| 一、准备工作
1. 远程连接工具的安装
PieTTY 是在PuTTY 基础上开发的,改进了Putty 的用户界面,提供了多语种支持。Putty
作为远程连接linux 的工具,支持SSH 和telnet。但是,我们使用的时候经常出现乱码。PieTTY
可以很好地解决这个问题。该软件不需要安装,直接打开使用即可,如图1.1 所示
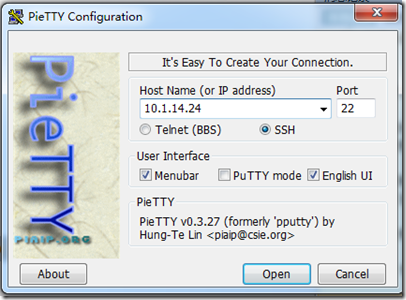
图 1.1
在Host Name 中输入Centos的ip 地址,其余设置使用默认值,然后点击最下面的“Open”按钮,就会提示输入用户名和密码,我们需要输入Centos的用户名root,密码hadoop
即可连接。如图1.2所示。
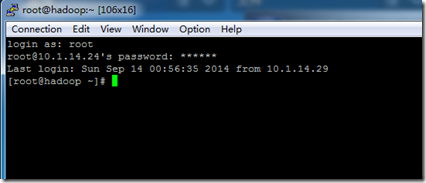
图 1.2
2. 文件传输工具的安装
WinSCP 是一个Windows 环境下使用SSH 的开源图形化SFTP 客户端,同时支持SCP 协议。它的主要功能就是在本地与远程计算机间安全地复制文件。这是一个开源的软件,被托管在全球最大开源软件托管平台SourceForge。
2.1WinSCP 安装
安装分成非常简单,按照提示一步步操作即可,中间没有需要做出选择、判断的地方。安装完成后,打开软件,如图1.3所示,输入相应信息,点击登陆,弹出新的窗口对话框,如图1.4所示。
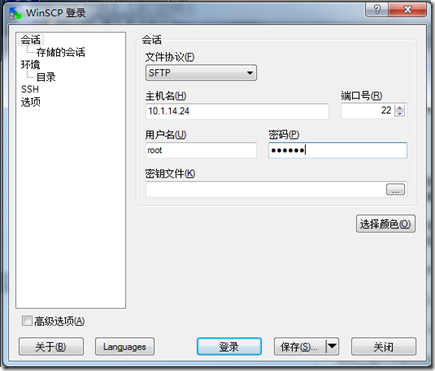
图 1.3
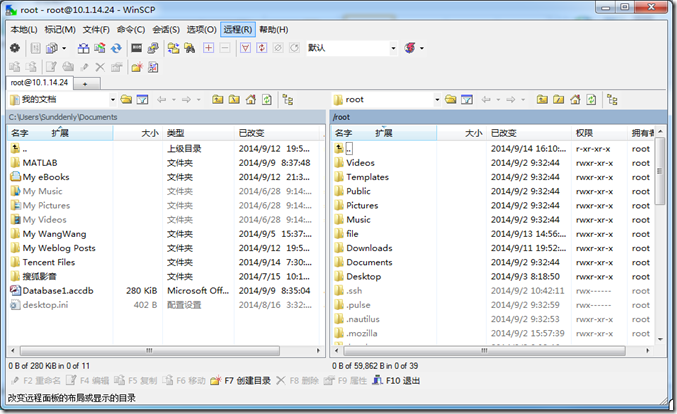
图 1.4
在图1.4中,左侧显示宿主机windows 的文件系统,右侧显示远程Centos 的文件系统。可以使用该工具进行宿主机和客户机之间的文件传输,类似FTP。下面的学习中,在Centos
中使用的很多软件就是通过WinSCP 从Windows 传输过去的。
二、hadoop的伪分布式安装
1. 设置宿主机(windows)与客户机(安装在虚拟机中的Linux)网络连接
1.1 host-only 宿主机与客户机单独组网。
好处:网络隔离
坏处:虚拟机与其他服务器之间不能通信
1.2 brige 客户机与宿主机在同一个局域网中。
好处:都在同一个局域网可以相互访问
坏处:不安全
此步骤前面已经介绍过,已完成
2. hadoop安装具体步骤
2.1 设置静态ip
在centos桌面右上角的图标上,右键修改。 执行命令 service
network restart,在Centos系统桌面右击选择open in terminal,然后输入命令,如图2.1。
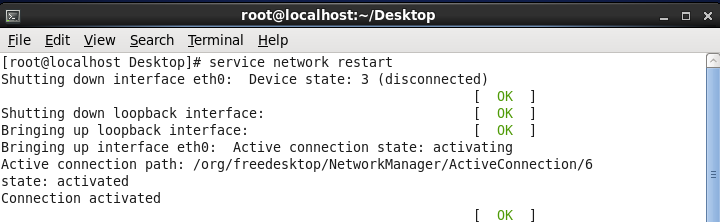
图 2.1
验证:执行命令 ifconfig如图2.2所示,表示静态ip设置成功。
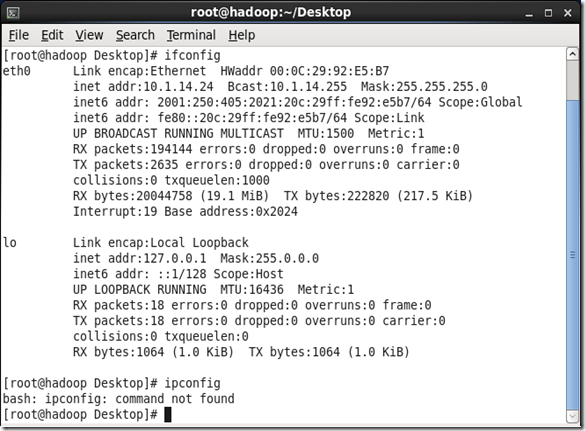
图 2.2
2.2 修改主机名
(1) 修改当前会话中的主机名,执行命令 hostname hadoop,如图2.3

图 2.3
(2) 修改配置文件中的主机名,执行命令 vi /etc/sysconfig/network,将HostName属性改为hadoop,如图2.4,2.5

图 2.4
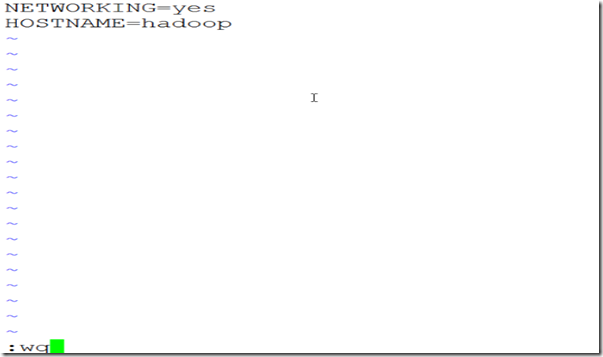
图 2.5
注意:vi 只读,不能写(vi 后直接跟文件名)
按a进入编辑模式---编辑,能读,也能写
Esc键,然后按“shift+:”组合键,输入wq保存退出,退出不存为q!
验证:重起机器 reboot -h now
关机 shutdown -h now
验证:重起机器 reboot -h now,之后用hostname命令查询主机名,是否为hadoop,如图2.6所示
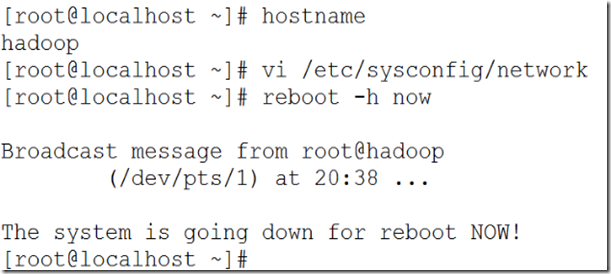
图 2.6
2.3 把主机名和ip名绑定 (即设置DNS 解析)
(1)执行命令 vi /etc/hosts,增加一行内容如下 10.1.14.24 hadoop
(2)保存退出,如图2.7

图 2.7
(3)验证:ping hadoop,验证是否成功,如图2.8所示绑定成功
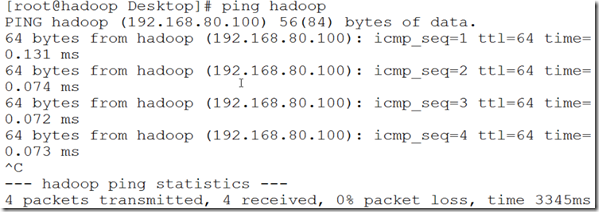
图2.8
2.4 关闭防火墙
执行命令 service iptables stop
验证:service iptables status,如图2.9所示防火墙关闭成功

图 2.9
2.5 关闭防火墙自动运行
执行命令 chkconfig iptables off
验证:chkconfig --list,如图2.10所示关闭成功

图 2.10
2.6 设置SSH(secure shell)的免密码登陆
如果我们需要远程管理其他机器的话,一般使用远程桌面或者telnet。linxu 服务器几乎都是命令行,所以只能使用telnet
了。telnet 的缺点是通信不加密,非常不安全,只适合于内网访问。为解决这个问题,推出了加密的通信协议,即SSH。SSH
的全称是Secure Shell,使用非对称加密方式,传输内容使用rsa 或者dsa 加密,可以有效避免网络窃听。hadoop
的进程之间通信使用ssh 方式,需要每次都要输入密码。为了实现自动化操作,我们下面配置SSH 的免密码登录方式。
首先到用户主目录下,如图2.11 所示。
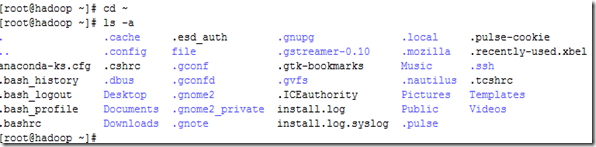
图 2.11
在“ls -a”命令显示的文件中,最后一列中间一项是“.ssh”,该文件夹是存放密钥的。注意该文件夹是以“.”开头的,是隐藏文件。待会我们生成的密钥都会放到这个文件夹中。
(1) 执行命令 ssh-keygen -t rsa 产生秘钥,位于~/.ssh文件夹中,如图2-12
所示。
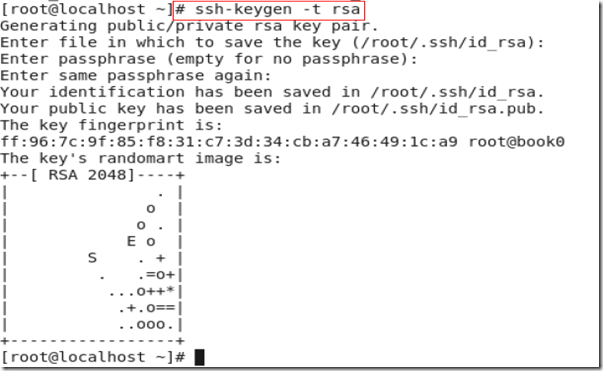
图 2.12
解释一下:命令“ssh-keygen -t rsa”表示使用rsa 加密方式生成密钥, 回车后,会提示三次输入信息,我们直接回车即可
(2) 执行命令 cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys,如图2.13
所示,多了两个文件,一个是公开密匙,一个是访问用户名字信息。
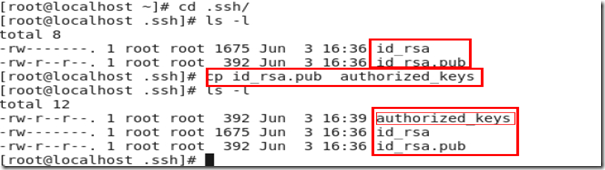
图 2.13
其中,命令“cp id_rsa.pub authorized_keys”用于生成授权文件。至此,配置部分完成了。
这里为什么要使用ssh 登录本机哪?
因为hadoop 在本机部署时,需要使用ssh 访问。 而文件夹“.ssh”中的三个文件的权限,是有要求的,“自己之外的任何人对每个文件都没有写权限”。另外,“.ssh”文件夹是700
权限。如果权限有问题,会造成SSH 访问失败。
(3) 现在开始验证SSH 无密码登录,ssh localhost 选择yes,然后exit退出(exit用于退出终端),如图2.14所示。
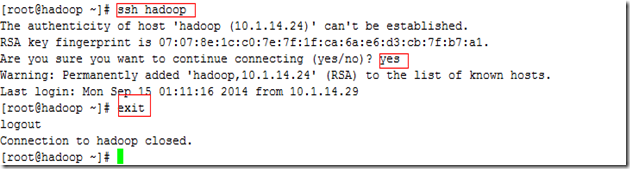
图 2.14
执行“ssh hadoop”意味着使用“ssh”通信协议访问主机“hadoop”,第一次执行时需要确认;第二次不再确认了。这就是无密码登录。当登录到对方机器后,退出使用命令“exit”。这两次操作时,注意观察主机名变化。读者可以执行命令“ssh
hadoop”,验证dns对hadoop 解析是否正确。
注意:使用命令ssh 时,一定要观察主机名的变化。在操作ssh时,由于大量的使用ssh
登录退出,忘记自己目前在哪台机器了,执行了大量错误的操作。另外,如果多次执行ssh,每次都要输入确认信息的话,说明配置失败了。
(a) 可以删除文件夹“.ssh”,重新配置。
(b) 也可以重启虚拟机再配置。
(c) 如果还搞不定,给你个绝招” 删除/etc/udev/rules.d/70-persistent-net.rules
文件,重启系统”。
2.7 安装jdk
我使用的版本是Oracle 的jdk-6u24-linux-i586.bin。
(1) 执行命令 rm -rf /usr/local/* 删除所有内容
(2) 使用winscp把jdk和hadoop安装包复制到linux中的/usr/local中,直接拖过去就行,如图2.15所示。
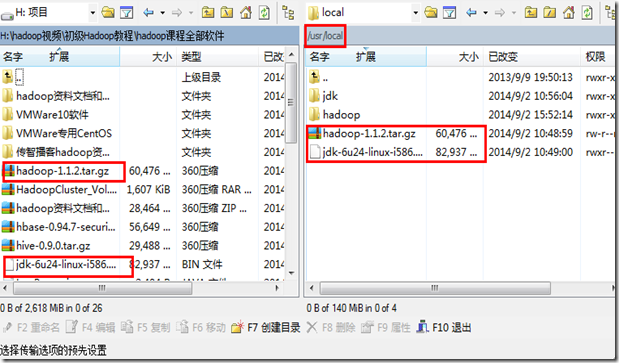
图 2.15
(3) 进入到/usr/local 目录下,执行命令 chmod u+x jdk-6u24-linux-i586.bin
授予执行权限
(4) 进入到/usr/local 目录下,执行命令 ./jdk-6u24-linux-i586.bin
解压文件,如图2.16所示

图 2.16
(5) 执行命令 mv jdk1.6.0_24 jdk 重命名 方便以后引用,如图2.17
所示

图 2.17
(6) 执行命令 vi /etc/profile 设置环境变量,增加两行内容
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
保存退出,如图2.18所示

图 2.18
执行命令 source /etc/profile 让该设置生效 注:若无法识别此命令,则可能自己的profile文件编辑错
验证:java -version,如图2.19所示

图 2.19
解释一下上面的配置内容:
“export”是关键字,用于设置环境变量。我们设置了两个环境变量,一个是JAVA_HOME,一个是PATH。对于环境变量的引用,使用“$”,多个环境变量之间的连接,使用“:”。命令“source”是为了让文件中的设置立刻生效。
2.8 安装hadoop
hadoop 的安装分为本地模式、伪分布模式、集群模式。本地模式是运行在本地,只负责存储,没有计算功能,不讲述。伪分布模式是在一台机器上模拟分布式部署,方便学习和调试。集群模式是在多个机器上配置hadoop,是真正的“分布式”。进入hadoop所在目录/usr/local,执行以下操作
(1) 执行命令 tar -zxvf hadoop-1.1.2.tar.gz
(2) 执行命令 mv hadoop-1.1.2 hadoop,这时hadoop 目录的完整路径是“/usr/local/hadoop”。
(3) 执行命令 vi /etc/profile 设置环境变量,增加一行内容,修改一行内容
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
保存退出
执行命令 source /etc/profile 让设置生效
(4) 修改hadoop的配置文件,位于$HADOOP_HOME/conf目录下
用WinSCP修改四个配置文件,分别是hadoop-env.sh,core-site.xml,hdfs-site.xml,mapred-site.xml修改哪个,双击点开哪个就行,如图
2.20所示
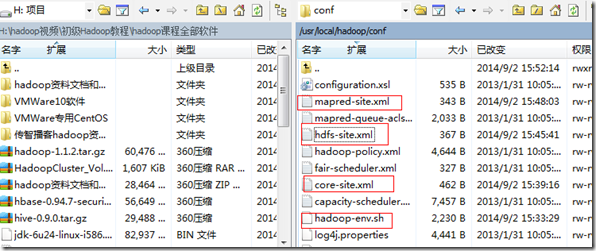
图 2.20
【hadoop-env.sh】
export JAVA_HOME=/usr/local/jdk/ |
【core-site.xml的修改内容如下】
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
<description>change your own hostname</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration> |
【hadfs.xml的修改内容如下】
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration> |
【mapred-site.xml的修改内容如下】
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop:9001</value>
<description>change your own hostname</description>
</property>
</configuration> |
(5) 执行命令 hadoop namenode -format 对hadoop进行格式化
(6) 执行命令 start-all.sh 启动 执行命令 stop-all.sh 将hadoop关闭
验证:
① 执行命令 jps 查看java进程(5个),如图2.21所示。
JobTracker、DataNode、NameNode、TaskTracker、SecondaryNameNode

图 2.21
② 通过linux中浏览器 hattp://hadoop:50070和http://hadoop50030
来验证。也可以可以修改C:\Windows\System32\drivers\etc\hosts文件,添加一行内容,10.1.14.24
hadoop。如果添加还不能访问,就关闭hadoop,重启hadoop,再次关闭Linux防火墙,这样就可以在Windows浏览器中中访问
hattp://hadoop:50070和http://hadoop50030,如图2.22,2.23所示

图 2.22 Windows下

2.23 Linux下
2.9 NameNode进程没有启动成功
1.没有格式化
2.配置文件只copy,不修改
3.hostname与ip没有绑定
4.SSH的免密码登陆没有配置成功
|





