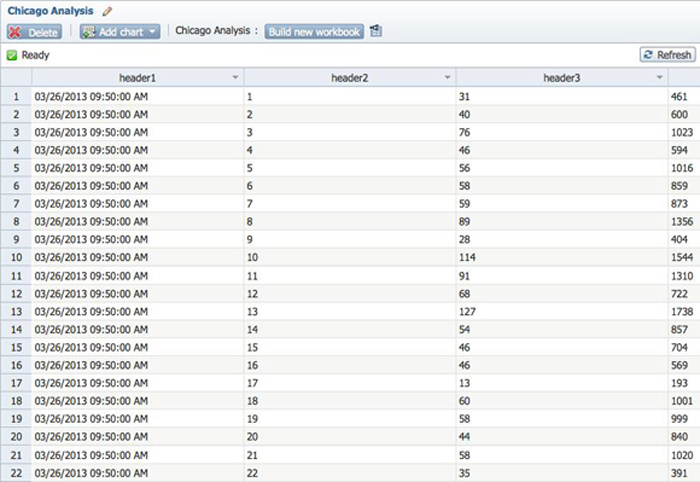
图 4. 导入 BigSheets 中的工作表数据
您还需要牢记的是,BigSheets 不是一个提取、搜索或过滤数据的工具,但它能够执行这些过程。这些任务应在
BigSheets 内应用可视化流程之前完成。请记住,一定要让您的数据和结构与您想要输出的图表类型保持一致。
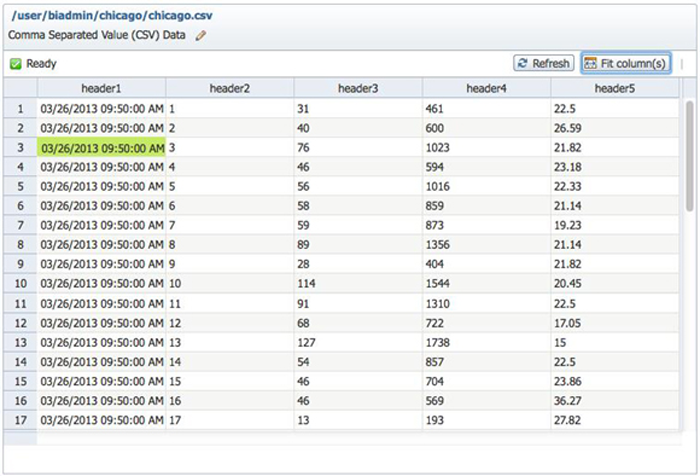
图 5. 打开一个 CSV 文件
使用云功能可视化数据
云 功能会生成一个标记云,类似于您在网站上看到云,常常用于显示关键词、标记或其他计数,这有助于显示数据集中的不同元素的相对频率。云功能一般对可统计或可量化的数据最有用,比如词汇出现次数。如果您愿意的话,BigSheets
将为您统计这些数据。例如,您可以使用一些统计操作类型数量的访问日志数据。
要使用云功能显示相对频率,可选择要统计的列,然后使用 Count occurrences
of value 字段。这会在整个数据集中的该字段内对惟一值执行基本的累积。您还可以设置顺序和限制。使用值数设置显示功能的限制。单击复选框完成这个步骤。
在创建图表定义后,必须运行该图表来生成实际的图表信息。这个过程可能会花费一些时间,具体情况依赖于需要处理的数据量。
图 6 显示了用与出现次数相对应的字号显示的不同操作。如果将鼠标悬停在一个词上,您将获得实际的数据计数。

图 6. 不同的操作以某种与出现次数对应的字号显示
使用热力图和可视地图可视化数据
您可以生成数据的热力图和可视地图,将有关不同实体的位置的信息覆盖在真实的美国或世界地图之上。如果您希望显示地理数据,此选项很有用。例如,城市人口热力图结合使用经纬度数据与人口数量。
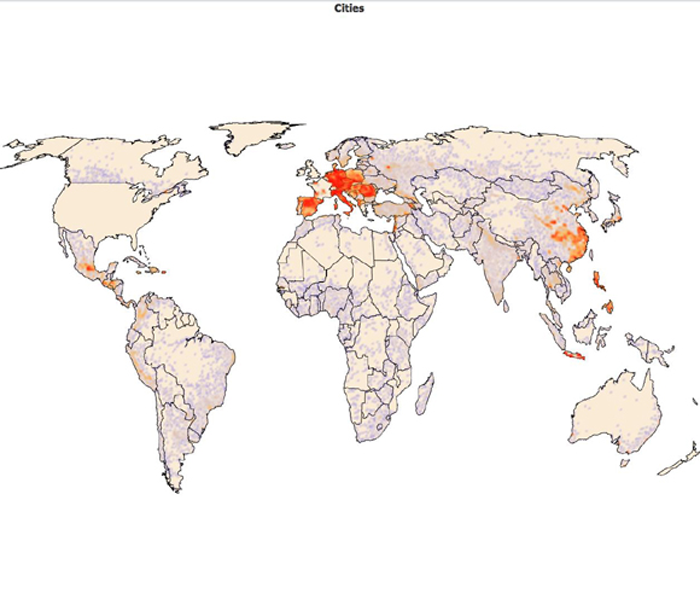
图 7. 城市人口热力图
使用传统图表可视化数据
更传统的图表类型(比如线图\条形图等)可用于以更熟悉的格式创建可视化表示
― 或许不太有趣。例如,您可以通过执行类似的计数,但将信息显示为水平条形图来创建访问日志信息的条形图。
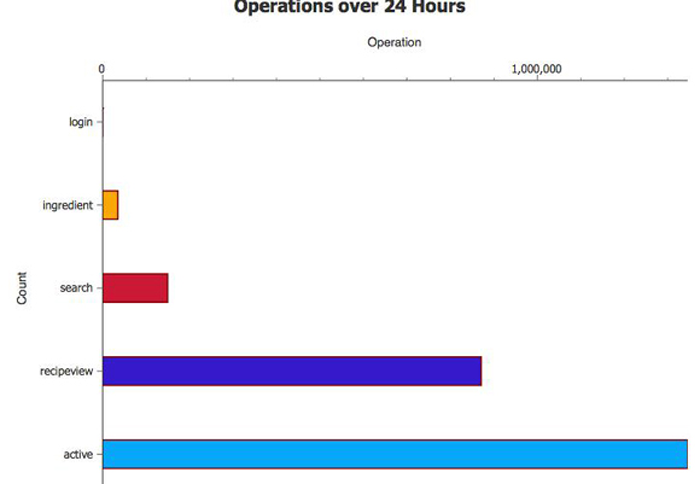
图 8. 访问日志信息的条形图
您可能会注意到,对于每个图表,BigSheets 提供的定义最有用。创建该定义后,就可以更新或创建您包含数据的原始源文件,这些图表可在源数据上运行,以便生成您需要的信息。
因此,您可以继续更新您的源数据,查看该信息的最新的可视化版本。更好的情况是,您可以让该流程成为一个在原始数据上执行许多不同步骤的工作流的一部分。
使用新工作簿集成其他数据
对分析数据的基本流程进行排序后,您可能希望执行更高级的分析。BigSheets
提供了基于您现有的工作簿解决方案创建新工作簿的能力,这个流程使您能够创建可用于分析数据的新表格。
例如,要从仅包含菜谱视图的访问日志信息中输出菜谱标题,然后将它们与存储在另一个文件中的菜谱标题信息相合并,我们需要在访问日志数据与菜谱
ID 和标题之间执行一次合并:
打开包含访问日志信息的工作簿。
单击 Build New WorkBook。此操作会创建一个包含多个阶段的新工作簿。每个阶段包含用于加载、合并和输出组合的数据的定义。首先单击
Add sheets,选择 Filter 操作,然后配置 access_log,以便仅选择 recipeview。
单击 Build New Workbook 并选择 Load。Load
功能配置工作簿,以便包含来自另一个工作簿的数据。选择该菜谱工作簿以获取可合并的数据。
现在,单击 Build New Workbook,选择 Join 并选择要合并的列:来自
access_log 的第 6 列 (recipeid) 和来自 recipes 的第 1 列。
完成工作簿定义后,就可以运行合并过程,这会使用菜谱标题信息解析整个 access_log。您需要运行该过程,确认合并顺利完成。
我们创建了一个工作簿,其中包含过滤器(用于选择 recipeviews)、菜谱数据的加载,以及将菜谱数据合并在一起的合并操作。有了基本的过滤器和合并操作,我们就可以重新创建标记云图表并生成一个图表。

图 9. 标记云图表
|





