|
ODPS是分布式的海量数据处理平台,提供了丰富的数据处理功能和灵活的编程框架。本文从ODPS面临的挑战、技术架构、Hadoop迁移到ODPS、应用实践注意点等方面带领我们初步了解了ODPS的现状与前景。
初识ODPS
ODPS是分布式的海量数据处理平台,提供了丰富的数据处理功能和灵活的编程框架,主要的功能组件有如下几个。
1.Tunnel服务:数据进出ODPS的唯一通道,提供高并发、高吞吐量的数据上传和下载服务。
2.SQL:基于SQL92并进行了本地化扩展,可用于构建大规模数据仓库和企业BI系统,是应用最为广泛的一类服务。
3.DAG编程模型:类似Hadoop MapReduce,相对SQL更加灵活,但需要一定的开发工作量,适用于特定的业务场景或者自主开发新算法等。
4.Graph编程模型:用于大数据量的图计算功能开发,如计算PageRank。
5.XLIB:提供诸如SVD分解、逻辑回归、随机森林等分布式算法,可用于机器学习、数据挖掘等场景。
6.安全:管控ODPS中的所有数据对象,所有的访问都必须经过鉴权,提供了ACL、Policy等灵活强大的管理方式。
ODPS采用抽象的作业处理框架将不同场景的各种计算任务统一在同一个平台之上,共享安全、存储、数据管理和资源调度,为来自不同用户需求的各种数据处理任务提供统一的编程接口和界面。
和阿里云的其他云计算服务一样,ODPS也是采用HTTP RESTful服务,并提供Java
SDK、命令行工具(Command Line Tool,CLT)和上传下载工具dship,以及阿里云官网提供统一的管理控制台界面。在阿里内部,有多个团队基于ODPS构建交互界面的Web集成开
发环境,提供数据采集、加工、处理分析、运营和维护的一条龙服务。基于ODPS进行应用开发,最直接的是使用CLT以及dship等工具。如果不能满足需
要,也可以进一步考虑使用ODPS SDK或RESTful API等进行定制开发,如图1所示。
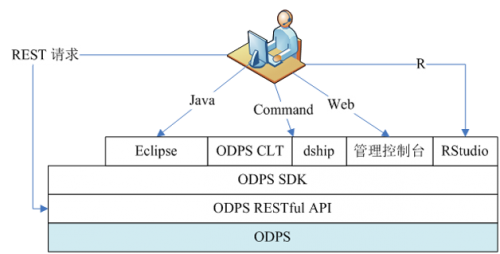
图1 ODPS应用开发模式
如果你的业务发展需要一个足够强大、能开箱即用的大数据处理平台,并且不想花费太多精力去关注这一切如何实现与运维,那么ODPS是一个非常理想的选择。
规模的挑战
在DT时代,数据是宝贵的生产资料,但不断扩大的数据规模给ODPS带来了极大的挑战。在阿里内部就曾直面这种情况:在可以预见的时间内,单个集群的规模无法再容纳所有的数据。
解 决方案是扩大单集群的规模,同时让应用系统可以管理多个集群。在这个背景下,ODPS作为一个海量数据的处理平台,结合5K项目开发了多集群管理的功能,
使得数据处理的规模跨上了一个新的台阶。当单个计算集群的存储或计算容量不足时,将数据重新分布到新的集群上。更重要的一点是,这种跨多个集群的能力,对
上层应用是透明的,用户在运行SQL或者Graph模型时,不必了解数据是分布在哪个物理集群上,如图2所示。
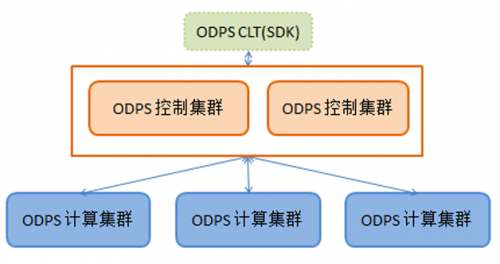
图2 ODPS的跨集群能力
网站日志分析
这 里,我们将基于最常见的网站日志分析这一应用场景,实践如何通过ODPS来构建企业数据仓库,包括数据的导入导出以及清洗转换。其ETL过程与基于传统数
据库的解决方法并不完全一致,在数据传输环节并没有太多的清洗转换,这项工作是在数据加载到ODPS后,用SQL来完成的。在数据加载到ODPS后,可以
充分利用平台的水平扩展能力,处理的数据量可以轻松地扩展到PB级别,而且作为一个统一的平台,除构建数据仓库外,在ODPS中利用内置的功能即可进行数
据挖掘和建模等工作。在实际工作中,数据采集、数仓构建和数据挖掘等都是由不同的团队来完成的,针对这一情况,ODPS中提供了完善的安全管理功能,可以
精确地控制每个人可以访问到的数据内容(下例中为突出主要的过程,忽略了用户的授权管理)。
数据来源于网站酷壳(CoolShell.cn)上的HTTP访问日志数据(access.log),格式如下:

一个典型的企业数据仓库通常包含数据采集、数据加工和存储、数据展现等几个过程,如图3所示。

图3 数据仓库主要过程
数据采集
真实的网站日志数据中不可避免地会存在很多脏数据,可以先通过脚本对源数据做简单的处理解析,去掉无意义的信息,例如第二个字段“-”。在数据量比较大的情
况下,单机处理可能成为瓶颈。这时可以将原始的数据先上传到ODPS,充分利用分布式处理的优势,通过ODPS
SQL对数据进行转换。
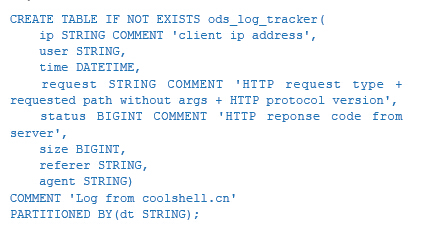
在ODPS中,大部分的数据都是以结构化的表形式存在的,因此第一步要创建ODS层源数据表。由于数据是每天导入ODPS中,所以采取分区表,以日期字符串作为分区,在ODPS
CLT中执行SQL如下:
假设当前数据是20140301这一天的,添加分区如下:

解析后的数据文件在/home/admin/data/20140301/output.log下,通过dship命令导入ODPS中,如下:

数据加工和存储
在 ods_log_tracker表中,request字段包含三个信息:HTTP方法、请求路径和HTTP协议版本,如“GET
/articles/4914.html HTTP/1.1”。在后续处理中,会统计方法为GET的请求总数,并对请求路径进行分析,因而可以把原始表的request字段拆解成三个字段
method、url和protocol。这里使用的是ODPS SQL内置的正则函数解析的字符串并生成表dw_log_parser:

与 传统的RDBMS相比,ODPS SQL面向大数据OLAP应用,没有事务,也没有提供update和delete功能。在写结果表时,尽量采用INSERT
OVERWRITE到某个分区来保证数据一致性(如果用户写错数据,只需要重写该分区,不会污染整张表)。如果采用INSERT
INTO某张表的方式,那么在作业因各种原因出现中断时,不方便确定断点并重新调度运行。
ODPS SQL提供了丰富的内置函数,极大方便了应用开发者。对于某些功能,如果SQL无法完成的话,那么可以通过实现UDF(用户自定义函数)来解决。例如希望将ip字段转化成数字形式,从而和另一张表关联查询,可以实现UDF,如下:

编译生成JAR包udf_ip2num.jar,将它作为资源上传到ODPS,然后创建函数并测试,如下:

表dual(需要用户自己创建)类似于Oracle中的dual表,包含一列和一行,经常用于查询一些伪列值(pseudo
column),是SQL开发调试的利器。
对于较复杂的数据分析需求,还可以通过ODPS DAG(类似MapReduce)编程模型来实现。篇幅限制,这里不一一介绍。
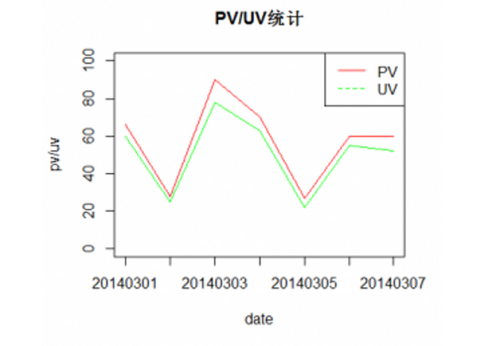
图4 PV/UV展示结果
数据展现
应 用数据集市往往是面向业务需求对数据仓库表进行查询分析,例如统计基于终端设备信息的PV和UV,生成结果表adm_user_measures。R是一
款开源的、功能强大的数据分析工具。通过R来绘图,展示结果报表可以有两种方式:一是通过dship命令将数据导出到本地,再通过R展现结果;二是在R环
境中安装RODPS Package,直接在R中读取表中的数据并展现。在RStudio中,基于小样本数据统计的展现结果如图4所示。
迁移到ODPS
Hadoop 作为开源的大数据处理平台,已得到了广泛应用。在使用Hadoop集群的用户,可以比较轻松地迁移到ODPS中,因为ODPS
SQL与Hive SQL 语法基本一致,而MapReduce作业可以迁移到更加灵活的DAG的执行模型。对于数据的迁移,可以通过ODPS
Tunnel来完成。
数 据通道服务ODPS Tunnel是ODPS与外部交互的统一数据通道,能提供高吞吐量的服务并且能够水平进行服务能力的扩展。Tunnel服务的SDK集成于ODPS
SDK中。实际上,dship也是调用SDK实现的客户端工具,支持本地文件的导入导出。我们鼓励用户根据自己的场景需求,开发自己的工具,例如基于
SDK开发对接其他数据源(如RDBMS)的工具。
把海量数据从Hadoop集群迁移到ODPS的基本思路是:实现一个Map Only程序,在Hadoop的Mapper中读取Hadoop源数据,调用ODPS
SDK写到ODPS中。执行逻辑大致如图5所示。
Hadoop MapReduce程序的执行逻辑主要包含两阶段:一是在客户端本地执行,如参数解析和设置、预处理等,这在main函数完成;二是在集群上执行
Mapper,多台Worker分布式执行map代码。在Mapper执行完成后,客户端有时还会做一些收尾工作,如执行状态汇总。
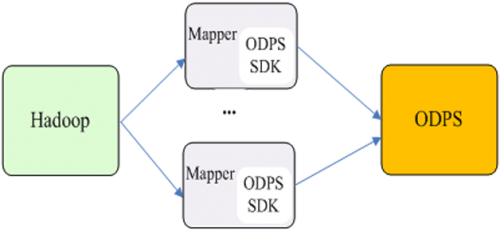
图5 Hadoop到ODPS的数据迁移
这 里,我们在客户端本地的main函数中解析参数,创建UploadSession,把SessionID传给Mapper,Mapper通过
SessionID获取UploadSession,实现写数据到ODPS。当Mapper执行完成后,客户端判断执行结果状态,执行Session的
commit操作,把成功上传的数据Move到结果表中。
默认情况下,Hadoop会自动根据文件数划分Mapper个数。在文件大小比较均匀时,这种方式没什么问题。然而存在大文件时,整个大文件只在一个Mapper中执行可能会很慢,造成性能瓶颈。这种情况下,应用程序可自己对文件进行切分。
下面实现一个类Hdfs2ODPS来完成这个功能。其中run函数完成了前面提到的主要逻辑,主要代码如下(其中包括了对ODPS
Tunnel的使用):


在 这个函数中,首先调用函数parseArguments对参数进行解析(后面会给出),然后初始化DataTunnel和UploadSession。创
建UploadSession后,获取SessionID,并设置到conf中,在集群上运行的Mapper类会通过该conf获取各个参数。然后,调用
runJob函数,其代码如下:

runJob 函数设置Hadoop conf,然后通过JobClient.runJob(conf);启动Mapper类在集群上运行,最后调用
conf.getNumMapTasks() 获取Task数,Task数即上传到ODPS的并发数。在Mapper中,可以通过
conf.getLong("mapred.task.partition")获取Task编号,其值范围为[0,
NumMapTasks)。因此,在Mapper中可以把Task编号作为上传的blockid。客户端在Mapper成功返回时,就完成commit所
有的Session。
应用实践注意点
与单机环境相比,在ODPS这样的分布式环境中进行开发,思维模式上需要有很大转变。下面分享一些实践中的注意点。
在 分布式环境下,数据传输需要涉及不同机器的通信协作,可以说它是使用ODPS整个过程中最不稳定的环节,因为它是一个开放性问题,由于数据源的不确定,如
文件格式、数据类型、中文字符编码格式、分隔符、不同系统(如Windows和Linux)下换行符不同,double类型的精度损失等,存在各种未知的
情况。脏数据也是不可避免的,在解析处理时,往往是把脏数据写到另一个文件中,便于后续人工介入查看,而不是直接丢弃。在上传数据时,Tunnel是
Append模式写入数据,因而如果多次写入同一份数据,就会存在数据重复。为了保证数据上传的“幂等性”,可以先删除要导入的分区,再上传,这样重复上
传也不会存在数据重复。收集数据是一切数据处理的开始,所以必须非常严谨可靠,保证数据的正确性,否则在该环节引入的正确性问题会导致后续处理全部出错,
且很难发现。
对于数据处理流程设计,要特别注意以下几点。
1.数据模型:好的数据模型事半功倍。
2.数据表的分区管理:如数据每天流入,按日期加工处理,则可以采取时间作为分区,在后续处理时可以避免全表扫描,同时也避免由于误操作污染全表数据。
3.数据倾斜:这是作业运行慢的一个主要原因,数据倾斜导致某台机器成为瓶颈,无法利用分布式系统的优势,主要可以从业务角度解决。
4.数据的产出时间:在数据处理Pipeline中,数据源往往是依赖上游业务生成的,上游业务的数据产出延迟很可能会影响到整个Pipeline结果的产出。
5.数据质量和监控:要有适当的监控措施,如某天发生数据抖动,要找出原因,及时发现潜在问题。
6.作业性能优化:优化可以给整个Pipeline的基线留出更多时间,而且往往消耗资源更少,节约成本。
7.数据生命周期管理:设置表的生命周期,可以及时删除临时中间表,否则随着业务规模扩大,数据会膨胀很快。
此外,数据比对、A/B测试、开发测试和生产尽可能采用两个独立的Project。简言之,在应用开发实践中,要理解计费规则,尽可能优化存储计算开销。
ODPS现状和前景
阿 里巴巴提出了“数据分享第一平台”的愿景,其多年来坚持投资开发ODPS平台的初心就是希望有一天能够以安全和市场的模式,让中小互联网企业能够使用阿里
巴巴最宝贵的数据。阿里内部提出了所有数据“存、通和用”,将不同业务数据关联起来,发挥整体作用。ODPS目前正在发展中,它在规模上,支持淘宝核心数
据仓库,每天有PB级的数据流入和加工;在正确性上,支持阿里金融的小额无担保贷款业务,其对数据计算的准确性要求非常苛刻;在安全上,支持支付宝数据全
部运行在ODPS平台上,由于支付宝要符合银行监管需要,对安全性要求非常高,除了支持各种授权和鉴权审查,ODPS平台还支持“最小访问权限”原则:作
业不但要检查是否有权限访问数据,而且在整个执行过程中,只允许访问自己的数据,不能访问其他数据。
前面的示例只是展现了ODPS的冰山一角。作为阿里巴巴云计算大数据平台,ODPS采用内聚式平台系统架构,各个组件紧凑内聚,除了结构化数据处理SQL、分布式编程模型MapReduce外,还包含图计算模型、实时流处理和机器学习平台,如图6所示。
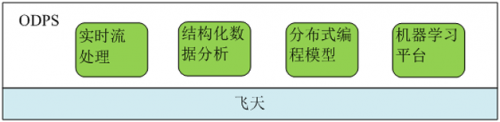
图6 ODPS功能模块
随着ODPS对外开放的不断推进和第三方数据的流入,相信会有各种创新在ODPS上生根发芽、开花结果。
尽管如此,云计算和大数据是两个新兴的领域,技术和产品发展日新月异。作为一个平台,虽然ODPS已在阿里内部被广泛使用,但在产品和技术上还有很多方面需要进一步完善和加强,希望ODPS能够和云计算大数据应用共同成长,成为业界最安全、最可靠和最方便易用的平台。
|





