|
��Է�����������ҪΪÿһ�������ֱ�װ�����ݣ�������ʾ������Ϊ sls_product_dim_part
������װ���� product_line_code Ϊ 991��992,993 �������������ݣ�Big SQL
���� sls_product_dim_part Ŀ¼��Ϊÿһ����������һ��Ŀ¼��
�嵥 18. װ�ط�����
sls_product_dim_load_991.sql
load hive data local inpath '../samples/data/sls_product_prt_991.txt'
overwrite into table gosalesdw. sls_product_dim_part partition (product_line_code=991);
sls_product_dim_load_992.sql
load hive data local inpath '../samples/data/sls_product_prt_992.txt'
into table gosalesdw.sls_product_dim_part partition (product_line_code=992);
~
sls_product_dim_load_993.sql
load hive data local inpath '../samples/data/sls_product_prt_993.txt'
into table gosaleSDW.sls_product_dim_part partition (product_line_code=993);
biadmin@imtebi1:/opt/ibm/biginsights/bin>
hadoop fs -ls /biginsights/hive/warehouse/gosalesdw.db/sls_product_dim_part
Found 3 items
drwxr-xr-x - biadmin supergroup
0 2013-12-15 07:52 /biginsights/hive/warehouse/gosalesdw.db/sls_product_dim_part/product_line_code=991
drwxr-xr-x - biadmin biadmgrp
0 2013-12-15 07:52 /biginsights/hive/warehouse/gosalesdw.db/sls_product_dim_part/product_line_code=992
drwxr-xr-x - biadmin biadmgrp
0 2013-12-15 07:53 /biginsights/hive/warehouse/gosalesdw.db/sls_product_dim_part/product_line_code=993 |
����Ҳ����ͨ��ִ�� http://172.16.42.202:8080/
������ BigInsights Console ���鿴������������Ŀ¼�ṹ��������ʾ��
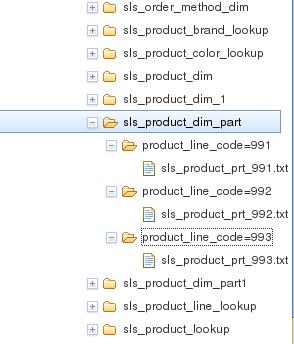
ͼ 10. ʹ�� BigInsights
Console �鿴������Ŀ¼�ṹ
Ŀǰ��Big SQL �ݲ�֧�� Hive �� Bucketed table��
Big SQL ����֧�ֻ������������ͣ�����֧�� Array ���鼰 Struct
�ṹ�����������͡�������������һ����ͬ������������ɣ����ǿ���ʹ���±������������е�Ԫ�أ����±�� 1
��ʼ���� phone[1]���ṹ����һϵ�в�ͬ����������ɣ����ǿ���ʹ�á�.�������ʽṹ�е�Ԫ�أ��� address.city��Ŀǰ����֧�ֽṹ��Ƕ�ס�������ʾ�����Ǵ�����
customer �������������鼰�ṹ�������ͣ�
�嵥 19. ���������������ͱ�
db25.sql
CREATE TABLE customer
(
id int,
name VARCHAR(100),
phones ARRAY (20)>,
address STRUCT(100), city:VARCHAR(100), state:VARCHAR(10), Country:VARCHAR(10),zip:VARCHAR(5)>
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' COLLECTION ITEMS TERMINATED BY ':';
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries>
jsqsh --user=biadmin --password=password --server localhost --port 7052 --driver=bigsql -i db25.sql
0 rows affected (total: 0.73s)
Data.txt
1|David Li|63618888-12345:63618888|PGP25F:Beijing:Beijing:China:100101
2|David Wang|63618888-12346:63618888|PGP25F:Beijing:Beijing:China:100101
3|Jason Zhang|63618888-12347:63618888|PGP25F:Beijing:Beijing:China:100101
4|David Yang|63618888-12348:63618888|PGP25F:Beijing:Beijing:China:100101
5|Jason Wang|63618888-12349:63618888|PGP25F:Beijing:Beijing:China:100101
loadcomp.sql
load hive data local inpath '../samples/data/data.txt' overwrite into table customer;
biadmin@imtebi1:/opt/> $BIGSQL_HOME/bin/jsqsh --user=biadmin
--password=password --server localhost --port 7052 --driver=bigsql -i loadcomp.sql
ok. (total: 15.17s)
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries>
jsqsh --user=biadmin --password=password --server localhost --port 7052 --driver=bigsql
JSqsh Release 1.5-ibm, Copyright (C) 2007-2013, Scott C. Gray
Type \help for available help topics. Using JLine.
[localhost][biadmin] 1> select name,phones[1],address.country from customer;
+-------------+----------------+---------+
| name | | Country |
+-------------+----------------+---------+
| David Li | 63618888-12345 | China |
| David Wang | 63618888-12346 | China |
| Jason Zhang | 63618888-12347 | China |
| David Yang | 63618888-12348 | China |
| Jason Wang | 63618888-12349 | China |
+-------------+----------------+---------+
5 rows in results(first row: 0.28s; total: 0.40s) |
���� Hive ��
Big SQL LOAD �����ֱ�ӴӴ洢�ڱ��ػ� BigInsights
�ֲ�ʽ�ļ�ϵͳ�е��ļ���Ӷ��ֹ�ϵ���ݿ�ϵͳ���� Netezza ����֧�ֵ� IBM PureData
Systems for Analytics��DB2 �� Teradata���ж�ȡ����װ�ص� Hive ���С�
������ʾ������ʹ�� Big SQL LOAD ����ӱ����ļ�װ�����ݵ�
Hive ����
�嵥 20. ���ļ�װ�����ݵ� Hive ��
--GOSALESDW.SLS_SALES_FACT
load hive data local inpath '../samples/data/GOSALESDW.SLS_ORDER_METHOD_DIM.txt'
overwrite into table SLS_ORDER_METHOD_DIM;
load hive data local inpath '../samples/data/GOSALESDW.SLS_SALES_FACT.txt'
overwrite into table SLS_SALES_FACT;
load hive data local inpath '../samples/data/GOSALESDW.SLS_ORDER_METHOD_DIM.txt'
overwrite into table SLS_SALES_ORDER_DIM; |
����Ҳ���Խ� DB2 ���ݿ� staff ���е�����װ�ص����Ǵ����� staff_sales
�������У�������ʾ����ʹ�ù�ϵ���ݿ�װ�����ݵ� Hive ��ʱ��������Ҫ����ص� JAR �����Ƶ� /opt/ibm/biginsights/sqoop/lib
Ŀ¼�£������� Big SQL �����������У����ǽ� DB2 �� db2jcc.jar, db2jcc_license_cu.jar
�ļ����Ƶ� /opt/ibm/biginsights/sqoop/lib�������� Big SQL ����
�嵥 21. �����ݿ�װ�����ݵ� Hive ��
db21.sql
create table staff_sales (
id smallint, name varchar(100),
years smallint, salary decimal, comm decimal)
partitioned by (dept smallint, job char(5)) ;
LOAD
USING JDBC CONNECTION URL 'jdbc:db2://imtebi1:50001/SAMPLE'
WITH PARAMETERS (user = 'db2inst1',password='password')
FROM TABLE STAFF
WHERE "dept=66 and job='Sales'"
INTO TABLE staff_sales
PARTITION ( dept=66 , job='Sales') APPEND
WITH LOAD PROPERTIES
(bigsql.load.num.map.tasks = 1) ;
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries>
jsqsh --user=biadmin --password=password --server localhost
--port 7052 --driver=bigsql -i db21.sql
0 rows affected (total: 0.65s)
3 rows affected (total: 1m28.84s)
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries>
jsqsh --user=biadmin --password=password --server localhost --port 7052 --driver=bigsql
JSqsh Release 1.5-ibm, Copyright (C) 2007-2013, Scott C. Gray
Type \help for available help topics. Using JLine.
[localhost][biadmin] 1> select * from staff_sales;
+-----+----------+-------+--------+------+------+-------+
| id | name | years | salary | comm | dept | job |
+-----+----------+-------+--------+------+------+-------+
| 280 | Wilson | 9 | 78674 | 811 | 66 | Sales |
| 310 | Graham | 13 | 71000 | 200 | 66 | Sales |
| 320 | Gonzales | 4 | 76858 | 844 | 66 | Sales |
+-----+----------+-------+--------+------+------+-------+
3 rows in results(first row: 0.36s; total: 0.37s)
|
���������� Hbase ��
���� Hbase ��
���ǿ���ͨ��ִ�� CREATE HBASE TABLE ���������� HBase
����Big SQL ��ʹ���Լ�ר���� HBase �洢�������������� HBase ���ݵĴ洢�������ô洢���������ṩ����ǿ��
HBase �������ܣ��������Դ�������н�������ֶΣ���������������Ϊ��ͬ��ָ����ͬ��ѹ���㷨���ṩ������
HBase ��������ȡ�������ʾ�����Ǵ����� SLS_HBASE_SALES_FACT ����
�嵥 22. ���� HBase ��
use gosalesdw;
CREATE HBASE TABLE SLS_HBASE_SALES_FACT ( ORDER_DAY_KEY int,
ORGANIZATION_KEY int, EMPLOYEE_KEY int, RETAILER_KEY int,
RETAILER_SITE_KEY int, PRODUCT_KEY int, PROMOTION_KEY int,
ORDER_METHOD_KEY int, SALES_ORDER_KEY int, SHIP_DAY_KEY int,
CLOSE_DAY_KEY int, QUANTITY int, UNIT_COST decimal(19,2),
UNIT_PRICE decimal(19,2), UNIT_SALE_PRICE decimal(19,2),
GROSS_MARGIN double, SALE_TOTAL decimal(19,2), GROSS_PROFIT decimal(19,2) )
column mapping
(key mapped by (ORDER_DAY_KEY,ORGANIZATION_KEY, EMPLOYEE_KEY,
RETAILER_KEY, RETAILER_SITE_KEY, PRODUCT_KEY, PROMOTION_KEY,
ORDER_METHOD_KEY) encoding binary,
cf1:sales_order mapped by (SALES_ORDER_KEY,
SHIP_DAY_KEY,CLOSE_DAY_KEY) separator '|' encoding string,
cf2:sales_data mapped by (QUANTITY, UNIT_COST, UNIT_PRICE,
UNIT_SALE_PRICE, GROSS_MARGIN, SALE_TOTAL,
GROSS_PROFIT) separator '|' encoding string )
column family options
(cf1 compression(gz) bloom filter( none) in memory,
cf2 compression(gz) bloom filter( none) in memory)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; |
���ǿ���Ϊ gosalesdw.SLS_HBASE_SALES_FACT
����������������������ʾ��
�嵥 23. ���� HBase ��������
CREATE INDEX index1 ON TABLE gosalesdw.SLS_HBASE_SALES_FACT(SALES_ORDER_KEY) AS 'HBASE'; |
����Ҳ����ʹ�� Hive �����ṩ�� HBase �洢�������������� HBase
�������ǣ�Big SQL ����ֱ�Ӷ�ȡ��Щ����������Ҫ�� Big SQL �д����ⲿ�������������� Big
SQL �У�ʹ���ⲿ���������Dz������ⲿ���ϴ����������������ǿ���Ϊ�Ѿ����ڵ� HBase ����������ⲿ�����൱�ڴ��������ͼ��������ʾ�����Ǵ�����
EXTERNAL_SALES_FACT HBase �ⲿ����
�嵥 24. ���� HBase �ⲿ��
CREATE external HBASE TABLE EXTERNAL_SALES_FACT ( ORDER_DAY_KEY int,
ORGANIZATION_KEY int, EMPLOYEE_KEY int, RETAILER_KEY int, RETAILER_SITE_KEY int,
PRODUCT_KEY int, PROMOTION_KEY int, ORDER_METHOD_KEY int, QUANTITY int,
UNIT_COST decimal(19,2), UNIT_PRICE decimal(19,2),
UNIT_SALE_PRICE decimal(19,2), GROSS_MARGIN double,
SALE_TOTAL decimal(19,2), GROSS_PROFIT decimal(19,2) )
column mapping
(key mapped by (ORDER_DAY_KEY,ORGANIZATION_KEY,
EMPLOYEE_KEY, RETAILER_KEY, RETAILER_SITE_KEY, PRODUCT_KEY,
PROMOTION_KEY, ORDER_METHOD_KEY) encoding binary,
cf1:sales_data mapped by (QUANTITY, UNIT_COST, UNIT_PRICE,
UNIT_SALE_PRICE, GROSS_MARGIN, SALE_TOTAL, GROSS_PROFIT)
separator '|' encoding string )
hbase table name 'gosalesdw.sls_hbase_sales_fact'; |
���� HBase ��
���ǿ���ʹ�� insert ���Ϊ HBase ���������ݣ�������ʾ��
�嵥 25. ʹ�� insert ���Ϊ HBase ����������
create hbase table hbase_staff (
id smallint, name varchar(100))
COLUMN MAPPING (
key mapped by (id),
cf:name mapped by (name)
);
insert into hbase_staff(id,name) values(202,'David Li'); |
ͬ����Big SQL LOAD �����ֱ�ӴӴ洢�ڱ��ػ� BigInsights
�ֲ�ʽ�ļ�ϵͳ�е��ļ���Ӷ��ֹ�ϵ���ݿ�ϵͳ���� Netezza ����֧�ֵ� IBM PureData
Systems for Analytics��DB2 �� Teradata���ж�ȡ����װ�ص� HBase
����
������ʾ������ʹ�� Big SQL LOAD ����� BigInsights
�ֲ�ʽ�ļ�ϵͳ�е��ļ�װ�����ݵ� HBase ���У�
�嵥 26. ���ļ�װ�����ݵ� HBase ��
load hbase data inpath 'hdfs://imtebi1.imte.com:9000/biginsights/GOSALESDW.SLS_SALES_FACT.txt'
DELIMITED FIELDS TERMINATED BY '\t' into table gosalesdw.SLS_HBASE_SALES_FACT; |
����Ҳ���Խ� DB2 ���ݿ� staff ���е�����װ�ص����Ǵ����� hbase_staff
HBase ���У�������ʾ����ʹ�ù�ϵ���ݿ�װ�����ݵ� HBase ��ʱ��������Ҫ����ص� JAR �����Ƶ�
/opt/ibm/biginsights/sqoop/lib Ŀ¼�£������� Big SQL �����������У����ǽ�
DB2 �� db2jcc.jar, db2jcc_license_cu.jar �ļ����Ƶ� /opt/ibm/biginsights/sqoop/lib��������
Big SQL ����
�嵥 27. �����ݿ�װ�����ݵ� HBase ��
db22.sql
create hbase table hbase_staff (
id smallint, name varchar(100))
COLUMN MAPPING (
key mapped by (id),
cf:name mapped by (name)
);
LOAD
USING JDBC CONNECTION URL 'jdbc:db2://imtebi1:50001/SAMPLE'
WITH PARAMETERS (user = 'dbinst1',password = 'password' )
FROM TABLE STAFF COLUMNS (ID, NAME)
WHERE " ID > 100 and NAME like 'S%' "
INTO hbase TABLE hbase_staff APPEND
WITH LOAD PROPERTIES (bigsql.load.num.map.tasks = 1);
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries>
jsqsh --user=biadmin --password=password --server localhost --port 7052 --driver=bigsql -i db22.sql
0 rows affected (total: 5.58s)
3 rows affected (total: 1m34.47s)
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries>
jsqsh --user=biadmin --password=password --server localhost --port 7052 --driver=bigsql
JSqsh Release 1.5-ibm, Copyright (C) 2007-2013, Scott C. Gray
Type \help for available help topics. Using JLine.
[localhost][biadmin] 1> select * from hbase_staff1;
+-----+----------+
| id | name |
+-----+----------+
| 190 | Sneider |
| 200 | Scoutten |
| 220 | Smith |
+-----+----------+
3 rows in results(first row: 1.70s; total: 1.70s) |
���ǻ�����ͨ�� select ��佫 DB2 ���ݿ� staff ���е�����װ�ص����Ǵ�����
hbase_staff1 HBase ���У�������ʾ��
�嵥 28. ͨ�� select ���װ�����ݵ� HBase ��
create hbase table hbase_staff1 (
id smallint, name varchar(100), dept smallint, job string, years smallint, salary string, comm string)
COLUMN MAPPING (
key mapped by (ID),
cf:name mapped by (name),
cf:dept mapped by (dept),
cf:job mapped by (job),
cf:years mapped by (years),
cf:salary mapped by (salary),
cf:comm mapped by(comm)
);
LOAD
USING JDBC CONNECTION URL 'jdbc:db2://imtebi1:50001/SAMPLE'
WITH PARAMETERS (user = 'db2inst1',password = 'password' )
FROM SQL QUERY 'select * from staff where $CONDITIONS'
INTO hbase TABLE hbase_staff1 APPEND
WITH LOAD PROPERTIES (bigsql.load.num.map.tasks = 1);
|
��ѯ����
Big SQL �ṩ���� ANSI SQL 92 ���� SQL �ӿڣ�֧��Ԥ�⡢���ơ����ӡ����ϡ�����ͷ������ݵ�
SELECT ��䡣�Ӳ�ѯ�ͳ����ı�����ʽ���� WITH �Ӿ俪ͷ�IJ�ѯ��Ҳ�ܵ�֧�֡�Big SQL �ṩ����ʮ�����õĺ���������һЩר����ʵ��
Hive �����Եĺ���������֧�ִ��ں����������Ҫ��SQL ����Ա����������ij��������ѯ���ص�������Big
SQL ֧�ֱ��� SQL �������ͣ����� tinyint, smallint, bigint, varchar(),
binary(), decimal(), timestamp, struct, array �ȡ���Ϥ SQL
���û�������ͨ�� Big SQL ֱ�ӷ��ʻ��� Hadoop �� BigInsights �����ݣ�������Ҫ�����е�Ӧ�ó���Ϊ
SQL �û����� Hadoop �������ṩ��һ����㡢��Ϥ�ķ�����
���⣬Big SQL �ṩ�˱��� JDBC/ODBC ���������û����е�
SQL ��������Ҳ����ֱ�ӷ��� BigInsights �����ݡ�
Big SQL ֧�ֲ�ѯ����������֧�� SQL UPDATE �� DELETE
��䡣INSERT ����֧������ HBase ����
�˰汾��֧����ͼ���û������Լ����������ڹ�ϵ���ݿ��кܳ���������������Լ�����ض������Լ��Ӧ��Ӧ�ó�����ִ�С�����ʹ��
GRANT �� REVOKE ������������ݷ��ʣ�����Ա��ʹ�ñ��� Hadoop ����ָ�� Hive
���ݵ��ļ�ϵͳ������Ȩ����ˣ�Ӧ�ڱ������Ͽ�����Ȩ�����������л��м����ϡ�
��ͳ����������� Hadoop ��̬ϵͳ��һ���֣����� Big SQL
������δ�漰���������������������ύ�ͻع���������֧�֡�
������ʾ�����ǿ���ʹ�� Big SQL ִ�и��ӵĶ�����Ӳ�ѯ������
�嵥 29. ������Ӳ�ѯ
GOSALESDW_Counts_With_Joins.sql
SELECT count(*)
FROM
GOSALESDW.SLS_ORDER_METHOD_DIM AS MD,
GOSALESDW.SLS_PRODUCT_DIM AS PD,
GOSALESDW.EMP_EMPLOYEE_DIM AS ED,
GOSALESDW.SLS_SALES_FACT AS SF
WHERE
PD.PRODUCT_KEY = SF.PRODUCT_KEY /*+ joinMethod = 'mapSideHash', buildTable = 'pd' +*/
AND PD.PRODUCT_NUMBER > 10000
AND PD.BASE_PRODUCT_KEY > 30
AND MD.ORDER_METHOD_KEY = SF.ORDER_METHOD_KEY /*+
joinMethod = 'mapSideHash', buildTable = 'md' +*/
AND ED.EMPLOYEE_KEY = SF.EMPLOYEE_KEY /*+ joinMethod = 'mapSideHash', buildTable = 'ed' +*/
AND ED.MANAGER_CODE1 > 20
AND MD.ORDER_METHOD_CODE > 5 ; |
���ǿ���ʹ�� with ������� SQL ��ѯ�� SQL ��ѯƬ����ִ�и����ӵIJ�ѯ��������ʹ��
limit ����������������������ʾ��
�嵥 30. with ���
GOSALESDW_starSchemaJoin.sql
WITH
SALES AS
(SELECT SF.*
FROM GOSALESDW.SLS_ORDER_METHOD_DIM AS MD,
GOSALESDW.SLS_PRODUCT_DIM AS PD, GOSALESDW.EMP_EMPLOYEE_DIM AS ED,
GOSALESDW.SLS_SALES_FACT AS SF
WHERE PD.PRODUCT_KEY = SF.PRODUCT_KEY /*+ joinMethod =
'mapSideHash', buildTable = 'pd' +*/
AND PD.PRODUCT_NUMBER > 10000
AND PD.BASE_PRODUCT_KEY > 30
AND MD.ORDER_METHOD_KEY = SF.ORDER_METHOD_KEY /*+
joinMethod = 'mapSideHash', buildTable = 'md' +*/
AND MD.ORDER_METHOD_CODE > 5
AND ED.EMPLOYEE_KEY = SF.EMPLOYEE_KEY /*+ joinMethod = 'mapSideHash', buildTable = 'ed' +*/
AND ED.MANAGER_CODE1 > 20),
INVENTORY AS
(SELECT IF.*
FROM GOSALESDW.GO_BRANCH_DIM AS BD, GOSALESDW.DIST_INVENTORY_FACT AS IF
WHERE IF.BRANCH_KEY = BD.BRANCH_KEY /*+ joinMethod = 'mapSideHash', buildTable = 'bd' +*/
AND BD.BRANCH_CODE > 20)
SELECT SALES.PRODUCT_KEY AS PROD_KEY, SUM(CAST
(INVENTORY.QUANTITY_SHIPPED AS BIGINT)) AS INV_SHIPPED,
SUM(CAST (SALES.QUANTITY AS BIGINT)) AS PROD_QUANTITY, RANK() OVER
( ORDER BY SUM(CAST (SALES.QUANTITY AS BIGINT)) DESC) AS PROD_RANK
FROM SALES, INVENTORY
WHERE SALES.PRODUCT_KEY = INVENTORY.PRODUCT_KEY
GROUP BY SALES.PRODUCT_KEY
Limit 20;
|
���ǻ�����ʹ�ô��ں���ִ�и��ӵ�ͳ�Ʋ�ѯ��������ʾ��
�嵥 31. ʹ�ô��ں���
GOSALESDW_rank.sql
SELECT EXTRACT(YEAR FROM CAST(CAST (order_day_key AS varchar(100)) AS timestamp)) AS year,
SUM (sale_total) AS total_sales,
RANK () OVER (ORDER BY SUM (sale_total) DESC) AS ranked_sales
FROM gosalesdw.sls_sales_fact
GROUP BY EXTRACT(YEAR FROM CAST(CAST (order_day_key AS varchar(100)) AS timestamp)); |
���⣬Big SQL ���ṩ��һ��Ԫ���ݱ������� syscat.tables��syscat.columns��syscat.schemas��syscat.indexcolumns��
������ʾ�����ǿ���ͨ����ѯ��ЩԪ���ݱ����˽� Big SQL �ж���ı�������Ϣ��
�嵥 32. Big SQL Ԫ���ݱ�
[localhost][biadmin] 1> select * from syscat.tables where tablename='sls_sales_order_dim';
+------------+---------------------+
| schemaname | tablename |
+------------+---------------------+
| gosalesdw | sls_sales_order_dim |
+------------+---------------------+
1 row in results(first row: 0.17s; total: 0.17s)
[localhost][biadmin] 1> select * from syscat.columns where tablename='sls_sales_order_dim';
+------------+------------+-------------+------
| schemaname | tablename | name | type | precision | scale | fulltype |
+------------+------------+-------------+------
| gosalesdw | sls_sales_ | sales_order | INT | 10 | 0 | int |
| | order_dim | _key | | | | |
| gosalesdw | sls_sales_ | order_detai | INT | 10 | 0 | int |
| | order_dim | l_code | | | | |
| gosalesdw | sls_sales_ | order_numbe | INT | 10 | 0 | int |
| | order_dim | r | | | | |
| gosalesdw | sls_sales_ | warehouse_b | INT | 10 | 0 | int |
| | order_dim | ranch_code | | | | |
+------------+------------+-------------+-----
4 rows in results(first row: 2.8s; total: 2.10s) |
��ѯ�Ż�
���ز�ѯ�� MapReduce ����
����֪����Hadoop �� MapReduce ��ܿ���ͨ�������� Mapper��Reducer
�����д������ģ���ݼ���ʵ�ָ�Ч���ݲ�ѯ�����ǣ�MapReduce Ҳ�����һЩ���п�����ÿ����һ��
mapper �� reducer ����ʱ�������漰�� JVM ������ֹͣ������mapper �Ὣ���е��м���д�����̣�reducer
ͨ����ȡ�����м��������������㣬����������������ʧЧ����������֮��ĵ���Ҳ��Ҫһ���Ŀ�����ͨ��������ÿ��������Ҫ�ߴ�
20-30 ��Ŀ����������һ���ϴ����ݼ��IJ��������Ժ��Բ��ƣ�������һ��С���ݼ��IJ�������ʹ���н�����ѯ�ض������ݼ���
HBase ������˵����Щ������Ȼ�Ͳ�̫���ʣ�Ϊ����������⣬Big SQL ���Ը��ݲ�ѯ�����ʡ����������������أ�ѡ��ʹ��
Hadoop �� MapReduce ��ܲ��д������ֲ�ѯ�������ڵ����ڵ��ϵ� Big SQL �������ϱ���ִ�����IJ�ѯ��
Ҳ���Բ��ֲ�ѯ������ Hadoop �� MapReduce �������ɣ����ֲ�ѯ������ Big SQL
����������ɡ�
Big SQL ����ִ�����¶�̬�����Ż���������߲�ѯ���ܣ�
��Լ� SQL ��ѯ��䣬�� SELECT c1,c2 FROM T1�������Զ�ѡ����ñ��ز�ѯ����ʹ��
Hadoop �� MapReduce �������
��Բ�ѯ��ÿһ��������������������ݼ���С�������� Big SQL ����������ִ�У����ǿ���ͨ������
$BIGSQL_HOME/conf/bigsql-site.xml �ļ��е� bigsql.localmode.size
�����������
���һ�ű���С����ʹ�� map-side hash join ���ӷ�ʽ��߲�ѯЧ�ʣ����ǿ���ͨ������
$BIGSQL_HOME/conf/bigsql-site.xml �ļ��е� bigsql.memoryjoin.size
�����������
�����Ը��� SQL ��ѯ��䣬���ǿ���ͨ��ʹ�� SQL ��ѯ��ʾ���Ż���ѯЧ�ʣ����磬���ǿ�������
/*+ accessmode='local' +*/ ��ѯ��ʾ���� Big SQL����� t1 �����ñ��ز�ѯģʽ��������ʾ��
�嵥 33. ���ñ��ز�ѯģʽ
SELECT c1 FROM t1 /*+ accessmode='local' +*/ WHERE c2 > 10 |
����Ҳ�������� session ������Ż���ʾ���Ż���ѯЧ�ʣ�������ʾ��
�嵥 34. ���� session �����Ż���ʾ
set force local on;
SELECT c1 FROM t1 WHERE c2 > 10; |
���� HBase ��������
Big SQL ֧��ʹ�� CREATE INDEX ���Ϊ HBase
����������������Щ�����ɸĽ��ڼ������������Ͻ��й��˵IJ�ѯ���������ܡ���������ֶεĹ��˲�ѯ���Զ�ʹ������������Ҳ����ͨ��
SQL ��ѯ��ʾǿ��ʹ�� HBase ����������������ʾ��
�嵥 35. HBase ����������ʾ
CREATE INDEX index1 ON TABLE gosalesdw.SLS_HBASE_SALES_FACT(SALES_ORDER_KEY) AS 'HBASE';
select count(*) from gosalesdw.sls_hbase_sales_fact
/*+ rowcachesize=2000,useindex='index1' +*/ where sales_order_key<195000; |
���ǿ��Ի��ڵ������ϼ������� HBase ����������
�ڴ��� HBase ��������ʱ����������������Ӧ�� HBase �������У�Big
SQL ʹ�� Map Reduce index builder �߳������������� HBase ��������ͨ��
synchronous coprocessor �߳���ͬ��������Ϣ������ͼ��ʾ��
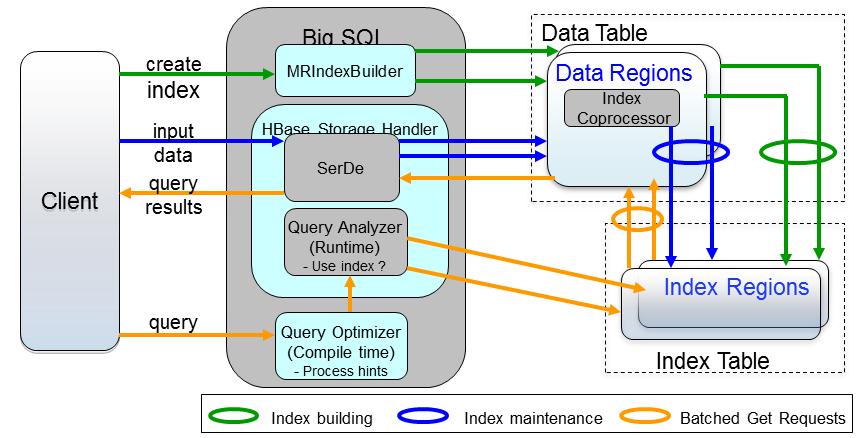
ͼ 11. HBase ���������ܹ�
��ʹ�� Big SQL �����ݲ��� HBase ���л�����һ���ļ������ݼ��ص�
HBase ����ʱ���Զ������������������ǣ��� BigInsights 2.1 �У�������Զ�̹�ϵ���ݿ�����ݼ��ص�
HBase ���в����Զ����±��ĸ����������෴������Ա��Ҫ���������´�����Ҫ��������
SQL �Ż���ʾ
Big SQL �IJ�ѯ�Ż����ᶯ̬�زο�ijЩͳ����Ϣ��ȷ��һ�ָ�Ч�����ݷ��ʲ��ԡ����ǣ���һЩ����£�Big
SQL ����û���㹻��ͳ����Ϣ���á����磬���Ļ�������Դ����δ�ṩ��Щ��Ϣ������Щ����£� Big SQL
����Ա���Ż���ʾǶ�����ѯ�п���������������Ϊ��ô����ʹ Big SQL ���ɸ��õ�ִ�мƻ�����ʾ�����ѯִ��ģʽ�����ػ��У������ӷ���������ʹ�õ���ء�
������˳��
������ FROM �Ӿ����ṩ�ı���˳�����Ϊ������ʾ�����������ӵIJ��ԡ��ڴ��������£�Big
SQL �ᰴ�������ṩ��˳����б����Ӳ�������ˣ�������ָ���ı���˳��������Ҫ��������ָ������˳��ʱ����Ҫ���ǣ�������������ƽ������������Ҫ����ѡ���Եı����ж�ν�ʻ���˵��������ݣ����߱����Ӳ�����ȥ���������ݣ��ŵ���ѯ��ǰ�ߣ�����������������ѯ��һ�ε���������
��������ʾ
��������ʾ��Ӱ����ζ�ȡ�������ȷ������Դ�Լ�����Ż���ѯ�IJ��ԡ���������ʾ��Ӱ���������Ϊ����ʹ��
MapReduce ִ�б����Ӳ�������ʹ�� hash ���Ӳ�����������Ӱ����ζ�ȡ�ض�����Դ�IJ��ԡ�
accessmode ��ʾ
accessmode ��ʾ����������ʹ�� MapReduce ���������ݣ�������
Big SQL ���������ش������ݡ�accessmode ��ʾ֧������ѡ��
Local - ָ���� Big SQL ���������ش������ݣ������� mapreduce
������ʽ��
mapreduce �� mr �C ָ��ʹ�� MapReduce ���������ݡ�MapReduce
�� Big SQL Ĭ�ϵĴ�����ʽ������κ�����Դ�Ĵ�����ʽ��֧�� MapReduce��Big SQL
���Զ�ѡ�� Big SQL ���������ش�����ʽ��
�±ߵ������У�accessmode ��ʾǿ�� Big SQL ������ T1
��˳����� Big SQL �����������ڴ沢ִ�оۺϲ�����
�嵥 36. accessmode ��ʾ
SELECT c1,count(*) from T1 /*+ accessmode='local' +*/ group by c1; |
accessmode= �� local ����ʾһ���������³�����
������㹻С������ MapReduce ��ҵ�Ŀ���Զ����˳����� Big
SQL �����������ڴ���д����Ŀ�����
ʹ�� TOP �� LIMIT �Ӿ����ȼ������ݷ��ؽ�����Ĵ�С��ע�⣬���ʹ����
GROUP BY �� ORDER BY �Ӿ䣬���漰��ȫ����������ʱ����Ӱ�� TOP �� LIMIT �Ӿ��Ԥ��Ч����
Big SQL �������������㹻���ڴ������в�ѯ�����ϱߵ������У��ۺϲ�������ȫ��
Big SQL �����������ڴ�����ɣ�ͬ�������ʹ���� ORDER BY �Ӿ䣬���ݻ����ڴ�������֮�أ�Ҳ��Ҫ
Big SQL �������������㹻���ڴ档
ע�⣬��ʹ�� accessmode= �� local ����ʾʱ������Ҫʹ�ô����ı����ڴ棬�ر��ǵ�����û�����ִ�ж����ѯʱ��
����Ҳ���Բ������� accessmode ��ʾǿ�Ʋ��� MapReduce
��ʽ���������ݣ�������ʾ :
�嵥 37. ���� MapReduce ��ʽ
select * from gosalesdw.sls_sales_order_dim /*+ accessmode = 'mr' +*/ where sales_order_key<100020; |
���⣬���ǻ��������� session ���� accessmode ��ʾ�������������Ự������Ч��������ʾ��
�嵥 38. �Ự�� accessmode ��ʾ
set force local on;
select * from gosalesdw.sls_sales_order_dim where sales_order_key<100020; |
������Ӽ����ط�����ʾ
���ж�����������Ӳ���ʱ�����ط���ģʽ��accessmode= �� local
������ǿ�ƺ����������ӵı����ñ��ط���ģʽ�� ������ʾ���������� t1 ��Ϊ���ط���ģʽ���������� SQL
��䶼���Ա��ط�ʽ���У���ʹ������ʽָ�� t2 ���� mapreduce ģʽ���У�
�嵥 39. ������ӱ��ط�����ʾ
SELECT t1.c1, count(*) FROM t1 /*+ accessmode='local' +*/, t2 WHERE t1.c2 = t2.c2 GROUP BY t1.c1; |
����ѯ�����漰���������������Ӳ���ʱ��������ܰ�������ָ����˳����б����Ӳ����ᵼ�����µ�����������˳����ʱ�����ܻᵼ�±����Ϊ���ط�����ʾ�ı�֮��ı�����
MapReduce ��ʽ���У����ǿ���ͨ���������б�Ϊ���ط���ģʽ��accessmode= �� local
������ǿ��������ѯ�Ա��ط�ʽ���С�
tablesize ��ʾ
�������Ӳ������漰��С��ʱ��Big SQL ������ʹ��һ�� MapReduce
��ҵ�������������ڴ��н������Ӳ����ı��Ӷ���߲�ѯЧ�ʡ� ������ʾ��ͨ���������ѯ��Ҫ���� MapReduce
��ҵ��һ�����ڱ����Ӳ�����һ�����ڷ��������
�嵥 40. �����Ӳ�
SELECT c1, count(*) from T1, T2 where T1.c2 = T2.c2 GROUP BY c1; |
��� T2 ����С�����ǿ���ʹ�������������߲�ѯЧ�ʣ�
�嵥 41. tablesize ��ʾ
SELECT c1, count(*) FROM T1, T2 /*+ tablesize='small' +*/ where T1.c2 = T2.c2 GROUP BY c1; |
�����ֻʹ��һ�� MapReduce ��ҵ��ɨ�� T1 ����ÿһ�� mapper
��������ڴ���ִ�к� T2 �����Ӳ��������������ͬһ������� reduce ����ɡ�
tablesize ��ʾ����ָ�������ڴ����ӣ�hash join����ʽ���Dz���
MapReduce ִ�б����Ӳ�����tablesize ��ʾ֧������ѡ��
small �C ָ���ñ��㹻С������װ���ڴ沢ִ�� hash ������
large �C Ĭ�����ã�����������ڴ����ӣ�hash join����ʽ��
�±����ӣ�����ָ�� GOSALESDW.GO_BRANCH_DIM ����һ���������ˣ����������ڴ����ӣ�hash
join����ʽ��
�嵥 42. ��������ڴ�����
SELECT count(*)
FROM
GOSALESDW.GO_BRANCH_DIM /*+ tablesize='large' +*/ AS BD ,
GOSALESDW.DIST_INVENTORY_FACT AS IF
WHERE
IF.BRANCH_KEY = BD.BRANCH_KEY
AND BD.BRANCH_CODE > 20; |
�±����ӣ�����ָ�� GOSALESDW.GO_BRANCH_DIM ����һ��С������ˣ��ᾡ�������ڴ����ӣ�hash
join����ʽ��
�嵥 43. �����ڴ�����
SELECT BD.BRANCH_KEY,count(*)
FROM
GOSALESDW.GO_BRANCH_DIM /*+ tablesize='small' +*/ AS BD ,
GOSALESDW.DIST_INVENTORY_FACT AS IF
WHERE
IF.BRANCH_KEY = BD.BRANCH_KEY
AND BD.BRANCH_CODE > 20
GROUP BY BD.BRANCH_KEY; |
HBase ��ʾ
��� HBase��Big SQL �ṩ���� SQL �Ż���ʾ��
1.rowcachesize ��ʾ
2.colbatchsize ��ʾ
3.useindex ��ʾ
rowcachesize ��ʾ
rowcachesize ��ʾ����ָ�����ݴ� region servers
���ص� Big SQL ( ���ظ� Big SQL �������������л� mappers or reducers
���д��� ) ��¼���Ĵ�С��������ÿ���������� HBase ���ݿ��ѯ�����ܡ���Ȼ�������ֵ���ù��ߣ�Ҳ�����ĸ����
region servers ����ѯ���б��أ�Big SQL �������� mappers or reducers�����ڴ档���û�����ã�rowcachesize
Ĭ��Ϊ 2000 �С�
������ʾ���������� rowcachesize ��СΪ 4000 �У�
�嵥 44. ���� rowcachesize ��С
SELECT c1, c3 FROM hbase_tab /*+ rowcachesize=4000
+*/ WHERE c2 > 10;
ע�⣬��Կ��������ǿ�����Ҫ��С rowcachesize ����ֵ������ÿ�ζ�ȡ�Ĵ�����������
colbatchsize ��ʾ
colbatchsize ��ʾ��Ҫ����������ijһ����ij�����ر����ֶζ�����̫����ڴ档colbatchsize
��ʾָ��ÿһ�ζ�ȡ������ region server ������ֶθ�����Ĭ��Ϊ -1����ʾ��ȡ���е��ֶΡ�
������ʾ���������� colbatchsize ��СΪ 5��
�嵥 45. ���� colbatchsize ��С
SELECT c1, c3 FROM hbase_tab /*+ colbatchsize=5 +*/ WHERE c2 > 10; |
useindex ��ʾ
useindex ��ʾ����ָ����ѯ�����ʹ�õ� HBase �����������ơ��ر��ǵ��ж����ѡ��������ʱ�����ǿ���ָ��ʹ���ĸ��ض�������������ʾ������Ϊ
gosalesdw.SLS_HBASE_SALES_FACT HBase �������� index1 ������������ָ���±߲�ѯ���ʹ�����Ǵ�����
index1 ������
�嵥 46. ���� HBase ��������
CREATE INDEX index1 ON TABLE gosalesdw.SLS_HBASE_SALES_FACT(SALES_ORDER_KEY) AS 'HBASE';
select count(*) from gosalesdw.sls_hbase_sales_fact
/*+ rowcachesize=2000,useindex='index1' +*/ where sales_order_key<195000; |
��� useindex ��ʾָ�������������ڣ�Big SQL ���ᱨ����
ʹ��������������߲�ѯ���ܣ����ǣ��� HBase �У�����������Ҫ���Ȳ�����������֮���ٲ������ݱ�������Ҫɨ���������ʱ��ϵͳ����Ҳ�Ƚϴ���������£�����
MapReduce ��ҵɨ�����ݱ�����Ч�ʸ��ߡ�
Join ��ʾ
���ǿ���ʹ�� Join ��ʾ����� MapReduce ��ҵ��ִ��Ч�ʡ�
joinmethod ��ʾ
joinmethod ��ʾ����ָ��ʹ�ñ����Ӳ����ķ�ʽ��Ŀǰ�� joinmethod
��ʾֻ֧�� mapsidehash ֵ��joinmethod ��ʾ�ġ� mapsidehash�����ñ�
tablesize ��ʾ��"small"���ø����壬�����Կ���ʹ����Щ�ֶν��� Hash
���Ӳ�����
������ʹ�� joinmethod ��ʾ�ġ� mapsidehash������ʱ������Ҫͬʱʹ��
buildtable ��ʾ��ָ�������Щ������ hash ������������ʾ�����������ָ����� T2 ����
c2 �ֶν��� Hash ���Ӳ�����
�嵥 47. ���� joinmethod ��ʾ
SELECT a.c1 FROM T1 as a, T2 as b WHERE a.c2
= b.c2 /*+ joinmethod='mapsidehash', buildtable='b' +*/ AND a.c3 = b.c3; |
buildtable ��ʾ
������ʹ�� joinmethod ��ʾ�ġ� mapsidehash������ʱ������Ҫͬʱʹ��
buildtable ��ʾ��ָ�������Щ������ hash ���������δͬʱָ������ʾ��������
Subquery ��ʾ
Big SQL �� SQL ��ѯ�������ͨ����д��ص� SQL �������߲�ѯ���ܣ��ر������
SQL �Ӳ�ѯ�����������дΪ�����Ӳ����� ������ʾ������±ߵIJ�ѯ��䣺
�嵥 48. �Ӳ�ѯ���
SELECT * FROM T1 WHERE c2 IN (SELECT c2 FROM T2
WHERE T2.c3 = T1.c3 AND t2.c4 = 'Fred'); |
Big SQL ���дΪ��
�嵥 49. ��д�Ӳ�ѯ���
SELECT T1.*
FROM T1, (SELECT c2, c3 FROM T2 WHERE t2.c4 = 'Fred') as D0
WHERE T1.c3 = D0.c3; |
��һЩ����£��Ӳ�ѯ����������С������˵��100 �м�¼����ʱ������д���������Ч�ʸ��ߣ����ǿ���ͨ��
rewrite ��ʾ��ֹ�Ӳ�ѯ��д���ܣ�������ʾ��
�嵥 50. ��ֹ�Ӳ�ѯ��д
SELECT * FROM T1 WHERE c2 IN (/*+ rewrite=false
+*/ SELECT c2 FROM T2 WHERE T2.c3 = T1.c3 AND t2.c4 = 'Fred'); |
Big SQL �������Ż�
�ڴ��Ż�
Ĭ������£�Big SQL �᳢��ʹ��ϵͳ�ڴ�� 1/3�����ǿ���ͨ�����û����������ı��ڴ�ʹ�������Ż�ϵͳ���ܡ�����������ɺ���Ҫ��������
Big SQL ������ʹ����Ч��
������ʾ�����ǿ���ʹ�� VERBOSE=true $BIGSQL_HOME/bin/bigsql
status ����鿴��ǰ Big SQL �������ڴ�ʹ�������
�嵥 51. �鿴�ڴ�ʹ�����
biadmin@imtebi1:/opt/ibm/biginsights> VERBOSE=true $BIGSQL_HOME/bin/bigsql status
Total memory on the machine = 3958600 KB
Max memory allocated to bigsql is: 1288m
BigSQL server is running (pid 8243) |
���ǿ���ͨ�����»������������� Big SQL ������ʹ���ڴ�����ֵ����Сֵ��������
Big SQL ��������Ч�µ����ã�������ʾ��
�嵥 52. �����ڴ�ʹ����
/opt/ibm/biginsights> export BIGSQL_CONF_INSTANCE_INITIAL_MEM=2g
/opt/ibm/biginsights> export BIGSQL_CONF_INSTANCE_MAX_MEM=4g
biadmin@imtebi1:/opt/ibm/biginsights> $BIGSQL_HOME/bin/bigsql stop
BigSQL pid 12611 stopped.
biadmin@imtebi1:/opt/ibm/biginsights> $BIGSQL_HOME/bin/bigsql start
BigSQL running, pid 12811.
/opt/ibm/biginsights> VERBOSE=true $BIGSQL_HOME/bin/bigsql status
Max memory allocated to bigsql is: 4g
BigSQL server is running (pid 12811) |
���� Big SQL ��������������ģʽ���ڴ��С������������Ҫ����Ϊ����������Ҫʹ���ڴ�����ɡ�������������漰�����ݿ���װ���ڴ��У����������߲�ѯЧ�ʡ�ͬʱ������ҲҪ���ǵ�����Զ����������ÿһ��������Ҫ�����ڴ���б��ش�����
����������
�� Hadoop �У����ǿ���ͨ������ҵ��������������ʱ���ܡ����� Big
SQL �᳢��ѡ�����ŵ����ԣ������Ҫ�Ļ������ǿ����ڷ��������ѯ�����ϵ�����Щ���ԡ��� $BIGSQL_HOME/conf/bigsql-site.xml
�ļ��а����� Big SQL �����������Ĭ����ҵ�������ã�����Ҳ����ʹ�� SET ���̬������ҵ���Ե����á��±ߣ����Ǽ�Ҫ���ܼ������õ�
Big SQL ��ҵ�������ã����� Big SQL ��ҵ����ֵ�����ľ������ݣ���ҿ��Բο� Big SQL
��Ϣ���ġ�
�嵥 53. ���� Big SQL ��ҵ����ֵ
bigsql.reducers.autocalculate [true] |
Ĭ��ֵΪ True��Big SQL ���Զ����� MapReduce ��ҵʹ��
reducers ��������
bigsql.reducers.bytes.per.reducer [1GB]
|
Ĭ��ֵΪ 1GB��ָ��ÿһ�� reducer ���Դ�������������
bigsql.memoryjoin.size [10MB] |
Ĭ��ֵΪ 10MB�������Ĵ�С���ڸ�ֵʱ��Big SQL ��ʹ�� map-side
memory join ��ʽ��
bigsql.localmode.size [200MB] |
Ĭ��ֵΪ 200MB�������б���������С�ڸ�ֵ��Big SQL ���Զ��ڷ������������С�
����Ҳ����ͨ�� SET ���̬�ı���ҵ����ֵ�����ã�������ʾ��
�嵥 54. ��̬�ı���ҵ����ֵ
biadmin@imtebi1:/opt/ibm/biginsights> $BIGSQL_HOME/bin/jsqsh -U biadmin -P password
JSqsh Release 1.5-ibm, Copyright (C) 2007-2013, Scott C. Gray
Type \help for available help topics. Using JLine.
[localhost][biadmin] 1> set bigsql.reducers.byte.per.reducer = 209715200;
1 row affected (total: 0.8s)
[localhost][biadmin] 1> SELECT * FROM T1 WHERE c2 IN
(SELECT c2 FROM T2 WHERE T2.c3 = T1.c3 AND t2.c4 = 'Fred');
+----+----+----+
| c1 | c2 | c3 |
+----+----+----+
| 2 | 2 | 2 |
+----+----+----+
1 row in results(first row: 14.69s; total: 14.69s)
|
|





