|
1 �Ⱦ�����
ȷ�����㼯Ⱥ�е�ÿ���ڵ��϶���װ�����б���������sun-JDK ��ssh��Hadoop
JavaTM1.5.x�����밲װ������ѡ��Sun��˾���е�Java�汾��
ssh ���밲װ���ұ�֤ sshdһֱ���У��Ա���Hadoop �ű�����Զ��Hadoop�ػ����̡�
2 ʵ�黷���
2.1 ������
����ϵͳ��Ubuntu
����Vmvare
��vmvare��װ��һ̨Ubuntu��������Ե������߿�¡��������̨�������
˵����
��֤�������ip��������ip��ͬһ��ip�Σ��������������������֮������ͨ�š�
Ϊ�˱�֤�������ip��������ip��ͬһ��ip�Σ��������������Ϊ������
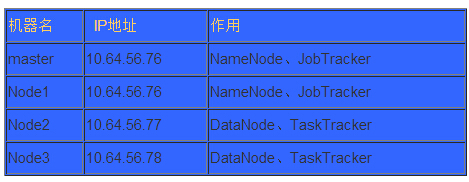
��������һ̨master������̨slave������ÿ̨������/etc/hosts��֤��̨����֮��ͨ�����������Ի��ã����磺
10.64.56.76 node1��master��
10.64.56.77 node2 ��slave1��
10.64.56.78 node3 ��slave2��
|
������Ϣ:
2.2 ��װJDK
#��װJDK
$ sudo apt-get install sun-java6-jdk1.2.3 |
�����װ��javaִ���ļ��Զ����ӵ�/usr/bin/Ŀ¼��
��֤ shell���� ��java -version ���Ƿ�����İ汾��һ�¡�
2.3���ء������û�
$ useradd hadoop
$ cd /home/hadoop |
�����еĻ����϶�������ͬ��Ŀ¼��Ҳ���Ծͽ�����ͬ���û���������Ը��û���home·������hadoop�İ�װ·����
���������еĻ����ϵİ�װ·�����ǣ�/home/hadoop/hadoop-0.20.203���������Ҫmkdir����/home/hadoop/�½�ѹhadoop����ʱ���Զ����ɣ�
����Ȼ����װ/usr/local/Ŀ¼�£�����/usr/local/hadoop-0.20.203/
chown -R hadoop /usr/local/hadoop-0.20.203/
chgrp -R hadoop /usr/local/hadoop-0.20.203/��
(��ò�Ҫʹ��root��װ,��Ϊ���Ƽ���������֮��ʹ��root���� ) |
2.4 ��װssh������
1�� ��װ��sudo apt-get install ssh
�����װ�����ֱ��ʹ��ssh���� �ˡ�
ִ��$ netstat -nat �鿴22�˿��Ƿ����ˡ�
���ԣ�ssh localhost��
���뵱ǰ�û������룬�س���ok�ˡ�˵����װ�ɹ���ͬʱssh��¼��Ҫ���롣
������Ĭ�ϰ�װ��ʽ���Ĭ�������ļ�����/etc/ssh/Ŀ¼�¡�sshd�����ļ��ǣ�/etc/ssh/sshd_config����
ע�⣺�����л��Ӷ���Ҫ��װssh��
2�� ���ã�
��Hadoop�����Ժ�Namenode��ͨ��SSH��Secure Shell����������ֹͣ����datanode�ϵĸ����ػ����̵ģ������Ҫ�ڽڵ�֮��ִ��ָ���ʱ���Dz���Ҫ�����������ʽ����������Ҫ����SSH���������빫Կ��֤����ʽ��
�Ա����е���̨����Ϊ��������node1�����ڵ㣬����Ҫ����node2��node3����Ҫȷ��ÿ̨�����϶���װ��ssh������datanode������sshd�����Ѿ�������
( ˵����hadoop@hadoop~]$ssh-keygen -t rsa
������Ϊhadoop�ϵ��û�hadoop��������Կ�ԣ�ѯ���䱣��·��ʱֱ�ӻس�����Ĭ��·��������ʾҪΪ���ɵ���Կ����passphrase��ʱ��ֱ�ӻس���Ҳ���ǽ����趨Ϊ�����롣���ɵ���Կ��id_rsa��id_rsa.pub��Ĭ�ϴ洢��/home/hadoop/.sshĿ¼��Ȼ��id_rsa.pub�����ݸ��Ƶ�ÿ������(Ҳ��������)��/home/dbrg/.ssh/authorized_keys�ļ��У�����������Ѿ���authorized_keys����ļ��ˣ������ļ�ĩβ����id_rsa.pub�е����ݣ����û��authorized_keys����ļ���ֱ�Ӹ��ƹ�ȥ����.)
3) ��������namenode��sshΪ��������ġ��Զ���¼��
�л���hadoop�û�( ��֤�û�hadoop�������������¼����Ϊ���Ǻ��氲װ��hadoop������hadoop�û���)
$ su hadoop
cd /home/hadoop
$ ssh-keygen -t rsa |
Ȼ��һֱ���س�
��ɺ���home��Ŀ¼�»���������ļ���.ssh
֮��ls �鿴�ļ�
cp id_rsa.pub authorized_keys |
���ԣ�
���ߣ�
��һ��ssh������ʾ��Ϣ��
The authenticity of host ��node1 (10.64.56.76)�� can��t be established.
RSA key fingerprint is 03:e0:30:cb:6e:13:a8:70:c9:7e:cf:ff:33:2a:67:30.
Are you sure you want to continue connecting (yes/no)?
|
���� yes �����������Ѹ÷��������ӵ������֪�������б���
�������ӳɹ��������������롣
4 ) ����authorized_keys��node2 ��node3
��
Ϊ�˱�֤node1�������������Զ���¼��node2��node3������node2��node3��ִ��
$ su hadoop
cd /home/hadoop
$ ssh-keygen -t rsa |
һ·���س�.
Ȼ��ص�node1������authorized_keys��node2 ��node3
[hadoop@hadoop .ssh]$ scp authorized_keys node2:/home/hadoop/.ssh/
[hadoop@hadoop .ssh]$ scp authorized_keys node3:/home/hadoop/.ssh/ |
�������ʾ��������,����hadoop�˺�����Ϳ����ˡ�
�Ķ���� authorized_keys �ļ�������Ȩ��
[hadoop@hadoop .ssh]$chmod 644 authorized_keys |
���ԣ�ssh node2����ssh node3����һ����Ҫ����yes����
�������Ҫ�������������óɹ����������Ҫ��������������ܲ�����ȷ��
2.5 ��װHadoop
#�л�Ϊhadoop�û�
su hadoop
wgethttp://apache.mirrors.tds.net//hadoop/common/hadoop-0.20.203.0/hadoop-0.20.203.0rc1.tar.gz
|
���ذ�װ����ֱ�ӽ�ѹ��װ���ɣ�
$ tar -zxvfhadoop-0.20.203.0rc1.tar.gz |
1 ) ��װHadoop��Ⱥͨ��Ҫ����װ������ѹ����Ⱥ�ڵ����л����ϡ����Ұ�װ·��Ҫһ�£����������HADOOP_HOMEָ����װ�ĸ�·����ͨ������Ⱥ������л�����HADOOP_HOME·����ͬ��
2 ) �����Ⱥ�ڻ����Ļ�����ȫһ����������һ̨���������úã�Ȼ������úõ�������hadoop-0.20.203�����ļ��п�����������������ͬλ�ü��ɡ�
3 ) ���Խ�Master�ϵ�Hadoopͨ��scp������ÿһ��Slave��ͬ��Ŀ¼�£�ͬʱ����ÿһ��Slave��Java_HOME
�IJ�ͬ����hadoop-env.sh ��
4) Ϊ�˷��㣬ʹ��hadoop�������start-all.sh�������Master��/etc/profile
�����������ݣ�
export HADOOP_HOME=/home/hadoop/hadoop-0.20.203
exportPATH=$PATH:$HADOOP_HOME/bin |
����Ϻ�ִ��source /etc/profile ��ʹ����Ч��
6������conf/hadoop-env.sh�ļ�
����conf/hadoop-env.sh�ļ�
#����
export JAVA_HOME=/usr/lib/jvm/java-6-sun/ |
������Ϊ���jdk�İ�װλ�á�
����hadoop��װ��
Bin/hadoop jar hadoop-0.20.2-examples.jarwordcount
conf/ /tmp/out |
3. ��Ⱥ���ã����нڵ���ͬ��
3.1�����ļ���conf/core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl"href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node1:49000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop_home/var</value>
</property>
</configuration> |
1��fs.default.name��NameNode��URI��hdfs://������:�˿�/
2��hadoop.tmp.dir ��Hadoop��Ĭ����ʱ·�������������ã�����������ڵ�������������Ī�������DataNode�������ˣ���ɾ�����ļ��е�tmpĿ¼���ɡ��������ɾ����NameNode�����Ĵ�Ŀ¼����ô����Ҫ����ִ��NameNode��ʽ�������
3.2�����ļ���conf/mapred-site.xml
<?xmlversion="1.0"?>
<?xml-stylesheettype="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>node1:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/home/hadoop/hadoop_home/var</value>
</property>
</configuration> |
1��mapred.job.tracker��JobTracker������������IP���Ͷ˿ڡ�����:�˿ڡ�
3.3�����ļ���conf/hdfs-site.xml
<?xmlversion="1.0"?>
<?xml-stylesheettype="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/name1, /home/hadoop/name2</value> #hadoop��nameĿ¼·��
<description> </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/data1, /home/hadoop/data2</value>
<description> </description>
</property>
<property>
<name>dfs.replication</name>
<!-- ���ǵļ�Ⱥ��������㣬����rep���� -->
<value>2</vaue>
</property>
</configuration> |
1�� dfs.name.dir��NameNode�־ô洢���ֿռ估������־�ı����ļ�ϵͳ·����
�����ֵ��һ�����ŷָ��Ŀ¼�б�ʱ��nametable���ݽ��ᱻ���Ƶ�����Ŀ¼�������౸�ݡ�
2�� dfs.data.dir��DataNode��ſ����ݵı����ļ�ϵͳ·�������ŷָ���б���
�����ֵ�Ƕ��ŷָ��Ŀ¼�б�ʱ�����ݽ����洢������Ŀ¼�£�ͨ���ֲ��ڲ�ͬ�豸�ϡ�
3��dfs.replication��������Ҫ���ݵ�������Ĭ����3������������ڼ�Ⱥ�Ļ������������
ע�⣺�˴���name1��name2��data1��data2Ŀ¼����Ԥ�ȴ�����hadoop��ʽ��ʱ���Զ����������Ԥ�ȴ��������������⡣
3.4����masters��slaves���ӽ��
����conf/masters��conf/slaves���������ӽ�㣬ע�����ʹ�������������ұ�֤����֮��ͨ�����������Ի�����ʣ�ÿ��������һ�С�
vi masters��
���룺
vi slaves��
���룺
���ý����������úõ�hadoop�ļ��п�����������Ⱥ�Ļ����У����ұ�֤��������ö�����������������ȷ�����磺�������������Java��װ·����һ����Ҫ��conf/hadoop-env.sh
$ scp -r /home/hadoop/hadoop-0.20.203 root@node2: /home/hadoop/ |
4 hadoop����
4.1 ��ʽ��һ���µķֲ�ʽ�ļ�ϵͳ
�ȸ�ʽ��һ���µķֲ�ʽ�ļ�ϵͳ
$ cd hadoop-0.20.203
$ bin/hadoop namenode -format |
�ɹ������ϵͳ�����
12/02/06 00:46:50 INFO namenode.NameNode:STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = ubuntu/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 0.20.203.0
STARTUP_MSG: build =http://svn.apache.org/repos/asf/hadoop/common
/branches/branch-0.20-security-203-r 1099333; compiled by 'oom' on Wed May 4 07:57:50 PDT 2011
************************************************************/
12/02/0600:46:50 INFO namenode.FSNamesystem: fsOwner=root,root
12/02/06 00:46:50 INFO namenode.FSNamesystem:supergroup=supergroup
12/02/06 00:46:50 INFO namenode.FSNamesystem:isPermissionEnabled=true
12/02/06 00:46:50 INFO common.Storage: Imagefile of size 94 saved in 0 seconds.
12/02/06 00:46:50 INFO common.Storage: Storagedirectory /opt/hadoop/hadoopfs/name1 has been successfully formatted.
12/02/06 00:46:50 INFO common.Storage: Imagefile of size 94 saved in 0 seconds.
12/02/06 00:46:50 INFO common.Storage: Storagedirectory /opt/hadoop/hadoopfs/name2 has been successfully formatted.
12/02/06 00:46:50 INFO namenode.NameNode:SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode atv-jiwan-ubuntu-0/127.0.0.1
************************************************************/
|
�鿴�����֤�ֲ�ʽ�ļ�ϵͳ��ʽ���ɹ�
ִ�������Ե�master�����Ͽ���/home/hadoop//name1��/home/hadoop//name2����Ŀ¼�������ڵ�master��������hadoop�����ڵ���������дӽڵ��hadoop��
4.2 �������нڵ�
������ʽ1��
$ bin/start-all.sh ��ͬʱ����HDFS��Map/Reduce�� |
ϵͳ�����
starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-ubuntu.out
node2: starting datanode, loggingto /usr/local/hadoop/logs/hadoop-hadoop-datanode-ubuntu.out
node3: starting datanode, loggingto /usr/local/hadoop/logs/hadoop-hadoop-datanode-ubuntu.out
node1: starting secondarynamenode,logging to /usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-ubuntu.out
starting jobtracker, logging to/usr/local/hadoop/logs/hadoop-hadoop-jobtracker-ubuntu.out
node2: starting tasktracker,logging to /usr/local/hadoop/logs/hadoop-hadoop-tasktracker-ubuntu.out
node3: starting tasktracker,logging to /usr/local/hadoop/logs/hadoop-hadoop-tasktracker-ubuntu.out
As you can see in slave's output above, it will automatically format it's storage directory
(specified by dfs.data.dir) if it is not formattedalready. It will also create the directory if it does not exist yet.
|
ִ�������Ե�master��node1����slave��node1��node2�������Ͽ���/home/hadoop/hadoopfs/data1��/home/hadoop/data2����Ŀ¼��
������ʽ2��
����Hadoop��Ⱥ��Ҫ����HDFS��Ⱥ��Map/Reduce��Ⱥ��
�ڷ����NameNode�ϣ������������������HDFS��
$ bin/start-dfs.sh����������HDFS��Ⱥ�� |
bin/start-dfs.sh�ű������NameNode��${HADOOP_CONF_DIR}/slaves�ļ������ݣ��������г���slave������DataNode�ػ����̡�
�ڷ����JobTracker�ϣ������������������Map/Reduce��
$bin/start-mapred.sh ����������Map/Reduce�� |
bin/start-mapred.sh�ű������JobTracker��${HADOOP_CONF_DIR}/slaves�ļ������ݣ��������г���slave������TaskTracker�ػ����̡�
4.3 �ر����нڵ�
�����ڵ�master�ر�hadoop�����ڵ��ر����дӽڵ��hadoop��
Hadoop�ػ����̵���־д�뵽 ${HADOOP_LOG_DIR} Ŀ¼
(Ĭ���� ${HADOOP_HOME}/logs).
5 .����
1�����NameNode��JobTracker������ӿڣ����ǵĵ�ַĬ��Ϊ��
NameNode - http://node1:50070/
JobTracker - http://node2:50030/ |
3�� ʹ��netstat �Cnat�鿴�˿�49000��49001�Ƿ�����ʹ�á�
4�� ʹ��jps�鿴����
Ҫ�����ػ������Ƿ��������У�����ʹ�� jps ����������� JVM ���̵�ps ʵ�ó�����������г�
5 ���ػ����̼�����̱�ʶ����
5���������ļ��������ֲ�ʽ�ļ�ϵͳ��
$ bin/hadoop fs -mkdir input
$ bin/hadoop fs -put conf/core-site.xml input |
���з��а��ṩ��ʾ������
$ bin/hadoop jar hadoop-0.20.2-examples.jar grep input output 'dfs[a-z.]+' |
6.����
Q: bin/hadoop jar hadoop-0.20.2-examples.jar
grep input output 'dfs[a-z.]+' ʲô��˼����
A: bin/hadoop jar��ʹ��hadoop����jar���� hadoop-0.20.2_examples.jar��jar�������֣�
grep ��Ҫʹ�õ��࣬��ߵ��Dz�����input output 'dfs[a-z.]+'
������������hadoopʾ�������е�grep����Ӧ��hdfs�ϵ�����Ŀ¼Ϊinput�����Ŀ¼Ϊoutput��
Q: ʲô��grep?
A: A map/reduce program that counts
the matches of a regex in the input.
�鿴����ļ���
������ļ��ӷֲ�ʽ�ļ�ϵͳ�����������ļ�ϵͳ�鿴��
$ bin/hadoop fs -get output output
$ cat output/* |
����
�ڷֲ�ʽ�ļ�ϵͳ�ϲ鿴����ļ���
$ bin/hadoop fs -cat output/* |
ͳ�ƽ����
root@v-jiwan-ubuntu-0:~/hadoop/hadoop-0.20.2-bak/hadoop-0.20.2#bin/hadoop fs -cat output/part-00000
3 dfs.class
2 dfs.period
1 dfs.file
1 dfs.replication
1 dfs.servers
1 dfsadmin |
7. HDFS����
hadoopdfs -ls �г�HDFS�µ��ļ�
hadoop dfs -ls in �г�HDFS��ij���ĵ��е��ļ�
hadoop dfs -put test1.txt test �ϴ��ļ���ָ��Ŀ¼��������������ֻ�����е�DataNode�����������ݲ���ɹ�
hadoop dfs -get in getin ��HDFS��ȡ�ļ�������������Ϊgetin��ͬputһ���ɲ����ļ�Ҳ�ɲ���Ŀ¼
hadoop dfs -rmr out ɾ��ָ���ļ���HDFS��
hadoop dfs -cat in/* �鿴HDFS��inĿ¼������
hadoop dfsadmin -report �鿴HDFS�Ļ���ͳ����Ϣ���������
hadoop dfsadmin -safemode leave �˳���ȫģʽ
hadoop dfsadmin -safemode enter ���밲ȫģʽ |
8.���ӽڵ�
����չ����HDFS��һ����Ҫ���ԣ��������¼ӵĽڵ��ϰ�װhadoop��Ȼ����$HADOOP_HOME/conf/master�ļ�������
NameNode��������Ȼ����NameNode�ڵ�����$HADOOP_HOME/conf/slaves�ļ��������¼ӽڵ����������ٽ������¼ӽڵ��������SSH����
�����������
Ȼ�����ͨ��http://(Masternode��������):50070�鿴�����ӵ�DataNode
9���ؾ���
start-balancer.sh������ʹDataNode�ڵ���ѡ���������ƽ��DataNode�ϵ����ݿ�ķֲ�
������:��������ʱ���Ȳ鿴logs�����а�����
10 SHell�Զ���װ�ű�
#!/bin/bash
#validate user or group
validate() {
if [ 'id -u' == 0 ];then
echo "must not be root!"
exit 0
else
echo "---------welcome to hadoop---------"
fi
}
#hadoop install
hd-dir() {
if [ ! -d /home/hadoop/ ];then
mkdir /home/hadoop/
else
echo "download hadoop will begin"
fi
}
download-hd() {
wget -c http://archive.apache.org/dist/hadoop/core/stable/hadoop-1.0.4.tar.gz -O /home/hadoop/hadoop-1.0.4.tar.gz
tar -xzvf /home/hadoop/hadoop-1.0.4.tar.gz -C /home/hadoop
rm /home/hadoop/hadoop-1.0.4.tar.gz
Ln -s /home/hadoop/hadoop-1.0.4 /home/hadoop/hadoop1.0.4
}
#hadoop conf
hd-conf() {
echo "export JAVA_HOME=/usr/lib/jvm/java-6-openjdk-i386" >> /home/hadoop/hadoop1.0.4/conf/hadoop-env.sh
echo "#set path jdk" >> /home/hadoop/.profile
echo "export JAVA_HOME=/usr/lib/jvm/java-6-openjdk-i386" >> /home/hadoop/.profile
echo "#hadoop path" >> /home/hadoop/.profile
echo "export HADOOP_HOME=/home/hadoop/hadoop1.0.4" >> /home/hadoop/.profile
echo "PATH=$PATH:$HADOOP_HOME/bin:$JAVA_HOME/bin" >> /home/hadoop/.profile
echo "HADOOP_HOME_WARN_SUPPRESS=1" >> /home/hadoop/.profile
#hadoop core-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/core-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/core-site.xml
echo "fs.default.name" >> /home/hadoop/hadoop1.0.4/conf/core-site.xml
echo "hdfs://hadoop-master:9000" >> /home/hadoop/hadoop1.0.4/conf/core-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/core-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/core-site.xml
echo "hadoop.tmp.dir" >> /home/hadoop/hadoop1.0.4/conf/core-site.xml
echo "/home/hadoop/tmp" >> /home/hadoop/hadoop1.0.4/conf/core-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/core-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/core-site.xml
#hadoop hdfs-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/hdfs-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/hdfs-site.xml
echo "dfs.name.dir" >> /home/hadoop/hadoop1.0.4/conf/hdfs-site.xml
echo "/home/hadoop/name" >> /home/hadoop/hadoop1.0.4/conf/hdfs-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/hdfs-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/hdfs-site.xml
echo "dfs.data.dir" >> /home/hadoop/hadoop1.0.4/conf/hdfs-site.xml
echo "/home/hadoop/data" >> /home/hadoop/hadoop1.0.4/conf/hdfs-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/hdfs-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/hdfs-site.xml
echo "dfs.replication" >> /home/hadoop/hadoop1.0.4/conf/hdfs-site.xml
echo "1" >> /home/hadoop/hadoop1.0.4/conf/hdfs-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/hdfs-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/hdfs-site.xml
# hadoop mapred-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/mapred-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/mapred-site.xml
echo "mapred.job.tracker" >> /home/hadoop/hadoop1.0.4/conf/mapred-site.xml
echo "hadoop-master:9001" >> /home/hadoop/hadoop1.0.4/conf/mapred-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/mapred-site.xml
echo "" >> /home/hadoop/hadoop1.0.4/conf/mapred-site.xml
#hadoop master
echo "hadoop-master" >> /home/hadoop/hadoop1.0.4/conf/masters
#hadoop slaves
echo "hadoop-master" >> /home/hadoop/hadoop1.0.4/conf/slaves
source /home/hadoop/.profile
}
hd-start() {
hadoop namenode -format
}
yes-or-no() {
echo "Is your name $* ?"
while true
do
echo -n "Enter yes or no: "
read x
case "$x" in
y | yes ) return 0;;
n | no ) return 1;;
* ) echo "Answer yes or no";;
esac
done
}
echo "Original params are $*"
if yes-or-no "$1"
then
echo "HI $1,nice name!"
validate
hd-dir
download-hd
hd-conf
else
echo "Never mind!"
fi
|
|





