|
���������һ��ͨ�������ڴ����ݿ�㣬�������������ֲ�ʽ���ݿ�ܹ����˷������ڽ�������߲���ϵͳ�����ݴ洢�ͷ������⣬���������ڵ������������ģ������ҵ���ӵĻ�����վ��
��Щ�껥����վ��չѸ�ͣ�ΪӦ�Ժ��������µĸ߲������ʣ������˸��ֲַ�ʽ�ܹ����˼�룬����Key-Value���棬���ݷ����ȡ������ڵ�����������վ���������������һ����Ҫ�ص㣬�������ݽṹ��������֮��Ĺ������Ա���ˣ�����Ͱ�Ҳ����ˣ���������������Ƶ��
���͵Ȼ�����վ���������졣
1. NoSQL ���鵤��ҩ��
NoSQL��Key-Value ������BigTable��Cassendra���ںܶ������վ�����ã��ܺõĽ���˺������ݴ洢�ͷ������⡣�����ڵ�����������վ��Key-Value��NoSQL�����ǽ����������鵤��ҩ��������ǽ�������һЩ����ģ�ͽ�Ϊ��Ӧ�á�
ԭ�����������棺
1������ģ����
�Ա��Ͱ���Ͱ͵Ļ�Ա���������������Ⱥ���ʵ������ģ���ӣ����Ը�����ʮ���ϰٸ������磺��Ա(Member)�Ͱ���������Ϣ����ϵ�����̡��˻��ȶ�������Ϣ�����⣬����ʵ��֮�䣬��Χʵ�������ʵ��֮�仹���ڸ��ӵĹ�����
2��ҵ���ӣ�
ģ�͵ĸ���Դ��ҵ������ĸ��ӡ�����������վ������ѯ�����ǽṹ����ѯ�����磺
���Ա��ϲ�ѯ�������ڽ��㻦���۸���50-200Ԫ����ʿT������
�ڰ���Ͱ��ϡ��г�ij����Ա���д������Ķ�����
�����ѯ����Ȼ������ͣ���Ҫ��Զ���������ֶ�, �������BigTable��Cassandra
�����Ļ���Column��Key-Value���ݿ⣬���Query API����ʤ�δ������� ����ڰ���Ͱͺ��Ա���Oracle��MySQL
�ȹ�ϵ���ݿ⽫��Ȼ������Ҫ��ɫ��
2. MySQL ��Ⱥ
����K-V����ȷǹ�ϵ���ݿ�����Ҫ������������ڸ߲��������µĸ�Ч��д���⣬���̶��ڿɿ��ij־û�(Durable)��߷�������
(Performance) ֮��ѡ��һ��ƽ��㡣�ڸ߶Ƚṹ��ϵͳ�У�ͬ���Ŀ�����ʹ������Ҫ��������Ľ��������
Ŀǰһ��ͨ�е������� MySQL ��д����ʽ��Ⱥ��1��������Masterд������Slave����Master��Slave���б�����ݵ�ͬ�������ȣ����ַ�������������ʵ�����ɿ��ҿ��С�
Ȼ����ֱ����DBִ��д��������Ȼ�ȽϺ�ʱ(�μ���1����2)�����ݸ��ƣ�Ҳ���ܴ��ڲ�һ����ʱ�����Ρ��Ƿ��и���ķ�����
3. �ڴ���ϵ���ݿ�
�ɿ��ij־û�ָ���ݴ洢�����̵��豸�ϡ�ͼ1չʾ�˴�ͳ�������ݿ�Ļ�������ģʽ��
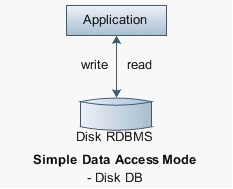
ͼ1
���־û��Ŀɿ��ԣ������ݿ����Ȳ��洢��������(Disk)���ڴ�洢������Զ���ڴ��̴洢���±�չʾ�����Oracle��Altibase���������ܶԱȣ������ڲ���Ͳ�ѯ��������Oracle��5-7����

��1. Oracle��Altibase���ܶԱ�
-����5���� ��7��

��2 Oracle��Altibase���ܶԱ�
�C ������ѯ10������7��
�ɴ˿ɼ���Pm >>> Pd
��Pm - �ڴ����ݿ��д���ܣ� Pd - �������ݿ��д���ܣ�
���ǰ�������ģ�����Ժ�ҵ������ԭ��ϵ���ݿ⣨RDBMS��������á���ˣ������㿼�ǿ����Ƶ�����һ�����˼·���ڴ���ϵ���ݿ⡣
��3. DBѡ�ͶԱȷ���
�����������ǿ��Խ��ڴ��ȿ���һ�֡����̡�����д����������ڴ����ݿ���У�����ֱ����������ݿ⽻������Ϻõı����˵���MySQL
��д����ܹ����ڵ�ʱ���ӳٺ�һ�������⡣����ͼ��ʾ��

ͼ2
4. �ڴ����ݿ�ij־û�
�������ջ���Ҫ�洢������(Disk)�ϣ��ڴ����ݿ��е����ݱ仯��Ҫ���Ƶ���������ݿ��ϡ���ʱ�����ڴ�����̸������ݵĹ��̿��Կ���ԭʼд�������첽��������Ȼ���첽����ʹ��ǰ�˵�д�����Եø��졣����ͼ��ʾ��

ͼ3
��������(OLTP)ϵͳ�У��ڴ����ݿ���������ʱ��Ҫ�ʹ������ݿⱣ��һ�¡�
��ˣ��ڴ����ݿ���Ҫ����ͬ�Ŀ�����壻�����ڵ�һ����ʱ�������������ݼ��ص��ڴ����ݿ��С�
5. �ڴ����ݿ⼯Ⱥ��
Ŀǰ�������MySQL��Ⱥ��ͨ����д���룬ˮƽ�з֣�ʵ�ֺ������ݴ洢��ΪӦ�Ժ������ݴ洢���ڴ����ݿ�ͬ����Ҫ����Ⱥ����ֱ��ˮƽ�зֲ��ԣ������Բ�����MySQL��Ⱥ�ܹ���ƻ�����ͬ������ͼ��ʾ������
Ameoba �Ƿֲ�ʽ���ݿ����������������·�ɵȿ��ơ�
Ψһ�IJ�ͬ�ǣ������ڴ����ݿ�ĸ����ܣ����Բ��ٽ��ж�д������ơ�

ͼ4
6. ��Ϸ�����Hybrid Shard��
�ӵ�4�ڵķ������ڴ�������������Ҫ�־û������̡�������Ҫһ�ֻ�Ϸ���(Hybrid
Shard)���������ԭ��һ��MySQL�ڵ�е���һ��ˮƽ����������һ���ڴ����ݿ�ڵ��һ��MySQL�ڵ㹲ͬ��ɡ�
H-Shard = MDB + MySQL.
�������ݿ�ܹ����γ����������ݿ�(2LDB)����Ϸ������ɵļ�Ⱥ��������ͼ��ʾ��
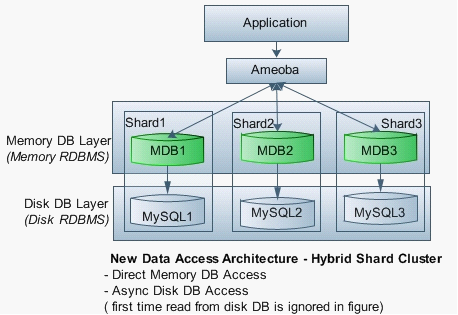
ͼ5
7. �ڴ����ݿ�ѡ��
�������ڴ����ݿ��Ʒ������ҵ�����Ѱ����ࡣ��ҵ���磺Altibase��Timesten��Berkley
DB�ȡ������ڵ��ţ����ڣ�֤ȯ�ȸ����ܼ���Ӧ�������ý�Ϊ�㷺����ҵ�湦��ǿ��Ȼ�����۸�Ƚϰ����ʺ�Ŀǰ������PC+����������ļܹ��˼�롣
��������ְ���й��ƶ�ϵͳ�ṩ�̣����мƷѡ���Ӫ��ϵͳ������Timesten�ṩ���������㣬������Ҫ���ڸ�Ƶ��С���ݼ��㣬��Ʒ����ۣ��Żݼ��㣬�ſصȣ����õ��ڵ�ģʽʹ�á�
��Դ�����Ʒ��Ҫ��H2��HsqlDB��Derby�ȡ��ڻ�Ϸ����ܹ��У��ڴ����ݿ⽫�е�OLTP��ְ����˳��˶�д�����⣬���ܵ��걸������ȶ���Ҫ��Ϊ�������������ء�
8. �¼ܹ�����ս
ͨ�������ڴ����ݿ���Ϊ�м�־ò㣬�ټ���ֲ�ʽ�ܹ���֧�ź������ݷ��ʣ����ּܹ�����ľ���ս�����ȶ�������������¼ܹ��ĸ��Ӷȣ�������ģMySQL��Ⱥ�ܹ�������ʼһ����
������ H2 ��һ����Դ�ĸ������ڴ����ݿ�Ϊ��˵����
1) ���� Ameoba �� H2
Ameoba �Ƿֲ�ʽ���ݿ���������� MySQL �����Ѿ��ڰ���Ͱͺ���ҵ���гɹ����á�����������ݿ�ڵ㿴��һ���洢��MySQL
Node �� H2 Node ���ޱ�������JDBC������DB�з֣�·�ɣ�����Ameoba ͳһ����
2) �첽�־û�
ÿ������Ϸ���= H2 + MySQL��˭�����H2 �е����ݱ���첽д��
MySQL��
�ȽϺõķ������ڴ����ݿ��ṩʵʱ�����ĸ�������Replicator) �����磺����������־���Ƶ�˫���ȱ����ơ�AltiBase
�Ȳ�Ʒ���ṩ�˴˹��ܡ�
3���߿�����
�ڴ����ݿ�һ�����������ݲ������ڡ��������Ҫ�������ݿ����첽д��MySQL���־û��洢��ͬʱҪ�н�׳���ݴ���Failover���ƣ���֤һ��H2�ڵ������ͬһ�������е��油H2�ڵ��������湤����
һ�ַ����Ƿֲ�ʽ���ݿ������ Ameoba ����������磺ÿ��Shard��H2������2���ڵ㣬����Primary-Secondaryģʽ����ͼ6��ʾ��

ͼ6
��һ�ַ�����ǰ���ᵽ���ڴ����ݿ�ʵʱ���ƹ��ܡ�
��Ȼ��Щ�ڴ�DB��H2������֧���ڴ棬���������洢�����������ṩ�Ĵ��̴洢�ͷ��ʷ����ɿ��Բ���
MySQL����ˣ�ʹ���ڴ�ʽPrimary-Secondary ģʽ��Ϊ���С�
4���ֲ�ʽ����
���ݿ��зּܹ������ֲ�ʽ�������⣬��һЩ����Ҫ��ϸߵij��������ľ���ս��Ameoba
Ŀǰ���ڽ���С�Ameoba + H2�������ͬ������ս��
Ŀǰһ�ֱȽ�һ����������������䴦������������������ һ�����������ҵ����ص㣬�������ݶ��������������ҵ��ʹ�ò���������ΪĿǰ��Ӧ�ã������Ǻ���ҵ�������Ҫ��Ҳ���ߡ�
9. ��һ��˼��
1�� ���������з�ģʽ
��һ�����ͻ�����վ����ͬ��Ӧ�ú�������Ҫ����ͬ�Ĵ����������崹ֱ�з�ģʽ�����ϣ�ѡ����������Ĺ��ܽ���ˮƽ�з֣����磺������������¼��
2�����ݻ��棨Data Cache��
��Ȼ�ڴ����ݿ��(MDB)�ܸ���Ч֧�Ž��������ݿ⣬�ر���Ӧ�Խṹ��Ӧ�ü����Ӳ�ѯ�����Ը�Ƶ�ȵIJ�ѯ(Query)��ʵ�����(Find)��Key-Value������Ȼ��һ���Ҫ����ơ�Cache���ṩ���ߵIJ�ѯ�ٶȣ������ٶ�MDB�ķ���ѹ�����ر��Ƕ�д�ܼ��ĸ߲�����������Ϊ����ܹ��У��ڴ����ݿ���Ȼ��Ϊһ�ִ洢Store��������Cache��

ͼ7
��ͼչʾ�ˣ�MDB��֮�ϻ���ҪDCL�����ṩ�����ܻ������
10. �ܽ�
���������һ��ͨ�������ڴ����ݿ�㣬���������㣬������ķֲ�ʽ���ݿ�ܹ����˷������ڽ�������߲���ϵͳ�ĸ��������ݴ洢�ͷ������⣬�����ǵ����������ҵ���ӵĻ�����վ�������˼���ǣ�
1�������ܣ���ͨ���ڴ����ݿ��ṩ�����ܹ�ϵ���ݿ��ȡ�������Ǵ˼ܹ�������ҪĿ�ꣻ
2���־û���ͨ���������ݿ⼰�첽д��ɳ־û���
3����������֧�ţ�ͨ����ֱ��ˮƽ����ʵ�ֺ������ݵ�֧�ţ�
4���߿����ԣ���Ameoba�����ϣ�ͨ�������ڵ��һ��ʵ��MDB�ĸ߿����ԣ������������ݿ����ʵ�����ݵĿ��ٻָ���
|





